DOI: https://doi.org/10.1007/s11192-023-04894-0
تاريخ النشر: 2024-01-08
تتلقى مخرجات البحث ذات الوصول المفتوح اقتباسات أكثر تنوعًا
© المؤلف(ون) 2024
الملخص
الهدف من الوصول المفتوح هو السماح لمزيد من الأشخاص بقراءة واستخدام مخرجات البحث. وقد تم الادعاء بوجود ارتباط ملحوظ بين مخرجات البحث ذات الاقتباسات العالية والوصول المفتوح كدليل على زيادة استخدام البحث، لكن هذا لا يزال مثيرًا للجدل. كما أن عدد الاقتباسات الأعلى لا يعني بالضرورة استخدامًا أوسع مثل الاقتباسات من مؤلفين من أماكن أكثر. هناك فجوة معرفية في فهمنا لمن يحصل على استخدام مخرجات البحث ذات الوصول المفتوح وأين يقع المستخدمون. هنا نتناول هذه الفجوة من خلال دراسة العلاقة بين حالة الوصول المفتوح لمخرجات البحث وتنوع مخرجات البحث التي تقتبسها. من خلال تحليل بيانات ببليوغرافية واسعة النطاق من 2010 إلى 2019، وجدنا ارتباطًا قويًا بين الوصول المفتوح وزيادة تنوع مصادر الاقتباس من قبل المؤسسات والدول والمناطق الفرعية والمناطق وحقول البحث، عبر مخرجات ذات عدد اقتباسات عالي ومتوسط-منخفض. أظهر الوصول المفتوح من خلال المستودعات التخصصية أو المؤسسية تأثيرًا أقوى من الوصول المفتوح عبر منصات الناشرين. تضيف هذه الدراسة منظورًا جديدًا لفهمنا لكيفية استخدام الاقتباسات لاستكشاف آثار الوصول المفتوح. كما توفر دليلًا جديدًا على نطاق عالمي لفوائد الوصول المفتوح كآلية لتوسيع استخدام البحث وزيادة تنوع المجتمعات التي تستفيد منه.
المقدمة
البحث ذي الصلة
ومع ذلك، توجد فجوة معرفية في الدراسة الشاملة والواسعة النطاق لتنوع الاقتباسات من حيث الجغرافيا وكيفية ارتباطها بـ OA.
المساهمة
- تمتد الدراسة بمفهوم تنوع الاقتباسات لتشمل المواقع الجغرافية لانتماءات المؤلفين للمخرجات المقتبسة بالإضافة إلى حقول البحث.
- تستند الدراسة إلى مجموعات بيانات متاحة للجمهور تشمل 19 مليون مخرج بحثي و420 مليون رابط اقتباس على مستوى العالم، مما يجعلها أكبر دراسة من نوعها حتى الآن.
- تمكن البيانات واسعة النطاق الدراسة من استكشاف قوة النتائج من خلال مقارنة النتائج عبر الزمن، وقياسات التنوع المختلفة، ومجموعات مختلفة من روابط الاقتباس والانتماء، وعدد الاقتباسات، وفحص اعتماداتها.
- تأخذ الدراسة أيضًا استكشافًا أوليًا في فحص ما إذا كانت هناك اختلافات عبر المناطق الجغرافية من حيث كيفية تأثير OA على تنوع الاقتباسات (على سبيل المثال، من أين تأتي الاقتباسات المتزايدة).
الطريقة
| الجدول 1 قائمة المصطلحات | ||
| المصطلح/المتغير | التعريف | وصف البيانات |
| مخرج الاقتباس (أو الورقة) | إذا كان المخرج A يشير إلى المخرج B، فإن المخرج A هو مخرج اقتباس للمخرج B | تحدد مخرجات الاقتباس باستخدام جدول روابط الاقتباس في MAG. يتم تضمين المخرجات التي تحتوي على DOIs من Crossref فقط |
| الفاعل المقتبس | فاعل يمكن أن يرتبط به أو يتميز به مخرج الاقتباس، مثل المؤلف، انتماء المؤلف، بلد انتماء المؤلف، مجال البحث، إلخ | بمجرد تحديد مخرج الاقتباس (كما هو موضح أعلاه)، يتم تحديد المؤلفين، انتماءات المؤلفين، وحقول البحث باستخدام MAG. ثم يتم تحديد المواقع الجغرافية لانتماءات المؤلفين (مثل، البلد، المنطقة الفرعية، المنطقة) باستخدام ROR |
| المؤلف المقتبس | مؤلف لمخرج اقتباس | انظر وصف البيانات لـ “الفاعل المقتبس” |
| المؤسسة المقتبسة | مؤسسة مدرجة كانتماء مؤلف في مخرج اقتباس | انظر وصف البيانات لـ “الفاعل المقتبس” |
| البلد المقتبس | بلد المؤسسة المقتبسة | انظر وصف البيانات لـ “الفاعل المقتبس” |
| المنطقة الفرعية المقتبسة | المنطقة الفرعية للمؤسسة المقتبسة | انظر وصف البيانات لـ “الفاعل المقتبس” |
| المنطقة المقتبسة | المنطقة للمؤسسة المقتبسة | انظر وصف البيانات لـ “الفاعل المقتبس” |
| عدد الاقتباسات | عدد الاقتباسات (مخرجات الاقتباس) التي حصل عليها مخرج | يتم حساب ذلك عن طريق عد عدد مخرجات الاقتباس. انظر وصف البيانات لـ “مخرجات الاقتباس” |
