DOI: https://doi.org/10.1007/s10796-025-10581-7
تاريخ النشر: 2025-02-25
الذكاء الاصطناعي التوليدي: تطور التكنولوجيا، التأثير الاجتماعي المتزايد، والفرص لأبحاث نظم المعلومات
© المؤلفون 2025
الملخص
أدت التطورات المستمرة والانفجارية في الذكاء الاصطناعي التوليدي (GenAI)، المبني على نماذج اللغة الكبيرة والخوارزميات ذات الصلة، إلى الكثير من الحماس والتكهنات حول التأثير المحتمل لهذه التكنولوجيا الجديدة. تشمل الادعاءات أن الذكاء الاصطناعي (AI) على وشك إحداث ثورة في الأعمال والمجتمع وتغيير الحياة الشخصية بشكل جذري. ومع ذلك، ليس من الواضح كيف أن هذه التكنولوجيا، بميزاتها المميزة بشكل كبير عن تقنيات الذكاء الاصطناعي السابقة، لديها القدرة التحويلية أو كيف يجب أن يتفاعل الباحثون في نظم المعلومات معها. في هذه الورقة، نعتبر الاتجاهات المتطورة والناشئة للذكاء الاصطناعي من أجل فحص تأثيراته الحالية والتنبؤ بتأثيراته المستقبلية. العديد من الأوراق الموجودة حول GenAI إما أنها تقنية للغاية بالنسبة لمعظم الباحثين في نظم المعلومات أو تفتقر إلى العمق اللازم لتقدير التأثيرات المحتملة لـ GenAI. لذلك، نحاول سد الفجوة بين المجتمعات التقنية والتنظيمية لـ GenAI من منظور اجتماعي تقني موجه نحو النظام. على وجه التحديد، نستكشف الميزات الفريدة لـ GenAI، التي تتجذر في التغيير المستمر من الرمزية إلى الاتصال، والخصائص النظامية العميقة والفطرية لنظم الإنسان-الذكاء الاصطناعي. نتتبع تطور الذكاء الاصطناعي الذي سبق مستوى التبني والتكيف والاستخدام الموجود اليوم، من أجل اقتراح أبحاث مستقبلية حول التأثيرات المختلفة لـ GenAI في كل من الأعمال والمجتمع في سياق أبحاث نظم المعلومات. تهدف جهودنا إلى المساهمة في إنشاء جدول أبحاث منظم جيدًا في مجتمع نظم المعلومات لدعم استراتيجيات وعمليات مبتكرة ممكنة بفضل هذه الموجة الجديدة من الذكاء الاصطناعي.
1 المقدمة
حصريًا نحو التعلم الآلي (ML) والذكاء الاصطناعي المستند إلى البيانات (سيرف، 2019)، حيث يتكون التعلم الآلي من طرق وخوارزميات تُستخدم لاستنتاج المعلومات من البيانات (غودفيلو وآخرون، 2020). مع اعتمادها الواسع، بدأ التعلم الآلي في تحويل المنظمات وحتى الصناعات بأكملها بسرعة.
طبيعة GenAI من منظور الأنظمة، يمكننا تطوير فهم دقيق لـ GenAI من خلال الاستفادة من المفاهيم والنظريات الموجودة في أبحاث نظم المعلومات. رابعًا، نحدد مواضيع مثمرة للبحث المستقبلي.
2 الأبحاث ذات الصلة
في مجال نظم المعلومات. يقترح سوسارلا وآخرون (2023) إمكانية الاستفادة من GenAI في قدرات مختلفة لإجراء العمل الأكاديمي. في سياق أوسع، يجادل سابهر وال وغروفر (2024) بأن التأثير الاجتماعي للذكاء الاصطناعي يعتمد على تطويره وتنفيذه. يؤكدون على أهمية النظر في مدى استبدال الذكاء الاصطناعي للبشر مقابل دعمه لهم، ودمج الحقائق المادية والرقمية، واحترام القيود البشرية. يحدد أوليري (2022) القضايا الناشئة المرتبطة بالنماذج اللغوية الكبيرة (LLMs) بشكل عام. يقدم العلاوي وآخرون (2024) اقتراحات حول كيفية تركيز مجال نظم المعلومات على دور GenAI من منظور إدارة المعرفة، مع تحديد فرص البحث ذات الصلة. نواصل هذه الجهود من خلال تقديم تحليل شامل وعام لـ GenAI كتكنولوجيا ونقترح أجندة مثمرة لدراسة نظم المعلومات.
2.1 الجهود السابقة في البحث في الذكاء الاصطناعي ونظم المعلومات
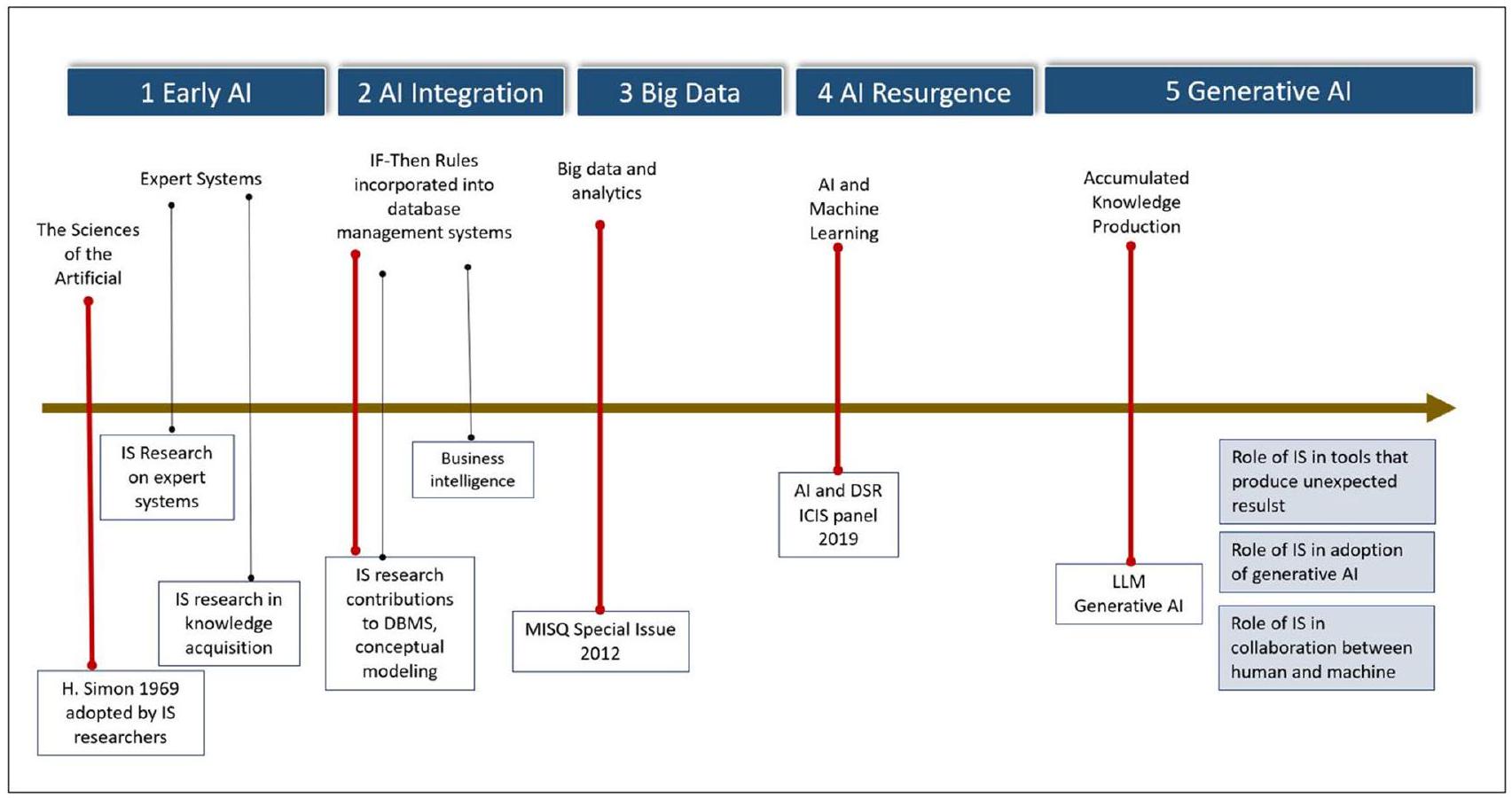
| السنة | أداة الذكاء الاصطناعي | أهمية الذكاء الاصطناعي | المرجع |
| 1952 | لعبة الداما | أثبتت أن الحواسيب يمكن أن تتعلم اللعب بمستوى عالٍ يكفي لتحدي لاعب بشري هاوٍ | صموئيل (1960) |
| 1955 | المفكر المنطقي | أثبت 38 نظرية من مبادئ الرياضيات؛ قدم مفاهيم حاسمة في الذكاء الاصطناعي (مثل، الاستدلال، معالجة القوائم، التفكير كبحث) | نيويل وآخرون (1962) |
| 1957 | المدرك | ولادة الاتصال؛ أساس الشبكات العصبية (NN)، التعلم العميق | روزنبلات (1961) |
| 1961 | MENACE | أول برنامج قادر على تعلم اللعب بشكل مثالي في لعبة إكس-أو | ميشي (1963) |
| 1965 | ELIZA | نظام معالجة اللغة الطبيعية الذي قلّد الطبيب من خلال الرد على أسئلة مشابهة للمعالج النفسي قبل أن تصبح المحادثة غير منطقية | فايتنباوم (1966) |
| 1969 | شاكِي الروبوت | أول روبوت متنقل عام قادر على التفكير، دمج البحث في الروبوتات مع رؤية الكمبيوتر ومعالجة اللغة الطبيعية | بيرترام (1972) |
| 1969 | الكتاب “المدركات” | سلط الضوء على الحدود غير المعترف بها لبنية المدرك ذو الطبقتين؛ تحول أساسي في أبحاث الذكاء الاصطناعي نحو الرمزية، متجاهلاً الاتصال | مينسكي وبابرت (1969) |
2.2 التطور من الذكاء الاصطناعي العام إلى الذكاء الاصطناعي التوليدي
2.3 تطور الذكاء الاصطناعي وتأثيره على أبحاث نظم المعلومات
| السنة | أداة الذكاء الاصطناعي | أهمية الذكاء الاصطناعي | المرجع |
| 1989 | خوارزمية Q-learning | “التعلم من المكافآت المتأخرة” يحسن التعلم المعزز | واتكينز (1989) |
| 1993 | حل “مهمة التعلم العميق جدًا” | العالم حل المهمة بأكثر من 1,000 طبقة في الشبكة العصبية المتكررة (RNN) | شمديهوبر (1993) |
| 1995 | نجاح SVM | تم تطبيق آلات الدعم المتجهة على تصنيف النصوص، والتعرف على الأحرف المكتوبة بخط اليد، وتصنيف الصور | كورتيس وفابنيك (1995) |
| 1997 | بنية LSTM | حسنت بنية الذاكرة طويلة وقصيرة المدى (LSTM) RNN من خلال القضاء على مشكلة الاعتماد على المدى الطويل | هوكرايتر وشمديهوبر (1997) |
| 1998 | تحسين التعلم القائم على التدرج | يجمع بين خوارزمية التدرج العشوائي مع خوارزمية الانتشار العكسي | ليكون وآخرون (1998) |
| 2002 | TD-Gammon تطابق أفضل لاعب | يجمع بين الشبكات العصبية والتعلم المعزز (RL) مع طريقة اللعب الذاتي | تيسارو (2002)؛ بلي وآخرون (2003) |
| 2005 | فاز الروبوت من جامعة ستانفورد بجائزة | قاد 131 ميلاً بشكل مستقل على مسار صحراوي غير متكرر في تحدي داربا الكبير | ثرون وآخرون (2006) |
| 2011 | فاز IBM Watson بجائزة Jeopardy | Watson هو نظام أسئلة وأجوبة يجمع بين التعرف على الصوت، وتوليد الصوت، واسترجاع المعلومات، من بين أمور أخرى | فيروتشي (2012) |
| 2012 | AlexNet | فاز بمسابقة ImageNet، مما قد يشير إلى نقطة تحول في التعلم العميق | كريزيفسكي وآخرون (2012)؛ كريزيفسكي وآخرون (2017) |
| 2014 | الشبكات التوليدية المتعارضة (GANs) | هياكل الشبكات العصبية العميقة المكونة من شبكتين؛ تتعلم تقليد توزيع البيانات لتوليد محتوى مثل الصور والموسيقى والكلام، إلخ | جودفيلو وآخرون (2014)؛ كينغما وويلينغ (2014) |
| 2017 | المحول | هيكل DL يعتمد على آلية الانتباه الذاتي، مهم في نمذجة اللغة والترجمة الآلية والإجابة على الأسئلة | فاسواني وآخرون (2017) |
| 2018 | OpenAI Five | هزمت فريقًا بشريًا في Dota 2، لعبة فيديو معقدة؛ أكثر واقعية من الشطرنج أو Go | باتشوك وآخرون (2018) |
| 2019 | GPT-2 | نموذج لغة غير خاضع للإشراف على نطاق واسع؛ يمكنه توليد فقرات نصية متماسكة، وفهم القراءة، والترجمة الآلية، والإجابة على الأسئلة، والتلخيص | رادفورد وآخرون (2019) |
3 الإطار النظري لفهم الذكاء الاصطناعي التوليدي
3.1 تصور الذكاء الاصطناعي التوليدي
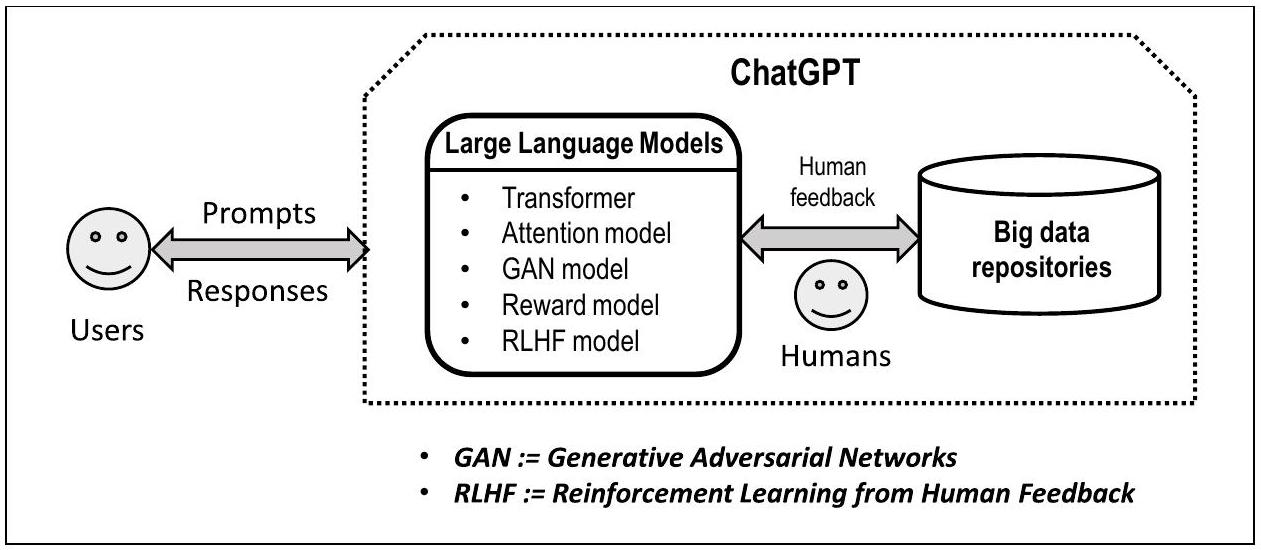
للغة الطبيعية البشرية في الشبكات العصبية العميقة مثل المحولات. كما هو الحال في العديد من تقنيات التعلم الآلي، يتم تدريب ChatGPT مسبقًا بناءً على النصوص الموجودة ثم يُستخدم للتنبؤ بالنتائج بناءً على نص المطالبة من المستخدم. يعني هذا النهج التنبؤي أن الاستجابات من ChatGPT احتمالية وبالتالي عرضة للخطأ بالضرورة. هذه الخاصية التنبؤية سهلة الفهم من قبل المحترفين الفنيين، ولكنها تتطلب شرحًا للمحترفين غير الفنيين.
