المجلة: Scientific Reports، المجلد: 14، العدد: 1
DOI: https://doi.org/10.1038/s41598-024-51755-8
PMID: https://pubmed.ncbi.nlm.nih.gov/38242984
تاريخ النشر: 2024-01-19
DOI: https://doi.org/10.1038/s41598-024-51755-8
PMID: https://pubmed.ncbi.nlm.nih.gov/38242984
تاريخ النشر: 2024-01-19
استراتيجيات التعلم العميق مع CReToNeXt-YOLOv5 للكشف المتقدم عن مشاعر وجه الخنزير
تؤكد هذه الدراسة على الأهمية القصوى للتعبيرات الوجهية في الخنازير، حيث تعمل كوسيلة متطورة للتواصل لقياس مشاعرها ورفاهيتها البدنية ونواياها. نظرًا للتحديات الكامنة في فك شفرة مثل هذه التعبيرات بسبب الهيكل البدائي لعضلات الوجه في الخنازير، قدمنا نموذجًا مبتكرًا للتعرف على تعبيرات وجه الخنازير يسمى CReToNeXtYOLOv5. يشمل النموذج المقترح العديد من التحسينات المصممة لزيادة الدقة والمهارة في الكشف. بشكل أساسي، أدى الانتقال من دالة خسارة CIOU إلى دالة خسارة EIOU إلى تحسين ديناميات التدريب، مما أدى إلى نتائج انحدار مدفوعة بالدقة. علاوة على ذلك، عزز دمج آلية الانتباه التناسقي حساسية النموذج لميزات التعبير المعقدة. كانت الابتكار الكبير هو دمج وحدة CReToNeXt، مما عزز قدرة النموذج على تمييز التعبيرات الدقيقة. أظهرت التجارب الفعالية أن CReToNeXtYOLOv5 حقق دقة متوسطة (mAP) تبلغ
مع تزايد المخاوف بشأن رفاهية الحيوانات في المجالات القانونية والاجتماعية، شهد تطبيق الرؤية الآلية في ضمان رفاهية الحيوانات زيادة ملحوظة. هذه التكنولوجيا، من خلال تسهيل الكشف الدقيق عن حالة الماشية، لا تبسط فقط ممارسات الإدارة ولكنها أيضًا تقلل بشكل كبير من التكاليف. تشمل التطبيقات الملحوظة العمل الرائد الذي قام به ميتشينغ وآخرون
لقد برز عالم مشاعر الحيوانات المعقد في مقدمة أبحاث رفاهية الحيوانات المعاصرة
بينما شهد مجال التعرف على الوجه البشري تحولات نموذجية بسبب الرؤية الآلية، أظهر تطبيقه على الحيوانات، وخاصة الخنازير، أيضًا تقدمًا واعدًا. شهادة على ذلك هي الدقة المذهلة
LSTM، المجهز بآليات انتباه متعددة، براعة في تمييز التعبيرات الوجهية، حيث حقق دقة متوسطة تبلغ
نظرًا للنمو الواسع في تطبيقات الرؤية الآلية، أصبحت التقدمات في تحديد الأبقار وإدارتها أيضًا محور التركيز. أظهرت الأعمال الرائدة مثل تلك التي قام بها كاواغوي وآخرون إمكانية تحليل منطقة الوجه لتحديد الأبقار بشكل مميز وتقدير أوقات التغذية، مما يبرز فائدتها في التشخيص المبكر للأمراض واضطرابات الحركة في الأبقار
لقد تطور مشهد التعرف على وجه الخنازير بلا شك، ومع ذلك لا يزال هناك فجوة واضحة في المنهجيات التي تهدف إلى فهم تعبيراتها. نظرًا لتكوين عضلات الوجه البسيط في الخنازير والتعقيدات الكامنة في الكشف عن التعبيرات، فإن هذه تمثل تحديًا ضخمًا. لمعالجة ذلك، قدمنا نموذج التعرف على تعبيرات وجه الخنازير القائم على CReToNeXt-YOLOv5. تمتد رؤية هذا النموذج إلى ما هو أبعد من مجرد التعرف؛ بل يسعى إلى قياس الفروق العاطفية للخنازير بشكل استباقي، مما يمهد الطريق للتدخلات السريعة وبالتالي تقليل المخاطر المحتملة. أخلاقيًا، يمكن أن يؤدي التعرف على مشاعر الخنازير والاستجابة لها إلى رفع معايير رفاهية الحيوانات بشكل كبير، مما يقدم التزامًا أخلاقيًا وعمليًا. وبالتالي، فإن هدفنا البحثي الرئيسي هو تحسين والتحقق من فعالية نموذج CReToNeXt-YOLOv5 في السيناريوهات الواقعية. إن بدء هذا النموذج لا يحمل فقط وعدًا تحويليًا هائلًا ولكنه أيضًا يمثل خطوة تقدمية في مجال دراسات المشاعر الحيوانية.
طرق
البيانات التجريبية
جمع تعبيرات وجه الخنازير
تم جمع قاعدة البيانات المستخدمة في هذه الدراسة من مزارع الخنازير في مقاطعة شانشي. تم تقسيم المزارع إلى منطقتين، كل منها بمساحة
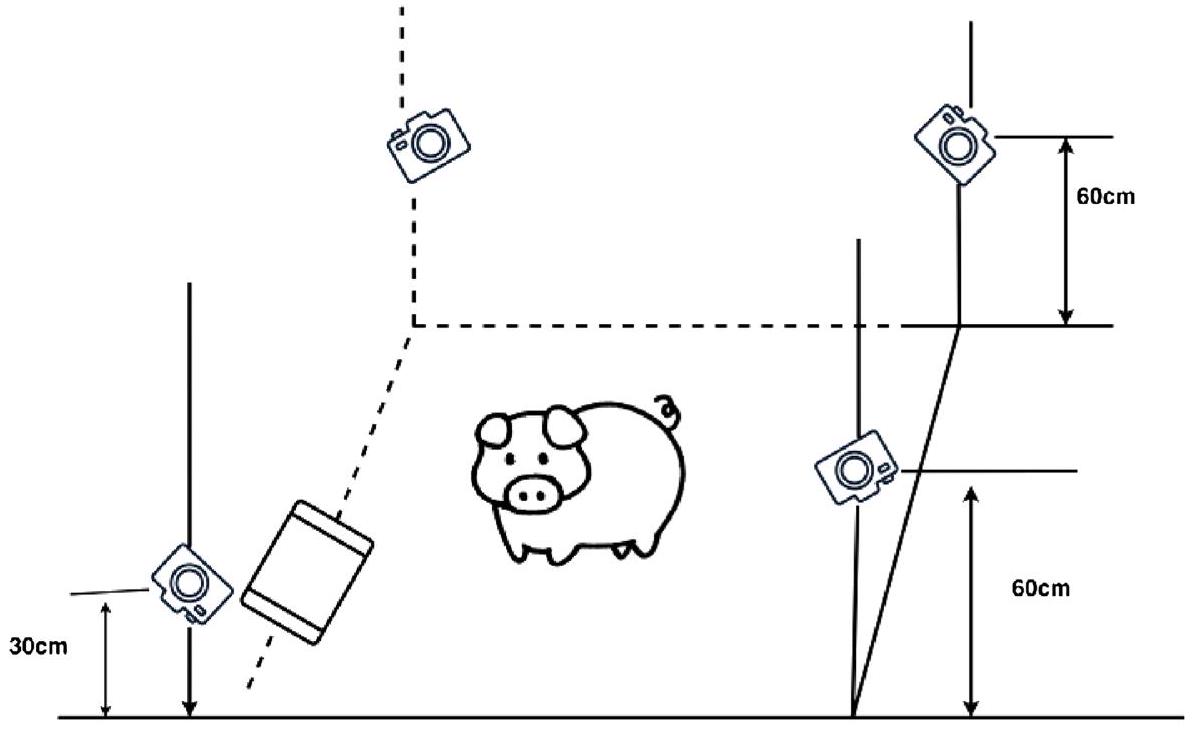
الشكل 1. مخطط حل التقاط الفيديو.
ومع ذلك، فإن التحديات الكامنة في مثل هذا البيئة الديناميكية، بما في ذلك تحركات الخنازير المتنوعة والاختلافات المحتملة بين الكاميرات، تتطلب تحققًا صارمًا من البيانات. أي صور تأثرت بتحركات الخنازير السريعة، أو عوائق غير متوقعة، أو إضاءة غير مواتية اعتبرت “غير صالحة” وتم التخلص منها لاحقًا. كما هو موضح في الشكل 2، أدت هذه العملية الصارمة للتصفية إلى مجموعة بيانات متنوعة ولكن موثوقة من 2700 صورة مصنفة.

الشكل 2. مخطط الفئات الأربع: (أ) للسعادة، (ب) للحياد، (ج) للخوف، (د) للغضب.
تعبيرات وجه الخنزير المسمى
يستند تصنيف التعبيرات إلى نتائج الأبحاث ذات الصلة
توسيع مجموعة بيانات تعبير وجه الخنزير
قبل توسيع مجموعة البيانات، خضعت المجموعة الأولية من الصور لسلسلة من خطوات المعالجة المسبقة لضمان التناسق وتعزيز الجودة للتدريب. تم تغيير حجم جميع الصور إلى دقة قياسية، مما يضمن التوحيد عبر مجموعة البيانات. علاوة على ذلك، تم تطبيق أي تقنيات تقليل الضوضاء أو التطبيع، مما أعد الصور لخطوات التعزيز اللاحقة. بالنسبة لتعزيز البيانات، يتم استخدام طرق التحويل الهندسي مثل التدوير، والانعكاس، والقص، وما إلى ذلك، وطرق تحويل البكسل مثل ضبط تباين HSV، والسطوع، والتشبع، وما إلى ذلك. من خلال تطبيق عمليات مثل تعزيز التباين (الشكل 3ب)، وتعزيز السطوع (الشكل 3ج)، وعمليات الانعكاس (الشكل 3د)، وتدوير الزاوية (الشكل 3هـ) على صور التدريب (الشكل 3أ)، يمكن الحصول على شبكة ذات قدرة تعميم أقوى. يساعد ذلك في تقليل الإفراط في التكيف ويوسع حجم مجموعة البيانات. بعد التعزيز، زاد حجم مجموعة البيانات إلى 5400 صورة. لتسهيل التعرف الفعال على تعبيرات الخنازير، تم استخدام برنامج وضع العلامات لوضع علامات على المناطق الوجهية للخنازير داخل صور إطار الفيديو. كانت هذه العملية دقيقة، مما يضمن أن كل تعبير تم وضع علامة عليه بشكل صحيح بناءً على ملامح الوجه والسياق الموقفي. بعد ذلك، من إجمالي الصور، تم تخصيص 3780 للتدريب، و1080 للتحقق، و540 المتبقية للاختبار.
تكوين بيئة التدريب
تم تكوين بيئة الأجهزة مع
| الفئة | التغيرات الوجهية | سياق المشهد | |||
| عين | أنف | شفاه | أذن | ||
| سعيد | عيون مغلقة قليلاً | لا شيء | رفع الشفة العليا | سحب الأذنين إلى الوراء | عموماً في حالة الأكل |
| محايد | لا شيء | لا شيء | لا شيء | لا شيء | طبيعي |
| خائف | عيون مغلقة قليلاً | تجاعيد مخفضة | لا شيء | آذان متدلية | عموماً في حالة صدمة |
| غاضب | عيون مفتوحة على مصراعيها | تجاعيد متعمقة | رفع الشفة العليا | لا شيء | عموماً قبل بدء فعل العدوان |
الجدول 1. وصف فئات تعبيرات الوجه.

الشكل 3. توسيع بيانات صورة تعبير الخنزير.
نموذج YOLOv5s
يمكن تصنيف YOLOv5 إلى أربعة نماذج بناءً على عمق الشبكة وعرضها، وهي s،
الإدخال
يتضمن مفهوم تعزيز بيانات الموزاييك اختيار أربع صور عشوائيًا وتطبيق قص عشوائي، وعمليات انعكاس، وتغيير الحجم، وتحولات أخرى عليها. ثم يتم دمج هذه الصور المحولة في صورة واحدة بطريقة موزعة عشوائيًا. تعزز هذه التقنية بشكل كبير مجموعة البيانات وتزيد من حجم الدفعة، مما يحسن كفاءة التدريب.
تكمن ابتكارات YOLOv5 في دمج حساب صندوق التثبيت أثناء التدريب. خلال عملية التدريب، يتم ضبط حجم صندوق التثبيت ديناميكيًا من خلال توقع صندوق محيط بناءً على مجموعة صناديق التثبيت الأولية، ومقارنته مع الحقيقة الأرضية، وحساب الخسارة، وتحديث حجم صندوق التثبيت وفقًا لذلك. تتيح هذه الطريقة لـ YOLOv5 التكيف وحساب القيم المثلى لصندوق التثبيت لمجموعات بيانات التدريب المختلفة.
عادةً ما يتم تغيير حجم الصور المستخدمة في خوارزمية YOLO إلى مقياس 1:1. ومع ذلك، في مشاريع الكشف في العالم الحقيقي، يختلف نسبة عرض الصورة. يؤدي فرض الحشو للحفاظ على نسبة
العمود الفقري
تلعب شبكة العمود الفقري دورًا حاسمًا في استخراج المعلومات والميزات من الصور المدخلة. في الشكل 5، بافتراض أن الصورة المدخلة هي
العنق
تلعب وحدة العنق دورًا حاسمًا في دمج الميزات المستخرجة بواسطة شبكة العمود الفقري بشكل فعال وتعزيز الأداء العام للشبكة. من خلال دمج العمليات من الأعلى إلى الأسفل ومن الأسفل إلى الأعلى، تعزز وحدة العنق قدرة الشبكة على دمج كل من المعلومات الدلالية ومعلومات التوطين، مما يؤدي إلى تحسين الأداء والدقة.
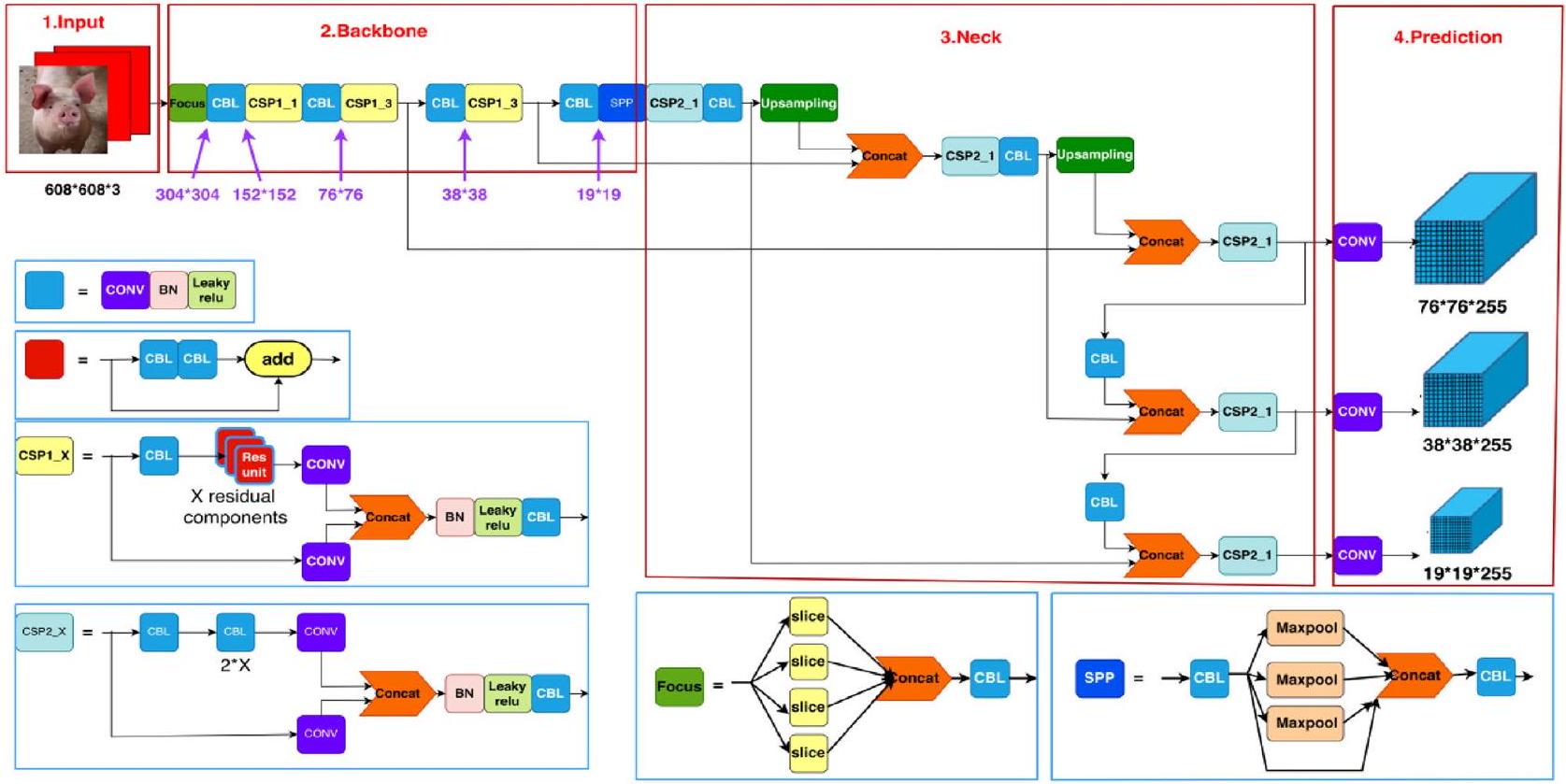
الشكل 4. هيكل شبكة YOLOv5s: الإدخال، العمود الفقري، العنق، والرأس (التنبؤ).
