DOI: https://doi.org/10.1007/s00521-023-09391-2
تاريخ النشر: 2024-01-11
تعزيز أنظمة توصية المحاصيل باستخدام الذكاء الاصطناعي القابل للتفسير: دراسة حول اتخاذ القرارات الزراعية
© المؤلف(ون) 2024
الملخص
أنظمة توصية المحاصيل هي أدوات لا تقدر بثمن للمزارعين، تساعدهم في اتخاذ قرارات مستنيرة بشأن اختيار المحاصيل لتحسين العوائد. تستفيد هذه الأنظمة من ثروة من البيانات، بما في ذلك خصائص التربة، وأداء المحاصيل التاريخي، وأنماط الطقس السائدة، لتقديم توصيات مخصصة. استجابةً للطلب المتزايد على الشفافية وقابلية التفسير في اتخاذ القرارات الزراعية، يقدم هذه الدراسة XAI-CROP، وهو خوارزمية مبتكرة تستفيد من مبادئ الذكاء الاصطناعي القابل للتفسير (XAI). الهدف الأساسي من XAI-CROP هو تمكين المزارعين من الحصول على رؤى مفهومة حول عملية التوصية، متجاوزة الطبيعة الغامضة لنماذج التعلم الآلي التقليدية. تقارن الدراسة بدقة بين XAI-CROP ونماذج التعلم الآلي البارزة، بما في ذلك تعزيز التدرج (GB)، شجرة القرار (DT)، الغابة العشوائية (RF)، بايزي الغاوسي الساذج (GNB)، وبايزي الساذج متعدد الوسائط (MNB). تستخدم تقييم الأداء ثلاثة مقاييس أساسية: متوسط الخطأ التربيعي (MSE)، ومتوسط الخطأ المطلق (MAE)، وR-squared (R2). تثبت النتائج التجريبية بشكل قاطع الأداء المتفوق لـ XAI-CROP. حيث يحقق MSE منخفضًا بشكل مثير للإعجاب قدره 0.9412، مما يشير إلى توقعات دقيقة للغاية لعوائد المحاصيل. علاوة على ذلك، مع MAE قدره 0.9874، يحافظ XAI-CROP باستمرار على الأخطاء دون العتبة الحرجة 1، مما يعزز موثوقيته.
1 المقدمة
تؤثر ظواهر الاحترار وتغير المناخ سلبًا على مستقبل الزراعة. تتطلب هذه العوامل، جنبًا إلى جنب مع متغيرات أخرى مثل المناخ والطقس والتربة واستخدام الأسمدة ونوع البذور، استخدام مجموعات بيانات متعددة لمعالجة هذه المشكلة المعقدة. تقليديًا، كان الاعتماد على النماذج الإحصائية في توقع إنتاج المحاصيل يستغرق وقتًا طويلاً وجهدًا كبيرًا. ومع ذلك، فإن إدخال البيانات الضخمة في السنوات الأخيرة قد فتح آفاقًا جديدة لأساليب تحليل أكثر تقدمًا، مثل التعلم الآلي. يمكن تصنيف نماذج التعلم الآلي إلى نماذج وصفية أو تنبؤية، اعتمادًا على أسئلة البحث والتحديات المطروحة. تُستخدم النماذج التنبؤية للتنبؤ بالمستقبل، بينما تُستخدم النماذج الوصفية للتعلم من البيانات وشرح الأحداث الماضية.
مع وجود شفافية وقابلية تفسير محدودة، مما يمكن أن يقلل من الثقة في النظام.
لقد ظهرت الذكاء الاصطناعي القابل للتفسير (XAI) كفرع فرعي من الذكاء الاصطناعي يهدف إلى تطوير نماذج تعلم الآلة القادرة على تقديم تفسيرات واضحة لقراراتها. من خلال دمج مبادئ XAI في أنظمة التوصية، يسعى الخوارزم إلى تعزيز الشفافية وقابلية التفسير للتوصيات المقدمة للمزارعين.
- شفافية محدودة وقابلية تفسير أنظمة توصية المحاصيل الحالية.
- نقص في التفسيرات الواضحة للأسباب وراء اختيارات النظام.
- تطوير خوارزمية تُدعى “XAI-CROP” تستخدم الذكاء الاصطناعي القابل للتفسير لتعزيز أنظمة توصية المحاصيل.
- تحسين الشفافية وقابلية التفسير في اتخاذ القرارات الزراعية.
- توفير تفسيرات واضحة لتوصيات النظام، مما يساعد المزارعين على فهم الأسباب وراء الخيارات.
- تم تقييم أداء XAI-CROP ومقارنته بأنظمة توصية المحاصيل الأخرى.
- تم العثور على أن XAI-CROP يتمتع بدقة وشفافية أفضل مقارنة بالأنظمة الأخرى.
- المساهمة في زيادة حجم الأبحاث حول استخدام الذكاء الاصطناعي القابل للتفسير في الزراعة.
- رؤية حول كيفية استغلال التكنولوجيا لمعالجة تحديات الأمن الغذائي والزراعة المستدامة.
2 الأعمال ذات الصلة
بيانات بيئية (الطقس والتربة). شاركوا في تحدي المحاصيل من سينجنتا لعام 2018 وكانت مشاركتهم ناجحة. حقق نموذجهم RMSE قدره
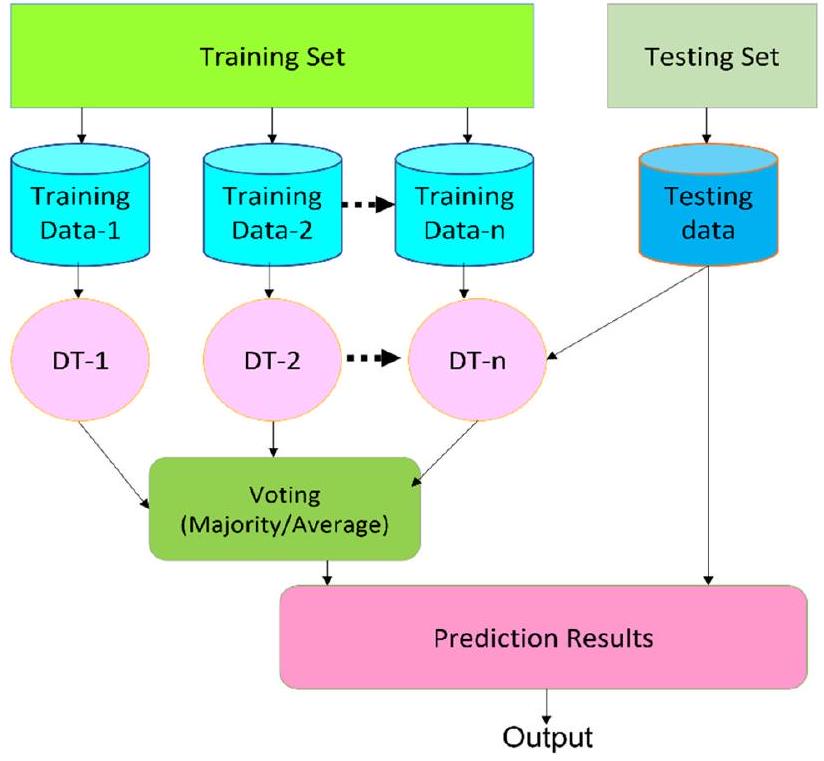
يحقق. استخدمت الدراسة خمسة نماذج مختلفة من التعلم الآلي، كل منها مع إعدادات مثلى للمعلمات الفائقة، لتدريب والتحقق من صحة الخوارزمية. حقق نموذج DecisionTreeRegressor درجة 0.9814، بينما حصل RandomForestRegressor على درجة 0.9903، وحصل ExtraTreeRegressor على درجة 0.9933، مما يدل على الدقة العالية وفعالية نهج CYPA.
| نموذج | وصف الخوارزمية | الإيجابيات | سلبيات | |||||
| تعزيز التدرج (GB) | تقنية تعلم الآلة التي تجمع بين نماذج ضعيفة متعددة لإنشاء نموذج قوي يمكنه إجراء توقعات دقيقة |
|
|
|||||
| شجرة القرار (DT) | نموذج شبيه بالشجرة حيث يمثل كل عقدة ميزة، ويمثل كل فرع قرارًا بناءً على تلك الميزة |
|
|
|||||
| الغابة العشوائية (RF) | طريقة تجميعية تقوم بإنشاء عدة أشجار قرار ومتوسط توقعاتها لتقليل الإفراط في التكيف وزيادة الدقة |
|
|
|||||
| بايزي الغوسي الساذج (GNB) | نموذج احتمالي يعتمد على نظرية بايز ويفترض أن الميزات مستقلة عن بعضها البعض |
|
|
|||||
| بايزي الساذج متعدد الوسائط (MNB) | امتداد لأسلوب بايز الغاوسي البسيط يمكنه التعامل مع البيانات ذات الأنماط أو المجموعات المتعددة |
|
|
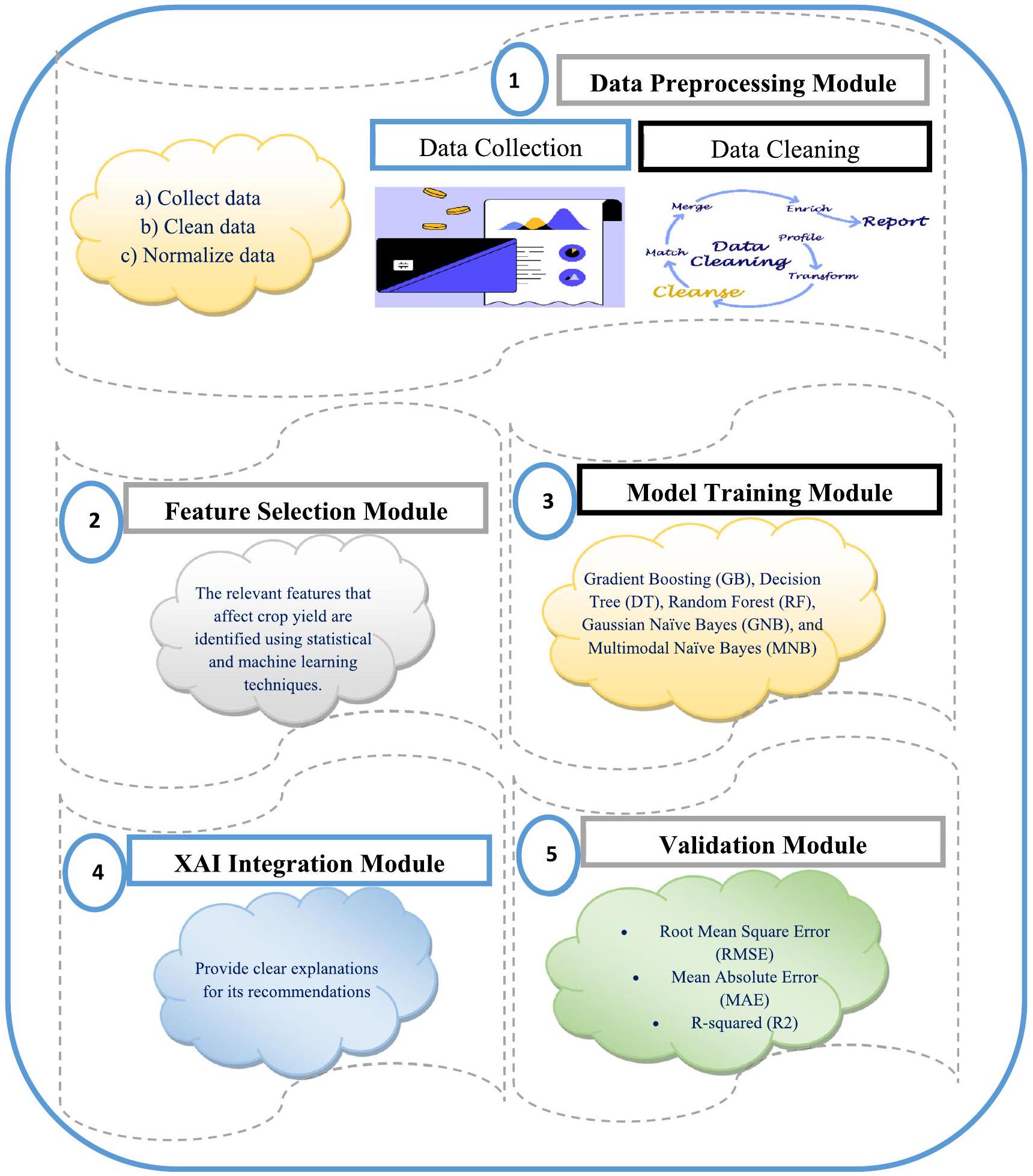
3 XAI-CROP: الذكاء الاصطناعي القابل للتفسير لأنظمة توصية المحاصيل
i. معالجة البيانات: في هذه المرحلة، يتم جمع ومعالجة البيانات المدخلة، والتي تشمل نوع التربة، وأنماط الطقس، والعوائد الزراعية التاريخية، لمزيد من التحليل.
