تقليل الميزات لتوقع سرطان الكبد الخلوي باستخدام خوارزميات التعلم الآلي Feature reduction for hepatocellular carcinoma prediction using machine learning algorithms
تقليل الميزات لتوقع سرطان الكبد الخلوي باستخدام خوارزميات التعلم الآلي
غادة مصطفىحمدي محمودطارق عبد الحفيظومحمد إي. العربي
الملخص
سرطان الكبد الخلوي (HCC) هو شكل شائع للغاية من سرطان الكبد يتطلب نماذج تنبؤية دقيقة للتشخيص المبكر والعلاج الفعال. لقد أظهرت خوارزميات التعلم الآلي نتائج واعدة في مجالات طبية متنوعة، بما في ذلك التنبؤ بالسرطان. في هذه الدراسة، نقترح نهجًا شاملاً لتنبؤ HCC من خلال مقارنة أداء خوارزميات التعلم الآلي المختلفة قبل وبعد تطبيق طرق تقليل الميزات. نحن نستخدم تقنيات تقليل الميزات الشائعة، مثل وزن الميزات، ارتباط الميزات المخفية، اختيار الميزات، والاختيار المحسن، لاستخراج مجموعة ميزات مخفضة تلتقط المعلومات الأكثر صلة المتعلقة بـ HCC. بعد ذلك، نطبق عدة خوارزميات، بما في ذلك بايزي البسيط، آلات الدعم الناقل (SVM)، الشبكات العصبية، شجرة القرار، وأقرب الجيران (KNN)، على كل من مجموعة البيانات الأصلية عالية الأبعاد ومجموعة الميزات المخفضة. من خلال مقارنة دقة التنبؤ، الدقة، درجة F، الاسترجاع، ووقت التنفيذ لكل خوارزمية، نقيم فعالية تقليل الميزات في تعزيز أداء نماذج التنبؤ بـ HCC. تظهر نتائجنا التجريبية، التي تم الحصول عليها باستخدام مجموعة بيانات شاملة تتكون من ميزات سريرية لمرضى HCC، أن تقليل الميزات يحسن بشكل كبير أداء جميع الخوارزميات التي تم فحصها. ومن الجدير بالذكر أن مجموعة الميزات المخفضة تتفوق باستمرار على مجموعة البيانات الأصلية عالية الأبعاد من حيث دقة التنبؤ ووقت التنفيذ. بعد تطبيق تقنيات تقليل الميزات، حققت الخوارزميات المستخدمة، وهي أشجار القرار، بايزي البسيط، KNN، الشبكات العصبية، وSVM، دقة تصل إلى، و ، على التوالي.
الكلمات المفتاحية: التعلم العميق، التعلم الآلي، سرطان الكبد الخلوي، سرطان الكبد، اختيار الميزات، الذكاء الاصطناعي
مقدمة
وفقًا لتقارير منظمة الصحة العالمية (WHO)، يتم تشخيص حوالي 14.1 مليون فرد بالسرطان كل عام، مما يؤدي إلى 8.2 مليون حالة وفاة على مستوى العالم [1]. سرطان الخلايا الكبدية (HCC) هو شكل من أشكال سرطان الكبد الذي ينشأ من الأمراض الكبدية المزمنة والتليف. تشير الدراسات الحديثة إلى أن HCC هو أكثر أنواع السرطان فتكًا على مستوى العالم، مما يؤدي إلى حوالي 600,000 حالة وفاة سنويًا [2]. علاوة على ذلك، يحتل سرطان الكبد المرتبة السادسة بين أكثر أنواع السرطان تشخيصًا على مستوى العالم. تظهر هذه الحقائق التأثير العالمي لسرطان الكبد (HCC) على حياة البشر. وبالتالي، من الضروري تقليل معدل الوفيات المرتبط بسرطان الكبد، وهو ما يمكن تحقيقه فقط من خلال الكشف المبكر. لتحقيق هذا الهدف، من الضروري الاستفادة من تقنيات استخراج البيانات وتعلم الآلة المختلفة لتطوير نظام تشخيص آلي يمكنه التنبؤ بدقة بسرطان الكبد، مما يضمن الكشف بشكل أكثر كفاءة وفي الوقت المناسب. استخراج البيانات هو مجال متعدد التخصصات يستخدم مبادئ من علوم الحاسوب والإحصاء لاستخراج معلومات قيمة، مثل الميزات أو القواعد، من البيانات المقدمة. من ناحية أخرى، يعد تعلم الآلة فرعًا من علوم الحاسوب يركز على التقنيات والمنهجيات التي من خلالها تكتسب الآلات المعرفة وتتعلم من التجربة. في العصر الحالي، تشهد تقنيات تعلم الآلة واستخراج البيانات نموًا سريعًا وتطبيقًا واسع النطاق في مجال التشخيص الطبي لمواجهة تحديات مختلفة.
بدأ بحثنا بالتركيز على الاعتراف بأهمية البيانات المعيارية. لوحظت اتجاهات واضحة في الأعمال السابقة – أداء أفضل للنموذج مع البيانات المعيارية. قادنا هذا الملاحظة إلى تعديل مجموعة البيانات لدينا وفقًا لذلك. بعد ذلك، قدمنا طرق اختيار الميزات، بدءًا من الطريقة القوية “إزالة الميزات التكرارية (RFE)”. تختبر هذه الطريقة أداء النموذج مع كل ميزة محتملة، وتقوم بإزالة الميزات بشكل منهجي وإعادة اختبار النموذج للعثور على أفضل تكرار. بعد ذلك، استخدمنا “تحليل المكونات الرئيسية (PCA)”، وهي طريقة شائعة لاستخراج الميزات. هدفها هو تقليل أبعاد مجموعة البيانات مع الحفاظ على أكبر قدر ممكن من المعلومات. تحقق PCA ذلك من خلال إنشاء متغيرات جديدة غير مرتبطة أو مكونات تعظم التباين بشكل متتابع. في دراستنا، تم استخدام PCA لتحويل مجموعة البيانات إلى مجموعة من المتغيرات غير المرتبطة خطيًا والتي تُسمى المكونات الرئيسية. أخيرًا، تم تطبيق مشغلات تحسين الميزات. من المعروف جيدًا أن تحسين اختيار مجموعات الميزات يمكن أن يحسن بشكل كبير من أداء المصنف. لتقييم أهمية ميزة ما لمهمة التصنيف، تم استخدام المعلومات المتبادلة. تلا ذلك تنفيذ خوارزميات تعلم الآلة المختلفة لتقييم أداء التصنيف.
يوجد تحدٍ واضح في شكل سرطان الكبد الخلوي (HCC) – وهو شكل قاتل من السرطان يتسم بالتعقيد التشخيصي. تعتبر النماذج التنبؤية الدقيقة والفعالة ضرورية للتشخيص في الوقت المناسب وعلاج محسن. ومع ذلك، فإن النماذج التنبؤية التقليدية تعاني من ‘لعنة الأبعاد’، وهي عقبة شائعة في مجموعات البيانات عالية الأبعاد المستخدمة في تشخيص HCC.
بيان المشكلة
على الرغم من كونها واحدة من أكثر أشكال السرطان فتكًا، إلا أن سرطان الكبد الخلوي (HCC) لا يزال محاطًا بجو من التعقيد التشخيصي. يمثل تطوير نماذج تنبؤية دقيقة وفعالة مسهلًا حاسمًا للتشخيص في الوقت المناسب والعلاج الفعال. وقد أعيقت النماذج التنبؤية التقليدية بسبب لعنة الأبعاد المرتبطة عادةً بمجموعات البيانات عالية الأبعاد التي تم الحصول عليها في تشخيص HCC، حيث أظهرت كفاءة محدودة.
سؤال البحث
هل يمكن أن تعزز تطبيق تقنيات تقليل الميزات البديلة بشكل كبير أداء خوارزميات التعلم الآلي في التنبؤ بسرطان الكبد الخلوي؟
فجوة البحث
لقد لاحظت الدراسات السابقة العلاقة الإيجابية بين تقليل أبعاد الميزات ودقة التنبؤ لخوارزميات التعلم الآلي. ومع ذلك، لا يزال هناك نقص واضح في الأساليب الشاملة التي تقارن أداء خوارزميات التعلم الآلي المختلفة تحت تأثير تقنيات تقليل الميزات المختلفة في مجال التنبؤ بسرطان الكبد الخلوي.
المساهمات
تُعد هذه الدراسة مساهمة مهمة في مجال التنبؤ بالسرطان الكبدي القابل للعلاج باستخدام الحاسوب من خلال مقارنة أداء خوارزميات التعلم الآلي المستخدمة بشكل واسع قبل وبعد تنفيذ تقنيات تقليل الميزات. يمكن تلخيص المساهمات الرئيسية على النحو التالي:
اعتماد تطبيع البيانات لتحسين أداء نموذجنا، كما عززت الدراسات السابقة.
تنفيذ طرق اختيار الميزات بما في ذلك ‘الإزالة التكرارية للميزات (RFE)’ و’تحليل المكونات الرئيسية (PCA)’ لتعزيز فعالية نموذجنا التنبؤي.
تقييم تأثير الميزات المختلفة على مهمة التصنيف من خلال استخدام المعلومات المتبادلة.
إجراء مقارنة أداء بين خوارزميات التعلم الآلي المختلفة، وتقييم نتائج تصنيفها.
معالجة أوجه القصور في الأبحاث الحالية من خلال إجراء مقارنة شاملة لعدة تقنيات تقليل الميزات وتأثيرها المقابل على نتائج مجموعة من خوارزميات التعلم الآلي، خاصة فيما يتعلق بتنبؤ سرطان الكبد (HCC).
تقدم مجال التنبؤ الحسابي لسرطان الكبد من خلال دراسة تغيرات الأداء في مجموعة متنوعة من خوارزميات التعلم الآلي قبل وبعد دمج تقنيات تقليل الميزات.
الأعمال ذات الصلة
في دراسة بحثية أجراها أباجيان وآخرون [14] شملت 36 مريضًا مصابًا بسرطان الكبد (HCC) خضعوا للعلاج الكيميائي عن طريق الشرايين. استخدموا تقنيات التعلم الآلي، وتحديدًا الانحدار الخطي والغابة العشوائية، وحققوا دقة عامة قدرها. في دراسة أجراها إيوانوس وآخرون [15] تركزت على التنبؤ بحدوث سرطان الكبد الخلوي (HCC) خلال 3 سنوات، تم تدريب شبكة عصبية متكررة (RNN) باستخدام بيانات من مرضى يعانون من تليف الكبد المرتبط بفيروس التهاب الكبد C (HCV). شمل مجموعة البيانات أربعة متغيرات تم قياسها في بداية الدراسة و27 متغيرًا تم قياسها على مدى الزمن، تم جمعها من 48,151 مريضًا يتلقون
الرعاية الصحية ضمن نظام وزارة شؤون المحاربين القدامى الأمريكية. أظهرت نتائج الدراسة أن نموذج RNN تفوق على الانحدار اللوجستي في التنبؤ بتطور HCC ضمن الإطار الزمني المحدد. حقق نموذج RNN دقة قدرها لجميع المرضى و للمرضى الذين حققوا استجابة فيروسية مستدامة (SVR) في التنبؤ بظهور سرطان الكبد الخلوي (HCC).
في دراسة بحثية أجراها نام وآخرون [16]، تم تطوير شبكة عصبية عميقة للتنبؤ بحدوث سرطان الكبد الخلوي (HCC) على مدى فترة 3 و5 سنوات في مرضى يعانون من تليف الكبد المرتبط بفيروس التهاب الكبد B (HBV) الذين كانوا يتلقون علاج إنتيكافير. فحصت الدراسة 424 مريضًا وأظهرت أن نموذج التعلم العميق (DL) تفوق على ستة نماذج أخرى تم الإبلاغ عنها سابقًا والتي استخدمت تقنيات نمذجة قديمة. بالإضافة إلى ذلك، تم اختبار نموذج DL على مجموعة تحقق تتكون من 316 مريضًا، وأشارت النتائج إلى مؤشر C لهاريل قدره 0.782، مما يدل على مستوى عالٍ من الدقة في التنبؤ بحدوث HCC في هؤلاء المرضى.
قام نام وآخرون [17] بالبناء على عملهم السابق من خلال تطوير MoRAL-AI، وهو نموذج ذكاء اصطناعي جديد يستخدم تقنيات التعلم العميق، لتحديد مرضى سرطان الكبد (HCC) المعرضين لخطر عودة الورم بعد الزرع. قام نموذج MoRAL-AI بتحليل عدة عوامل تنبؤية بما في ذلك حجم الورم، عمر المريض، مستويات ألفا فيتو بروتين (AFP) في الدم، ووقت البروثرومبين لتوليد توقعات المخاطر. أظهرت نتائج الدراسة أن MoRAL-AI تفوق على نماذج التنبؤ التقليدية مثل معايير ميلان، UCSF، حتى سبعة، ومعايير كيوتو في تحديد أي مرضى HCC يواجهون خطر عودة مرتفع بعد الزرع. على وجه التحديد، حقق MoRAL-AI مؤشر C قدره 0.75 لدقة التنبؤ مقارنةً بـ, و0.50 للنماذج الأخرى على التوالي، مع كون هذا الفرق ذا دلالة إحصائية (). باختصار، مثل MoRAL-AI نهجًا محسنًا لتحديد مرضى HCC الذين من المحتمل أن يعانوا من عودة بعد زراعة الكبد.
في دراستهم، قام علي وآخرون [18] بتقييم الأداء التنبؤي لمختلف خوارزميات التعلم الآلي لسرطان الكبد الخلوي (HCC)، بما في ذلك الانحدار اللوجستي، أقرب الجيران (KNN)، شجرة القرار، الغابة العشوائية، وآلة الدعم الناقل (SVM). بالإضافة إلى ذلك، اقترحوا واختبروا نهجًا تركيبيًا جديدًا يستخدم تحليل التمييز الخطي (LDA)، الخوارزمية الجينية (GA)، وSVM. عند مقارنة جميع النماذج، أظهرت النتائج أن نهج LDA-GA-SVM حقق أفضل قدرة تنبؤية شاملة. على وجه التحديد، حقق LDA-GA-SVM أعلى دقة قدرها 0.899، وحساسية قدرها 0.892، ونوعية قدرها 0.906. كانت هذه المقاييس الأداء متفوقة على تلك التي تم الحصول عليها عند استخدام الخوارزميات الفردية الأخرى التي تم تقييمها – الانحدار اللوجستي، KNN، شجرة القرار، الغابة العشوائية، وSVM بمفردها. لذلك، اقترحت نتائج الدراسة أن نموذج LDA-GA-SVM المركب قد يكون الأداة الأكثر فعالية المعتمدة على التعلم الآلي للتنبؤ بـ HCC مقارنة بالخوارزميات البديلة التي تم تحليلها.
قيم كاو وآخرون [19] الأداء التنبؤي لمختلف نماذج التعلم الآلي – الانحدار اللوجستي، أقرب الجيران (KNN)، شجرة القرار (DT)، بايز الساذج (NB)، والشبكة العصبية العميقة (DNN) – باستخدام مجموعة البيانات الأصلية. تراوحت دقة النماذج من 57.5 إلى. تراوحت الدقة بين 40.7 و, بينما كانت معدلات الاسترجاع بين 20.0 و. تراوحت معدلات الإيجابيات الكاذبة بين 10.7 و وقيم الانحراف المعياري تراوحت من 0.026 إلى 0.058. من بين النماذج المدربة على مجموعة البيانات الأصلية، أظهر KNN أفضل قدرة تنبؤية شاملة. على وجه التحديد، حقق KNN
دقة قدرها، دقة قدرها، معدل استرجاع قدره، ومعدل إيجابيات كاذبة قدره مع انحراف معياري قدره 0.042. تشير هذه النتائج إلى أنه من بين الخوارزميات التي تم اختبارها على البيانات غير المعدلة، قدم KNN أكثر التنبؤات دقة وموثوقية لحالة المرض.
في دراسة أجراها زانغ وآخرون [20] تم تحديد 237 مريضًا مصابًا بسرطان الكبد، تقريبًا (92 مريضًا) تم التعرف عليهم على أنهم يحملون علامة إيجابية لـ MVI. كانت هذه المجموعة، بمتوسط عمر 52، تتكون في الغالب من الذكور (86 من 92). بينما كان الباقي من المرضى (145 مريضًا) سلبيين لـ MVI، بمتوسط عمر 54 ونسبة ذكور إلى إناث أكثر توازنًا (124 ذكرًا إلى 21 أنثى). كان لدى المرضى الذين يعانون من MVI أورام أكبر، وارتفاع في حدوث كبسولات الورم، ومستويات مرتفعة من بعض البروتينات مقارنةً بأولئك الذين لا يعانون من MVI.
في دراسة أجريت بواسطة [21] بعد إجراء تحليل التعلم الآلي، حددوا ثمانية متغيرات رئيسية (العمر، الشرايين داخل الورم، ألفا فيتو بروتين، مستوى السكر في الدم قبل العملية، عدد الأورام، نسبة السكر إلى اللمفاويات، تليف الكبد، والصفائح الدموية قبل العملية) لتطوير ستة نماذج تنبؤية متميزة. من بين هذه النماذج، أظهر نموذج XGBoost أداءً متفوقًا، كما يتضح من منطقة تحت منحنى التشغيل الخاص بالمستقبل (AUC-ROC) بقيم 0.993 ( فترة الثقة: ، و في مجموعات البيانات التدريبية، والتحقق، والاختبار، على التوالي. علاوة على ذلك، أظهرت تحليل منحنى المعايرة وتحليل منحنى القرار أن نموذج XGBoost أظهر أداءً تنبؤيًا ملائمًا ويمتلك قيمة عملية في التطبيقات السريرية.
مدفوعين بتطوير أنظمة تشخيصية مختلفة تعتمد على نماذج التعلم الآلي لتحسين دقة اتخاذ القرار بشأن تشخيص HCC والتنبؤ، قمنا أيضًا بإجراء نهج لتعزيز التنبؤ بسرطان الكبد الخلوي (HCC) من خلال طرق تقليل الميزات. تسلط هذه الدراسة الضوء على فعالية تقليل الميزات في تعزيز أداء تقنيات الذكاء الاصطناعي المختلفة لتنبؤ عقيدات HCC. من خلال تبسيط البيانات، تمكنوا من تحسين دقة الخوارزميات مثل بايز الساذج، الشبكات العصبية، شجرة القرار، SVM، وKNN بشكل كبير.
المواد والأساليب
وصف قاعدة البيانات
تم استخدام بيانات المرضى السريرية من قاعدة بيانات أطلس جينوم السرطان (TCGA) في هذه الدراسة، توفر مجموعة بيانات TCGA LIHC السريرية موردًا قويًا للتحقيق في المشهد السريري لسرطان الكبد الخلوي (HCC). تشمل هذه البيانات، التي تغطي تنوعًا في التركيبة السكانية للمرضى، وخصائص الورم، وتفاصيل العلاج، والنتائج السريرية، نهجًا متعدد الأبعاد لفهم تقدم المرض وإبلاغ مسارات البحث [22-24].
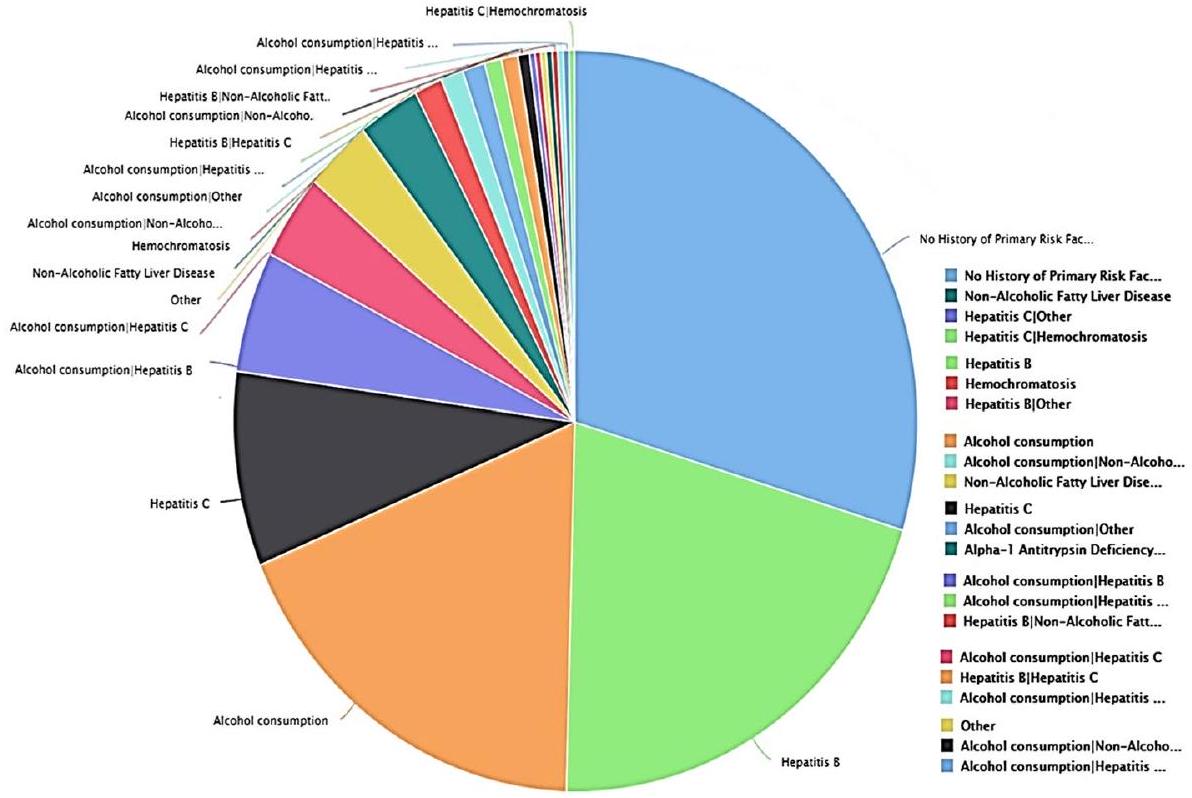
التركيبة السكانية للمرضى: يوفر العمر، الجنس، العرق، العوامل الاجتماعية الاقتصادية، والتاريخ الطبي سياقًا لتحليل وبائيات المرض وعوامل الخطر المحتملة كما هو موضح في الشكل 1. يمكن أن تُعلم العلاقات بين هذه المتغيرات والنتائج السريرية استراتيجيات الوقاية المستهدفة والتدخل المبكر.
