DOI: https://doi.org/10.1016/j.im.2025.104103
تاريخ النشر: 2025-01-10
معالجة التحيز في الذكاء الاصطناعي التوليدي: التحديات وفرص البحث في إدارة المعلومات
https://doi.org/10.1016/j.im.2025.104103
معالجة التحيز في الذكاء الاصطناعي التوليدي: التحديات وفرص البحث في إدارة المعلومات
الملخص
لقد حولت تقنيات الذكاء الاصطناعي التوليدي، وخاصة نماذج اللغة الكبيرة (LLMs)، أنظمة إدارة المعلومات ولكنها أدخلت تحيزات كبيرة يمكن أن تضر بفعاليتها في إبلاغ اتخاذ القرارات التجارية. تقدم هذه التحديات للباحثين في إدارة المعلومات فرصة فريدة لتطوير هذا المجال من خلال تحديد ومعالجة هذه التحيزات عبر تطبيقات واسعة لنماذج اللغة الكبيرة. بناءً على المناقشة حول مصادر التحيز والأساليب الحالية لاكتشاف التحيز والتخفيف منه، يسعى هذا البحث إلى تحديد الفجوات والفرص للبحث المستقبلي. من خلال دمج الاعتبارات الأخلاقية، والآثار السياسية، ووجهات النظر الاجتماعية التقنية، نركز على تطوير إطار عمل يغطي أصحاب المصلحة الرئيسيين في أنظمة الذكاء الاصطناعي التوليدي، مقترحين أسئلة بحث رئيسية، وملهمين للنقاش. هدفنا هو توفير مسارات قابلة للتنفيذ للباحثين لمعالجة التحيز في تطبيقات نماذج اللغة الكبيرة، وبالتالي تعزيز البحث في إدارة المعلومات الذي يوجه في النهاية الممارسات التجارية. يدعو إطار العمل الخاص بنا وأجندة البحث إلى نهج متعددة التخصصات، وأساليب مبتكرة، ووجهات نظر ديناميكية، وتقييم صارم لضمان العدالة والشفافية في أنظمة المعلومات المدفوعة بالذكاء الاصطناعي التوليدي. نتوقع أن تكون هذه الدراسة دعوة للعمل للباحثين في إدارة المعلومات لمعالجة هذه القضية الحرجة، مما يوجه تحسين العدالة والفعالية في الأنظمة المعتمدة على نماذج اللغة الكبيرة للممارسات التجارية.
1. المقدمة
من التحيز والمعلومات المضللة (تيليس، 2023). تواجه الشركات أيضًا تحديات في الاستفادة من GenAI بشكل فعال، حيث أن تحيز النموذج والثقة هما العقبتان الرئيسيتان أمام تنفيذها الناجح (ديلويت، 2024). نظرًا للدور الحاسم لأنظمة GenAI في إدارة المعلومات، من الضروري أن يفهم الباحثون والممارسون التحيزات التي قد تستمر هذه الأنظمة في تعزيزها، مما يضمن بقائها عادلة ومنصفة وموثوقة.
2. الخلفية والسياق
2.1. تعريف تحيز الذكاء الاصطناعي التوليدي
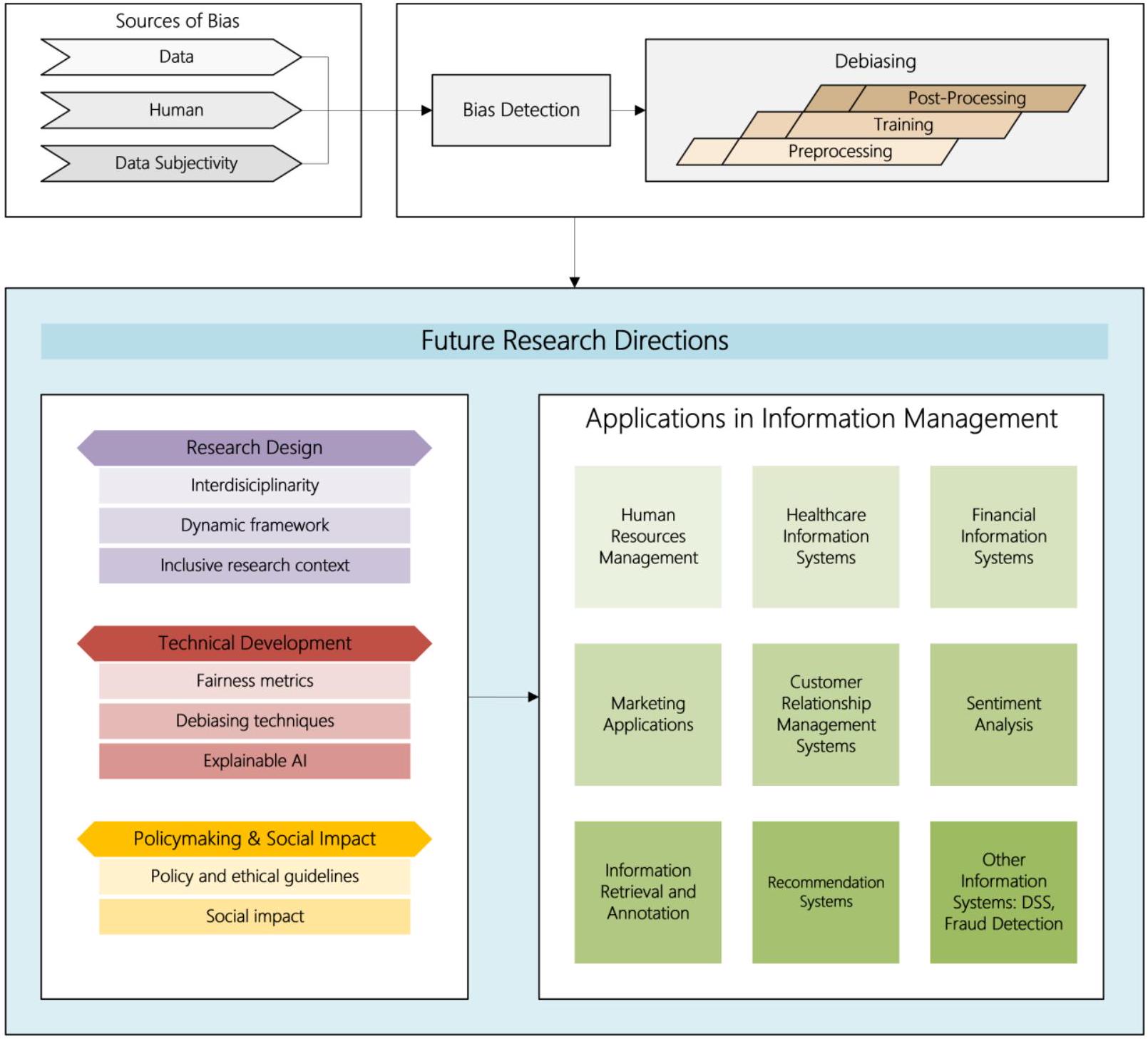
2.2. مصادر التحيز
2.3 اكتشاف وقياس التحيز
2.4. إزالة التحيز
وجهات النظر في توقعات النماذج (بهنام غادر وميليوس، 2022). يمكن أن تخفف هذه التقنيات مجتمعة من التحيز في مرحلة المعالجة المسبقة، مما يضمن مخرجات أكثر توازنًا وإنصافًا لنماذج اللغة الكبيرة.