النماذج الاتصالانية – ChatGPT توليدي لأنه ينشئ اتصالات جديدة بين الكلمات عبر نماذج اللغة الكبيرة. كما هو ملاحظ، تطور الذكاء الاصطناعي إلى نماذج اتصالانية بعد استكشاف النماذج الرمزية ثم حقق نجاحًا كبيرًا في معالجة اللغة الطبيعية عبر نماذج اللغة الكبيرة، مما أدى إلى ChatGPT وأدوات مماثلة (تشانغ وآخرون، 2023). تقوم الشبكات العصبية أساسًا بإنشاء اتصالات بسيطة وموزونة بين الجمل والكلمات بعد عمليات الترميز، مما يسمح بحسابات التعلم الآلي على مئات المليارات من المدخلات (مثل رموز النص). لم يكن من الممكن تحقيق نجاح ChatGPT لأن النماذج الرمزية البحتة يصعب توسيعها إلى مستويات البيانات الضخمة. هذا الاتصالانية
| المفهوم | التعريف | السنة |
| GAN | تقوم الشبكات التنافسية التوليدية (GAN) بتدريب نموذجين في وقت واحد: نموذج توليدي يلتقط توزيع البيانات ونموذج تمييزي يقدر احتمال أن عينة جاءت من بيانات التدريب | 2014 |
| الانتباه | تُستخدم آلية الانتباه في التعلم الآلي ومعالجة اللغة الطبيعية لزيادة دقة النموذج من خلال التركيز على البيانات ذات الصلة لتمكين النموذج من التركيز على مجالات معينة من بيانات الإدخال، مما يمنح وزنًا أكبر للميزات الحاسمة وتجاهل غير المهمة | 2015 |
| المحول | المحولات هي نوع من الشبكات العصبية مصممة للتعامل مع الاعتماديات بعيدة المدى في النص، والتقاط العلاقات بين الكلمات والسماح للنموذج بفهم السياق والمعنى عبر تسلسلات كبيرة من المدخلات. على سبيل المثال، العلاقة والملاءمة بين اللون والسماء والزرقاء في السؤال: “ما هو لون السماء؟” تؤدي إلى الناتج: “السماء زرقاء.” | 2017 |
| المكافأة | نموذج المكافأة هو نهج في الذكاء الاصطناعي حيث يتلقى النموذج مكافأة أو درجة لاستجاباته للمطالبات المعطاة. تعمل هذه الإشارة المكافئة كتعزيز، موجهة نموذج الذكاء الاصطناعي لإنتاج النتائج المرغوبة | 2020 |
| RLHF | في التعلم الآلي، التعلم المعزز من ردود الفعل البشرية (RLHF) هو تقنية لمواءمة وكيل ذكي مع تفضيلات البشر | 2023 |
القدرات العامة – ChatGPT عامة لأن النماذج الاتصالانية لا تميز بين القطاعات التجارية أو مجالات المعرفة. يمكن أن يخدم ChatGPT واحد مليارات المستخدمين للأسئلة والأجوبة، دون أن يكون مقيدًا بسياقات محددة. هذه الميزة هي نتيجة لنماذج اللغة الكبيرة والشبكات العصبية العملاقة من الاتصالات. ومع ذلك، فإن هذه القدرة، التي تعتمد على مجموعة بيانات كبيرة، تعاني أيضًا من انخفاض الدقة وإمكانية الهلوسة (أي، اختراع مخرجات غير منطقية).
التكامل مع محركات البحث – تكمل نتائج ChatGPT تلك من محركات البحث لأن الأولى تنبؤية؛ والأخيرة هي ببساطة مجموعة من الوثائق الموجودة ذات الصلة باستعلام المستخدم. على هذا النحو، يمكن اعتبار ChatGPT ملخصًا للوثائق الموجودة التي ترتبط بشكل أكثر دقة باستعلام المستخدم، بينما توفر محركات البحث ببساطة قائمة بنتائج البحث للمستخدم. بطريقة ما، تقدم ChatGPT نتيجة أولية للمستخدم، الذي قد يعالج الإجابة من ChatGPT بشكل أكبر. هناك علاقة مثلثية بين المستخدم وChatGPT ومحرك البحث حيث قد يحدد المستخدم كيفية استخدام ومعالجة النتائج من ChatGPT ومحرك البحث. يجب أن يكون هذا موضوع بحث مثمر للغاية حول كيفية إدارة نظام معالجة المعرفة هذا. لن تحل العلاقة المثلثية محل محركات البحث لأن نتائج ChatGPT قد لا تلبي جميع احتياجات المستخدمين، على الرغم من أن بعض المستخدمين قد يقبلون النتائج، دون استخدام محرك البحث مرة أخرى (دوبين وآخرون، 2023).
قدرة الفهم لدى ChatGPT – كيفية فهم ChatGPT للنصوص مقارنة بالبشر هو موضوع بحث مهم. يتعلم البشر طوال حياتهم، بدءًا من الطفولة، ويغنون عقولهم بمعرفة جديدة دون توقف طوال حياتهم. يعبر الناس عن الأفكار، ويتبادلون الآراء، ويخلقون مفاهيم وكلمات ونظريات جديدة. يمكن لـ ChatGPT معالجة كميات هائلة من النصوص في الوثائق الموجودة وتوليد نصوص جديدة بناءً على طلبات المستخدمين. ومع ذلك، لوحظ أن الذكاء الاصطناعي لا يمكنه فهم معنى السياق بالمعنى البشري لأنه لا يتعامل مع المعنى الدلالي العميق للكلمات التي يعالجها، مما يوضح أن هناك فجوة كبيرة جدًا لا تزال قائمة بين الذكاء الاصطناعي-
ليس من المعقول ببساطة أن نؤكد أن ChatGPT يمكنه فهم أو استيعاب الوثائق بالمعنى البشري. هناك فرق كبير بين إنتاج نص جديد وابتكار أفكار جديدة.
3.2 نظرية الأنظمة: شرح الذكاء الاصطناعي التقليدي مقابل الذكاء الاصطناعي التوليدي
تظهر هذه الخصائص عندما تصبح المكونات جزءًا من الكل وتبدأ في التفاعل مع بعضها البعض بطريقة معينة. نظرًا لأن أي مكون لا يمتلك خاصية ناشئة، فإن الخصائص الناشئة غالبًا ما لا يمكن اشتقاقها من معرفة خصائص المكونات. على سبيل المثال، التضامن هو خاصية ناشئة لحزب سياسي؛ لا يمتلك أي عضو في الحزب هذه الخاصية. تعتمد هذه الخاصية، ليس فقط على معتقدات وسلوكيات الأعضاء الأفراد (بالإضافة إلى عوامل خارجية)، ولكن أيضًا على التاريخ والديناميات والتفاعلات بين أعضائه. وبالمثل، فإن الشفافية هي الخاصية الناشئة للشبكة العصبية بأكملها. بينما قد تكون مكونات الشبكة العصبية الفردية مفهومة للإنسان، عندما يتم تجميع هذه المكونات معًا، قد تفتقر إلى الشفافية. وبالمثل، فإن المخرجات التي تبدو بشرية من ChatGPT هي ناشئة من البنية المعمارية الخاصة بالاتصال والشبكات اللغوية الطبيعية لـ GenAI، والتي، إذا تم فصلها واستخدامها بشكل منفصل، ستفشل في تقديم أنواع مماثلة من المخرجات.
الأنظمة أيضًا ملموسة، لأنها مصنوعة من مكونات ملموسة – البشر وقطعهم الفنية (لوهمان، 1995).
إنتاجية اللغات البشرية. من أجل هدف، يمكن إنتاج تعبيرات مختلفة بلا حدود. أيضًا، وفقًا لـ UG، فإن مخرجات اللغة الطبيعية متماسكة ومكتفية ذاتيًا. على سبيل المثال، الجملة، الفقرة، أو المقالة جميعها لها هيكل داخلي متسق ومتناسق، موجه بمبادئ ومعلمات UG.
غير قابلة للاستخدام بمفردها، ولكنها تتطلب تفسيرًا ودمجًا في أنظمة أكبر (مفاهيمية أو ملموسة). على سبيل المثال، يمكن أن ينتج نموذج التعلم الآلي مخاطر ائتمانية لعميل، بناءً على متجه ميزات محدد مسبقًا يتوافق مع معلمات عميل معين. ومع ذلك، يجب تفسير النتائج مثل
- الظهور القوي. بينما قد تمتلك أنظمة الذكاء الاصطناعي السابقة خصائص ناشئة، فإن GenAI لديه قدرة ملحوظة على التصرف بطريقة لا يمكن اشتقاقها مباشرة من خصائص مكوناته وتكون بعيدة جدًا عنها. وذلك لأن نتائج GenAI هي نتيجة تحولات من المطالبات بالاقتران مع المعرفة المعقدة لنظام GenAI. يمكن أن يكون للظهور القوي عواقب إيجابية (مثل القدرة على إنتاج محتوى إبداعي) وسلبية (مثل صعوبة السيطرة على GenAI وضمان عدم إيذائه أو الإضرار بالناس).
- الجدة الإنتاجية. متجذرة في الظهور القوي هي الجدة الإنتاجية. لدى الذكاء الاصطناعي الإنتاجي القدرة على إنتاج مخرجات متوقعة وغير متوقعة، بناءً على مدخل معين.