خصائص الورم: تسمح المعلومات التفصيلية حول حجم الورم، المرحلة، الدرجة، الموقع، ووجود مرض الكبد الأساسي بتصنيف مجموعات المرضى وتسهيل التحقيق في أنماط تقدم الورم.
الشكل 1 تاريخ عوامل خطر سرطان الكبد الخلوي في مجموعة بيانات TCGA LIHC
تفاصيل العلاج: تسمح البيانات حول الإجراءات الجراحية، بروتوكولات الإشعاع، وأنظمة العلاج الكيميائي بإجراء دراسات فعالية مقارنة وتحديد استراتيجيات العلاج المثلى لمجموعات المرضى المختلفة.
النتائج السريرية: تقدم البيانات حول البقاء على قيد الحياة بشكل عام، البقاء خاليًا من المرض، الوقت حتى العودة، والاستجابة للعلاج نقاط نهاية مهمة لتقييم فعالية العلاج وإبلاغ اتخاذ القرار السريري.
القيود: على الرغم من أن مجموعة البيانات السريرية TCGA LIHC شاملة، من المهم الاعتراف بالقيود المحتملة بسبب عدم اتساق جمع البيانات، وغياب بيانات المتابعة، وانحياز الاختيار. من الضروري أخذ هذه القيود بعين الاعتبار لضمان تفسير دقيق للنتائج واستنتاجات بحث مستنيرة.
تتكون مجموعة البيانات المستخدمة في هذه الدراسة من 77 ميزة لكل من 377 مريضًا في المجموع. تشير علامة مجموعة البيانات إلى حالة الورم ويمكن أن تأخذ قيمة “خالية من الورم” أو “مع ورم”. لا تعني عبارة “خالية من الورم” حالة من الطبيعية، بل تشير بدلاً من ذلك إلى غياب أو استمرار الورم (الورم). إنها تمثل بيانًا بشأن تقدم المرض الأولي أو عدمه. من الضروري الإشارة إلى أن هناك قيمًا مفقودة لكل ميزة في مجموعة البيانات التي تحتوي على معلومات جميع الميزات. ضمن الأدبيات الموجودة، يتم استخدام نهجين متميزين بشكل شائع لمعالجة القيم المفقودة. تتضمن الطريقة الأولى إزالة جميع العينات التي تحتوي على قيم مفقودة، لكن هذه الطريقة غير قابلة للتطبيق في حالتنا لأنها ستؤدي إلى فقدان جزء كبير من العينات. وبالتالي، اخترنا استخدام طريقة التعويض لملء القيم المفقودة. تم معالجة البيانات المفقودة من خلال مجموعة متنوعة من طرق التعويض خلال الدراسات [25-28]. استخدمنا نهجًا إحصائيًا لتعويض القيم المفقودة عن طريق استبدالها بالقيمة المتوسطة للعمود أو الميزة المقابلة التي كانت تحتوي على القيمة المفقودة. تم العثور عليه. تم تقديم معلومات مفصلة حول الميزات السريرية لمجموعة بيانات TCGA في الجدول 1.
المنهجية
يتضمن البحث المقترح نهجًا متعدد الجوانب لتعزيز توقع سرطان الكبد (HCC) من خلال طرق تقليل الميزات بما في ذلك أهمية الميزات، ارتباط الميزات المخفية، واختيار الميزات [29] باستخدام خوارزميات مختلفة. شملت المرحلة الأولية مراجعة شاملة للأدبيات الحالية حول تطبيقات التعلم العميق في تقييم المخاطر، والتشخيص، والتنبؤ، والعلاج لمرضى HCC. بعد ذلك، تم إجراء تحليل دقيق للمتغيرات السريرية. ثم تم تنفيذ خوارزميات التعلم العميق والتعلم الآلي لتوقع HCC، مع دمج تقنيات تقليل الميزات المختلفة. الهدف العام هو إثبات تفوق استخدام طرق اختيار الميزات البديلة مقارنة باستخدام جميع الميزات ضمن نماذج التعلم الآلي لتحقيق توقع دقيق لـ HCC.
في هذه الدراسة، تتضمن سير العمل لتدريب مجموعة بيانات باستخدام وزن الميزات، ارتباط الميزات، التطبيع، وعوامل التحسين في RapidMiner [30] سلسلة من الخطوات المصممة لتعزيز عملية بناء النموذج.
أولاً، تم تحميل مجموعة البيانات في RapidMiner، وتم إضافة المشغلين المعنيين إلى العملية. يسمح مشغل الأوزان بتعيين الأهمية أو الدلالة للعينات الفردية أو السمات في مجموعة البيانات. كان هذا مفيدًا عندما تحمل بعض العينات أو السمات وزنًا أو أهمية أكبر في التحليل.
بعد ذلك، تم تطبيق عامل الارتباط لتحديد وقياس العلاقات بين السمات المختلفة في مجموعة البيانات. يساعد ذلك في فهم السمات التي ترتبط بقوة مع المتغير المستهدف أو مع بعضها البعض. يمكن أن توجه هذه المعلومات اختيار الميزات وت eliminate السمات الزائدة أو المرتبطة بشدة، مما يقلل من أبعاد مجموعة البيانات.
بعد تحليل الارتباط، تم استخدام عامل التطبيع لتعديل وتوحيد السمات العددية في مجموعة البيانات. تضمن هذه الخطوة أن تكون جميع السمات لها نطاقات وتوزيعات مشابهة، مما يمنع أي سمة واحدة من الهيمنة على عملية تدريب النموذج بسبب الاختلافات في مقاييسها. يعزز التطبيع استقرار وتوافق خوارزميات مختلفة مما يؤدي إلى تحسين أداء النموذج.
بعد التطبيع، تم استخدام مشغل التحسين لاختيار المجموعة الفرعية الأكثر صلة من الميزات من مجموعة البيانات. يستخدم خوارزميات التحسين وقياسات إحصائية لتقييم مساهمة كل سمة في أداء النموذج. من خلال تقييم مجموعات الميزات المختلفة بشكل تكراري، حدد مشغل التحسين مجموعة السمات التي تعظم دقة النموذج أو غيرها من مقاييس الأداء المحددة. ساعدت هذه الخطوة في تقليل الضوضاء، وتحسين كفاءة النموذج، وزيادة قابلية التفسير.
بمجرد تحديد مجموعة الميزات المحسّنة، تم تقسيم مجموعة البيانات إلى مجموعات تدريب واختبار، حيث تم استخدام 301 مثالًا للتدريب و75 مثالًا للاختبار باستخدام أخذ عينات مناسبة.تقنيات.فيفي حالتنا، استخدمنا “العينة الطبقية” التي تتضمن إنشاء مجموعات فرعية عشوائية مع ضمان أن تظل توزيع الفئات داخل تلك المجموعات الفرعية متسقة مع التوزيع العام للفئات في مجموعة الأمثلة بأكملها.
الجدول 1 معلومات حول ميزات المتغيرات السريرية لمجموعة بيانات TCGA
ميزات
وصف
نوع
القيم
علاج الانصمام بالتبخير المساعد
علاج الانصمام بالتبخير المساعد
ثنائي
لا (364)، نعم (13)
العمر عند التشخيص
العمر عند التشخيص المرضي الأولي
عدد صحيح
الحد الأدنى (16)، الحد الأقصى (90)
مسار انتشار AJCC المرضي PM
م pathologic
اسمي
M0 (272)، MX (101)، M (4)
عقد AJCC المرضية PN
“ن” مرضي
اسمي
ن0 (257)، نكس (115)، ن1 (4)
مرحلة الورم المرضية وفقًا لجمعية السرطان الأمريكية
المرحلة المرضية
اسمي
المرحلة الأولى (175)، المرحلة الثانية (87)، المرحلة الثالثة A (65)، المرحلة الثالثة B (9)، المرحلة الثالثة C (9)، المرحلة الثالثة (3)، المرحلة الرابعة (2)، المرحلة الرابعة B (2)، [اختلاف] (2)، المرحلة الرابعة A (1)
إجراء المختبر نتيجة ألفا فيتو بروتين الحد الأدنى للقيمة الطبيعية
عدد صحيح
الحد الأدنى (0)، الحد الأقصى (6)
نطاق طبيعي لمستوى ألفا فيتوبروتين العلوي
إجراء المختبر نتيجة ألفا فيتوبروتين الحد الأعلى للقيمة الطبيعية
عدد صحيح
الحد الأدنى (6)، الحد الأقصى (44)
رمز شريطي لمريض BCR
رمز شريطي لمريض BCR
اسمي
مثال: TCGA-2V-A95S
معرف المريض bcr
معرف المريض bcr
اسمي
مثال: 0004D251-3F70-4395-B175C94C2F5B1B81
البيليروبين الكلي
نتيجة إجمالي البيليروبين في إجراء المختبر تحدد الحد الأعلى للقيمة الطبيعية
حقيقي
الحد الأدنى (0.100)، الحد الأقصى (19)
نطاق القيم الطبيعية للبيليروبين الكلي – الأدنى
نتيجة إجمالي البيليروبين في إجراء المختبر تحدد الحد الأدنى للقيمة الطبيعية
حقيقي
الحد الأدنى (0)، الحد الأقصى (1)
نطاق القيم الطبيعية للبيلي rubin الكلي العلوي
نتائج إجمالي البيليروبين في إجراء المختبر ضمن الحد الأعلى للقيمة الطبيعية
حقيقي
الحد الأدنى (0.200)، الحد الأقصى (21)
أعياد ميلاد لـ
أيام حتى الولادة
عدد صحيح
الحد الأدنى (-32,120)، الحد الأقصى (-5862)
تصنيف تشايلد-بيو
درجة تصنيف تشايلد-بيو
اسمي
أ (223)، ب (21)، ج (1)
العيادة م
العيادة م
اسمي
[غير قابل للتطبيق] 377
العيادة ن
العيادة ن
اسمي
[غير قابل للتطبيق] 377
المرحلة السريرية
المرحلة السريرية
اسمي
[غير قابل للتطبيق] 377
السريري T
السريري T
اسمي
مستوى الكرياتينين قبل الاستئصال
نتيجة مختبر مصل الكرياتينين في علم الدم بالقيمة بوحدة ملغ/دل
حقيقي
الحد الأدنى (0.400)، الحد الأقصى (124)
نطاق طبيعي منخفض للكرياتينين
نتائج الكرياتينين في إجراء المختبر أقل من الحد الطبيعي
حقيقي
الحد الأدنى (0)، الحد الأقصى (62)
نطاق مستوى الكرياتينين الطبيعي العلوي
نتائج الكرياتينين في إجراء المختبر عند الحد الأعلى للقيمة الطبيعية
حقيقي
الحد الأدنى (0.900)، الحد الأقصى (120)
الأيام حتى التشخيص المرضي الأولي
الأيام حتى التشخيص المرضي الأولي
عدد صحيح
0
أيام الموت إلى
أيام حتى الموت
عدد صحيح
الحد الأدنى (- 1)، الحد الأقصى (3258)
الجدول 1 (مستمر)
ميزات
وصف
نوع
القيم
إجراء جراحي نهائي
اسم طريقة جمع العينة
اسمي
استئصال الفص 145
استئصال جزء، متعدد 89
استئصال جزء، فردي 88
أخرى (حدد) 26
استئصال الفص الرئوي الموسع 25
لا 3
استئصال الكبد الكلي مع زراعة 1
رمز المرض
رمز المرض
اسمي
[غير متوفر] 377
درجة ECOG
مجموعة أبحاث الأورام السرطانية الشرقية
عدد صحيح
الحد الأدنى (0)، الحد الأقصى (4)
العرق
العرق
اسمي
ليس من أصل إسباني أو لاتيني 340
هيسباني أو لاتيني 18
الـ 17 الأخرى
[غير متوفر] 2
المشاركة خارج العقد اللمفاوية
المشاركة خارج العقد اللمفاوية
اسمي
[غير قابل للتطبيق] 377
مؤشر تاريخ العائلة للسرطان
تاريخ السرطان العائلي النسبي 3
ثنائي
لا 263
نعم 114
عدد الأقارب في تاريخ العائلة مع السرطان
عدد الأقارب من الدرجة الأولى الذين تم تشخيصهم بالسرطان
عدد صحيح
الحد الأدنى (0)، الحد الأقصى (9)
تاريخ إكمال النموذج
تاريخ إكمال النموذج
تاريخ – وقت
تراوح من (20-12-2010) إلى (9-7-2015)
جنس
جنس
ثنائي
ذكر 255
أنثى 122
الطول سم عند التشخيص
ارتفاع
عدد صحيح
الحد الأدنى (64)، الحد الأقصى (196)
التهاب الكبد مع الأنسجة
نوع مدى التهاب الأنسجة الكبدية المجاورة
اسمي
لا شيء 257، خفيف 101، شديد 19
التشخيص النسيجي
النوع النسيجي
اسمي
سرطان الخلايا الكبدية 367
سرطان الكبد والقنوات الصفراوية (مختلط) 7
سرطان الفيبرولاميلار 3
تاريخ عوامل خطر سرطان الكبد
عوامل خطر سرطان الكبد التاريخية
اسمي
معظم (لا تاريخ لعوامل الخطر الأولية 112
التهاب الكبد B 78
استهلاك الكحول 69
التهاب الكبد C 32
استهلاك الكحول|التهاب الكبد B 20
استهلاك الكحول|التهاب الكبد C 14
الـ 12 الأخرى
مرض الكبد الدهني غير الكحولي 11)
تاريخ العلاج المساعد قبل الجراحة
تاريخ العلاج المساعد قبل الجراحة
ثنائي
لا 375
نعم 2
تاريخ الأورام الخبيثة الأخرى
تشخيص سابق
ثنائي
لا 340
نعم 37
التصنيف الدولي للأمراض 10
التصنيف الدولي للأمراض 10
اسمي
C22.0 377
تصنيف الأمراض الدولي (ICD-O-3) علم الأنسجة
تصنيف الأمراض الدولي (ICD-O-3) علم الأنسجة
اسمي
8170/3 360، 8180/3 7
8171/3 4، 8174/3 4
8173/3 1، 8310/3 1
موقع icd o 3
موقع icd o 3
اسمي
C22.0 377
تم التحقق من الموافقة المستنيرة
تم التحقق من الموافقة المستنيرة
اسمي
نعم 377
درجة تليف إسحاق
فئة درجة إيشاك لتليف الكبد
اسمي
0-لا تليف 76
تشمع الكبد المتقدم 72
1,2—تليف البوابة 31
3,4—ألياف سباتا 30
5-تكوين عقيدي وتليف غير مكتمل 9
الجدول 1 (مستمر)
ميزات
وصف
نوع
القيم
أيام الاتصال الأخيرة إلى
الأيام حتى المتابعة الأخيرة
عدد صحيح
ماكس(3675)
مؤشر تشخيص حدث ورم جديد
حدث ورم جديد بعد العلاج الأولي
اسمي
لا 279
نعم 98
عوامل خطر أخرى لسرطان الكبد
عوامل خطر سرطان الكبد التاريخية الأخرى
اسمي
معظم (لا 345
التدخين 6
استخدام التبغ 6
تليف الكبد 2)
معرف المريض
معرف المريض
اسمي
مثال: 4072
علاج دوائي مساعد
علاج ما بعد الجراحة
ثنائي
لا 362
نعم 15
عدد الصفائح الدموية قبل الاستئصال
نتائج الصفائح الدموية لإجراء المختبر القيمة المحددة
عدد صحيح
منماكس
نطاق الصفائح الدموية الطبيعي الأدنى
نتائج الصفائح الدموية في إجراء المختبر عند الحد الأدنى للقيمة الطبيعية
عدد صحيح
منماكس
الحد الأعلى لنطاق الصفائح الدموية
نتائج الصفائح الدموية في إجراء المختبر عند الحد الأعلى للقيمة الطبيعية
عدد صحيح
منماكس
رمز المشروع
رمز المشروع
اسمي
[غير متوفر] 377
جمع مستقبلي
مؤشر جمع الأنسجة المحتمل
ثنائي
لا 249
نعم 128
نطاق القيمة الطبيعية لوقت البروثرومبين INR الأدنى
نتائج نسبة التطبيع الدولية لإجراءات المختبر الحد الأدنى للقيمة الطبيعية
حقيقي
الحد الأدنى (0)، الحد الأقصى (11)
وقت البروثرومبين INR عند الشراء
نتيجة قيمة زمن البروثرومبين لإجراء المختبر
حقيقي
الحد الأدنى (0.800)، الحد الأقصى (36.400)
النطاق الطبيعي العلوي لوقت البروثرومبين
نتائج نسبة التطبيع الدولية لإجراءات المختبر الحد الأعلى للقيمة الطبيعية
حقيقي
الحد الأدنى (1)، الحد الأقصى (15)
سباق
سباق
اسمي
الأبيض 187
آسيوي 161
أسود أو أمريكي من أصل أفريقي 17
العشرة الأخرى
الأمريكيون الهنود أو سكان ألاسكا الأصليين 2
علاج إشعاعي مساعد
العلاج الإشعاعي
ثنائي
لا 373
نعم 4
ورم متبقي
ورم متبقي
اسمي
R0 332، RX 22
R1 17، R2 1
جمع استرجاعي
مؤشر جمع الأنسجة الرجعي
ثنائي
نعم 249
لا 128
نطاق الألبومين في المصل الطبيعي الأدنى
نتائج ألبومين إجراء المختبر في الحد الأدنى للقيمة الطبيعية
حقيقي
الحد الأدنى (0.300)، الحد الأقصى (3800)
نطاق المعيار العلوي لألبومين المصل
نتيجة ألبومين إجراء المختبر الحد الأعلى للقيمة الطبيعية
حقيقي
الحد الأدنى (0.500)، الحد الأقصى (5100)
ألبومين المصل قبل الاستئصال
نتيجة ألبومين إجراء المختبر القيمة المحددة
حقيقي
الحد الأدنى (0.200)، الحد الأقصى (5200)
مرحلة أخرى
مرحلة أخرى
اسمي
[غير متوفر] 377
إجراء جراحي آخر
اسم الإجراء الجراحي نص محدد آخر
ثنائي
لا 351
استئصال الفص الكبدي الأيمن مع استئصالالجزء 1
موقع مصدر الأنسجة
موقع مصدر الأنسجة
اسمي
معظم (DD 151)
الجدول 1 (مستمر)
ميزات
وصف
نوع
القيم
درجة الورم
درجة النسيج الورمي
اسمي
جي 2 183، جي 3 124
G1 55، G4 13
[غير متوفر] 1
حالة الورم
حالة ورم الشخص السرطاني
ثنائي
خالي من الورم 236
مع الورم 141
موقع نسيج الورم
موقع نسيج الورم
اسمي
الكبد 377
غزو الأوعية الدموية
نوع غزو خلايا الورم الوعائي
اسمي
لا شيء 230
مايكرو 94
ماكرو 17
سيرولوجيا التهاب الكبد الفيروسي
سيرولوجيا التهاب الكبد الفيروسي
اسمي
معظم (لا توجد نتائج 211)
الحالة الحيوية
الحالة الحيوية
ثنائي
أليف 286
ميت 91
الوزن كجم عند التشخيص
وزن
عدد صحيح
الحد الأدنى (40)، الحد الأقصى (172)
سنة التشخيص المرضي الأولي
سنة التشخيص المرضي الأولي
عدد صحيح
مين (1995)، ماكس (2013)
أخيرًا، تم تطبيق تقنيات النمذجة المختلفة، مثل أشجار القرار، ونايف بايز، وKNN، والشبكات العصبية، وSVM لتدريب النموذج باستخدام الميزات المختارة والأوزان المعينة.