iii. اختيار الميزات: يتم تحديد الميزات ذات الصلة التي تؤثر على محصول الزراعة باستخدام تقنيات إحصائية وتقنيات تعلم الآلة. ثم تُستخدم هذه الميزات كمدخلات لنموذج XAI-CROP.
iii. تدريب النموذج: يتم تدريب نموذج XAI-CROP على مجموعة بيانات لزراعة المحاصيل في الهند، والتي تتضمن معلومات عن إنتاج المحاصيل، نوع التربة، أنماط الطقس، وإنتاج المحاصيل التاريخي. يعتمد النموذج على خوارزمية شجرة القرار التي تولد توصيات بناءً على البيانات المدخلة مثل الموقع، الموسم، والإنتاج لكل كيلومتر مربع، والمساحة، والمحصول.
iv. دمج الذكاء الاصطناعي القابل للتفسير: يستخدم نموذج XAI-CROP تقنية تُسمى “تفسيرات نموذجية محلية غير مرتبطة” (LIME) لتقديم تفسيرات واضحة لتوصياته. LIME هي تقنية لشرح توقعات نماذج التعلم الآلي من خلال إنشاء نماذج محلية تقارب توقعات النموذج الأصلي.
v. التحقق: يتم التحقق من نموذج XAI-CROP باستخدام مجموعة بيانات التحقق لتقييم أدائه في التنبؤ بعائد المحاصيل. دقة النموذج هي
تم قياسها باستخدام خطأ الجذر التربيعي المتوسط (RMSE) وخطأ القيمة المطلقة المتوسطة (MAE) ومعامل التحديد (R2).
3.1 معالجة البيانات
3.2 اختيار الميزات
- إدخال:
- البيانات المجمعة
- الإخراج:
- البيانات المعالجة مسبقًا
- الخطوات:
// الخطوة 1: جمع بيانات الإدخال
بيانات_التربة = قراءة_csv(‘بيانات_التربة.csv’)
بيانات الطقساقرأ_csv(‘بيانات_الطقس.csv’)
بيانات إنتاج المحاصيلاقرأ_csv(‘crop_yield_data.csv’)
// الخطوة 2: تنظيف البيانات
بيانات التربةإزالة_التكرارات(بيانات_التربة)
بيانات الطقسإزالة_القيم_المفقودة(بيانات_الطقس)
بيانات إنتاج المحاصيلإزالة_التكرارات(بيانات_محصول_الزراعة)
// الخطوة 3: تحويل البيانات
بيانات التربةتحويل_المتغيرات_الفئوية(بيانات_التربة)
بيانات الطقستحويل_المتغيرات_الفئوية(بيانات_الطقس)
// الخطوة 4: دمج البيانات
بيانات المحاصيلدمج_المجموعات(بيانات_التربة، بيانات_الطقس، بيانات_محصول_الزراعة)
// الخطوة 5: تطبيع البيانات
بيانات المحاصيلnormalize_data(crop_data)
// الخطوة 6: تقسيم البيانات
بيانات التدريب، بيانات الاختبارتقسيم_البيانات(بيانات_المحاصيل، نسبة_التدريب=0.8)
- الإدخال:
- مجموعة البيانات المعالجة مسبقًا
- الإخراج:
- الميزات المختارة لنموذج XAI-CROP
- الخطوات:
- قم بتقسيم مجموعة البيانات إلى مجموعة تدريب ومجموعة اختبار.
- تطبيق تقنيات إحصائية لتحديد الميزات التي لها تأثير كبير على محصول الزراعة.
- تطبيق تقنيات التعلم الآلي لتحديد الميزات المهمة.
- رتب الميزات المحددة بناءً على درجات أهميتها.
- اختر الأعلى
الميزات التي تحمل أعلى درجات الأهمية كمدخلات لنموذج XAI-CROP. - أعد الميزات المحددة كإخراج.
3.3 تدريب النموذج
مجموعة بيانات تحتوي على معلومات حول محصول الزراعة، نوع التربة، أنماط الطقس، والمحاصيل التاريخية. (ii) تقسيم مجموعة البيانات إلى مجموعات تدريب واختبار باستخدام نسبة محددة مسبقًا. (iii) إنشاء مصنف شجرة قرار وتعيين
معلمات الخوارزمية. (iv) تدريب مصنف شجرة القرار باستخدام مجموعة بيانات التدريب. (v) تقييم أداء النموذج على مجموعة بيانات الاختبار باستخدام مقاييس مختلفة مثل الدقة، والموثوقية، والاسترجاع، ودرجة F1. (vi) إذا لم يكن أداء النموذج مرضيًا، قم بضبط المعلمات الفائقة لخوارزمية شجرة القرار وأعد تدريب النموذج. (vii) حفظ النموذج المدرب للاستخدام في المستقبل.
توفر GB نتائج توقعات أكثر دقة من خلال ملاءمة وتحديث معلمات النموذج الجديدة. وبالتالي، يتم بناء متعلم أساسي جديد وتحسين نتائج التدرج السالب من دالة الخسارة المتعلقة بالكل التجميعي.
- Input:
- Selected Features
- Output:
- Trained Model
- Steps:
# Load dataset
dataset = load_dataset()
# Split dataset into training and testing sets
train_set, test_set $=$ split_dataset(dataset)
# Prepare input data for decision tree model
input_data $=$ prepare_input_data(train_set, relevant_features)
# Train decision tree model
model $=$ train_decision_tree(input_data)
# Test model accuracy
accuracy $=$ test_model(model, test_set)
# Evaluate model performance
performance_metrics $=$ evaluate_performance(model, test_set)
3.4 ضبط المعلمات الفائقة
بينما يمكن استخدام خسارة اللوغاريتم (خسارة اللوغ) لمهام التصنيف. ومن الجدير بالذكر أنه عند إضافة شجرة جديدة إلى النموذج، لا تتغير الأشجار الحالية كما هو موضح في الشكل 2. الشجرة القرار التي تم تقديمها تناسب المتبقيات من النموذج الحالي [37].
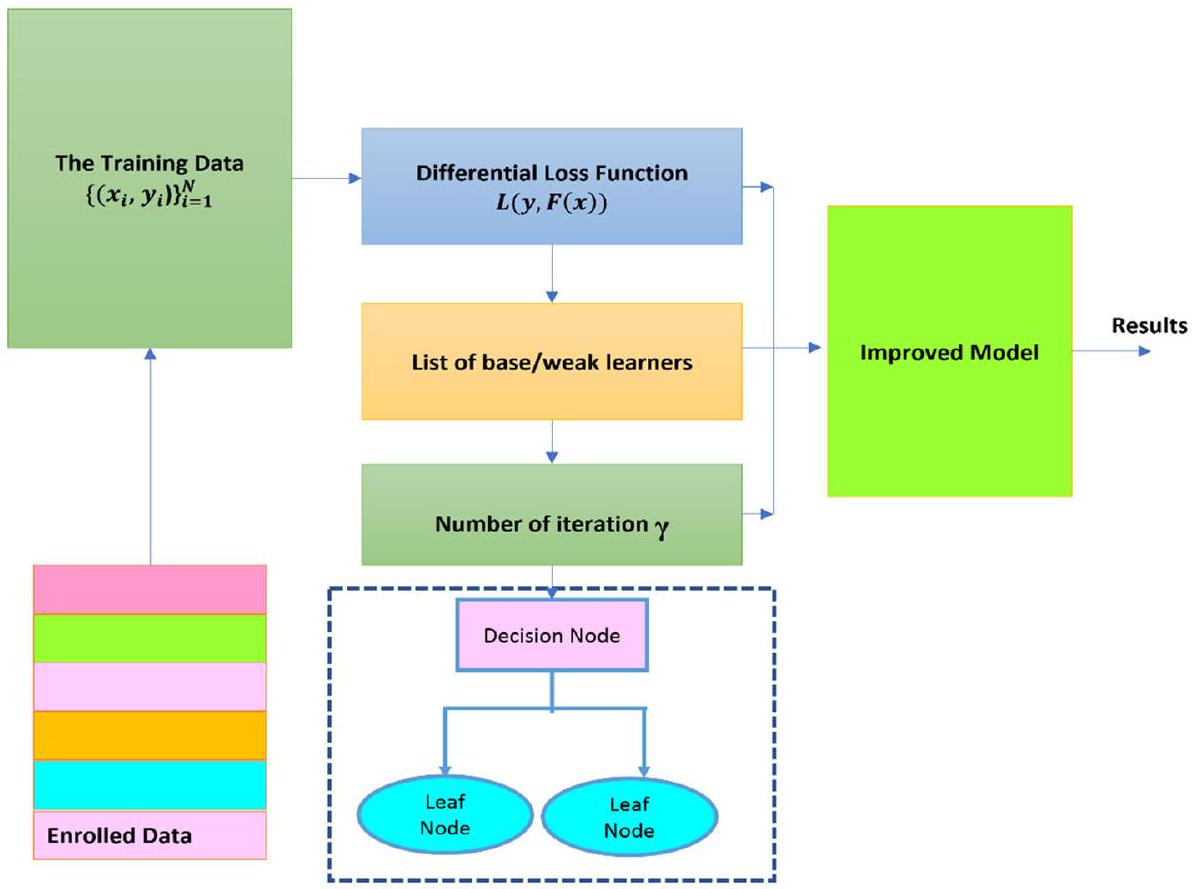
الكثير من الأشجار يزيد من خطر الإفراط في التكيف، مما قد يؤدي إلى أداء عام ضعيف للنموذج [38].