3. الاتجاهات المستقبلية لأبحاث إدارة المعلومات
3.1 تصميم البحث
القيود الحاسوبية؟ سيساعد معالجة هذه الأسئلة في إنشاء أطر عمل قوية للتعليقات الديناميكية والدراسات الطولية، مما يضمن بقاء أنظمة نماذج اللغة الكبيرة عادلة وشفافة واستجابة للتحيزات الناشئة بمرور الوقت.
3.2 التطوير الفني
3.3 صنع السياسات والأثر الاجتماعي
4. المجالات التطبيقية لممارسة إدارة المعلومات
الحاجة إلى الترميز والتحقق البشري. ومع ذلك، يمكن أن تؤدي التحيزات الكامنة في نماذج اللغة الكبيرة إلى نتائج منحازة، مما يؤثر على قرارات الأعمال في مجالات مثل تطوير المنتجات وخدمة العملاء. على سبيل المثال، لوحظ أن ChatGPT يمنح مشاعر إيجابية أكثر للدول ذات درجات مؤشر التنمية البشرية (HDI) الأعلى، مما يكشف عن تحيز في التمثيل العادل. بالإضافة إلى ذلك، تكافح العديد من النماذج المعتمدة على نماذج اللغة الكبيرة في تفسير الفروق الدقيقة مثل السخرية أو التهكم وقد تفضل لغات معينة. يجب على الباحثين في إدارة المعلومات التركيز على تحسين نماذج اللغة الكبيرة لمعالجة التحيز، وتعزيز الشفافية، وضمان تحليل مشاعر عادل ودقيق. تشمل الأسئلة البحثية ذات الصلة: (1) كيف يمكن معالجة التحيزات في خوارزميات تحليل المشاعر باستخدام نماذج اللغة الكبيرة لضمان تحليل عادل ودقيق لتعليقات العملاء عبر مناطق وثقافات مختلفة؟ (2) إلى أي مدى يمكن تدريب نماذج اللغة الكبيرة على تفسير الفروق الدقيقة مثل السخرية والتهكم بشكل أفضل، مما يقلل من التحيزات اللغوية؟ سيساهم معالجة هذه الأسئلة في تطوير نماذج تحليل مشاعر أكثر شمولية ودقة، مما يسمح لنماذج اللغة الكبيرة بالتقاط الفروق اللغوية بشكل أفضل مع تقليل التحيزات الإقليمية والثقافية في أنظمة تعليقات العملاء.
خلفيات محددة بشكل غير عادل للتحقيقات في الاحتيال. ومن ثم، فإن سؤالًا حاسمًا آخر هو: (2) ما الأساليب التي يمكن أن تقلل من معدلات الإيجابيات الخاطئة في أنظمة كشف الاحتيال المعتمدة على النماذج اللغوية الكبيرة لتجنب الممارسات التمييزية ضد مجموعات ديموغرافية معينة؟ لدى علماء إدارة المعلومات فرص واسعة لمعالجة التحيز في هذه الأنظمة المعلوماتية، مما يعزز عدالة نتائج الأعمال.
5. الخاتمة
References
- Abbasi, A., Parsons, J., Pant, G., Sheng, O. R. L., & Sarker, S. (2024). Pathways for design research on artificial intelligence. Information Systems Research, 35(2), 441-459.
- An, H., Acquaye, C., Wang, C., Li, Z., & Rudinger, R. (2024). Do large language models discriminate in hiring decisions on the basis of race, ethnicity, and gender?. arXiv preprint arXiv:2406.10486.
- Armstrong, L., Liu, A., MacNeil, S., & Metaxa, D. (2024). The silicone ceiling: Auditing GPT’s race and gender biases in hiring. arXiv preprint arXiv:2405.04412.
- BehnamGhader, P., & Milios, A. (2022). An analysis of social biases present in BERT variants across multiple languages. In Workshop on Trustworthy and Socially Responsible Machine Learning, NeurIPS 2022.
- Binns, R. (2023). Fairness in machine learning: Lessons from political philosophy. Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency (FAccT), 149-159. doi:10.1145/3442188.3445923.
- Bommasani, R., Hudson, D. A., Adeli, E., Altman, R., Arora, S., von Arx, S., … & Liang, P. (2023). On the opportunities and risks of foundation models. Journal of Machine Learning Research, 24(1), 1-82.
- Boyer, C. B., Dahabreh, I. J., & Steingrimsson, J. A. (2023). Assessing model performance for counterfactual predictions. Journal of Computational Statistics, 45(3), 567-589.
- Brown, N. B. (2024). Enhancing trust in LLMs: Algorithms for comparing and interpreting LLMs. arXiv preprint arXiv:2406.01943.
