DOI: https://doi.org/10.1038/s41467-023-44673-2
PMID: https://pubmed.ncbi.nlm.nih.gov/38225246
تاريخ النشر: 2024-01-15
ترميز المعلومات العاطفية متعددة الأنماط من خلال واجهة وجه لاسلكية مدمجة في الجلد مخصصة
تاريخ القبول: 28 ديسمبر 2023
تاريخ النشر على الإنترنت: 15 يناير 2024
(أ) تحقق من التحديثات
الملخص
تعتبر المشاعر والعواطف والمزاجات من العوامل الأساسية التي تعزز التفاعل بين البشر والآلات والأنظمة المتنوعة. ومع ذلك، فإن طبيعتها المجردة والغموض تجعل من الصعب استخراج المعلومات العاطفية بدقة واستغلالها. هنا، نطور نظامًا للتعرف على مشاعر الإنسان متعددة الأنماط يمكنه استخدام المعلومات العاطفية الشاملة بكفاءة من خلال دمج بيانات التعبير اللفظي وغير اللفظي. يتكون هذا النظام من نظام واجهة وجه مدمجة في الجلد مخصصة (PSiFI) تعمل بالطاقة الذاتية، وسهلة الاستخدام، وقابلة للتمدد، وشفافة، وتتميز بمستشعر ثنائي الاتجاه للضغط والاهتزاز مما يمكننا من استشعار ودمج بيانات التعبير اللفظي وغير اللفظي للمرة الأولى. إنه متكامل تمامًا مع دائرة معالجة البيانات لنقل البيانات لاسلكيًا مما يسمح بإجراء التعرف على المشاعر في الوقت الحقيقي. بمساعدة التعلم الآلي، يتم تنفيذ مهام التعرف على مشاعر الإنسان بدقة في الوقت الحقيقي حتى أثناء ارتداء القناع، وتم عرض تطبيق الكونسيرج الرقمي في بيئة الواقع الافتراضي.
البيانات المجمعة من عدة أنماط، مثل الكلام، تعبير الوجه، الإيماءات، ومجموعة متنوعة من الإشارات الفسيولوجية (مثل درجة الحرارة، والنشاط الكهربائي الجلدي)
