DOI: https://doi.org/10.3390/diagnostics14020144
PMID: https://pubmed.ncbi.nlm.nih.gov/38248021
تاريخ النشر: 2024-01-08
نماذج تنبؤية قائمة على التعلم الآلي لاكتشاف الأمراض القلبية الوعائية
تمت المراجعة: 21 ديسمبر 2023
تم القبول: 25 ديسمبر 2023
نُشر: 8 يناير 2024
الملخص
تشكل الأمراض القلبية الوعائية تحديًا صحيًا عالميًا كبيرًا يبرز الحاجة الملحة لتطوير طرق كشف دقيقة وأكثر فعالية. ساهمت العديد من الدراسات في تقديم رؤى قيمة في هذا المجال، ولكن لا يزال من الضروري تحسين النماذج التنبؤية ومعالجة الفجوات في أساليب الكشف الحالية. على سبيل المثال، لم تأخذ بعض الدراسات السابقة في الاعتبار تحدي مجموعات البيانات غير المتوازنة، مما يمكن أن يؤدي إلى توقعات متحيزة، خاصة عندما تتضمن مجموعات البيانات فئات أقلية. يركز هذا البحث بشكل أساسي على الكشف المبكر عن أمراض القلب، وخاصة احتشاء عضلة القلب، باستخدام تقنيات التعلم الآلي. يتناول التحدي المتمثل في مجموعات البيانات غير المتوازنة من خلال إجراء مراجعة شاملة للأدبيات لتحديد استراتيجيات فعالة. تم استخدام سبعة مصنفات من التعلم الآلي والتعلم العميق، بما في ذلك الجيران الأقرب، آلة الدعم الناقل، الانحدار اللوجستي، الشبكة العصبية التلافيفية، تعزيز التدرج، XGBoost، والغابة العشوائية، لتعزيز دقة توقعات أمراض القلب. يستكشف البحث مصنفات مختلفة وأدائها، مما يوفر رؤى قيمة لتطوير نماذج تنبؤية قوية لاحتشاء عضلة القلب. تؤكد نتائج الدراسة على فعالية ضبط نموذج XGBoost بدقة لأمراض القلب الوعائية. تؤدي هذه التحسينات إلى نتائج ملحوظة:
1. المقدمة
لمكافحة وتقليل تأثير الأمراض القلبية الوعائية على مستوى العالم. هناك عوامل خطر تساهم في تطور الأمراض القلبية الوعائية، بما في ذلك ضغط الدم، وزيادة الوزن والسمنة، والملفات الدهنية غير الطبيعية، واضطرابات الجلوكوز أو حالات السكري، واستخدام التبغ أو عادات التدخين، وقلة النشاط البدني أو نمط الحياة الخامل، واستهلاك الكحول، ومستويات الكوليسترول. تتوقع منظمة الصحة العالمية أن تظل الأمراض القلبية الوعائية سببًا للوفاة، مما يشكل تهديدًا كبيرًا للحياة البشرية في المستقبل المنظور، وربما حتى بعد عام 2030.
2. الأعمال ذات الصلة
2.1. نهج التعلم الآلي
المجموعات البيانية. من المهم أنه في تعلم الآلة، لا نوجه الآلات بشكل خاص حول أين تستكشف للحصول على رؤى؛ بدلاً من ذلك، تمكّن الخوارزميات الآلات من التعلم وتكييف تقنياتها ومخرجاتها مع اكتشاف بيانات وسيناريوهات جديدة. تسمح هذه الطبيعة التكرارية لتعلم الآلة بتحسين مستمر وتكيف، مما يجعلها أداة قوية لمعالجة وتحليل مجموعات البيانات المعقدة.
2.2. نهج التعلم العميق
تعلم الميزات المعقدة من البيانات بشكل فعال، مما يؤدي إلى تحسين دقة التصنيف. كشفت النتائج التجريبية من الدراسة عن نتائج واعدة، حيث حقق النموذج الهجين دقة قدرها
| دراسة | طريقة | النتائج | ||||||
| موهان وآخرون [21] | غابة عشوائية هجينة مع نموذج خطي (HRFLM) |
|
||||||
| SVM | دقة 83% SVM | |||||||
| سينغ وآخرون [22] |
|
|
||||||
| غافهان وآخرون [23] | الشبكة العصبية |
|
||||||
| كافيثا وآخرون [24] | نموذج هجين (غابة عشوائية (RF) وشجرة قرار (DT)) | الدقة: 88% | ||||||
| الدقة: 99.14% | ||||||||
| أميري وأرمانو [25] | تصنيف – CART |
|
||||||
| ليو وكيم [26] |
|
الدقة: 98.4% |
2.3. جمع البيانات والمعالجة المسبقة
الخصائص، بما في ذلك عدم تجانس سمك الأوعية، والهياكل الوعائية المعقدة في الخلفية، ووجود الضوضاء. كانت مجموعة البيانات تتكون من 130 صورة أشعة سينية لتصوير الأوعية التاجية، كل منها بحجم
| دراسة | مجموعة بيانات | التحضير والنمذجة | النتائج |
| القرني وآخرون [27] | صور تصوير الأوعية التاجية بالأشعة السينية المستخرجة من قاعدة بيانات سريرية. | التدريب: 100 صورة الاختبار: 30 صورة نموذج ASCARIS (استنادًا إلى ميزات اللون والقطر والشكل). | الدقة: 97% |
| أويار وإلهان [30] | مجموعة بيانات كليفلاند لأمراض القلب. | إزالة 6 حالات تحتوي على إدخالات مفقودة من مجموعة البيانات وتصنيف سمة التشخيص (num) إلى فئتين: الغياب (num
|
دقة مجموعة الاختبار: 97.78% الدقة الإجمالية: 96.63% |
| دينغ وآخرون [31] | قاعدة بيانات فواي ECG وقاعدة بيانات PTB العامة | مرحلة التدريب لاكتساب الديناميات ومرحلة الاختبار لإعادة استخدام الديناميات نموذج Res-BiLSTM-Net القائم على الانتباه | درجات F1 تتراوح من 0.72 إلى 0.98 |
| داس وآخرون [32] | مجموعة بيانات UCI | برمجيات الشبكات العصبية المعتمدة على SAS | دقة التدريب:
|
2.4. المناقشات حول قيود البحث
تطبيق التعلم الآلي لاكتشاف أمراض القلب والأوعية الدموية [10،33-36]. على سبيل المثال، اقترحت الدراسات [8،37-40] طرقًا مختلفة للتنقيب عن البيانات والتعلم الآلي استنادًا إلى تقسيم نبضات القلب وعملية الاختيار، صور تخطيط القلب، صور الشرايين السباتية، وغيرها.
