تقنية محسّنة تعتمد على التصويت الناعم في تعلم الآلة للكشف عن سرطان الثدي باستخدام اختيار ميزات فعّال وتوازن الفئات SMOTE-ENN An improved soft voting-based machine learning technique to detect breast cancer utilizing effective feature selection and SMOTE-ENN class balancing
يُعتبر سرطان الثدي السبب الرئيسي للوفاة بين النساء على مستوى العالم، وهو يصبح أكثر انتشارًا. يمكن أن يقلل الكشف المبكر والتشخيص الدقيق لسرطان الثدي من معدل وفيات المرض. لقد استفادت التقدمات الأخيرة في تعلم الآلة في هذا الصدد. ومع ذلك، إذا كانت مجموعة البيانات تحتوي على ميزات مكررة أو غير ذات صلة، فإن الخوارزميات المعتمدة على تعلم الآلة غير قادرة على تقديم النتائج المطلوبة. لمعالجة هذه المشكلة، تم استخدام سلسلة من الاستراتيجيات الفعّالة مثل مقياس القوة المتين لتوسيع البيانات، وتقنية زيادة العينة للأقليات الاصطناعية – الجار الأقرب المعدل (SMOTE-ENN) لتحقيق توازن الفئات، وطرق اختيار الميزات مثل بوروتا واختيار الميزات المعتمد على المعامل (CBFS). من أجل تصنيف سرطان الثدي بدقة وموثوقية أكبر، تقترح هذه الدراسة نموذج تجميع يعتمد على التصويت الناعم يستفيد من قدرات ثلاثة مصنفات متنوعة: الشبكة العصبية متعددة الطبقات (MLP)، آلة الدعم الناقل (SVM)، وزيادة التدرج المتطرف (XGBoost). لإظهار كفاءة نموذج التجميع المقترح، يتم مقارنته بمصنفاته الأساسية باستخدام مجموعة بيانات تشخيص سرطان الثدي في ويسكونسن (WDBC). أظهرت نتائج التجربة أن المصنف المعتمد على التصويت الناعم حقق درجات عالية بدقة تبلغ ، ودقة تبلغ ، واسترجاع يبلغ ، ودرجة F1 تبلغ ، وAUC تبلغ 1.0 عندما تم تدريبه على الميزات المثلى المستمدة من طريقة CBFS. ومع ذلك، مع التحقق المتقاطع بعشرة أضعاف (10-FCV)، يظهر متوسط درجة دقة تبلغ 99.34%. كشفت تحليل شامل للنتائج أن التقنية المقترحة تفوقت على الطرق الحالية المتطورة بسبب معالجة البيانات الفعّالة، واختيار الميزات، وطرق التجميع.
الكلمات الرئيسية: سرطان الثدي ⋅ تعلم الآلة ⋅ WDBC ⋅ SMOTE-ENN ⋅ مصنف التصويت الناعم ⋅ بوروتا
1 المقدمة
السرطان هو مرض ينشأ عندما تتطور خلايا الجسم بشكل غير طبيعي، وتخترق الأنسجة المحيطة، وتنتشر إلى مناطق أخرى من الجسم إذا تُركت دون علاج. سرطان الثدي هو نوع من الأورام التي تبدأ في الأنابيب المنتجة للحليب (القنوات) أو الفصوص في الثدي. يمكن أن تكون ورمًا خبيثًا أو حميدًا. في حالة الورم الحميد، تبقى الخلايا في القنوات ولا تنتشر إلى الأنسجة الدهنية والضامة في الثدي. في المقابل، تخترق خلايا الورم الخبيث الأنسجة الدهنية والضامة في الثدي من خلال اختراق جدران القناة والفص. يحتل سرطان الثدي المرتبة الثانية في العالم من حيث الحدوث والشدة، حيث إنه قاتل بشكل خاص ومرضي للنساء [1]. يؤثر على حوالي واحدة من كل ثماني نساء على مستوى العالم [2]. من ناحية أخرى، يمثل الرجال 0.5-1% من جميع حالات سرطان الثدي. في عام 2020، سجلت منظمة الصحة العالمية 2.3 مليون
حالة جديدة من سرطان الثدي لدى النساء، مع 685,000 حالة وفاة على مستوى العالم [3]. في عام 2023، وفقًا لجمعية السرطان الأمريكية (ACS)، كان هناك حوالي 297,790 حالة جديدة من سرطان الثدي الغازي و55,720 حالة جديدة من سرطان القنوات في الموقع (DCIS) في الولايات المتحدة. بالإضافة إلى ذلك، توفيت 91,708 امرأة بسبب سرطان الثدي [4].
تهدف مبادرة منظمة الصحة العالمية العالمية لسرطان الثدي (GBCI) إلى إنقاذ 2.5 مليون حياة على مستوى العالم من سرطان الثدي بين عامي 2020 و2040 من خلال خفض معدل الوفيات بنسبة 2.5 في المئة كل عام. لتحقيق هذا الهدف، يعد الكشف المبكر عن سرطان الثدي أمرًا حاسمًا لأنه يسمح بالتدخل الفوري ويعزز فرصة تحقيق نتائج علاجية ناجحة [1]. ومع ذلك، فإن العديد من الدول غير قادرة على الكشف المبكر عن سرطان الثدي بسبب نقص المرافق التشخيصية والعلاجية الفعّالة، فضلاً عن نقص الأطباء المدربين بشكل جيد. يزيد تأخير علاج السرطان من الوفيات، كما تفعل الآثار الصحية والتكاليف المرتبطة. لمواجهة هذا التحدي، تحتاج هذه الدول إلى إنفاق كبير على الصحة العامة، وتطوير مختبرات إضافية وأقسام علم الأمراض مجهزة بالتكنولوجيا المناسبة، وتثقيف المزيد من الأشخاص لأداء العمليات التشخيصية [5].
يتم تشخيص سرطان الثدي باستخدام أدوات التصوير الطبي وعلم الأمراض. تعتبر الماموجرام واحدة من أبرز تقنيات التصوير لاختبار سرطان الثدي؛ ومع ذلك، فإن دقتها تتراوح من 68 إلى [6]. الخزعة هي عملية تعتمد على علم الأمراض وهي قوية ودقيقة للغاية ولكن من ناحية أخرى، فهي محفوفة بالمخاطر، مكلفة، تستغرق وقتًا طويلاً، وتعتبر تدخلاً [7]. إجراء آخر يعتمد على علم الأمراض يُستخدم على نطاق واسع هو اختبار الشفط بالإبرة الدقيقة (FNA)، والذي يُعتبر موثوقًا، بسيطًا، آمنًا، قليل التدخل، وله معدل إيجابي زائف منخفض. كما أنه يوفر الوقت والمال [8].
تفتح التطورات الأخيرة في تقنيات تعلم الآلة (ML) في قطاع الرعاية الصحية آفاقًا جديدة لـ FNA [8]. لتعزيز فعالية FNA كأداة تشخيصية، استخدمت العديد من الدراسات تقنيات ML على مستوى العالم. يمكن أن تجعل تقنيات ML الكشف عن سرطان الثدي أكثر كفاءة من خلال أتمتته والتغلب على الصعوبات المرتبطة بأنظمة الكشف عن السرطان التقليدية، التي تميل إلى الأخطاء، وتستغرق وقتًا طويلاً، وتكون مكلفة، وتعتمد بشكل أساسي على معرفة علماء الأمراض [9]. كما أنها قادرة على الكشف عن السرطان في مراحل مبكرة، مما يمكن أن يؤدي إلى تحسين نتائج العلاج وزيادة معدلات البقاء على قيد الحياة. وفقًا لدراسة براوز [10]، فإن التشخيصات المهنية دقيقة بنسبة 79.97%، مقارنةً بـ 91.1% لتشخيصات ML. تم استخدام خوارزميات ML الأكثر استخدامًا مثل الغابة العشوائية (RF) [1، 11-13]، الجار الأقرب (KNN) [2-4، 7]، SVM [1، 12، 13، 15، 16]، شجرة القرار [1، 12-14، 16، 17]، الانحدار اللوجستي (LR) [1، 13، 16]، بايز الساذج (NB) [12، 13]، زيادة التدرج (GB) [1، 15]، أدا بوست (AB) [1]، MLP [15]، والشبكة العصبية الاصطناعية (ANN) [13، 15] للكشف عن سرطان الثدي باستخدام طرق مختلفة، بما في ذلك طريقة FNA.
ومع ذلك، لا يمكن للعديد من طرق تعلم الآلة الأداء بشكل جيد في تصنيف سرطان الثدي بسبب الخصائص غير المهمة وغير المرغوب فيها في مجموعة البيانات. لذلك، يعد اختيار الميزات أمرًا حاسمًا لاختيار الميزات ذات الصلة وتحقيق أقصى دقة. هدفه هو تقليل كمية البيانات للمصنف من خلال إزالة البيانات غير ذات الصلة، والبيانات الزائدة، والبيانات الضوضائية لتعزيز تصنيف سرطان الثدي [18]. إنه يعزز أداء المصنف من حيث دقة الكشف وتكاليف الحوسبة [19]. تم تحليل تقنيات اختيار الميزات المختلفة مثل اختيار الميزات بيرسون (PFS) [1، 20]، وإزالة الميزات التكرارية (RFE) [11، 15، 17]، وتحليل المكونات الرئيسية (PCA) [14]، ومشغل الانكماش والاختيار المطلق الأدنى (LASSO) [12]، وعامل التضخم في التباين (VIF) [11، 20]، وإغاثة [12]، واختيار الميزات المتسلسل (SFS) [12]، واختيار الميزات المعتمد على الارتباط (CBFS) [15]، وأهمية الميزات [17]، واكتساب المعلومات [20] من قبل الباحثين لفعاليتها في اختيار أفضل الميزات.
هنا، يقدم المؤلفون مراجعة شاملة للأبحاث التي تستخدم ميزات FNA في مجموعة بيانات WDBC للكشف عن سرطان الثدي، مع تسليط الضوء على تقنيات تعلم الآلة واختيار الميزات.
حقق مصطفى علي حسن دلفي وآخرون [11] في كيفية أداء طرق اختيار الميزات المختلفة، بما في ذلك RFE وVIF واختيار الميزات المعتمد على النموذج والاختيار الأحادي المتغير، في الكشف عن سرطان الثدي باستخدام مصنف الغابة العشوائية. أظهرت نتائج الاختبار أن VIF مع 25 ميزة تفوقت على تقنيات الميزات الأخرى المستخدمة، محققة دقة تبلغ 98.8% ودرجة F1 تبلغ 98%.
لدراسة تأثير القيم الشاذة وPFS على مجموعة بيانات WDBC، استخدم ب. يوسوفا وآخرون [1] سبعة خوارزميات تعلم آلي. كشفت النتائج أن مصنفات LR وRF وAB حققت دقة 99.12% بعد إزالة القيم الشاذة من مجموعة البيانات. علاوة على ذلك، تفوقت RF على الآخرين عندما تم تطبيق اختيار الميزات باستخدام ارتباط بيرسون على مجموعة البيانات المصفاة من القيم الشاذة. لاكتشاف سرطان الثدي، استخدم هاريكومار راجاجورو وآخرون [14] PCA كطريقة لاختيار الميزات وDT وKNN للتصنيف. أظهرت النتائج التجريبية باستخدام WDBC أن KNN أدت أداءً أفضل من DT.
استخدم إركان أككور وآخرون [12] ثلاث طرق لاختيار الميزات – الاختيار الأمامي المتسلسل (SFS)، والتخفيف، وLASSO – للعثور على الميزات ذات الصلة في مجموعات بيانات WDBC وMammographic Breast Cancer Dataset (MBCD) وقاموا بتغذيتها إلى SVM وKNN وNB والتعلم الجماعي وDT للتصنيف. تم تحسين جميع هذه المصنفات باستخدام تحسين بايزي. أظهر SVM المحسن باستخدام LASSO أفضل النتائج على كلا المجموعتين، مع دقة على WDBC و97.95% على MBCD.
لزيادة الكفاءة التشخيصية لسرطان الثدي، اقترح كامياب كريمي وآخرون [13] خوارزميتين جديدتين لاختيار الميزات تعتمد على الميتاهيرستيك: خوارزمية المنافسة الإمبراطورية (ICA) وخوارزمية الخفاش (BA). تم استخدام KNN وSVM وDT،
NB وAB وتحليل التمييز الخطي (LDA) وRF وLR وANN للتصنيف. أظهرت التحليل المقارن أن RF وBA تفوقا على الطرق الأخرى مع دقة.
طوّر سنم عامر وآخرون [15] طريقة جديدة للتعلم الآلي لتحديد سرطان الثدي، تتكون من اختيار الميزات المعتمد على الارتباط، تليها إزالة الميزات التكرارية (RFE)، وأسفرت عن 11 ميزة مثلى. بعد ذلك، تم تطبيق الميزات المستخرجة على SVM وRF وGB وANN وMLP للتحليل المقارن. وفقًا للنتائج، تفوق نموذج MLP على الآخرين، مع أقصى دقة قدرها .
اقترح محمد س. هاشم وآخرون [16] طريقة تجميع تعتمد على التصويت الناعم تجمع بين LR وSVM وDT لتصنيف سرطان الثدي. قبل التصنيف، تم استخدام تقنية SMOTE لمعالجة مشكلة عدم توازن مجموعة البيانات، وتم استخدام طرق ارتباط بيرسون والمعلومات المتبادلة لاختيار الميزات. مع WDBC، حققت الطريقة المقترحة 99.3% دقة، بينما كانت دقة التحقق المتقاطع بعشر مرات 98.2%.
قد تؤثر البيانات على طريقة اختيار ميزات واحدة، مما يؤثر على أداء المصنف. للتغلب على هذه المشكلة، قدمت ماريزا ميرا-غاونا وآخرون [17] تقنية اختيار ميزات تجميعية تجمع بين ثلاث خوارزميات لاختيار الميزات (SelectKBest وRFE وFeature Importance). تم تقييم الطريقة المقترحة على ثلاث مجموعات بيانات، بما في ذلك WDBC. تم استخدام LR وDT كمصنفات وتم تدريبها على الميزات المكتسبة من طريقة اختيار الميزات التجميعية. كشفت النتائج المقارنة أن LR تفوقت بدقة قدرها .
اقترح مينا ساميناساب وآخرون [20] مجموعة الصحة الميتا، وهي تقنية تجميع تعتمد على التكديس للكشف السريع عن سرطان الثدي. تتكون الطريقة المقترحة من خطوتين رئيسيتين: اختيار الميزات والتصنيف. تم إجراء اختيار الميزات باستخدام ثلاث طرق منفصلة: VIF وارتباط بيرسون وكسب المعلومات. بعد ذلك، تم دمج الميزات المختارة باستخدام نهج الأشجار الإضافية. تضمنت المرحلة الثانية التكديس، والتجميع، والتعزيز، والتصويت لإنشاء نموذج تجميعي لتحسين تصنيف سرطان الثدي. وفقًا للنتائج، حصل الإطار على 97% في درجة F1 و98.2% دقة عند تقييمه ضد مجموعة بيانات WDBC.
طور زكسيان هوانغ وآخرون [21] نهج تعلم آلي يعتمد على الغابات العشوائية للتجميع الهرمي (HCRF) لتحسين دقة التصنيف. بالإضافة إلى HCRF، استخدم المؤلفون نهج قياس أهمية المتغيرات (VIM) لاختيار الميزات لإزالة البيانات غير الضرورية من مجموعات بيانات سرطان الثدي. حقق HCRF ونهج VIM دقة قدرها 97.05% و97.76% على مجموعات بيانات WDBC وWBC، على التوالي.
اقترح لو كومار سينغ وآخرون [22] استراتيجية جديدة هجينة لتحسين الميتاهيرستيك لاختيار الميزات المؤثرة. دمج المؤلفون خوارزمية تحسين البحث الجاذبي (GSOA) وتحسين البطريق الإمبراطوري (EPO) لإنشاء التقنية الهجينة (hGSEPO)، حيث كانت GSOA مسؤولة عن البحث العالمي وEPO مسؤولة عن البحث المحلي. على مجموعة بيانات WDBC، حققت الطريقة دقة، و استرجاع، و دقة.
أجرى أخيليش كومار سينغ وآخرون [23] تحليلًا مقارنًا للكشف عن سرطان الثدي باستخدام ست طرق تعلم آلي (LR وKNN وSVM وRF ونموذج Keras التسلسلي وDT). أظهرت النتائج التجريبية أن جميع المصنفات المستخدمة حققت أكثر من دقة على مجموعة بيانات WDBC.
في عام 2024، أجرى عقيل أحمد خان وآخرون [24] دراسة تفحص فعالية SVM وMLP وRF وDT وNB وKNN لتحديد سرطان الثدي، سواء مع أو بدون استخدام تقنيات تقليل الأبعاد: PCA وLDA وتحليل العوامل. تم تقييم نتائج التجربة على ثلاث مجموعات بيانات، بما في ذلك WDBC. أشارت النتائج إلى أن MLP تفوقت على الآخرين دون استخدام تقنيات تقليل الأبعاد، محققة دقة قدرها على WDBC. ومع ذلك، حقق SVM باستخدام طريقة تحليل العوامل لتقليل الأبعاد أعلى دقة قدرها على مجموعة البيانات الأخرى، أي WBC.
استخدم إيمان كاظم عجلان وآخرون آلة التعلم المتطرفة (ELM) لتصنيف أورام الثدي إلى فئات حميدة وسرطانية، محققين درجة دقة قدرها ، ودرجة دقة قدرها ، ودرجة استرجاع قدرها ، ودرجة F1 قدرها على مجموعة بيانات WDBC. تم تلخيص الأعمال ذات الصلة في الجدول 1.
تظهر مراجعة الأدبيات الشاملة للقسم أعلاه أن جهودًا كبيرة تُبذل لتطوير فضاء الميزات ونماذج التصنيف التي تساهم في الكشف عن سرطان الثدي. ومع ذلك، حدد المؤلفون فجوات بحثية كبيرة تحتاج إلى معالجة لتحسين تشخيص سرطان الثدي، كما هو موضح أدناه.
أولاً، أولت الأبحاث السابقة اهتمامًا أقل لاستراتيجيات قياس البيانات المناسبة، وهي خطوة معالجة مسبقة حاسمة تؤثر على أداء التصنيف. ثانيًا، فشلت الطريقة السابقة في معالجة مشكلة عدم توازن الفئات، مما أدى إلى تحيز مصنفات التعلم الآلي نحو الفئة الغالبة. وبالتالي، فإن التغلب على مخاوف عدم توازن الفئات أمر حاسم لتعميم النموذج.