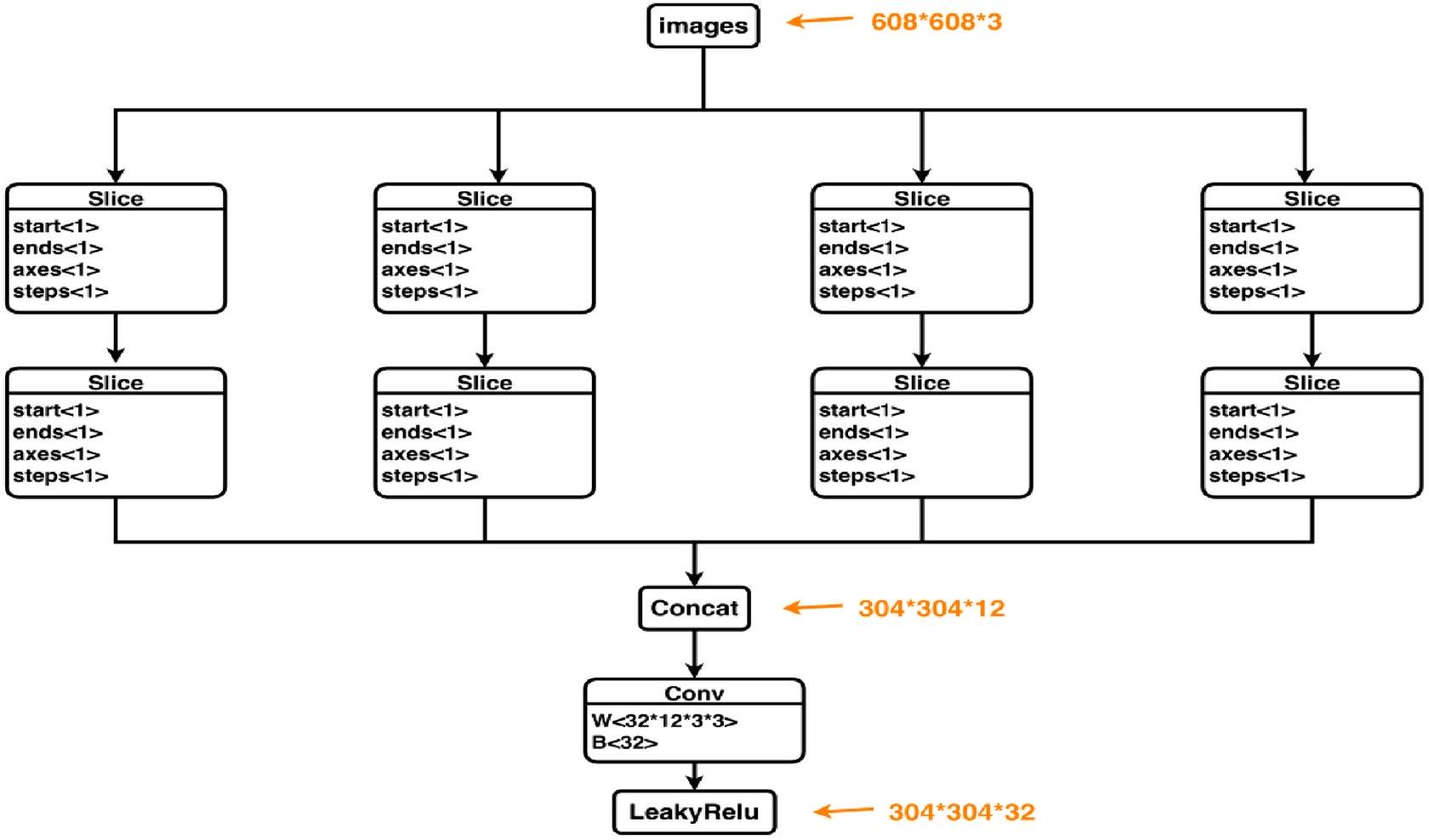
الشكل 5. هيكل التركيز.
الرأس (التنبؤ)
تستخدم جزء الرأس بشكل أساسي لاكتشاف الهدف، ويقوم الرأس بتوسيع عدد القنوات من خلال
نموذج التعرف على تعبيرات وجه الخنزير CReToNeXt-YOLOv5
للتعرف بشكل فعال على تعبيرات الوجه في الخنازير، تم استخدام نموذج CReToNeXt-YOLOv5 لتصنيف والتعرف على أربعة أنواع من التعبيرات في صور وجه الخنزير. تم إعداد مزرعة خنازير في مقاطعة شانشي، وتم جمع لقطات فيديو للخنازير باستخدام كاميرا فيديو. ثم تم استخراج صور الوجه للخنازير من مقاطع الفيديو. من أجل تحسين دقة التعرف على التعبيرات وتحقيق تحديد دقيق للأهداف، تم استخدام دالة خسارة EIOU بدلاً من دالة خسارة CIOU. بالإضافة إلى ذلك، تم دمج آلية الانتباه التناسبي لتعزيز حساسية النموذج لميزات التعبير. تم تقديم وحدة CReToNeXt أيضًا لتعزيز قدرة النموذج على اكتشاف التعبيرات الدقيقة.
تشمل نقاط تحسين نموذج CReToNeXt-YOLOv5 دمج آلية الانتباه، ودمج وحدة CReToNeXt لتعزيز عنق النموذج وتحسين أداء الكشف، واستخدام دالة خسارة EIOU المحسنة في قسم الرأس. يتم توضيح إطار التحسين لنموذج CReToNeXt-YOLOv5 في الشكل 6.
آلية الانتباه التناسبي
تمت دراسة آليات الانتباه بشكل موسع لتحسين قدرات الشبكات العصبية العميقة، خاصة في التقاط معلومات “ما” و”أين”. ومع ذلك، فإن تطبيقها في الشبكات المحمولة يتخلف بشكل كبير عن الشبكات الأكبر بسبب القيود الحسابية. تركز آلية الانتباه Squeeze-and-Excitation (SE) بشكل أساسي على ترميز المعلومات بين القنوات مع تجاهل المعلومات الموضعية، التي تلعب دورًا حاسمًا في التقاط هياكل الكائنات في المهام البصرية. حاولت وحدة الانتباه الكتلي التلافيفي (CBAM) دمج المعلومات الموضعية عن طريق تقليل أبعاد القناة من التنسور المدخل وحساب الانتباه المكاني باستخدام التلافيف، كما هو موضح في الشكل 7a. ومع ذلك، فإن المهام البصرية بطبيعتها
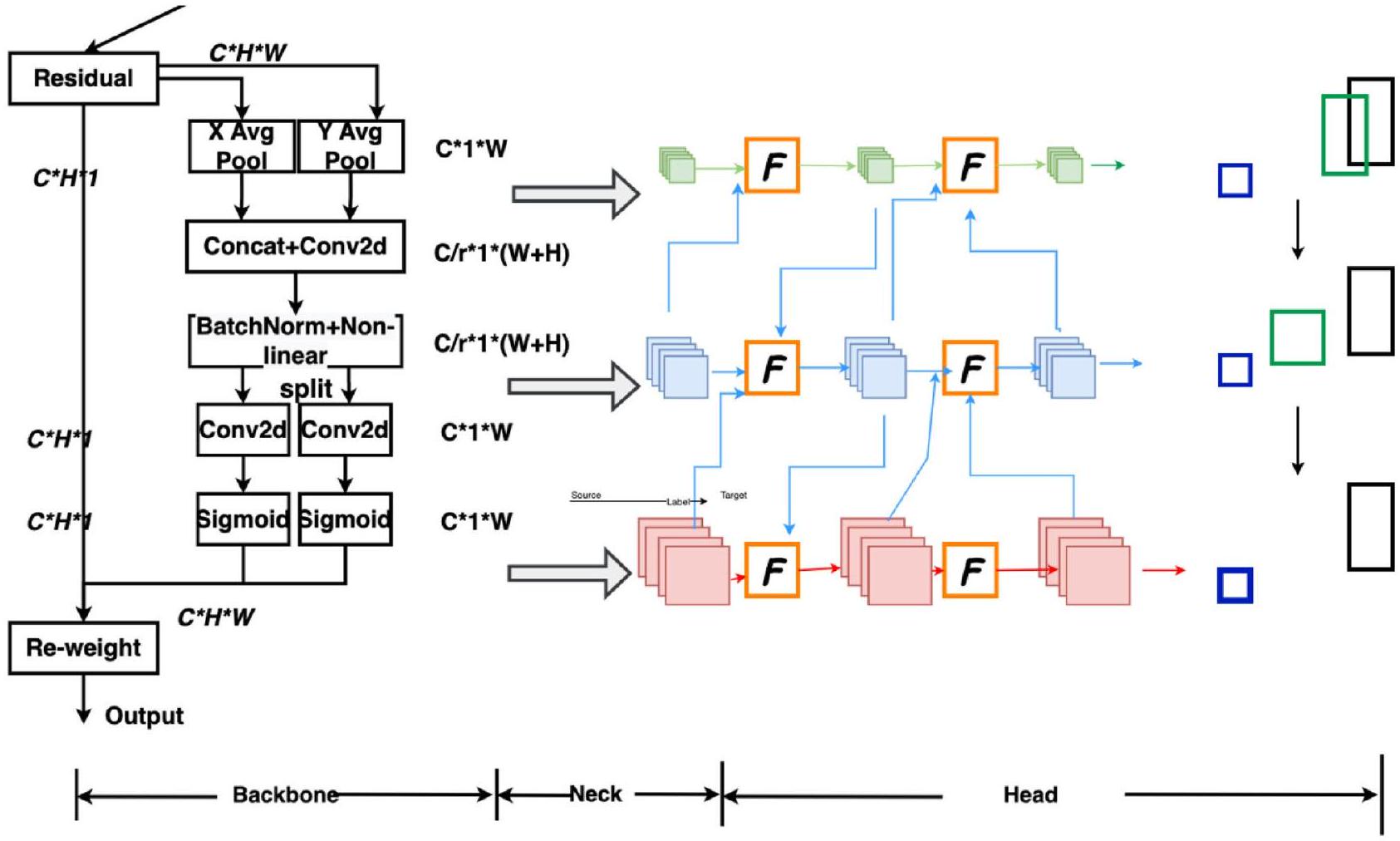
الشكل 6. إطار محسّن لنموذج CReToNeXt-YOLOv5: آلية الانتباه التناسبي؛ دالة خسارة EIOU؛ وحدة CReToNeXt.
الشكل 7. هيكل آلية الانتباه CBAM مقارنة بآلية الانتباه التناسبي: (أ) مخطط هيكل CBAM؛ (ب) مخطط هيكل الانتباه التناسبي.
تنطوي على اعتمادات بعيدة المدى لا يمكن نمذجتها بفعالية فقط من خلال العلاقات المحلية التي تلتقطها التلافيف.
إن دمج آلية الانتباه التناسبي يعزز تركيز الشبكة على الهدف المراد اكتشافه ويحسن نتائج الكشف. عند دمجه مع الهيكل الموضح في الشكل 7b أدناه، فإن المفهوم الرئيسي للانتباه التناسبي هو كما يلي: يتم تجميع الميزات المدخلة بشكل منفصل في اتجاه h واتجاه w، مما يؤدي إلى
تضمين معلومات الإحداثيات. يقوم نموذج الانتباه القنوي بترميز المعلومات المكانية عالميًا باستخدام طريقة التجميع العالمي. ومع ذلك، تؤدي هذه الطريقة إلى فقدان معلومات الموقع حيث يتم ضغط المعلومات المكانية العالمية في موصوف القناة خلال عملية الترميز. لمعالجة هذه المشكلة، يتم تحليل التجميع العالمي وفقًا للمعادلة (2) وتحويله إلى عملية ترميز ميزات أحادية البعد، مما يحافظ على معلومات الموقع.
x هو المدخل وكل قناة يتم ترميزها أولاً على طول الإحداثيات الأفقية والعمودية باستخدام نواة تجميع بحجم
وبالمثل، يمكن التعبير عن مخرجات القناة c بعرض
توليد الانتباه التناسبي. تم تطوير الانتباه التناسبي بناءً على ثلاثة معايير رئيسية: (أ) البساطة في تنفيذ التحويل الجديد ضمن البيئة المحمولة. (ب) القدرة على التقاط منطقة الاهتمام بدقة من خلال الاستفادة من معلومات الموقع الملتقطة. (ج) التقاط العلاقات بين القنوات بكفاءة. بمجرد تنفيذ التحويل الجديد في تضمين المعلومات، تستمر التحويلات السابقة مع عملية الدمج، تليها وظيفة تحويل تلافيفية.
دالة خسارة EIOU
تم اعتماد دالة خسارة EIOU بدلاً من دالة خسارة CIOU المستخدمة في خوارزمية YOLOv5 لتحسين نموذج التدريب. يحسن هذا التغيير بشكل كبير دقة خوارزمية التعرف على تعبيرات وجه الخنزير ويمكّن من التعرف السريع والدقيق على الأهداف. تطور دوال خسارة الانحدار على مدى السنوات القليلة الماضية هو كما يلي: IOU_Loss
عندما لا يتقاطع صندوق التنبؤ مع صندوق الحقيقة الأرضية، فإن IoU (التقاطع على الاتحاد) لا يعكس المسافة الفعلية بين الصندوقين، مما يؤدي إلى قيمة خسارة IoU تساوي صفر. يمكن أن يؤثر ذلك سلبًا على تراجع التدرج، مما يجعل من الصعب تدريب النموذج بفعالية. علاوة على ذلك، لا يمثل IoU بدقة مدى التداخل بين صناديق التنبؤ والحقيقة الأرضية. تعالج دالة خسارة DIoU (Distance-IoU) هذه القضايا من خلال دمج عوامل مثل المسافة، والتداخل، والمقياس بين صناديق التنبؤ والحقيقة الأرضية. يؤدي ذلك إلى انحدار أكثر استقرارًا لصندوق التنبؤ المستهدف. b تمثل مركز صندوق التنبؤ، b
في YOLOv5s، تم استخدام دالة خسارة CIOU (Complete IoU) لتعزيز التوافق بين صندوق التنبؤ وصندوق الحقيقة الأرضية. يبني ذلك على دالة خسارة DIOU (Distance-IoU) من خلال دمج عقوبات إضافية لمقياس، وطول، وعرض صندوق الكشف. التعبيرات لدالة CIOU_Loss هي كما يلي:
حيث
نسب الأبعاد، كقيم نسبية، تقدم بعض الغموض ولا تأخذ في الاعتبار التوازن بين العينات الصعبة والسهلة (Zhang et al., 2022). استجابةً لذلك، يقوم EIOU_Loss بتقسيم نسبة الأبعاد إلى الفرق في العرض والارتفاع بين صندوق التحديد المتوقع وصندوق التحديد الخارجي الأدنى، استنادًا إلى CIOU_Loss. ثم يتم حساب أطوال وعرض صناديق الهدف والمرساة بشكل منفصل. من خلال تقليل الفرق بين عرض وارتفاع صناديق الهدف والمرساة، يتم زيادة سرعة التقارب ودقة الانحدار. بالإضافة إلى ذلك، يتم تقديم Focal Loss لتحقيق التوازن بين العينات في مهمة انحدار صندوق التحديد. يتم التعبير عنها كما يلي:
تمت مقارنة مزايا وعيوب كل دالة خسارة بناءً على العوامل الهندسية الثلاثة الرئيسية لتقدير إطار الحدود (مساحة التداخل، مسافة المركز، ونسبة الأبعاد) (الجدول 2). عند استبدال دالة خسارة إطار التثبيت في YOLOv5s بـ EIOU_Loss، أظهرت الأداء تحسنًا ملحوظًا مقارنةً بـ IOU_Loss الأصلية وDIOU_Loss وCIOU_Loss وغيرها.
وحدة CReToNeXt
DAMO-YOLO، وهو نهج متقدم لاكتشاف الأهداف، يضع معيارًا جديدًا من خلال دمج تقنيات متطورة مثل البحث في بنية الشبكات العصبية (NAS)، وشبكة الهرم العام المعاد تشكيلها (RepGFPN)، ورؤوس خفيفة الوزن فعالة، وزيادة التقطير الاستراتيجي. واحدة من التحسينات الأساسية في DAMO-YOLO هي استبدال كتلة CSPStage الموجودة في بنية YOLOv5 بوحدة CReToNeXt المبتكرة، مما يجعل النموذج أكثر تكيفًا وكفاءة في مهام اكتشاف الأجسام، مما يؤدي إلى مقاييس أداء لا مثيل لها.