3. المواد والأساليب
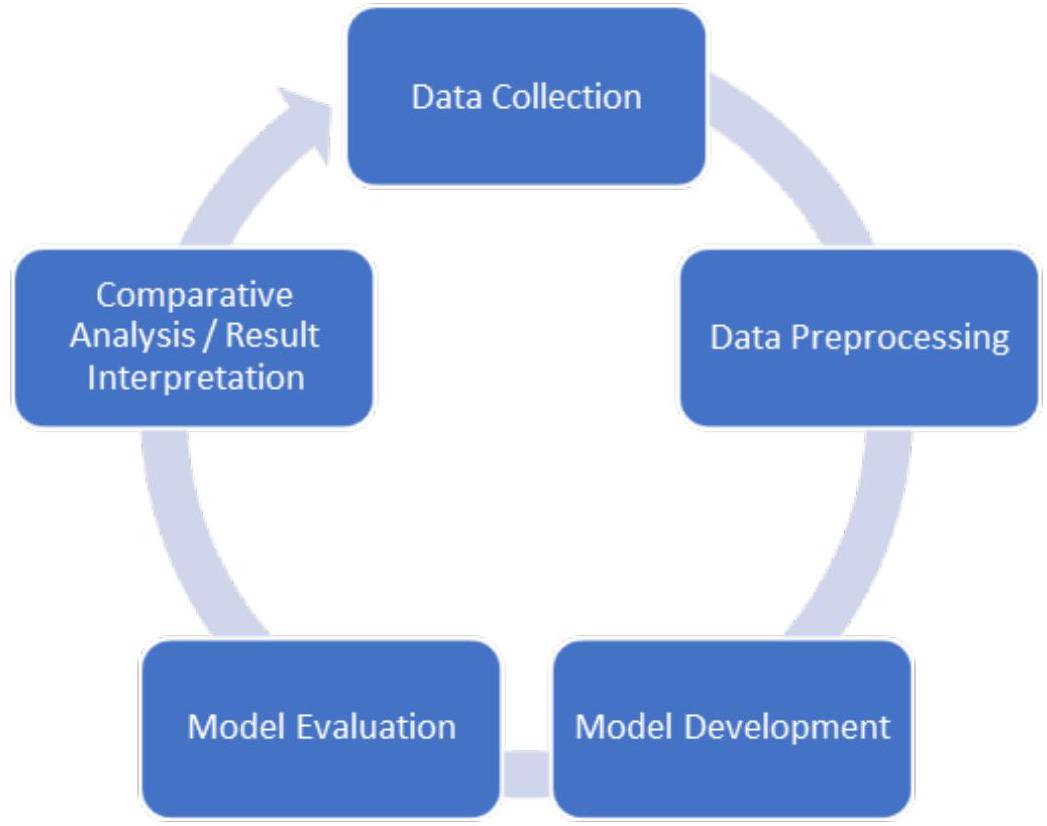
3.1. مجموعات البيانات
| ميزات | تفاصيل |
| 1. رقم المريض | معرّف فريد فردي. |
| 2. العمر | تمثيل رقمي لعمر المرضى بالسنوات. |
| 3. الجنس | ثنائي (1،
|
| 4. ألم في الصدر | اسمي (
|
| 5. ضغط الدم أثناء الراحة | رقمي (94-200 (بالمليمتر زئبقي)) |
| 6. كوليسترول المصل | رقمي (126-564 (ملغ/دل)) |
| 7. سكر الدم الصائم | ثنائي (
|
| 8. راحة كهربائية | اسمي (0، 1، 2 (القيمة 0: طبيعي، القيمة 1: وجود شذوذ في موجة ST-T (انعكاسات موجة T و/أو ارتفاع أو انخفاض في ST
|
| 9. الحد الأقصى لمعدل ضربات القلب | رقمي (71-202) |
| 10. تمرين أنجيا | ثنائي (0، 1 (0 = لا،
|
| 11. القمة القديمة | رقمي (0-6.2) |
| 12. انحدار | اسمي (1، 2، 3 (1 مائل للأعلى، 2 مستوي، 3 مائل للأسفل)) |
| 13. عدد الأوعية الرئيسية | رقمي (0، 1، 2، 3) |
| 14. هدف | ثنائي (0،1 (0 = غياب مرض القلب، 1 = وجود مرض القلب)) |
| ميزات | تفاصيل |
| 1. العمر | ميزة فئوية تمثل الجنس، حيث يتم ترميز الذكر كـ 1 والأنثى كـ 0. |
| 3. سي بي | خاصية تصنيفية تشير إلى الأنواع المختلفة من آلام الصدر التي يشعر بها المريض. 0 للذبحة الصدرية النمطية، 1 للذبحة الصدرية غير النمطية، 2 للألم غير الذبحي، و3 للألم غير المصحوب بأعراض. |
| 4. ضغط الدم | القياس العددي لضغط دم المريض في حالة الراحة، المسجل في
|
| 5. كول | قيمة عددية تشير إلى شدة الكوليسترول في مصل الدم لدى المريض، محسوبة بـ
|
| 7. تخطيط القلب أثناء الراحة | ميزة فئوية تصف نتيجة تخطيط القلب الكهربائي الذي تم إجراؤه أثناء الراحة. 0 للنتيجة الطبيعية، 1 لوجود شذوذ في موجات ST-T، و2 للدلالات على احتمال أو تأكيد تضخم البطين الأيسر وفقًا لمعايير إستي. |
| 8. ثلاخ | ميزة فئوية تشير إلى ما إذا كانت الذبحة الصدرية الناتجة عن التمارين موجودة. 0 تعني لا، بينما 1 تعني نعم. |
| 10. القمة القديمة | قيمة عددية تشير إلى انخفاض ST الناتج عن التمرين مقارنة بحالة الراحة. |
| 11. الميل | خاصية تصنيفية تمثل ميل جزء ST خلال أقصى جهد بدني. يمكن أن تأخذ ثلاث قيم: 0 للميل الصاعد، 1 للأفقي، و2 للميل النازل. |
| 12. كا | ميزة تصنيفية تشير إلى عدد الأوعية الدموية الرئيسية، تتراوح من 0 إلى 3. |
| 13 ثال | تمثيل فئوي لاضطراب دموي يسمى الثلاسيميا. 0 للفراغ، 1 لتدفق الدم الطبيعي، 2 للعيوب الثابتة (تشير إلى عدم وجود تدفق دم في جزء من القلب)، و3 للعيوب القابلة للعكس (تشير إلى تدفق دم غير طبيعي ولكن يمكن ملاحظته). |
| 14. هدف | المتغير المستهدف للتنبؤ بأمراض القلب، مشفرًا كـ 1 للمرضى الذين يعانون من أمراض القلب و0 للمرضى الذين لا يعانون من أمراض القلب. |
3.2. معالجة البيانات المسبقة
3.3. تطوير النموذج
3.4. تقييم النموذج
4. النتائج
4.1. نتائج المعالجة المسبقة
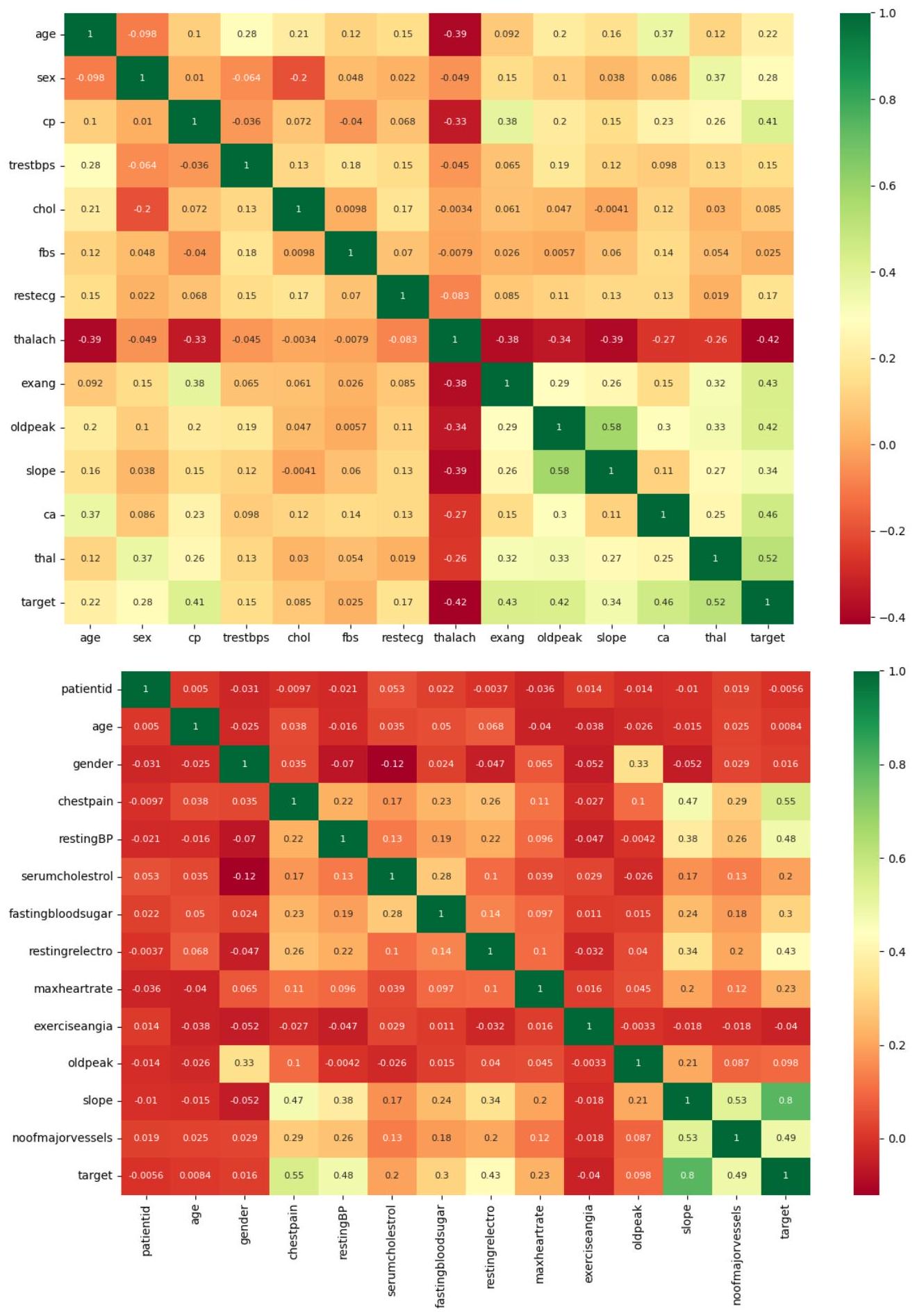
