DOI: https://doi.org/10.1186/s12911-025-02961-5
PMID: https://pubmed.ncbi.nlm.nih.gov/40065373
تاريخ النشر: 2025-03-10
تقدم التحليل الموضوعي المدفوع بالذكاء الاصطناعي في البحث النوعي: دراسة مقارنة لتسعة نماذج توليدية على بيانات الليشمانيا الجلدية
الملخص
الخلفية كجزء من البحث النوعي، فإن التحليل الموضوعي يتطلب وقتًا طويلاً وتقنية عالية. لقد جلب ظهور الذكاء الاصطناعي التوليدي، وخاصة نماذج اللغة الكبيرة، الأمل في تعزيز وتحسين جزئي للتحليل الموضوعي. الطرق قامت الدراسة بتقييم الفعالية النسبية للتحليل الموضوعي التقليدي مقابل التحليل الموضوعي المدعوم بالذكاء الاصطناعي عند التحقيق في التأثير النفسي الاجتماعي لندبات الليشمانيا الجلدية. تم تحليل 448 استجابة من المشاركين من دراسة أساسية، مقارنة بين تسعة نماذج توليدية للذكاء الاصطناعي: Llama 3.1 405B، Claude 3.5 Sonnet، NotebookLM، Gemini 1.5 Advanced Ultra، ChatGPT o1-Pro، ChatGPT o1، GrokV2، DeepSeekV3، Gemini 2.0 Advanced مع التحليل اليدوي من قبل خبراء. حافظ برنامج Jamovi على صرامة منهجية من خلال حسابات معامل كوهين كابا لتقييم التوافق وقياس التشابه عبر بايثون باستخدام حسابات مؤشر جاكارد. النتائج أظهرت نماذج الذكاء الاصطناعي المتقدمة توافقًا مثيرًا للإعجاب مع المعايير المرجعية؛ حيث كان لبعضها توافق مثالي (مؤشر جاكارد = 1.00). أظهرت التحليلات المحددة حسب الجنس أداءً متسقًا عبر المجموعات الفرعية، مما سمح بفهم دقيق للعواقب النفسية الاجتماعية. طورت عملية النظرية المستندة إلى البيانات الإطار الخاص بالدائرة الهشة من الضعف التي دمجت رؤى جديدة حول التعقيد النفسي الاجتماعي المرتبط بالليشمانيا الجلدية بينما أسست أبعادًا جديدة. الاستنتاجات تُظهر هذه الدراسة كيف يمكن دمج الذكاء الاصطناعي في منهجية البحث النوعي، لا سيما في التحليل النفسي الاجتماعي المعقد. وبالتالي، أثبتت نماذج التعلم العميق للذكاء الاصطناعي كفاءتها العالية ودقتها. تشير هذه النتائج إلى أن الاتجاهات المستقبلية لمنهجية البحث النوعي يجب أن تركز على الحفاظ على الصرامة التحليلية من خلال استخدام التكنولوجيا باستخدام مزيج من قدرات الذكاء الاصطناعي وخبرة البشر وفقًا لقائمة مراجعة موحدة للمستقبل لضمان الشفافية الكاملة في العملية. الكلمات الرئيسية الذكاء الاصطناعي في البحث النوعي، نماذج اللغة الكبيرة، التحليل الموضوعي، تطوير النظرية المستندة إلى البيانات، معالجة اللغة الطبيعية، أتمتة البحث، الليشمانيا الجلدية.
الخلفية
هناك العديد من الأمثلة حيث يمكن استخدام الذكاء الاصطناعي لتعزيز المكونات الشاملة للتحليل النوعي من خلال أتمتة خطوات البحث النوعي التي يعتبرها معظم الباحثين مملة أو متكررة، بما في ذلك النسخ والترجمة والترميز الأولي للنصوص. إن أتمتة هذه العمليات اليدوية تعزز من إنتاج النتائج، وتسمح بالتركيز أكثر على التحليلات التفسيرية وتساعد في تقليل التحيز المحتمل. كما تشير إلى ميزة محتملة أخرى تتمثل في أن الخوارزميات التحليلية التي يستخدمها الذكاء الاصطناعي يمكن تحليلها بواسطة عتبات سلوكية لا يمكن للبشر الوصول إليها، مما يسمح بإجراء تحليلات أكثر دقة تتجاوز النطاق الذي قد يغفله البشر.
يمكن تشغيل ( overlook) [13]. بالإضافة إلى ذلك، يمكن أن يكون نص الذكاء الاصطناعي بمثابة مقارنة قيمة لتفسير الأبحاث، مما قد يكشف عن التحيزات ويوسع الأطر التفسيرية.
علاوة على ذلك، تتطلب الأبحاث النوعية تفسيرًا غامرًا، وقبولًا للتأملات غير العادية، ومرونة في النماذج من الباحث، والتي تعتبر جزءًا من عملية التحليل، مما يجعلها مفهومة بشكل خاطئ للغاية بالنسبة لخوارزميات الذكاء الاصطناعي. لذلك، يجب توخي الحذر عند استخدام الذكاء الاصطناعي وتفسير النتائج المستندة إلى الذكاء الاصطناعي. ومن ثم، يحتاج الباحثون إلى التحقق من نتائجهم الجارية من خلال إجراء إجراءات صارمة لمراقبة الجودة، بما في ذلك التقييم الدقيق والتحقق من مخرجات البحث. في هذا السياق، تسعى هذه الدراسة إلى تقييم ما إذا كان ChatGPT o1-Pro ومجموعة متنوعة من ثمانية نماذج أخرى من الذكاء الاصطناعي التوليدي يمكن أن تحسن دقة التركيب النوعي في الأدلة المعقدة المتعلقة بالعبء النفسي والاجتماعي لندبات الليشمانيا الجلدية عند مقارنتها بأساليب التحليل النوعي التقليدية التي يقودها البشر.
المواد
تصميم الدراسة
المشاركون
يوليو 2024 وديسمبر 2024 كانتا فترتين لاختيار نماذج الذكاء الاصطناعي المختلفة. النماذج المختارة تعكس أحدث ما في التعلم العميق لتوليد اللغة وتم الترويج لها كأدوات أفضل لتطبيق خوارزميات معالجة اللغة الطبيعية. تضمنت نماذج مجموعة يوليو Llama 3.1 405B، Claude 3.5 Sonnet، NotebookLM، Gemini 1.5 Advanced Ultra ونماذج ChatGPT o1-preview. بينما تضمنت مجموعة ديسمبر ChatGPT o1 التي حلت محل النموذج السابق، GrokV2، DeepSeekV3، وGemini 2.0 Advanced. النموذج التاسع الذي تم إضافته كان في ديسمبر 2024 نموذج تجاري متقدم جداً تم إصداره حديثاً ChatGPT o1-Pro.
تمت مقارنة النتائج من كلا النهجين مع النتائج المرجعية (المرجع A) التي تتعلق بالقرار البشري باستخدام برنامج Nvivo، كما هو موضح في المواد التكميلية 1. تم إصدار هذه النتائج المرجعية A من تحليل متعدد التخصصات بواسطة فريق متعدد الجنسيات من الأنثروبولوجيين وعلماء الاجتماع والأساتذة والمتخصصين في الصحة العامة البيطرية والبشرية الذين تم تشكيلهم سابقاً بواسطة بينيس وآخرون، 2017 [20].
موقع الدراسة
وصف الأدوات المستخدمة
نموذج لغوي مدعوم بالتعلم الآلي والعميق ومطور في أبحاث Google يعرف باسم Notebook LM، يسمح التحليل والتوليف التفاعلي للعلماء لمجموعات نصية كبيرة [24]. نموذج DeepMind Gemini 1.5 Advanced Ultra هو نموذج معالجة لغة طبيعية
يدعم تحليلات أكثر تعقيداً وتوليفاً دقيقاً كما تم تسويقه [25]. وهذا يجعل كلا الأداتين مناسبين لتحليل المحتوى الأكاديمي أو المهني حيث تم تصميمهما بهياكل لتوليف كميات كبيرة من البيانات. في ديسمبر، تم تقديم نماذج جديدة ومحدثة أخرى. Gemini 2.0 Advanced هو النموذج الذي يحسن القدرات في المهام المعقدة مثل البرمجة، الرياضيات، المنطق، والتعليم [26]. GrokV2 هو نموذج دردشة الذكاء الاصطناعي من X الذي تم بناؤه مباشرة في منصة X (المعروفة سابقاً بتويتر) [27]. DeepSeekV3 مشهور بنموذجه اللغوي مفتوح المصدر الكبير مع مزيج من بنية الخبراء مجاناً بالكامل [28]. ChatGPT o1 هو النسخة الجديدة من GPT4 (المحول المدرب مسبقاً التوليدي). هذا النموذج لمعالجة اللغة الطبيعية حل محل وظيفة o1-preview في ديسمبر. يتم تقديمه بخصوصية قضاء المزيد من الوقت في التفكير قبل فهم هيكل المهمة وحلها بشكل أكثر فعالية [29]. أخيراً، ChatGPT o1-Pro، نموذج تم إنتاجه بواسطة OpenAI يكلف 200 دولار شهرياً، هو الأكثر فائدة للمهام المهنية بما في ذلك البحث الأكاديمي والتحليل الذي يحتاج إلى نتائج ذكاء اصطناعي متسقة وعالية الجودة عبر تفاعلات متعددة من الطلبات، والفهم، والتفكير [30].
إجراءات جمع البيانات والتحضير
عملية تحليل البيانات
المرحلة 1A: تحليل دقة الترميز النوعي لاستجابات الطلاب
تم ترميز كل استجابة بشكل مستقل، باستخدام خمس فئات: 1: تأثير نفسي سلبي؛ 2: تأثير طبيعي أو لا تأثير؛ 3: تأثير مختلط بين السلبي والطبيعي؛ 4: لا استجابة محددة للسؤال؛ 0: لا استجابة (صندوق فارغ). تم استخدام تسعة نماذج ذكاء اصطناعي توليدية خلال هذه المرحلة لتحليل الاقتباسات مرتين (ترميز 1، 2)، مع الكتابة فوق نتائج التحليل الأول قبل بدء الثاني لتجنب أي تأثير تعلم على النموذج. علاوة على ذلك، كانت نماذج الذكاء الاصطناعي

ومع ذلك، تم صياغة نفس الطلب لنماذج الذكاء الاصطناعي دون تعلم مسبق (انظر الطلبات في المرحلة 1A في المواد التكميلية 3). تم حفظ النتائج التي تم الحصول عليها في تنسيق Excel أو CSV نصي. تم مرافقة تحليل البيانات بتسجيل فيديو لتوثيق العملية. جعل إجراء نفس التحليل مرتين لكل نموذج من الممكن مقارنة الاتساق الداخلي لجميع استجابات الطلاب (المواد التكميلية 1). على سبيل المثال، تم تسهيل تصنيف متقاطع لجميع استجابات الطلاب باستخدام مؤشر كابا لكوهين، الذي تم استخدامه لتحديد مدى أداء أنماط معينة مستمدة من الترميز الداخلي والخارجي مقارنة بتلك المستمدة من دفتر الرموز المرجعية (المواد التكميلية 4).
لهذا التحليل الجديد، تم استهداف فقط مجموعة فرعية من 79 طالباً أعلنوا أنهم متأثرون بداء الليشمانيا الجلدي. لحساب كابا كوهين باستخدام برنامج Jamovi، تم إعداد ملف Excel جديد ليشمل فقط بيانات الاختيار حول الطلاب المستهدفين (المواد التكميلية 5).
المرحلة 1C: تحليل مستوى الأهمية بين استجابات الطلاب المعلنة بأنها متأثرة بداء الليشمانيا الجلدي، ومقارنتها حسب الجنس حول طرق التحليل المستخدمة
- (P) وجود تأثير نفسي اجتماعي. إعادة تصنيف 1 إلى P (تأثير نفسي).
- (N) لا أو ربما من تأثير نفسي (N). إعادة تصنيف 2 أو 3 إلى N (لا تأثير نفسي).
- (U) لا رد محدد على السؤال أو لا رد على الإطلاق. إعادة تصنيف 0 أو 4 إلى U (غير محدد).
المرحلة 2: ملخص نوعي للمواضيع والمواضيع الفرعية
تم تنفيذ طريقة 2-1 مرتين لجميع النماذج التسعة لتوليد الذكاء الاصطناعي (بعد كل إكمال، تم حذف النتائج السابقة قبل إعادة تشغيل نفس الطلب). نتيجةً لهذا الطلب، تم إنشاء نصين لكل نموذج، تم تسجيلهما كملفات PDF تُعرف باسم “1st” و”2nd”. في الوقت نفسه، استخدمت طريقة 2-2 طلبًا موحدًا آخر، مما أدى إلى إنشاء ملفين PDF إضافيين يُطلق عليهما “3rd” و”4th”. لفهم هذه العملية بشكل أفضل، تتوفر عرضان فيديو في [32] و[33].