| حقول البحث | مجال البحث (أو التخصص) المعين لمخرج معين | نستخدم البيانات كما هو محدد بواسطة “حقول المستوى 0” في MAG تحت تسلسل MAG لـ “المفاهيم” المعينة للمخرجات. المستوى 0 هو أعلى المفاهيم الأبوية في تسلسل مفاهيم MAG، أي، أكثر المصطلحات عمومية |
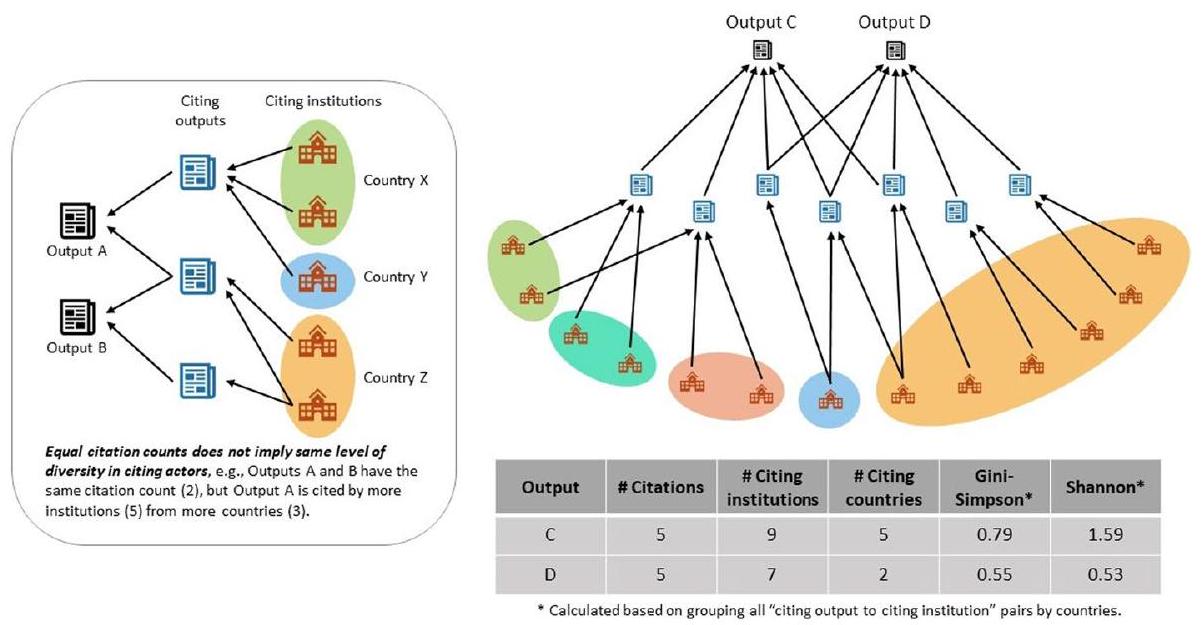
| تنوع الاقتباسات | مصطلح يصف مدى تنوع اقتباسات مخرج ما من حيث روابطها بالفاعلين المقتبسين | هناك العديد من الطرق لتحديد تنوع روابط المخرج-الفاعل المقتبس. يتم استخدام مؤشر جيني-سيمبسون وإنتروبيا شانون لهذه الدراسة. يتم حسابها باستخدام روابط الاقتباس في MAG وتعيينات حقول البحث، وبيانات ROR التنظيمية |
| مؤشر جيني-سيمبسون (مؤشر تنوع جيني) | مقياس تنوع يحدد احتمال أن تنتمي رابطتين عشوائيتين من المخرج إلى الفاعل المقتبس إلى نفس مجموعة الفاعلين المقتبسين | بالنسبة لمخرج معين، يتم حساب مؤشر جيني-سيمبسون عن طريق وضع جميع روابط المخرج-الفاعل المقتبس في صناديق وفقًا لمجموعات مختلفة من الفاعلين المقتبسين (مثل، البلدان). ثم يتم حساب النسب لهذه الروابط في كل صندوق (بلد). أخيرًا، يتم تطبيق صيغة مؤشر جيني-سيمبسون |
| المصطلح/المتغير | التعريف | وصف البيانات |
| إنتروبيا شانون (مؤشر شانون) | مقياس تنوع يحدد مستوى عدم اليقين في توقع تعيين مجموعة الفاعل المقتبس لرابط مخرج-فاعل مقتبس تم اختياره عشوائيًا | يتم حساب ذلك بنفس العملية مثل مؤشر جيني-سيمبسون باستثناء استبدال الصيغة بصيغة إنتروبيا شانون |
| مخرجات الوصول المفتوح (OPEN) | مخرجات يمكن الوصول إليها مجانًا عبر منصات الناشرين أو مستودعات الوصول المفتوح | يتم تحديد حالة الوصول المفتوح لمخرج وفقًا لبيانات Unpaywall |
| مخرجات الذهب (GOLD) | مخرجات يمكن الوصول إليها مجانًا عبر منصات الناشرين مع تراخيص مفتوحة | يتم تحديد حالة الذهب لمخرج وفقًا لبيانات Unpaywall |
| مخرجات الأخضر (GREEN) | مخرجات يمكن الوصول إليها مجانًا عبر مستودعات تخصصية ومؤسسية | يتم تحديد حالة الأخضر لمخرج وفقًا لبيانات Unpaywall |
| مخرجات مغلقة (CLOSED) | مخرجات لا تتوفر نسخ وصول مفتوح من منصات الناشرين أو مستودعات مفتوحة | يتم تحديد حالة الوصول المفتوح لمخرج وفقًا لبيانات Unpaywall |
| ميزة الاقتباس من الوصول المفتوح (OACA) | هذا بيان يعني أن الوصول المفتوح يزيد من عدد الاقتباسات التي يحصل عليها مخرج | NA |
| ميزة تنوع الاقتباس من الوصول المفتوح | هذا بيان يعني أن الوصول المفتوح يوسع تنوع الاقتباسات التي يحصل عليها مخرج | NA |
| نسبة (%) التغيير في إجمالي الاقتباسات | إجمالي الاقتباسات لمخرجات الوصول المفتوح ناقص إجمالي الاقتباسات لمخرجات غير الوصول المفتوح، ثم مقسومًا على إجمالي الاقتباسات لمخرجات غير الوصول المفتوح، ومضروبًا في مئة | يتم حساب ذلك لمجموعة محددة من المخرجات المستهدفة، ومخرجات الاقتباس من فاعل مقتبس محدد. على سبيل المثال، قد نكون مهتمين بالاقتباسات من المنطقة الفرعية Y إلى المنطقة الفرعية
|
| نسبة (%) المتوسط في الاقتباسات | متوسط عدد الاقتباسات لمخرجات الوصول المفتوح، مقسومًا على متوسط عدد الاقتباسات لمخرجات غير الوصول المفتوح، ومضروبًا في مئة | يتم حساب ذلك بطريقة مشابهة لما سبق، باستثناء أن عدد الاقتباسات يتم حسابه كمتوسط عبر عدد المخرجات المستهدفة في كل من مجموعات OPEN وCLOSED |
| تقدير كثافة النواة (KDEs) | هذا تقدير غير معلمي لدالة الكثافة الاحتمالية لمتغير عشوائي معين. في دراستنا نهتم بمقارنة تقديرات الكثافة (KDEs) بين المخرجات المفتوحة والمخرجات المغلقة. | تم إنشاء هذا باستخدام الدالة create_distplot في حزمة Plotly Figure Factory بلغة بايثون. وقد طبقنا هذا التقدير على 10,000 عينة من المخرجات المفتوحة و10,000 عينة من المخرجات المغلقة، على التوالي، لكل تركيب من مقياس التنوع، نوع الجهة المستشهدة، وسنوات النشر. |
بيانات الإدخال
مرصد COKI الأكاديمي
- academic-observatory.observatory.doi20220730
- academic-observatory.mag.PaperReferences20211206