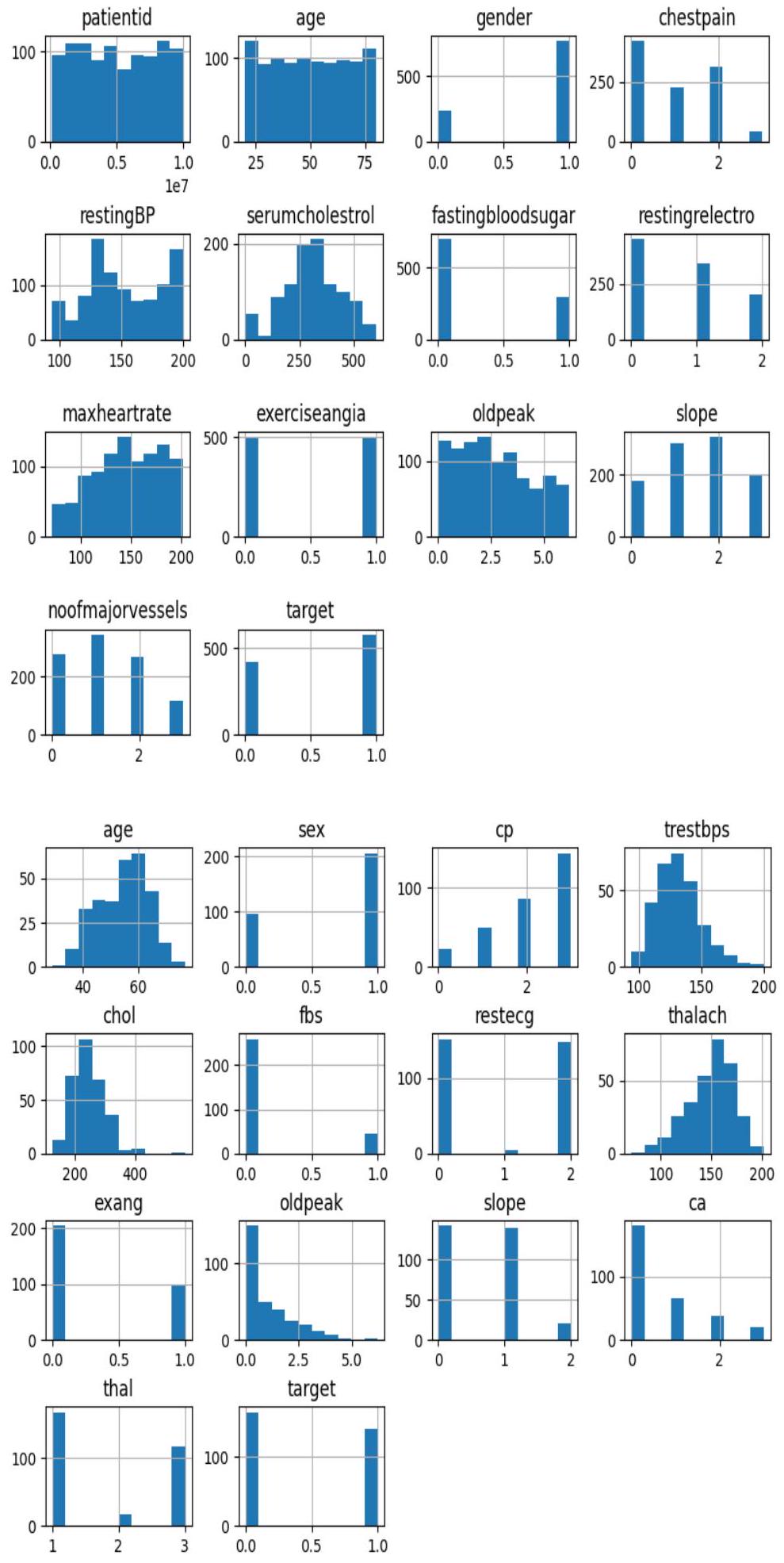
أمراض القلب كليفلاند
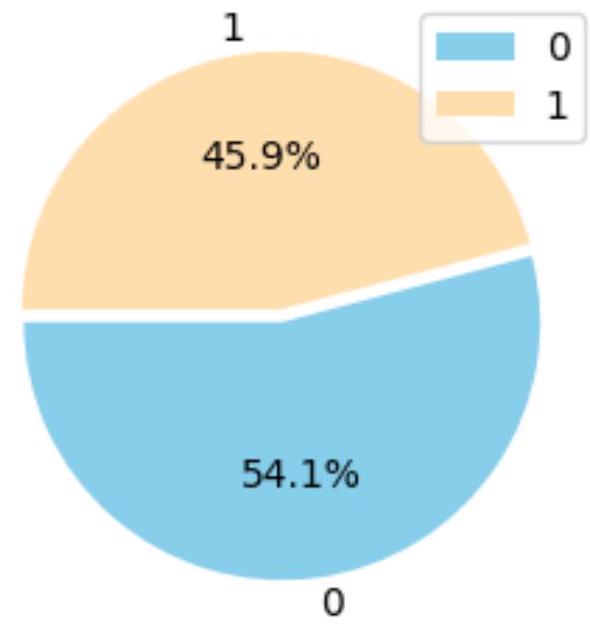
أمراض القلب والأوعية الدموية
4.2. نتائج أقرب الجيران (KNN)
| نموذج التصنيف | الدقة (بالنسبة المئوية) | |
| مجموعة البيانات 1 | مجموعة البيانات 2 | |
| KNN | 96.50% | 96.55% |
| RF | 98.63% | 94.44% |
| LR | 96.55% | 93.10% |
| جي بي | 99.13% | 90.00% |
| SVM | 95.00% | 80.65% |
| سي إن إن | 99.14% | 87.50% |
| إكس جي بوست | 99.14% | 90.00% |
| نموذج التصنيف | استرجاع (بالنسبة المئوية) | |
| مجموعة البيانات 1 | مجموعة البيانات 2 | |
| KNN | 97.44% | 87.50% |
| RF | 98.97% | 85.61% |
| LR | 95.73% | ٨٤.٣٨٪ |
| جي بي | 97.44% | 84.38% |
| SVM | 97.44% | 78.12% |
| سي إن إن | 98.29% | 89.77% |
| إكس جي بوست | 98.29% | ٨٤.٣٨٪ |
| نموذج التصنيف | درجة F1 (بالنسبة المئوية) | |
| مجموعة البيانات 1 | مجموعة البيانات 2 | |
| KNN | 97.02% | 91.80% |
| RF | 98.80% | 89.81% |
| LR | 96.14% | ٨٨.٥٢٪ |
| جي بي | 98.28% | 87.10% |
| SVM | 96.20% | 79.37% |
| سي إن إن | 97.80% | 87.50% |
| إكس جي بوست | 98.71% | 87.10% |
| نموذج التصنيف | الدقة (بالنسبة المئوية) | |
| مجموعة البيانات 1 | مجموعة البيانات 2 | |
| KNN | 96.50% | 91.80% |
| RF | 98.60% | 91.09% |
| LR | 95.50% | ٨٨.٥٢٪ |
| جي بي | ٩٨٫٠٠٪ | 86.89% |
| SVM | 95.50% | 78.69% |
| سي إن إن | 97.50% | 86.89% |
| إكس جي بوست | 98.50% | 86.89% |
4.3. نتائج الغابة العشوائية
وصلت درجة الاسترجاع، التي تقيس قدرة النموذج على التعرف على الحالات الإيجابية الحقيقية، إلى قيمة ملحوظة قدرها
4.4. نتائج الانحدار اللوجستي (LR)
4.5. نتائج تعزيز التدرج (GB)
4.6. نتائج آلة الدعم الناقل (SVM)
4.7. نتائج الشبكة العصبية التلافيفية (CNN)
4.8. نتائج XGBoost
5. المناقشة
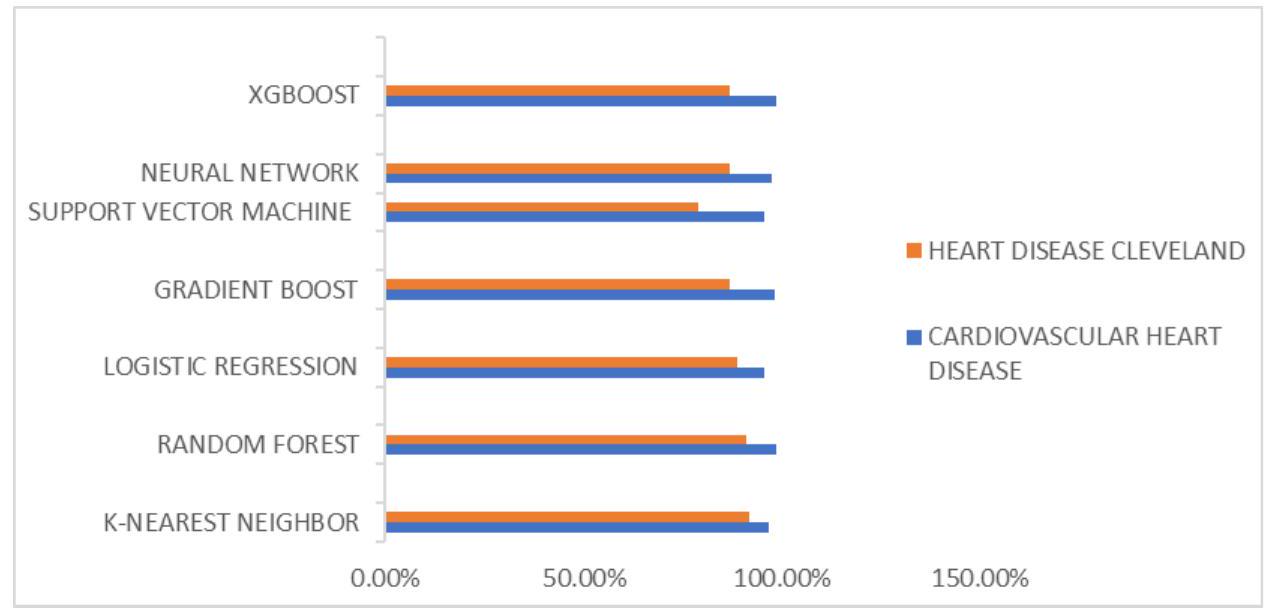
في مجموعة بيانات أمراض القلب في كليفلاند. تؤكد هذه المستويات العالية من الدقة على موثوقية النماذج، مما يجعلها أدوات قيمة لتشخيص أمراض القلب.
6. الاستنتاجات وآفاق المستقبل
يساهم في الجانب الابتكاري من نهجنا. من المهم أن نتائج نماذجنا تظهر تحسناً ملحوظاً في دقة التنبؤ، مما يضع معيار أداء متفوق.
تم دعم هذا العمل وتمويله من قبل عمادة البحث العلمي في جامعة الإمام محمد بن سعود الإسلامية (IMSIU) (رقم المنحة IMSIU-RG23077).
بيان الموافقة المستنيرة: غير قابل للتطبيق.
بيان توفر البيانات: تتوفر مجموعات البيانات عبر الإنترنت وعند الطلب.
الشكر والتقدير: يعبّر المؤلفون عن تقديرهم لعمادة البحث العلمي في جامعة الإمام محمد بن سعود الإسلامية لدعمها هذا العمل من خلال منحة رقم IMSIU-RG23077.
References
- World Health Organization. WHO Cardiovascular Diseases. Available online: https://www.who.int/health-topics/ cardiovascular-diseases#tab=tab_1 (accessed on 19 January 2022).