النتائج
نظام واجهة الوجه المتكاملة مع الجلد المخصصة (PSiFI)
آلية العمل وخصائص وحدة استشعار الإجهاد
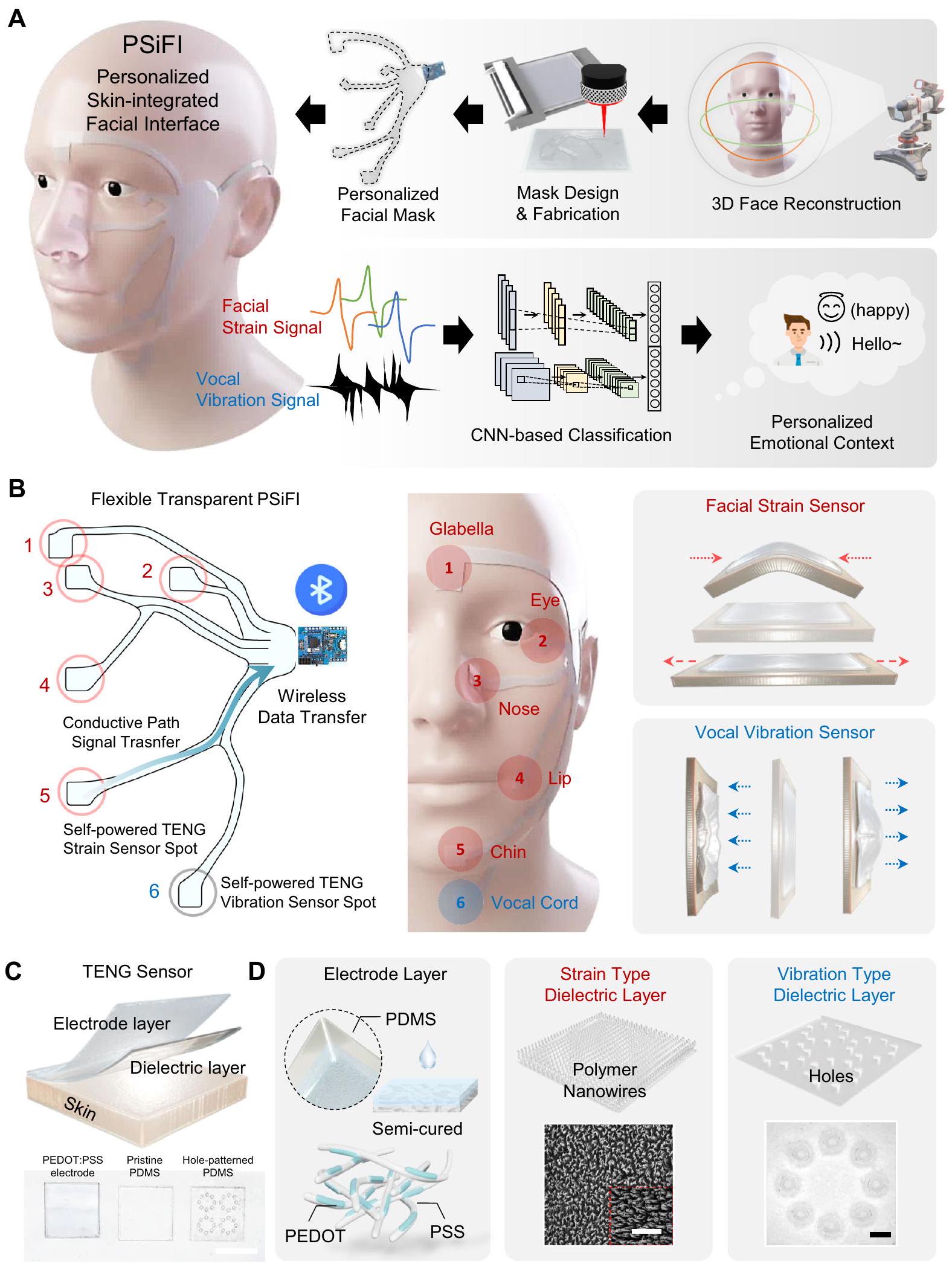
نظام الدائرة هو وظيفة وحدة استشعار الإجهاد لدينا. كما هو موضح بشكل تخطيطي في الشكل 2A، تم تصنيع وحدة استشعار الإجهاد باستخدام PDMS النانوي لمنطقة الاتصال الفعالة العالية كطبقة عازلة وPDMS المدمج بـ PEDOT:PSS كطبقة إلكترود لصنع TES بهيكل إلكترود واحد لتسهيل تكوين بسيط ليكون مستشعرات قابلة للارتداء. تم فصل هاتين الطبقتين بواسطة شريط مزدوج الجوانب تم تطبيقه على كلا طرفي الطبقات كفاصل ليكون
تولد باستمرار سلسلة من الإشارات الكهربائية خلال دورة التشغيل. بالإضافة إلى ذلك، جميع الأجزاء في وحدات الاستشعار مصنوعة من مواد قابلة للتمدد وصديقة للبشرة ويمكن تحضيرها من خلال عمليات تصنيع قابلة للتوسع (للتفاصيل انظر قسم “الطرق” والشكل التكميلي 4). تسمح هذه الخصائص للمواد المستخدمة في وحدة استشعار الإجهاد لجهاز الاستشعار لدينا بالاحتفاظ بموصلية كهربائية جيدة نسبيًا حتى تحت التمدد في نطاق
إجهاد جلد الوجه أثناء التعبير الوجه وضمان متانة وحدة الاستشعار. كما هو موضح بشكل تخطيطي في الشكل 2B، يتراكم جهد كهربائي بسبب الفرق بين سلسلة الكهرباء الساكنة بناءً على اختلاف الألفة للإلكترونات، حيث لعب PDMS مادة سلبية كهربائيًا عن طريق استلام الإلكترونات ولعب الإلكترود القابل للتمدد القائم على PEDOT:PSS