DOI: https://doi.org/10.1145/3652154
تاريخ النشر: 2024-03-28
التنقل في تعقيد اعتماد الذكاء الاصطناعي التوليدي في هندسة البرمجيات
الملخص
تستكشف هذه الورقة اعتماد أدوات الذكاء الاصطناعي التوليدي (AI) ضمن مجال هندسة البرمجيات، مع التركيز على العوامل المؤثرة على المستويات الفردية والتكنولوجية والاجتماعية. قمنا بتطبيق نهج مختلط متقارب لتقديم فهم شامل لديناميات اعتماد الذكاء الاصطناعي. بدأنا بإجراء استبيان مع 100 مهندس برمجيات، مستندين إلى نموذج قبول التكنولوجيا (TAM) ونظرية انتشار الابتكار (DOI) ونظرية التعلم الاجتماعي المعرفي (SCT) كإطارات نظرية توجيهية. باستخدام منهجية جيويا، استخلصنا نموذجًا نظريًا لاعتماد الذكاء الاصطناعي في هندسة البرمجيات: إطار التعاون والتكيف بين الإنسان والذكاء الاصطناعي (HACAF). تم التحقق من صحة هذا النموذج باستخدام نمذجة المعادلات الهيكلية – المربعات الصغرى الجزئية (PLS-SEM) استنادًا إلى بيانات من 183 مهندس برمجيات. تشير النتائج إلى أنه في هذه المرحلة المبكرة من دمج الذكاء الاصطناعي، فإن توافق أدوات الذكاء الاصطناعي مع سير العمل الحالي في التطوير هو ما يدفع اعتمادها بشكل أساسي، مما يتحدى نظريات قبول التكنولوجيا التقليدية. يبدو أن تأثير الفائدة المدركة والعوامل الاجتماعية والابتكار الشخصي أقل وضوحًا مما كان متوقعًا. تقدم الدراسة رؤى حاسمة لتصميم أدوات الذكاء الاصطناعي المستقبلية وتوفر إطارًا لتطوير استراتيجيات تنفيذ تنظيمية فعالة.
تنسيق مرجع ACM:
1 المقدمة
في مسعانا لاستكشاف سؤال بحثنا، قمنا بتطبيق نهج مختلط متقارب، مستكشفين اعتماد الذكاء الاصطناعي التوليدي ونماذج اللغة الكبيرة ضمن مجال هندسة البرمجيات. لتأطير فهمنا لاعتماد الذكاء الاصطناعي، أشرنا إلى ثلاثة إطارات نظرية رئيسية تفحص التأثيرات على المستويات الفردية والتكنولوجية والاجتماعية. شملت هذه الإطارات نموذج قبول التكنولوجيا (TAM) [110]، ونظرية انتشار الابتكار (DOI) [85]، ونظرية التعلم الاجتماعي المعرفي (SCT) [9]. من خلال دمج هذه النظريات المعتمدة جيدًا، تمكنا من فهم شامل لمحددات اعتماد نماذج اللغة واستكشاف الطرق المميزة التي يتم بها تشغيل هذه المتغيرات في مجال هندسة البرمجيات. بدأنا بحثنا بإجراء استبيان مع مجموعة من 100 مهندس برمجيات. تأثر تصميم هذا الاستبيان بالأبعاد الرئيسية لنظرياتنا المختارة. تم تحليل البيانات المجمعة باستخدام منهجية جيويا [38]، مما سهل تطوير نموذجنا النظري الأولي. تم التحقق من صحة هذا النموذج النظري المؤقت باستخدام نمذجة المعادلات الهيكلية – المربعات الصغرى الجزئية (PLS-SEM)، مدعومًا بالبيانات التي تم جمعها من 183 مهندس برمجيات. تعزز تقارب الرؤى المستمدة من هذه التحقيق الشامل والمتعدد الأبعاد فهمنا لاعتماد الذكاء الاصطناعي ضمن هندسة البرمجيات. علاوة على ذلك، من خلال فهم ديناميات الاعتماد وتأثير هذه التقنيات المدمرة، يحمل هذا البحث إمكانية توجيه تصميم أدوات الذكاء الاصطناعي المستقبلية وتقديم توصيات ذات صلة لاستراتيجيات التنفيذ على مستوى المنظمة. في الواقع، تمثل أدوات الذكاء الاصطناعي التوليدية ابتكارًا مدمراً في مجال هندسة البرمجيات، كما عرّف مفهوم “الابتكار المدمر” لكريستنسن [18]. تستهدف هذه الأدوات، بينما تستهدف في البداية تطبيقات متخصصة أو شرائح سوق غير مخدومة، إمكانية إحداث ثورة في ممارسات هندسة البرمجيات التقليدية. إن قدرتها على أتمتة المهام المعقدة، وتوليد الشيفرة، وتقديم حلول استنادًا إلى مجموعات بيانات ضخمة تتحدى الوضع الراهن ويمكن أن تؤدي إلى تحول جذري في
كيف يتم الاقتراب من تطوير البرمجيات. مع مرور الوقت، ومع تزايد دقة هذه الأدوات واعتمادها على نطاق واسع، قد تحل محل المنهجيات والأدوات الراسخة، تمامًا كما تعيد الابتكارات المدمرة تشكيل الصناعات. من خلال فهم ديناميات اعتماد هذه التقنيات التحويلية، تقدم هذه الدراسة رؤى حول مسارها المحتمل وآثارها، مما يوجه تصميم أدوات الذكاء الاصطناعي المستقبلية ويقدم توصيات لتنفيذها الاستراتيجي عبر المنظمات.
2 الأعمال ذات الصلة
2.1 تقييم الكود المُولد: الصحة والجودة
2.2 معايير التقييم: أساليب متنوعة
تؤكد هذه الاختلافات على الطبيعة المتعددة الأبعاد لتوليد الشيفرة بواسطة الذكاء الاصطناعي والأبعاد المختلفة التي تحتاج إلى تقييم.
2.3 تعزيز إنتاجية الكود
2.4 مقارنة الطرق
2.5 القضايا التربوية
2.6 تأثير الذكاء الاصطناعي على عملية تطوير البرمجيات
إمكانات وتحديات أدوات الذكاء الاصطناعي في تطوير البرمجيات، كما أنها تقدم وجهات نظر فريدة، مما يوسع النقاش ليشمل جوانب مثل القضايا القانونية، وتغييرات سير العمل، وتكاليف الوقت.
2.7 تأثير المجتمع والثقة في أدوات الذكاء الاصطناعي
2.8 الذكاء الاصطناعي التوليدي في الأنشطة غير البرمجية
2.9 قابلية استخدام مساعدي البرمجة بالذكاء الاصطناعي
3 توليد النظرية
3.1 الأساس النظري
3.1.1 نموذج قبول التكنولوجيا (TAM). تم الإشادة بنموذج قبول التكنولوجيا على نطاق واسع لملاءمته وكفاءته في التنبؤ بشرح قبول أشكال مختلفة من التكنولوجيا [110]. تشكل مكوناته الأساسية – الفائدة المدركة وسهولة الاستخدام المدركة – نقطة انطلاق ممتازة لفهم سلوك الاعتماد. على سبيل المثال، إذا تم اعتبار نماذج اللغة مفيدة وسهلة الاستخدام، فمن المرجح أن يتبناها مهندسو البرمجيات. نظرًا لصلابته وبساطته، يوفر نموذج قبول التكنولوجيا أساسًا لفهم المحددات الأساسية لاعتماد التكنولوجيا ويساعد في تشخيص الحواجز الأساسية لاعتماد نماذج اللغة.
3.1.2 نظرية انتشار الابتكار (DOI). بينما يركز نموذج قبول التكنولوجيا بشكل أساسي على تصورات المستخدمين، تكمل نظرية انتشار الابتكار نموذج قبول التكنولوجيا من خلال معالجة الخصائص التكنولوجية التي تؤثر على الاعتماد. حدد روجرز [85] السمات الرئيسية للابتكارات – الميزة النسبية، والتوافق، والتعقيد، وقابلية التجربة، والملاحظة – التي تؤثر بشكل كبير على معدلات اعتمادها. كابتكار في هندسة البرمجيات، يمكن أن يتشكل قبول نماذج اللغة من خلال هذه السمات. على سبيل المثال، قد تكون الميزة النسبية لنماذج اللغة مقارنة بأساليب البرمجة التقليدية دافعًا قويًا للاعتماد. قد يلعب توافق نماذج اللغة مع الممارسات الحالية وتعقيد هذه النماذج أيضًا أدوارًا حاسمة. وبالتالي، تضيف نظرية انتشار الابتكار عمقًا إلى فهمنا للعوامل المحددة للتكنولوجيا التي تؤثر على اعتماد نماذج اللغة.
3.1.3 النظرية الاجتماعية المعرفية (SCT). لا تحدث قرار اعتماد تقنيات جديدة في فراغ. إنه يتأثر بالبيئة الاجتماعية التي يعمل فيها الأفراد. تدخل النظرية الاجتماعية المعرفية في اللعب
هنا من خلال التأكيد على العوامل الاجتماعية والبيئية التي تؤثر على سلوكيات الأفراد [9]. هندسة البرمجيات، مثل أي مهنة، لها ثقافتها الخاصة، ومعاييرها، ومعتقداتها المشتركة التي يمكن أن تشكل بشكل كبير اعتماد نماذج اللغة. على سبيل المثال، قد تشجع المعايير السائدة أو مدى استخدام الأقران على استخدام نماذج اللغة أو تثبطه. علاوة على ذلك، قد تؤثر الكفاءة الذاتية للأفراد – التي تتشكل جزئيًا من خلال بيئتهم الاجتماعية – على استعدادهم للتفاعل مع هذه الأداة الجديدة. لذلك، تضيف SCT طبقة اجتماعية إلى فهمنا لاعتماد نماذج اللغة.
3.2 إرشادات استبيان المسح
- الفائدة المدركة: “إلى أي مدى تعتقد أن استخدام نماذج اللغة يزيد من كفاءتك كمهندس برمجيات؟” تم تصميم هذا السؤال لقياس كيف يدرك مهندسو البرمجيات المكاسب المحتملة في الإنتاجية من استخدام LLMs.
- سهولة الاستخدام المدركة: “ما مدى سهولة تعلم كيفية استخدام نموذج لغة جديد بشكل فعال؟” يهدف هذا السؤال إلى التقاط الجهد المعرفي المدرك المطلوب لتعلم والتكيف مع LLMs.
- نية السلوك: “ما مدى احتمال استخدامك لنموذج لغة في عملك في الأشهر الستة المقبلة؟ ولأي مهام؟” تهدف هذه الأسئلة إلى تقييم نية مهندسي البرمجيات لاعتماد LLMs في مهامهم القريبة.
- التوافق: “كيف يختلف استخدام نموذج لغة عن ممارساتك الحالية في هندسة البرمجيات؟” يقيم هذا السؤال الملاءمة المدركة لـ LLMs مع الممارسات الحالية وسير العمل.
- الميزة النسبية: “ما الفوائد المحتملة التي تعتقد أن نماذج اللغة تقدمها مقارنة بأساليبك الحالية؟” يساعد هذا السؤال في تحديد الفوائد المدركة لـ LLMs مقارنة بالأساليب التقليدية.
- التعقيد: “ما المخاوف التي لديك بشأن استخدام نموذج لغة في عملك؟” يهدف هذا السؤال إلى تسليط الضوء على أي حواجز أو تحديات مدركة مرتبطة باعتماد LLM.
تشمل عوامل المستوى الاجتماعي، المستندة إلى نظرية الإدراك الاجتماعي، التأثير الاجتماعي، والعوامل البيئية، والكفاءة الذاتية: - التأثير الاجتماعي: “إلى أي مدى يؤثر زملاؤك أو أقرانك على قراراتك لاستخدام نماذج اللغة؟” يفحص هذا السؤال تأثير المعايير الاجتماعية وآراء الزملاء على قبول LLMs.
- العوامل البيئية: “في رأيك، إلى أي مدى تشعر أن منظمتك تدعم اعتماد نماذج اللغة كتكنولوجيا قياسية؟” يستكشف هذا السؤال دور الدعم التنظيمي في تعزيز اعتماد LLM.
- الكفاءة الذاتية: “ما مدى أهمية أن يُنظر إليك كشخص يستخدم التكنولوجيا المتطورة في عملك؟” يهدف هذا السؤال إلى التقاط ثقة الفرد في قدرته على استخدام تقنيات متقدمة مثل LLMs بشكل فعال.
من خلال هذه الأسئلة في استبيان المسح، نسعى لفهم التفاعل المعقد بين العوامل الفردية والتكنولوجية والاجتماعية التي تسهم في اعتماد واستخدام الأدوات المدعومة بـ LLM بين مهندسي البرمجيات.
3.3 المشاركون
3.4 تحليل البيانات النوعية
“تحسين الكفاءة”، الذي يمثل منطقة تأثير عامة في هندسة البرمجيات من خلال استخدام LLMs. يوضح هذا المثال التقدم التحليلي من اقتباسات المشاركين المحددة إلى فئات موضوعية أوسع، مما يوضح منهجية دراستنا.
4 النتائج
4.1 الفائدة المدركة لـ LLMs في هندسة البرمجيات
4.1.1 تحسين الكفاءة. واحدة من الفوائد المدركة الرئيسية لـ LLMs هي قدرتها على تحسين الكفاءة. كما هو موضح في الجدول 1، فإن تحسين الكفاءة هو البعد المجمّع الأكثر ذكرًا (55%). يدرك المهندسون أن LLMs يمكن أن تؤتمت بعض المهام، وتقلل من الوقت والجهد، وتبسط المهام المملة. على سبيل المثال، أشار R-15 إلى أن LLMs يمكن أن “تزيد من كفاءتي من خلال أتمتة بعض المهام وتقليل الوقت والجهد الذي يستغرقه الترميز اليدوي والوثائق.” يتماشى هذا الاكتشاف مع تأكيد نموذج قبول التكنولوجيا على الفائدة المدركة، الذي يفترض أن المستخدمين سيتبنون التكنولوجيا إذا رأوا أنها مفيدة في تعزيز أدائهم [29].
4.1.2 الفوائد الخاصة بالمهام. جانب آخر من الفائدة المدركة هو الفوائد الخاصة بالمهام التي تقدمها LLMs، مثل تصحيح الأخطاء، وتعلم الميزات الجديدة، وتوليد مقتطفات من الشيفرة. كما ذكر R-30، زادت LLMs بشكل كبير من كفاءتهم من خلال مساعدتهم في “تصحيح الشيفرة بشكل أسرع، وتعلم الميزات الجديدة دون الحاجة إلى مسح الوثائق بالكامل، وتوفير مقتطفات شيفرة مفيدة للعمل.” تمثل هذه الفئة
4.1.3 أداة تكميلية. تُعتبر LLMs أيضًا أداة تكميلية للخبرة البشرية والحكم. أشار R-17 إلى أن “نماذج اللغة لديها القدرة على تعزيز الإنتاجية والكفاءة في هندسة البرمجيات، ولكن يجب استخدامها كأداة جنبًا إلى جنب مع الخبرة البشرية والحكم.” يبرز هذا التصور أهمية تحقيق التوازن بين فوائد LLMs والحاجة إلى الإشراف البشري، وهو جانب قد يؤثر على الفائدة المدركة العامة للتكنولوجيا.
4.1.4 قابلية تطبيق محدودة ومخاوف تتعلق بالجودة. بينما أبلغ العديد من المستجيبين عن آراء إيجابية حول LLMs، أعرب البعض عن مخاوف بشأن قابلية تطبيقها المحدودة (
اعتماد واسع النطاق. ومع ذلك، تبرز المخاوف المتعلقة بقابلية التطبيق المحدودة والجودة أهمية معالجة هذه القيود لتعزيز الفائدة المدركة وبالتالي قبول LLMs. يتماشى هذا التحليل مع إطار نموذج قبول التكنولوجيا، الذي يؤكد أن الفائدة المدركة هي محدد حاسم لقبول التكنولوجيا [29].
| معرف | اقتباس | المفاهيم من الدرجة الأولى | الموضوعات من الدرجة الثانية | الأبعاد المجمعة | (%) |
| R-15 | يمكن أن تزيد من كفاءتي بشكل كبير من خلال أتمتة بعض المهام وتقليل الوقت والجهد الذي يستغرقه الترميز اليدوي والوثائق | أتمتة المهام، تقليل الوقت والجهد، الترميز اليدوي، الوثائق | تحسينات الكفاءة الخاصة بالمهام | تحسين الكفاءة | 55 |
| R-28 | يزيد بشكل كبير من كفاءتي خاصة في المهام البسيطة | زيادة الكفاءة، المهام البسيطة | تحسينات الكفاءة الخاصة بالمهام | تحسين الكفاءة | 55 |
| R-52 | إنهم يساعدون فقط في المهام الرتيبة والبسيطة (مثل تعريف المنشئين وكتابة أنظمة التحقق من إدخال المستخدم على سبيل المثال). | المهام الرتيبة، المهام البسيطة | تحسينات الكفاءة الخاصة بالمهام | تحسين الكفاءة | 55 |
| R-67 | أوفر 10% – 20% من الوقت | توفير الوقت | توفير الوقت | توفير الوقت | 24 |
| R-30 | بالتأكيد يساعد كثيرًا، في الأيام القليلة الماضية التي كنت أستخدم فيها ChatGPT (مع GPT 3-5)، زادت كفاءتي بشكل كبير. يساعدني في تصحيح الأخطاء في الكود بشكل أسرع، والتعرف على ميزات جديدة دون الحاجة إلى مسح الوثائق بالكامل، وتزويدي بمقتطفات كود مفيدة لعملي. | زيادة الكفاءة، تصحيح الأخطاء، تعلم ميزات جديدة، مقتطفات كود | فوائد خاصة بالمهام، تعزيز التعلم | فوائد خاصة بالمهام | 26 |
| R-17 | أعتقد أن نماذج اللغة يمكن أن تزيد من كفاءة مهندسي البرمجيات من خلال أتمتة مهام معينة، مثل توليد الكود، والاختبار، والوثائق. بالإضافة إلى ذلك، يمكن أن تساعد نماذج اللغة في تحليل البيانات واتخاذ القرارات، مما يسمح للمهندسين باتخاذ خيارات مستنيرة بناءً على مجموعات بيانات كبيرة. بشكل عام، تمتلك نماذج اللغة القدرة على تعزيز الإنتاجية والكفاءة في هندسة البرمجيات، ولكن يجب استخدامها كأداة بجانب الخبرة البشرية والحكم. | أتمتة المهام، تحليل البيانات، اتخاذ القرار، الخبرة البشرية، الحكم | أداة مكملة، تحسين الكفاءة | أداة مكملة | 18 |
| R-21 | بشكل طفيف جدًا. إنه جيد للمهام العامة، لكن النماذج ليس لديها أي معرفة بواجهات برمجة التطبيقات الداخلية لدينا لذا يصعب تطبيقها. | قابلية تطبيق محدودة، واجهات برمجة التطبيقات الداخلية، المهام العامة | قابلية تطبيق محدودة | قابلية تطبيق محدودة | 15 |
| R-41 | أنا أكثر كفاءة بكثير عند استخدام نموذج لغة لأنه يساعدني على فهم كود الشركة بشكل أسرع. | زيادة الكفاءة، فهم كود الشركة، التعلم الأسرع | تعزيز التعلم | تعزيز التعلم | 12 |
| R-76 | بينما في معظم الأوقات، ترتكب نماذج اللغة أخطاء صغيرة، مما يتطلب وقتًا إضافيًا للتحقق من مخرجاتها، فإن الوقت الذي توفره من خلال القيام بالأجزاء المملة من البرمجة نيابة عنك بالتأكيد يفوق ذلك في رأيي. سأقول إن استخدام المساعد على سبيل المثال قد زاد من كفاءتي في البرمجة بحوالي
|
توفير الوقت، التحقق من المخرجات، زيادة الكفاءة | توفير الوقت، مخاوف الجودة | توفير الوقت، مخاوف الجودة | 24,9 |
| R-55 | أعتقد أنه يساعد ولكن عليك مراجعة وفهم الكود على أي حال. لذا لا أعرف إذا كان يجعلك أكثر كفاءة. | مراجعة الكود، الفهم، مخاوف الكفاءة | مخاوف الجودة | مخاوف الجودة | 9 |
4.2 سهولة استخدام نماذج اللغة الكبيرة في هندسة البرمجيات
4.2.1 عملية التعلم. يكشف تحليلنا أن عملية التعلم هي عامل حاسم يؤثر على سهولة استخدام نماذج اللغة الكبيرة في هندسة البرمجيات. كما هو موضح في الجدول 2، أفاد R-54 بأنه “بمجرد أن تعودت على التكنولوجيا، أصبح من الأسهل بكثير استخدامها.” يتماشى هذا الاكتشاف مع نموذج قبول التكنولوجيا المقترح من قبل [29]، الذي يقترح أن سهولة الاستخدام المدركة للتكنولوجيا مرتبطة مباشرة بتبنيها. علاوة على ذلك، أكدت الأبحاث السابقة على دور
التعلم في تبني التقنيات الجديدة [110]. في هذا السياق، يبدو أن منحنى التعلم المرتبط بنماذج اللغة الكبيرة هو محدد أساسي لسهولة استخدامها المدركة.
4.2.2 الخبرة السابقة. تؤكد بيانات استبيان الأسئلة أيضًا على أهمية الخبرة السابقة في تشكيل سهولة استخدام نماذج اللغة الكبيرة. على سبيل المثال، ذكر R-20 أنه “أعتقد أنه سهل عندما تعرف المفاهيم المختلفة.” يتماشى هذا الملاحظة مع الأدبيات حول تبني التكنولوجيا، التي تقترح أن الأفراد الذين لديهم خبرة سابقة في تقنيات ذات صلة هم أكثر عرضة لرؤية التكنولوجيا الجديدة على أنها سهلة الاستخدام [24]. في حالة نماذج اللغة الكبيرة، يمكن أن يسهل وجود خلفية في لغات البرمجة أو معالجة اللغة الطبيعية (NLP) تبنيها في هندسة البرمجيات.
4.2.3 الفروق الفردية. موضوع رئيسي آخر ظهر من تحليلنا هو دور الفروق الفردية في تشكيل سهولة استخدام نماذج اللغة الكبيرة. كما أشار R-9، “يعتمد ذلك على الشخص وكيف اعتادوا على العمل.” يدعم هذا الاكتشاف الفكرة القائلة بأن الخصائص الفردية، مثل أسلوب التفكير والابتكار الشخصي، يمكن أن تؤثر على سهولة استخدام التكنولوجيا المدركة [94]. في سياق نماذج اللغة الكبيرة، قد يعتمد مدى رؤية مهندسي البرمجيات لها على أنها سهلة الاستخدام على تفضيلاتهم الفريدة، وأنماط التعلم، وطرق حل المشكلات.
4.2.4 الحدسية وواجهة المستخدم. كانت الحدسية لنماذج اللغة الكبيرة وتصميم واجهة المستخدم الخاصة بها أيضًا عوامل مهمة في تحليلنا. على سبيل المثال، ذكر R-89 أن “تم تصميمها بشكل أساسي لتكون سهلة الاستخدام من قبل المستهلك العادي.” يتماشى هذا الملاحظة مع عمل [69]، الذي جادل بأن واجهة المستخدم المصممة بشكل جيد يمكن أن تعزز بشكل كبير سهولة استخدام التكنولوجيا المدركة. في حالة نماذج اللغة الكبيرة، يمكن أن تسهل واجهة مستخدم حدسية وسهلة الاستخدام تبنيها بين مهندسي البرمجيات.
4.2.5 تعقيد المهام. أخيرًا، يبدو أن تعقيد المهام التي تستخدم من أجلها نماذج اللغة الكبيرة في هندسة البرمجيات يؤثر على سهولة استخدامها المدركة. كما أشار R-53، “يمكن أن يختلف صعوبة تعلم كيفية استخدامها بشكل فعال حسب كيفية استخدامك لها، ولكن في الغالب، يتراوح من ليس صعبًا جدًا إلى صعب جدًا.” يتماشى هذا الاكتشاف مع نموذج ملاءمة المهمة والتكنولوجيا [41]، الذي يفترض أن الملاءمة بين التكنولوجيا والمهمة التي تهدف إليها تؤثر على سهولة الاستخدام المدركة للتكنولوجيا، وفي النهاية، على تبنيها. في سياق نماذج اللغة الكبيرة، يبدو أن مهندسي البرمجيات قد يجدونها أسهل للاستخدام في مهام معينة، بينما قد تتطلب مهام أخرى مستوى أعلى من الخبرة والمعرفة.