منهجية التحليل
تم تنفيذ التحليل في استعلامات SQL نموذجية يتم تشغيلها عبر إطار تقارير آلي تم تنفيذه بلغة بايثون. الخطوة الأولى هي تجميع الانتماءات المرتبطة بالاقتباسات الواردة لكل من 37 مليون مخرج و424 مليون رابط اقتباس في فترة الوقت المستهدفة. يتم تخزين الجدول الناتج “citation_diversity_global” في قاعدة بيانات BigQuery السحابية من جوجل. يتم تصفية التحليلات اللاحقة واستعلامات SQL المقابلة لتقليلها إلى المخرجات التي تحتوي على اقتباسين أو أكثر، والتي تتوافق مع 19 مليون مخرج مع 420 مليون رابط اقتباس. القرار بالاعتبار فقط المخرجات التي تحتوي على اقتباسين أو أكثر يعتمد على حقيقة أن قياس التنوع للمخرجات التي تحتوي على صفر اقتباسات هو أمر غير منطقي وأن المخرجات التي تحتوي على اقتباس واحد فقط ستُعطى بشكل تافه درجة تنوع تساوي صفر. ومع ذلك، يتم الاحتفاظ بهذه المخرجات في الجدول أعلاه لأغراض التحقق.
الدلالة الإحصائية
ما سبق، اتخذنا البديل في استكشاف اتساق ميزة تنوع الاقتباسات OA عبر طرق متعددة لتحليل مجموعة المخرجات. ومع ذلك، حيثما كان ذلك ممكنًا، قمنا بتضمين بعض تحليلات أخذ العينات الفرعية للتأكيد على أن هذا الاتساق يتم الحفاظ عليه عبر عينات صغيرة قابلة للمقارنة بالنسبة للبيانات الكاملة.
النتائج
مقارنة فئات OA
مقارنة الجغرافيا
متانة النتائج
تأثير متسق عبر الزمن والمقاييس والفئات
بسبب وجود مخرجات أكثر حداثة تحتوي على عدد أقل من الاقتباسات. يتم تقديم هذه النتائج في الأشكال التكميلية A.
مجالات البحث. ولكن بالنسبة للأغلبية من المجالات التي تغطيها مجموعة بياناتنا بشكل جيد، فإن ميزة تنوع الاقتباسات في الوصول المفتوح واضحة، بما في ذلك التخصصات المختلفة عن العلوم الطبية الحيوية، مما يظهر أن التأثير قوي عبر العلوم الطبيعية والبيولوجية والسريرية، وفي عدة مجالات من العلوم الاجتماعية.
العلاقات بين تنوع الاقتباسات وعدد الاقتباسات
الاقتباسات بين المناطق الفرعية والمناطق
نقاش
المزيد من الموارد هم أكثر احتمالًا لجعل أعمالهم مفتوحة). تشير هذه إلى أن التركيز على عدد الاقتباسات لا يمكنه رسم الصورة الكاملة لفوائد الوصول المفتوح. قد تتلقى مخرجات مفتوحة المزيد من الاقتباسات، ولكن قد تستمر هذه الاقتباسات في القدوم من نفس مجموعات الباحثين. على العكس، قد لا تتلقى مخرجات مفتوحة المزيد من الاقتباسات، ولكن قد تأتي الاقتباسات من مجموعة أوسع من مستخدمي البحث. ومن ثم، نجادل بأن التحول إلى فهم تنوع الاقتباسات يوفر دليلًا أقوى وأكثر معنى لفوائد الوصول المفتوح في الوصول إلى جماهير أوسع.
قيود البيانات
- المخرجات البحثية المدرجة في تحليلنا هي تلك التي تم تعيين DOIs لها بواسطة Crossref. نحن ندرك أن هناك وكالات تسجيل DOI أخرى تعين DOIs للمخرجات البحثية (مثل البنية التحتية الوطنية للمعرفة في الصين – CNKI) وهذه ليست مدرجة حاليًا في نظامنا. وبالتالي، قد تكون هناك قيود في تغطيتنا لبعض مناطق آسيا وأفريقيا جنوب الصحراء ومناطق أخرى. هناك أيضًا قضايا عامة تتعلق بتغطية بعض مجالات البحث حيث لا تُستخدم DOIs تقليديًا على نطاق واسع (مثل الفن، العلوم السياسية، إلخ). بالإضافة إلى ذلك، قد تكون هناك قضايا تتعلق بنوافذ التحرك من حيث تعيين المخرجات لمجالات البحث، كنتيجة للتغيرات الثقافية والمنهجية على مر الزمن (مثل تعيين مخرجات الهندسة لعلوم المواد وعلوم الحاسوب في السنوات الأخيرة).
- البيانات حول مجالات البحث المستخدمة في تحليلنا مستخرجة مباشرة من MAG. استخدم MAG أساليب التعلم الآلي لتصنيف المخرجات البحثية إلى “مفاهيم” وبناء تسلسل هرمي لهذه المفاهيم (وانغ وآخرون، 2020). نحن نستخدم فقط المفاهيم المحددة في المستوى 0 (أكثر المفاهيم عمومية أو أعلى المفاهيم الأبوية) من التسلسل الهرمي. من الممكن أن تختلف نتائجنا بناءً على مجالات البحث إذا تم استخدام مجموعة بيانات مختلفة حول مجالات البحث أو التخصصات. يجب أن نلاحظ أيضًا أن MAG قد تم إيقافه الآن، وسيتم استخدام مصدر بديل في الأعمال المستقبلية (مثل OpenAlex).