وحدة CReToNeXt، في جوهرها، مصممة كعنصر من شبكة عصبية تلافيفية، تتخصص في المهمة المعقدة لاستخراج ميزات الصورة. تستند فلسفة تصميم CReToNeXt إلى آلية المعالجة المنقسمة. عند استلام مدخل، تقوم الوحدة بكفاءة بتقسيمه إلى فرعين متميزين، يخضع كل منهما لعملياته التلافيفية المتخصصة. تسمح هذه العمليات المتميزة للوحدة بالتقاط مجموعة أوسع من ميزات الصورة، مما يضمن تمثيلاً شاملاً. بعد هذه العمليات، يتم دمج المخرجات من كلا الفرعين، مما يحافظ على غنى الميزات المستخرجة.
من خلال التعمق في تعقيدات تصميمه، يمكن توسيع وحدة CReToNeXt وجعلها أكثر قوة. يتم تحقيق ذلك من خلال تكديس عدة نسخ من BasicBlock_
| خسارة | تداخل | نقطة المركز | نسبة العرض إلى الارتفاع | المزايا | العيوب | ||
| خسارة IOU |
|
|
|
عدم التغير تحت التحجيم؛ عدم السلبية؛ التجانس؛ التماثل؛ عدم المساواة المثلثية |
|
||
| خسارة GIOU |
|
|
|
حل المشكلة التي تكون فيها الخسارة تساوي 0 عندما لا يوجد تداخل بين صندوق الكشف والصندوق الحقيقي |
|
||
| خسارة DIOU |
|
|
|
يمكن تسريع التقارب | تأخذ عملية الانحدار في الاعتبار نسبة العرض إلى الارتفاع لصندوق الحدود وهناك مجال لمزيد من التحسين في الدقة | ||
| خسارة CIOU |
|
|
|
تم زيادة فقدان مقياس إطار الكشف، الطول والعرض بحيث تكون الإطارات المتوقعة أكثر توافقًا مع الإطارات الحقيقية. |
|
||
| خسارة EIOU |
|
|
|
تم استبدال نسبة العرض إلى الارتفاع بحساب منفصل لفارق العرض والارتفاع، بينما تم تقديم خسارة التركيز لمعالجة مشكلة عدم التوازن بين العينات الصعبة والسهلة. |
الجدول 2. مقارنة دوال الخسارة.
بينما تخضع المخرجات من الفرعين لعملية الدمج، يتم توجيهها بعد ذلك عبر طبقة تلافيفية لاحقة، والتي تقوم بتنقيح وإخراج مجموعة الميزات النهائية. إن التصميم المعقد والمفصل لوحدة CReToNeXt لا يعزز فقط القدرة التشغيلية لـ YOLOv5، بل ينقي أيضًا قدرته على التقاط وتمثيل المعلومات الدلالية المعقدة الموجودة داخل الصور، مما يجعلها أداة لا تقدر بثمن في عالم اكتشاف الأشياء.
مؤشرات تقييم نموذج YOLOv5
لتقييم مزايا نماذج التعرف على التعبيرات بدقة، تم اختيار الدقة، ومتوسط الدقة المتوسطة، والاسترجاع، ودرجة F1 للتقييم.
دقة
تشير الدقة إلى ما إذا كانت المنطقة المكتشفة هي دائمًا المنطقة الصحيحة، مع قيمة مثالية تبلغ 1. صيغة الحساب كما في المعادلة (11). TP: الفئة الحقيقية للعينة هي مثال إيجابي ويتنبأ النموذج بنتيجة إيجابية وتنبؤ صحيح. FP: الفئة الحقيقية للعينة هي مثال سلبي، ولكن النموذج يتنبأ بها كمثال إيجابي ويتنبأ بها بشكل غير صحيح.
mAP
mAP تشير إلى الدقة المتوسطة وتدل على جودة الكشف، حيث تمثل القيم الأعلى أداءً أفضل في الكشف، كما هو مكتوب في المعادلة (12). N تشير إلى العدد الإجمالي للعينة،
استدعاء
يتم حساب الاسترجاع كما في المعادلة (13)، مما يشير إلى ما إذا كانت الكشف شاملًا وما إذا كانت جميع المناطق التي يجب الكشف عنها قد تم الكشف عنها، مع قيمة مثالية تبلغ 1. FN: الفئة الحقيقية للعينة هي مثال إيجابي، بينما يتنبأ النموذج بأنها مثال سلبي ويتنبأ بها بشكل غير صحيح.
درجة F1
تشير درجة F1 إلى مقياس لمشكلة التصنيف. إنها المتوسط المجموع للدقة والاسترجاع، مع حد أقصى يبلغ 1 وحد أدنى يبلغ 0.
النتائج والمناقشة
في هذا الجزء، بدأنا تجارب صارمة باستخدام مجموعة بيانات مختارة بعناية من تعبيرات وجه الخنازير، وكان الهدف الرئيسي هو التحقق من فعالية نموذج CReToNeXt-YOLOv5 المقترح. انقسم مسارنا البحثي إلى ذراعين رئيسيين: التحقق الداخلي من النموذج وتحليل مقارن ضد نماذج الكشف عن الأهداف المعاصرة.
خلال مرحلة التحقق الذاتي، قمنا بدراسة المزايا التشغيلية لآلية الانتباه المنسق، ودالة خسارة EIOU، ووحدة CReToNeXt ضمن نموذجنا. بشكل أكثر تحديدًا، تحت خلفية تجريبية متناسقة، قمنا بتعطيل هذه المكونات المنفصلة وقارنّا النتائج من حالات نشاطها وعدم نشاطها، مما قدم رؤى حول مساهماتها الفردية والجماعية في أداء النموذج. علاوة على ذلك، لتسليط الضوء على الميزة التنافسية لنموذج YOLOv5 لدينا في مجال التعرف على تعبيرات الوجه لدى الخنازير، اخترنا بحكمة Faster R-CNN وYOLOv4 وYOLOv8 كمعايير مقارنة.
من المهم التأكيد على أن YOLOv5، عند مقارنته بتكراراته اللاحقة، قد حصل على تدقيق واسع النطاق وتأييد، مما يظهر نضجًا واستقرارًا جديرين بالثناء. في عملية اختيار النموذج لدينا، بالإضافة إلى الأداء الخالص، كان الاستقرار والقبول الجماعي ضمن مجتمع البحث الأوسع لهما وزن كبير. بينما أذهل YOLOv7 بمعدلات المAP العالية بشكل مبكر خلال التدريب الأولي، إلا أنه أشار في الوقت نفسه إلى احتمالية التعرض للإفراط في التكيف، خاصة في مجموعات البيانات الخاصة بالسياق. وهذا يثير القلق بشأن قابليتها القوية للتطبيق في السيناريوهات الواقعية. تركيز عدسة بحثنا منصب على التعرف في الوقت الحقيقي على تعبيرات الإجهاد الحراري في الخنازير، مما يجعل مرونة وموثوقية النموذج المختار أمرًا بالغ الأهمية. مدفوعين بهذه الاعتبارات، كان تحولنا إلى YOLOv5s كهيكل أساسي مدروسًا واستراتيجيًا، مما وفر لنا لوحة واسعة للتفاؤلات والتحسينات المستقبلية.
أداء نماذج التعرف على تعبيرات وجه الخنزير في تدريب البيانات والتحقق منها
كما هو موضح في الشكل 8أ، يوفر منحنى الدقة والاسترجاع فهمًا دقيقًا لأداء نموذج CReToNeXt-YOLOv5 عبر فئات مختلفة. واحدة من الملاحظات الملحوظة من هذا التمثيل هي درجات الثقة للنموذج. عمومًا، ترتبط درجة الثقة الأعلى بقدرة كشف متفوقة، ونموذجنا يجسد هذه الاتجاه، مما يشير إلى تميزه في مهام كشف الأجسام. يعزز المAP البالغ 0.894 هذا، مما يبرز قوة النموذج ودقته العالية في الكشف بشكل عام. عند الانتقال إلى منحنى الاسترجاع، الموضح في الشكل 8ب، تشير القيمة 0.990 إلى براعة النموذج في كشف الأهداف، على الرغم من أنه قد لا تزال هناك فرص صغيرة للتحسين لضمان التعرف على كل حالة حقيقية. ربما الأهم من ذلك، أن درجة F1، المعروضة في الشكل 8ج، تلخص مقياس الأداء الشامل، موحدة بين الدقة والاسترجاع. تعتبر درجة F1 مؤشرًا لا غنى عنه، وغالبًا ما تشير إلى التوازن الذي يحافظ عليه النموذج بين الإيجابيات الكاذبة والسلبيات الكاذبة. في سياقنا، تعتبر درجة F1 البالغة 0.84 ليست فقط جديرة بالثناء ولكنها تشير إلى توازن جيد تم تحقيقه من قبل نموذج CReToNeXt-YOLOv5 بين الدقة والاسترجاع، مما يضع معيارًا لتكرارات النموذج اللاحقة وجهود البحث.
تقدم مصفوفة الالتباس، كما هو موضح في الشكل 9، فهمًا شاملاً لأداء نموذج CReToNeXt-YOLOv5 في تمييز تعبيرات وجه الخنزير المختلفة. بشكل مثير للإعجاب، يظهر النموذج قدرة قوية بشكل خاص في التعرف على تعبير “السعادة”، مسجلاً إياه بدقة عالية. ومع ذلك، تظهر بعض التحديات عندما يتعلق الأمر بالتمييز بين درجات “الخوف” و”الغضب” الدقيقة. يخلط النموذج أحيانًا بين “الخوف” و”السعادة” والعكس صحيح، مما يشير إلى منطقة محتملة للتحسين في التمييز بين التعبيرات الإيجابية والأكثر هدوءًا أو السلبية.
علاوة على ذلك، يظهر جانب ملحوظ في التعرف على تعبير “الحياد”. هذه الفئة، بطبيعتها دقيقة، تمثل تحديًا، حيث يتم تجاهل نسبة كبيرة منها وتصنيفها كخلفية. قد يشير هذا إلى حساسية النموذج تجاه الإشارات الدقيقة أو الحاجة إلى بيانات تدريب أغنى لهذه الفئة المحددة. ملاحظة مثيرة أخرى هي التصنيف الخاطئ العرضي لما هو في الأساس ضوضاء خلفية كحالات عاطفية متميزة. وهذا يشير إلى إمكانية تحسين قدرات تصفية الضوضاء للنموذج.
باختصار، بينما يظهر النموذج قوة في بعض الفئات العاطفية، هناك مجال للتحسين. تعمل مصفوفة الالتباس كدليل، مبرزًا مجالات مثل تمييز الدقائق في بعض العواطف وتحسين تصفية الضوضاء الخلفية، مما يمهد الطريق لتكرارات مستقبلية أكثر دقة ووضوحًا.
يوضح الشكل 10 نتائج اختبار نموذج CReToNeXt-YOLOv5، مقارنًا بين تسميات دفعات التحقق (الموضحة في الجزء (أ)) مقابل توقعاتها المقابلة (المميزة في الجزء (ب)). عند لمحة، يمكن للمرء أن يميز براعة النموذج الدقيقة في التقاط طيف تعبيرات وجه الخنزير، مع درجة دقة جديرة بالثناء في التعرف على العواطف مثل ‘الحياد’ و’الخوف’ و’الغضب’ وخصوصًا ‘السعادة’. عند التعمق أكثر في الرؤى التي يقدمها هذا التمثيل البصري، يتم التأكيد بشكل خاص على براعة النموذج في قدرته على فك تشفير تعبيرات ‘السعادة’ بدقة عالية، مما يعكس درجة عالية من الدقة في نطاق
ومع ذلك، تصبح الأمور أكثر غموضًا قليلاً عند التنقل في مجالات العواطف الأكثر هدوءًا أو تعقيدًا مثل ‘الخوف’ و’الغضب’، حيث سجل كلاهما مستوى دقة قدره
في جوهرها، يقدم الشكل 10 فسيفساء من نقاط القوة في نموذج CReToNeXt-YOLOv5 وطرق التحسين المحتملة. بينما يتفوق في كشف العواطف الواضحة مثل السعادة، هناك حدود مثيرة في تحسين حساسيته تجاه النسيج الأكثر تعقيدًا من العواطف، بهدف الوصول إلى تكرار يجسد النطاق الكامل وعمق تعبيرات وجه الخنزير بدقة لا مثيل لها.
نتائج التحقق الذاتي وتحليل نموذج CReToNeXt-YOLOv5
تظهر النتائج التجريبية على مجموعة بيانات صور تعبيرات الخنزير ذات التسمية الذاتية في الجدول 3. كان المAP لنموذج CReToNeXt-YOLOv5 هو
في سياق تحسين النموذج من أجل دقة وقوة أفضل، تم دمج آليتين قويتين للانتباه، وهما CBAM وآلية الانتباه التناسبي، في إطار Yolov5s، وتم تقييم مساهماتهما الفردية بدقة. تكشف التحليلات الشاملة أن دمج آلية الانتباه التناسبي، كما يتضح من مقاييسها، قدم تحسين أداء أكثر تفوقًا مقارنة بآلية CBAM. بشكل محدد، عند ملاحظة المAP، وهو مؤشر حاسم لتوازن دقة النموذج واسترجاعه، تفوق النموذج المزود بآلية الانتباه التناسبي قليلاً على نظيره CBAM، مما يعكس قدرة كشف أفضل بشكل طفيف. علاوة على ذلك، أظهر النموذج المعزز بآلية الانتباه التناسبي أيضًا تحسينًا ملحوظًا في كشف تعبير “الحياد”، وهو مهمة صعبة بطبيعتها نظرًا لدقة التعبيرات الحيادية. وهذا يشير إلى أن هذه الآلية قد تمنح النموذج ميزة في تمييز الميزات الدقيقة في مجموعة البيانات. بينما قدمت كلتا الآليتين نتائج جديرة بالثناء، كان القرار بتفضيل آلية الانتباه التناسبي على CBAM مدفوعًا بأدائها العام المتفوق والمتسق عبر مقاييس مختلفة. يبرز الاختيار أهمية
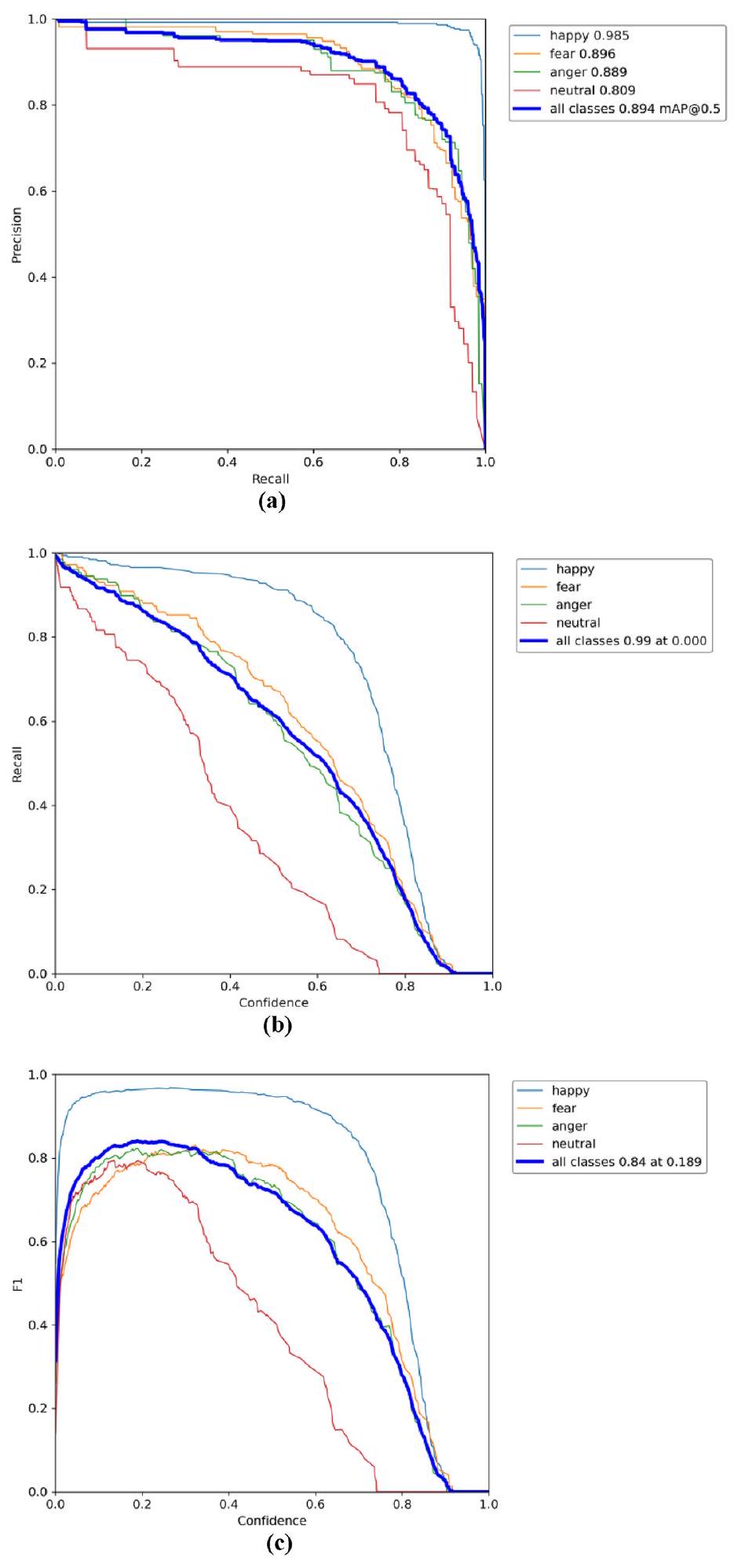
الشكل 8. نتائج اختبار نموذج CReToNeXt-YOLOv5: (أ) يمثل منحنى الدقة والاسترجاع، موضحًا اتجاهًا مثاليًا لأداء النموذج عبر عتبات مختلفة. الخط الأزرق المتصل: يمثل متوسط الدقة العامة (mAP) للنموذج، مما يدل على دقة اكتشاف إجمالية تبلغ 0.894 عبر جميع الفئات؛ (ب) يمثل معدل الاسترجاع، محققًا علامة عالية تبلغ 0.99، مما يشير إلى كفاءة النموذج في تحديد الحالات ذات الصلة؛ (ج) يدل على درجة F1 عبر جميع الفئات، حيث تصل إلى ذروتها عند 0.84 عند عتبة 0.189، مما يبرز أداء النموذج المتوازن بين الدقة والاسترجاع.