مادة إيجابية كهربائيًا عن طريق التبرع بالإلكترونات في TES. بالإضافة إلى ذلك، تجعل وحدة استشعار الإجهاد لدينا منطقة الاتصال تتغير عند التمدد وتحقق حتى حالات انثناء بحيث يمكنها اكتشاف حركة الإجهاد ثنائية الاتجاه بين مستشعرات الإجهاد المعتمدة على الكهرباء الساكنة للمرة الأولى، حسب علمنا. وبالمثل، تم عرض الإشارات الناتجة من وحدة استشعار الإجهاد لدينا خلال دورة الانثناء والتمدد في الشكل 2C. تم توضيح الآلية الشاملة لعمل مستشعر الإجهاد ثنائي الاتجاه لكل وضع في الشكل التكميلي 5.
آلية العمل وخصائص وحدة استشعار الصوت
معلومات إلى نظام الدائرة. كما هو موضح في الشكل 3A، تم تصنيع وحدة استشعار الصوت باستخدام طبقة عازلة من PDMS ذات ثقوب مصممة وطبقة إلكترود من PDMS المدمج مع PEDOT:PSS لصنع TES. تم إدخال الثقوب في وحدة استشعار الصوت كثقوب صوتية تعمل ليس فقط كأوعية تواصل لتهوية الهواء بين سطحي الاتصال والهواء المحيط، مما يؤدي إلى تحسين استجابة التردد المسطح، ولكن أيضًا تقلل من الصلابة من خلال تحسين حركة حافة الأغشية.
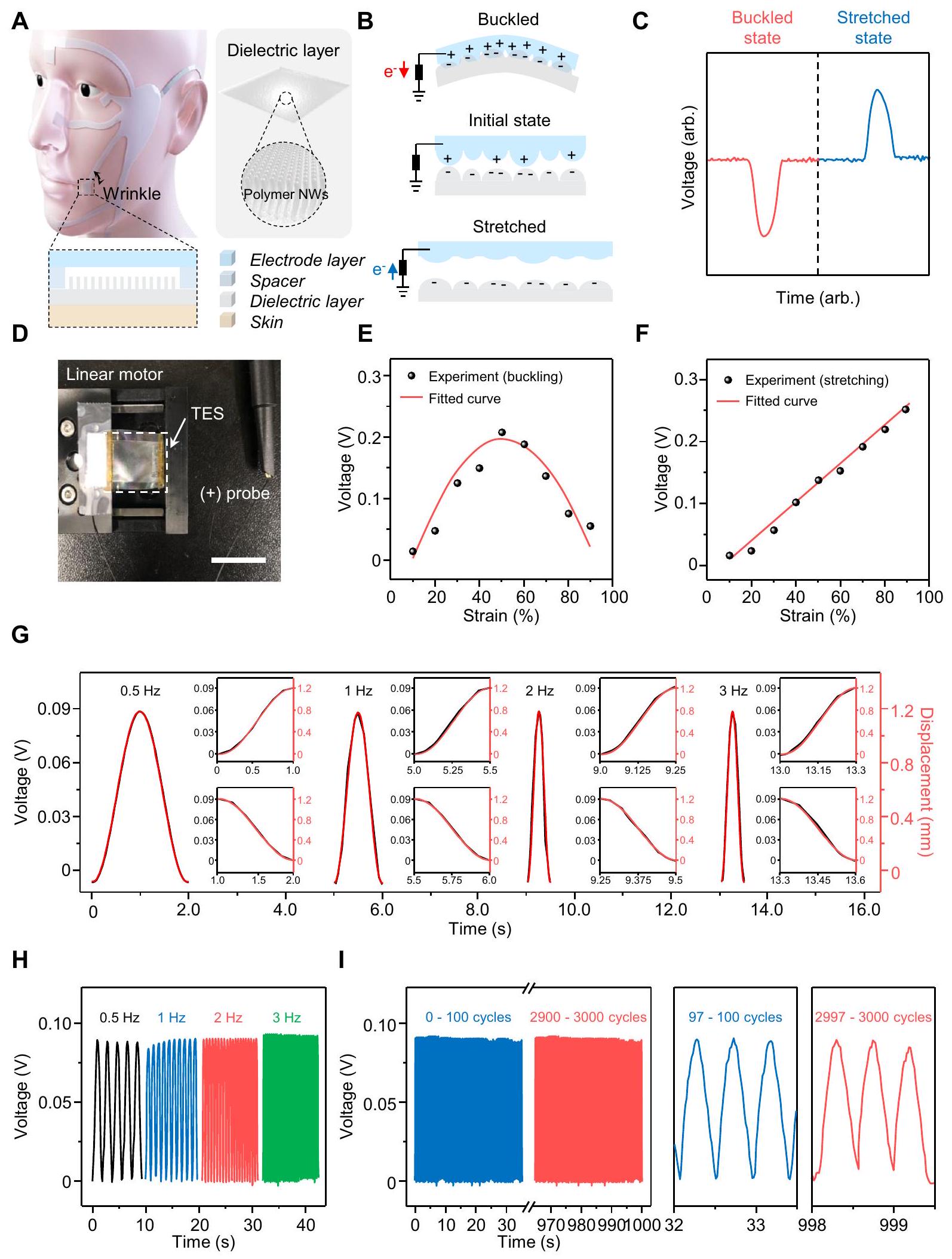
رسم توضيحي تخطيطي لوحدة استشعار الإجهاد. إدراج: عرض مكبر لوحدة الاستشعار التي تكشف عن إجهاد الوجه. ب توزيع الجهد الكهربائي لوحدة استشعار الإجهاد في حالة الانحناء والتمدد. ج إشارات كهربائية ناتجة عن وحدة استشعار الإجهاد خلال دورة الانحناء والتمدد. د صورة حقيقية للإعداد التجريبي لقياسات الناتج. مقياس الرسم: 1 سم. هـ و F قياس الحساسية