3.5 وحدة تكامل XAI
الخوارزمية 4 خوارزمية تكامل XAI
- الخطوات:
# تحميل نموذج XAI-CROP
xai_crop_modelload_model(‘xai_crop_model.h5’)
# اختيار عينة من مجموعة بيانات التحقق لتوليد تفسير
samplevalidation_dataset.sample()
# توليد اضطرابات للعينة المختارة لإنشاء مجموعة بيانات لتدريب النموذج المحلي
perturbed_datasetgenerate_perturbations(sample, num_perturbations)
# تدريب نموذج انحدار خطي على مجموعة البيانات المضطربة
local_modeltrain_linear_regression(perturbed_dataset)
# حساب وزن كل ميزة في النموذج المحلي
weightscalculate_feature_weights(local_model)
# توليد تفسير من خلال تسليط الضوء على الميزات التي تساهم أكثر في
توقع نموذج XAI-CROP للعينة المختارة
explanationgenerate_explanation(sample, weights)
قوة وموثوقية توقعات النموذج، مع تسهيل أيضًا قابلية تفسير النتائج وشرحها.
3.6 وحدة التحقق
الخوارزمية 5 خوارزمية التحقق مكونًا حيويًا، تشمل ثلاث خطوات رئيسية موضحة في الخوارزمية 5. تم تصميم هذه الخطوات لضمان
- الإدخال:
- النموذج المدرب
- الإخراج:
- مقاييس الأداء
- الخطوات:
function validate(XAI-CROP model, validation dataset)
# الخطوة 3a
validation_features, validation_targetseparate_features_target(validation dataset)
# الخطوة 3b
predicted_crop_yieldXAI-CROP model.predict(validation_features)
# الخطوة 3d
rmsemean
maemean(abs(validation_target – predicted_crop_yield))
– sum((validation_target – predicted_crop_yield)^2) / sum((validation_target –
mean(validation_target))^2)
# الخطوة 3e
return rmse, mae, r2
4 التنفيذ والتقييم
4.1 البرمجيات
4.2 مجموعة بيانات إنتاج المحاصيل
4.3 مقاييس الأداء
ii. متوسط الخطأ المطلق (MAE): يقيس MAE متوسط الفرق المطلق بين درجات الإنفاق المتوقعة والفعلية. يمكن حساب MAE كما هو موضح في المعادلة (2).
iii. R-squared: R-squared هو مقياس إحصائي يمثل نسبة التباين في المتغير التابع الذي يفسره المتغيرات المستقلة. يمكن حساب R-squared كما هو موضح في المعادلة (3).
| اسم المنطقة | الموسم | المساحة | الإنتاج | المحصول | |
| 0 | شمال ووسط أندامان | ربيع | 294.5 | 90.8 | تور |
| 1 | جنوب أندامان | ربيع | 20.5 | 13.2 | تور |
| 2 | أنانتابور | خريف | 21400.0 | 2600.0 | تور |
| 3 | أنانتابور | خريف | 27400.0 | 9100.0 | تور |
| 4 | أنانتابور | خريف | 30693.0 | 7888.0 | تور |
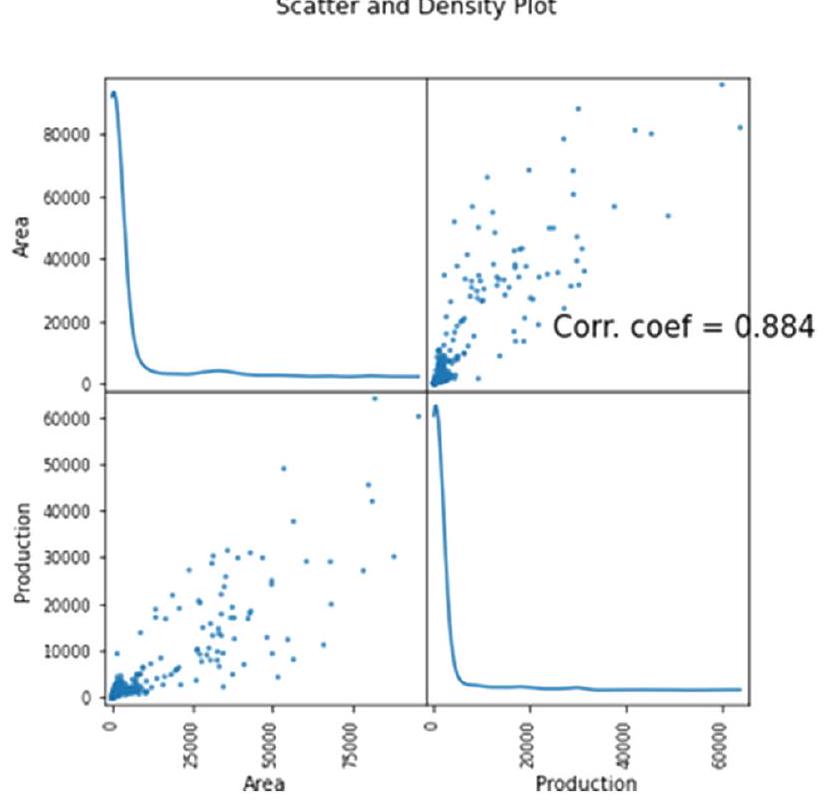
4.4 تقييم الأداء
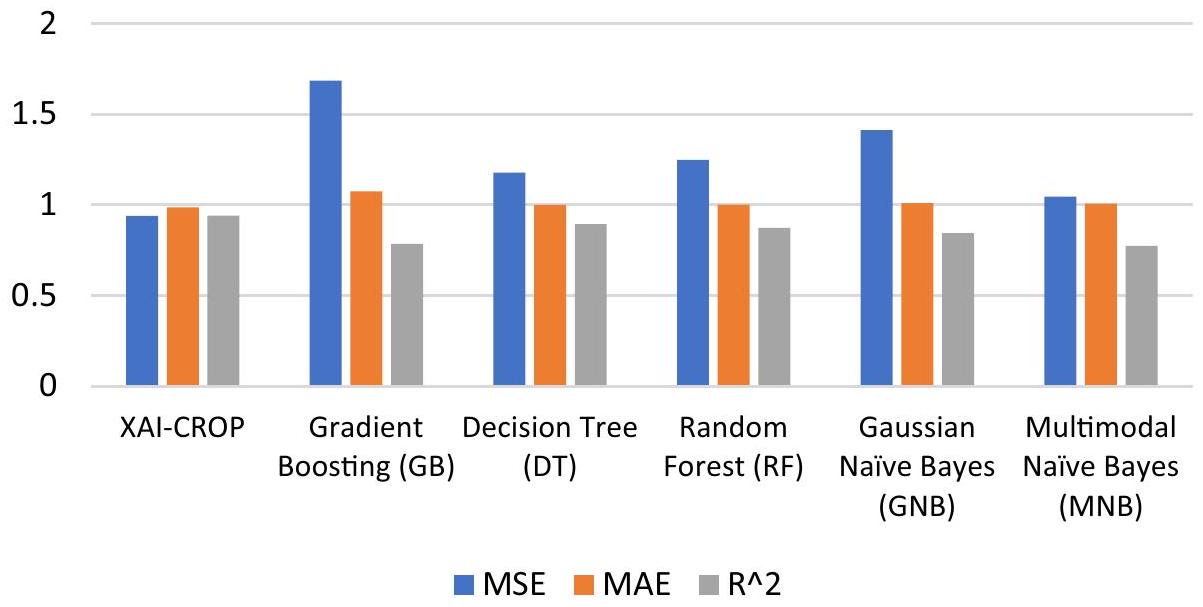
| النموذج | MSE | MAE | R^2 |
| XAI-CROP | 0.9412 | 0.9874 | 0.94152 |
| تعزيز التدرج (GB) | 1.6861 | 1.0745 | 0.78521 |
| شجرة القرار (DT) | 1.1785 | 1.0002 | 0.8942 |
| الغابة العشوائية (RF) | 1.2487 | 1.0015 | 0.8745 |
| بايزي Gaussian (GNB) | 1.4123 | 1.0098 | 0.8456 |
| بايزي متعدد الأبعاد (MNB) | 1.0452 | 1.0078 | 0.77521 |
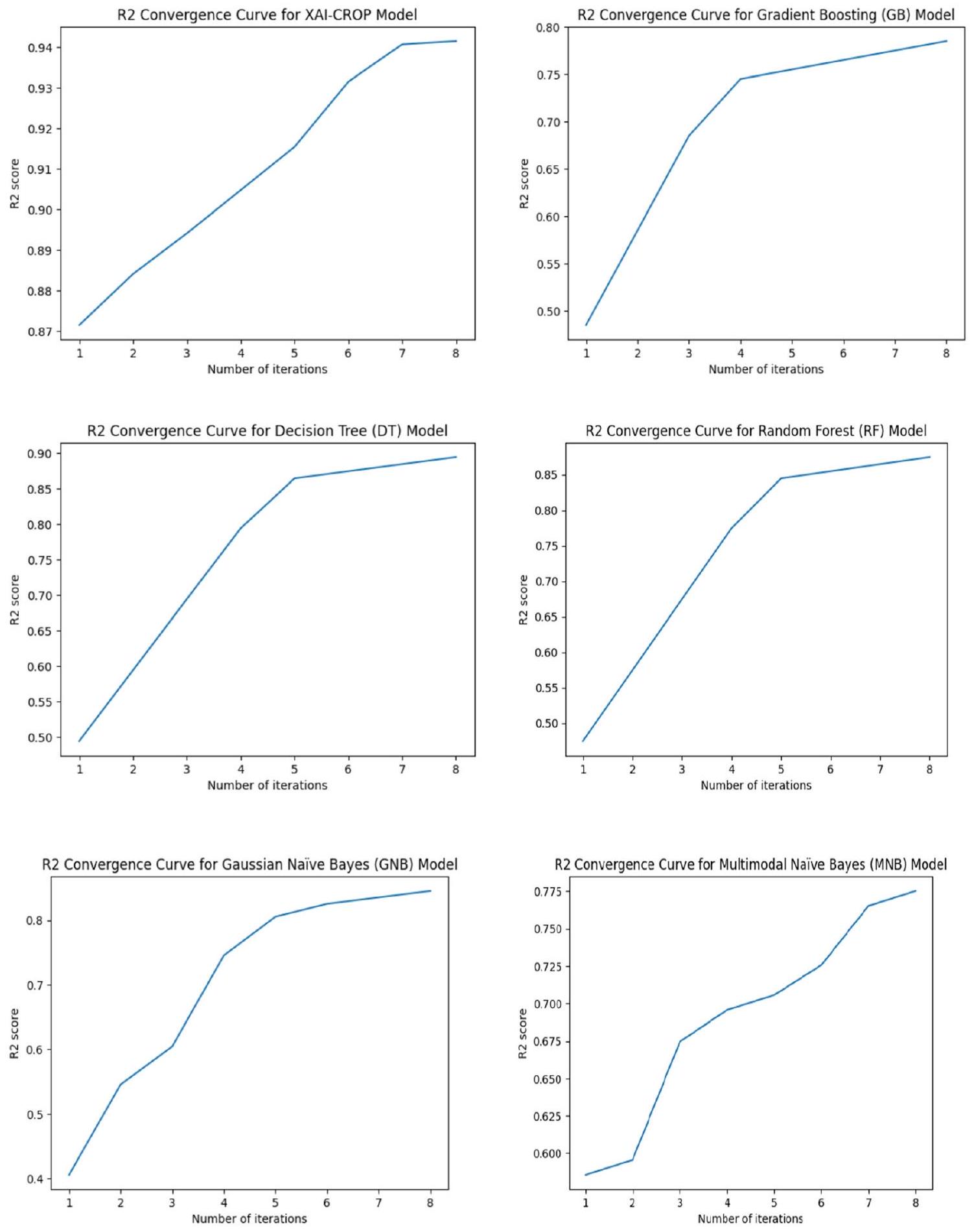
تقدم التعلم، وسرعة التقارب، وإمكانية الإفراط في التكيف أو نقص التكيف. يمكن ملاحظة وتحليل أنماط مثل هضاب التقارب، والتقلبات، أو التحسينات السريعة في معدل R2، مما يساعد في تقييم ومقارنة النماذج.