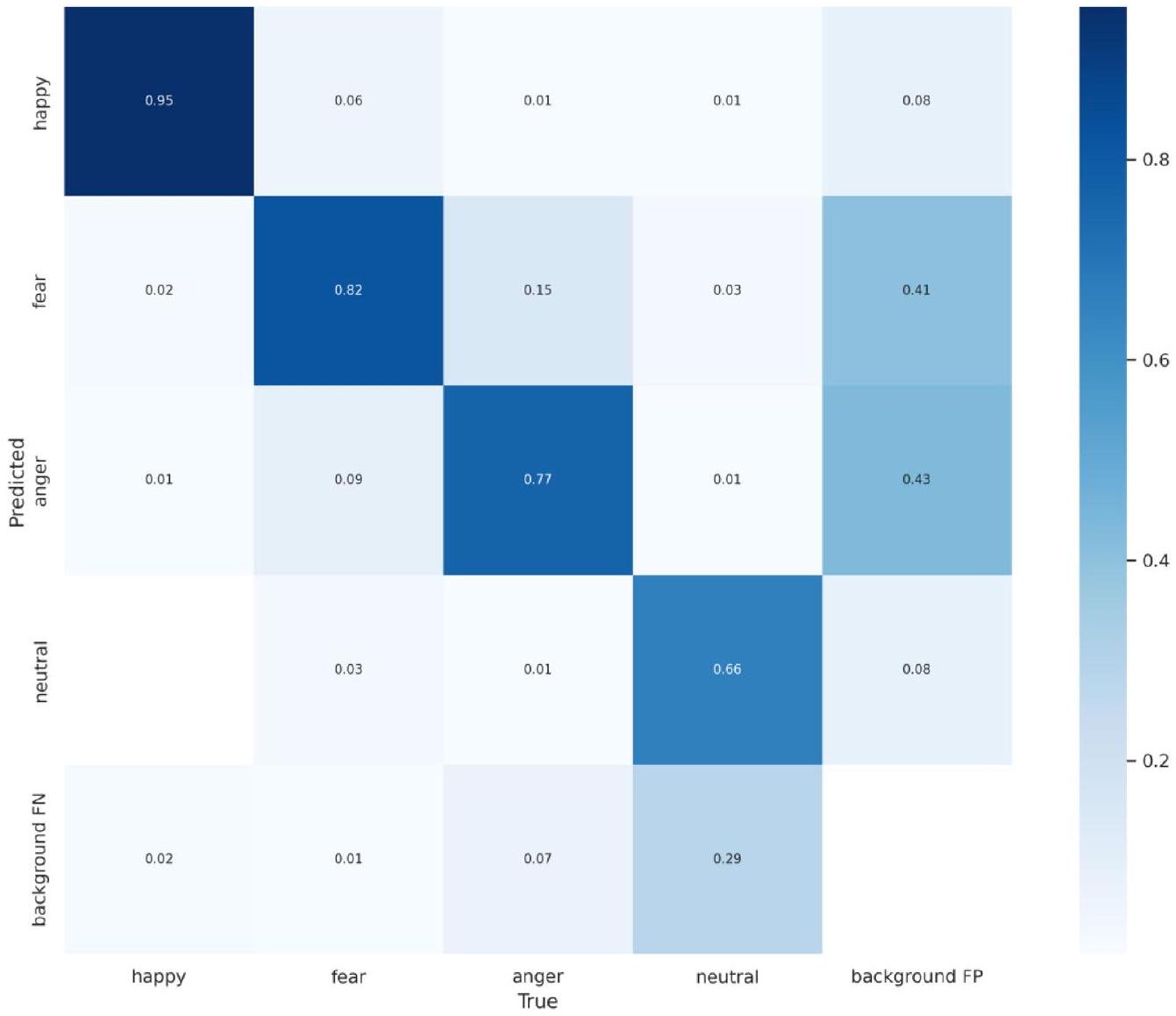
الشكل 9. مصفوفة الالتباس لنموذج CReToNeXt-YOLOv5.
التجريب التكراري والقرارات المستندة إلى البيانات في تحسين النموذج، مما يضمن أن التحسين المختار يقدم تحسينات نظرية وعملية على قدرات النظام.
يوفر الشكل 12 مقارنة لنتائج التنبؤ لأربع فئات تعبيرية بين النماذج المحسّنة. من الواضح أن فئة السعادة يمكن تمييزها بسهولة، مع دقة تتجاوز
تتناول إضافة آلية الانتباه التناسقي هذه المشكلة من خلال تفكيك انتباه القناة إلى عمليتين منفصلتين لترميز الميزات أحادية البعد. تقوم هذه العمليات بتجميع الميزات على طول اتجاهين مكانيين بشكل فردي. تتيح هذه الطريقة التقاط الاعتمادات البعيدة على طول اتجاه مكاني واحد مع الحفاظ على معلومات الموقع الدقيقة على طول الاتجاه الآخر. يتم ترميز خرائط الميزات الناتجة كخرائط انتباه مدركة للاتجاه والموقع، والتي يمكن تطبيقها بطريقة تكاملية على خرائط الميزات المدخلة. يعزز هذا من تمثيل الكائنات ذات الاهتمام ويحسن بشكل فعال دقة التعرف على فئة الحياد.
دمج آلية الانتباه التناسقي في إطار عمل YOLOv5s لاكتشاف تعبيرات وجه الخنازير يجسد مزيجًا من الدقة والفهم المكاني في تقنيات اكتشاف الكائنات. بالنسبة لمهمة دقيقة مثل اكتشاف تعبيرات وجه الخنازير المتنوعة، تلعب التفاصيل الدقيقة والمكانية دورًا محوريًا. غالبًا ما تكافح النماذج التقليدية لالتقاط هذه الإشارات الدقيقة، خاصة عندما تتشارك التعبيرات في أوجه التشابه. مع آلية الانتباه التناسقي، يتم تزويد النموذج بالقدرة على التركيز انتقائيًا على المناطق في خريطة الميزات التي تكون الأكثر معلوماتية لتعبير معين. من خلال وزن هذه المناطق بشكل أكبر في الطبقات اللاحقة، يصبح النموذج أكثر قدرة على التمييز بين التعبيرات التي قد تبدو متشابهة في العادة.
إن دمج دالة خسارة EIOU في إطار عمل YOLOv5s لاكتشاف تعبيرات وجه الخنازير يجسد تطور منهجيات اكتشاف الكائنات. تعتمد دالة خسارة EIOU (التقاطع المعزز على الاتحاد) على دالة خسارة IOU الأساسية، المعروفة بفعاليتها في مهام انحدار صناديق الحدود. ومع ذلك، تقوم EIOU بمزيد من التحسين من خلال معالجة بعض العيوب الموجودة في حسابات IOU التقليدية.
بالنسبة للمهمة الدقيقة المتمثلة في اكتشاف تعبيرات وجه الخنازير المتنوعة، تصبح دقة صناديق الحدود أمرًا بالغ الأهمية. يمكن أن تؤثر الأخطاء أو عدم الدقة في هذه الصناديق بشكل كبير على أداء النموذج، حيث يمكن أن تكون الفروق بين بعض التعبيرات دقيقة ومحددة. وظيفة خسارة EIOU تخفف من هذه المشكلات بشكل خاص من خلال النظر ليس فقط في التداخل بين صناديق الحدود المتوقعة والفعلية ولكن أيضًا
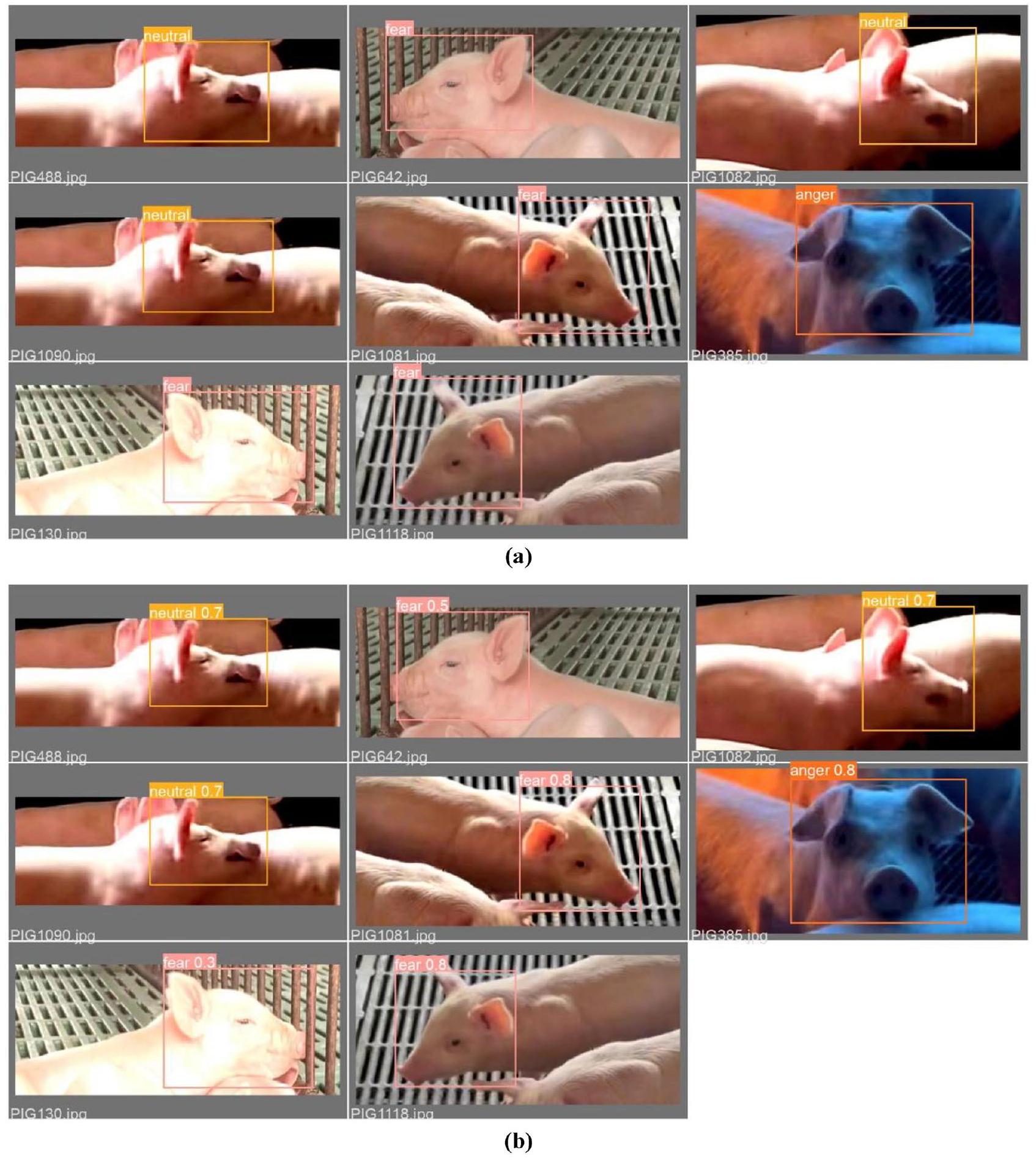
الشكل 10. نتائج اختبار نموذج CReToNeXt-YOLOv5: (أ) تسميات دفعة التحقق; (ب) توقعات دفعة التحقق.
الخصائص الهندسية والموضعية لهذه الصناديق. من خلال القيام بذلك، يضمن تطابقًا أكثر شمولاً، مما يلتقط الفروق الدقيقة التي قد يتم تجاهلها بواسطة دوال الخسارة التقليدية. علاوة على ذلك، يقلل EIOU من عقوبة التنبؤات التي تكون قريبة ولكنها ليست متطابقة تمامًا، مما يجعل عملية التعلم أكثر تسامحًا واستقرارًا. هذه المقاربة الدقيقة لتراجع صناديق الحدود، التي يسهلها دالة خسارة EIOU، تجعلها مكونًا حيويًا في تعزيز دقة نموذج YOLOv5s في الكشف عن تعبيرات وجه الخنازير. تضمن عملية التراجع عن الخطأ المعقدة المدفوعة بواسطة EIOU أن يتم تحسين تنبؤات النموذج باستمرار، مما يؤدي إلى نتائج كشف متفوقة عبر سيناريوهات متنوعة.
إن دمج وحدة CReToNeXt في إطار عمل YOLOv5s لاكتشاف تعبيرات الوجه الأربعة للخنازير يمثل تقدمًا كبيرًا في نماذج اكتشاف الكائنات. يستفيد هذا الدمج من نقاط القوة في وحدة CReToNeXt، مستفيدًا من قدراتها المتفوقة في استخراج الميزات وتنسيقها.
| نموذج | دقة | معدل الدقة المتوسطة | استدعاء | درجة F1 | |||
| سعيد | محايد | خوف | غضب | ||||
| يولو 5 إس | 0.974 | 0.691 | 0.806 | 0.835 | 0.827 | 0.779 | 0.77 |
| Yolov5s + EIOU | 0.978 | 0.689 | 0.839 | 0.824 | 0.832 | 0.798 | 0.77 |
| Yolov5s + CBAM | 0.981 | 0.760 | 0.858 | 0.841 | 0.860 | 0.815 | 0.65 |
| Yolov5s + coordAtt | 0.984 | 0.803 | 0.864 | 0.831 | 0.870 | 0.827 | 0.67 |
| Yolov5s + coordAtt + EIOU | 0.984 | 0.775 | 0.868 | 0.877 | 0.876 | 0.826 | 0.82 |
| Yolov5s + coordAtt + EIOU + CReToNeXt | 0.985 | 0.809 | 0.896 | 0.889 | 0.894 | 0.990 | 0.84 |
الجدول 3. نتائج التحقق الذاتي لنموذج CReToNeXt-YOLOv5.
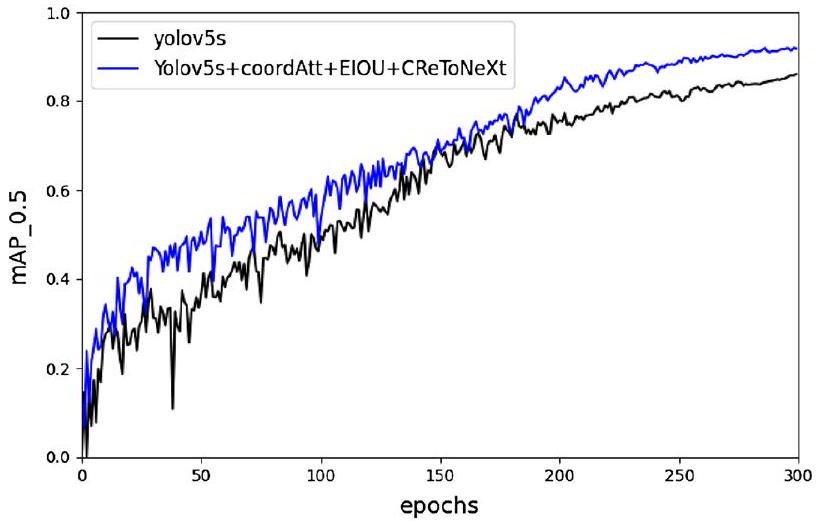
الشكل 11. رسم مقارنة المAP بين نموذج CReToNeXt-YOLOv5 ونموذج YOLOv5.