- تعريفنا لتنوع الاقتباسات يعتمد على توزيع “روابط المخرجات إلى روابط الاقتباس” عبر مجموعات الاقتباس. وهذا يعني أنه إذا كان هناك مخرج مقتبس له مؤلفون متعددون ينتمون إلى انتسابات متعددة، فمن المحتمل أن يستنتج روابط متعددة من المخرج إلى روابط الاقتباس. بعبارة أخرى، قد ينتمي هذا المخرج المقتبس إلى مناطق متعددة (على سبيل المثال). قد يكون لهذا تأثير على المخرجات ذات الاقتباسات المنخفضة مع وجود مخرج واحد على الأقل مقتبس له عدد كبير بشكل استثنائي من المؤلفين من انتسابات متعددة. ومع ذلك، كشفت فحوصات الجودة لدينا عن عدد قليل جدًا من هذه الحالات (أي، القيم المتطرفة) وليس لها تأثير واضح على النتائج العامة. قد تكون هناك طرق أخرى لتعريف أو قياس تنوع الاقتباسات التي تتضمن مثل هذه الحالات.
استنتاج
…التوزيع الإلكتروني العالمي للأدبيات العلمية التي تمت مراجعتها من قبل الأقران والوصول المجاني وغير المقيد إليها من قبل جميع العلماء والباحثين والمعلمين والطلاب والعقول الفضولية الأخرى.
توفير منفعة عامة ست
“…تسرع البحث، وتثري التعليم، وتشارك تعلم الأغنياء مع الفقراء والفقراء مع الأغنياء، وتجعل هذه الأدبيات مفيدة قدر الإمكان، وتضع الأساس لتوحيد الإنسانية في محادثة فكرية مشتركة وسعي للمعرفة”.
“…مهمة إزالة الحواجز أمام الوصول المفتوح وبناء مستقبل يكون فيه البحث والتعليم في كل جزء من العالم أكثر حرية للازدهار”.
الإعلانات
الوصول المفتوح هذه المقالة مرخصة بموجب رخصة المشاع الإبداعي للاستخدام الدولي 4.0، والتي تسمح بالاستخدام والمشاركة والتكيف والتوزيع وإعادة الإنتاج في أي وسيلة أو صيغة، طالما أنك تعطي الائتمان المناسب للمؤلفين الأصليين والمصدر، وتوفر رابطًا لرخصة المشاع الإبداعي، وتوضح ما إذا كانت هناك تغييرات قد تم إجراؤها. الصور أو المواد الأخرى من طرف ثالث في هذه المقالة مشمولة في رخصة المشاع الإبداعي للمقالة، ما لم يُشار إلى خلاف ذلك في سطر الائتمان للمادة. إذا لم تكن المادة مشمولة في رخصة المشاع الإبداعي للمقالة واستخدامك المقصود غير مسموح به بموجب اللوائح القانونية أو يتجاوز الاستخدام المسموح به، ستحتاج إلى الحصول على إذن مباشرة من صاحب حقوق الطبع والنشر. لعرض نسخة من هذه الرخصة، قم بزيارة http://creativecommons.org/licenses/by/4.0/.
References
Basson, I., Blanckenberg, J. P., & Prozesky, H. (2021). Do open access journal articles experience a citation advantage? Results and methodological reflections of an application of multiple measures to an analysis by WoS subject areas. Scientometrics, 126, 459-484. https://doi.org/10.1007/s11192-020-03734-9
Chan, L., Cuplinskas, D., Eisen, M., Friend, F., Genova, Y., Guédon, J., Hagemann, M., Harnad, S., Johnson, R., Kupryte, R., La Manna, M., Rév, I., Segbert, M., de Souza, S., Suber P., Velterop, J. (2002). Read the declaration-Budapest Open Access Initiative. Retrieved September 6, 2022, from https://www.budap estopenaccessinitiative.org/read/
Dahler-Larsen, P. (2018). Making citations of publications in languages other than English visible: on the feasibility of a PLOTE-index. Research Evaluation, 27(3), 212-221. https://doi.org/10.1093/reseval/rvy010
Davis, P. M. (2011). Open access, readership, citations: A randomized controlled trial of scientific journal publishing. The FASEB Journal, 25(7), 2129-2134. https://doi.org/10.1096/fj.11-183988
Diprose, J., Neylon, C., & Kramer, B. (2022). Language Diversity in Scholarly Publishing. Curtin Open Knowledge Initiative News. Retrieved September 5, 2023, from https://openknowledge.community/languagediversity/
Dorta-González, P., González-Betancor, S. M., & Dorta-González, M. I. (2017). Reconsidering the gold open access citation advantage postulate in a multidisciplinary context: An analysis of the subject categories in the Web of Science database 2009-2014. Scientometrics, 112, 877-901. https://doi.org/10.1007/ s11192-017-2422-y
Hosking, R., Diprose, J. P., Roelofs, A., Chien, T.-Y., Handcock, R. N., Kramer, B., Napier, K., Montgomery, L., & Neylon, C. (2022). Academic observatory workflows [software]. Zenodo. https://doi.org/10.5281/ zenodo. 6366694
Hua, F., Sun, H., Walsh, T., Worthington, H., & Glenny, A. (2016). Open access to journal articles in dentistry: Prevalence and citation impact. Journal of Dentistry, 47, 41-48. https://doi.org/10.1016/j.jdent.2016.02. 005
Huang, C.-K., & Neylon, C. (2022). Curtin-open-knowledge-initiative/citation-diversity: Codes and data for open access research outputs receive more diverse citations [software]. Zenodo. https://doi.org/10.5281/ zenodo. 7081118
Hutchins, B. I., Yuan, X., Anderson, J. M., & Santangelo, G. M. (2016). Relative citation ratio (RCR): A new metric that uses citation rates to measure influence at the article level. PLoS Biology, 14(9), e1002541. https://doi.org/10.1371/journal.pbio. 1002541
Lewis, C. L. (2018). The open access citation advantage: Does it exist and what does it mean for libraries? Information Technology and Libraries, 37(3), 50-65. https://doi.org/10.6017/ital.v37i3.10604
Linkov, V., O’Doherty, K., Choi, E., & Han, G. (2021). Linguistic diversity index: a scientometric measure to enhance the relevance of small and minority group languages. SAGE Open, 11(2), 1-9. https://doi.org/10. 1177/21582440211009191
