المجلة: Scientific Reports، المجلد: 14، العدد: 1
DOI: https://doi.org/10.1038/s41598-024-51184-7
PMID: https://pubmed.ncbi.nlm.nih.gov/38177293
تاريخ النشر: 2024-01-04
DOI: https://doi.org/10.1038/s41598-024-51184-7
PMID: https://pubmed.ncbi.nlm.nih.gov/38177293
تاريخ النشر: 2024-01-04
تعزيز التنبؤ بأمراض القلب باستخدام نموذج المحول المعتمد على الانتباه الذاتي
تستمر أمراض القلب والأوعية الدموية (CVDs) في كونها السبب الرئيسي لأكثر من 17 مليون حالة وفاة حول العالم. الكشف المبكر عن فشل القلب بدقة عالية أمر بالغ الأهمية للتجارب السريرية والعلاج. سيتم تصنيف المرضى إلى أنواع مختلفة من أمراض القلب بناءً على خصائص مثل ضغط الدم، مستويات الكوليسترول، معدل ضربات القلب، وخصائص أخرى. باستخدام نظام آلي، يمكننا تقديم تشخيصات مبكرة لأولئك المعرضين لفشل القلب من خلال تحليل خصائصهم. في هذا العمل، نستخدم نموذج محول جديد قائم على آلية الانتباه الذاتي، يجمع بين آليات الانتباه الذاتي وشبكات المحولات لتوقع خطر الإصابة بأمراض القلب والأوعية الدموية. تلتقط طبقات الانتباه الذاتي المعلومات السياقية وتولد تمثيلات تُنمذج بفعالية الأنماط المعقدة في البيانات. توفر آليات الانتباه الذاتي قابلية التفسير من خلال منح كل مكون من مكونات تسلسل الإدخال وزن انتباه معين. يشمل ذلك تعديل طبقات الإدخال والإخراج، وإضافة المزيد من الطبقات، وتعديل عمليات الانتباه لجمع المعلومات ذات الصلة. كما يجعل هذا من الممكن للأطباء فهم أي ميزات من البيانات ساهمت في توقعات النموذج. تم اختبار النموذج المقترح على مجموعة بيانات كليفلاند، وهي مجموعة بيانات معيارية من مستودع التعلم الآلي بجامعة كاليفورنيا إيرفين (UCI). بالمقارنة مع عدة طرق أساسية، حققنا أعلى دقة بلغت…
يشير مرض القلب إلى أي حالة تعيق قدرة القلب على العمل بشكل طبيعي. في السنوات الأخيرة، أصبح مرض القلب والأوعية الدموية السبب الرئيسي للوفاة في العالم. من المتوقع أن يرتفع انتشار فشل القلب الاحتقاني (CHF) بنسبة
التشخيص، بالإضافة إلى تعزيز التدخلات السريعة والعلاجات لتحقيق نتائج أفضل للمرضى، من خلال الاستفادة من التطورات الحديثة في خوارزميات التعلم العميق ومنهجيات البيانات الضخمة. على الرغم من إمكاناتها، يمكن أن تكون نماذج التعلم العميق مكلفة حسابيًا وتستغرق وقتًا أطول للتدريب
سيستفيد المرضى الذين يعانون من فشل القلب والمجتمع ككل من خدمات تشخيصية دقيقة ومنظمة
يتم تنظيم بقية الورقة على النحو التالي: يقدم قسم “الأعمال ذات الصلة” نظرة عامة على الأعمال ذات الصلة. في قسم “القيود والدوافع”، نتعمق في الخلفية والدوافع. يتم عرض وصف المشكلة التفصيلي في قسم “الإطار المقترح”. تُناقش التجارب التي أُجريت في هذا العمل في قسم “التجارب”. يتم شرح النتائج والمناقشة في قسم “النتائج والمناقشة”. وأخيرًا، يختتم قسم “الاستنتاجات” هذا العمل ويقدم الاتجاهات المستقبلية.
الأعمال ذات الصلة
أمراض القلب هي واحدة من الأسباب الرئيسية للوفاة في جميع أنحاء العالم. باستخدام تقنيات الذكاء الاصطناعي، من الممكن مراقبة بعض الخصائص مثل ضغط الدم، وزن الجسم، الكوليسترول، مستوى السكر، ومعدل ضربات القلب لتحديد أمراض القلب في مراحلها الأولية. تقنيات التعلم الآلي والتعلم العميق تحدث ثورة في نظام الرعاية الصحية الحالي، ومع ذلك، من الصعب التنبؤ بأمراض القلب بدقة وموثوقية.
للتشخيص الدقيق لأمراض صمامات القلب (VHDs)، تم توفير نموذج تعلم عميق قوي وعالي الأداء
بمساعدة بيانات السجلات الصحية الإلكترونية المتسلسلة، أُجريت الدراسة في
توقع بقاء المرضى على قيد الحياة. تهدف الدراسة إلى تعظيم دقة التنبؤ بنتائج البقاء على قيد الحياة للمرضى الذين يعانون من فشل القلب من خلال استخدام طرق التجميع وتطبيق تقنية SMOTE لإعادة توازن البيانات. أُجريت الدراسة في
توقع بقاء المرضى على قيد الحياة. تهدف الدراسة إلى تعظيم دقة التنبؤ بنتائج البقاء على قيد الحياة للمرضى الذين يعانون من فشل القلب من خلال استخدام طرق التجميع وتطبيق تقنية SMOTE لإعادة توازن البيانات. أُجريت الدراسة في
تُظهر الأبحاث الحديثة الطرق المختلفة المستخدمة لزيادة دقة التنبؤ بأمراض القلب. لقد أحرز الباحثون تقدمًا هائلًا في تحسين دقة وفعالية نماذج التنبؤ من خلال استخدام التعلم التجميعي.
القيود والدوافع
تشمل إحصائيات أمراض القلب غالبًا الخصائص الزمنية، مثل تاريخ المريض بالإضافة إلى التغيرات مع مرور الوقت. يُعد المعالجة الفعالة للبيانات التسلسلية باستخدام أساليب التعلم الآلي تحديًا. لم تقدم الدراسات السابقة دعمًا كافيًا لتحسين نتائج المرضى. في هذا القسم، نوضح محدوديات طرق التنبؤ بأمراض القلب السابقة، ونوضح دوافع عملنا لتطوير نموذج محسن، ونبرز المساهمات الرئيسية والابتكارات في دراستنا.
قيود الأعمال السابقة
المصادر الأساسية لإدخال البيانات لتشخيص أمراض القلب هي خصائص صحة المريض التي تحتوي على بيانات بفئات ونصوص غير منظمة. العيوب الرئيسية في طرق التنبؤ بأمراض القلب الحالية هي نمذجة سمات مجموعة بيانات الإدخال، حساب عوامل خطر السمات، والحصول على دقة تنبؤ عالية.
الشبكات العصبية التقليدية المتكررة (RNNs) عرضة لمشاكل تلاشي وتوسع التدرج. تتميز شبكات الذاكرة طويلة الأمد القياسية (LSTM) بعيب عدم القدرة على التعامل مع فترات زمنية غير منتظمة. ومع ذلك، فإن عدم انتظام التوقيت أمر شائع في العديد من تطبيقات الرعاية الصحية.
الدافع
أنظمة التنبؤ بالأمراض هي أفضل الممارسات للقضاء على الأخطاء البشرية في تشخيص الأمراض والمساعدة في الوقاية من الأمراض من خلال التعرف المبكر.
علاوة على ذلك، يتميز النموذج المقترح بهيكل شبكة بسيط وقابل للتوازي، مما يؤدي إلى أوقات تدريب أسرع بشكل ملحوظ مقارنة بتقنيات التنبؤ بأمراض القلب الحالية. هذا التحسين يجعلها أكثر كفاءة من خلال معالجة الصعوبات المرتبطة بتدريب النموذج وتنفيذه في بيئات الرعاية الصحية الفعلية.
المساهمات الرئيسية والحداثة
تقدم هذه الدراسة نموذج تنبؤي جديد يستخدم عملية الانتباه الذاتي. تم إنشاء النموذج مع مراعاة القابلية للتفسير والتوازي، مما يتيح حسابًا فعالًا مع الحفاظ على مستوى محترم من دقة التنبؤ. عنصر رئيسي في نموذجنا هو الانتباه الذاتي، الذي يتأثر بشكل ملحوظ بالعمل المنجز في
- طور نموذجًا مبتكرًا ومرنًا قائمًا على الانتباه مصمم خصيصًا لتوقع أمراض القلب. بالإضافة إلى دقته الاستثنائية في التنبؤ، يعرض هذا النموذج أيضًا قابليته للتكيف مع مجموعة متنوعة من مهام التنبؤ والتقييم المتعلقة بالمخاطر الأخرى. وبفضل قابليته للتكيف، يمكن استخدامه بشكل جيد عبر مجموعة متنوعة من المجالات، مما يجعله أداة مهمة للعديد من قضايا التنبؤ بالنتائج المختلفة. تجعل مرونته مناسبة لمختلف السيناريوهات الصحية وتوسع إمكانياته لمواجهة مجموعة واسعة من المهام التنبؤية تتجاوز توقع أمراض القلب.
- تحقيق العوامل الرئيسية التي تؤدي إلى خطر الإصابة بأمراض القلب وتحديد أي عوامل خطر غير معروفة سابقًا قد تكون ذات صلة.
- صمم استراتيجية تعتمد على نموذج المحول (Transformer) تكون أكثر دقة ونجاحًا من نماذج التعلم الآلي التقليدية الحالية في التنبؤ باحتمالية الإصابة بأمراض القلب.
- يتم فحص كفاءة نموذج المحول في الكشف عن احتمالية الإصابة بأمراض القلب عبر فئات ديموغرافية متعددة، مثل العمر والجنس والعرق/الإثنية، كما يتم دراسة إمكانية التقييم الشخصي للمخاطر.
- تم فحص قدرة نموذج المحول على تحديد الأمراض القلبية المحتملة فيما يتعلق بتأثيرات تقنيات معالجة البيانات المسبقة المختلفة. تم تطبيق عدة طرق للمعالجة المسبقة على بيانات الإدخال، وتم دراسة تأثيراتها على أداء النموذج ودقته بعناية.
الإطار المقترح
الهدف من هذا البحث هو تطوير نموذج محول قائم على الانتباه الذاتي لتقييم مخاطر أمراض القلب والأوعية الدموية باستخدام مجموعة بيانات كليفلاند. تحتوي هذه المجموعة على مجموعة متنوعة من المكونات الطبية وغير الطبية التي يمكن استخدامها لتحديد ما إذا كان المريض يعاني من مرض قلبي. تتضمن مجموعة البيانات متغيرات مستمرة وتصنيفية، إلى جانب ميزات أخرى. يصبح من الصعب تحديد العوامل الأكثر أهمية وفهم صلتها في تشخيص أمراض القلب. علاوة على ذلك، قد يكون من الصعب استخلاص نتائج ذات مغزى نظرًا لأن بعض الميزات يصعب تقييمها سريريًا.