- Buolamwini, J., & Gebru, T. (2023). Gender shades: Intersectional accuracy disparities in commercial gender classification. Journal of Artificial Intelligence Research, 76, 1-35. doi:10.1613/jair.1.12345.
- Buscemi, A., & Proverbio, D. (2024). Chatgpt vs gemini vs llama on multilingual sentiment analysis. arXiv preprint arXiv:2402.01715.
- Caliskan, A., Bryson, J. J., & Narayanan, A. (2017). Semantics derived automatically from language corpora contain human-like biases. Science, 356(6334), 183-186.
- Chamberlain, H. (2024). The perils and promise of using Generative AI for KYC screening. https://www.finextra.com/blogposting/26788/the-perils-and-promise-of-using-generative-ai-for-kycscreening.
- Chen, R., Yang, J., Xiong, H., Bai, J., Hu, T., Hao, J., … & Liu, Z. (2024). Fast model debias with machine unlearning. Advances in Neural Information Processing Systems, 36.
- Chinta, S. V., Wang, Z., Yin, Z., Hoang, N., Gonzalez, M., Quy, T. L., & Zhang, W. (2024). FairAIED: Navigating fairness, bias, and ethics in educational AI applications. arXiv preprint arXiv:2407.18745.
- Chowdhery, A., Narang, S., Devlin, J., Bosma, M., Mishra, G., Roberts, A., … & Fiedel, N. (2023). Palm: Scaling language modeling with pathways. Journal of Machine Learning Research, 24(240), 1-113.
- Dai, S., Xu, C., Xu, S., Pang, L., Dong, Z., & Xu, J. (2024). Bias and unfairness in information retrieval Systems: New challenges in the LLM era. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (pp. 6437-6447).
- Davis, A. M., Mankad, S., Corbett, C. J., & Katok, E. (2024). The best of both worlds: Machine learning and behavioral science in operations management. Manufacturing & Service Operations Management, 26(5), 1605-1621.
- Deldjoo, Y. (2024). Understanding biases in ChatGPT-based recommender systems: Provider fairness, temporal stability, and recency. ACM Transactions on Recommender Systems. https://doi.org/10.1145/3690655.
- Deloitte (2024). Now decides next: Moving from potential to performance. Deloitte’s state of Generative AI in the enterprise, Quarter three report, August 2024, https://www2.deloitte.com/content/dam/Deloitte/us/Documents/consulting/us-state-of-gen-ai-q3.pdf.
- Dolci, T., Azzalini, F., & Tanelli, M. (2023). Improving gender-related fairness in sentence encoders: A semantics-based approach. Data Science and Engineering, 8(2), 177-195.
- Dong, X., Wang, Y., Yu, P. S., & Caverlee, J. (2024). Disclosure and mitigation of gender bias in LLMs. arXiv preprint arXiv:2402.11190.
- Du, M., Mukherjee, S., Cheng, Y., Shokouhi, M., Hu, X., & Awadallah, A. H. (2021). Robustness challenges in model distillation and pruning for natural language understanding. arXiv preprint arXiv:2110.08419.
- Ferdaus, M. M., Abdelguerfi, M., Ioup, E., Niles, K. N., Pathak, K., & Sloan, S. (2024). Towards trustworthy AI: A review of ethical and robust large language models. arXiv preprint arXiv:2407.13934.
- Gallegos, I. O., Rossi, R. A., Barrow, J., Tanjim, M. M., Kim, S., Dernoncourt, F., … & Ahmed, N. K. (2024). Bias and fairness in large language models: A survey. Computational Linguistics, 50(3) 1-79.
- Gautam, S., & Srinath, M. (2024). Blind spots and biases: Exploring the role of annotator cognitive biases in NLP. arXiv preprint arXiv:2404.19071.
- Gebru, T., Morgenstern, J., Vecchione, B., Wortman Vaughan, J., Wallach, H., Daumé III, H., & Crawford, K. (2021). Datasheets for datasets. Communications of the ACM, 64(2), 86-92.
- Geerligs, C. (2024). Information extraction from contracts using Large Language Models (Doctoral dissertation). https://fse.studenttheses.ub.rug.nl/34210.
- Georgiou, G. P. (2024). ChatGPT exhibits bias towards developed countries over developing ones, as indicated by a sentiment analysis approach. https://www.researchgate.net/publication/382069262_ChatGPT_exhibits_bias_towards_developed_countri es_over_developing_ones_as_indicated_by_a_sentiment_analysis_approach.
- Gururangan, S., Marasović, A., Swayamdipta, S., Lo, K., Beltagy, I., Downey, D., & Smith, N. A. (2020). Don’t stop pretraining: Adapt language models to domains and tasks. arXiv preprint arXiv:2004.10964.
- Haltaufderheide, J., & Ranisch, R. (2024). The ethics of ChatGPT in medicine and healthcare: A systematic review on Large Language Models (LLMs). NPJ Digital Medicine, 7(1), 183.
- He, J., Xia, M., Fellbaum, C., & Chen, D. (2022). MABEL: Attenuating gender bias using textual entailment data. arXiv preprint arXiv:2210.14975.
- Hecks, E. (2024). How to identify and mitigate AI bias in marketing. https://blog.hubspot.com/ai/algorithmic-bias.
- Hovy, D., & Prabhumoye, S. (2021). The importance of modeling social factors of language: Theory and practice. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 588-602. doi:10.18653/v1/2021.naacl-main.47.
- Hutchinson, B., & Mitchell, M. (2019). 50 years of test (un) fairness: Lessons for machine learning. In Proceedings of the conference on fairness, accountability, and transparency (pp. 49-58).
- IBM. (2024). What are LLMs? https://www.ibm.com/topics/large-language-models.
- Jiao, J., Afroogh, S., Xu, Y., & Phillips, C. (2024). Navigating LLM ethics: Advancements, challenges, and future directions. arXiv preprint arXiv:2406.18841.
- Kaneko, M., Bollegala, D., Okazaki, N., & Baldwin, T. (2024). Evaluating gender bias in large language models via chain-of-thought prompting. arXiv preprint arXiv:2401.15585.