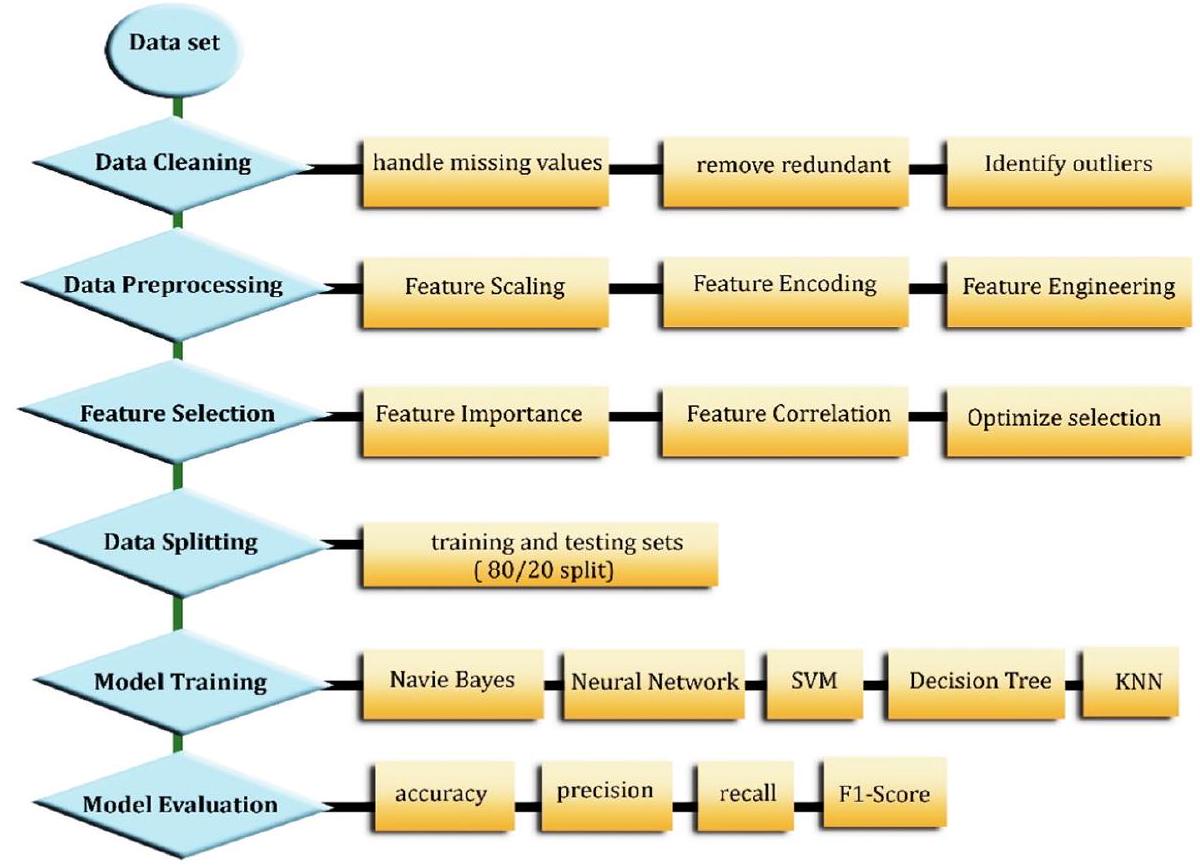
يتطلب استخراج رؤى ذات مغزى من مجموعة بيانات TCGA LIHC من خلال مهام الانحدار اعتبارًا دقيقًا للنموذج المختار. تؤثر عدة عوامل على هذا الاختيار، بما في ذلك حجم البيانات، وأنواع الميزات، واحتياجات القابلية للتفسير، والموارد الحاسوبية. بالنسبة لمجموعات البيانات ذات الأحجام المتوسطة، مثل تلك التي قد يتم مواجهتها ضمن TCGA LIHC، فإن نموذج بايز البسيط يقدم خيارًا قويًا. تعتبر أشجار القرار مناسبة بشكل خاص للتعامل مع البيانات المفقودة الموجودة في مجموعات البيانات الواقعية، مما يلغي الحاجة إلى خطوات استيفاء إضافية. يبرز نموذج الجيران الأقرب (KNN) لكفاءته، حيث يقارن مباشرة بين نقاط البيانات الجديدة ومدخلات TCGA LIHC الموجودة للتنبؤ دون مرحلة تدريب منفصلة. يمكن للنماذج الأكثر تعقيدًا مثل الشبكات العصبية اكتشاف الأنماط الخفية داخل البيانات من خلال التعلم التلقائي للميزات. أخيرًا، تقدم آلات الدعم الناقل (SVMs) قوة تحمل للضوضاء، وهي تحدٍ شائع في مجموعات بيانات TCGA LIHC. من خلال weighing هذه العوامل بعناية وتقييم أداء النموذج على مجموعة TCGA LIHC الفرعية المحددة المستخدمة، يتم تقييم أداء النموذج باستخدام مقاييس الأداء مثل الدقة، والوضوح، ودرجة F، والاسترجاع. ملخص لعملية تقليل البيانات لتوقع سرطان الكبد الخلوي، كما هو موضح في الشكل 2.
النتائج والمناقشة
معالجة البيانات المسبقة
تكونت مجموعة البيانات في البداية من 77 ميزة. خلال عملية تنظيف البيانات، تم استبدال 28 إدخالًا بقيم غير معروفة في عمود “حالة الورم” بـ “مع ورم”. بالإضافة إلى ذلك، تم تقديم ميزتين جديدتين لمزيد من التحليل: “الوزن المثالي” بناءً على مؤشر كتلة الجسم (BMI)، مصنفة كطبيعي، زائد الوزن، أو سمنة، و”مرحلة العمر” مصنفة كمرحلة البلوغ المتوسطة، أو مرحلة البلوغ المتأخرة، أو مرحلة البلوغ المبكرة. تم التخلص من المعلومات الزائدة مثل العمر، الطول، الوزن، وأعمدة أخرى تحتوي على قيم مكررة، غير متاحة، أو غير قابلة للتطبيق، بالإضافة إلى معرفات المرضى. ونتيجة لذلك، تتكون مجموعة البيانات النهائية الآن من 59 ميزة. توضح الشكل 3 العلاقة
الشكل 2 مخطط سير عمل تقليل البيانات لتوقع سرطان الكبد
الشكل 3 توضيح للمرضى الذين يعانون من السمنة مقابل عدد الأقارب من العائلة الذين لديهم تاريخ من السرطان
بين المرضى الذين يعانون من السمنة وعدد أفراد الأسرة الذين لديهم تاريخ من السرطان. تشير نتائجنا إلى أن المريض الذي يعاني من السمنة كان لديه أعلى عدد من أفراد الأسرة الذين لديهم هذا التاريخ الطبي.
أهمية الميزة
بعد تنظيف البيانات، تم وزن الميزات المتبقية البالغ عددها 59 باستخدام أنواع مختلفة من مشغلات الوزن بعد استبدال القيم المفقودة باستخدام RapidMiner. أولاً، قمنا بتطبيق “الوزن حسب مكسب المعلومات”. لتحديد مدى ارتباط كل سمة بسمة الفئة، يستخدم مشغل الوزن حسب مكسب المعلومات حسابًا يسمى مكسب المعلومات. تعتبر السمات ذات الدرجات الأعلى أكثر أهمية.
بينما يعتبر كسب المعلومات موثوقًا عمومًا لتقييم أهمية السمات [32]، إلا أن له عيبًا محتملاً. يمكن أن يبالغ أحيانًا في تقدير أهمية السمات التي تحتوي على عدد كبير جدًا من القيم الممكنة. للتغلب على قيود كسب المعلومات، وخاصة حساسيتها تجاه السمات التي تحتوي على العديد من القيم الفريدة، استخدمنا نسبة كسب المعلومات من خلال تحليل المعلومات التي تقدمها كل سمة لفهم الفئة المستهدفة، حيث تعطي هذه الطريقة أوزانًا تعكس أهميتها النسبية. كلما كانت السمة أكثر فائدة في التنبؤ بالفئة، زادت وزنها.
ثانيًا، نستخدم مشغل “الوزن حسب الإغاثة”. يُعتبر واحدًا من أكثر الخوارزميات فعالية وبساطة في تقييم جودة الميزات، وقد حقق الإغاثة اعترافًا كبيرًا. المفهوم الأساسي وراء الإغاثة هو قياس جودة الميزات بناءً على قدرتها على التمييز بين حالات من نفس الفئة وحالات من فئات مختلفة قريبة[33، 34]. من خلال أخذ عينات من الأمثلة ومقارنة قيم الميزات بين أقرب الأمثلة من نفس الفئة والفئات المختلفة، يحسب الإغاثة صلة الميزات كما هو موضح في [35].
الشيفرة الزائفة لخوارزمية الإغاثة:
خوارزمية الإغاثة
يتطلب: لكل مجموعة تدريبية S، متجه من قيم الميزات وقيمة الفئة عدد حالات التدريب عدد الميزات
المعلمة: عدد حالات التدريب العشوائية من n المستخدمة لتحديث W
تهيئة جميع أوزان الميزات
لـ إلى m قم
اختر عشوائيًا حالة “الهدف”
ابحث عن أقرب ضربة “H” وأقرب فشل (الحالات)
لـ إلى a قم
انتهى
انتهى
أعد متجه الوزن W لدرجات الميزات التي تحسب جودة الميزات
الارتباط الخفي للميزات
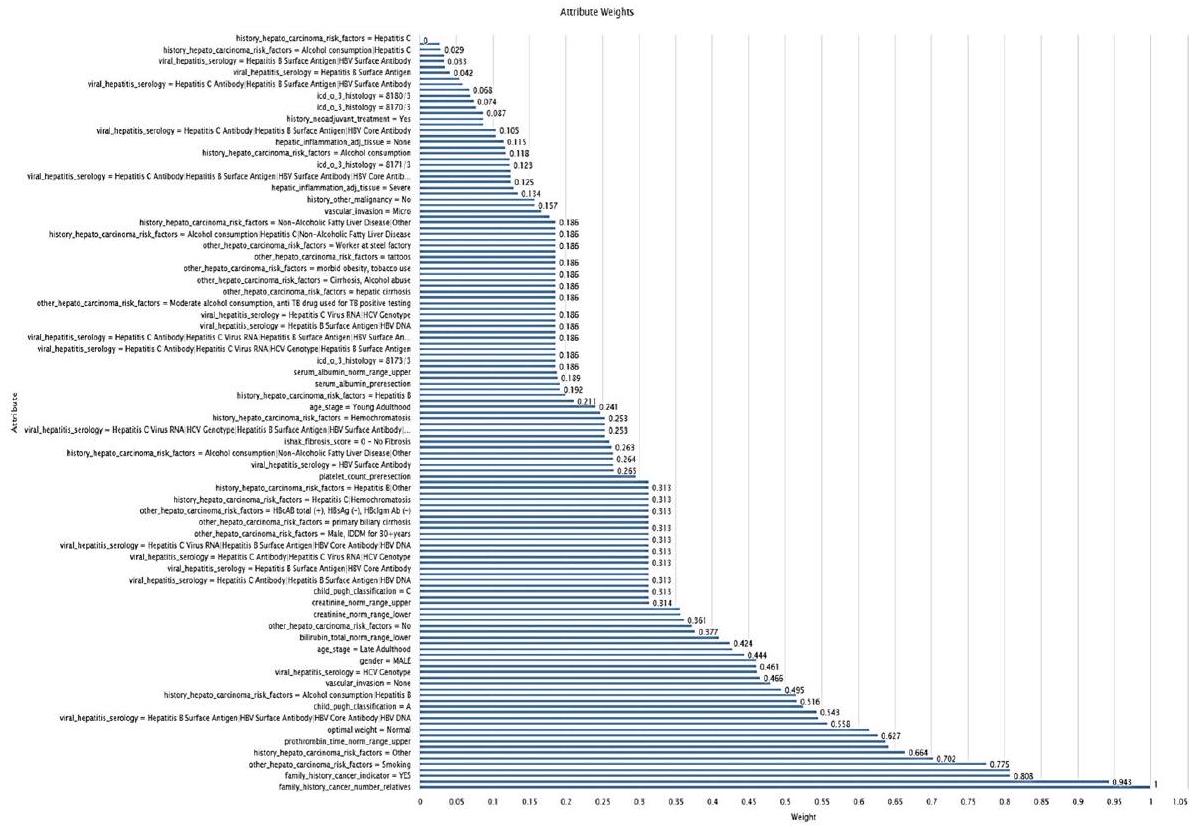
الوزن حسب الارتباط هو منهجية اختيار الميزات المستخدمة ضمن إطار عمل Rapid Miner Studio [36]. تركز هذه الطريقة على تحديد أهمية الميزات من خلال قياس ارتباطها بالمتغير المستهدف [37]. من خلال تعيين أوزان للميزات الفردية كما هو موضح في الشكل 4 بناءً على معاملات الارتباط الخاصة بها، فإن “الوزن حسب الارتباط” يعطي الأولوية لتلك الميزات التي تظهر ارتباطًا أقوى
الشكل 4 توضيح تعيين الأوزان للميزات الفردية بناءً على معاملات الارتباط الخاصة بها
الارتباطات. تسهل هذه الآلية [38] تحديد واختيار الميزات الأكثر تأثيرًا، مما يعزز فعالية ودقة عمليات تحليل البيانات ونمذجة البيانات ضمن Rapid Miner Studio.
اختيار الميزات
التطبيع هو تقنية تستخدم لإعادة قياس القيم لتناسب ضمن نطاق محدد. إنها ضرورية بشكل خاص عند التعامل مع السمات التي تمتلك وحدات ومقاييس متباينة [39، 40].
تم التحقيق في أهمية تطبيع البيانات في تطوير نماذج تنبؤية دقيقة عبر العديد من خوارزميات التعلم الآلي [41]، بما في ذلك الجيران الأقرب (NN) [42]، والشبكات العصبية الاصطناعية (ANN) [43] وآلات الدعم الناقل (SVM) [44]. وقد أكد العديد من الباحثين التأثير الإيجابي لتطبيع البيانات على تحسين أداء التصنيف في مجالات متنوعة [45]. تشمل الأمثلة تصنيف البيانات الطبية [46، 47]، وأنظمة القياسات الحيوية متعددة الأنماط [48]، وتصنيف المركبات [49]، واكتشاف المحركات المعطلة [50]، وتوقع سوق الأسهم [51]، وتصنيف الأوراق [52]، وتصنيف بيانات الموافقة على الائتمان [53]، وعلم الجينوم [54]، ومجالات تطبيقية أخرى [55، 56]. الغرض من مشغل التطبيع هو تنفيذ عملية التطبيع على السمات المختارة. هناك أربع طرق تطبيع متاحة، مع استخدام طريقة “تحويل النطاق” في هذه الحالة. تقوم هذه الطريقة بتطبيع جميع قيم السمات إلى نطاق محدد [57]. عند اختيار هذه الطريقة، تصبح معلمتان إضافيتان، وهما “الحد الأدنى” و”الحد الأقصى”، مرئيتين في
لوحة المعلمات. يتم تعيين أكبر قيمة في مجموعة السمات إلى “الحد الأقصى”، بينما يتم تعيين أصغر قيمة إلى “الحد الأدنى”. يتم قياس جميع القيم الأخرى بشكل نسبي لتناسب ضمن النطاق المقدم. من الجدير بالذكر أن هذه الطريقة قد تتأثر بالقيم الشاذة، حيث تتكيف الحدود نحوها. ومع ذلك، فإنها تحتفظ بالتوزيع الأصلي لنقاط البيانات، مما يجعلها مناسبة لأغراض إخفاء البيانات أيضًا.
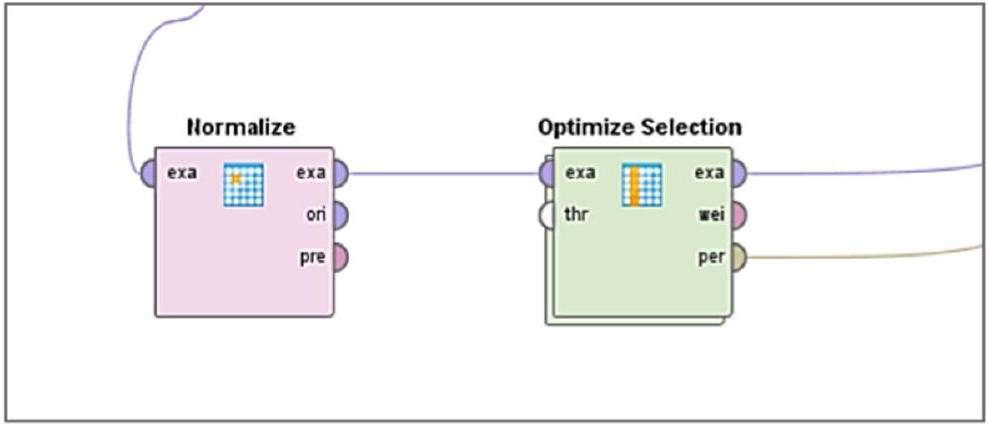
الاختيار المحسن هو تقنية قيمة تستخدم في RapidMiner. تلعب هذه الطريقة دورًا أساسيًا في تبسيط عملية بناء النموذج من خلال تحديد واختيار المجموعة الأكثر صلة من الميزات تلقائيًا من مجموعة بيانات معينة [58، 59]. من خلال الاستفادة من خوارزميات التحسين والتدابير الإحصائية، تهدف وظيفة الاختيار المحسن في RapidMiner إلى تعزيز كل من كفاءة وفعالية النماذج التنبؤية. تتضمن عملية الاختيار المحسن تقييم مجموعات ميزات مختلفة بشكل تكراري وتقييم تأثيرها على أداء النموذج [60]. يقوم المشغل كما هو موضح في الشكل 5، بتنفيذ خوارزميتين لتحديد الميزات الجشعة الحتمية: “الاختيار الأمامي” و”الإزالة الخلفية.”
الهدف من خوارزمية الاختيار الأمامي هو توليد المجموعة الأكثر فعالية من الميزات مع تجاهل الميزات غير ذات الصلة وغير المهمة [61-63]. تبدأ بإنشاء مجموعة أولية من الأفراد، حيث تمثل عدد السمات في مجموعة الأمثلة المدخلة. يستخدم كل فرد في المجموعة ميزة واحدة فقط. ثم يتم تقييم مجموعات السمات، ويتم اختيار أفضل k مجموعات بناءً على أدائها. بالنسبة لكل من المجموعات المختارة k، تستمر الخوارزمية كما يلي: إذا كان هناك سمات غير مستخدمة، يتم عمل نسخ من مجموعة السمات، ويتم إضافة سمة واحدة غير مستخدمة سابقًا إلى كل نسخة من المجموعة. تستمر الخوارزمية إلى الخطوة التالية طالما كان هناك تحسين في الأداء في آخر p تكرارات. تبدأ تقنية الإزالة الخلفية بمجموعة سمات تتضمن جميع الميزات [64، 65]. تقوم بتقييم جميع مجموعات السمات وتختار أفضل k مجموعات بناءً على أدائها. بالنسبة لكل من المجموعات المختارة k، تستمر الخوارزمية كما يلي: إذا كان هناك سمات مستخدمة حاليًا، يتم عمل نسخ من مجموعة السمات، ويتم إزالة سمة واحدة مستخدمة سابقًا من كل نسخة من المجموعة. تستمر الخوارزمية إلى الخطوة التالية طالما كان هناك تحسين في الأداء في آخر p تكرارات.
الشكل 5 مشغلات التطبيع والتحسين في Rapid Miner
الكود الزائف لعملية اختيار الميزات باستخدام البحث الجشع الأمامي (FGS):
$mathrm{FGS}^{(0)}=emptyset$;
$mathrm{F}^{(0)}={mathrm{f} 1, mathrm{f} 2, ldots, mathrm{f} 361} ;$
$mathrm{i}=0$;
opt $=0$; output which is the best performance score
iter $=0$; iteration index
While ( $mathrm{i}<mathrm{n}$ )
$mathrm{k}=$ size $mathrm{F}^{(mathrm{i})}$ :
$max =0$;
feature $=0$;
for j from 1 to k
score $=operatorname{eval}left(mathrm{F}_{mathrm{j}}{ }^{(mathrm{i})}right) ;$
if (score > max)
$max =mathrm{score} ;$ feature $=mathrm{F}_{mathrm{j}}{ }^{(mathrm{i})} ;$
endif
end for
if ( $max >mathrm{opt}$ ) opt = max; iter = i
endif
$mathrm{FS}^{(mathrm{i}+1)} leftarrow mathrm{FS}^{mathrm{i}}+$ feature; $mathrm{Fi}+1=mathrm{F}(mathrm{i})-$ feature; $mathrm{i}++$;
end while
تفاصيل حول معلمات المشغلين المستخدمين في RapidMiner موجودة في الجدول 2.
قبل تقليل الميزات، غالبًا ما تواجه نماذج التعلم الآلي تحديات مثل الأبعاد العالية والميزات الزائدة أو غير ذات الصلة [66-68]. يمكن أن تؤثر هذه القضايا سلبًا على كل من الدقة ووقت التنفيذ. مع عدد كبير من الميزات، قد تكافح النماذج لاستخراج أنماط ذات مغزى من البيانات، مما يؤدي إلى الإفراط في التكيف أو ضعف التعميم. بالإضافة إلى ذلك، تزداد التعقيد الحسابي للتدريب والاستدلال بشكل كبير مع زيادة عدد الميزات. ومع ذلك، بعد تطبيق تقنيات تقليل الميزات، مثل تقليل الأبعاد أو اختيار الميزات، شهدت النماذج تحسينًا في الأداء من حيث الدقة كما هو موضح في الشكل 6، ووقت التنفيذ كما هو موضح في الشكل 7.