نتائج دفتر السجل من Llama 3.1 405B تم ترميزها كنموذج “B”. نتائج NotebookLM تم ترميزها كنموذج “C”؛ نتائج Gemini 1.5 Advanced Ultra تم ترميزها كنموذج “D”؛ نتائج Claude 3.5 Sonnet تنتمي إلى نموذج “E”؛ نتائج ChatGPT o1-Pro تقع تحت نموذج “F”؛ نتائج ChatGPT o1 تم ترميزها كنموذج “G”؛ تم ترميز GrokV2 كنموذج “H”؛ DeepSeekV3 تم ترميزها كنموذج “K” وأخيرًا، تم ترميز Gemini 2.0 Advanced كنموذج “M”.
تم تقديم موجه المرجع A في المرحلة 2 في نموذج ذكاء اصطناعي منفصل يسمى Perplexity Pro لتطوير موضوعات المرجع A وموضوعاته الفرعية بشكل مستقل [34]. في الواقع، باستخدام موجهات منظمة (المادة التكميلية 11) التي تجمع المعلومات من النص المنشور الذي تمت مراجعته من قبل الأقران والإطار الذي تم تضمينه سابقًا في مقال بينيس وآخرون 2017 والمقدم في المادة التكميلية 12. أربع تكرارات من نفس الشيء
تم إنشاء المطالبات باستخدام نموذج Perplexity لتغطية النتائج المستهدفة المشتركة بين المطالبات الأربعة المتعاقبة التي تم إنشاؤها، كما هو موضح في [35]. تهدف هذه الطريقة إلى ضمان التناسق مع المعرفة التي تم تأسيسها سابقًا مع الاستفادة من إمكانيات الذكاء الاصطناعي في التوليف والتنظيم الموضوعي المنهجي.
المرحلة 3: التحليل المقارن لدقة الموضوعات الفرعية في التركيب بواسطة النماذج B و C و D و E و F و G و H و K و M المدعومة بالذكاء الاصطناعي. مقارنةً بالمرجع
ثم، تم تطبيق طلب للمرحلة 3A (انظر المواد التكميلية 15) بشكل منهجي لكل نموذج محدد. من خلال إدخال حرف “X”، لم يكن هناك حاجة لاستبدال حرف النموذج المحدد B، C، D، E، F، G، H، K، وM يدويًا لكل طلب. (كما هو موضح في عرض الفيديو) [36]. يجب ملاحظة أن استخدام NotebookLM كان مدفوعًا كونه النموذج الوحيد الذي يمكنه قبول أكثر من 50 موردًا كمرفقات لنفس المشروع، مما ساعد على إعادة إنتاج النتائج من خلال إعادة تشغيل نفس الطلبات المتكررة. علاوة على ذلك، كانت إمكانية اختيار موارد دقيقة في كل مرة مثالية لتجنب أي تعلم غير مقصود قد يؤثر على توليد نتائج النموذج المحدد.
ثم، المرحلة 3B، تم حساب دقة الموضوعات الفرعية المحددة باستخدام النماذج المدعومة بالذكاء الاصطناعي مقارنةً بالنتائج المرجعية (A) مع تطبيق مؤشر جاكارد.
إن مؤشر جاكارد يُعرف بأنه النسبة بين التقاطع والاتحاد لمجموعات الموضوعات الفرعية المرجعية المتعلقة بالموضوعات الفرعية لكل من النماذج المستخدمة من خلال تطبيق الصيغة التالية:
نظرية مؤسسية لرؤى إطار جديدة
| المقارنة بين الأزواج | تقدير الاتساق الداخلي (الأول مقابل الثاني) | تقدير التوافق الخارجي مع المرجع الأولي A |
| مانا_1 | 0.88 [0.83، 0.92] | 0.74 [0.68، 0.80] |
| مانا_2 | 0.82 [0.77، 0.87] | |
| كلود_الأول | 0.99 [0.97، 1.00] | 0.78 [0.73، 0.84] |
| كلود_2 | 0.78 [0.73، 0.84] | |
| نوتبوك إل إم_1 | 0.93 [0.89، 0.96] | 0.72 [0.65، 0.78] |
| نوتبوك إل إم_2 | 0.76 [0.71، 0.82] | |
| جمني1.5_1 | 0.92 [0.89، 0.96] | 0.73 [0.67، 0.79] |
| جمني1.5_2 | 0.77 [0.72، 0.83] | |
| لاما_1 | 0.79 [0.73، 0.86] | 0.75 [0.68، 0.82] |
| لاما_2 | 0.78 [0.72, 0.83] | |
| شات جي بي تي – 01_1 | 0.80 [0.75، 0.85] | 0.77 [0.71، 0.82] |
| شات جي بي تي-01_2 | 0.71 [0.65، 0.76] | |
| شات جي بي تي-01 برو_1 | 0.97 [0.94، 0.99] | 0.79 [0.74، 0.85] |
| شات جي بي تي – 01 برو – 2 | 0.79 [0.73، 0.84] | |
| جروك V2_1 | 0.78 [0.72، 0.84] | 0.66 [0.60، 0.73] |
| جروك V2_2 | 0.77 [0.71، 0.83] | |
| ديب سيك V3_1 | 0.90 [0.86، 0.94] | 0.76 [0.70، 0.81] |
| ديب سيك V3_2 | 0.75 [0.69، 0.81] | |
| جمني2.0_1 | 0.79 [0.74، 0.85] | 0.63 [0.57، 0.69] |
| جمني2.0_2 | 0.76 [0.70، 0.82] |
تفي الدراسة بمعايير SRQR (معايير الإبلاغ عن البحث النوعي) الموجودة في المادة التكميلية 21 [42].
النتائج
توثقت النتائج في الجدول 2 أنماطًا محددة عبر مجموعات الجنس في قدرات التحليل النوعي المدعوم بالذكاء الاصطناعي. أظهرت Llama 3.1 405B توافقًا خارجيًا مستمرًا مع المرجع A (Карра
| نموذج | كابا_الجميع_الأول ضد ريف_A | كابا_الجميع_الثاني ضد ريف_أ | التناسق الداخلي جميع 1 ضد 2 | كابا_أنثى_الأولى ضد ريف_أ | كابا_أنثى_المرتبة الثانية ضد ريف_أ | الاتساق الداخلي الإناث 1 مقابل 2 | كابا_ذكر_الأول ضد ريف_أ | كابا_ ذكر_ الثاني ضد ريف_أ | الاتساق الداخلي الذكور 1 مقابل 2 |
| رجل | 0.59 (0.42-0.77) | 0.77 (0.63-0.92) | 0.82 (0.72-0.93) | 0.47 (0.15-0.79) | 0.76 (0.44-1.00) | 0.57 (0.25-0.90) | 0.63 (0.44-0.83) | 0.78 (0.61-0.94) | 0.88 (0.80-0.96) |
| سونيت كلود 3.5 | 0.66 (0.51-0.81) | 0.71 (0.54-0.87) | 0.98 (0.94-1.00) | 0.80 (0.52-1.00) | 0.80 (0.52-1.00) | 1.00 (1.00-1.00) | 0.64 (0.47-0.81) | 0.70 (0.51-0.89) | 0.97 (0.92-1.00) |
| نوتبوك إل إم | 0.76 (0.64-0.88) | 0.82 (0.71-0.93) | 0.91 (0.81-1.00) | 0.64 (0.38-0.90) | 0.78 (0.56-1.00) | 0.73 (0.41-1.00) | 0.80 (0.67-0.93) | 0.83 (0.71-0.95) | 0.97 (0.91-1.00) |
| جمني 1.5 المتقدم ألترا | 0.77 (0.63-0.90) | 0.82 (0.71-0.93) | 0.97 (0.92-1.00) | 0.78 (0.58-0.99) | 0.88 (0.70-1.00) | 0.90 (0.73-1.00) | 0.76 (0.59-0.93) | 0.80 (0.67-0.93) | 0.99 (0.98-1.00) |
| لياما 405B | 0.82 (0.68-0.97) | 0.83 (0.68-0.97) | 0.97 (0.92-1.00) | 0.82 (0.51-1.00) | 0.82 (0.51-1.00) | 1.00 (1.00-1.00) | 0.82 (0.66-0.98) | 0.83 (0.67-0.99) | 0.95 (0.88-1.00) |
| شات جي بي تي 01 | 0.78 (0.64-0.92) | 0.70 (0.58-0.83) | 0.79 (0.67-0.92) | 0.80 (0.52-1.00) | 0.64 (0.38-0.90) | 0.85 (0.63-1.00) | 0.77 (0.62-0.93) | 0.73 (0.59-0.86) | 0.78 (0.62-0.93) |
| شات جي بي تي o1_PRO | 0.81 (0.69-0.94) | 0.81 (0.69-0.94) | 1.00 (1.00-1.00) | 0.80 (0.52-1.00) | 0.80 (0.52-1.00) | 1.00 (1.00-1.00) | 0.82 (0.68-0.96) | 0.82 (0.68-0.96) | 1.00 (1.00-1.00) |
| غروك V2 | 0.76 (0.64-0.87) | 0.79 (0.66-0.91) | 0.90 (0.80-0.99) | 0.77 (0.56-0.98) | 0.80 (0.52-1.00) | 0.74 (0.50-0.99) | 0.75 (0.61-0.89) | 0.80 (0.67-0.94) | 0.94 (0.86-1.00) |
| ديب سيك V3 | 0.78 (0.66-0.90) | 0.75 (0.61-0.90) | 0.92 (0.81-1.00) | 0.64 (0.38-0.90) | 0.80 (0.52-1.00) | 0.85 (0.63-1.00) | 0.83 (0.71-0.95) | 0.76 (0.59-0.93) | 0.93 (0.80-1.00) |
| جمني 2.0 المتقدم | 0.69 (0.54-0.84) | 0.73 (0.62-0.85) | 0.80 (0.65-0.94) | 0.96 (0.90-1.00) | 0.80 (0.52-1.00) | 0.85 (0.85-1.00) | 0.63 (0.45-0.82) | 0.74 (0.60-0.87) | 0.80 (0.64-0.95) |
حدد التحليل خمسة مواضيع رئيسية تشمل 24 موضوعًا فرعيًا مميزًا، كما هو موضح في الجدول 4: مفهوم الذات (أربعة مواضيع فرعية تتناول الهوية الشخصية)، صورة الجسم (ثلاثة مواضيع فرعية تركز على المظهر)، الوصمة الاجتماعية (خمسة مواضيع فرعية تفحص التأثيرات بين الأفراد)، الوصمة الذاتية (ستة مواضيع فرعية توضح الاستجابات النفسية)، وسلوك البحث عن الصحة (ستة مواضيع فرعية تغطي التكيف والعلاج).
أخيرًا، سمحت لنا نظرية الأساس المستندة إلى الذكاء الاصطناعي المتبعة في المرحلة 3C بالحصول على نتائج جديدة من المواضيع والمواضيع الفرعية المقدمة في الملف الإضافي 10qua. تم استخدام تلك النتائج لإنشاء الإطار النهائي.
أنتج التحليل إطار دائرة الفراكتال للثغرات، وهو إطار متكامل لفهم التأثيرات النفسية والاجتماعية متعددة المستويات لمرض الليشمانيا الجلدية (الشكل 2)، ويتكون من خمس دوائر مترابطة: الجوهر الشخصي، دائرة العلاقات، المجال الاجتماعي الثقافي، السياق المؤسسي، وعوامل المرونة. وقد تضمن هذا الإطار أبعادًا لم يتم تناولها سابقًا، بما في ذلك الوصمة الناتجة عن الارتباط، والوصمة الهيكلية، والتجارب الخاصة بالجنس.
تقدم الهيكل الدائري للإطار، الذي يبرز التفاعلات المستمرة بين المجالات، فهمًا أكثر دقة لكيفية تفاعل مستويات التأثير المختلفة واستمرارها في تعزيز نقاط الضعف. ومن الأهمية الخاصة العناصر التي تم تحديدها حديثًا مثل الوصمة الناتجة عن الارتباط التي تؤثر على أفراد الأسرة والجهات المقربة، والوصمة الهيكلية التي تشمل الحواجز النظامية، والتجارب المحددة حسب الجنس التي تبرز التأثيرات غير المتناسبة على النساء والفتيات.