مجموعة البيانات والمعالجة المسبقة
في هذا العمل، نتنبأ بأمراض القلب باستخدام مجموعة بيانات كليفلاند من جامعة كاليفورنيا إيرفين.
هيكل نموذج قائم على الانتباه
تمثل خصائص المريض والتدابير التشخيصية بواسطة سلسلة من ميزات الإدخال التي تُستخدم لترميز كل حالة في مجموعة البيانات. في هذا العمل، لقد قمنا بـ…
تضمين الإدخال وترميز الموضع
في نموذج المحول القائم على الانتباه الذاتي، يُعد تضمين الإدخال وترميز الموضع عمليتين حاسمتين تسبقان آلية الانتباه الذاتي. يتم تمثيل تسلسل الإدخال باستخدام هذه المراحل بطريقة مناسبة لطبقات الانتباه الذاتي المتعاقبة. تُترجم المتغيرات الفئوية والخصائص العددية لكل عينة إلى تمثيلات متجهية مستمرة من خلال تضمين الإدخال. في هذه الدراسة، نستخدم طبقة تضمين لتحويل القيم المنفصلة لكل متغير فئوي إلى متجهات مستمرة. يتم دمج الخصائص العددية المقاسة لكل عينة وتضمينات الفئة في متجه واحد. لدينا
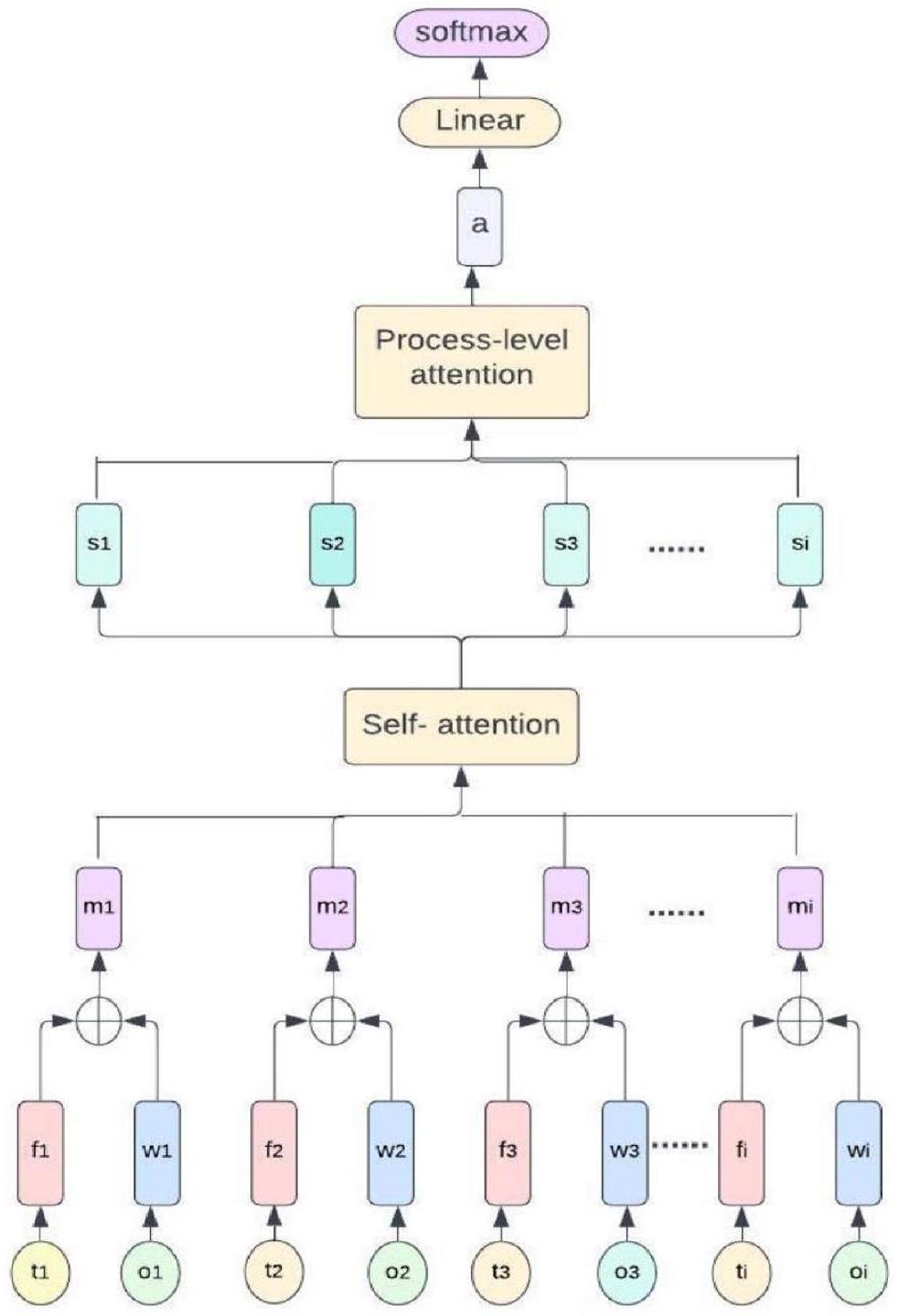
الشكل 1. نظرة عامة على النموذج المقترح.
التسلسل. يقوم نموذج المحول المعتمد على الانتباه الذاتي بمعالجة تسلسل الإدخال بكفاءة، حيث يجمع بين تمثيلات الميزات والمعلومات الموضعية من خلال تنفيذ مراحل تضمين الإدخال وترميز الموضع.
مشفر المحول
يتم تمثيل مجموعة بيانات أمراض القلب كسلسلة من الخصائص المدمجة وترميزات المواضع. لتحديد العلاقات واستخلاص تمثيلات ذات معنى من تسلسل الإدخال، يتم تطبيق مجموعة من طبقات مشفر المحول. تتضمن طبقة المشفر آلية الانتباه الذاتي وشبكة عصبية تغذية أمامية. يتم حساب ناتج طبقة مشفر المحول كما يلي،
الانتباه الذاتي
قدرة نموذج المحول على إيجاد روابط بين الميزات التي تتجاوز التتابع المتجاور هي ميزة أخرى مثيرة للاهتمام في هذا النظام. تُستخدم تقنية الانتباه الذاتي لاستخراج العلاقات بين النقاط المختلفة في التسلسل داخل كل طبقة من طبقات مشفر المحول. يتم استخدام التشابه بين متجهات الاستعلام والمفتاح لتحديد أوزان الانتباه (AW) لكل نقطة. توضح هذه الأوزان الأهمية النسبية لكل موقع. يمكن حساب أوزان الانتباه كما يلي:
أين
معلمات التعلم
شبكة التغذية الأمامية
لتعزيز التمثيلات بشكل أكبر، اتبع استراتيجية الانتباه الذاتي من خلال تطبيق شبكة عصبية تغذية أمامية على كل نقطة بشكل منفصل. تفصل دالة تنشيط غير خطية بين الطبقتين الخطيتين اللتين تشكلان شبكة التغذية الأمامية. اربط خصائص الإدخال بمخرجات آلية الانتباه الذاتي ومخرجات شبكة التغذية الأمامية لإنشاء وصلات متبقية. يتم تطبيع الخصائص بعد كل طبقة فرعية باستخدام طريقة تطبيع الطبقة.
طبقة الإخراج
لاكتشاف وجود مرض القلب، استخدم الناتج النهائي من طبقات فك التشفير في المحول ومرره عبر طبقة متصلة بالكامل. لتحديد احتمالات الناتج النهائي، استخدم دالة السوفتمكس.
تدريب النموذج
يُستخدم محسن آدم كتقنية تحسين لتدريب النموذج لتحديد احتمالية الإصابة بأمراض القلب. لاكتشاف ما إذا كان الشخص مصابًا بأمراض القلب أم لا، يتم استخدام دالة خسارة الانتروبيا الثنائية المتقاطعة لتمييز بين الاحتمالات المتوقعة وتسميات البيانات الفعلية. تسعى طريقة التدريب إلى تحديد القيم المثالية لمتجه الأوزان W ومصطلح الانحياز b التي تقلل من دالة الخسارة. يتم تعزيز دقة التنبؤ للنموذج بواسطة محسن آدم، الذي يقوم بتعديل الأوزان والانحيازات بشكل تكراري أثناء التدريب.
توقع المرض
باستخدام مجموعة بيانات الاختبار، قم بتقييم النموذج المدرب باستخدام مقاييس التقييم ذات الصلة بما في ذلك الدقة، الدقة النوعية، الاستدعاء، ومقياس F1. باستخدام النموذج المدرب، توقع احتمال تشخيص مريض جديد بمرض القلب بناءً على قيم ميزات المريض. قم بتحليل أهمية الميزات أو المعاملات التي تعلمها النموذج لتحديد الأهمية النسبية للعوامل المختلفة في تحديد مرض القلب. الشكل 2 يمثل النموذج المقترح لتوقع مرض القلب.
تجارب
أمراض القلب هي سبب بارز للوفاة على مستوى العالم، ويمكن للتنبؤ الفعال بأمراض القلب أن يحسن بشكل كبير نتائج المرضى.
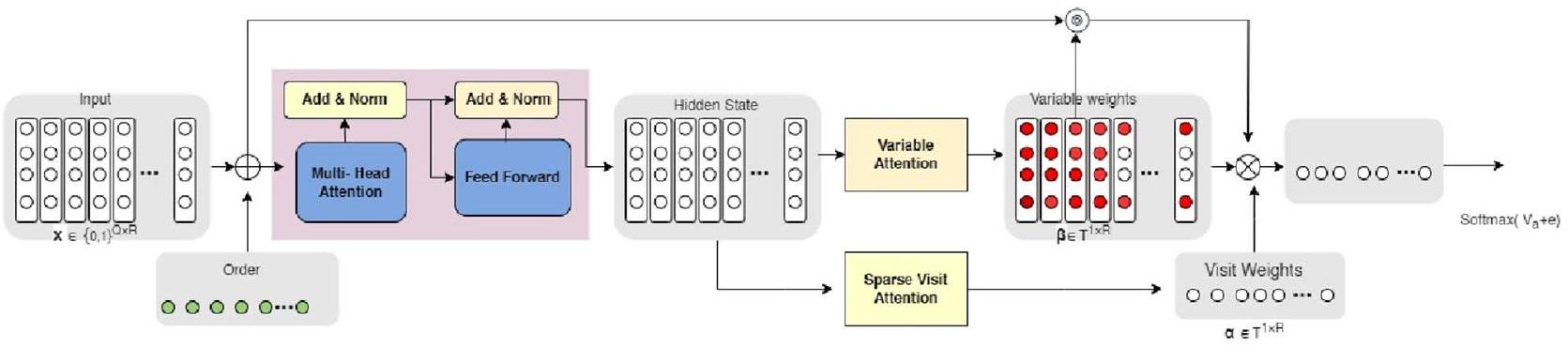
الشكل 2. هيكل النموذج المقترح المستخدم لتوقع أمراض القلب.