المخرجات هي منتجات لمليارات من المعلمات المضبوطة من خلال مليارات من التكرارات على بيانات تدريب كبيرة. بينما ترتبط هذه المخرجات في النهاية ببيانات التدريب، تكمن الجدة في طرق جديدة لتحويل البيانات وتحديد الأنماط غير المرئية. - المدخلات والمخرجات النظامية. تمتلك الذكاء الاصطناعي التوليدي القدرة على قبول وإنتاج مخرجات متماسكة ومكتفية ذاتيًا (مثل الردود المكتفية ذاتيًا، المقالات، الصور، الرسوم المتحركة، الموسيقى). بشكل فعال، ينتج الذكاء الاصطناعي التوليدي أنظمة مفاهيمية مكتفية ذاتيًا (على عكس مقتطفات من قواعد القرار)، جنبًا إلى جنب مع مكونات النظام. بمعنى آخر، يتم رسم الأنظمة كمخرجات من مدخلات النظام بناءً على خوارزميات التحويل المتطورة.
3.3 المنظور الاجتماعي التقني
لتكنولوجيا الذكاء الاصطناعي التوليدي في سياق أنظمة أخرى، ومنظمات، وأفراد، وعمليات. على وجه التحديد، الخصائص الأساسية المميزة للذكاء الاصطناعي التوليدي من الظهور القوي، والجدة، والمدخلات والمخرجات النظامية، تنتج تحديات وفرص جديدة للتحقيق في تصميم واستخدام وتأثير هذه التكنولوجيا في السياقات التنظيمية والاجتماعية. يسمح هذا التحقيق لمستخدمي نظم المعلومات بتبني واستغلال المعرفة الواسعة الموجودة عن المنظمات والأنظمة ودمج هذه المعرفة مع الأسس الجديدة للذكاء الاصطناعي التوليدي. على سبيل المثال، مع الأبحاث الواسعة في نظم المعلومات حول التجارة الإلكترونية والتخصيص، فإن دمج الذكاء الاصطناعي التوليدي في منصات التجارة الإلكترونية (مثل محرك بحث Bing) يخلق فرصًا للتحقيق في: دور الذكاء الاصطناعي التوليدي في اعتماد المستخدم؛ الثقة تجاه تقنيات التجارة الإلكترونية؛ والقدرة على تسهيل التجارة وتبادل المعلومات. بسبب الخصائص الثلاثة الجديدة جوهريًا للذكاء الاصطناعي التوليدي (انظر الشكل 3)، يمكن ربط هذه التكنولوجيا بطرق جديدة مع الأنظمة الأوسع. يمكن أن يؤدي ذلك إلى فرصة بحث لدراسة تقاطع الجوانب التقنية للذكاء الاصطناعي التوليدي والطرق التي تنجح أو تفشل بها هذه القدرات في دعم وتعزيز الأنظمة التي تصبح جزءًا منها، أو تتفاعل معها.
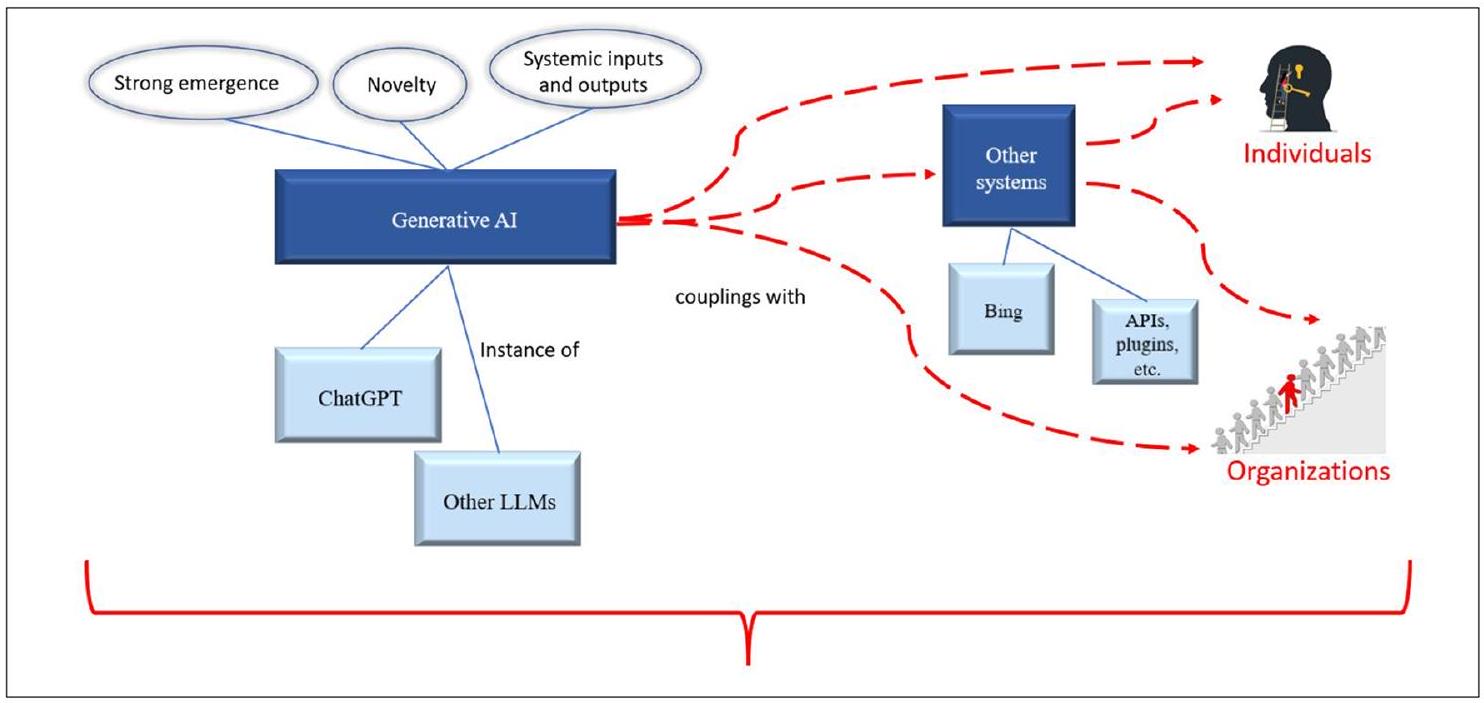
4 فرص البحث لأبحاث نظم المعلومات
4.1 الاضطراب والتأثير
4.2 التعاون بين الإنسان والآلة
التخصصات الأكاديمية تدرس التعاون بين الإنسان والذكاء الاصطناعي، فإن أنظمة المعلومات لديها قدرة طبيعية ومسؤولية للمساعدة في تحقيق تقدم في مجالات مثل: تصميم أنظمة الإنسان والذكاء الاصطناعي؛ سلوكيات الإنسان والذكاء الاصطناعي؛ القضايا الاقتصادية للأعمال والمجتمعات المدعومة بالذكاء الاصطناعي؛ والقضايا التنظيمية للشركات التي تعتمد بشكل كبير على الذكاء الاصطناعي. يمكن أن تشمل الموضوعات النموذجية في التعاون بين الإنسان والذكاء الاصطناعي ما يلي:
4.3 الجانب المظلم للذكاء الاصطناعي التوليدي
تفاقم التشوهات الموجودة. لقد أظهرت أدوات مثل ChatGPT أنها تعرض مجموعة متنوعة من هذه التحيزات، بما في ذلك السياسية، والأخلاقية، والثقافية (موتوكي وآخرون، 2024). وبالتالي، يبدو أن GenAI الحديثة متحيزة نحو الديمقراطيين في الولايات المتحدة، ولولا دي سيلفا في البرازيل، وحزب العمال في المملكة المتحدة (موتوكي وآخرون، 2024). إذا تُركت هذه التحيزات دون معالجة، يمكن أن تؤدي إلى قرارات خاطئة بناءً على هذه الأدوات وقد تقوض الثقة في أدوات GenAI معينة، أو بائعيها، أو صناعة الذكاء الاصطناعي بأكملها.
4.4 تصميم الأنظمة باستخدام الذكاء الاصطناعي التوليدي
مجموعة من المحترفين غير المتخصصين في تكنولوجيا المعلومات الذين يتحفزون لاتخاذ المبادرة الذاتية والإجراءات لتنفيذ تغيير مرغوب باستخدام تكنولوجيا المعلومات. يقوم موظفو المنظمات غير المتخصصين في تكنولوجيا المعلومات بشكل متزايد بتنفيذ حلولهم الخاصة، مثل الحلول البديلة للأنظمة الحالية (Alter، 2015) وحلول جديدة تمامًا، خاصة في مجالات مثل التحليلات (Khatri & Samuel، 2019). يحدث تمكين المستخدمين، ليس فقط داخل المنظمات التجارية، ولكن أيضًا داخل المجتمع بشكل عام، حيث يستفيد الناس من قدرات GenAI لتطوير المواقع الإلكترونية والتطبيقات ووسائط الإعلام الرقمية. يتحدى هذا التطوير من الأسفل إلى الأعلى من قبل المستخدمين الم empowered العلاقة بين تكنولوجيا المعلومات والمستخدمين (Chua & Storey، 2016)، مما يؤدي إلى آفاق جديدة للبحث حول كيفية دعم هؤلاء المستخدمين بشكل أفضل.
تحسين أداء أنظمة الذكاء الاصطناعي. تقدم تقنية استرجاع المعلومات المعززة (RAG) نهجًا واعدًا من خلال تزويد نماذج اللغة الكبيرة (LLM) بمعرفة إضافية محددة المجال لتحسين أداء المخرجات (Ke et al.، 2024). وبالمثل، يوفر التعلم في السياق (ICL) نماذج اللغة الكبيرة بأمثلة وتعليمات ذات صلة من خلال المحفزات. يزرع هذا النهج سلسلة من الأفكار أثناء توليد الاستجابة، مما يؤدي إلى قدرة النظام على استخدام المعلومات والمعرفة المكتسبة بشكل متماسك في الوقت الحقيقي (Tang et al.، 2023). يجب على الباحثين في نظم المعلومات التركيز على أسئلة بحثية تستكشف كيفية تنفيذ هذه الأساليب المعززة بشكل أكثر فعالية في إنتاج وإدارة المعرفة في السياقات التنظيمية. قد تشمل هذه الموضوعات المتعلقة بالاستفادة من الأساليب التقليدية لنظم المعلومات لالتقاط المعرفة الهيكلية، مثل من خلال النماذج المفاهيمية. يعد تمثيل المعرفة جزءًا أساسيًا وتقليديًا من البحث في نظم المعلومات (Burton-Jones et al.، 2017؛ Recker et al.، 2021)، مما يجعل مجتمع نظم المعلومات في وضع جيد لدعم RAG وICL ومبادرات أخرى مماثلة.
4.5 مواضيع بحثية مهمة في نظم المعلومات
- فهم وتحسين تكنولوجيا الأعمال بناءً على الذكاء الاصطناعي التوليدي. سيكون لدى باحثي علم التصميم في نظم المعلومات فرصة لدراسة القضايا التكنولوجية في تطبيقات الذكاء الاصطناعي التوليدي في الأعمال.
- فهم تأثيرات الذكاء الاصطناعي التوليدي على الأفراد بما في ذلك العمال والمستخدمين العامين. ستستخدم تطبيقات الذكاء الاصطناعي التوليدي والمكونات الإضافية بشكل متزايد من قبل الأعمال.
| التحديات | مواضيع البحث والأمثلة | ||||||||
| فهم وتحسين تكنولوجيا الأعمال بناءً على الذكاء الاصطناعي التوليدي |
|
||||||||
| فهم تأثيرات الذكاء الاصطناعي التوليدي على الأفراد بما في ذلك العمال والمستخدمين العامين |
|
||||||||
| فهم تأثيرات الذكاء الاصطناعي التوليدي على المنظمات من حيث العمليات والهياكل |
|
||||||||
| فهم التأثيرات بين المنظمات للذكاء الاصطناعي التوليدي |
|
||||||||
| فهم المجالات التجارية الحرجة لاعتماد الذكاء الاصطناعي التوليدي |
|
||||||||
| فهم القضايا القانونية والحوكمة للذكاء الاصطناعي التوليدي |
|
||||||||
| فهم القضايا الاجتماعية الأوسع للذكاء الاصطناعي التوليدي |
|
- فهم تأثيرات الذكاء الاصطناعي التوليدي على المنظمات من حيث العمليات والهياكل. سيؤثر الذكاء الاصطناعي التوليدي بلا شك على قدرات تكنولوجيا المعلومات والأفراد، مما يؤدي إلى تغييرات في العمليات والهياكل التجارية.
- فهم التأثيرات بين المنظمات. عندما يتخلل الذكاء الاصطناعي التوليدي المنظمات، ستختلف أنواع التفاعلات بين المنظمات، مما يؤدي إلى تغييرات في العلاقات والتفاعلات.
- فهم المجالات التجارية الحرجة. يمكن أن تكون تأثيرات البحث أكثر أهمية في المجالات التجارية الحرجة مثل الرعاية الصحية والمالية؛ لذلك، يجب إيلاء اهتمام خاص لهذه المجالات.