الشكل 12. استنادًا إلى نموذج YOLOV5 المحسن، مقارنة دقة الكشف لأربع فئات تعبيرية.
في قلب وحدة CReToNeXt تكمن قدرتها على تقسيم بيانات الإدخال إلى مسارين متميزين، مما يخضع كل منهما لعمليات تلافيفية مختلفة. هذه الآلية ذات المسارين تلعب دورًا حيويًا في التقاط كل من الميزات الدقيقة والمحلية والتفاصيل الأوسع والسياقية من الصورة المدخلة. بالنسبة للمهمة المطروحة، وهي تمييز تعبيرات الوجه الدقيقة في الخنازير، لا يمكن المبالغة في أهمية هذا النهج. يتم التقاط التغيرات الطفيفة في حركة عضلات الوجه، التي غالبًا ما تميز بين عاطفة وأخرى، بدقة وتأكيد من خلال هذه الطريقة. ميزة أخرى مثيرة للاهتمام في دمج CReToNeXt هي مرونتها في أبعاد خريطة الميزات. نظرًا للاختلافات الجوهرية في تعبيرات الوجه، فإن ضمان قدرة النموذج على استيعاب تحكم دقيق في قنوات خريطة الميزات أمر حاسم. هذا مهم بشكل خاص للتعقيد.
العواطف التي قد تظهر من خلال مجموعة من الإشارات الدقيقة على الوجه. علاوة على ذلك، فإن الإدراج الاختياري لطبقة تجميع الهرم المكاني في وحدة CReToNeXt يسهل استخراج الميزات متعددة المقاييس. نظرًا للاختلاف في الحجم والاتجاه الذي يمكن أن تكون عليه تعبيرات الوجه، اعتمادًا على وضعية الخنزير والمسافة من الكاميرا، يضمن هذا النهج متعدد المقاييس أن يظل النموذج قويًا وغير متأثر بمثل هذه التغييرات.
العواطف التي قد تظهر من خلال مجموعة من الإشارات الدقيقة على الوجه. علاوة على ذلك، فإن الإدراج الاختياري لطبقة تجميع الهرم المكاني في وحدة CReToNeXt يسهل استخراج الميزات متعددة المقاييس. نظرًا للاختلاف في الحجم والاتجاه الذي يمكن أن تكون عليه تعبيرات الوجه، اعتمادًا على وضعية الخنزير والمسافة من الكاميرا، يضمن هذا النهج متعدد المقاييس أن يظل النموذج قويًا وغير متأثر بمثل هذه التغييرات.
باختصار، فإن دمج وحدة CReToNeXt في بنية YOLOv5s يوفر تحسينًا شاملًا، خاصةً في المهمة الصعبة المتمثلة في التعرف على تعبيرات وجه الخنازير. من خلال إدارة استخراج الميزات متعددة المقاييس بمهارة، والتقاط الفروق الدقيقة في الوجه، وتنسيق السياق الأوسع، تهيئ CReToNeXt الساحة لتحقيق دقة ووضوح لا مثيل لهما في هذا المجال.
مقارنة نماذج كشف الأهداف من نفس النوع
بالنسبة للمهمة المعقدة المتمثلة في اكتشاف تعبيرات الوجه في الخنازير، يصبح الخوارزمية الأساسية المختارة محورية. بينما يتضح التقدم في سلسلة YOLO من خلال تطوراتها في إصدارات مثل YOLOv7، فإن تقاربها السريع نحو
تركيزنا الأساسي لا يكمن فقط في تحقيق أرقام عالية خلال التدريب ولكن في ضمان أداء ثابت وموثوق في التطبيقات الحقيقية. هذا صحيح بشكل خاص في الساحة الصعبة للتعرف على تعبيرات الإجهاد الحراري في الخنازير، وهو سيناريو مليء بالإشارات الوجهية الدقيقة وظروف بيئية متغيرة. لذلك، فإن الخوارزمية الموثوقة والقوية أكثر قيمة من الخوارزمية الحساسة للغاية، مما يقودنا إلى اعتماد دراساتنا على بنية YOLOv5s. تقدم YOLOv5s توازنًا جديرًا بالثناء بين الدقة والسرعة دون أن تصل إلى مرحلة الاستقرار مبكرًا، مما يمنحنا مجالًا واسعًا للتعزيزات والتعديلات المخصصة.
لكن كيف تقارن YOLOv5s مع نظرائها في نفس الفئة؟ عند مقارنتها مع أمثال Faster R-CNN وYOLOv4 وYOLOv8، تصبح براعة YOLOv5s واضحة. يستخدم Faster R-CNN، وهو كاشف من مرحلتين، شبكة اقتراح المنطقة (RPN) لتحديد مناطق الأجسام المحتملة، والتي يتم تحسينها وتصنيفها لاحقًا. بينما غالبًا ما يزود هذا العمق المنهجي Faster R-CNN بدقة ملحوظة، خاصة مع الأجسام الصغيرة والمعبأة بكثافة، إلا أنه يأتي على حساب زيادة الحمل الحاسوبي، مما قد يجعل التطبيقات في الوقت الحقيقي تحديًا. تُظهر YOLOv4، التي تشترك في بنية الكشف من مرحلة واحدة المميزة لـ YOLO، أداءً متوازنًا، حيث تتفاخر بتحسينات على أسلافها ولكنها لا تصل إلى دقة YOLOv5. من خلال تقسيم الصورة بالكامل إلى خلايا شبكية وأداء الكشف والتصنيف المتزامن للأجسام، تقدم سرعات في الوقت الحقيقي، مما يجعلها جذابة بشكل خاص للتطبيقات التي تتطلب ردود فعل سريعة. تُعتبر YOLOv8 نموذجًا متقدمًا (SOTA)، يبني على الأساس الناجح لأسلافه في سلسلة YOLO. من خلال تقديم ميزات جديدة وتحسينات، تهدف YOLOv8 إلى تعزيز الأداء والمرونة. تشمل الابتكارات الملحوظة شبكة العمود الفقري المعاد تصميمها، ورأس الكشف بدون مرساة، ودالة خسارة جديدة.
في الشكل 13أ، كانت دقة متوسط الدقة (mAP) لـ Faster R-CNN عند
في الختام، بينما قد يبدو YOLOv7 مغريًا بسبب تقاربه السريع، فإن ظلال الإفراط في التكيف التي تلقيها تجعلها أقل موثوقية للتطبيقات الواقعية مثل التعرف على تعبيرات وجه الخنازير. من ناحية أخرى، تظهر YOLOv5، عند مقارنتها بـ Faster R-CNN وYOLOv4 وYOLOv8، كخوارزمية لا توفر فقط اكتشافًا سريعًا ولكن أيضًا تتيح مجالًا كبيرًا للتحسين، مما يمهد الطريق لتقدمات دقيقة ومخصصة للتطبيقات.
تحليل كفاءة CReToNeXt-YOLOv5 عبر فئات عاطفية متنوعة
تعتبر فعالية نموذج CReToNeXt-YOLOv5 في تمييز تعبيرات الوجه المتنوعة في الخنازير ملحوظة، ولتقدير قوته حقًا، يجب الغوص أعمق في أدائه عبر حالات عاطفية محددة. عند النظر في تعبيرات الغضب في الخنازير، التي تتميز بملامح مثل التجاعيد العميقة والعينين المفتوحتين على مصراعيهما، يبرز CReToNeXt-YOLOv5. آليته ذات المسارين، التي تعد جزءًا لا يتجزأ من هيكله، تلتقط بمهارة كل من الميزات البارزة والنواحي الأكثر دقة، مثل سحب الشفة العليا لأعلى.
الخوف، وهو عاطفة معقدة أخرى في الخنازير، يظهر من خلال إشارات مثل العيون المغلقة قليلاً، وتقليل التجاعيد، وآذان متهدلة. يتفوق النموذج هنا أيضًا، ويرجع ذلك إلى حد كبير إلى طبقة تجميع الهرم المكاني داخل وحدة CReToNeXt، التي تسهل استخراج الميزات متعددة المقاييس. تضمن هذه الميزة الديناميكية أن يحتفظ النموذج بدقته في اكتشاف الخوف بغض النظر عن متغيرات مثل وضعية الخنزير أو مسافته من الكاميرا.
تظهر تجليات السعادة في الخنازير، على الرغم من أنها تبدو واضحة مع العيون المغلقة قليلاً، وسحب الشفة العليا لأعلى، وآذان مرفوعة للخلف، تحدياتها الخاصة. تتطلب هذه التعبيرات، التي تكون واضحة بشكل خاص في حالة الأكل، نموذجًا يمكنه تحديد مثل هذه اللحظات العابرة بدقة. ترتقي آلية الانتباه في النموذج، التي تسمح بالتركيز الانتقائي على المناطق الحيوية مثل الفم والعينين، إلى هذا التحدي، مما يضمن عدم تجاهل هذه اللحظات من الفرح.
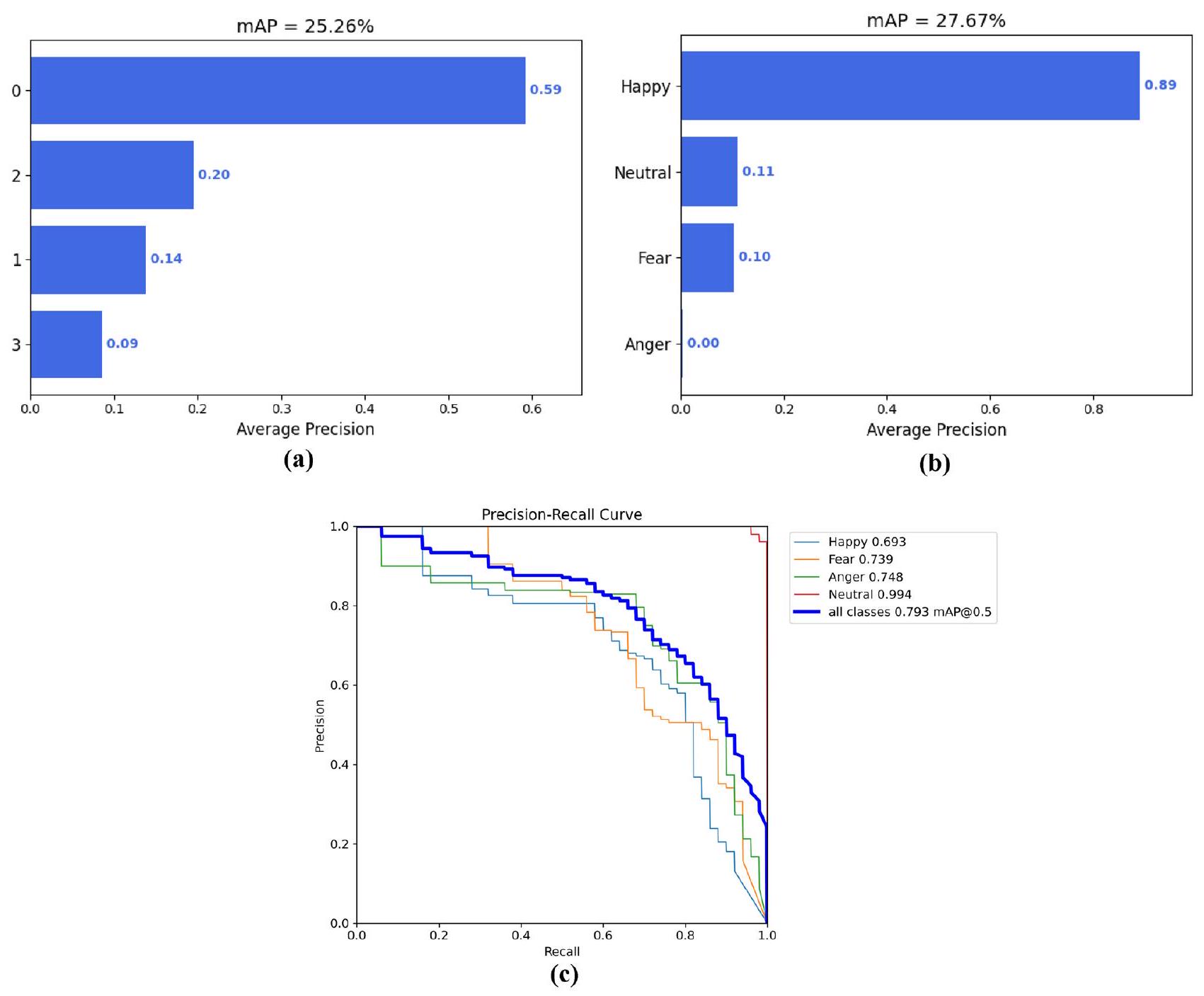
الشكل 13. تحليل مقارن لـ mAP لتعرف التعبيرات: (أ) نموذج Faster R-CNN، (ب) نموذج YOLOv4، و(ج) نموذج YOLOv8.
ربما تكون التعبيرات المحايدة هي الأكثر صعوبة في الاكتشاف، أساسًا بسبب نقص الميزات المميزة. ومع ذلك، فإن هذه الحالة من الطبيعية تقدم بيانات أساسية حاسمة حول الصحة العاطفية للخنزير. تعتبر آلية الانتباه التناسقي للنموذج حاسمة هنا، حيث تمنح النموذج القدرة على اكتشاف حتى أدق الانحرافات عن الحالة المحايدة، وهو إنجاز قد تفشل فيه العديد من النماذج التقليدية.
علاوة على ذلك، فإن كفاءة نموذج CReToNeXt-YOLOv5 ليست مجرد نتاج مكوناته الفردية ولكن بالأحرى من تشغيلها التآزري. يساهم التصميم ذو المسارين لـ CReToNeXt، جنبًا إلى جنب مع الخصوصية المكانية لآلية CoordAtt والرؤية الشاملة التي توفرها دالة EIOU، بشكل جماعي في دقته المثالية. يضمن هذا المزيج القوي أن النموذج لا يكتشف فقط ولكن أيضًا يصنف بدقة كل تعبير وجه، مما يضع معيارًا جديدًا في مجال التعرف على تعبيرات الوجه في الماشية.
القيود في تحليل تعبيرات الخنازير باستخدام CReToNeXt-YOLOv5
عند التعمق في نموذج CReToNeXt-YOLOv5 الخاص بنا الذي يهدف إلى التعرف على تعبيرات وجه الخنازير وتصنيفها، اكتشفنا بعض التعقيدات الدقيقة التي يمكن اعتبارها قيودًا محتملة على دراستنا. بشكل أساسي، تلتقط مجموعة البيانات الخاصة بنا سلوك الخنازير في سياقات محددة، لا سيما تحت فئة “السعادة”، حيث يتم جمع معظم البيانات خلال أوقات التغذية. قد يؤدي هذا التخصص عن غير قصد إلى تضييق نطاق قابلية تعميم النموذج عند تقديم تعبيرات الخنازير السعيدة خارج سيناريوهات التغذية، على الرغم من أنه يوفر معيارًا واضحًا لتحليلاتنا. بالإضافة إلى ذلك، فإن التنوع الموجود في فئة “الحيادية”، الذي يشمل بيئات متعددة، يقدم تباينًا قد يتحدى دقة النموذج التنبؤية. كما ظهرت تحديات عملية خلال جمع البيانات، نظرًا لديناميات حركة الخنازير، وزوايا الكاميرا، وظروف الإضاءة المتغيرة، وكلها قد تؤثر بشكل طفيف على جودة البيانات المجمعة. بينما بذلنا جهدًا للتخفيف من هذه الأمور من خلال استخدام استراتيجية متعددة الكاميرات وزوايا متعددة، فإن عدم القدرة على التنبؤ بهذه المتغيرات قد لا يزال يؤثر على فعالية النموذج بشكل شامل. علاوة على ذلك، هناك خطر محتمل أن مجموعة البيانات الخاصة بنا
قد لا تمثل بالكامل مجموعة سلالات الخنازير، أو الفئات العمرية، أو الحالات الصحية، مما قد يقدم تيارًا خفيًا من التحيز. بينما نتقدم إلى الأمام، من الضروري أن تعترف الأبحاث اللاحقة بهذه التفاصيل وتعالجها، ساعيةً إلى أداة أكثر شمولاً للتعرف على تعبيرات وجه الخنازير.
قد لا تمثل بالكامل مجموعة سلالات الخنازير، أو الفئات العمرية، أو الحالات الصحية، مما قد يقدم تيارًا خفيًا من التحيز. بينما نتقدم إلى الأمام، من الضروري أن تعترف الأبحاث اللاحقة بهذه التفاصيل وتعالجها، ساعيةً إلى أداة أكثر شمولاً للتعرف على تعبيرات وجه الخنازير.
