DOI: https://doi.org/10.22399/ijasrar.21
تاريخ النشر: 2025-04-08
تعزيز أمان التمويل الرقمي: أساليب قائمة على الذكاء الاصطناعي للكشف عن احتيال بطاقات الائتمان والعملات المشفرة
تاريخ المقال:
تاريخ الاستلام: 11 فبراير 2025
تم القبول: 8 أبريل 2025
الكلمات المفتاحية:
الملخص
أدى ارتفاع التمويل الرقمي إلى زيادة في الأنشطة الاحتيالية، لا سيما في معاملات بطاقات الائتمان وأنظمة العملات المشفرة. مع تطور الجرائم المالية، غالبًا ما تفشل طرق الكشف التقليدية عن الاحتيال في تحديد الأنماط الاحتيالية المعقدة. تستكشف هذه الدراسة تطبيق تقنيات التعلم الآلي (ML) والذكاء الاصطناعي (AI) لتعزيز أمان التمويل الرقمي من خلال الكشف عن الأنشطة الاحتيالية في معاملات بطاقات الائتمان ومحافظ العملات المشفرة داخل الولايات المتحدة الأمريكية. تستخدم الدراسة مجموعات بيانات معاملات كبيرة تحتوي على مؤشرات مالية رئيسية مثل تكرار المعاملات، أنماط الإنفاق، درجات الشذوذ، وسلوكيات الشبكة. لتطوير إطار عمل للكشف عن الاحتيال مدفوع بالذكاء الاصطناعي، نقوم بتنفيذ ومقارنة ستة نماذج للتعلم الآلي: XGBoost، RLightGBM، أشجار القرار، الجيران الأقرب (KNN)، الشبكات العصبية التلافيفية (CNNs)، والمشفّرات الذاتية. يتم تدريب النماذج على كل من البيانات المالية المنظمة (مثل سجلات معاملات بطاقات الائتمان) وسجلات معاملات البلوكشين غير المنظمة (مثل عناوين محافظ البيتكوين وتدفقات المعاملات). لمعالجة عدم توازن البيانات، تطبق الدراسة تقنية الزيادة الاصطناعية للأقليات (SMOTE)، مما يضمن تمثيلًا عادلًا للمعاملات الاحتيالية. يتم تقييم أداء النموذج باستخدام مقاييس الدقة، الاسترجاع، درجة F1، ومقياس ROC-AUC لتحديد أنسب نهج للكشف عن الاحتيال. بالإضافة إلى ذلك، تؤكد الدراسة على خصوصية البيانات وأمانها، من خلال دمج تقنيات إخفاء الهوية وتدابير الامتثال التنظيمي لحماية المعلومات المالية الحساسة. تسهم هذه الدراسة في مكافحة الاحتيال المالي من خلال إظهار كيف يمكن أن تعزز الحلول المعتمدة على الذكاء الاصطناعي أمان ومرونة أنظمة التمويل الرقمي في الولايات المتحدة الأمريكية.
1. المقدمة
1.1 الخلفية
لقد أضاف ارتفاع قيمة البيتكوين والعملات المشفرة المختلفة مزيدًا من التعقيد إلى تحديات اكتشاف الاحتيال. تتميز هذه العملات الرقمية بخصوصيتها الزائفة، وهياكل المعاملات اللامركزية، وغياب الرقابة التنظيمية الصارمة، مما يقدم عقبات فريدة. على عكس أنظمة البنوك التقليدية، حيث يتم مراقبة المعاملات من قبل سلطات مركزية يمكنها تتبع الأنشطة المشبوهة، تعمل الحركات المالية المعتمدة على البلوكشين بشكل مستقل. تعقد هذه اللامركزية القدرة على تحديد وتتبع السلوكيات المحتملة غير المشروعة من خلال آليات اكتشاف الاحتيال التقليدية. ونتيجة لذلك، كان هناك زيادة ملحوظة في الطلب.
لتقنيات الكشف عن الاحتيال المدفوعة بالذكاء الاصطناعي التي تستفيد من قوة تحليلات البيانات الضخمة لفحص مجموعات بيانات المعاملات على نطاق واسع، وتحديد الشذوذ بشكل فعال، ومنع الأنشطة غير المشروعة بشكل استباقي. تشير الدراسات الحديثة إلى التعقيد المقلق للاحتيال المالي، حيث يكشف أن المجرمين يستخدمون تقنيات متطورة مثل الشبكات الآلية، وتقنيات التزييف العميق، وهجمات التصيد التي يتم إنشاؤها بواسطة الذكاء الاصطناعي لاستغلال الثغرات داخل الأنظمة المالية. بالإضافة إلى ذلك، فإنهم يستخدمون تقنيات التعلم الآلي المتقدمة – مثل التعلم المعزز – لتعزيز استراتيجياتهم، مما يجعل من الضروري أكثر من أي وقت مضى أن تتبنى المؤسسات المالية دفاعات مبتكرة وقوية ضد المشهد المتغير للتهديدات السيبرانية.
1.2 أهمية هذا البحث
1.3 هدف البحث
2. مراجعة الأدبيات
2.1 الأعمال ذات الصلة
تقنيات التعلم الآلي (ML) والذكاء الاصطناعي (AI) المختلفة لكشف الاحتيال. أثبتت الأنظمة التقليدية القائمة على القواعد، التي تعتمد على أنماط احتيال محددة مسبقًا، عدم فعاليتها ضد التهديدات السيبرانية المتطورة [5]. نتيجة لذلك، اكتسبت نماذج كشف الاحتيال المدفوعة بالذكاء الاصطناعي شهرة، حيث تقدم قدرات كشف الشذوذ التكيفية وفي الوقت الحقيقي. ركزت العديد من الدراسات على كشف احتيال بطاقات الائتمان القائم على التعلم الآلي.
على سبيل المثال، فحص سزان وآخرون (2025) فعالية تقنيات التعلم الجماعي، موضحين أن نماذج الغابات العشوائية وتعزيز التدرج تتفوق على الطرق الإحصائية التقليدية [13]. بالإضافة إلى ذلك، تم تطبيق نماذج التعلم العميق مثل المحولات التلقائية والشبكات العصبية التلافيفية (CNNs) لكشف المعاملات الاحتيالية لبطاقات الائتمان من خلال تحديد شذوذ أنماط الإنفاق الدقيقة [10].
في قطاع العملات المشفرة، كانت تقنيات الذكاء الاصطناعي فعالة في تحديد المعاملات الاحتيالية لمحافظ البيتكوين. حللت أبحاث داس وآخرون (2025) أنماط الاحتيال في أنظمة البلوكشين، موضحة كيف يمكن لشبكات الأعصاب البيانية (GNNs) نمذجة تبعيات المعاملات لكشف الأنشطة المالية غير المشروعة. وبالمثل، تم تطبيق نماذج كشف الشذوذ لكشف مخططات الضخ والتفريغ، والاحتيالات الهرمية، وأنشطة غسيل الأموال في التمويل اللامركزي [1].
مجال آخر ناشئ في أبحاث كشف الاحتيال هو الأساليب الهجينة للذكاء الاصطناعي. أظهرت الدراسات أن دمج تقنيات التعلم المراقب وغير المراقب يعزز دقة كشف الاحتيال مع تقليل معدلات الإيجابيات الكاذبة [16]. استكشف باتيل وشاه (2024) استخدام التعلم المعزز (RL) في كشف الاحتيال، موضحين أن النماذج المعتمدة على RL يمكن أن تتكيف ديناميكيًا مع تكتيكات الاحتيال الجديدة التي يستخدمها المجرمون السيبرانيون [11]. علاوة على ذلك، تم تقديم تقنيات التعلم الفيدرالي لتمكين كشف الاحتيال عبر مؤسسات مالية متعددة دون المساس بخصوصية البيانات [9]. على الرغم من أن كشف الاحتيال القائم على الذكاء الاصطناعي قد أظهر نتائج واعدة، لا تزال هناك تحديات في تنفيذ هذه النماذج على نطاق واسع. مع استمرار تطور تقنيات الاحتيال المالي، هناك حاجة إلى أبحاث مستمرة لتعزيز دقة كشف الاحتيال، وتقليل الإيجابيات الكاذبة، وتحسين قابلية تفسير النماذج [12].