كانت هناك قيود أخرى تتمثل في أن معظم الأبحاث صنفت سرطان الثدي باستخدام مصنفات فردية بدلاً من التجميعات، التي تكون أكثر دقة واستقرارًا من المصنفات الفردية. لتصميم نظام أفضل للكشف عن سرطان الثدي، من الضروري حل هذه القيود.
لحل المشكلة الأولى، تستخدم هذه الدراسة مقياس القوة المتين، الذي يكون أقل عرضة للقيم الشاذة من المقاييس الأخرى المستخدمة بشكل شائع. بالإضافة إلى ذلك، يضمن أن جميع مقاييس السمات تقع ضمن نطاق قابل للمقارنة. القضية الثانية المتعلقة بالفئة
الجدول 1 ملخص مراجعة الأدبيات
المرجع.
السنة
الطرق
الدقة
القيود
[11]
2024
RFE وVIF واختيار الميزات المعتمد على النموذج والميزات الأحادية باستخدام RF
98.8%
– تم استخدام دقة ودرجات F1 فقط لتقييم النموذج، مع تجاهل مقاييس أساسية أخرى
– فشلت في معالجة مشكلة عدم توازن الفئة، مما أدى إلى نتائج متحيزة
– غياب طريقة تقييم التحقق المتقاطع
[13]
2023
SVM وDT وNB وAB وLDA وRF وLR وANN وICA وBA
99.12%
– فشلت في معالجة مشكلة عدم توازن الفئة
– استخدمت ميتاهيرستيك لاختيار الميزات، وهي طريقة أكثر استهلاكًا للموارد الحاسوبية
– غياب طريقة تقييم التحقق المتقاطع
[14]
2019
PCA مع خوارزمية K-NN كمصنف
95.95%
– تم استخدام الدقة فقط لتقييم النموذج، مع تجاهل مقاييس أساسية أخرى
[15]
2022
SVM وRF وGB وANN وMLP وCBFS وRFE
99.12%
– تم استخدام الدقة فقط لتقييم النموذج، مع تجاهل مقاييس أساسية أخرى
[16]
2023
PC-MI، مصنف يعتمد على التصويت الناعم يجمع بين LR وSVM وDT
99.3% ودقة 10-FCV-97.24%
– لم يتم إجراء اختيار الميزات وقياس الميزات، وهو أمر ضروري لنموذج فعال ودقيق وغير متجاوز
– تتطلب دقة الدراسات المقترحة مزيدًا من التحسين
[17]
2021
اختيار الميزات الجماعي (SelectKBest، RFE، وأهمية الميزات)، شجرة القرار والانحدار اللوجستي
93.85%
– تم استخدام الدقة فقط لتقييم النموذج، متجاهلاً مقاييس أساسية أخرى
– فشل في معالجة مشكلة عدم توازن الفئات
[1]
2021
اختيار الميزات باستخدام ارتباط بيرسون، الانحدار اللوجستي، الغابات العشوائية، تعزيز التدرج، وغيرها
99.12%
– فشل في معالجة مشكلة عدم توازن الفئات
– تم استخدام الدقة فقط لتقييم النموذج، متجاهلاً مقاييس أساسية أخرى
[20]
٢٠٢٢
مجموعة الأشجار الإضافية لاختيار الميزات
نهج قائم على التكديس للتصنيف
98.2%
لم يتم إجراء اختيار الميزات وتقييس الميزات، وهو ما يعد ضروريًا لنموذج فعال ودقيق وغير متجاوز.
– غياب طريقة تقييم التحقق المتبادل
[21]
٢٠٢٢
HCRF و VIM
97.05%
لم يتم إجراء اختيار الميزات وتقييس الميزات، وهو ما يعد ضروريًا لنموذج فعال ودقيق وغير متجاوز.
– غياب طريقة تقييم التحقق المتبادل
[22]
2024
جي إس أو إيه، إي بي أو، و هـ جي إس إي بي أو
97.66%
لم يتم إجراء اختيار الميزات وتقييس الميزات، وهو أمر ضروري لنموذج فعال ودقيق وغير متجاوز.
– استخدام أسلوب ميتا-هيوريستيكي لاختيار الميزات، وهو نهج أكثر كثافة حسابية
– غياب طريقة تقييم التحقق المتبادل
[23]
٢٠٢٤
LR، KNN، SVM، RF، نموذج Keras التسلسلي، وDT
98%
-لم تقم الدراسة المقترحة بتنفيذ أي تقنيات لموازنة الفئات أو تقنيات التعديل. قد يؤدي ذلك إلى نتائج متحيزة.
– غياب طريقة تقييم التحقق المتبادل
[24]
2024
SVM، MLP، RF، DT، NB، و KNN، PCA، LDA، FA
98.26%
– تم تخطي اختيار الميزات وتقييس الميزات، وهما أمران حاسمان لنموذج فعال ودقيق وغير متجاوز.
الجدول 1 (مستمر)
مرجع
سنة
طرق
دقة
القيود
[25]
٢٠٢٤
إلم
94.52%
لم يتم إجراء اختيار الميزات وتقييس الميزات، وهو ما يعد ضروريًا لنموذج فعال ودقيق وغير متجاوز.
– فشل في معالجة مشكلة عدم توازن الفئات، مما أدى إلى نتائج متحيزة
-غياب طريقة تقييم التحقق المتبادل
يتم معالجة عدم التوازن من خلال استخدام SMOTE-ENN. هذه الطريقة الهجينة المبتكرة في أخذ العينات تخلق عينات أكثر تمثيلاً للفئة الأقل تمثيلاً بينما تقلل من العينات الضوضائية. يستخدم هذا العمل نهجي بوروتا وCBFS لاختيار الميزات الأكثر ملاءمة، والتي يتم تصنيفها بعد ذلك باستخدام إطار تعلم جماعي يعتمد على التصويت الناعم. يجمع النموذج الجماعي بين ثلاثة نماذج (SVM وXGBoost وMLP) ويمكن أن يوفر دقة أفضل من مصنف واحد، حيث إنه أقل عرضة للتكيف المفرط.
مجتمعة، يمكن أن تساعد التقنية المقترحة صناعة الطب في تشخيص سرطان الثدي بدقة وفعالية أكبر في مرحلة مبكرة، مما يحسن معدلات البقاء. يمكن أن تعالج القيود المفروضة على أساليب فحص سرطان الثدي التقليدية من خلال تقديم رؤية ثانية للأطباء الشرعيين وتقليل معدل الإيجابيات الكاذبة.
علاوة على ذلك، قد يتم استخدام هذه التكنولوجيا مع مجموعات بيانات طبية أخرى للكشف عن الأمراض بسرعة وكفاءة وبشكل اقتصادي.
تشمل أبرز نقاط المخطوطة:
لتحسين قابلية فصل البيانات، قام المؤلفون بتطبيع مجموعة بيانات WDBC باستخدام مقياس روبرت، الذي يعد أكثر كفاءة وفعالية في التعامل مع القيم الشاذة.
استخدم المؤلفون SMOTE-ENN، وهي طريقة متقدمة لموازنة الفئات الهجينة، لتصنيف الفئة الأقلية بفعالية وتقليل الحساسية لعدم التوازن في الفئات.
لزيادة أداء التصنيف والحساب مع تجنب مشاكل الإفراط في التكيف، يتم تحديد الميزات المثلى من خلال تحليل استراتيجيتين لاختيار الميزات: بوروتا واختيار الميزات المعتمد على المعاملات (CBFS).
لتحسين تصنيف سرطان الثدي، استخدم نموذج تجميعي يعتمد على التصويت الناعم يدمج ثلاثة نماذج (SVM، XGBoost، وMLP).
أظهرت نتائج الاختبارات أن نظام الكشف الآلي المقترح عن سرطان الثدي تفوق على التقنيات السابقة.
2 الطرق والمواد
تصف هذه القسم مجموعة بيانات WDBC وتقدم نظرة عامة على الاستراتيجية المقترحة، وخطوات المعالجة المسبقة، وتقنيات اختيار الميزات، والخوارزميات التصنيف المستخدمة، ومقاييس الأداء لتقييم فعالية الدراسة. قام المؤلفون بتطوير جميع التجارب باستخدام بايثون وبيئة تطوير Jupyter Notebook على جهاز كمبيوتر مزود بمعالج Intel Core i5 وذاكرة RAM سعة 8 جيجابايت.
2.1 مجموعة البيانات
تستند هذه العمل إلى مجموعة بيانات WBCD من أرشيف UCI ML، والتي تحتوي على 569 عينة و30 ميزة عددية مع ميزة تعريف واحدة. إنها مجموعة بيانات مرجعية معترف بها على نطاق واسع ومتاحة للجمهور لتصنيف الثدييات الحميدة والخبيثة. لا تحتوي على قيم مفقودة. في هذه المجموعة، تم تقدير الخصائص العشر ذات القيم الحقيقية – نصف القطر، والملمس، والتجويف، والمحيط، والمساحة، والنعومة، والنقاط المقعرة، والكثافة، والتناظر، والأبعاد الفراكتالية – من نوى أورام الثدي في صور FNA الرقمية. بعد ذلك، تم حساب المتوسط، والخطأ القياسي، و”الأسوأ” (متوسط القيم الثلاثة القصوى) لهذه الخصائص العشر، مما أسفر عن 30 ميزة توفر بيانات غنية ولكنها مترابطة للتحليل. يوضح الجدول 2 وصف هذه الميزات.
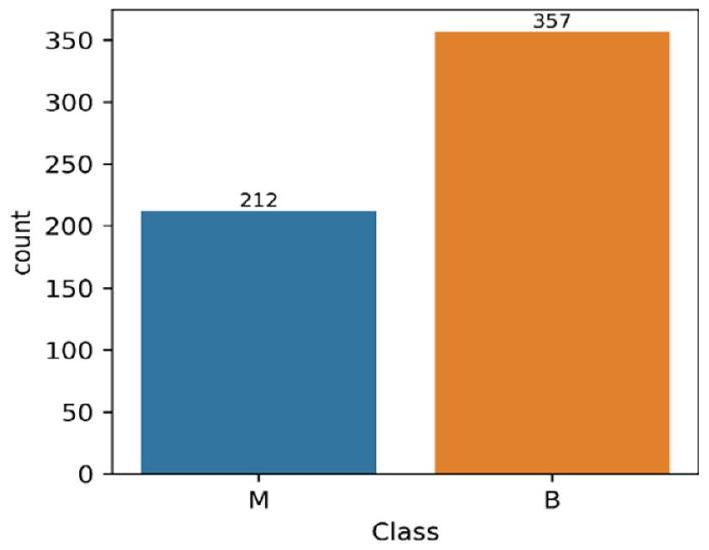
على الرغم من أن مجموعة البيانات قيمة، إلا أن هناك بعض القيود، بما في ذلك أنها منحازة بطبيعتها، كما هو موضح في الشكل 1، الذي يتكون من 357 حالة طبيعية و212 حالة خبيثة. قد يؤدي ذلك إلى تفضيل النموذج للفئة الغالبة (الطبيعية) وإنتاج نتائج متحيزة. قيد آخر هو أنها صغيرة نسبيًا من حيث الحجم، مما قد لا يعكس بشكل كاف تنوع حالات سرطان الثدي في العالم الحقيقي.
بالإضافة إلى ذلك، فإن مجموعة البيانات هذه تفتقر أيضًا إلى المعلومات السريرية مثل العمر، الجنس، حجم الكتلة، تغيير حجم الثدي، وما إلى ذلك، والتي يمكن أن توفر رؤى قيمة وتحسن دقة التشخيص. علاوة على ذلك، تم تطويرها في مركز طبي واحد، مما يثير القلق بشأن قابليتها للتعميم. ومع ذلك، مع طرق المعالجة المسبقة والتحقق المناسبة، لا تزال مجموعات بيانات WDBC تقدم مصدرًا قيمًا لتطوير وتقييم تقنيات التعلم الآلي لاكتشاف سرطان الثدي في القطاع الطبي.
الجدول 3 يحتوي على إحصائيات حول مجموعة بيانات WDBC، بما في ذلك نوع الورم، معرف الفئة، عدد الميزات، وعينات التدريب والاختبار لكل فئة.
الجدول 2 خصائص مجموعة بيانات WDBC
رقم السجل
ميزات
نطاق المتوسط
نطاق الخطأ القياسي
أسوأ نطاق
1
نصف القطر
6.98-28.11
0.112-2.873
7.93-36.04
2
ملمس
9.71-39.28
0.36-4.89
12.02-49.54
٣
تحدب
0.000-0.427
0.000-0.396
0.000-1.252
٤
المحيط
٤٣.٧٩-١٨٨.٥٠
0.76-21.98
50.41-251.20
٥
تناظر
0.106-0.304
0.008-0.079
0.157-0.664
٦
منطقة
143.50-2501.0
6.80-542.20
185.20-4254.0
٧
نقاط مقعرة
0.000-0.201
0.000-0.053
0.000-0.291
٨
نعومة
0.053-0.163
0.002-0.031
0.071-0.223
9
البُعد الفركتالي
0.050-0.097
0.001-0.030
0.055-0.208
10
الانضغاط
0.019-0.345
0.002-0.135
0.027-1.058
الشكل 1 مجموعة بيانات WDBC
جدول 3 إحصائيات مجموعة بيانات WDBC
نوع ورم الثدي
معرف فئة الورم
لا. الميزات
مجموعة التدريب (70%)
مجموعة الاختبار (30%)
عدد الحالات
حميد
0
31
249
١٠٨
٣٥٧
خبيث
1
31
149
63
212
2.2 نظرة عامة على البحث المقترح
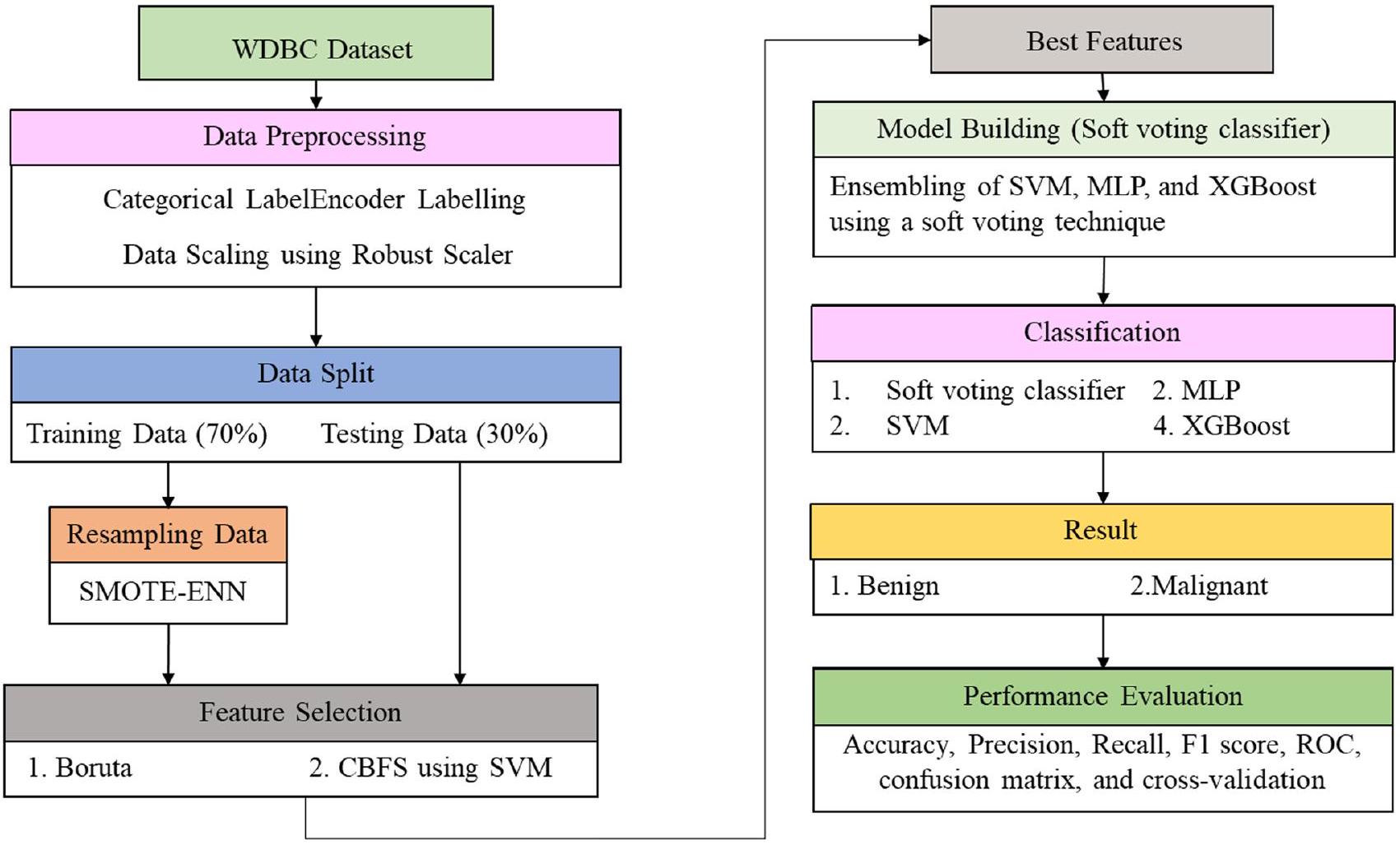
كجزء من الجهود المبذولة لتحسين دقة وكفاءة تشخيص سرطان الثدي، يتم إجراء أبحاث واسعة النطاق. بمجرد اختيار مجموعة البيانات، يتم استخدام خطوات متعددة لمعالجة البيانات مسبقًا. الخطوات الرئيسية هي استخدام مقياس قوي لتعديل البيانات وSMOTE-ENN لتحقيق توازن الفئات. بعد ذلك، يتم استخدام تقنيتين لاختيار الميزات، وهما بوروتا وCBFS، لاختيار الميزات الأكثر معلوماتية وتمييزًا. يتم استرجاع عشر ميزات من كل تقنية. أنشأ هذا العمل مصنف تصويت ناعم للتصنيف يتضمن SVM وXGBoost وMLP. لإظهار فائدة المصنف المقترح، يتم مقارنته بمصنفاته الأساسية باستخدام الميزات الكاملة ومجموعات الميزات المستمدة من بوروتا وCBFS. بالإضافة إلى ذلك، يتم مقارنة الطريقة المقترحة بتقنيات سرطان الثدي السابقة. الشكل 2 يظهر مخطط تدفق التقنية المقترحة.