الاستنتاجات
في سعيينا لفهم الشبكة المعقدة من المشاعر التي تظهرها الماشية، أدركنا أن تعبيرات الوجه تعمل كقناة محورية. هذه التعبيرات لا تشير فقط إلى الرفاهية العاطفية ولكن أيضًا تسلط الضوء على الصحة النفسية للحيوانات، مما يجعل اكتشافها وتصنيفها بدقة أمرًا ذا أهمية قصوى. ومعالجة التحديات الكامنة، مثل الهيكل الأساسي لعضلات وجه الخنازير والفروق الدقيقة في التعبيرات التي غالبًا ما تفلت من الاكتشاف، بدأنا في إنشاء مجموعة بيانات متعددة المشاهد لتعبيرات وجه الخنازير. ثراء هذه المجموعة، التي تشمل سيناريوهات بقاء متنوعة، وحالات عاطفية، ووجهات نظر متنوعة، تشكل أساسًا شاملاً للتعرف على تعبيرات وجه الخنازير. أدت أعمالنا الرائدة إلى تطوير نموذج CReToNeXt-YOLOv5، المصمم لتصنيف والتعرف بمهارة على تعبيرات وجه الخنازير. يمكن أن تُعزى الخطوات الملحوظة التي حققناها في تعزيز معدلات التعرف على التعبيرات إلى تكاملات استراتيجية مثل آلية انتباه CoordAtt، ودالة خسارة EIOU المبتكرة، وجوهر وحدة CReToNeXt. لا تعزز هذه التآزر فقط القوة التقنية لرؤية الآلة ولكنها تتناغم بعمق مع الهدف الشامل المتمثل في تعزيز ممارسات الزراعة الذكية والإنسانية.
عند مقارنتها بالعمالقة في مجال اكتشاف الأهداف، تبرز تفوق CReToNeXt-YOLOv5 بشكل لا يمكن إنكاره. بينما يضع نموذج YOLOv5، المعروف بسرعته في الاستدلال ودقته، معيارًا جديرًا بالثناء، فإن نموذجنا لا يطابقه فحسب، بل يتجاوزه أيضًا، مسجلاً mAP مثيرًا للإعجاب قدره
ومع ذلك، فإن نموذجنا، على الرغم من إنجازاته، ليس بدون تحدياته. لقد أدت البيئات المتنوعة التي تقع فيها قاعدة بيانات الفئة الحيادية، مع العوامل المؤثرة المتعددة، إلى تحقيق معدلات تعرف دون المستوى في بعض الأحيان. معالجة هذه التعقيدات، وتنقيح نهجنا، وتوسيع مجموعة بياناتنا بمشاهد وسلالات خنازير متنوعة تمثل مساعينا المستقبلية. من خلال تحقيق هذه الأهداف، نهدف إلى تعزيز قوة النموذج وضمان قابليته للتطبيق بشكل أوسع، ليس فقط في بيئات البحث ولكن في سيناريوهات إدارة الماشية في العالم الحقيقي، مما يرفع في النهاية معايير رفاهية الحيوانات.
توفر البيانات
جميع الأكواد التي تم إنشاؤها خلال هذه الدراسة متاحة في مستودع Github. الروابط إلى الأكواد موضحة في النص المرتبط أدناه. كود مشروع CReToNeXt-YOLOv5: https://github.com/Nielili1998/pig-face-expression-recognition. مجموعات البيانات التي تم إنشاؤها و/أو تحليلها في الدراسة الحالية غير متاحة للجمهور بسبب جمع البيانات بالتعاون مع مزارع الخنازير التابعة لجهات خارجية، ولكنها متاحة من المؤلفين المعنيين عند الطلب المعقول. تأكيد أن هذه الخنازير لم يتم التعامل معها من قبل المؤلفين خلال الدراسة. تأكيد أن جميع البروتوكولات التجريبية قد تمت الموافقة عليها من قبل المؤسسة المعينة و/أو مجلس الترخيص. تأكيد أن جميع الطرق قد تم تنفيذها وفقًا للإرشادات واللوائح ذات الصلة.
تاريخ الاستلام: 28 يونيو 2023؛ تاريخ القبول: 9 يناير 2024
نُشر على الإنترنت: 19 يناير 2024
نُشر على الإنترنت: 19 يناير 2024
References
- Meiqing, W. et al. Towards re-identification for long-term tracking of group housed pigs. Biosyst. Eng. 222 (2022).
- Huang, W., Zhu, W., Ma, C., Guo, Y. & Chen, C. Identification of group-housed pigs based on Gabor and Local Binary Pattern features. Biosyst. Eng. 166, (2018).
- Kremer, L., Holkenborg, S. K., Reimert, I., Bolhuis, J. & Webb, L. The nuts and bolts of animal emotion. Neurosci. Biobehav. Rev. 113, 273-286 (2020).
- Fraser, D. & Duncan, I. J. ‘Pleasures’, ‘pains’ and animal welfare: Toward a natural history of affect. Anim. Welf. 7, 383-396 (1998).
- Burrows, A. M., Waller, B. M., Parr, L. A. & Bonar, C. J. Muscles of facial expression in the chimpanzee (Pan troglodytes): Descriptive, comparative and phylogenetic contexts. J. Anat. 208, 153-167 (2006).
- Wada, N., Shinya, M. & Shiraishi, M. [Short Paper] Pig Face Recognition Using Eigenspace Method. undefined 1, undefined (2013).
- Camerlink, I., Coulange, E., Farish, M., Baxter, E. M. & Turner, S. P. Facial expression as a potential measure of both intent and emotion. Sci. Rep. 8, 17602 (2018).
- Hansen, M. F. et al. Towards on-farm pig face recognition using convolutional neural networks. Comput. Ind. 98, 145-152 (2018).
- Hansen, M. F. et al. Towards facial expression recognition for on-farm welfare assessment in pigs. Agriculture 11, 847 (2021).
- Marsot, M. et al. An adaptive pig face recognition approach using convolutional neural networks. Comput. Electron. Agric. 173, 105386 (2020).
- Wang, R., Gao, R., Li, Q. & Dong, J. Pig face recognition based on metric learning by combining a residual network and attention mechanism. Agriculture 13, 144 (2023).
- Wen, C. et al. Pig facial expression recognition using multi-attention cascaded LSTM model. Nongye Gongcheng Xuebao/Trans. Chin. Soc. Agric. Eng. 37, 181-190 (2021).
- Kawagoe, Y., Kobayashi, I. & Zin, T. T. Facial region analysis for individual identification of cows and feeding time estimation. Agriculture 13, 1016 (2023).
- Zin, T. T. et al. Automatic cow location tracking system using ear tag visual analysis. Sensors 20, 3564 (2020).
- Zin, T. T. et al. In 2020 IEEE 2nd Global Conference on Life Sciences and Technologies (LifeTech). 65-66 (IEEE).
- Phyo, C. N., Zin, T. T., Hama, H. & Kobayashi, I. In 2018 International Conference on Image and Vision Computing New Zealand (IVCNZ). 1-5 (IEEE).
- Chen, Z. et al. Plant disease recognition model based on improved YOLOv5. Agronomy 12, 365 (2022).
- Xu, X. et al. DAMO-YOLO: A report on real-time object detection design. arXiv preprint arXiv:2211.15444 (2022).
الشكر والتقدير
تم دعم هذا العمل من قبل برنامج البحث والتطوير الرئيسي في شانشي تحت الموضوع: تعزيز الجينات، ابتكار الجينات، وعرض خنازير جينفن البيضاء مع التركيز على البحث في تكنولوجيا قياس أداء الإنتاج الذكي لخنازير جينفن البيضاء [رقم المشروع: 202102140601005، رقم الموضوع: 202102140604005-2]؛ والدراسة حول آلية التفاعل متعددة المراحل لالتصاق الأغشية الحيوية البكتيرية في حظائر الماشية والدواجن التي تتوسطها مجالات كهربائية نبضية عالية الجهد [رقم المشروع: 2023-092].
مساهمات المؤلفين
L.L.N. أجرى التجربة (التجارب)، وحلل النتائج، وكتب المخطوطة. B.G.L. قدم التمويل للمشروع. Y.H.D. نسق مع مزرعة الخنازير للتصوير. J.F. و X.Y.S. أعدوا الأشكال 4 و 5. Z.Y.L. تصور التجربة (التجارب). راجع جميع المؤلفين المخطوطة.
المصالح المتنافسة
يعلن المؤلفون عدم وجود مصالح متنافسة.
معلومات إضافية
يجب توجيه المراسلات والطلبات للحصول على المواد إلى Z.L.
معلومات إعادة الطبع والتصاريح متاحة علىwww.nature.com/reprints.
ملاحظة الناشر تظل Springer Nature محايدة فيما يتعلق بالمطالبات القضائية في الخرائط المنشورة والانتماءات المؤسسية.
معلومات إعادة الطبع والتصاريح متاحة علىwww.nature.com/reprints.
ملاحظة الناشر تظل Springer Nature محايدة فيما يتعلق بالمطالبات القضائية في الخرائط المنشورة والانتماءات المؤسسية.
الوصول المفتوح هذه المقالة مرخصة بموجب رخصة المشاع الإبداعي للاستخدام والمشاركة والتكيف والتوزيع وإعادة الإنتاج في أي وسيلة أو تنسيق، طالما أنك تعطي الائتمان المناسب للمؤلفين الأصليين والمصدر، وتوفر رابطًا لرخصة المشاع الإبداعي، وتوضح ما إذا كانت هناك تغييرات قد تم إجراؤها. الصور أو المواد الأخرى من طرف ثالث في هذه المقالة مشمولة في رخصة المشاع الإبداعي للمقالة، ما لم يُشار إلى خلاف ذلك في سطر ائتمان للمادة. إذا لم تكن المادة مشمولة في رخصة المشاع الإبداعي للمقالة واستخدامك المقصود غير مسموح به بموجب اللوائح القانونية أو يتجاوز الاستخدام المسموح به، ستحتاج إلى الحصول على إذن مباشرة من صاحب حقوق الطبع والنشر. لعرض نسخة من هذه الرخصة، قم بزيارةhttp://creativecommons.org/licenses/by/4.0/.
© المؤلفون 2024
© المؤلفون 2024
كلية علوم المعلومات والهندسة، جامعة شانشي الزراعية، تايغو 030801، شانشي، الصين. كلية علوم الحيوان، جامعة شانشي الزراعية، تايغو 030801، شانشي، الصين. كلية الهندسة الزراعية، جامعة شانشي الزراعية، تايغو 030801، شانشي، الصين. البريد الإلكتروني: Izysyb@126.com
Journal: Scientific Reports, Volume: 14, Issue: 1
DOI: https://doi.org/10.1038/s41598-024-51755-8
PMID: https://pubmed.ncbi.nlm.nih.gov/38242984
Publication Date: 2024-01-19
DOI: https://doi.org/10.1038/s41598-024-51755-8
PMID: https://pubmed.ncbi.nlm.nih.gov/38242984
Publication Date: 2024-01-19
Deep learning strategies with CReToNeXt-YOLOv5 for advanced pig face emotion detection
This study underscores the paramount importance of facial expressions in pigs, serving as a sophisticated mode of communication to gauge their emotions, physical well-being, and intentions. Given the inherent challenges in deciphering such expressions due to pigs’ rudimentary facial muscle structure, we introduced an avant-garde pig facial expression recognition model named CReToNeXtYOLOv5. The proposed model encompasses several refinements tailored for heightened accuracy and adeptness in detection. Primarily, the transition from the CIOU to the EIOU loss function optimized the training dynamics, leading to precision-driven regression outcomes. Furthermore, the incorporation of the Coordinate Attention mechanism accentuated the model’s sensitivity to intricate expression features. A significant innovation was the integration of the CReToNeXt module, fortifying the model’s prowess in discerning nuanced expressions. Efficacy trials revealed that CReToNeXtYOLOv5 clinched a mean average precision (mAP) of
With growing concerns surrounding animal welfare in legal and social spheres, the application of machine vision in ensuring animal well-being has seen a remarkable upsurge. This technology, by facilitating precise livestock condition detection, not only simplifies management practices but also significantly curtails costs. Noteworthy applications include the pioneering work by Meiqing et al.
The intricate world of animal emotions has come to the forefront in contemporary animal welfare research
While the domain of human facial recognition has witnessed paradigm shifts due to machine vision, its application to animals, particularly pigs, has similarly shown promising advancements. A testament to this is the staggering
LSTM framework, endowed with multiple attention mechanisms, has shown prowess in discerning facial expressions, boasting an average accuracy of
Given the expansive growth in machine vision applications, advancements in cow identification and management have also come into focus. Pioneering works such as those by Kawagoe et al. demonstrated the potential of facial region analysis for distinct cow identification and the estimation of feeding times, showcasing its utility in the early diagnosis of diseases and movement disorders in cows
The landscape of pig face recognition has undoubtedly evolved, yet there remains a glaring gap in methodologies aimed at understanding their expressions. Given the simplistic facial muscle configuration in pigs and the complexities intrinsic to expression detection, this is a monumental challenge. Addressing this, we introduced the CReToNeXt-YOLOv5-based pig expression recognition model. This model’s vision extends beyond mere identification; it seeks to proactively gauge the emotional nuances of pigs, paving the way for prompt interventions and subsequently reducing potential adversities. Ethically, recognizing and responding to pig emotions can profoundly elevate animal welfare standards, presenting both a moral and practical obligation. As such, our primary research objective is to optimize and validate the efficacy of the CReToNeXt-YOLOv5 model in real-world scenarios. The inception of this model not only holds vast transformative promise but also signifies a progressive stride in the realm of animal emotional studies.
Methods
Experimental data
Pig facial expression collection
The database used in this study was collected from pig farms in Shanxi Province. The farms were divided into two areas, each measuring
Figure 1. Diagram of the video capture solution.
However, the inherent challenges of such a dynamic environment, including varied pig movements and potential inconsistencies between cameras, necessitated stringent data validation. Any imagery affected by rapid pig movements, unanticipated obstructions, or unfavorable lighting was deemed “invalid” and subsequently discarded. As illustrated in Fig. 2, this rigorous filtering process resulted in a diverse yet reliable dataset of 2700 categorized images.
Figure 2. Diagram of the four categories: (a) for happy, (b) for neutral, (c) for fear, (d) for anger.
Pig facial expressions labelled
Expression labeling is based on relevant research findings
Pig facial expression dataset expansion
Before the dataset expansion, the initial set of images underwent a series of pre-processing steps to ensure consistency and enhance the quality for training. All images were resized to a standard resolution, ensuring uniformity across the dataset. Furthermore, any noise reduction or normalization techniques were applied, preparing the images for the subsequent augmentation steps. For data augmentation, geometric transformation methods such as rotation, flipping, cropping, etc., and pixel transformation methods such as adjusting HSV contrast, brightness, saturation, etc., are employed. By applying operations such as contrast enhancement (Fig. 3b), brightness enhancement (Fig. 3c), image flipping (Fig. 3d), and angle rotation (Fig. 3e) to the training images (Fig. 3a), a network with stronger generalization ability can be obtained. This helps reduce overfitting and expands the dataset size. Post augmentation, the dataset size surged to 5400 images. To facilitate effective pig expression recognition, labeling software was employed to annotate the facial regions of pigs within video frame images. This annotation process was meticulous, ensuring that each expression was correctly labeled based on the facial features and the situational context. Subsequently, out of the total images, 3780 were earmarked for training, 1080 for validation, and the remaining 540 for testing.
Training environment configuration
The hardware environment is configured with a
| Category | Facial changes | Scene context | |||
| Eye | Nose | Lip | Ear | ||
| Happy | Eyes slightly closed | None | Pull up the upper lip | Pull back the ears | Generally in the eating state |
| Neutral | None | None | None | None | Normalcy |
| Fear | Eyes slightly closed | Reduced wrinkles | None | Droopy ears | Generally in a state of shock |
| Anger | Eyes wide open | Deepened wrinkles | Pull up the upper lip | None | Generally before initiating an act of aggression |
Table 1. Description of facial expression categories.
Figure 3. Pig expression image data expansion.
YOLOv5s model
YOLOv5 can be categorized into four models based on its network depth and breadth, namely s,
Input
The concept of Mosaic data augmentation involves randomly selecting four images and applying random cropping, flipping, scaling, and other transformations to them. These transformed images are then merged into a single image in a randomly distributed manner. This technique significantly enhances the dataset and increases the batch_size, thereby improving training efficiency.
The innovation of YOLOv5 lies in the incorporation of anchor box calculation during training. During the training process, the anchor box size is dynamically adjusted by predicting a bounding box based on the initial anchor box set, comparing it with the ground truth, calculating the loss, and updating the anchor box size accordingly. This approach allows YOLOv5 to adapt and calculate the optimal anchor box values for different training datasets.
The images used in the YOLO algorithm are typically resized to a scale of 1:1. However, in real-world detection projects, the aspect ratio of images varies. Forcing padding to maintain a
Backbone
The backbone network plays a crucial role in extracting information and features from the input images. In Fig. 5, assuming the input image is
Neck
The Neck module plays a crucial role in effectively integrating the features extracted by the backbone network and enhancing the overall performance of the network. By combining the top-down and bottom-up processes, the Neck module enhances the network’s ability to incorporate both semantic and localization information, resulting in improved performance and accuracy.
Figure 4. YOLOv5s network structure: input, backbone, neck, and head (prediction).
Figure 5. Focus structure.