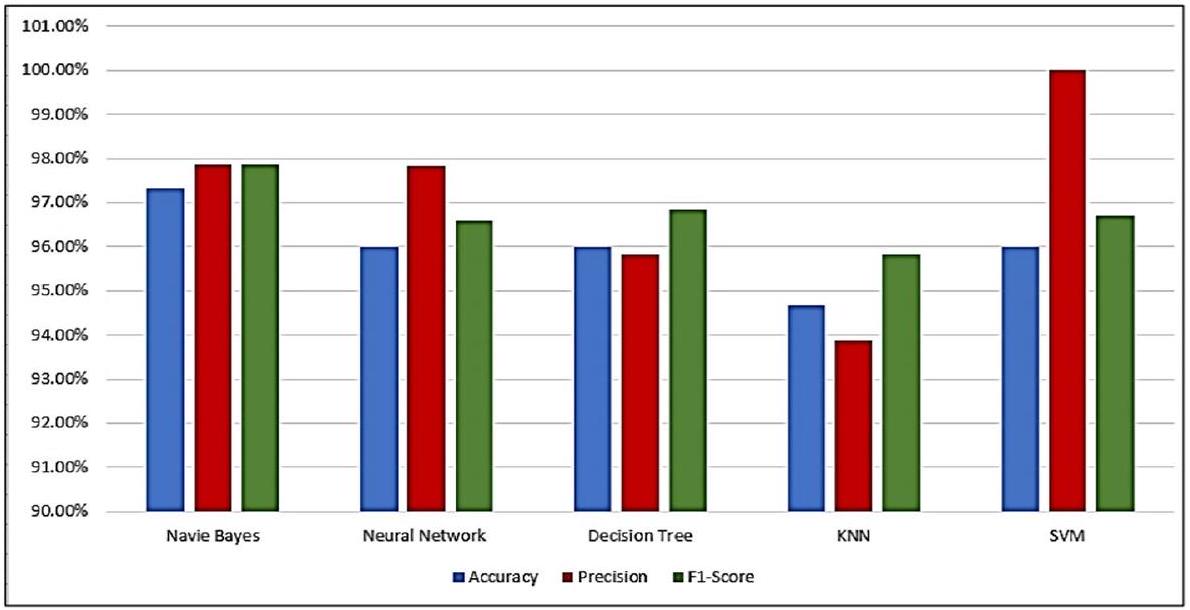
الجدولان 3 و 4 يقدمان ملخصًا لتطبيق تقنيات التعلم العميق والتعلم الآلي المختلفة على مجموعة بيانات المتغيرات السريرية TCGA LIHC لتوقع سرطان الكبد (HCC). يتضمن هذا الملخص أداء هذه التقنيات قبل وبعد تطبيق طرق تقليل الميزات. شملت الخوارزميات المستخدمة في هذه الدراسة Naive Bayes، والشبكة العصبية، وشجرة القرار، وSVM، وKNN. كان التركيز الرئيسي للتقييم على توقع عقيدات HCC. تشير النتائج إلى أن كل من نماذج التعلم العميق ونماذج التعلم الآلي أظهرت أداءً ممتازًا بعد تنفيذ طرق تقليل الميزات.
الجدول 2 معلومات حول معلمات المشغلين المستخدمين في RapidMiner
المشغلون المستخدمون
المعلمات
تعيين الدور
السمة
حالة الورم
الدور
التسمية
استبدال القيم المفقودة
قيمة الاستبدال
المتوسط
الوزن حسب كسب المعلومات
تطبيع الوزن
صحيح
ترتيب الأوزان
صحيح
اتجاه الترتيب
تصاعدي
الوزن حسب الإغاثة
عدد الجيران
10
نسبة العينة
1.0
من الاسمي إلى الرقمي
نوع الترميز
ترميز وهمي
اختيار حسب الوزن
علاقة الوزن
أكبر أو يساوي
الوزن
0.1
تقسيم البيانات
الأجزاء
النسبة: 0.8-0.2
نوع العينة
العينة الطبقية
تطبيع
الطريقة
تحويل النطاق
الحد الأدنى
0
الحد الأقصى
1.0
تحسين الاختيار
اتجاه الاختيار
أمامي
الحد الأقصى لعدد الأجيال
Naive Bayes(6)، شجرة القرار (7)، الشبكات العصبية (6)، SVM(4)، KNN(7)
Naive Bayes
تصحيح لابلاس
صحيح
شجرة القرار
المعيار
نسبة الكسب
العمق الأقصى
10
الثقة
0.1
الكسب الأدنى
0.01
حجم الورقة الأدنى
2
الحجم الأدنى للتقسيم
4
عدد بدائل ما قبل التقليم
3
KNN
K
1
نوع القياس
مسافة إقليدية مختلطة
الشبكة العصبية
دورات التدريب
200
معدل التعلم
0.01
الزخم
0.9
SVM
نوع النواة
متعدد الحدود
درجة النواة
2.0
ذاكرة التخزين المؤقت للنواة
200
الحد الأقصى للتكرار
100,000
C
10
تقارب إبسيلون
0.001
قبل تقليل الميزات، كانت نموذج الشبكة العصبية لدينا تعاني في التدريب، محققة دقة قدرها بتكلفة 5 دقائق بطيئة. نشأت هذه البطء من صعوبة النموذج في التنقل عبر تعقيدات فضاء الميزات عالي الأبعاد، وغالبًا ما كان يتعثر في معلومات غير ذات صلة أو زائدة. ومع ذلك، بعد تطبيق تقنيات تقليل الميزات، تخلص النموذج من الأعباء الزائدة، وظهر بشكل رشيق وفعال. وقد اجتاز التدريب بسهولة، محققًا نتيجة ملحوظة.في دقيقة واحدة و10 ثوانٍ فقط. هذه التحسينات الجذرية هي شهادة على قوة تقليل الميزات. من خلال القضاء على الميزات المزعجة وغير الضرورية، مهدنا الطريق لـ
الشكل 6 أداء الخوارزميات المستخدمة في توقع سرطان الكبد (HCC) على مجموعة بيانات المتغيرات السريرية TCGA LIHC بعد طرق تقليل الميزات
الشكل 7 وقت تنفيذ الخوارزميات المستخدمة في توقع HCC، قبل وبعد طرق تقليل الميزات بالثواني
النموذج يركز على العلاقات ذات المعنى الحقيقي داخل البيانات، مما يؤدي إلى عملية تعلم أكثر دقة وكفاءة. هذه التحسينات تمهد الطريق لتوقعات أسرع في الوقت الحقيقي، وتقليل التكاليف الحاسوبية، وفي النهاية، نموذج أكثر قوة وقابلية للتطبيق.
تطبيق تقنيات تقليل الميزات على نموذج بايز البسيط يؤدي إلى تحسينات ملحوظة في كل من الدقة ووقت التنفيذ. على وجه التحديد، يحقق النموذج معدل دقة مثير للإعجاب قدرهعلاوة على ذلك، تم تقليل وقت التنفيذ بشكل كبير إلى 49 ثانية فقط، مما يبرز كفاءة النموذج المحسّنة في المعالجة وإجراء التنبؤات. تسلط هذه التحسينات الضوء على فعالية تقليل الميزات في تحسين أداء نموذج بايز البسيط، مما يؤدي إلى دقة أعلى وأوقات تنفيذ أسرع.
قبل تنفيذ تقليل الميزات، يحقق نموذج شجرة القرار دقة ملحوظة تبلغلكن يتطلب مدة تنفيذ طويلة نسبيًا تبلغ 4 دقائق
الجدول 3 مقارنة الأداء عند استخدام كل من خوارزميات التعلم العميق والتعلم الآلي لتوقع سرطان الكبد الخلوي، على مجموعة بيانات المتغيرات السريرية TCGA LIHC قبل طرق تقليل الميزات
نهج
معايير التنبؤ
صحيح (مع ورم)
صحيح (خالي من الورم)
الدقة (%)
الدقة (%)
درجة F1 (%)
وقت التنفيذ
بايزي الساذج
توقع. مع ورم
٢٤
٣
٨٨.٨٩٪
90.67%
92.63%
4 دقائق و 2 ثواني
خالي من الورم المتوقع
٤
٤٤
91.67%
نسبة الاسترجاع (%)
85.71%
93.62%
الشبكة العصبية
توقع. مع ورم
١٣
٣
81.25%
76.00%
83.02%
5 دقائق
خالي من الورم المتوقع
15
٤٤
74.58%
نسبة الاسترجاع (%)
٤٦.٤٣٪
93.62%
شجرة القرار
توقع. مع ورم
21
0
100%
90.67%
93.05%
4 دقائق و 12 ثانية
ورم خالي متوقع
٧
٤٧
87.04%
استرجاع (%)
75%
100%
SVM
توقع. مع ورم
23
1
95.83%
92%
93.56%
5 دقائق و 14 ثانية
خالي من الورم المتوقع
٥
٤٦
90.20%
استرجاع (%)
82.14%
97.87%
KNN
توقع. مع ورم
١٨
0
100%
86.67%
90.38%
4 دقائق و 45 ثانية
ورم خالي متوقع
10
٤٧
82.46%
استرجاع (%)
64.29%
100%
و 12 ثانية. ومع ذلك، بعد تطبيق تقنيات تقليل الميزات، يحقق النموذج تحسينات ملحوظة. ويحقق معدل دقة مثير للإعجاب قدره، مما يدل على تحسين الدقة عند تصنيف الحالات. علاوة على ذلك، تم تقليل وقت التنفيذ بشكل كبير إلى دقيقة واحدة و9 ثوانٍ فقط. تؤكد هذه التحسينات فعالية تقليل الميزات في تحسين أداء نموذج شجرة القرار، مما يؤدي إلى دقة أعلى بشكل ملحوظ وتنفيذ أسرع. علاوة على ذلك، يظهر كل من نموذج SVM ونموذج KNN دقة متفوقة، حيث حقق نموذج SVM الدقة ونموذج KNN الذي يحققالدقة. ومن الجدير بالذكر أن أوقات التنفيذ لهذه النماذج هي دقيقة واحدة و48 ثانية لـ SVM ودقيقة واحدة و2 ثانية لـ KNN، على التوالي.
نقاش
تم تطوير مجموعة من خوارزميات التعلم الآلي لتوقع سرطان الكبد الخلوي. تستكشف الدراسة [69] استخدام مجموعة من تقنيات التعلم الآلي (التعلم الجماعي) للتنبؤ بمدة بقاء سرطان الكبد الخلوي.
الجدول 4 مقارنة الأداء عند استخدام كل من خوارزميات التعلم العميق والتعلم الآلي لتوقع سرطان الكبد الخلوي، على مجموعة بيانات المتغيرات السريرية TCGA LIHC بعد طرق تقليل الميزات
نهج
معايير التنبؤ
صحيح (مع ورم)
صحيح (خالي من الورم)
الدقة (%)
الدقة (%)
درجة F1 (%)
وقت التنفيذ
بايزي الساذج
توقع. مع ورم
27
1
96.43%
97.33%
97.87%
49 ثانية
خالي من الورم المتوقع
1
٤٦
97.87%
استرجاع (%)
96.43%
97.87%
شبكة عصبية
توقع. مع ورم
27
2
93.10%
96%
96.59%
1 دقيقة و 10 ثواني
خالي من الورم المتوقع
1
٤٥
97.83%
استرجاع (%)
96.43%
95.4%
شجرة القرار
توقع. مع ورم
٢٦
1
96.30%
96%
96.83%
1 دقيقة و 9 ثواني
خالي من الورم المتوقع
2
٤٦
95.83%
استرجاع (%)
92.86%
97.87%
SVM
توقع. مع ورم
٢٨
٣
90.32%
٩٦٫٠٠٪
٩٦.٧٠٪
1 دقيقة و 48 ثانية
خالي من الورم المتوقع
0
٤٤
100%
استرجاع (%)
100%
93.62%
KNN
توقع. مع ورم
٢٥
1
96.15%
94.67%
95.83%
1 دقيقة و 2 ثانية
خالي من الورم المتوقع
٣
٤٦
93.88%
استرجاع (%)
89.29%
97.87%
سيبقى مرضى سرطان الكبد (HCC) على قيد الحياة. يأخذ النموذج في الاعتبار عوامل مختلفة قد تؤثر على البقاء، بما في ذلك موقع المريض، وعوامل الخطر، وتفاصيل من التجارب السريرية.
اختبر الباحثون خمسة عشر نموذجًا مختلفًا، كل منها يتضمن تنظيف البيانات، وتقليل الميزات غير الضرورية، ثم تصنيف المرضى بناءً على الوقت المتوقع لبقائهم. لتحديد العوامل الأكثر أهمية، يستخدمون أربع طرق: الانحدار LASSO، والانحدار Ridge، وخوارزمية جينية، وغابة عشوائية. يتم استخدام العوامل الأكثر تأثيرًا فقط للتنبؤ.
النماذج التي يقومون ببنائها تشمل تنويعات من تصنيف الدعم النووي، وتصنيف ريدج (RCV)، وتعلم التجميع المعزز (GBEL)، كل منها مدمج مع إما تنظيم L1 أو L2 أو محسن بواسطة خوارزمية جينية أو غابة عشوائية. يتم تقييم هذه النماذج بناءً على مدى دقتها في التنبؤ بالبقاء، باستخدام مقاييس مثل الدقة، والحساسية، والمساحة تحت المنحنى (AUC).
تظهر نتائجهم أن نموذج RFGBEL (الغابة العشوائية المدمجة مع التعلم بالتحسين التدريجي) يحقق أفضل أداء مقارنةً بالنماذج الأخرى. يحقق هذا النموذج دقة تزيد عنونتيجة AUC عالية تبلغ 0.932، مما يشير إلى قوة قدرات التنبؤ. أخيرًا، يقارنون نموذج RFGBEL الخاص بهم بالطرق الحالية ويظهرون قدرته المتفوقة على التنبؤ ببقاء مرضى HCC.
كما يقترح الباحثون في الدراسة [70] نموذج NCA-GA-SVM جديد للتنبؤ ببقاء مرضى سرطان الكبد. يجمع هذا النموذج بين تقنيات معروفة ذات أداء عالٍ (NCA، GA) لتحسين تصنيف SVM. وقد حقق دقة عالية (على مجموعة بيانات تضم 165 مريضًا.
تطورت هذه الدراسة [71] نموذجًا دقيقًا للغاية لتشخيص سرطان الكبد (HCC) يستفيد من مزيج من المسارات البيولوجية الشخصية وتعلم الآلة. حقق النموذج أداءً استثنائيًا في الاختبارات الداخلية (AUROC>0.98) وأظهر قابلية جيدة للتعميم على البيانات الخارجية. تشير هذه النتائج إلى أن هذا النموذج لديه إمكانات كبيرة للتطبيق في العالم الحقيقي في تشخيص HCC. استخدم كيانى وآخرون [72] صورة مجهرية من مجموعة بيانات TCGA واستفادوا من أداة شبكة عصبية تلافيفية (CNN) تُدعى “مساعد سرطان الكبد”، حيث حققت تمييزًا دقيقًا بين سرطان الخلايا الكبدية (HCC) وسرطان القنوات الصفراوية. ومن الجدير بالذكر أن النموذج حقق دقة تشخيصية تبلغ 0.885، مما يبرز فعاليته في التعرف بدقة والتمييز بين هذين الشكلين المتميزين من سرطان الكبد.
في دراسة أجراها وانغ وآخرون [73]، تم استخدام تقنية التعلم العميق التي تتضمن شبكة عصبية تلافيفية (CNN) لأتمتة تحديد وتصنيف النوى الفردية في صور الأنسجة. تم تدريب الشبكة العصبية التلافيفية باستخدام مقاطع الأنسجة الملونة بصبغة H&E لأورام الكبد الخلوية (HCC) من مجموعة بيانات TCGA. بعد ذلك، تم إجراء عملية استخراج الميزات، مما أسفر عن تحديد 246 ميزة كمية للصورة. باستخدام نهج التعلم غير المراقب، تم إجراء تحليل تجميع، والذي أسفر عن نتائج مثيرة للاهتمام. بشكل مفاجئ، كشفت هذه التحليلات عن وجود ثلاثة أنواع نسيجية متميزة داخل أورام HCC. من المهم أن هذه الأنواع الفرعية لم تكن مرتبطة بالعناقيد الجينومية التي تم تأسيسها سابقًا وأظهرت توقعات مختلفة. أظهرت هذه الدراسة إمكانيات تحليل الصور المعتمد على CNN في الكشف عن أنواع نسيجية فريدة، مما يوفر رؤى قيمة حول توقعات أورام HCC. تعرض الجدول 5 مجموعة من النماذج المقترحة من قبل مؤلفين مختلفين، والتي تم تطبيقها على مشاكل مختلفة تتعلق بـ HCC باستخدام مجموعة بيانات TCGA. يمثل الجدول 5 دراسات المرضى الذين يعانون من سرطان الكبد الخلوي بناءً على مجموعة بيانات TCGA LIHC.
في هذا العمل، اقترحنا نهجًا يهدف إلى تحسين توقع سرطان الكبد الخلوي (HCC) من خلال نهج شامل يتضمن استراتيجيات متعددة. تشمل هذه الاستراتيجيات تقليل عدد الميزات المستخدمة في نموذج التوقع من خلال طرق مثل تحليل أهمية الميزات، واستكشاف الارتباطات الخفية بين الميزات، واستخدام خوارزميات متنوعة لتوقع HCC باستخدام المتغيرات السريرية. استخدمنا المتغيرات السريرية من TCGA LIHC ولكن كان من الضروري تنظيف البيانات لمعالجة أي تناقضات أو قيم مفقودة أو أخطاء. ثم تم تنسيق البيانات وإعدادها لمزيد من التحليل الذي شمل توسيع نطاق البيانات إلى نطاق مشترك، وترميز المتغيرات الفئوية، أو إجراء هندسة الميزات لإنشاء ميزات جديدة من الميزات الموجودة. بعد تحديد مجموعة الميزات المحسّنة، تم تقسيم مجموعة البيانات إلى مجموعتين: مجموعة تدريب تحتوي على 301 مثال ومجموعة اختبار تحتوي على 75 مثال. تم إجراء هذا التقسيم باستخدام تقنية أخذ العينات المعروفة باسم “أخذ العينات الطبقية”. تضمن هذه التقنية أن يتم إنشاء مجموعات فرعية عشوائية مع الحفاظ على توزيع الفئات بشكل متسق داخل
الجدول 5 دراسات المرضى الذين يعانون من سرطان الكبد الخلوي بناءً على مجموعة بيانات TCGA LIHC
دراسة
مجموعة البيانات
الخوارزمية
السنة
الدقة
دينغ وآخرون [74]
مجموعة بيانات TCGA و HCCDB18
طريقة التجميع المتسقة غير المراقبة
2022
مقارنة تعبير الجينات في الجليكوليس والكلسترول في العينات الطبيعية والسرطانية
تشنغ وآخرون [75]
مجموعة بيانات TCGA-LIHC
تحليل الانحدار كوكس
2022
كانت قيم AUC لبقاء المرضى لمدة 3 سنوات و 5 سنوات 0.783 و 0.828 على التوالي،
ياماشيتا وآخرون [76]
ستانفورد-HCCDET؛ TCGA
شبكة عصبية تلافيفية
2021
كانت AUROC لتصنيف أنسجة الورم 0.952 (95% CI 0.948، 0.957) على مجموعة الاختبار الداخلية
سايلارد وآخرون [77]
المركز الفرنسي و TCGA
شبكة عصبية تلافيفية
2020
تظهر هذه النماذج المعتمدة على CNN أداءً متفوقًا مقارنة بالنماذج التقليدية، حيث تحقق C-index يتراوح بين 0.75 إلى 0.78
توهم وآخرون [78]
TCGA-LIHC
ANN
2021
حددت الشبكة العصبية الاصطناعية (ANN) مجموعة من 15 جينًا أظهرت أهمية طبيعية أكبر من 50%
كياني وآخرون [72]
TCGA
CNN
2020
من خلال استخدام أداة معتمدة على CNN، كان تصنيف سرطان الكبد الخلوي وسرطان القناة الصفراوية يظهر معدل دقة تشخيصية قدره 0.885
لياو وآخرون [22]
TCGA ومركز في الصين
شبكة عصبية تلافيفية
2020
كانت توقعات الطفرات تتجاوز قيمة منطقة تحت المنحنى (AUC) قدرها 0.70
وانغ وآخرون [73]
TCGA-LIHC
شبكة عصبية تلافيفية
2020
أظهر النموذج دقة عالية، حيث حقق معدل تصنيف إجمالي قدره 99% لخلايا الورم و 97% للخلايا اللمفاوية
شي وآخرون [79]
مركز واحد في الصين؛ TCGA
شبكة عصبية تلافيفية
2021
يقوم التعلم العميق “بتقسيم مجموعة الدراسة إلى خمس مجموعات ذات توقعات متميزة في كل من مجموعة تشونغشان ( ) ومجموعة TCGA ( )”
تلك المجموعات الفرعية، تتماشى مع توزيع الفئة الإجمالية في مجموعة البيانات بأكملها. بعبارة أخرى، يساعد أخذ العينات الطبقية في الحفاظ على التمثيل النسبي للفئات المختلفة أثناء إنشاء مجموعات التدريب والاختبار، وهو أمر ضروري للحفاظ على سلامة مجموعة البيانات وضمان تقييم موثوق للنموذج. يؤدي تطبيق تقنيات تقليل الميزات على نموذج بايز الساذج إلى تحسينات كبيرة في الدقة ووقت التنفيذ. مع تنفيذ هذه التقنيات، يحقق النموذج معدل دقة مثير للإعجاب قدره . بالإضافة إلى ذلك، يتم تقليل وقت التنفيذ بشكل كبير إلى 49 ثانية فقط، مما يظهر الكفاءة المحسّنة للنموذج في المعالجة وإجراء التوقعات. هذه التحسينات
توضح بوضوح فعالية تقليل الميزات في تحسين أداء نموذج بايز الساذج، مما يؤدي إلى دقة أعلى وأوقات تنفيذ أسرع.