- Konsynski, B. R., Kathuria, A., & Karhade, P. P. (2024). Cognitive reapportionment and the art of letting go: A theoretical framework for the allocation of decision rights. Journal of Management Information Systems, 41(2), 328-340.
- Kusner, M. J., Loftus, J., Russell, C., & Silva, R. (2017). Counterfactual fairness. Advances in neural information processing systems, 30.
- Lawton, G. (2024). AI transparency: What is it and why do we need it? https://www.techtarget.com/searchcio/tip/AI-transparency-What-is-it-and-why-do-we-need-it.
- Le Bras, R., Swayamdipta, S., Bhagavatula, C., Zellers, R., Peters, M., Sabharwal, A., & Choi, Y. (2020). Adversarial filters of dataset biases. In International Conference on Machine Learning (pp. 1078-1088).
- Levy, S., Karver, T. S., Adler, W. D., Kaufman, M. R., & Dredze, M. (2024). Evaluating biases in contextdependent health questions. arXiv preprint arXiv:2403.04858.
- Li, Y., Du, M., Wang, X., & Wang, Y. (2023). Prompt tuning pushes farther, contrastive learning pulls closer: A two-stage approach to mitigate social biases. arXiv preprint arXiv:2307.01595.
- Liu, Z. (2024). Cultural bias in large language models: A comprehensive analysis and mitigation strategies. Journal of Transcultural Communication. https://doi.org/10.1515/jtc-2023-0019.
- Lu, K., Mardziel, P., Wu, F., Amancharla, P., & Datta, A. (2020). Gender bias in neural natural language processing. Logic, language, and security: Essays dedicated to Andre Scedrov on the occasion of his 65th birthday, 189-202.
- Lucas, S. (2024). ChatGPT bias and the risks of AI in recruiting. https://www.ere.net/articles/chatgpt-bias-and-the-risks-of-ai-in-recruiting.
- Ma, S., Chen, Q., Wang, X., Zheng, C., Peng, Z., Yin, M., & Ma, X. (2024). Towards human-AI deliberation: Design and evaluation of LLM-empowered deliberative AI for ai-assisted decision-making. arXiv preprint arXiv:2403.16812.
- Manis, K. T., & Madhavaram, S. (2023). AI-enabled marketing capabilities and the hierarchy of capabilities: Conceptualization, proposition development, and research avenues. Journal of Business Research, 157, 113485.
- Maudslay, R. H., Gonen, H., Cotterell, R., & Teufel, S. (2019). It’s all in the name: Mitigating gender bias with name-based counterfactual data substitution. arXiv preprint arXiv:1909.00871.
- Mei, K., Fereidooni, S., & Caliskan, A. (2023). Bias against 93 stigmatized groups in masked language models and downstream sentiment classification tasks. In Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency (pp. 1699-1710).
- Mehrabi, N., Morstatter, F., Saxena, N., Lerman, K., & Galstyan, A. (2021). A survey on bias and fairness in machine learning. ACM Computing Surveys, 54(6), 115. https://doi.org/10.1145/3457607.
- Narayan, M., Pasmore, J., Sampaio, E., Raghavan, V., & Waters, G. (2024). Bias neutralization framework: Measuring fairness in large language models with bias intelligence quotient (BiQ). arXiv preprint arXiv:2404.18276.
- Oh, C., Won, H., So, J., Kim, T., Kim, Y., Choi, H., & Song, K. (2022). Learning fair representation via distributional contrastive disentanglement. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (pp. 1295-1305).
- Omrani Sabbaghi, S., Wolfe, R., & Caliskan, A. (2023). Evaluating biased attitude associations of language models in an intersectional context. In Proceedings of the 2023 AAAI/ACM Conference on AI, Ethics, and Society (pp. 542-553).
- O’Neil, C. (2017). Weapons of math destruction: How big data increases inequality and threatens democracy. Crown.
- PhummaArin, A. (2024). Beyond the screen: Addressing algorithmic bias in advertising. https://www.dxglobal.com/insights/beyond-the-screen-addressing-algorithmic-bias-in-advertising.
- Radcliffe, T., Lockhart, E., & Wetherington, J. (2024). Automated prompt engineering for semantic vulnerabilities in large language models. Authorea Preprints.
- Raji, I. D., Smart, A., White, R. N., Mitchell, M., Gebru, T., Hutchinson, B., … & Barnes, P. (2020). Closing the AI accountability gap: Defining an end-to-end framework for internal algorithmic auditing. In Proceedings of the 2020 conference on fairness, accountability, and transparency (pp. 33-44).
- Ray, A., Ghasemkhani, H., & Martinelli, C. (2024). Competition and cognition in the market for online news. Journal of Management Information Systems, 41(2), 367-393.
- Roy, D., & Dutta, M. (2022). A systematic review and research perspective on recommender systems. Journal of Big Data, 9(1), 59.
- Sachdeva, A., Kim, A., & Dennis, A. R. (2024). Taking the chat out of chatbot? Collecting user reviews with chatbots and web forms. Journal of Management Information Systems, 41(1), 146-177.
- Saffarizadeh, K., Keil, M., & Maruping, L. (2024). Relationship between trust in the AI creator and trust in AI systems: The crucial role of AI alignment and steerability. Journal of Management Information Systems, 41(3), 645-681.
- Santurkar, S., Durmus, E., Ladhak, F., Lee, C., Liang, P., & Hashimoto, T. (2023). Whose opinions do language models reflect?. In International Conference on Machine Learning, 29971-30004.
- Schick, T., Udupa, S., & Schütze, H. (2021). Self-diagnosis and self-debiasing: A proposal for reducing corpus-based bias in NLP. Transactions of the Association for Computational Linguistics, 9, 1408-1424.
- Shahriar, S., Lund, B., Mannuru, N. R., Arshad, M. A., Hayawi, K., Bevara, R. V. K., & Batool, L. (2024). Putting GPT-4o to the sword: A comprehensive evaluation of language, vision, speech, and multimodal proficiency. Journal of Artificial Intelligence Research, 25(1), 1-30. doi:10.1613/jair.1.12456.