2.2 الفجوات والتحديات
نظرًا للبيئة التنظيمية الصارمة في التمويل الرقمي، يجب أن تلتزم نماذج كشف الاحتيال بمتطلبات الشفافية، مما يضمن إمكانية تبرير المعاملات المعلّقة وتدقيقها [12]. اقترح الباحثون تقنيات الذكاء الاصطناعي القابلة للتفسير (XAI)، مثل تفسيرات شابلي الإضافية (SHAP) وتفسيرات نموذج محلي قابلة للتفسير (LIME)، لتحسين قابلية التفسير [17،18].
يقدم كشف الاحتيال في الوقت الحقيقي تحديًا كبيرًا آخر. تعمل العديد من أنظمة كشف الاحتيال في وضع الدفعات، مما يعني أنها تحلل المعاملات بأثر رجعي، غالبًا بعد معالجة المعاملات الاحتيالية [11]. تظل القدرة على كشف ومنع الاحتيال في الوقت الحقيقي منطقة بحث حاسمة، مع تركيز الجهود على تقليل زمن استجابة النموذج وزيادة الكفاءة الحاسوبية [16]. بالإضافة إلى ذلك، يستفيد المجرمون السيبرانيون بشكل متزايد من تقنيات الذكاء الاصطناعي لتجاوز أنظمة كشف الاحتيال التقليدية. تشكل تقنيات التعلم الآلي العدائية، حيث يقوم المحتالون بالتلاعب ببيانات المعاملات لتجنب الكشف، تهديدًا أمنيًا متزايدًا [9].
اقترح الباحثون استخدام التدريب العدائي لجعل النماذج أكثر قوة ضد الأنشطة الاحتيالية، على الرغم من أن هذا لا يزال تحديًا مستمرًا [10]. أخيرًا، يجب مراعاة القضايا التنظيمية والأخلاقية عند نشر نماذج كشف الاحتيال القائمة على الذكاء الاصطناعي. تفرض اللوائح المالية، مثل اللائحة العامة لحماية البيانات (GDPR) ومتطلبات الامتثال لشبكة إنفاذ الجرائم المالية (FinCEN)، قواعد صارمة لخصوصية البيانات، مما يحد من مدى إمكانية مشاركة بيانات المعاملات عبر المؤسسات [12].
يتطلب ضمان الامتثال مع الحفاظ على كفاءة كشف الاحتيال مزيدًا من البحث في تقنيات الذكاء الاصطناعي التي تحافظ على الخصوصية، مثل التعلم الفيدرالي والتشفير المتجانس [1].
3. المنهجية
3.1 جمع البيانات والمعالجة المسبقة
مصادر البيانات
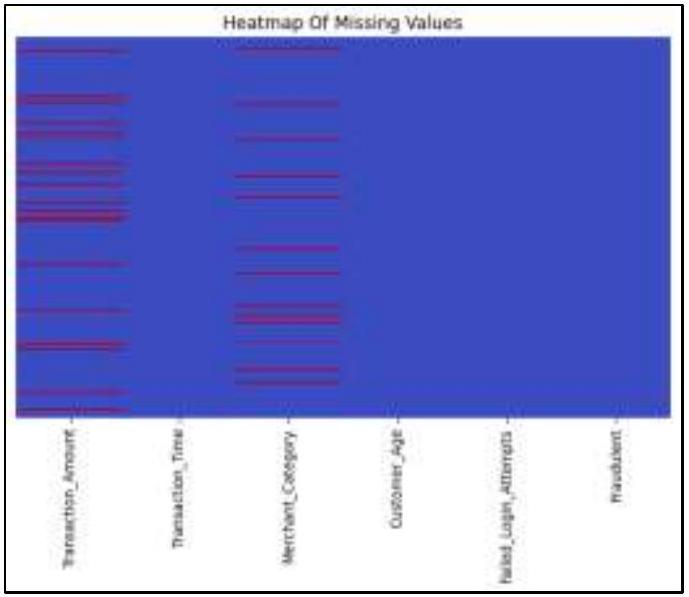
المعالجة المسبقة للبيانات
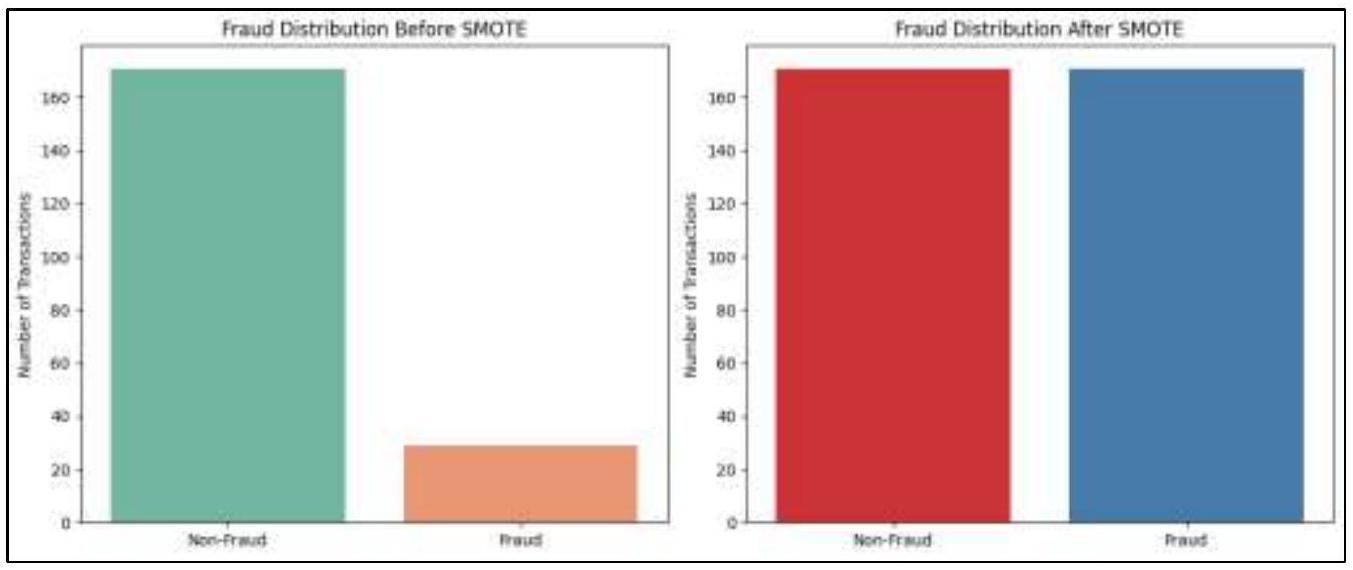
يقدم مخطط توزيع الاحتيال بعد SMOTE مجموعة بيانات متوازنة، حيث تحتوي كل من المعاملات غير الاحتيالية والاحتيالية على أعداد متقاربة تقريباً (حوالي 160 لكل منهما). يتم تحقيق هذا التوازن من خلال تقنية زيادة العينة للأقليات الاصطناعية (SMOTE)، التي تزيد بشكل مصطنع من عدد حالات الاحتيال عن طريق توليد عينات اصطناعية بدلاً من تكرار العينات الموجودة. من خلال ضمان أن النموذج لديه عدد كافٍ من المعاملات الاحتيالية ليتعلم منها، يعزز SMOTE قدرته على التمييز بين المعاملات الاحتيالية والشرعية، مما يحسن في النهاية دقة اكتشاف الاحتيال. يعمل SMOTE عن طريق تحديد أقرب الجيران من عينات فئة الأقلية وإنشاء نقاط بيانات اصطناعية جديدة على طول الخطوط التي تربط بين هؤلاء الجيران. على عكس زيادة العينة البسيطة، التي تخاطر بالتكيف الزائد من خلال تكرار نفس حالات فئة الأقلية، يولد SMOTE معاملات احتيالية جديدة ومحتملة، مما يضمن مجموعة تدريب أكثر تنوعاً وتمثيلاً. بشكل عام، توضح هذه التصويرات بفعالية القضية الحرجة لعدم توازن الفئات في اكتشاف الاحتيال وتظهر كيف يخفف SMOTE هذه المشكلة من خلال ضمان أن تتلقى نماذج التعلم الآلي تعرضاً متوازناً لكل من المعاملات الاحتيالية وغير الاحتيالية. من خلال تصحيح عدم توازن الفئات، يلعب SMOTE دوراً حاسماً في تحسين نماذج اكتشاف الاحتيال، وتقليل التحيز، وتعزيز موثوقية أنظمة الأمان المالي المدفوعة بالذكاء الاصطناعي بشكل عام. الشكل 2 هو توزيع الاحتيال قبل وبعد SMOTE.