- فهم القضايا القانونية والحوكمة. يمكن أن يؤدي الذكاء الاصطناعي إلى نتائج سلبية ويؤدي إلى الجانب المظلم للذكاء الاصطناعي التوليدي، مما يتطلب دراسة القضايا القانونية والحوكمة.
- فهم القضايا الاجتماعية الأوسع. مع تطبيق الذكاء الاصطناعي التوليدي في مختلف القطاعات التجارية، يجب دراسة قضايا اجتماعية إضافية، مثل الخصوصية والأمان.
5 الخاتمة
الإعلانات
References
Ackoff, R. L., & Emery, F. E. (2005). On purposeful systems: An interdisciplinary analysis of individual and social behavior as a system of purposeful events. Routledge.
Agrawal, S. (2023). Are LLMs the master of all trades?: Exploring domain-agnostic reasoning skills of LLMs. arXiv preprint arXiv:2303.12810.
Alavi, M., Leidner, D. E., & Mousavi, R. (2024). A knowledge management perspective of generative artificial intelligence. Journal of the Association for Information Systems, 25(1), 1-12.
Alavi, M., & Westerman, G. (2023). How generative AI will transform knowledge work. Harvard Business Review. https://hbr.org/2023/ 11/how-generative-ai-will-transform-knowledge-work. Accessed 20 Sept 2024.
Alavi, M. (2024). Generative AI and job crafting: A new frontier in knowledge work support. Harvard Business Review
Alter, S. (2015). Sociotechnical systems through a work system lens: A possible path for reconciling system conceptualizations, business realities, and humanist values in IS development. In STPIS 2015 (1st international workshop on socio-technical perspective in IS development) associated with CAISE 2015 (conference on advanced information system engineering).
Basilan, M. (2023). What are griefbots? AI-powered tech used to ‘resurrect’ the dead raises ethical questions. International Business Times. Retrieved 06/19/2023 from https://www.ibtimes.com/ what-are-griefbots-ai-powered-tech-used-resurrect-dead-raises-ethical-questions-3694800. Accessed 20 Sept 2024.
Batini, C., Lenzerini, M., & Navathe, S. B. (1986). A comparative analysis of methodologies for database schema integration. ACM Computing Surveys (CSUR), 18(4), 323-364.
Bedué, P., & Fritzsche, A. (2022). Can we trust AI? An empirical investigation of trust requirements and guide to successful AI adoption. Journal of Enterprise Information Management, 35(2), 530-549.
Bender, E. M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021). On the dangers of stochastic parrots: Can language models be too big? In Proceedings of the 2021 ACM conference on fairness, accountability, and transparency. ACCT ’21 Canada March 3-10, 2021.
Berente, N., Gu, B., Recker, J., & Santhanam, R. (2021). Managing artificial intelligence. MIS Quarterly, 45(3), 1433-1450.
Bertram, E. (1972). Even permutations as a product of two conjugate cycles. Journal of Combinatorial Theory, Series A, 12(3), 368-380.
Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent Dirichlet allocation. Journal of Machine Learning Research, 3(Jan), 993-1022.
Bunge, M. (1979). Basic philosophy. Reidel Publishing Co. Dordrecht.
Bunge, M. (1996). Finding philosophy in social science. Yale University Press.
Bunge, M. (2018). Systems everywhere. In C. Negoita (Ed.), Cybernetics and applied systems (pp. 23-41). CRC Press.
Burton-Jones, A., Recker, J., Indulska, M., Green, P., & Weber, R. (2017). Assessing representation theory with a framework for pursuing success and failure. MIS Quarterly, 41(4), 1307-1334.
Cerf, V. G. (2019). AI is not an excuse! Communications of the ACM (Vol 62, Issue 10, pp. 7-7). ACM New York.
Chang, Y. B., & Gurbaxani, V. (2012). Information technology outsourcing, knowledge transfer, and firm productivity: An empirical analysis. MIS Quarterly, 36(4), 1043-1063.
Chang, Y., Wang, X., Wang, J., Wu, Y., Yang, L., Zhu, K., Chen, H., Yi, X., Wang, C., & Wang, Y. (2024). A survey on evaluation of large language models. ACM Transactions on Intelligent Systems and Technology, 15(3), 1-45.
Chatterjee, S., Sarker, S., Lee, M. J., Xiao, X., & Elbanna, A. (2021). A possible conceptualization of the information systems (IS) artifact: A general systems theory perspective 1. Information Systems Journal, 31(4), 550-578.
Chomsky, N. (1986). Knowledge of language: Its nature, origin, and use. Greenwood Publishing Group.
Chua, C. E. H., & Storey, V. C. (2016). Bottom-up enterprise information systems: Rethinking the roles of central IT departments. Communications of the ACM, 60(1), 66-72.
Cortes, C., & Vapnik, V. (1995). Support-vector networks. Machine Learning, 20, 273-297.
Crevier, D. (1993). AI: the tumultuous history of the search for artificial intelligence. Basic Books, Inc.
Delipetrev, B., Tsinaraki, C., & Kostić, U. (2020). Historical evolution of artificial intelligence, EUR 30221EN. Publications Office of the European Union. https://publications.jrc.ec.europa.eu/repos itory/handle/JRC120469
Demetis, D., & Lee, A. S. (2018). When humans using the IT artifact becomes IT using the human artifact. Journal of the Association for Information Systems, 19(10), 5.
Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., & Fei-Fei, L. (2009). Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition (pp. 248-255).
Dubin, J. A., Bains, S. S., Chen, Z., Hameed, D., Nace, J., Mont, M. A., & Delanois, R. E. (2023). Using a Google web search analysis to assess the utility of ChatGPT in total joint arthroplasty. The Journal of Arthroplasty, 38(7), 1195-1202.
Dwivedi, Y. K., Kshetri, N., Hughes, L., Slade, E. L., Jeyaraj, A., Kar, A. K., Baabdullah, A. M., Koohang, A., Raghavan, V., & Ahuja, M. (2023). “So what if ChatGPT wrote it?” Multidisciplinary perspectives on opportunities, challenges and implications of
generative conversational AI for research, practice and policy. International Journal of Information Management, 71, 102642.
Feldman, M. S., & Pentland, B. T. (2003). Reconceptualizing organizational routines as a source of flexibility and change. Administrative Science Quarterly, 48(1), 94-118.
Ferrucci, D. A. (2012). Introduction to “this is Watson.”. IBM Journal of Research and Development, 56(3.4), 1: 1-1-1: 115.
French, A., Storey, V. C., & Wallace, L. (2024). A typology of disinformation intentionality and impact. Information Systems Journal, 34(4), 1324-1354.
Fügener, A., Grahl, J., Gupta, A., & Ketter, W. (2021). Will humans-in-the-loop become Borgs? Merits and pitfalls of working with AI. MIS Quarterly (MISQ), 45(3b), 1527-1556.
Fui-Hoon Nah, F., Zheng, R., Cai, J., Siau, K., & Chen, L. (2023). Generative AI and ChatGPT: Applications, challenges, and AIhuman collaboration. Journal of Information Technology Case and Application Research, 25(3), 277-304.
Gewitz, D. (2023). How to use ChatGPT to write code. https://www. zdnet.com/article/how-to-use-chatgpt-to-write-code/. Accessed 20 Sept 2024.
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., & Bengio, Y. (2020). Generative adversarial networks. Communications of the ACM, 63(11), 139-144.
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., & Bengio, Y. (2014). Generative adversarial nets. Advances in Neural Information Processing Systems, 27, 1-9.
Hagendorff, T., & Fabi, S. (2022). Methodological reflections for AI alignment research using human feedback. arXiv preprint arXiv:2301.06859.
Haidt, J., & Schmidt, E. (2023). AI is about to make social media (much) more toxic. The Atlantic.
Harmon, P., & King, D. (1985). Expert systems. John Wiley & Sons. Inc.
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735-1780.
Holland, J. H. (1992). Genetic algorithms. Scientific American, 267(1), 66-73.
Jarvenpaa, S., & Klein, S. (2024). New frontiers in information systems theorizing: Human-gAI collaboration. Journal of the Association for Information Systems, 25(1), 110-121.
Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., Ishii, E., Bang, Y. J., Madotto, A., & Fung, P. (2023). Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12), 1-38.
Kajtazi, M., Holmberg, N., & Sarker, S. (2023). The changing nature of teaching future IS professionals in the era of generative AI. In In (Vol. 25, pp. 415-422). Taylor & Francis.
Kanbach, D. K., Heiduk, L., Blueher, G., Schreiter, M., & Lahmann, A. (2023). The GenAI is out of the bottle: Generative artificial intelligence from a business model innovation perspective. Review of Managerial Science, 1-32.
Kaneko, M., & Baldwin, T. (2024). A little leak will sink a great ship: survey of transparency for large language models from start to finish. arXiv preprint arXiv:2403.16139.
Ke, Y., Jin, L., Elangovan, K., Abdullah, H. R., Liu, N., Sia, A. T. H., Soh, C. R., Tung, J. Y. M., Ong, J. C. L., & Ting, D. S. W. (2024). Development and testing of retrieval augmented generation in large language models–A case study report. arXiv preprint arXiv:2402.01733.
Kelly, S. M. (2023). Snapchat’s new AI Chatbot is already raising alarms among teens and parents. Retrieved 06/19/2023 from https://edition.cnn.com/2023/04/27/tech/snapchat-my-ai-conce rns-wellness/index.html. .
Khatri, V., & Samuel, B. M. (2019). Analytics for managerial work. Communications of the ACM, 62(4), 100-100.
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2017). Imagenet classification with deep convolutional neural networks. Communications of the ACM, 60(6), 84-90.
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems, 25.
LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11), 2278-2324.
Legner, C., Eymann, T., Hess, T., Matt, C., Böhmann, T., Drews, P., Mädche, A., Urbach, N., & Ahlemann, F. (2017). Digitalization: Opportunity and challenge for the business and information systems engineering community. Business & Information Systems Engineering, 59, 301-308.
Li, Z., Yang, Z., & Wang, M. (2023). Reinforcement learning with human feedback: Learning dynamic choices via pessimism. arXiv preprint arXiv:2305.18438.
Li, K., & Wieringa, P. A. (2000). Understanding perceived complexity in human supervisory control. Cognition, Technology & Work, 2, 75-88.
Lima, P. U., & Custodio, L. M. (2004). Artificial intelligence and systems theory: Applied to cooperative robots. International Journal of Advanced Robotic Systems, 3(1), 15.
Luhmann, N. (1995). Social systems. Stanford University Press, Palo Alto.
Lukyanenko, R., Parsons, J., Wiersma, Y. F., & Maddah, M. (2019). Expecting the unexpected: Effects of data collection design choices on the quality of crowdsourced user-generated content. MIS Quarterly, 43(2), 623-648.
Lukyanenko, R., Maass, W., & Storey, V. C. (2022a). Trust in artificial intelligence: From a foundational trust framework to emerging research opportunities. Electronic Markets, 32(4), 1993-2020.
Lukyanenko, R., Storey, V. C., & Pastor, O. (2022b). System: A core conceptual modeling construct for capturing complexity. Data & Knowledge Engineering, 141, 102062.
Luong, M.-T., Pham, H., & Manning, C. D. (2015). Effective approaches to attention-based neural machine translation. arXiv preprint arXiv:1508.04025.
Lyu, Q., Havaldar, S., Stein, A., Zhang, L., Rao, D., Wong, E., Apidianaki, M., & Callison-Burch, C. (2023). Faithful chain-ofthought reasoning. arXiv preprint arXiv:2301.13379.
McCarthy, J. (1959). Programs with common sense. In Proceedings of the Teddington conference on the mechanization of thought processes (pp. 75-91). Her Majesty’s Stationary Office.
Mei, Q., Xie, Y., Yuan, W., & Jackson, M. O. (2024). A Turing test of whether AI chatbots are behaviorally similar to humans. Proceedings of the National Academy of Sciences, 121(9), e2313925121.
Michie, D. (1963). Experiments on the mechanization of game-learning Part I. Characterization of the model and its parameters. The Computer Journal, 6(3), 232-236.
Minsky, M., & Papert, S. (1969). Perceptron: An introduction to computational geometry. MIT Press.
Motoki, F., Pinho Neto, V., & Rodrigues, V. (2024). More human than human: Measuring ChatGPT political bias. Public Choice, 198(1), 3-23.
Newell, A., Shaw, J. C., & Simon, H. A. (1962). The processes of creative thinking. In Contemporary approaches to creative thinking, 1958. University of Colorado.
Pachocki, J., Roditty, L., Sidford, A., Tov, R., & Williams, V. V. (2018). Approximating cycles in directed graphs: Fast algorithms for
girth and roundtrip spanners. In Proceedings of the twenty-ninth annual ACM-SIAM symposium on discrete algorithms.
Park, S. Y., Kuo, P.-Y., Barbarin, A., Kaziunas, E., Chow, A., Singh, K., Wilcox, L., & Lasecki, W. S. (2019). Identifying challenges and opportunities in human-AI collaboration in healthcare. In Conference companion publication of the 2019 on computer supported cooperative work and social computing.