نقاش
| توزيع الجنس | النتائج الأولى | النتائج الثانية | |||||||
| P | ن | أنت | تشي
|
P | ن | أنت | تشي
|
||
| المرجع أ ل63 ردًا |
|
٢٥ | ٦ | 0 | 0.65 | ||||
|
|
23 | ٨ | 1 | ||||||
| المرجع أ لعدد 79 ردًا |
|
٢٥ | ٦ | ٤ | 0.14 | ||||
|
|
23 | ٨ | ١٣ | ||||||
| رجل لـ 63 ردًا |
|
٢٤ | ٧ | 0 | 0.01* | 27 | ٤ | 0 | 0.04* |
|
|
21 | ٤ | ٧ | ٢٢ | ٤ | ٦ | |||
| رجل لـ 79 ردًا |
|
٢٤ | ٧ | ٤ | 0.006* | 27 | ٤ | ٤ | 0.01* |
|
|
21 | ٤ | 19 | ٢٢ | ٤ | ١٨ | |||
| كلود سونيت لـ 63 ردًا |
|
26 | ٤ | 1 | 0.13 | 26 | ٤ | 1 | 0.1 |
|
|
21 | ٥ | ٦ | 21 | ٤ | ٧ | |||
| كلود سونيت لـ 79 ردًا |
|
26 | ٤ | ٥ | 0.027* | 26 | ٤ | ٥ | 0.02* |
|
|
21 | ٥ | ١٨ | 21 | ٤ | 19 | |||
| NoteboookLM لـ 63 ردود |
|
٢٤ | ٥ | 2 | 0.39 | ٢٥ | ٥ | 1 | 0.28 |
|
|
٢٢ | ٤ | ٦ | ٢٢ | ٥ | ٥ | |||
| NoteboookLM لـ 79 ردود |
|
٢٤ | ٥ | ٦ | 0.06 | ٢٥ | ٥ | ٥ | 0.05 |
|
|
٢٢ | ٤ | ١٨ | ٢٢ | ٥ | 17 | |||
| جمني 1.5 لـ 63 استجابة |
|
٢٥ | ٥ | 1 | 0.28 | ٢٤ | ٦ | 1 | 0.25 |
|
|
٢٢ | ٥ | ٥ | 23 | ٤ | ٥ | |||
| جمني 1.5 لـ 79 استجابة |
|
٢٥ | ٥ | ٥ | 0.05 | ٢٤ | ٦ | ٥ | 0.04* |
|
|
٢٢ | ٥ | 17 | 23 | ٤ | 17 | |||
| لاما لـ 63 ردًا |
|
26 | ٥ | 0 | 0.75 | 26 | ٥ | 0 | 0.36 |
|
|
٢٥ | ٧ | 0 | 23 | 9 | 0 | |||
| لاما لـ 79 ردًا |
|
26 | ٥ | ٤ | 0.18 | 26 | ٥ | ٤ | 0.12 |
|
|
٢٥ | ٧ | 12 | 23 | 9 | 12 | |||
| ChatGPT o1 لـ 63 ردود |
|
26 | ٤ | 1 | 0.09 | ٢٥ | ٥ | 1 | 0.21 |
|
|
٢٢ | ٣ | ٧ | 19 | 10 | ٣ | |||
| ChatGPT o1 لـ 79 ردود |
|
26 | ٤ | ٥ | 0.02* | ٢٥ | ٥ | ٥ | 0.04* |
|
|
٢٢ | ٣ | 19 | 19 | 10 | 15 | |||
| ChatGPT o1 PRO لـ 63 ردًا |
|
26 | ٤ | 1 | 0.19 | 26 | ٤ | 1 | 0.19 |
|
|
23 | ٣ | ٦ | 23 | ٣ | ٦ | |||
| ChatGPT o1 PRO مقابل 79 ردًا |
|
26 | ٤ | ٥ | 0.03* | 26 | ٤ | ٥ | 0.03* |
|
|
23 | ٣ | 18 | 23 | ٣ | 18 | |||
| جروك V2 لـ 63 ردًا |
|
٢٤ | ٦ | 1 | 0.74 | 26 | ٤ | 1 | 0.52 |
|
|
23 | ٦ | ٣ | ٢٤ | ٤ | ٤ | |||
| جروك V2 لـ 79 ردًا |
|
٢٤ | ٦ | ٥ | 0.13 | 26 | ٤ | ٥ | 0.08 |
|
|
٢٣ | ٦ | 15 | ٢٤ | ٤ | 16 | |||
| DeepSeekV3 لـ 63 استجابة |
|
25 | ٥ | 1 | 0.31 | 26 | ٤ | 1 | 0.17 |
|
|
23 | ٤ | ٥ | ٢٢ | ٤ | ٦ | |||
| DeepSeekV3 لـ 79 استجابة |
|
٢٥ | ٥ | ٥ | 0.05 | 26 | ٤ | ٥ | 0.03* |
|
|
23 | ٤ | 17 | ٢٢ | ٤ | ١٨ | |||
| جمني 2.0 لـ 63 استجابة |
|
٢٥ | ٤ | 2 | 0.11 | 26 | ٤ | 1 | 0.28 |
|
|
18 | ٧ | ٧ | ٢٢ | ٦ | ٤ | |||
| جمني 2.0 لـ 79 استجابة |
|
٢٥ | ٤ | ٦ | 0.01 | 26 | ٤ | ٥ | 0.07 |
|
|
١٨ | ٧ | 19 | ٢٢ | ٦ | 16 | |||
(N) لا أو ربما من التأثير النفسي (N). إعادة ترميز 2 أو 3 إلى N (لا تأثير نفسي)
(U) لا رد محدد على السؤال أو لا رد على الإطلاق. إعادة ترميز 0 أو 4 إلى U (غير محدد)
(*)
| الموضوع الرئيسي | مرجع الموضوع الفرعي A | شرح موجز للموضوع الفرعي للمرجع A |
| تصور الذات | الثقة بالنفس | فقدان الثقة بالنفس بسبب الندوب |
| تقدير الذات | انخفاض تقدير الذات المرتبط بالمظهر | |
| الوعي الذاتي | زيادة الوعي بالمظهر الجسدي | |
| احتقار الذات | الكراهية الذاتية بسبب الندوب | |
| صورة الجسم | جمال الجسم | الانشغال بجمال الجسم |
| مظهر الوجه | أهمية المظهر الوجه | |
| آثار الندبات التجميلية | التأثيرات التجميلية للندوب | |
| وصمة اجتماعية | عائلة | العلاقات الأسرية المتأثرة بخوف العدوى |
| تجنب من قبل الآخرين | تجنب الآخرين بسبب الندوب | |
| ازدراء اجتماعي | الازدراء الاجتماعي للندوب | |
| صعوبات الزواج | صعوبات الزواج المرتبطة بالمظهر الجسدي | |
| خوف من الرفض | خوف من الرفض الاجتماعي والعدوى | |
| الوصمة الذاتية | إحراج | مشاعر الانزعاج المرتبطة بالندوب |
| عار | تشعر بالخجل من مظهرك في الأماكن العامة | |
| قلق |  |
|
| حزن | |
|
| الاكتئاب | الاكتئاب الناتج عن الندوب | |
| أفكار انتحارية | أفكار انتحارية مرتبطة بالندوب | |
| سلوك البحث عن الصحة | تقليدي | استخدام العلاجات التقليدية لعلاج الندبات |
| العلاجات التقليدية | العلاجات الطبية التقليدية غالبًا ما تكون غير فعالة. | |
| استراتيجيات التكيف | استراتيجيات التكيف لإخفاء الندوب | |
| الدعم النفسي | أحتاج إلى دعم نفسي للتعامل مع الندوب. | |
| تدخل الحكومة | دعوة للتدخل الحكومي لضمان الرعاية بأسعار معقولة. |
دقة وتناسق نماذج الذكاء الاصطناعي التطورية
من خلال معاملات كابا الموزونة ومؤشرات جاكارد، وهي مقاييس مقبولة على نطاق واسع لمدى موثوقية التحليلات. إحدى الرؤى المهمة المتعلقة بمعالجة الاستجابات الغامضة: كانت النسخ السابقة من النموذج أكثر عرضة لتصنيف الاستجابات على أنها غير محددة (U)، خاصة عندما كانت البيانات معقدة. هذا يعالج التحسن الملحوظ في قدرة النماذج الجديدة على معالجة التحليل النوعي الطبوغرافي بعمق وفهم أفضل للتحولات السلوكية النفسية الاجتماعية. هذا التحسين في القدرة التحليلية يلبي ضرورة موثوقية تصنيفات استجابات الذكاء الاصطناعي هذه.
تعتبر عمليات مراقبة الجودة من حيث التطوير أو الوصول إلى استنتاج بناءً على إمكانية إعادة إنتاج التحليل أكثر وأكثر ضرورة في بعض النماذج [16]. على سبيل المثال، أصبح من الممكن الآن إجراء تحليل المشاعر باستخدام أحدث النماذج اللغوية، خاصة تلك التي تستهدف وسائل التواصل الاجتماعي مثل Grok وLlama، وهو ما لم يكن ممكنًا مع LLM قبل ثلاث سنوات فقط [44]. لم يتم الوصول بعد إلى سباق عالمي لإنشاء نماذج ذكاء اصطناعي توليدية أكثر تقدمًا قادرة على إجراء تحليل نوعي دقيق وحساس للبيانات [45]. ومع ذلك، استنادًا إلى مؤشر جاكارد، من السهل تأكيد أنه في هذه الدراسة الحديثة، تميل أحدث إصدارات نماذج الذكاء الاصطناعي الجديدة (ChatGPT، Gemini، DeepSeek) على مدى الشهرين إلى الأربعة أشهر الماضية إلى أن تكون أكثر دقة في أي تحليل نوعي. لذلك، في المستقبل، سيكون هناك المزيد من النماذج المدربة مسبقًا وأقل من المطالبات اليدوية لتحليل دقة أسهل ومراجعة [17، 46].
فعالية التثليث المدعوم بالذكاء الاصطناعي
تظهر هذه الدراسة أن نماذج الذكاء الاصطناعي يمكن أن تعمل كأداة مثلثية آلية، مما يجعل التحليلات تتجاوز البيانات الأولية وتنتج أطرًا تفسيرية أو فرضيات أكثر [48]. يمكن أن تترجم هذه النماذج اللغات واللهجات المنطوقة في جمل (أو اقتباسات) مشابهة مثل الدارجة المغربية، الأمازيغية المغربية، العربية المغربية أو الفرنسية دون مشكلة كبيرة. كان من المتوقع أن يؤثر الارتفاع المتوقع في التكرارات بشكل إيجابي على تدابير مراقبة الجودة والمثلثية.
رؤى نظرية grounded A.l.
| نموذج(نماذج) | جاكار (A, X1_X2) | جاكارد (A، X3_X4) | جاكار (A, X1_X2_X3_X4) | مواضيع فرعية مشتركة
|
مواضيع فرعية فردية
|
صيغة حساب مؤشر جاكارد لأربعة تركيبات نوعية لنفس النموذج J (A, X) |
| ب: ليما 3.1 | 0.67 | 0.63 | 0.79 | 19 | ٢٤ | 19 / (24 + 19-19) |
| ج: نوتبوك إل إم | 0.54 | 0.54 | 0.63 | 15 | ٢٤ | 15 / (24+15-15) |
| دي: جمنائي 1.5 أدف أولترا | 0.58 | 0.71 | 0.75 | ١٨ | ٢٤ | 18 / (24 + 18 – 18) |
| إي: كلود 3.5 سونيت | 0.50 | 0.83 | 0.83 | 20 | ٢٤ | 20 / (24+20-20) |
| F: دردشة GPTo1 PRO | 0.96 | 1.00 | 1.00 | ٢٤ | ٢٤ | 24 / (24+24-24) |
| جي: دردشة جي بي تي 01 | 0.87 | 0.96 | 1.00 | ٢٤ | ٢٤ | 24 / (24 + 24 – 24) |
| H: جروك V2 | 0.92 | 0.96 | 1.00 | ٢٤ | ٢٤ | 24 / (24+24-24) |
| K: DeepSeek V3 | 0.83 | 1.00 | 1.00 | ٢٤ | ٢٤ | 24 / (24 + 24 – 24) |
| M: جمنائي 2.0 المتقدم | 0.87 | 0.92 | 0.92 | ٢٢ | ٢٤ | 22 / (24+22-22) |
دائرة الفراكتل للثغرات
هذا النهج الهجين. الاتساق في هذا الإطار (الشكل 2)، خاصة فيما يتعلق بالدراسات الخاصة بالجنس، يعني سهولة فهم الفرق بين الآثار النفسية الاجتماعية ووجود مثل هذه الآثار النفسية الاجتماعية، متجاوزاً إمكانية التصنيف المفرط لاستكشاف بعض هذه الأفكار والبنى التي تؤكد على المرونة. في الواقع، تشير المرونة إلى طرق أوسع للتعامل مع التجارب الفردية والظروف الهيكلية المرتبطة بثغرات CL. هذه الأدلة بارزة بشكل خاص في التحليلات الخاصة بالجنس، حيث أظهرت الذكاء الاصطناعي قدرته على التقاط الفروق الدقيقة في التجارب الحياتية، وهي عملية حيوية لتطوير النظرية المستندة [14] والمنهجية [7]. علاوة على ذلك، شملت الموضوعات الفرعية التي تم التقاطها بناءً على تحليل الاقتباسات جميع الجوانب المختارة، مثل ما تم تقديمه في المراجعة المنهجية التي تستكشف الآثار الثقافية للجنس على تصورات CL [50]. هذه الطريقة المقترحة للتعامل مع هذه الظاهرة النوعية باستخدام الذكاء الاصطناعي تستند إلى المفهوم الذي تم اقتراحه لأول مرة في عام 2021 والذي ركز على تطوير التعايش المتناغم والتعاون بين نماذج الذكاء الاصطناعي التوليدية والبشر في تحليل البيانات النوعية [51].