Head (prediction)
The Head part is mainly used to detect the target, and Head expands the number of channels by
CReToNeXt-YOLOv5 pig face expression recognition model
To effectively recognize facial expressions in pigs, the CReToNeXt-YOLOv5 model was utilized to classify and recognize four types of expressions in pig face images. A pig farm was set up in Shanxi Province, and video footage of pigs was collected using a video camera. Facial images of the pigs were then extracted from the videos. In order to improve the accuracy of expression recognition and achieve precise identification of targets, the EIOU loss function was employed instead of the CIOU loss function. Additionally, the Coordinate Attention mechanism was incorporated to enhance the model’s sensitivity to expression features. The CReToNeXt module was also introduced to enhance the model’s ability to detect subtle expressions.
The improvement points of the CReToNeXt-YOLOv5 model include incorporating the attention mechanism backbone, integrating the CReToNeXt module to enhance the model’s neck and improve detection performance, and utilizing the optimized EIOU loss function in the Head section. The improvement framework of the CRe-ToNeXt-YOLOv5 model is illustrated in Fig. 6.
Coordinate attention mechanism
Attention mechanisms have been extensively studied to improve the capabilities of deep neural networks, particularly in capturing “what” and “where” information. However, their application in mobile networks significantly lags behind that of larger networks due to computational limitations. Squeeze-and-Excitation (SE) attention primarily focuses on encoding inter-channel information while disregarding positional information, which plays a crucial role in capturing object structures in visual tasks. The Convolutional Block Attention Module (CBAM) attempted to incorporate positional information by reducing the channel dimensionality of the input tensor and computing spatial attention using convolutions, as shown in Fig. 7a. However, visual tasks inherently
Figure 6. Improved framework for the CReToNeXt-YOLOv5 model: coordinate attention mechanism; EIOU loss function; CReToNeXt module.
Figure 7. The structure of CBAM attentional mechanism compared with coordinate attention mechanism: (a) CBAM structure diagram; (b) coordinate attention structure diagram.
involve long-range dependencies that cannot be effectively modeled solely through local relationships captured by convolutions.
The incorporation of the Coordinate Attention mechanism enhances the network’s focus on the target to be detected and improves the detection results. When combined with the structure depicted in Fig. 7b below, the main concept of Coordinate Attention is as follows: the input features are separately pooled in the h-direction and w -direction, resulting in
Coordinate information embedding. The channel attention module globally encodes spatial information using the global pooling method. However, this approach leads to a loss of location information since the global spatial information is compressed in the channel descriptor during the encoding process. To address this issue, the global pooling is decomposed according to Eq. (2) and transformed into a one-dimensional feature encoding operation, preserving the location information.
x is the input and each channel is first encoded along the horizontal and vertical coordinates using a pooling kernel of size
Likewise, the output of the cth channel of width
Coordinate attention generation. Coordinate Attention was developed based on three primary criteria: (a) simplicity in implementing the new transformation within the mobile environment. (b) The ability to accurately capture the region of interest by leveraging the captured location information. (c) Efficiently capturing relationships between channels. Once the new transformation in information embedding is performed, the previous transformation continues with a concatenate operation, followed by a convolutional transform function.
EIOU loss function
The EIOU loss function was adopted instead of the CIOU loss function used in the YOLOv5 algorithm to optimize the training model. This change significantly improves the accuracy of the pig face facial expression recognition algorithm and enables fast and accurate recognition of targets. The evolution of regression loss functions over the past few years is as follows: IOU_Loss
When the predicted bounding box does not intersect with the ground truth bounding box, the IoU (Intersection over Union) does not reflect the actual distance between the two boxes, resulting in a IoU loss value of zero. This can negatively impact gradient backpropagation, making it difficult to train the model effectively. Furthermore, the IoU does not accurately represent the extent of overlap between the predicted and ground truth boxes. The DIoU (Distance-IoU) loss function addresses these issues by incorporating factors such as distance, overlap, and scale between the predicted and ground truth bounding boxes. This leads to more stable regression of the target bounding box. b represents the centroid of the predicted box, b
In YOLOv5s, the CIOU (Complete IoU) loss function was utilized to enhance the alignment between the predicted bounding box and the ground truth bounding box. It builds upon the DIOU (Distance-IoU) loss by incorporating additional penalties for the scale, length, and width of the detection bounding box. The expressions for the CIOU_Loss are as follows:
where
The aspect ratios, as relative values, introduce some ambiguity and do not consider the balance between difficult and easy samples (Zhang et al., 2022). In response to this, EIOU_Loss divides the aspect ratio into the difference in width and height between the predicted bounding box and the minimum external bounding box, based on the CIOU_Loss. The lengths and widths of the target and anchor boxes are then calculated separately. By minimizing the difference between the widths and heights of the target and anchor boxes, the convergence speed and regression accuracy are increased. Additionally, Focal Loss is introduced to balance the samples in the bounding box regression task. It is expressed as follows:
The advantages and disadvantages of each loss function were compared based on the three main geometric factors of bounding box regression (overlap area, centroid distance, and aspect ratio) (Table 2). When replacing the anchor frame loss function in YOLOv5s with EIOU_Loss, the performance showed significant improvement compared to the original IOU_Loss, DIOU_Loss, CIOU_Loss, and others.
CReToNeXt module
DAMO-YOLO, a forefront target detection approach, establishes a new benchmark by seamlessly integrating state-of-the-art technologies such as Neural Architecture Search (NAS), the innovative Reparameterized Generalized Feature Pyramid Network (RepGFPN), efficient lightweight heads, and strategic distillation augmentation. One of the cornerstone enhancements in DAMO-YOLO is the replacement of the CSPStage block found in the YOLOv5 architecture with the innovative CReToNeXt module, making the model more adaptive and proficient in object detection tasks, leading to unparalleled performance metrics
The CReToNeXt module, at its core, is designed as a convolutional neural network component, which specializes in the intricate task of image feature extraction. The design philosophy behind CReToNeXt is rooted in its bifurcated processing mechanism. Upon receiving an input, the module efficiently divides it into two distinct branches, each subjected to its specialized convolutional operations. These differentiated operations allow the module to capture a wider variety of image features, ensuring a comprehensive representation. Post these operations, the outputs from both branches are concatenated, preserving the richness of the extracted features.
Going deeper into its design intricacies, the CReToNeXt module can be expanded and made more robust. This is achieved by layering multiple instances of the BasicBlock_
| Loss | Overlap | Centre point | Aspect Ratio | Advantages | Disadvantages | ||
| IOU_Loss |
|
|
|
Scale invariance; non-negativity; homogeneity; symmetry; triangular inequality |
|
||
| GIOU_Loss |
|
|
|
Solve the problem that loss equals 0 when there is no overlap between the detection box and the real box |
|
||
| DIOU_Loss |
|
|
|
Convergence can be accelerated | The regression process takes into account the aspect ratio of the Bounding box and there is room for further improvement in accuracy | ||
| CIOU_Loss |
|
|
|
The loss of detection frame scale, length and width has been increased so that the predicted frames will be more consistent with the real ones |
|
||
| EIOU_Loss |
|
|
|
The aspect ratio is replaced by a separate calculation of the difference in width and height, whereas Focal Loss is introduced to address the problem of unbalanced hard and easy samples |
Table 2. Comparison of loss functions.
As the outputs from the two branches undergo the concatenation process, they are then channeled through a subsequent convolutional layer, which refines and outputs the final feature set. This intricate and detailed design of the CReToNeXt module not only augments YOLOv5’s operational capacity but also refines its ability to capture and represent intricate semantic information contained within images, making it an invaluable tool in the world of object detection.
YOLOv5 model evaluation indicators
To accurately judge the merits of the expression recognition models, Precision, mAP, Recall, and F1-score were selected for evaluation.
Precision
Precision indicates whether the detected area is always the correct area, with an ideal value of 1 . The calculation formula is as in Eq. (11). TP: the true category of the sample is a positive example and the model predicts a positive outcome and correct prediction. FP: the true category of the sample is a negative example, but the model predicts it as a positive example and predicts it incorrectly.
mAP
mAP refers to the average accuracy and indicates the quality of the detection, with higher values representing better detection performance, as written in Eq. (12). N denotes the total number of samples,
Recall
The recall is calculated as Eq. (13), indicating whether the detection is comprehensive and whether all areas that should be detected are detected, with an ideal value of 1 . FN: the true category of the sample is a positive example, whereas the model predicts it as a negative example and predicts it incorrectly.
F1-score
The F 1 -score refers to a measure of the classification problem. It is the summed average of precision and recall, with a maximum of 1 and a minimum of 0 .
Results and discussion
In this segment, we embarked on rigorous experimentation with a meticulously curated dataset of swine facial expressions, the overarching aim being to discern the efficacy of our proposed CReToNeXt-YOLOv5 model. Our investigative trajectory bifurcated into two pivotal arms: an intrinsic validation of the model and a comparative analysis against contemporaneous target detection paradigms.
During the self-validation phase, we scrutinized the operational merits of coordinate attention mechanism, the EIOU loss function and the CReToNeXt module within our model. More specifically, under a harmonized experimental backdrop, we disabled these discrete components and juxtaposed results from their active and inactive states, offering insights into their individual and collective contributions to model performance. Further, to cast into sharp relief the competitive edge of our YOLOv5 paradigm in the domain of porcine facial expression recognition, we judiciously selected Faster R-CNN, YOLOv4, and YOLOv8 as comparative benchmarks.
It warrants emphasis that, juxtaposed against its subsequent iterations, YOLOv5 has garnered widespread vetting and endorsement, manifesting commendable maturity and stability. In our model selection crucible, beyond sheer performance, the stability and the collective acceptance within the broader research fraternity weighed heavily. While YOLOv7 dazzled with their precociously high mAPs during preliminary training, it simultaneously flagged potential overfitting susceptibilities, especially in context-specific datasets. This begets apprehensions regarding their robust applicability in real-world scenarios. Our research lens is keenly focused on the real-time recognition of porcine thermal stress expressions, making the resilience and reliability of the chosen paradigm paramount. Driven by these considerations, our pivot to the YOLOv5s as the foundational architecture was both deliberate and strategic, furnishing us with an expansive canvas for future optimizations and refinements.
Performance of pig face expression recognition models in data training and validation
As depicted in Fig. 8a, the Precision-Recall Curve offers a nuanced understanding of the CReToNeXt-YOLOv5 model’s performance across different categories. One of the remarkable takeaways from this representation is the model’s confidence scores. Generally, a higher confidence score is synonymous with superior detection ability, and our model exemplifies this trend, suggesting its proficient discernment in object detection tasks. The mAP of 0.894 further consolidates this, emphasizing the model’s robustness and high overall detection accuracy. Transitioning to the Recall Curve, illustrated in Fig. 8b, the value of 0.990 denotes the model’s adeptness in target detection, although there might still be minor opportunities for refinement in ensuring every genuine instance is identified. Perhaps most tellingly, the F1-score, showcased in Fig. 8c, encapsulates a holistic performance metric, harmonizing precision and recall. An F1-score is an indispensable indicator, often signifying the balance a model maintains between false positives and false negatives. In our context, an F1-score of 0.84 is not only commendable but indicative of a well-optimized balance the CReToNeXt-YOLOv5 model has achieved between precision and recall, setting a benchmark for subsequent model iterations and research endeavors.
The confusion matrix, as illustrated in Fig. 9, offers a holistic understanding of the CReToNeXt-YOLOv5 model’s performance in discerning distinct pig facial expressions. Impressively, the model shows a particularly strong aptitude in identifying the “happy” expression, registering it with a high accuracy. However, certain challenges emerge when it comes to distinguishing between the nuanced shades of “fear” and “anger”. The model occasionally confuses “fear” for “happy” and vice-versa, indicating a potential area for improvement in distinguishing between positive and more subdued or negative expressions.
Furthermore, a notable aspect arises in the identification of the “neutral” expression. This category, inherently subtle by nature, poses a challenge, with a significant percentage being overlooked and classified as background. This might point towards the model’s sensitivity to subtle cues or the need for richer training data for this particular class. Another interesting observation is the occasional misclassification of what is essentially background noise as distinct emotional states. This points towards the potential for refining the model’s noise filtering capabilities.
In summary, while the model showcases robustness in certain emotional categories, there’s room for refinement. The confusion matrix serves as a guide, highlighting areas like distinguishing subtleties in certain emotions and improving background noise filtering, thus paving the way for more nuanced and precise future iterations.
Figure 10 elucidates the test outcomes of the CReToNeXt-YOLOv5 model, juxtaposing validation batch labels (depicted in part (a)) against their corresponding predictions (highlighted in part (b)). At a glance, one can discern the model’s nuanced proficiency in capturing the spectrum of pig facial expressions, with a commendable degree of accuracy in identifying emotions such as ‘neutral’, ‘fear’, ‘anger’, and particularly ‘happy’. Delving deeper into the insights offered by this visual representation, the model’s prowess is particularly underscored in its ability to accurately decode ‘happy’ expressions, reflecting a high degree of precision in the range of
However, the waters become slightly murkier when navigating the realms of more subdued or complex emotions like ‘fear’ and ‘anger’, both registering at a
In essence, Fig. 10 presents a mosaic of the CReToNeXt-YOLOv5 model’s strengths and potential avenues for enhancement. While it excels in detecting unequivocal emotions like happiness, there lies an exciting frontier in refining its sensitivity to the more intricate tapestry of emotions, ultimately aiming for an iteration that encapsulates the full breadth and depth of pig facial expressions with unparalleled precision.
Self-validation results and analysis of the CReToNeXt-YOLOv5 model
The experimental results on the self-labeled pig expression image dataset are shown in Table 3. The mAP of the CReToNeXt-YOLOv5 model was
In the course of refining the model for improved accuracy and robustness, two potent attention mechanisms, CBAM and Coordinate Attention Mechanism, were integrated into the Yolov5s framework, and their individual contributions were meticulously evaluated. A thorough analysis reveals that the integration of the Coordinate Attention Mechanism, as evidenced by its metrics, offered a more superior performance enhancement compared to the CBAM mechanism. Specifically, when observing the mAP, which is a crucial indicator of a model’s precision and recall balance, the Coordinate Attention Mechanism-equipped model slightly outperformed its CBAM counterpart, reflecting a marginally better overall object detection capability. Furthermore, the model enhanced with the Coordinate Attention Mechanism also showcased a marked improvement in detecting the “Neutral” emotion, an inherently challenging task given the subtlety of neutral expressions. This suggests that this mechanism might offer the model an edge in discerning subtle features in the dataset. While both mechanisms provided commendable results, the decision to favor the Coordinate Attention Mechanism over CBAM was driven by its overall superior and consistent performance across various metrics. The choice underscores the importance of
Figure 8. CReToNeXt-YOLOv5 model test results: (a) represents the precision-recall curve, showcasing an optimal trend of model performance over different thresholds. Solid blue line: represents the mean average precision (mAP) of the model, denoting an overall detection accuracy of 0.894 across all categories; (b) represents the recall rate, achieving a high mark of 0.99 , indicating the model’s proficiency in identifying relevant instances; (c) denotes the F1-score across all classes, peaking at 0.84 at a threshold of 0.189 , highlighting the model’s balanced performance between precision and recall.
Figure 9. Confusion Matrix for the CReToNeXt-YOLOv5 Model.
iterative experimentation and data-driven decisions in model optimization, ensuring that the chosen refinement offers both theoretical and practical improvements to the system’s capabilities.
Figure 12 provides a comparison of the prediction results for the four expression categories among the optimized models. It is evident that the Happy category is easily distinguishable, with an accuracy exceeding
The inclusion of the Coordinate Attention mechanism addresses this issue by decomposing the channel attention into two separate 1 -dimensional feature encoding processes. These processes aggregate features along two spatial directions individually. This approach allows for capturing remote dependencies along one spatial direction while preserving precise location information along the other. The resulting feature maps are encoded as direction and location-aware attention maps, which can be applied in a complementary manner to the input feature maps. This enhances the representation of objects of interest and effectively improves the accuracy of Neutral category recognition.
Incorporating the Coordinate Attention Mechanism into the YOLOv5s framework for pig facial expression detection epitomizes the blend of precision and spatial understanding in object detection techniques. For a nuanced task like detecting varying pig facial expressions, the minute, spatially-specific details play a pivotal role. Traditional models often struggle with capturing these subtle cues, especially when expressions share commonalities. With the Coordinate Attention Mechanism, the model is endowed with the ability to selectively focus on regions of the feature map that are most informative for a particular expression. By weighting these regions more heavily in the subsequent layers, the model becomes more adept at distinguishing between expressions that might otherwise appear similar.
The integration of the EIOU loss function into the YOLOv5s framework for pig facial expression detection epitomizes the evolution of object detection methodologies. The EIOU (enhanced intersection over union) loss function builds on the foundational IOU loss, renowned for its efficacy in bounding box regression tasks. However, EIOU further refines this by addressing certain pitfalls inherent in traditional IOU computations.