2.3 معالجة البيانات
تُقلل معالجة البيانات المسبقة الضوضاء وعدم التناسق في البيانات بينما تستخرج رؤى حاسمة لتحسين الجودة والموثوقية. إنها خطوة حيوية في تعلم الآلة لأنها تساعد في تحسين أداء التصنيف من خلال إعداد البيانات للمرحلة التالية. تُعتبر تنظيف البيانات، والتطبيع، وتوازن الفئات من أكثر طرق إعداد البيانات استخدامًا.
الشكل 2 النموذج المقترح
الطرق. في هذه الدراسة، لتعزيز جودة وفهم مجموعة بيانات WDBC، قام المؤلفون بإزالة العمود الأخير “غير مسمى”، حيث كان يحتوي على قيم فارغة، وأعادوا تسمية متغير الفئة المستهدفة، أي “التشخيص”، إلى “الفئة”. يتم استخدام مقياس قوي لضمان أن جميع مقاييس السمات تقع ضمن نطاق مشابه، ويتم استخدام SMOTE-ENN لمعالجة الطبيعة المنحرفة لمجموعة البيانات المعنية. تتعامل ML مع البيانات العددية. ومع ذلك، نظرًا لأن الفئة المستهدفة (التشخيص) فئوية، يتم استخدام إجراء ترميز التسمية لتحويل التسميات (M) إلى 1 و(B) إلى 0. يتم تقديم أوصاف قياس البيانات عبر مقياس قوي وتوازن الفئة عبر SOMTE-ENN في الأقسام الفرعية التالية.
2.3.1 قياس البيانات (مقياس قوي)
يعد قياس البيانات خطوة مهمة في معالجة البيانات في أنظمة التعلم الآلي، تهدف إلى ضمان أن جميع مقاييس السمات تقع ضمن نطاق مشابه [26]. ستعزز تقنية القياس الجيدة أداء نموذج التصنيف. علاوة على ذلك، يمكن أن تكون استراتيجية القياس غير الفعالة أو السيئة أكثر ضررًا لنموذج التصنيف من عدم قياس البيانات على الإطلاق [27]. لتحقيق أداء تصنيف عالي، قام المؤلفون بتطبيع مجموعة بيانات WDBC باستخدام مقياس قوي، الذي يكون أكثر قدرة وفعالية في التعامل مع القيم الشاذة من طرق تطبيع البيانات الأخرى المستخدمة بشكل متكرر مثل مقياس الحد الأدنى والحد الأقصى والمقياس القياسي.
تستخدم طريقة القياس القوي نطاق الربع (IQR)، وهو الفرق بين الربع الأول والثالث، لقياس البيانات المتمركزة حول الوسيط. يتم تعريفه باستخدام المعادلة (1) الموضحة أدناه:
2.3.2 توازن مجموعة البيانات (SOMTE-ENN)
في صناعة الطب، يعد تصنيف البيانات غير المتوازن شائعًا ويمكن أن يؤثر سلبًا على فعالية أنظمة التصنيف، مما يسبب تحيزًا في النتائج [28]. من الضروري معالجة هذه المشكلة لتقليل التحيز وتحقيق تصنيف مثالي
الأداء. في هذا العمل، تقوم طريقة إعادة أخذ العينات SOMTE-ENN بتوازن مجموعة التدريب المنحرفة مع 249 عينة حميدة و149 عينة خبيثة، مما ينتج 225 عينة حميدة و230 عينة خبيثة لجعل المجموعة متوازنة وتمثل. إنها تقنية إعادة أخذ عينات هجينة متقدمة تجمع بين SMOTE (زيادة العينة) وENN (تقليل العينة). في طريقة SMOTE، يتم زيادة عدد عينات الفئة الأقلية من خلال التداخل الخطي لكل عينة من الفئة الأقلية وجيرانها الأقرب k بشكل عشوائي [29]، كما هو موضح في المعادلة SMOTE (2). ومع ذلك، قد تؤدي العينات التي تم إنشاؤها بواسطة SMOTE إلى إدخال ضوضاء في الفئة الأقلية [30]. تستخدم ENN تقنية تقليل العينة لإزالة العينات الضوضائية لجعل العينات التركيبية أكثر تمثيلًا [31].
في هذه المعادلة، تمثل عينة من الفئة الأقلية، هي عينة جارة مختارة عشوائيًا من من جيرانه الأقرب k، و هو رقم عشوائي بين 0 و1.
2.4 اختيار الميزات
تختار طريقة اختيار الميزات الميزات الأساسية بينما ترفض الميزات الزائدة وغير الضرورية الموجودة في مجموعات البيانات. يمكن أن يقلل اختيار الميزات الفعال من تعقيد مجموعة البيانات مع الاحتفاظ بالدقة. تم استخدام مجموعة متنوعة من التخصصات بنجاح في اختيار الميزات، بما في ذلك التشخيص الطبي، حيث تؤدي الميزات المخفضة إلى تقليل التكاليف للاختبارات والتشخيصات [32]. يمكن أن يساعد في تصنيف الخباثة من خلال تقليل البيانات الضوضائية والمكررة وغير المتسقة من مجموعة بيانات سرطان الثدي، مما قد يعقد الإجراء. لذلك، لبناء نظام فعال لاكتشاف سرطان الثدي، استخدمت هذه الدراسة تقنيتين لاختيار الميزات: Boruta [33] وCBFS.
2.4.1 اختيار ميزات Boruta
Boruta هي طريقة متقدمة لاختيار الميزات تهدف إلى تحديد الميزات الأكثر معلوماتية المتعلقة بمشاكل التصنيف [34]. إنها طريقة تعتمد على الغابة العشوائية تستخدم مقياس الأهمية. الهدف من هذه الاستراتيجية هو اختيار مجموعة السمات الأكثر فائدة للفئة الناتجة، بدلاً من اختيار المجموعة الأكثر تكثيفًا من الميزات التي تناسب نموذجًا معينًا [35].
الخطوات المتبعة في خوارزمية Boruta هي كما يلي [36]:
إنشاء ميزة الظل المقابلة لكل ميزة في مجموعة البيانات الأصلية من خلال خلط عشوائي للقيم.
توسيع مجموعة البيانات بخصائص الظل.
تدريب الغابة العشوائية/XGBoost على مجموعة البيانات الموسعة وجمع درجات Z لكل ميزة في قاعدة البيانات الأصلية مع أعلى درجة Z بين ميزات الظل.
تقييم أهمية كل ميزة أصلية من خلال مقارنة درجتها Z مع أعلى درجة Z بين ميزات الظل. تُعتبر الميزات التي تسجل أعلى من أعلى درجة Z بين ميزات الظل مهمة، بينما تُعتبر البقية غير مهمة.
إزالة جميع الميزات العشوائية أو الظل.
تكرار التقنية أعلاه حتى يتم استيفاء معايير التوقف أو يصبح اختيار الميزات مستقرًا.
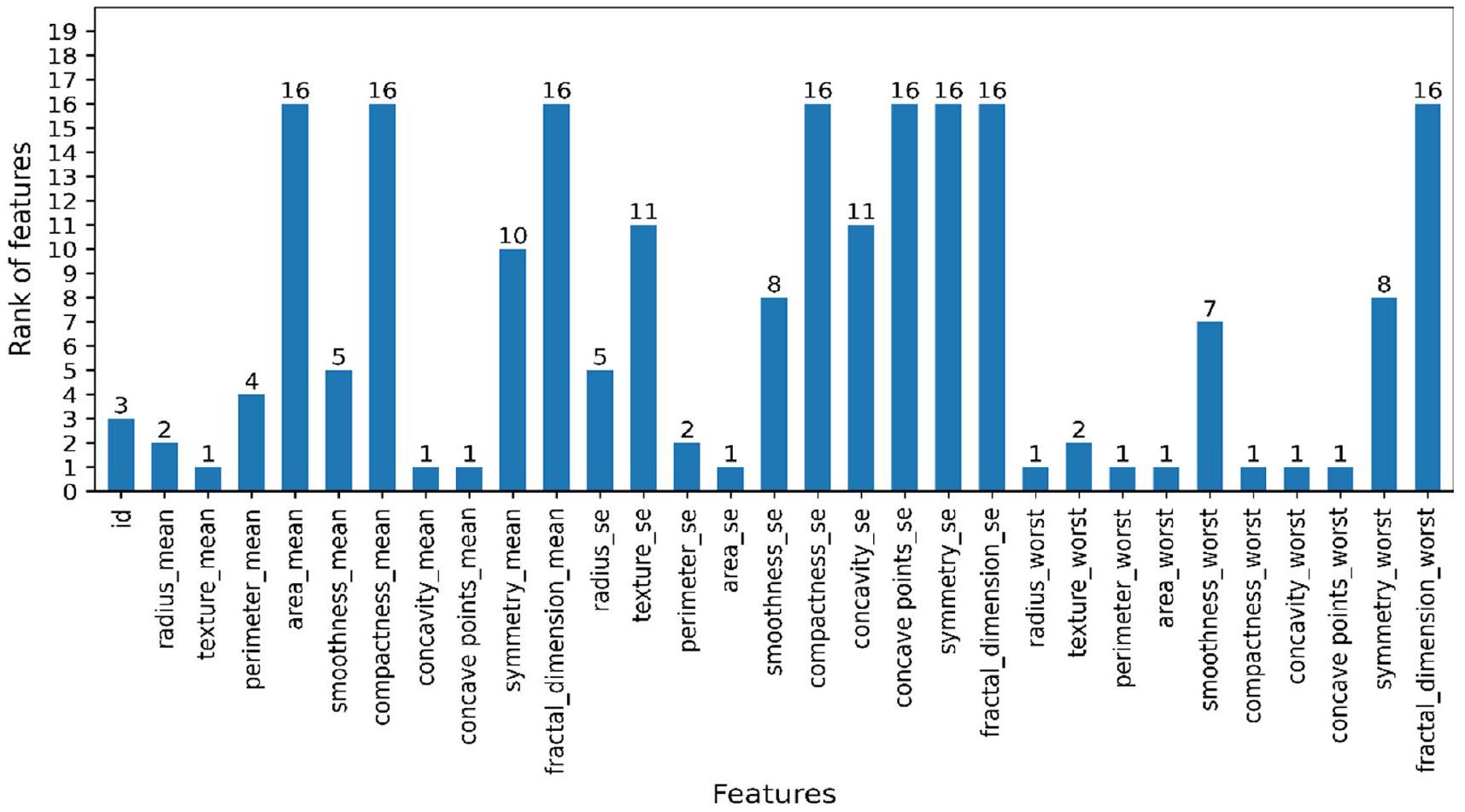
في هذه الدراسة، عندما يتم استخدام Boruta مع XGBoost لاختيار الميزات على WDBC، فإنه يمنح مرتبة واحدة (أعلى مرتبة) لعشر ميزات بناءً على أهميتها لتصنيف سرطان الثدي، كما هو موضح في الشكل 3. درجات z لهذه الميزات هي -0.173822 لـ texture_mean، وconcavity_mean لـ لنقاط التقعر_mean، -0.156225 لـ area_se، 0.296342 لـ radius_worst، 1.039188 لـ perimeter_worst، -0.156062 لـ area_worst، 0.191384 لـ compactness_worst، 0.223847 لـ concavity_worst و0.091067 لـ concave points_worst.
2.4.2 اختيار الميزات المعتمد على المعاملات (CBFS)
اختيار الميزات المعتمد على المعاملات (CBFS) هو نهج تعلم آلي يحدد ويعطي الأولوية لأهم الميزات بناءً على مساهمتها في مهام التصنيف [37]. تم الإبلاغ عن هذه الاستراتيجية لأول مرة في [38]، وتسعى لتحديد المستوى الفائق الأمثل لفصل مكونات البيانات إلى مجموعات متميزة. تستخدم نماذج خطية مثل Perceptron، والانحدار الخطي، والانحدار اللوجستي، وSVM، وغيرها لتقييم الميزات بناءً على معاملاتها. يمكن تفسير حجم المعامل لكل ميزة على أنه أهميتها؛ حيث يشير معامل أكبر إلى أن العنصر كان أكثر
الشكل 3 تصنيف الميزات باستخدام Boruta
أهمية في التصنيف. علاوة على ذلك، فإنه يوفر معلومات حول الاتجاه وقوة تأثيرها على المتغير المستهدف. تحتوي الميزة ذات المعامل الإيجابي على ارتباط إيجابي مع المتغير المستهدف، بينما تمثل الميزة ذات المعامل السلبي علاقة سلبية مع المتغير المستهدف.
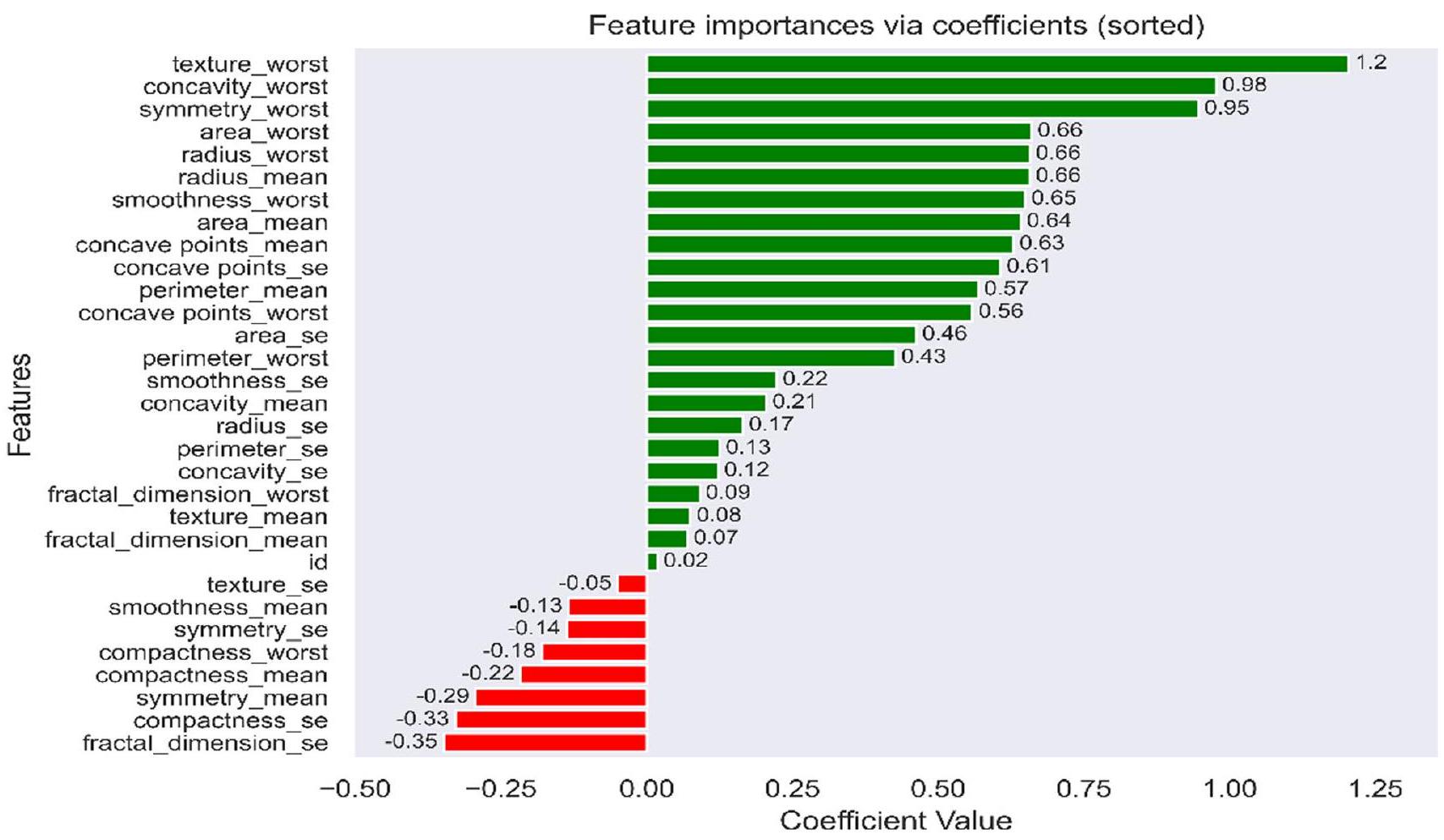
تستخدم هذه الدراسة SVM خطي لتعيين معاملات أو أوزان لميزات FNA في مجموعة بيانات WDBC بناءً على أهميتها أو صلتها بتصنيف سرطان الثدي. علاوة على ذلك، يتم اختيار أفضل عشر ميزات ذات أعلى قيم معامل مطلقة لتصنيف سرطان الثدي. يوضح الشكل 4 أهمية الميزات بناءً على درجة معاملها المطلقة. التمثيل الرياضي لدالة حدود القرار لـ SVM الخطي هو كما يلي، باستخدام المعادلة (3) [39].
هنا، هي دالة القرار أو التنبؤ التي تتنبأ بالفئة المستهدفة من متجه ميزة الإدخال، تشير إلى متجه الوزن العمودي على المستوى الفائق.
استخدام هذه الطريقة لاختيار الميزات يعزز أداء المصنف ويجعله أكثر بساطة وقابلية للتفسير. علاوة على ذلك، يمكن أن يخفف من صعوبات الإفراط في التكيف، مما يجعل المصنف أكثر عمومية [40].
2.5 التصنيف
تهدف هذه الدراسة إلى إنشاء نظام أفضل وأكثر دقة لاكتشاف سرطان الثدي، حيث طورت مصنف تصويت ناعم يدمج SVM وXGBoost وMLP. بالإضافة إلى ذلك، يتم استخدام تقنيتين فعاليتين لاختيار الميزات في هذه الدراسة لتعزيز أداء التصنيف من خلال إزالة الميزات غير ذات الصلة. لتقييم فعالية المصنف المقترح، يتم مقارنته بمصنفاته الأساسية. لهذا، يتم إجراء دراسة مقارنة باستخدام جميع الميزات، وعشر ميزات من Boruta، وعشر ميزات من CBFS. يتم إجراء الاختبارات التالية لتنفيذ دراسة المقارنة:
التصنيف باستخدام التصويت الناعم ومصنفه الأساسي مع جميع الميزات.
التصنيف باستخدام التصويت الناعم ومصنفه الأساسي مع عشر ميزات مختارة من Boruta.
التصنيف باستخدام التصويت الناعم ومصنفه الأساسي مع عشر ميزات مختارة من CBFS.