القيود
على الرغم من أن التعلم الآلي والتعلم العميق قد أظهرا وعدًا في تطبيقات طبية متنوعة، بما في ذلك توقع سرطان الكبد الخلوي (HCC)، إلا أن هناك العديد من القيود المرتبطة باستخدامها في هذا السياق.
تتمثل إحدى القيود الرئيسية في الحاجة إلى مجموعات بيانات كبيرة وعالية الجودة. تعتمد خوارزميات التعلم الآلي، بما في ذلك نماذج التعلم العميق، بشكل كبير على كميات هائلة من البيانات المنسقة جيدًا لتعلم الأنماط وإجراء توقعات دقيقة. ومع ذلك، فإن الحصول على مثل هذه المجموعات من البيانات لتوقع HCC يمكن أن يكون تحديًا بسبب ندرة المرض والحاجة إلى بيانات سريرية وصور شاملة. إن التوافر المحدود لمجموعات بيانات HCC المعلّمة يعيق تطوير وتقييم نماذج قوية.
تعتبر القابلية للتفسير والشرح أمرًا حيويًا في اتخاذ القرارات الطبية، وهذه هي قيود أخرى لنموذج التعلم العميق. على الرغم من أن هذه النماذج قد أظهرت قدرات تنبؤية ملحوظة، إلا أنها غالبًا ما تعمل كصناديق سوداء، مما يجعل من الصعب فهم الأسباب الكامنة وراء توقعاتها. تثير هذه الافتقار إلى القابلية للتفسير مخاوف في البيئات الطبية، حيث يحتاج الأطباء إلى الثقة في عملية اتخاذ القرار وفهم العوامل التي تسهم في التوقع.
يمكن أن تكون القابلية للتعميم لنماذج التعلم الآلي والتعلم العميق أيضًا قيدًا. قد لا تؤدي النماذج المدربة على مجموعات سكانية أو مجموعات بيانات محددة بشكل جيد عند تطبيقها على مجموعات مرضى أو إعدادات مختلفة. يمكن أن تؤدي التباينات في خصائص الورم، والملفات الجينية، والخصائص السكانية للمرضى إلى تحديات في تطوير نماذج يمكن أن تتوقع HCC بشكل فعال عبر مجموعات سكانية متنوعة. علاوة على ذلك، فإن إمكانية التحيز في نماذج التعلم الآلي هي قيد آخر. يمكن أن يتم إدخال التحيزات أثناء عملية جمع البيانات، مثل نقص تمثيل مجموعات سكانية معينة أو عوامل مشوشة. إذا تم تدريب النماذج على مجموعات بيانات متحيزة، فقد تستمر أو حتى تضخم التحيزات الموجودة، مما يؤدي إلى توقعات غير دقيقة وفجوات في نتائج الرعاية الصحية.
الخاتمة والعمل المستقبلي
في الختام، ركزت هذه الدراسة على التنبؤ بسرطان الكبد الخلوي (HCC)، وهو شكل شائع من سرطان الكبد، باستخدام خوارزميات التعلم الآلي. كان الهدف هو تقييم فعالية تقنيات تقليل الميزات في تعزيز أداء نماذج التنبؤ بـ HCC. من خلال مقارنة أداء خوارزميات التعلم الآلي المختلفة على كل من مجموعة البيانات الأصلية عالية الأبعاد ومجموعة فرعية من الميزات المخفضة، أظهرت هذه الدراسة أن تقليل الميزات يحسن بشكل كبير من دقة ووقت تنفيذ نماذج التنبؤ بـ HCC. ساعدت تقنيات تقليل الميزات المستخدمة، بما في ذلك وزن الميزات، ارتباط الميزات المخفية، اختيار الميزات، والاختيار المحسن، في استخراج مجموعة ميزات مخفضة تلتقط المعلومات الأكثر صلة المتعلقة بـ HCC. أظهرت النتائج التجريبية المستمدة من مجموعة بيانات شاملة للميزات السريرية لمرضى HCC أن مجموعة الميزات المخفضة تفوقت باستمرار على مجموعة البيانات الأصلية عالية الأبعاد من حيث دقة التنبؤ. حققت خوارزميات أشجار القرار، بايزي البسيط، الجيران الأقرب، الشبكات العصبية، وآلات الدعم الناقل (SVM) دقة بلغت 96%، 97.33%، 94.67%. ، و ، على التوالي، بعد تطبيق تقنيات تقليل الميزات. تشير هذه النتائج إلى أن طرق تقليل الميزات يمكن استخدامها بفعالية في نماذج توقع سرطان الكبد، مما يؤدي إلى تحسين الدقة وتقليل أوقات التنفيذ. إن تطبيق خوارزميات التعلم الآلي، جنبًا إلى جنب مع تقنيات تقليل الميزات، يحمل إمكانيات كبيرة للتشخيص المبكر والعلاج الفعال لسرطان الكبد، مما يحسن في النهاية نتائج المرضى.
بينما تظهر النماذج الحالية التي تستخدم المتغيرات السريرية لتوقع سرطان الكبد (HCC) وعدًا، هناك عدة مجالات للعمل المستقبلي لتحسين الدقة، وتخصيص تقييم المخاطر، وفي النهاية توجيه نتائج أفضل للمرضى. دمج البيانات متعددة الأنماط من خلال استكشاف دمج البيانات السريرية مع أنماط أخرى مثل المعلومات الجينية، وبيانات التصوير (الرنين المغناطيسي، الأشعة المقطعية)، والبيانات الحيوية المستندة إلى الدم. يمكن أن تكون نماذج التعلم العميق بارعة بشكل خاص في التعامل مع مثل هذه المصادر المتنوعة من البيانات. أيضًا، يجب تدريب النماذج والتحقق من صحتها على مجموعات بيانات كبيرة ومتنوعة جغرافيًا لضمان القابلية للتعميم وتجنب الإفراط في التكيف مع مجموعات سكانية محددة. يجب أخذ وجود حالات مزمنة أخرى مثل السكري أو التهاب الكبد في الاعتبار، والتي قد تؤثر على تطور سرطان الكبد. تطوير نماذج يمكن أن تدمج البيانات الطولية (التغيرات في المتغيرات السريرية مع مرور الوقت) للتنبؤ بتغيرات المخاطر وتحديد المرضى ذوي المخاطر العالية في وقت مبكر. من خلال التركيز على هذه الاتجاهات المستقبلية، يمكننا تحسين دقة وفائدة النماذج التنبؤية لسرطان الكبد باستخدام المتغيرات السريرية، مما يؤدي إلى الكشف المبكر، وتحسين تصنيف المخاطر، وفي النهاية تحسين نتائج المرضى.
مساهمات المؤلفين
تم تنفيذ هذا العمل بالتعاون بين جميع المؤلفين. قام جميع المؤلفين بتصميم الدراسة، وأجروا التحليل الإحصائي، وكتبوا البروتوكول. قام جميع المؤلفين بإدارة تحليلات الدراسة، وإدارة البحث في الأدبيات، وكتبوا المسودة الأولى من المخطوطة. قرأ جميع المؤلفين ووافقوا على المخطوطة النهائية.
تمويل
تم توفير تمويل الوصول المفتوح من قبل هيئة تمويل العلوم والتكنولوجيا والابتكار (STDF) بالتعاون مع البنك المصري للمعرفة (EKB). لم تتلقَ هذه البحث أي منحة محددة من وكالات التمويل في القطاعات العامة أو التجارية أو غير الربحية.
لا يحتوي هذا المقال على أي دراسات مع مشاركين بشريين أو حيوانات أجراها أي من المؤلفين.
موافقة على النشر
جميع المؤلفين قد قرأوا ووافقوا على النسخة المنشورة من المخطوطة.
المصالح المتنافسة
يعلن المؤلفون أنهم ليس لديهم أي مصالح مالية متنافسة معروفة أو علاقات شخصية قد تبدو أنها تؤثر على العمل المبلغ عنه في هذه الورقة.
تاريخ الاستلام: 27 فبراير 2024 تاريخ القبول: 31 مايو 2024 نُشر على الإنترنت: 18 يونيو 2024
References
Torre LA, et al. Global cancer statistics, 2012. CA Cancer J Clin. 2015;65(2):87-108.
DeWaal D, et al. Hexokinase-2 depletion inhibits glycolysis and induces oxidative phosphorylation in hepatocellular carcinoma and sensitizes to metformin. Nat Commun. 2018;9(1):446.
Santos MS, et al. A new cluster-based oversampling method for improving survival prediction of hepatocellular carcinoma patients. J Biomed Inform. 2015;58:49-59.
Ali L, Bukhari S. An approach based on mutually informed neural networks to optimize the generalization capabilities of decision support systems developed for heart failure prediction. Irbm. 2021;42(5):345-52.
Książek W, et al. A novel machine learning approach for early detection of hepatocellular carcinoma patients. Cogn Syst Res. 2019;54:116-27.
Ali L et al. A multi-model framework for evaluating type of speech samples having complementary information about Parkinson’s disease. In: 2019 International conference on electrical, communication, and computer engineering (ICECCE). IEEE; 2019.
Abdar M, et al. A new nested ensemble technique for automated diagnosis of breast cancer. Pattern Recogn Lett. 2020;132:123-31.
Zheng B, Yoon SW, Lam SS. Breast cancer diagnosis based on feature extraction using a hybrid of K-means and support vector machine algorithms. Expert Syst Appl. 2014;41(4):1476-82.
Shi J, et al. Multimodal neuroimaging feature learning with multimodal stacked deep polynomial networks for diagnosis of Alzheimer’s disease. IEEE J Biomed Health Inform. 2017;22(1):173-83.
Zhi X, et al. Efficient discriminative clustering via QR decomposition-based linear discriminant analysis. Knowl-Based Syst. 2018;153:117-32.
Ali L et al. Early detection of heart failure by reducing the time complexity of the machine learning based predictive model. In: 2019 international conference on electrical, communication, and computer engineering (ICECCE). IEEE; 2019.
Ravikulan A, Rostami K. Leveraging machine learning for early recurrence prediction in hepatocellular carcinoma: a step towards precision medicine. World J Gastroenterol. 2024;30(5):424.
Hong H, et al. Prediction of hepatocellular carcinoma development in Korean patients after hepatitis C cure with direct-acting antivirals. Gut and Liver. 2024;18(1):147.
Abajian A, et al. Predicting treatment response to intra-arterial therapies for hepatocellular carcinoma with the use of supervised machine learning—an artificial intelligence concept. J Vasc Intervent Radiol. 2018;29(6):850-7.
Ioannou GN, et al. Assessment of a deep learning model to predict hepatocellular carcinoma in patients with hepatitis C cirrhosis. JAMA Netw Open. 2020;3(9):e2015626-e2015626.
Nam JY, et al. Deep learning model for prediction of hepatocellular carcinoma in patients with HBV-related cirrhosis on antiviral therapy. JHEP Rep. 2020;2(6): 100175.
Nam JY, et al. Novel model to predict HCC recurrence after liver transplantation obtained using deep learning: a multicenter study. Cancers. 2020;12(10):2791.
Ali MA, et al. A novel method for survival prediction of hepatocellular carcinoma using feature-selection techniques. Appl Sci. 2022;12(13):6427.
Cao , et al. Prediction model for recurrence of hepatocellular carcinoma after resection by using neighbor2vec based algorithms. Wiley Interdiscip R Data Min Knowl Discov. 2021;11(2): e1390.
Zhang Y, et al. Deep learning with 3D convolutional neural network for noninvasive prediction of microvascular invasion in hepatocellular carcinoma. J Magn Reson Imaging. 2021;54(1):134-43.
Zhang Y-B, et al. Development of a machine learning-based model for predicting risk of early postoperative recurrence of hepatocellular carcinoma. World J Gastroenterol. 2023;29(43):5804.
Liao H, et al. Deep learning-based classification and mutation prediction from histopathological images of hepatocellular carcinoma. Clin Transl Med. 2020;10(2): e102.
Deng , et al. Mining TCGA database for tumor microenvironment-related genes of prognostic value in hepatocelIular carcinoma. BioMed Res Int. 2019;2019:2408348.
Wang K , et al. A novel immune-related genes prognosis biomarker for hepatocellular carcinoma. Aging (Albany NY). 2021;13(1):675.
Bannister CA, et al. A genetic programming approach to development of clinical prediction models: a case study in symptomatic cardiovascular disease. PLoS ONE. 2018;13(9): e0202685.
Dong Y, et al. A novel surgical predictive model for Chinese Crohn’s disease patients. Medicine. 2019;98(46): e17510.
Karhade AV, et al. Development of machine learning algorithms for prediction of prolonged opioid prescription after surgery for lumbar disc herniation. Spine J. 2019;19(11):1764-71.
Scheer JK, et al. Development of a preoperative predictive model for major complications following adult spinal deformity surgery. J Neurosurg Spine. 2017;26(6):736-43.
Adams S, Beling PA, Cogill R. Feature selection for hidden Markov models and hidden semi-Markov models. IEEE Access. 2016;4:1642-57.
Bjaoui M et al. Depth insight for data scientist with RapidMiner «an innovative tool for Al and big data towards medical applications». In: Proceedings of the 2nd international conference on digital tools & uses congress; 2020.
Roy SP, Kasat A. Diabetic prediction with ensemble model and feature selection using information gain method. In: 2024 2nd international conference on intelligent data communication technologies and internet of things (IDCloT). IEEE; 2024.
Ihianle IK, et al. Minimising redundancy, maximising relevance: HRV feature selection for stress classification. Expert Syst Appl. 2024;239: 122490.
Robnik-Šikonja M, Kononenko I. Theoretical and empirical analysis of ReliefF and RReliefF. Mach Learn. 2003;53:23-69.
Shukla AK, et al. Knowledge discovery in medical and biological datasets by integration of Relief-F and correlation feature selection techniques. J Intell Fuzzy Syst. 2020;38(5):6637-48.
Haq AU, et al. A hybrid intelligent system framework for the prediction of heart disease using machine learning algorithms. Mob Inf Syst. 2018;2018:1-21.
Theng D, Bhoyar KK. Feature selection techniques for machine learning: a survey of more than two decades of research. Knowl Inf Syst. 2024;66(3):1575-637.
Gao J, et al. Information gain ratio-based subfeature grouping empowers particle swarm optimization for feature selection. Knowl-Based Syst. 2024;286: 111380.
Wang X, Yan Y, Ma X. Feature selection method based on differential correlation information entropy. Neural Process Lett. 2020;52:1339-58.
Singh D, Singh B. Investigating the impact of data normalization on classification performance. Appl Soft Comput. 2020;97: 105524.
Raju VG et al. Study the influence of normalization/transformation process on the accuracy of supervised classification. In: 2020 third international conference on smart systems and inventive technology (ICSSIT). IEEE; 2020.
Zhou S, et al. Breast cancer prediction based on multiple machine learning algorithms. Technol Cancer Res Treat. 2024;23:15330338241234792.
Aksoy S, Haralick RM. Feature normalization and likelihood-based similarity measures for image retrieval. Pattern Recogn Lett. 2001;22(5):563-82.
Ajbar W, et al. Development of artificial neural networks for the prediction of the pressure field along a horizontal pipe conveying high-viscosity two-phase flow. Flow Meas Instrum. 2024;96: 102541.
Hsu CW, Chang CC, Lin CJ. A practical guide to support vector classification, Taipei, Taiwan; 2003.
Parashar G, Chaudhary A, Pandey D. Machine learning for prediction of cardiovascular disease and respiratory disease: a review. SN Comput Sci. 2024;5(1):196.
Jayalakshmi T, Santhakumaran A. Statistical normalization and back propagation for classification. Int J Comput Theory Eng. 2011;3(1):1793-8201.
Acharya UR, et al. Automated diagnosis of glaucoma using texture and higher order spectra features. IEEE Trans Inf Technol Biomed. 2011;15(3):449-55.
Snelick R, et al. Large-scale evaluation of multimodal biometric authentication using state-of-the-art systems. IEEE Trans Pattern Anal Mach Intell. 2005;27(3):450-5.
Wen , et al. Efficient feature selection and classification for vehicle detection. IEEE Trans Circuits Syst Video Technol. 2014;25(3):508-17.
Esfahani ET, Wang S, Sundararajan V. Multisensor wireless system for eccentricity and bearing fault detection in induction motors. IEEE/ASME Trans Mechatron. 2013;19(3):818-26.
Pan J, Zhuang Y, Fong S. The impact of data normalization on stock market prediction: using SVM and technical indicators. In: Soft computing in data science: second international conference, SCDS 2016, Kuala Lumpur, Malaysia, September 21-22, 2016, Proceedings 2. Springer; 2016.
Kadir A et al. Leaf classification using shape, color, and texture features; 2013. arXiv preprint arXiv:1401.4447.
Wang C-M, Huang Y-F. Evolutionary-based feature selection approaches with new criteria for data mining: a case study of credit approval data. Expert Syst Appl. 2009;36(3):5900-8.
Wu W, et al. Evaluation of normalization methods for cDNA microarray data by k-NN classification. BMC Bioinform. 2005;6:1-21.
Liu Z. A method of SVM with normalization in intrusion detection. Procedia Environ Sci. 2011;11:256-62.
Su D et al. Anomadroid: profiling android applications’ behaviors for identifying unknown malapps. In: 2016 IEEE Trustcom/BigDataSE/ISPA. IEEE; 2016.
Peterson RA. Finding optimal normalizing transformations via best normalize. R Journal. 2021;13(1):310-29.
El-Hasnony IM, et al. Improved feature selection model for big data analytics. IEEE Access. 2020;8:66989-7004.
Song X-F, et al. A fast hybrid feature selection based on correlation-guided clustering and particle swarm optimization for high-dimensional data. IEEE Trans Cybern. 2021;52(9):9573-86.
Mohamad , et al. Enhancing big data feature selection using a hybrid correlation-based feature selection. Electronics. 2021;10(23):2984.
Khaire UM, Dhanalakshmi R. Stability of feature selection algorithm: a review. J King Saud Univ Comput Inf Sci. 2022;34(4):1060-73.
Camattari F et al. Greedy feature selection: Classifier-dependent feature selection via greedy methods. arXiv preprint arXiv:2403.05138; 2024.
Chen W, Sun X. Dynamic multi-label feature selection algorithm based on label importance and label correlation. Int J Mach Learn Cybern. 2024. https://doi.org/10.1007/s13042-024-02098-3.
Habib M, Okayli M. Evaluating the sensitivity of machine learning models to data preprocessing technique in concrete compressive strength estimation. Arab J Sci Eng. 2024. https://doi.org/10.1007/s13369-024-08776-2.
Peng , et al. scFSNN: a feature selection method based on neural network for single-cell RNA-seq data. BMC Genomics. 2024;25(1):264.
Ayesha S, Hanif MK, Talib R. Overview and comparative study of dimensionality reduction techniques for high dimensional data. Inf Fus. 2020;59:44-58.
Ray P, Reddy SS, Banerjee T. Various dimension reduction techniques for high dimensional data analysis: a review. Artif Intell Rev. 2021;54:3473-515.
Zebari R, et al. A comprehensive review of dimensionality reduction techniques for feature selection and feature extraction. J Appl Sci Technol Trends. 2020;1(2):56-70.
Sharma M, Kumar N. Improved hepatocellular carcinoma fatality prognosis using ensemble learning approach. J Ambient Intell Humaniz Comput. 2022;13(12):5763-77.
Książek W, Turza F, Pławiak P. NCA-GA-SVM: a new two-level feature selection method based on neighborhood component analysis and genetic algorithm in hepatocellular carcinoma fatality prognosis. Int J Numer Methods Biomed Eng. 2022;38(6): e3599.
Cheng B, Zhou P, Chen Y. Machine-learning algorithms based on personalized pathways for a novel predictive model for the diagnosis of hepatocellular carcinoma. BMC Bioinform. 2022;23(1):248.
Kiani A, et al. Impact of a deep learning assistant on the histopathologic classification of liver cancer. NPJ Dig Med. 2020;3(1):23.
Wang H, et al. Single-cell spatial analysis of tumor and immune microenvironment on whole-slide image reveals hepatocellular carcinoma subtypes. Cancers. 2020;12(12):3562.
Deng W, et al. Classification and prognostic characteristics of hepatocellular carcinoma based on glycolysis cholesterol synthesis axis. J Oncol. 2022. https://doi.org/10.1155/2022/2014625.
Cheng , et al. Identification and construction of a 13 -gene risk model for prognosis prediction in hepatocellular carcinoma patients. J Clin Lab Anal. 2022;36(5): e24377.
Yamashita R, et al. Deep learning predicts postsurgical recurrence of hepatocellular carcinoma from digital histopathologic images. Sci Rep. 2021;11(1):1-14.
Saillard C , et al. Predicting survival after hepatocellular carcinoma resection using deep learning on histological slides. Hepatology. 2020;72(6):2000-13.
Tohme S, et al. The use of machine learning to create a risk score to predict survival in patients with hepatocellular carcinoma: a TCGA cohort analysis. Can J Gastroenterol Hepatol. 2021. https://doi.org/10.1155/2021/5212953.
Shi J-Y, et al. Exploring prognostic indicators in the pathological images of hepatocellular carcinoma based on deep learning. Gut. 2021;70(5):951-61.
ملاحظة الناشر
تظل شركة سبرينجر ناتشر محايدة فيما يتعلق بالمطالبات القضائية في الخرائط المنشورة والانتماءات المؤسسية.