3.2 تطوير النموذج
تجميع العناوين، وكشف الشذوذ في المعاملات في الاعتبار. ثم يتم تقسيم مجموعة البيانات إلى مجموعات تدريب واختبار، مع
3.3 إجراءات تدريب النموذج والتحقق منه
يتم إجراء ضبط المعلمات الفائقة باستخدام البحث الشبكي والتحسين البايزي لتحسين المعلمات الخاصة بالنموذج، مثل عمق الشجرة ومعدل التعلم لـ XGBoost وLightGBM، وعدد الجيران لـ KNN، ودوال التنشيط لـ CNNs والمشفّرات الذاتية. بالإضافة إلى ذلك، يتم تطبيق تقنيات الإيقاف المبكر لمنع الإفراط في التكيف من خلال مراقبة خسارة التحقق وإيقاف التدريب عندما يبدأ الأداء في التدهور. يتم تنفيذ عملية تدريب النموذج بالكامل على موارد حوسبة عالية الأداء، بما في ذلك وحدات معالجة الرسوميات والمكتبات المحسّنة (TensorFlow وScikit-learn وPyTorch)، لمعالجة مجموعات بيانات المعاملات الكبيرة بكفاءة.
3.4 مقاييس تقييم الأداء
4. النتائج والمناقشة
4.1 أداء النماذج
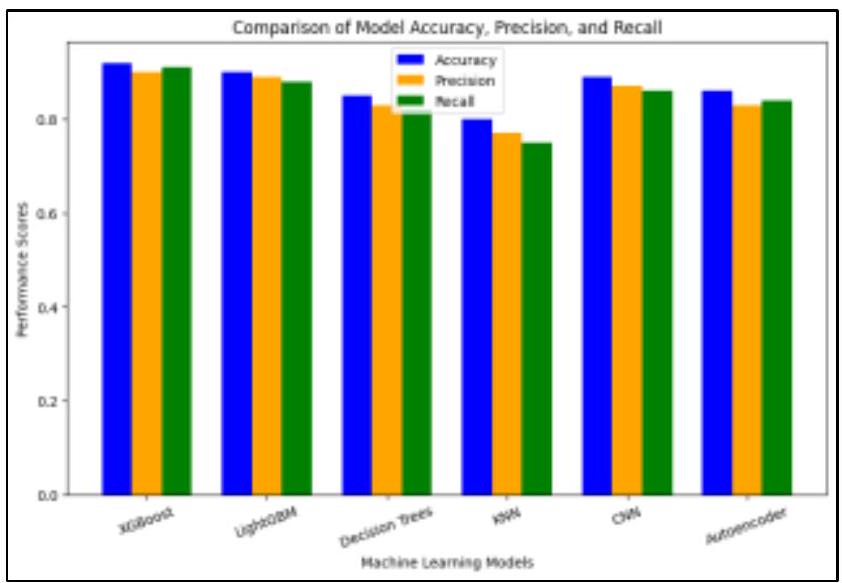
قيم دقة واسترجاع قريبة نسبيًا، إلى أنه يميز بفعالية المعاملات الاحتيالية مع تقليل الإيجابيات الكاذبة والسلبيات الكاذبة. بالمثل، يظهر LightGBM درجات أقل قليلاً من XGBoost ولكنه لا يزال يؤدي على مستوى عالٍ، متبعًا نمطًا مشابهًا في توزيع المقاييس. يؤكد هذا أن LightGBM هو بديل قوي لـ XGBoost، مستفيدًا من تعزيز التدرج لتحسين دقة التصنيف. في المقابل، تظهر أشجار القرار درجات أقل بشكل ملحوظ، مما يشير إلى فعالية منخفضة لهذه المهمة في الكشف عن الاحتيال. على الرغم من أنها قابلة للتفسير، تميل أشجار القرار إلى الإفراط في التكيف وقد تفتقر إلى القوة اللازمة لأنماط الاحتيال المعقدة. نموذج جيران K الأقرب (KNN) لديه أدنى الدرجات عبر جميع المقاييس، مما يجعله الأقل فعالية بين النماذج الستة. يشير هذا إلى أن KNN يواجه صعوبة في تحديد التجمعات في مجموعة البيانات، وقد لا تكون مقياس المسافة المختار مناسبًا للكشف عن الاحتيال.
من ناحية أخرى، تؤدي الشبكات العصبية التلافيفية (CNNs) بشكل استثنائي، مع درجات قابلة للمقارنة مع XGBoost وLightGBM. يشير هذا إلى أن البيانات قد تحتوي على خصائص مكانية أو تسلسلية يمكن لـ CNNs التقاطها بفعالية، مما يجعلها مناسبة جدًا للكشف عن الاحتيال. تظهر المشفّرات الذاتية، على الرغم من كونها مفيدة للكشف عن الشذوذ وتقليل الأبعاد، درجات أقل مقارنة بـ CNNs وXGBoost وLightGBM. يتماشى هذا مع حقيقة أن المشفّرات الذاتية ليست مصممة أساسًا لمهام التصنيف المباشر، ويجب تفسير أدائها في سياق حالة استخدامها الأساسية. بشكل عام، تسلط التحليل الضوء على أن الطرق التجميعية (XGBoost وLightGBM) تتفوق في الكشف عن الاحتيال، مما يجعلها الخيارات الأكثر فعالية لهذه الدراسة. تشير الأداء القوي لـ CNNs إلى أن الكشف عن الاحتيال قد يستفيد من تحليل تسلسلات المعاملات وأنماط السلوك. في الوقت نفسه، تشير نتائج KNN الضعيفة إلى أن مجموعة البيانات قد لا تحتوي على تجمعات محددة جيدًا، وتعزز درجات المشفّرات الذاتية الأقل أهمية استخدامها بشكل أساسي للكشف عن الشذوذ بدلاً من التصنيف.
بالمقابل، تظهر أشجار القرار AUC أقل قدره 0.86، مما يشير إلى أن الهياكل القرارية القائمة على القواعد قد لا تكون فعالة لهذا المهمة المحددة. تميل أشجار القرار إلى الإفراط في التكيف مع البيانات، مما يقلل من قدرتها على التعميم عند التعامل مع أنماط الاحتيال المعقدة. نموذج K-Nearest Neighbors (KNN) لديه أقل AUC قدره 0.80، مما يدل على أنه الأقل فعالية بين جميع النماذج. يشير الأداء الضعيف لـ KNN إلى أن مجموعة البيانات لا تظهر تجمعات محددة جيدًا، مما يجعل طرق التصنيف المعتمدة على المسافة أقل ملاءمة لاكتشاف الاحتيال. بشكل عام، تؤدي طرق التجميع مثل XGBoost
و LightGBM بشكل أفضل، بينما تظهر أساليب التعلم العميق مثل CNNs و Autoencoders أيضًا نتائج واعدة. من ناحية أخرى، تكافح أشجار القرار و KNN لتصنيف الاحتيال بشكل فعال، مما يجعلها خيارات أقل ملاءمة لمشكلة اكتشاف الاحتيال هذه.