4.3 النية السلوكية لنماذج اللغة الكبيرة في هندسة البرمجيات
| ID | اقتباس | المفاهيم من الدرجة الأولى | الموضوعات الثانية | الأبعاد المجمعة | (%) |
| R-46 | سهل كلما مارست أكثر | الممارسة، التحسين | الممارسة والتحسين | عملية التعلم | 54 |
| R-4 | يستغرق بعض الوقت والتفاني | الوقت، التفاني | منحنى التعلم | عملية التعلم | 54 |
| R-96 | ومع ذلك، بالنسبة للمهام الأكثر تقدمًا، قد يستغرق الأمر بعض الوقت لصياغة أسئلتك بشكل صحيح | المهام المتقدمة، الوقت | منحنى التعلم | عملية التعلم | 54 |
| R-30 | في الأسبوع الأول من استخدامه، ستبدأ بالفعل في زيادة كفاءتك | الكفاءة، الوقت | الممارسة والتحسين | عملية التعلم | ٥٤ |
| R-33 | لكي تكون أكثر كفاءة، يتطلب الأمر تعلم العبارات المحددة التي تعطيك الإجابة الدقيقة التي تتوقعها. | الكفاءة، مطالب محددة | الممارسة والتحسين | عملية التعلم | ٥٤ |
| R-17 | يعتمد ذلك على تعقيد وقدرات النموذج، بالإضافة إلى خبرة ومعرفة المستخدم السابقة. | التعقيد، تجربة المستخدم، المعرفة السابقة | عوامل فردية | الأرض الفردية | 26 |
| R-98 | من السهل عندما تعرف لغة أخرى مشابهة لها | المعرفة السابقة، لغة مشابهة | عوامل فردية | الأرض الفردية | 26 |
| R-5 | سهل للغاية | سهولة الاستخدام | سهولة الاستخدام المدركة | سهولة التبني المدركة | ١٣ |
| R-52 | سهل الاستخدام، صعب الإتقان في التعليمات | سهولة الاستخدام، الإتقان | إتقان | سهولة التبني المدركة | ١٣ |
| R-74 | الجزء الصعب هو فهم ما إذا كانت الاستجابة المقدمة صحيحة ومرتبطة بما يحتاجه الشخص. | جودة الاستجابة، العلاقة بالاحتياجات | الصعوبة المدركة | فعالية النموذج | ٦ |
4.3.1 تحسين الكود والصيانة. أشار جزء كبير من مهندسي البرمجيات إلى نيتهم استخدام نماذج اللغة الكبيرة لتحسين وصيانة قاعدة الشيفرة الخاصة بهم. يتماشى هذا الاكتشاف مع مفهوم الفائدة المدركة في نموذج قبول التكنولوجيا، حيث يمكن أن يؤدي استخدام نماذج اللغة الكبيرة في إعادة هيكلة الكود، والالتزام بأنماط التصميم، وتنفيذ مبادئ SOLID إلى تحسين جودة البرمجيات وقابلية الصيانة. على سبيل المثال، ذكر R-8: “أفكر في شراء اشتراك في ChatGPT-4، بشكل أساسي لإعادة هيكلة (الكود القديم) أو لجعله يتماشى مع أنماط تصميم معينة. يمكن أن يساعد أيضًا في إعادة هيكلة الكود لجعله أكثر توافقًا مع مبادئ SOLID.” تسلط هذه الاقتباس الضوء على القيمة المحتملة لنماذج اللغة الكبيرة في معالجة التحديات الشائعة في هندسة البرمجيات.
4.3.2 الكفاءة والأتمتة. تم اعتبار نماذج اللغة الكبيرة مفيدة لأتمتة المهام المتكررة وزيادة الكفاءة. تتوافق هذه النظرة مع كل من الفائدة المدركة وسهولة الاستخدام المدركة في نموذج قبول التكنولوجيا، حيث يمكن أن تؤدي أتمتة المهام إلى توفير الوقت وتبسيط عملية التطوير. قال R-35: “أعتقد أنني قد أبدأ في استخدام نموذج لغة بشكل متزايد، خاصة لأتمتة المهام التي يمكن أن يؤديها نموذج اللغة والتي تستغرق وقتًا كبيرًا.” يمكن أن يؤدي اعتماد نماذج اللغة الكبيرة لأتمتة المهام إلى تحسين إنتاجية مهندسي البرمجيات.
4.3.3 التعلم وحل المشكلات. كان استخدام نماذج اللغة الكبيرة للتعلم وحل المشكلات موضوعًا آخر تم تحديده، وهو متماشي مع الفائدة المدركة لنموذج قبول التكنولوجيا. أعرب مهندسو البرمجيات عن نيتهم في استخدام نماذج اللغة الكبيرة لمهام مثل العثور على الوثائق، وتوضيح الشيفرة المربكة، والبحث عن معلومات حول الأسئلة المتعلقة بالبرمجة. كما ذكر R-25، “من المحتمل جدًا. في الغالب للعثور على الوثائق الخاصة بالمكتبات، وإعادة هيكلة وتوضيح الشيفرة المربكة.” يمكن أن تكون نماذج اللغة الكبيرة أداة قيمة للتعلم وحل المشكلات لمهندسي البرمجيات، تدعم التطوير المهني المستمر.
4.3.4 التطبيقات المتخصصة. ذكر المستجيبون الاستخدام المحتمل لنماذج اللغة الكبيرة لمهام محددة، مثل كتابة الوظائف الأساسية، وتحديد المهام، وصياغة الرسائل الإلكترونية. يرتبط هذا الموضوع بالفائدة المتصورة لنماذج اللغة الكبيرة في تلبية احتياجات معينة في هندسة البرمجيات. على سبيل المثال، ذكر R-62، “من المحتمل جدًا. لكتابة الوظائف الأساسية، وتحديد المهام، وللرسائل الإلكترونية.
يمكن أن يوفر اعتماد نماذج اللغة الكبيرة (LLMs) لتطبيقات متخصصة فوائد مستهدفة لمهندسي البرمجيات في عملهم اليومي.
4.3.5 حواجز القبول والمخاوف. على الرغم من الفوائد المحتملة لنماذج اللغة الكبيرة، أعرب بعض مهندسي البرمجيات عن مخاوف وحواجز أمام القبول، مثل التكلفة، والاعتماد على خدمات الطرف الثالث، والمشاكل الأخلاقية المحتملة. تتماشى هذه المخاوف مع مفهوم سهولة الاستخدام المدركة في نموذج قبول التكنولوجيا، حيث يمكن أن تعيق اعتماد نماذج اللغة الكبيرة [110]. على سبيل المثال، ذكر R-60: “قد تكون التكلفة والاعتماد على خدمة طرف ثالث مصدر قلق.” فهم هذه المخاوف ومعالجتها أمر ضروري لتعزيز اعتماد نماذج اللغة الكبيرة في هندسة البرمجيات.
| هوية | اقتباس | مفاهيم من الدرجة الأولى | الموضوعات الثانية | الأبعاد الإجمالية | (% ) |
| R-8 | من المحتمل جداً. أنا أفكر في شراء اشتراك في ChatGPT-4، بشكل أساسي لإعادة هيكلة (الكود القديم) أو لجعله يتماشى مع أنماط تصميم معينة. يمكن أن يساعد أيضاً في إعادة هيكلة الكود لجعله أكثر توافقاً مع مبادئ SOLID. | إعادة هيكلة الكود، أنماط التصميم، مبادئ SOLID | توليد الشيفرة وإعادة هيكلتها | تحسين وصيانة الشيفرة | 42 |
| R-35 | أعتقد أنني قد أبدأ في استخدام لغة بشكل متزايد، خاصة لأتمتة المهام التي يمكن أن يؤديها نموذج اللغة والتي تستغرق وقتًا كبيرًا. | أتمتة المهام، توفير الوقت | أتمتة المهام وتحسينها | الكفاءة والأتمتة | ٣٥ |
| R-25 | من المحتمل جدًا. غالبًا ما يكون ذلك للعثور على الوثائق الخاصة بالمكتبات، وإعادة هيكلة الكود وتوضيح الكود المربك. | ابحث عن الوثائق، أعد هيكلة الكود، وضح الكود المربك | البحث عن المعلومات والتعلم | التعلم وحل المشكلات | ٢٨ |
| R-7 | جربته مع بعض الأسئلة الأساسية المتعلقة بالبرمجة بالفعل. | أسئلة البرمجة الأساسية | البحث عن المعلومات والتعلم | التعلم وحل المشكلات | ٢٨ |
| R-62 | من المحتمل جدًا. لكتابة الوظائف الأساسية، وتحديد المهام، وللرسائل الإلكترونية | كتابة الوظائف الأساسية، تحديد المهام، البريد الإلكتروني | حالات استخدام محددة بالمهام | التطبيقات المتخصصة | 20 |
| R-17 | من المحتمل جدًا في ترجمة اللغة، تلخيص النصوص وتوليد النصوص | ترجمة اللغة، تلخيص النص، توليد النص | مهام معالجة اللغة الطبيعية | معالجة اللغة الطبيعية وتوليد المحتوى | ١٨ |
| R-46 | كتابة اختبارات آلية | كتابة اختبارات آلية | اختبار والتحقق من الشيفرة | ضمان الجودة والتحقق | 15 |
| R-69 | ليس من المحتمل | عدم التبني | عدم اليقين أو عدم التبني | حواجز ومخاوف التبني | 12 |
| R-60 | قد تكون التكلفة والاعتماد على خدمة طرف ثالث مصدر قلق. | التكلفة، الاعتماد على خدمات الطرف الثالث | حواجز التبني | حواجز ومخاوف التبني | 12 |
4.4 توافق نماذج اللغة الكبيرة في هندسة البرمجيات
4.4.1 تحسين الكفاءة. كان تحسين الكفاءة هو الموضوع الأكثر تكرارًا في البيانات، مع
4.4.2 المساعدة والدعم. ظهرت المساعدة والدعم كأكثر الموضوعات تكرارًا في البيانات، حيث تمثل
4.4.3 التشابه مع الممارسات الحالية. تم الإبلاغ عن التشابه مع الممارسات الحالية من قبل
4.4.4 التكيف والتعلم. تم الإبلاغ عن التكيف والتعلم من قبل
4.5 تعقيد نماذج اللغة الكبيرة في هندسة البرمجيات
| معرف | اقتباس | مفاهيم من الدرجة الأولى | توافق | الموضوعات من الدرجة الثانية | الأبعاد المجمعة | (%) |
| R-19 | يمكن استخدام نماذج اللغة لأتمتة مهام معينة في هندسة البرمجيات… | أتمتة المهام، تسريع العملية | تحسين مهام هندسة البرمجيات | تحسين الكفاءة | 39 | |
| R-27 | ينقل عبء البحث مني إلى الخوارزمية. | نقل العبء، الخوارزمية | تحسين مهام هندسة البرمجيات | تحسين الكفاءة | 39 | |
| R-35 | سيسرع نموذج اللغة مهام البحث عن قطع معينة من الشيفرة من مواقع متعددة. | تسريع المهام، بحث الشيفرة | تحسين مهام هندسة البرمجيات | تحسين الكفاءة | 39 | |
| R-1 | يقدم يدًا إضافية ويمكن أن يوفر المساعدة للأشياء التي لا أعرفها ولا أستطيع العثور عليها باستخدام بحث تقليدي. | يد إضافية، مساعدة | تقديم المساعدة والدعم | المساعدة والدعم | 28 | |
| R-15 | لا يوجد فرق كبير حيث يتم استخدام نموذج اللغة فقط لمساعدتي في ممارسات هندسة البرمجيات الحالية. | تشابه، مساعدة | مساعدة | التشابه مع الممارسات الحالية | التشابه مع الممارسات الحالية | 16 |
| R-5 | ليس مختلفًا كثيرًا، إنه مثل البحث في جوجل لكنني لا أحتاج إلى تصفية الكثير من المعلومات. | تشابه، تصفية أقل | التشابه مع الممارسات الحالية | التشابه مع الممارسات الحالية | 16 | |
| R-46 | إنه شيء جديد: عليك أن تتعلم كيفية استخدامه. | تعلم، تكيف | الحاجة إلى التكيف والتعلم | التكيف والتعلم | 11 | |
| R-87 | يمثل استخدام نموذج اللغة نموذجًا جديدًا بالنسبة لي… | نموذج جديد، تكيف | الحاجة إلى التكيف والتعلم | التكيف والتعلم | 11 | |
| R-99 | أكثر تفاعلية وشخصية مقارنة بالبحث العادي في جوجل. | تفاعلي، شخصي | استخدام شخصي وتفاعلي | الشخصية والتفاعل | 10 | |
| R-58 | يقدم استجابة أكثر تحديدًا وتخصيصًا تم تجميعها من الكثير من المحتوى المتاح عبر الإنترنت… | محدد، استجابة مخصصة | استخدام شخصي وتفاعلي | الشخصية والتفاعل | 10 | |
4.5.1 مخاوف أمن الوظائف. ظهرت مخاوف فقدان الوظائف وتخفيض قيمة المهارات كقضية مهمة بين المستجيبين (
4.5.2 الاعتماد والركود. أعرب بعض المستجيبين (
4.5.3 أمان البيانات والخصوصية. تم تحديد مخاوف أمان البيانات والخصوصية من قبل
4.5.4 جودة ودقة الشيفرة المولدة. كما أعرب المستجيبون عن مخاوف بشأن جودة ودقة الشيفرة المولدة بواسطة نماذج اللغة الكبيرة (13% تكرار). علق المستجيب R-49، “نماذج اللغة ليست مثالية، لذا سأكون خائفًا من أنها قد تسبب أخطاء.” إن ضمان موثوقية ودقة الشيفرة المولدة أمر ضروري لاعتماد نماذج اللغة الكبيرة [81]. لمعالجة هذه القضية، يجب على المطورين وضع أفضل الممارسات لمراجعة الشيفرة والتحقق منها، بالإضافة إلى الاستثمار في تحسين أداء النماذج [115].
4.5.5 الاعتبارات الأخلاقية والقانونية. تم تحديد الاعتبارات الأخلاقية والقانونية، مثل حقوق التأليف وحقوق الملكية الفكرية، من قبل
4.5.6 التحيز وقابلية التفسير. أشار بعض المستجيبين (
4.5.7 التكامل والتوافق. تم ذكر قضايا التكامل والتوافق من قبل
| معرف | اقتباس | المفاهيم من الدرجة الأولى | الموضوعات من الدرجة الثانية | الأبعاد المجمعة | (%) |
| R-15 | أنا قلق من أنها يمكن أن تؤتمت الكثير من المهام وتجعل معظم عملي عتيقًا. | الأتمتة، استبدال المهام، العتيقة | فقدان الوظائف، انخفاض قيمة المهارات | مخاوف أمان الوظائف | 25 |
| R-34 | قلقي هو أن المبرمجين المبتدئين الآخرين يستخدمونها دون فهم الكود ويتسببون في أخطاء (مزيد من العمل بالنسبة لي). | المبرمجون المبتدئون، نقص الفهم، الأخطاء | انخفاض في فهم الكود، الاعتماد على نماذج اللغة | الاعتماد والرضا | 16 |
| R-17 | من حيث الخصوصية، حيث يمكن تدريب نماذج اللغة على بيانات حساسة أو شخصية، مثل الرسائل الإلكترونية، الرسائل، أو الوثائق. قد يثير هذا مخاوف بشأن الخصوصية وحماية البيانات، خاصة إذا تم استخدام نموذج اللغة في بيئة سحابية أو تم مشاركته مع أطراف ثالثة. | الخصوصية، حماية البيانات، البيانات الحساسة | سرية البيانات، خطر التعرض | أمان البيانات والخصوصية | 15 |
| R-49 | نماذج اللغة ليست مثالية، لذا سأكون خائفًا من أنها ستسبب أخطاء. | عدم كمال نموذج اللغة، الأخطاء | كود غير صحيح أو غير مُدار بشكل جيد | جودة ودقة الكود الناتج | 13 |
| R-28 | حقوق المؤلفين من الصعب نسبها | الملكية، الحقوق | مخاوف قانونية | اعتبارات أخلاقية وقانونية | 8 |
| R-87 | المخاوف التي لدي بشأن استخدام نماذج اللغة في عملي تشمل قضايا التحيز، قابلية التفسير، والضعف الأمني المحتمل. | التحيز، قابلية التفسير، الثغرات الأمنية | الثقة في النتائج الناتجة، التداخل- | التحيز وقابلية التفسير | 7 |
| R-6 | قد لا تكون متوافقة مع الأنظمة في مكان عملي. | التوافق، الأنظمة | تحديات التكامل | التوافق والتكامل | 5 |
| R-5 | قد تصبح مهاراتي البرمجية “صدئة” إذا اعتمدت عليها كثيرًا، مثل التصحيح التلقائي، أشعر أن قواعدي اللغوية الآن أسوأ لأن هاتفي يفهم حتى الكلمات غير المكتملة ولا أستطيع تذكر الطريقة الصحيحة لكتابة بعض الكلمات بسبب ذلك. | الاعتماد على نماذج اللغة، تدهور المهارات، التصحيح التلقائي | انخفاض المهارات الشخصية | تدهور المهارات | 3 |
4.6 الميزة النسبية لنماذج اللغة الكبيرة في هندسة البرمجيات
4.6.1 كفاءة الوقت. كان موضوعًا متكررًا في تحليلنا هو كفاءة الوقت التي توفرها نماذج اللغة الكبيرة، كما أفاد
4.6.2 جودة الكود. ظهرت تحسينات في جودة الكود كميزة رئيسية أخرى لنماذج اللغة الكبيرة، حيث أشار
4.6.3 تجربة المستخدم. لوحظ أن نماذج اللغة الكبيرة تعزز تجربة المستخدم العامة، حيث أشار
4.6.4 التعلم وتطوير المهارات. وُجد أيضًا أن نماذج اللغة الكبيرة تسهل التعلم وتطوير المهارات، كما أفاد
4.6.5 التخصيص والتخصيص الشخصي. أخيرًا، تم تسليط الضوء على التخصيص والتخصيص الشخصي كميزات من قبل
يمكن تسهيل هندسة البرمجيات من خلال قدرتها على تقديم فوائد واضحة مقارنة بالطرق الحالية [85]. علاوة على ذلك، تسلط نتائجنا الضوء على إمكانية نماذج اللغة الكبيرة في إحداث ثورة في مجال هندسة البرمجيات من خلال تبسيط العمليات، وتعزيز تجربة المستخدم، وتعزيز التعلم المستمر والتحسين.
| معرف | اقتباس | المفاهيم من الدرجة الأولى | الموضوعات من الدرجة الثانية | الأبعاد المجمعة | (%) |
| R-25 | أعتقد أن أفضل شيء هو أن الوقت الذي يقضى في البحث عن أشياء معينة أقل بكثير مما كان عليه في السابق. | بحث موفر للوقت | إكمال المهام | كفاءة الوقت | 42 |
| R-37 | إنه يولد كودًا أبسط وأكثر قابلية للفهم، ويعمل بطريقة أكثر تنظيمًا ويقلل الأخطاء. | كود قابل للفهم، تقليل الأخطاء | بسيط وقوي | جودة الكود | 14 |
| R-67 | نماذج اللغة أسهل في الاستخدام وأسرع لأنك تستطيع إرسال رسائل كما لو كنت تتحدث مع إنسان | أسهل في الاستخدام، أسرع | سهولة التواصل | تجربة المستخدم | 11 |
| R-23 | أعتقد أنه مع نماذج اللغة لا تحتاج إلى قضاء الكثير من الوقت في تعلم الأشياء ‘التقنية’ | وقت أقل للتعلم | تعلم مبسط | التعلم وتطوير المهارات | 9 |
| R-64 | يمكن أن يساعدني في تخطي الكود النمطي والمقتطفات التي كتبتها مئات المرات من قبل. يمكن أن يساعد أيضًا في تعلم بناء الجمل للغات جديدة. | كود نمطي، تعلم لغات جديدة | توليد الكود والأتمتة | قابلية التكيف مع الأتمتة | 8 |
| R-35 | أعتقد أنه قد يكون أكثر كفاءة ويوفر بعض الوقت. | كفاءة، توفير الوقت | حلول مبتكرة | الإبداع والابتكار | 3 |
| R-11 | أعتقد أنه يمكن أن يقدم وجهات نظر واضحة لم تؤخذ في الاعتبار | وجهات نظر جديدة | وجهات نظر متنوعة | رؤى واتخاذ القرار | 4 |
| R-68 | حلول أسرع وأكثر فعالية للمشكلات | حلول أسرع للمشكلات | استكشاف فعال | حل المشكلات | 6 |
| R-53 | يمكن أن تساعد نماذج اللغة (برمجة زوجية) في تقليل الأخطاء وزيادة الكفاءة بشكل عام. | أخطاء أقل، زيادة الكفاءة | مساعدة تعاونية | العمل الجماعي والتعاون | 5 |
| R-94 | تقدم معلومات أكثر هضمًا، ويمكننا “تشكيل” المعلومات كما نريد (مثل: طلب من نموذج اللغة الرد باستخدام جمل قصيرة، أو الشرح بالتفصيل حول مواضيع معينة، إلخ) | معلومات سهلة الهضم، تخصيص | استجابات مرنة | تخصيص وتفصيل | 8 |
4.7 التأثير الاجتماعي لنماذج اللغة الكبيرة في هندسة البرمجيات
4.7.1 لا تأثير. كشف تحليلنا أن
4.7.2 تأثير منخفض. تم الإبلاغ عن تأثير منخفض من قبل
4.7.3 تأثير معتدل. كشف تحليلنا أن
4.7.4 تأثير عالي. أخيرًا، أفاد 26% من المستجيبين بتأثير عالي من أقرانهم وزملائهم (مثل: R-97، R-79، R-27). تشير هذه النتيجة إلى أن نسبة كبيرة من مهندسي البرمجيات تتأثر بشدة بالاستخدام الجماعي والحماس لنماذج اللغة الكبيرة ضمن دوائرهم المهنية. تتماشى هذه النتيجة مع تركيز نظرية الإدراك الاجتماعي على التفاعلات المتبادلة بين الأفراد وبيئتهم الاجتماعية، فضلاً عن الأدبيات حول اعتماد التكنولوجيا في المنظمات [85]. في هذه الحالة، قد ينبع مستوى التأثير العالي من الفوائد المدركة لنماذج اللغة الكبيرة، والتعاون، والحماس المشترك لاستكشاف إمكانيات التكنولوجيا.
| معرف | اقتباس | مفاهيم من الدرجة الأولى | مواضيع من الدرجة الثانية | أبعاد مجمعة | (%) |
| R-66 | زملائي لا يؤثرون على قراراتي لاستخدام نماذج اللغة | لا تأثير | اتخاذ قرارات مستقلة | لا تأثير | 29 |
| R-24 | ليس على الإطلاق. | لا تأثير | اتخاذ قرارات مستقلة | لا تأثير | 29 |
| R-58 | بعضهم مؤيد، لكن ذلك لا يؤثر على رأيي أو طريقة استخدامي له | آخرون مؤيدون، لا تأثير على الرأي أو الاستخدام | تقييم مستقل | لا تأثير | 29 |
| R-97 | كثيرًا، لأننا نستخدمه يوميًا ويتم تشجيعه. | استخدام يومي، تشجيع | اعتماد قوي | تأثير عالي | 26 |
| R-79 | نحن جميعًا نستخدمها، لذا نشجع بعضنا البعض على استخدامها أيضًا | استخدام جماعي، تشجيع متبادل | تعاون ودعم | تأثير عالي | 26 |
| R-27 | بشدة، كل من أعرفه حريص على استكشاف إمكانياتها. | تأثير قوي، استكشاف الإمكانيات | اعتماد متحمس | تأثير عالي | 26 |
| R-45 | ليس كثيرًا | تأثير ضئيل | مستوى منخفض من التأثير | تأثير منخفض | 24 |
| R-99 | ليس حقًا. | تأثير ضئيل | مستوى منخفض من التأثير | تأثير منخفض | 24 |
| R-9 | أتخذ قراراتي الخاصة … لكنني غالبًا ما أبحث عن مدخلات وتعليقات من زملائي وأقراني … | قرار مستقل، مدخلات وتعليقات من الأقران | تقدير آراء الأقران | تأثير معتدل | 21 |
| R-82 | هناك بعض التأثير لكن لا أعتقد أنه أمر كبير لأن الجميع يستخدمه بدافع الفضول | بعض التأثير، اعتماد مدفوع بالفضول | فضول واستكشاف | تأثير معتدل | 21 |
4.8 الكفاءة الذاتية لنماذج اللغة الكبيرة في هندسة البرمجيات
يُنظر إليك على أنك متقدم. ستتم مناقشة هذه الأبعاد بالتفصيل في الفقرات الفرعية التالية، مع تسليط الضوء على دورها في تشكيل كفاءة المطورين الذاتية وسلوك اعتمادهم لنماذج اللغة الكبيرة في هندسة البرمجيات. يمكن العثور على هيكل البيانات في الجدول 8.