CAQDAS مقابل الأنظمة النوعية – الذكاء الاصطناعي
نموذج توليدي جديد قائم على الذكاء الاصطناعي يستهدف الباحثين النوعيين لتمكينهم من تحليل كميات أكبر من البيانات النوعية وتحسين جودتها وتغطيتها وأهميتها. بالإضافة إلى ذلك، يمكن تطبيق مثل هذه النماذج التوليدية للذكاء الاصطناعي في العديد من التخصصات الصحية الأخرى، وقد حققت أحدث نماذج التفكير بالذكاء الاصطناعي نتائج تتجاوز تفكير الأطباء البشر دون أي حواجز لغوية أو تواصلية [53-55].
المتطلبات المسبقة لممارسة البحث النوعي بالذكاء الاصطناعي
الأساليب الكلاسيكية، من أجل تفكير أكثر صرامة حول الأساليب النوعية المستندة إلى التجارب غير العادية [57]. قد يحتاج الباحثون إلى تعزيز مهارات أخرى، مثل مثلث الذكاء الاصطناعي، لقراءة وتقييم جودة مثل هذه النتائج. بخلاف ذلك، لدى الذكاء الاصطناعي القدرة على المساعدة في تبسيط بعض جوانب عمليات التحليل النوعي من خلال تقليل عدد تباين المحققين مع الحفاظ على عمق التحليل البشري.
القيود والآفاق
تمثل قيود أخرى تجلت منهجياً في التحليل مرتبطة بنموذج Llama 405B الذي قدم نمطًا تحليليًا مميزًا، خاصة عند التعامل مع عينة الاستجابة 63، حيث أظهر حسمًا ملحوظًا من خلال تقليل التصنيفات غير القابلة للتحديد، وتقليل الفئات غير المؤكدة وإظهار قدرة عالية على إجراء تمييز ثنائي بين وجود وغياب الآثار النفسية الاجتماعية. ومع ذلك، يجب توخي الحذر بشأن هذا الحسم خوفًا من تصنيفه المفرط المحتمل [59]. اعتبار آخر مهم هو أن تكنولوجيا الذكاء الاصطناعي تتقدم بسرعة. تمثل النتائج ما يمكن أن يفعله الذكاء الاصطناعي في وقت معين. ومع ذلك، كما هو موضح في قسم النتائج لجمنائي وChatGPT، قد تحتوي الإصدارات المستقبلية على ميزات وتطورات أفضل. قد يكون قبول أو عدم استخدام أدوات الذكاء الاصطناعي التوليدية من قبل الباحثين الجامعيين الكبار أو من قبل الباحثين ذوي الإنتاجية البحثية العالية موضوع نقاش مرتبط بأخلاقيات استخدام الذكاء الاصطناعي في البحث النوعي [60]. يجب أن تهدف الأبحاث المستقبلية إلى إجراء دراسات شاملة ضمن خلفيات ثقافية ولغوية متنوعة، وفحص أداء الذكاء الاصطناعي عبر
حالات صحية وسياقات نفسية اجتماعية مختلفة، وتأسيس أطر موحدة لتقييم البحث النوعي المدعوم بالذكاء الاصطناعي. بعض الإنتاجات قيد المراجعة بالفعل، وستتبعها المزيد من الإنتاجات القابلة للتنبؤ قريبًا [61، 62]. سيوسع هذا من موثوقية وفائدة التحليل النوعي المعزز بالذكاء الاصطناعي في أبحاث الرعاية الصحية من أجل نشر أفضل مع أعلى تأثيرات مؤثرة بدلاً من الاقتباسات.
الخاتمة
الاختصارات
| الذكاء الاصطناعي. | الذكاء الاصطناعي (التوليدي) |
| CAQDAS | برامج تحليل البيانات النوعية المدعومة بالحاسوب |
| CL | الليشمانيا الجلدية |
| LLMs | نماذج اللغة الكبيرة |
| NLP | معالجة اللغة الطبيعية |
| SRQR | معايير تقارير البحث النوعي |
المعلومات التكميلية
المادة التكميلية 1: ملف إضافي 1bis. المرحلة 1A قاعدة بيانات كاملة 31 122024
المادة التكميلية 3: الملف الإضافي 1. المحفزات المستخدمة في المرحلة 1A
المادة التكميلية 4: الملف الإضافي 1تر. حساب كابا كوهين للمرحلة 1A 31122024
شكر وتقدير
مساهمات المؤلفين
تمويل
توفر البيانات
الإعلانات
موافقة الأخلاقيات والموافقة على المشاركة
(بنس وآخرون، 2017) [20]. تمت الموافقة على الدراسة الأصلية من قبل اللجنة الأخلاقية للبحوث الطبية الحيوية في الرباط، المغرب (CERB). لم يكن هناك حاجة لموافقة أخلاقية إضافية، حيث كانت هذه الدراسة تتعلق بتحليل بيانات ثانوية. كانت مجموعة البيانات المستخدمة مجهولة الهوية بالكامل، ولم تحدث أي تفاعلات جديدة مع المشاركين البشريين. يعترف المؤلفون بأنجرامرلي.كومتم استخدام Microsoft Office Version 6.8.263 للمساعدة في تحرير اللغة، ولكن لم يتم استخدامه لإنشاء محتوى أصلي.
موافقة على النشر
المصالح المتنافسة
نُشر على الإنترنت: 10 مارس 2025
References
- De Paoli S. Performing an inductive thematic analysis of semi-structured interviews with a large Language model: an exploration and provocation on the limits of the approach. Soc Sci Comput Rev. 2024;42:997-1019.
- Hitch D. Artificial intelligence augmented qualitative analysis: the way of the future?? Qual Health Res. 2024;34:595-606.
- Chapman A, Hadfield M, Chapman C. Qualitative research in healthcare: an introduction to grounded theory using thematic analysis. J R Coll Physicians Edinb. 2015;45:201-5.
- Leech NL, Onwuegbuzie AJ. Beyond constant comparison qualitative data analysis: using NVivo. Sch Psychol Q. 2011;26:70-84.
- Starks H, Brown Trinidad S. Choose your method: a comparison of phenomenology, discourse analysis, and grounded theory. Qual Health Res. 2007;17:1372-80.
- Stough LM, Lee S. Grounded theory approaches used in educational research journals. Int J Qual Methods. 2021;20:16094069211052203.
- Charmaz K, Thornberg R. The pursuit of quality in grounded theory. Qual Res Psychol. 2021;18:305-27.
- André E. Reflections on qualitative data analysis software- possibilities, limitations and challenges in qualitative educational research. Rev Electrónica En Educ Pedagog. 2020;4:41-55.
- Pérez Gamboa AJ, Díaz-Guerra DD. Artificial intelligence for the development of qualitative studies. LatIA. 2023;1:4.
- Sawicki J, Ganzha M, Paprzycki M. The state of the art of natural language processing-A systematic automated review of NLP literature using NLP techniques. Data Intell. 2023;5:707-49.
- Abdüsselam MS. Qualitative data analysis in the age of artificial general intelligence. Int J Adv Nat Sci Eng Res. 2023.
- Morgan DL. Exploring the use of artificial intelligence for qualitative data analysis: the case of ChatGPT. Int J Qual Methods. 2023;22:16094069231211248.
- Atkinson CF. Cheap, quick, and rigorous: artificial intelligence and the systematic literature review. Soc Sci Comput Rev. 2024;42:376-93.
- Zhang H, Wu C, Xie J, Lyu Y, Cai J, Carroll JM. Redefining qualitative analysis in the AI era: utilizing ChatGPT for efficient thematic analysis. 2024. https://arxiv. org/abs/2309.10771
- Zala K, Acharya B, Mashru M, Palaniappan D, Gerogiannis VC, Kanavos A, et al. Transformative automation: AI in scientific literature reviews. Int J Adv Comput Sci Appl IJACSA. 2024;15.
- Rodrigues Dos Anjos J, De Souza MG, Serrano De Andrade Neto A, Campello De Souza B. An analysis of the generative AI use as analyst in qualitative research in science education. Rev Pesqui Qual. 2024;12:01-29.
- Chubb LA. Me and the machines: possibilities and pitfalls of using artificial intelligence for qualitative data analysis. Int J Qual Methods. 2023;22:16094069231193593.
- Christou P. How to use Artificial Intelligence (AI) as a resource, methodological and analysis tool in qualitative research? Qual Rep. 2023. https://doi.org/1 0.46743/2160-3715/2023.6406
- Antons D, Breidbach CF, Joshi AM, Salge TO. Computational literature reviews: method, algorithms, and roadmap. Organ Res Methods. 2023;26:107-38.
- Bennis I, Thys S, Filali H, De Brouwere V, Sahibi H, Boelaert M. Psychosocial impact of scars due to cutaneous leishmaniasis on high school students in errachidia province, Morocco. Infect Dis Poverty. 2017;6:46.
- Alderton DL, Ackley C, Trueba ML. The psychosocial impacts of skinneglected tropical diseases (SNTDs) as perceived by the affected persons: a systematic review. PLoS Negl Trop Dis. 2024;18:e0012391.
- Llama 3. 1. Meta Llama. https://Ilama.meta.com/. Accessed 4 Aug 2024.
- Introducing Claude 3.5 Sonnet Anthropic. https://www.anthropic.com/ne ws/claude-3-5-sonnet. Accessed 4 Aug 2024.
- NotebookLM| Note Taking & Research Assistant. Powered by Al. https://noteb ooklm.google/. Accessed 4 Aug 2024.
- Gemini Ultra. Google DeepMind. 2024. https://deepmind.google/technologi es/gemini/ultra/. Accessed 4 Aug 2024.
- Gemini Advanced. accédez aux modèles d’IA les plus performants de Google avec Gemini 2.0. Gemini. https://gemini.google/advanced/. Accessed 6 Jan 2025.
- Grok. X (formerly Twitter). https://x.com/i/grok. Accessed 6 Jan 2025.
- DeepSeek. https://www.deepseek.com/. Accessed 6 Jan 2025.
- Learning to Reason with LLMs. https://openai.com/index/learning-to-reaso n-with-Ilms/. Accessed 6 Jan 2025.
- Introducing ChatGPT Pro. https://openai.com/index/introducing-chatgpt-pro /. Accessed 6 Jan 2025.
- French translation of participants’ responses to the last question. Available online https://static-content.springer.com/esm/art%3A10.1186%2Fs40249-0 17-0267-5/MediaObjects/40249_2017_267_MOESM4_ESM.pdf
- I Bennis. Additional file 5bis Phase 21 Claude 3.5 Sonnet 1st video demonstration. 2025. https://www.youtube.com/watch?v=UmJI7DGYheo. Accessed 8 Jan 2025.
- Bennis I. Additional file 5ter Phase 22 Gemini 20 Advanced 4th video demonstration. 2025. https://www.youtube.com/watch?v=o25Hd3vw7R8. Accessed 8 Jan 2025.
- Perplexity collaborates with Amazon Web Services to launch Enterprise Pro. h ttps://www.perplexity.ai/hub/blog/perplexity-collaborates-with-amazon-we b-services-to-launch-enterprise-pro. Accessed 6 Jan 2025.
- I Bennis. Additional file 6ter Phase 2 Reference A Perplexity results video demonstration. 2025. https://www.youtube.com/watch?v=jTwjw5WHZ7w. Accessed 8 Jan 2025.
- I Bennis. Additional file 8bis Phase 3A All AI Models results 20250106 video demonstration. 2025. https://www.youtube.com/watch?v=EboN18on4rl. Accessed 8 Jan 2025.