Perez, C. (2010). Technological revolutions and techno-economic paradigms. Cambridge Journal of Economics, 34(1), 185-202.
Qiu, L., & Benbasat, I. (2010). A study of demographic embodiments of product recommendation agents in electronic commerce. International Journal of Human-Computer Studies, 68(10), 669-688.
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners. OpenAI Blog, 1(8), 9.
Rajput, W. (2023). Integrating ChatGPT in the enterprise. https://www. linkedin.com/pulse/integrating-chatgpt-enterprise-wasim-rajput. Accessed 20 Sept 2024.
Recker, J. C., Lukyanenko, R., Jabbari Sabegh, M., Samuel, B., & Castellanos, A. (2021). From representation to mediation: A new agenda for conceptual modeling research in a digital world. MIS Quarterly, 45(1), 269-300.
Reis, L., Maier, C., Mattke, J., Creutzenberg, M., & Weitzel, T. (2020). Addressing user resistance would have prevented a healthcare AI project failure. MIS Quarterly Executive, 19(4).
Rosenblatt, F. (1961). Principles of neurodynamics : Perceptrons and the theory of brain mechanisms. Spartan Books.
Rotman, D. (2023). ChatGPT is about to revolutionize the economy. In We need to decide what that looks like. MIT Technology Review.
Russell, S., & Norvig, P. (2016). Artificial intelligence: A modern approach. Pearson.
Saba, W. S. (2023). Stochastic LLMs do not understand language: Towards symbolic, explainable and ontologically based LLMS. In International conference on conceptual modeling (pp. 3-19). ER 2023.
Sabherwal, R., & Grover, V. (2024). The societal impacts of generative artificial intelligence: A balanced perspective. Journal of the Association for Information Systems, 25(1), 13-22.
Samuel, A. L. (1960). Programming computers to play games. In Advances in computers (Vol. 1, pp. 165-192). Elsevier.
Sarker, S., Chatterjee, S., Xiao, X., & Elbanna, A. (2019). The sociotechnical axis of cohesion for the IS discipline: Its historical legacy and its continued relevance. MIS Quarterly, 43(3), 695-720.
Savage, N. (2020). The race to the top among the world’s leaders in artificial intelligence. Nature, 588(7837), S102-S102.
Savage, N. (2023). Drug discovery companies are customizing ChatGPT: Here’s how. Nature Biotechnology.
Schlindwein, S. L., & Ison, R. (2004). Human knowing and perceived complexity: Implications for systems practice. Emergence: Complexity and Organization, 6(3), 27-32.
Schmidhuber, J. (1993). Habilitation thesis: System modeling and optimization. Page 150 ff demonstrates credit assignment across the equivalent of 1,200 layers in an unfold.
Schmidhuber, J. (2015). Deep learning in neural networks: An overview. Neural Networks, 61, 85-117.
Segev, A., & Zhao, J. L. (1994). Rule management in expert database systems. Management Science, 40(6), 685-707.
Seidel, S., Berente, N., Lindberg, A., Lyytinen, K., & Nickerson, J. V. (2018). Autonomous tools and design: A triple-loop approach to humanmachine learning. Communications of the ACM, 62(1), 50-57.
Seseri, R. (2023). Generative AI: A paradigm shift in enterprise and startup opportunities. https://www.cio.com/article/474720/gener
ative-ai-a-paradigm-shift-in-enterprise-and-startup-opportunit ies.html. Accessed 20 Sept 2024.
Skyttner, L. (2001). General systems theory. World Scientific.
Smolensky, R. (1987). Algebraic methods in the theory of lower bounds for Boolean circuit complexity. In Proceedings of the nineteenth annual ACM symposium on theory of computing.
Sowa, K., Przegalinska, A., & Ciechanowski, L. (2021). Cobots in knowledge work: Human-AI collaboration in managerial professions. Journal of Business Research, 125, 135-142.
Stohr, E. A., & Zhao, J. L. (2001). Workflow automation: Overview and research issues. Information Systems Frontiers, 3, 281-296.
Storey, V. C. (2025). Knowledge management in a world of generative AI: Impact and Implications. In ACM Transactions on Management Information Systems.
Storey, V. C., Lukyanenko, R., Maass, W., & Parsons, J. (2022). Explainable AI: Opening the black box or Pandora’s Box? Communications of the ACM, 65(4), 27-29.
Susarla, A., Gopal, R., Thatcher, J. B., & Sarker, S. (2023). The Janus effect of generative AI: Charting the path for responsible conduct of scholarly activities in information systems. Information Systems Research, 34(2), 399-408.
Tang, Y., Puduppully, R., Liu, Z., & Chen, N. (2023). In-context learning of large language models for controlled dialogue summarization: A holistic benchmark and empirical analysis. In Proceedings of the 4th new frontiers in summarization workshop.
Tarafdar, M., D’arcy, J., Turel, O., & Gupta, A. (2014). The dark side of information technology. MIT Sloan Management Review.
Tesauro, G. (2002). Programming backgammon using self-teaching neural nets. Artificial Intelligence, 134(1-2), 181-199.
Thrun, S., Montemerlo, M., Dahlkamp, H., Stavens, D., Aron, A., Diebel, J., Fong, P., Gale, J., Halpenny, M., & Hoffmann, G. (2006). Stanley: The robot that won the DARPA grand challenge. Journal of Field Robotics, 23(9), 661-692.
Turing, A. M. (1950). Computing machinery and intelligence. The essential Turing: The ideas that gave birth to the computer age. Mind, LIX(236), 433-460.
Turing, A. M. (2012). Computing machinery and intelligence (1950). In The essential Turing: The ideas that gave birth to the computer age (pp. 433-464).
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 30.
Verganti, R., Vendraminelli, L., & Iansiti, M. (2020). Innovation and design in the age of artificial intelligence. Journal of Product Innovation Management, 37(3), 212-227.
Walters, W. P., & Murcko, M. (2020). Assessing the impact of generative AI on medicinal chemistry. Nature Biotechnology, 38(2), 143-145.
Wang, D., Weisz, J. D., Muller, M., Ram, P., Geyer, W., Dugan, C., Tausczik, Y., Samulowitz, H., & Gray, A. (2019). Human-AI collaboration in data science: Exploring data scientists’ perceptions of automated AI. In Proceedings of the ACM on human-computer interaction, 3(CSCW) (pp. 1-24).
Watkins, C. J. C. H. (1989). Learning from delayed rewards. Ph.D. Thesis, King’s College.
Weizenbaum, J. (1966). ELIZA-A computer program for the study of natural language communication between man and machine. Communications of the ACM, 9(1), 36-45.
Wu, S. P.-J., Straub, D. W., & Liang, T.-P. (2015). How information technology governance mechanisms and strategic alignment influence organizational performance. MIS Quarterly, 39(2), 497-518.
Wu, C.-J., Raghavendra, R., Gupta, U., Acun, B., Ardalani, N., Maeng, K., Chang, G., Aga, F., Huang, J., & Bai, C. (2022). Sustainable AI: Environmental implications, challenges and opportunities. Proceedings of Machine Learning and Systems, 4, 795-813.
Yao, B., Chen, G., Zou, R., Lu, Y., Li, J., Zhang, S., Liu, S., Hendler, J., & Wang, D. (2023). More samples or more prompt inputs? Exploring effective in-context sampling for LLM few-shot prompt engineering. arXiv preprint arXiv:2311.09782.
Yeshchenko, A., Di Ciccio, C., Mendling, J., & Polyvyanyy, A. (2019). Comprehensive process drift detection with visual analytics. In Conceptual modeling: 38th international conference, ER 2019, Salvador, Brazil, November 4-7, 2019, Proceedings (p. 38).
Yu, X., Lyu, Y., & Tsang, I. (2020). Intrinsic reward driven imitation learning via generative model. In International conference on machine learning.
Yue, W. T., Wang, Q.-H., & Hui, K. L. (2019). See no evil, hear no evil? Dissecting the impact of online hacker forums. MIS Quarterly, 43(1), 73.
Zamfirescu-Pereira, J., Wong, R. Y., Hartmann, B., & Yang, Q. (2023). Why Johnny can’t prompt: How non-AI experts try (and fail) to design LLM prompts. In Proceedings of the 2023 CHI conference on human factors in computing systems.
Zhang, B., Zhu, J., & Su, H. (2023). Toward the third generation artificial intelligence. Science China Information Sciences, 66(2), 1-19.
Zhang, J., Lan, T., Zhu, M., Liu, Z., Hoang, T., Kokane, S., Yao, W., Tan, J., Prabhakar, A., & Chen, H. (2024a). xLAM: A family of large action models to empower AI agent systems. arXiv preprint arXiv:2409.03215.
Zhang, J., Mills, D. J., & Huang, H.-W. (2024b). Enhancing travel planning and experiences with multimodal ChatGPT 4.0. In Proceedings of the 2024 international conference on innovation in artificial intelligence.
Zhao, W. (2022). Inspired, but not mimicking: A conversation between artificial intelligence and human intelligence. National Science Review, 9(6), nwac068.
Zhuang, Y., Yu, Y., Wang, K., Sun, H., & Zhang, C. (2023). Toolqa: A dataset for LLM question answering with external tools. Advances in Neural Information Processing Systems, 36, 50117-50143.
Zuboff, S. (1988). In the age of the smart machine: The future of work and power. Basic Books, Inc.
J. Leon Zhao is a Presidential Chair Professor, Director of Center on Blockchain and Intelligent Technology, Co-head of Information Systems and Operations Management, School of Management and Economics, Chinese University of Hong Kong, Shenzhen. He was a chair professor at City University of Hong Kong and Eller Professor at University of Arizona, respectively. He has edited over 20 special issues
for academic journals including MIS Quarterly, Information Systems Research, and Journal of Operations Management. He received an IBM Faculty Award in 2005, and National Chang Jiang Scholar Chair Professorship first at Tsinghua University in 2009 and again at the Chinese University of Hong Kong, Shenzhen in 2022.
- J. Leon Zhao
leonzhao@cuhk.edu.cn
Roman Lukyanenko
romanl@virginia.edu
1 Georgia State University, Atlanta, GA, USA
City University of Hong Kong, Kowloon, Hong Kong SAR, China 3 Chinese University of Hong Kong, Shenzhen, China
4 University of Virginia, Charlottesville, VA, USA There could be other forms of data, but the basis is textual. Generative AI can “understand” an image because it has seen something similar before. Past images are associated with certain textual data; therefore, new images will also be associated with related textual data. The authors thank an anonymous reviewer for this positioning. Transformer-based pre-trained models approach the humanlevel benchmark with General Language Understanding Evaluation (GLUE), which is based on a collection of English language comprehension problems, rapidly. From the GLUE benchmark, a more rigorous SuperGLUE benchmark test was developed, whereby the models rapidly improved and surpassed human-level standards. From OpenAI’s own evaluations, GPT-4 performs exceptionally well on a variety of tests, including reasonings and other examinations (https://cdn. openai.com/papers/gpt-4.pdf). https://medium.com/mlearning-ai/an-ai-model-that-is-energy-effic ient-is-just-as-important-as-its-purpose-71d17822a183
DOI: https://doi.org/10.1007/s10796-025-10581-7
Publication Date: 2025-02-25
Generative Artificial Intelligence: Evolving Technology, Growing Societal Impact, and Opportunities for Information Systems Research
© The Author(s) 2025
Abstract
The continuing, explosive developments in generative artificial intelligence (GenAI), built on large language models and related algorithms, has led to much excitement and speculation about the potential impact of this new technology. Claims include artificial intelligence (AI) being poised to revolutionize business and society and dramatically change personal life. However, it is not clear how this technology, with its significantly distinct features from past AI technologies, has transformative potential or how researchers in information systems should react to it. In this paper, we consider the evolving and emerging trends of AI in order to examine its present and predict its future impacts. Many existing papers on GenAI are either too technical for most information systems researchers or lack the depth needed to appreciate the potential impacts of GenAI. We, therefore, attempt to bridge the technical and organizational communities of GenAI from a system-oriented sociotechnical perspective. Specifically, we explore the unique features of GenAI, which are rooted in the continued change from symbolism to connectionism, and the deep systemic and inherent properties of human-AI ecosystems. We retrace the evolution of AI that proceeded the level of adoption, adaption, and use found today, in order to propose future research on various impacts of GenAI in both business and society within the context of information systems research. Our efforts are intended to contribute to the creation of a well-structured research agenda in the information systems community to support innovative strategies and operations enabled by this new wave of AI.
1 Introduction
exclusively toward machine learning (ML) and data-driven AI (Cerf, 2019), where machine learning consists of methods and algorithms that are used to make inferences from data (Goodfellow et al., 2020). With its widespread adoption, ML has begun to rapidly transform organizations and even entire industries.
nature of GenAI from a systems perspective, we can develop a nuanced understanding of GenAI by leveraging existing concepts and theories of IS research. Fourth, we identify fruitful topics for future research.