- Ramesh, A.N.; Kambhampati, C.; Monson, J.R.; Drew, P.J. Artificial intelligence in medicine. Ann. R. Coll. Surg. Engl. 2004, 86, 334. [CrossRef] [PubMed]
- Abdellatif, A.; Mubarak, H.; Abdellatef, H.; Kanesan, J.; Abdelltif, Y.; Chow, C.-O.; Chuah, J.H.; Gheni, H.M.; Kendall, G. Computational detection and interpretation of heart disease based on conditional variational auto-encoder and stacked ensemblelearning framework. Biomed. Signal Process. Control 2024, 88, 105644. [CrossRef]
- Tartarisco, G.; Cicceri, G.; Bruschetta, R.; Tonacci, A.; Campisi, S.; Vitabile, S.; Cerasa, A.; Distefano, S.; Pellegrino, A.; Modesti, P.A.; et al. An intelligent Medical Cyber-Physical System to support heart valve disease screening and diagnosis. Expert Syst. Appl. 2024, 238, 121772. [CrossRef]
- Cuevas-Chávez, A.; Hernández, Y.; Ortiz-Hernandez, J.; Sánchez-Jiménez, E.; Ochoa-Ruiz, G.; Pérez, J.; González-Serna, G. A Systematic Review of Machine Learning and IoT Applied to the Prediction and Monitoring of Cardiovascular Diseases. Healthcare 2023, 11, 2240. [CrossRef] [PubMed]
- Plati, D.K.; Tripoliti, E.E.; Bechlioulis, A.; Rammos, A.; Dimou, I.; Lakkas, L.; Watson, C.; McDonald, K.; Ledwidge, M.; Pharithi, R.; et al. A Machine Learning Approach for Chronic Heart Failure Diagnosis. Diagnostics 2021, 11, 1863. [CrossRef] [PubMed]
- Kim, J.O.; Jeong, Y.-S.; Kim, J.H.; Lee, J.-W.; Park, D.; Kim, H.-S. Machine Learning-Based Cardiovascular Disease Prediction Model: A Cohort Study on the Korean National Health Insurance Service Health Screening Database. Diagnostics 2021, 11, 943. [CrossRef]
- Mhamdi, L.; Dammak, O.; Cottin, F.; Ben Dhaou, I. Artificial Intelligence for Cardiac Diseases Diagnosis and Prediction Using ECG Images on Embedded Systems. Biomedicines 2022, 10, 2013. [CrossRef]
- Özbilgin, F.; Kurnaz, Ç.; Aydın, E. Prediction of Coronary Artery Disease Using Machine Learning Techniques with Iris Analysis. Diagnostics 2023, 13, 1081. [CrossRef]
- Brites, I.S.G.; da Silva, L.M.; Barbosa, J.L.V.; Rigo, S.J.; Correia, S.D.; Leithardt, V.R.Q. Machine Learning and IoT Applied to Cardiovascular Diseases Identification through Heart Sounds: A Literature Review. Repositório Comum (Repositório Científico de Acesso Aberto de Portugal). 2021. Available online: https://www.preprints.org/manuscript/202110.0161/v1 (accessed on 15 June 2023).