الشكل 4 أهمية الميزات بناءً على قيمة معامل SVM
وصف المصنف المقترح ومصنفاته الأساسية موضح أدناه:
2.5.1 مصنف التصويت الناعم
المصنف التجميعي هو تقنية معقدة في التعلم الآلي تجمع بين عدة مصنفات وتستخدم قدراتها لتحقيق أداء تصنيف ممتاز [41]. هناك طرق مختلفة لدمج المصنفات الفردية في تجميع؛ التصويت هو أحد الآليات الأساسية حيث يتم تجميع التنبؤات من النماذج المدمجة لتحديد النتيجة النهائية. يمكن أن يكون مصنف التصويت من ثلاثة أنواع: ناعم، صلب، ومرجح [42]. في التصويت الناعم، يتم حساب متوسط احتمالات كل فئة لتوليد الفئة النهائية الناتجة. في مصنف التجميع ذو التصويت الصلب، يحدد عدد الأصوات الفئة المستهدفة، وفي نهج التصويت المرجح، يختلف وزن كل مصنف بناءً على أدائه.
في الرعاية الصحية، يجب أن يكون مصنف التعلم الآلي دقيقًا وموثوقًا وجديرًا بالثقة بسبب الطبيعة الحرجة لصنع القرار التي تؤثر مباشرة على صحة المريض. يهدف هذا العمل إلى إنشاء مصنف تعلم آلي أكثر دقة وموثوقية واستقرارًا لتصنيف سرطان الثدي. لهذا الغرض، يتم دمج SVM وMLP وXGBoost في تجميع بتصويت ناعم للاستفادة من الذكاء الجماعي لهذه النماذج المتنوعة. يمكن أن يجعل هذا النهج من التصويت الناعم قرارات أكثر كفاءة من مصنف واحد من خلال أخذ في الاعتبار عدم اليقين المرتبط بالمصنفات الفردية [43،44]. يمكنه معالجة مخاوف الإفراط في التخصيص والتحيز مع تقليل خطأ التنبؤ وتعزيز التعميم [45]. علاوة على ذلك، يحسن مصنف التصويت الناعم من قابلية تفسير النموذج وشفافيته من خلال استخدام تقديرات الاحتمالية من المصنفات المدمجة. في الواقع، فإن مصنف التصويت الناعم المقترح قابل للتكيف وقد أظهر أداءً استثنائيًا في تطبيقات التعلم الآلي المختلفة [46].
2.5.2 آلة الدعم الناقل (SVM)
SVM هو مصنف متقدم في التعلم الآلي يستخدم للتعامل مع تحديات التصنيف والانحدار [47]. يسعى لتحديد المستوى الفائق الذي يوفر الأداء الأمثل والهامش لفصل نقاط بيانات المتجه المدخلة إلى فئات منفصلة [48]. تعتبر المتجهات الداعمة، كأقرب مكونات البيانات إلى حدود القرار، حاسمة في تحديد المستوى الفائق الذي له أكبر هامش [49]. يعمل SVM بشكل جيد على مجموعات البيانات الصغيرة وعالية الأبعاد، بما في ذلك تلك التي تحتوي على ميزات أكثر من العينات، حيث تفشل المصنفات التقليدية. لاستيعاب الخطية في البيانات، يقوم SVM بإنشاء
حد قرار خطي يقسم نقاط البيانات إلى فئات منفصلة. يمكن لـ SVM أيضًا التعامل مع عدم الخطية في البيانات من خلال تحويلها إلى مساحة جديدة ذات أبعاد عالية باستخدام دوال النواة [49]، مما يجعله أداة فعالة لاستخراج الميزات والتصنيف. تعتبر دالة الأساس الشعاعي (RBF) والدالة السينية والدالة متعددة الحدود من أكثر دوال النواة شيوعًا لجعل البيانات أكثر قابلية للفصل. علاوة على ذلك، فإن SVM مقاوم للقيم الشاذة ولديه عدد كبير من المعلمات الفائقة التي يمكن تعديلها لزيادة الأداء.
2.5.3 الشبكة العصبية متعددة الطبقات (MLP)
الشبكة العصبية متعددة الطبقات (MLP) هي شبكة عصبية اصطناعية ذات تغذية أمامية (FFANN) تشبه الدماغ البشري. تتكون من طبقة إدخال، وطبقة أو أكثر من الطبقات المخفية بناءً على التعقيد، وطبقة إخراج. كل طبقة تتكون من خلايا عصبية متصلة بخلايا عصبية في الطبقات المجاورة، وكل اتصال له وزن بناءً على قوته [50]. مثل غيرها من FFANNs، تنتقل المعلومات في اتجاه واحد من الإدخال إلى الإخراج عبر الطبقات المخفية [51] في MLP، تحدد أحجام متجه الإدخال والفئة الناتجة عدد الخلايا العصبية في طبقات الإدخال والإخراج، على التوالي. ومع ذلك، يجب تحديد كمية الطبقات المخفية والخلايا العصبية داخل هذه الطبقات تجريبيًا لأن الكثير منها يؤدي إلى الإفراط في التخصيص، وقليل منها يؤدي إلى نقص التخصيص. تقوم الشبكة العصبية متعددة الطبقات (MLP) بتدريب الشبكة من خلال استخدام تقنيات الانتشار العكسي وتقنيات تحسين قائمة على التدرج. إنها طريقة فعالة قائمة على الانتشار العكسي في التعلم الآلي يمكن أن تكشف وتقرب العلاقة غير الخطية بين الخصائص المدخلة والمخرجات المرغوبة، مما يجعلها مفيدة في مجموعة متنوعة من تطبيقات التعلم الآلي.
2.5.4 تعزيز التدرج المتطرف (XGBoost)
تعزيز التدرج المتطرف [52] (XGBoost) هو طريقة متقدمة في التعلم الآلي معروفة بأدائها الرائع وقابليتها للتطبيق عبر مجموعة واسعة من التطبيقات. إطار تعلم تجميعي، وهو تعزيز التدرج [50]، يعمل بشكل جيد في مهام التصنيف والانحدار. يبني XGBoost سلسلة من المتعلمين الضعفاء، عادةً أشجار القرار، ويحسن دقتها بشكل تكراري من خلال تقليل دالة الخسارة [53].
لديه العديد من الخصائص الفريدة، بما في ذلك استراتيجيات التنظيم التي تتجنب الإفراط في التخصيص، والتعامل القوي مع البيانات المفقودة، ودعم العمليات المتوازية للتعامل مع مجموعات البيانات الكبيرة. بشكل عام، هو نموذج تعلم آلي متعدد الاستخدامات بسبب سرعته ودقته ومرونته وقابليته للتوسع وقابلية تفسيره.
2.6 مقاييس الأداء
كجزء من هذا البحث، تتم مقارنة دقة المصنفات وحساسيتها ودقتها ودرجة F1، مع وبدون استراتيجيات اختيار الميزات. يتم استخدام مقياسين إضافيين (ROC ومقياس الالتباس) أيضًا لتصور أداء التصنيف. يتم تقديم شرح لمقاييس الأداء أدناه.
تعتمد دقة المصنف على مدى جودة تصنيفه للبيانات إلى فئات ذات صلة. تعرض النسبة المئوية للحالات المصنفة بشكل صحيح عبر جميع الحالات. المعادلة (4) تتضمن صيغة الدقة.
تقدر الدقة عدد الحالات الإيجابية التي تم تصنيفها بدقة مقارنة بجميع الحالات التي تم التنبؤ بها إيجابيًا. يتم تحديدها باستخدام المعادلة (5) أدناه.
يمكن تعريف الاسترجاع على أنه نسبة الحالات الإيجابية التي تم التعرف عليها بشكل صحيح إلى العدد الإجمالي للحالات الإيجابية الحقيقية، والمعروفة أيضًا باسم الحساسية. يتم حسابها باستخدام المعادلة (6).
تأخذ درجة F1 المتوسط التوافقي (HM) لحساسية المصنف في التعلم الآلي ودقته للحصول على قيمة نهائية واحدة كنتيجة. تحتوي المعادلة (7) على صيغة مقاييس درجة F1.
الجدول 4 أداء مصنف التصويت الناعم ومصنفاته الأساسية مع جميع الميزات
المصنف
الدقة (%)
الدقة (%)
الاسترجاع (%)
درجة F1 (%)
SVM
98.25
98.39
96.83
97.60
MLP
97.66
96.83
96.83
96.83
XGBoost
96.49
93.85
96.83
95.31
مصنف التصويت الناعم
98.25
98.39
96.83
97.60
الجدول 5 أداء مصنف التصويت الناعم ومصنفاته الأساسية مع 10 ميزات مختارة عبر بوروتا وCBFS
نهج اختيار الميزات
المصنفات
الدقة (%)
الدقة (%)
الاسترجاع (%)
درجة F1 (%)
اختيار ميزات بوروتا
SVM
97.08
93.94
98.41
96.12
MLP
97.66
95.38
98.41
96.88
XGBoost
96.49
92.54
98.41
95.38
مصنف التصويت الناعم
97.08
93.94
98.41
96.12
اختيار الميزات القائم على المعامل
SVM
98.25
98.39
96.83
97.60
MLP
98.25
96.88
98.41
97.64
XGBoost
96.49
92.54
98.41
95.38
مصنف التصويت الناعم
99.42
100.00
98.41
99.20
هنا الحالات الإيجابية الحقيقية، الحالات السلبية الحقيقية، الحالات الإيجابية الزائفة، الحالات السلبية الزائفة.
مصفوفة الالتباس، المعروفة أيضًا بمصفوفة الأخطاء [54]، تصور أداء التصنيف في شكل مصفوفة. تعرض عدد التقديرات الصحيحة وغير الصحيحة من قبل المصنف في كل فئة. تساعدك على فهم الفئات التي يخطئ المصنف في تفسيرها كأخرى [55].
خصائص التشغيل المستقبلية (ROC) هي أداة رسومية إضافية لتصور وتقييم أداء المصنف التشخيصي [56]. كما أنها تستخدم على نطاق واسع لمقارنة أداء المصنفات من خلال إظهار معدل الكشف عن الإيجابيات الحقيقية (TPR) مقابل معدل الإيجابيات الزائفة (FPR). المصنفات المثلى لديها درجة استرجاع/حساسية/TPR تبلغ 1.0 ودرجة FPR تبلغ 0، مما ينتج عنه AUC قدره 1 [57]. بالإضافة إلى ذلك، فإن قيمة AUC البالغة 0.5 تشير إلى التخمين العشوائي.
3 النتائج
في هذا القسم، يقدم المؤلفون نتائج التصنيف لمصنف التصويت الناعم المقترح ومصنفاته الأساسية عند تطبيق جميع الميزات أو الميزات المختارة. تعرض الجدول 4 درجات الأداء للمصنفات عند تطبيق جميع الميزات. يقارن الجدول 5 درجاتهم لاستراتيجيتين لاختيار الميزات، بوروتا وCBFS. يتم استخدام نهج التحقق المتقاطع بعشر مرات لتقييم أكثر موثوقية لأداء الطريقة المقترحة. علاوة على ذلك، يقارن الجدول 6 فعالية النهج المقترح مع نهج متقدم آخر.
في مجموعة بيانات الاختبار، يظهر الجدول 4 الدقة والدقة والاسترجاع ودرجة F1 لمصنف التصويت الناعم ومصنفاته الأساسية بعد التدريب على جميع الميزات. يكشف أن مصنف التصويت الناعم وSVM حققا أداءً قابلاً للمقارنة وتم تصنيفهما في المرتبة الأولى، بينما تم تصنيف MLP في المرتبة الثانية، وXGBoost هو الأقل كفاءة عبر جميع الميزات. ومع ذلك، تبقى درجة الاسترجاع كما هي عبر جميع المصنفات، أي 96.83%.
في الجدول 5، يقارن المؤلفون ويقيمون أداء المصنفات بناءً على نهجي اختيار الميزات بوروتا وCBFS. عند فحص طريقة بوروتا، حققت مصنفات مثل SVM وMLP وXGBoost ونماذج التصويت الناعم درجات جيدة، مع مستويات دقة تتراوح من إلى . ومع ذلك، عند استخدام CBFS، تحقق المصنفات دقة أكبر من بوروتا. أدت مصنفات SVM وMLP أداءً استثنائيًا عند اقترانها بطريقة CBFS وحققت درجة دقة قدرها . من المثير للاهتمام أن مصنف التصويت الناعم يتفوق على المصنفات الأخرى عند استخدام CBFS، مع درجة دقة ملحوظة قدرها ودرجة دقة مثالية قدرها . XGBoost هو المصنف الوحيد الذي يظهر أداءً متسقًا عبر كلا طريقتي الاختيار. مقارنةً ببوروتا، يبدو أن طريقة CBFS
الجدول 6 مقارنة أداء الطريقة المقترحة والطرق القديمة على مجموعة بيانات WDBC
مرجع.
طرق
ميزات
دقة (%)
دقة (%)
استرجاع (%)
درجة F1 (%)
التحقق المتقاطع
[11]
اختيار الميزات القائم على RFE وVIF والنموذج الأحادي مع RF
الارتباط بيرسون والمعلومات المتبادلة (PC-MI)، مصنف التصويت الناعم الذي يجمع بين LR وSVM وDT
18
99.3
100
98.46
99.2
10-FCV
دقة-97.24%
[17]
اختيار الميزات الجماعية (SelectKBest وRFE وأهمية الميزات) وDT وLR
10
93.85
[20]
أشجار إضافية جماعية لاختيار الميزات
ونموذج قائم على التجميع للتصنيف
14
98.2
98.5
96.8
97.6
[21]
مقياس أهمية المتغيرات (VIM) والتجميع الهرمي للغابات العشوائية (HCRF)
24
97.05
97.32
94.77
[22]
GSOA وEPO وhGSEPO
97.66
100
96.87
95.16
النهج المقترح
مصنف التصويت الناعم مع CBFS
10
99.42
100
98.41
99.20
دقة 10-FCV-99.34%
تسلط النتائج في هذا القسم الضوء على أهمية اختيار واستخدام الميزات والمصنفات المناسبة لتحسين أداء التصنيف في أنظمة الكشف عن سرطان الثدي
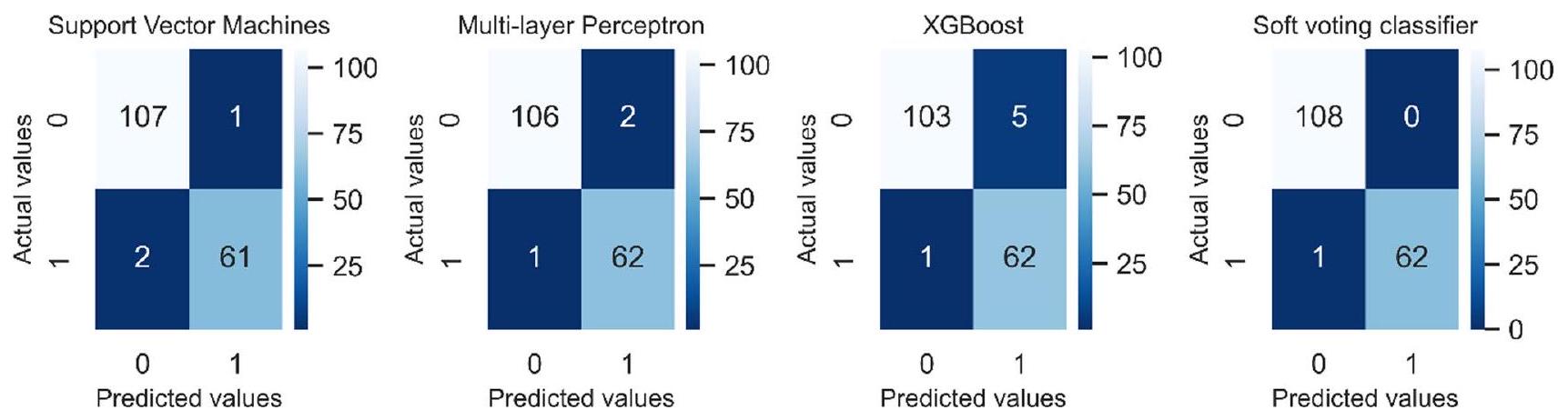
الشكل 5 مصفوفات الارتباك للمصنفات مع ميزات CBFS
يظهر الشكل 6 منحنى ROC لمصنف التصويت الناعم ومصنفاته الأساسية
لتحقيق أداء أفضل قليلاً من حيث التعرف بدقة على الحالات الإيجابية مع الحفاظ على مستوى عالٍ من الدقة.
يقارن الشكل 5 مصفوفات الارتباك لمصنفات مختلفة عند اقترانها بطريقة CBFS. وفقًا لنتائج مصفوفات الارتباك، يتفوق مصنف التصويت الناعم على المصنفات الأخرى. إنه يحدد جميع الحالات الحميدة بشكل صحيح بينما يخطئ في تحديد عينة واحدة خبيثة فقط في بيانات الاختبار. XGBoost هو الأقل فعالية في تصنيف الحالات الحميدة، بينما SVM غير فعالة في اكتشاف الحالات الخبيثة مقارنةً بالآخرين. كما أن MLP عمل بشكل جيد؛ فقد أخطأ في تشخيص حالة واحدة طبيعية وحالتين خبيثتين.
تعتبر خاصية استقبال التشغيل (ROC) مقياسًا شائعًا لعرض أداء المصنف الثنائي، خاصة عندما تكون الفئات غير متوازنة. يتم استخدامها عادةً لتقييم ومقارنة فعالية النماذج المختلفة. إنها رسم بياني ثنائي الأبعاد لتوضيح العلاقة بين معدل الإيجابيات الحقيقية (الحساسية) ومعدل الإيجابيات الكاذبة (1 – الخصوصية) عند عتبات مختلفة [58]. يمكن أن تقدم تقييمًا أكثر شمولاً لأداء التصنيف مقارنةً بالقياسات ذات القيمة الواحدة مثل الدقة والدقة ومعدل الخطأ أو تكلفة الخطأ [56]. AUC، الذي يعني المساحة تحت منحنى ROC، هو إحصائية مستخدمة على نطاق واسع لتقييم النماذج. يمكن حسابه باستخدام قاعدة شبه المنحرف. قيمة AUC دائمًا ما تقع بين 0 و1. عادةً، تشير الخط المائل على منحنى ROC إلى التخمين العشوائي مع AUC قدره 0.5.