- Shankar, S., Zamfirescu-Pereira, J. D., Hartmann, B., Parameswaran, A. G., & Arawjo, I. (2024). Who validates the validators? Aligning LLM-assisted evaluation of LLM outputs with human preferences. arXiv preprint arXiv:2404.12272.
- Shulman, J. D., & Gu, Z. (2024). Making inclusive product design a reality: How company culture and research bias impact investment. Marketing Science, 43(1), 73-91. doi:10.1287/mksc.2023.1438.
- Sokolová, Z., Harahus, M., Staš, J., Kupcová, E., Sokol, M., Koctúrová, M., & Juhár, J. (2024). Measuring and mitigating stereotype bias in language models: An overview of debiasing techniques. In 2024 International Symposium ELMAR (pp. 241-246). IEEE.
- Stanczak, K., & Augenstein, I. (2021). A survey on gender bias in natural language processing. arXiv preprint arXiv:2112.14168.
- Subramanian, N. (2024). AI, leadership, and innovation: Transforming the future of business. https://www.digitalfirstmagazine.com/ai-leadership-and-innovation-transforming-the-future-of-business.
- Subramanian, S., Han, X., Baldwin, T., Cohn, T., & Frermann, L. (2021). Evaluating debiasing techniques for intersectional biases. arXiv preprint arXiv:2109.10441.
- Sun, Z., Du, L., Ding, X., Ma, Y., Qiu, K., Liu, T., & Qin, B. (2024). Causal-guided active learning for debiasing large language models. arXiv preprint arXiv:2408.12942.
- Susarla, A., Gopal, R., Thatcher, J. B., & Sarker, S. (2023). The Janus effect of generative AI: Charting the path for responsible conduct of scholarly activities in information systems. Information Systems Research, 34(2), 399-408.
- TELUS. (2023). TELUS International survey reveals customer concerns about bias in generative AI. https://www.telusinternational.com/about/newsroom/survey-bias-in-generative-ai.
- Tokpo, E., Delobelle, P., Berendt, B., & Calders, T. (2023). How far can it go?: On intrinsic gender bias mitigation for text classification. arXiv preprint arXiv:2301.12855.
- Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M. A., Lacroix, T., … & Lample, G. (2023). Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
- Triandis, H. C. (2018). Individualism and collectivism. Routledge.
- Wankhade, M., Rao, A. C. S., & Kulkarni, C. (2022). A survey on sentiment analysis methods, applications, and challenges. Artificial Intelligence Review, 55(7), 5731-5780.
- Xue, J., Wang, Y. C., Wei, C., Liu, X., Woo, J., & Kuo, C. C. J. (2023). Bias and fairness in chatbots: An overview. arXiv preprint arXiv:2309.08836.
- Yee, L. & Chui, M. (2023). The economic potential of generative AI: The next productivity frontier. https://www.mckinsey.com/featured-insights/mckinsey-live/webinars/the-economic-potential-ofgenerative-ai-the-next-productivity-frontier.
- Yin, S., Fu, C., Zhao, S., Li, K., Sun, X., Xu, T., & Chen, E. (2024). A survey on multimodal large language models. National Science Review, nwae403.
- Zhang, B. H., Lemoine, B., & Mitchell, M. (2018). Mitigating unwanted biases with adversarial learning. Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society (pp.335-340). arXiv preprint arXiv:1801.07593.
- Zhao, W. X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., … & Wen, J. R. (2023). A survey of large language models. arXiv preprint arXiv:2303.18223.
DOI: https://doi.org/10.1016/j.im.2025.104103
Publication Date: 2025-01-10
Addressing Bias in Generative AI: Challenges and Research Opportunities in Information Management
https://doi.org/10.1016/j.im.2025.104103
Addressing Bias in Generative AI: Challenges and Research Opportunities in Information Management
Abstract
Generative AI technologies, particularly Large Language Models (LLMs), have transformed information management systems but introduced substantial biases that can compromise their effectiveness in informing business decision-making. This challenge presents information management scholars with a unique opportunity to advance the field by identifying and addressing these biases across extensive applications of LLMs. Building on the discussion on bias sources and current methods for detecting and mitigating bias, this paper seeks to identify gaps and opportunities for future research. By incorporating ethical considerations, policy implications, and sociotechnical perspectives, we focus on developing a framework that covers major stakeholders of Generative AI systems, proposing key research questions, and inspiring discussion. Our goal is to provide actionable pathways for researchers to address bias in LLM applications, thereby advancing research in information management that ultimately informs business practices. Our forward-looking framework and research agenda advocate interdisciplinary approaches, innovative methods, dynamic perspectives, and rigorous evaluation to ensure fairness and transparency in Generative AI-driven information systems. We expect this study to serve as a call to action for information management scholars to tackle this critical issue, guiding the improvement of fairness and effectiveness in LLM-based systems for business practice.
1. Introduction
from bias and misinformation (TELUS, 2023). Companies also face challenges in leveraging GenAI effectively, with model bias and trust being primary obstacles to its successful implementation (Deloitte, 2024). Given the crucial role of GenAI systems in information management, it is paramount for researchers and practitioners to understand and mitigate the biases these systems may perpetuate, ensuring they remain fair, equitable, and trustworthy.
2. Background and Context
2.1. Defining Generative AI Bias
2.2. Sources of Bias
2.3 Detecting and Quantifying Bias
2.4. Debiasing
perspectives in model predictions (BehnamGhader and Milios, 2022). These techniques collectively can mitigate bias at the preprocessing stage, ensuring more balanced and fairer LLM outputs.
3. Future Directions for Information Management Research
3.1 Research Design
computational limitations? Addressing these questions will facilitate the creation of robust frameworks for dynamic feedback and longitudinal studies, ensuring LLM systems remain fair, transparent, and responsive to emerging biases over time.