الترميز الموضعي. استخدم تقنية الانتباه الذاتي لتمكين النموذج من التركيز على مكونات مختلفة من تسلسل الإدخال أثناء إنتاج تمثيلات واعية للسياق لكل سمة. أنشئ بنية النموذج بتحديد الطبقات الأساسية، مثل طبقات الانتباه الذاتي، والطبقات التغذوية الأمامية، وطبقات التصنيف. استخدم إطار عمل PyTorch 2.0 لتنفيذ نموذج المحول المعتمد على الانتباه الذاتي. من خلال استخدام النهج المقترح، نهدف إلى زيادة دقة التنبؤ بأمراض القلب والمساهمة في إنشاء أنظمة دعم اتخاذ القرار السريري الأكثر فعالية.
يعرض الجدول 1 المعلمات المستخدمة لتدريب وتقييم نموذج المحول القائم على الانتباه الذاتي لتوقع أمراض القلب باستخدام مجموعة بيانات كليفلاند. يتكون النموذج من طبقة تضمين، وطبقات مشفر المحول، وطبقة متصلة بالكامل للتصنيف. يتم التكرار عبر مجموعة بيانات التدريب في دفعات صغيرة، حساب الخسارة، التراجع العكسي، واستخدام المحسن لتحديث أوزان النموذج. بعد تدريب النموذج، يتم تقييم أدائه على مجموعة الاختبار. تحليل توقعات النموذج وتفسير الأنماط المكتسبة. تحديد الخصائص الرئيسية لآلية الانتباه الذاتي وأوزان الانتباه. في هذا العمل، نقوم بتنفيذ مهام التصنيف الثنائي ومتعدد الفئات في التجارب. بالنسبة لمشكلة التصنيف الثنائي، نتوقع وجود أو غياب مرض القلب. بالنسبة لمشكلة التصنيف ذات الأربع فئات، نقسم التسميات إلى أربع فئات فريدة لتعكس مستويات مختلفة من خطر مرض القلب. يعرض الجدول 2 عدد الفئات المستخدمة في التجارب. من أجل التحقق من أداء نموذج المحول القائم على الانتباه الذاتي، قمنا بمقارنته مع عدة طرق أساسية مختلفة.
النهج الأساسية
أجرينا دراسة مقارنة باستخدام عدد من الطرق الأساسية المستخدمة بشكل متكرر في التنبؤ بأمراض القلب. بحثنا في الشبكات العصبية التلافيفية (CNN)، الشبكات العصبية المتكررة (RNN)، الشبكات العصبية المتكررة مع ميزات إضافية (RNN +)، نموذج الانتباه العكسي الزمني (RETAIN)، وDipole كطرق أساسية. استخدمنا تصميمًا تجريبيًا متطابقًا لكل استراتيجية أساسية، بما في ذلك إعداد البيانات، تدريب النموذج، التحقق، ضبط المعاملات الفائقة، وتقييم مجموعة الاختبار.
سي إن إن
يتكون نموذج الشبكة العصبية الالتفافية المقدم من قبل البلوي وآخرون من ثلاث طبقات التفافية.
| معامل | الوصف |
| نموذج | نموذج المحول القائم على الانتباه الذاتي |
| أبعاد الإدخال = 14 | بُعد ميزات الإدخال |
| أبعاد المخرجات = 2، 4 | عدد فئات المخرجات |
| d-model = 128 | بُعد حالات النموذج الخفية |
| nhead = 4 | رؤوس الانتباه في الانتباه الذاتي متعدد الرؤوس |
| عدد الطبقات = 4 | الطبقات في المشفر |
| معدل التسرب = 0.2 | احتمالية التسرب الدراسي |
| حجم الدفعة = 32، 64 | عدد العينات |
| العصور
|
عدد التكرارات |
| معدل التعلم = 0.001 | معدل التعلم |
| المحسّن = آدم | المحسّن المستخدم لتحديث المعلمات |
| خسارة التدريب | متوسط خسارة التنبؤ خلال مجموعة بيانات التدريب |
| الانتروبيا المتقاطعة | دالة الخسارة |
| خسارة الاختبار | متوسط الخسارة على مجموعة بيانات الاختبار |
الجدول 1. معلمات النموذج المقترح المستخدمة في التجارب.
| قيمة الصف | الوصف |
| ثنائي | مشكلة تصنيف ثنائية الفئة |
| الفئة 0 | لا أمراض قلبية |
| الصف الأول | وجود مرض القلب |
| متعدد الفئات | مشكلة تصنيف بأربع فئات |
| الفئة 0 | لا أمراض قلبية |
| الصف الأول | خطر منخفض للإصابة بأمراض القلب |
| الصف الثاني | خطر معتدل للإصابة بأمراض القلب |
| الصف الثالث | خطر مرتفع للإصابة بأمراض القلب |
الجدول 2. التصنيف الثنائي ومتعدد الفئات.
مرض الشريان التاجي (CHD)، دراسة أجريت
الشبكة العصبية المتكررة
أحد النماذج الأولى
الشبكة العصبية المتكررة +
لتحسين الأداء أو معالجة بعض القضايا، يشير RNN + إلى توسيع أو دمج الشبكات العصبية المتكررة مع مكونات أخرى. من خلال دمج الحالات الخفية، يدمج امتداد RNN + لنموذج RNN آلية انتباه قائمة على الموقع في طبقة الإخراج.
احتفظ
RETAIN هو نموذج تنبؤي متقدم يستخدم آلية انتباه ذات مستويين، مما يعزز كل من وظيفته وقابليته للتفسير. يتم الحفاظ على دقة التنبؤ المشابهة لشبكات RNN من خلال نموذج الانتباه العصبي الفريد المعروف باسم RETAIN، والذي تم تخصيصه لتمكين تفسير شامل لنتائج التنبؤ. السمة الرئيسية لـ RETAIN هي آلية الانتباه الخاصة به، التي تحاكي نهج اتخاذ القرار السريري للأطباء. الفكرة الأساسية التي يقوم عليها RETAIN هي استخدام انتباه على مستوى السياق وانتباه على مستوى الزمن لوصف العلاقة بين تسلسلات الإدخال والمتغير الهدف. تتيح هذه الآلية لـ RETAIN التركيز على مكونات تسلسل الإدخال المهمة وتقييمها، مما يمكّن من فهم أعمق لتنبؤات النموذج. يظهر RETAIN أداءً مماثلاً لشبكات RNN ولا يضحي بدقة التنبؤ على الرغم من قابليته للتفسير.
ثنائي القطب
يستخدم نموذج Dipole شبكة عصبية متكررة ثنائية الاتجاه مع ثلاث طرق انتباه. في هذه الحالة، اخترنا نسخة من Dipole أظهرت أداءً متفوقًا. تم تنفيذ طبقة التضمين في نموذج Dipole كشبكة متعددة الطبقات (MLP) مع تفعيل ReLu. لاحظوا أن آلية الانتباه المحلية هي الأفضل من بين الطرق الثلاث. بناءً على هذا الاكتشاف، قمنا بتعديل آلية الانتباه المحلية في نموذجنا لإنتاج المتجه السياقي النهائي المستخدم في التنبؤ. يتبع مخرج الشبكة العصبية المتكررة ثنائية الاتجاه مع طبقة الانتباه طبقة تصنيف. تقوم هذه الطبقة بتعيين التمثيلات المتعلمة إلى تسميات التصنيف المطلوبة وتتنبأ باحتمالية كل فئة. أُجري هذا التحليل المقارن لتقييم أداء نموذج المحول القائم على الانتباه الذاتي مقابل هذه الطرق القياسية. من خلال مقارنة مقاييس أداء نموذج المحول مع تلك الخاصة بالنماذج الأساسية، تمكنا من فهم نقاط القوة والضعف والإمكانات للنموذج كطريقة محسنة لتوقع أمراض القلب.
إعداد البيئة
تم تنفيذ تجارب العمل المقترح باستخدام PyTorch 2.0. تم إجراء جميع عمليات التدريب على جهاز كمبيوتر مزود بمعالج Intel Core i9 7900X، وذاكرة وصول عشوائي بسعة 128 جيجابايت، وبطاقتي رسومات Nvidia Titan V، وCUDA 9.0. لتدريب نموذجنا الافتراضي، نستخدم محسن آدم، مع…
مقياس التقييم
في هذه الدراسة، يتم قياس مهام التصنيف باستخدام مقياس الدقة. حيث يحسب نسبة الأمثلة التي تم التعرف عليها بشكل صحيح في مجموعة البيانات مقارنةً بجميع الحالات. في هذه الحالة الخاصة، يتم التعبير عن عدد الأحداث لمستخدم معين بعدد الطيات (
بينما تمثل FFP وFFN الإيجابيات الكاذبة والسلبيات الكاذبة على التوالي، تمثل TTP وTTN الإيجابيات الحقيقية والسلبيات الحقيقية.
النتائج والمناقشة
قارن أداء نموذج المحول المقترح المعتمد على الانتباه الذاتي مع التقنيات الأساسية. حدد أي نموذج يمتلك أفضل دقة في التنبؤ وقدرات التعميم من خلال حساب دقة كل نموذج. تُظهر النتائج التجريبية التي تم تحقيقها في مهمة التنبؤ بأمراض القلب في الجدول 3. توضح النتائج مدى تفوق استراتيجيتنا المقترحة على جميع النماذج المرجعية، بما في ذلك RNN وRETAIN. تجاوز حلنا هذه النماذج الأساسية من حيث الأداء ودقة التنبؤ، والتي تُعتبر عادةً من الأساليب المتقدمة في التنبؤ بأمراض القلب. علاوة على ذلك، لاحظنا فجوة أداء أوسع بين نهجنا والنموذج المعتمد على RNN في مجموعة بياناتنا. يوفر الجدول مقارنة شاملة بين كفاءة الحوسبة والدقة بين النماذج المختلفة التي اعتُبرت كنماذج أساسية. للتحقق من أداء النموذج على مجموعة بيانات متنوعة، استخدمنا مجموعة بيانات أمراض القلب والأوعية الدموية المتاحة مجانًا على موقع Kaggle. تتكون هذه المجموعة من 70,000 حالة تحتوي على 11 ميزة مستقلة. يشير عمود وقت الحوسبة تحديدًا إلى المدة المطلوبة لتدريب كل نموذج مرة واحدة على كامل مجموعة بيانات التدريب لكل حقبة. كما هو واضح من الجدول، يظهر النموذج المقترح أوقات تدريب أسرع مقارنة بالنماذج الأساسية. كما يحقق النموذج المقترح أعلى دقة بلغت
يمكن عزو هذه الميزة إلى البنية المباشرة والقابلة للتوازي لنموذجنا المقترح. من ناحية أخرى، تواجه نماذج الشبكات العصبية المتكررة (RNN) صعوبات بسبب طبيعتها التسلسلية، مما يؤدي إلى فترات تدريب أطول، خاصة عند العمل مع مجموعات بيانات تحتوي على تسلسلات طويلة. كما أن قابلية تفسير النموذج المقترح مقارنةً بـ RNN تُعد ميزة رئيسية. في حين أن نماذج RNN صعبة التفسير، يوفر نموذجنا المقترح وضوحًا أكبر وأسهل في الفهم. في تطبيقات الرعاية الصحية، يمكن أن تكون هذه القابلية للتفسير مفيدة جدًا لأنها تمنح الممارسين الطبيين رؤى حول الأسباب الكامنة وراء توقع فشل القلب (HF) وتسريع عملية اتخاذ القرار. تمثل الشكل 3 التدريب والاختبار
| نموذج | زمن الحساب
|
الدقة
|
| سي إن إن | ٤٫٥٣ | 0.747 |
| الشبكة العصبية المتكررة | 1.43 | 0.783 |
| الشبكة العصبية المتكررة+ | ٣٫٥٢ | 0.871 |
| احتفظ | ٤٫٤٥ | 0.850 |
| ثنائي القطب | 2.12 | 0.894 |
| مقترح | 1.90 | 0.965 |
الجدول 3. زمن الحساب والدقة باستخدام مجموعة بيانات كليفلاند.