5 مناقشة النتائج
مع معدلات خطأ منخفضة وقيمة R-squared عالية تشير إلى دقتها وقابليتها للتفسير في شرح تباين البيانات.
يعمل بحثنا كخطوة محورية للتقدم المستقبلي.
على سبيل المثال، شرح كيف يمكن أن تتضمن عملية اتخاذ القرار لدى المزارع النموذج. قد يتطلب ذلك شرحًا شاملاً لكيفية تنفيذ اقتراحات النموذج في العالم الحقيقي أو دليل خطوة بخطوة.
6 يمكن تنفيذ عدة آثار في العالم الحقيقي مثل:
- الزراعة الدقيقة: يمكن استخدام النموذج المقترح لتقديم توصيات مخصصة للمحاصيل للمزارعين بناءً على عوامل مثل جودة التربة، وظروف الطقس، والبيانات التاريخية، ومتطلبات المحاصيل المحددة. يمكن أن يساعد ذلك في تحسين تخصيص الموارد، وزيادة غلة المحاصيل، وتقليل الأثر البيئي من خلال تقليل استخدام الأسمدة والمبيدات.
- ممارسات الزراعة المستدامة: من خلال دمج الذكاء الاصطناعي القابل للتفسير في أنظمة توصية المحاصيل، يمكن أن يساعد النموذج المقترح المزارعين في اعتماد ممارسات زراعية مستدامة. يمكن أن يوفر رؤى حول الأثر البيئي لاختيارات المحاصيل المختلفة ويوصي باستراتيجيات صديقة للبيئة، مثل تدوير المحاصيل أو الزراعة المختلطة، لتعزيز صحة التربة والحفاظ على التنوع البيولوجي.
- التكيف مع تغير المناخ: مع تأثير تغير المناخ على الإنتاجية الزراعية والأنماط، يمكن أن يساعد النموذج المقترح المزارعين في التكيف مع الظروف المتغيرة. من خلال تحليل البيانات المناخية التاريخية ودمج النماذج التنبؤية، يمكنه توليد توصيات لاختيارات المحاصيل المقاومة التي تتناسب بشكل أفضل مع تحمل الأحداث المناخية المتطرفة أو الأنماط المناخية المتغيرة.
- دعم الزراعة الصغيرة: غالبًا ما يواجه المزارعون الصغار تحديات فريدة من حيث الموارد المحدودة والوصول إلى المعلومات. يمكن أن يقدم النموذج المقترح توصيات مخصصة للمحاصيل ويوفر رؤى قيمة لدعم اتخاذ القرار للمزارعين الصغار، مما يساعدهم على زيادة إنتاجيتهم وربحيتهم.
- دعم القرار للمستشارين الزراعيين: يمكن للمستشارين الزراعيين استخدام النموذج المقترح لتقديم توصيات خبراء للمزارعين. من خلال دمج الذكاء الاصطناعي القابل للتفسير، يمكن للنموذج تقديم الأسباب والتبريرات الأساسية لتوصيات المحاصيل المحددة بشكل شفاف، مما يمكّن المستشارين من التواصل بفعالية وكسب ثقة المزارعين.
7 الخاتمة
تعقيدات الزراعة الحديثة واتخاذ قرارات مستنيرة من أجل زراعة المحاصيل المستدامة والفعالة. نأمل أن تسهم هذه الأبحاث في تقدم الممارسات الزراعية على مستوى العالم، وتعزيز الأمن الغذائي والاستدامة البيئية.
الإقرارات
الوصول المفتوح هذه المقالة مرخصة بموجب رخصة المشاع الإبداعي للاستخدام الدولي 4.0، والتي تسمح بالاستخدام والمشاركة والتكيف والتوزيع وإعادة الإنتاج في أي وسيلة أو صيغة، طالما أنك تعطي الائتمان المناسب للمؤلفين الأصليين والمصدر، وتوفر رابطًا لرخصة المشاع الإبداعي، وتوضح ما إذا كانت هناك تغييرات قد تم إجراؤها. الصور أو المواد الأخرى من طرف ثالث في هذه المقالة مشمولة في رخصة المشاع الإبداعي للمقالة، ما لم يُشار إلى خلاف ذلك في سطر الائتمان للمادة. إذا لم تكن المادة مشمولة في رخصة المشاع الإبداعي للمقالة وكان استخدامك المقصود غير مسموح به بموجب اللوائح القانونية أو يتجاوز الاستخدام المسموح به، ستحتاج إلى الحصول على إذن مباشرة من صاحب حقوق الطبع والنشر. لعرض نسخة من هذه الرخصة، قم بزيارة http://creativecommons. org/licenses/by/4.0/.
References
- Bhadouria R, et al. (2019) Agriculture in the era of climate change: Consequences and effects. In Climate Change and Agricultural Ecosystems, Elsevier, 1-23.
- Xu X et al (2019) Design of an integrated climatic assessment indicator (ICAI) for wheat production: a case study in Jiangsu Province, China. Ecol Ind 101:943-953
- Bali N, Singla A (2021) Deep learning based wheat crop yield prediction model in punjab region of north india. Appl Artif Intell 35(15):1304-1328
- Van Klompenburg T, Kassahun A, Catal C (2020) Crop yield prediction using machine learning: A systematic literature review. Comput Electron Agric 177:105709
- Alpaydin E (2020) Introduction to machine learning. MIT press.
- Tarek Z et al (2023) Soil erosion status prediction using a novel random forest model optimized by random search method. Sustainability 15(9):9. https://doi.org/10.3390/su15097114
- Shams MY, Tarek Z, Elshewey AM, Hany M, Darwish A, Hassanien AE (2023) A machine learning-based model for predicting temperature under the effects of climate change. In: The Power of Data: Driving Climate Change with Data Science and Artificial Intelligence Innovations, A. E. Hassanien and A. Darwish, Eds., in Studies in Big Data. Cham: Springer Nature Switzerland, 2023: 61-81. https://doi.org/10.1007/978-3-031-22456-0_4.
- Elshewey AM et al (2023) A novel WD-SARIMAX model for temperature forecasting using daily Delhi climate dataset. Sustainability 15(1):1. https://doi.org/10.3390/su15010757
- Porter JR, Xie L, Challinor AJ, Cochrane K, Howden SM, Iqbal MM, Lobell DB, Travasso MI (2014) Food security and food production systems. Part A: Global and Sectoral Aspects. Contribution of Working Group II to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change, 1(1): 485-533 (2014).
- Rosenzweig C et al (2013) The agricultural model intercomparison and improvement project (AgMIP): protocols and pilot studies. Agric For Meteorol 170:166-182
- Khater HA, Gamel SA (2023) Early diagnosis of respiratory system diseases (RSD) using deep convolutional neural networks. J Ambient Intell Human Comput 14:12273-12283
- Lobell DB, Asseng S (2017) Comparing estimates of climate change impacts from process-based and statistical crop models. Environ Res Lett 12(1):015001
- Schlenker W, Roberts MJ (2009) Nonlinear temperature effects indicate severe damages to US crop yields under climate change. Proc Natl Acad Sci 106(37):15594-15598
- Roberts MJ, Braun NO, Sinclair TR, Lobell DB, Schlenker W (2017) Comparing and combining process-based crop models and statistical models with some implications for climate change. Environ Res Lett 12(9):095010
- Roberts MJ, Schlenker W, Eyer J (2013) Agronomic weather measures in econometric models of crop yield with implications for climate change. Am J Agr Econ 95(2):236-243
- Patel K, Patel HB (2023) Multi-criteria agriculture recommendation system using machine learning for crop and fertilizesrs prediction. Curr Agricult Res J 11(1), 2023.