في الآونة الأخيرة، استخدمت أبحاث ML والتنقيب عن البيانات بشكل متزايد رسومات ROC في اتخاذ القرارات الطبية. من السهل حسابها وتفسيرها [59]. توضح منحنيات ROC قدرة نموذج توقع المخاطر على التمييز بين المرضى الذين يعانون من مرض معين والذين لا يعانون منه. يوضح الشكل 6 منحنيات ROC للمصنف المقترح ومصنفاته الأساسية. وفقًا للنتائج، أظهرت جميع المصنفات قيم AUC عالية جدًا، قريبة من 1، مما يشير إلى أداء ممتاز في التمييز بين حالات سرطان الثدي الحميدة والخبيثة. أظهر مصنف التصويت الناعم أعلى AUC (0.9985)، أفضل قليلاً من مصنفاته الأساسية. تعادل MLP وXGBoost في المرتبة الثانية مع AUC قدره 0.9982، بينما احتل SVM المرتبة الثالثة مع AUC قدره 0.9978.
باستخدام مجموعة بيانات WDBC، يقارن الجدول 6 التقنية المقترحة مع الدراسات السابقة في تصنيف سرطان الثدي. يظهر أن الطريقة المقترحة، وهي مصنف التصويت الناعم مع طريقة CBFS، تتفوق على الأساليب الحالية من حيث الدقة وغيرها من القياسات الهامة. لديها القدرة على تقليل أخطاء التحليل اليدوي مع تسهيل تصنيف سرطان الثدي بدقة أكبر، مما يؤدي إلى تحسين معدل البقاء.
4 المناقشة
تستخدم هذه الدراسة تقنية التجميع القائمة على التصويت الناعم ومقياس Robust الفعال للتقليل، وSMOTE-ENN لموازنة الفئات، وCBFS لاختيار الميزات، والتي أدت بشكل جيد في جميع المقاييس. لذلك، يُوصى بشدة بهذا النهج للكشف عن سرطان الثدي. تظهر النتائج في الجدولين 4 و5 أن مصنف التصويت الناعم يحسن تشخيص سرطان الثدي عند اقترانه بطريقة CBFS. وفقًا للقيم في هذه الجداول، تفوقت أفضل عشر ميزات CBFS على مجموعة الميزات الكاملة، بما في ذلك الميزات العشر لبوروتا.
تقدم مجموعة الميزات المثلى فوائد تصنيف متنوعة، بما في ذلك تقليل وقت المعالجة، وتحسين أداء التصنيف، وزيادة القابلية للتعميم [19]. تكشف نتائج الجدول أن أهمية الميزات المعتمدة على المعامل وحدها أكثر تمييزًا وإعلامًا في التمييز بين الأورام الحميدة والخبيثة.
كما يدعو المؤلفون إلى استخدام نموذج التجميع القائم على التصويت الناعم المقترح للتصنيف القوي والدقيق لسرطان الثدي. كما يمكن ملاحظته من الشكل 5، تم تصنيف فئة واحدة فقط بشكل خاطئ، مما يدل على قوته وفائدته في تجميع التوقعات من مجموعة متنوعة من النماذج. يمكن أن يتخذ نهج التصويت الناعم قرارات أكثر كفاءة من مصنف واحد من خلال مراعاة عدم اليقين المرتبط بكل مصنف [43،44]. يمكنه معالجة مخاوف الإفراط في التخصيص والتحيز مع تقليل خطأ التوقع وزيادة التعميم [45]. كما يحسن مصنف التصويت الناعم من قابلية تفسير النموذج وشفافيته من خلال استخدام تقديرات الاحتمالية من المصنفات المدمجة.
يوضح الجدول 6 أن الطريقة المقترحة قدمت جودة تصنيف أعلى من الأعمال السابقة الرائدة.
تبلغ درجة دقتها المتوسطة للتحقق المتقاطع بعشر مرات . تؤكد نتائج التحقق المتبادل أن الطريقة المقترحة متسقة وموثوقة للكشف التلقائي عن سرطان الثدي. علاوة على ذلك، تعتمد العديد من الدراسات في هذه الجدول فقط على الدقة كمقياس للتقييم، متجاهلة مقاييس أخرى مثل الدقة، والاسترجاع، ودرجة F1. كل هذه المقاييس حاسمة لتقييم الأداء التشخيصي للمصنفات بدقة، خاصة عندما يكون هناك عدم توازن في الفئات، كما هو الحال في مجموعة بيانات WDBC. لذلك، بالإضافة إلى الدقة، يتم استخدام مقاييس حاسمة أخرى مثل الاسترجاع، ودرجة FI، والدقة لإظهار موثوقية النموذج المقترح في الكشف عن سرطان الثدي. تهدف هذه الدراسة إلى تحسين نماذج التعلم الآلي لتصنيف أورام سرطان الثدي بشكل موثوق، مما يؤدي إلى انخفاض معدلات الوفيات وتحسين نتائج المرضى.
بشكل عام، تقوم الطريقة المقترحة بأتمتة تحليل ميزات FNA، مما يسمح لأطباء الأمراض بالكشف عن سرطان الثدي بشكل أكثر كفاءة وسرعة ودقة وبتكلفة أقل. يمكن أن تحسن معدلات البقاء على قيد الحياة من خلال تقليل الأخطاء المرتبطة بتقييم خصائص FNA يدويًا.
بجانب هذه الفوائد، هناك بعض القيود على هذه الدراسة. أولاً، حيث استخدمت هذه التجربة مجموعة بيانات واحدة فقط، لضمان تعميم النتائج، يجب تطبيق الطريقة المقترحة على مجموعة متنوعة من مجموعات بيانات سرطان الثدي في المستقبل. نقطة ضعف أخرى في هذا البحث هي أنه يعتمد على مجموعة بيانات WDBC الصغيرة، لذا قد يتم استخدام مجموعة بيانات أكبر للتحقق من النتائج بشكل أكبر.
حد آخر من هذه الدراسة هو أن جميع المصنفات المستخدمة تم تنفيذها على الإعدادات الافتراضية دون تحسين المعلمات الفائقة. لذلك، في المستقبل، هناك حاجة إلى المزيد من التجارب للتحقيق في تأثير تحسين المعلمات الفائقة على أداء المصنفات. كما تفتقر هذه الدراسة إلى المعلومات السريرية مثل العمر، والجنس، وحجم الكتلة، وتغير حجم الثدي، وما إلى ذلك. في المستقبل، يمكن إنشاء إطار عمل أكثر فعالية من خلال دمج الميزات السريرية.
5 الاستنتاج
سرطان الثدي هو مرض شائع بمعدل وفيات مرتفع على مستوى العالم، بما في ذلك في الهند. لذلك، تسعى هذه العمل إلى تحسين طرق تصنيف سرطان الثدي الحالية من خلال استخدام خوارزميات التعلم الآلي لتحليل ميزات FNA في مجموعة بيانات WDBC. هناك ثلاثة مكونات رئيسية للنظام المقترح: المعالجة المسبقة، واختيار الميزات، والتصنيف. خلال المعالجة المسبقة، يتم استخدام مقياس قوي لتوسيع البيانات، ثم يتم استخدام SMOTE-ENN (تقنية هجينة متقدمة) للتعامل مع مجموعة بيانات WDBC المنحرفة. يتم استخدام Boruta وCBFS وتحليلها لتحديد الميزات ذات الخصائص المميزة العالية مع إزالة الميزات غير الضرورية أو المكررة. كل نهج يختار عشرة ميزات؛ ومع ذلك، فإن المجموعات الفرعية
من الميزات التي تم إنشاؤها بواسطة CBFS أكثر تمييزًا وتظهر نتائج أفضل. من أجل التصنيف الدقيق، قدم المؤلفون نموذج مصنف تصويت ناعم لتجميع قوة وفائدة ثلاثة مصنفات تعلم آلي (SVM، MLP، وXGBoost). تظهر التجربة أن مصنف التصويت الناعم لديه أعلى دقة اختبار تبلغ عند تطبيق عشرة ميزات قائمة على المعامل. يظهر متوسط درجة دقة قدرها لعملية التحقق المتبادل بعشرة أضعاف. بناءً على النتائج، يمكن للمؤلفين أن يستنتجوا أن النهج المقترح للكشف عن سرطان الثدي فعال ويتفوق على الطرق الحديثة، مما يعزز معدلات البقاء.
مساهمات المؤلفين إندو تشيلار: الكتابة – المسودة الأصلية والبرمجيات. أجمر سينغ: المنهجية، التصور. قام كلا المستخدمين بمراجعة وتحرير المخطوطة.
التمويل يعلن المؤلفون أنه لم يتم تلقي أي أموال أو منح أو دعم آخر خلال إعداد هذه المخطوطة.
توفر البيانات مجموعات البيانات المستخدمة خلال الدراسة الحالية متاحة للجمهور، [متاحة من: https://archive.ics.uci.edu/dataset/17/ سرطان+الثدي+ويسكونسن+التشخيص].
الإعلانات
موافقة الأخلاقيات والموافقة على المشاركة تستخدم هذه الدراسة قواعد بيانات عامة تم الاستشهاد بها في المرجع. لذلك، فإن هذا القسم غير قابل للتطبيق.
المصالح المتنافسة ليس لدى المؤلفين أي مصالح مالية أو غير مالية ذات صلة للإفصاح عنها.
الوصول المفتوح هذه المقالة مرخصة بموجب رخصة المشاع الإبداعي للاستخدام غير التجاري – بدون اشتقاقات 4.0 الدولية، والتي تسمح بأي استخدام غير تجاري، ومشاركة، وتوزيع، وإعادة إنتاج في أي وسيلة أو تنسيق، طالما أنك تعطي الائتمان المناسب للمؤلفين الأصليين والمصدر، وتوفر رابطًا لرخصة المشاع الإبداعي، وتوضح إذا كنت قد قمت بتعديل المادة المرخصة. ليس لديك إذن بموجب هذه الرخصة لمشاركة المواد المعدلة المشتقة من هذه المقالة أو أجزاء منها. الصور أو المواد الأخرى من طرف ثالث في هذه المقالة مشمولة في رخصة المشاع الإبداعي للمقالة، ما لم يُشار إلى خلاف ذلك في سطر ائتمان للمادة. إذا لم تكن المادة مشمولة في رخصة المشاع الإبداعي للمقالة واستخدامك المقصود غير مسموح به بموجب اللوائح القانونية أو يتجاوز الاستخدام المسموح به، ستحتاج إلى الحصول على إذن مباشرة من صاحب حقوق الطبع والنشر. لعرض نسخة من هذه الرخصة، قم بزيارة http://creativecommons.org/licenses/by-nc-nd/4.0/.
References
Yusuf AB, Dima RM, Aina SK. Optimized breast cancer classification using feature selection and outliers detection. J Niger Soc Phys Sci. 2021;3:298-307.
Sun YS, Zhao Z, Yang ZN, Xu F, Lu HJ, Zhu ZY, Shi W, Jiang J, Yao PP, Zhu HP. Risk factors and preventions of breast cancer. Int J Biol Sci. 2017;13:1387.
Shafique R, Rustam F, Choi GS, de la Díez IT, Mahmood A, Lipari V, Velasco CLR, Ashraf I. Breast cancer prediction using fine needle aspiration features and upsampling with supervised machine learning. Cancers (Basel). 2023;15:681.
Khandezamin Z, Naderan M, Rashti MJ. Detection and classification of breast cancer using logistic regression feature selection and GMDH classifier. J Biomed Inform. 2020;111: 103591.
Yu YH, Wei W, Liu JL. Diagnostic value of fine-needle aspiration biopsy for breast mass: a systematic review and meta-analysis. BMC Cancer. 2012;12:1-14.
Fritz P, Raoufi R, Dalquen P, et al. Artificial intelligence assisted diagnoses of fine-needle aspiration of breast diseases: a single-center experience. J Dig Health. 2023;2023:1-11.
He W, Liu T, Han Y, et al. A review: the detection of cancer cells in histopathology based on machine vision. Comput Biol Med. 2022;146: 105636.
Brause RW. Medical analysis and diagnosis by neural networks. In: Medical Data Analysis: Second International Symposium, ISMDA 2001 Madrid, Spain, October 8-9, 2001 Proceedings 2. Springer, 2001. p. 1-13.
Ali M, Dalfi H, Chaabouni S, Fakhfakh A. Breast cancer detection using random forest supported by feature selection. Int J Intell Syst Appl Eng. 2024;12:223-38.
Akkur E, Turk F, Erogul O. Breast cancer diagnosis using feature selection approaches and bayesian optimization. Comput Syst Sci Eng. 2023. https://doi.org/10.32604/csse.2023.033003.
Karimi K, Ghodratnama A, Tavakkoli-Moghaddam R. Two new feature selection methods based on learn-heuristic techniques for breast cancer prediction: a comprehensive analysis. Ann Oper Res. 2023;328:665-700.
Rajaguru H, Sannasi Chakravarthy SR. Analysis of decision tree and k -nearest neighbor algorithm in the classification of breast cancer. Asian Pac J Cancer Prev APJCP. 2019;20:3777.
Aamir S, Rahim A, Aamir Z, Abbasi SF, Khan MS, Alhaisoni M, Khan MA, Khan K, Ahmad J. Predicting breast cancer leveraging supervised machine learning techniques. Comput Math Methods Med. 2022;2022:5869529.
Hashim MS, Yassin AA. Breast cancer prediction using soft voting classifier based on machine learning models. IAENG Int J Comput Sci. 2023. https://doi.org/10.37917/ijeee.19.2.6.
Mera-Gaona M, López DM, Vargas-Canas R, Neumann U. Framework for the ensemble of feature selection methods. Appl Sci (Switzerland). 2021;11:8122.
Peng H, Long F, Ding C. Feature selection based on mutual information: Criteria of Max-Dependency, Max-Relevance, and Min-Redundancy. IEEE Trans Pattern Anal Mach Intell. 2005;27:1226-38.
Cai J, Luo J, Wang S, Yang S. Feature selection in machine learning: a new perspective. Neurocomputing. 2018;300:70-9.
Samieinasab M, Torabzadeh SA, Behnam A, Aghsami A, Jolai F. Meta-health stack: a new approach for breast cancer prediction. Healthcare Anal. 2022;2: 100010.
Huang Z, Chen D. A breast cancer diagnosis method based on VIM feature selection and hierarchical clustering random forest algorithm. IEEE Access. 2022;10:3284-93.
Singh LK, Khanna M, Singh R. Efficient feature selection for breast cancer classification using soft computing approach: a novel clinical decision support system. Multimed Tools Appl. 2024;83:43223-76.
Singh AK. Breast Cancer Classification Using ML on WDBC. In: Machine Vision and Augmented Intelligence: Select Proceedings of MAI 2022. Springer, 2023. p. 609-619.
Ahmed Khan A, Abu Bakr M. Enhancing breast cancer diagnosis with integrated dimensionality reduction and machine learning techniques. J Comput Biomed Inf. 2024. https://doi.org/10.56979/702/2024.
Kadhim Ajlan I, Murad H, Salim AA, fadhil bin yousif A. Extreme Learning machine algorithm for breast Cancer diagnosis. Multimed Tools Appl 2024; 1-24.
Ahsan MM, Mahmud MAP, Saha PK, Gupta KD, Siddique Z. Effect of data scaling methods on machine learning algorithms and model performance. Technologies (Basel). 2021. https://doi.org/10.3390/technologies9030052.
de Amorim LBV, Cavalcanti GDC, Cruz RMO. The choice of scaling technique matters for classification performance. Appl Soft Comput. 2023;133: 109924.
Xu Z, Shen D, Nie T, Kou Y. A hybrid sampling algorithm combining M-SMOTE and ENN based on Random forest for medical imbalanced data. J Biomed Inform. 2020. https://doi.org/10.1016/j.jbi.2020.103465.
Wang J. Prediction of postoperative recovery in patients with acoustic neuroma using machine learning and SMOTE-ENN techniques. Math Biosci Eng. 2022. https://doi.org/10.3934/mbe.2022487.
Sun J, Lang J, Fujita H, Li H. Imbalanced enterprise credit evaluation with DTE-SBD: Decision tree ensemble based on SMOTE and bagging with differentiated sampling rates. Inf Sci (NY). 2018. https://doi.org/10.1016/j.ins.2017.10.017.
Arafa A, El-Fishawy N, Badawy M, Radad M. RN-SMOTE: reduced noise SMOTE based on DBSCAN for enhancing imbalanced data classification. J King Saud Univ Comput Inf Sci. 2022. https://doi.org/10.1016/j.jksuci.2022.06.005.
Remeseiro B, Bolon-Canedo V. A review of feature selection methods in medical applications. Comput Biol Med. 2019;112: 103375.
Masrur Ahmed AA, Deo RC, Feng Q, Ghahramani A, Raj N, Yin Z, Yang L. Deep learning hybrid model with Boruta-Random forest optimiser algorithm for streamflow forecasting with climate mode indices, rainfall, and periodicity. J Hydrol (Amst). 2021. https://doi.org/10.1016/j. jhydrol.2021.126350.
Zhou H, Xin Y, Li S. A diabetes prediction model based on Boruta feature selection and ensemble learning. BMC Bioinformatics. 2023. https://doi.org/10.1186/s12859-023-05300-5.
Kursa MB, Rudnicki WR. Feature selection with the boruta package. J Stat Softw. 2010;36:1-13.
Sindhwani V, Bhattacharya P, Rakshit S. Information theoretic feature crediting in multiclass support vector machines. 2001. https://doi. org/10.1137/1.9781611972719.16.
Mladenić D, Brank J, Grobelnik M, Milic-Frayling N. Feature selection using linear classifier weights: Interaction with classification models. In: Proceedings of the 27th annual international ACM SIGIR conference on Research and development in information retrieval. 2004. p. 234-241.
Khaire UM, Dhanalakshmi R. Stability of feature selection algorithm: a review. J King Saud Univ Comput Inform Sci. 2022. https://doi.org/ 10.1016/j.jksuci.2019.06.012.
Rai N, Kaushik N, Kumar D, Raj C, Ali A. Mortality prediction of COVID-19 patients using soft voting classifier. Int J Cognit Comput Eng. 2022. https://doi.org/10.1016/j.ijcce.2022.09.001.
Jani R, Shariful Islam Shanto M, Mohsin Kabir M, Saifur Rahman M, Mridha MF. Heart Disease Prediction and Analysis Using Ensemble Architecture. 2022 International Conference on Decision Aid Sciences and Applications, DASA 2022. 2022. https://doi.org/10.1109/DASA5 4658.2022.9765237.
Nahar N, Ara F, Neloy MAI, Barua V, Hossain MS, Andersson K. A comparative analysis of the ensemble method for liver disease prediction. In: ICIET 2019-2nd International Conference on Innovation in Engineering and Technology. IEEE, 2019. p. 1-6.
Saqlain M, Jargalsaikhan B, Lee JY. A voting ensemble classifier for wafer map defect patterns identification in semiconductor manufacturing. IEEE Trans Semicond Manuf. 2019;32:171-82.