Naik, C., Sugimoto, C. R., Larivière, V., Leng, C., & Guo, W. (2023). Impact of geographic diversity on citation of collaborative research. Quantitative Science Studies, 4(2), 442-465. https://doi.org/10.1162/qss_a_ 00248
Neylon, C., & Huang, C.-K. (2022). The global state of open access 2021. Zenodo. https://doi.org/10.5281/ zenodo. 7059176
Neylon, C., Ozaygen, A., Montgomery, L., Huang, C.-K., Pyne, R., Lucraft, M., & Emery, C. (2021). More readers in more places: the benefits of open access for scholarly books. Insights, 34(1), 27. https://doi.org/ 10.1629/uksg. 558
Seppänen, J.-T., Värri, H., & Ylönen, I. (2022). Co-citation percentile rank and JYUcite: A new network-standardized output-level citation influence metric and its implementation using dimensions API. Scientometrics, 127, 3523-3541. https://doi.org/10.1007/s11192-022-04393-8
Sotudeh, H. (2020). Does open access citation advantage depend on paper topics? Journal of Information Science, 46(5), 696-709. https://doi.org/10.1177/0165551519865489
Tennant, J. P., Waldner, F., Jacques, D. C., Masuzzo, P., Collister, L. B., & Hartgerink, C. H. (2016). The academic, economic and societal impacts of open access: An evidence-based review. F1000 Research, 5, 632. https://doi.org/10.12688/f1000research.8460.3
The World Bank. (2022). Research and development expenditure (% of GDP). World Bank Group. Retrieved September 6, 2022, from https://data.worldbank.org/indicator/GB.XPD.RSDV.GD.ZS
Wang, K., Shen, Z., Huang, C., Wu, C., Dong, Y., & Kanakia, A. (2020). Microsoft academic graph: When experts are not enough. Quantitative Science Studies, 1(1), 396-413. https://doi.org/10.1162/qss_a_00021
Zhang, L., & Watson, E. M. (2017). Measuring the impact of gold and green open access. The Journal of Academic Librarianship, 43(4), 337-345. https://doi.org/10.1016/j.acalib.2017.06.004
- Chun-Kai Huang
karl.huang@curtin.edu.au
1 Centre for Culture and Technology, Curtin University, Bentley, WA, Australia
2 Curtin Institute for Data Science, Curtin University, Bentley, WA, Australia
3 Faculty of Education, Te Herenga Waka – Victoria University of Wellington, Wellington, New Zealand
DOI: https://doi.org/10.1007/s11192-023-04894-0
Publication Date: 2024-01-08
Open access research outputs receive more diverse citations
© The Author(s) 2024
Abstract
The goal of open access is to allow more people to read and use research outputs. An observed association between highly cited research outputs and open access has been claimed as evidence of increased usage of the research, but this remains controversial. A higher citation count also does not necessarily imply wider usage such as citations by authors from more places. A knowledge gap exists in our understanding of who gets to use open access research outputs and where users are located. Here we address this gap by examining the association between an output’s open access status and the diversity of research outputs that cite it. By analysing large-scale bibliographic data from 2010 to 2019, we found a robust association between open access and increased diversity of citation sources by institutions, countries, subregions, regions, and fields of research, across outputs with both high and medium-low citation counts. Open access through disciplinary or institutional repositories showed a stronger effect than open access via publisher platforms. This study adds a new perspective to our understanding of how citations can be used to explore the effects of open access. It also provides new evidence at global scale of the benefits of open access as a mechanism for widening the use of research and increasing the diversity of the communities that benefit from it.
Introduction
Relevant research
outputs. However, a knowledge gap exists in the comprehensive and large-scale study of citation diversity in terms of geographies and how it relates to OA .
Contribution
- The study extends the concept of citation diversity to consider the geographic locations of author affiliations of citing outputs in addition to the fields of research.
- The study draws on publicly available datasets that include 19 million research outputs and 420 million citation links worldwide, making it the largest study of this type to date.
- The large-scale data also enables the study to explore the robustness of the results by comparing results across time, different measures of diversity, various groupings of citation-affiliation links, citation counts, and examining their dependencies.
- The study also takes a first exploration in examining whether there are differences across geographic regions in terms of how OA influences citation diversity (e.g., where increased citations come from).
Method
| Table 1 List of terms | ||
| Term/variable | Definition | Data description |
| Citing output (or paper) | If Output A references Output B, then Output A is a citing output for Output B | Citing outputs are identified using the table of reference links in MAG. Only outputs with Crossref DOIs are included |