- Papandrianos, N.I.; Feleki, A.; Papageorgiou, E.I.; Martini, C. Deep Learning-Based Automated Diagnosis for Coronary Artery Disease Using SPECT-MPI Images. J. Clin. Med. 2022, 11, 3918. [CrossRef]
- Al-Absi, H.R.H.; Islam, M.T.; Refaee, M.A.; Chowdhury, M.E.H.; Alam, T. Cardiovascular Disease Diagnosis from DXA Scan and Retinal Images Using Deep Learning. Sensors 2022, 22, 4310. [CrossRef]
- El Naqa, I.; Murphy, M.J. What Is Machine Learning? Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 3-11.
- Bhardwaj, R.; Nambiar, A.R.; Dutta, D. A study of machine learning in healthcare. In Proceedings of the 2017 IEEE 41st Annual Computer Software and Applications Conference (COMPSAC), Torino, Italy, 4-8 July 2017; IEEE: New York, NY, USA, 2017; Volume 2, pp. 236-241.
- Brownlee, J. What is Machine Learning: A Tour of Authoritative Definitions and a Handy One-Liner You Can Use. Available online: www.machinelearningmastery.com (accessed on 25 November 2023).
- Oresko, J.J.; Jin, Z.; Cheng, J.; Huang, S.; Sun, Y.; Duschl, H.; Cheng, A.C. A wearable smartphone-based platform for real-time cardiovascular disease detection via electrocardiogram processing. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 734-740. [CrossRef] [PubMed]
- Sharean, T.M.A.M.; Johncy, G. Deep learning models on Heart Disease Estimation-A review. J. Artif. Intell. 2022, 4, 122-130. [CrossRef]
- Sudha, V.K.; Kumar, D. Hybrid CNN and LSTM network For heart disease prediction. SN Comput. Sci. 2023, 4, 172. [CrossRef]
- Bhardwaj, R.; Sethi, A.; Nambiar, R. Big data in genomics: An overview. In Proceedings of the 2014 IEEE International Conference on Big Data (Big Data), Beijing, China, 4-7 August 2014; IEEE: New York, NY, USA, 2014; pp. 45-49.
- Kayyali, B.; Knott, D.; Van Kuiken, S. The Big-Data Revolution in US Health Care: Accelerating Value and Innovation; Mc Kinsey & Company: Chicago, IL, USA, 2013; Volume 2, pp. 1-13.
- Mohan, S.; Thirumalai, C.; Srivastava, G. Effective heart disease prediction using hybrid machine learning techniques. IEEE Access 2019, 7, 81542-81554. [CrossRef]
- Singh, A.; Kumar, R. February. Heart disease prediction using machine learning algorithms. In Proceedings of the 2020 International Conference on Electrical and Electronics Engineering (ICE3), Gorakhpur, India, 14-15 February 2020; IEEE: New York, NY, USA, 2020; pp. 452-457.
- Gavhane, A.; Kokkula, G.; Pandya, I.; Devadkar, K. March. Prediction of heart disease using machine learning. In Proceedings of the 2018 Second International Conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 29-31 March 2018; IEEE: New York, NY, USA, 2018; pp. 1275-1278.
- Kavitha, M.; Gnaneswar, G.; Dinesh, R.; Sai, Y.R.; Suraj, R.S. Heart disease prediction using hybrid machine learning model. In Proceedings of the 2021 6th International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 20-22 January 2021; IEEE: New York, NY, USA, 2021; pp. 1329-1333.
- Amiri, A.M.; Armano, G. Heart sound analysis for diagnosis of heart diseases in newborns. APCBEE Procedia 2013, 7, 109-116. [CrossRef]
- Liu, M.; Kim, Y. Classification of heart diseases based on ECG signals using long short-term memory. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18-21 July 2018; IEEE: New York, NY, USA, 2018; pp. 2707-2710.
- Algarni, M.; Al-Rezqi, A.; Saeed, F.; Alsaeedi, A.; Ghabban, F. Multi-constraints based deep learning model for automated segmentation and diagnosis of coronary artery disease in X-ray angiographic images. PeerJ Comput. Sci. 2022, 8, e993. [CrossRef] [PubMed]
- Hasan, A.M.; Shin, J.; Das, U.; Srizon, A.Y. Identifying prognostic features for predicting heart failure by using machine learning algorithm. In Proceedings of the ICBET’21: 2021 11th International Conference on Biomedical Engineering and Technology, Tokyo, Japan, 17-20 March 2021; pp. 40-46.
- Deepika, K.; Seema, S. Predictive analytics to prevent and control chronic diseases. In Proceedings of the 2016 2nd International Conference on Applied and Theoretical Computing and Communication Technology (iCATccT), Bangalore, India, 21-23 July 2016; IEEE: New York, NY, USA, 2016; pp. 381-386.
- Uyar, K.; Ilhan, A. Diagnosis of heart disease using genetic algorithm based trained recurrent fuzzy neural networks. Procedia Comput. Sci. 2017, 120, 588-593. [CrossRef]
- Deng, M.; Wang, C.; Tang, M.; Zheng, T. Extracting cardiac dynamics within ECG signal for human identification and cardiovascular diseases classification. Neural Netw. 2018, 100, 70-83. [CrossRef]
- Das, R.; Turkoglu, I.; Sengur, A. Effective diagnosis of heart disease through neural networks ensembles. Expert Syst. Appl. 2009, 36, 7675-7680. [CrossRef]
- Huang, J.-D.; Wang, J.; Ramsey, E.; Leavey, G.; Chico, T.J.A.; Condell, J. Applying artificial intelligence to wearable sensor data to diagnose and predict cardiovascular disease: A review. Sensors 2022, 22, 8002. [CrossRef]
- Moshawrab, M.; Adda, M.; Bouzouane, A.; Ibrahim, H.; Raad, A. Smart Wearables for the Detection of Cardiovascular Diseases: A Systematic Literature Review. Sensors 2023, 23, 828. [CrossRef] [PubMed]
- Alkayyali, Z.K.; Idris, S.A.B.; Abu-Naser, S.S. A Systematic Literature Review of Deep and Machine Learning Algorithms in Cardiovascular Diseases Diagnosis. J. Theor. Appl. Inf. Technol. 2023, 101, 1353-1365.