| نموذج | زمن الحساب (ثانية) | الدقة (%) |
| سي إن إن | ٩٫٧٤ | 0.713 |
| الشبكة العصبية المتكررة | ٣٫٩٦ | 0.779 |
| الشبكة العصبية المتكررة+ | ٦٫٣٨ | 0.863 |
| احتفظ | ٧٫١٢ | 0.832 |
| ثنائي القطب | ٥٫٦١ | 0.876 |
| مقترح | ٣٫٥٧ | 0.952 |
الجدول 4. زمن الحساب والدقة باستخدام مجموعة بيانات أمراض القلب والأوعية الدموية.
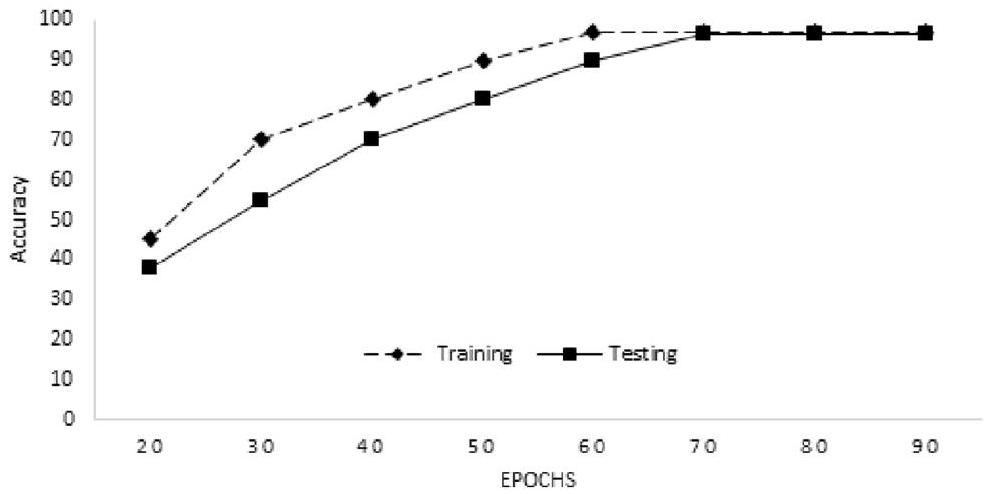
الشكل 3. دقة التدريب والاختبار للنموذج.
دقة النموذج المقترح. لقد حققنا
الدراسة التي أجريت في
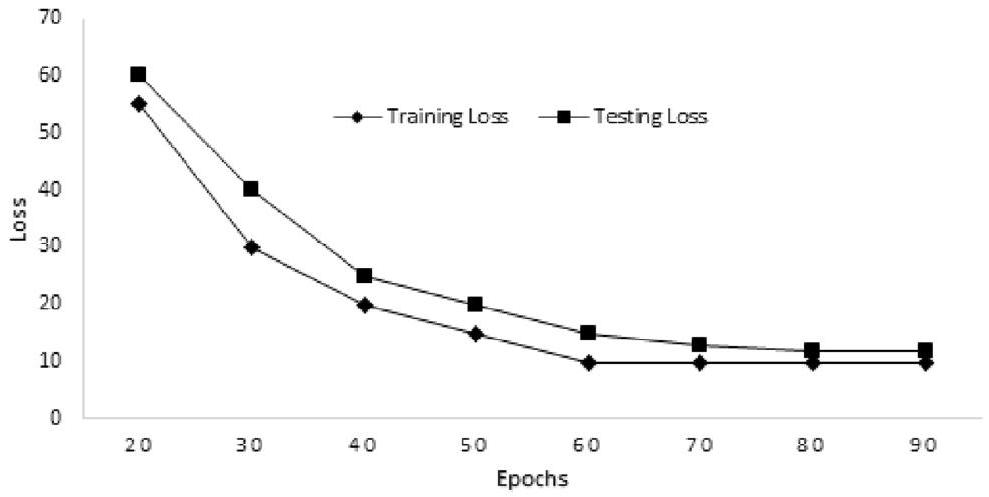
الشكل 4. خسارة التدريب والاختبار للنموذج.
| المؤلفون | السنة | النهج | الدقة (%) |
| الدراسة
|
2019 | HRFLM | 88.7 |
| الدراسة
|
2021 | نموذج NF | 91 |
| الدراسة
|
2022 | GBA | 89.7 |
| الدراسة
|
2023 | NB SVM DT | 90 |
| الدراسة
|
2023 | XGBH | 80.6 |
| المقترح | 2023 | نموذج المحول | 96.51 |
الجدول 5. مقارنة مع دراسات ذات صلة مختلفة.
| المؤلفون | السنة | الخوارزمية | الدقة (%) |
| الدراسة
|
2020 | NB, DT, RF, K-NN | 90.78 |
| الدراسة
|
2021 | DT, RF, هجين | 88.7 |
| الدراسة
|
2022 | hyOPTXg باستخدام XGBoost | 94.7 |
| الدراسة
|
2022 | GAPSO-RF | 95.6 |
| المقترح | 2023 | نموذج المحول | 96.51 |
الجدول 6. مقارنة الأداء على نفس مجموعة البيانات.
البحث المبلغ عنه في
الاستراتيجية المقترحة تتفوق على الأساليب الحديثة، بدقة ملحوظة قدرها
القيود في النموذج المقترح هي؛ يصبح من الصعب فهم بنية المحولات، خاصة عندما تصبح أعمق وأكثر تعقيدًا. خصوصًا لفهم كيف يولد النموذج توقعات معينة أو ما هي عناصر التسلسل الأساسية. لمعالجة هذه المشكلة، استخدمنا طرق تصور الانتباه، التي أعطتنا رؤى مفيدة حول عملية اتخاذ القرار في الإطار.
الخاتمة
في هذا العمل، طورنا نموذج محول جديد قائم على الانتباه لمهمة توقع أمراض القلب. طبق هذا النموذج قوة آليات الانتباه على مستوى الموضع وطبقات الانتباه الذاتي لتعلم تمثيل التسلسل الكامل، على عكس طرق RNN التقليدية. من خلال استخدام هذه الآلية المميزة، تمكنا من تحديد وتقييم الأوزان النسبية لمكونات التسلسل المختلفة، مما حسن فعالية التنبؤ. بالإضافة إلى أمراض القلب، يمكن أداء مجموعة متنوعة من مهام التنبؤ بالمخاطر السريرية باستخدام التقنية المقترحة بسبب مرونتها. الميزة الأساسية لهذه البنية هي طوبولوجيا الشبكة المصممة جيدًا، التي تتيح أقصى توازي. على عكس النماذج القائمة على RNN، التي تعاني من المعالجة التسلسلية والتوازي المحدود، يسمح النموذج المقترح بالحوسبة الفعالة والمتزامنة عبر التسلسل بأكمله. يعمل النموذج المقترح بشكل جيد في الظروف الواقعية باستخدام مجموعة بيانات معيارية ويقلل من أوقات التدريب والاستدلال. للتحقق من الأداء، أجرينا تجارب مختلفة وقارننا نتائجها مع دراسات ذات صلة لإثبات أن النموذج المقترح أكثر دقة من الأساليب الحديثة. الطريقة المقترحة قابلة للتكيف، مما يبرز إمكاناتها للاستخدام في مجموعة من السياقات الصحية بخلاف توقع أمراض القلب، مما يوفر بيانات معلوماتية ويساعد في اتخاذ القرار.
في المستقبل، نرغب في دمج التعلم بالنقل مع النموذج المقترح لتعزيز أدائه، خاصة في سيناريوهات التعامل مع بيانات معنونة محدودة.
توفر البيانات
ستكون مجموعات البيانات والكود متاحة من المؤلف المراسل عند الطلب.
تاريخ الاستلام: 3 أكتوبر 2023؛ تاريخ القبول: 1 يناير 2024
نشر عبر الإنترنت: 04 يناير 2024
تاريخ الاستلام: 3 أكتوبر 2023؛ تاريخ القبول: 1 يناير 2024
نشر عبر الإنترنت: 04 يناير 2024
References
- Virani, S. S. et al. Heart disease and stroke statistics-2021 update: A report from the american heart association. Circulation 143(8), e254-e743 (2021).
- Groenewegen, A., Rutten, F. H., Mosterd, A. & Hoes, A. W. Epidemiology of heart failure. Eur. J. Heart Fail. 22(8), 1342-1356 (2020).
- Ghosh, S. K., Ponnalagu, R., Tripathy, R. & Acharya, U. R. Automated detection of heart valve diseases using chirplet transform and multiclass composite classifier with pcg signals. Comput. Biol. Med. 118, 103632 (2020).
- Ahsan, M. M. & Siddique, Z. Machine learning-based heart disease diagnosis: A systematic literature review. Artif. Intell. Med. 128, 102289 (2022).
- Torre-Cruz, J. et al. Unsupervised detection and classification of heartbeats using the dissimilarity matrix in pcg signals. Comput. Methods Programs Biomed. 221, 106909 (2022).
- Khan, W. et al. Sql and nosql database software architecture performance analysis and assessments-a systematic literature review. Big Data Cogn. Comput. 7(2), 97 (2023).
- Ahmed, S. F. et al. Deep learning modelling techniques: Current progress, applications, advantages, and challenges. Artif. Intell. Rev. 1, 1-97 (2023).