2 Related Research
in the IS discipline. Susarla et al. (2023) suggest the potential of leveraging GenAI in various capacities to conduct scholarly work. In a broader context, Sabherwal and Grover (2024) argue that the societal impact of artificial intelligence is contingent upon its development and implementation. They emphasize the importance of considering the extent to which AI replaces versus supports humans, integrates physical and digital realities, and respects human limitations. O’Leary (2022) identifies emerging issues associated with large language models (LLMs) generally. Alavi et al. (2024) provide suggestions for how the IS discipline could focus on the role of GenAI from a knowledge management perspective, identifying related research opportunities. We continue these efforts by offering a broad and comprehensive analysis of GenAI as a technology and suggest a fruitful agenda for IS scholarship.
2.1 Prior Efforts of Research in AI and Information Systems
| Year | AI Artifact | AI Significance | Reference |
| 1952 | Checkers | Demonstrated computers can learn to play at level high enough to challenge amateur human player | Samuel (1960) |
| 1955 | Logic Theorist | Proven 38 theorems from Principia Mathematica; introduced critical concepts in artificial intelligence (e.g., heuristics, list processing, reasoning as search) | Newell et al. (1962) |
| 1957 | Perceptron | Birth of connectionism; foundation of Neural Networks (NN), Deep Learning | Rosenblatt (1961) |
| 1961 | MENACE | First program capable of learning to play perfect game of Tic-Tac-Toe | Michie (1963) |
| 1965 | ELIZA | Natural language processing system imitated doctor by responding to questions similar to psychotherapist before conversation became nonsensical | Weizenbaum (1966) |
| 1969 | Shakey the Robot | First general-purpose mobile robot capable of reasoning, integrated research in robotics with computer vision and natural language processing | Bertram (1972) |
| 1969 | The book “Perceptrons” | Highlighted unrecognized limits of feed-forward, two-layered perceptron structure; fundamental shift in AI research to symbolic, disregarding connectionism | Minsky and Papert (1969) |
2.2 Evolution from General AI to Generative AI
2.3 AI Evolution and the Impact on IS Research
| Year | AI Artifact | AI Significance | Reference |
| 1989 | Q-learning algorithm | “Learning from Delayed Rewards” improves reinforcement learning | Watkins (1989) |
| 1993 | Solved “very deep learning” task | Scientist solved task with over 1,000 layers in the recurrent neural network (RNN) | Schmidhuber (1993) |
| 1995 | SVM success | Support vector machines applied to text categorization, handwritten character recognition, and image classification | Cortes and Vapnik (1995) |
| 1997 | LSTM architecture | Long short-term memory (LSTM) architecture improved RNN by eliminating the long-term dependency problem | Hochreiter and Schmidhuber (1997) |
| 1998 | Improved gradient-based learning | Combines stochastic gradient descent algorithm with the backpropagation algorithm | LeCun et al. (1998) |
| 2002 | TD-Gammon matched best player | Combines neural nets and Reinforcement Learning (RL) with the self-play method | Tesauro (2002); Blei et al. (2003) |
| 2005 | Stanford robot won award | Drove 131 miles autonomously along an unrehearsed desert track in DARPA Grand Challenge | Thrun et al. (2006) |
| 2011 | IBM Watson won Jeopardy | Watson is Q&A system combining speech recognition, voice synthesis, and information retrieval, among others | Ferrucci (2012) |
| 2012 | AlexNet | Won ImageNet competition, possibly marking inflection point of deep learning | Krizhevsky et al. (2012); Krizhevsky et al. (2017) |
| 2014 | Generative Adversarial Networks (GANs) | Deep neural net architectures composed of two nets; learn to mimic distribution of data to generate content like images, music, speech, etc | Goodfellow et al. (2014); Kingma and Welling (2014) |
| 2017 | Transformer | DL architecture based on self-attention mechanism, important in language modelling, machine translation, and question answering | Vaswani et al. (2017) |
| 2018 | OpenAI Five | Defeated human team at Dota 2, complex video game messier; more realistic than Chess or Go | Pachocki et al. (2018) |
| 2019 | GPT-2 | Large-scale unsupervised language model; can generate coherent paragraphs of text, reading comprehension, machine translation, question answering, and summarization | Radford et al. (2019) |
3 Theoretical Framework for Understanding Generative AI
3.1 Conceptualization of Generative AI
of human natural language in deep neural networks such as transformers. As in many machine learning techniques, ChatGPT is pre-trained based on existing texts and then used to predict outcomes based on prompt text from the user. This predictive approach means that the responses from ChatGPT are probabilistic and therefore necessarily error prone. This predictive property is easy to comprehend by technical professionals, but requires explanation for non-technical professionals.
Connectionist models – ChatGPT is generative in that it creates new connections among words via large language models. As noted, AI evolved into connectionist paradigms after exploring symbolic paradigms and then achieved great success in natural language processing via large language models, leading to ChatGPT and similar tools (Zhang et al., 2023). Neural networks essentially create simple and weighted connections among sentences and words after coding manipulations, allowing machine learning computations on hundreds of billions of inputs (e.g., text tokens). The success of ChatGPT would not have been possible because pure symbolic models are difficult to scale to big data levels. This connectionism
| Concept | Definition | Year |
| GAN | Generative adversarial networks (GAN) simultaneously train two models: a generative model that captures the data distribution and a discriminative model that estimates the probability that a sample came from the training data | 2014 |
| Attention | The attention mechanism is used in machine learning and natural language processing to increase model accuracy by focusing on relevant data to enable the model to focus on certain areas of the input data, giving more weight to crucial features and disregarding unimportant ones | 2015 |
| Transformer | Transformers are a type of neural network designed to handle long-range dependencies in text, capturing relationships between words and allowing a model to understand context and meaning across large sequences of inputs. For example, the relevancy and relationship between color, sky, and blue in the question: “What is the color of the sky?” lead to the output: “The sky is blue.” | 2017 |
| Reward | Reward modeling is an approach in AI where a model receives a reward or score for its responses to given prompts. This reward signal serves as a reinforcement, guiding the AI model to produce desired outcomes | 2020 |
| RLHF | In machine learning, reinforcement learning from human feedback (RLHF) is a technique to align an intelligent agent to human preferences | 2023 |
Generic capabilities – ChatGPT is generic because connectionist models do not distinguish among business sectors or knowledge domains. A single ChatGPT can serve billions of users for questions and answers, without being limited to specific contexts. This feature is a result of its large language models and gigantic neural networks of connections. However, this capability, which is based on a large-scale dataset, also suffers from low accuracy and the possibility of hallucination (that is, making up nonsensical outputs).
Complementarity with search engines – ChatGPT results complement those from search engines because the former is predictive; the latter is simply a collection of existing documents relevant to the user query. As such, ChatGPT can be considered a summary of existing documents that are more precisely related to a user query, whereas a search engine simply provides a list of search results to the user. In some way, ChatGPT offers a preliminary result to a user, who may further process the answer by ChatGPT. There is a triangular relationship amongst a user, ChatGPT, and a search engine whereby the user may determine how to use and process the results from ChatGPT and the search engine. This should be a very fruitful research topic on how to manage this knowledge processing ecosystem. The triangular relationship will not replace search engines because the results from ChatGPT might not meet all users’ needs, although some users might accept the results, without using the search engine again (Dubin et al., 2023).
Ability of understanding by ChatGPT – How ChatGPT comprehends or understands texts in comparison to humans is an important subject of research. Humans learn throughout their lifetime, starting in childhood, and enriching their brains with new knowledge without creasing throughout their entire lifetime. People express ideas, exchange opinions, and create new concepts, words, and theories. ChatGPT can process extremely large amounts of text in existing documents and generate new text, based on user requests. However, it has been noted that AI cannot understand the meaning of a context in the human sense because it does not deal with the deep semantic meaning of the words it processes, demonstrating that there is still a very large gap between artificial intelli-
gence and human intelligence (Zhao, 2022). It is simply not reasonable to assert that ChatGPT can understand or comprehend documents in human sense. There is a significant difference between the generation of new text and creation of new ideas.
3.2 Systems Theory: Traditional versus Generative AI Explained
components (Bedau & Humphreys, 2008). These properties emerge when the components become part of the whole and begin interacting with one another in a specific way. Since no component possesses an emergent property, the emergent properties are often not derivable from the knowledge of the properties of the components. For example, solidarity is an emergent property of a political party; no member of the party has this property. This property depends, not only on the beliefs and behaviors of the individual members (as well as extraneous factors), but also on the history, dynamics, and interactions among its members. Similarly, transparency is the emergent property of the entire neural network. While the individual neural network components may be understandable to a human, when these components are put together, they may lack transparency. Similarly, humansounding outputs of ChatGPT are emergent from the specific connectionist and natural language architecture of GenAI, which, if de-coupled and used separately will fail to render similar types of outputs (Mei et al., 2024).
systems are also concrete, since they are made of concrete components – humans and their artifacts (Luhmann, 1995).
generativity of human languages. For a goal, infinitely different expressions can be generated. Also, following UG, the outputs of natural language are coherent and self-contained. For example, a sentence, a paragraph, or an essay all have internally consistent and coherent structure, guided by the principles and parameters of UG.
not usable by themselves, but required interpretation and integration into larger (conceptual or concrete) systems. For example, a machine learning model could generate a credit risk for a customer, based on a predefined feature vector corresponding to parameters of a particular customer. However, the results such as
- Strong Emergence. Whereas previous AI systems might possess emergent properties, GenAI has a particular significant ability to behave in a manner that is not directly derivable from the properties of its components and is very distant from them. This is because the outcomes of GenAI are the result of transformations from the prompts in combination with the complex knowledge of a GenAI system. Strong emergence can have both positive (e.g., ability to generate creative content) and negative consequences (e.g., difficulty to control GenAI and assure it does not harm or disadvantage people).
- Generative Novelty. Rooted in strong emergence is generative novelty. Generative AI has the capacity to produce both expected and unexpected outputs, based on a given
input. The outputs are products of billions of parameters tuned through billions of iterations over big training data. While these outputs are ultimately grounded in training data, the novelty lies in new ways to transform data and identify unseen patterns. - Systemic inputs and outputs. Generative AI has the ability to accept and produce coherent, self-contained outputs (such as self-contained responses, essays, images, animations, music). Effectively, GenAI produces self-contained conceptual systems (as opposed to snippets of decision rules), along with system components. That is to say, the systems as outputs are mapped from the system inputs based on the sophisticated transformation algorithms.
3.3 Sociotechnical Perspective
of GenAI technology within the context of other systems, organizations, individuals, and processes. Specifically, the distinct foundational properties of GenAI of strong emergence, novelty and systemic inputs and outputs, produce new challenges and opportunities for investigating the design, use and impact of this technology in organizational and societal contexts. Such investigation permits information systems users to adopt and leverage the extensive existing knowledge of organizations and systems and to integrate this knowledge with the new fundamentals of GenAI. For example, with extensive information systems research on e-commerce and personalization, the integration of GenAI in e-commerce platforms (e.g., the Bing search engine) creates opportunities to investigate: the role of generative artificial intelligence in user adoption; trust towards e-commerce technologies; and the ability to facilitate commerce and information exchange. Because of the three fundamentally new properties of GenAI (See Fig. 3), this technology can be coupled in novel ways with the broader systems. This can lead to a research opportunity to study the intersection of the technical aspects of GenAI and the ways in which these capabilities succeed or fail to support, augment, and enhance the systems they become part of, or interact with.
4 Research Opportunities for Information Systems Research
4.1 Disruption and Impact
4.2 Human Machine Collaboration
academic disciplines study human-AI collaboration, information systems have a natural capability and responsibility to help make progress in areas such as: design of humanAI systems; human and AI behaviors; economic issues of AI-assisted businesses and societies; and organizational issues of AI-intensive firms. Sample topics in human-AI collaboration can include the following:
4.3 Dark-Side of Generative AI
compound existing distortions. Tools such as ChatGPT, have been shown to exhibit a variety of such biases, including political, moral and cultural (Motoki et al., 2024). Hence, modern GenAI appear to be the biased towards the Democrats in the US, Lula de Silva in Brazil, and the Labour Party in the UK (Motoki et al., 2024). If left unaddressed, such biases can result in erroneous decisions based on these tools and may undermine trust in particular GenAI tools, their vendors, or the entire artificial intelligence industry.