- Niwattanakul S, Singthongchai J, Naenudorn E, Wanapu S. Using of Jaccard Coefficient for Keywords Similarity. Hong Kong. 2013. https://www.iaeng.org/ publication/IMECS2013/IMECS2013_pp380-384.pdf
- Zahrotun L. Comparison Jaccard similarity, cosine similarity and combined both of the data clustering with shared nearest neighbor method. Comput Eng Appl J. 2016;5:11-8.
- Vijaymeena MK, Kavitha K. A survey on similarity measures in text mining. Mach Learn Appl Int J. 2016;3:19-28.
- Bennis I. Additional file 10ter Grounded theory analysis 20250106 video demonstration. 2025. https://www.youtube.com/watch?v=8XbjpP_bR1U. Accessed 8 Jan 2025.
- Napkin AI. Jan – The visual AI for business storytelling. Napkin AI. https://www w.napkin.ai. Accessed 72025.
- O’Brien BC, Harris IB, Beckman TJ, Reed DA, Cook DA. Standards for reporting qualitative research: A synthesis of recommendations. Acad Med. 2014;89:1245-51.
- LeBeau B, Ellison S, Aloe AM. Reproducible analyses in education research. Rev Res Educ. 2021;45:195-222.
- Md A, Ali Khan A-E. Sentiment analysis through machine learning. J Southwest Jiaotong Univ. 2021;56.
- Martin S, Beecham E, Kursumovic E, Armstrong RA, Cook TM, Déom N et al. Comparing human vs. machine-assisted analysis to develop a new approach for. Big Qualitative Data Anal. 2024;2024.07.16.24310275.
- Aditya G. Understanding and addressing AI hallucinations in healthcare and life sciences. Int J Health Sci. 2024;7:1-11.
- Donkoh S, Mensah J. Application of triangulation in qualitative research. J Appl Biotechnol Bioeng. 2023;10:6-9.
- Thomas J, Harden A. Methods for the thematic synthesis of qualitative research in systematic reviews. BMC Med Res Methodol. 2008;8:45.
- Using AI. In Grounded Theory research – a proposed framework for a ChatGPT-based research assistant. Accessed 7 Jan 2025. https://osf.io/preprin ts/socarxiv/a2dc4_v1
- Wenning B, Price H, Nuwangi H, Reda KT, Walters B, Ehsanullah R, et al. Exploring the cultural effects of gender on perceptions of cutaneous leishmaniasis: a systematic literature review. Glob Health Res Policy. 2022;7:1-13.
- Feuston JL, Brubaker JR. Putting tools in their place: the role of time and perspective in Human-AI collaboration for qualitative analysis. Proc ACM Hum-Comput Interact. 2021;5:1-25.
- Levitt HM. Qualitative generalization, not to the population but to the phenomenon: reconceptualizing variation in qualitative research. Qual Psychol. 2021;8:95-110.
- Levine DM, Tuwani R, Kompa B, Varma A, Finlayson SG, Mehrotra A, et al. The diagnostic and triage accuracy of the GPT-3 artificial intelligence model: an observational study. Lancet Digit Health. 2024;6:e555-61.
- Tanaka Y, Nakata T, Aiga K, Etani T, Muramatsu R, Katagiri S, et al. Performance of generative pretrained transformer on the National medical licensing examination in Japan. PLOS Digit Health; 2024;3(1):e0000433.
- Fang C, Wu Y, Fu W, Ling J, Wang Y, Liu X, et al. How does ChatGPT-4 preform on non-English National medical licensing examination? An evaluation in Chinese Language. PLOS Digit Health. 2023;2:e0000397.
- Karjus A. Machine-assisted mixed methods: augmenting humanities and social sciences with artificial intelligence. 2023. https://arxiv.org/abs/2309.143 79
- Kim H, Sefcik JS, Bradway C. Characteristics of qualitative descriptive studies: A systematic review. Res Nurs Health. 2017;40:23-42.
- Weidener L, Fischer M. Teaching AI ethics in medical education: A scoping review of current literature and practices. Perspect Med Educ. 2023;12.
- Tao K, Osman ZA, Tzou PL, Rhee S-Y, Ahluwalia V, Shafer RW. GPT-4 performance on querying scientific publications: reproducibility, accuracy, and impact of an instruction sheet. BMC Med Res Methodol. 2024;24:139.
- Marshall DT, Naff DB. The ethics of using artificial intelligence in qualitative research. J Empir Res Hum Res Ethics. 2024;19:92-102.
- Leça M, de Valença M, Santos L, de Santos R. S. Applications and Implications of Large Language Models in Qualitative Analysis: A New Frontier for Empirical Software Engineering. 2024. https://arxiv.org/abs/2412.06564
- Schroeder H, Quéré MAL, Randazzo C, Mimno D, Schoenebeck S. Large Language Models in Qualitative Research: Can We Do the Data Justice? 2024. https://doi.org/10.48550/ARXIV.2410.07362
ملاحظة الناشر
- *المراسلات:
عصام بنيس
issambennis@gmail.com; issambennis@um6ss.ma
¹مدرسة محمد السادس الدولية للصحة العامة، جامعة محمد السادس للعلوم والصحة، الدار البيضاء، المغرب
DOI: https://doi.org/10.1186/s12911-025-02961-5
PMID: https://pubmed.ncbi.nlm.nih.gov/40065373
Publication Date: 2025-03-10
Advancing AI-driven thematic analysis in qualitative research: a comparative study of nine generative models on Cutaneous Leishmaniasis data
Abstract
Background As part of qualitative research, the thematic analysis is time-consuming and technical. The rise of generative artificial intelligence (A.I.), especially large language models, has brought hope in enhancing and partly automating thematic analysis. Methods The study assessed the relative efficacy of conventional against AI-assisted thematic analysis when investigating the psychosocial impact of cutaneous leishmaniasis (CL) scars. Four hundred forty-eight participant responses from a core study were analysed comparing nine A.I. generative models: Llama 3.1 405B, Claude 3.5 Sonnet, NotebookLM, Gemini 1.5 Advanced Ultra, ChatGPT o1-Pro, ChatGPT o1, GrokV2, DeepSeekV3, Gemini 2.0 Advanced with manual expert analysis. Jamovi software maintained methodological rigour through Cohen’s Kappa coefficient calculations for concordance assessment and similarity measurement via Python using Jaccard index computations. Results Advanced A.I. models showed impressive congruence with reference standards; some even had perfect concordance (Jaccard index = 1.00). Gender-specific analyses demonstrated consistent performance across subgroups, allowing a nuanced understanding of psychosocial consequences. The grounded theory process developed the framework for the fragile circle of vulnerabilities that incorporated new insights into CL-related psychosocial complexity while establishing novel dimensions. Conclusions This study shows how A.I. can be incorporated in qualitative research methodology, particularly in complex psychosocial analysis. Consequently, the A.I. deep learning models proved to be highly efficient and accurate. These findings imply that the future directions for qualitative research methodology should focus on maintaining analytical rigour through the utilisation of technology using a combination of A.I. capabilities and human expertise following standardised future checklist of reporting full process transparency. Keywords Artificial intelligence in qualitative research, Large language models, Thematic analysis, Grounded theory development, Natural language processing, Research automation, Cutaneous leishmaniasis
Background
There are several examples where A.I. is applicable to enhance the holistic components of qualitative analysis by automating the steps of qualitative research that most researchers consider tedious or repetitive, including transcription, translation and initial coding texts [11]. Automating these manual workflows turbocharges result generation, allows focus more on interpretative analytics and aids with potential bias [9]. They also indicate another potential advantage in that the analytical algorithms that A.I. use can be analysed by behavioural thresholds unattainable by humans so that more nuanced analyses beyond the scope (which humans may miss or
overlook) are possible to run [13]. In addition, A.I. text can serve as a valuable comparator for research interpretation, potentially uncovering biases and expanding interpretative frameworks
Furthermore, qualitative research requires immersive interpretation, acceptance of unusual reflections, and flexibility paradigms from the researcher, considered part of the analysis process, making it incredibly misunderstood for A.I. algorithms to prompt [2, 18]. Therefore, caution must be taken while using A.I. and interpreting A.I. based results [18, 19]. Hence, researchers need to check and verify their ongoing results by doing strict quality control procedures, including rigorous appraisal and validation of research outputs [12, 13, 17]. In this context, this study seeks to assess whether ChatGPT o1-Pro and a diverse set of eight other generative A.I. models can improve the accuracy of qualitative synthesis in complex evidence concerning the psychosocial burden of cutaneous leishmaniasis scarring when compared to traditional human-led qualitative analysis approaches.
Materials
Study design
Participants
July 2024 and December 2024 were two time slots for choosing the different A.I. models. The selected models reflect the latest in deep learning for language generation and was promoted as applicating better natural language-processing algorithms. Models from the July cohort included Llama 3.1 405B, Claude 3.5 Sonnet, NotebookLM, Gemini 1.5 Advanced Ultra and ChatGPT o1-preview models. While from the December cohort included ChatGPT o1 that replaced the preview one, GrokV2, DeepSeekV3, and Gemini 2.0 Advanced. The 9th model that was added was in December 2024 a recently released very advanced commercial model ChatGPT o1-Pro.
The results from both approaches were compared with reference findings (Named Reference A) corresponding to the human decision with Nvivo software, as shown in Suplementary material 1. These reference A findings were issued from a multi-disciplinary analysis by a multinational team of anthropologists, sociologists, professors and specialists in veterinary and human public health built earlier by Bennis et al., 2017 [20].
Study location
Description of instruments used
A language model powered by machine and deep learning and developed at Google Research known as Notebook LM, scientists-interactive-exploration allows for analysis and synthesis of large text corpora [24]. The DeepMind Gemini 1.5 Advanced Ultra is a NLP model
that supports more intricate analysis and exact synthesis as marketed [25]. This makes both tools suitable to analyse academic or professional content since they have been designed with architectures for synthesising large volumes of data. In December, other updated and new models were introduced. Gemini 2.0 Advanced is the model that improves capabilities in complex tasks like programming, mathematics, logic, and teaching [26]. GrokV2 is X’s A.I. chatbot model solution ended up building directly into the X platform (Former Twitter) [27]. DeepSeekV3 is famous for its large open-source language model with a mixture of expert architecture fully free of charge [28]. ChatGPT o1 is the new version of GPT4 (Generative Pre-trained Transformer). This natural language processing model replaced in December the o1-preview functionality. It is presented with the particularity to spend more time reasoning before understanding the task structure and solving it more effectively [29]. Lastly, ChatGPT o1-Pro, a model produced by OpenAI that costs 200 dollars per month, is the most useful for professional tasks including academic research and analysis that need consistent, high-quality A.I. results across multiple requests interactions, understanding, and reasoning [30].
Data collection and preparation procedures
Data analysis process
Phase 1A: analysis of the accuracy of qualitative coding of student responses
Each response was coded independently, using five categories: 1: Negative psychological effect; 2: Normal effect or no effect; 3: Mixed effect between negative and normal; 4: No specific response to the question; 0 : No response (empty box). The nine generative A.I. models were used during this phase to analyse the quotes twice (coded 1st, 2nd), overwriting the results of the first analysis before launching the second to avoid any learning effect on the model. Moreover, the A.I. models were
However, the same prompt was formulated for the A.I. models without prior learning (See prompts of Phase 1A in Supplementary material 3). The results obtained were saved in Excel or text CSV format. Analysing the data was accompanied by a video capture to record the process. Carrying out the same analysis twice for each model made it possible to compare the internal consistency of all the students’ responses (Supplementary material 1 ). For instance, a cross-classification of all students’ responses was facilitated using Cohen’s kappa index, which was used to determine how well specific patterns derived from internal and external coding performed compared to those derived from the reference codebook (Supplementary material 4).
For this new analysis, only the subgroup of 79 students who declared themselves affected with cutaneous leishmaniasis was targeted. To calculate the Cohen Kappa using the Jamovi software, a new Excel file was prepared to include only the data selection about the targeted students (Supplementary material 5).
Phase 1C: analysis of the significance level between the students’ responses declared affected by cutaneous leishmaniasis, comparing them by gender about the analysis methods used
- (P) Presence of psychosocial effect. Re-categorisation 1 to P (Psychological effect).
- (N) No or maybe of psychological effect (N). Re-categorisation 2 or 3 to N (No psychological effect).
- (U) No specific reply to the question or no reply at all. Re-categorisation 0 or 4 to U (Undecided).
Phase 2: qualitative summary of themes and sub-themes
The method 2-1 prompt was done twice for all the nine A.I. generative models (After each completion, prior results were deleted before rerunning the same prompt). As a result of this prompt, two file texts were created per model, recorded as PDF files known as “1st” and “2nd”. Meanwhile, method 2-2 prompt used another unified request, leading to two additional PDFs named “3rd” and “4th”. To better understand this process, two video demonstrations are available in [32] and [33].