4.8.1 أهمية أن يُنظر إليك على أنك متقدم. كما هو موضح في الجدول،
4.8.2 التركيز على العملية والكفاءة. كشفت تحليلاتنا أن
4.8.3 أهمية منخفضة لأن يُنظر إليهم على أنهم متطورون. مجموعة أصغر من المستجيبين (
4.9 العوامل البيئية لنماذج اللغة الكبيرة في هندسة البرمجيات
| معرف | اقتباس | المفاهيم من الدرجة الأولى | المواضيع من الدرجة الثانية | الأبعاد المجمعة | (%) |
| R-2 | البقاء على اطلاع بأحدث التقنيات أمر حاسم في مجالي. | أهمية التكنولوجيا المتطورة | التأكيد على أهمية التكنولوجيا المتطورة | أهمية أن يُنظر إليك على أنك متطور | 57 |
| R-30 | أمر مهم جدًا. لا أريد أن يتم استبدالي بشخص يُنظر إليه على أنه كذلك بينما لا أكون. | الخوف من الاستبدال | التأكيد على أهمية التكنولوجيا المتطورة | أهمية أن يُنظر إليك على أنك متطور | 57 |
| R-57 | من المهم أن أظهر أنني قادر على التكيف. | قدرة التكيف | التأكيد على أهمية التكنولوجيا المتطورة | أهمية أن يُنظر إليك على أنك متطور | 57 |
| R-77 | أعتقد أنه من المهم حقًا أن أكون دائمًا على اطلاع بأحدث التقنيات | أهمية البقاء على اطلاع | التأكيد على أهمية التكنولوجيا المتطورة | أهمية أن يُنظر إليك على أنك متطور | 57 |
| R-10 | من المهم بالنسبة لي لأنه يساعدني على البقاء في المقدمة وتقديم حلول مبتكرة تلبي احتياجات العملاء المتطورة. | البقاء في المقدمة، حلول مبتكرة | التركيز على العملية والكفاءة | التركيز على العملية والكفاءة | 35 |
| R-19 | في عملي كمطور برمجيات، من المهم بالنسبة لي أن أبقى على اطلاع بأحدث الاتجاهات والتقنيات في هندسة البرمجيات، بما في ذلك نماذج اللغة. […] | تلبية احتياجات العملاء، التكنولوجيا المناسبة | التركيز على العملية والكفاءة | التركيز على العملية والكفاءة | 35 |
| R-47 | ليس كثيرًا، عملي يعتمد في الغالب على التقنيات التي يقررها الآخرون. | استخدام التقنيات المحددة | التركيز على العملية والكفاءة | التركيز على العملية والكفاءة | 35 |
| R-100 | قليلًا، لكن التكنولوجيا المتطورة لا تعني دائمًا كفاءة أعلى. والكفاءة هي المفتاح. | الكفاءة، ليست دائمًا متطورة | التركيز على العملية والكفاءة | التركيز على العملية والكفاءة | 35 |
| R-21 | ليس على الإطلاق. أبحث عن الاستقرار، وليس تنفيذ أحدث التقنيات المتطورة في سير العمل الخاص بي. | الاستقرار، رفض التكنولوجيا المتطورة | أهمية منخفضة لأن يُنظر إليهم على أنهم متطورون | أهمية منخفضة لأن يُنظر إليهم على أنهم متطورون | 8 |
| R-66 | لا أجد أنه من المهم أن يُنظر إلي كشخص يستخدم التكنولوجيا المتطورة في عملي. تركيزي هو على استخدام الأدوات الأكثر فعالية للمهام المطروحة. | أهمية منخفضة للتكنولوجيا المتطورة، أدوات فعالة | أهمية منخفضة لأن يُنظر إليهم على أنهم متطورون | أهمية منخفضة لأن يُنظر إليهم على أنهم متطورون | 8 |
4.9.2 الموقف المحايد. يعكس بعد الموقف المحايد المؤسسات التي لا تدعم ولا تعارض بنشاط اعتماد نماذج اللغة الكبيرة (
4.9.3 الدعم المشروط. تظهر بعض المؤسسات في عيّنتنا بعد الدعم المشروط (
4.9.4 الدعم المحدود. يمثل بعد الدعم المحدود (
4.9.5 غياب الدعم. أخيرًا، يمثل بعد غياب الدعم (
| هوية | اقتباس | مفاهيم من الدرجة الأولى | الموضوعات الثانية | الأبعاد الإجمالية | (% ) |
| R-5 | الكثير، يدفعون ثمنه ويشجعوننا على استخدامه | تشجيع، دفع | ترويج نشط | موقف داعم | 42 |
| R-45 | داعم للغاية | دعم قوي | داعم للغاية | موقف داعم | 42 |
| R-84 | أعتقد أن منظمتنا محايدة، الأمر متروك للموظف. | محايد، خيار الموظف | نقص في الرأي القوي | موقف محايد | 20 |
| R-26 | إذا كان ذلك يجلب مزيدًا من المزايا للفريق وطريقة عملنا، ويجعل الأمور أسرع، فإنهم يدعمون اعتماد نماذج اللغة. | المزايا، الكفاءة، الدعم المشروط | الدعم بشروط | الدعم المشروط | 19 |
| R-21 | على الإطلاق. نحن ضد فن الذكاء الاصطناعي، وأيضًا ضد الذكاء الاصطناعي عندما يتعلق الأمر بالبرمجة. لقد فشل في تلبية متطلباتنا على أي حال أثناء الاختبار. | غير داعم، ضد الذكاء الاصطناعي | معارضة لتكنولوجيا الذكاء الاصطناعي | نقص الدعم | 15 |
| R-74 | ليس كثيرًا، لأنه قد ينتهك حقوق الطبع والنشر ويشكل أيضًا بعض المخاوف الأمنية بشأن الملكية الفكرية الخاصة. | مخاوف حقوق الطبع والنشر، مخاوف أمنية، دعم محدود | المخاوف التي تؤدي إلى نقص الدعم | نقص الدعم | 15 |
| R-92 | لا أعرف، لكنهم لا يعارضون ذلك. | عدم اليقين، لا معارضة | غير متأكد | عدم اليقين | 14 |
| R-61 | منظمتي تدعمني إلى حد ما لكنها غير متأكدة. | دعم جزئي، عدم اليقين | ازدواجية | عدم اليقين | 14 |
| R-79 | هم يدعمون استخدامه كأداة مساعدة، وليس كأداة رئيسية. | الدعم، سياق محدود | تطبيق محدود | دعم محدود | 12 |
| R-64 | هم يعارضونهم عند العمل على ميزات جديدة، لكنهم يمكن أن يكونوا مفيدين جدًا في تصحيح الأخطاء. | المعارضة، تصحيح الأخطاء، سياق محدد | الدعم في سياقات محددة | دعم محدود | 12 |
4.10 الرؤى الرئيسية للدراسة النوعية
5 إطار التعاون والتكيف بين الإنسان والذكاء الاصطناعي (HACAF)
تقييم نماذج اللغة الكبيرة بناءً على قدرتها على تبسيط عمليات البرمجة، وتعزيز جودة الكود، وتسريع جداول المشروع. علاوة على ذلك، فإن التركيز على العملية والكفاءة الموجود في دراستنا يبرز أهمية هذا البناء في التأثير على اعتماد نماذج اللغة الكبيرة.
5.1 النموذج النظري والافتراضات
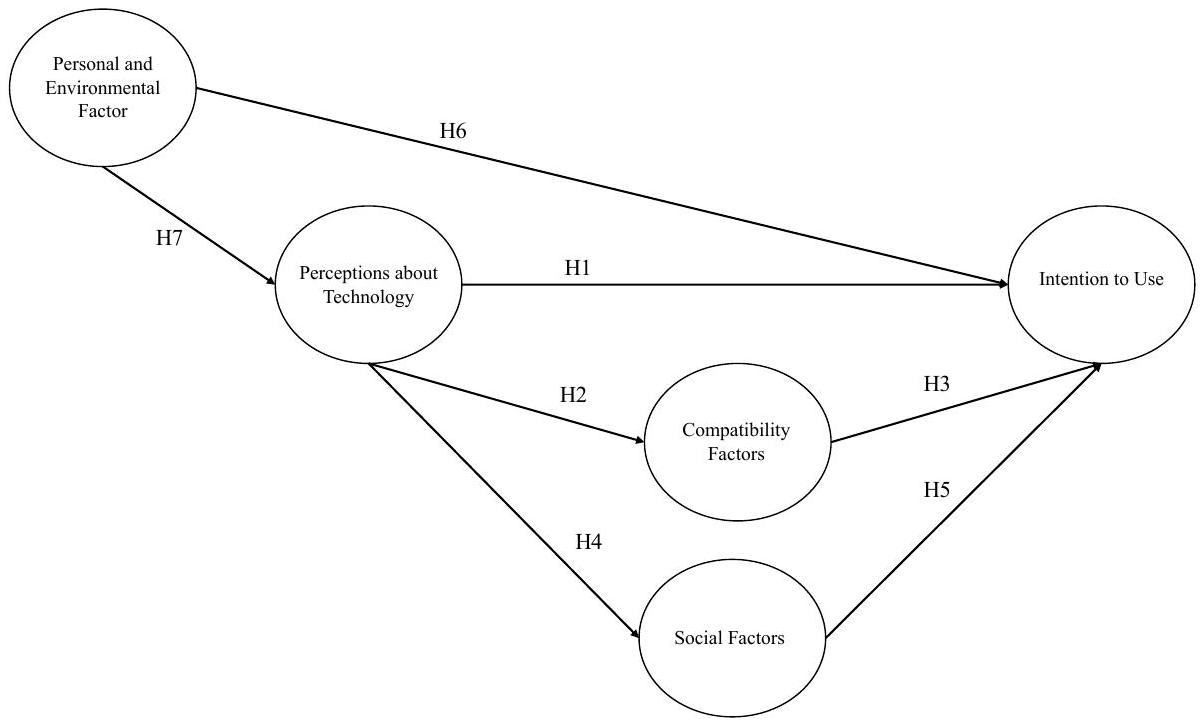
وتعزيز التأثير الإيجابي لتصورات حول التكنولوجيا على نية استخدام نماذج اللغة الكبيرة.
6 التحقق من النظرية
6.1 النمذجة الهيكلية باستخدام المربعات الصغرى الجزئية
6.1.1 تطوير المقياس. تم إعداد الاستبيان بمساعدة نظرية إضافية. قمنا بتنظيم استبياننا من خلال تكييف الأدوات من الأبحاث السابقة. جميع العناصر المستخدمة لتعريف كل بنية والمراجع المستخدمة لتشكيل الأسئلة ملخصة في الجدول 20. تم تقييم كل بنية من خلال عناصر أحادية البعد على مقياس ليكرت من 7 نقاط تشير إلى مستويات الاتفاق.
6.1.2 جمع بيانات الاستبيان. تم تحديد الحد الأدنى لحجم العينة من خلال إجراء تحليل قوة مسبق باستخدام G*Power. مع حجم تأثير قدره
6.1.3 ديموغرافيات المشاركين. شمل استبياننا مجموعة متنوعة من 184 مستجيبًا، تتكون من
6.2 تقييم نموذج القياس
6.2.1 الصلاحية التمييزية. في هذا السياق، تشير الصلاحية التمييزية إلى تميز أو تفرد متغير كامن واحد مقارنة بآخر. هذا يعد معلمة أساسية لتحديد ما إذا كانت بنى معينة هي في الأساس نفس الشيء وتمثل جوانب مختلفة من المعرفة. لتقييمها، استخدمنا نسبة الارتباطات بين المتغيرات المختلفة (HTMT) المعروفة بأدائها المتفوق على اختبارات أخرى مثل معيار فورنل-لاركر. يجب أن تكون قيم HTMT مثالية أقل من 0.90.
| CF | IU | PEF | PT | |
| عوامل التوافق (CF) | ||||
| نية الاستخدام (IU) | 0.756 | |||
| العوامل الشخصية والبيئية (PEF) | 0.372 | 0.272 | ||
| المدركات حول التكنولوجيا (PT) | 0.848 | 0.633 | 0.338 | |
| العوامل الاجتماعية (SF) | 0.403 | 0.371 | 0.441 | 0.437 |
6.2.2 موثوقية الاتساق الداخلي. يسعى هذا الاختبار إلى تأكيد أن العناصر تقيس المتغيرات الكامنة بطريقة متسقة وموثوقة. على هذا النحو، نشير إلى قيم ألفا كرونباخ، وrho_a، وrho_c المعروضة في الجدول 11، والتي يجب أن تتجاوز جميعها 0.60 [70]. يمكننا أن نستنتج أن اختباراتنا تلبي معايير الموثوقية.
| ألفا كرونباخ | rho_a | rho_c | AVE | |
| عوامل التوافق (CF) | 0.856 | 0.866 | 0.902 | 0.699 |
| نية الاستخدام (IU) | 0.939 | 0.941 | 0.961 | 0.891 |
| العوامل الشخصية والبيئية (PEF) | 0.876 | 0.905 | 0.914 | 0.727 |
| المدركات حول التكنولوجيا (PT) | 0.948 | 0.950 | 0.956 | 0.685 |
| العوامل الاجتماعية (SF) | 0.875 | 0.906 | 0.940 | 0.887 |
| عنصر | CF | آي يو | PEF | بي تي | SF |
| CF2 | 0.896 | 0.626 | 0.293 | 0.686 | 0.333 |
| CF3 | 0.856 | 0.657 | 0.352 | 0.666 | 0.305 |
| CF5 | 0.775 | 0.482 | 0.248 | 0.547 | 0.250 |
| CF6 | 0.811 | 0.505 | 0.236 | 0.654 | 0.289 |
| آي يو 1 | 0.662 | 0.935 | 0.238 | 0.560 | 0.293 |
| آي يو 2 | 0.602 | 0.945 | 0.235 | 0.558 | 0.337 |
| آي يو 3 | 0.671 | 0.951 | 0.267 | 0.577 | 0.330 |
| PEF4 | 0.293 | 0.198 | 0.811 | 0.276 | 0.277 |
| PEF5 | 0.156 | 0.130 | 0.838 | 0.214 | 0.250 |
| PEF6 | 0.362 | 0.316 | 0.892 | 0.300 | 0.394 |
| PEF7 | 0.298 | 0.200 | 0.867 | 0.258 | 0.391 |
| PT1 | 0.658 | 0.581 | 0.251 | 0.841 | 0.340 |
| PT11 | 0.641 | 0.521 | 0.178 | 0.855 | 0.318 |
| PT12 | 0.490 | 0.415 | 0.362 | 0.703 | 0.350 |
| بي تي 13 | 0.639 | 0.491 | 0.295 | 0.856 | 0.327 |
| بي تي 14 | 0.612 | 0.460 | 0.267 | 0.851 | 0.330 |
| PT2 | 0.663 | 0.545 | 0.281 | 0.827 | 0.378 |
| PT3 | 0.676 | 0.503 | 0.262 | 0.854 | 0.344 |
| بي تي 4 | 0.655 | 0.511 | 0.271 | 0.874 | 0.383 |
| بي تي 6 | 0.669 | 0.550 | 0.234 | 0.866 | 0.٣٢٣ |
| بي تي 7 | 0.622 | 0.353 | 0.191 | 0.727 | 0.243 |
| SF1 | 0.295 | 0.291 | 0.388 | 0.325 | 0.929 |
| SF2 | 0.365 | 0.342 | 0.359 | 0.427 | 0.955 |
6.3 تقييم النموذج الهيكلي
6.3.1 تحليل التداخل. في البداية، نقوم بتحليل العلاقة بين المتغير الخارجي (العوامل الشخصية والبيئية) وبقية المتغيرات الداخلية. يجب أن تكون هذه المتغيرات مستقلة لتجنب أي تحيز محتمل في تقديرات المسار. يجب أن تكون قيمة اختبار عامل تضخم التباين (VIF) أقل من خمسة [63]، والذي يكشف عن التعدد الخطي (أي، درجة متطرفة من التداخل). قيم VIF لدينا أقل من هذا العتبة، حيث تتراوح من 4.710 (للعنصر IU_3) إلى 2.034 (PEF_4). وبالتالي، نستنتج أن نموذجنا لا يعاني من مشاكل التعدد الخطي.
6.3.2 علاقات المسار: الأهمية والملاءمة. تمثل معاملات المسار العلاقات المفترضة بين المتغيرات الكامنة. إنها موحدة، مما يعني أن قيمها يمكن أن تتراوح
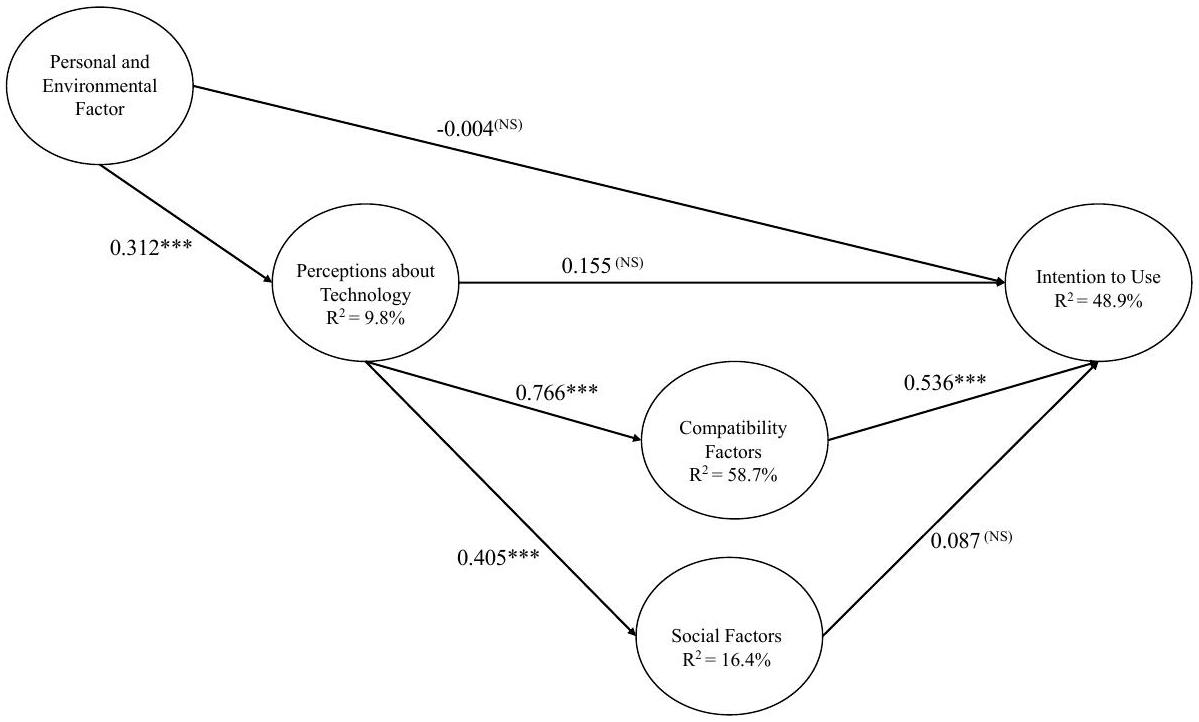
| فرضية | معامل | متوسط البوتستراب | الانحراف المعياري | ت |
|
| H1:
|
0.155 | 0.150 | 0.122 | 1.271 | 0.204 |
| H2: PT
|
0.766 | 0.766 | 0.047 | ١٦.٤٠٥ | 0.000 |
| H3:
|
0.536 | 0.537 | 0.090 | 5.936 | 0.000 |
| H4:
|
0.405 | 0.408 | 0.076 | ٥.٣٤٦ | 0.000 |
| H5: SF
|
0.087 | 0.090 | 0.064 | 1.373 | 0.170 |
| H6: PEF
|
-0.004 | -0.004 | 0.056 | 0.064 | 0.949 |
| H7: PEF
|
0.313 | 0.317 | 0.072 | ٤.٣١٣ | 0.000 |
| بناء |
|
|
| عوامل التوافق | 0.587 | 0.585 |
| نية الاستخدام | 0.489 | 0.477 |
| العوامل الشخصية والبيئية | 0.098 | 0.093 |
| العوامل الاجتماعية | 0.164 | 0.159 |
| بناء | جذر متوسط مربع الخطأ | ماي |
|
| عوامل التوافق | 0.089 | 0.984 | 0.752 |
| نية الاستخدام | 0.046 | 1.012 | 0.761 |
| الآراء حول التكنولوجيا | 0.076 | 0.998 | 0.733 |
| العوامل الاجتماعية | 0.078 | 0.971 | 0.755 |
| البنى | CF | آي يو | PEF | PT | SF |
| عوامل التوافق | 0.225 | ||||
| نية الاستخدام | |||||
| العوامل الشخصية والبيئية | 0.000 | 0.108 | |||
| الآراء حول التكنولوجيا | 1.426 | 0.196 | |||
| العوامل الاجتماعية | 0.018 | 0.011 |
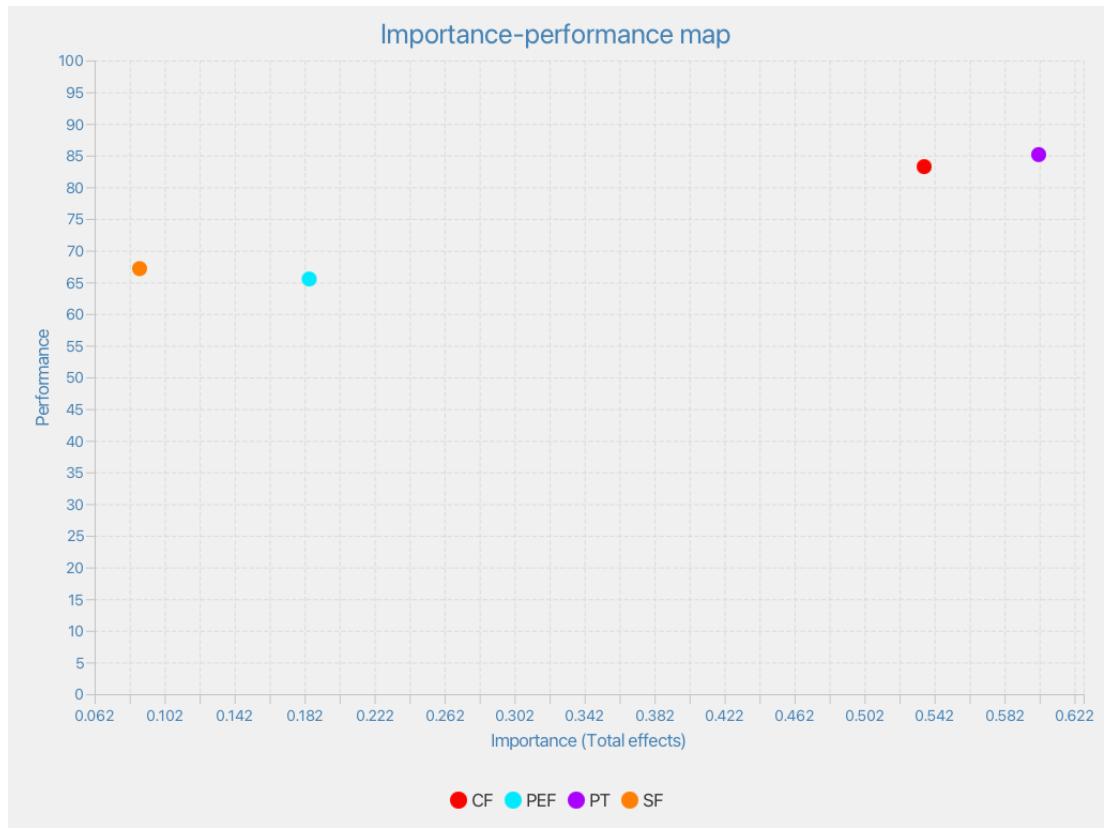
6.4 تحديد العوامل الرئيسية للتبني: تحليل باستخدام خريطة الأهمية والأداء
| البنية | أداء البنى |
| CF | 83.257 |
| PEF | 65.519 |
| PT | 85.138 |
| SF | 67.161 |
| البنية | CF | IU | PEF | PT | SF |
| CF | 0.646 | ||||
| IU | |||||
| PEF | 0.240 | 0.167 | 0.313 | 0.127 | |
| PT | 0.767 | 0.540 | 0.405 | ||
| SF | 0.110 |
7 المناقشة
| الفرضية | النتائج | التداعيات |
| H1: التصورات حول التكنولوجيا
|
غير مدعومة. لم نجد علاقة مباشرة بين التصورات حول التكنولوجيا والنية في الاستخدام. | تصور التكنولوجيا وحده لا يحفز اعتماد أداة ذكاء اصطناعي توليدي. |
| H2: التصورات حول التكنولوجيا
|
مدعومة. هذه العلاقة هي الأقوى في النموذج مع معامل مسار قدره 0.77 مع حجم تأثير كبير جدًا (1.43). | استيعاب قدرات أدوات الذكاء الاصطناعي التوليدي وإمكانية دمجها في سير العمل الحالي لتطوير البرمجيات أمر حاسم. |
| H3: عوامل التوافق
|
مدعومة. هذه العلاقة متناظرة مع فرضية H2 (مع معامل مسار كبير قدره 0.54 وحجم تأثير كبير قدره 0.66)، والتي تفسر في الغالب النية في استخدام LLMs. تظهر IPMA أن عوامل التوافق هي العنصر الأكثر أهمية لتحسين النية في الاستخدام. بالإضافة إلى ذلك، تفسر، تقريبًا بمفردها، اعتماد أدوات الذكاء الاصطناعي بحجم تأثير مرتفع جدًا
|
يعتمد اعتماد أدوات الذكاء الاصطناعي التوليدي بشكل كبير على تكاملها الناجح مع سير العمل الحالي لتطوير البرمجيات. |
| H4: التصورات حول التكنولوجيا
|
مدعومة. نبلغ عن معامل مسار كبير (0.40) مع حجم تأثير متوسط (0.20). الطريقة التي يتم بها تصور الذكاء الاصطناعي التوليدي تؤثر بشكل إيجابي على كفاءة المطورين الذاتية. | يعتبر المطورون LLMs كعوامل تسهيل حيوية في إكمال المهام بشكل أكثر فعالية. |
| H5: العوامل الاجتماعية
|
غير مدعومة. العلاقة بين العوامل الاجتماعية والنية في الاستخدام ليست ذات دلالة. | على الرغم من أن أدوات الذكاء الاصطناعي التوليدي تعتبر عوامل تمكين مهمة لكفاءة المطورين الذاتية، إلا أن هذا التصور لا يترجم إلى اعتماد. |
| H6: العوامل الشخصية والبيئية
|
غير مدعومة. هذه العلاقة ليست ذات دلالة. | لا تؤثر الابتكارية الشخصية والدعم التنظيمي بشكل كبير على اعتماد المطورين لأدوات الذكاء الاصطناعي التوليدي. |
| H7: العوامل الشخصية والبيئية
|
مدعومة. وجدنا علاقة كبيرة بين العوامل الشخصية والبيئية والتصورات حول التكنولوجيا مع معامل مسار قدره 0.31 وحجم تأثير صغير إلى متوسط (0.11). | كما هو متوقع، فإن ميل المطور للتجربة مع أدوات الذكاء الاصطناعي التوليدي، جنبًا إلى جنب مع الدعم التنظيمي المدرك، يؤثر بشكل إيجابي على تصور التكنولوجيا. |
أن يتم تأكيد العلاقات ضمن نموذج HACAF بشكل أكبر. إن عدم التحقق الحالي من جميع العلاقات ضمن نموذج إطار عملنا لا يقلل من فائدته ولكنه يقدم رؤى أولية حول العوامل التي تشكل اعتماد أدوات الذكاء الاصطناعي التوليدي في هذه المرحلة.