Mahajan P, Uddin S, Hajati F, Moni MA. Ensemble learning for disease prediction: a review. Healthcare (Switzerland). 2023. https://doi. org/10.3390/healthcare11121808.
Latha CBC, Jeeva SC. Improving the accuracy of prediction of heart disease risk based on ensemble classification techniques. Inform Med Unlocked. 2019. https://doi.org/10.1016/j.imu.2019.100203.
Janardhanan P, Heena L, Sabika F. Effectiveness of support vector machines in medical data mining. J Commun Software Syst. 2015. https://doi.org/10.24138/jcomss.v11i1.114.
Brereton RG, Lloyd GR. Support Vector Machines for classification and regression. Analyst. 2010. https://doi.org/10.1039/b918972f.
Mohd Amiruddin AAA, Zabiri H, Taqvi SAA, Tufa LD. Neural network applications in fault diagnosis and detection: an overview of implementations in engineering-related systems. Neural Comput Appl. 2020. https://doi.org/10.1007/s00521-018-3911-5.
Lange N, Bishop CM, Ripley BD. Neural networks for pattern recognition. J Am Stat Assoc. 1997. https://doi.org/10.2307/2965437.
Chen T, Guestrin C. XGBoost: A scalable tree boosting system. In: Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2016. p. 785-794.
Gündoğdu S. Efficient prediction of early-stage diabetes using XGBoost classifier with random forest feature selection technique. Multimed Tools Appl. 2023. https://doi.org/10.1007/s11042-023-15165-8.
Das C, Sahoo AK, Pradhan C. Multicriteria recommender system using different approaches. In: Cognitive Big Data Intelligence with a Metaheuristic Approach. Academic Press, 2021. p. 259-277.
Tiwari A. Supervised learning: From theory to applications. In: Artificial Intelligence and Machine Learning for EDGE Computing. Academic Press, 2022. p. 23-32.
Fawcett T. An introduction to ROC analysis. Pattern Recognit Lett. 2006;27:861-74.
Mandrekar JN. Receiver operating characteristic curve in diagnostic test assessment. J Thorac Oncol. 2010;5:1315-6.
Bradley AP. The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognit. 1997. https:// doi.org/10.1016/S0031-3203(96)00142-2.
Kaymak U, Ben-David A, Potharst R. The AUK: a simple alternative to the AUC. Eng Appl Artif Intell. 2012. https://doi.org/10.1016/j.engap pai.2012.02.012.
Publisher’s Note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Indu Chhillar, indu.chhillar@dseu.ac.in; Ajmer Singh, ajmer.saini@gmail.com | ¹Computer Science & Engineering, Deenbandhu Chhotu Ram University of Science and Technology, Murthal, Haryana, India.
Breast cancer is the primary cause of death among women globally, and it is becoming more prevalent. Early detection and precise diagnosis of breast cancer can reduce the disease’s mortality rate. Recent advances in machine learning have benefited in this regard. However, if the dataset contains duplicate or irrelevant features, machine learning-based algorithms are unable to give the intended results. To address this issue, a series of effective strategies such as the Robust Scaler is used for data scaling, Synthetic Minority Over-sampling Technique-Edited Nearest Neighbor (SMOTEENN) is utilized for class balancing, and Boruta and Coefficient-Based Feature Selection (CBFS) methods are employed for feature selection. For more accurate and reliable breast cancer classification, this study proposes a soft voting-based ensemble model that harnesses the capabilities of three diverse classifiers: Multilayer Perceptron (MLP), Support Vector Machine (SVM), and Extreme Gradient Boosting (XGBoost). To show the efficiency of the proposed ensemble model, it is compared with its base classifiers using the Wisconsin Diagnosis Breast Cancer Dataset (WDBC). The results of the experiment revealed that the soft voting classifier achieved high scores with an accuracy of , precision of , recall of , F1 score of , and AUC of 1.0 when it is trained on optimal features obtained from the CBFS method. However, with tenfold cross-validation (10-FCV), it shows a mean accuracy score of 99.34%. A comprehensive analysis of the results revealed that the suggested technique outperformed the existing state-of-the-art methods due to the efficient data preprocessing, feature selection, and ensemble methods.
Keywords Breast cancer ⋅ Machine learning ⋅ WDBC ⋅ SMOTE-ENN ⋅ Soft voting classifier ⋅ Boruta
1 Introduction
Cancer is a disease that arises when the body’s cells develop abnormally, infiltrate surrounding tissues, and spread to other body regions if left untreated. Breast cancer is a type of tumor that begins in the milk-producing tubes (ducts) or lobules of the breast. It can be a malignant or benign tumor. In the case of a benign tumor, cells remain in the ducts and do not spread to the fatty and connective tissues of the breast. In contrast, malignant tumor cells invade the breast’s fatty and connective tissues by piercing the duct and lobular walls. Breast cancer ranks second in the world in terms of incidence and severity, as it is particularly deadly and morbid for women [1]. It affects around one in every eight women globally [2]. Men, on the other hand, account for 0.5-1% of all breast cancer cases. In 2020, the WHO recorded 2.3 million
novel breast cancer incidences in women, with 685,000 deaths globally [3]. In 2023, as per the American Cancer Society (ACS), there were approximately 297,790 new instances of invasive breast cancer and 55,720 novel incidences of ductal carcinoma in situ (DCIS) in the US. In addition, 91,708 women died from breast cancer [4].
The WHO Global Breast Cancer Initiative (GBCI) aims to save 2.5 million lives worldwide from breast cancer between 2020 and 2040 by lowering the death rate by 2.5 percent each year. To attain this goal, early detection of breast cancer is critical since it allows for prompt intervention and enhances the chance of successful treatment outcomes [1]. However, many nations are unable to detect breast cancer early because of a lack of effective diagnostic and treatment facilities, as well as a scarcity of well-trained doctors. Cancer treatment delay increases mortality, as do the associated health implications and costs. To meet this challenge, these nations need to spend extensively on public health, develop extra labs and pathology departments equipped with the appropriate technology, and educate more people to perform diagnostic operations [5].
Breast cancer is diagnosed using biomedical imaging and pathology tools. Mammography is one of the most prominent imaging techniques to test for breast cancer; however, its accuracy varies from 68 to [6]. Biopsy is a pathologybased process that is quite robust and accurate but on the other hand, it is risky, expensive, time-consuming, and invasive [7]. Another pathology-based procedure that is widely used is the fine needle aspiration (FNA) test, which is reliable, straightforward, safe, minimally invasive, and has a low false positive rate. It also saves time and money [8].
Recent breakthroughs in machine learning (ML) techniques in the healthcare sector are opening up new avenues for FNA [8]. To boost the efficacy of FNA as a diagnostic tool, several studies have been using ML worldwide. ML techniques can make breast cancer detection more efficient by automating it and overcoming the difficulties associated with traditional cancer detection systems, which are prone to errors, lengthy, costly, and primarily rely on pathologists’ knowledge [9]. They are also able to detect cancer at earlier stages, which can result in better treatment outcomes and improved survival rates. According to Brause’s study [10], professional diagnoses are 79.97% accurate, compared to 91.1% for ML diagnoses. Random Forest (RF) [1, 11-13], K-Nearest Neighbor (KNN) [2-4, 7], SVM [1, 12, 13, 15, 16], Decision Tree [1, 12-14, 16, 17], Logistic Regression (LR) [1, 13, 16], Naïve Bayes (NB) [12, 13], Gradient Boosting (GB) [1, 15], AdaBoost (AB) [1], MLP [15], and Artificial Neural Network (ANN) [13, 15] the most employed ML algorithms have been used to detect breast cancer using different modalities, including the FNA method.
However, many machine learning methods cannot perform well in classifying breast cancer due to the unimportant and undesired characteristics in the dataset. Therefore, feature selection is critical for choosing the relevant features and attaining maximum accuracy. Its purpose is to limit the classifier’s data quantity by removing irrelevant, redundant, and noisy data to boost breast cancer classification [18]. It enhances classifier performance in terms of detection accuracy and computing costs [19]. Various feature selection techniques such as Pearson Feature Selection (PFS) [1, 20], Recursive Feature Elimination (RFE) [11, 15, 17], Principal Component Analysis (PCA) [14], Least Absolute Shrinkage and Selection Operator (LASSO) [12], Variance Inflation Factor (VIF) [11, 20], Relief [12], Sequential Feature Selection (SFS) [12], Correlation Based Feature Selection (CBFS) [15], Feature Importance [17], and Information Gain [20] have been commonly analyzed by researchers for their effectiveness in selecting the best features.
Here, the authors present a comprehensive review of research using FNA features in the WDBC dataset to detect breast cancer, highlighting machine learning and feature selection techniques.
Mustafa Ali Hasan Dalfi et al. [11] investigated how different feature selection methods, including RFE, VIF, modelbased, and univariate feature selection, performed in breast cancer detection with a random forest classifier. The testing results revealed that VIF with 25 features outperformed the other applied feature techniques, achieving 98.8% accuracy and 98% F1 score.
To study the impact of outliers and PFS on the WDBC dataset, B. Yusufa et al. [1] used seven machine-learning algorithms. The findings revealed that LR, RF, and AB classifiers obtained 99.12% accuracy after eliminating outliers from the dataset. Furthermore, RF beat the others when the outlier-filtered dataset was subjected to Pearson correlation feature selection. To detect breast cancer, Harikumar Rajaguru et al. [14] used PCA as a feature selection technique and DT and KNN for the categorization. The experimental results using WDBC showed that KNN performed better than DT.
Erkan Akkur et al. [12] employed three feature selection approaches-Sequential Forward Selection (SFS), relief, and LASSO-to find relevant features in the WDBC and Mammographic Breast Cancer Dataset (MBCD) datasets and fed them into SVM, KNN, NB, ensemble learning, and DT for classification. All these classifiers were optimized using Bayesian optimization. Optimized SVM with LASSO showed the best results on both datasets, with accuracy on WDBC and 97.95% on MBCD.
To increase the diagnostic efficiency of breast cancer, Kamyab Karimi et al. [13] proposed two novel metaheuristicbased feature selection algorithms: an imperialist competitive algorithm (ICA) and a bat algorithm (BA). KNN, SVM, DT,
NB, AB, Linear Discriminant Analysis (LDA), RF, LR, and ANN were used for classification. The comparative analysis revealed that RF and BA beat the other methods with accuracy.
Sanam Aamir et al. [15] developed a novel ML method for breast cancer identification, consisting of correlation-based feature selection, followed by Recursive Feature Elimination (RFE), and yielded 11 optimum features. After that, the extracted features were applied to SVM, RF, GB, ANN, and MLP for comparative analysis. According to the results, the MLP model beat the others, with a maximum accuracy of .
Mohammed S. Hashim et al. [16] proposed a soft voting-based ensemble method combining LR, SVM, and DT to classify breast cancer. Before classification, the SMOTE technique was used to address the unbalanced dataset issue, and the Pearson correlation and mutual information methods were used for feature selection. With WDBC, the proposed ensemble method achieved 99.3% accuracy, while the tenfold cross-validation accuracy score was 98.2%.
The data may influence a single feature selection approach, affecting the classifier’s performance. To overcome this issue, Maritza Mera-Gaona et al. [17] introduced an ensemble feature selection technique that combines three feature selection algorithms (SelectKBest, RFE, and Feature Importance). The suggested method was evaluated on three datasets, including WDBC. LR and DT were used as classifiers and trained on features acquired from the ensemble feature selection approach. The comparative results revealed that LR outperformed with an accuracy of .
Mina Samieinasab et al. [20] proposed the Meta-Health Stack, a stacking-based ensemble technique for quickly detecting breast cancer. The proposed method consists of two major steps: feature selection and classification. The feature selection was performed using three separate methods: VIF, Pearson’s correlation, and Information Gain. After that, the selected features were combined using the Extra Trees approach. The second phase involved stacking, bagging, boosting, and voting to create an ensemble model for improved breast cancer classification. As per the results, the framework scored 97% F1 score and 98.2% accuracy when evaluated against the WDBC dataset.
Zexian Huang et al. [21] developed a Hierarchical Clustering Random Forest (HCRF) machine learning approach to improve classification accuracy. In addition to HCRF, the authors used the Variable Importance Measure (VIM) feature selection approach to remove unnecessary data from breast cancer data sets. The HCRF and the VIM approach obtained 97.05% and 97.76% accuracy on the WDBC and WBC datasets, respectively.
Law Kumar Singh et al. [22] suggested a novel hybrid metaheuristic optimization strategy for selecting influential features. The authors merged the Gravitational Search Optimization Algorithm (GSOA) and Emperor Penguin Optimization (EPO) to create the hybrid technique (hGSEPO), in which GSOA was responsible for global search and EPO was responsible for local search. On the WDBC dataset, the method achieved accuracy, recall, and precision.
Akhilesh Kumar Singh et al. [23] did a comparative analysis for breast cancer detection using six ML methods (LR, KNN, SVM, RF, Keras sequential model, and DT). The experimental results showed that all employed classifiers achieved more than accuracy on the WDBC dataset.
In 2024, Aqeel Ahmed Khan et al. [24] conducted a study examining the efficacy of SVM, MLP, RF, DT, NB, and KNN for breast cancer identification, both with and without employing dimensionality reduction techniques: PCA, LDA, and factor analysis. The experiment results were evaluated on three datasets, including WDBC. The results indicated that the MLP outperformed others without employing dimensionality reduction techniques, achieving an accuracy of on WDBC. However, SVM with factor analysis dimensional reduction method achieved the highest accuracy of on the other dataset i.e., WBC.
Iman Kadhim Ajlan et al. [25] employed the extreme learning machine (ELM) to classify breast tumors into benign and cancerous categories, achieving a accuracy score, precision score, recall score, and F1 score on the WDBC dataset. The related work is summarized in Table 1.
A comprehensive literature review of the above section demonstrates that significant efforts are being made to develop feature space and classification models contributing to breast cancer detection. The authors, however, identified significant research gaps that need to be addressed to improve breast cancer diagnosis, as detailed below.
First, earlier research paid less attention to appropriate data scaling strategies, which is a crucial preprocessing step that influences classification performance. Second, the prior approach failed to address the imbalanced class problem, resulting in ML classifiers biased towards the majority category. Thus, overcoming class imbalance concerns is critical to generalizing the model.
Another limitation was that most research classified breast cancer using individual classifiers rather than ensembles, which are more accurate and stable than single classifiers. To design a better breast cancer detection system, it is necessary to resolve these constraints.
To solve the first issue, this study uses the Robust Scaler, which is less susceptible to outliers than other commonly used scalers. In addition, it ensures that all attribute scales fall within a comparable range. The second issue of class
Table 1 Literature Review Summary
Ref.
Year
Methods
Accuracy
Limitations
[11]
2024
RFE, VIF, model-based, and univariate feature selection with RF
98.8%
– Only accuracy and F1 scores were used for model evaluation, ignoring other essential metrics
– Failed to address the imbalanced class problem, resulting in biased outcomes
– Absence of cross-validation evaluation method
[13]
2023
SVM, DT, NB, AB, LDA, RF, LR, ANN, ICA and BA
99.12%
– Failed to address the imbalanced class problem
– Employed meta-heuristic for feature selection, a more computationally intensive approach
– Absence of cross-validation evaluation method
[14]
2019
PCA with K-NN algorithm as a classifier
95.95%
– Only accuracy was used for model evaluation, ignoring other essential metrics
[15]
2022
SVM, RF, GB, ANN, MLP, CBFS, and RFE
99.12%
– Only accuracy was used for model evaluation, ignoring other essential metrics
[16]
2023
PC-MI, a soft voting classifier that combines LR, SVM, and DT
99.3% and 10-FCV Accuracy-97.24%
– Feature selection and feature scaling were not done, which is necessary for an efficient, accurate, and non-overfitting model
– The accuracy of the proposed studies requires further improvement
[17]
2021
Ensemble feature selection (SelectKBest, RFE, and Feature Importance), DT and LR
93.85%
– Only accuracy was used for model evaluation, ignoring other essential metrics
– Failed to address the imbalanced class problem
[1]
2021
Pearson correlation feature selection, LR, RF, AB, GB and others
99.12%
– Failed to address the imbalanced class problem
– Only accuracy was used for model evaluation, ignoring other essential metrics
[20]
2022
Extra trees ensemble for feature selection
And stacking-based approach for classification
98.2%
– Feature selection and feature scaling were not done, which is necessary for an efficient, accurate, and non-overfitting model
– Absence of cross-validation evaluation method
[21]
2022
HCRF and VIM
97.05%
– Feature selection and feature scaling were not done, which is necessary for an efficient, accurate, and non-overfitting model
– Absence of cross-validation evaluation method
[22]
2024
GSOA, EPO, and hGSEPO
97.66%
– Feature selection and feature scaling were not done, which is necessary for an efficient, accurate, and non-overfitting model
– Employed Meta-heuristic for feature selection, a more computationally intensive approach
– Absence of cross-validation evaluation method
[23]
2024
LR, KNN, SVM, RF, Keras sequential model, and DT
98%
-The proposed study did not implement any class-balancing and scaling techniques. This may result in biased outcomes
– Absence of cross-validation evaluation method
[24]
2024
SVM, MLP, RF, DT, NB, and KNN, PCA, LDA, FA
98.26%
– Feature selection and feature scaling were skipped, which are crucial for an effective, accurate, and non-overfitting model
Table 1 (continued)
Ref.
Year
Methods
Accuracy
Limitations
[25]
2024
ELM
94.52%
– Feature selection and feature scaling were not done, which is necessary for an efficient, accurate, and non-overfitting model
– Failed to address the imbalanced class problem, resulting in biased outcomes
-Absence of cross-validation evaluation method
imbalance is addressed by employing SMOTE-ENN. This innovative hybrid sampling approach creates more representative samples for the minority class while reducing noisy samples. This work uses Boruta and CBFS approaches to select the most suitable features, which are then categorized using an ensemble learning framework based on soft voting. The ensemble model combines three models (SVM, XGBoost, and MLP) and can provide better accuracy than a single classifier, as it is less vulnerable to overfitting.
Taken together, the proposed technique can help the medical industry diagnose breast cancer more accurately and effectively at an early stage, thereby improving survival rates. It can address the limitations of traditional breast cancer screening approaches by offering pathologists a second view and reducing the false positive rate.
Furthermore, this technology might be used with other medical datasets to detect illness quickly, efficiently, and economically.
The highlights of the manuscript include:
To improve the separability of the data, the authors normalized the WDBC dataset with the Robust Scaler, which is more competent and effective at handling outliers.