*المراسلات: غادة مصطفى عبد العزيز 8_pg@fcis.bsu.edu.eg; د. hamdimahmoud@yahoo.com; طارق@mu.edu.eg; محمد. elaraby@fcis.bsu.edu.eg قسم علوم الحاسوب، كلية الحاسبات والذكاء الاصطناعي، جامعة بني سويف الوطنية، بني سويف، مصر قسم علوم الحاسوب، كلية العلوم، جامعة المنيا، المنيا، مصر وحدة علوم الحاسوب، جامعة ديروط، المنيا، مصر
Feature reduction for hepatocellular carcinoma prediction using machine learning algorithms
Ghada Mostafa , Hamdi Mahmoud , Tarek Abd El-Hafeez and Mohamed E. ElAraby
Abstract
Hepatocellular carcinoma (HCC) is a highly prevalent form of liver cancer that necessitates accurate prediction models for early diagnosis and effective treatment. Machine learning algorithms have demonstrated promising results in various medical domains, including cancer prediction. In this study, we propose a comprehensive approach for HCC prediction by comparing the performance of different machine learning algorithms before and after applying feature reduction methods. We employ popular feature reduction techniques, such as weighting features, hidden features correlation, feature selection, and optimized selection, to extract a reduced feature subset that captures the most relevant information related to HCC. Subsequently, we apply multiple algorithms, including Naive Bayes, support vector machines (SVM), Neural Networks, Decision Tree, and K nearest neighbors (KNN), to both the original high-dimensional dataset and the reduced feature set. By comparing the predictive accuracy, precision, F Score, recall, and execution time of each algorithm, we assess the effectiveness of feature reduction in enhancing the performance of HCC prediction models. Our experimental results, obtained using a comprehensive dataset comprising clinical features of HCC patients, demonstrate that feature reduction significantly improves the performance of all examined algorithms. Notably, the reduced feature set consistently outperforms the original high-dimensional dataset in terms of prediction accuracy and execution time. After applying feature reduction techniques, the employed algorithms, namely decision trees, Naive Bayes, KNN, neural networks, and SVM achieved accuracies of , and , respectively.
According to reports from the World Health Organization (WHO), approximately 14.1 million individuals are diagnosed with cancer each year, resulting in 8.2 million deaths globally [1]. Hepatocellular carcinoma (HCC) is a form of liver cancer that arises from chronic liver disease and cirrhosis. Recent studies indicate that HCC is the most lethal cancer worldwide, leading to approximately 600,000 deaths annually [2]. Furthermore, liver cancer holds the sixth position among the most frequently diagnosed cancers worldwide
[3]. These facts demonstrate the global impact of HCC on human lives. Consequently, it is crucial to reduce the mortality rate associated with HCC, which can only be achieved through early detection. To accomplish this goal, it is imperative to leverage various data mining and machine learning techniques to develop an automated diagnostic system that can accurately predict HCC, ensuring more efficient and timely detection. Data mining is a multidisciplinary domain that employs principles from computer science and statistics to extract valuable information, such as features or rules, from provided data [4]. Conversely, machine learning is a branch of computer science that focuses on techniques and methodologies through which machines acquire knowledge and learn from experience [5]. In the present era, machine learning techniques and data mining are experiencing rapid growth and extensive application in the realm of medical diagnostics to tackle various challenges such as [6-13].
Our research began with a focus on acknowledging the importance of normalized data. A clear trend was observed in previous work-better model performance with normalized data. This observation led us to adapt our dataset accordingly. Next, we introduced feature selection methods, starting with the powerful “Recursive Feature Elimination (RFE)”. This method tests the model’s performance with each potential feature, systematically removing features and re-testing the model to find the best iteration. Next, we used “Principal Component Analysis (PCA)”, which is a popular method for feature extraction. Its goal is to reduce the dimensionality of a data set while preserving as much of the information as possible. PCA accomplishes this by creating new uncorrelated variables or components that successively maximize variance. In our study, PCA was utilized to transform the data set into a set of linearly uncorrelated variables termed principal components. Finally, optimization feature operators were applied. It is well recognized that optimizing the selection of feature subsets can significantly improve the performance of a classifier. To rate the importance of a feature for the classification task, mutual information was utilized. This was followed by executing various machine learning algorithms to assess classification performance.
A clear challenge exists in the form of Hepatocellular Carcinoma (HCC)-a lethal form of cancer cloaked in diagnostic complexity. Accurate, efficient predictive models are crucial for timely diagnosis and optimized treatment. However, conventional predictive models are hindered by the ‘dimensionality curse’, a common obstacle in high-dimensional datasets used in HCC diagnosis.
Problem statement
Despite being one of the most lethal forms of cancer, Hepatocellular Carcinoma (HCC) remains shrouded in an air of diagnostic complexity. The development of accurate and efficient predictive models represents a critical facilitator of timely diagnosis and effective treatment. Stunted by the dimensionality curse commonly associated with high-dimensional datasets acquired in HCC diagnosis, traditional predictive models have demonstrated limited proficiency.
Research question
Can the application of alternative feature reduction techniques significantly enhance the performance of machine learning algorithms in the prediction of Hepatocellular Carcinoma?
Research gap
Previous studies have noted the positive relationship between reducing feature dimensionality and the predictive accuracy of machine learning algorithms. However, there remains a conspicuous lack of comprehensive approaches that compare the performance of various machine learning algorithms under the influence of different feature reduction techniques in the domain of hepatocellular carcinoma prediction.
Contributions
This study heralds an important contribution to the field of computational HCC prediction by comparing the performance of much-utilized machine learning algorithms before and after the implementation of feature reduction techniques. The main contributions can be summarized as follows:
Adoption of data normalization to improve our model’s performance, as reinforced by earlier studies.
Execution of feature selection methods including ‘Recursive Feature Elimination (RFE)’ and ‘Principal Component Analysis (PCA)’ to boost the effectiveness of our predictive model.
Assessment of the influence of various features on the task of classification by deploying mutual information.
Conducting a performance comparison of differing machine learning algorithms, gauging their classification results.
Addressing existing research shortcomings by performing an extensive comparison of multiple feature reduction techniques and their corresponding impact on the outcomes of a range of machine learning algorithms, particularly about Hepatocellular Carcinoma (HCC) prediction.
Advancing the computational prediction field for HCC by examining performance shifts in a variety of machine learning algorithms both before and after the integration of feature reduction techniques.
Related work
In a research study by Abajian et al. [14] a study involving 36 patients with HCC who underwent transarterial chemoembolization. They employed machine learning techniques, specifically linear regression, and random forest, and achieved an overall accuracy of . In a study by Ioannou et al. [15] focused on predicting the occurrence of hepatocellular carcinoma (HCC) within 3 years, a recurrent neural network (RNN) was trained using data from patients with hepatitis C virus (HCV)related cirrhosis. The dataset included four variables measured at the beginning of the study and 27 variables measured over time, collected from 48,151 patients receiving
healthcare within the US Department of Veterans Affairs system. The findings of the study demonstrated that the RNN model outperformed logistic regression in predicting the development of HCC within the specified timeframe. The RNN achieved an accuracy of for all patients and for patients who achieved sustained virologic response (SVR) in predicting the onset of hepatocellular carcinoma (HCC).
In a research study conducted by Nam et al. [16], a deep neural network was developed to predict the occurrence of hepatocellular carcinoma (HCC) over a 3 – and 5 -year period in patients with hepatitis B virus (HBV)-related cirrhosis who were undergoing entecavir therapy. The study examined 424 patients and demonstrated that the deep learning (DL) model outperformed six other previously reported models that utilized older modeling techniques. Additionally, the DL model was tested on a validation cohort consisting of 316 patients, and the results indicated a Harrell’s C-index of 0.782 , indicating a high level of accuracy in predicting the incidence of HCC in these patients.
Nam et al. [17] built upon their previous work by developing MoRAL-AI, a novel artificial intelligence model utilizing deep learning techniques, to identify liver cancer (HCC) patients at high risk of tumor recurrence after transplantation. The MoRALAI model analyzed several prognostic factors including tumor size, patient age, blood alpha-fetoprotein (AFP) levels, and prothrombin time to generate risk predictions. Results of the study demonstrated that MoRAL-AI outperformed traditional prediction models such as the Milan, UCSF, up-to-seven, and Kyoto criteria in determining which HCC patients faced elevated recurrence risk post-transplant. Specifically, MoRAL-AI achieved a C-index of 0.75 for prognostic accuracy compared to , and 0.50 for the other models respectively, with this difference being statistically significant ( ). In summary, MoRAL-AI represented an improved approach for identifying HCC patients likely to experience recurrence following liver transplantation.
In their study, Ali et al. [18] evaluated the predictive performance of various machine learning algorithms for hepatocellular carcinoma (HCC), including logistic regression, k-nearest neighbors (KNN), decision tree, random forest, and support vector machine (SVM). Additionally, they proposed and tested a novel combination approach utilizing linear discriminant analysis (LDA), genetic algorithm (GA), and SVM. When comparing all models, the results demonstrated the LDA-GA-SVM approach yielded the best overall predictive ability. Specifically, the LDA-GA-SVM achieved the highest accuracy of 0.899 , sensitivity of 0.892 , and specificity of 0.906 . These performance metrics were superior to those obtained when using the other individual algorithms evaluatedlogistic regression, KNN, decision tree, random forest, and SVM alone. Therefore, the study findings suggested the LDA-GA-SVM composite model may be the most effective machine learning-based predictive tool for HCC compared to the alternative algorithms analyzed.
Cao et al. [19] evaluated the predictive performance of various machine learning mod-els-logistic regression, k-nearest neighbors (KNN), decision tree (DT), naïve Bayes (NB), and deep neural network (DNN)-using the original dataset. The accuracy of the models ranged from 57.5 to . Precision varied between 40.7 and , while recall rates were between 20.0 and . False positive rates fell between 10.7 and and standard deviation values ranged from 0.026 to 0.058 . Among the models trained on the original dataset, KNN exhibited the best overall predictive ability. Specifically, KNN
achieved an accuracy of , precision of , recall rate of , and a false positive rate of with a standard deviation of 0.042 . These results indicate that of the algorithms tested on the unmodified data, KNN provided the most accurate and reliable predictions of disease status.
In a study by Zhang et al. [20] 237 patients with liver cancer, almost ( 92 patients) were identified as having a positive marker for MVI. This group, with an average age of 52 , was predominantly male ( 86 out of 92 ). The remaining of patients ( 145 patients) were MVI-negative, with an average age of 54 and a more balanced male-to-female ratio ( 124 males to 21 females). Patients with MVI had larger tumors, a higher occurrence of tumor capsules, and elevated levels of certain proteins compared to those without MVI.
In a study by [21] After conducting machine learning analysis, they identified eight key feature variables (age, intratumoral arteries, alpha-fetoprotein, pre-operative blood glucose, number of tumors, glucose-to-lymphocyte ratio, liver cirrhosis, and pre-operative platelets) to develop six distinct prediction models. Among these models, the XGBoost model exhibited superior performance, as evidenced by the area under the receiver operating characteristic curve (AUC-ROC) values of 0.993 ( confidence interval: , and in the training, validation, and test datasets, respectively. Furthermore, calibration curve analysis and decision curve analysis demonstrated that the XGBoost model exhibited favorable predictive performance and possessed practical value in clinical applications.
Motivated by the development of different diagnostic systems based on machine learning models to improve the precision of decision-making about HCC diagnosis and prediction we also conducted an approach to enhance hepatocellular carcinoma (HCC) prediction through Feature reduction methods. This study highlights the effectiveness of feature reduction in boosting the performance of various AI techniques for HCC nodule prediction. By streamlining the data, they were able to significantly improve the accuracy of algorithms like Naive Bayes, Neural Networks, Decision Tree, SVM, and KNN.
Materials and methods
Database description
Clinical patient data from the Cancer Genome Atlas (TCGA) database were used in this study, The TCGA LIHC clinical data set offers a robust resource for investigating the clinical landscape of hepatocellular carcinoma (HCC). This data, encompassing diverse patient demographics, tumor characteristics, treatment details, and clinical outcomes, facilitates a multi-faceted approach to understanding disease progression and informing research avenues [22-24].
Patient demographics: Age, sex, ethnicity, socioeconomic factors, and medical history provide context for analyzing disease epidemiology and potential risk factors as shown in Fig. 1. Correlations between these variables and clinical outcomes can inform targeted prevention and early intervention strategies.
Tumor characteristics: Detailed information on tumor size, stage, grade, location, and presence of underlying liver disease allows for stratification of patient populations and facilitates investigation of tumor progression patterns.
Fig. 1 Hepatocellular carcinoma risk factors history in TCGA LIHC data set
Treatment details: Data on surgical procedures, radiation protocols, and chemotherapy regimens allows for comparative effectiveness studies and identification of optimal treatment strategies for different patient subgroups.
Clinical outcomes: Data on overall survival, disease-free survival, time to recurrence, and response to treatment offer important endpoints for evaluating treatment efficacy and informing clinical decision-making.
Limitations: While the TCGA LIHC clinical data set is comprehensive, it’s important to acknowledge potential limitations due to data collection inconsistencies, missing follow-up data, and selection bias. Careful consideration of these limitations is necessary to ensure accurate interpretation of results and informed research conclusions.
The dataset employed in this study comprised 77 features for each of the 377 patients in total. The label of the dataset denotes tumor status and can assume a value of “tumorfree” or “with tumor”. The term “tumor-free” does not imply a state of normalcy, but instead refers to the absence or persistence of the neoplasm (tumor). It represents a statement regarding the progression or lack thereof of the initial disease. It is crucial to mention that there are missing values for each feature in the dataset that have the information of all features. Within the existing body of literature, two distinct approaches are commonly employed to address missing values. The first method involves removing all samples that contain missing values, but this approach is not feasible in our case as it would result in the loss of a significant portion of the samples. Consequently, we opted to employ the imputation method to fill in the missing values. Missing data was addressed through a diverse range of imputation methods during the studies [25-28]. We utilized a statistical approach to impute missing values by substituting them with the mean value of the corresponding column or feature in which the missing value was
found. Elaborate information is provided about the clinical features of the TCGA dataset in Table 1.
Methodology
The proposed research entails a multi-pronged approach to enhance hepatocellular carcinoma (HCC) prediction through Feature reduction methods including feature importance, hidden feature correlation, and feature selection [29] using different algorithms. The initial phase involved a thorough review of existing literature on deep learning applications in risk assessment, diagnosis, prognosis, and therapy for HCC patients. Subsequently, a meticulous analysis of clinical variables was conducted. Deep learning and machine learning algorithms were then implemented for HCC prediction, incorporating various feature reduction techniques. The overarching objective is to demonstrably validate the superiority of employing alternative feature selection methods compared to using all features within the machine learning models for achieving accurate HCC prediction.
In this study, the workflow for training a dataset using feature weight, feature correlation, Normalization, and optimization operators in RapidMiner [30] involves a series of steps designed to enhance the model-building process.
First, the dataset was loaded into RapidMiner, and the relevant operators were added to the process. The weights operator allows assigning importance or significance to individual instances or attributes in the dataset. This was useful when certain instances or attributes carry more weight or relevance in the analysis.
Next, the correlation operator was applied to identify and measure the relationships between different attributes in the dataset. It helps in understanding which attributes are strongly correlated with the target variable or with each other. This information can guide feature selection and eliminate redundant or highly correlated attributes, reducing the dimensionality of the dataset.
After the correlation analysis, the normalization operator was utilized to scale and standardize the numerical attributes in the dataset. This step ensures that all attributes have similar ranges and distributions, preventing any single attribute from dominating the model training process due to differences in their scales. Normalization enhances the stability and convergence of various algorithms leading to improved model performance.
Following normalization, the optimization operator was employed to select the most relevant subset of features from the dataset. It uses optimization algorithms and statistical measures to evaluate the contribution of each attribute to the model’s performance. By iteratively evaluating different feature subsets, the optimization operator identified the combination of attributes that maximizes the model’s accuracy or other defined performance metrics. This step helped in reducing noise, improving model efficiency, and enhancing interpretability.
Once the optimized feature subset was determined, the dataset was divided into training and testing sets 301 examples for train and 75 examples for test using appropriate sampling techniques.in our case, we used “Stratified sampling” which involves creating random subsets while ensuring that the distribution of classes within those subsets remains consistent with the overall class distribution in the entire example set.
Table 1 Information about the features of the TCGA dataset clinical variables
Features
Description
Type
Values
Ablation embolization tx adjuvant
Ablation embolization tx adjuvant
Binominal
No (364), Yes (13)
Age at diagnosis
Age at initial pathologic diagnosis
Integer
Min (16), Max (90)
ajcc metastasis pathologic pm
Pathologic M
Nominal
M0 (272), MX (101), M (4)
ajcc nodes pathologic pn
Pathologic N
Nominal
N0 (257), NX (115), N1 (4)
ajcc pathologic tumor stage
Pathologic stage
Nominal
Stage I (175), Stage II (87), Stage IIIA (65), Stage IIIB (9), Stage IIIC (9), Stage III (3), Stage IV (2), Stage IVB (2), [discrepancy] (2),Stage IVA (1)
Laboratory procedure alphafetoprotein outcome value
Integer
Min (1), Max (2035400)
Alpha fetoprotien norm range lower
Laboratory procedure alphafetoprotein outcome lower limit of normal value
Integer
Min (0), Max (6)
Alpha fetoprotien norm range upper
Laboratory procedure alphafetoprotein outcome upper limit of normal value
Integer
Min (6), Max (44)
bcr patient barcode
bcr patient barcode
Nominal
Ex:TCGA-2V-A95S
bcr patient uuid
bcr patient uuid
Nominal
Ex: 0004D251-3F70-4395-B175C94C2F5B1B81
Bilirubin total
Laboratory procedure total bilirubin result specified the upper limit of the normal value
Real
Min (0.100), Max (19)
Bilirubin total norm range lower
Laboratory procedure total bilirubin result specified a lower limit of normal value
Real
Min (0), Max (1)
Bilirubin total norm range upper
Laboratory procedure total bilirubin results in upper limit normal value
Real
Min (0.200), Max (21)
Birthdays to
Days to birth
Integer
Min (- 32,120),Max (-5862)
Child-pugh classification
Child-Pugh classification grade
Nominal
A (223), B (21), C (1)
Clinical M
Clinical M
Nominal
[Not applicable] 377
Clinical N
Clinical N
Nominal
[Not applicable] 377
Clinical stage
Clinical stage
Nominal
[Not applicable] 377
Clinical T
Clinical T
Nominal
Creatinine level preresection
Hematology serum creatinine laboratory result value in mg dl
Real
Min (0.400),Max (124)
Creatinine norm range lower
Laboratory procedure creatinine results lower the limit of normal value
Real
Min (0), Max (62)
Creatinine norm range upper
Laboratory procedure creatinine results in the upper limit of normal value
Real
Min (0.900), Max (120)
Days to initial pathologic diagnosis
Days to initial pathologic diagnosis
Integer
0
Death days to
Days to death
Integer
Min (- 1), Max (3258)
Table 1 (continued)
Features
Description
Type
Values
Definitive surgical procedure
Specimen collection method name
Nominal
Lobectomy 145
Segmentectomy, Multiple 89
Segmentectomy, Single 88
Other (specify) 26
Extended Lobectomy 25
No 3
Total Hepatectomy with Transplant 1
Disease code
Disease code
Nominal
[Not available] 377
ECOG score
Eastern Cancer Oncology Group
Integer
Min (0), Max(4)
Ethnicity
Ethnicity
Nominal
NOT HISPANIC OR LATINO 340
HISPANIC OR LATINO 18
Other 17
[Not available] 2
Extranodal involvement
Extranodal involvement
Nominal
[Not applicable] 377
Family history cancer indicator
Relative family cancer history ind 3
Binominal
NO 263
YES 114
Family history cancer number of relatives
Cancer diagnosis first-degree relative number
Integer
Min (0), Max (9)
Form completion date
Form completion date
Date -Time
Ranged from (20-12-2010) to (9-7-2015)
Gender
Gender
Binominal
MALE 255
FEMALE 122
Height cm at diagnosis
Height
Integer
Min (64), Max (196)
Hepatic inflammation adj tissue
Adjacent hepatic tissue inflammation extent type
Nominal
None 257, Mild 101, Severe 19
Histologic diagnosis
Histological type
Nominal
Hepatocellular Carcinoma 367
Hepatocholangiocarcinoma (Mixed) 7
Fibrolamellar Carcinoma 3
History of hepato carcinoma risk factors
History hepato carcinoma risk factor
Nominal
Most (no history of primary risk factors 112
Hepatitis B 78
Alcohol consumption 69
Hepatitis C 32
Alcohol consumption|Hepatitis B 20
Alcohol consumption|Hepatitis C 14
Other 12
Non-Alcoholic Fatty Liver Disease 11)
History neoadjuvant treatment
History of neoadjuvant treatment
Binominal
No 375
Yes 2
History other malignancy
Prior dx
Binominal
No 340
Yes 37
icd 10
icd 10
Nominal
C22.0 377
icd o 3 histology
icd o 3 histology
Nominal
8170/3 360, 8180/3 7
8171/3 4, 8174/3 4
8173/3 1, 8310/3 1
icd o 3 site
icd o 3 site
Nominal
C22.0 377
Informed consent verified
Informed consent verified
Nominal
YES 377
Ishak fibrosis score
Liver fibrosis ishak score category
Nominal
0-No Fibrosis 76
6-Established Cirrhosis 72
1,2—Portal Fibrosis 31
3,4—Fibrous Speta 30
5-Nodular Formation and Incomplete Cirrhosis 9
Table 1 (continued)
Features
Description
Type
Values
Last contact days to
Days to the last follow-up
Integer
Max(3675)
New tumor event dx indicator
New tumor event after initial treatment
Nominal
NO 279
YES 98
Other hepato carcinoma risk factors
History hepato carcinoma risk factors other
Nominal
Most (No 345
Smoking 6
Tobacco use 6
Cirrhosis 2)
Patient id
Patient id
Nominal
EX: 4072
Pharmaceutical tx adjuvant
Postoperative rx tx
Binominal
NO 362
YES 15
Platelet count pre-resection
Lab procedure platelet results specified value
Integer
Min , Max
Platelet norm range lower
Laboratory procedure platelet results in a lower limit of normal value
Integer
Min , Max
Platelet norm range upper
Laboratory procedure platelet results in the upper limit of normal value
Integer
Min , Max
Project code
Project code
Nominal
[Not available] 377
Prospective collection
Tissue prospective collection indicator
Binominal
NO 249
YES 128
Prothrom time INR norm range lower
Laboratory procedure international normalization ratio results lower limit of normal value
Real
Min (0), Max (11)
Prothrombin time INR at procurement
laboratory procedure prothrombin time result value
Real
Min (0.800), Max (36.400)
Prothrombin time norm range upper
Laboratory procedure international normalization ratio results upper limit of the normal value
Real
Min (1), Max (15)
Race
Race
Nominal
WHITE 187
ASIAN 161
BLACK OR AFRICAN AMERICAN 17
Other 10
AMERICAN INDIAN OR ALASKA NATIVE 2
Radiation treatment adjuvant
Radiation therapy
Binominal
NO 373
YES 4
Residual tumor
Residual tumor
Nominal
R0 332, RX 22
R1 17,R2 1
Retrospective collection
Tissue retrospective collection indicator
Binominal
YES 249
NO 128
Serum albumin norm range lower
Laboratory procedure albumin results in a lower limit of normal value
Real
Min (0.300), Max (3800)
Serum albumin norm range upper
Laboratory procedure albumin result upper limit of normal value
Real
Min (0.500), Max (5100)
Serum albumin preresection
laboratory procedure albumin result specified value
Real
Min (0.200), Max (5200)
Stage other
Stage other
Nominal
[Not available] 377
Surgical procedure other
Surgical procedure name other specific text
Binominal
No 351
R hepatic lobectomy w/resection of segment 1
Tissue source site
Tissue source site
Nominal
Most (DD 151)
Table 1 (continued)
Features
Description
Type
Values
Tumor grade
Neoplasm histologic grade
Nominal
G2 183,G3 124
G1 55,G4 13
[Not Available] 1
Tumor status
Person neoplasm cancer status
Binominal
TUMOR FREE 236
WITH TUMOR 141
Tumor tissue site
Tumor tissue site
Nominal
Liver 377
Vascular invasion
Vascular tumor cell invasion type
Nominal
None 230
Micro 94
Macro 17
Viral hepatitis serology
Viral hepatitis serology
Nominal
Most (no results 211)
Vital status
Vital status
Binominal
Alive 286
Dead 91
Weight kg at diagnosis
Weight
Integer
Min (40), Max (172)
Year of initial pathologic diagnosis
Year of initial pathologic diagnosis
Integer
Min (1995), Max (2013)
Finally, various modeling techniques, such as decision trees, Naive Bayes, KNN, neural networks, and SVM were applied to train the model using the selected features and the assigned weights.