أثناء الانبعاج
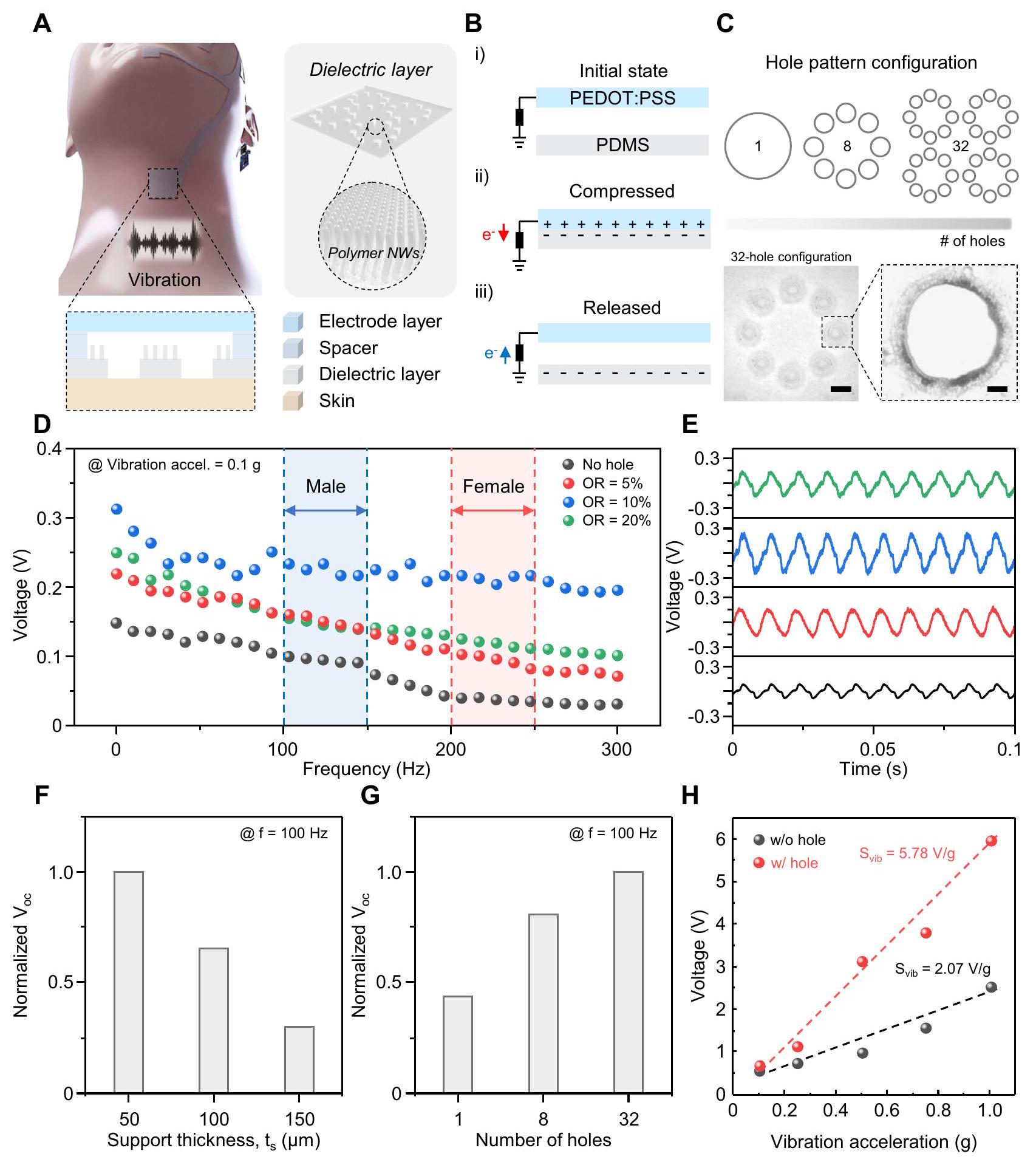
رسم توضيحي تخطيطي لوحدة استشعار الاهتزاز. في الإطار: عرض مكبر لوحدة الاستشعار التي تكتشف اهتزاز الحبال الصوتية.
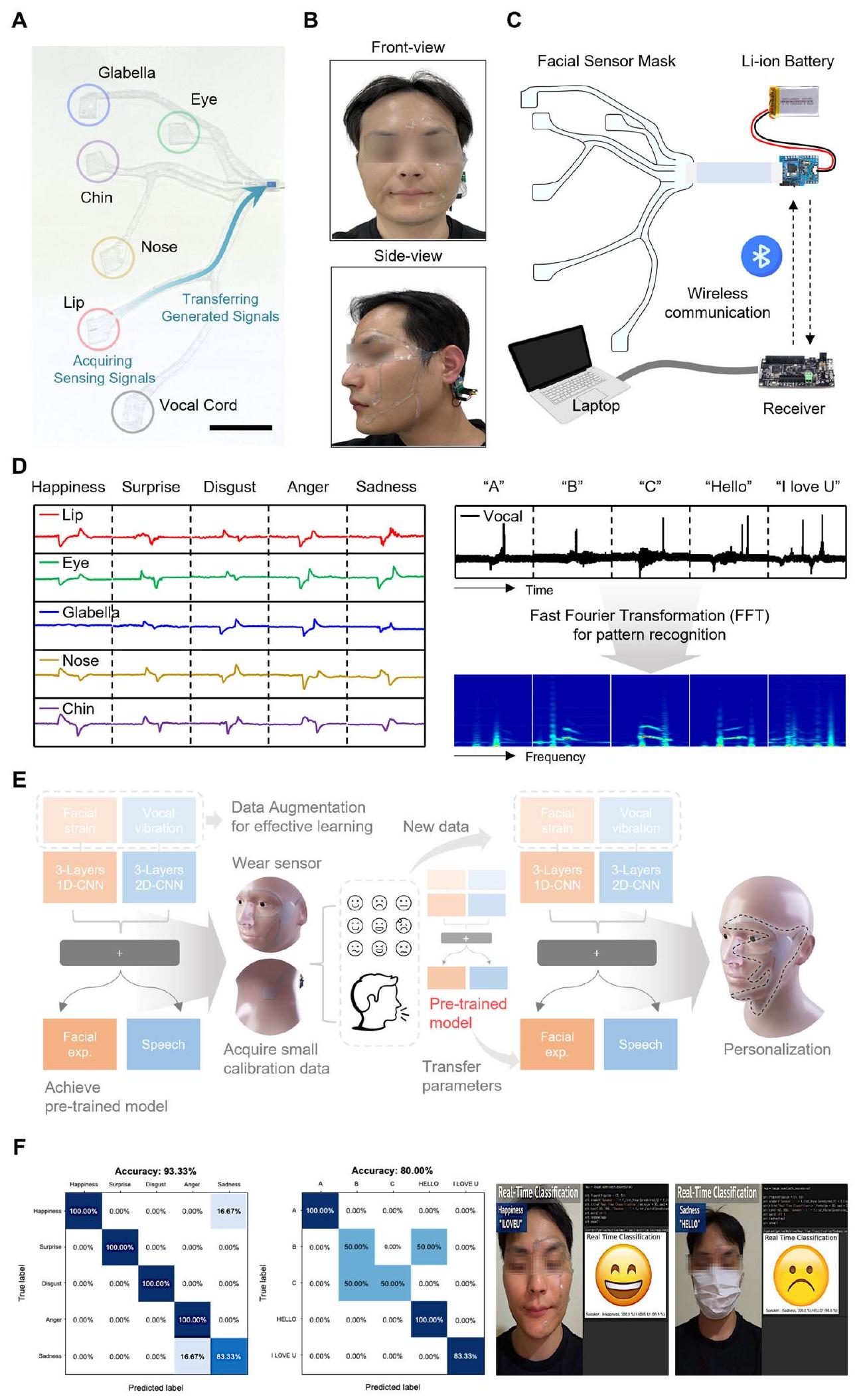
عملية معالجة البيانات اللاسلكية وتصنيف الوقت الحقيقي القائم على التعلم الآلي
بعد أن قام المشارك الأول بالتدريب مع المصنف باستخدام طريقة التدريب المذكورة أعلاه، كان المشاركون التاليون يرتدون جهاز PSiFI وكانوا قادرين على التدريب السريع مع المصنف من خلال تكرار 10 مرات فقط على كلا التعبيرين، مما سمح بنجاح بعرض التصنيف في الوقت الحقيقي. عندما يتعلق الأمر بالتطبيق العملي، مقارنةً بأساليب التصنيف الأخرى المعتمدة على أنواع مختلفة من كاميرات الفيديو والميكروفونات، فإن قناع PSiFI لدينا خالٍ من القيود البيئية مثل الموقع، والعوائق، والوقت. كما هو موضح في الشكل 4F، أظهر نتيجة التصنيف في الوقت الحقيقي للتعبيرات اللفظية وغير اللفظية المجمعة دون أي قيود دقة عالية جدًا بلغت 93.3% وحتى دقة جيدة من
تطبيق كونسيرج رقمي في بيئة الواقع الافتراضي
نقاش
التفاعل بين الإنسان والآلة مع سياق عاطفي مخصص
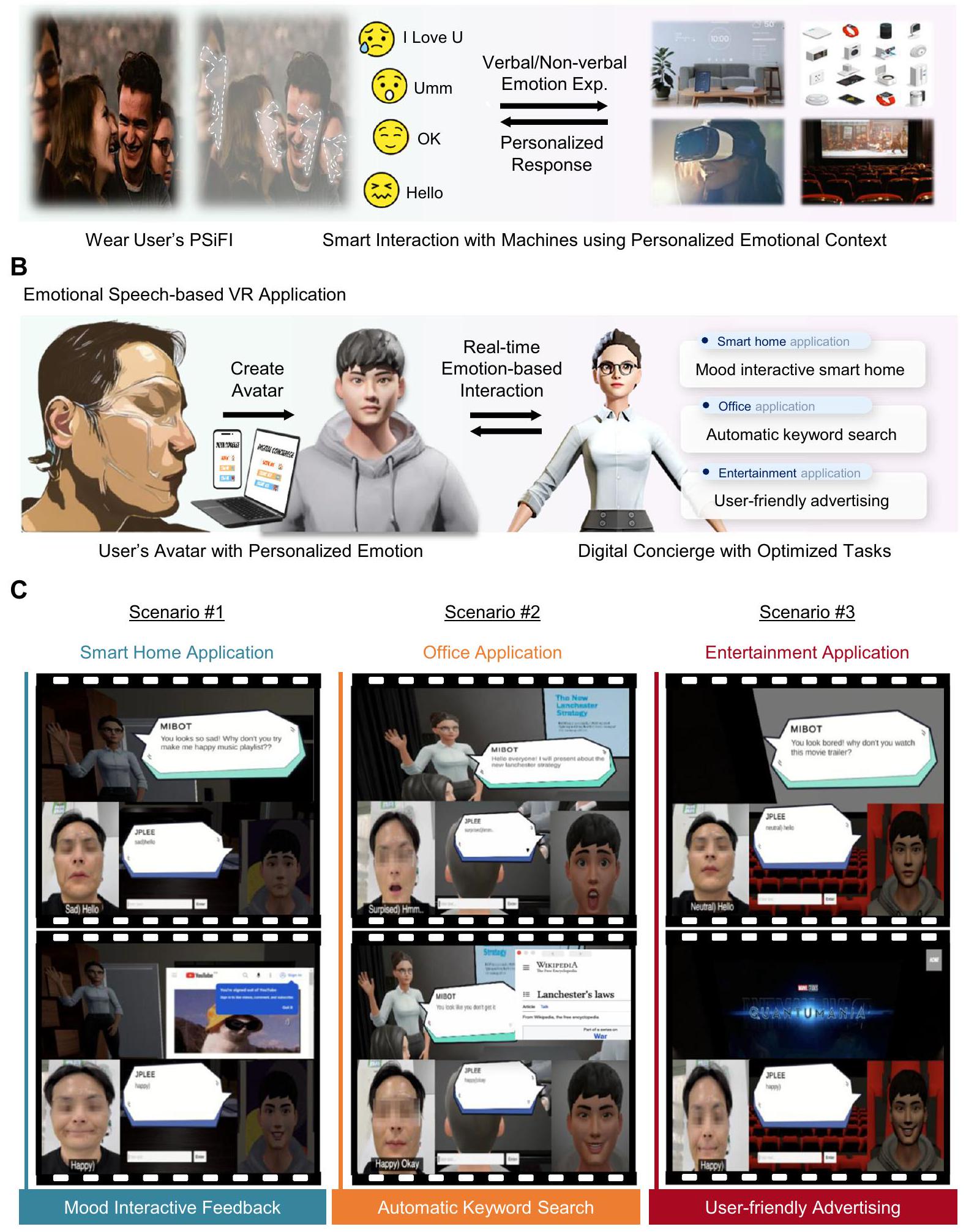
صور لثلاث سيناريوهات مختلفة كمهام (مثل ردود الفعل التفاعلية المزاجية، البحث التلقائي عن الكلمات الرئيسية، والإعلانات سهلة الاستخدام) لمساعد رقمي من المحتمل أن تحدث في أماكن متنوعة مثل المنزل، المكتب، والمسرح في بيئة الواقع الافتراضي لبرنامج يونيتي.