7.1 الآثار
- تقييم الأدوات: يجب على المنظمات بدء تقييم شامل للأدوات المدفوعة بالذكاء الاصطناعي المتاحة، مع التركيز على توافقها مع العمليات الحالية والاحتياجات المحددة لفرق التطوير الخاصة بهم.
- اختبار تجريبي: قبل التنفيذ على نطاق واسع، قم بإجراء اختبارات تجريبية مع مجموعة فرعية من المشاريع لقياس تأثير الأداة على وقت التطوير، وجودة البرمجيات، ورضا المستخدم.
- برامج التدريب: تقديم جلسات تدريبية للمطورين لتعريفهم بتفاصيل الأدوات المدروسة، لضمان قدرتهم على الاستفادة القصوى من قدرات الأداة.
- حلقة التغذية الراجعة: إنشاء آلية للتغذية الراجعة حيث يمكن للمطورين الإبلاغ عن أداء الأداة، وأي تحديات واجهتهم، ومجالات التحسين. يمكن أن توجه هذه التغذية الراجعة التحسينات التكرارية وتضمن أن تظل الأداة متوافقة مع ممارسات التطوير المتطورة.
- تحليل التكلفة والفائدة: تقييم العائد على الاستثمار من اعتماد أداة الذكاء الاصطناعي بانتظام، مع الأخذ في الاعتبار عوامل مثل تحسين الكفاءة، وتقليل الأخطاء، ورضا المستخدمين.
نظرًا لنتائجنا حول أهمية عوامل التوافق في دفع اعتماد الذكاء الاصطناعي، هناك حاجة ملحة للتعليم والتدريب المستمر في الذكاء الاصطناعي مع تزايد انتشاره في هندسة البرمجيات. بشكل ملموس، نقترح: - وحدات تدريب مخصصة: يجب على المنظمات تطوير وتقديم وحدات تدريب مخصصة تركز على دمج أدوات الذكاء الاصطناعي ضمن سير العمل الحالي لتطوير البرمجيات. يجب أن تتناول هذه الوحدات الجوانب التقنية والتعاونية لاستخدام الذكاء الاصطناعي في بيئات العمل الجماعي.
- ورش عمل منتظمة: استضافة ورش عمل وندوات منتظمة تضم خبراء في مجال الذكاء الاصطناعي. سيوفر ذلك للموظفين رؤى حول أحدث التطورات وأفضل الممارسات في تطوير البرمجيات المدفوعة بالذكاء الاصطناعي.
- التعاون مع مزودي أدوات الذكاء الاصطناعي: إقامة شراكات مع مزودي أدوات الذكاء الاصطناعي لتسهيل جلسات تدريب عملية، مما يضمن أن تكون القوى العاملة قادرة على الاستفادة الكاملة من إمكانيات هذه الأدوات.
- تعزيز التآزر بين الصناعة والأكاديميا: لسد الفجوة بين المعرفة النظرية والتطبيق العملي، يجب على المؤسسات الأكاديمية تعزيز التعاون الأعمق مع قادة الصناعة. من خلال تصميم مناهج هندسة البرمجيات التي تركز على التطوير المدفوع بالذكاء الاصطناعي، يمكننا ضمان أن يكون الخريجون ليسوا فقط على دراية بالتقنيات الحالية ولكن أيضًا متوافقين مع التحديات والفرص الحقيقية في الصناعة.
- التكرارات المدفوعة بالتغذية الراجعة: إنشاء آليات لجمع التغذية الراجعة من الموظفين الذين يخضعون للتدريب. يمكن أن تكون هذه التغذية الراجعة حاسمة في تحسين محتوى التدريب والأساليب، مما يضمن أنها تظل ذات صلة وفعالة.
تؤكد دراستنا أيضًا على أهمية نهج الإنسان في الحلقة عند دمج الذكاء الاصطناعي في هندسة البرمجيات. لاستخدام الإمكانات الكاملة لأدوات الذكاء الاصطناعي مع ضمان أنها تعزز، بدلاً من استبدال، القدرات البشرية، يُوصى بالخطوات القابلة للتنفيذ التالية: - تصميم الذكاء الاصطناعي الموجه نحو المستخدم: يجب على مطوري أدوات الذكاء الاصطناعي إعطاء الأولوية لفلسفة تصميم موجهة نحو المستخدم، مما يضمن أن تكون الأدوات بديهية وتتكامل بسلاسة في سير عمل المطورين.
- آليات الشفافية: تنفيذ آليات داخل أنظمة الذكاء الاصطناعي توضح عمليات اتخاذ القرار الخاصة بها. سيمكن ذلك المطورين من فهم واقتناع باقتراحات وقرارات الذكاء الاصطناعي.
- ميزات المعايرة: تجهيز أدوات الذكاء الاصطناعي بميزات تسمح للمطورين بمعايرتها أو ضبطها بناءً على متطلبات المشروع المحددة وحكمهم المهني.
- حلقة التغذية الراجعة: إنشاء حلقات تغذية راجعة تكرارية حيث يمكن للمطورين تقديم ملاحظات حول مخرجات أدوات الذكاء الاصطناعي، والتي يمكن استخدامها بعد ذلك لتحسين أداء الأداة بمرور الوقت.
- مساحات العمل التعاونية: تصميم مساحات عمل تعاونية حيث يمكن لكل من أدوات الذكاء الاصطناعي والمطورين المساهمة في الوقت الحقيقي، مما يعزز علاقة تكافلية تستفيد من نقاط القوة لدى كلا الطرفين.
- التدريب المستمر: مع تطور أدوات الذكاء الاصطناعي، يجب توفير فرص تدريب مستمرة للمطورين لضمان قدرتهم على التعاون بفعالية مع أحدث إصدارات هذه الأدوات.
- تحليل المتطلبات: قبل الغوص في اعتماد الذكاء الاصطناعي، يجب على المنظمات إجراء تحليل شامل لاحتياجاتها المحددة. يتضمن ذلك فهم التحديات التي تواجهها وتحديد كيفية معالجة الذكاء الاصطناعي لها.
- تقييم الموارد: تقييم الموارد المتاحة، سواء من حيث الأجهزة أو الخبرة البشرية. سيساعد ذلك في اختيار حلول الذكاء الاصطناعي التي تمتلك المنظمة القدرة على نشرها وصيانتها.
- تحديد القيود: التعرف على أي قيود، سواء كانت ميزانية أو زمنية أو تقنية، قد تؤثر على نشر وتشغيل حلول الذكاء الاصطناعي.
- آلية التغذية الراجعة: إنشاء آلية للمطورين وغيرهم من أصحاب المصلحة لتقديم التغذية الراجعة حول أدوات الذكاء الاصطناعي، مما يضمن تحسينها وتحسينها بمرور الوقت.
- المراجعة المستمرة: مراجعة استراتيجية اعتماد الذكاء الاصطناعي بشكل دوري لضمان أنها تظل متوافقة مع الاحتياجات والسياقات المتطورة للمنظمة.
- ثغرات أمنية: سلطت دراسات حديثة، مثل تلك التي أجراها تسامادوس وآخرون [106]، الضوء على الثغرات الأمنية الكامنة في الذكاء الاصطناعي، خاصة مع النماذج اللغوية الكبيرة. تؤكد نتائجهم على الحاجة إلى فهم شامل لقدرات هذه النماذج وثغراتها.
- مسؤولية مزود النموذج: يجب على مزودي النماذج، في سعيهم لتعزيز الاعتماد، أن يكونوا استباقيين في توضيح الثغرات المحتملة وتقديم إرشادات حول أفضل الممارسات لمواجهة هذه المخاطر. مع تطور تقنيات النماذج اللغوية الكبيرة بسرعة، فإن المراجعات والتدقيقات الدورية أمر بالغ الأهمية لضمان الشفافية والامتثال للمعايير الأخلاقية.
- تدابير أمان المنصة: يجب على المنصات التي تدمج النماذج اللغوية الكبيرة تعزيز بروتوكولات الأمان الخاصة بها، مما يضمن استعدادها لمواجهة التحديات الفريدة التي تطرحها هذه النماذج. عند اعتماد أو استخدام النماذج اللغوية الكبيرة، من الحكمة اختيار نماذج من مصادر موثوقة ومثبتة، مما يضمن كل من الاعتمادية والأمان.
- حوارات أصحاب المصلحة: يمكن أن تعزز المحادثات المفتوحة بين أصحاب المصلحة، بما في ذلك المطورين والمستخدمين والجهات التنظيمية، اعتمادًا أكثر مسؤولية وأخلاقية لأدوات الذكاء الاصطناعي التوليدية في هندسة البرمجيات.
باختصار، فإن دمج تقنيات الذكاء الاصطناعي، وخاصة أدوات الذكاء الاصطناعي التوليدية مثل النماذج اللغوية الكبيرة، في هندسة البرمجيات يحمل إمكانات هائلة لتعزيز عملية التطوير وتحسين جودة البرمجيات بشكل عام. من خلال الاعتراف بالتحديات المرتبطة
مع اعتماد الذكاء الاصطناعي – مع الأخذ في الاعتبار نتائجنا حول أهمية عوامل التوافق – يمكن للمنظمات الاستفادة بفعالية من أدوات وأساليب مدفوعة بالذكاء الاصطناعي لتحقيق نتائج محسنة في مساعي تطوير البرمجيات الخاصة بهم.
7.2 القيود
8 الاستنتاج
المواد التكميلية
شكر وتقدير
REFERENCES
[2] Ritu Agarwal and Jayesh Prasad. 1999. Are individual differences germane to the acceptance of new information technologies? Decision Sciences 30, 2 (1999), 361-391.
[3] AI, B. 2023. BLACKBOX AI – useblackbox.io. https://www.useblackbox.io/ Accessed: October 17, 2023.
[4] Icek Ajzen. 1991. The theory of planned behavior. Organizational Behavior and Human Decision Processes 50, 2 (1991), 179-211.
[5] Icek Ajzen. 2020. The theory of planned behavior: Frequently asked questions. Human Behavior and Emerging Technologies 2, 4 (2020), 314-324.
[6] Amazon Web Services. 2023. Code-Whisperer – Amazon Web Services. https://aws.amazon.com/es/codewhisperer/ Accessed: October 17, 2023.
[7] Alejandro Barredo Arrieta, Natalia Díaz-Rodríguez, Javier Del Ser, Adrien Bennetot, Siham Tabik, Alberto Barbado, Salvador Garcia, Sergio Gil-Lopez, Daniel Molina, Richard Benjamins, et al. 2020. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Information Fusion 58 (2020), 82-115.
[8] S. Baltes and P. Ralph. 2020. Sampling in Software Engineering Research: A Critical Review and Guidelines. arXiv:2002.07764 (2020).
[9] Albert Bandura. 2014. Social cognitive theory of moral thought and action. In Handbook of moral behavior and development. Psychology press, 69-128.
[10] Albert Bandura, W. H. Freeman, and Richard Lightsey. 1999. Self-Efficacy: The Exercise of Control. Fournal of Cognitive Psychotherapy 13, 2 (1999), 158-166.
[11] Shraddha Barke, Michael B James, and Nadia Polikarpova. 2023. Grounded copilot: How programmers interact with code-generating models. Proceedings of the ACM on Programming Languages 7 (2023), 85-111.
[12] James Bessen. 2019. Automation and jobs: When technology boosts employment. Economic Policy 34, 100 (2019), 589-626.
[13] Christian Bird, Denae Ford, Thomas Zimmermann, Nicole Forsgren, Eirini Kalliamvakou, Travis Lowdermilk, and Idan Gazit. 2022. Taking Flight with Copilot: Early insights and opportunities of AI-powered pair-programming tools. Queue 20, 6 (2022), 35-57.
[14] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in Neural Information Processing Systems 33 (2020), 1877-1901.
[15] Javier Cámara, Javier Troya, Lola Burgueño, and Antonio Vallecillo. 2023. On the assessment of generative AI in modeling tasks: an experience report with ChatGPT and UML. Software and Systems Modeling (2023), 1-13.
[16] Ruijia Cheng, Ruotong Wang, Thomas Zimmermann, and Denae Ford. 2022. “It would work for me too”: How Online Communities Shape Software Developers’ Trust in AI-Powered Code Generation Tools. arXiv preprint arXiv:2212.03491 (2022).
[17] W. W. Chin. 1998. The partial least squares approach to structural equation modeling. Modern Methods for Business Research 295, 2 (1998), 295-336.
[18] Clayton M. Christensen. 1997. The Innovator’s Dilemma: When New Technologies Cause Great Firms to Fail. Harvard Business Review Press.
[19] Michael Chui et al. 2023. The economic potential of generative AI: The next productivity frontier. https://www.mckinsey.com/capabilities/mckinsey-digital/our-insights/the-economic-potential-of-generative-ai-the-next-productivity-frontier. [Accessed 03-Jul-2023].
[20] Victoria Clarke, Virginia Braun, and Nikki Hayfield. 2015. Thematic analysis. Qualitative psychology: A practical guide to research methods 3 (2015), 222-248.
[21] CodeComplete. 2023. CodeComplete: AI Coding Assistant for Enterprise. https://codecomplete.ai/ Accessed: October 17, 2023.
[22] Codeium. 2023. Codeium • Free AI Code Completion and Chat. https://codeium.com/ Accessed: October 17, 2023.
[23] J. Cohen. 1988. Statistical Power Analysis for the Behavioral Sciences. Routledge.
[24] Deborah R Compeau and Christopher A Higgins. 1995. Computer self-efficacy: Development of a measure and initial test. MIS Quarterly (1995), 189-211.
[25] J. Corbin and A. Strauss. 1990. Grounded theory research: Procedures, canons, and evaluative criteria. Qualitative Sociology 13, 1 (1990), 3-21.
[26] J. Creswell. 2013. Research design: Qualitative, quantitative, and mixed methods approaches. Sage.
[27] Arghavan Moradi Dakhel, Vahid Majdinasab, Amin Nikanjam, Foutse Khomh, Michel C Desmarais, and Zhen Ming Jack Jiang. 2023. Github copilot ai pair programmer: Asset or liability? 7ournal of Systems and Software 203
(2023), 111734.
[28] Anastasia Danilova, Alena Naiakshina, Stefan Horstmann, and Matthew Smith. 2021. Do you really code? Designing and Evaluating Screening Questions for Online Surveys with Programmers. In International Conference on Software Engineering. IEEE, 537-548.
[29] F. Davis. 1989. Perceived usefulness, perceived ease of use, and user acceptance of information technology. MIS Quarterly 13, 3 (1989), 319-340.
[30] Fred D Davis, Richard P Bagozzi, and Paul R Warshaw. 1989. User acceptance of computer technology: A comparison of two theoretical models. Management science 35, 8 (1989), 982-1003.
[31] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2019).
[32] Paul Dourish. 2003. The appropriation of interactive technologies: Some lessons from placeless documents. Computer Supported Cooperative Work 12 (2003), 465-490.
[33] Christof Ebert and Panos Louridas. 2023. Generative AI for software practitioners. IEEE Software 40, 4 (2023), 30-38.
[34] Neil A Ernst and Gabriele Bavota. 2022. Ai-driven development is here: Should you worry? IEEE Software 39, 2 (2022), 106-110.
[35] Carl Benedikt Frey and Michael A Osborne. 2017. The future of employment: How susceptible are jobs to computerisation? Technological Forecasting and Social Change 114 (2017), 254-280.
[36] Yanjie Gao, Xiaoxiang Shi, Haoxiang Lin, Hongyu Zhang, Hao Wu, Rui Li, and Mao Yang. 2023. An Empirical Study on Quality Issues of Deep Learning Platform. In International Conference on Software Engineering: Software Engineering in Practice. IEEE, 455-466.
[37] D. Gefen, D. Straub, and M.-C. Boudreau. 2000. Structural equation modeling and regression: Guidelines for research practice. Communications of the Association for Information Systems 4, 1 (2000), 7.
[38] D. Gioia, K. Corley, and A. Hamilton. 2013. Seeking qualitative rigor in inductive research: Notes on the Gioia methodology. Organizational Research Methods 16, 1 (2013), 15-31.
[39] D. Gioia, J. Thomas, S. Clark, and K. Chittipeddi. 1994. Symbolism and strategic change in academia: The dynamics of sensemaking and influence. Organization Science 5, 3 (1994), 363-383.
[40] B. Glaser and A. Strauss. 2017. Discovery of grounded theory: Strategies for qualitative research. Routledge.
[41] Dale L Goodhue and Ronald L Thompson. 1995. Task-technology fit and individual performance. MIS quarterly (1995), 213-236.
[42] Roberto Gozalo-Brizuela and Eduardo C Garrido-Merchán. 2023. A survey of Generative AI Applications. arXiv preprint arXiv:2306.02781 (2023).
[43] F. J. Gravetter and L.-A. B. Forzano. 2018. Research methods for the behavioral sciences. Cengage Learning.
[44] Stine Grodal, Michel Anteby, and Audrey L Holm. 2021. Achieving rigor in qualitative analysis: The role of active categorization in theory building. Academy of Management Review 46, 3 (2021), 591-612.
[45] E. Guba. 1981. Criteria for assessing the trustworthiness of naturalistic inquiries. Educational Communication and Technology fournal 29, 2 (1981), 75-91.
[46] J. F. Hair Jr, G T. M Hult, C. Ringle, and M. Sarstedt. 2016. A primer on partial least squares structural equation modeling (PLS-SEM). Sage.
[47] Douglas M Hawkins. 2004. The problem of overfitting. Journal of chemical information and computer sciences 44, 1 (2004), 1-12.
[48] Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. 2019. The curious case of neural text degeneration. arXiv preprint arXiv:1904.09751 (2019).
[49] Saki Imai. 2022. Is github copilot a substitute for human pair-programming? an empirical study. In Proceedings of the ACM/IEEE International Conference on Software Engineering: Companion Proceedings. 319-321.
[50] L. Isabella. 1990. Evolving interpretations as a change unfolds: How managers construe key organizational events. Academy of Management Journal 33, 1 (1990), 7-41.
[51] Mateusz Jaworski and Dariusz Piotrkowski. 2023. Study of software developers’ experience using the Github Copilot Tool in the software development process.
[52] Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361 (2020).
[53] Ron Kohavi. 1995. A study of cross-validation and bootstrap for accuracy estimation and model selection. In Ijcai, Vol. 14. 1137-1145.
[54] Rajiv Kohli and Nigel P Melville. 2019. Digital innovation: A review and synthesis. Information Systems 7ournal 29, 1 (2019), 200-223.
[55] U. Kulkarni, S. Ravindran, and R. Freeze. 2006. A knowledge management success model: Theoretical development and empirical validation. Journal of Management Information Systems 23, 3 (2006), 309-347.
[56] W. Lewis, R. Agarwal, and V. Sambamurthy. 2003. Sources of influence on beliefs about information technology use: An empirical study of knowledge workers. MIS Quarterly (2003), 657-678.