The logbook results from Llama 3.1 405B were coded as Model “B”. NotebookLM results coded Model “C”; Gemini 1.5 Advanced Ultra results coded Model “D”; Claude 3.5 Sonnet results belong to Model “E”; ChatGPT o1-Pro results fall under Model “F”; ChatGPT o1 results coded Model “G”; GrokV2 were coded as Model “H”; DeepSeekV3 coded as Model “K” and finally, Gemini 2.0 Advanced coded as Model “M”.
Phase 2 Reference A’s prompt was introduced in a separate A.I. model named Perplexity Pro to independently develop this Reference A themes and sub-themes [34]. Indeed, using structured prompts (Supplementary material 11) that synthesise information from the published peer-reviewed text and framework previously included in the Bennis et al. 2017 article and presented in Supplementary material 12. Four iterations of the same
prompt were made using the Perplexity model to cover the targeted results shared between the four successive prompts generated, as shown in [35]. This approach aims to ensure consistency with previously established knowledge while leveraging A.I.’s potential for systematic thematic synthesis and organisation.
Phase 3: comparative analysis of the sub-themes accuracy of the synthesis by models B, C, D, E, F, G, H, K and M supported by A.I. Compared to reference
Then, a prompt for Phase 3A (see Supplementary material 15 ) was applied systematically for each specific model. By introducing the ” X ” letter, there was no need to replace manually for each prompt the specific model letter B, C, D, E, F, G, H, K, and M. (as shown in the video demonstration) [36]. It should be noted that using NotebookLM was motivated by being the only model that could accept more than 50 resources as attachments for the same project, which helped the reproducibility of the results by rerunning the same repetitive prompts. Moreover, the possibility of selecting precise resources each time was perfect for avoiding any unintended learning that could influence the generation of specific model results.
Then, phase 3B, calculated the accuracy of the subthemes identified using the Models supported by A.I. compared to the reference results (A) with the application of Jaccard’s index.
Indeed, Jaccard’s index is defined as the ratio between the intersection and union of the sets of reference subthemes concerning the sub-themes of each of the models used by applying the following formula:
Grounded theory for new framework insights
| Pair-Wise comparaison | Estimation of internal consistency (1st vs. 2nd) | Estimation of the external consistency with the initial reference A |
| ManA_1st | 0.88 [0.83, 0.92] | 0.74 [0.68, 0.80] |
| ManA_2nd | 0.82 [0.77, 0.87] | |
| Claude_1st | 0.99 [0.97, 1.00] | 0.78 [0.73, 0.84] |
| Claude_2nd | 0.78 [0.73, 0.84] | |
| NoteboookLM_1st | 0.93 [0.89, 0.96] | 0.72 [0.65, 0.78] |
| NoteboookLM_2nd | 0.76 [0.71, 0.82] | |
| Gemini1.5_1st | 0.92 [0.89, 0.96] | 0.73 [0.67, 0.79] |
| Gemini1.5_2nd | 0.77 [0.72, 0.83] | |
| LlaMA_1st | 0.79 [0.73, 0.86] | 0.75 [0.68, 0.82] |
| LlaMA_2nd | 0.78 [0.72, 0.83] | |
| ChatGPT-o1_1st | 0.80 [0.75, 0.85] | 0.77 [0.71, 0.82] |
| ChatGPT-o1_2nd | 0.71 [0.65, 0.76] | |
| ChatGPT-o1PRO_1st | 0.97 [0.94, 0.99] | 0.79 [0.74, 0.85] |
| ChatGPT-o1PRO_2nd | 0.79 [0.73, 0.84] | |
| GrokV2_1st | 0.78 [0.72, 0.84] | 0.66 [0.60, 0.73] |
| GrokV2_2nd | 0.77 [0.71, 0.83] | |
| DeepSeekV3_1st | 0.90 [0.86, 0.94] | 0.76 [0.70, 0.81] |
| DeepSeekV3_2nd | 0.75 [0.69, 0.81] | |
| Gemini2.0_1st | 0.79 [0.74, 0.85] | 0.63 [0.57, 0.69] |
| Gemini2.0_2nd | 0.76 [0.70, 0.82] |
The study meets the SRQR (Standards for Reporting Qualitative Research) found in Supplementary material 21 [42].
Results
The results in Table 2 documented specific patterns across gender subgroups in AI-driven qualitative analysis capabilities. Llama 3.1 405B demonstrated consistent external alignment with Reference A (Карра
| Model | Kappa_All_1st Vs Ref_A | Kappa_All_2nd Vs Ref_A | Internal_Consistency All 1st Vs 2nd | Kappa_ Female_1st Vs Ref_A | Kappa_ Female_2nd Vs Ref_A | Internal_Consistency Female 1st Vs 2nd | Kappa_Male_1st Vs Ref_A | Kappa_ Male_2nd Vs Ref_A | Internal_Consistency Male 1st Vs 2nd |
| Man | 0.59 (0.42-0.77) | 0.77 (0.63-0.92) | 0.82 (0.72-0.93) | 0.47 (0.15-0.79) | 0.76 (0.44-1.00) | 0.57 (0.25-0.90) | 0.63 (0.44-0.83) | 0.78 (0.61-0.94) | 0.88 (0.80-0.96) |
| Claude 3.5 Sonnet | 0.66 (0.51-0.81) | 0.71 (0.54-0.87) | 0.98 (0.94-1.00) | 0.80 (0.52-1.00) | 0.80 (0.52-1.00) | 1.00 (1.00-1.00) | 0.64 (0.47-0.81) | 0.70 (0.51-0.89) | 0.97 (0.92-1.00) |
| NoteboookLM | 0.76 (0.64-0.88) | 0.82 (0.71-0.93) | 0.91 (0.81-1.00) | 0.64 (0.38-0.90) | 0.78 (0.56-1.00) | 0.73 (0.41-1.00) | 0.80 (0.67-0.93) | 0.83 (0.71-0.95) | 0.97 (0.91-1.00) |
| Gemini1.5 Advanced Ultra | 0.77 (0.63-0.90) | 0.82 (0.71-0.93) | 0.97 (0.92-1.00) | 0.78 (0.58-0.99) | 0.88 (0.70-1.00) | 0.90 (0.73-1.00) | 0.76 (0.59-0.93) | 0.80 (0.67-0.93) | 0.99 (0.98-1.00) |
| LIaMA 405B | 0.82 (0.68-0.97) | 0.83 (0.68-0.97) | 0.97 (0.92-1.00) | 0.82 (0.51-1.00) | 0.82 (0.51-1.00) | 1.00 (1.00-1.00) | 0.82 (0.66-0.98) | 0.83 (0.67-0.99) | 0.95 (0.88-1.00) |
| ChatGPT o1 | 0.78 (0.64-0.92) | 0.70 (0.58-0.83) | 0.79 (0.67-0.92) | 0.80 (0.52-1.00) | 0.64 (0.38-0.90) | 0.85 (0.63-1.00) | 0.77 (0.62-0.93) | 0.73 (0.59-0.86) | 0.78 (0.62-0.93) |
| ChatGPT o1_PRO | 0.81 (0.69-0.94) | 0.81 (0.69-0.94) | 1.00 (1.00-1.00) | 0.80 (0.52-1.00) | 0.80 (0.52-1.00) | 1.00 (1.00-1.00) | 0.82 (0.68-0.96) | 0.82 (0.68-0.96) | 1.00 (1.00-1.00) |
| GrokV2 | 0.76 (0.64-0.87) | 0.79 (0.66-0.91) | 0.90 (0.80-0.99) | 0.77 (0.56-0.98) | 0.80 (0.52-1.00) | 0.74 (0.50-0.99) | 0.75 (0.61-0.89) | 0.80 (0.67-0.94) | 0.94 (0.86-1.00) |
| DeepSeekV3 | 0.78 (0.66-0.90) | 0.75 (0.61-0.90) | 0.92 (0.81-1.00) | 0.64 (0.38-0.90) | 0.80 (0.52-1.00) | 0.85 (0.63-1.00) | 0.83 (0.71-0.95) | 0.76 (0.59-0.93) | 0.93 (0.80-1.00) |
| Gemini2.0 Advanced | 0.69 (0.54-0.84) | 0.73 (0.62-0.85) | 0.80 (0.65-0.94) | 0.96 (0.90-1.00) | 0.80 (0.52-1.00) | 0.85 (0.85-1.00) | 0.63 (0.45-0.82) | 0.74 (0.60-0.87) | 0.80 (0.64-0.95) |
The analysis identified five main themes encompassing 24 distinct sub-themes, as presented in Table 4: SelfConcept (four sub-themes addressing personal identity), Body Image (three sub-themes focusing on appearance), Social Stigma (five sub-themes examining interpersonal effects), Self-Stigma (six sub-themes detailing psychological responses), and Health Seeking Behaviour (six subthemes covering coping and treatment).
Finally, the A.I. grounded theory followed in phase 3C allowed us to get new themes and subthemes results presented in Additional file 10qua. Those results were used to create the final framework.
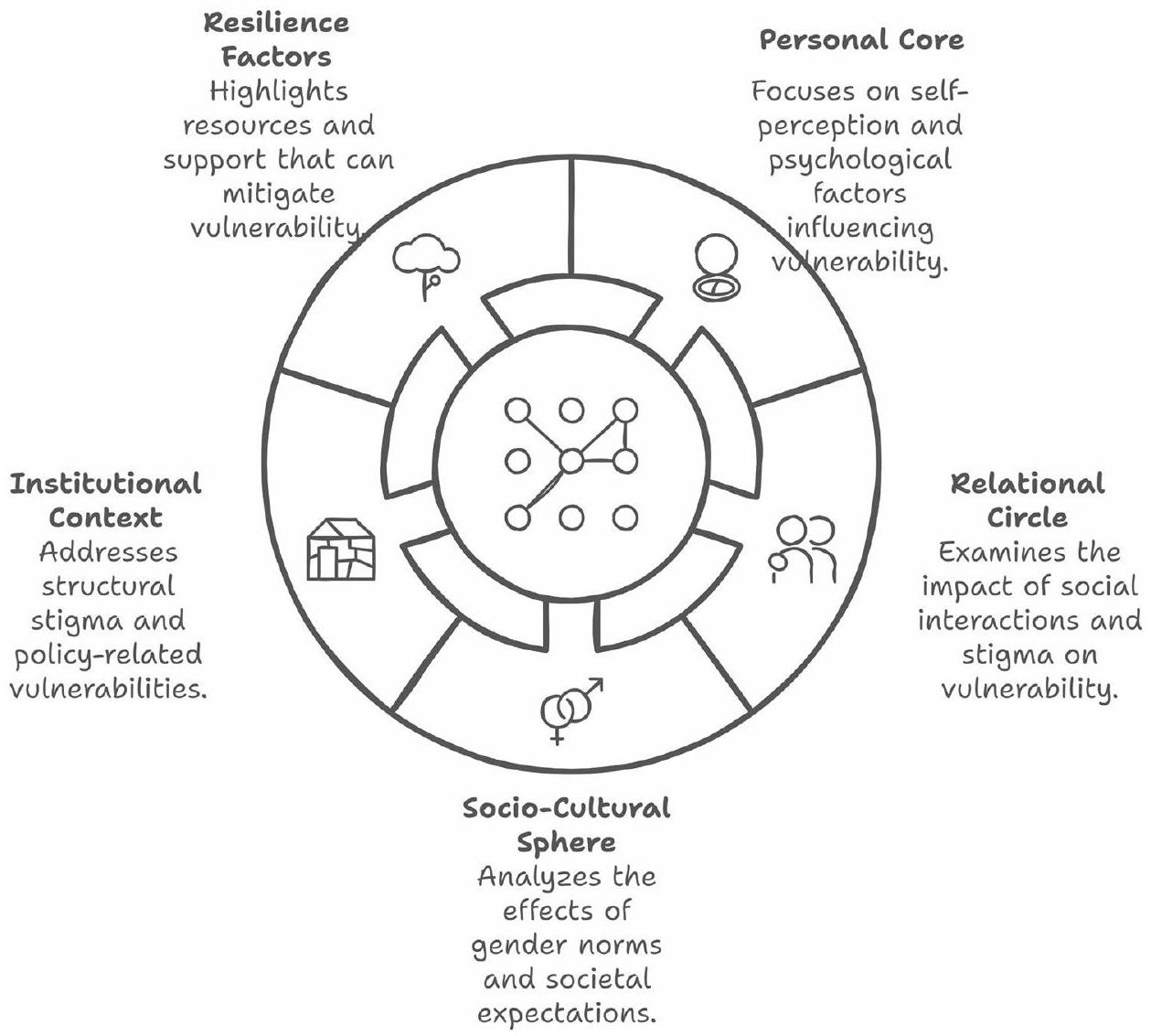
The analysis generated the Fractal circle of vulnerabilities framework, an integrated framework for understanding multi-level psychosocial impacts of cutaneous leishmaniasis (Fig. 2), comprising five interconnected spheres: Personal Core, Relational Circle, Socio-Cultural Sphere, Institutional Context, and Resilience Factors. This framework incorporated previously unaddressed dimensions, including stigma by association, structural stigma, and gender-specific experiences.