- Perumal, V., Abueidda, D., Koric, S. & Kontsos, A. Temporal convolutional networks for data-driven thermal modeling of directed energy deposition. J. Manuf. Process. 85, 405-416 (2023).
- Yu, L., Simig, D., Flaherty, C., Aghajanyan, A., Zettlemoyer, L. & Lewis, M. Megabyte: Predicting million-byte sequences with multiscale transformers. arXiv preprint arXiv:2305.07185 (2023).
- Reedha, R., Dericquebourg, E., Canals, R. & Hafiane, A. Transformer neural network for weed and crop classification of high resolution uav images. Remote Sens. 14(3), 592 (2022).
- Oh, S. L. et al. Classification of heart sound signals using a novel deep wavenet model. Comput. Methods Programs Biomed. 196, 105604 (2020).
- Deng, M. et al. Heart sound classification based on improved mfcc features and convolutional recurrent neural networks. Neural Netw. 130, 22-32 (2020).
- Jin, B. et al. Predicting the risk of heart failure with ehr sequential data modeling. IEEE Access 6, 9256-9261 (2018).
- El-Shafiey, M. G., Hagag, A., El-Dahshan, E.-S.A. & Ismail, M. A. A hybrid ga and pso optimized approach for heart-disease prediction based on random forest. Multimed. Tools Appl. 81(13), 18155-18179 (2022).
- Shah, D., Patel, S. & Bharti, S. K. Heart disease prediction using machine learning techniques. SN Comput. Sci. 1, 1-6 (2020).
- Nouman, A. & Muneer, S. A systematic literature review on heart disease prediction using blockchain and machine learning techniques. Int. J. Comput. Innov. Sci. 1(4), 1-6 (2022).
- Khan, A. et al. A novel study on machine learning algorithm-based cardiovascular disease prediction. Health Social Care Commun. 23, 1-10 (2023).
- Saqlain, S. M. et al. Fisher score and matthews correlation coefficient-based feature subset selection for heart disease diagnosis using support vector machines. Knowl. Inf. Syst. 58, 139-167 (2019).
- Li, M. et al. Automated icd-9 coding via a deep learning approach. IEEE/ACM Trans. Comput. Biol. Bioinf. 16(4), 1193-1202 (2018).
- Choi, E., Schuetz, A., Stewart, W. F. & Sun, J. Using recurrent neural network models for early detection of heart failure onset. J. Am. Med. Inform. Assoc. 24(2), 361-370 (2017).
- Roy, A. M. & Bhaduri, J. Densesph-yolov5: An automated damage detection model based on densenet and swin-transformer prediction head-enabled yolov5 with attention mechanism. Adv. Eng. Inform. 56, 102007 (2023).
- Jiang, B., Chen, S., Wang, B. & Luo, B. Mglnn: Semi-supervised learning via multiple graph cooperative learning neural networks. Neural Netw. 153, 204-214 (2022).
- Jamil, S. & Roy, A. M. An efficient and robust phonocardiography (pcg)-based valvular heart diseases (vhd) detection framework using vision transformer (vit). Comput. Biol. Med. 158, 106734 (2023).
- Nakai, M. et al. Development of a cardiovascular disease risk prediction model using the suita study, a population-based prospective cohort study in japan. J. Atheroscler. Thromb. 27(11), 1160-1175 (2020).
- Kavitha, M., Gnaneswar, G., Dinesh, R., Sai, Y. R. & Suraj, R. S. Heart disease prediction using hybrid machine learning model. In 6th International Conference on Inventive Computation Technologies (ICICT), 1329-1333 (IEEE, 2021).
- Ishaq, A. et al. Improving the prediction of heart failure patients’ survival using smote and effective data mining techniques. IEEE Access 9, 39707-39716 (2021).
- Deepika. P. & Sasikala, S. Enhanced model for prediction and classification of cardiovascular disease using decision tree with particle swarm optimization. In 4 th International Conference on Electronics, Communication and Aerospace Technology (ICECA), 1068-1072 (IEEE, 2020).
- Latha, C. B. C. & Jeeva, S. C. Improving the accuracy of prediction of heart disease risk based on ensemble classification techniques. Inform. Med. Unlocked 16, 100203 (2019).
- Yahya, W. B., Rosenberg, R. & Ulm, K. Microarray-based classification of histopathologic responses of locally advanced rectal carcinomas to neoadjuvant radio chemotherapy treatment. Turkiye Klinikleri J. Biostat., 6 (1) (2014).
- Gandhi, M. & Singh, S. N. Predictions in heart disease using techniques of data mining. In International Conference on Futuristic Trends on Computational Analysis and Knowledge Management (ABLAZE), 520-525 (IEEE, 2015).
- Koyi, L. P., Borra, T. & Prasad, G. L. V. A research survey on state-of-the-art heart disease prediction systems. In International Conference on Artificial Intelligence and Smart Systems (ICAIS), 799-806 (IEEE, 2021).
- Zhenya, Q. & Zhang, Z. A hybrid cost-sensitive ensemble for heart disease prediction. BMC Med. Inform. Decis. Mak. 21, 1-18 (2021).
- Choi, E., Bahadori, M. T., Searles, E., Coffey, C., Thompson, M., Bost, J., Tejedor-Sojo, J. & Sun, J. Multi-layer representation learning for medical concepts. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 1495-1504 (2016).
- Baytas, I. M., Xiao, C., Zhang, X., Wang, F., Jain, A. K. & Zhou, J. Patient subtyping via time-aware lstm networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 65-74 (2017).
- Manju, R., Harinee, P., Gangolli, S. S. & Bhuvana, N. Evolution of computational intelligence in modern medicine for health care informatics. In Translating Healthcare Through Intelligent Computational Methods, 395-411 (Springer, 2023).
- Janosi, A., Steinbrunn, W., Pfisterer, M. & Detrano, R. Heart disease. UCI Machine Learning Repository, (1988).
- Albelwi, S. & Mahmood, A. A framework for designing the architectures of deep convolutional neural networks. Entropy 19(6), 242 (2017).
- Dutta, A., Batabyal, T., Basu, M. & Acton, S. T. An efficient convolutional neural network for coronary heart disease prediction. Expert Syst. Appl. 159, 113408 (2020).
- Mikolov, T., Karafiát, M., Burget, L., Cernocky, J. & Khudanpur, S. Recurrent neural network based language model. In Interspeech, vol. 2, 1045-1048 (Makuhari, 2010).
- Goodfellow, I., Bengio, Y. & Courville, A. Deep Learning. (MIT press, 2016).
- Sahu, K., Minz, S. Implementation of optimal leaf feature selection-based plant leaf disease classification framework with rnn+ gru technique. In Advanced Communication and Intelligent Systems: First International Conference, ICACIS, Virtual Event, 576-592 (Springer, 2023).
- Choi, E. et al. Retain: An interpretable predictive model for healthcare using reverse time attention mechanism. Adv. Neural Inf. Process. Syst. 29, 1-9 (2016).
- Ma, F., Chitta, R., Zhou, J., You, Q., Sun, T. & Gao, J. Dipole: Diagnosis prediction in healthcare via attention-based bidirectional recurrent neural networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 1903-1911 (2017).
- Nick, T. G. & Campbell, K. M. Logistic regression. Top. Biostat. 1, 273-301 (2007).
- Arumugam, K. et al. Multiple disease prediction using machine learning algorithms. Mater. Today Proc. 80, 3682-3685 (2023).
- Casalino, G., Castellano, G., Kaymak, U. & Zaza, G. Balancing accuracy and interpretability through neuro-fuzzy models for cardiovascular risk assessment. In Proceedings of the 2021 IEEE Symposium Series on Computational Intelligence (SSCI), 1-8 (IEEE, Orlando, FL, USA, 2021).
- Mohan, S., Thirumalai, C. & Srivastava, G. Effective heart disease prediction using hybrid machine learning techniques. IEEE Access 7, 81542-81554 (2019).
- Theerthagiri, P. & Vidya, J. Cardiovascular disease prediction using recursive feature elimination and gradient boosting classification techniques. Expert Syst. 39, e13064 (2022).
- Peng, M. et al. A cardiovascular disease risk score model based on high contribution characteristics. Appl. Sci. 13(2), 893 (2023).
- Srinivas, P. & Katarya, R. hyoptxg: Optuna hyper-parameter optimization framework for predicting cardiovascular disease using xgboost. Biomed. Signal Process. Control 73, 103456 (2022).
الشكر والتقدير
تم دعم هذا العمل جزئيًا من قبل Lun Startup Studio، الرياض 11543، المملكة العربية السعودية.
مساهمات المؤلفين
كل مؤلف في هذه الورقة يجلب خبرات ووجهات نظر فريدة للورقة: A.U.R.، يقدم العمل المقترح وقيود الأبحاث السابقة ذات الصلة بالورقة. Y.A.، يناقش قسم المقدمة للعمل. A.Z.، يحقق بدقة في العمل المقترح ويقدم اقتراحات للتحسين والإعداد الفني. K.U.، يساعد في مراجعة الورقة، كما يعمل على تنقيح الورقة، بما في ذلك التحقق من القواعد اللغوية وما إلى ذلك. K.R.،
يفحص الإعداد الكامل للورقة، يراجعها ويقدم اقتراحات للتحسين، والتي تم دمجها. T.S.، يراجع الورقة بأكملها ويقدم اقتراحات للتحسين، والتي تم دمجها.
يفحص الإعداد الكامل للورقة، يراجعها ويقدم اقتراحات للتحسين، والتي تم دمجها. T.S.، يراجع الورقة بأكملها ويقدم اقتراحات للتحسين، والتي تم دمجها.
المصالح المتنافسة
يعلن المؤلفون عدم وجود مصالح متنافسة.
معلومات إضافية
يجب توجيه المراسلات والطلبات المتعلقة بالمواد إلى A.U.R.
معلومات إعادة الطبع والأذونات متاحة على www.nature.com/reprints.
ملاحظة الناشر: تظل Springer Nature محايدة فيما يتعلق بالمطالبات القضائية في الخرائط المنشورة والانتماءات المؤسسية.
معلومات إعادة الطبع والأذونات متاحة على www.nature.com/reprints.
ملاحظة الناشر: تظل Springer Nature محايدة فيما يتعلق بالمطالبات القضائية في الخرائط المنشورة والانتماءات المؤسسية.
الوصول المفتوح هذه المقالة مرخصة بموجب رخصة المشاع الإبداعي النسبة 4.0 الدولية، التي تسمح بالاستخدام والمشاركة والتكييف والتوزيع وإعادة الإنتاج بأي وسيط أو صيغة، طالما أنك تعطي الفضل المناسب للمؤلف(ين) الأصلي(ين) والمصدر، وتوفر رابطًا إلى رخصة المشاع الإبداعي، وتشير إلى ما إذا تم إجراء تغييرات. الصور أو المواد الأخرى التابعة لأطراف ثالثة في هذه المقالة مشمولة في رخصة المشاع الإبداعي للمقالة، ما لم يُذكر خلاف ذلك في سطر الائتمان للمواد. إذا لم تكن المواد مشمولة في رخصة المشاع الإبداعي للمقالة وكان استخدامك المقصود غير مسموح به بموجب التنظيم القانوني أو يتجاوز الاستخدام المسموح به، فستحتاج إلى الحصول على إذن مباشرة من صاحب حقوق الطبع والنشر. لعرض نسخة من هذه الرخصة، قم بزيارة http://creativecommons.org/licenses/by/4.0/.