- Mittal N, Bhanja A (2023) Implementation and identification of crop based on soil texture using AI. In: 2023 4th International Conference on Electronics and Sustainable Communication Systems (ICESC), IEEE. 1467-1471.
- Fenz S, Neubauer T, Heurix J, Friedel JK, Wohlmuth M-L (2023) AI- and data-driven pre-crop values and crop rotation matrices. Eur J Agron 150:126949. https://doi.org/10.1016/j.eja.2023. 126949
- Arif MS, Mukheimer A, Asif D (2023) Enhancing the early detection of chronic kidney disease: a robust machine learning model. Big Data Cognit Comput 7(3):3. https://doi.org/10.3390/ bdcc7030144
- Asif D, Bibi M, Arif MS, Mukheimer A (2023) Enhancing heart disease prediction through ensemble learning techniques with hyperparameter optimization. Algorithms 16(6):6. https://doi.org/ 10.3390/a16060308
- Nawaz Y, Arif MS, Shatanawi W, Nazeer A (2021) An explicit fourth-order compact numerical scheme for heat transfer of
boundary layer flow. Energies 14(12):12. https://doi.org/10.3390/ en14123396 - Nawaz Y, Arif MS, Abodayeh K (2022) A third-order two-stage numerical scheme for fractional stokes problems: a comparative computational study. J Comput Nonlinear Dyn 17:101004. https://doi.org/10.1115/1.4054800
- Nawaz Y, Arif MS, Abodayeh K (2022) An explicit-implicit numerical scheme for time fractional boundary layer flows. Int J Numer Meth Fluids 94(7):920-940. https://doi.org/10.1002/fld. 5078
- McEldowney JF (2021) Climate change and the law. In: the impacts of climate change, Elsevier. 503-519.
- de Oliveira AC, Marini N, Farias DR (2014) Climate change: New breeding pressures and goals. Encyclopedia Agricult Food Syst 2014:284-293
- Williams TO, et al. (2015) Climate smart agriculture in the African context. Unlocking Africa’s Agricultural Potentials for Transformation to Scale, FAO and UNEP, Abdou Diouf International Conference, Dakar, Senegal, pp. 1-26, 2015.
- Reddy PS, Amarnath B, Sankari M (2023) Study on machine learning and back propagation for crop recommendation system. In: 2023 International Conference on Sustainable Computing and Data Communication Systems (ICSCDS), IEEE. 1533-1537.
- You J, Li X, Low M, Lobell D, Ermon S (2017) Deep gaussian process for crop yield prediction based on remote sensing data. In: Thirty-First AAAI conference on artificial intelligence.
- Paudel D et al (2021) Machine learning for large-scale crop yield forecasting. Agric Syst 187:103016
- Sun J, Lai Z, Di L, Sun Z, Tao J, Shen Y (2020) Multilevel deep learning network for county-level corn yield estimation in the us corn belt. IEEE J Selected Top Appl Earth Obs
- Yoon HS et al (2021) Akkermansia muciniphila secretes a glu-cagon-like peptide-1-inducing protein that improves glucose homeostasis and ameliorates metabolic disease in mice. Nat Microbiol 6(5):5. https://doi.org/10.1038/s41564-021-00880-5
- Khaki S, Wang L (2022) Crop Yield Prediction Using Deep Neural Networks. Front Plant Sci 10, 2019, Accessed: Sep. 27, 2022. Available: https://doi.org/10.3389/fpls.2019.00621
- Abbas F, Afzaal H, Farooque AA, Tang S (2020) Crop yield prediction through proximal sensing and machine learning algorithms. Agronomy 10(7):7. https://doi.org/10.3390/ agronomy10071046
- Talaat FM (2023) Crop yield prediction algorithm (CYPA) in precision agriculture based on IoT techniques and climate changes. Neural Comput Applic. https://doi.org/10.1007/s00521-023-08619-5
- Friedman JH (2001) Greedy function approximation: a gradient boosting machine. Ann Stat 29(5):1189-1232
- Natekin A, Knoll A (2022) Gradient boosting machines, a tutorial. Front Neurorobotics 7, 2013, Accessed: Sep. 27, 2022. Available: https://doi.org/10.3389/fnbot.2013.00021
- Ke G, et al. (2017) LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In: Advances in Neural Information Processing Systems, 2017, 30. Accessed: Sep. 27, 2022. Available: https://proceedings.neurips.cc/paper/2017/hash/ 6449f44a102fde848669bdd9eb6b76fa-Abstract.html
- Rao H et al (2019) Feature selection based on artificial bee colony and gradient boosting decision tree. Appl Soft Comput 74:634-642. https://doi.org/10.1016/j.asoc.2018.10.036
- Freund Y, Mason L (1999) The alternating decision tree learning algorithm. In: Icml, 1999, 99, pp. 124-133.
- Feng J, Yu Y, Zhou Z-H (2018) Multi-Layered Gradient Boosting Decision Trees. In: Advances in Neural Information Processing Systems, 2018, 31. Accessed: Sep. 27, 2022. Available: https:// proceedings.neurips.cc/paper/2018/hash/39027dfad5138c9 ca0c474d71db915c3-Abstract.html
- Pretorius A, Bierman S, Steel SJ (2016) A meta-analysis of research in random forests for classification. In: 2016 Pattern Recognition Association of South Africa and Robotics and Mechatronics International Conference (PRASA-RobMech), 2016, pp. 1-6.
- Sun C, Li X, Guo R (2021) Research on electrical fire risk assessment technology of cultural building based on random forest algorithm. In: 2021 International Conference on Aviation Safety and Information Technology, New York, NY, USA, Dec. 2021, pp. 769-773. https://doi.org/10.1145/3510858.3511382.
- Geenen PL, van der Gaag LC, Loeffen WLA, Elbers ARW (2011) Constructing naive Bayesian classifiers for veterinary medicine: A case study in the clinical diagnosis of classical swine fever. Res Vet Sci 91(1):64-70. https://doi.org/10.1016/j.rvsc. 2010.08.006
- Xu S (2018) Bayesian Naïve Bayes classifiers to text classification. J Inf Sci 44(1):48-59. https://doi.org/10.1177/016555151 6677946
- Kibriya AM, Frank E, Pfahringer B, Holmes G (2005) Multinomial naive bayes for text categorization revisited. In: AI 2004: Advances in Artificial Intelligence, Berlin, Heidelberg, 2005, pp. 488-499. https://doi.org/10.1007/978-3-540-30549-1_43.
- Jiang L, Wang S, Li C, Zhang L (2016) Structure extended multinomial naive Bayes. Inf Sci 329:346-356. https://doi.org/10. 1016/j.ins.2015.09.037
- https://www.kaggle.com/datasets/ananysharma/crop-yield.
- Elshewey A, Shams M, Tarek Z, Megahed M, El-kenawy E-S, El-dosuky M (2023) Weight prediction using the hybrid stackedLSTM food selection model. CSSE, 46(1): 765-781, 2023, https://doi.org/10.32604/csse.2023.034324.
- Shams MY, Elshewey AM, El-kenawy E-SM, Ibrahim A, Talaat FM, Tarek Z (2023) Water quality prediction using machine learning models based on grid search method. Multimed Tools Appl. https://doi.org/10.1007/s11042-023-16737-4
- Ryo M (2022) Explainable artificial intelligence and interpretable machine learning for agricultural data analysis. Artif Intell Agricult 6:257-265. https://doi.org/10.1016/j.aiia.2022.11. 003
- Doshi Z, Nadkarni S, Agrawal R, Shah N (2018) AgroConsultant: Intelligent crop recommendation system using machine learning algorithms. In: 2018 Fourth International Conference on Computing Communication Control and Automation (ICCUBEA), Aug. 2018, pp. 1-6. https://doi.org/10.1109/ICCUBEA.2018. 8697349.
- Taleizadeh AA, Amjadian A, Hashemi-Petroodi SE, Moon I (2023) Supply chain coordination based on mean-variance risk optimisation: pricing, warranty, and full-refund decisions. Int J Syst Sci: Oper Logist 10(1):2249808. https://doi.org/10.1080/ 23302674.2023 .2249808
- Gharaei A, Amjadian A, Shavandi A, Amjadian A (2023) An augmented Lagrangian approach with general constraints to solve nonlinear models of the large-scale reliable inventory systems. J Comb Optim 45(2):78. https://doi.org/10.1007/s10878-023-01002-z
- Taleizadeh AA, Varzi AM, Amjadian A, Noori-daryan M, Konstantaras I (2023) How cash-back strategy affect sale rate under refund and customers’ credit. Oper Res Int J 23(1):19. https://doi. org/10.1007/s12351-023-00752-2
- Talaat FM (2022) Effective deep Q-networks (EDQN) strategy for resource allocation based on optimized reinforcement learning algorithm. Multimed Tools Appl 81(17). https://doi.org/10. 1007/s11042-022-13000-0
- Talaat FM (2022) Effective prediction and resource allocation method (EPRAM) in fog computing environment for smart healthcare system. Multimed Tools Appl
- Talaat Fatma M, Alshathri Samah, Nasr Aida A (2022) A new reliable system for managing virtualcloud network. Comput Mater Continua 73(3):5863-5885. https://doi.org/10.32604/cmc. 2022.026547
- El-Rashidy N, ElSayed NE, El-Ghamry A, Talaat FM (2022) Prediction of gestational diabetes based on explainable deep learning and fog computing. Soft Comput 26(21):11435-11450
- El-Rashidy N, Ebrahim N, el Ghamry A, Talaat FM (2022) Utilizing fog computing and explainable deep learning techniques for gestational diabetes prediction. Neural Comput Applic. https://doi.org/10.1007/s00521-022-08007-59. FaivdullahL,AzaharF,HtikeZZ,Naing
- Hanaa S, Fatma BT (2022) Detection and classification using deep learning and sine-cosine fitnessgrey wolf optimization. Bioengineering 10(1):18. https://doi.org/10.3390/bioengineering 10010018
- Talaat FM (2023) Real-time facial emotion recognition system among children with autism based on deep learning and IoT. Neural Comput Appl 35(3), https://doi.org/10.1007/s00521-023-08372-9
- Talaat FM (2023) Crop yield prediction algorithm (CYPA) in precision agriculture based on IoT techniques and climate changes, April 2023, Neural Comput Appl 35(2), https://doi.org/10. 1007/s00521-023-08619-5
- Hassan E, El-Rashidy N, Talaat FM (2022) Review: Mask R-CNN Models. May 2022, https://doi.org/10.21608/njccs.2022. 280047.