Extracting meaningful insights from the TCGA LIHC dataset through regression tasks requires careful consideration of the chosen model. Several factors influence this selection, including data size, feature types, interpretability needs, and computational resources. For datasets with moderate sizes, similar to what might be encountered within TCGA LIHC, Naive Bayes offers a strong option. Decision trees are particularly wellsuited for handling missing data inherent to real-world datasets, eliminating the need for extra imputation steps. K-Nearest Neighbors (KNN) stands out for its efficiency, directly comparing new data points to existing TCGA LIHC entries for prediction without a separate training phase. More complex models like neural networks can uncover hidden patterns within the data through automatic feature learning. Finally, Support Vector Machines (SVMs) offer robustness to noise, a common challenge in TCGA LIHC datasets. By carefully weighing these factors and evaluating model performance on the specific TCGA LIHC subset used, the model’s performance is then evaluated using performance measures like accuracy, precision, F Score, and recall. A Summary of the Data Reduction Workflow for Predicting Hepatocellular Carcinoma, as Depicted in Fig. 2.
Results and discussion
Data preprocessing
The dataset initially consisted of 77 features. During the data cleaning process, 28 entries with unknown values in the “TUMOR status” column were replaced with “With TUMOR”. In addition, two new features were introduced for further analysis: “optimal weight” based on Body Mass Index (BMI), categorized as Normal, Overweight, or Obesity, and “age stage” categorized as Middle Adulthood, Late Adulthood, or Young Adulthood. Redundant information such as age, height, weight, and other columns with repeated, unavailable, or inapplicable values, as well as patient IDs, were eliminated. As a result, the final dataset now comprises 59 features. Figure 3 illustrates the relationship
Fig. 2 Outline of data reduction workflow for Hepatocellular carcinoma Prediction
Fig. 3 Illustration of patients with obesity VS number of family relatives having a history of cancer
between patients with obesity and the number of family members with a history of cancer. Our findings indicate that the patient with obesity had the highest number of family members with this medical history.
Feature importance
After data cleansing the remaining 59 features were weighted with different types of weight operators after replacing missing values using RapidMiner. First, we applied “Weight by Information Gain”. To determine how relevant each attribute is to the class attribute, the Weight by Information Gain operator uses a calculation called information gain [31]. Attributes with higher scores are considered more important.
While information gain is generally reliable for assessing attribute relevance [32], it does have a potential drawback. It can sometimes overestimate the importance of attributes that have a very large number of possible values. To overcome the limitations of information gain, particularly its sensitivity to attributes with numerous unique values, we used the information gain ratio by analyzing the information each attribute provides for understanding the target class, this method assigns weights that reflect their relative importance. The more insightful an attribute is for predicting the category, the higher its weight will be.
Secondly, we use the “Weight by Relief” operator. Considered one of the most effective and straightforward algorithms for evaluating feature quality, Relief has gained significant recognition. The fundamental concept behind Relief is to gauge the quality of features based on their ability to differentiate between instances of the same class and instances of different classes that are nearby[33, 34]. By sampling examples and comparing the feature values between the nearest examples of the same class and different classes, Relief calculates the relevance of features as described in [35].
Pseudocode of the Relief algorithm:
RELIEF Algorithm
Require: for each training instance set S , a vector of feature values and the class value number of training instances number of features
Parameter: number of random training instances out of n used to update W
Initialize all feature weights
For to m do
Randomly select a “target” instance
Find the nearest hit “H” and nearest miss (instances)
For to a do
End for
End for
Return the weight vector W of feature scores that compute the quality of features
Hidden feature correlation
Weight by Correlation is a feature selection methodology employed within the framework of Rapid Miner Studio [36]. This approach focuses on ascertaining the salience of features by quantifying their correlation with the target variable [37]. By assigning weights to individual features as shown in Fig. 4 based on their correlation coefficients, “Weight by Correlation” prioritizes those features that exhibit stronger
Fig. 4 Illustration of assigning weights to individual features based on their correlation coefficients
correlations. This weighting mechanism [38] facilitates the identification and selection of the most influential features, thereby enhancing the efficacy and precision of data analysis and modeling processes within Rapid Miner Studio.
Feature selection
Normalization is a technique employed to rescale values to fit within a specific range. It is particularly crucial when handling attributes that possess varying units and scales [39, 40].
The significance of data normalization in developing precise predictive models has been investigated across multiple machine learning algorithms [41], including Nearest Neighbors (NN) [42], Artificial Neural Networks (ANN) [43] and Support Vector Machines (SVM) [44]. Several researchers have confirmed the positive impact of data normalization on enhancing classification performance in various domains [45]. Examples include medical data classification [46, 47], multimodal biometrics systems [48], vehicle classification [49], faulty motor detection[50], stock market prediction [51], leaf classification [52], credit approval data classification [53], genomics [54], and other application areas [55,56]. The purpose of the normalization operator is to perform the normalization process on selected attributes. There are four available normalization methods, with the “Range transformation” method being utilized in this case. This method normalizes all attribute values to a specified range [57]. Upon selecting this method, two additional parameters, namely “min” and “max”, become visible in the
parameters panel. The largest value in the attribute set is assigned to “max”, while the smallest value is assigned to “min.” All other values are proportionally scaled to fit within the provided range. It is worth noting that this method may be affected by outliers, as the boundaries adjust towards them. However, it retains the original distribution of the data points, making it suitable for data anonymization purposes as well.
Optimized selection is a valuable technique utilized in RapidMiner. This approach plays an essential role in streamlining the model-building process by automatically identifying and selecting the most relevant subset of features from a given dataset [58, 59]. By leveraging optimization algorithms and statistical measures, RapidMiner’s optimized selection functionality aims to enhance both the efficiency and efficacy of predictive models. The process of optimized selection involves iteratively evaluating different feature subsets and assessing their impact on the model’s performance [60]. The operator as shown in Fig. 5, implements two deterministic greedy feature selection algorithms: “forward selection” and “backward elimination.”
The goal of the forward selection algorithm is to generate the most effective subset of features while disregarding irrelevant and insignificant ones [61-63]. It begins by creating an initial population of individuals, where represents the number of attributes in the input Example Set. Each individual in the population uses only one feature. The attribute sets are then evaluated, and the top k sets are selected based on their performance. For each of the k selected sets, the algorithm proceeds as follows: If there are unused attributes, copies of the attribute set are made, and exactly one previously unused attribute is added to each copy of the set. The algorithm continues to the next step as long as there has been an improvement in performance in the last p iterations. The Backward Elimination technique begins with an attribute set that includes all features [64, 65]. It evaluates all attribute sets and chooses the top k sets based on their performance. For each of the selected k sets, the algorithm proceeds as follows: If there are attributes currently used, copies of the attribute set are made, and exactly one previously used attribute is removed from each copy of the set. The algorithm continues to the next step as long as there has been an improvement in performance in the last p iterations.
Fig. 5 Normalize and Optimize selection operators in Rapid Miner
Pseudocode of Forward Greedy Search (FGS) Feature Selection:
$mathrm{FGS}^{(0)}=emptyset$;
$mathrm{F}^{(0)}={mathrm{f} 1, mathrm{f} 2, ldots, mathrm{f} 361} ;$
$mathrm{i}=0$;
opt $=0$; output which is the best performance score
iter $=0$; iteration index
While ( $mathrm{i}<mathrm{n}$ )
$mathrm{k}=$ size $mathrm{F}^{(mathrm{i})}$ :
$max =0$;
feature $=0$;
for j from 1 to k
score $=operatorname{eval}left(mathrm{F}_{mathrm{j}}{ }^{(mathrm{i})}right) ;$
if (score > max)
$max =mathrm{score} ;$ feature $=mathrm{F}_{mathrm{j}}{ }^{(mathrm{i})} ;$
endif
end for
if ( $max >mathrm{opt}$ ) opt = max; iter = i
endif
$mathrm{FS}^{(mathrm{i}+1)} leftarrow mathrm{FS}^{mathrm{i}}+$ feature; $mathrm{Fi}+1=mathrm{F}(mathrm{i})-$ feature; $mathrm{i}++$;
end while
Details regarding the parameters of the operators employed in RapidMiner are in Table 2.
Before feature reduction, machine learning models often face challenges such as high dimensionality and redundant or irrelevant features [66-68]. These issues can negatively impact both accuracy and execution time. With a large number of features, models may struggle to extract meaningful patterns from the data, leading to overfitting or poor generalization. Additionally, the computational complexity of training and inference increases significantly with the increasing number of features. However, after feature reduction techniques were applied, such as dimensionality reduction or feature selection, the models experienced improved performance in terms of accuracy as shown in Fig. 6, and execution time as shown in Fig. 7.
Tables 3 and 4 present a summary of the application of various deep learning and machine learning techniques on the TCGA LIHC clinical variables dataset for predicting hepatocellular carcinoma (HCC). This summary includes the performance of these techniques both before and after feature reduction methods were applied. The algorithms utilized in this study encompassed Naive Bayes, Neural Network, Decision Tree, SVM, and KNN. The primary focus of the evaluation was on the prediction of HCC nodules. The results indicate that both the deep learning models and machine learning models exhibited outstanding performance after the implementation of feature reduction methods.
Table 2 Information about the parameters of used operators in RapidMiner
Used operators
Parameters
Set role
Attribute
Tumor_stauts
Role
Label
Replace missing values
Replacement value
Average
Weight by information gain
Normalize weight
True
Sort weights
True
Sort direction
Ascending
Weight by relief
Number of neighbors
10
Sample ratio
1.0
Nominal to numerical
Coding type
Dummy coding
Select by weight
Weight relation
Greater equals
Weight
0.1
Split data
Partitions
Ratio:0.8-0.2
Sampling type
Stratified sampling
Normalize
Method
Range transformation
Min
0
Max
1.0
Optimize selection
Selection direction
Forward
Max Number of generations
Naive Bayes(6),decision tree (7),Neural nets(6),SVM(4),KNN(7)
Naive Bayes
Laplace correction
True
Decision tree
Criterion
Gain ratio
Maximal depth
10
Confidence
0.1
Minimal gain
0.01
Minimal leaf size
2
Minimal size for split
4
Number of pre-pruning alternatives
3
KNN
K
1
Measure type
Mixed Euclidean Distance
Neural network
Training cycles
200
Learning rate
0.01
Momentum
0.9
SVM
Kernel type
Polynomial
Kernel degree
2.0
Kernel cache
200
Max iteration
100,000
C
10
Convergence epsilon
0.001
Before feature reduction, our Neural Network model lumbered through training, achieving an accuracy of at the cost of a sluggish 5 min . This sluggishness stemmed from the model struggling to navigate the complexities of a high-dimensional feature space, often getting tangled in irrelevant or redundant information. However, after applying feature reduction techniques, the model shed its excess baggage, emerging lean and mean. It effortlessly soared through training, achieving a remarkable in a mere 1 min and 10 s . This drastic improvement is a testament to the power of feature reduction. By eliminating noisy and superfluous features, we cleared the path for
Fig. 6 Performance of used algorithms for HCC Prediction, on the TCGA LIHC clinical variables dataset after feature reduction methods
Fig. 7 Execution time of used algorithms for HCC prediction, before and after feature reduction methods in seconds
the model to focus on the truly meaningful relationships within the data, resulting in a more accurate and efficient learning process. This optimization paves the way for faster real-time predictions, reduced computational costs, and ultimately, a more robust and deployable model.
Applying feature reduction techniques to the Naive Bayes model yields notable enhancements in both accuracy and execution time. Specifically, the model achieves an impressive accuracy rate of . Moreover, the execution time is significantly reduced to a mere 49 s , showcasing the model’s enhanced efficiency in processing and making predictions. These improvements highlight the effectiveness of feature reduction in optimizing the Naive Bayes model’s performance, resulting in superior accuracy and faster execution times.
Before implementing feature reduction, the Decision Tree model attains a commendable accuracy of but necessitates a relatively lengthy execution duration of 4 min
Table 3 Performance comparison when using each of the deep learning and machine learning algorithms for HCC Prediction, on the TCGA LIHC clinical variables dataset Before Feature Reduction Methods
Approach
Prediction criteria
TRUE (WITH TUMOR)
TRUE (TUMORFREE)
Precision (%)
Accuracy (%)
F1-score (%)
Execution time
Naive Bayes
Pred. WITH TUMOR
24
3
88.89%
90.67%
92.63%
4 min and 2 s
Pred. TUMOR FREE
4
44
91.67%
Recall (%)
85.71%
93.62%
Neural Network
Pred. WITH TUMOR
13
3
81.25%
76.00%
83.02%
5 min
Pred. TUMOR FREE
15
44
74.58%
Recall (%)
46.43%
93.62%
Decision Tree
Pred. WITH TUMOR
21
0
100%
90.67%
93.05%
4 min and 12 s
Pred. TUMOR FREE
7
47
87.04%
Recall (%)
75%
100%
SVM
Pred. WITH TUMOR
23
1
95.83%
92%
93.56%
5 min and 14 s
Pred. TUMOR FREE
5
46
90.20%
Recall (%)
82.14%
97.87%
KNN
Pred. WITH TUMOR
18
0
100%
86.67%
90.38%
4 min and 45 s
Pred. TUMOR FREE
10
47
82.46%
Recall (%)
64.29%
100%
and 12 s . Nevertheless, following the application of feature reduction techniques, the model undergoes noteworthy enhancements. It accomplishes an impressive accuracy rate of , demonstrating improved precision when classifying instances. Furthermore, the execution time is significantly reduced to a mere 1 min and 9 s . These enhancements underscore the efficacy of feature reduction in optimizing the performance of the Decision Tree model, leading to substantially higher accuracy and faster execution. Moreover, both the SVM and KNN models exhibit superior accuracy, with the SVM model achieving accuracy and the KNN model achieving accuracy. Notably, the execution times for these models are 1 min and 48 s for SVM and 1 min and 2 s for KNN, respectively.
Discussion
A multitude of machine-learning algorithms have been developed for the prediction of hepatocellular carcinoma. The study [69] explores using a combination of machine learning techniques (ensemble learning) to predict how long Hepatocellular
Table 4 Performance comparison when using each of the deep learning and machine learning algorithms for HCC Prediction, on the TCGA LIHC clinical variables dataset After Feature Reduction Methods
Approach
Prediction criteria
TRUE (WITH TUMOR)
TRUE (TUMORFREE)
Precision (%)
Accuracy (%)
F1-score (%)
Execution Time
Naive Bayes
Pred. WITH TUMOR
27
1
96.43%
97.33%
97.87%
49 s
Pred. TUMOR FREE
1
46
97.87%
Recall (%)
96.43%
97.87%
Neural network
Pred. WITH TUMOR
27
2
93.10%
96%
96.59%
1 min and 10 s
Pred. TUMOR FREE
1
45
97.83%
Recall (%)
96.43%
95.4%
Decision tree
Pred. WITH TUMOR
26
1
96.30%
96%
96.83%
1 min and 9 s
Pred. TUMOR FREE
2
46
95.83%
Recall (%)
92.86%
97.87%
SVM
Pred. WITH TUMOR
28
3
90.32%
96.00%
96.70%
1 min and 48 s
Pred. TUMOR FREE
0
44
100%
Recall (%)
100%
93.62%
KNN
Pred. WITH TUMOR
25
1
96.15%
94.67%
95.83%
1 min and 2 s
Pred. TUMOR FREE
3
46
93.88%
Recall (%)
89.29%
97.87%
Carcinoma (HCC) patients will survive. The model considers various factors that might influence survival, including patient location, risk factors, and details from clinical trials.
The researchers test fifteen different models, each involving data cleaning, reducing unnecessary features, and then classifying patients based on their predicted survival time. To identify the most important factors, they use four methods: LASSO regression, Ridge regression, a Genetic Algorithm, and a Random Forest. Only the most influential factors are used for prediction.
The models they build include variations of Nu-Support Vector Classification, Ridge Classification (RCV), and Gradient Boosting Ensemble Learning (GBEL), each combined with either L1 or L2 regularization or optimized by a Genetic Algorithm or Random Forest. These models are evaluated based on how accurately they predict survival, using metrics like accuracy, sensitivity, and Area Under the Curve (AUC).
Their findings show that the RFGBEL model (Random Forest combined with Gradient Boosting Ensemble Learning) performs best compared to the others. This model achieves an accuracy of over and a high AUC score of 0.932 , indicating strong
prediction capabilities. Finally, they compare their RFGBEL model to existing methods and demonstrate its superior ability to predict HCC patient survival.
Also, researchers in the study [70] propose a new NCA-GA-SVM model for predicting HCC survival. This model combines known high-performing techniques (NCA, GA) to improve SVM classification. It achieved high accuracy ( ) on a dataset of 165 patients.
This study [71] developed a highly accurate model for diagnosing liver cancer (HCC) that leverages a combination of personalized biological pathways and machine learning. The model achieved exceptional performance in internal testing (AUROC>0.98) and demonstrated good generalizability to external data. These results suggest this model has great potential for real-world application in HCC diagnosis. Kiani et al. [72] used a microscopic image from the TCGA dataset and utilized a convolutional neural network (CNN) tool named the “Liver Cancer Assistant,” it accomplished precise discrimination between hepatocellular carcinoma (HCC) and cholangiocarcinoma. Notably, the model achieved a diagnostic accuracy of 0.885 , highlighting its efficacy in accurately identifying and distinguishing between these two distinct forms of liver cancer.
In a study conducted by Wang et al. [73], a deep learning technique involving a convolutional neural network (CNN) was utilized to automate the identification and classification of individual nuclei in tissue images. The CNN was trained using H&E-stained tissue sections of hepatocellular carcinoma (HCC) tumors from the TCGA dataset. Subsequently, a process of feature extraction was carried out, resulting in the identification of 246 quantitative image features. Using an unsupervised learning approach, a clustering analysis was performed, which yielded intriguing results. Surprisingly, this analysis unveiled the existence of three distinct histologic subtypes within the HCC tumors. Importantly, these subtypes were found to be unrelated to previously established genomic clusters and exhibited different prognoses. This study demonstrated the potential of CNN-based image analysis in revealing unique histologic subtypes, offering valuable insights into the prognosis of HCC tumors. Table 5 displays a collection of models proposed by different authors, which have been applied to various HCC-related problems using the TCGA dataset. Table 5 represents the Studies of patients with hepatocellular carcinoma based on the TCGA LIHC dataset.