© المؤلف(ون) 2024
© المؤلف(ون) 2024
معهد ريفاه لهندسة النظم، جامعة ريفاه الدولية إسلام أباد، إسلام أباد 46000، باكستان. قسم نظم المعلومات، كلية الحاسبات وتقنية المعلومات، جامعة الملك عبدالعزيز، 21443 جدة، المملكة العربية السعودية. قسم البحث والتطوير، Lun Startup Studio، 11543 الرياض، المملكة العربية السعودية. قسم علم الحيوان، جامعة كوهات للعلوم والتكنولوجيا، كوهات 26000، باكستان. قسم الهندسة، جامعة مانشستر متروبوليتان، مانشستر M15 6BH، المملكة المتحدة. قسم هندسة الكهرباء والإلكترونيات، جامعة جوهانسبرغ، جوهانسبرغ 2006، جنوب أفريقيا. البريد الإلكتروني: atta.rahman@ riphah.edu.pk
Journal: Scientific Reports, Volume: 14, Issue: 1
DOI: https://doi.org/10.1038/s41598-024-51184-7
PMID: https://pubmed.ncbi.nlm.nih.gov/38177293
Publication Date: 2024-01-04
DOI: https://doi.org/10.1038/s41598-024-51184-7
PMID: https://pubmed.ncbi.nlm.nih.gov/38177293
Publication Date: 2024-01-04
Enhancing heart disease prediction using a self-attention-based transformer model
Cardiovascular diseases (CVDs) continue to be the leading cause of more than 17 million mortalities worldwide. The early detection of heart failure with high accuracy is crucial for clinical trials and therapy. Patients will be categorized into various types of heart disease based on characteristics like blood pressure, cholesterol levels, heart rate, and other characteristics. With the use of an automatic system, we can provide early diagnoses for those who are prone to heart failure by analyzing their characteristics. In this work, we deploy a novel self-attention-based transformer model, that combines self-attention mechanisms and transformer networks to predict CVD risk. The self-attention layers capture contextual information and generate representations that effectively model complex patterns in the data. Self-attention mechanisms provide interpretability by giving each component of the input sequence a certain amount of attention weight. This includes adjusting the input and output layers, incorporating more layers, and modifying the attention processes to collect relevant information. This also makes it possible for physicians to comprehend which features of the data contributed to the model’s predictions. The proposed model is tested on the Cleveland dataset, a benchmark dataset of the University of California Irvine (UCI) machine learning (ML) repository. Comparing the proposed model to several baseline approaches, we achieved the highest accuracy of
Heart disease refers to any condition that impairs the heart’s capacity to function normally. In recent years, CVD has become the leading cause of death in the world. Congestive heart failure (CHF) prevalence is expected to rise by
diagnosis, as well as promote quick interventions and treatments for better patient outcomes, by utilizing recent developments in DL algorithms and big data methodologies. Despite their potential, DL models can be computationally expensive and take longer to train
Patients with heart failure and society as a whole would benefit from accurate, organized diagnostic services
The remainder of the paper is organized as follows: “Related work” section provides an overview of the related work. In “Limitation and motivation” section, we delve into the background and motivation. The detailed problem description is presented in “Proposed framework” section. The experiments conducted in this work are discussed in “Experiments” section. The results and discussion are explained in “Results and discussion” section. Finally, “Conclusions” section concludes this work and gives future directions.
Related work
Heart disease is one of the primary reasons for mortality worldwide. With the use of Artificial Intelligence (AI) approaches, it is possible to monitor certain characteristics such as blood pressure, body weight, cholesterol, sugar level, and heart rate to determine cardiac disease in its initial stages. ML and DL techniques are revolutionizing the current healthcare system however it is challenging to predict cardiac disease accurately and reliably
For the precise diagnosis of valve heart diseases (VHDs), a robust and high-performing DL model has been provided
With the help of sequential electronic health record (EHR) data, the study conducted in
patient survival prediction. The study aims to maximize the accuracy of forecasting the survival outcomes for patients with heart failure by using ensemble methods and applying SMOTE to rebalance the data. The study conducted in
patient survival prediction. The study aims to maximize the accuracy of forecasting the survival outcomes for patients with heart failure by using ensemble methods and applying SMOTE to rebalance the data. The study conducted in
The most current research demonstrates the various methods used to increase heart disease prediction accuracy. Researchers have made tremendous progress in improving the precision and effectiveness of prediction models through the use of ensemble learning
Limitation and motivation
Statistics of heart disease often include temporal characteristics, such as the history of the patient as well as variations over time. Effectively processing sequential data using ML approaches is challenging. Previous studies didn’t provide sufficient support for better patient outcomes. In this section, we outline the limitations of previous heart disease prediction methods, clarify our work motivations for developing an improved model, and highlight the key contributions and novelties of our study.
Previous works limitations
The primary input sources for heart disease diagnosis are patient health characteristics containing data with categories and unstructured text. The main shortcomings of the current heart disease prediction methods are the modeling of input dataset attributes, computation of attribute risk factors, and obtaining high prediction accuracy
Traditional RNNs are prone to vanishing and expanding gradient problems. The Standard Long Short-Term Memory (LSTM) networks have the drawback of being unable to handle irregular periods of time. However, timing inconsistency is typical in many healthcare applications
Motivation
Disease prediction systems are best practices for eliminating human errors in disease diagnosis and aiding in disease prevention through early identification
Furthermore, the proposed model has a straightforward and parallelizable network structure, which leads to noticeably quicker training times than existing heart disease prediction techniques. This enhancement makes them more efficient by addressing the difficulties associated with model training and implementation in actual healthcare settings.
Key contributions and novelty
This study presents a novel prediction model that makes use of the self-attention process. The model is created with interpretability and parallelizability in mind, enabling effective computing while maintaining a respectable level of prediction accuracy. A key element of our model is self-attention, which is notably influenced by the work done in
- Developed an innovative and resilient attention-based model specifically tailored for predicting heart disease. In addition to its exceptional accuracy in prediction, this model also displays its adaptability to a variety of other risk prediction and evaluation tasks. Due to its adaptability, it can be used well across a variety of domains, making it an important tool for many different outcome prediction issues. Its versatility makes it suitable for various healthcare scenarios and expands its potential to tackle a broad range of predictive tasks beyond heart disease prediction.
- Investigate the key factors that lead to the risk of developing heart disease and identify any previously unknown risk factors that may be relevant.
- Design a Transformer model-based strategy that is more precise and successful than current conventional ML models in forecasting the likelihood of heart disease.
- The Transformer model’s efficiency in detecting the likelihood of heart disease across multiple demographic categories, such as age, gender, and race/ethnicity, is examined, and the possibility for personalized risk assessment is also investigated.
- The ability of the Transformer model to identify potential cardiac disease was examined in relation to the impacts of various data preprocessing techniques. Several pre-processing methods were applied to the input data, and their effects on the model’s functionality and accuracy were carefully examined.
Proposed framework
The goal of this research is to develop a self-attention-based transformer model for assessing CVD risk utilizing the Cleveland dataset. This dataset contains a variety of medical and non-medical components that can be used to identify whether a patient has cardiac disease. The dataset comprises both continuous and categorical variables, among other features. It becomes challenging to identify the most important factors and comprehend their relevance in heart disease prognosis. Furthermore, it might be challenging to draw meaningful findings since some of the features are challenging to evaluate clinically.
Dataset and preprocessing
In this work, we predict cardiac disease using the UC Irvine Cleveland dataset
Attention-based model architecture
The patient characteristics and diagnostic measures are represented by a series of input features that are used to encode each instance in the dataset. In this work, we have
Input embedding and position encoding
In the self-attention-based transformer model, input embedding and position encoding are two crucial processes that come before the self-attention mechanism. The input sequence is represented using these stages in a way that is appropriate for the successive self-attention layers. The categorical variables and numerical characteristics of each instance are translated to continuous vector representations through input embedding. In this study, we use an embedding layer to convert discrete values for each category variable into continuous vectors. Each instance’s scaled numerical characteristics and category embeddings are combined into a single vector. We have
Figure 1. Overview of the proposed model.
sequence. The self-attention-based transformer model efficiently processes the input sequence, collecting both feature representations and positional information by executing input embedding and position encoding stages.
Transformer encoder
The heart disease dataset is represented as a series of embedded characteristics and positional encodings. To identify relationships and extract meaningful representations from the input sequence, apply a stack of Transformer encoder layers. The encoder layer includes a self-attention mechanism and a feed-forward neural network. The output of the Transformer encoder layer is computed as,
Self-attention
The ability of the Transformer model to find links between features that go beyond sequence adjacency is another intriguing feature of this system. The self-attention technique is utilized to extract the relationships between various points in the sequence inside each Transformer Encoder layer. The similarity between the query and key vectors is used to determine the attention weights (AW) for each point. These AWs illustrate the relative importance of each position. AW can be calculated as follows:
where
The learning parameters
Feed-forward network
To further enhance the representations, follow the self-attention strategy by applying a feed-forward neural network to each point separately. A non-linear activation function separates the two linear layers that make up the feed-forward network. Connect the input characteristics to the output of the self-attention mechanism and the output of the feed-forward network to create residual connections. The features after each sublayer are normalized using the layer normalization method.
Output layer
To detect the existence of heart disease, use the final output from the Transformer Decoder layers and feed it through a fully connected layer. To determine the final output probabilities, use the softmax function.
Training the model
The Adam optimizer is used as an optimization technique to train the model for determining the likelihood of heart disease. To find whether a subject has heart disease or not, the binary cross-entropy loss function is employed to distinguish between the predicted probabilities and the actual data labels. The training method seeks to identify the ideal values for the weight vector W and the bias term b that minimize the loss function. The prediction accuracy of the model is enhanced by the Adam optimizer, which iteratively modifies the weights and biases during training.
Disease prediction
Using the test dataset, evaluate the trained model using relevant evaluation measures including accuracy, precision, recall, and F1-score. Using the trained model, forecast the likelihood that a new patient will be diagnosed with heart disease based on the feature values of the patient. Analyze the feature importance or coefficients learned by the model to identify the relative importance of different factors in determining heart disease. Figure 2 represents the proposed model for heart disease prediction.