- Siam AI, Gamel SA, Talaat FM (2023) Automatic stress detection in car drivers based on non-invasive physiological signals using machine learning techniques. Neural Comput Applic. https://doi.org/10.1007/s00521-023-08428-w
- Talaat FM, Gamel SA (2023) A2M-LEUK: attention-augmented algorithm for blood cancer detection in children, June 2023, Neural Comput Appl. https://doi.org/10.1007/s00521-023-086788
- Gamel SA, Hassan E, El-Rashidy N et al (2023) Exploring the effects of pandemics on transportation through correlations and deep learning techniques. Multimed Tools Appl. https://doi.org/ 10.1007/s11042-023-15803-1
- Talaat FM, ZainEldin H (2023) An improved fire detection approach based on YOLO-v8 for smart cities. Neural Comput Applic. https://doi.org/10.1007/s00521-023-08809-1
- Alnaggar M, Siam AI, Handosa M, Medhat T, Rashad MZ (2023) Video-based real-time monitoring for heart rate and respiration rate. Expert Syst Appl 1(225):120135
- Alnaggar M, Handosa M, Medhat T, Z Rashad M (2023) Thyroid Disease multi-class classification based on optimized gradient boosting model. Egypt J Artif Intell. 2(1):1-4.
- Alnaggar M, Handosa M, Medhat T, Rashad MZ (2023) An IoTbased framework for detecting heart conditions using machine learning. Int J Adv Comput Sci Appl. 14(4).
- Alhussan AA, Talaat FM, El-kenawy ES, Abdelhamid AA, Ibrahim A, Khafaga DS, Alnaggar M (2023) Facial expression recognition model depending on optimized support vector machine. Comput Mater Continua. 76(1).
- Fatma M. Talaat
fatma.nada@ai.kfs.edu.eg
Mahmoud Y. Shams
mahmoud.yasin@ai.kfs.edu.eg
Samah A. Gamel
sgamel@horus.edu.eg
Faculty of Artificial Intelligence, Kafrelsheikh University, Kafrelsheikh, Egypt
2 Faculty of Engineering, Horus University, Damietta, Egypt
3 Faculty of Computer Science and Engineering, New Mansoura University, Gamasa 35712, Egypt
4 Nile Higher Institute for Engineering and Technology, Mansoura, Egypt
DOI: https://doi.org/10.1007/s00521-023-09391-2
Publication Date: 2024-01-11
Enhancing crop recommendation systems with explainable artificial intelligence: a study on agricultural decision-making
© The Author(s) 2024
Abstract
Crop Recommendation Systems are invaluable tools for farmers, assisting them in making informed decisions about crop selection to optimize yields. These systems leverage a wealth of data, including soil characteristics, historical crop performance, and prevailing weather patterns, to provide personalized recommendations. In response to the growing demand for transparency and interpretability in agricultural decision-making, this study introduces XAI-CROP an innovative algorithm that harnesses eXplainable artificial intelligence (XAI) principles. The fundamental objective of XAICROP is to empower farmers with comprehensible insights into the recommendation process, surpassing the opaque nature of conventional machine learning models. The study rigorously compares XAI-CROP with prominent machine learning models, including Gradient Boosting (GB), Decision Tree (DT), Random Forest (RF), Gaussian Naïve Bayes (GNB), and Multimodal Naïve Bayes (MNB). Performance evaluation employs three essential metrics: Mean Squared Error (MSE), Mean Absolute Error (MAE), and R-squared (R2). The empirical results unequivocally establish the superior performance of XAI-CROP. It achieves an impressively low MSE of 0.9412 , indicating highly accurate crop yield predictions. Moreover, with an MAE of 0.9874, XAI-CROP consistently maintains errors below the critical threshold of 1, reinforcing its reliability. The robust
1 Introduction
warming, and climate variability, have a negative impact on the future of agriculture. These factors, combined with other variables such as climate, weather, soil, fertilizer use, and seed variety, necessitate the use of multiple datasets to address this complex problem [3]. Traditionally, predicting crop production has relied on statistical models, which can be time-consuming and arduous. However, the introduction of big data in recent years has opened up new possibilities for more advanced analysis methods, such as machine learning [4]. Machine learning models can be categorized as either descriptive or predictive, depending on the research questions and challenges at hand. Predictive models are employed to forecast the future, while descriptive models are used to learn from the data and explain past events [5-8].
with limited transparency and interpretability, which can reduce trust in the system.
eXplainable artificial intelligence (XAI) has emerged as a subfield of AI that aims to develop machine learning models capable of providing clear explanations for their decisions. By incorporating XAI principles into CRS, the algorithm seeks to enhance the transparency and interpretability of the recommendations provided to farmers.
- Limited transparency and interpretability of current crop recommendation systems.
- Lack of clear explanations for the reasoning behind the system’s choices.
- Development of an algorithm called “XAI-CROP” that utilizes eXplainable artificial intelligence to enhance crop recommendation systems.
- Improvement of transparency and interpretability in agricultural decision-making.
- Provision of clear explanations for the system’s recommendations, helping farmers understand the reasoning behind the choices.
- The performance of XAI-CROP was assessed and compared to other crop recommendation systems.
- XAI-CROP was found to have better accuracy and transparency compared to other systems.
- Contribution to the growing body of research on the use of XAI in agriculture.
- Insight into how the technology can be leveraged to address the challenges of food security and sustainable agriculture.
2 Related work
environmental (weather and soil) data. They participated in the 2018 Syngenta Crop Challenge and their submission was successful. Their model achieved an RMSE of
yields. The study used five different machine learning models, each with optimal hyperparameter settings, to train and validate the algorithm. The DecisionTreeRegressor achieved a score of 0.9814, RandomForestRegressor scored 0.9903, and ExtraTreeRegressor scored 0.9933, indicating the high accuracy and effectiveness of the CYPA approach.
| Model | Algorithm Description | Pros | Cons | |||||
| Gradient Boosting (GB) | A machine learning technique that combines multiple weak models to create a strong model that can make accurate predictions |
|
|
|||||
| Decision Tree (DT) | A tree-like model where each node represents a feature, and each branch represents a decision based on that feature |
|
|
|||||
| Random Forest (RF) | An ensemble method that creates multiple decision trees and averages their predictions to reduce overfitting and increase accuracy |
|
|
|||||
| Gaussian Naïve Bayes (GNB) | A probabilistic model based on Bayes’ theorem that assumes features are independent of each other |
|
|
|||||
| Multimodal Naïve Bayes (MNB) | An extension of Gaussian Naïve Bayes that can handle data with multiple modes or clusters |
|
|
3 XAI-CROP: eXplainable artificial intelligence for CROP recommendation systems
i. Data Preprocessing: In this phase, the input data, which includes soil type, weather patterns, and historical crop yields, are collected and processed for further analysis.
ii. Feature Selection: The relevant features that affect crop yield are identified using statistical and machine learning techniques. These features are then used as input for the XAI-CROP model.
iii. Model Training: The XAI-CROP model is trained on a dataset of crop cultivation in India, which includes information on crop yield, soil type, weather patterns, and historical crop yields. The model is based on a decision tree algorithm that generates recommendations based on the input data such as location, season, and production per square kilometer, area, and crop.
iv. XAI Integration: The XAI-CROP model utilizes a technique called “Local Interpretable Model-agnostic Explanations” (LIME) to provide clear explanations for its recommendations. LIME is a technique for explaining the predictions of machine learning models by generating local models that approximate the predictions of the original model.
v. Validation: The XAI-CROP model is validated using a validation dataset to assess its performance in predicting crop yield. The model’s accuracy is
measured using Root Mean Square Error (RMSE), Mean Absolute Error (MAE), and R-squared (R2).
3.1 Data preprocessing
3.2 Feature selection
- Input:
- Collected data
- Output:
- Preprocessed data
- Steps:
// Step 1: Collect input data
soil_data = read_csv(‘soil_data.csv’)
weather_dataread_csv(‘weather_data.csv’)
crop_yield_dataread_csv(‘crop_yield_data.csv’)
// Step 2: Data cleaning
soil_dataremove_duplicates(soil_data)
weather_dataremove_missing_values(weather_data)
crop_yield_dataremove_duplicates(crop_yield_data)
// Step 3: Data transformation
soil_dataconvert_categorical_variables(soil_data)
weather_dataconvert_categorical_variables(weather_data)
// Step 4: Data integration
crop_datajoin_datasets(soil_data, weather_data, crop_yield_data)
// Step 5: Data normalization
crop_datanormalize_data(crop_data)
// Step 6: Data splitting
train_data, test_datasplit_data(crop_data, train_ratio=0.8)
- Input:
- Preprocessed dataset
- Output:
- Selected features for the XAI-CROP model
- Steps:
- Split the dataset into training and testing set.
- Apply statistical techniques to identify features that have a significant impact on crop yield.
- Apply machine learning techniques to identify important features.
- Rank the identified features based on their importance scores.
- Select the top
features that have the highest importance scores as input for the XAI-CROP model. - Return the selected features as output.
3.3 Model training
dataset containing information on crop yield, soil type, weather patterns, and historical crop yields. (ii) Split the dataset into training and testing sets using a predefined ratio. (iii) Instantiate a decision tree classifier and set the
parameters for the algorithm. (iv) Train the decision tree classifier using the training dataset. (v) Evaluate the performance of the model on the testing dataset using various metrics such as accuracy, precision, recall, and F1-score. (vi) If the performance of the model is not satisfactory, tune the hyperparameters of the decision tree algorithm and retrain the model. (vii) Save the trained model for future use.
the GB provide more accurate prediction results by fit and update the new model parameters. Hence, a new base leaner is constructed and improve the negative gradient results from loss function related to the whole ensemble [35, 36].
- Input:
- Selected Features
- Output:
- Trained Model
- Steps:
# Load dataset
dataset = load_dataset()
# Split dataset into training and testing sets
train_set, test_set $=$ split_dataset(dataset)
# Prepare input data for decision tree model
input_data $=$ prepare_input_data(train_set, relevant_features)
# Train decision tree model
model $=$ train_decision_tree(input_data)
# Test model accuracy
accuracy $=$ test_model(model, test_set)
# Evaluate model performance
performance_metrics $=$ evaluate_performance(model, test_set)
3.4 Hyperparameters tuning
while logarithmic loss (log loss) can be used for classification tasks. It is worth mentioning that when a new tree is added to the model, the current trees do not alter as shown in Fig. 2. The decision tree that was introduced fits the residuals from the present model [37].
too many trees increases the risk of overfitting, which can lead to poor generalization performance of the model [38].