The authors employed SMOTE-ENN, an advanced hybrid class balancing method, to effectively classify the minority class and limit sensitivity to class imbalance.
To maximize classification and computation performance while avoiding overfitting issues, the optimal features are identified by analyzing two feature selection strategies: Boruta and Coefficient-Based Feature Selection (CBFS).
For improved breast cancer classification, use a soft voting-based ensemble model that integrates three models (SVM, XGBoost, and MLP).
The testing results showed that the suggested automated breast cancer detection system outperformed earlier techniques.
2 Methods and materials
This section describes the WDBC dataset and provides an overview of the suggested strategy, preprocessing steps, feature selection techniques, classification algorithms utilized, and performance metrics to assess the study’s effectiveness. The authors developed all experiments using Python and the Jupyter Notebook IDE on a PC powered by an Intel Core i5 CPU and 8 GB RAM.
2.1 Dataset
This work is based on the WBCD dataset from the UCI ML archive, which contains 569 samples and 30 numerical features with one ID feature. It is a benchmark dataset widely recognized and publicly available for binary classification of benign and malignant breast tumors. It has no missing values. In this dataset, the ten real-valued characteristics-radius, texture, concavity, perimeter, area, smoothness, concave points, compactness, symmetry, and fractal dimension-were estimated from breast tumor nuclei in FNA digitized images. After that, the mean, standard error, and “worst” (the mean of three extreme values) of these ten qualities were calculated, yielding 30 features that provide rich but correlated data for analysis. Table 2 shows the description of these features.
Although the dataset is valuable, there are a few limitations, including that it is skewed in nature, as illustrated in Fig. 1, which comprises 357 normal cases and 212 malignant instances. This may lead the model to favor the majority class (normal) and produce biased results. Another limitation is that it is relatively small in size, which may not adequately reflect the diversity of breast cancer cases in the real world.
In addition, this dataset also lacks clinical information such as age, gender, lump size, breast size change, etc., which could provide valuable insights and improve diagnostic accuracy. Moreover, it was developed at one medical center, raising concerns about its generalizability. However, with suitable preprocessing and validation methods, the WDBC datasets still offer a valuable source for developing and evaluating machine learning techniques for breast cancer detection in the medical sector.
Table 3 contains statistics on the WDBC dataset, including tumor type, category ID, number of features, and training and testing samples for each category.
Table 2 Characteristics of the WDBC dataset
Sr. no.
Features
Mean range
Standard error range
Worst range
1
Radius
6.98-28.11
0.112-2.873
7.93-36.04
2
Texture
9.71-39.28
0.36-4.89
12.02-49.54
3
Concavity
0.000-0.427
0.000-0.396
0.000-1.252
4
Perimeter
43.79-188.50
0.76-21.98
50.41-251.20
5
Symmetry
0.106-0.304
0.008-0.079
0.157-0.664
6
Area
143.50-2501.0
6.80-542.20
185.20-4254.0
7
Concave points
0.000-0.201
0.000-0.053
0.000-0.291
8
Smoothness
0.053-0.163
0.002-0.031
0.071-0.223
9
Fractal dimension
0.050-0.097
0.001-0.030
0.055-0.208
10
Compactness
0.019-0.345
0.002-0.135
0.027-1.058
Fig. 1 WDBC dataset
Table 3 WDBC dataset statistics
Type of breast tumor
Tumor category id
No. features
Training set (70%)
Testing set (30%)
No. of instances
Benign
0
31
249
108
357
Malignant
1
31
149
63
212
2.2 Overview of the suggested research
As part of the efforts to improve breast cancer diagnosis accuracy and efficiency, extensive research is being conducted. Once the dataset has been selected, multiple steps are used to preprocess the data. The main steps are the Robust Scaler for data scaling and SMOTE-ENN for class balancing. Following that, two feature selection techniques, Boruta and CBFS, are used to select the most informative and discriminative features. Ten features are retrieved from each technique. This work created a soft voting classifier for classification that incorporates SVM, XGBoost, and MLP. To demonstrate the usefulness of the suggested soft voting classifier, it is compared to its base classifiers using complete features, and subsets of features derived from Boruta and CBFS. Additionally, the proposed method is compared to previous breast cancer techniques. Figure 2 shows a flowgraph of the suggested technique.
2.3 Data preprocessing
Data preprocessing reduces noise and inconsistencies in the data while extracting critical insights to improve quality and reliability. It is a vital step in ML since it helps optimize classification performance by preparing the data for the next phases. Data cleansing, normalization, and class balancing are the most generally used data preparation
Fig. 2 Proposed Model
methods. In this study, to enhance the quality and comprehensibility of the WDBC dataset, the authors removed the last column “unnamed,” as it contained empty values, and renamed the target class variable, i.e., “diagnosis,” with “class.” Robust Scaler is used to ensure that all attribute scales fall within a similar range, and SMOTE-ENN is employed to tackle the skewed nature of the considered dataset. ML deals with numerical data. However, because the target class (diagnosis) is categorical, the label encoder procedure is used to turn the labels ( M ) into 1 and ( B ) into 0 . The descriptions of data scaling via Robust Scaler and class balancing via SOMTE-ENN are given in the next subsections.
2.3.1 Data scaling (Robust Scaler)
Scaling of data is an important preprocessing step in machine learning systems, intending to ensure that all attribute scales fall within a similar range [26]. A good scaling technique will boost the performance of the classification model. Furthermore, an ineffective or bad scaling strategy can be more harmful to the classification model than not scaling the data at all [27]. To achieve high classification performance, the authors normalized the WDBC dataset using the Robust Scaler, which is more capable and effective at dealing with outliers than other frequently used data normalization methods such as the min-max and standard scaler.
The robust scaling approach uses the interquartile range (IQR), which is the difference between the first and third quartiles, to scale data centered on the median. It is defined using Eq. (1) given below:
2.3.2 Dataset balancing (SOMTE-ENN)
In the medical industry, unbalanced data categorization is prevalent and can impair the efficacy of classification systems, causing bias in the results [28]. It is necessary to address this issue to reduce bias and achieve optimal classification
performance. In this work, the SOMTE-ENN resampling method balances the skewed training set with 249 benign and 149 malignant samples, yielding 225 benign and 230 malignant samples to make the set balanced and representative. It is an advanced hybrid resampling technique that combines SMOTE (over-sampling) and ENN (under-sampling) methodologies. In the SMOTE method, the number of minority class samples is increased by a linear interpolation of each minority class sample and its k nearest neighbors at random [29], as illustrated in the SMOTE Eq. (2). However, SMOTE-generated samples may introduce noise in the minority class [30]. ENN uses an under-sampling technique to remove noisy samples to make synthesis samples more representative [31].
In this equation, represents a minority class sample, is a randomly selected neighbor sample from ‘s k nearest neighbors, and is a random number between 0 and 1 .
2.4 Feature selection
A feature selection approach selects essential features while rejecting redundant and unnecessary features present in datasets. Effective feature selection can reduce dataset complexity while retaining accuracy. A variety of disciplines have successfully used feature selection, including medical diagnosis, where reduced features lead to lower costs for tests and diagnoses [32]. It can aid in malignancy classification by reducing noisy, duplicate, and inconsistent data from the breast cancer dataset, which can complicate the procedure. Therefore, to build an effective breast cancer detection system, this research employed two feature selection techniques: Boruta [33] and CBFS.
2.4.1 Boruta feature selection
Boruta is a sophisticated wrapper feature selection method intended to determine the most informative features relevant to classification problems [34]. It is a random forest-based method that uses the significance measure. The goal of this strategy is to pick the set of attributes that are most beneficial to the output class, as opposed to selecting the most condensed set of features that suits a given model [35].
The steps involved in the Boruta algorithm are as follows [36]:
Generate the shadow feature corresponding to each feature in the original dataset by a random shuffle of values.
Extend the dataset with shadow characteristics.
Train the Random Forest/XGBoost on the extended dataset and collect Z-scores for each feature in the original database along with the maximum Z-score among shadow features.
Assess the importance of each original feature by comparing its Z-score with the maximum Z-score among its shadow features. Features that score higher than the maximum Z-score among shadow features are deemed important, while the rest are regarded as unimportant.
Remove all randomized or shadow features.
Repeat the technique above until the stopping criteria are met or feature selection becomes stable.
In this study, when Boruta with XGBoost is employed for feature selection on WDBC, it assigns one rank (the highest rank) to ten features based on their significance for breast cancer categorization, as shown in Fig. 3. The z-scores of these features are -0.173822 for texture_mean, concavity_mean for for concave points_mean, -0.156225 for area_se, 0.296342 for radius_worst, 1.039188 for perimeter_worst, -0.156062 for area_worst, 0.191384 for compactness_worst, 0.223847 for concavity_worst and 0.091067 for concave points_worst.
2.4.2 Coefficient-based feature selection (CBFS)
Coefficient-Based Feature Selection (CBFS) is a machine-learning approach that identifies and prioritizes the most essential features based on their contribution to classification tasks [37]. This strategy, first reported in [38], seeks to identify the optimal hyperplane for separating data components into distinct groups. It uses linear models like Perceptron, Linear Regression, Logistic Regression, SVM, and others to evaluate features based on their coefficients. The magnitude of the coefficient for each feature may be interpreted as its relevance; a larger coefficient suggests that the item was more
Fig. 3 Feature Ranking using Boruta
significant in the classification. Furthermore, it provides information on the direction and strength of their effect on the target variable. A feature with a positive coefficient has a positive association with the target variable, whereas one with a negative coefficient represents a negative relationship with the target variable.
This work employs linear SVM to assign coefficients or weights to FNA features in the WDBC dataset depending on their significance or relevance to breast cancer classification. Further, the top ten qualities with the highest absolute coefficient values are chosen for categorizing breast cancer. Figure 4 shows the features’ importance based on their absolute coefficient score. The mathematical representation of a linear SVM’s decision boundary function is as follows, using Eq. (3) [39].
Here, is the decision or prediction function that predicts the target class of an input feature vector, denotes the weight vector normal to the hyperplane.
Using this method for feature selection enhances classifier performance and makes it more simple and interpretable. Furthermore, it can alleviate overfitting difficulties, making the classifier more generalizable [40].
2.5 Classification
Intending to create a better and more accurate breast cancer detection system, this research developed a soft voting classifier that integrates SVM, XGBoost, and MLP. In addition, two effective feature selection techniques are used in this study to boost classification performance by removing irrelevant features. To assess the effectiveness of the suggested classifier, it is compared to its base classifiers. For this, a comparison study is conducted using all features, ten Boruta features, and ten CBFS features. The following tests are performed to execute the comparison study:
Classification using soft voting and its base classifier with all features.
Classification using soft voting and its base classifier with ten selected features from Boruta.
Classification using soft voting and its base classifier with ten selected features from CBFS.
Fig. 4 Feature Importance based on SVM coefficient value
The description of the proposed classifier and its base classifiers is given below:
2.5.1 Soft voting classifier
The ensemble classifier is an intricate ML technique that combines multiple classifiers and uses their capabilities to achieve excellent classification performance [41]. There are various ways to integrate individual classifiers into an ensemble; voting is one of the fundamental mechanisms where predictions from integrated models are aggregated to determine the final result. A voting classifier can be of three types: soft, hard, and weighted [42]. In soft-voting, the predicted probabilities of each class are averaged to generate the final output class. In a hard-voting ensemble classifier, the number of votes determines the target class, and in the weighted voting approach, each classifier varies in weight based on its performance.
In healthcare, the ML classifier must be accurate, reliable, and trustworthy due to the critical nature of decision-making that directly impacts the patient’s health. This work aims to create a more accurate, reliable, and stable ML classifier for breast cancer classification. For this purpose, SVM, MLP, and XGBoost are combined into a soft-voting ensemble to harness the collective intelligence of these diverse models. This soft voting approach can make more efficient decisions than a single classifier by taking into account the uncertainty associated with individual classifiers [43,44]. It can tackle overfitting and bias concerns while lowering prediction error and enhancing generalization [45]. Furthermore, the soft voting classifier improves model interpretability and transparency by using probability estimates from integrated classifiers. In reality, the proposed soft voting classifier is adaptable and has shown exceptional performance in various machine-learning applications [46].
2.5.2 Support vector machine (SVM)
SVM is a sophisticated ML classifier used to handle classification and regression challenges [47]. It seeks to determine the hyperplane that provides the optimum performance and margin for separating the input vector data points into discrete classes [48]. Support vectors, as the data components closest to the decision boundary, are critical in identifying the hyperplane with the largest margin [49]. SVM performs well on small and high-dimensional data sets, including those with more features than samples, where conventional classifiers fail. To accommodate linearity in data, SVM generates a
linear decision boundary that divides data points into discrete classes. SVM can also deal with nonlinearities in data by translating it into a new space with high dimensions using kernel functions [49], making it an effective feature extraction and classification tool. Radial Basis Function (RBF), sigmoid, and polynomial are the most common kernel functions to make data more separable. Furthermore, SVM is resistant to outliers and has a wide number of hyperparameters that may be adjusted to increase performance.
2.5.3 Multilayer perceptron (MLP)
A multilayer perceptron (MLP) is a feed-forward artificial neural network (FFANN) that resembles the human brain. It comprises an input layer, one or more hidden layers based on complexity, and an output layer. Every layer is made up of neurons that are connected to neurons in adjoining layers, and each connection is weighted based on its strength [50]. Similar to other FFANNs, information travels in one direction from the input to the output via hidden layers [51] In MLP, input vector and output class sizes define the number of neurons in the input and output layers, respectively. However, the quantity of hidden layers and neurons inside these layers should be determined experimentally because too many induce overfitting, and too few cause underfitting. The Multilayer Perceptron (MLP) trains the network by employing backpropagation and gradient-based optimization techniques. It is an effective backpropagation-based ML approach that can detect and approximate the nonlinear relationship between input characteristics and desired outputs, making it beneficial in a variety of machine-learning applications.
2.5.4 Extreme gradient boosting (XGBoost)
Extreme Gradient Boosting [52] (XGBoost) is an advanced ML method known for its incredible performance and applicability across a wide range of applications. An ensemble learning framework, namely gradient boosting [50], performs well on classification and regression tasks. XGBoost builds a series of weak learners, generally decision trees, and iteratively improves their accuracy by reducing a loss function [53].
It has several unique properties, including regularisation strategies that avoid overfitting, robust handling of missing data, and parallel process support to handle large datasets. Overall, it is a versatile ML model because of its speed, accuracy, flexibility, scalability, and interpretability.
2.6 Performance metrics
As part of this research, the classifiers’ accuracy, sensitivity, precision, and F1 score are compared, with and without feature selection strategies. Two additional metrics (ROC and the confusion metric) are also used to visualize classification performance. The explanation of performance measurements is provided below.
A classifier’s accuracy depends on how well it classifies data into relevant categories. It displays the percentage of correctly categorized instances across all instances. Equation (4) includes the accuracy formula.
Precision estimates how many positive instances are accurately classified compared to all positively predicted instances. It is determined using Eq. (5) below.
Recall can be defined as the proportion of correctly identified positive instances to the entire number of true positive instances, also known as sensitivity. It is calculated using Eq. (6).
The F1 score takes the harmonic mean (HM) of an ML classifier’s sensitivity and precision to obtain one final value as a result. Equation (7) contains the F1 score metrics formula.
Table 4 The performance of the soft voting classifier and its base classifiers with all features
Classifier
Accuracy (%)
Precision (%)
Recall (%)
F1 score (%)
SVM
98.25
98.39
96.83
97.60
MLP
97.66
96.83
96.83
96.83
XGBoost
96.49
93.85
96.83
95.31
Soft Voting Classifier
98.25
98.39
96.83
97.60
Table 5 The performance of the soft voting classifier and its base classifiers with 10 selected features via Boruta and CBFS
A confusion matrix, also known as an error matrix [54], visualizes classification performance in matrix format. It displays the number of correct and incorrect estimations by the classifier in each category. It helps you understand which categories the classifier misinterprets as others [55].
Receiver Operating Characteristics (ROC) is an additional graphical tool for visualizing and evaluating a classifier’s diagnostic performance [56]. It is also widely used for comparing classifiers’ performance by showing their true positive (TPR) detection rate versus their false positive rate (FPR). The optimal classifiers have a 1.0 recall/sensitivity/TPR score and a 0 FPR score, yielding an AUC of 1 [57]. In addition, a 0.5 AUC value shows random guessing.
3 Results
In this section, the authors report the classification results of the proposed soft voting classifier and its base classifiers when all features or selected features are applied. Table 4 exhibits the performance scores of the classifiers when all features are applied. Table 5 compares their scores for two feature selection strategies, Boruta and CBFS. A tenfold crossvalidation approach is utilized for a more reliable assessment of the proposed method’s performance. Furthermore, Table 6 compares the efficacy of the suggested approach with different cutting-edge approaches.
On the test dataset, Table 4 shows the accuracy, precision, recall, and F1 score of the soft voting classifier and its basic classifiers after training on all features. It reveals that the soft voting classifier and SVM obtained comparable performance and are ranked first, whereas MLP is ranked second, and XGBoost is the least efficient across all features. The recall score, however, stays the same across all classifiers, i.e., 96.83%.
In Table 5, the authors compare and evaluate the performance of classifiers based on the Boruta and CBFS feature selection approaches. In examining the Boruta method, classifiers such as SVM, MLP, XGBoost, and soft voting models scored well, with accuracy levels ranging from to . However, when using CBFS, classifiers achieve even greater accuracy than Boruta. SVM and MLP classifiers performed exceptionally well when coupled with the CBFS method and achieved a accuracy score. Interestingly, the soft voting classifier beats other classifiers when using CBFS, with a remarkable accuracy score of and a perfect precision score of . XGBoost is the only classifier that demonstrates consistent performance across both selection methods. Compared to Boruta, the CBFS method appears
Table 6 Performance comparison of the proposed and older approaches on the WDBC dataset
Ref.