For the nuanced task of detecting varied pig facial expressions, the precision of bounding boxes becomes paramount. Misalignments or inaccuracies in these bounding boxes can drastically affect model performance, as the differences between certain expressions can be subtle and localized. The EIOU loss function specifically mitigates such issues by considering not only the overlap between predicted and actual bounding boxes but also
Figure 10. CReToNeXt-YOLOv5 model test results: (a) Val_batch_labels; (b) Val_batch_pred.
the geometric and positional characteristics of these boxes. By doing so, it ensures a more holistic matching, capturing finer discrepancies that might be overlooked by traditional loss functions. Furthermore, EIOU minimizes the penalization of predictions that are close yet not perfectly aligned, making the learning process more forgiving and stable. This nuanced approach to bounding box regression, facilitated by the EIOU loss function, makes it a crucial component in enhancing the YOLOv5s model’s accuracy for pig facial expression detection. The sophisticated error backpropagation driven by EIOU ensures that the model’s predictions are consistently refined, leading to superior detection results across varied scenarios.
Incorporating the CReToNeXt module into the YOLOv5s framework for detecting the four facial expressions of pigs represents a significant advancement in object detection models. The integration capitalizes on the strengths of the CReToNeXt module, leveraging its superior feature extraction and harmonization capabilities.
| Model | Precision | mAP | Recall | F1-score | |||
| Happy | Neutral | Fear | Anger | ||||
| Yolov5s | 0.974 | 0.691 | 0.806 | 0.835 | 0.827 | 0.779 | 0.77 |
| Yolov5s + EIOU | 0.978 | 0.689 | 0.839 | 0.824 | 0.832 | 0.798 | 0.77 |
| Yolov5s + CBAM | 0.981 | 0.760 | 0.858 | 0.841 | 0.860 | 0.815 | 0.65 |
| Yolov5s + coordAtt | 0.984 | 0.803 | 0.864 | 0.831 | 0.870 | 0.827 | 0.67 |
| Yolov5s + coordAtt + EIOU | 0.984 | 0.775 | 0.868 | 0.877 | 0.876 | 0.826 | 0.82 |
| Yolov5s + coordAtt + EIOU + CReToNeXt | 0.985 | 0.809 | 0.896 | 0.889 | 0.894 | 0.990 | 0.84 |
Table 3. Self-validation results of the CReToNeXt-YOLOv5 model.
Figure 11. The mAP comparison graph between the CReToNeXt-YOLOv5 model and the YOLOv5 model.
Figure 12. Based on the improved YOLOV5 model, the comparison of the detection accuracy of four expression categories.
At the heart of the CReToNeXt module lies its ability to bifurcate input data into two distinct pathways, subjecting each to different convolutional operations. This dual-path mechanism is instrumental in capturing both fine-grained, localized features and broader, contextual details from the input image. For the task at hand, discerning nuanced facial expressions in pigs, the importance of this approach cannot be overstated. Subtle variations in facial muscle movement, which often distinguish one emotion from another, are meticulously captured and emphasized through this method. Another compelling advantage of CReToNeXt’s incorporation is its flexibility in feature map dimensionality. Given the inherent disparities in facial expressions, ensuring that the model can accommodate a granular control over feature map channels is critical. This is especially pertinent for complex
emotions that might manifest through a combination of minute facial cues. Furthermore, the optional inclusion of the Spatial Pyramid Pooling layer in the CReToNeXt module facilitates multi-scale feature extraction. Given the variance in size and orientation that facial expressions can have, depending on the pig’s posture and distance from the camera, this multi-scale approach ensures that the model remains robust and invariant to such changes.
emotions that might manifest through a combination of minute facial cues. Furthermore, the optional inclusion of the Spatial Pyramid Pooling layer in the CReToNeXt module facilitates multi-scale feature extraction. Given the variance in size and orientation that facial expressions can have, depending on the pig’s posture and distance from the camera, this multi-scale approach ensures that the model remains robust and invariant to such changes.
In summary, the integration of the CReToNeXt module into the YOLOv5s architecture provides a holistic improvement, particularly for the challenging task of pig facial expression recognition. By adeptly managing multi-scale feature extraction, capturing fine-grained facial nuances, and harmonizing broader context, CReToNeXt sets the stage for unparalleled accuracy and precision in this domain.
Comparison of target detection models of the same type
For the intricate task of detecting facial expressions in pigs, the foundational algorithm of choice becomes pivotal. While the progression in the YOLO series is evident through its advancements in versions like YOLOv7, their lightning-fast convergence to
Our primary focus lies not just in achieving high numbers during training but ensuring steadfast and reliable performance in genuine applications. This is especially true for the challenging arena of recognizing thermal stress-induced expressions in pigs, a scenario filled with subtle facial cues and varying environmental conditions. Therefore, a reliable and robust algorithm is more valuable than a hypersensitive one, leading us to base our studies on the YOLOv5s architecture. YOLOv5s offers a commendable balance of accuracy and speed without prematurely plateauing, granting us ample room for tailored enhancements and adjustments.
But how does YOLOv5s fare against other contemporaries in its league? When juxtaposed against the likes of Faster R-CNN, YOLOv4, and YOLOv8, YOLOv5s’s prowess becomes evident. Faster R-CNN, a two-stage detector, employs a Region Proposal Network (RPN) to earmark potential object regions, which are then refined and classified. While this methodological depth often equips Faster R-CNN with remarkable precision, especially with smaller and densely packed objects, it comes at the cost of increased computational load, potentially making real-time applications challenging. YOLOv4, sharing YOLO’s hallmark single-stage detection architecture, exhibits a balanced performance, boasting improvements over its predecessors but not quite matching the finesse of YOLOv5. By segmenting the entire image into grid cells and performing simultaneous object detection and classification, it offers real-time speeds, making it particularly attractive for applications demanding prompt feedback. YOLOv8 stands as a state-of-the-art (SOTA) model, building upon the successful foundation of its predecessors in the YOLO series. Introducing novel features and improvements, YOLOv8 aims to enhance performance and flexibility. Noteworthy innovations include a redesigned backbone network, a novel Anchor-Free detection head, and a new loss function.
In Fig. 13a, the Faster R-CNN’s Mean Average Precision (mAP) stood at
In conclusion, while YOLOv7 might seem tantalizing due to their blazing-fast convergence, the shadows of overfitting they cast render them less reliable for real-world applications like pig facial expression recognition. On the other hand, YOLOv5, when weighed against Faster R-CNN, YOLOv4, and YOLOv8, emerges as an algorithm that not only provides rapid detection but also allows considerable enhancement leeway, setting the stage for precision-tuned, application-specific advancements.
Analyzing the proficiency of CReToNeXt-YOLOv5 across varied emotional categories
The efficacy of the CReToNeXt-YOLOv5 model in discerning diverse facial expressions in pigs is noteworthy, and to truly appreciate its prowess, one must delve deeper into its performance across specific emotional states. When considering the angry expressions in pigs, characterized by features like deepened wrinkles and wideopen eyes, the CReToNeXt-YOLOv5 stands out. Its dual-path mechanism, integral to its architecture, adeptly captures both the pronounced features and the more subtle nuances, such as the upward pull of the upper lip.
Fear, another intricate emotion in pigs, reveals itself through cues like slightly closed eyes, reduced wrinkles, and droopy ears. The model excels here too, due in large part to the Spatial Pyramid Pooling layer within the CReToNeXt module, which facilitates multi-scale feature extraction. This dynamic feature ensures that the model retains its accuracy in detecting fear regardless of variables like the pig’s posture or its distance from the camera.
The manifestations of happiness in pigs, though appearing clear-cut with slightly closed eyes, an upward tugging of the upper lip, and ears pulled back, present their own challenges. These expressions, especially evident in an eating state, require a model that can precisely pinpoint such fleeting moments. The model’s attention mechanism, which permits selective focus on crucial regions like the mouth and eyes, rises to this challenge, ensuring that these moments of joy are not overlooked.
Figure 13. Comparative analysis of mAP for expression recognition: (a) faster R-CNN model, (b) YOLOv4 model, and (c) YOLOv8 model.
Perhaps the most challenging to detect are the neutral expressions, primarily because of their lack of distinctive features. Yet, it is this very state of normalcy that offers crucial baseline data on a pig’s emotional health. The model’s Coordinate Attention Mechanism is particularly crucial here, granting the model the finesse to detect even the minutest deviations from a neutral state, a feat that many traditional models might falter at.
Furthermore, the CReToNeXt-YOLOv5 model’s proficiency is not merely a product of its individual components but rather their synergistic operation. The dual-path design of the CReToNeXt, combined with the spatial specificity of the CoordAtt mechanism and the holistic perspective provided by the EIOU function, collectively contribute to its impeccable accuracy. This robust amalgamation ensures that the model doesn’t just detect but also precisely classifies each facial expression, setting a new benchmark in the realm of facial expression recognition in livestock.
Limitations in Swine expression analysis with CReToNeXt-YOLOv5
In delving into our CReToNeXt-YOLOv5 model aimed at recognizing and classifying swine facial expressions, we’ve discerned certain nuanced intricacies that can be viewed as potential limitations to our study. Primarily, our dataset predominantly captures swine behavior in specific contexts, particularly under the “Happy” category, where most data are accrued during feeding times. This specificity could inadvertently narrow the model’s generalizability when presented with joyful pig expressions outside of feeding scenarios, despite offering a clear benchmark for our analyses. Additionally, the diversity inherent in the “Neutral” category, encompassing myriad environments, introduces variability which, in turn, could challenge the model’s predictive precision. Practical challenges also arose during data acquisition, given the dynamics of swine movement, camera angles, and varying lighting conditions, all of which could subtly skew the quality of data collected. While we’ve endeavored to mitigate these by employing a multi-camera and multi-angle strategy, the inherent unpredictability of these variables could still influence the model’s holistic efficacy. Furthermore, there’s a plausible risk that our dataset
might not fully represent the gamut of swine breeds, age groups, or health conditions, potentially introducing an undercurrent of bias. As we venture forward, it’s imperative for subsequent research to both acknowledge and address these subtleties, striving for a more encompassing tool for swine facial expression recognition.
might not fully represent the gamut of swine breeds, age groups, or health conditions, potentially introducing an undercurrent of bias. As we venture forward, it’s imperative for subsequent research to both acknowledge and address these subtleties, striving for a more encompassing tool for swine facial expression recognition.
Conclusions
In our quest to comprehend the intricate web of emotions exhibited by livestock, we recognized that facial expressions serve as a pivotal channel. These expressions not only hint at the emotional well-being but also shed light on the psychological health of the animals, making their accurate detection and classification of paramount importance. Addressing inherent challenges, such as the pigs’ rudimentary facial muscle structure and nuances in expressions that often evade detection, we embarked on creating a versatile multi-scene pig facial expression dataset. The richness of this dataset, encompassing varied survival scenarios, emotional states, and diverse perspectives, forms a comprehensive foundation for pig facial expression recognition. Our pioneering work led to the development of the CReToNeXt-YOLOv5 model, tailored to adeptly classify and recognize pig facial expressions. The remarkable strides we made in boosting the expression recognition rates can be attributed to strategic integrations like the CoordAtt attention mechanism, the innovative EIOU loss function, and the essence of the CReToNeXt module. This synergy doesn’t merely bolster the technical prowess of machine vision but resonates deeply with the overarching goal of advancing humane and intelligent livestock farming practices.
Benchmarked against stalwarts in the realm of target detection, CReToNeXt-YOLOv5’s superiority emerges undeniably. While the YOLOv5 model, known for its rapid inference and accuracy, sets a commendable standard, our model not only matches but surpasses it, registering an impressive mAP of
Nevertheless, our model, despite its accomplishments, isn’t without its challenges. The diverse environments where the Neutral category database is located, compounded with multifaceted influencing factors, have sometimes yielded suboptimal recognition rates. Addressing these intricacies, refining our approach, and expanding our dataset with varied scenes and pig breeds stand as our future endeavors. By achieving these, we aim to bolster the model’s robustness and ensure its broader applicability, not just in research settings but in real-world livestock management scenarios, ultimately uplifting animal welfare standards.
Data availability
All code generated during this study are available in the Github repository. Links to the code are provided in the below hyperlinked text. Code of CReToNeXt-YOLOv5 project: https://github.com/Nielili1998/pig-face-expre ssion-recognition. The datasets generated and/or analysed in the current study are not publicly available due to data being collected in collaboration with third-party pig farms, but are available from the respective authors upon reasonable request. Confirmation that these pigs were not handled by the authors during the study. Confirmation that all experimental protocols have been approved by the designated institution and/or licensing board. Confirm that all methods were performed in accordance with relevant guidelines and regulations.
Received: 28 June 2023; Accepted: 9 January 2024
Published online: 19 January 2024
Published online: 19 January 2024
References
- Meiqing, W. et al. Towards re-identification for long-term tracking of group housed pigs. Biosyst. Eng. 222 (2022).
- Huang, W., Zhu, W., Ma, C., Guo, Y. & Chen, C. Identification of group-housed pigs based on Gabor and Local Binary Pattern features. Biosyst. Eng. 166, (2018).
- Kremer, L., Holkenborg, S. K., Reimert, I., Bolhuis, J. & Webb, L. The nuts and bolts of animal emotion. Neurosci. Biobehav. Rev. 113, 273-286 (2020).
- Fraser, D. & Duncan, I. J. ‘Pleasures’, ‘pains’ and animal welfare: Toward a natural history of affect. Anim. Welf. 7, 383-396 (1998).
- Burrows, A. M., Waller, B. M., Parr, L. A. & Bonar, C. J. Muscles of facial expression in the chimpanzee (Pan troglodytes): Descriptive, comparative and phylogenetic contexts. J. Anat. 208, 153-167 (2006).
- Wada, N., Shinya, M. & Shiraishi, M. [Short Paper] Pig Face Recognition Using Eigenspace Method. undefined 1, undefined (2013).
- Camerlink, I., Coulange, E., Farish, M., Baxter, E. M. & Turner, S. P. Facial expression as a potential measure of both intent and emotion. Sci. Rep. 8, 17602 (2018).
- Hansen, M. F. et al. Towards on-farm pig face recognition using convolutional neural networks. Comput. Ind. 98, 145-152 (2018).
- Hansen, M. F. et al. Towards facial expression recognition for on-farm welfare assessment in pigs. Agriculture 11, 847 (2021).
- Marsot, M. et al. An adaptive pig face recognition approach using convolutional neural networks. Comput. Electron. Agric. 173, 105386 (2020).
- Wang, R., Gao, R., Li, Q. & Dong, J. Pig face recognition based on metric learning by combining a residual network and attention mechanism. Agriculture 13, 144 (2023).
- Wen, C. et al. Pig facial expression recognition using multi-attention cascaded LSTM model. Nongye Gongcheng Xuebao/Trans. Chin. Soc. Agric. Eng. 37, 181-190 (2021).
- Kawagoe, Y., Kobayashi, I. & Zin, T. T. Facial region analysis for individual identification of cows and feeding time estimation. Agriculture 13, 1016 (2023).
- Zin, T. T. et al. Automatic cow location tracking system using ear tag visual analysis. Sensors 20, 3564 (2020).
- Zin, T. T. et al. In 2020 IEEE 2nd Global Conference on Life Sciences and Technologies (LifeTech). 65-66 (IEEE).
- Phyo, C. N., Zin, T. T., Hama, H. & Kobayashi, I. In 2018 International Conference on Image and Vision Computing New Zealand (IVCNZ). 1-5 (IEEE).
- Chen, Z. et al. Plant disease recognition model based on improved YOLOv5. Agronomy 12, 365 (2022).
- Xu, X. et al. DAMO-YOLO: A report on real-time object detection design. arXiv preprint arXiv:2211.15444 (2022).
Acknowledgements
This work was supported by the Shanxi Key R&D Program under the topic: Genetic Enhancement, Germplasm Innovation, and Demonstration of Jinfen White Pigs with a focus on the Research on Intelligent Production Performance Measurement Technology of Jinfen White Pigs [project number: 202102140601005, topic number: 202102140604005-2]; and the study on the multiphase reaction mechanism of bacterial biofilm attachment in livestock and poultry houses mediated by high-voltage pulsed electric fields [project number: 2023-092].
Author contributions
L.L.N. conducted the experiment(s), analyzed the results, and wrote the manuscript. B.G.L. provided funding for the project. Y.H.D. coordinated with the pig farm for photography. J.F. and X.Y.S. prepared Figs. 4 and 5. Z.Y.L. conceived the experiment(s). All authors reviewed the manuscript.
Competing interests
The authors declare no competing interests.
Additional information
Correspondence and requests for materials should be addressed to Z.L.
Reprints and permissions information is available at www.nature.com/reprints.
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Reprints and permissions information is available at www.nature.com/reprints.
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
© The Author(s) 2024
© The Author(s) 2024
College of Information Science and Engineering, Shanxi Agricultural University, Taigu 030801, Shanxi, China. College of Animal Science, Shanxi Agricultural University, Taigu 030801, Shanxi, China. College of Agricultural Engineering, Shanxi Agricultural University, Taigu 030801, Shanxi, China. email: Izysyb@126.com