In this work, we proposed an approach that aims to improve the prediction of hepatocellular carcinoma (HCC) through a comprehensive approach that involves multiple strategies. These strategies include reducing the number of features used in the prediction model through methods such as analyzing feature importance, exploring hidden feature correlations, and employing various algorithms for HCC prediction using clinical variables. We utilized TCGA LIHC clinical variables but the data needed to be cleaned to address any inconsistencies, missing values, or errors. Then the data was formatted and prepared for further analysis which involved scaling the data to a common range, encoding categorical variables, or performing feature engineering to create new features from existing ones. After identifying the optimized feature subset, the dataset was split into two sets: a training set with 301 examples and a testing set with 75 examples. This division was performed using a sampling technique called “Stratified sampling.” This sampling technique ensures that random subsets are created while maintaining the consistent distribution of classes within
Table 5 Studies of patients with hepatocellular carcinoma based on the TCGA LIHC dataset
Study
Dataset
Algorithm
Year
Accuracy
Deng et al. [74]
TCGA and HCCDB18 datasets
Unsupervised consistent clustering method
2022
Comparison of Glycolysis and Cholesterol Gene Expression in Normal and Tumor Samples
Cheng et al. [75]
TCGA-LIHC data set
Cox regression analysis
2022
AUC values of the patient’s 3-year and 5-year Overall Survival were 0.783 and 0.828 , respectively,
Yamashita et al. [76]
Stanford-HCCDET; TCGA
Convolution neural network
2021
The AUROC for tumor tile classification was 0.952 (95% CI 0.948, 0.957) on the internal test set
Saillard et al. [77]
French center and TCGA
Convolution neural network
2020
These CNN-based models demonstrate superior performance compared to traditional models, achieving a C-index ranging from 0.75 to 0.78
Tohme et al. [78]
TCGA-LIHC
ANN
2021
The artificial neural network (ANN) identified a set of 15 genes that exhibited a normalized importance greater than 50%
Kiani et al. [72]
TCGA
CNN
2020
By employing a CNN-based tool, classifying between hepatocellular carcinoma and cholangiocarcinoma exhibited a diagnostic accuracy rate of 0.885
Liao et al. [22]
TCGA and a center in China
Convolution neural network
2020
The predictions of mutations were surpassing an Area Under the Curve (AUC) value of 0.70
Wang et al. [73]
TCGA-LIHC
Convolution neural network
2020
The model demonstrated high accuracy, achieving an overall classification rate of 99% for tumor cells and 97% for lymphocytes
Shi et al. [79]
1 center in China; TCGA
Convolution neural network
2021
The deep learning-based “stratifies the study population into five groups with distinct prognoses in both the Zhongshan cohort ( ) and TCGA cohort ( )”
those subsets, aligning with the overall class distribution in the entire dataset. In other words, Stratified sampling helps to preserve the proportional representation of different classes during the creation of training and testing sets, which is essential for maintaining the integrity of the dataset and ensuring reliable model evaluation. The application of feature reduction techniques to the Naive Bayes model leads to significant improvements in accuracy and execution time. With these techniques implemented, the model achieves an impressive accuracy rate of . Additionally, the execution time is drastically reduced to just 49 s , demonstrating the enhanced efficiency of the model in processing and making predictions. These enhancements
clearly illustrate the effectiveness of feature reduction in optimizing the performance of the Naive Bayes model, resulting in higher accuracy and faster execution times.
Limitations
Although machine learning and deep learning have shown promise in various medical applications, including hepatocellular carcinoma (HCC) prediction, there are several limitations associated with their use in this context.
One major limitation is the requirement for large and high-quality datasets. Machine learning algorithms, including deep learning models, heavily rely on vast amounts of well-curated data to learn patterns and make accurate predictions. However, acquiring such datasets for HCC prediction can be challenging due to the rarity of the disease and the need for comprehensive clinical and imaging data. The limited availability of annotated HCC datasets hampers the development and evaluation of robust models.
Interpretability and explainability are crucial in medical decision-making, and this is another limitation of the deep learning model. While these models have demonstrated remarkable predictive capabilities, they often function as black boxes, making it difficult to understand the underlying reasons behind their predictions. This lack of interpretability raises concerns in medical settings, where clinicians need to have confidence in the decision-making process and understand the factors contributing to a prediction.
The generalizability of machine learning and deep learning models can also be a limitation. Models trained on specific populations or datasets may not perform as well when applied to different patient populations or settings. The heterogeneity of HCC, including variations in tumor characteristics, genetic profiles, and patient demographics, can introduce challenges in developing models that can effectively predict HCC across diverse populations. Furthermore, the potential for bias in machine learning models is another limitation. Biases can be introduced during the data collection process, such as underrepresentation of certain demographic groups or confounding factors. If the models are trained on biased datasets, they may perpetuate or even amplify existing biases, leading to inaccurate predictions and disparities in healthcare outcomes.
Conclusion and future work
In conclusion, this study focused on the prediction of hepatocellular carcinoma (HCC), a prevalent form of liver cancer, using machine learning algorithms. The objective was to assess the effectiveness of feature reduction techniques in enhancing the performance of HCC prediction models. By comparing the performance of various machine learning algorithms on both the original high-dimensional dataset and a reduced feature subset, this study demonstrated that feature reduction significantly improves the accuracy and execution time of HCC prediction models. The employed feature reduction techniques, including weighting features, hidden features correlation, feature selection, and optimized selection, helped extract a reduced feature set that captured the most relevant information related to HCC. The experimental results obtained from a comprehensive dataset of clinical features of HCC patients showed that the reduced feature set consistently outperformed the original high-dimensional dataset in terms of prediction accuracy. The decision trees, Naive Bayes, K-nearest neighbors, neural networks, and support vector machines (SVM) algorithms achieved accuracies of 96%, 97.33%, 94.67%, , and , respectively, after applying feature reduction techniques. These findings suggest that feature reduction methods can be effectively employed in HCC prediction models, leading to improved accuracy and faster execution times. The application of machine learning algorithms, combined with feature reduction techniques, holds great potential for the early diagnosis and effective treatment of HCC, ultimately improving patient outcomes.
While current models using clinical variables for HCC prediction show promise, there are several areas for future work to improve accuracy, personalize risk assessment, and ultimately guide better patient outcomes. Integrating Multimodal Data by Exploring combining clinical data with other modalities like genetic information, imaging data (MRI, CT scans), and blood-based biomarkers. Deep learning models can be particularly adept at handling such diverse data sources. Also, train and validate models on large, geographically diverse datasets to ensure generalizability and avoid overfitting to specific populations. Account for the presence of other chronic conditions like diabetes or hepatitis that may influence HCC development. Develop models that can incorporate longitudinal data (changes in clinical variables over time) to predict risk changes and identify high-risk patients earlier. By focusing on these future work directions, we can improve the accuracy and clinical utility of HCC prediction models using clinical variables, leading to earlier detection, better risk stratification, and ultimately improved patient outcomes.
Author contributions
This work was carried out in collaboration among all authors. All Authors designed the study, performed the statistical analysis, and wrote the protocol. All Authors managed the analyses of the study, managed the literature searches, and wrote the first draft of the manuscript. All authors read and approved the final manuscript.
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB). This research did not receive any specific grant from funding agencies in the public, commercial, or not-for-profit sectors.
This article does not contain any studies with human participants or animals performed by any of the authors.
Consent for publication
All authors have read and agreed to the published version of the manuscript.
Competing interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Received: 27 February 2024 Accepted: 31 May 2024
Published online: 18 June 2024
References
Torre LA, et al. Global cancer statistics, 2012. CA Cancer J Clin. 2015;65(2):87-108.
DeWaal D, et al. Hexokinase-2 depletion inhibits glycolysis and induces oxidative phosphorylation in hepatocellular carcinoma and sensitizes to metformin. Nat Commun. 2018;9(1):446.
Santos MS, et al. A new cluster-based oversampling method for improving survival prediction of hepatocellular carcinoma patients. J Biomed Inform. 2015;58:49-59.
Ali L, Bukhari S. An approach based on mutually informed neural networks to optimize the generalization capabilities of decision support systems developed for heart failure prediction. Irbm. 2021;42(5):345-52.
Książek W, et al. A novel machine learning approach for early detection of hepatocellular carcinoma patients. Cogn Syst Res. 2019;54:116-27.
Ali L et al. A multi-model framework for evaluating type of speech samples having complementary information about Parkinson’s disease. In: 2019 International conference on electrical, communication, and computer engineering (ICECCE). IEEE; 2019.
Abdar M, et al. A new nested ensemble technique for automated diagnosis of breast cancer. Pattern Recogn Lett. 2020;132:123-31.
Zheng B, Yoon SW, Lam SS. Breast cancer diagnosis based on feature extraction using a hybrid of K-means and support vector machine algorithms. Expert Syst Appl. 2014;41(4):1476-82.
Shi J, et al. Multimodal neuroimaging feature learning with multimodal stacked deep polynomial networks for diagnosis of Alzheimer’s disease. IEEE J Biomed Health Inform. 2017;22(1):173-83.
Zhi X, et al. Efficient discriminative clustering via QR decomposition-based linear discriminant analysis. Knowl-Based Syst. 2018;153:117-32.
Ali L et al. Early detection of heart failure by reducing the time complexity of the machine learning based predictive model. In: 2019 international conference on electrical, communication, and computer engineering (ICECCE). IEEE; 2019.
Ravikulan A, Rostami K. Leveraging machine learning for early recurrence prediction in hepatocellular carcinoma: a step towards precision medicine. World J Gastroenterol. 2024;30(5):424.
Hong H, et al. Prediction of hepatocellular carcinoma development in Korean patients after hepatitis C cure with direct-acting antivirals. Gut and Liver. 2024;18(1):147.
Abajian A, et al. Predicting treatment response to intra-arterial therapies for hepatocellular carcinoma with the use of supervised machine learning—an artificial intelligence concept. J Vasc Intervent Radiol. 2018;29(6):850-7.
Ioannou GN, et al. Assessment of a deep learning model to predict hepatocellular carcinoma in patients with hepatitis C cirrhosis. JAMA Netw Open. 2020;3(9):e2015626-e2015626.
Nam JY, et al. Deep learning model for prediction of hepatocellular carcinoma in patients with HBV-related cirrhosis on antiviral therapy. JHEP Rep. 2020;2(6): 100175.
Nam JY, et al. Novel model to predict HCC recurrence after liver transplantation obtained using deep learning: a multicenter study. Cancers. 2020;12(10):2791.
Ali MA, et al. A novel method for survival prediction of hepatocellular carcinoma using feature-selection techniques. Appl Sci. 2022;12(13):6427.
Cao , et al. Prediction model for recurrence of hepatocellular carcinoma after resection by using neighbor2vec based algorithms. Wiley Interdiscip R Data Min Knowl Discov. 2021;11(2): e1390.
Zhang Y, et al. Deep learning with 3D convolutional neural network for noninvasive prediction of microvascular invasion in hepatocellular carcinoma. J Magn Reson Imaging. 2021;54(1):134-43.
Zhang Y-B, et al. Development of a machine learning-based model for predicting risk of early postoperative recurrence of hepatocellular carcinoma. World J Gastroenterol. 2023;29(43):5804.
Liao H, et al. Deep learning-based classification and mutation prediction from histopathological images of hepatocellular carcinoma. Clin Transl Med. 2020;10(2): e102.
Deng , et al. Mining TCGA database for tumor microenvironment-related genes of prognostic value in hepatocelIular carcinoma. BioMed Res Int. 2019;2019:2408348.
Wang K , et al. A novel immune-related genes prognosis biomarker for hepatocellular carcinoma. Aging (Albany NY). 2021;13(1):675.
Bannister CA, et al. A genetic programming approach to development of clinical prediction models: a case study in symptomatic cardiovascular disease. PLoS ONE. 2018;13(9): e0202685.
Dong Y, et al. A novel surgical predictive model for Chinese Crohn’s disease patients. Medicine. 2019;98(46): e17510.
Karhade AV, et al. Development of machine learning algorithms for prediction of prolonged opioid prescription after surgery for lumbar disc herniation. Spine J. 2019;19(11):1764-71.
Scheer JK, et al. Development of a preoperative predictive model for major complications following adult spinal deformity surgery. J Neurosurg Spine. 2017;26(6):736-43.
Adams S, Beling PA, Cogill R. Feature selection for hidden Markov models and hidden semi-Markov models. IEEE Access. 2016;4:1642-57.
Bjaoui M et al. Depth insight for data scientist with RapidMiner «an innovative tool for Al and big data towards medical applications». In: Proceedings of the 2nd international conference on digital tools & uses congress; 2020.
Roy SP, Kasat A. Diabetic prediction with ensemble model and feature selection using information gain method. In: 2024 2nd international conference on intelligent data communication technologies and internet of things (IDCloT). IEEE; 2024.
Ihianle IK, et al. Minimising redundancy, maximising relevance: HRV feature selection for stress classification. Expert Syst Appl. 2024;239: 122490.
Robnik-Šikonja M, Kononenko I. Theoretical and empirical analysis of ReliefF and RReliefF. Mach Learn. 2003;53:23-69.
Shukla AK, et al. Knowledge discovery in medical and biological datasets by integration of Relief-F and correlation feature selection techniques. J Intell Fuzzy Syst. 2020;38(5):6637-48.
Haq AU, et al. A hybrid intelligent system framework for the prediction of heart disease using machine learning algorithms. Mob Inf Syst. 2018;2018:1-21.
Theng D, Bhoyar KK. Feature selection techniques for machine learning: a survey of more than two decades of research. Knowl Inf Syst. 2024;66(3):1575-637.
Gao J, et al. Information gain ratio-based subfeature grouping empowers particle swarm optimization for feature selection. Knowl-Based Syst. 2024;286: 111380.
Wang X, Yan Y, Ma X. Feature selection method based on differential correlation information entropy. Neural Process Lett. 2020;52:1339-58.
Singh D, Singh B. Investigating the impact of data normalization on classification performance. Appl Soft Comput. 2020;97: 105524.
Raju VG et al. Study the influence of normalization/transformation process on the accuracy of supervised classification. In: 2020 third international conference on smart systems and inventive technology (ICSSIT). IEEE; 2020.
Zhou S, et al. Breast cancer prediction based on multiple machine learning algorithms. Technol Cancer Res Treat. 2024;23:15330338241234792.
Aksoy S, Haralick RM. Feature normalization and likelihood-based similarity measures for image retrieval. Pattern Recogn Lett. 2001;22(5):563-82.
Ajbar W, et al. Development of artificial neural networks for the prediction of the pressure field along a horizontal pipe conveying high-viscosity two-phase flow. Flow Meas Instrum. 2024;96: 102541.
Hsu CW, Chang CC, Lin CJ. A practical guide to support vector classification, Taipei, Taiwan; 2003.
Parashar G, Chaudhary A, Pandey D. Machine learning for prediction of cardiovascular disease and respiratory disease: a review. SN Comput Sci. 2024;5(1):196.
Jayalakshmi T, Santhakumaran A. Statistical normalization and back propagation for classification. Int J Comput Theory Eng. 2011;3(1):1793-8201.
Acharya UR, et al. Automated diagnosis of glaucoma using texture and higher order spectra features. IEEE Trans Inf Technol Biomed. 2011;15(3):449-55.
Snelick R, et al. Large-scale evaluation of multimodal biometric authentication using state-of-the-art systems. IEEE Trans Pattern Anal Mach Intell. 2005;27(3):450-5.
Wen , et al. Efficient feature selection and classification for vehicle detection. IEEE Trans Circuits Syst Video Technol. 2014;25(3):508-17.
Esfahani ET, Wang S, Sundararajan V. Multisensor wireless system for eccentricity and bearing fault detection in induction motors. IEEE/ASME Trans Mechatron. 2013;19(3):818-26.
Pan J, Zhuang Y, Fong S. The impact of data normalization on stock market prediction: using SVM and technical indicators. In: Soft computing in data science: second international conference, SCDS 2016, Kuala Lumpur, Malaysia, September 21-22, 2016, Proceedings 2. Springer; 2016.
Kadir A et al. Leaf classification using shape, color, and texture features; 2013. arXiv preprint arXiv:1401.4447.
Wang C-M, Huang Y-F. Evolutionary-based feature selection approaches with new criteria for data mining: a case study of credit approval data. Expert Syst Appl. 2009;36(3):5900-8.
Wu W, et al. Evaluation of normalization methods for cDNA microarray data by k-NN classification. BMC Bioinform. 2005;6:1-21.
Liu Z. A method of SVM with normalization in intrusion detection. Procedia Environ Sci. 2011;11:256-62.
Su D et al. Anomadroid: profiling android applications’ behaviors for identifying unknown malapps. In: 2016 IEEE Trustcom/BigDataSE/ISPA. IEEE; 2016.
Peterson RA. Finding optimal normalizing transformations via best normalize. R Journal. 2021;13(1):310-29.
El-Hasnony IM, et al. Improved feature selection model for big data analytics. IEEE Access. 2020;8:66989-7004.
Song X-F, et al. A fast hybrid feature selection based on correlation-guided clustering and particle swarm optimization for high-dimensional data. IEEE Trans Cybern. 2021;52(9):9573-86.
Mohamad , et al. Enhancing big data feature selection using a hybrid correlation-based feature selection. Electronics. 2021;10(23):2984.
Khaire UM, Dhanalakshmi R. Stability of feature selection algorithm: a review. J King Saud Univ Comput Inf Sci. 2022;34(4):1060-73.
Camattari F et al. Greedy feature selection: Classifier-dependent feature selection via greedy methods. arXiv preprint arXiv:2403.05138; 2024.
Chen W, Sun X. Dynamic multi-label feature selection algorithm based on label importance and label correlation. Int J Mach Learn Cybern. 2024. https://doi.org/10.1007/s13042-024-02098-3.
Habib M, Okayli M. Evaluating the sensitivity of machine learning models to data preprocessing technique in concrete compressive strength estimation. Arab J Sci Eng. 2024. https://doi.org/10.1007/s13369-024-08776-2.
Peng , et al. scFSNN: a feature selection method based on neural network for single-cell RNA-seq data. BMC Genomics. 2024;25(1):264.
Ayesha S, Hanif MK, Talib R. Overview and comparative study of dimensionality reduction techniques for high dimensional data. Inf Fus. 2020;59:44-58.
Ray P, Reddy SS, Banerjee T. Various dimension reduction techniques for high dimensional data analysis: a review. Artif Intell Rev. 2021;54:3473-515.
Zebari R, et al. A comprehensive review of dimensionality reduction techniques for feature selection and feature extraction. J Appl Sci Technol Trends. 2020;1(2):56-70.
Sharma M, Kumar N. Improved hepatocellular carcinoma fatality prognosis using ensemble learning approach. J Ambient Intell Humaniz Comput. 2022;13(12):5763-77.
Książek W, Turza F, Pławiak P. NCA-GA-SVM: a new two-level feature selection method based on neighborhood component analysis and genetic algorithm in hepatocellular carcinoma fatality prognosis. Int J Numer Methods Biomed Eng. 2022;38(6): e3599.
Cheng B, Zhou P, Chen Y. Machine-learning algorithms based on personalized pathways for a novel predictive model for the diagnosis of hepatocellular carcinoma. BMC Bioinform. 2022;23(1):248.
Kiani A, et al. Impact of a deep learning assistant on the histopathologic classification of liver cancer. NPJ Dig Med. 2020;3(1):23.
Wang H, et al. Single-cell spatial analysis of tumor and immune microenvironment on whole-slide image reveals hepatocellular carcinoma subtypes. Cancers. 2020;12(12):3562.
Deng W, et al. Classification and prognostic characteristics of hepatocellular carcinoma based on glycolysis cholesterol synthesis axis. J Oncol. 2022. https://doi.org/10.1155/2022/2014625.
Cheng , et al. Identification and construction of a 13 -gene risk model for prognosis prediction in hepatocellular carcinoma patients. J Clin Lab Anal. 2022;36(5): e24377.
Yamashita R, et al. Deep learning predicts postsurgical recurrence of hepatocellular carcinoma from digital histopathologic images. Sci Rep. 2021;11(1):1-14.
Saillard C , et al. Predicting survival after hepatocellular carcinoma resection using deep learning on histological slides. Hepatology. 2020;72(6):2000-13.
Tohme S, et al. The use of machine learning to create a risk score to predict survival in patients with hepatocellular carcinoma: a TCGA cohort analysis. Can J Gastroenterol Hepatol. 2021. https://doi.org/10.1155/2021/5212953.
Shi J-Y, et al. Exploring prognostic indicators in the pathological images of hepatocellular carcinoma based on deep learning. Gut. 2021;70(5):951-61.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
*Correspondence:
GhadaMostafaAbdelaziz8_ pg@fcis.bsu.edu.eg; Dr_ hamdimahmoud@yahoo.com; tarek@mu.edu.eg; Mohamed. elaraby@fcis.bsu.edu.eg Computer Science Department, Faculty of Computers and Artificial Intelligence, Beni-Suef National University, Beni-Suef, Egypt Department of Computer Science, Faculty of Science, Minia University, El-Minia, Egypt Computer Science Unit, Deraya University, El-Minia, Egypt