4.4 Designing Systems with Generative AI
group of non-IT professionals who are motivated to take autonomous initiative and action to implement a desired change using information technology. Organizational nonIT employees increasingly implement their own solutions, such as workarounds to existing systems (Alter, 2015) and completely new solutions, especially in areas such as analytics (Khatri & Samuel, 2019). User empowerment is occurring, not only within business organizations, but also within society broadly, as people leverage GenAI’s capabilities to develop websites, apps and digital media. This bottom-up development by empowered users challenges the relationship between IT and users (Chua & Storey, 2016), leading to new avenues for research on how to best support such users.
fine-tune the AI systems’ performance. Retrieval augmented generation (RAG) offers a promising approach by providing LLM with additional domain-specific knowledge to improve output performance (Ke et al., 2024). Similarly, in-context learning (ICL) provides LLMs with relevant examples and instructions through prompts. This approach instills a chain of thought during response generation, leading to a system’s ability to coherently utilize information and knowledge learned in real time (Tang et al., 2023). Researchers in information systems should focus on research questions that explore how to most effectively implement these augmenting methods in knowledge production and management in organizational contexts. This could include topics related to leveraging traditional to information systems approaches for capturing structured domain knowledge, such as through conceptual models. Knowledge representation is a fundamental and traditional part of research in information systems (Burton-Jones et al., 2017; Recker et al., 2021), making the IS community well-positioned to support RAG, ICL and other, similar initiatives.
4.5 Significant IS Research Topics
- Understand and improve business technology based on GenAI. Design science researchers in information systems will have an opportunity to study technological issues in GenAI applications in business.
- Understand the impacts of GenAI on individuals including workers and general users. GenAI applications and plug-ins will be increasingly used by business work-
| Challenges | Research topics and examples | ||||||||
| Understand and improve business technology based on GenAI |
|
||||||||
| Understand the impacts of GenAI on individuals including workers and general users |
|
||||||||
| Understand the impacts of GenAI on organizations in terms of processes and structures |
|
||||||||
| Understand inter-organizational impacts of GenAI |
|
||||||||
| Understand mission-critical business domains for GenAI adoption |
|
||||||||
| Understand legal and governance issues of GenAI |
|
||||||||
| Understand broader societal issues of GenAI |
|
- Understand the impacts of GenAI on organizations in terms of processes and structures. GenAI will undoubtedly affect the capabilities of IT and individuals, leading to changes in business processes and structures.
- Understand inter-organizational impacts. When GenAI permeates organizations, the types of interactions between and among organizations will vary, leading to relationship and interactive changes.
- Understand mission-critical business domains. Research impacts can be more significant in mission-critical business domains such as healthcare and finance; therefore, special attention should be paid to these areas.
- Understand legal and governance issues. AI can lead to negative outcomes and leading to a dark-side of GenAI, requiring the studies of legal and governance issues.
- Understand broader societal issues. As GenAI is applied in various business sectors, additional societal issues, such as privacy and security, should be studied.
5 Conclusion
Declarations
References
Ackoff, R. L., & Emery, F. E. (2005). On purposeful systems: An interdisciplinary analysis of individual and social behavior as a system of purposeful events. Routledge.
Agrawal, S. (2023). Are LLMs the master of all trades?: Exploring domain-agnostic reasoning skills of LLMs. arXiv preprint arXiv:2303.12810.
Alavi, M., Leidner, D. E., & Mousavi, R. (2024). A knowledge management perspective of generative artificial intelligence. Journal of the Association for Information Systems, 25(1), 1-12.
Alavi, M., & Westerman, G. (2023). How generative AI will transform knowledge work. Harvard Business Review. https://hbr.org/2023/ 11/how-generative-ai-will-transform-knowledge-work. Accessed 20 Sept 2024.
Alavi, M. (2024). Generative AI and job crafting: A new frontier in knowledge work support. Harvard Business Review
Alter, S. (2015). Sociotechnical systems through a work system lens: A possible path for reconciling system conceptualizations, business realities, and humanist values in IS development. In STPIS 2015 (1st international workshop on socio-technical perspective in IS development) associated with CAISE 2015 (conference on advanced information system engineering).
Basilan, M. (2023). What are griefbots? AI-powered tech used to ‘resurrect’ the dead raises ethical questions. International Business Times. Retrieved 06/19/2023 from https://www.ibtimes.com/ what-are-griefbots-ai-powered-tech-used-resurrect-dead-raises-ethical-questions-3694800. Accessed 20 Sept 2024.
Batini, C., Lenzerini, M., & Navathe, S. B. (1986). A comparative analysis of methodologies for database schema integration. ACM Computing Surveys (CSUR), 18(4), 323-364.
Bedué, P., & Fritzsche, A. (2022). Can we trust AI? An empirical investigation of trust requirements and guide to successful AI adoption. Journal of Enterprise Information Management, 35(2), 530-549.
Bender, E. M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021). On the dangers of stochastic parrots: Can language models be too big? In Proceedings of the 2021 ACM conference on fairness, accountability, and transparency. ACCT ’21 Canada March 3-10, 2021.
Berente, N., Gu, B., Recker, J., & Santhanam, R. (2021). Managing artificial intelligence. MIS Quarterly, 45(3), 1433-1450.
Bertram, E. (1972). Even permutations as a product of two conjugate cycles. Journal of Combinatorial Theory, Series A, 12(3), 368-380.
Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent Dirichlet allocation. Journal of Machine Learning Research, 3(Jan), 993-1022.
Bunge, M. (1979). Basic philosophy. Reidel Publishing Co. Dordrecht.
Bunge, M. (1996). Finding philosophy in social science. Yale University Press.
Bunge, M. (2018). Systems everywhere. In C. Negoita (Ed.), Cybernetics and applied systems (pp. 23-41). CRC Press.
Burton-Jones, A., Recker, J., Indulska, M., Green, P., & Weber, R. (2017). Assessing representation theory with a framework for pursuing success and failure. MIS Quarterly, 41(4), 1307-1334.
Cerf, V. G. (2019). AI is not an excuse! Communications of the ACM (Vol 62, Issue 10, pp. 7-7). ACM New York.
Chang, Y. B., & Gurbaxani, V. (2012). Information technology outsourcing, knowledge transfer, and firm productivity: An empirical analysis. MIS Quarterly, 36(4), 1043-1063.
Chang, Y., Wang, X., Wang, J., Wu, Y., Yang, L., Zhu, K., Chen, H., Yi, X., Wang, C., & Wang, Y. (2024). A survey on evaluation of large language models. ACM Transactions on Intelligent Systems and Technology, 15(3), 1-45.
Chatterjee, S., Sarker, S., Lee, M. J., Xiao, X., & Elbanna, A. (2021). A possible conceptualization of the information systems (IS) artifact: A general systems theory perspective 1. Information Systems Journal, 31(4), 550-578.
Chomsky, N. (1986). Knowledge of language: Its nature, origin, and use. Greenwood Publishing Group.
Chua, C. E. H., & Storey, V. C. (2016). Bottom-up enterprise information systems: Rethinking the roles of central IT departments. Communications of the ACM, 60(1), 66-72.
Cortes, C., & Vapnik, V. (1995). Support-vector networks. Machine Learning, 20, 273-297.
Crevier, D. (1993). AI: the tumultuous history of the search for artificial intelligence. Basic Books, Inc.
Delipetrev, B., Tsinaraki, C., & Kostić, U. (2020). Historical evolution of artificial intelligence, EUR 30221EN. Publications Office of the European Union. https://publications.jrc.ec.europa.eu/repos itory/handle/JRC120469
Demetis, D., & Lee, A. S. (2018). When humans using the IT artifact becomes IT using the human artifact. Journal of the Association for Information Systems, 19(10), 5.
Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., & Fei-Fei, L. (2009). Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition (pp. 248-255).
Dubin, J. A., Bains, S. S., Chen, Z., Hameed, D., Nace, J., Mont, M. A., & Delanois, R. E. (2023). Using a Google web search analysis to assess the utility of ChatGPT in total joint arthroplasty. The Journal of Arthroplasty, 38(7), 1195-1202.
Dwivedi, Y. K., Kshetri, N., Hughes, L., Slade, E. L., Jeyaraj, A., Kar, A. K., Baabdullah, A. M., Koohang, A., Raghavan, V., & Ahuja, M. (2023). “So what if ChatGPT wrote it?” Multidisciplinary perspectives on opportunities, challenges and implications of
generative conversational AI for research, practice and policy. International Journal of Information Management, 71, 102642.
Feldman, M. S., & Pentland, B. T. (2003). Reconceptualizing organizational routines as a source of flexibility and change. Administrative Science Quarterly, 48(1), 94-118.
Ferrucci, D. A. (2012). Introduction to “this is Watson.”. IBM Journal of Research and Development, 56(3.4), 1: 1-1-1: 115.
French, A., Storey, V. C., & Wallace, L. (2024). A typology of disinformation intentionality and impact. Information Systems Journal, 34(4), 1324-1354.
Fügener, A., Grahl, J., Gupta, A., & Ketter, W. (2021). Will humans-in-the-loop become Borgs? Merits and pitfalls of working with AI. MIS Quarterly (MISQ), 45(3b), 1527-1556.
Fui-Hoon Nah, F., Zheng, R., Cai, J., Siau, K., & Chen, L. (2023). Generative AI and ChatGPT: Applications, challenges, and AIhuman collaboration. Journal of Information Technology Case and Application Research, 25(3), 277-304.
Gewitz, D. (2023). How to use ChatGPT to write code. https://www. zdnet.com/article/how-to-use-chatgpt-to-write-code/. Accessed 20 Sept 2024.
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., & Bengio, Y. (2020). Generative adversarial networks. Communications of the ACM, 63(11), 139-144.
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., & Bengio, Y. (2014). Generative adversarial nets. Advances in Neural Information Processing Systems, 27, 1-9.
Hagendorff, T., & Fabi, S. (2022). Methodological reflections for AI alignment research using human feedback. arXiv preprint arXiv:2301.06859.
Haidt, J., & Schmidt, E. (2023). AI is about to make social media (much) more toxic. The Atlantic.
Harmon, P., & King, D. (1985). Expert systems. John Wiley & Sons. Inc.
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735-1780.
Holland, J. H. (1992). Genetic algorithms. Scientific American, 267(1), 66-73.
Jarvenpaa, S., & Klein, S. (2024). New frontiers in information systems theorizing: Human-gAI collaboration. Journal of the Association for Information Systems, 25(1), 110-121.
Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., Ishii, E., Bang, Y. J., Madotto, A., & Fung, P. (2023). Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12), 1-38.
Kajtazi, M., Holmberg, N., & Sarker, S. (2023). The changing nature of teaching future IS professionals in the era of generative AI. In In (Vol. 25, pp. 415-422). Taylor & Francis.
Kanbach, D. K., Heiduk, L., Blueher, G., Schreiter, M., & Lahmann, A. (2023). The GenAI is out of the bottle: Generative artificial intelligence from a business model innovation perspective. Review of Managerial Science, 1-32.
Kaneko, M., & Baldwin, T. (2024). A little leak will sink a great ship: survey of transparency for large language models from start to finish. arXiv preprint arXiv:2403.16139.
Ke, Y., Jin, L., Elangovan, K., Abdullah, H. R., Liu, N., Sia, A. T. H., Soh, C. R., Tung, J. Y. M., Ong, J. C. L., & Ting, D. S. W. (2024). Development and testing of retrieval augmented generation in large language models–A case study report. arXiv preprint arXiv:2402.01733.
Kelly, S. M. (2023). Snapchat’s new AI Chatbot is already raising alarms among teens and parents. Retrieved 06/19/2023 from https://edition.cnn.com/2023/04/27/tech/snapchat-my-ai-conce rns-wellness/index.html. .
Khatri, V., & Samuel, B. M. (2019). Analytics for managerial work. Communications of the ACM, 62(4), 100-100.
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2017). Imagenet classification with deep convolutional neural networks. Communications of the ACM, 60(6), 84-90.
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems, 25.
LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11), 2278-2324.
Legner, C., Eymann, T., Hess, T., Matt, C., Böhmann, T., Drews, P., Mädche, A., Urbach, N., & Ahlemann, F. (2017). Digitalization: Opportunity and challenge for the business and information systems engineering community. Business & Information Systems Engineering, 59, 301-308.
Li, Z., Yang, Z., & Wang, M. (2023). Reinforcement learning with human feedback: Learning dynamic choices via pessimism. arXiv preprint arXiv:2305.18438.
Li, K., & Wieringa, P. A. (2000). Understanding perceived complexity in human supervisory control. Cognition, Technology & Work, 2, 75-88.
Lima, P. U., & Custodio, L. M. (2004). Artificial intelligence and systems theory: Applied to cooperative robots. International Journal of Advanced Robotic Systems, 3(1), 15.
Luhmann, N. (1995). Social systems. Stanford University Press, Palo Alto.
Lukyanenko, R., Parsons, J., Wiersma, Y. F., & Maddah, M. (2019). Expecting the unexpected: Effects of data collection design choices on the quality of crowdsourced user-generated content. MIS Quarterly, 43(2), 623-648.
Lukyanenko, R., Maass, W., & Storey, V. C. (2022a). Trust in artificial intelligence: From a foundational trust framework to emerging research opportunities. Electronic Markets, 32(4), 1993-2020.
Lukyanenko, R., Storey, V. C., & Pastor, O. (2022b). System: A core conceptual modeling construct for capturing complexity. Data & Knowledge Engineering, 141, 102062.
Luong, M.-T., Pham, H., & Manning, C. D. (2015). Effective approaches to attention-based neural machine translation. arXiv preprint arXiv:1508.04025.