The framework’s circular structure, highlighting continuous interactions between spheres, introduces a more nuanced understanding of how different levels of influence interact and perpetuate vulnerabilities. Of particular significance are the newly identified elements such as stigma by association affecting family members and close contacts, structural stigma encompassing systemic barriers, and gender-specific experiences highlighting disproportionate impacts on women and girls.
Discussion
| Gender repartition | 1st Results | 2nd Results | |||||||
| P | N | U | Chi
|
P | N | U | Chi
|
||
| Ref A for 63 responses |
|
25 | 6 | 0 | 0.65 | ||||
|
|
23 | 8 | 1 | ||||||
| Ref A for 79 responses |
|
25 | 6 | 4 | 0.14 | ||||
|
|
23 | 8 | 13 | ||||||
| Man for 63 responses |
|
24 | 7 | 0 | 0.01* | 27 | 4 | 0 | 0.04* |
|
|
21 | 4 | 7 | 22 | 4 | 6 | |||
| Man for 79 responses |
|
24 | 7 | 4 | 0.006* | 27 | 4 | 4 | 0.01* |
|
|
21 | 4 | 19 | 22 | 4 | 18 | |||
| Claude Sonnet for 63 responses |
|
26 | 4 | 1 | 0.13 | 26 | 4 | 1 | 0.1 |
|
|
21 | 5 | 6 | 21 | 4 | 7 | |||
| Claude Sonnet for 79 responses |
|
26 | 4 | 5 | 0.027* | 26 | 4 | 5 | 0.02* |
|
|
21 | 5 | 18 | 21 | 4 | 19 | |||
| NoteboookLM for 63 responses |
|
24 | 5 | 2 | 0.39 | 25 | 5 | 1 | 0.28 |
|
|
22 | 4 | 6 | 22 | 5 | 5 | |||
| NoteboookLM for 79 responses |
|
24 | 5 | 6 | 0.06 | 25 | 5 | 5 | 0.05 |
|
|
22 | 4 | 18 | 22 | 5 | 17 | |||
| Gemini1.5 for 63 responses |
|
25 | 5 | 1 | 0.28 | 24 | 6 | 1 | 0.25 |
|
|
22 | 5 | 5 | 23 | 4 | 5 | |||
| Gemini1.5 for 79 responses |
|
25 | 5 | 5 | 0.05 | 24 | 6 | 5 | 0.04* |
|
|
22 | 5 | 17 | 23 | 4 | 17 | |||
| LlaMA for 63 responses |
|
26 | 5 | 0 | 0.75 | 26 | 5 | 0 | 0.36 |
|
|
25 | 7 | 0 | 23 | 9 | 0 | |||
| LlaMA for 79 responses |
|
26 | 5 | 4 | 0.18 | 26 | 5 | 4 | 0.12 |
|
|
25 | 7 | 12 | 23 | 9 | 12 | |||
| ChatGPT o1 for 63 responses |
|
26 | 4 | 1 | 0.09 | 25 | 5 | 1 | 0.21 |
|
|
22 | 3 | 7 | 19 | 10 | 3 | |||
| ChatGPT o1 for 79 responses |
|
26 | 4 | 5 | 0.02* | 25 | 5 | 5 | 0.04* |
|
|
22 | 3 | 19 | 19 | 10 | 15 | |||
| ChatGPT o1 PRO for 63 responses |
|
26 | 4 | 1 | 0.19 | 26 | 4 | 1 | 0.19 |
|
|
23 | 3 | 6 | 23 | 3 | 6 | |||
| ChatGPT o1 PRO for 79 responses |
|
26 | 4 | 5 | 0.03* | 26 | 4 | 5 | 0.03* |
|
|
23 | 3 | 18 | 23 | 3 | 18 | |||
| GrokV2 for 63 responses |
|
24 | 6 | 1 | 0.74 | 26 | 4 | 1 | 0.52 |
|
|
23 | 6 | 3 | 24 | 4 | 4 | |||
| GrokV2 for 79 responses |
|
24 | 6 | 5 | 0.13 | 26 | 4 | 5 | 0.08 |
|
|
23 | 6 | 15 | 24 | 4 | 16 | |||
| DeepSeekV3 for 63 responses |
|
25 | 5 | 1 | 0.31 | 26 | 4 | 1 | 0.17 |
|
|
23 | 4 | 5 | 22 | 4 | 6 | |||
| DeepSeekV3 for 79 responses |
|
25 | 5 | 5 | 0.05 | 26 | 4 | 5 | 0.03* |
|
|
23 | 4 | 17 | 22 | 4 | 18 | |||
| Gemini2.0 for 63 responses |
|
25 | 4 | 2 | 0.11 | 26 | 4 | 1 | 0.28 |
|
|
18 | 7 | 7 | 22 | 6 | 4 | |||
| Gemini2.0 for 79 responses |
|
25 | 4 | 6 | 0.01 | 26 | 4 | 5 | 0.07 |
|
|
18 | 7 | 19 | 22 | 6 | 16 | |||
(N) No or maybe of psychological effect (N). Recoding 2 or 3 to N (No psychological effect)
(U) No specific reply to the question or no reply at all. Recoding 0 or 4 to U (Undecided)
(*)
| Main theme | Sub-theme reference A | Brief explanation of subtheme of reference A |
| Self-Concept | Self-Confidence | Loss of self-confidence due to scars |
| Self-Esteem | Reduced self-esteem linked to appearance | |
| Self-Awareness | Increased awareness of physical appearance | |
| Self-Contempt | Self-loathing because of scars | |
| Body Image | Body Beauty | Preoccupation with body beauty |
| Face Appearance | The importance of facial appearance | |
| Scars Cosmetic Effects | Cosmetic effects of scars | |
| Social Stigma | Family | Family relationships affected by fear of contagion |
| Avoidance by Others | Avoidance by others because of scars | |
| Social Contempt | Social contempt for scars | |
| Marriage Difficulties | Marriage difficulties linked to physical appearance | |
| Fear of rejection | Fear of social rejection and contagion | |
| Self-Stigma | Embarrassment | Feelings of discomfort associated with scars |
| Shame | Ashamed of the way you look in public | |
| Anxiety | |
|
| Sadness | |
|
| Depression | Depression caused by scars | |
| Suicidal Ideas | Suicidal thoughts associated with scars | |
| Health Seeking Behaviour | Traditional | Using traditional remedies to treat scars |
| Conventional Treatments | Conventional medical treatments are often ineffective. | |
| Coping Strategies | Coping strategies to hide scars | |
| Psychological Support | Need psychological support to deal with scars. | |
| Government Intervention | Call for government intervention to ensure affordable care. |
The accuracy and consistency of A.I. evolutive models
via their weighted Kappa coefficients and their Jaccard indices, widely accepted measures of trustworthiness of analytics [1]. One important insight related to treating ambiguous responses: earlier model versions were much more prone to label responses as undecided (U), especially when complex data were involved. This addresses the notable improvement of new models’ ability to process topographic-qualitative in-depth analysis and better understand psychosocial behavioural transformations [43]. This enhancement of analytic capacity fulfils a necessity for the reliability of such A.I. responses categorisations.
Quality control processes in terms of development or making a conclusion based on the potential of reproducibility of the analysis more and more in some models is needed urgently [16]. For example, it would now be possible to conduct sentiment analysis using the most advanced linguistic models, especially those targeting social media like Grok and Llama, which was not the case with LLM just three years before [44]. A worldwide race for creating more advanced reasoning A.I. generative models capable of conducting delicate, sentimental qualitative data analysis has not yet been reached [45]. Nevertheless, based on the Jaccard index, it is easy to confirm that in this recent study, the latest versions of new A.I. models (ChatGPT, Gemini, DeepSeek) over the past two through four months tend to be more accurate for any qualitative analysis. Therefore, in future, there will be more pre-trained models and fewer manual prompts for an easier accuracy analysis and review [17, 46].
Al-assisted triangulation efficacy
This study shows that A.I. models can serve as automated triangulation, making analyses go beyond the initial data and producing more interpretative frames or hypotheses [48]. These models could translate languages and dialects spoken in similar sentences (or quotes) like Moroccan Darija, Moroccan Amazigh, Moroccan Arabic or French without much problem. An anticipated rise in iterations was expected to affect quality control measures and triangulation positively.
A.l. grounded theory insights
| Model(s) | Jaccard (A, X1_X2) | Jaccard (A, X3_X4) | Jaccard (A, X1_X2_X3_X4) | Shared sub-themes
|
Single sub-themes
|
The formula for calculating the Jaccard index for four qualitative syntheses of the same model J (A, X) |
| B: LIaMA 3.1 | 0.67 | 0.63 | 0.79 | 19 | 24 | 19 / (24 + 19-19) |
| C: NotebookLM | 0.54 | 0.54 | 0.63 | 15 | 24 | 15 / (24+15-15) |
| D: Gemini1.5 Adv Ultra | 0.58 | 0.71 | 0.75 | 18 | 24 | 18 / (24 + 18-18) |
| E: Claude 3.5 Sonnet | 0.50 | 0.83 | 0.83 | 20 | 24 | 20 / (24+20-20) |
| F: Chat GPTo1 PRO | 0.96 | 1.00 | 1.00 | 24 | 24 | 24 / (24+24-24) |
| G: Chat GPTo1 | 0.87 | 0.96 | 1.00 | 24 | 24 | 24 / (24 + 24-24) |
| H: Grok V2 | 0.92 | 0.96 | 1.00 | 24 | 24 | 24 / (24+24-24) |
| K: DeepSeek V3 | 0.83 | 1.00 | 1.00 | 24 | 24 | 24 / (24 + 24-24) |
| M: Gemini2.0 Advanced | 0.87 | 0.92 | 0.92 | 22 | 24 | 22 / (24+22-22) |
Fractal Circle of Vulnerabilities
this hybrid approach. The consistency in this framework (Fig. 2), especially concerning gender-specific studies, implies the facility to understand the difference between psychosocial effects and the existence of such psychosocial effects, jumping the possibility of over-classification to explore some of these ideas and constructs that stress resilience. Indeed, resilience points towards broader ways to deal with individual experiences and structural conditions associated with CL vulnerabilities. Such evidence is particularly salient in gender-specific analyses, where A.I. has demonstrated its capacity to capture nuanced differences in lived experiences, a process vital to grounded theory development [14] and methodology [7]. Moreover, the captured subthemes based on the quote analysis included all the aspects selected, like what was presented in the systematic review exploring the cultural effects of gender on perceptions of CL [50]. This proposed way to deal with this qualitative phenomenon using A.I. is based on the concept first proposed in 2021 that focused on developing harmonious coexistence and collaboration between A.I. generative models and humans in qualitative data analysis [51].
CAQDAS vs qualitative -AI systems
A new AI-based generative model targets qualitative researchers to enable them to analyse larger volumes of qualitative data and improve its quality, coverage and importance. Additionally, such A.I. generative models could be applied in many other health disciplines, and most recent AI reasoning models achieved results exceeding human physicians’ reasoning without any language or communication barriers [53-55].
Prerequisites for AI qualitative research practice
the classical approaches, for more rigorous thinking on qualitative methods based on non-ordinary experiences [57]. Researchers may need to foster other skills, such as A.I. triangulation, to read and assess the quality of such findings. Other than this, A.I. has the potential to help streamline some aspects of qualitative analytic processes by thereby minimising the number of investigators’ heterogeneity while maintaining human analysis depth.
Limitations and prospects
Another limitation methodologically manifested itself in the analysis is linked to the Llama 405B model that presented a distinguishing analytical pattern, especially when handling the 63 -response sample, where it showed remarkable decisiveness by reducing undecidable categorisations, lowering uncertain categories and demonstrating a high ability to make binary distinctions between presence and absence of psychosocial effects. However, this decisiveness must be taken caution for fear of its potential over-classification [59]. Another weighty consideration is that A.I. technology is fast advancing. The findings represent what A.I. can do at a given time. However, as shown in the results section for Gemini and ChatGPT, future versions may have better features and advancements. Accepting or not using A.I. generative tools by senior university researchers or by researchers with high research productivity could be a subject of debate linked to the ethics of using A.I. in qualitative research [60]. Further research should aim to conduct wide-ranging studies within diverse cultural and linguistic backgrounds, examine A.I. performance across
different health conditions and psychosocial contexts, and establish standardised frameworks for evaluating AI-supported qualitative research. Some productions are already under review, and more predictable ones will follow shortly [61, 62]. This would broaden the reliability and usefulness of AI-enhanced qualitative analysis in healthcare research for a better publication with the highest influential impacts rather than citations.