[57] Y. Li, D. Choi, J. Chung, N. Kushman, J. Schrittwieser, R. Leblond, T. Eccles, J. Keeling, F. Gimeno, A. D. Lago, T. Hubert, P. Choy, C. de Masson d’Autume, I. Babuschkin, X. Chen, P.-S. Huang, J. Welbl, S. Gowal, A. Cherepanov, J. Molloy, D. J. Mankowitz, E. S. Robson, P. Kohli, N. de Freitas, K. Kavukcuoglu, and O. Vinyals. 2023. AlphaCode alphacode.deepmind.com. https://alphacode.deepmind.com/ Accessed: October 17, 2023.
[58] Jenny T Liang, Chenyang Yang, and Brad A Myers. 2023. Understanding the Usability of AI Programming Assistants. arXiv preprint arXiv:2303.17125 (2023).
[59] Y. Lincoln and E. Guba. 1985. Naturalistic inquiry. Sage.
[60] Mai Skjott Linneberg and Steffen Korsgaard. 2019. Coding qualitative data: A synthesis guiding the novice. Qualitative Research fournal 19, 3 (2019), 259-270.
[61] K. Locke. 1996. Rewriting the discovery of grounded theory after 25 years? Journal of Management Inquiry 5, 3 (1996), 239-245.
[62] Antonio Mastropaolo, Luca Pascarella, Emanuela Guglielmi, Matteo Ciniselli, Simone Scalabrino, Rocco Oliveto, and Gabriele Bavota. 2023. On the robustness of code generation techniques: An empirical study on github copilot. arXiv preprint arXiv:2302.00438 (2023).
[63] J. Miles. 2014. Tolerance and Variance Inflation Factor. American Cancer Society.
[64] Brent Daniel Mittelstadt, Patrick Allo, Mariarosaria Taddeo, Sandra Wachter, and Luciano Floridi. 2016. The ethics of algorithms: Mapping the debate. Big Data & Society 3, 2 (2016).
[65] Geoffrey A Moore and Regis McKenna. 1999. Crossing the chasm. (1999).
[66] Hussein Mozannar, Gagan Bansal, Adam Fourney, and Eric Horvitz. 2022. Reading between the lines: Modeling user behavior and costs in AI-assisted programming. arXiv preprint arXiv:2210.14306 (2022).
[67] mutable.ai. 2023. AI Accelerated Software Development. – mutable.ai. https://mutable.ai/ Accessed: October 17, 2023.
[68] Nhan Nguyen and Sarah Nadi. 2022. An empirical evaluation of GitHub copilot’s code suggestions. In Proceedings of the International Conference on Mining Software Repositories. 1-5.
[69] Oded Nov and Chen Ye. 2008. Users’ personality and perceived ease of use of digital libraries: The case for resistance to change. Journal of the American Society for Information Science and Technology 59, 5 (2008), 845-851.
[70] J. Nunnally. 1978. Psychometric methods. McGraw-Hill.
[71] General Assembly of the World Medical Association et al. 2014. World Medical Association Declaration of Helsinki: ethical principles for medical research involving human subjects. The 7ournal of the American College of Dentists 81, 3 (2014), 14.
[72] OpenAI. 2023. GPT-4 Technical Report. arXiv:2303.08774 [cs.CL]
[73] Ipek Ozkaya. 2023. The next frontier in software development: AI-augmented software development processes. IEEE Software 40, 4 (2023), 4-9.
[74] Stefan Palan and Christian Schitter. 2018. Prolific.ac–A subject pool for online experiments. Journal of Behavioral and Experimental Finance 17 (2018), 22-27.
[75] Sida Peng, Eirini Kalliamvakou, Peter Cihon, and Mert Demirer. 2023. The impact of ai on developer productivity: Evidence from github copilot. arXiv preprint arXiv:2302.06590 (2023).
[76] Anthony Peruma, Steven Simmons, Eman Abdullah AlOmar, Christian D Newman, Mohamed Wiem Mkaouer, and Ali Ouni. 2022. How do i refactor this? An empirical study on refactoring trends and topics in Stack Overflow. Empirical Software Engineering 27, 1 (2022), 11.
[77] James Prather, Brent N Reeves, Paul Denny, Brett A Becker, Juho Leinonen, Andrew Luxton-Reilly, Garrett Powell, James Finnie-Ansley, and Eddie Antonio Santos. 2023. ” It’s Weird That it Knows What I Want”: Usability and Interactions with Copilot for Novice Programmers. arXiv preprint arXiv:2304.02491 (2023).
[78] Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners. OpenAI blog 1, 8 (2019), 9.
[79] Paul Ralph et al. 2020. Empirical standards for software engineering research. arXiv preprint arXiv:2010.03525 (2020).
[80] M. Ramkumar, T. Schoenherr, S. Wagner, and M. Jenamani. 2019. Q-TAM: A quality technology acceptance model for predicting organizational buyers’ continuance intentions for e-procurement services. International fournal of Production Economics 216 (2019), 333-348.
[81] Baishakhi Ray, Daryl Posnett, Vladimir Filkov, and Premkumar Devanbu. 2014. A large scale study of programming languages and code quality in github. In International Symposium on Foundations of Software Engineering. ACM, 155-165.
[82] replit. 2023. Ghostwriter – Code faster with AI – replit.com. https://replit.com/site/ghostwriter Accessed: October 17, 2023.
[83] C. M. Ringle and M. Sarstedt. 2016. Gain more insight from your PLS-SEM results: The importance-performance map analysis. Industrial Management & Data Systems 116, 9 (2016), 1865-1886.
[84] C. M. Ringle, S. Wende, and J.-M. Becker. 2015. SmartPLS 3.
[85] Everett M. Rogers. 2010. Diffusion of Innovations. Simon and Schuster.
[86] Daniel Russo. 2021. The agile success model: a mixed-methods study of a large-scale agile transformation. ACM Transactions on Software Engineering and Methodology 30, 4 (2021), 1-46.
[87] D. Russo, P. Ciancarini, T. Falasconi, and M. Tomasi. 2018. A Meta Model for Information Systems Quality: a Mixed-Study of the Financial Sector. ACM Transactions on Management Information Systems 9, 3 (2018).
[88] Daniel Russo, Paul H P Hanel, Seraphina Altnickel, and Niels van Berkel. 2021. The daily life of software engineers during the covid-19 pandemic. In International Conference on Software Engineering. IEEE, 364-373.
[89] Daniel Russo, Paul H P Hanel, Seraphina Altnickel, and Niels van Berkel. 2021. Predictors of Well-being and Productivity among Software Professionals during the COVID-19 Pandemic-A Longitudinal Study. Empirical Software Engineering 26, 62 (2021), 1-64. https://doi.org/10.1007/s10664-021-09945-9
[90] Daniel Russo and Klaas-Jan Stol. 2020. Gender Differences in Personality Traits of Software Engineers. IEEE Transactions on Software Engineering 48, 3 (2020), 16.
[91] Daniel Russo and Klaas-Jan Stol. 2021. PLS-SEM for software engineering research: An introduction and survey. Comput. Surveys 54, 4 (2021), 1-38.
[92] Mahadev Satyanarayanan. 2001. Pervasive computing: Vision and challenges. IEEE Personal Communications 8, 4 (2001), 10-17.
[93] Albrecht Schmidt. 2023. Speeding Up the Engineering of Interactive Systems with Generative AI. In ACM SIGCHI Symposium on Engineering Interactive Computing Systems. 7-8.
[94] AH Segars and V Grover. 1993. Re-examining perceived ease of use and usefulness: A confirmatory factor analysis. MIS Quarterly 17, 4 (1993), 517-525.
[95] Galit Shmueli, Soumya Ray, Juan Manuel Velasquez Estrada, and Suneel Babu Chatla. 2016. The elephant in the room: Predictive performance of PLS models. Journal of Business Research 69, 10 (2016), 4552-4564.
[96] G. Shmueli, M. Sarstedt, J. F. Hair, J Cheah, H. Ting, S. Vaithilingam, and C. M. Ringle. 2019. Predictive model assessment in PLS-SEM: guidelines for using PLSpredict. European fournal of Marketing 53, 11 (2019).
[97] Dominik Sobania, Martin Briesch, and Franz Rothlauf. 2022. Choose your programming copilot: A comparison of the program synthesis performance of github copilot and genetic programming. In Proceedings of the Genetic and Evolutionary Computation Conference. 1019-1027.
[98] Klaas-Jan Stol and Brian Fitzgerald. 2018. The ABC of software engineering research. ACM Transactions on Software Engineering and Methodology 27, 3 (2018), 11.
[99] A. Strauss and J. Corbin. 1990. Basics of qualitative research: Grounded theory procedures and techniques. Sage.
[100] Tabnine. 2023. AI Assistant for software developers – Tabnine. https://www.tabnine.com/ Accessed: October 17, 2023.
[101] Emmanuel Tenakwah. 2021. What do employees want?: Halting record-setting turnovers globally. Strategic HR Review 20, 6 (2021), 206-210.
[102] Ronald L Thompson, Christopher A Higgins, and Jane M Howell. 1991. Personal Computing: Toward a Conceptual Model of Utilization. MIS Quarterly 15, 1 (1991), 125-143.
[103] Haoye Tian, Weiqi Lu, Tsz On Li, Xunzhu Tang, Shing-Chi Cheung, Jacques Klein, and Tegawendé F Bissyandé. 2023. Is ChatGPT the Ultimate Programming Assistant-How far is it? arXiv preprint arXiv:2304.11938 (2023).
[104] Gholamreza Torkzadeh, Jerry Cha-Jan Chang, and Didem Demirhan. 2006. A contingency model of computer and Internet self-efficacy. Information & Management 43, 4 (2006), 541-550.
[105] Louis G. Tornatzky and Katherine J. Klein. 1982. Innovation characteristics and innovation adoption-implementation: A meta-analysis of findings. IEEE Transactions on Engineering Management 29, 1 (1982), 28-45.
[106] Andreas Tsamados, Luciano Floridi, and Mariarosaria Taddeo. 2023. The Cybersecurity Crisis of Artificial Intelligence: Unrestrained Adoption and Natural Language-Based Attacks. Available at SSRN 4578165 (2023).
[107] Priyan Vaithilingam, Tianyi Zhang, and Elena L Glassman. 2022. Expectation vs. experience: Evaluating the usability of code generation tools powered by large language models. In International Conference on Human Factors in Computing Systems. 1-7.
[108] J. Van Maanen. 1979. The fact of fiction in organizational ethnography. Administrative Science Quarterly 24, 4 (1979), 539-550.
[109] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in Neural Information Processing Systems 30 (2017).
[110] Viswanath Venkatesh and Fred D Davis. 2000. A theoretical extension of the technology acceptance model: four longitudinal field studies. Management science 46, 2 (2000), 186-204.
[111] Viswanath Venkatesh, Michael G Morris, Gordon B Davis, and Fred D Davis. 2003. User acceptance of information technology: toward a unified view. MIS quarterly (2003), 425-478.
[112] Viswanath Venkatesh, James YL Thong, and Xin Xu. 2016. Unified theory of acceptance and use of technology: A synthesis and the road ahead. Journal of the Association for Information Systems 17, 5 (2016), 328-376.
[113] Vv.AA. 2023. The widespread adoption of AI by companies will take a while. https://www.economist.com/leaders/ 2023/06/29/the-widespread-adoption-of-ai-by-companies-will-take-a-while
[114] Ruotong Wang, Ruijia Cheng, Denae Ford, and Thomas Zimmermann. 2023. Investigating and Designing for Trust in AI-powered Code Generation Tools. arXiv preprint arXiv:2305.11248 (2023).
[115] Bolin Wei, Ge Li, Xin Xia, Zhiyi Fu, and Zhi Jin. 2019. Code generation as a dual task of code summarization. In International Conference on Neural Information Processing Systems. 6563-6573.
[116] Michel Wermelinger. 2023. Using GitHub Copilot to solve simple programming problems. In Proceedings of the ACM Technical Symposium on Computer Science Education. 172-178.
[117] C. Wohlin, P. Runeson, M. Höst, M. Ohlsson, B. Regnell, and A. Wesslén. 2012. Experimentation in Software Engineering. Springer Science & Business Media.
[118] Burak Yetistiren, Isik Ozsoy, and Eray Tuzun. 2022. Assessing the quality of GitHub copilot’s code generation. In Proceedings of the International Conference on Predictive Models and Data Analytics in Software Engineering. 62-71.
[119] Beiqi Zhang, Peng Liang, Xiyu (Thomas) Zhou, Aakash Ahmad, and Muhammad Waseem. 2023. Practices and Challenges of Using GitHub Copilot: An Empirical Study. arXiv preprint arXiv:2303.08733 (2023).
[120] Daniel Zhang, Saurabh Mishra, Erik Brynjolfsson, John Etchemendy, Deep Ganguli, Barbara Grosz, Terah Lyons, James Manyika, Juan Carlos Niebles, Michael Sellitto, et al. 2021. The AI index 2021 annual report. arXiv preprint arXiv:2103.06312 (2021).
[121] Q. Zheng, X. Xia, X. Zou, Y. Dong, S. Wang, Y. Xue, Z. Wang, L. Shen, A. Wang, Y. Li, T. Su, Z. Yang, and J. Tang. 2023. GitHub – THUDM/CodeGeeX: CodeGeeX: An Open Multilingual Code Generation Model. https: //github.com/THUDM/CodeGeeX Accessed: October 17, 2023.
أ الملحق أ (أداة الاستطلاع)
| البناء | معرف العنصر | الأسئلة | المرجع |
| الآراء حول التكنولوجيا | PT_1 | استخدام نماذج اللغة الكبيرة في عملي يمكنني من إنجاز المهام بشكل أسرع. | [29, 111] |
| PT_2 | استخدام نماذج اللغة الكبيرة سيحسن من أدائي في العمل. | [29, 111] | |
| PT_3 | استخدام نماذج اللغة الكبيرة في عملي سيزيد من إنتاجيتي. | [29, 111] | |
| PT_4 | استخدام نماذج اللغة الكبيرة سيعزز من فعاليتي في العمل. | [29, 111] | |
| PT_5 | (*) استخدام نماذج اللغة الكبيرة سيجعل من الأسهل القيام بعملي. | [29, 111] | |
| PT_6 | سأجد نماذج اللغة الكبيرة مفيدة في عملي. | [29, 111] | |
| PT_7 | سأجد نماذج اللغة الكبيرة سهلة الاستخدام. | [29, 111] | |
| PT_8 | (*) سيكون من السهل بالنسبة لي أن أصبح بارعًا في استخدام نماذج اللغة الكبيرة. | [29, 111] | |
| PT_9 | (*) سأجد نماذج اللغة الكبيرة مرنة للتفاعل معها. | [29, 111] | |
| PT_10 | (*) سيكون من السهل بالنسبة لي تعلم تشغيل نماذج اللغة الكبيرة. | [65, 111] | |
| PT_11 | استخدام نماذج اللغة الكبيرة سيمكنني من إنجاز المهام بشكل أسرع. | [29, 111] | |
| PT_12 | استخدام نماذج اللغة الكبيرة سيحسن من جودة العمل الذي أقوم به. | [65, 111] | |
| PT_13 | استخدام نماذج اللغة الكبيرة سيجعل من الأسهل القيام بعملي. | [65, 111] | |
| PT_14 | استخدام نماذج اللغة الكبيرة سيعزز من فعاليتي في العمل. | [65, 111] | |
| PT_15 | (*) استخدام نموذج لغوي كبير يمنحني تحكمًا أكبر في عملي. | [4, 111] | |
| عوامل التوافق | CF_1 | (*) استخدام نماذج اللغة الكبيرة متوافق مع جميع جوانب عملي. | [65, 111] |
| CF_2 | أعتقد أن استخدام نموذج اللغة الكبير يتناسب جيدًا مع الطريقة التي أحب أن أعمل بها. | [٦٥، ١١١] | |
| CF_3 | استخدام نموذج اللغة الكبير يتناسب مع أسلوب عملي. | [65, 111] | |
| CF_4 | (*) لدي السيطرة على استخدام نماذج اللغة الكبيرة. | [4, 111] | |
| CF_5 | لدي المعرفة اللازمة لاستخدام نماذج اللغة الكبيرة. | [4, 111] | |
| CF_6 | نظرًا للموارد والفرص والمعرفة اللازمة لاستخدام نماذج اللغة الكبيرة، سيكون من السهل بالنسبة لي استخدام هذه النماذج. | [4, 111] | |
| العوامل الاجتماعية | SF_1 | الأشخاص الذين يؤثرون على سلوكي يعتقدون أنه يجب علي استخدام نماذج اللغة الكبيرة. | [٤، ١١١] |
| SF_2 | الأشخاص الذين يهمونني يعتقدون أنه يجب علي استخدام نماذج اللغة الكبيرة. | [4, 111] | |
| SF_3 | (*) أستخدم نماذج اللغة الكبيرة بسبب نسبة الزملاء الذين يستخدمون النظام. | [١٠٢، ١١١] | |
| SF_4 | (*) الأشخاص في منظمتي الذين يستخدمون نماذج اللغة الكبيرة يتمتعون بمزيد من الهيبة مقارنةً بأولئك الذين لا يستخدمونها. | [٦٥، ١١١] | |
| العوامل الشخصية والبيئية | PEF_1 | (*) إذا سمعت عن تقنية جديدة مثل نماذج اللغة الكبيرة، سأبحث عن طرق للتجربة معها. | [111] |
| PEF_2 | (*) بين أقراني، عادةً ما أكون الأول في تجربة تقنيات جديدة مثل نماذج اللغة الكبيرة. | [1] | |
| PEF_3 | (*) أحب أن أجرب تقنيات جديدة. | [1] | |
| PEF_4 | منظمتي توفر الموارد اللازمة لاستخدام نماذج اللغة الكبيرة بفعالية. | [٥٥، ١١١] | |
| PEF_5 | منظمتنا تقدم جلسات تدريب كافية لتعزيز مهاراتنا في استخدام نماذج اللغة الكبيرة. | [٥٥، ١١١] | |
| PEF_6 | تشجع منظمتنا على استخدام نماذج اللغة الكبيرة في عملنا اليومي. | [٥٦، ١١١] | |
| PEF_7 | أشعر أن هناك دعمًا من الإدارة العليا في منظمتي لاستخدام نماذج اللغة الكبيرة. | [٥٦، ١١١] | |
| نية الاستخدام | آي يو_1 | أعتزم استخدام نماذج اللغة الكبيرة بشكل أكثر شمولاً في الأشهر القادمة. | [٢٩، ١١١] |
| آي يو_2 | أتوقع أنني سأستخدم نماذج اللغة الكبيرة بشكل أكثر شمولاً في الأشهر القادمة. | [٢٩، ١١١] | |
| آي يو_3 | أخطط لاستخدام LLM بشكل أكثر شمولاً في الأشهر القادمة. | [٢٩، ١١١] |
الملحق ب (تحليل الإفراط في التكيف)
- عنوان المؤلف: دانيال روسو،daniel.russo@cs.aau.dkقسم علوم الحاسوب، جامعة آلبورغ، شارع أ. سي. مايرز فايينغ، 15، 2450، كوبنهاغن، الدنمارك.يتم منح الإذن لعمل نسخ رقمية أو ورقية من كل أو جزء من هذا العمل للاستخدام الشخصي أو في الفصول الدراسية دون رسوم، بشرط ألا يتم صنع النسخ أو توزيعها لأغراض ربحية أو تجارية وأن تحمل النسخ هذا الإشعار والاستشهاد الكامل في الصفحة الأولى. يجب احترام حقوق الطبع والنشر للمكونات التي تعود ملكيتها لجهات أخرى غير ACM. يُسمح بالتلخيص مع الإشارة إلى المصدر. لنسخ أي شيء آخر، أو إعادة نشره، أو نشره على الخوادم أو إعادة توزيعه إلى القوائم، يتطلب إذنًا محددًا مسبقًا و/أو رسومًا. يرجى طلب الإذن منpermissions@acm.org.
لقد التزمنا باستمرار بالتعويض المقترح من قبل Prolific. للرجوع إليك، تم دفع المشاركين في الساعة مقابل وقتهم، أي، لهذا التحقيق. للحصول على مقارنة شاملة بين القياسات الانعكاسية والتكوينية، انظر روسو وستول (2021). على الرغم من أن أحجام التأثير الأكبر ليست مشكلة بحد ذاتها، إلا أنها قد تشير أحيانًا إلى خطر محتمل للإفراط في التكيف. ومع ذلك، فقد أجرينا فحصًا شاملاً لهذه المسألة المحتملة في الملحق ب وخلصنا إلى أن الإفراط في التكيف غير موجود في نموذجنا. رابط حزمة النسخ المتماثل:https://doi.org/10.5281/zenodo.8124332.
DOI: https://doi.org/10.1145/3652154
Publication Date: 2024-03-28
Navigating the Complexity of Generative AI Adoption in Software Engineering
Abstract
This paper explores the adoption of Generative Artificial Intelligence (AI) tools within the domain of software engineering, focusing on the influencing factors at the individual, technological, and social levels. We applied a convergent mixed-methods approach to offer a comprehensive understanding of AI adoption dynamics. We initially conducted a questionnaire survey with 100 software engineers, drawing upon the Technology Acceptance Model (TAM), the Diffusion of Innovation Theory (DOI), and the Social Cognitive Theory (SCT) as guiding theoretical frameworks. Employing the Gioia Methodology, we derived a theoretical model of AI adoption in software engineering: the Human-AI Collaboration and Adaptation Framework (HACAF). This model was then validated using Partial Least Squares – Structural Equation Modeling (PLS-SEM) based on data from 183 software engineers. Findings indicate that at this early stage of AI integration, the compatibility of AI tools within existing development workflows predominantly drives their adoption, challenging conventional technology acceptance theories. The impact of perceived usefulness, social factors, and personal innovativeness seems less pronounced than expected. The study provides crucial insights for future AI tool design and offers a framework for developing effective organizational implementation strategies.
ACM Reference Format:
1 INTRODUCTION
In our endeavor to explore our research question, we have applied a convergent mixed-methods approach, investigating the adoption of Generative AI and Large Language Models within the sphere of software engineering. To frame our understanding of AI adoption, we referenced three principal theoretical frameworks examining individual, technological, and social-level influences. These frameworks included the Technology Acceptance Model (TAM) [110], the Diffusion of Innovation Theory (DOI) [85], and the Social Cognitive Theory (SCT) [9]. By incorporating these well-validated theories, we could thoroughly comprehend the determinants of language model adoption and investigate the distinct ways these variables are operationalized in the software engineering domain. We initiated our research by conducting a questionnaire survey with a cohort of 100 software engineers. The design of these questionnaire survey was influenced by the main dimensions of our selected theories. The collected data was analyzed using the Gioia Methodology [38], facilitating the development of our preliminary theoretical model. This provisional theoretical model was then validation using Partial Least Squares – Structural Equation Modeling (PLS-SEM), supported by data collected from 183 software engineers. The convergence of insights derived from this comprehensive and multifaceted investigation enhances our understanding of AI adoption within software engineering. Moreover, by understanding the adoption dynamics and impact of these disruptive technologies, this research holds potential to guide the design of future AI tools and offer pertinent recommendations for organization-wide implementation strategies. Indeed, generative AI tools represent a disruptive innovation in the software engineering domain, as defined by Christensen’s concept of “disruptive innovation” [18]. These tools, while initially targeting niche applications or underserved market segments, have the potential to revolutionize traditional software engineering practices. Their ability to automate complex tasks, generate code, and offer solutions based on vast datasets challenges the status quo and can lead to a paradigm shift in
how software development is approached. Over time, as these tools become more refined and widely adopted, they could displace established methodologies and tools, much like how disruptive innovations reshape industries. By understanding the adoption dynamics of such transformative technologies, this research offers insights into their potential trajectory and implications, guiding the design of future AI tools and providing recommendations for their strategic implementation across organizations.
2 RELATED WORK
2.1 Assessing Generated Code: Correctness and Quality
2.2 Evaluation Criteria: Diverse Approaches
efficiency [118]. These differences underscore the multifaceted nature of AI code generation and the various dimensions that need assessment.
2.3 Enhancing Code Productivity
2.4 Comparing Methods
2.5 Pedagogical Concerns
2.6 AI’s Influence on Software Development Process
potential and challenges of AI tools in software development, they also bring unique perspectives to the table, expanding the discourse to include aspects like legal concerns, workflow changes, and time costs.