- Jafari, M.; Shoeibi, A.; Khodatars, M.; Ghassemi, N.; Moridian, P.; Alizadehsani, R.; Khosravi, A.; Ling, S.H.; Delfan, N.; Zhang, Y.-D.; et al. Automated diagnosis of cardiovascular diseases from cardiac magnetic resonance imaging using deep learning models: A review. Comput. Biol. Med. 2023, 160, 106998. [CrossRef] [PubMed]
- Kim, H.; Ishag, M.I.M.; Piao, M.; Kwon, T.; Ryu, K.H. A data mining approach for cardiovascular disease diagnosis using heart rate variability and images of carotid arteries. Symmetry 2016, 8, 47. [CrossRef]
- Boulares, M.; Alotaibi, R.; AlMansour, A.; Barnawi, A. Cardiovascular disease recognition based on heartbeat segmentation and selection process. Int. J. Environ. Res. Public Health 2021, 18, 10952. [CrossRef] [PubMed]
- Moradi, H.; Al-Hourani, A.; Concilia, G.; Khoshmanesh, F.; Nezami, F.R.; Needham, S.; Baratchi, S.; Khoshmanesh, K. Recent developments in modeling, imaging, and monitoring of cardiovascular diseases using machine learning. Biophys. Rev. 2023, 15, 19-33. [CrossRef]
- Bhatt, C.M.; Patel, P.; Ghetia, T.; Mazzeo, P.L. Effective heart disease prediction using machine learning techniques. Algorithms 2023, 16, 88. [CrossRef]
- Zhang, S.; Yuan, Y.; Yao, Z.; Wang, X.; Lei, Z. Improvement of the performance of models for predicting coronary artery disease based on XGBoost algorithm and feature processing technology. Electronics 2022, 11, 315. [CrossRef]
- Hagan, R.; Gillan, C.J.; Mallett, F. Comparison of machine learning methods for the classification of cardiovascular disease. Inform. Med. Unlocked 2021, 24, 100606. [CrossRef]
- Ghongade, O.S.; Reddy, S.K.S.; Tokala, S.; Hajarathaiah, K.; Enduri, M.K.; Anamalamudi, S. A Comparison of Neural Networks and Machine Learning Methods for Prediction of Heart Disease. In Proceedings of the 2023 3rd International Conference on Intelligent Communication and Computational Techniques (ICCT), Jaipur, India, 19-20 January 2023; pp. 1-7.
DOI: https://doi.org/10.3390/diagnostics14020144
PMID: https://pubmed.ncbi.nlm.nih.gov/38248021
Publication Date: 2024-01-08
Machine Learning-Based Predictive Models for Detection of Cardiovascular Diseases
Revised: 21 December 2023
Accepted: 25 December 2023
Published: 8 January 2024
Abstract
Cardiovascular diseases present a significant global health challenge that emphasizes the critical need for developing accurate and more effective detection methods. Several studies have contributed valuable insights in this field, but it is still necessary to advance the predictive models and address the gaps in the existing detection approaches. For instance, some of the previous studies have not considered the challenge of imbalanced datasets, which can lead to biased predictions, especially when the datasets include minority classes. This study’s primary focus is the early detection of heart diseases, particularly myocardial infarction, using machine learning techniques. It tackles the challenge of imbalanced datasets by conducting a comprehensive literature review to identify effective strategies. Seven machine learning and deep learning classifiers, including K-Nearest Neighbors, Support Vector Machine, Logistic Regression, Convolutional Neural Network, Gradient Boost, XGBoost, and Random Forest, were deployed to enhance the accuracy of heart disease predictions. The research explores different classifiers and their performance, providing valuable insights for developing robust prediction models for myocardial infarction. The study’s outcomes emphasize the effectiveness of meticulously fine-tuning an XGBoost model for cardiovascular diseases. This optimization yields remarkable results:
1. Introduction
to combatting and lessening the impact of cardiovascular diseases worldwide. There are risk factors that contribute to the development of CVDs, including blood pressure, excess body weight and obesity, abnormal lipid profiles, glucose irregularities or diabetes conditions, tobacco usage or smoking habits, physical inactivity or sedentary lifestyle, alcohol consumption, and cholesterol levels. The WHO predicts that CVD will remain a cause of mortality, silently posing a substantial threat to human life for the foreseeable future, possibly even beyond 2030.
2. Related Works
2.1. Machine Learning Approach
datasets. Importantly, in machine learning, we do not particularly instruct machines on where to explore for insights; instead, the algorithms enable the machines to learn and adapt their techniques and outputs as they uncover new-found data and scenarios. This iterative nature of machine learning allows for continuous improvement and adaptation, making it a powerful tool for processing and analyzing complex datasets [14].
2.2. Deep Learning Approach
effectively learn complex features from the data, leading to improved classification accuracy. Experimental results from the study revealed promising outcomes, with the hybrid model achieving an accuracy of
| Study | Method | Results | ||||||
| Mohan et al. [21] | Hybrid Random Forest with Linear Model (HRFLM) |
|
||||||
| SVM | 83% Accuracy SVM | |||||||
| Singh et al. [22] |
|
|
||||||
| Gavhane et al. [23] | Neural Network |
|
||||||
| Kavitha et al. [24] | Hybrid Model (Random Forest (RF) and Decision Tree (DT)) | Accuracy: 88% | ||||||
| Accuracy: 99.14% | ||||||||
| Amiri and Armano [25] | Classification-CART |
|
||||||
| Liu and Kim [26] |
|
Accuracy: 98.4% |
2.3. Datasets Collection and Preprocessing
istics, including uneven vessel thickness, complex vascular structures in the background, and the presence of noise. The dataset consisted of 130 X-ray coronary angiograms, each having a size of
| Study | Dataset | Preprocessing and Modeling | Results |
| Algarni et al. [27] | Coronary artery X-ray angiography images obtained from a clinical database. | Training: 100 images Test: 30 images ASCARIS model (based on color, diameter, and shape features). | Accuracy: 97% |
| Uyar and İlhan [30] | Cleveland dataset for heart disease. | Removal of 6 instances with missing entries from the dataset and categorization of the diagnosis attribute (num) into two classes: absence (num
|
Testing set accuracy: 97.78% Overall accuracy: 96.63% |
| Deng et al. [31] | Fuwai ECG database and public PTB database | training phase for dynamics acquisition and a test phase for dynamics reuse Attention-based Res-BiLSTM-Net model | F1 scores ranging from 0.72 to 0.98 |
| Das et al. [32] | UCI dataset | SAS-based software Neural Networks | Training accuracy:
|
2.4. Discussions on the Research Limitations
applying machine learning for cardiovascular disease detection [10,33-36]. For instance, the studies [8,37-40] proposed different data mining and machine learning methods based on heartbeat segmentation and selection process, ECG images, images of carotid arteries, and others.