من العوامل الخارجية مثل الوقت والمكان والعقبات. علاوة على ذلك، أدركنا الاتصال اللاسلكي للبيانات من أجل التعرف على المشاعر البشرية في الوقت الحقيقي بمساعدة وحدة معالجة البيانات المصممة ونموذج التعلم السريع التكيف، وحققنا معيارًا مقبولًا من حيث دقة الاختبار حتى مع الحواجز مثل القناع. أخيرًا، عرضنا لأول مرة تطبيق الكونسيرج الرقمي في بيئة الواقع الافتراضي القادر على الاستجابة لنوايا المستخدم بناءً على معلومات الكلام العاطفي للمستخدم. نعتقد أن PSiFI يمكن أن يساعد ويعجل الاستخدام النشط للمشاعر من أجل التحول الرقمي في المستقبل القريب.
طرق
المواد
تحضير تشتت موصل وموصل قابل للتمدد
تصنيع تعديل سطح الفيلم العازل القائم على الأسلاك النانوية
تصنيع أفلام عازلة بنمط ثقوب
تصنيع وحدات استشعار ذاتية الطاقة
توصيف وقياس
إرفاق الجهاز على الجلد
تعلم الآلة للتعرف على المشاعر
عرض التطبيق
تم إنشاء الصور الرمزية المستخدمة في بيئات الواقع الافتراضي ببساطة من صورة فردية باستخدامريدي بلاير.ميالموقع الإلكتروني. في العرض التوضيحي، قام الصورة الرمزية المولدة بتنفيذ السيناريو بناءً على المعلومات الحية المرسلة من PSiFI وتلقى استجابات تكيفية من الصورة الرمزية المسماة MIBOT التي تم إنشاؤها افتراضيًا لخدمة الكونسيرج الرقمي.
ملخص التقرير
توفر البيانات
توفر الشيفرة
References
- Rahman, M. M., Poddar, A., Alam, M. G. R. & Dey, S. K. Affective state recognition through EEG signals feature level fusion and ensemble classifier. Preprint at https://doi.org/10.48550/arXiv.2102. 07127 (2021).
- Niklander, S. & Niklander, G. Combining sentimental and content analysis for recognizing and interpreting human affects. in HCl International 2017—Posters’ Extended Abstracts (ed. Stephanidis, C.) 465-468 (Springer International Publishing, 2017).
- Torres, E. P., Torres, E. A., Hernández-Álvarez, M., Yoo, S. G. & EEGBased, B. C. I. Emotion recognition: a survey. Sensors 20, 5083 (2020).
- Palaniswamy, S. & Suchitra, A. Robust pose & illumination invariant emotion recognition from facial images using deep learning for human-machine interface. In 2019 4th International Conference on Computational Systems and Information Technology for Sustainable Solution (CSITSS) 1-6 (2019).
- Thirunavukkarasu, G. S., Abdi, H. & Mohajer, N. A smart HMI for driving safety using emotion prediction of EEG signals. In 2016 IEEE International Conference on Systems, Man, and Cybernetics (SMC) 004148-004153 (2016).
- Huo, F., Zhao, Y., Chai, C. & Fang, F. A user experience map design method based on emotional quantification of in-vehicle HMI. Humanit. Sci. Soc. Commun. 10, 1-10 (2023).
- Breazeal, C. Emotion and sociable humanoid robots. Int. J. Hum.-Comput. Stud. 59, 119-155 (2003).
- Stock-Homburg, R. Survey of emotions in human-robot interactions: perspectives from robotic psychology on 20 years of research. Int. J. Soc. Robot. 14, 389-411 (2022).
- Chuah, S. H.-W. & Yu, J. The future of service: The power of emotion in human-robot interaction. J. Retail. Consum. Serv. 61, 102551 (2021).
- Consoli, D. A new concept of marketing: the emotional marketing. BRAND Broad Res. Account. Negot. Distrib. 1, 52-59 (2010).
- Bagozzi, R. P., Gopinath, M. & Nyer, P. U. The role. Emot. Mark. J. Acad. Mark. Sci. 27, 184-206 (1999).
- Yung, R., Khoo-Lattimore, C. & Potter, L. E. Virtual reality and tourism marketing: conceptualizing a framework on presence, emotion, and intention. Curr. Issues Tour. 24, 1505-1525 (2021).
- Hasnul, M. A., Aziz, N. A. A., Alelyani, S., Mohana, M. & Aziz, A. A. Electrocardiogram-based emotion recognition systems and their applications in healthcare-a review. Sensors 21, 5015 (2021).
- Dhuheir, M. et al. Emotion recognition for healthcare surveillance systems using neural networks: a survey. Preprint at https://doi.org/ 10.48550/arXiv.2107.05989 (2021).
- Jiménez-Herrera, M. F. et al. Emotions and feelings in critical and emergency caring situations: a qualitative study. BMC Nurs. 19, 60 (2020).
- Schutz, P. A., Hong, J. Y., Cross, D. I. & Osbon, J. N. Reflections on investigating emotion in educational activity settings. Educ. Psychol. Rev. 18, 343-360 (2006).
- Tyng, C. M., Amin, H. U., Saad, M. N. M. & Malik, A. S. The influences of emotion on learning and memory. Front. Psychol. 8, 1454 (2017).
- Li, L., Gow, A. D. I. & Zhou, J. The role of positive emotions in education: a neuroscience perspective. Mind Brain Educ. 14, 220-234 (2020).
- Ben-Ze’Ev, A. The Subtlety of Emotions (MIT Press, 2001).
- Lane, R. D. & Pollermann, B. Z. Complexity of emotion representations. in The Wisdom in Feeling: Psychological Processes in Emotional Intelligence 271-293 (The Guilford Press, 2002).
- Boehner, K., DePaula, R., Dourish, P. & Sengers, P. How emotion is made and measured. Int. J. Hum.-Comput. Stud. 65, 275-291 (2007).
- Mauss, I. B. & Robinson, M. D. Measures of emotion: a review. Cogn. Emot. 23, 209-237 (2009).
- Meiselman, H. L. Emotion Measurement (Woodhead Publishing, 2016).
- Ioannou, S. V. et al. Emotion recognition through facial expression analysis based on a neurofuzzy network. Neural Netw. 18, 423-435 (2005).
- Tarnowski, P., Kołodziej, M., Majkowski, A. & Rak, R. J. Emotion recognition using facial expressions. Procedia Comput. Sci. 108, 1175-1184 (2017).