2.7 Community Influence and Trust in AI Tools
2.8 Generative AI in Non-Coding Activities
2.9 Usability of AI Programming Assistants
3 THEORY GENERATION
3.1 Theoretical foundation
3.1.1 Technology Acceptance Model (TAM). TAM has been widely acclaimed for its relevance and efficiency in predicting and explaining the acceptance of various forms of technology [110]. Its core constructs-perceived usefulness and perceived ease of use-serve as an excellent starting point for understanding adoption behavior. For instance, if language models are perceived as beneficial and easy to use, software engineers are more likely to embrace them. Given its robustness and simplicity, TAM provides a foundation for understanding the fundamental determinants of technology adoption and aids in diagnosing the basic barriers to language model adoption.
3.1.2 Diffusion of Innovation Theory (DOI). While TAM primarily focuses on user perceptions, DOI complements TAM by addressing the technological characteristics influencing adoption. Rogers [85] identified key attributes of innovations-relative advantage, compatibility, complexity, trialability, and observability-that significantly affect their adoption rates. As an innovation in software engineering, the acceptance of language models could be shaped by these attributes. For example, the relative advantage of language models over traditional programming methods could be a strong motivator for adoption. The compatibility of language models with existing practices and the complexity of these models might also play crucial roles. Thus, DOI adds depth to our understanding of technology-specific factors influencing language model adoption.
3.1.3 Social Cognitive Theory (SCT). The decision to adopt new technologies does not occur in a vacuum. It is influenced by the social milieu within which individuals operate. SCT comes into play
here by emphasizing the social and environmental factors that influence individual behaviors [9]. Software engineering, like any profession, has its own culture, norms, and shared beliefs that could significantly shape the adoption of language models. For instance, the prevailing norm or the extent of peer usage could encourage or discourage language model use. Moreover, the self-efficacy of indi-viduals-shaped in part by their social environment-might affect their willingness to engage with such a new tool. SCT, therefore, adds a social layer to our understanding of language model adoption.
3.2 Questionnaire Survey Guideline
- Perceived Usefulness:”To what extent do you think using language models increases your efficiency as a software engineer?” This question is designed to gauge how software engineers perceive the potential productivity gains from using LLMs.
- Perceived Ease of Use: “How easy do you think it is to learn how to use a new language model effectively?” This question aims to capture the perceived cognitive effort required to learn and adapt to LLMs.
- Behavioral Intention: “How likely are you to use a language model in your work in the next six months? And for which tasks?” These questions aim to evaluate the intention of software engineers to adopt LLMs in their near-future tasks.
- Compatibility: “How is using a language model different from your current software engineering practices?” This question assesses the perceived fit of LLMs with existing practices and workflows.
- Relative Advantage: “What potential benefits do you think language models offer over your current methods?” This question helps identify the perceived benefits of LLMs compared to traditional methods.
- Complexity: “What concerns do you have about using a language model in your work?” This question aims to highlight any perceived barriers or challenges associated with LLM adoption.
Social-level factors, grounded in the Social Cognitive Theory, encompass social influence, environmental factors, and self-efficacy: - Social Influence: “How much do your colleagues or peers influence your decisions to use language models?” This question examines the impact of social norms and colleagues’ opinions on the acceptance of LLMs.
- Environmental Factors: “In your opinion, to what extent do you feel your organization is supportive of adopting language models as a standard technology?” This question explores the role of organizational support in fostering LLM adoption.
- Self-Efficacy: “How important is it to you to be seen as someone who uses cutting-edge technology in your work?” This question aims to capture an individual’s self-confidence in their ability to use advanced technologies like LLMs effectively.
Through these questionnaire survey questions, we strive to understand the complex interplay of individual, technological, and social factors that contribute to the adoption and usage of LLMpowered tools among software engineers.
3.3 Participants
3.4 Analysis of the Qualitative Data
“Efficiency Improvement,” representing a generalized area of impact in software engineering through the use of LLMs. This example illustrates the analytical progression from specific participant quotes to broader thematic categories, demonstrating the methodology of our study.
4 RESULTS
4.1 Perceived Usefulness of LLMs in Software Engineering
4.1.1 Efficiency Improvement. One of the main perceived benefits of LLMs is their ability to improve efficiency. As shown in Table 1, efficiency improvement is the most frequently mentioned aggregate dimension (55%). Engineers recognize that LLMs can automate certain tasks, reduce time and effort, and simplify monotonous tasks. For example, R-15 highlighted that LLMs can “increase my efficiency by automating certain tasks and reducing the time and effort it takes for manual coding and documentation.” This finding aligns with the TAM’s emphasis on perceived usefulness, which posits that users will adopt technology if they perceive it to be useful in enhancing their performance [29].
4.1.2 Task-Specific Benefits. Another aspect of perceived usefulness is the task-specific benefits LLMs provide, such as debugging, learning new features, and generating code snippets. As R-30 mentioned, LLMs have significantly increased their efficiency by helping them “debug code faster, learn about new features without scanning the whole documentation, and providing useful code snippets for work.” This category represents
4.1.3 Complementary Tool. LLMs are also viewed as a complementary tool to human expertise and judgment. R-17 pointed out that “language models have the potential to enhance productivity and efficiency in software engineering, but they should be used as a tool alongside human expertise and judgment.” This perception highlights the importance of balancing the benefits of LLMs with the need for human oversight, an aspect that may influence the overall perceived usefulness of the technology.
4.1.4 Limited Applicability and Quality Concerns. While many respondents reported positive perceptions of LLMs, some expressed concerns about their limited applicability (
widespread adoption. However, the concerns related to limited applicability and quality highlight the importance of addressing these limitations to enhance the perceived usefulness and, consequently, the acceptance of LLMs. This analysis aligns with the TAM framework, which emphasizes that perceived usefulness is a critical determinant of technology acceptance [29].
| ID | Quote | 1st Order Concepts | 2nd Themes | Aggregate Dimensions | (%) |
| R-15 | The can greatly increase my efficiently by automating certain tasks and reducing the time and effort it take for manual coding and documentation | Automating tasks, reducing time and effort, manual coding, documentation | Task-specific efficiency improvements | Efficiency Improvement | 55 |
| R-28 | it increases considerably my efficiency specially in simple tasks | Increased efficiency, simple tasks | Task-specific efficiency improvements | Efficiency Improvement | 55 |
| R-52 | They help only in monotonous and simple tasks (defining constructors and writing user input validating systems for example). | Monotonous tasks, simple tasks | Task-specific efficiency improvements | Efficiency Improvement | 55 |
| R-67 | I save 10% – 20% of time | Time savings | Time savings | Time Savings | 24 |
| R-30 | It certainly helps a lot, these last few days that I’ve been particularly using ChatGPT (with GPT 3-5), my efficiency has gone up by quite a bit. It helps me debug code faster, learn about new features without scanning the whole documentation, and providing me useful code snippets for my work. | Increased efficiency, debugging, learning new features, code snippets | Task-specific benefits, learning enhancement | Task-Specific Benefits | 26 |
| R-17 | I think language models can increase the efficiency of software engineers by automating certain tasks, such as code generation, testing, and documentation. Additionally, language models can help with data analysis and decision-making, allowing engineers to make informed choices based on large datasets. Overall, language models have the potential to enhance productivity and efficiency in software engineering, but they should be used as a tool alongside human expertise and judgement. | Automating tasks, data analysis, decision-making, human expertise, judgement | Complementary tool, efficiency improvement | Complementary Tool | 18 |
| R-21 | Very slightly. It’s nice for generic tasks, but the models have zero knowledge about our internal APIs so they’re really hard to apply. | Limited applicability, internal APIs, generic tasks | Limited applicability | Limited Applicability | 15 |
| R-41 | I’m much more efficient using a language model as it have been helping me to understand the company’s code much faster. | Increased efficiency, understanding company code, faster learning | Learning enhancement | Learning Enhancement | 12 |
| R-76 | While most of the time, language models get small things wrong, thereby requiring extra time for checking their output, the time they save by doing especially the boring parts of coding for you definitely outweighs this in my opinion. I would say using copilot for example has increased my coding efficiency by about
|
Time savings, checking output, increased efficiency | Time savings, quality concerns | Time Savings, Quality Concerns | 24,9 |
| R-55 | I think it helps but then you have to review and understand the code anyway. So I don’t know if it makes you more efficient. | Code review, understanding, efficiency concerns | Quality concerns | Quality Concerns | 9 |
4.2 Perceived Ease of Use of LLMs in Software Engineering
4.2.1 Learning Process. Our analysis reveals that the learning process is a crucial factor influencing the perceived ease of use of LLMs in software engineering. As shown in Table 2, R-54 reported that “once I got familiar with the technology, it became much easier to use.” This finding aligns with the Technology Acceptance Model proposed by [29], which suggests that the perceived ease of use of a technology is directly related to its adoption. Moreover, prior research has emphasized the role of
learning in the adoption of new technologies [110]. In this context, the learning curve associated with LLMs appears to be an essential determinant of their perceived ease of use.
4.2.2 Prior Experience. The questionnaire survey data also underscore the importance of prior experience in shaping the perceived ease of use of LLMs. For example, R-20 stated that “I think it is easy when you know the different concepts.” This observation is consistent with the literature on technology adoption, which suggests that individuals with prior experience in related technologies are more likely to perceive a new technology as easy to use [24]. In the case of LLMs, having a background in programming languages or natural language processing (NLP) could facilitate their adoption in software engineering.
4.2.3 Individual Differences. Another key theme that emerged from our analysis is the role of individual differences in shaping the perceived ease of use of LLMs. As R-9 noted, “it depends on the person and how they are used to work.” This finding supports the notion that individual characteristics, such as cognitive style and personal innovativeness, can influence the perceived ease of use of a technology [94]. In the context of LLMs, the extent to which software engineers perceive them as easy to use may depend on their unique preferences, learning styles, and problem-solving approaches.
4.2.4 Intuitiveness and User Interface. The intuitiveness of LLMs and their user interface design also emerged as important factors in our analysis. For instance, R-89 mentioned that “they were pretty much made for ease of use by the average consumer.” This observation aligns with the work of [69], who argued that a well-designed user interface can significantly enhance the perceived ease of use of a technology. In the case of LLMs, an intuitive and user-friendly interface could facilitate their adoption among software engineers.
4.2.5 Task Complexity. Finally, the complexity of the tasks that LLMs are used for in software engineering appears to influence their perceived ease of use. As R-53 noted, “the difficulty to learn how to use them effectively can vary as it depends on how you’re using it, but for the most part, it ranges from not too hard to very hard.” This finding is consistent with the Task-Technology Fit model [41], which posits that thefit between the technology and the task it is intended for affects the technology’s perceived ease of use and, ultimately, its adoption. In the context of LLMs, it seems that software engineers may find them easier to use for certain tasks, while others might require a higher level of expertise and knowledge.
4.3 Behavioral Intention of LLMs in Software Engineering
| ID | Quote | 1st Order Concepts | 2nd Themes | Aggregate Dimensions | (%) |
| R-46 | easy as you practice more | Practice, Improvement | Practice and improvement | Learning Process | 54 |
| R-4 | it takes some time and dedication | Time, Dedication | Learning curve | Learning Process | 54 |
| R-96 | However, for more advanced tasks, it can take some time to word your questions correctly | Advanced tasks, Time | Learning curve | Learning Process | 54 |
| R-30 | In the first week of using it, you will be already increasing your efficiency | Efficiency, Time | Practice and improvement | Learning Process | 54 |
| R-33 | To be more efficient, it requires to learn the specific prompts that give you an exact answer you expect | Efficiency, Specific prompts | Practice and improvement | Learning Process | 54 |
| R-17 | depends on the complexity and capabilities of the model, as well as the user’s prior experience and knowledge | Complexity, User experience, Prior knowledge | Individual factors | Individual ground ground | 26 |
| R-98 | It is easy when you know another language that is similar to it | Prior knowledge, Similar language | Individual factors | Individual ground | 26 |
| R-5 | Extremely easy | Ease of use | Perceived ease of use | Perceived Ease of Adoption | 13 |
| R-52 | Easy to use, hard to master the prompts | Ease of use, Mastery | Mastery | Perceived Ease of Adoption | 13 |
| R-74 | The difficult part is to understand if the response given is correct and related to what someone needs | Response quality, Relation to needs | Perceived difficulty | Model Effectiveness | 6 |
4.3.1 Code Improvement and Maintenance. A significant portion of software engineers indicated their intention to use LLMs to improve and maintain their codebase. This finding aligns with the TAM’s concept of perceived usefulness, as using LLMs for code refactoring, adherence to design patterns, and implementation of SOLID principles can enhance software quality and maintainability [76]. For instance, R-8 mentioned, “I am considering purchasing a ChatGPT-4 subscription, mainly to refactor (legacy) code or to make it adhere to certain design patterns. It could also help refactoring code to make it more SOLID.” This quote highlights the potential value of LLMs in addressing common software engineering challenges.
4.3.2 Efficiency and Automation. LLMs were perceived to be useful for automating repetitive tasks and increasing efficiency. This perception corresponds to both perceived usefulness and perceived ease of use in the TAM, as task automation can lead to time savings and streamline the development process [110]. R-35 stated, “I believe I may start using a language model more and more, especially to automate tasks which can be performed by a language model and which take a significant amount of time.” The adoption of LLMs for task automation can potentially improve software engineers’ productivity.
4.3.3 Learning and Problem Solving. The use of LLMs for learning and problem solving was another theme identified, which is in line with the TAM’s perceived usefulness. Software engineers expressed the intention to use LLMs for tasks such as finding documentation, clarifying confusing code, and seeking information on programming-related questions. As R-25 stated, “Very likely. Mostly to find documentation for libraries, refactor and clarify confusing code.” LLMs can serve as a valuable learning and problem-solving tool for software engineers, supporting continuous professional development.
4.3.4 Specialized Applications. Respondents mentioned the potential use of LLMs for specific tasks, such as writing basic functionalities, defining tasks, and composing emails. This theme is related to the perceived usefulness of LLMs in addressing particular software engineering needs. R-62, for example, mentioned, “Very likely. For writing basic functionalities, defining tasks, for emails.” The
adoption of LLMs for specialized applications can provide targeted benefits to software engineers in their daily work.
4.3.5 Adoption Barriers and Concerns. Despite the potential benefits of LLMs, some software engineers expressed concerns and barriers to adoption, such as cost, dependency on third-party services, and potential ethical issues. These concerns align with the TAM’s concept of perceived ease of use, as they can hinder the adoption of LLMs [110]. For instance, R-60 stated, “The cost and dependency on a third-party service might be a concern.” Understanding and addressing these concerns is essential for promoting LLM adoption in software engineering.
| ID | Quote | 1st Order Concepts | 2nd Themes | Aggregate Dimensions | (%) |
| R-8 | Very likely. I am considering purchasing a ChatGPT-4 subscription, mainly to refactor (legacy) code or to make it adhere to certain design patterns. It could also help refactoring code to make it more SOLID. | Refactor code, Design patterns, SOLID principles | Code generation and refactoring | Code Improvement and Maintenance | 42 |
| R-35 | I believe I may start using a language more and more, especially to automate tasks which can be performed by a language model and which take a significant amount of time. | Automate tasks, Time-saving | Task automation and optimization | Efficiency and Automation | 35 |
| R-25 | Very likely. Mostly to find documentation for libraries, refactor and clarify confusing code. | Find documentation, Refactor code, Clarify confusing code | Information seeking and learning | Learning and Problem Solving | 28 |
| R-7 | Tried it out with some basic programming related questions already. | Basic programming questions | Information seeking and learning | Learning and Problem Solving | 28 |
| R-62 | Very likely. For writing basic functionalities, defining tasks, for emails | Writing basic functionalities, Defining tasks, Emails | Task-specific use cases | Specialized Applications | 20 |
| R-17 | Very likely in language translation, text summarization and text generation | Language translation, Text summarization, Text generation | Natural language processing tasks | NLP and Content Generation | 18 |
| R-46 | Writing automated tests | Writing automated tests | Testing and code validation | Quality Assurance and Validation | 15 |
| R-69 | Not likely | Non-adoption | Uncertainty or nonadoption | Adoption Barriers and Concerns | 12 |
| R-60 | The cost and dependency on a third-party service might be a concern. | Cost, Dependency on third-party service | Adoption barriers | Adoption Barriers and Concerns | 12 |
4.4 Compatibility of LLMs in Software Engineering
4.4.1 Improved Efficiency. Improved Efficiency was the most frequently occurring theme in the data, with
4.4.2 Assistance and Support. Assistance and Support emerged as the second most frequent theme in the data, representing
4.4.3 Similarity to Current Practices. Similarity to Current Practices was reported by
4.4.4 Adaptation and Learning. Adaptation and Learning was reported by
4.5 Complexity of LLMs in Software Engineering
| ID | Quote | 1st Order cepts | Con- | 2nd Themes | Aggregate Dimensions | (%) |
| R-19 | Language models can be used to automate certain tasks in software engineering… | Automate tasks, Speed up process | Improved software engineering tasks | Improved Efficiency | 39 | |
| R-27 | It shifts the burden of research from me to the algorithm. | Shift burden, Algorithm | Improved software engineering tasks | Improved Efficiency | 39 | |
| R-35 | A language model will speed up the tasks of going to look for specific pieces of code from multiple websites. | Speed up tasks, Code search | Improved software engineering tasks | Improved Efficiency | 39 | |
| R-1 | It gives an extra hand and can provide assistance for things I don’t know and can’t find with a traditional search. | Extra hand, Assistance | Providing help and support | Assistance and Support | 28 | |
| R-15 | There is not much of a difference as the language model is just used to assist my current software engineering practices. | Similarity, tance | Assis- | Similarity to current practices | Similarity to Current Practices | 16 |
| R-5 | Not that different, it’s like Googling but I don’t need to filter as much information. | Similarity, Less filtering | Similarity to current practices | Similarity to Current Practices | 16 | |
| R-46 | It’s something new: you have to learn how to use it. | Learning, Adaptation | Need for adaptation and learning | Adaptation Learning | 11 | |
| R-87 | Using a language model represents a new paradigm for me… | New paradigm, Adaptation | Need for adaptation and learning | Adaptation Learning | 11 | |
| R-99 | Far more interactive and personalized compared to normal google searches. | Interactive, Personalized | Personalized and interactive use | Personalization and Interaction | 10 | |
| R-58 | It offers a more specific and tailored response compiled from a lot of content available online… | Specific, Tailored response | Personalized and interactive use | Personalization and Interaction | 10 | |
4.5.1 Job Security Concerns. The fear of job loss and skill devaluation emerged as a significant concern among respondents (
4.5.2 Dependence and Complacency. Some respondents (
4.5.3 Data Security and Privacy. Data security and privacy concerns were identified by
4.5.4 Quality and Accuracy of Generated Code. Respondents also raised concerns about the quality and accuracy of code generated by LLMs (13% frequency). Respondent R-49 remarked, “Language models aren’t perfect, so I would be afraid that they would cause errors.” Ensuring the reliability and accuracy of generated code is essential for LLM adoption [81]. To address this issue, developers should establish best practices for code review and validation, as well as invest in improving the models’ performance [115].
4.5.5 Ethical and Legal Considerations. Ethical and legal considerations, such as authorship and intellectual property rights, were identified by
4.5.6 Bias and Explainability. Some respondents (
4.5.7 Integration and Compatibility. Integration and compatibility issues were mentioned by
| ID | Quote | 1st Order cepts | 2nd Themes | Aggregate Dimensions | (%) |
| R-15 | I’m concerned that it can automate a lot of tasks and make most of my work obsolete. | Automation, task replacement, obsolescence | Job loss, skill devaluation | Job security concerns | 25 |
| R-34 | My concern is other junior programmers using it without understanding the code and causing bugs (more work for me). | Junior programmers, lack of understanding, bugs | Decline in code understanding, reliance on language models | Dependence and complacency | 16 |
| R-17 | In terms of privacy, as language models can be trained on sensitive or personal data, such as emails, messages, or documents. This may raise privacy and data protection concerns, especially if the language model is used in a cloud-based environment or shared with third parties. | Privacy, data protection, sensitive data | Data confidentiality, exposure risk | Data security and privacy | 15 |
| R-49 | Language models aren’t perfect, so I would be afraid that they would cause errors. | Language model imperfection, errors | Incorrect or poorly maintained code | Quality and accuracy of generated code | 13 |
| R-28 | Author rights are tricky to attribute | Authorship, rights | Legal concerns | Ethical and legal considerations | 8 |
| R-87 | Concerns I have about using language models in my work include issues of bias, explainability, and potential security vulnerabilities. | Bias, explainability, security vulnerabilities | Trust in generated results, inter- | Bias and explainability | 7 |
| R-6 | Might not be compatible with the systems at my workplace. | Compatibility, systems | Integration challenges | Compatibility and integration | 5 |
| R-5 | My programming skills might get “rusty” if I rely too much on it, like with autocorrect, I feel my grammar is now worse because my phone understands even incomplete words and I can’t remember the proper way of writing some words because of this. | Relying on language models, skill deterioration, autocorrect | Personal skill decline | Skill deterioration | 3 |
4.6 Relative Advantage of LLMs in Software Engineering
4.6.1 Time Efficiency. A recurring theme in our analysis was the time efficiency provided by LLMs, as reported by
4.6.2 Code Quality. Improvements in code quality emerged as another key advantage of LLMs, with
4.6.3 User Experience. LLMs were noted to enhance the overall user experience, with
4.6.4 Learning and Skill Development. LLMs were also found to facilitate learning and skill development, as reported by
4.6.5 Customization and Personalization. Finally, customization and personalization were highlighted as advantages by
software engineering can be facilitated by their ability to provide clear benefits over existing methods [85]. Moreover, our results highlight the potential of LLMs to revolutionize the field of software engineering by streamlining processes, enhancing user experience, and fostering continuous learning and improvement.
| ID | Quote | 1st Order Concepts | 2nd Themes | Aggregate Dimensions | (%) |
| R-25 | I believe the best thing is the time spent searching for certain things is way lower than before. | Time-saving search | Task Completion | Time Efficiency | 42 |
| R-37 | It generates a simpler and more understandable code, working in a more organized way and reducing errors. | Understandable code, Reduced errors | Code Simplicity & Robustness | Code Quality | 14 |
| R-67 | Language models are easier to use and faster because you can send messages like for human | Easier to use, Faster | Ease of Communication | User Experience | 11 |
| R-23 | I think with language models you don’t have to spend that much time learning ‘technical’ things | Less time learning | Simplified Learning | Learning and Skill Development | 9 |
| R-64 | It can help me jump over boilerplate code and snippets I typed hundreds of times before. It can also help in learning new languages’ syntax. | Boilerplate code, Learning new languages | Code Generation & Automation | Automation Adaptability | 8 |
| R-35 | I believe it might be more efficient and save some time. | Efficient, Timesaving | Innovative Solutions | Creativity & Innovation | 3 |
| R-11 | I think it can bring clear points of view to the table that weren’t take into consideration | New points of view | Diverse Perspectives | Insights & Decisionmaking | 4 |
| R-68 | More effective and faster problem resolution | Faster problem resolution | Effective Troubleshooting | Problem-solving | 6 |
| R-53 | Language models (paired programming) can help make fewer mistakes and overall increase efficiency. | Fewer mistakes, Increased efficiency | Collaborative Assistance | Teamwork & Collaboration | 5 |
| R-94 | It gives more digested information, and we can “mold” the information how we want (e.g. asking the language model to respond using short setences, or to explain in detail certain topics, etc) | Digestible information, Customization | Flexible Responses | Customization & Personalization | 8 |
4.7 Social Influence of LLMs in Software Engineering
4.7.1 No Influence. Our analysis revealed that
4.7.2 Low Influence. Low influence was reported by
4.7.3 Moderate Influence. Our analysis revealed that
4.7.4 High Influence. Finally, 26% of the respondents reported high influence from their peers and colleagues (e.g., R-97, R-79, R-27). This finding suggests that a considerable proportion of software engineers are strongly influenced by the collective use and enthusiasm for LLMs within their professional circles. This result aligns with the Social Cognitive Theory’s focus on the reciprocal interactions between individuals and their social environment, as well as the literature on technology adoption in organizations [85]. In this case, the high level of influence may stem from the perceived benefits of LLMs, collaboration, and shared enthusiasm for exploring the technology’s possibilities.
| ID | Quote | 1st Order Concepts | 2nd Themes | Aggregate Dimensions | (%) |
| R-66 | My colleagues don’t influence on my decisions to use language models | No influence | Independent decision-making | No Influence | 29 |
| R-24 | Not at all. | No influence | Independent decision-making | No Influence | 29 |
| R-58 | Some are in favor, but it doesn’t influence my opinion or way of using it | Others in favor, no influence on opinion or usage | Independent evaluation | No Influence | 29 |
| R-97 | Very much, as we use it on a daily basis and it is encouraged. | Use on a daily basis, encouraged | Strong adoption | High Influence | 26 |
| R-79 | We all use them, so we encourage each other to use them as well | Collective use, mutual encouragement | Collaboration and support | High Influence | 26 |
| R-27 | Greatly, everyone I know is keen on exploring their possibilities. | Strong influence, exploring possibilities | Enthusiastic adoption | High Influence | 26 |
| R-45 | Not much | Minimal influence | Low level of influence | Low Influence | 24 |
| R-99 | Not really. | Minimal influence | Low level of influence | Low Influence | 24 |
| R-9 | I make my own decisions … but I often seek input and feedback from my colleagues and peers … | Independent decision, input and feedback from peers | Valuing peer opinions | Moderate Influence | 21 |
| R-82 | There’s some influence but I don’t think it’s a big deal because everyone uses it out of curiosity | Some influence, curiosity-driven adoption | Curiosity and exploration | Moderate Influence | 21 |
4.8 Self-efficacy of LLMs in Software Engineering
seen as cutting-edge. These dimensions will be discussed in detail in the following subsubsections, highlighting their role in shaping developers’ self-efficacy and adoption behavior of LLMs in software engineering. The data structure can be found in Table 8.