3.2 Technical Development
3.3 Policymaking and Social Impact
4. Applied Areas of Information Management Practice
need for coding and human validation. However, LLMs’ inherent biases can lead to skewed results, influencing business decisions in areas such as product development and customer service. For instance, it has been observed that ChatGPT assigns more positive sentiments to countries with higher Human Development Index (HDI) scores, revealing a bias in fair representation (Georgiou, 2024). Additionally, many LLM-based models struggle with interpreting nuances such as irony or sarcasm and may favor certain languages (Buscemi and Proverbio, 2024). Information management researchers should focus on improving LLMs to address bias, enhance transparency, and ensure fair and accurate sentiment analysis. Pertinent research questions include: (1) How can biases in sentiment analysis algorithms using LLMs be addressed to ensure fair and accurate customer feedback analysis across different regions and cultures? (2) To what extent can LLMs be trained to better interpret nuances like sarcasm and irony, minimizing linguistic biases? Addressing these questions will lead to more inclusive and precise sentiment analysis models, allowing LLMs to better capture linguistic nuances while minimizing regional and cultural biases in customer feedback systems.
specific backgrounds are unfairly targeted for fraud investigations. Hence, another critical question is: (2) What methods can reduce false positive rates in LLM-based fraud detection systems to avoid discriminatory practices against specific demographic groups? Information management scholars have extensive opportunities to address the bias in these information systems, thereby enhancing the fairness of business outcomes.
5. Conclusion
References
- Abbasi, A., Parsons, J., Pant, G., Sheng, O. R. L., & Sarker, S. (2024). Pathways for design research on artificial intelligence. Information Systems Research, 35(2), 441-459.
- An, H., Acquaye, C., Wang, C., Li, Z., & Rudinger, R. (2024). Do large language models discriminate in hiring decisions on the basis of race, ethnicity, and gender?. arXiv preprint arXiv:2406.10486.
- Armstrong, L., Liu, A., MacNeil, S., & Metaxa, D. (2024). The silicone ceiling: Auditing GPT’s race and gender biases in hiring. arXiv preprint arXiv:2405.04412.
- BehnamGhader, P., & Milios, A. (2022). An analysis of social biases present in BERT variants across multiple languages. In Workshop on Trustworthy and Socially Responsible Machine Learning, NeurIPS 2022.
- Binns, R. (2023). Fairness in machine learning: Lessons from political philosophy. Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency (FAccT), 149-159. doi:10.1145/3442188.3445923.
- Bommasani, R., Hudson, D. A., Adeli, E., Altman, R., Arora, S., von Arx, S., … & Liang, P. (2023). On the opportunities and risks of foundation models. Journal of Machine Learning Research, 24(1), 1-82.
- Boyer, C. B., Dahabreh, I. J., & Steingrimsson, J. A. (2023). Assessing model performance for counterfactual predictions. Journal of Computational Statistics, 45(3), 567-589.
- Brown, N. B. (2024). Enhancing trust in LLMs: Algorithms for comparing and interpreting LLMs. arXiv preprint arXiv:2406.01943.
- Buolamwini, J., & Gebru, T. (2023). Gender shades: Intersectional accuracy disparities in commercial gender classification. Journal of Artificial Intelligence Research, 76, 1-35. doi:10.1613/jair.1.12345.
- Buscemi, A., & Proverbio, D. (2024). Chatgpt vs gemini vs llama on multilingual sentiment analysis. arXiv preprint arXiv:2402.01715.
- Caliskan, A., Bryson, J. J., & Narayanan, A. (2017). Semantics derived automatically from language corpora contain human-like biases. Science, 356(6334), 183-186.
- Chamberlain, H. (2024). The perils and promise of using Generative AI for KYC screening. https://www.finextra.com/blogposting/26788/the-perils-and-promise-of-using-generative-ai-for-kycscreening.
- Chen, R., Yang, J., Xiong, H., Bai, J., Hu, T., Hao, J., … & Liu, Z. (2024). Fast model debias with machine unlearning. Advances in Neural Information Processing Systems, 36.
- Chinta, S. V., Wang, Z., Yin, Z., Hoang, N., Gonzalez, M., Quy, T. L., & Zhang, W. (2024). FairAIED: Navigating fairness, bias, and ethics in educational AI applications. arXiv preprint arXiv:2407.18745.
- Chowdhery, A., Narang, S., Devlin, J., Bosma, M., Mishra, G., Roberts, A., … & Fiedel, N. (2023). Palm: Scaling language modeling with pathways. Journal of Machine Learning Research, 24(240), 1-113.
- Dai, S., Xu, C., Xu, S., Pang, L., Dong, Z., & Xu, J. (2024). Bias and unfairness in information retrieval Systems: New challenges in the LLM era. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (pp. 6437-6447).
- Davis, A. M., Mankad, S., Corbett, C. J., & Katok, E. (2024). The best of both worlds: Machine learning and behavioral science in operations management. Manufacturing & Service Operations Management, 26(5), 1605-1621.
- Deldjoo, Y. (2024). Understanding biases in ChatGPT-based recommender systems: Provider fairness, temporal stability, and recency. ACM Transactions on Recommender Systems. https://doi.org/10.1145/3690655.
- Deloitte (2024). Now decides next: Moving from potential to performance. Deloitte’s state of Generative AI in the enterprise, Quarter three report, August 2024, https://www2.deloitte.com/content/dam/Deloitte/us/Documents/consulting/us-state-of-gen-ai-q3.pdf.
- Dolci, T., Azzalini, F., & Tanelli, M. (2023). Improving gender-related fairness in sentence encoders: A semantics-based approach. Data Science and Engineering, 8(2), 177-195.
- Dong, X., Wang, Y., Yu, P. S., & Caverlee, J. (2024). Disclosure and mitigation of gender bias in LLMs. arXiv preprint arXiv:2402.11190.
- Du, M., Mukherjee, S., Cheng, Y., Shokouhi, M., Hu, X., & Awadallah, A. H. (2021). Robustness challenges in model distillation and pruning for natural language understanding. arXiv preprint arXiv:2110.08419.
- Ferdaus, M. M., Abdelguerfi, M., Ioup, E., Niles, K. N., Pathak, K., & Sloan, S. (2024). Towards trustworthy AI: A review of ethical and robust large language models. arXiv preprint arXiv:2407.13934.
- Gallegos, I. O., Rossi, R. A., Barrow, J., Tanjim, M. M., Kim, S., Dernoncourt, F., … & Ahmed, N. K. (2024). Bias and fairness in large language models: A survey. Computational Linguistics, 50(3) 1-79.