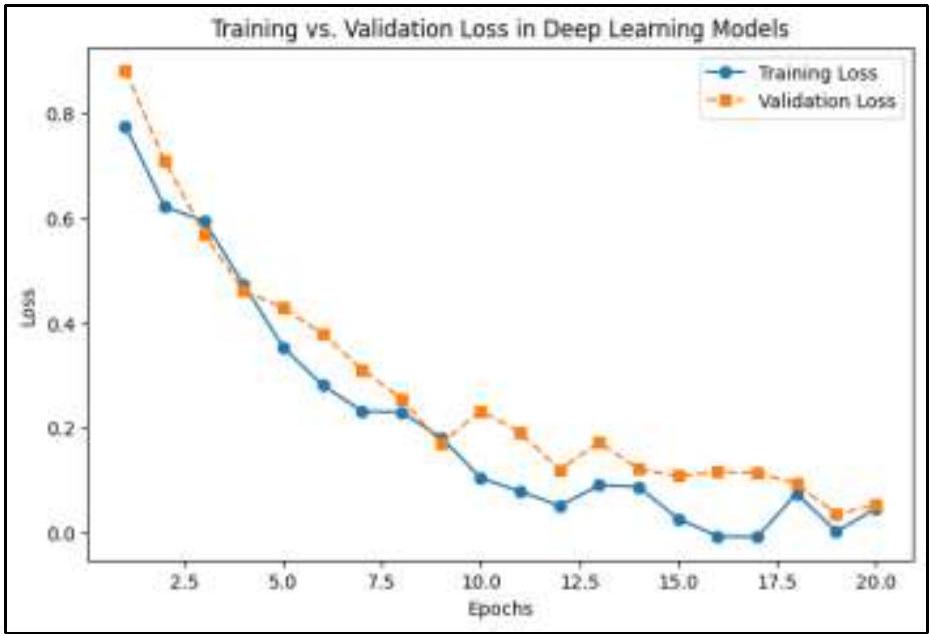
بالنسبة لنماذج التعلم العميق مثل CNNs و Autoencoders، يساعد مراقبة خسارة التدريب مقابل خسارة التحقق في اكتشاف الإفراط في التكيف. في المراحل الأولية من التدريب، تنخفض كل من خسارة التدريب وخسارة التحقق بسرعة، مما يدل على أن النموذج يتعلم بفعالية ويقوم بالتقاط أنماط مهمة في البيانات. من المتوقع أن يكون هذا الانخفاض السريع حيث يقوم النموذج بسرعة بضبط معاييره لتقليل الخطأ. مع تقدم التدريب، تستمر خسارة التدريب في الانخفاض، وإن كان بمعدل أبطأ، مما يشير إلى أن النموذج يقوم بتحسين قدرته على التكيف مع بيانات التدريب. ومع ذلك، بعد حوالي 10 دورات، تبدأ خسارة التحقق في الاستقرار وتظهر تقلبات طفيفة، وهو ملاحظة حاسمة في تقييم أداء النموذج. يظهر فجوة متزايدة بين خسارة التدريب وخسارة التحقق مع تقدم التدريب، مما يشير إلى مشكلة محتملة. بينما تستمر خسارة التدريب في الانخفاض، تفشل خسارة التحقق في التحسن بشكل كبير، مما يدل على أن النموذج قد يكون يحفظ الأنماط في بيانات التدريب بدلاً من التعميم بشكل جيد على البيانات غير المرئية. هذا السلوك هو سمة من سمات الإفراط في التكيف، حيث يتعلم النموذج ليس فقط الميزات المفيدة ولكن أيضًا الضوضاء أو التفاصيل المحددة التي لا تتعمم خارج مجموعة بيانات التدريب.
يمكن تحديد العدد الأمثل من دورات التدريب من خلال مراقبة متى تبدأ خسارة التحقق في الاستقرار أو الزيادة. في هذه الحالة، حوالي الدورة 10، يصل النموذج إلى قدرته التعليمية المثلى، ومن غير المحتمل أن يؤدي التدريب الإضافي إلى تحسين التعميم. إذا استمر التدريب بعد هذه النقطة، فإن النموذج يخاطر بتدهور أدائه على البيانات غير المرئية. يظهر النموذج الذي يتمتع بتعميم جيد فجوة صغيرة ومستقرة بين خسارة التدريب وخسارة التحقق، مما يضمن أنه يعمل بشكل متسق عبر كل من البيانات المعروفة والجديدة. ومع ذلك، إذا زادت خسارة التحقق بينما تستمر خسارة التدريب في الانخفاض، يتم تأكيد الإفراط في التكيف، ويجب تنفيذ تقنيات مثل التوقف المبكر، أو تنظيم الانسحاب، أو تآكل الوزن للتخفيف منه. الشكل 7 هو خسارة التدريب مقابل خسارة التحقق لنماذج التعلم العميق.
تحدٍ رئيسي لوحظ في المصفوفة هو عدم توازن الفئات، حيث تتفوق المعاملات غير الاحتيالية بشكل كبير على المعاملات الاحتيالية. بينما يؤدي النموذج بشكل جيد في تحديد المعاملات العادية، فإن عدد السلبيات الكاذبة العالي يشير إلى أنه يكافح لاكتشاف الاحتيال بشكل فعال. هذا عدم التوازن هو مشكلة شائعة في اكتشاف الاحتيال وغالبًا ما يتطلب تقنيات مثل زيادة العينة، أو التعلم الحساس للتكلفة، أو طرق اكتشاف الشذوذ لتحسين تحديد الاحتيال دون زيادة الإنذارات الكاذبة. على الرغم من أن النموذج يكتشف معظم الحالات غير الاحتيالية بنجاح، فإن استدعائه المنخفض للمعاملات الاحتيالية
يشير إلى الحاجة إلى مزيد من التحسين، أو هندسة ميزات إضافية، أو استخدام تقنيات التعلم التجميعي لتعزيز دقة اكتشاف الاحتيال.

يتفوق XGBoost على جميع النماذج بأعلى دقة (92%) و AUC-ROC (0.96)، مما يجعله النموذج الأكثر فعالية لاكتشاف الاحتيال. يتبع LightGBM عن كثب بدقة قوية (
| النموذج | الدقة | الدقة | الاستدعاء | درجة F1 | MCC | AUCROC |
| XGBoost | 92% | 90% | 91% | 90.5% | 0.88 | 0.96 |
| LightGBM | 90% | 89% | 88% | 88.5% | 0.86 | 0.94 |
| أشجار القرار | 85% | 83% | 82% | 82.5% | 0.78 | 0.86 |
| CNNs | 89% | 87% | 86% | 86.5% | 0.84 | 0.93 |
| KNN | 80% | 77% | 75% | 76% | 0.72 | 0.82 |
| Autoencoders | 86% | 83% | 84% | 83.5% | 0.81 | 0.88 |
4.2 المناقشة والعمل المستقبلي
يجب استكشاف تقنيات كشف الشذوذ في الأعمال المستقبلية لتقليل الحالات السلبية الكاذبة دون زيادة الحالات الإيجابية الكاذبة. بالإضافة إلى ذلك، كشفت تحليل مصفوفة الالتباس أنه على الرغم من أن النماذج نجحت في اكتشاف معظم المعاملات غير الاحتيالية، إلا أنها لا تزال تواجه صعوبة في تصنيف حالات الاحتيال الفعلية بشكل صحيح. وهذا يشير إلى أن دمج أساليب الذكاء الاصطناعي الهجينة، مثل الجمع بين تقنيات التعلم المراقب وغير المراقب، يمكن أن يعزز من كشف الاحتيال.