| Citing actor | An actor upon which a citing output can be affiliated or characterised, e.g., author, author affiliation, country of author affiliation, field of research, etc | Once a citing output is identified (as above), the authors, author affiliations, and fields of research are identified using MAG. Then geographic locations of author affiliations (e.g., country, subregion, region) are identified using ROR |
| Citing author | An author of a citing output | See data description for “Citing actor” |
| Citing institution | An institution that is included as an author affiliation in a citing output | See data description for “Citing actor” |
| Citing country | The country of a citing institution | See data description for “Citing actor” |
| Citing subregion | The subregion of a citing institution | See data description for “Citing actor” |
| Citing region | The region of a citing institution | See data description for “Citing actor” |
| Citation count | The number of citations (citing outputs) that an output received | This is calculated by counting the number of citing outputs. See data description of “Citing outputs” |
| Fields of research | The field of research (or subject discipline) assigned to a given output | We use data as defined by MAG’s “Level 0 fields” under the MAG hierarchy of “concepts” assigned to outputs. Level 0 is the highest-level parent concepts in the MAG concepts hierarchy, i.e., most broad terms |
| Citation diversity | A term describing how diverse an output’s citations are in terms of their links to citing actors | There are many ways to quantify diversity of the output-tociting actor links. The Gini-Simpson Index and the Shannon Entropy are used for this study. These are calculated using MAG’s citation links and fields of research assignments, and ROR’s organisational metadata |
| Gini-Simpson Index (Gini’s Diversity Index) | A diversity measure that quantifies the probability that two randomly selected output-to-citing actor links belong to the same citing actor group | For a given output, the Gini-Simpson Index is calculated by first placing all output-to-citing actor links into bins according to different groups of citing actors (e.g., countries). Then proportions of these links in each bin (country) is calculated. Finally, the Gini-Simpson Index formula is applied |
| Term/variable | Definition | Data description |
| Shannon Entropy (Shannon Index) | A diversity measure that quantifies the level of uncertainty in predicting the citing actor group assignment of a randomly selected output-to-citing actor link | This is calculated following the same process as Gini-Simpson Index except with the formula replaced by the Shannon Entropy formula |
| Open access outputs (OPEN) | Outputs that are freely accessible via either publisher platforms or OA repositories | An output’s OA status is determined as per Unpaywall data |
| Gold outputs (GOLD) | Outputs that are freely accessible via publisher platforms with open licences | An output’s GOLD status is determined as per Unpaywall data |
| Green outputs (GREEN) | Outputs that are freely accessible via disciplinary and institutional repositories | An output’s GREEN status is determined as per Unpaywall data |
| Closed outputs (CLOSED) | Outputs with no OA copies available from publisher platforms nor open repositories | An output’s OA status is determined as per Unpaywall data |
| Open access citation advantage (OACA) | This is a statement implying that OA increases the number of citations that an output receives | NA |
| Open access citation diversity advantage | This is a statement implying that OA widens the diversity of citations that an output receives | NA |
| Percentage (%) change in total citations | Total citations to OA outputs minus total citations to non-OA outputs, then divided by total citations to non-OA outputs, and multiplied by one hundred | This is calculated for a specified set of target outputs, and citing outputs from a specified citing actor. For example, we may be interested in the citations from subregion Y to subregion
|
| Percentage (%) ratio in average citations | The average number of citations to OA outputs, divided by the average number of citations to non-OA outputs, and times by one hundred | This is calculated in a similar way to the above, except the citation count is averaged across the number of target outputs in each of OPEN and CLOSED sets |
| Kernel density estimate (KDEs) | This is a non-parametric estimate of the probability density function of a given random variable. In our study we are interested in comparing KDEs between OPEN and CLOSED outputs | This is created using the create_distplot function in the Plotly Figure Factory package in Python. We applied this estimation to 10,000 sampled OPEN outputs and 10,000 sampled CLOSED outputs, respectively, for each combination of diversity measure, citing actor type, and years of publication |
Input data
COKI academic observatory