- Abdat, F., Maaoui, C. & Pruski, A. Human-computer interaction using emotion recognition from facial expression. In 2011 UKSim 5th European Symposium on Computer Modeling and Simulation (ed Sterritt, R.) 196-201 (IEEE computer society, 2011).
- Akçay, M. B. & Oğuz, K. Speech emotion recognition: emotional models, databases, features, preprocessing methods, supporting modalities, and classifiers. Speech Commun. 116, 56-76 (2020).
- Issa, D., Fatih Demirci, M. & Yazici, A. Speech emotion recognition with deep convolutional neural networks. Biomed. Signal Process. Control 59, 101894 (2020).
- Lech, M., Stolar, M., Best, C. & Bolia, R. Real-time speech emotion recognition using a pre-trained image classification network: effects of bandwidth reduction and companding. Front. Comput. Sci. 2, 14 (2020).
- Nandwani, P. & Verma, R. A review on sentiment analysis and emotion detection from text. Soc. Netw. Anal. Min. 11, 81 (2021).
- Acheampong, F. A., Wenyu, C. & Nunoo-Mensah, H. Text-based emotion detection: advances, challenges, and opportunities. Eng. Rep. 2, e12189 (2020).
- Alm, C. O., Roth, D. & Sproat, R. Emotions from text: machine learning for text-based emotion prediction. In Proc. Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing 579-586 (Association for Computational Linguistics, 2005).
- Murugappan, M., Ramachandran, N. & Sazali, Y. Classification of human emotion from EEG using discrete wavelet transform. J. Biomedical Science and Engineering 3, 390-396 (2010).
- Gannouni, S., Aledaily, A., Belwafi, K. & Aboalsamh, H. Emotion detection using electroencephalography signals and a zero-time windowing-based epoch estimation and relevant electrode identification. Sci. Rep. 11, 7071 (2021).
- Jenke, R., Peer, A. & Buss, M. Feature Extraction and Selection for Emotion Recognition from EEG. IEEE Trans. Affect. Comput. 5, 327-339 (2014).
- Balconi, M., Bortolotti, A. & Gonzaga, L. Emotional face recognition, EMG response, and medial prefrontal activity in empathic behaviour. Neurosci. Res. 71, 251-259 (2011).
- Künecke, J., Hildebrandt, A., Recio, G., Sommer, W. & Wilhelm, O. Facial EMG responses to emotional expressions are related to emotion perception ability. PLoS ONE 9, e84053 (2014).
- Kulke, L., Feyerabend, D. & Schacht, A. A comparison of the affectiva imotions facial expression analysis software with EMG for identifying facial expressions of emotion. Front. Psychol. 11, 329 (2020).
- Brás, S., Ferreira, J. H. T., Soares, S. C. & Pinho, A. J. Biometric and emotion identification: an ECG compression based method. Front. Psychol. 9, 467 (2018).
- Selvaraj, J., Murugappan, M., Wan, K. & Yaacob, S. Classification of emotional states from electrocardiogram signals: a non-linear approach based on hurst. Biomed. Eng. OnLine 12, 44 (2013).
- Agrafioti, F., Hatzinakos, D. & Anderson, A. K. ECG pattern analysis for emotion detection. IEEE Trans. Affect. Comput. 3, 102-115 (2012).
- Goshvarpour, A., Abbasi, A. & Goshvarpour, A. An accurate emotion recognition system using ECG and GSR signals and matching pursuit method. Biomed. J. 40, 355-368 (2017).
- Dutta, S., Mishra, B. K., Mitra, A. & Chakraborty, A. An analysis of emotion recognition based on GSR signal. ECS Trans. 107, 12535 (2022).
- Wu, G., Liu, G. & Hao, M. The analysis of emotion recognition from GSR based on PSO. In 2010 International Symposium on Intelligence Information Processing and Trusted Computing. (ed Sterritt, R.) 360-363 (IEEE computer society, 2010).
- Wang, Y. et al. A durable nanomesh on-skin strain gauge for natural skin motion monitoring with minimum mechanical constraints. Sci. Adv. 6, eabb7043 (2020).
- Roh, E., Hwang, B.-U., Kim, D., Kim, B.-Y. & Lee, N.-E. Stretchable, transparent, ultrasensitive, and patchable strain sensor for human-machine interfaces comprising a nanohybrid of carbon nanotubes and conductive elastomers. ACS Nano 9, 6252-6261 (2015).
- Su, M. et al. Nanoparticle based curve arrays for multirecognition flexible electronics. Adv. Mater. 28, 1369-1374 (2016).
- Yoon, S., Sim, J. K. & Cho, Y.-H. A flexible and wearable human stress monitoring patch. Sci. Rep. 6, 23468 (2016).
- Jeong, Y. R. et al. A skin-attachable, stretchable integrated system based on liquid GalnSn for wireless human motion monitoring with multi-site sensing capabilities. NPG Asia Mater. 9, e443-e443 (2017).
- Hua, Q. et al. Skin-inspired highly stretchable and conformable matrix networks for multifunctional sensing. Nat. Commun. 9, 244 (2018).
- Ramli, N. A., Nordin, A. N. & Zainul Azlan, N. Development of low cost screen-printed piezoresistive strain sensor for facial expressions recognition systems. Microelectron. Eng. 234, 111440 (2020).
- Sun, T. et al. Decoding of facial strains via conformable piezoelectric interfaces. Nat. Biomed. Eng. 4, 954-972 (2020).
- Wang, M. et al. Gesture recognition using a bioinspired learning architecture that integrates visual data with somatosensory data from stretchable sensors. Nat. Electron. 3, 563-570 (2020).
- Zhou, Z. et al. Sign-to-speech translation using machine-learningassisted stretchable sensor arrays. Nat. Electron. 3, 571-578 (2020).
- Wang, Y. et al. All-weather, natural silent speech recognition via machine-learning-assisted tattoo-like electronics. Npj Flex. Electron. 5, 20 (2021).
- Zhuang, M. et al. Highly robust and wearable facial expression recognition via deep-learning-assisted, soft epidermal electronics. Research 2021, 2021/9759601 (2021).
- Zheng, W.-L., Dong, B.-N. & Lu, B.-L. Multimodal emotion recognition using EEG and eye tracking data. In 2014 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, (ed Melley, D.) 5040-5043 (IEEE express conference publishing, Chicago, IL, USA, 2014).
- Schirmer, A. & Adolphs, R. Emotion perception from face, voice, and touch: comparisons and convergence. Trends Cogn. Sci. 21, 216-228 (2017).
- Ahmed, N., Aghbari, Z. A. & Girija, S. A systematic survey on multimodal emotion recognition using learning algorithms. Intell. Syst. Appl. 17, 200171 (2023).
- Zhang, R. & Olin, H. Material choices for triboelectric nanogenerators: a critical review. EcoMat 2, e12062 (2020).