4.8.1 Importance of Being Seen as Cutting-edge. As shown in the Table,
4.8.2 Focus on Practicality and Efficiency. Our analysis revealed that
4.8.3 Low Importance of Being Seen as Cutting-edge. A smaller group of respondents (
4.9 Environmental Factors of LLMs in Software Engineering
| ID | Quote | 1st Order cepts | 2nd Themes | Aggregate Dimensions | (%) |
| R-2 | Being up-to-date with cutting-edge technology is crucial in my line of work. | Importance cutting-edge | Emphasizing cutting-edge importance | Importance of being seen as cutting-edge | 57 |
| R-30 | Very important. I don’t want to be replaced with someone who’s seen like that while I don’t. | Fear of being replaced | Emphasizing cutting-edge importance | Importance of being seen as cutting-edge | 57 |
| R-57 | It’s important to show I’m capable of adapting. | Capability of adapting | Emphasizing cutting-edge importance | Importance of being seen as cutting-edge | 57 |
| R-77 | I think is really important to be always up to date with new technologies | Importance of being up to date | Emphasizing cutting-edge importance | Importance of being seen as cutting-edge | 57 |
| R-10 | it is important for me because it helps me to stay ahead of the curve and deliver innovative solutions that meet evolving customer needs. | Staying ahead, innovative solutions | Focus on practicality and efficiency | Focus on practicality and efficiency | 35 |
| R-19 | In my work as a software developer, it is important for me to keep up to date with the latest trends and technologies in software engineering, including language models. […] | Meeting clients’ needs, appropriate tech | Focus on practicality and efficiency | Focus on practicality and efficiency | 35 |
| R-47 | Not much, my work is mostly based on the technologies others decide to use. | Using decided technologies | Focus on practicality and efficiency | Focus on practicality and efficiency | 35 |
| R-100 | A little bit, but cutting-edge technology does not always mean higher efficiency. And efficiency is key. | Efficiency, not always cutting-edge | Focus on practicality and efficiency | Focus on practicality and efficiency | 35 |
| R-21 | Not at all. I’m looking for stability, not implementing the next bleeding-edge thing in my workflow. | Stability, rejecting cutting-edge tech | Low importance of being seen as cutting-edge | Low importance of being seen as cutting-edge | 8 |
| R-66 | I don’t find it important to be seen as someone who uses cuttingedge technology in my work. My focus is on using the most effective tools for the task at hand. | Low importance of cutting-edge, effective tools | Low importance of being seen as cutting-edge | Low importance of being seen as cutting-edge | 8 |
4.9.2 Neutral Stance. The Neutral Stance dimension reflects organizations that neither actively support nor oppose the adoption of LLMs (
4.9.3 Conditional Support. Some organizations in our sample exhibit a Conditional Support dimension (
4.9.4 Limited Support. The Limited Support dimension (
4.9.5 Lack of Support. Finally, the Lack of Support dimension (
| ID | Quote | 1st Order Concepts | 2nd Themes | Aggregate Dimensions | (%) |
| R-5 | A lot, they pay for it and encourage us to use it | encouragement, payment | active promotion | Supportive Attitude | 42 |
| R-45 | Very supportive | strong support | highly supportive | Supportive Attitude | 42 |
| R-84 | I think my organization is neutral, is up to the employee | neutral, employee choice | lack of strong opinion | Neutral Stance | 20 |
| R-26 | If it brings more advantages to the team and the way we work, and make things faster, they are supportive of adopting language models. | advantages, efficiency, conditional support | support with conditions | Conditional Support | 19 |
| R-21 | Not at all. We are anti-AI art, and also anti-AI when it comes to code. It failed to comply with our requirements anyway in testing. | not supportive, antiAI | opposition to AI technology | Lack of Support | 15 |
| R-74 | Not much, since it might break copyright and also poses some security concerns about proprietary intellectual property | copyright concerns, security concerns, limited support | concerns leading to lack of support | Lack of Support | 15 |
| R-92 | I don’t know, they don’t oppose it though | uncertainty, no opposition | unsure | Uncertainty | 14 |
| R-61 | My organization is somewhat supportive but they are not sure | partial support, uncertainty | ambivalence | Uncertainty | 14 |
| R-79 | They’re supportive of using it as a support tool, not as a main tool | support, limited context | limited application | Limited Support | 12 |
| R-64 | They oppose them when working on new features but for debugging, they can be quite helpful. | opposition, debugging, specific context | support in specific contexts | Limited Support | 12 |
4.10 Key Insights of the Qualitative Study
5 THE HUMAN-AI COLLABORATION AND ADAPTATION FRAMEWORK (HACAF)
assess LLMs based on their potential to streamline coding processes, enhance code quality, and expedite project timelines. Furthermore, the focus on practicality and efficiency found in our study underscores the importance of this construct in influencing the adoption of LLMs.
5.1 Theoretical Model and Hypotheses
and IU LLMs, strengthening the positive effect of Perceptions about the technology on Intention to Use LLMs.
6 THEORY VALIDATION
6.1 Partial Least Squares – Structural Equation Modeling
6.1.1 Scale Development. The survey was crafted with the assistance of supplementary theory. We structured our survey by adapting instruments from previous research. All items utilized to define each construct and the references used to shape the questions are summarized in Table 20. Each construct was assessed through uni-dimensional items on a 7-point Likert scale indicating levels of agreement.
6.1.2 Survey Data Collection. The minimum sample size was determined by conducting an a priori power analysis with G*Power. With an effect size of
6.1.3 Participant Demographics. Our survey encompassed a diverse set of 184 respondents, comprising
6.2 Evaluation of the Measurement Model
6.2.1 Discriminant Validity. In this context, discriminant validity refers to the distinctness or uniqueness of one latent variable compared to another. This serves as an essential parameter for determining whether two constructs are essentially the same and represent varying facets of knowledge. For its evaluation, we utilized the Heterotrait-Monotrait ratio of correlations (HTMT) which is recognized for its superior performance over other tests like the Fornell-Larcker criterion. The HTMT values should ideally be below 0.90 .
| CF | IU | PEF | PT | |
| Compatibility Factors (CF) | ||||
| Intention to Use (IU) | 0.756 | |||
| Personal and Environmental Factors (PEF) | 0.372 | 0.272 | ||
| Perceptions about the Technology (PT) | 0.848 | 0.633 | 0.338 | |
| Social Factors (SF) | 0.403 | 0.371 | 0.441 | 0.437 |
6.2.2 Internal Consistency Reliability. This test seeks to confirm that the items are gauging the latent variables in a consistent and reliable manner. As such, we refer to the Cronbach’s Alpha, rho_a, and rho_c values showcased in Table 11, all of which should exceed 0.60 [70]. We can conclude that our tests meet the reliability criterea.
| Cronbach’s alpha | rho_a | rho_c | AVE | |
| Compatibility Factors (CF) | 0.856 | 0.866 | 0.902 | 0.699 |
| Intention to Use (IU) | 0.939 | 0.941 | 0.961 | 0.891 |
| Personal and Environmental Factors (PEF) | 0.876 | 0.905 | 0.914 | 0.727 |
| Perceptions about the Technology (PT) | 0.948 | 0.950 | 0.956 | 0.685 |
| Social Factors (SF) | 0.875 | 0.906 | 0.940 | 0.887 |
| Item | CF | IU | PEF | PT | SF |
| CF2 | 0.896 | 0.626 | 0.293 | 0.686 | 0.333 |
| CF3 | 0.856 | 0.657 | 0.352 | 0.666 | 0.305 |
| CF5 | 0.775 | 0.482 | 0.248 | 0.547 | 0.250 |
| CF6 | 0.811 | 0.505 | 0.236 | 0.654 | 0.289 |
| IU1 | 0.662 | 0.935 | 0.238 | 0.560 | 0.293 |
| IU2 | 0.602 | 0.945 | 0.235 | 0.558 | 0.337 |
| IU3 | 0.671 | 0.951 | 0.267 | 0.577 | 0.330 |
| PEF4 | 0.293 | 0.198 | 0.811 | 0.276 | 0.277 |
| PEF5 | 0.156 | 0.130 | 0.838 | 0.214 | 0.250 |
| PEF6 | 0.362 | 0.316 | 0.892 | 0.300 | 0.394 |
| PEF7 | 0.298 | 0.200 | 0.867 | 0.258 | 0.391 |
| PT1 | 0.658 | 0.581 | 0.251 | 0.841 | 0.340 |
| PT11 | 0.641 | 0.521 | 0.178 | 0.855 | 0.318 |
| PT12 | 0.490 | 0.415 | 0.362 | 0.703 | 0.350 |
| PT13 | 0.639 | 0.491 | 0.295 | 0.856 | 0.327 |
| PT14 | 0.612 | 0.460 | 0.267 | 0.851 | 0.330 |
| PT2 | 0.663 | 0.545 | 0.281 | 0.827 | 0.378 |
| PT3 | 0.676 | 0.503 | 0.262 | 0.854 | 0.344 |
| PT4 | 0.655 | 0.511 | 0.271 | 0.874 | 0.383 |
| PT6 | 0.669 | 0.550 | 0.234 | 0.866 | 0.323 |
| PT7 | 0.622 | 0.353 | 0.191 | 0.727 | 0.243 |
| SF1 | 0.295 | 0.291 | 0.388 | 0.325 | 0.929 |
| SF2 | 0.365 | 0.342 | 0.359 | 0.427 | 0.955 |
6.3 Evaluation of the Structural Model
6.3.1 Collinearity Analysis. Initially, we analyze the correlation between the exogenous variable (Personal and environmental factors) and other endogenous variables. These should be independent to prevent any potential bias in the path estimations. The Variance Inflation Factor (VIF) test, which detects multicollinearity (i.e., an extreme degree of collinearity), should have a value under five [63]. Our VIF values are below this threshold, ranging from 4.710 (for the IU_3 item) to 2.034 (PEF_4). Consequently, we deduce that our model doesn’t suffer from multicollinearity issues.
6.3.2 Path Relations: Significance and Relevance. Path coefficients represent the hypothesized relationships between latent variables. They are standardized, meaning their values can range
| Hypothesis | Coefficient | Bootstrap Mean | St.Dev. | T |
|
| H1:
|
0.155 | 0.150 | 0.122 | 1.271 | 0.204 |
| H2: PT
|
0.766 | 0.766 | 0.047 | 16.405 | 0.000 |
| H3:
|
0.536 | 0.537 | 0.090 | 5.936 | 0.000 |
| H4:
|
0.405 | 0.408 | 0.076 | 5.346 | 0.000 |
| H5: SF
|
0.087 | 0.090 | 0.064 | 1.373 | 0.170 |
| H6: PEF
|
-0.004 | -0.004 | 0.056 | 0.064 | 0.949 |
| H7: PEF
|
0.313 | 0.317 | 0.072 | 4.313 | 0.000 |
| Construct |
|
|
| Compatibility Factors | 0.587 | 0.585 |
| Intention to Use | 0.489 | 0.477 |
| Personal and Environmental Factors | 0.098 | 0.093 |
| Social Factors | 0.164 | 0.159 |
| Construct | RMSE | MAE |
|
| Compatibility Factors | 0.089 | 0.984 | 0.752 |
| Intention to Use | 0.046 | 1.012 | 0.761 |
| Perceptions about the Technology | 0.076 | 0.998 | 0.733 |
| Social Factors | 0.078 | 0.971 | 0.755 |
| Constructs | CF | IU | PEF | PT | SF |
| Compatibility Factors | 0.225 | ||||
| Intention to Use | |||||
| Personal and Environmental Factors | 0.000 | 0.108 | |||
| Perceptions about the Technology | 1.426 | 0.196 | |||
| Social Factors | 0.018 | 0.011 |
6.4 Determining Key Factors for Adoption: An Analysis using Importance-Performance Map
| Construct | Construct Performances |
| CF | 83.257 |
| PEF | 65.519 |
| PT | 85.138 |
| SF | 67.161 |
| Construct | CF | IU | PEF | PT | SF |
| CF | 0.646 | ||||
| IU | |||||
| PEF | 0.240 | 0.167 | 0.313 | 0.127 | |
| PT | 0.767 | 0.540 | 0.405 | ||
| SF | 0.110 |
7 DISCUSSION
| Hypothesis | Findings | Implications |
| H1: Perceptions about the technology
|
Not supported. We did not find a direct relationship between Perceptions about the technology and Intention to Use. | Perception of the technology alone does not instigate the adoption of a Generative AI tool. |
| H2: Perceptions about the technology
|
Supported. This relationship is the strongest of the model with a path coefficient of 0.77 with a very large effect size (1.43). | Assimilating the capabilities of Generative AI tools and their potential integration into existing software development workflows is crucial. |
| H3: Compatibility Factors
|
Supported. This relation is symmetrical to the H 2 hyphotesis (with a considerable path coefficient of 0.54 and a large effect size of 0.66 ), which mostly explains the intention to use of LLMs. The IPMA shows that Compatibility Factors are the most important element to improve the Intention to Use. Additionally, they explain, almost single handed, the adoption of AI tools with a very high
|
The adoption of Generative AI tools hinges largely on their successful integration with existing software development workflows. |
| H4: Perceptions about the technology
|
Supported. We report a substantial path coefficient ( 0.40 ) with a medium effect size (0.20). The way Generative AI is perceived positively influence developer’s self-efficacy. | Developers consider LLMs as vital facilitators in completing tasks more effectively. |
| H5: Social factors
|
Not supported. The relationship between Social factors and Intention to Use is not significant. | Although Generative AI tools are deemed important enablers of developers’ self-efficacy, this perception does not translate into adoption. |
| H6: Personal and environmental factors
|
Not supported. This relationship is not significant. | Personal innovativeness and organizational support do not significantly influence developers’ adoption of Generative AI tools. |
| H7: Personal and environmental factors
|
Supported. We found a significant relationship between Personal and environmental factors and Perceptions about the technology with a path coefficient of 0.31 and a small to medium effect size (0.11). | As expected, a developer’s propensity to experiment with Generative AI tools, along with perceived organizational support, positively impact the perception of the technology. |
that the relationships within HACAF will be further corroborated. The current non-validation of all relationships within our framework model does not detract from its utility but offers initial insights into the factors shaping the adoption of Generative AI tools at this stage.
7.1 Implications
- Tool Evaluation: Organizations should initiate a thorough evaluation of available AI-driven tools, focusing on their compatibility with current processes and the specific needs of their development teams.
- Pilot Testing: Before a full-scale implementation, conduct pilot tests with a subset of projects to gauge the tool’s impact on development time, software quality, and user satisfaction.
- Training Programs: Introduce training sessions for developers to familiarize them with the nuances of the selected AI tools, ensuring they can leverage the tool’s capabilities to the fullest.
- Feedback Loop: Establish a feedback mechanism where developers can report on the tool’s performance, any challenges faced, and areas of improvement. This feedback can guide iterative refinements and ensure the tool remains aligned with evolving development practices.
- Cost-Benefit Analysis: Regularly assess the return on investment from the AI tool adoption, considering factors like improved efficiency, reduced errors, and user satisfaction.
Given our findings on the importance of Compatibility Factors in driving AI adoption, there is an urgent need for continuous education and training in AI as it becomes more prevalent in software engineering. Concretely, we suggest: - Tailored Training Modules: Organizations should develop and offer tailored training modules that focus on the integration of AI tools within existing software development workflows. These modules should address both the technical and collaborative aspects of using AI in team settings.
- Regular Workshops: Host regular workshops and seminars featuring experts in the field of AI. This will provide employees with insights into the latest advancements and best practices in AI-driven software development.
- Collaboration with AI Tool Providers: Forge partnerships with AI tool providers to facilitate hands-on training sessions, ensuring that the workforce is adept at leveraging the full potential of these tools.
- Strengthening Industry-Academic Synergy: To bridge the gap between theoretical knowledge and practical application, academic institutions should foster deeper collaborations with industry leaders. By co-designing software engineering curricula that emphasize AI-driven development, we can ensure that graduates are not only well-versed in current technologies but also attuned to the real-world challenges and opportunities of the industry.
- Feedback-Driven Iterations: Establish mechanisms to gather feedback from employees undergoing training. This feedback can be instrumental in refining training content and methodologies, ensuring they remain relevant and effective.
Our study also underscores the significance of the human-in-the-loop approach when incorporating AI in software engineering. To use the full potential of AI tools while ensuring they augment, rather than replace, human capabilities, the following actionable steps are recommended: - User-Centric AI Design: AI tool developers should prioritize a user-centric design philosophy, ensuring that the tools are intuitive and seamlessly integrate into the developers’ workflow.
- Transparency Mechanisms: Implement mechanisms within AI systems that elucidate their decision-making processes. This will empower developers to understand and trust the AI’s suggestions and decisions.
- Calibration Features: Equip AI tools with features that allow developers to calibrate or finetune them based on specific project requirements and their professional judgment.
- Feedback Loops: Establish iterative feedback loops where developers can provide feedback on AI tool outputs, which can then be used to refine and improve the tool’s performance over time.
- Collaborative Workspaces: Design collaborative workspaces where both AI tools and developers can contribute in real-time, fostering a symbiotic relationship that leverages the strengths of both.
- Continuous Training: As AI tools evolve, provide developers with continuous training opportunities to ensure they can effectively collaborate with the latest versions of these tools.
- Requirement Analysis: Before diving into AI adoption, organizations should conduct a thorough analysis of their specific needs. This involves understanding the challenges they face and identifying how AI can address them.
- Resource Evaluation: Assess the available resources, both in terms of hardware and human expertise. This will help in selecting AI solutions that the organization has the capacity to deploy and maintain.
- Constraint Identification: Recognize any constraints, be they budgetary, temporal, or technical, that might impact the deployment and operation of AI solutions.
- Feedback Mechanism: Establish a mechanism for developers and other stakeholders to provide feedback on the AI tools, ensuring that they are refined and optimized over time.
- Continuous Review: Periodically review the AI adoption strategy to ensure it remains aligned with the evolving needs and contexts of the organization.
- Security Vulnerabilities: Recent studies, such as the one by Tsamados et al. [106], have shed light on the security vulnerabilities inherent to artificial intelligence, particularly with LLMs. Their findings underscore the need for a thorough understanding of these models’ capabilities and vulnerabilities.
- Model Provider Responsibility: Model providers, in their quest to foster adoption, should be proactive in detailing potential vulnerabilities and offering guidelines on best practices to counteract these risks. As LLM technologies evolve rapidly, periodic reviews and audits are paramount to ensure transparency and adherence to ethical standards.
- Platform Security Measures: Platforms integrating LLMs should amplify their security protocols, ensuring they are prepared to tackle the unique challenges presented by these models. When adopting or utilizing LLMs, it’s prudent to choose models from well-established and trustworthy sources, guaranteeing both dependability and security.
- Stakeholder Dialogues: Open conversations among stakeholders, encompassing developers, users, and regulatory entities, can champion a more responsible and ethical adoption of Generative AI tools in software engineering.
In summary, the integration of AI techniques, especially Generative AI tools like LLMs, in software engineering holds immense potential for enhancing the development process and improving overall software quality. By acknowledging and addressing the challenges associated
with AI adoption-taking into consideration our findings on the importance of Compatibility Fac-tors-organizations can effectively leverage AI-driven tools and methodologies to realize enhanced outcomes in their software development pursuits.
7.2 Limitations
8 CONCLUSION
SUPPLEMENTARY MATERIALS
ACKNOWLEDGMENT
REFERENCES
[2] Ritu Agarwal and Jayesh Prasad. 1999. Are individual differences germane to the acceptance of new information technologies? Decision Sciences 30, 2 (1999), 361-391.
[3] AI, B. 2023. BLACKBOX AI – useblackbox.io. https://www.useblackbox.io/ Accessed: October 17, 2023.
[4] Icek Ajzen. 1991. The theory of planned behavior. Organizational Behavior and Human Decision Processes 50, 2 (1991), 179-211.
[5] Icek Ajzen. 2020. The theory of planned behavior: Frequently asked questions. Human Behavior and Emerging Technologies 2, 4 (2020), 314-324.
[6] Amazon Web Services. 2023. Code-Whisperer – Amazon Web Services. https://aws.amazon.com/es/codewhisperer/ Accessed: October 17, 2023.
[7] Alejandro Barredo Arrieta, Natalia Díaz-Rodríguez, Javier Del Ser, Adrien Bennetot, Siham Tabik, Alberto Barbado, Salvador Garcia, Sergio Gil-Lopez, Daniel Molina, Richard Benjamins, et al. 2020. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Information Fusion 58 (2020), 82-115.
[8] S. Baltes and P. Ralph. 2020. Sampling in Software Engineering Research: A Critical Review and Guidelines. arXiv:2002.07764 (2020).
[9] Albert Bandura. 2014. Social cognitive theory of moral thought and action. In Handbook of moral behavior and development. Psychology press, 69-128.
[10] Albert Bandura, W. H. Freeman, and Richard Lightsey. 1999. Self-Efficacy: The Exercise of Control. Fournal of Cognitive Psychotherapy 13, 2 (1999), 158-166.
[11] Shraddha Barke, Michael B James, and Nadia Polikarpova. 2023. Grounded copilot: How programmers interact with code-generating models. Proceedings of the ACM on Programming Languages 7 (2023), 85-111.
[12] James Bessen. 2019. Automation and jobs: When technology boosts employment. Economic Policy 34, 100 (2019), 589-626.
[13] Christian Bird, Denae Ford, Thomas Zimmermann, Nicole Forsgren, Eirini Kalliamvakou, Travis Lowdermilk, and Idan Gazit. 2022. Taking Flight with Copilot: Early insights and opportunities of AI-powered pair-programming tools. Queue 20, 6 (2022), 35-57.
[14] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in Neural Information Processing Systems 33 (2020), 1877-1901.
[15] Javier Cámara, Javier Troya, Lola Burgueño, and Antonio Vallecillo. 2023. On the assessment of generative AI in modeling tasks: an experience report with ChatGPT and UML. Software and Systems Modeling (2023), 1-13.
[16] Ruijia Cheng, Ruotong Wang, Thomas Zimmermann, and Denae Ford. 2022. “It would work for me too”: How Online Communities Shape Software Developers’ Trust in AI-Powered Code Generation Tools. arXiv preprint arXiv:2212.03491 (2022).