3.5 XAI integration module
Algorithm 4 XAI Integration Algorithm
- Steps:
# Load the XAI-CROP model
xai_crop_modelload_model(‘xai_crop_model.h5’)
# Select a sample from the validation dataset for which to generate an explanation
samplevalidation_dataset.sample()
# Generate perturbations of the selected sample to create a dataset for local model training
perturbed_datasetgenerate_perturbations(sample, num_perturbations)
# Train a linear regression model on the perturbed dataset
local_modeltrain_linear_regression(perturbed_dataset)
# Calculate the weight of each feature in the local model
weightscalculate_feature_weights(local_model)
# Generate an explanation by highlighting the features that contribute the most to the
XAI-CROP model’s prediction for the selected sample
explanationgenerate_explanation(sample, weights)
the robustness and reliability of the model’s predictions, while also facilitating the interpretability and explainability of the results.
3.6 Validation module
Algorithm 5 Validation Algorithm crucial component, encompassing three main steps that are depicted in Algorithm 5. These steps are designed to ensure
- Input:
- Trained Model
- Output:
- Performance Metrics
- Steps:
function validate(XAI-CROP model, validation dataset)
# Step 3a
validation_features, validation_targetseparate_features_target(validation dataset)
# Step 3b
predicted_crop_yieldXAI-CROP model.predict(validation_features)
# Step 3d
rmsemean
maemean(abs(validation_target – predicted_crop_yield))
– sum((validation_target – predicted_crop_yield)^2) / sum((validation_target –
mean(validation_target))^2)
# Step 3e
return rmse, mae, r2
4 Implementation and evaluation
4.1 Software
4.2 Crop yield dataset
4.3 Performance metrics
ii. Mean Absolute Error (MAE): MAE measures the average absolute difference between the predicted and actual spending scores. MAE can be calculated as in Eq. (2).
iii. R-squared: R-squared is a statistical measure representing the proportion of variance in the dependent variable explained by the independent variables. R-squared can be calculated as in Eq. (3).
| District_Name | Season | Area | Production | Crop | |
| 0 | NORTH AND MIDDLE ANDAMAN | Rabi | 294.5 | 90.8 | Tur |
| 1 | SOUTH ANDAMANS | Rabi | 20.5 | 13.2 | Tur |
| 2 | ANANTAPUR | Kharif | 21400.0 | 2600.0 | Tur |
| 3 | ANANTAPUR | Kharif | 27400.0 | 9100.0 | Tur |
| 4 | ANANTAPUR | Kharif | 30693.0 | 7888.0 | Tur |
4.4 Performance evaluation
| Model | MSE | MAE | R^2 |
| XAI-CROP | 0.9412 | 0.9874 | 0.94152 |
| Gradient Boosting (GB) | 1.6861 | 1.0745 | 0.78521 |
| Decision Tree (DT) | 1.1785 | 1.0002 | 0.8942 |
| Random Forest (RF) | 1.2487 | 1.0015 | 0.8745 |
| Gaussian Naïve Bayes (GNB) | 1.4123 | 1.0098 | 0.8456 |
| Multimodal Naïve Bayes (MNB) | 1.0452 | 1.0078 | 0.77521 |
learning progress, convergence speed, and potential for overfitting or underfitting. Patterns such as convergence plateaus, fluctuations, or rapid improvements in the R2 score can be observed and analyzed, aiding in the evaluation and comparison of the models.
5 Results discussion
with low error rates and a high R -squared value indicating its accuracy and interpretability in explaining the data’s variability.
work serves as a pivotal stepping stone for future advancements.
for example, explain how a farmer’s decision-making process could incorporate the model. This could entail a comprehensive explanation of how the model’s suggestions are implemented in the real world or a step-by-step manual.
6 Several real-world implications can be done in the real world such as:
- Precision Agriculture: The proposed model can be utilized to provide personalized crop recommendations to farmers based on factors such as soil quality, weather conditions, historical data, and specific crop requirements. This can help optimize resource allocation, improve crop yield, and minimize environmental impact by reducing the use of fertilizers and pesticides.
- Sustainable Farming Practices: By incorporating explainable AI into crop recommendation systems, the proposed model can assist farmers in adopting sustainable farming practices. It can provide insights into the ecological impact of different crop choices and recommend environmentally friendly strategies, such as crop rotation or intercropping, to enhance soil health and biodiversity preservation.
- Climate Change Adaptation: With climate change affecting agricultural productivity and patterns, the proposed model can aid farmers in adapting to changing conditions. By analyzing historical climate data and incorporating predictive models, it can generate recommendations for resilient crop choices that are better suited to withstand extreme weather events or shifting climate patterns.
- Small-Scale Farming Support: Small-scale farmers often face unique challenges in terms of limited resources and access to information. The proposed model can offer tailored crop recommendations and provide valuable insights to support decision-making for small-scale farmers, helping them maximize their productivity and profitability.
- Decision Support for Agricultural Advisors: Agricultural advisors and consultants can utilize the proposed model to provide expert recommendations to farmers. By incorporating explainable AI, the model can transparently present the underlying reasoning and justifications for specific crop recommendations, enabling advisors to effectively communicate and gain trust from farmers.
7 Conclusion
complexities of modern farming and make informed choices for sustainable and efficient crop cultivation. It is our hope that this research contributes to the advancement of agricultural practices worldwide, promoting food security and environmental sustainability.
Declarations
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons. org/licenses/by/4.0/.
References
- Bhadouria R, et al. (2019) Agriculture in the era of climate change: Consequences and effects. In Climate Change and Agricultural Ecosystems, Elsevier, 1-23.
- Xu X et al (2019) Design of an integrated climatic assessment indicator (ICAI) for wheat production: a case study in Jiangsu Province, China. Ecol Ind 101:943-953
- Bali N, Singla A (2021) Deep learning based wheat crop yield prediction model in punjab region of north india. Appl Artif Intell 35(15):1304-1328
- Van Klompenburg T, Kassahun A, Catal C (2020) Crop yield prediction using machine learning: A systematic literature review. Comput Electron Agric 177:105709
- Alpaydin E (2020) Introduction to machine learning. MIT press.
- Tarek Z et al (2023) Soil erosion status prediction using a novel random forest model optimized by random search method. Sustainability 15(9):9. https://doi.org/10.3390/su15097114
- Shams MY, Tarek Z, Elshewey AM, Hany M, Darwish A, Hassanien AE (2023) A machine learning-based model for predicting temperature under the effects of climate change. In: The Power of Data: Driving Climate Change with Data Science and Artificial Intelligence Innovations, A. E. Hassanien and A. Darwish, Eds., in Studies in Big Data. Cham: Springer Nature Switzerland, 2023: 61-81. https://doi.org/10.1007/978-3-031-22456-0_4.
- Elshewey AM et al (2023) A novel WD-SARIMAX model for temperature forecasting using daily Delhi climate dataset. Sustainability 15(1):1. https://doi.org/10.3390/su15010757
- Porter JR, Xie L, Challinor AJ, Cochrane K, Howden SM, Iqbal MM, Lobell DB, Travasso MI (2014) Food security and food production systems. Part A: Global and Sectoral Aspects. Contribution of Working Group II to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change, 1(1): 485-533 (2014).
- Rosenzweig C et al (2013) The agricultural model intercomparison and improvement project (AgMIP): protocols and pilot studies. Agric For Meteorol 170:166-182
- Khater HA, Gamel SA (2023) Early diagnosis of respiratory system diseases (RSD) using deep convolutional neural networks. J Ambient Intell Human Comput 14:12273-12283
- Lobell DB, Asseng S (2017) Comparing estimates of climate change impacts from process-based and statistical crop models. Environ Res Lett 12(1):015001
- Schlenker W, Roberts MJ (2009) Nonlinear temperature effects indicate severe damages to US crop yields under climate change. Proc Natl Acad Sci 106(37):15594-15598
- Roberts MJ, Braun NO, Sinclair TR, Lobell DB, Schlenker W (2017) Comparing and combining process-based crop models and statistical models with some implications for climate change. Environ Res Lett 12(9):095010
- Roberts MJ, Schlenker W, Eyer J (2013) Agronomic weather measures in econometric models of crop yield with implications for climate change. Am J Agr Econ 95(2):236-243
- Patel K, Patel HB (2023) Multi-criteria agriculture recommendation system using machine learning for crop and fertilizesrs prediction. Curr Agricult Res J 11(1), 2023.
- Mittal N, Bhanja A (2023) Implementation and identification of crop based on soil texture using AI. In: 2023 4th International Conference on Electronics and Sustainable Communication Systems (ICESC), IEEE. 1467-1471.
- Fenz S, Neubauer T, Heurix J, Friedel JK, Wohlmuth M-L (2023) AI- and data-driven pre-crop values and crop rotation matrices. Eur J Agron 150:126949. https://doi.org/10.1016/j.eja.2023. 126949
- Arif MS, Mukheimer A, Asif D (2023) Enhancing the early detection of chronic kidney disease: a robust machine learning model. Big Data Cognit Comput 7(3):3. https://doi.org/10.3390/ bdcc7030144
- Asif D, Bibi M, Arif MS, Mukheimer A (2023) Enhancing heart disease prediction through ensemble learning techniques with hyperparameter optimization. Algorithms 16(6):6. https://doi.org/ 10.3390/a16060308
- Nawaz Y, Arif MS, Shatanawi W, Nazeer A (2021) An explicit fourth-order compact numerical scheme for heat transfer of
boundary layer flow. Energies 14(12):12. https://doi.org/10.3390/ en14123396 - Nawaz Y, Arif MS, Abodayeh K (2022) A third-order two-stage numerical scheme for fractional stokes problems: a comparative computational study. J Comput Nonlinear Dyn 17:101004. https://doi.org/10.1115/1.4054800
- Nawaz Y, Arif MS, Abodayeh K (2022) An explicit-implicit numerical scheme for time fractional boundary layer flows. Int J Numer Meth Fluids 94(7):920-940. https://doi.org/10.1002/fld. 5078
- McEldowney JF (2021) Climate change and the law. In: the impacts of climate change, Elsevier. 503-519.
- de Oliveira AC, Marini N, Farias DR (2014) Climate change: New breeding pressures and goals. Encyclopedia Agricult Food Syst 2014:284-293
- Williams TO, et al. (2015) Climate smart agriculture in the African context. Unlocking Africa’s Agricultural Potentials for Transformation to Scale, FAO and UNEP, Abdou Diouf International Conference, Dakar, Senegal, pp. 1-26, 2015.