- Kim, W.-G. et al. Triboelectric nanogenerator: structure, mechanism, and applications. ACS Nano 15, 258-287 (2021).
- Schumann, N. P., Bongers, K., Guntinas-Lichius, O. & Scholle, H. C. Facial muscle activation patterns in healthy male humans: a multichannel surface EMG study. J. Neurosci. Methods 187, 120-128 (2010).
- Lee, J.-G. et al. Quantitative anatomical analysis of facial expression using a 3D motion capture system: application to cosmetic surgery and facial recognition technology: quantitative anatomical analysis of facial expression. Clin. Anat. 28, 735-744 (2015).
- Zarins, U. Anatomy of Facial Expression (Exonicus Incorporated, 2018).
- Kim, K. N. et al. Surface dipole enhanced instantaneous charge pair generation in triboelectric nanogenerator. Nano Energy 26, 360-370 (2016).
- Lee, J. P. et al. Boosting the energy conversion efficiency of a combined triboelectric nanogenerator-capacitor. Nano Energy 56, 571-580 (2019).
- Lu, Y. et al. Decoding lip language using triboelectric sensors with deep learning. Nat. Commun. 13, 1401 (2022).
- Yang, J. et al. Triboelectrification-based organic film nanogenerator for acoustic energy harvesting and self-powered active acoustic sensing. ACS Nano 8, 2649-2657 (2014).
- Yang, J. et al. Eardrum-inspired active sensors for self-powered cardiovascular system characterization and throat-attached antiinterference voice recognition. Adv. Mater. 27, 1316-1326 (2015).
- Lee, S. et al. An ultrathin conformable vibration-responsive electronic skin for quantitative vocal recognition. Nat. Commun. 10, 2468 (2019).
- Calvert, D. R. Clinical measurement of speech and voice, by Ronald J. Baken, PhD, 528 pp, paper, College-Hill Press, Boston, MA, 1987, $35.00. Laryngoscope 98, 905-906 (1988).
- Diemer, J., Alpers, G. W., Peperkorn, H. M., Shiban, Y. & Mühlberger, A. The impact of perception and presence on emotional reactions: a review of research in virtual reality. Front. Psychol. 6, 26 (2015).
- Allcoat, D. & Mühlenen, A. von. Learning in virtual reality: Effects on performance, emotion and engagement. Res. Learn. Technol. 26, 2140 (2018).
- Colombo, D., Díaz-García, A., Fernandez-Álvarez, J. & Botella, C. Virtual reality for the enhancement of emotion regulation. Clin. Psychol. Psychother. 28, 519-537 (2021).
شكر وتقدير
مساهمات المؤلفين
المصالح المتنافسة
معلومات إضافية
http://www.nature.com/reprints
© المؤلف(ون) 2024
مدرسة علوم المواد والهندسة، المعهد الوطني للعلوم والتكنولوجيا في أولسان، أولسان 44919، كوريا الجنوبية. مدرسة علوم المواد والهندسة، جامعة نانيانغ التكنولوجية، 50 شارع نانيانغ، سنغافورة 639798، سنغافورة. مركز المواد القابلة للبرمجة متعددة الأبعاد، المعهد الوطني للعلوم والتكنولوجيا في أولسان، أولسان 44919، كوريا الجنوبية. البريد الإلكتروني:pslee@ntu.edu.sg; jiyunkim@unist.ac.kr
DOI: https://doi.org/10.1038/s41467-023-44673-2
PMID: https://pubmed.ncbi.nlm.nih.gov/38225246
Publication Date: 2024-01-15
Encoding of multi-modal emotional information via personalized skin-integrated wireless facial interface
Accepted: 28 December 2023
Published online: 15 January 2024
(A) Check for updates
Abstract
Human affects such as emotions, moods, feelings are increasingly being considered as key parameter to enhance the interaction of human with diverse machines and systems. However, their intrinsically abstract and ambiguous nature make it challenging to accurately extract and exploit the emotional information. Here, we develop a multi-modal human emotion recognition system which can efficiently utilize comprehensive emotional information by combining verbal and non-verbal expression data. This system is composed of personalized skin-integrated facial interface (PSiFI) system that is self-powered, facile, stretchable, transparent, featuring a first bidirectional triboelectric strain and vibration sensor enabling us to sense and combine the verbal and non-verbal expression data for the first time. It is fully integrated with a data processing circuit for wireless data transfer allowing real-time emotion recognition to be performed. With the help of machine learning, various human emotion recognition tasks are done accurately in real time even while wearing mask and demonstrated digital concierge application in VR environment.
combined data from multiple modalities, such as speech, facial expression, gesture, and various physiological signals (e.g., temperature, electrodermal activity)
Results
Personalized skin-integrated facial interface (PSiFI) system
Working mechanism and characterization of the strain sensing unit
circuit system is the function of our strain sensing unit. As depicted schematically in Fig. 2A, the strain sensing unit was fabricated with the nanostructured PDMS for its high effective contact area as a dielectric layer and PEDOT:PSS embedded PDMS as an electrode layer to make TES with the single electrode structure for simple configuration to be facilitated as wearable sensors. These two layers were separated by double sided tapes applied to both ends of the layers as a spacer to be
consistently generate a series of electrical signals during the operation cycle. Besides, all the parts in the sensing units are made of stretchable and skin-friendly viable materials and can be prepared through scalable fabrication processes (for the details see the “Methods” section and Supplementary Fig. 4). These characteristics of the materials used in the strain sensing unit allow our strain sensor to retain relatively good electrical conductivity even under stretching in the range of
facial skin strain during facial expression and guarantee robustness of the sensing unit. As schematically shown in Fig. 2B, an electrical potential builds up due to the difference between triboelectric series based on different affinity for electrons, which the PDMS played a triboelectrically negative material by receiving electrons and the PEDOT:PSS based stretchable electrode played a triboelectrically positive material by donating electrons in TES. On top of that, our strain sensing unit makes the contact area changes when stretched and achieved even buckled states so that it can detect bidirectional strain motion among the triboelectric based strain sensors for the first time, according to our knowledge. Correspondingly, the generated output signals of our strain sensing unit during the buckle-stretch cycle were shown in Fig. 2C. The comprehensive working mechanism of the bidirectional strain sensor for each mode was demonstrated in Supplementary Fig. 5.
Working mechanism and characterization of the vocal sensing unit
information to the circuit system. As shown in Fig. 3A, the vocal sensing unit was fabricated with the holes patterned PDMS as dielectric layer and PEDOT:PSS embedded PDMS as an electrode layer to make TES. The holes were introduced into the vocal sensing unit as acoustic holes which not only act as communicating vessels to ventilate an air between two contact surfaces to the ambient air, which results in enhanced flat frequency response but also reduce the stiffness by improving the movement of the rim of diaphragms
A Schematic illustration of the strain sensing unit. Inset: enlarged view of the sensing unit detecting facial strain. B Electrical potential distribution of the strain sensing unit under buckled and stretched state. C Output electrical signals of the strain sensing unit during the buckle-stretch cycle. D Real image of experimental set-up for output measurements. Scale bar: 1 cm . E and F Sensitivity measurement
during buckling (
A Schematic illustration of the vibration sensing unit. Inset: enlarged view of the sensing unit detecting vocal-cord vibration.