Methods
Features
Accuracy (%)
Precision (%)
Recall (%)
F1 score (%)
Cross-validation
[11]
RFE, VIF, model-based, and univariate feature selection with RF
Imperialist competitive algorithm (ICA), bat algorithm (BA), and RF
10
99.12
99.1
98.58
98.8
[14]
PCA with K-NN algorithm as a classifier
95.95
[15]
Recursive feature elimination, correlation-based feature selection, SVM, RF, GB, ANN, and MLP
11
99.12
5-FCV
Accuracy-99.12%
[16]
Pearson Correlation and Mutual Information (PC-MI), a soft voting classifier that combines LR, SVM, and DT
18
99.3
100
98.46
99.2
10-FCV
Accuracy-97.24%
[17]
Ensemble feature selection (SelectKBest, RFE, and Feature Importance), DT and LR
10
93.85
[20]
Extra trees ensemble for feature selection
And stacking-based approach for classification
14
98.2
98.5
96.8
97.6
[21]
Variable Importance Measure (VIM) and Hierarchical Clustering Random Forest (HCRF)
24
97.05
97.32
94.77
[22]
GSOA, EPO, and hGSEPO
97.66
100
96.87
95.16
Proposed Approach
Soft voting classifier with CBFS
10
99.42
100
98.41
99.20
10-FCV Accuracy-99.34%
The results in this section highlight the importance of choosing and utilizing suitable features and classifiers for improving the classification performance of breast cancer detection systems
Fig. 5 Confusion matrices of Classifiers with CBFS features
Fig. 6 shows the ROC curve of the soft voting classifier and its base classifiers
to have slightly better performance in terms of accurately identifying positive instances while maintaining a high level of precision.
Figure 5 compares the confusion matrices of different classifiers when coupled with the CBFS method. According to the findings of the confusion matrices, the soft voting classifier beats other classifiers. It correctly identifies all benign cases while misidentifying just one malignant sample in the test data. XGBoost is the least effective in categorizing benign cases, whereas SVM is ineffective at detecting malignant cases compared to the others. MLP also worked well; it misdiagnosed one normal and two malignant samples.
The Receiver Operating Characteristic (ROC)is a popular metric for displaying binary classifier performance, particularly when classes are imbalanced. It is commonly employed to assess and compare the efficacy of various models. It is a two-dimensional graph to illustrate the relationship between the rate of true positives (sensitivity) and the rate of false positives ( 1 -specificity) at various thresholds [58]. It can offer a more comprehensive evaluation of categorization performance compared to single-value measurements like accuracy, precision, mistake rate, or error cost [56]. The AUC, which stands for the Area Under the ROC curve, is a widely used statistic for evaluating models. It may be calculated using the trapezoidal rule. The value of the AUC always falls between 0 and 1. Typically, the diagonal line on the ROC curve indicates random guessing with a 0.5 AUC.
In recent times, ML and data mining research have increasingly utilized ROC graphs in medical decision-making. It is straightforward to calculate and interpret [59]. ROC curves illustrate the ability of a risk prediction model to differentiate between patients who have a certain ailment and those who do not. Figure 6 depicts the ROC curves of the proposed classifier and its base classifiers. As per the results, all classifiers showed very high AUC values, close to 1, which suggests excellent performance in distinguishing between benign and malignant breast cancer cases. The soft voting classifier showed the highest AUC (0.9985), slightly better than its base classifiers. MLP and XGBoost tied for second place with an AUC of 0.9982, while SVM ranked third with an AUC of 0.9978.
Using the WDBC dataset, Table 6 compares the suggested technique with prior breast cancer categorization studies. It shows that the proposed method, a soft voting classifier with the CBFS method, outperforms current approaches in terms of accuracy and other crucial measure. It has the potential to reduce manual analysis errors while facilitating more accurate breast cancer classification, which leads to an improved survival rate.
4 Discussion
This study employs the soft voting-based ensemble technique and the effective Robust Scaler for scaling, SMOTE-ENN for class balancing, and CBFS for feature selection, which performed well on all metrics. Therefore, this approach is highly recommended for breast cancer detection. The results in Tables 4 and 5 show that a soft voting classifier improves breast cancer diagnosis when coupled with the CBFS method. According to the values in these tables, the ten optimal CBFS features outperformed the complete set of features, including the ten Boruta features.
The optimal feature set offers various classification benefits, including reduced processing time, improved classification performance, and better generalizability [19]. The table findings reveal that coefficient-based feature importance alone is more discriminative and informative in discriminating between benign and malignant tumors.
The authors also advocate the use of the proposed soft voting-based ensemble model for robust and accurate classification of breast cancer. As can be observed from Fig. 5, only one class is misclassified, demonstrating its strength and usefulness in aggregating predictions from a variety of models. The soft voting approach can make more efficient decisions than a single classifier by considering the uncertainty associated with each classifier [43,44]. It can tackle overfitting and bias concerns while lowering prediction error and enhancing generalization [45]. The soft voting classifier also improves model interpretability and transparency by using probability estimates from integrated classifiers.
Table 6 depicts that the proposed method provided higher classification quality than previous state-of-the-art work.
Its mean accuracy score for tenfold cross-validation is . The cross-validation results confirm that the suggested method is consistent and reliable for automatic breast cancer detection. Furthermore, many studies in this table rely solely on accuracy as an assessment metric, neglecting other metrics such as precision, recall, and F1 score. All these are crucial for accurately assessing the diagnostic performance of the classifiers, especially when there is an imbalance in classes, as in the WDBC dataset. Therefore, in addition to accuracy, other critical metrics such as recall, FI score, and precision are employed to demonstrate the proposed model’s reliability in breast cancer detection. This study intends to improve machine learning models to reliably classify breast cancer tumors, resulting in lower death rates and better patient outcomes.
Overall, the proposed approach automates FNA feature analysis, allowing pathologists to detect breast cancer more efficiently, quickly, correctly, and cost-effectively. It can improve survival rates by reducing errors associated with manually evaluating FNA characteristics.
Besides these benefits, there are some limitations to this study. First, as this experiment utilized only one dataset, to ensure the results are generalized, the proposed method needs to be applied to a variety of breast cancer datasets in the future. Another weakness of this research is that it relies on the tiny WDBC dataset, so a larger dataset may be used to verify the results further.
One more limitation of this study is that all employed classifiers are implemented on the default settings without optimizing the hyperparameters. Therefore, in the future, more experiments are required to investigate the effects of hyperparameter optimization on classifiers’ performance. This work also lacks clinical information such as age, gender, lump size, breast size change, etc. In the future, a more effective framework could be created by incorporating clinical features.
5 Conclusion
Breast cancer is a prevalent disease with a high fatality rate globally, including in India. Thus, this work seeks to improve existing breast cancer categorization methods by using ML algorithms to analyze FNA features in the WDBC dataset. There are three key components to the proposed system: preprocessing, feature selection, and classification. During preprocessing, a Robust Scaler is used for data scaling, and then SMOTE-ENN (an advanced hybrid technique) is employed to deal with the skewed WDBC dataset. Boruta and CBFS are employed and analyzed to identify features with high distinguishing traits while removing unnecessary or duplicate features. Each approach selects ten features; however, the subsets
of features generated by CBFS are more discriminative and show better results. For accurate classification, the authors have introduced a soft voting classifier model for aggregating the strength and usefulness of three ML classifiers (SVM, MLP, and XGBoost). The experiment shows that the soft voting classifier has the highest test accuracy of when applying ten coefficient-based features. It shows a mean accuracy score of for tenfold cross-validation. Based on the findings, the authors can conclude that the proposed approach for breast cancer detection is effective and superior to state-of-the-art methods, enhancing survival rates.
Author contributions Indu Chhillar: Writing—original draft and Software. Ajmer Singh: Methodology, Conceptualization. Both users reviewed and edited the manuscript.
Funding The authors declare that no funds, grants, or other support were received during the preparation of this manuscript.
Data availability The datasets used during the current study are publicly available, [Available from: https://archive.ics.uci.edu/dataset/17/ breast+cancer+wisconsin+diagnostic].
Declarations
Ethics approval and consent to participate This study uses public databases cited in the reference. Thus, this section is not applicable.
Competing interests The authors have no relevant financial or non-financial interests to disclose.
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
References
Yusuf AB, Dima RM, Aina SK. Optimized breast cancer classification using feature selection and outliers detection. J Niger Soc Phys Sci. 2021;3:298-307.
Sun YS, Zhao Z, Yang ZN, Xu F, Lu HJ, Zhu ZY, Shi W, Jiang J, Yao PP, Zhu HP. Risk factors and preventions of breast cancer. Int J Biol Sci. 2017;13:1387.
Shafique R, Rustam F, Choi GS, de la Díez IT, Mahmood A, Lipari V, Velasco CLR, Ashraf I. Breast cancer prediction using fine needle aspiration features and upsampling with supervised machine learning. Cancers (Basel). 2023;15:681.
Khandezamin Z, Naderan M, Rashti MJ. Detection and classification of breast cancer using logistic regression feature selection and GMDH classifier. J Biomed Inform. 2020;111: 103591.
Yu YH, Wei W, Liu JL. Diagnostic value of fine-needle aspiration biopsy for breast mass: a systematic review and meta-analysis. BMC Cancer. 2012;12:1-14.
Fritz P, Raoufi R, Dalquen P, et al. Artificial intelligence assisted diagnoses of fine-needle aspiration of breast diseases: a single-center experience. J Dig Health. 2023;2023:1-11.
He W, Liu T, Han Y, et al. A review: the detection of cancer cells in histopathology based on machine vision. Comput Biol Med. 2022;146: 105636.
Brause RW. Medical analysis and diagnosis by neural networks. In: Medical Data Analysis: Second International Symposium, ISMDA 2001 Madrid, Spain, October 8-9, 2001 Proceedings 2. Springer, 2001. p. 1-13.
Ali M, Dalfi H, Chaabouni S, Fakhfakh A. Breast cancer detection using random forest supported by feature selection. Int J Intell Syst Appl Eng. 2024;12:223-38.
Akkur E, Turk F, Erogul O. Breast cancer diagnosis using feature selection approaches and bayesian optimization. Comput Syst Sci Eng. 2023. https://doi.org/10.32604/csse.2023.033003.
Karimi K, Ghodratnama A, Tavakkoli-Moghaddam R. Two new feature selection methods based on learn-heuristic techniques for breast cancer prediction: a comprehensive analysis. Ann Oper Res. 2023;328:665-700.
Rajaguru H, Sannasi Chakravarthy SR. Analysis of decision tree and k -nearest neighbor algorithm in the classification of breast cancer. Asian Pac J Cancer Prev APJCP. 2019;20:3777.
Aamir S, Rahim A, Aamir Z, Abbasi SF, Khan MS, Alhaisoni M, Khan MA, Khan K, Ahmad J. Predicting breast cancer leveraging supervised machine learning techniques. Comput Math Methods Med. 2022;2022:5869529.
Hashim MS, Yassin AA. Breast cancer prediction using soft voting classifier based on machine learning models. IAENG Int J Comput Sci. 2023. https://doi.org/10.37917/ijeee.19.2.6.
Mera-Gaona M, López DM, Vargas-Canas R, Neumann U. Framework for the ensemble of feature selection methods. Appl Sci (Switzerland). 2021;11:8122.
Peng H, Long F, Ding C. Feature selection based on mutual information: Criteria of Max-Dependency, Max-Relevance, and Min-Redundancy. IEEE Trans Pattern Anal Mach Intell. 2005;27:1226-38.
Cai J, Luo J, Wang S, Yang S. Feature selection in machine learning: a new perspective. Neurocomputing. 2018;300:70-9.
Samieinasab M, Torabzadeh SA, Behnam A, Aghsami A, Jolai F. Meta-health stack: a new approach for breast cancer prediction. Healthcare Anal. 2022;2: 100010.
Huang Z, Chen D. A breast cancer diagnosis method based on VIM feature selection and hierarchical clustering random forest algorithm. IEEE Access. 2022;10:3284-93.
Singh LK, Khanna M, Singh R. Efficient feature selection for breast cancer classification using soft computing approach: a novel clinical decision support system. Multimed Tools Appl. 2024;83:43223-76.
Singh AK. Breast Cancer Classification Using ML on WDBC. In: Machine Vision and Augmented Intelligence: Select Proceedings of MAI 2022. Springer, 2023. p. 609-619.
Ahmed Khan A, Abu Bakr M. Enhancing breast cancer diagnosis with integrated dimensionality reduction and machine learning techniques. J Comput Biomed Inf. 2024. https://doi.org/10.56979/702/2024.
Kadhim Ajlan I, Murad H, Salim AA, fadhil bin yousif A. Extreme Learning machine algorithm for breast Cancer diagnosis. Multimed Tools Appl 2024; 1-24.
Ahsan MM, Mahmud MAP, Saha PK, Gupta KD, Siddique Z. Effect of data scaling methods on machine learning algorithms and model performance. Technologies (Basel). 2021. https://doi.org/10.3390/technologies9030052.
de Amorim LBV, Cavalcanti GDC, Cruz RMO. The choice of scaling technique matters for classification performance. Appl Soft Comput. 2023;133: 109924.
Xu Z, Shen D, Nie T, Kou Y. A hybrid sampling algorithm combining M-SMOTE and ENN based on Random forest for medical imbalanced data. J Biomed Inform. 2020. https://doi.org/10.1016/j.jbi.2020.103465.
Wang J. Prediction of postoperative recovery in patients with acoustic neuroma using machine learning and SMOTE-ENN techniques. Math Biosci Eng. 2022. https://doi.org/10.3934/mbe.2022487.
Sun J, Lang J, Fujita H, Li H. Imbalanced enterprise credit evaluation with DTE-SBD: Decision tree ensemble based on SMOTE and bagging with differentiated sampling rates. Inf Sci (NY). 2018. https://doi.org/10.1016/j.ins.2017.10.017.
Arafa A, El-Fishawy N, Badawy M, Radad M. RN-SMOTE: reduced noise SMOTE based on DBSCAN for enhancing imbalanced data classification. J King Saud Univ Comput Inf Sci. 2022. https://doi.org/10.1016/j.jksuci.2022.06.005.
Remeseiro B, Bolon-Canedo V. A review of feature selection methods in medical applications. Comput Biol Med. 2019;112: 103375.
Masrur Ahmed AA, Deo RC, Feng Q, Ghahramani A, Raj N, Yin Z, Yang L. Deep learning hybrid model with Boruta-Random forest optimiser algorithm for streamflow forecasting with climate mode indices, rainfall, and periodicity. J Hydrol (Amst). 2021. https://doi.org/10.1016/j. jhydrol.2021.126350.
Zhou H, Xin Y, Li S. A diabetes prediction model based on Boruta feature selection and ensemble learning. BMC Bioinformatics. 2023. https://doi.org/10.1186/s12859-023-05300-5.
Kursa MB, Rudnicki WR. Feature selection with the boruta package. J Stat Softw. 2010;36:1-13.
Sindhwani V, Bhattacharya P, Rakshit S. Information theoretic feature crediting in multiclass support vector machines. 2001. https://doi. org/10.1137/1.9781611972719.16.
Mladenić D, Brank J, Grobelnik M, Milic-Frayling N. Feature selection using linear classifier weights: Interaction with classification models. In: Proceedings of the 27th annual international ACM SIGIR conference on Research and development in information retrieval. 2004. p. 234-241.
Khaire UM, Dhanalakshmi R. Stability of feature selection algorithm: a review. J King Saud Univ Comput Inform Sci. 2022. https://doi.org/ 10.1016/j.jksuci.2019.06.012.
Rai N, Kaushik N, Kumar D, Raj C, Ali A. Mortality prediction of COVID-19 patients using soft voting classifier. Int J Cognit Comput Eng. 2022. https://doi.org/10.1016/j.ijcce.2022.09.001.
Jani R, Shariful Islam Shanto M, Mohsin Kabir M, Saifur Rahman M, Mridha MF. Heart Disease Prediction and Analysis Using Ensemble Architecture. 2022 International Conference on Decision Aid Sciences and Applications, DASA 2022. 2022. https://doi.org/10.1109/DASA5 4658.2022.9765237.
Nahar N, Ara F, Neloy MAI, Barua V, Hossain MS, Andersson K. A comparative analysis of the ensemble method for liver disease prediction. In: ICIET 2019-2nd International Conference on Innovation in Engineering and Technology. IEEE, 2019. p. 1-6.
Saqlain M, Jargalsaikhan B, Lee JY. A voting ensemble classifier for wafer map defect patterns identification in semiconductor manufacturing. IEEE Trans Semicond Manuf. 2019;32:171-82.
Mahajan P, Uddin S, Hajati F, Moni MA. Ensemble learning for disease prediction: a review. Healthcare (Switzerland). 2023. https://doi. org/10.3390/healthcare11121808.
Latha CBC, Jeeva SC. Improving the accuracy of prediction of heart disease risk based on ensemble classification techniques. Inform Med Unlocked. 2019. https://doi.org/10.1016/j.imu.2019.100203.
Janardhanan P, Heena L, Sabika F. Effectiveness of support vector machines in medical data mining. J Commun Software Syst. 2015. https://doi.org/10.24138/jcomss.v11i1.114.
Brereton RG, Lloyd GR. Support Vector Machines for classification and regression. Analyst. 2010. https://doi.org/10.1039/b918972f.
Mohd Amiruddin AAA, Zabiri H, Taqvi SAA, Tufa LD. Neural network applications in fault diagnosis and detection: an overview of implementations in engineering-related systems. Neural Comput Appl. 2020. https://doi.org/10.1007/s00521-018-3911-5.
Lange N, Bishop CM, Ripley BD. Neural networks for pattern recognition. J Am Stat Assoc. 1997. https://doi.org/10.2307/2965437.
Chen T, Guestrin C. XGBoost: A scalable tree boosting system. In: Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2016. p. 785-794.
Gündoğdu S. Efficient prediction of early-stage diabetes using XGBoost classifier with random forest feature selection technique. Multimed Tools Appl. 2023. https://doi.org/10.1007/s11042-023-15165-8.
Das C, Sahoo AK, Pradhan C. Multicriteria recommender system using different approaches. In: Cognitive Big Data Intelligence with a Metaheuristic Approach. Academic Press, 2021. p. 259-277.
Tiwari A. Supervised learning: From theory to applications. In: Artificial Intelligence and Machine Learning for EDGE Computing. Academic Press, 2022. p. 23-32.
Fawcett T. An introduction to ROC analysis. Pattern Recognit Lett. 2006;27:861-74.
Mandrekar JN. Receiver operating characteristic curve in diagnostic test assessment. J Thorac Oncol. 2010;5:1315-6.
Bradley AP. The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognit. 1997. https:// doi.org/10.1016/S0031-3203(96)00142-2.
Kaymak U, Ben-David A, Potharst R. The AUK: a simple alternative to the AUC. Eng Appl Artif Intell. 2012. https://doi.org/10.1016/j.engap pai.2012.02.012.
Publisher’s Note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Indu Chhillar, indu.chhillar@dseu.ac.in; Ajmer Singh, ajmer.saini@gmail.com | ¹Computer Science & Engineering, Deenbandhu Chhotu Ram University of Science and Technology, Murthal, Haryana, India.