Lyu, Q., Havaldar, S., Stein, A., Zhang, L., Rao, D., Wong, E., Apidianaki, M., & Callison-Burch, C. (2023). Faithful chain-ofthought reasoning. arXiv preprint arXiv:2301.13379.
McCarthy, J. (1959). Programs with common sense. In Proceedings of the Teddington conference on the mechanization of thought processes (pp. 75-91). Her Majesty’s Stationary Office.
Mei, Q., Xie, Y., Yuan, W., & Jackson, M. O. (2024). A Turing test of whether AI chatbots are behaviorally similar to humans. Proceedings of the National Academy of Sciences, 121(9), e2313925121.
Michie, D. (1963). Experiments on the mechanization of game-learning Part I. Characterization of the model and its parameters. The Computer Journal, 6(3), 232-236.
Minsky, M., & Papert, S. (1969). Perceptron: An introduction to computational geometry. MIT Press.
Motoki, F., Pinho Neto, V., & Rodrigues, V. (2024). More human than human: Measuring ChatGPT political bias. Public Choice, 198(1), 3-23.
Newell, A., Shaw, J. C., & Simon, H. A. (1962). The processes of creative thinking. In Contemporary approaches to creative thinking, 1958. University of Colorado.
Pachocki, J., Roditty, L., Sidford, A., Tov, R., & Williams, V. V. (2018). Approximating cycles in directed graphs: Fast algorithms for
girth and roundtrip spanners. In Proceedings of the twenty-ninth annual ACM-SIAM symposium on discrete algorithms.
Park, S. Y., Kuo, P.-Y., Barbarin, A., Kaziunas, E., Chow, A., Singh, K., Wilcox, L., & Lasecki, W. S. (2019). Identifying challenges and opportunities in human-AI collaboration in healthcare. In Conference companion publication of the 2019 on computer supported cooperative work and social computing.
Perez, C. (2010). Technological revolutions and techno-economic paradigms. Cambridge Journal of Economics, 34(1), 185-202.
Qiu, L., & Benbasat, I. (2010). A study of demographic embodiments of product recommendation agents in electronic commerce. International Journal of Human-Computer Studies, 68(10), 669-688.
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners. OpenAI Blog, 1(8), 9.
Rajput, W. (2023). Integrating ChatGPT in the enterprise. https://www. linkedin.com/pulse/integrating-chatgpt-enterprise-wasim-rajput. Accessed 20 Sept 2024.
Recker, J. C., Lukyanenko, R., Jabbari Sabegh, M., Samuel, B., & Castellanos, A. (2021). From representation to mediation: A new agenda for conceptual modeling research in a digital world. MIS Quarterly, 45(1), 269-300.
Reis, L., Maier, C., Mattke, J., Creutzenberg, M., & Weitzel, T. (2020). Addressing user resistance would have prevented a healthcare AI project failure. MIS Quarterly Executive, 19(4).
Rosenblatt, F. (1961). Principles of neurodynamics : Perceptrons and the theory of brain mechanisms. Spartan Books.
Rotman, D. (2023). ChatGPT is about to revolutionize the economy. In We need to decide what that looks like. MIT Technology Review.
Russell, S., & Norvig, P. (2016). Artificial intelligence: A modern approach. Pearson.
Saba, W. S. (2023). Stochastic LLMs do not understand language: Towards symbolic, explainable and ontologically based LLMS. In International conference on conceptual modeling (pp. 3-19). ER 2023.
Sabherwal, R., & Grover, V. (2024). The societal impacts of generative artificial intelligence: A balanced perspective. Journal of the Association for Information Systems, 25(1), 13-22.
Samuel, A. L. (1960). Programming computers to play games. In Advances in computers (Vol. 1, pp. 165-192). Elsevier.
Sarker, S., Chatterjee, S., Xiao, X., & Elbanna, A. (2019). The sociotechnical axis of cohesion for the IS discipline: Its historical legacy and its continued relevance. MIS Quarterly, 43(3), 695-720.
Savage, N. (2020). The race to the top among the world’s leaders in artificial intelligence. Nature, 588(7837), S102-S102.
Savage, N. (2023). Drug discovery companies are customizing ChatGPT: Here’s how. Nature Biotechnology.
Schlindwein, S. L., & Ison, R. (2004). Human knowing and perceived complexity: Implications for systems practice. Emergence: Complexity and Organization, 6(3), 27-32.
Schmidhuber, J. (1993). Habilitation thesis: System modeling and optimization. Page 150 ff demonstrates credit assignment across the equivalent of 1,200 layers in an unfold.
Schmidhuber, J. (2015). Deep learning in neural networks: An overview. Neural Networks, 61, 85-117.
Segev, A., & Zhao, J. L. (1994). Rule management in expert database systems. Management Science, 40(6), 685-707.
Seidel, S., Berente, N., Lindberg, A., Lyytinen, K., & Nickerson, J. V. (2018). Autonomous tools and design: A triple-loop approach to humanmachine learning. Communications of the ACM, 62(1), 50-57.
Seseri, R. (2023). Generative AI: A paradigm shift in enterprise and startup opportunities. https://www.cio.com/article/474720/gener
ative-ai-a-paradigm-shift-in-enterprise-and-startup-opportunit ies.html. Accessed 20 Sept 2024.
Skyttner, L. (2001). General systems theory. World Scientific.
Smolensky, R. (1987). Algebraic methods in the theory of lower bounds for Boolean circuit complexity. In Proceedings of the nineteenth annual ACM symposium on theory of computing.
Sowa, K., Przegalinska, A., & Ciechanowski, L. (2021). Cobots in knowledge work: Human-AI collaboration in managerial professions. Journal of Business Research, 125, 135-142.
Stohr, E. A., & Zhao, J. L. (2001). Workflow automation: Overview and research issues. Information Systems Frontiers, 3, 281-296.
Storey, V. C. (2025). Knowledge management in a world of generative AI: Impact and Implications. In ACM Transactions on Management Information Systems.
Storey, V. C., Lukyanenko, R., Maass, W., & Parsons, J. (2022). Explainable AI: Opening the black box or Pandora’s Box? Communications of the ACM, 65(4), 27-29.
Susarla, A., Gopal, R., Thatcher, J. B., & Sarker, S. (2023). The Janus effect of generative AI: Charting the path for responsible conduct of scholarly activities in information systems. Information Systems Research, 34(2), 399-408.
Tang, Y., Puduppully, R., Liu, Z., & Chen, N. (2023). In-context learning of large language models for controlled dialogue summarization: A holistic benchmark and empirical analysis. In Proceedings of the 4th new frontiers in summarization workshop.
Tarafdar, M., D’arcy, J., Turel, O., & Gupta, A. (2014). The dark side of information technology. MIT Sloan Management Review.
Tesauro, G. (2002). Programming backgammon using self-teaching neural nets. Artificial Intelligence, 134(1-2), 181-199.
Thrun, S., Montemerlo, M., Dahlkamp, H., Stavens, D., Aron, A., Diebel, J., Fong, P., Gale, J., Halpenny, M., & Hoffmann, G. (2006). Stanley: The robot that won the DARPA grand challenge. Journal of Field Robotics, 23(9), 661-692.
Turing, A. M. (1950). Computing machinery and intelligence. The essential Turing: The ideas that gave birth to the computer age. Mind, LIX(236), 433-460.
Turing, A. M. (2012). Computing machinery and intelligence (1950). In The essential Turing: The ideas that gave birth to the computer age (pp. 433-464).
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 30.
Verganti, R., Vendraminelli, L., & Iansiti, M. (2020). Innovation and design in the age of artificial intelligence. Journal of Product Innovation Management, 37(3), 212-227.
Walters, W. P., & Murcko, M. (2020). Assessing the impact of generative AI on medicinal chemistry. Nature Biotechnology, 38(2), 143-145.
Wang, D., Weisz, J. D., Muller, M., Ram, P., Geyer, W., Dugan, C., Tausczik, Y., Samulowitz, H., & Gray, A. (2019). Human-AI collaboration in data science: Exploring data scientists’ perceptions of automated AI. In Proceedings of the ACM on human-computer interaction, 3(CSCW) (pp. 1-24).
Watkins, C. J. C. H. (1989). Learning from delayed rewards. Ph.D. Thesis, King’s College.
Weizenbaum, J. (1966). ELIZA-A computer program for the study of natural language communication between man and machine. Communications of the ACM, 9(1), 36-45.
Wu, S. P.-J., Straub, D. W., & Liang, T.-P. (2015). How information technology governance mechanisms and strategic alignment influence organizational performance. MIS Quarterly, 39(2), 497-518.
Wu, C.-J., Raghavendra, R., Gupta, U., Acun, B., Ardalani, N., Maeng, K., Chang, G., Aga, F., Huang, J., & Bai, C. (2022). Sustainable AI: Environmental implications, challenges and opportunities. Proceedings of Machine Learning and Systems, 4, 795-813.
Yao, B., Chen, G., Zou, R., Lu, Y., Li, J., Zhang, S., Liu, S., Hendler, J., & Wang, D. (2023). More samples or more prompt inputs? Exploring effective in-context sampling for LLM few-shot prompt engineering. arXiv preprint arXiv:2311.09782.
Yeshchenko, A., Di Ciccio, C., Mendling, J., & Polyvyanyy, A. (2019). Comprehensive process drift detection with visual analytics. In Conceptual modeling: 38th international conference, ER 2019, Salvador, Brazil, November 4-7, 2019, Proceedings (p. 38).
Yu, X., Lyu, Y., & Tsang, I. (2020). Intrinsic reward driven imitation learning via generative model. In International conference on machine learning.
Yue, W. T., Wang, Q.-H., & Hui, K. L. (2019). See no evil, hear no evil? Dissecting the impact of online hacker forums. MIS Quarterly, 43(1), 73.
Zamfirescu-Pereira, J., Wong, R. Y., Hartmann, B., & Yang, Q. (2023). Why Johnny can’t prompt: How non-AI experts try (and fail) to design LLM prompts. In Proceedings of the 2023 CHI conference on human factors in computing systems.
Zhang, B., Zhu, J., & Su, H. (2023). Toward the third generation artificial intelligence. Science China Information Sciences, 66(2), 1-19.
Zhang, J., Lan, T., Zhu, M., Liu, Z., Hoang, T., Kokane, S., Yao, W., Tan, J., Prabhakar, A., & Chen, H. (2024a). xLAM: A family of large action models to empower AI agent systems. arXiv preprint arXiv:2409.03215.
Zhang, J., Mills, D. J., & Huang, H.-W. (2024b). Enhancing travel planning and experiences with multimodal ChatGPT 4.0. In Proceedings of the 2024 international conference on innovation in artificial intelligence.
Zhao, W. (2022). Inspired, but not mimicking: A conversation between artificial intelligence and human intelligence. National Science Review, 9(6), nwac068.
Zhuang, Y., Yu, Y., Wang, K., Sun, H., & Zhang, C. (2023). Toolqa: A dataset for LLM question answering with external tools. Advances in Neural Information Processing Systems, 36, 50117-50143.
Zuboff, S. (1988). In the age of the smart machine: The future of work and power. Basic Books, Inc.
J. Leon Zhao is a Presidential Chair Professor, Director of Center on Blockchain and Intelligent Technology, Co-head of Information Systems and Operations Management, School of Management and Economics, Chinese University of Hong Kong, Shenzhen. He was a chair professor at City University of Hong Kong and Eller Professor at University of Arizona, respectively. He has edited over 20 special issues
for academic journals including MIS Quarterly, Information Systems Research, and Journal of Operations Management. He received an IBM Faculty Award in 2005, and National Chang Jiang Scholar Chair Professorship first at Tsinghua University in 2009 and again at the Chinese University of Hong Kong, Shenzhen in 2022.
- J. Leon Zhao
leonzhao@cuhk.edu.cn
Roman Lukyanenko
romanl@virginia.edu
1 Georgia State University, Atlanta, GA, USA
City University of Hong Kong, Kowloon, Hong Kong SAR, China 3 Chinese University of Hong Kong, Shenzhen, China
4 University of Virginia, Charlottesville, VA, USA There could be other forms of data, but the basis is textual. Generative AI can “understand” an image because it has seen something similar before. Past images are associated with certain textual data; therefore, new images will also be associated with related textual data. The authors thank an anonymous reviewer for this positioning. Transformer-based pre-trained models approach the humanlevel benchmark with General Language Understanding Evaluation (GLUE), which is based on a collection of English language comprehension problems, rapidly. From the GLUE benchmark, a more rigorous SuperGLUE benchmark test was developed, whereby the models rapidly improved and surpassed human-level standards. From OpenAI’s own evaluations, GPT-4 performs exceptionally well on a variety of tests, including reasonings and other examinations (https://cdn. openai.com/papers/gpt-4.pdf). https://medium.com/mlearning-ai/an-ai-model-that-is-energy-effic ient-is-just-as-important-as-its-purpose-71d17822a183