- Gautam, S., & Srinath, M. (2024). Blind spots and biases: Exploring the role of annotator cognitive biases in NLP. arXiv preprint arXiv:2404.19071.
- Gebru, T., Morgenstern, J., Vecchione, B., Wortman Vaughan, J., Wallach, H., Daumé III, H., & Crawford, K. (2021). Datasheets for datasets. Communications of the ACM, 64(2), 86-92.
- Geerligs, C. (2024). Information extraction from contracts using Large Language Models (Doctoral dissertation). https://fse.studenttheses.ub.rug.nl/34210.
- Georgiou, G. P. (2024). ChatGPT exhibits bias towards developed countries over developing ones, as indicated by a sentiment analysis approach. https://www.researchgate.net/publication/382069262_ChatGPT_exhibits_bias_towards_developed_countri es_over_developing_ones_as_indicated_by_a_sentiment_analysis_approach.
- Gururangan, S., Marasović, A., Swayamdipta, S., Lo, K., Beltagy, I., Downey, D., & Smith, N. A. (2020). Don’t stop pretraining: Adapt language models to domains and tasks. arXiv preprint arXiv:2004.10964.
- Haltaufderheide, J., & Ranisch, R. (2024). The ethics of ChatGPT in medicine and healthcare: A systematic review on Large Language Models (LLMs). NPJ Digital Medicine, 7(1), 183.
- He, J., Xia, M., Fellbaum, C., & Chen, D. (2022). MABEL: Attenuating gender bias using textual entailment data. arXiv preprint arXiv:2210.14975.
- Hecks, E. (2024). How to identify and mitigate AI bias in marketing. https://blog.hubspot.com/ai/algorithmic-bias.
- Hovy, D., & Prabhumoye, S. (2021). The importance of modeling social factors of language: Theory and practice. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 588-602. doi:10.18653/v1/2021.naacl-main.47.
- Hutchinson, B., & Mitchell, M. (2019). 50 years of test (un) fairness: Lessons for machine learning. In Proceedings of the conference on fairness, accountability, and transparency (pp. 49-58).
- IBM. (2024). What are LLMs? https://www.ibm.com/topics/large-language-models.
- Jiao, J., Afroogh, S., Xu, Y., & Phillips, C. (2024). Navigating LLM ethics: Advancements, challenges, and future directions. arXiv preprint arXiv:2406.18841.
- Kaneko, M., Bollegala, D., Okazaki, N., & Baldwin, T. (2024). Evaluating gender bias in large language models via chain-of-thought prompting. arXiv preprint arXiv:2401.15585.
- Konsynski, B. R., Kathuria, A., & Karhade, P. P. (2024). Cognitive reapportionment and the art of letting go: A theoretical framework for the allocation of decision rights. Journal of Management Information Systems, 41(2), 328-340.
- Kusner, M. J., Loftus, J., Russell, C., & Silva, R. (2017). Counterfactual fairness. Advances in neural information processing systems, 30.
- Lawton, G. (2024). AI transparency: What is it and why do we need it? https://www.techtarget.com/searchcio/tip/AI-transparency-What-is-it-and-why-do-we-need-it.
- Le Bras, R., Swayamdipta, S., Bhagavatula, C., Zellers, R., Peters, M., Sabharwal, A., & Choi, Y. (2020). Adversarial filters of dataset biases. In International Conference on Machine Learning (pp. 1078-1088).
- Levy, S., Karver, T. S., Adler, W. D., Kaufman, M. R., & Dredze, M. (2024). Evaluating biases in contextdependent health questions. arXiv preprint arXiv:2403.04858.
- Li, Y., Du, M., Wang, X., & Wang, Y. (2023). Prompt tuning pushes farther, contrastive learning pulls closer: A two-stage approach to mitigate social biases. arXiv preprint arXiv:2307.01595.
- Liu, Z. (2024). Cultural bias in large language models: A comprehensive analysis and mitigation strategies. Journal of Transcultural Communication. https://doi.org/10.1515/jtc-2023-0019.
- Lu, K., Mardziel, P., Wu, F., Amancharla, P., & Datta, A. (2020). Gender bias in neural natural language processing. Logic, language, and security: Essays dedicated to Andre Scedrov on the occasion of his 65th birthday, 189-202.
- Lucas, S. (2024). ChatGPT bias and the risks of AI in recruiting. https://www.ere.net/articles/chatgpt-bias-and-the-risks-of-ai-in-recruiting.
- Ma, S., Chen, Q., Wang, X., Zheng, C., Peng, Z., Yin, M., & Ma, X. (2024). Towards human-AI deliberation: Design and evaluation of LLM-empowered deliberative AI for ai-assisted decision-making. arXiv preprint arXiv:2403.16812.
- Manis, K. T., & Madhavaram, S. (2023). AI-enabled marketing capabilities and the hierarchy of capabilities: Conceptualization, proposition development, and research avenues. Journal of Business Research, 157, 113485.
- Maudslay, R. H., Gonen, H., Cotterell, R., & Teufel, S. (2019). It’s all in the name: Mitigating gender bias with name-based counterfactual data substitution. arXiv preprint arXiv:1909.00871.
- Mei, K., Fereidooni, S., & Caliskan, A. (2023). Bias against 93 stigmatized groups in masked language models and downstream sentiment classification tasks. In Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency (pp. 1699-1710).
- Mehrabi, N., Morstatter, F., Saxena, N., Lerman, K., & Galstyan, A. (2021). A survey on bias and fairness in machine learning. ACM Computing Surveys, 54(6), 115. https://doi.org/10.1145/3457607.
- Narayan, M., Pasmore, J., Sampaio, E., Raghavan, V., & Waters, G. (2024). Bias neutralization framework: Measuring fairness in large language models with bias intelligence quotient (BiQ). arXiv preprint arXiv:2404.18276.
- Oh, C., Won, H., So, J., Kim, T., Kim, Y., Choi, H., & Song, K. (2022). Learning fair representation via distributional contrastive disentanglement. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (pp. 1295-1305).