- Reddy PS, Amarnath B, Sankari M (2023) Study on machine learning and back propagation for crop recommendation system. In: 2023 International Conference on Sustainable Computing and Data Communication Systems (ICSCDS), IEEE. 1533-1537.
- You J, Li X, Low M, Lobell D, Ermon S (2017) Deep gaussian process for crop yield prediction based on remote sensing data. In: Thirty-First AAAI conference on artificial intelligence.
- Paudel D et al (2021) Machine learning for large-scale crop yield forecasting. Agric Syst 187:103016
- Sun J, Lai Z, Di L, Sun Z, Tao J, Shen Y (2020) Multilevel deep learning network for county-level corn yield estimation in the us corn belt. IEEE J Selected Top Appl Earth Obs
- Yoon HS et al (2021) Akkermansia muciniphila secretes a glu-cagon-like peptide-1-inducing protein that improves glucose homeostasis and ameliorates metabolic disease in mice. Nat Microbiol 6(5):5. https://doi.org/10.1038/s41564-021-00880-5
- Khaki S, Wang L (2022) Crop Yield Prediction Using Deep Neural Networks. Front Plant Sci 10, 2019, Accessed: Sep. 27, 2022. Available: https://doi.org/10.3389/fpls.2019.00621
- Abbas F, Afzaal H, Farooque AA, Tang S (2020) Crop yield prediction through proximal sensing and machine learning algorithms. Agronomy 10(7):7. https://doi.org/10.3390/ agronomy10071046
- Talaat FM (2023) Crop yield prediction algorithm (CYPA) in precision agriculture based on IoT techniques and climate changes. Neural Comput Applic. https://doi.org/10.1007/s00521-023-08619-5
- Friedman JH (2001) Greedy function approximation: a gradient boosting machine. Ann Stat 29(5):1189-1232
- Natekin A, Knoll A (2022) Gradient boosting machines, a tutorial. Front Neurorobotics 7, 2013, Accessed: Sep. 27, 2022. Available: https://doi.org/10.3389/fnbot.2013.00021
- Ke G, et al. (2017) LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In: Advances in Neural Information Processing Systems, 2017, 30. Accessed: Sep. 27, 2022. Available: https://proceedings.neurips.cc/paper/2017/hash/ 6449f44a102fde848669bdd9eb6b76fa-Abstract.html
- Rao H et al (2019) Feature selection based on artificial bee colony and gradient boosting decision tree. Appl Soft Comput 74:634-642. https://doi.org/10.1016/j.asoc.2018.10.036
- Freund Y, Mason L (1999) The alternating decision tree learning algorithm. In: Icml, 1999, 99, pp. 124-133.
- Feng J, Yu Y, Zhou Z-H (2018) Multi-Layered Gradient Boosting Decision Trees. In: Advances in Neural Information Processing Systems, 2018, 31. Accessed: Sep. 27, 2022. Available: https:// proceedings.neurips.cc/paper/2018/hash/39027dfad5138c9 ca0c474d71db915c3-Abstract.html
- Pretorius A, Bierman S, Steel SJ (2016) A meta-analysis of research in random forests for classification. In: 2016 Pattern Recognition Association of South Africa and Robotics and Mechatronics International Conference (PRASA-RobMech), 2016, pp. 1-6.
- Sun C, Li X, Guo R (2021) Research on electrical fire risk assessment technology of cultural building based on random forest algorithm. In: 2021 International Conference on Aviation Safety and Information Technology, New York, NY, USA, Dec. 2021, pp. 769-773. https://doi.org/10.1145/3510858.3511382.
- Geenen PL, van der Gaag LC, Loeffen WLA, Elbers ARW (2011) Constructing naive Bayesian classifiers for veterinary medicine: A case study in the clinical diagnosis of classical swine fever. Res Vet Sci 91(1):64-70. https://doi.org/10.1016/j.rvsc. 2010.08.006
- Xu S (2018) Bayesian Naïve Bayes classifiers to text classification. J Inf Sci 44(1):48-59. https://doi.org/10.1177/016555151 6677946
- Kibriya AM, Frank E, Pfahringer B, Holmes G (2005) Multinomial naive bayes for text categorization revisited. In: AI 2004: Advances in Artificial Intelligence, Berlin, Heidelberg, 2005, pp. 488-499. https://doi.org/10.1007/978-3-540-30549-1_43.
- Jiang L, Wang S, Li C, Zhang L (2016) Structure extended multinomial naive Bayes. Inf Sci 329:346-356. https://doi.org/10. 1016/j.ins.2015.09.037
- https://www.kaggle.com/datasets/ananysharma/crop-yield.
- Elshewey A, Shams M, Tarek Z, Megahed M, El-kenawy E-S, El-dosuky M (2023) Weight prediction using the hybrid stackedLSTM food selection model. CSSE, 46(1): 765-781, 2023, https://doi.org/10.32604/csse.2023.034324.
- Shams MY, Elshewey AM, El-kenawy E-SM, Ibrahim A, Talaat FM, Tarek Z (2023) Water quality prediction using machine learning models based on grid search method. Multimed Tools Appl. https://doi.org/10.1007/s11042-023-16737-4
- Ryo M (2022) Explainable artificial intelligence and interpretable machine learning for agricultural data analysis. Artif Intell Agricult 6:257-265. https://doi.org/10.1016/j.aiia.2022.11. 003
- Doshi Z, Nadkarni S, Agrawal R, Shah N (2018) AgroConsultant: Intelligent crop recommendation system using machine learning algorithms. In: 2018 Fourth International Conference on Computing Communication Control and Automation (ICCUBEA), Aug. 2018, pp. 1-6. https://doi.org/10.1109/ICCUBEA.2018. 8697349.
- Taleizadeh AA, Amjadian A, Hashemi-Petroodi SE, Moon I (2023) Supply chain coordination based on mean-variance risk optimisation: pricing, warranty, and full-refund decisions. Int J Syst Sci: Oper Logist 10(1):2249808. https://doi.org/10.1080/ 23302674.2023 .2249808
- Gharaei A, Amjadian A, Shavandi A, Amjadian A (2023) An augmented Lagrangian approach with general constraints to solve nonlinear models of the large-scale reliable inventory systems. J Comb Optim 45(2):78. https://doi.org/10.1007/s10878-023-01002-z
- Taleizadeh AA, Varzi AM, Amjadian A, Noori-daryan M, Konstantaras I (2023) How cash-back strategy affect sale rate under refund and customers’ credit. Oper Res Int J 23(1):19. https://doi. org/10.1007/s12351-023-00752-2
- Talaat FM (2022) Effective deep Q-networks (EDQN) strategy for resource allocation based on optimized reinforcement learning algorithm. Multimed Tools Appl 81(17). https://doi.org/10. 1007/s11042-022-13000-0
- Talaat FM (2022) Effective prediction and resource allocation method (EPRAM) in fog computing environment for smart healthcare system. Multimed Tools Appl
- Talaat Fatma M, Alshathri Samah, Nasr Aida A (2022) A new reliable system for managing virtualcloud network. Comput Mater Continua 73(3):5863-5885. https://doi.org/10.32604/cmc. 2022.026547
- El-Rashidy N, ElSayed NE, El-Ghamry A, Talaat FM (2022) Prediction of gestational diabetes based on explainable deep learning and fog computing. Soft Comput 26(21):11435-11450
- El-Rashidy N, Ebrahim N, el Ghamry A, Talaat FM (2022) Utilizing fog computing and explainable deep learning techniques for gestational diabetes prediction. Neural Comput Applic. https://doi.org/10.1007/s00521-022-08007-59. FaivdullahL,AzaharF,HtikeZZ,Naing
- Hanaa S, Fatma BT (2022) Detection and classification using deep learning and sine-cosine fitnessgrey wolf optimization. Bioengineering 10(1):18. https://doi.org/10.3390/bioengineering 10010018
- Talaat FM (2023) Real-time facial emotion recognition system among children with autism based on deep learning and IoT. Neural Comput Appl 35(3), https://doi.org/10.1007/s00521-023-08372-9
- Talaat FM (2023) Crop yield prediction algorithm (CYPA) in precision agriculture based on IoT techniques and climate changes, April 2023, Neural Comput Appl 35(2), https://doi.org/10. 1007/s00521-023-08619-5
- Hassan E, El-Rashidy N, Talaat FM (2022) Review: Mask R-CNN Models. May 2022, https://doi.org/10.21608/njccs.2022. 280047.
- Siam AI, Gamel SA, Talaat FM (2023) Automatic stress detection in car drivers based on non-invasive physiological signals using machine learning techniques. Neural Comput Applic. https://doi.org/10.1007/s00521-023-08428-w
- Talaat FM, Gamel SA (2023) A2M-LEUK: attention-augmented algorithm for blood cancer detection in children, June 2023, Neural Comput Appl. https://doi.org/10.1007/s00521-023-086788
- Gamel SA, Hassan E, El-Rashidy N et al (2023) Exploring the effects of pandemics on transportation through correlations and deep learning techniques. Multimed Tools Appl. https://doi.org/ 10.1007/s11042-023-15803-1
- Talaat FM, ZainEldin H (2023) An improved fire detection approach based on YOLO-v8 for smart cities. Neural Comput Applic. https://doi.org/10.1007/s00521-023-08809-1
- Alnaggar M, Siam AI, Handosa M, Medhat T, Rashad MZ (2023) Video-based real-time monitoring for heart rate and respiration rate. Expert Syst Appl 1(225):120135
- Alnaggar M, Handosa M, Medhat T, Z Rashad M (2023) Thyroid Disease multi-class classification based on optimized gradient boosting model. Egypt J Artif Intell. 2(1):1-4.
- Alnaggar M, Handosa M, Medhat T, Rashad MZ (2023) An IoTbased framework for detecting heart conditions using machine learning. Int J Adv Comput Sci Appl. 14(4).
- Alhussan AA, Talaat FM, El-kenawy ES, Abdelhamid AA, Ibrahim A, Khafaga DS, Alnaggar M (2023) Facial expression recognition model depending on optimized support vector machine. Comput Mater Continua. 76(1).
- Fatma M. Talaat
fatma.nada@ai.kfs.edu.eg
Mahmoud Y. Shams
mahmoud.yasin@ai.kfs.edu.eg
Samah A. Gamel
sgamel@horus.edu.eg
Faculty of Artificial Intelligence, Kafrelsheikh University, Kafrelsheikh, Egypt
2 Faculty of Engineering, Horus University, Damietta, Egypt
3 Faculty of Computer Science and Engineering, New Mansoura University, Gamasa 35712, Egypt
4 Nile Higher Institute for Engineering and Technology, Mansoura, Egypt