- “academic-observatory.observatory.doi20220730”
- “academic-observatory.mag.PaperReferences20211206”
Analysis methodology
The analysis is implemented in template SQL queries that are run via an automated reporting framework implemented in Python. The first step is the aggregation of the affiliations associated with incoming citations for each of the 37 million outputs and 424 million citation links in the target time period. The resulting table “citation_diversity_global” is stored in Google’s cloud-based BigQuery database. Subsequent analyses and corresponding SQL queries further filter this down to outputs with two or more citations, which corresponds to 19 million outputs with 420 million citation links. The decision to only consider outputs with two or more citations is based on the fact that measuring diversity for outputs with zero citations is nonsensical and outputs with only one citation will trivially be assigned a diversity score of zero. However, these outputs are kept in the table above for validation purposes.
Statistical significance
above, we have taken the alternative in exploring the consistency of the OA citation diversity advantage across multiple ways of analysing the corpus of outputs. However, where possible, we have included some subsampling analyses to emphasise that this consistency is maintained across comparable but small samples relative to the whole data.
Results
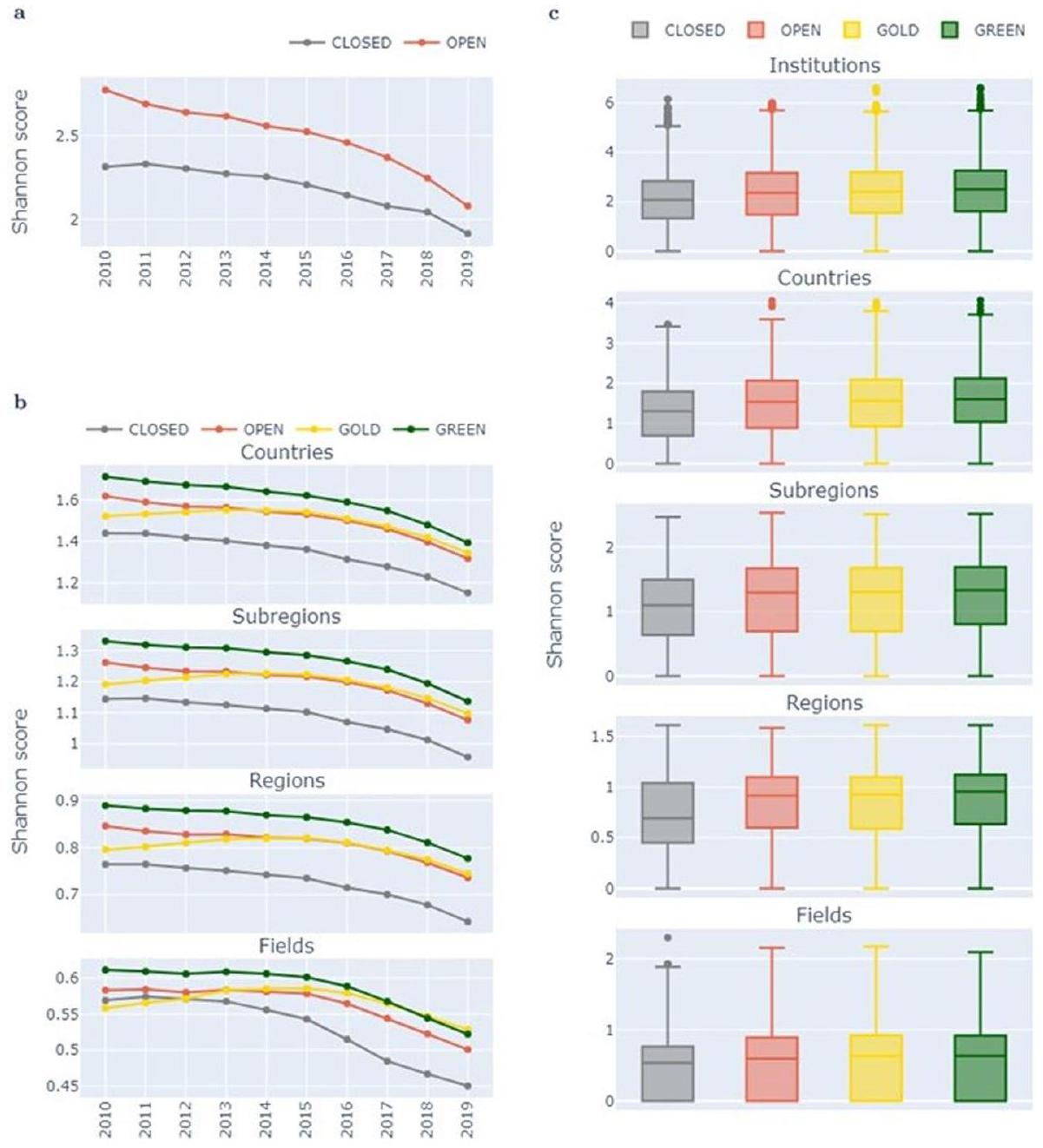
Comparing OA categories
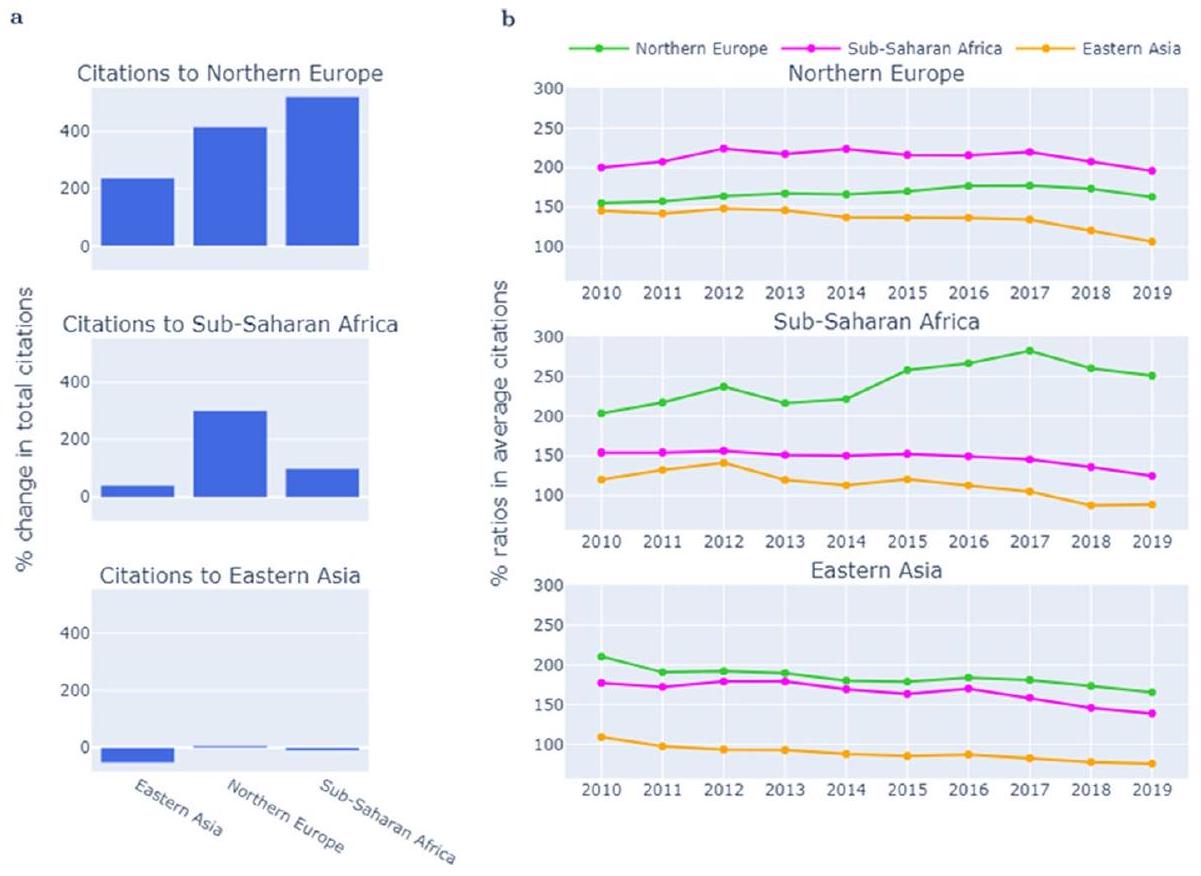
Comparing geographies
Robustness of results
A consistent effect across time, measures, and categories
counts due to more recent outputs having fewer citations. These results are presented in Supplementary Figures A.
fields of research. But for the majority of fields where our dataset has good coverage, the OA citation diversity advantage is clearly seen, including for disciplines distinct from biomedical sciences showing that the effect is robust across natural, biological and clinical sciences, and in several areas of social sciences.
Relationships between citation diversity and citation count
Citations between subregions and regions
Discussion
more resources are more likely to make their work OA ). These imply that the focus on citation counting is not able to paint the full picture of the benefits of OA. An OPEN output may receive more citations, but these citations may continue to come from the same groups of researchers. Conversely, an OPEN output may not have received more citations, but the citations may come from a broader set of research users. Hence, we argue that a shift to understanding the diversity of citations provides a stronger and more meaningful evidence of the benefits of OA in reaching wider audiences.
Data limitations
- Research outputs included in our analysis are those that are assigned DOIs by Crossref. We acknowledge that there are other DOI registration agencies that assign DOIs to research outputs (e.g., China National Knowledge Infrastructure-CNKI) and these are not currently indexed in our system. Consequently, there may be limitations in our coverage of certain areas of Asia, Sub-Saharan Africa and other regions. There are also general issues with coverage of certain fields of research where DOIs are not traditionally used in scale (such as in Art, Political Sciences, etc.). In addition, there may be issues of moving windows in terms of assignments of outputs to fields of research, as results of both cultural and methodological changes over time (e.g., Engineering outputs being assigned to Material Science and Computer Science in more recent years).
- The data on fields of research used in our analysis are directly extracted from MAG. MAG used machine learning approaches to classify research outputs into “concepts” and build a hierarchy of these concepts (Wang et al., 2020). We only use the concepts specified in level 0 (most broad or highest parent concepts) of the hierarchy. It is possible that our results based on fields of research may differ if a different set of data on fields of research or subject disciplines is used. We should also note that MAG is now discontinued, and an alternative source will be used in future work (e.g., OpenAlex).
- Our definition of citation diversity is based on the distribution of “output-to-citation actor links” across citation actor groups. This does imply that if a citing output has multiple authors belonging to multiple affiliations, then it will possibly infer multiple output-to-citing actor links. In other words, this citing output may belong to multiple regions (for example). This may have an impact on low-citation outputs with at least one citing output with extraordinarily large number of authors from multiple affiliations. However, our quality checks revealed very low number of such cases (i.e., outliers) and they have no obvious impact on the overall findings. There may be other ways to define or measure citation diversity that incorporate such cases.