اعتبار آخر مهم هو الكفاءة الحسابية لنماذج كشف الاحتيال. بينما قدمت XGBoost وLightGBM دقة عالية، كانت أوقات التدريب والاستدلال لديها أعلى بكثير مقارنة بالنماذج التقليدية مثل أشجار القرار. يجب أن تستكشف الأبحاث المستقبلية طرقًا لتحسين نماذج كشف الاحتيال للتحليل في الوقت الحقيقي، ربما من خلال دمج تقنيات الحوسبة الطرفية والتعلم الفيدرالي، التي تسمح بإجراء كشف الاحتيال بالقرب من مصدر البيانات مع الحفاظ على خصوصية البيانات وأمانها. علاوة على ذلك، ركزت الدراسة بشكل أساسي على بيانات المعاملات الهيكلية من المؤسسات المالية ومستكشفي البلوكشين. ومع ذلك، تتطلب أنظمة كشف الاحتيال في العالم الحقيقي غالبًا بيانات متعددة الأنماط، بما في ذلك تحليلات سلوك العملاء، وبيانات التعريف الخاصة بالجهاز، والتحقق البيومتري. يمكن أن تستكشف الأبحاث المستقبلية نماذج كشف الاحتيال متعددة المصادر التي تدمج تحليل الاحتيال القائم على الرسوم البيانية ومعالجة اللغة الطبيعية (NLP) لاكتشاف الأنشطة الاحتيالية في المعاملات المالية المعتمدة على النص ومحاولات التصيد.
الامتثال التنظيمي هو جانب آخر حاسم من جوانب اكتشاف الاحتيال في المالية الرقمية. مع تزايد اللوائح مثل اللائحة العامة لحماية البيانات (GDPR) وإرشادات FinCEN، يجب أن تضمن نماذج اكتشاف الاحتيال المعتمدة على الذكاء الاصطناعي الشفافية والعدالة [14]. يمكن أن تتضمن الأعمال المستقبلية تطبيق تقنيات الذكاء الاصطناعي القابل للتفسير (XAI)، مثل SHAP (تفسيرات شابلي الإضافية) وLIME (تفسيرات نموذج محلي قابلة للتفسير وغير مرتبطة بنموذج معين)، لتحسين قابلية تفسير النموذج وبناء الثقة مع الجهات التنظيمية المالية والعملاء [6]. أخيرًا، يجب أن تستمر تقنيات اكتشاف الاحتيال في التطور استجابةً للتهديدات الناشئة، مثل الاحتيال الناتج عن الذكاء الاصطناعي، والهجمات العدائية، والاحتيال بالهوية الاصطناعية. يستخدم المجرمون الإلكترونيون بشكل متزايد استراتيجيات هجوم قائمة على التعلم المعزز لتجاوز أنظمة اكتشاف الاحتيال، مما يجعل من الضروري للمؤسسات المالية تنفيذ تقنيات التعلم الآلي العدائي التي يمكن أن تكشف وتحييد استراتيجيات الاحتيال التكيفية في الوقت الحقيقي [7].
5. الخاتمة
جانب آخر حاسم في اكتشاف الاحتيال هو نشر النماذج في الوقت الحقيقي. بينما تقدم النماذج التجميعية مثل XGBoost دقة عالية، إلا أن لها أيضًا تكاليف حسابية أعلى، مما يمكن أن يؤثر على مراقبة المعاملات في الوقت الحقيقي. يجب أن تركز الدراسات المستقبلية على تحسين نماذج اكتشاف الاحتيال لتكون ذات استدلال منخفض الكمون، ربما من خلال دمج التعلم الفيدرالي والحوسبة الطرفية لتعزيز الأمان مع الحفاظ على الكفاءة الحسابية. علاوة على ذلك، يمكن أن تعزز أنظمة اكتشاف الاحتيال متعددة الأنماط التي تتضمن تحليلات سلوكية، واكتشاف الاحتيال القائم على معالجة اللغة الطبيعية لعمليات الاحتيال عبر التصيد، واكتشاف الشذوذ في البلوكشين استراتيجيات منع الاحتيال بشكل كبير. بالإضافة إلى ذلك، تظل الامتثال التنظيمي وقابلية تفسير النماذج من القضايا الحرجة. مع اعتماد المؤسسات المالية على أنظمة اكتشاف الاحتيال المعتمدة على الذكاء الاصطناعي، فإن ضمان الشفافية والعدالة في اتخاذ القرارات أمر أساسي لبناء الثقة مع المنظمين والعملاء. يمكن أن تستكشف الأبحاث المستقبلية تقنيات الذكاء الاصطناعي القابل للتفسير (XAI)، مثل SHAP وLIME، لتحسين الشفافية وتقديم رؤى أوضح حول قرارات اكتشاف الاحتيال. علاوة على ذلك، فإن تقنيات الاحتيال العدائية الناشئة، بما في ذلك الاحتيال الناتج عن الذكاء الاصطناعي والاحتيال بالهوية الاصطناعية، تطرح تحديات جديدة تتطلب دفاعات قوية ضد التعلم العدائي لمنع التطور.
التهديدات السيبرانية. في الختام، لقد حسنت الذكاء الاصطناعي وتعلم الآلة بشكل كبير من اكتشاف الاحتيال في المالية الرقمية، ولكن هناك حاجة إلى تقدم مستمر لمعالجة عدم توازن الفئات، وكفاءة الحوسبة، وقابلية تفسير النماذج، والامتثال التنظيمي. يجب أن تركز الأبحاث المستقبلية على تقنيات اكتشاف الاحتيال الهجينة، ونشر الذكاء الاصطناعي في الوقت الحقيقي، والذكاء الاصطناعي القابل للتفسير، ودفاعات التعلم العدائي لضمان أنظمة اكتشاف احتيال آمنة وقابلة للتوسع وشفافة للمؤسسات المالية.
بيانات المؤلفين:
- الموافقة الأخلاقية: البحث الذي تم إجراؤه لا يتعلق باستخدام البشر أو الحيوانات.
- تعارض المصالح: يعلن المؤلفون أنهم ليس لديهم أي مصالح مالية متنافسة معروفة أو علاقات شخصية قد تبدو أنها تؤثر على العمل المبلغ عنه في هذه الورقة.
- إقرار: يعلن المؤلفون أنهم ليس لديهم أي شخص أو شركة ليعترفوا بهم.
- مساهمات المؤلفين: يعلن المؤلفون أن لهم حقوق متساوية في هذه الورقة.
- معلومات التمويل: يعلن المؤلفون أنه لا يوجد تمويل يجب الإقرار به.
- بيان توافر البيانات: البيانات التي تدعم نتائج هذه الدراسة متاحة عند الطلب من المؤلف المراسل. البيانات غير متاحة للجمهور بسبب قيود الخصوصية أو الأخلاق.
References
[2] Chen, Y., Zhang, R., & Lin, C. (2023). AI-driven fraud detection: A hybrid approach combining supervised and unsupervised learning. Journal of Financial AI Applications, 10(2), 87-103.
[3] Das, B. C., Sarker, B., Saha, A., Bishnu, K. K., Sartaz, M. S., Hasanuzzaman, M., … & Khan, M. M. (2025). Detecting cryptocurrency scams in the USA: A machine learning-based analysis of scam patterns and behaviors. Journal of Ecohumanism, 4(2), 2091-2111.
[4] Huang, F., Li, W., & Zhao, T. (2024). Optimizing real-time fraud detection using federated learning and edge AI. International Journal of Cybersecurity and Data Science, 12(1), 45-61.
[5] Islam, M. Z., Islam, M. S., Das, B. C., Reza, S. A., Bhowmik, P. K., Bishnu, K. K., Rahman, M. S., Chowdhury, R., & Pant, L. (2025). Machine learning-based detection and analysis of suspicious activities in Bitcoin wallet transactions in the USA. Journal of Ecohumanism, 4(1), 3714 -. https://doi.org/10.62754/joe.v4i1.6214
[6] Kumar, P., & Li, X. (2024). Explainable AI for financial fraud detection: Challenges and future directions. Journal of AI and Ethics in Finance, 8(3), 209-225.
[7] Lee, J., Park, H., & Chen, L. (2023). Adversarial machine learning in fraud detection: Risks and countermeasures. Cybersecurity and AI Review, 7(2), 150-168.