- Omrani Sabbaghi, S., Wolfe, R., & Caliskan, A. (2023). Evaluating biased attitude associations of language models in an intersectional context. In Proceedings of the 2023 AAAI/ACM Conference on AI, Ethics, and Society (pp. 542-553).
- O’Neil, C. (2017). Weapons of math destruction: How big data increases inequality and threatens democracy. Crown.
- PhummaArin, A. (2024). Beyond the screen: Addressing algorithmic bias in advertising. https://www.dxglobal.com/insights/beyond-the-screen-addressing-algorithmic-bias-in-advertising.
- Radcliffe, T., Lockhart, E., & Wetherington, J. (2024). Automated prompt engineering for semantic vulnerabilities in large language models. Authorea Preprints.
- Raji, I. D., Smart, A., White, R. N., Mitchell, M., Gebru, T., Hutchinson, B., … & Barnes, P. (2020). Closing the AI accountability gap: Defining an end-to-end framework for internal algorithmic auditing. In Proceedings of the 2020 conference on fairness, accountability, and transparency (pp. 33-44).
- Ray, A., Ghasemkhani, H., & Martinelli, C. (2024). Competition and cognition in the market for online news. Journal of Management Information Systems, 41(2), 367-393.
- Roy, D., & Dutta, M. (2022). A systematic review and research perspective on recommender systems. Journal of Big Data, 9(1), 59.
- Sachdeva, A., Kim, A., & Dennis, A. R. (2024). Taking the chat out of chatbot? Collecting user reviews with chatbots and web forms. Journal of Management Information Systems, 41(1), 146-177.
- Saffarizadeh, K., Keil, M., & Maruping, L. (2024). Relationship between trust in the AI creator and trust in AI systems: The crucial role of AI alignment and steerability. Journal of Management Information Systems, 41(3), 645-681.
- Santurkar, S., Durmus, E., Ladhak, F., Lee, C., Liang, P., & Hashimoto, T. (2023). Whose opinions do language models reflect?. In International Conference on Machine Learning, 29971-30004.
- Schick, T., Udupa, S., & Schütze, H. (2021). Self-diagnosis and self-debiasing: A proposal for reducing corpus-based bias in NLP. Transactions of the Association for Computational Linguistics, 9, 1408-1424.
- Shahriar, S., Lund, B., Mannuru, N. R., Arshad, M. A., Hayawi, K., Bevara, R. V. K., & Batool, L. (2024). Putting GPT-4o to the sword: A comprehensive evaluation of language, vision, speech, and multimodal proficiency. Journal of Artificial Intelligence Research, 25(1), 1-30. doi:10.1613/jair.1.12456.
- Shankar, S., Zamfirescu-Pereira, J. D., Hartmann, B., Parameswaran, A. G., & Arawjo, I. (2024). Who validates the validators? Aligning LLM-assisted evaluation of LLM outputs with human preferences. arXiv preprint arXiv:2404.12272.
- Shulman, J. D., & Gu, Z. (2024). Making inclusive product design a reality: How company culture and research bias impact investment. Marketing Science, 43(1), 73-91. doi:10.1287/mksc.2023.1438.
- Sokolová, Z., Harahus, M., Staš, J., Kupcová, E., Sokol, M., Koctúrová, M., & Juhár, J. (2024). Measuring and mitigating stereotype bias in language models: An overview of debiasing techniques. In 2024 International Symposium ELMAR (pp. 241-246). IEEE.
- Stanczak, K., & Augenstein, I. (2021). A survey on gender bias in natural language processing. arXiv preprint arXiv:2112.14168.
- Subramanian, N. (2024). AI, leadership, and innovation: Transforming the future of business. https://www.digitalfirstmagazine.com/ai-leadership-and-innovation-transforming-the-future-of-business.
- Subramanian, S., Han, X., Baldwin, T., Cohn, T., & Frermann, L. (2021). Evaluating debiasing techniques for intersectional biases. arXiv preprint arXiv:2109.10441.
- Sun, Z., Du, L., Ding, X., Ma, Y., Qiu, K., Liu, T., & Qin, B. (2024). Causal-guided active learning for debiasing large language models. arXiv preprint arXiv:2408.12942.
- Susarla, A., Gopal, R., Thatcher, J. B., & Sarker, S. (2023). The Janus effect of generative AI: Charting the path for responsible conduct of scholarly activities in information systems. Information Systems Research, 34(2), 399-408.
- TELUS. (2023). TELUS International survey reveals customer concerns about bias in generative AI. https://www.telusinternational.com/about/newsroom/survey-bias-in-generative-ai.
- Tokpo, E., Delobelle, P., Berendt, B., & Calders, T. (2023). How far can it go?: On intrinsic gender bias mitigation for text classification. arXiv preprint arXiv:2301.12855.
- Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M. A., Lacroix, T., … & Lample, G. (2023). Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
- Triandis, H. C. (2018). Individualism and collectivism. Routledge.
- Wankhade, M., Rao, A. C. S., & Kulkarni, C. (2022). A survey on sentiment analysis methods, applications, and challenges. Artificial Intelligence Review, 55(7), 5731-5780.
- Xue, J., Wang, Y. C., Wei, C., Liu, X., Woo, J., & Kuo, C. C. J. (2023). Bias and fairness in chatbots: An overview. arXiv preprint arXiv:2309.08836.
- Yee, L. & Chui, M. (2023). The economic potential of generative AI: The next productivity frontier. https://www.mckinsey.com/featured-insights/mckinsey-live/webinars/the-economic-potential-ofgenerative-ai-the-next-productivity-frontier.
- Yin, S., Fu, C., Zhao, S., Li, K., Sun, X., Xu, T., & Chen, E. (2024). A survey on multimodal large language models. National Science Review, nwae403.
- Zhang, B. H., Lemoine, B., & Mitchell, M. (2018). Mitigating unwanted biases with adversarial learning. Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society (pp.335-340). arXiv preprint arXiv:1801.07593.
- Zhao, W. X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., … & Wen, J. R. (2023). A survey of large language models. arXiv preprint arXiv:2303.18223.