[17] W. W. Chin. 1998. The partial least squares approach to structural equation modeling. Modern Methods for Business Research 295, 2 (1998), 295-336.
[18] Clayton M. Christensen. 1997. The Innovator’s Dilemma: When New Technologies Cause Great Firms to Fail. Harvard Business Review Press.
[19] Michael Chui et al. 2023. The economic potential of generative AI: The next productivity frontier. https://www.mckinsey.com/capabilities/mckinsey-digital/our-insights/the-economic-potential-of-generative-ai-the-next-productivity-frontier. [Accessed 03-Jul-2023].
[20] Victoria Clarke, Virginia Braun, and Nikki Hayfield. 2015. Thematic analysis. Qualitative psychology: A practical guide to research methods 3 (2015), 222-248.
[21] CodeComplete. 2023. CodeComplete: AI Coding Assistant for Enterprise. https://codecomplete.ai/ Accessed: October 17, 2023.
[22] Codeium. 2023. Codeium • Free AI Code Completion and Chat. https://codeium.com/ Accessed: October 17, 2023.
[23] J. Cohen. 1988. Statistical Power Analysis for the Behavioral Sciences. Routledge.
[24] Deborah R Compeau and Christopher A Higgins. 1995. Computer self-efficacy: Development of a measure and initial test. MIS Quarterly (1995), 189-211.
[25] J. Corbin and A. Strauss. 1990. Grounded theory research: Procedures, canons, and evaluative criteria. Qualitative Sociology 13, 1 (1990), 3-21.
[26] J. Creswell. 2013. Research design: Qualitative, quantitative, and mixed methods approaches. Sage.
[27] Arghavan Moradi Dakhel, Vahid Majdinasab, Amin Nikanjam, Foutse Khomh, Michel C Desmarais, and Zhen Ming Jack Jiang. 2023. Github copilot ai pair programmer: Asset or liability? 7ournal of Systems and Software 203
(2023), 111734.
[28] Anastasia Danilova, Alena Naiakshina, Stefan Horstmann, and Matthew Smith. 2021. Do you really code? Designing and Evaluating Screening Questions for Online Surveys with Programmers. In International Conference on Software Engineering. IEEE, 537-548.
[29] F. Davis. 1989. Perceived usefulness, perceived ease of use, and user acceptance of information technology. MIS Quarterly 13, 3 (1989), 319-340.
[30] Fred D Davis, Richard P Bagozzi, and Paul R Warshaw. 1989. User acceptance of computer technology: A comparison of two theoretical models. Management science 35, 8 (1989), 982-1003.
[31] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2019).
[32] Paul Dourish. 2003. The appropriation of interactive technologies: Some lessons from placeless documents. Computer Supported Cooperative Work 12 (2003), 465-490.
[33] Christof Ebert and Panos Louridas. 2023. Generative AI for software practitioners. IEEE Software 40, 4 (2023), 30-38.
[34] Neil A Ernst and Gabriele Bavota. 2022. Ai-driven development is here: Should you worry? IEEE Software 39, 2 (2022), 106-110.
[35] Carl Benedikt Frey and Michael A Osborne. 2017. The future of employment: How susceptible are jobs to computerisation? Technological Forecasting and Social Change 114 (2017), 254-280.
[36] Yanjie Gao, Xiaoxiang Shi, Haoxiang Lin, Hongyu Zhang, Hao Wu, Rui Li, and Mao Yang. 2023. An Empirical Study on Quality Issues of Deep Learning Platform. In International Conference on Software Engineering: Software Engineering in Practice. IEEE, 455-466.
[37] D. Gefen, D. Straub, and M.-C. Boudreau. 2000. Structural equation modeling and regression: Guidelines for research practice. Communications of the Association for Information Systems 4, 1 (2000), 7.
[38] D. Gioia, K. Corley, and A. Hamilton. 2013. Seeking qualitative rigor in inductive research: Notes on the Gioia methodology. Organizational Research Methods 16, 1 (2013), 15-31.
[39] D. Gioia, J. Thomas, S. Clark, and K. Chittipeddi. 1994. Symbolism and strategic change in academia: The dynamics of sensemaking and influence. Organization Science 5, 3 (1994), 363-383.
[40] B. Glaser and A. Strauss. 2017. Discovery of grounded theory: Strategies for qualitative research. Routledge.
[41] Dale L Goodhue and Ronald L Thompson. 1995. Task-technology fit and individual performance. MIS quarterly (1995), 213-236.
[42] Roberto Gozalo-Brizuela and Eduardo C Garrido-Merchán. 2023. A survey of Generative AI Applications. arXiv preprint arXiv:2306.02781 (2023).
[43] F. J. Gravetter and L.-A. B. Forzano. 2018. Research methods for the behavioral sciences. Cengage Learning.
[44] Stine Grodal, Michel Anteby, and Audrey L Holm. 2021. Achieving rigor in qualitative analysis: The role of active categorization in theory building. Academy of Management Review 46, 3 (2021), 591-612.
[45] E. Guba. 1981. Criteria for assessing the trustworthiness of naturalistic inquiries. Educational Communication and Technology fournal 29, 2 (1981), 75-91.
[46] J. F. Hair Jr, G T. M Hult, C. Ringle, and M. Sarstedt. 2016. A primer on partial least squares structural equation modeling (PLS-SEM). Sage.
[47] Douglas M Hawkins. 2004. The problem of overfitting. Journal of chemical information and computer sciences 44, 1 (2004), 1-12.
[48] Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. 2019. The curious case of neural text degeneration. arXiv preprint arXiv:1904.09751 (2019).
[49] Saki Imai. 2022. Is github copilot a substitute for human pair-programming? an empirical study. In Proceedings of the ACM/IEEE International Conference on Software Engineering: Companion Proceedings. 319-321.
[50] L. Isabella. 1990. Evolving interpretations as a change unfolds: How managers construe key organizational events. Academy of Management Journal 33, 1 (1990), 7-41.
[51] Mateusz Jaworski and Dariusz Piotrkowski. 2023. Study of software developers’ experience using the Github Copilot Tool in the software development process.
[52] Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361 (2020).
[53] Ron Kohavi. 1995. A study of cross-validation and bootstrap for accuracy estimation and model selection. In Ijcai, Vol. 14. 1137-1145.
[54] Rajiv Kohli and Nigel P Melville. 2019. Digital innovation: A review and synthesis. Information Systems 7ournal 29, 1 (2019), 200-223.
[55] U. Kulkarni, S. Ravindran, and R. Freeze. 2006. A knowledge management success model: Theoretical development and empirical validation. Journal of Management Information Systems 23, 3 (2006), 309-347.
[56] W. Lewis, R. Agarwal, and V. Sambamurthy. 2003. Sources of influence on beliefs about information technology use: An empirical study of knowledge workers. MIS Quarterly (2003), 657-678.
[57] Y. Li, D. Choi, J. Chung, N. Kushman, J. Schrittwieser, R. Leblond, T. Eccles, J. Keeling, F. Gimeno, A. D. Lago, T. Hubert, P. Choy, C. de Masson d’Autume, I. Babuschkin, X. Chen, P.-S. Huang, J. Welbl, S. Gowal, A. Cherepanov, J. Molloy, D. J. Mankowitz, E. S. Robson, P. Kohli, N. de Freitas, K. Kavukcuoglu, and O. Vinyals. 2023. AlphaCode alphacode.deepmind.com. https://alphacode.deepmind.com/ Accessed: October 17, 2023.
[58] Jenny T Liang, Chenyang Yang, and Brad A Myers. 2023. Understanding the Usability of AI Programming Assistants. arXiv preprint arXiv:2303.17125 (2023).
[59] Y. Lincoln and E. Guba. 1985. Naturalistic inquiry. Sage.
[60] Mai Skjott Linneberg and Steffen Korsgaard. 2019. Coding qualitative data: A synthesis guiding the novice. Qualitative Research fournal 19, 3 (2019), 259-270.
[61] K. Locke. 1996. Rewriting the discovery of grounded theory after 25 years? Journal of Management Inquiry 5, 3 (1996), 239-245.
[62] Antonio Mastropaolo, Luca Pascarella, Emanuela Guglielmi, Matteo Ciniselli, Simone Scalabrino, Rocco Oliveto, and Gabriele Bavota. 2023. On the robustness of code generation techniques: An empirical study on github copilot. arXiv preprint arXiv:2302.00438 (2023).
[63] J. Miles. 2014. Tolerance and Variance Inflation Factor. American Cancer Society.
[64] Brent Daniel Mittelstadt, Patrick Allo, Mariarosaria Taddeo, Sandra Wachter, and Luciano Floridi. 2016. The ethics of algorithms: Mapping the debate. Big Data & Society 3, 2 (2016).
[65] Geoffrey A Moore and Regis McKenna. 1999. Crossing the chasm. (1999).
[66] Hussein Mozannar, Gagan Bansal, Adam Fourney, and Eric Horvitz. 2022. Reading between the lines: Modeling user behavior and costs in AI-assisted programming. arXiv preprint arXiv:2210.14306 (2022).
[67] mutable.ai. 2023. AI Accelerated Software Development. – mutable.ai. https://mutable.ai/ Accessed: October 17, 2023.
[68] Nhan Nguyen and Sarah Nadi. 2022. An empirical evaluation of GitHub copilot’s code suggestions. In Proceedings of the International Conference on Mining Software Repositories. 1-5.
[69] Oded Nov and Chen Ye. 2008. Users’ personality and perceived ease of use of digital libraries: The case for resistance to change. Journal of the American Society for Information Science and Technology 59, 5 (2008), 845-851.
[70] J. Nunnally. 1978. Psychometric methods. McGraw-Hill.
[71] General Assembly of the World Medical Association et al. 2014. World Medical Association Declaration of Helsinki: ethical principles for medical research involving human subjects. The 7ournal of the American College of Dentists 81, 3 (2014), 14.
[72] OpenAI. 2023. GPT-4 Technical Report. arXiv:2303.08774 [cs.CL]
[73] Ipek Ozkaya. 2023. The next frontier in software development: AI-augmented software development processes. IEEE Software 40, 4 (2023), 4-9.
[74] Stefan Palan and Christian Schitter. 2018. Prolific.ac–A subject pool for online experiments. Journal of Behavioral and Experimental Finance 17 (2018), 22-27.
[75] Sida Peng, Eirini Kalliamvakou, Peter Cihon, and Mert Demirer. 2023. The impact of ai on developer productivity: Evidence from github copilot. arXiv preprint arXiv:2302.06590 (2023).
[76] Anthony Peruma, Steven Simmons, Eman Abdullah AlOmar, Christian D Newman, Mohamed Wiem Mkaouer, and Ali Ouni. 2022. How do i refactor this? An empirical study on refactoring trends and topics in Stack Overflow. Empirical Software Engineering 27, 1 (2022), 11.
[77] James Prather, Brent N Reeves, Paul Denny, Brett A Becker, Juho Leinonen, Andrew Luxton-Reilly, Garrett Powell, James Finnie-Ansley, and Eddie Antonio Santos. 2023. ” It’s Weird That it Knows What I Want”: Usability and Interactions with Copilot for Novice Programmers. arXiv preprint arXiv:2304.02491 (2023).
[78] Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners. OpenAI blog 1, 8 (2019), 9.
[79] Paul Ralph et al. 2020. Empirical standards for software engineering research. arXiv preprint arXiv:2010.03525 (2020).
[80] M. Ramkumar, T. Schoenherr, S. Wagner, and M. Jenamani. 2019. Q-TAM: A quality technology acceptance model for predicting organizational buyers’ continuance intentions for e-procurement services. International fournal of Production Economics 216 (2019), 333-348.
[81] Baishakhi Ray, Daryl Posnett, Vladimir Filkov, and Premkumar Devanbu. 2014. A large scale study of programming languages and code quality in github. In International Symposium on Foundations of Software Engineering. ACM, 155-165.
[82] replit. 2023. Ghostwriter – Code faster with AI – replit.com. https://replit.com/site/ghostwriter Accessed: October 17, 2023.
[83] C. M. Ringle and M. Sarstedt. 2016. Gain more insight from your PLS-SEM results: The importance-performance map analysis. Industrial Management & Data Systems 116, 9 (2016), 1865-1886.
[84] C. M. Ringle, S. Wende, and J.-M. Becker. 2015. SmartPLS 3.
[85] Everett M. Rogers. 2010. Diffusion of Innovations. Simon and Schuster.
[86] Daniel Russo. 2021. The agile success model: a mixed-methods study of a large-scale agile transformation. ACM Transactions on Software Engineering and Methodology 30, 4 (2021), 1-46.
[87] D. Russo, P. Ciancarini, T. Falasconi, and M. Tomasi. 2018. A Meta Model for Information Systems Quality: a Mixed-Study of the Financial Sector. ACM Transactions on Management Information Systems 9, 3 (2018).
[88] Daniel Russo, Paul H P Hanel, Seraphina Altnickel, and Niels van Berkel. 2021. The daily life of software engineers during the covid-19 pandemic. In International Conference on Software Engineering. IEEE, 364-373.
[89] Daniel Russo, Paul H P Hanel, Seraphina Altnickel, and Niels van Berkel. 2021. Predictors of Well-being and Productivity among Software Professionals during the COVID-19 Pandemic-A Longitudinal Study. Empirical Software Engineering 26, 62 (2021), 1-64. https://doi.org/10.1007/s10664-021-09945-9
[90] Daniel Russo and Klaas-Jan Stol. 2020. Gender Differences in Personality Traits of Software Engineers. IEEE Transactions on Software Engineering 48, 3 (2020), 16.
[91] Daniel Russo and Klaas-Jan Stol. 2021. PLS-SEM for software engineering research: An introduction and survey. Comput. Surveys 54, 4 (2021), 1-38.
[92] Mahadev Satyanarayanan. 2001. Pervasive computing: Vision and challenges. IEEE Personal Communications 8, 4 (2001), 10-17.
[93] Albrecht Schmidt. 2023. Speeding Up the Engineering of Interactive Systems with Generative AI. In ACM SIGCHI Symposium on Engineering Interactive Computing Systems. 7-8.
[94] AH Segars and V Grover. 1993. Re-examining perceived ease of use and usefulness: A confirmatory factor analysis. MIS Quarterly 17, 4 (1993), 517-525.
[95] Galit Shmueli, Soumya Ray, Juan Manuel Velasquez Estrada, and Suneel Babu Chatla. 2016. The elephant in the room: Predictive performance of PLS models. Journal of Business Research 69, 10 (2016), 4552-4564.
[96] G. Shmueli, M. Sarstedt, J. F. Hair, J Cheah, H. Ting, S. Vaithilingam, and C. M. Ringle. 2019. Predictive model assessment in PLS-SEM: guidelines for using PLSpredict. European fournal of Marketing 53, 11 (2019).
[97] Dominik Sobania, Martin Briesch, and Franz Rothlauf. 2022. Choose your programming copilot: A comparison of the program synthesis performance of github copilot and genetic programming. In Proceedings of the Genetic and Evolutionary Computation Conference. 1019-1027.
[98] Klaas-Jan Stol and Brian Fitzgerald. 2018. The ABC of software engineering research. ACM Transactions on Software Engineering and Methodology 27, 3 (2018), 11.
[99] A. Strauss and J. Corbin. 1990. Basics of qualitative research: Grounded theory procedures and techniques. Sage.
[100] Tabnine. 2023. AI Assistant for software developers – Tabnine. https://www.tabnine.com/ Accessed: October 17, 2023.
[101] Emmanuel Tenakwah. 2021. What do employees want?: Halting record-setting turnovers globally. Strategic HR Review 20, 6 (2021), 206-210.
[102] Ronald L Thompson, Christopher A Higgins, and Jane M Howell. 1991. Personal Computing: Toward a Conceptual Model of Utilization. MIS Quarterly 15, 1 (1991), 125-143.
[103] Haoye Tian, Weiqi Lu, Tsz On Li, Xunzhu Tang, Shing-Chi Cheung, Jacques Klein, and Tegawendé F Bissyandé. 2023. Is ChatGPT the Ultimate Programming Assistant-How far is it? arXiv preprint arXiv:2304.11938 (2023).
[104] Gholamreza Torkzadeh, Jerry Cha-Jan Chang, and Didem Demirhan. 2006. A contingency model of computer and Internet self-efficacy. Information & Management 43, 4 (2006), 541-550.
[105] Louis G. Tornatzky and Katherine J. Klein. 1982. Innovation characteristics and innovation adoption-implementation: A meta-analysis of findings. IEEE Transactions on Engineering Management 29, 1 (1982), 28-45.
[106] Andreas Tsamados, Luciano Floridi, and Mariarosaria Taddeo. 2023. The Cybersecurity Crisis of Artificial Intelligence: Unrestrained Adoption and Natural Language-Based Attacks. Available at SSRN 4578165 (2023).
[107] Priyan Vaithilingam, Tianyi Zhang, and Elena L Glassman. 2022. Expectation vs. experience: Evaluating the usability of code generation tools powered by large language models. In International Conference on Human Factors in Computing Systems. 1-7.
[108] J. Van Maanen. 1979. The fact of fiction in organizational ethnography. Administrative Science Quarterly 24, 4 (1979), 539-550.
[109] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in Neural Information Processing Systems 30 (2017).
[110] Viswanath Venkatesh and Fred D Davis. 2000. A theoretical extension of the technology acceptance model: four longitudinal field studies. Management science 46, 2 (2000), 186-204.
[111] Viswanath Venkatesh, Michael G Morris, Gordon B Davis, and Fred D Davis. 2003. User acceptance of information technology: toward a unified view. MIS quarterly (2003), 425-478.
[112] Viswanath Venkatesh, James YL Thong, and Xin Xu. 2016. Unified theory of acceptance and use of technology: A synthesis and the road ahead. Journal of the Association for Information Systems 17, 5 (2016), 328-376.
[113] Vv.AA. 2023. The widespread adoption of AI by companies will take a while. https://www.economist.com/leaders/ 2023/06/29/the-widespread-adoption-of-ai-by-companies-will-take-a-while
[114] Ruotong Wang, Ruijia Cheng, Denae Ford, and Thomas Zimmermann. 2023. Investigating and Designing for Trust in AI-powered Code Generation Tools. arXiv preprint arXiv:2305.11248 (2023).
[115] Bolin Wei, Ge Li, Xin Xia, Zhiyi Fu, and Zhi Jin. 2019. Code generation as a dual task of code summarization. In International Conference on Neural Information Processing Systems. 6563-6573.
[116] Michel Wermelinger. 2023. Using GitHub Copilot to solve simple programming problems. In Proceedings of the ACM Technical Symposium on Computer Science Education. 172-178.
[117] C. Wohlin, P. Runeson, M. Höst, M. Ohlsson, B. Regnell, and A. Wesslén. 2012. Experimentation in Software Engineering. Springer Science & Business Media.
[118] Burak Yetistiren, Isik Ozsoy, and Eray Tuzun. 2022. Assessing the quality of GitHub copilot’s code generation. In Proceedings of the International Conference on Predictive Models and Data Analytics in Software Engineering. 62-71.
[119] Beiqi Zhang, Peng Liang, Xiyu (Thomas) Zhou, Aakash Ahmad, and Muhammad Waseem. 2023. Practices and Challenges of Using GitHub Copilot: An Empirical Study. arXiv preprint arXiv:2303.08733 (2023).
[120] Daniel Zhang, Saurabh Mishra, Erik Brynjolfsson, John Etchemendy, Deep Ganguli, Barbara Grosz, Terah Lyons, James Manyika, Juan Carlos Niebles, Michael Sellitto, et al. 2021. The AI index 2021 annual report. arXiv preprint arXiv:2103.06312 (2021).
[121] Q. Zheng, X. Xia, X. Zou, Y. Dong, S. Wang, Y. Xue, Z. Wang, L. Shen, A. Wang, Y. Li, T. Su, Z. Yang, and J. Tang. 2023. GitHub – THUDM/CodeGeeX: CodeGeeX: An Open Multilingual Code Generation Model. https: //github.com/THUDM/CodeGeeX Accessed: October 17, 2023.
A APPENDIX A (SURVEY INSTRUMENT)
| Construct | Item ID | Questions | Reference |
| Perceptions about the Technology | PT_1 | Using LLMs in my job enables me to accomplish tasks more quickly. | [29, 111] |
| PT_2 | Using LLMs would improve my job performance. | [29, 111] | |
| PT_3 | Using LLMs in my job would increase my productivity. | [29, 111] | |
| PT_4 | Using LLMs would enhance my effectiveness on the job. | [29, 111] | |
| PT_5 | (*) Using LLMs would make it easier to do my job. | [29, 111] | |
| PT_6 | I would find LLMs useful in my job. | [29, 111] | |
| PT_7 | I would find LLMs easy to use. | [29, 111] | |
| PT_8 | (*) It would be easy for me to become skillful at using LLMs. | [29, 111] | |
| PT_9 | (*) I would find LLMs flexible to interact with. | [29, 111] | |
| PT_10 | (*) Learning to operate LLMs would be easy for me. | [65, 111] | |
| PT_11 | Using LLMs would enable me to accomplish tasks more quickly. | [29, 111] | |
| PT_12 | Using LLMs would improve the quality of work I do. | [65, 111] | |
| PT_13 | Using LLMs would make it easier to do my job. | [65, 111] | |
| PT_14 | Using LLMs would enhance my effectiveness on the job. | [65, 111] | |
| PT_15 | (*) Using a LLM gives me greater control over my work. | [4, 111] | |
| Compatibility Factors | CF_1 | (*) Using LLMs is compatible with all aspects of my work. | [65, 111] |
| CF_2 | I think that using a LLM fits well with the way I like to work. | [65, 111] | |
| CF_3 | Using a LLM fits into my work style. | [65, 111] | |
| CF_4 | (*) I have control over using LLMs. | [4, 111] | |
| CF_5 | I have the knowledge necessary to use LLMs. | [4, 111] | |
| CF_6 | Given the resources, opportunities, and knowledge it takes to use the LLMs, it would be easy for me to use LLMs. | [4, 111] | |
| Social Factors | SF_1 | People who influence my behaviour think that I should use LLMs. | [4, 111] |
| SF_2 | People who are important to me think that I should use LLMs. | [4, 111] | |
| SF_3 | (*) I use LLMs because of the proportion of coworkers who use the system. | [102, 111] | |
| SF_4 | (*) People in my organisation who use LLMs have more prestige than those who do not. | [65, 111] | |
| Personal and Environmental Factors | PEF_1 | (*) If I heard about a new technology like LLMs, I would look for ways to experiment with it. | [111] |
| PEF_2 | (*) Among my peers, I am usually the first to try out new technologies like LLMs. | [1] | |
| PEF_3 | (*) I like to experiment with new technologies. | [1] | |
| PEF_4 | My organization provides the necessary resources for using LLMs effectively. | [55, 111] | |
| PEF_5 | My organization offers sufficient training sessions to enhance our skills in using LLMs. | [55, 111] | |
| PEF_6 | My organization encourages the use of LLMs in our daily work. | [56, 111] | |
| PEF_7 | I feel that there is top management support in my organization for using LLMs. | [56, 111] | |
| Intention to Use | IU_1 | I intend to use LLMs more extensively in the next months. | [29, 111] |
| IU_2 | I predict I would use LLMs more extensively in the next months. | [29, 111] | |
| IU_3 | I plan to use LLM more extensively in the next months. | [29, 111] |
B APPENDIX B (OVERFITTING ANALYSIS)
- Author’s address: Daniel Russo, daniel.russo@cs.aau.dk, Department of Computer Science, Aalborg University, A.C. Meyers Vaenge, 15, 2450, Copenhagen, Denmark.Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than ACM must be honored. Abstracting with credit is permitted. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from permissions@acm.org.
We consistently adhered to the suggested compensation by Prolific. For your reference, participants were paid per hour for their time i.e., for this investigation. For a comprehensive comparison between reflective and formative measures, see Russo & Stol (2021). Although larger effect sizes are not inherently problematic, they can occasionally suggest a potential risk of overfitting. However, we have performed a comprehensive examination of this potential issue in Appendix B and concluded that overfitting is not present in our model. Link to the replication package: https://doi.org/10.5281/zenodo.8124332.