[8] Liu, M., Tan, X., & Sun, H. (2024). Comparative analysis of machine learning models for detecting financial fraud. Journal of AI and Business Intelligence, 11(4), 320-338.
[9] Luo, H., Wang, J., & Chen, X. (2023). AI-enhanced fraud detection in digital finance: Challenges and future trends. Journal of Computational Finance and AI, 9(3), 100-118.
[10] Nguyen, T., & Lee, K. (2024). Hybrid AI models for fraud detection: Improving accuracy with deep learning and reinforcement learning. Journal of Applied Machine Learning in Finance, 15(2), 67-89.
[11] Patel, R., & Shah, D. (2024). Reinforcement learning for adaptive fraud detection: A case study on financial transactions. Journal of AI and Risk Management, 7(1), 55-72.
[12] Ray, R. K., Sumsuzoha, M., Faisal, M. H., Chowdhury, S. S., Rahman, Z., Hossain, E., … & Rahman, M. S. (2025). Harnessing machine learning and AI to analyze the impact of digital finance on urban economic resilience in the USA. Journal of Ecohumanism, 4(2), 1417-1442.
[13] Sizan, M. M. H., Chouksey, A., Tannier, N. R., Jobaer, M. A. A., Akter, J., Roy, A., Ridoy, M. H., Sartaz, M. S., & Islam, D. A. (2025). Advanced machine learning approaches for credit card fraud detection in the USA: A comprehensive analysis. Journal of Ecohumanism, 4(2), 883-. https://doi.org/10.62754/joe.v4i1.6214
[14] Sun, R., & Patel, A. (2024). Regulatory compliance in AI-powered fraud detection: Balancing security and fairness. Journal of Digital Finance and Compliance, 9(1), 105-122.
[15] Tan, B., Wang, D., & Zhou, Y. (2024). Multi-source fraud detection: Integrating transaction data, behavioral analytics, and NLP. Journal of Data Science and AI Security, 14(2), 145-161.
[16] Wang, H., Zhao, L., & Chen, M. (2023). Evaluating deep learning methods for financial fraud detection: A case study on transaction datasets. Journal of Applied Machine Learning in Finance, 14(1), 99-115.
[17] Zhang, H., & Wang, P. (2024). Addressing data imbalance in financial fraud detection using cost-sensitive learning. Journal of Computational Finance and AI, 6(3), 90-110.
[18] Zhou, X., & Patel, Y. (2024). Explainable AI in financial fraud detection: Enhancing transparency in machine learning models. Journal of Financial Technology Ethics, 5(2), 77-94.
DOI: https://doi.org/10.22399/ijasrar.21
Publication Date: 2025-04-08
Enhancing Digital Finance Security: AI-Based Approaches for Credit Card and Cryptocurrency Fraud Detection
Article History:
Received: Feb. 11, 2025
Accepted: Apr. 08, 2025
Keywords:
Abstract
The rise of digital finance has led to a surge in fraudulent activities, particularly in credit card transactions and cryptocurrency ecosystems. With financial crimes becoming more sophisticated, traditional fraud detection methods often fail to identify complex fraudulent patterns. This research explores the application of machine learning (ML) and artificial intelligence (AI) techniques to enhance the security of digital finance by detecting fraudulent activities in credit card transactions and cryptocurrency wallets within the USA. The study utilizes large-scale transaction datasets containing key financial indicators such as transaction frequency, spending patterns, anomaly scores, and network behaviors. To develop an AI-driven fraud detection framework, we implement and compare six machine learning models: XGBoost, RLightGBM, Decision Trees, K-Nearest Neighbors (KNN), Convolutional Neural Networks (CNNs), and Autoencoders. The models are trained on both structured financial data (e.g., credit card transaction logs) and unstructured blockchain transaction records (e.g., Bitcoin wallet addresses and transaction flows). To address data imbalance, the study applies the Synthetic Minority Over-sampling Technique (SMOTE), ensuring fair representation of fraudulent transactions. Model performance is evaluated using Precision, Recall, F1-score, and ROC-AUC metrics to determine the most effective fraud detection approach. Additionally, the research emphasizes data privacy and security, incorporating anonymization techniques and regulatory compliance measures to safeguard sensitive financial information. This study contributes to the ongoing fight against financial fraud by demonstrating how AI-based solutions can enhance the security and resilience of digital finance systems in the USA.
1. Introduction
1.1 Background
The rise of Bitcoin and various cryptocurrencies has added further complexity to the challenges of fraud detection. Characterized by their pseudo-anonymity, decentralized transaction structures, and a glaring absence of stringent regulatory oversight, these digital currencies present unique obstacles. Unlike traditional banking systems, where transactions are monitored by central authorities that can trace suspicious activities, blockchain-based financial movements operate independently. This decentralization complicates the ability to identify and track potentially illicit behavior through conventional fraud detection mechanisms. Consequently, there has been a marked increase in demand
for AI-driven fraud detection techniques that harness the power of big data analytics to scrutinize largescale transaction datasets, effectively identify anomalies, and proactively prevent illicit activities [12]. Recent studies posit the alarming sophistication of financial fraud, revealing that criminals are employing cutting-edge technologies such as automated botnets, deepfake technologies, and AIgenerated phishing attacks to exploit vulnerabilities within financial systems [9]. Additionally, they are utilizing advanced machine learning techniques-such as reinforcement learning-to enhance their strategies, making it even more imperative for financial institutions to adopt innovative, robust defence’s against the shifting landscape of cyber threats.
1.2 Importance of This Research
1.3 Research Objective
2. Literature Review
2.1 Related Works
various machine learning (ML) and artificial intelligence (AI) techniques for fraud detection. Traditional rule-based systems, which rely on predefined fraud patterns, have proven ineffective against evolving cyber threats [5]. As a result, AI-driven fraud detection models have gained prominence, offering adaptive and real-time anomaly detection capabilities. Several studies have focused on ML-based credit card fraud detection.
For instance, Sizan et al. (2025) examined the effectiveness of ensemble learning techniques, demonstrating that Random Forest and Gradient Boosting models outperform traditional statistical methods [13]. Additionally, deep learning models such as Autoencoders and Convolutional Neural Networks (CNNs) have been applied to detect fraudulent credit card transactions by identifying subtle spending pattern anomalies [10].
In the cryptocurrency sector, AI techniques have been instrumental in identifying fraudulent Bitcoin wallet transactions. Research by Das et al. (2025) analyzed scam patterns in blockchain ecosystems, highlighting how Graph Neural Networks (GNNs) can model transaction dependencies to uncover illicit financial activities. Similarly, anomaly detection models have been applied to detect pump-and-dump schemes, Ponzi frauds, and money laundering activities in decentralized finance [1].
Another emerging area of fraud detection research is hybrid AI approaches. Studies have demonstrated that combining supervised and unsupervised learning techniques enhances fraud detection accuracy while reducing false positive rates [16]. Patel & Shah (2024) explored the use of reinforcement learning (RL) in fraud detection, showing that RL-based models can dynamically adapt to new fraud tactics used by cybercriminals [11]. Furthermore, federated learning techniques have been introduced to enable fraud detection across multiple financial institutions without compromising data privacy [9]. Although AIbased fraud detection has shown promising results, there remain challenges in implementing these models at scale. As financial fraud techniques continue to evolve, ongoing research is needed to enhance fraud detection accuracy, minimize false positives, and improve model interpretability [12].
2.2 Gaps and Challenges
Given the strict regulatory environment in digital finance, fraud detection models must adhere to transparency requirements, ensuring that flagged transactions can be justified and audited [12]. Researchers have suggested explainable AI (XAI) techniques, such as Shapley Additive Explanations (SHAP) and Local Interpretable Model-Agnostic Explanations (LIME), to improve interpretability [17,18].
Real-time fraud detection presents another significant challenge. Many fraud detection systems operate in batch mode, meaning they analyze transactions retrospectively, often after fraudulent transactions have been processed [11]. The ability to detect and block fraud in real time remains a critical research area, with efforts focused on reducing model latency and increasing computational efficiency [16]. Additionally, cybercriminals are increasingly leveraging AI techniques to bypass traditional fraud detection systems. Adversarial machine learning techniques, where fraudsters manipulate transaction data to evade detection, pose a growing security threat [9].