Experiments
Heart disease is a prominent cause of death globally, and effective prediction of heart disease can considerably improve patient outcomes
Figure 2. Architecture of proposed model used for heart disease prediction.
positional encoding. Utilize the self-attention technique to enable the model to focus on various input sequence components while producing context-aware representations for each attribute. Create the model architecture by specifying the essential layers, such as self-attention, feed-forward, and classification layers. Use the PyTorch 2.0. framework to implement the Self-Attention-based Transformer model. By using the proposed approach, we want to increase heart disease prediction accuracy and contribute to the creation of more effective clinical decision support systems.
Table 1 displays the parameters used to train and evaluate the self-attention-based Transformer model for heart disease prediction utilizing the Cleveland dataset. The model consists of an embedding layer, Transformer encoder layers, and a fully connected layer for classification. Iterate through the training dataset in mini-batches, compute the loss, backpropagate, and use the optimizer to update the model weights. After training the model, assess its performance on the testing set. Analyze the model’s predictions and interpret the learned patterns. Determine the self-attention mechanism’s key characteristics and attention weights. In this work, we carry out both binary and multi-class classification tasks in the experiments. For the binary classification problem, we predict the presence or absence of heart disease. For the four-class classification problem, we divide the labels into four unique classes to reflect various risk levels of heart disease. Table 2 displays the number of classes used in the experiments. In order to validate the self-attention-based Transformer model performance, we compared it with various baseline approaches.
Baseline approaches
We carried out a comparison study using a number of baseline methods frequently employed for heart disease prediction. We investigated CNN, RNN, RNN + (RNN with additional features), RETAIN (Reverse Time Attention Model), and Dipole as the baseline methods. We used an identical experimental design for each baseline strategy, including data preparation, model training, validation, hyperparameter adjustment, and assessment of the testing set.
CNN
Three convolutional layers make up the CNN model presented by Albelwi et al.
| Parameter | Description |
| Model | Self-attention-based transformer model |
| Input dimension = 14 | Input features dimension |
| Output dimension = 2, 4 | Number of output classes |
| d-model = 128 | Dimensionality of the model’s hidden states |
| nhead = 4 | Attention heads in the multi-head self-attention |
| Num-layers = 4 | Layers in the encoder |
| Dropout = 0.2 | Dropout probability |
| Batch-size = 32, 64 | Number of samples |
| Epochs
|
number of iterations |
| Learning-rate = 0.001 | Learning rate |
| Optimizer = Adam | optimizer used for updating the parameters |
| Train-loss | Avg raining loss over the training dataset |
| Cross entropy | Loss function |
| Test-loss | Avg loss over the testing dataset |
Table 1. Parameters of the proposed model used in the experiments.
| Class value | Description |
| Binary | Two class classification problem |
| Class 0 | no heart disease |
| Class 1 | presence of heart disease |
| Multi-class | four-class classification problem |
| Class 0 | no heart disease |
| Class 1 | low risk of heart disease |
| Class 2 | moderate risk of heart disease |
| Class 3 | high risk of heart disease |
Table 2. Binary and multiclass classification.
of coronary heart disease (CHD), a study done
RNN
One of the first models
RNN +
To improve performance or handle certain issues, RNN + refers to the expansion or combining of RNNs with other components. By integrating the hidden states, the RNN + extension of the RNN model incorporates a location-based attention mechanism into the output layer
RETAIN
RETAIN is a state-of-the-art predictive model that leverages a two-level attention mechanism, enhancing both its functionality and interpretability. RNNs-like prediction accuracy is maintained by the unique neural attention model known as RETAIN, which is customized to enable thorough interpretation of prediction findings. The key characteristic of RETAIN is its attention mechanism, which emulates the clinical decision-making approach of doctors. The fundamental idea underlying RETAIN is to use context-level attention and time-level attention to describe the link between input sequences and the target variable. This attention mechanism allows RETAIN to draw attention to and weigh the important input sequence components, enabling a more in-depth comprehension of the model’s predictions. RETAIN exhibits performance that is comparable to RNNs and does not sacrifice prediction accuracy despite its interpretability.
Dipole
Dipole employs a bi-directional RNN with three attention methods. In this case, we choose a variation of Dipole that has demonstrated superior performance. The embedding layer of the Dipole model is implemented as a multi-layer perceptron (MLP) with ReLu activation. They observed that, the local-based attention mechanism performs the best out of the three methods. Based on this discovery, we modify our model’s local-based attention mechanism to produce the final context vector that is used for prediction. The output of the bi-directional RNN with an attention layer is followed by a classification layer. This layer assigns the learned representations to the required classification labels and forecasts the probability for each class. This comparative analysis was conducted to assess the self-attention-based Transformer model’s performance against these standard methods. By comparing the Transformer model’s performance measures to those of the baselines, we were able to gain insight into the model’s strengths, shortcomings, and potential as an improved technique for heart disease prediction.
Environment setting
The experiments of the proposed work are implemented using PyTorch 2.0. All training is carried out on a computer with an Intel Core i97900X processor, 128GB of RAM, 2 Nvidia Titan V graphics cards, and CUDA 9.0. For training our hypothetical model, we use Adam optimizer, with
Evaluation metric
In this study, the classification tasks are measured using the accuracy metric. It calculates the percentage of properly identified examples in a dataset relative to all occurrences. In this particular case, the number of events for a particular user is expressed by the number of folds (
whereas FFP and FFN represent false positives and false negatives, respectively, TTP and TTN represent true positives and true negatives.
Results and discussion
Compare the performance of the suggested Self-Attention-based Transformer Model to the baseline techniques. Determine which model has the best prediction accuracy and generalization capabilities by calculating the accuracy of each model. The experimental results achieved in the heart disease prediction task are shown in Table 3. The outcomes demonstrate how much better our suggested strategy is than all benchmark models, including RNN and RETAIN. Our solution surpassed these baseline models in terms of performance and predicted accuracy, which are commonly regarded as state-of-the-art approaches for heart disease prediction. Furthermore, we saw a wider performance disparity between our approach and the RNN-based model in our dataset. The table provides a comprehensive comparison of computing efficiency and accuracy among the different models considered as baselines. In order to validate the model performance on diverse dataset, we used the cardiovascular disease dataset, which is freely available on Kaggle. This dataset consists of 70,000 instances having 11 independent features. The computing time column specifically indicates the duration required to train each model once on the entire training dataset per epoch. As evident from the table, the proposed model exhibits faster training times in comparison to baseline models. The proposed model also achieves the highest accuracy of
This advantage can be attributed to the straightforward and parallelizable structure of our suggested model. RNN models, on the other hand, encounter difficulties because of their sequential nature, leading to longer training durations, especially when working with datasets containing prolonged sequences. The suggested model’s interpretability when compared to RNN is also a key advantage. While RNN models are difficult to interpret, our proposed model provides more clarity and is simpler to understand. In healthcare applications, this interpretability can be quite helpful because it gives medical practitioners insights into the underlying causes of heart failure (HF) prediction and speeds up the decision-making process. Figure 3 represents the training and testing
| Model | Computation time
|
Accuracy
|
| CNN | 4.53 | 0.747 |
| RNN | 1.43 | 0.783 |
| RNN+ | 3.52 | 0.871 |
| RETAIN | 4.45 | 0.850 |
| Dipole | 2.12 | 0.894 |
| Proposed | 1.90 | 0.965 |
Table 3. Computation time and accuracy using Cleveland dataset.
| Model | Computation time (s) | Accuracy (%) |
| CNN | 9.74 | 0.713 |
| RNN | 3.96 | 0.779 |
| RNN+ | 6.38 | 0.863 |
| RETAIN | 7.12 | 0.832 |
| Dipole | 5.61 | 0.876 |
| Proposed | 3.57 | 0.952 |
Table 4. Computation time and accuracy using cardiovascular disease dataset.
Figure 3. Training and testing accuracy of the model.
accuracy of the proposed model. We achieved
The study conducted in
Figure 4. Training and testing loss of the model.
| Authors | Year | Approach | Accuracy (%) |
| Study
|
2019 | HRFLM | 88.7 |
| Study
|
2021 | NF model | 91 |
| Study
|
2022 | GBA | 89.7 |
| Study
|
2023 | NB SVM DT | 90 |
| Study
|
2023 | XGBH | 80.6 |
| Proposed | 2023 | Transformer model | 96.51 |
Table 5. Comparison with various related studies.
| Authors | Year | Algorithm | Accuracy (%) |
| Study
|
2020 | NB, DT, RF, K-NN | 90.78 |
| Study
|
2021 | DT, RF, Hybrid | 88.7 |
| Study
|
2022 | hyOPTXg using XGBoost | 94.7 |
| Study
|
2022 | GAPSO-RF | 95.6 |
| Proposed | 2023 | Transformer model | 96.51 |
Table 6. Performance comparison on same dataset.
The research reported in
The proposed strategy surpasses state-of-the-art approaches, with a remarkable accuracy of
The limitation of the proposed model is; It becomes difficult to understand the transformers architecture, particularly when it becomes deeper and complicated. Especially, to grasp how the model generates particular predictions or what sequence elements are essentials. To address this issue, we used attention visualization approaches, which gave us helpful insight about the framework’s decision-making process.
Conclusion
In this work, we developed a novel attention-based transformer model for the task of heart disease prediction. This model applied the strength of position-level attention mechanisms and self-attention layers to learn the representation of the complete sequence, in contrast to conventional RNN methods. Through the use of this distinct mechanism, we were able to identify and evaluate the relative weights of the various sequence components, improving the effectiveness of prediction. Beyond heart disease, a variety of clinical risk prediction tasks can be performed using the proposed technique due to its versatility. The fundamental advantage of this architecture is its well-designed network topology, which enables maximum parallelization. In contrast to RNN-based models, which suffer from sequential processing and limited parallelization, the proposed paradigm permits efficient and simultaneous computing across the whole sequence. The proposed model performs well in real-world circumstances using benchmark dataset and reduces training and inference times. To validate the performance, we conducted various experiments and compared their results with various related study to demonstrate that the proposed model is more accurate than cutting-edge methods. The proposed method is adaptable, which highlights its potential for usage in a range of healthcare contexts beyond heart disease prediction, providing informative data and assisting in decision-making.
In future, we want to Integrate transfer learning with the proposed model to enhance its performance, especially in the scenarios of dealing with limited labeled data.
Data availability
The datasets and code will be available from the corresponding author on request.
Received: 3 October 2023; Accepted: 1 January 2024
Published online: 04 January 2024
Received: 3 October 2023; Accepted: 1 January 2024
Published online: 04 January 2024
References
- Virani, S. S. et al. Heart disease and stroke statistics-2021 update: A report from the american heart association. Circulation 143(8), e254-e743 (2021).
- Groenewegen, A., Rutten, F. H., Mosterd, A. & Hoes, A. W. Epidemiology of heart failure. Eur. J. Heart Fail. 22(8), 1342-1356 (2020).
- Ghosh, S. K., Ponnalagu, R., Tripathy, R. & Acharya, U. R. Automated detection of heart valve diseases using chirplet transform and multiclass composite classifier with pcg signals. Comput. Biol. Med. 118, 103632 (2020).