Conclusion
Abbreviations
| A.I. | Artificial intelligence (Generative) |
| CAQDAS | Computer-assisted qualitative data analysis software |
| CL | Cutaneous Leishmaniasis |
| LLMs | Large Language Models |
| NLP | Natural language processing |
| SRQR | Standards for Reporting Qualitative Research |
Supplementary Information
Supplementary Material 1: Additional file 1bis. Phase 1A Full database 31 122024
Supplementary Material 3: Additional file 1. Prompts used in Phase 1A
Supplementary Material 4: Additional file 1ter. Phase1A Kappa Cohen R calculation 31122024
Acknowledgements
Author contributions
Funding
Data availability
Declarations
Ethics approval and consent to participate
(Bennis et al., 2017) [20]. The original study was approved by the Ethical Committee of Biomedical Research in Rabat, Morocco (CERB). No additional ethics approval was required, as this study involved secondary data analysis. The dataset used was fully anonymised, and no new interactions with human participants occurred. The authors acknowledge that Grammarly.com for Microsoft Office Version 6.8.263 was used for language editing assistance, but it was not employed for generating original content.
Consent for publication
Competing interests
Published online: 10 March 2025
References
- De Paoli S. Performing an inductive thematic analysis of semi-structured interviews with a large Language model: an exploration and provocation on the limits of the approach. Soc Sci Comput Rev. 2024;42:997-1019.
- Hitch D. Artificial intelligence augmented qualitative analysis: the way of the future?? Qual Health Res. 2024;34:595-606.
- Chapman A, Hadfield M, Chapman C. Qualitative research in healthcare: an introduction to grounded theory using thematic analysis. J R Coll Physicians Edinb. 2015;45:201-5.
- Leech NL, Onwuegbuzie AJ. Beyond constant comparison qualitative data analysis: using NVivo. Sch Psychol Q. 2011;26:70-84.
- Starks H, Brown Trinidad S. Choose your method: a comparison of phenomenology, discourse analysis, and grounded theory. Qual Health Res. 2007;17:1372-80.
- Stough LM, Lee S. Grounded theory approaches used in educational research journals. Int J Qual Methods. 2021;20:16094069211052203.
- Charmaz K, Thornberg R. The pursuit of quality in grounded theory. Qual Res Psychol. 2021;18:305-27.
- André E. Reflections on qualitative data analysis software- possibilities, limitations and challenges in qualitative educational research. Rev Electrónica En Educ Pedagog. 2020;4:41-55.
- Pérez Gamboa AJ, Díaz-Guerra DD. Artificial intelligence for the development of qualitative studies. LatIA. 2023;1:4.
- Sawicki J, Ganzha M, Paprzycki M. The state of the art of natural language processing-A systematic automated review of NLP literature using NLP techniques. Data Intell. 2023;5:707-49.
- Abdüsselam MS. Qualitative data analysis in the age of artificial general intelligence. Int J Adv Nat Sci Eng Res. 2023.
- Morgan DL. Exploring the use of artificial intelligence for qualitative data analysis: the case of ChatGPT. Int J Qual Methods. 2023;22:16094069231211248.
- Atkinson CF. Cheap, quick, and rigorous: artificial intelligence and the systematic literature review. Soc Sci Comput Rev. 2024;42:376-93.
- Zhang H, Wu C, Xie J, Lyu Y, Cai J, Carroll JM. Redefining qualitative analysis in the AI era: utilizing ChatGPT for efficient thematic analysis. 2024. https://arxiv. org/abs/2309.10771
- Zala K, Acharya B, Mashru M, Palaniappan D, Gerogiannis VC, Kanavos A, et al. Transformative automation: AI in scientific literature reviews. Int J Adv Comput Sci Appl IJACSA. 2024;15.
- Rodrigues Dos Anjos J, De Souza MG, Serrano De Andrade Neto A, Campello De Souza B. An analysis of the generative AI use as analyst in qualitative research in science education. Rev Pesqui Qual. 2024;12:01-29.
- Chubb LA. Me and the machines: possibilities and pitfalls of using artificial intelligence for qualitative data analysis. Int J Qual Methods. 2023;22:16094069231193593.
- Christou P. How to use Artificial Intelligence (AI) as a resource, methodological and analysis tool in qualitative research? Qual Rep. 2023. https://doi.org/1 0.46743/2160-3715/2023.6406
- Antons D, Breidbach CF, Joshi AM, Salge TO. Computational literature reviews: method, algorithms, and roadmap. Organ Res Methods. 2023;26:107-38.
- Bennis I, Thys S, Filali H, De Brouwere V, Sahibi H, Boelaert M. Psychosocial impact of scars due to cutaneous leishmaniasis on high school students in errachidia province, Morocco. Infect Dis Poverty. 2017;6:46.
- Alderton DL, Ackley C, Trueba ML. The psychosocial impacts of skinneglected tropical diseases (SNTDs) as perceived by the affected persons: a systematic review. PLoS Negl Trop Dis. 2024;18:e0012391.
- Llama 3. 1. Meta Llama. https://Ilama.meta.com/. Accessed 4 Aug 2024.
- Introducing Claude 3.5 Sonnet Anthropic. https://www.anthropic.com/ne ws/claude-3-5-sonnet. Accessed 4 Aug 2024.
- NotebookLM| Note Taking & Research Assistant. Powered by Al. https://noteb ooklm.google/. Accessed 4 Aug 2024.
- Gemini Ultra. Google DeepMind. 2024. https://deepmind.google/technologi es/gemini/ultra/. Accessed 4 Aug 2024.
- Gemini Advanced. accédez aux modèles d’IA les plus performants de Google avec Gemini 2.0. Gemini. https://gemini.google/advanced/. Accessed 6 Jan 2025.
- Grok. X (formerly Twitter). https://x.com/i/grok. Accessed 6 Jan 2025.
- DeepSeek. https://www.deepseek.com/. Accessed 6 Jan 2025.
- Learning to Reason with LLMs. https://openai.com/index/learning-to-reaso n-with-Ilms/. Accessed 6 Jan 2025.
- Introducing ChatGPT Pro. https://openai.com/index/introducing-chatgpt-pro /. Accessed 6 Jan 2025.
- French translation of participants’ responses to the last question. Available online https://static-content.springer.com/esm/art%3A10.1186%2Fs40249-0 17-0267-5/MediaObjects/40249_2017_267_MOESM4_ESM.pdf
- I Bennis. Additional file 5bis Phase 21 Claude 3.5 Sonnet 1st video demonstration. 2025. https://www.youtube.com/watch?v=UmJI7DGYheo. Accessed 8 Jan 2025.
- Bennis I. Additional file 5ter Phase 22 Gemini 20 Advanced 4th video demonstration. 2025. https://www.youtube.com/watch?v=o25Hd3vw7R8. Accessed 8 Jan 2025.
- Perplexity collaborates with Amazon Web Services to launch Enterprise Pro. h ttps://www.perplexity.ai/hub/blog/perplexity-collaborates-with-amazon-we b-services-to-launch-enterprise-pro. Accessed 6 Jan 2025.
- I Bennis. Additional file 6ter Phase 2 Reference A Perplexity results video demonstration. 2025. https://www.youtube.com/watch?v=jTwjw5WHZ7w. Accessed 8 Jan 2025.
- I Bennis. Additional file 8bis Phase 3A All AI Models results 20250106 video demonstration. 2025. https://www.youtube.com/watch?v=EboN18on4rl. Accessed 8 Jan 2025.
- Niwattanakul S, Singthongchai J, Naenudorn E, Wanapu S. Using of Jaccard Coefficient for Keywords Similarity. Hong Kong. 2013. https://www.iaeng.org/ publication/IMECS2013/IMECS2013_pp380-384.pdf
- Zahrotun L. Comparison Jaccard similarity, cosine similarity and combined both of the data clustering with shared nearest neighbor method. Comput Eng Appl J. 2016;5:11-8.
- Vijaymeena MK, Kavitha K. A survey on similarity measures in text mining. Mach Learn Appl Int J. 2016;3:19-28.
- Bennis I. Additional file 10ter Grounded theory analysis 20250106 video demonstration. 2025. https://www.youtube.com/watch?v=8XbjpP_bR1U. Accessed 8 Jan 2025.
- Napkin AI. Jan – The visual AI for business storytelling. Napkin AI. https://www w.napkin.ai. Accessed 72025.
- O’Brien BC, Harris IB, Beckman TJ, Reed DA, Cook DA. Standards for reporting qualitative research: A synthesis of recommendations. Acad Med. 2014;89:1245-51.
- LeBeau B, Ellison S, Aloe AM. Reproducible analyses in education research. Rev Res Educ. 2021;45:195-222.
- Md A, Ali Khan A-E. Sentiment analysis through machine learning. J Southwest Jiaotong Univ. 2021;56.
- Martin S, Beecham E, Kursumovic E, Armstrong RA, Cook TM, Déom N et al. Comparing human vs. machine-assisted analysis to develop a new approach for. Big Qualitative Data Anal. 2024;2024.07.16.24310275.
- Aditya G. Understanding and addressing AI hallucinations in healthcare and life sciences. Int J Health Sci. 2024;7:1-11.
- Donkoh S, Mensah J. Application of triangulation in qualitative research. J Appl Biotechnol Bioeng. 2023;10:6-9.
- Thomas J, Harden A. Methods for the thematic synthesis of qualitative research in systematic reviews. BMC Med Res Methodol. 2008;8:45.
- Using AI. In Grounded Theory research – a proposed framework for a ChatGPT-based research assistant. Accessed 7 Jan 2025. https://osf.io/preprin ts/socarxiv/a2dc4_v1
- Wenning B, Price H, Nuwangi H, Reda KT, Walters B, Ehsanullah R, et al. Exploring the cultural effects of gender on perceptions of cutaneous leishmaniasis: a systematic literature review. Glob Health Res Policy. 2022;7:1-13.
- Feuston JL, Brubaker JR. Putting tools in their place: the role of time and perspective in Human-AI collaboration for qualitative analysis. Proc ACM Hum-Comput Interact. 2021;5:1-25.
- Levitt HM. Qualitative generalization, not to the population but to the phenomenon: reconceptualizing variation in qualitative research. Qual Psychol. 2021;8:95-110.
- Levine DM, Tuwani R, Kompa B, Varma A, Finlayson SG, Mehrotra A, et al. The diagnostic and triage accuracy of the GPT-3 artificial intelligence model: an observational study. Lancet Digit Health. 2024;6:e555-61.
- Tanaka Y, Nakata T, Aiga K, Etani T, Muramatsu R, Katagiri S, et al. Performance of generative pretrained transformer on the National medical licensing examination in Japan. PLOS Digit Health; 2024;3(1):e0000433.
- Fang C, Wu Y, Fu W, Ling J, Wang Y, Liu X, et al. How does ChatGPT-4 preform on non-English National medical licensing examination? An evaluation in Chinese Language. PLOS Digit Health. 2023;2:e0000397.
- Karjus A. Machine-assisted mixed methods: augmenting humanities and social sciences with artificial intelligence. 2023. https://arxiv.org/abs/2309.143 79
- Kim H, Sefcik JS, Bradway C. Characteristics of qualitative descriptive studies: A systematic review. Res Nurs Health. 2017;40:23-42.
- Weidener L, Fischer M. Teaching AI ethics in medical education: A scoping review of current literature and practices. Perspect Med Educ. 2023;12.
- Tao K, Osman ZA, Tzou PL, Rhee S-Y, Ahluwalia V, Shafer RW. GPT-4 performance on querying scientific publications: reproducibility, accuracy, and impact of an instruction sheet. BMC Med Res Methodol. 2024;24:139.
- Marshall DT, Naff DB. The ethics of using artificial intelligence in qualitative research. J Empir Res Hum Res Ethics. 2024;19:92-102.
- Leça M, de Valença M, Santos L, de Santos R. S. Applications and Implications of Large Language Models in Qualitative Analysis: A New Frontier for Empirical Software Engineering. 2024. https://arxiv.org/abs/2412.06564
- Schroeder H, Quéré MAL, Randazzo C, Mimno D, Schoenebeck S. Large Language Models in Qualitative Research: Can We Do the Data Justice? 2024. https://doi.org/10.48550/ARXIV.2410.07362
Publisher’s note
- *Correspondence:
Issam Bennis
issambennis@gmail.com; issambennis@um6ss.ma
¹Mohammed VI International School of Public Health, Mohammed VI University of Sciences and Health, Casablanca, Morocco