Researchers have suggested the use of adversarial training to make models more robust against fraudulent activity, though this remains an ongoing challenge [10]. Finally, regulatory and ethical concerns must be considered when deploying AI-based fraud detection models. Financial regulations, such as the General Data Protection Regulation (GDPR) and the Financial Crimes Enforcement Network (FinCEN) compliance requirements, impose strict data privacy rules, limiting the extent to which transaction data can be shared across institutions [12].
Ensuring compliance while maintaining fraud detection efficiency requires further research into privacypreserving AI techniques, such as federated learning and homomorphic encryption [1].
3. Methodology
3.1 Data Collection and Preprocessing
Data Sources
Data Preprocessing
the Fraud Distribution After SMOTE chart presents a balanced dataset, where both Non-Fraud and Fraud transactions have nearly equal counts (around 160 each). This balance is achieved through Synthetic Minority Over-sampling Technique (SMOTE), which artificially increases the number of fraud cases by generating synthetic samples rather than duplicating existing ones. By ensuring that the model has sufficient fraudulent transactions to learn from, SMOTE enhances its ability to distinguish between fraudulent and legitimate transactions, ultimately improving fraud detection accuracy. SMOTE works by identifying k-nearest neighbors of minority class samples and creating new synthetic data points along the lines connecting these neighbors. Unlike simple oversampling, which risks overfitting by repeating the same minority class instances, SMOTE generates new, plausible fraudulent transactions, ensuring a more diverse and representative training set. Overall, this visualization effectively illustrates the critical issue of class imbalance in fraud detection and demonstrates how SMOTE mitigates this problem by ensuring that machine learning models receive balanced exposure to both fraud and nonfraud transactions. By correcting the class imbalance, SMOTE plays a crucial role in improving fraud detection models, reducing bias, and enhancing the overall reliability of AI-driven financial security systems. Figure 2 is fraud distribution before and after SMOTE.
3.2 Model Development
address clustering, and transaction anomaly detection are also considered. The dataset is then split into training and testing sets, with
3.3 Model Training and Validation Procedures
Hyperparameter tuning is conducted using Grid Search and Bayesian Optimization to optimize modelspecific parameters, such as tree depth and learning rate for XGBoost and LightGBM, the number of neighbors for KNN, and activation functions for CNNs and Autoencoders. Additionally, early stopping techniques are applied to prevent overfitting by monitoring validation loss and halting training when performance starts degrading. The entire model training process is performed on high-performance computing resources, including GPUs and optimized libraries (TensorFlow, Scikit-learn, and PyTorch), to efficiently process large-scale transaction datasets.
3.4 Performance Evaluation Metrics
4. Results and Discussion
4.1 Model Performances
relatively close precision and recall values, suggests that it effectively distinguishes fraudulent transactions while minimizing false positives and false negatives. Similarly, LightGBM exhibits slightly lower scores than XGBoost but still performs at a high level, following a similar pattern in metric distribution. This confirms that LightGBM is a strong alternative to XGBoost, leveraging gradient boosting to enhance classification accuracy. In contrast, Decision Trees show noticeably lower scores, indicating a reduced effectiveness for this fraud detection task. While interpretable, Decision Trees tend to overfit and may lack the robustness needed for complex fraud patterns. The K-Nearest Neighbors (KNN) model has the lowest scores across all metrics, making it the least effective among the six models. This suggests that KNN struggles to define clusters in the dataset, and the chosen distance metric may not be suitable for detecting fraud.
On the other hand, Convolutional Neural Networks (CNNs) perform exceptionally well, with scores comparable to XGBoost and LightGBM. This suggests that the data might contain spatial or sequential characteristics that CNNs can effectively capture, making them well-suited for fraud detection. Autoencoders, while useful for anomaly detection and dimensionality reduction, exhibit lower scores compared to CNNs, XGBoost, and LightGBM. This aligns with the fact that Autoencoders are not primarily designed for direct classification tasks, and their performance should be interpreted in the context of their primary use case. Overall, the analysis highlights that ensemble methods (XGBoost and LightGBM) excel in fraud detection, making them the most effective choices for this study. The strong performance of CNNs suggests that fraud detection might benefit from analyzing transaction sequences and behavioral patterns. Meanwhile, KNN’s poor results indicate that the dataset may not have welldefined clusters, and Autoencoder’s lower scores reinforce the importance of using it primarily for anomaly detection rather than classification.
In contrast, Decision Trees show a lower AUC of 0.86, suggesting that rule-based decision structures may not be as effective for this particular task. Decision Trees tend to overfit the data, reducing their generalization capability when handling complex fraud patterns. The K-Nearest Neighbors (KNN) model has the lowest AUC of 0.80 , indicating that it is the least effective among all models. KNN’s poor performance suggests that the dataset does not exhibit well-defined clusters, making distance-based classification methods less suitable for fraud detection. Overall, ensemble methods such as XGBoost
and LightGBM perform best, while deep learning approaches like CNNs and Autoencoders also show promising results. On the other hand, Decision Trees and KNN struggle to classify fraud effectively, making them less suitable choices for this fraud detection problem.
For deep learning models like CNNs and Autoencoders, monitoring training loss vs. validation loss helps detect overfitting. In the initial stages of training, both training and validation loss decrease rapidly, indicating that the model is learning effectively and capturing important patterns in the data. This rapid decline is expected as the model quickly adjusts its parameters to minimize error. As training progresses, the training loss continues to decrease, albeit at a slower rate, suggesting that the model is refining its ability to fit the training data. However, after around 10 epochs, the validation loss begins to plateau and shows minor fluctuations, which is a crucial observation in model performance evaluation. A growing gap between training and validation loss emerges as training progresses, signaling a potential issue. While the training loss keeps decreasing, the validation loss fails to improve significantly, indicating that the model may be memorizing patterns in the training data rather than generalizing well to unseen data. This behavior is characteristic of overfitting, where the model learns not only useful features but also noise or specific details that do not generalize beyond the training dataset.
The optimal number of training epochs can be determined by monitoring when the validation loss starts to plateau or increase. In this case, around epoch 10, the model reaches its optimal learning capacity, and further training is unlikely to improve generalization. If training continues beyond this point, the model risks degrading its performance on unseen data. A well-generalized model exhibits a small and stable gap between training and validation loss, ensuring that it performs consistently across both known and new data. However, if validation loss increases while training loss keeps decreasing, overfitting is confirmed, and techniques such as early stopping, dropout regularization, or weight decay should be implemented to mitigate it. Figure 7 is training loss vs. validation loss for deep learning models.
A major challenge observed in the matrix is the class imbalance, where non-fraudulent transactions vastly outnumber fraudulent ones. While the model performs well in identifying normal transactions, its high number of false negatives suggests it struggles to detect fraud effectively. This imbalance is a common issue in fraud detection and often requires techniques such as oversampling, cost-sensitive learning, or anomaly detection methods to improve fraud identification without increasing false alarms. Although the model successfully detects most non-fraud cases, its low recall for fraudulent transactions
suggests the need for further optimization, additional feature engineering, or the use of ensemble learning techniques to enhance fraud detection accuracy.
XGBoost outperforms all models with the highest Accuracy (92%) and AUC-ROC ( 0.96 ), making it the most effective fraud detection model. LightGBM follows closely with strong Precision (
| Model | Accuracy | Precision | Recall | F1-Score | MCC | AUCROC |
| XGBoost | 92% | 90% | 91% | 90.5% | 0.88 | 0.96 |
| LightGBM | 90% | 89% | 88% | 88.5% | 0.86 | 0.94 |
| Decision Trees | 85% | 83% | 82% | 82.5% | 0.78 | 0.86 |
| CNNs | 89% | 87% | 86% | 86.5% | 0.84 | 0.93 |
| KNN | 80% | 77% | 75% | 76% | 0.72 | 0.82 |
| Autoencoders | 86% | 83% | 84% | 83.5% | 0.81 | 0.88 |
4.2 Discussion and Future Work
anomaly detection techniques should be explored in future work to further reduce false negatives without increasing false positives [17]. Additionally, the confusion matrix analysis revealed that although the models successfully detected most non-fraudulent transactions, they still struggled with misclassifying actual fraud cases. This suggests that integrating hybrid AI approaches, such as combining supervised and unsupervised learning techniques, could enhance fraud detection [2].