- Ahsan, M. M. & Siddique, Z. Machine learning-based heart disease diagnosis: A systematic literature review. Artif. Intell. Med. 128, 102289 (2022).
- Torre-Cruz, J. et al. Unsupervised detection and classification of heartbeats using the dissimilarity matrix in pcg signals. Comput. Methods Programs Biomed. 221, 106909 (2022).
- Khan, W. et al. Sql and nosql database software architecture performance analysis and assessments-a systematic literature review. Big Data Cogn. Comput. 7(2), 97 (2023).
- Ahmed, S. F. et al. Deep learning modelling techniques: Current progress, applications, advantages, and challenges. Artif. Intell. Rev. 1, 1-97 (2023).
- Perumal, V., Abueidda, D., Koric, S. & Kontsos, A. Temporal convolutional networks for data-driven thermal modeling of directed energy deposition. J. Manuf. Process. 85, 405-416 (2023).
- Yu, L., Simig, D., Flaherty, C., Aghajanyan, A., Zettlemoyer, L. & Lewis, M. Megabyte: Predicting million-byte sequences with multiscale transformers. arXiv preprint arXiv:2305.07185 (2023).
- Reedha, R., Dericquebourg, E., Canals, R. & Hafiane, A. Transformer neural network for weed and crop classification of high resolution uav images. Remote Sens. 14(3), 592 (2022).
- Oh, S. L. et al. Classification of heart sound signals using a novel deep wavenet model. Comput. Methods Programs Biomed. 196, 105604 (2020).
- Deng, M. et al. Heart sound classification based on improved mfcc features and convolutional recurrent neural networks. Neural Netw. 130, 22-32 (2020).
- Jin, B. et al. Predicting the risk of heart failure with ehr sequential data modeling. IEEE Access 6, 9256-9261 (2018).
- El-Shafiey, M. G., Hagag, A., El-Dahshan, E.-S.A. & Ismail, M. A. A hybrid ga and pso optimized approach for heart-disease prediction based on random forest. Multimed. Tools Appl. 81(13), 18155-18179 (2022).
- Shah, D., Patel, S. & Bharti, S. K. Heart disease prediction using machine learning techniques. SN Comput. Sci. 1, 1-6 (2020).
- Nouman, A. & Muneer, S. A systematic literature review on heart disease prediction using blockchain and machine learning techniques. Int. J. Comput. Innov. Sci. 1(4), 1-6 (2022).
- Khan, A. et al. A novel study on machine learning algorithm-based cardiovascular disease prediction. Health Social Care Commun. 23, 1-10 (2023).
- Saqlain, S. M. et al. Fisher score and matthews correlation coefficient-based feature subset selection for heart disease diagnosis using support vector machines. Knowl. Inf. Syst. 58, 139-167 (2019).
- Li, M. et al. Automated icd-9 coding via a deep learning approach. IEEE/ACM Trans. Comput. Biol. Bioinf. 16(4), 1193-1202 (2018).
- Choi, E., Schuetz, A., Stewart, W. F. & Sun, J. Using recurrent neural network models for early detection of heart failure onset. J. Am. Med. Inform. Assoc. 24(2), 361-370 (2017).
- Roy, A. M. & Bhaduri, J. Densesph-yolov5: An automated damage detection model based on densenet and swin-transformer prediction head-enabled yolov5 with attention mechanism. Adv. Eng. Inform. 56, 102007 (2023).
- Jiang, B., Chen, S., Wang, B. & Luo, B. Mglnn: Semi-supervised learning via multiple graph cooperative learning neural networks. Neural Netw. 153, 204-214 (2022).
- Jamil, S. & Roy, A. M. An efficient and robust phonocardiography (pcg)-based valvular heart diseases (vhd) detection framework using vision transformer (vit). Comput. Biol. Med. 158, 106734 (2023).
- Nakai, M. et al. Development of a cardiovascular disease risk prediction model using the suita study, a population-based prospective cohort study in japan. J. Atheroscler. Thromb. 27(11), 1160-1175 (2020).
- Kavitha, M., Gnaneswar, G., Dinesh, R., Sai, Y. R. & Suraj, R. S. Heart disease prediction using hybrid machine learning model. In 6th International Conference on Inventive Computation Technologies (ICICT), 1329-1333 (IEEE, 2021).
- Ishaq, A. et al. Improving the prediction of heart failure patients’ survival using smote and effective data mining techniques. IEEE Access 9, 39707-39716 (2021).
- Deepika. P. & Sasikala, S. Enhanced model for prediction and classification of cardiovascular disease using decision tree with particle swarm optimization. In 4 th International Conference on Electronics, Communication and Aerospace Technology (ICECA), 1068-1072 (IEEE, 2020).
- Latha, C. B. C. & Jeeva, S. C. Improving the accuracy of prediction of heart disease risk based on ensemble classification techniques. Inform. Med. Unlocked 16, 100203 (2019).
- Yahya, W. B., Rosenberg, R. & Ulm, K. Microarray-based classification of histopathologic responses of locally advanced rectal carcinomas to neoadjuvant radio chemotherapy treatment. Turkiye Klinikleri J. Biostat., 6 (1) (2014).
- Gandhi, M. & Singh, S. N. Predictions in heart disease using techniques of data mining. In International Conference on Futuristic Trends on Computational Analysis and Knowledge Management (ABLAZE), 520-525 (IEEE, 2015).
- Koyi, L. P., Borra, T. & Prasad, G. L. V. A research survey on state-of-the-art heart disease prediction systems. In International Conference on Artificial Intelligence and Smart Systems (ICAIS), 799-806 (IEEE, 2021).
- Zhenya, Q. & Zhang, Z. A hybrid cost-sensitive ensemble for heart disease prediction. BMC Med. Inform. Decis. Mak. 21, 1-18 (2021).
- Choi, E., Bahadori, M. T., Searles, E., Coffey, C., Thompson, M., Bost, J., Tejedor-Sojo, J. & Sun, J. Multi-layer representation learning for medical concepts. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 1495-1504 (2016).
- Baytas, I. M., Xiao, C., Zhang, X., Wang, F., Jain, A. K. & Zhou, J. Patient subtyping via time-aware lstm networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 65-74 (2017).
- Manju, R., Harinee, P., Gangolli, S. S. & Bhuvana, N. Evolution of computational intelligence in modern medicine for health care informatics. In Translating Healthcare Through Intelligent Computational Methods, 395-411 (Springer, 2023).
- Janosi, A., Steinbrunn, W., Pfisterer, M. & Detrano, R. Heart disease. UCI Machine Learning Repository, (1988).
- Albelwi, S. & Mahmood, A. A framework for designing the architectures of deep convolutional neural networks. Entropy 19(6), 242 (2017).
- Dutta, A., Batabyal, T., Basu, M. & Acton, S. T. An efficient convolutional neural network for coronary heart disease prediction. Expert Syst. Appl. 159, 113408 (2020).
- Mikolov, T., Karafiát, M., Burget, L., Cernocky, J. & Khudanpur, S. Recurrent neural network based language model. In Interspeech, vol. 2, 1045-1048 (Makuhari, 2010).
- Goodfellow, I., Bengio, Y. & Courville, A. Deep Learning. (MIT press, 2016).
- Sahu, K., Minz, S. Implementation of optimal leaf feature selection-based plant leaf disease classification framework with rnn+ gru technique. In Advanced Communication and Intelligent Systems: First International Conference, ICACIS, Virtual Event, 576-592 (Springer, 2023).
- Choi, E. et al. Retain: An interpretable predictive model for healthcare using reverse time attention mechanism. Adv. Neural Inf. Process. Syst. 29, 1-9 (2016).
- Ma, F., Chitta, R., Zhou, J., You, Q., Sun, T. & Gao, J. Dipole: Diagnosis prediction in healthcare via attention-based bidirectional recurrent neural networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 1903-1911 (2017).
- Nick, T. G. & Campbell, K. M. Logistic regression. Top. Biostat. 1, 273-301 (2007).
- Arumugam, K. et al. Multiple disease prediction using machine learning algorithms. Mater. Today Proc. 80, 3682-3685 (2023).
- Casalino, G., Castellano, G., Kaymak, U. & Zaza, G. Balancing accuracy and interpretability through neuro-fuzzy models for cardiovascular risk assessment. In Proceedings of the 2021 IEEE Symposium Series on Computational Intelligence (SSCI), 1-8 (IEEE, Orlando, FL, USA, 2021).
- Mohan, S., Thirumalai, C. & Srivastava, G. Effective heart disease prediction using hybrid machine learning techniques. IEEE Access 7, 81542-81554 (2019).
- Theerthagiri, P. & Vidya, J. Cardiovascular disease prediction using recursive feature elimination and gradient boosting classification techniques. Expert Syst. 39, e13064 (2022).
- Peng, M. et al. A cardiovascular disease risk score model based on high contribution characteristics. Appl. Sci. 13(2), 893 (2023).
- Srinivas, P. & Katarya, R. hyoptxg: Optuna hyper-parameter optimization framework for predicting cardiovascular disease using xgboost. Biomed. Signal Process. Control 73, 103456 (2022).
Acknowledgements
This work was partially supported by Lun Startup Studio, Riyadh 11543, Saudi Arabia.
Author contributions
Each author of this paper brings unique expertise and perspectives to the paper: A.U.R., provides the proposed work and previous research limitations relevant to the paper. Y.A., discusses the introduction section of the work. A.Z., thoroughly investigate the proposed work and provides suggestion for improvement and technical set up. K.U., helps in reviewing of the paper, also he works on paper polishing, including checking for grammar etc. K.R.,
checks the complete setup of the paper, review it and give suggestion for enhancement, which are incorporated. T.S., review the whole paper and give suggestion for enhancement, which are incorporated.
checks the complete setup of the paper, review it and give suggestion for enhancement, which are incorporated. T.S., review the whole paper and give suggestion for enhancement, which are incorporated.
Competing interests
The authors declare no competing interests.
Additional information
Correspondence and requests for materials should be addressed to A.U.R.
Reprints and permissions information is available at www.nature.com/reprints.
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Reprints and permissions information is available at www.nature.com/reprints.
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
© The Author(s) 2024
© The Author(s) 2024
Riphah Institute of System Engineering, Riphah International University Islamabad, Islamabad 46000, Pakistan. Department of Information Systems, FCIT, King Abdulaziz University, 21443 Jeddah, Saudi Arabia. Research and Development Department, Lun Startup Studio, 11543 Riyadh, Saudi Arabia. Department of Zoology, Kohat University of Science and Technology, Kohat 26000, Pakistan. Department of Engineering, Manchester Metropolitan University, Manchester M15 6BH, UK. Department of Electrical and Electronic Engineering Science, University of Johannesburg, Johannesburg 2006, South Africa. email: atta.rahman@ riphah.edu.pk