3. Materials and Methods
3.1. Datasets
| Features | Details |
| 1. Patient Id | Individual unique identifier. |
| 2. Age | Numeric representation of patients’ age in years. |
| 3. Gender | Binary (1,
|
| 4. Chestpain | Nominal (
|
| 5. restingBP | Numeric (94-200 (in mm HG)) |
| 6. serumcholestrol | Numeric (126-564 (in mg/dL)) |
| 7. fastingbloodsugar | Binary (
|
| 8. restingrelectro | Nominal (0, 1, 2 (Value 0: normal, Value 1: having ST-T wave abnormality (T wave inversions and/or ST elevation or depression of
|
| 9. maxheartrate | Numeric (71-202) |
| 10. exerciseangia | Binary (0, 1 (0 = no,
|
| 11. oldpeak | Numeric (0-6.2) |
| 12. slope | Nominal (1, 2, 3 (1-upsloping, 2-flat, 3-downsloping)) |
| 13. noofmajorvessels | Numeric (0, 1, 2, 3) |
| 14. target | Binary (0,1 (0 = Absence of Heart Disease, 1= Presence of Heart Disease)) |
| Features | Details |
| 1. Age | Categorical feature representing gender, where Male is encoded as 1 and Female as 0. |
| 3. cp | Categorical attribute indicating the various types of chest pain felt by the patient. 0 for typical angina, 1 for atypical angina, 2 for non-anginal pain, and 3 for asymptomatic. |
| 4. trestbps | Numerical measurement of the patient’s blood pressure at rest, recorded in
|
| 5. chol | Numeric value indicating the serum cholesterol intensity of the patient, calculated in
|
| 7. restecg | Categorical feature describing the result of the electrocardiogram conducted at rest. 0 for normal, 1 for ST-T wave abnormalities, and 2 for indications of probable or definite left ventricular hypertrophy according to Estes’ criteria. |
| 8. thalach | Categorical feature denoting whether exercise-induced angina is present. 0 signifies no, while 1 signifies yes. |
| 10. oldpeak | Numeric value indicating exercise-induced ST-depression relative to the rest state. |
| 11. slope | Categorical attribute representing the slope of the ST segment during peak exercise. It can take three values: 0 for up-sloping, 1 for flat, and 2 for down-sloping. |
| 12. ca | Categorical feature indicating the number of major blood vessels, ranging from 0 to 3. |
| 13 thal | Categorical representation of a blood disorder called thalassemia. 0 for NULL, 1 for normal blood flow, 2 for fixed defects (indicating no blood flow in a portion of the heart), and 3 for reversible defects (indicating abnormal but observable blood flow). |
| 14. target | The target variable to predict heart disease, encoded as 1 for patients with heart disease and 0 for patients without heart disease. |
3.2. Data Pre-Processing
3.3. Model Development
3.4. Model Evaluation
4. Results
4.1. Pre-Processing Results
Heart Disease Cleveland
Cardiovascular Heart Disease
4.2. K-Nearest Neighbors (KNN) Results
| Classification Model | Precision (in %) | |
| Dataset 1 | Dataset 2 | |
| KNN | 96.50% | 96.55% |
| RF | 98.63% | 94.44% |
| LR | 96.55% | 93.10% |
| GB | 99.13% | 90.00% |
| SVM | 95.00% | 80.65% |
| CNN | 99.14% | 87.50% |
| XGBoost | 99.14% | 90.00% |
| Classification Model | Recall (in %) | |
| Dataset 1 | Dataset 2 | |
| KNN | 97.44% | 87.50% |
| RF | 98.97% | 85.61% |
| LR | 95.73% | 84.38% |
| GB | 97.44% | 84.38% |
| SVM | 97.44% | 78.12% |
| CNN | 98.29% | 89.77% |
| XGBoost | 98.29% | 84.38% |
| Classification Model | F1-Score (in %) | |
| Dataset 1 | Dataset 2 | |
| KNN | 97.02% | 91.80% |
| RF | 98.80% | 89.81% |
| LR | 96.14% | 88.52% |
| GB | 98.28% | 87.10% |
| SVM | 96.20% | 79.37% |
| CNN | 97.80% | 87.50% |
| XGBoost | 98.71% | 87.10% |
| Classification Model | Accuracy (in %) | |
| Dataset 1 | Dataset 2 | |
| KNN | 96.50% | 91.80% |
| RF | 98.60% | 91.09% |
| LR | 95.50% | 88.52% |
| GB | 98.00% | 86.89% |
| SVM | 95.50% | 78.69% |
| CNN | 97.50% | 86.89% |
| XGBoost | 98.50% | 86.89% |
4.3. Random Forest Results
the recall score, measuring the model’s aptitude for recognizing genuine positive cases, reached a remarkable value of
4.4. Logistic Regression (LR) Results
4.5. Gradient Boosting (GB) Results
4.6. Support Vector Machine (SVM) Results
4.7. Convolutional Neural Network (CNN) Results
4.8. XGBoost Results
5. Discussion
in the Heart Disease Cleveland Dataset. These high levels of accuracy emphasize the models’ reliability, positioning them as valuable tools for diagnosing heart disease.
6. Conclusions and Future Scope
contributing to the innovative aspect of our approach. Importantly, the outcomes of our models exhibit a noteworthy improvement in predictive accuracy, establishing a superior performance benchmark.
Funding: This work was supported and funded by the Deanship of Scientific Research at Imam Mohammad Ibn Saud Islamic University (IMSIU) (grant number IMSIU-RG23077).
Informed Consent Statement: Not applicable.
Data Availability Statement: The datasets are available online and upon request.
Acknowledgments: The authors extend their appreciation to the Deanship of Scientific Research at Imam Mohammad Ibn Saud Islamic University for funding this work through Grant Number IMSIU-RG23077.
References
- World Health Organization. WHO Cardiovascular Diseases. Available online: https://www.who.int/health-topics/ cardiovascular-diseases#tab=tab_1 (accessed on 19 January 2022).
- Ramesh, A.N.; Kambhampati, C.; Monson, J.R.; Drew, P.J. Artificial intelligence in medicine. Ann. R. Coll. Surg. Engl. 2004, 86, 334. [CrossRef] [PubMed]
- Abdellatif, A.; Mubarak, H.; Abdellatef, H.; Kanesan, J.; Abdelltif, Y.; Chow, C.-O.; Chuah, J.H.; Gheni, H.M.; Kendall, G. Computational detection and interpretation of heart disease based on conditional variational auto-encoder and stacked ensemblelearning framework. Biomed. Signal Process. Control 2024, 88, 105644. [CrossRef]
- Tartarisco, G.; Cicceri, G.; Bruschetta, R.; Tonacci, A.; Campisi, S.; Vitabile, S.; Cerasa, A.; Distefano, S.; Pellegrino, A.; Modesti, P.A.; et al. An intelligent Medical Cyber-Physical System to support heart valve disease screening and diagnosis. Expert Syst. Appl. 2024, 238, 121772. [CrossRef]
- Cuevas-Chávez, A.; Hernández, Y.; Ortiz-Hernandez, J.; Sánchez-Jiménez, E.; Ochoa-Ruiz, G.; Pérez, J.; González-Serna, G. A Systematic Review of Machine Learning and IoT Applied to the Prediction and Monitoring of Cardiovascular Diseases. Healthcare 2023, 11, 2240. [CrossRef] [PubMed]
- Plati, D.K.; Tripoliti, E.E.; Bechlioulis, A.; Rammos, A.; Dimou, I.; Lakkas, L.; Watson, C.; McDonald, K.; Ledwidge, M.; Pharithi, R.; et al. A Machine Learning Approach for Chronic Heart Failure Diagnosis. Diagnostics 2021, 11, 1863. [CrossRef] [PubMed]
- Kim, J.O.; Jeong, Y.-S.; Kim, J.H.; Lee, J.-W.; Park, D.; Kim, H.-S. Machine Learning-Based Cardiovascular Disease Prediction Model: A Cohort Study on the Korean National Health Insurance Service Health Screening Database. Diagnostics 2021, 11, 943. [CrossRef]
- Mhamdi, L.; Dammak, O.; Cottin, F.; Ben Dhaou, I. Artificial Intelligence for Cardiac Diseases Diagnosis and Prediction Using ECG Images on Embedded Systems. Biomedicines 2022, 10, 2013. [CrossRef]
- Özbilgin, F.; Kurnaz, Ç.; Aydın, E. Prediction of Coronary Artery Disease Using Machine Learning Techniques with Iris Analysis. Diagnostics 2023, 13, 1081. [CrossRef]
- Brites, I.S.G.; da Silva, L.M.; Barbosa, J.L.V.; Rigo, S.J.; Correia, S.D.; Leithardt, V.R.Q. Machine Learning and IoT Applied to Cardiovascular Diseases Identification through Heart Sounds: A Literature Review. Repositório Comum (Repositório Científico de Acesso Aberto de Portugal). 2021. Available online: https://www.preprints.org/manuscript/202110.0161/v1 (accessed on 15 June 2023).
- Papandrianos, N.I.; Feleki, A.; Papageorgiou, E.I.; Martini, C. Deep Learning-Based Automated Diagnosis for Coronary Artery Disease Using SPECT-MPI Images. J. Clin. Med. 2022, 11, 3918. [CrossRef]
- Al-Absi, H.R.H.; Islam, M.T.; Refaee, M.A.; Chowdhury, M.E.H.; Alam, T. Cardiovascular Disease Diagnosis from DXA Scan and Retinal Images Using Deep Learning. Sensors 2022, 22, 4310. [CrossRef]
- El Naqa, I.; Murphy, M.J. What Is Machine Learning? Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 3-11.