Conclusion
“…the world-wide electronic distribution of the peer-reviewed journal literature and completely free and unrestricted access to it by all scientists, scholars, teachers, students, and other curious minds.”
providing a public good which will
“…accelerate research, enrich education, share the learning of the rich with the poor and the poor with the rich, make this literature as useful as it can be, and lay the foundation for uniting humanity in a common intellectual conversation and quest for knowledge”.
“…the task of removing the barriers to open access and building a future in which research and education in every part of the world are that much more free to flourish”.
Declarations
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
References
Basson, I., Blanckenberg, J. P., & Prozesky, H. (2021). Do open access journal articles experience a citation advantage? Results and methodological reflections of an application of multiple measures to an analysis by WoS subject areas. Scientometrics, 126, 459-484. https://doi.org/10.1007/s11192-020-03734-9
Chan, L., Cuplinskas, D., Eisen, M., Friend, F., Genova, Y., Guédon, J., Hagemann, M., Harnad, S., Johnson, R., Kupryte, R., La Manna, M., Rév, I., Segbert, M., de Souza, S., Suber P., Velterop, J. (2002). Read the declaration-Budapest Open Access Initiative. Retrieved September 6, 2022, from https://www.budap estopenaccessinitiative.org/read/
Dahler-Larsen, P. (2018). Making citations of publications in languages other than English visible: on the feasibility of a PLOTE-index. Research Evaluation, 27(3), 212-221. https://doi.org/10.1093/reseval/rvy010
Davis, P. M. (2011). Open access, readership, citations: A randomized controlled trial of scientific journal publishing. The FASEB Journal, 25(7), 2129-2134. https://doi.org/10.1096/fj.11-183988
Diprose, J., Neylon, C., & Kramer, B. (2022). Language Diversity in Scholarly Publishing. Curtin Open Knowledge Initiative News. Retrieved September 5, 2023, from https://openknowledge.community/languagediversity/
Dorta-González, P., González-Betancor, S. M., & Dorta-González, M. I. (2017). Reconsidering the gold open access citation advantage postulate in a multidisciplinary context: An analysis of the subject categories in the Web of Science database 2009-2014. Scientometrics, 112, 877-901. https://doi.org/10.1007/ s11192-017-2422-y
Hosking, R., Diprose, J. P., Roelofs, A., Chien, T.-Y., Handcock, R. N., Kramer, B., Napier, K., Montgomery, L., & Neylon, C. (2022). Academic observatory workflows [software]. Zenodo. https://doi.org/10.5281/ zenodo. 6366694
Hua, F., Sun, H., Walsh, T., Worthington, H., & Glenny, A. (2016). Open access to journal articles in dentistry: Prevalence and citation impact. Journal of Dentistry, 47, 41-48. https://doi.org/10.1016/j.jdent.2016.02. 005
Huang, C.-K., & Neylon, C. (2022). Curtin-open-knowledge-initiative/citation-diversity: Codes and data for open access research outputs receive more diverse citations [software]. Zenodo. https://doi.org/10.5281/ zenodo. 7081118
Hutchins, B. I., Yuan, X., Anderson, J. M., & Santangelo, G. M. (2016). Relative citation ratio (RCR): A new metric that uses citation rates to measure influence at the article level. PLoS Biology, 14(9), e1002541. https://doi.org/10.1371/journal.pbio. 1002541
Lewis, C. L. (2018). The open access citation advantage: Does it exist and what does it mean for libraries? Information Technology and Libraries, 37(3), 50-65. https://doi.org/10.6017/ital.v37i3.10604
Linkov, V., O’Doherty, K., Choi, E., & Han, G. (2021). Linguistic diversity index: a scientometric measure to enhance the relevance of small and minority group languages. SAGE Open, 11(2), 1-9. https://doi.org/10. 1177/21582440211009191
Naik, C., Sugimoto, C. R., Larivière, V., Leng, C., & Guo, W. (2023). Impact of geographic diversity on citation of collaborative research. Quantitative Science Studies, 4(2), 442-465. https://doi.org/10.1162/qss_a_ 00248
Neylon, C., & Huang, C.-K. (2022). The global state of open access 2021. Zenodo. https://doi.org/10.5281/ zenodo. 7059176
Neylon, C., Ozaygen, A., Montgomery, L., Huang, C.-K., Pyne, R., Lucraft, M., & Emery, C. (2021). More readers in more places: the benefits of open access for scholarly books. Insights, 34(1), 27. https://doi.org/ 10.1629/uksg. 558
Seppänen, J.-T., Värri, H., & Ylönen, I. (2022). Co-citation percentile rank and JYUcite: A new network-standardized output-level citation influence metric and its implementation using dimensions API. Scientometrics, 127, 3523-3541. https://doi.org/10.1007/s11192-022-04393-8
Sotudeh, H. (2020). Does open access citation advantage depend on paper topics? Journal of Information Science, 46(5), 696-709. https://doi.org/10.1177/0165551519865489
Tennant, J. P., Waldner, F., Jacques, D. C., Masuzzo, P., Collister, L. B., & Hartgerink, C. H. (2016). The academic, economic and societal impacts of open access: An evidence-based review. F1000 Research, 5, 632. https://doi.org/10.12688/f1000research.8460.3
The World Bank. (2022). Research and development expenditure (% of GDP). World Bank Group. Retrieved September 6, 2022, from https://data.worldbank.org/indicator/GB.XPD.RSDV.GD.ZS
Wang, K., Shen, Z., Huang, C., Wu, C., Dong, Y., & Kanakia, A. (2020). Microsoft academic graph: When experts are not enough. Quantitative Science Studies, 1(1), 396-413. https://doi.org/10.1162/qss_a_00021
Zhang, L., & Watson, E. M. (2017). Measuring the impact of gold and green open access. The Journal of Academic Librarianship, 43(4), 337-345. https://doi.org/10.1016/j.acalib.2017.06.004
- Chun-Kai Huang
karl.huang@curtin.edu.au
1 Centre for Culture and Technology, Curtin University, Bentley, WA, Australia
2 Curtin Institute for Data Science, Curtin University, Bentley, WA, Australia
3 Faculty of Education, Te Herenga Waka – Victoria University of Wellington, Wellington, New Zealand