Another important consideration is the computational efficiency of fraud detection models. While XGBoost and LightGBM delivered high accuracy, their training and inference times were significantly higher compared to traditional models such as Decision Trees. Future research should explore ways to optimize fraud detection models for real-time analysis, possibly by incorporating edge computing and federated learning techniques, which allow fraud detection to be performed closer to the data source while maintaining data privacy and security [4]. Furthermore, the study primarily focused on structured transaction data from financial institutions and blockchain explorers. However, real-world fraud detection systems often require multimodal data, including customer behavioral analytics, device metadata, and biometric verification. Future research could explore multi-source fraud detection models that integrate graph-based fraud analysis and Natural Language Processing (NLP) to detect fraudulent activities in text-based financial transactions and phishing attempts [15].
Regulatory compliance is another crucial aspect of fraud detection in digital finance. With increasing regulations such as GDPR and FinCEN guidelines, AI-based fraud detection models must ensure explainability, transparency, and fairness [14]. Future work could involve the application of explainable AI (XAI) techniques, such as SHAP (Shapley Additive Explanations) and LIME (Local Interpretable Model-Agnostic Explanations), to improve model interpretability and build trust with financial regulators and customers [6]. Finally, fraud detection techniques must continue to evolve in response to emerging threats, such as AI-generated fraud, adversarial attacks, and synthetic identity fraud. Cybercriminals are increasingly using reinforcement learning-based attack strategies to bypass fraud detection systems, making it necessary for financial institutions to implement adversarial machine learning techniques that can detect and neutralize adaptive fraud strategies in real time [7].
5. Conclusion
Another crucial aspect of fraud detection is real-time model deployment. While ensemble models like XGBoost deliver high accuracy, they also have higher computational costs, which can impact real-time transaction monitoring. Future studies should focus on optimizing fraud detection models for lowlatency inference, possibly by integrating federated learning and edge computing to enhance security while maintaining computational efficiency. Furthermore, multimodal fraud detection systems that incorporate behavioral analytics, NLP-based fraud detection for phishing scams, and blockchain anomaly detection could significantly enhance fraud prevention strategies. Additionally, regulatory compliance and model interpretability remain critical concerns. As financial institutions adopt AI-based fraud detection systems, ensuring explainability and fairness in decision-making is essential for building trust with regulators and customers. Future research could explore explainable AI (XAI) techniques, such as SHAP and LIME, to improve transparency and provide clearer insights into fraud detection decisions. Moreover, emerging adversarial fraud techniques, including AI-generated fraud and synthetic identity fraud, pose new challenges that require robust adversarial learning defenses to prevent evolving
cyber threats. In conclusion, AI and machine learning have significantly improved fraud detection in digital finance, but continuous advancements are needed to address class imbalance, computational efficiency, model interpretability, and regulatory compliance. Future research should focus on hybrid fraud detection techniques, real-time AI deployment, explainable AI, and adversarial learning defenses to ensure secure, scalable, and transparent fraud detection systems for financial institutions.
Author Statements:
- Ethical approval: The conducted research is not related to either human or animal use.
- Conflict of interest: The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper
- Acknowledgement: The authors declare that they have nobody or no-company to acknowledge.
- Author contributions: The authors declare that they have equal right on this paper.
- Funding information: The authors declare that there is no funding to be acknowledged.
- Data availability statement: The data that support the findings of this study are available on request from the corresponding author. The data are not publicly available due to privacy or ethical restrictions.
References
[2] Chen, Y., Zhang, R., & Lin, C. (2023). AI-driven fraud detection: A hybrid approach combining supervised and unsupervised learning. Journal of Financial AI Applications, 10(2), 87-103.
[3] Das, B. C., Sarker, B., Saha, A., Bishnu, K. K., Sartaz, M. S., Hasanuzzaman, M., … & Khan, M. M. (2025). Detecting cryptocurrency scams in the USA: A machine learning-based analysis of scam patterns and behaviors. Journal of Ecohumanism, 4(2), 2091-2111.
[4] Huang, F., Li, W., & Zhao, T. (2024). Optimizing real-time fraud detection using federated learning and edge AI. International Journal of Cybersecurity and Data Science, 12(1), 45-61.
[5] Islam, M. Z., Islam, M. S., Das, B. C., Reza, S. A., Bhowmik, P. K., Bishnu, K. K., Rahman, M. S., Chowdhury, R., & Pant, L. (2025). Machine learning-based detection and analysis of suspicious activities in Bitcoin wallet transactions in the USA. Journal of Ecohumanism, 4(1), 3714 -. https://doi.org/10.62754/joe.v4i1.6214
[6] Kumar, P., & Li, X. (2024). Explainable AI for financial fraud detection: Challenges and future directions. Journal of AI and Ethics in Finance, 8(3), 209-225.
[7] Lee, J., Park, H., & Chen, L. (2023). Adversarial machine learning in fraud detection: Risks and countermeasures. Cybersecurity and AI Review, 7(2), 150-168.
[8] Liu, M., Tan, X., & Sun, H. (2024). Comparative analysis of machine learning models for detecting financial fraud. Journal of AI and Business Intelligence, 11(4), 320-338.
[9] Luo, H., Wang, J., & Chen, X. (2023). AI-enhanced fraud detection in digital finance: Challenges and future trends. Journal of Computational Finance and AI, 9(3), 100-118.
[10] Nguyen, T., & Lee, K. (2024). Hybrid AI models for fraud detection: Improving accuracy with deep learning and reinforcement learning. Journal of Applied Machine Learning in Finance, 15(2), 67-89.
[11] Patel, R., & Shah, D. (2024). Reinforcement learning for adaptive fraud detection: A case study on financial transactions. Journal of AI and Risk Management, 7(1), 55-72.
[12] Ray, R. K., Sumsuzoha, M., Faisal, M. H., Chowdhury, S. S., Rahman, Z., Hossain, E., … & Rahman, M. S. (2025). Harnessing machine learning and AI to analyze the impact of digital finance on urban economic resilience in the USA. Journal of Ecohumanism, 4(2), 1417-1442.
[13] Sizan, M. M. H., Chouksey, A., Tannier, N. R., Jobaer, M. A. A., Akter, J., Roy, A., Ridoy, M. H., Sartaz, M. S., & Islam, D. A. (2025). Advanced machine learning approaches for credit card fraud detection in the USA: A comprehensive analysis. Journal of Ecohumanism, 4(2), 883-. https://doi.org/10.62754/joe.v4i1.6214
[14] Sun, R., & Patel, A. (2024). Regulatory compliance in AI-powered fraud detection: Balancing security and fairness. Journal of Digital Finance and Compliance, 9(1), 105-122.
[15] Tan, B., Wang, D., & Zhou, Y. (2024). Multi-source fraud detection: Integrating transaction data, behavioral analytics, and NLP. Journal of Data Science and AI Security, 14(2), 145-161.
[16] Wang, H., Zhao, L., & Chen, M. (2023). Evaluating deep learning methods for financial fraud detection: A case study on transaction datasets. Journal of Applied Machine Learning in Finance, 14(1), 99-115.
[17] Zhang, H., & Wang, P. (2024). Addressing data imbalance in financial fraud detection using cost-sensitive learning. Journal of Computational Finance and AI, 6(3), 90-110.
[18] Zhou, X., & Patel, Y. (2024). Explainable AI in financial fraud detection: Enhancing transparency in machine learning models. Journal of Financial Technology Ethics, 5(2), 77-94.