- Bhardwaj, R.; Nambiar, A.R.; Dutta, D. A study of machine learning in healthcare. In Proceedings of the 2017 IEEE 41st Annual Computer Software and Applications Conference (COMPSAC), Torino, Italy, 4-8 July 2017; IEEE: New York, NY, USA, 2017; Volume 2, pp. 236-241.
- Brownlee, J. What is Machine Learning: A Tour of Authoritative Definitions and a Handy One-Liner You Can Use. Available online: www.machinelearningmastery.com (accessed on 25 November 2023).
- Oresko, J.J.; Jin, Z.; Cheng, J.; Huang, S.; Sun, Y.; Duschl, H.; Cheng, A.C. A wearable smartphone-based platform for real-time cardiovascular disease detection via electrocardiogram processing. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 734-740. [CrossRef] [PubMed]
- Sharean, T.M.A.M.; Johncy, G. Deep learning models on Heart Disease Estimation-A review. J. Artif. Intell. 2022, 4, 122-130. [CrossRef]
- Sudha, V.K.; Kumar, D. Hybrid CNN and LSTM network For heart disease prediction. SN Comput. Sci. 2023, 4, 172. [CrossRef]
- Bhardwaj, R.; Sethi, A.; Nambiar, R. Big data in genomics: An overview. In Proceedings of the 2014 IEEE International Conference on Big Data (Big Data), Beijing, China, 4-7 August 2014; IEEE: New York, NY, USA, 2014; pp. 45-49.
- Kayyali, B.; Knott, D.; Van Kuiken, S. The Big-Data Revolution in US Health Care: Accelerating Value and Innovation; Mc Kinsey & Company: Chicago, IL, USA, 2013; Volume 2, pp. 1-13.
- Mohan, S.; Thirumalai, C.; Srivastava, G. Effective heart disease prediction using hybrid machine learning techniques. IEEE Access 2019, 7, 81542-81554. [CrossRef]
- Singh, A.; Kumar, R. February. Heart disease prediction using machine learning algorithms. In Proceedings of the 2020 International Conference on Electrical and Electronics Engineering (ICE3), Gorakhpur, India, 14-15 February 2020; IEEE: New York, NY, USA, 2020; pp. 452-457.
- Gavhane, A.; Kokkula, G.; Pandya, I.; Devadkar, K. March. Prediction of heart disease using machine learning. In Proceedings of the 2018 Second International Conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 29-31 March 2018; IEEE: New York, NY, USA, 2018; pp. 1275-1278.
- Kavitha, M.; Gnaneswar, G.; Dinesh, R.; Sai, Y.R.; Suraj, R.S. Heart disease prediction using hybrid machine learning model. In Proceedings of the 2021 6th International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 20-22 January 2021; IEEE: New York, NY, USA, 2021; pp. 1329-1333.
- Amiri, A.M.; Armano, G. Heart sound analysis for diagnosis of heart diseases in newborns. APCBEE Procedia 2013, 7, 109-116. [CrossRef]
- Liu, M.; Kim, Y. Classification of heart diseases based on ECG signals using long short-term memory. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18-21 July 2018; IEEE: New York, NY, USA, 2018; pp. 2707-2710.
- Algarni, M.; Al-Rezqi, A.; Saeed, F.; Alsaeedi, A.; Ghabban, F. Multi-constraints based deep learning model for automated segmentation and diagnosis of coronary artery disease in X-ray angiographic images. PeerJ Comput. Sci. 2022, 8, e993. [CrossRef] [PubMed]
- Hasan, A.M.; Shin, J.; Das, U.; Srizon, A.Y. Identifying prognostic features for predicting heart failure by using machine learning algorithm. In Proceedings of the ICBET’21: 2021 11th International Conference on Biomedical Engineering and Technology, Tokyo, Japan, 17-20 March 2021; pp. 40-46.
- Deepika, K.; Seema, S. Predictive analytics to prevent and control chronic diseases. In Proceedings of the 2016 2nd International Conference on Applied and Theoretical Computing and Communication Technology (iCATccT), Bangalore, India, 21-23 July 2016; IEEE: New York, NY, USA, 2016; pp. 381-386.
- Uyar, K.; Ilhan, A. Diagnosis of heart disease using genetic algorithm based trained recurrent fuzzy neural networks. Procedia Comput. Sci. 2017, 120, 588-593. [CrossRef]
- Deng, M.; Wang, C.; Tang, M.; Zheng, T. Extracting cardiac dynamics within ECG signal for human identification and cardiovascular diseases classification. Neural Netw. 2018, 100, 70-83. [CrossRef]
- Das, R.; Turkoglu, I.; Sengur, A. Effective diagnosis of heart disease through neural networks ensembles. Expert Syst. Appl. 2009, 36, 7675-7680. [CrossRef]
- Huang, J.-D.; Wang, J.; Ramsey, E.; Leavey, G.; Chico, T.J.A.; Condell, J. Applying artificial intelligence to wearable sensor data to diagnose and predict cardiovascular disease: A review. Sensors 2022, 22, 8002. [CrossRef]
- Moshawrab, M.; Adda, M.; Bouzouane, A.; Ibrahim, H.; Raad, A. Smart Wearables for the Detection of Cardiovascular Diseases: A Systematic Literature Review. Sensors 2023, 23, 828. [CrossRef] [PubMed]
- Alkayyali, Z.K.; Idris, S.A.B.; Abu-Naser, S.S. A Systematic Literature Review of Deep and Machine Learning Algorithms in Cardiovascular Diseases Diagnosis. J. Theor. Appl. Inf. Technol. 2023, 101, 1353-1365.
- Jafari, M.; Shoeibi, A.; Khodatars, M.; Ghassemi, N.; Moridian, P.; Alizadehsani, R.; Khosravi, A.; Ling, S.H.; Delfan, N.; Zhang, Y.-D.; et al. Automated diagnosis of cardiovascular diseases from cardiac magnetic resonance imaging using deep learning models: A review. Comput. Biol. Med. 2023, 160, 106998. [CrossRef] [PubMed]
- Kim, H.; Ishag, M.I.M.; Piao, M.; Kwon, T.; Ryu, K.H. A data mining approach for cardiovascular disease diagnosis using heart rate variability and images of carotid arteries. Symmetry 2016, 8, 47. [CrossRef]
- Boulares, M.; Alotaibi, R.; AlMansour, A.; Barnawi, A. Cardiovascular disease recognition based on heartbeat segmentation and selection process. Int. J. Environ. Res. Public Health 2021, 18, 10952. [CrossRef] [PubMed]
- Moradi, H.; Al-Hourani, A.; Concilia, G.; Khoshmanesh, F.; Nezami, F.R.; Needham, S.; Baratchi, S.; Khoshmanesh, K. Recent developments in modeling, imaging, and monitoring of cardiovascular diseases using machine learning. Biophys. Rev. 2023, 15, 19-33. [CrossRef]
- Bhatt, C.M.; Patel, P.; Ghetia, T.; Mazzeo, P.L. Effective heart disease prediction using machine learning techniques. Algorithms 2023, 16, 88. [CrossRef]
- Zhang, S.; Yuan, Y.; Yao, Z.; Wang, X.; Lei, Z. Improvement of the performance of models for predicting coronary artery disease based on XGBoost algorithm and feature processing technology. Electronics 2022, 11, 315. [CrossRef]
- Hagan, R.; Gillan, C.J.; Mallett, F. Comparison of machine learning methods for the classification of cardiovascular disease. Inform. Med. Unlocked 2021, 24, 100606. [CrossRef]
- Ghongade, O.S.; Reddy, S.K.S.; Tokala, S.; Hajarathaiah, K.; Enduri, M.K.; Anamalamudi, S. A Comparison of Neural Networks and Machine Learning Methods for Prediction of Heart Disease. In Proceedings of the 2023 3rd International Conference on Intelligent Communication and Computational Techniques (ICCT), Jaipur, India, 19-20 January 2023; pp. 1-7.