Wireless data processing process and machine learning based real time classification
after the initial participant had firstly trained with the classifier by the above-mentioned training method, the following participants were wearing with the PSiFI device and able to fast train with the classifier by only repeating 10 times each on both expressions, which successfully allow the real-time classification to be demonstrated. When it comes to practical application, compared with other classification methods based on various kinds of video camera and microphone, our PSiFI mask is free from environmental restrictions such as the location, obstruction, and time. As shown in Fig. 4F, the real-time classification result for combined verbal/nonverbal expressions without any restriction exhibited very high accuracy of 93.3% and even the decent accuracy of
Digital concierge application in VR environment
Discussion
Human-Machine Interaction with Personalized Emotional Context
images of three different scenarios as tasks (such as mood interactive feedback, automatic keyword search and user-friendly advertising) of digital concierge which likely take place in various places such as home, office and theater in VR environment of Unity software.
of external factors such as time, place, and obstacles. Furthermore, we realized wireless data communication for real-time human emotion recognition with the help of designed data-processing circuit unit and the rapid adapting learning model and achieved acceptable standard in terms of test accuracy even with the barrier such as mask. Finally, we first demonstrated digital concierge application in VR environment capable of responding to user’s intention based on the user’s emotional speech information. We believe that the PSiFI could assist and accelerate the active usage of emotions for digital transformation in the near future.
Methods
Materials
Preparation of conductive dispersion and stretchable conductor
Fabrication of nanowire-based surface modification of dielectric film
Fabrication of hole-patterned dielectric films
Fabrication of self-powered sensing units
Characterization and measurement
Attachment of the device on the skin
Machine learning for emotion recognition
Demonstration of the application
avatars used in the VR environments were simply created from individual photo using readyplayer.me website. In demonstration, the generated avatar proceeded the scenario based on the real-time information transmitted from PSiFI and got adaptive responses from the avatar called MIBOT virtually created for digital concierge.
Reporting summary
Data availability
Code availability
References
- Rahman, M. M., Poddar, A., Alam, M. G. R. & Dey, S. K. Affective state recognition through EEG signals feature level fusion and ensemble classifier. Preprint at https://doi.org/10.48550/arXiv.2102. 07127 (2021).
- Niklander, S. & Niklander, G. Combining sentimental and content analysis for recognizing and interpreting human affects. in HCl International 2017—Posters’ Extended Abstracts (ed. Stephanidis, C.) 465-468 (Springer International Publishing, 2017).
- Torres, E. P., Torres, E. A., Hernández-Álvarez, M., Yoo, S. G. & EEGBased, B. C. I. Emotion recognition: a survey. Sensors 20, 5083 (2020).
- Palaniswamy, S. & Suchitra, A. Robust pose & illumination invariant emotion recognition from facial images using deep learning for human-machine interface. In 2019 4th International Conference on Computational Systems and Information Technology for Sustainable Solution (CSITSS) 1-6 (2019).
- Thirunavukkarasu, G. S., Abdi, H. & Mohajer, N. A smart HMI for driving safety using emotion prediction of EEG signals. In 2016 IEEE International Conference on Systems, Man, and Cybernetics (SMC) 004148-004153 (2016).
- Huo, F., Zhao, Y., Chai, C. & Fang, F. A user experience map design method based on emotional quantification of in-vehicle HMI. Humanit. Sci. Soc. Commun. 10, 1-10 (2023).
- Breazeal, C. Emotion and sociable humanoid robots. Int. J. Hum.-Comput. Stud. 59, 119-155 (2003).
- Stock-Homburg, R. Survey of emotions in human-robot interactions: perspectives from robotic psychology on 20 years of research. Int. J. Soc. Robot. 14, 389-411 (2022).
- Chuah, S. H.-W. & Yu, J. The future of service: The power of emotion in human-robot interaction. J. Retail. Consum. Serv. 61, 102551 (2021).
- Consoli, D. A new concept of marketing: the emotional marketing. BRAND Broad Res. Account. Negot. Distrib. 1, 52-59 (2010).
- Bagozzi, R. P., Gopinath, M. & Nyer, P. U. The role. Emot. Mark. J. Acad. Mark. Sci. 27, 184-206 (1999).
- Yung, R., Khoo-Lattimore, C. & Potter, L. E. Virtual reality and tourism marketing: conceptualizing a framework on presence, emotion, and intention. Curr. Issues Tour. 24, 1505-1525 (2021).
- Hasnul, M. A., Aziz, N. A. A., Alelyani, S., Mohana, M. & Aziz, A. A. Electrocardiogram-based emotion recognition systems and their applications in healthcare-a review. Sensors 21, 5015 (2021).
- Dhuheir, M. et al. Emotion recognition for healthcare surveillance systems using neural networks: a survey. Preprint at https://doi.org/ 10.48550/arXiv.2107.05989 (2021).
- Jiménez-Herrera, M. F. et al. Emotions and feelings in critical and emergency caring situations: a qualitative study. BMC Nurs. 19, 60 (2020).
- Schutz, P. A., Hong, J. Y., Cross, D. I. & Osbon, J. N. Reflections on investigating emotion in educational activity settings. Educ. Psychol. Rev. 18, 343-360 (2006).
- Tyng, C. M., Amin, H. U., Saad, M. N. M. & Malik, A. S. The influences of emotion on learning and memory. Front. Psychol. 8, 1454 (2017).
- Li, L., Gow, A. D. I. & Zhou, J. The role of positive emotions in education: a neuroscience perspective. Mind Brain Educ. 14, 220-234 (2020).
- Ben-Ze’Ev, A. The Subtlety of Emotions (MIT Press, 2001).
- Lane, R. D. & Pollermann, B. Z. Complexity of emotion representations. in The Wisdom in Feeling: Psychological Processes in Emotional Intelligence 271-293 (The Guilford Press, 2002).
- Boehner, K., DePaula, R., Dourish, P. & Sengers, P. How emotion is made and measured. Int. J. Hum.-Comput. Stud. 65, 275-291 (2007).
- Mauss, I. B. & Robinson, M. D. Measures of emotion: a review. Cogn. Emot. 23, 209-237 (2009).
- Meiselman, H. L. Emotion Measurement (Woodhead Publishing, 2016).
- Ioannou, S. V. et al. Emotion recognition through facial expression analysis based on a neurofuzzy network. Neural Netw. 18, 423-435 (2005).
- Tarnowski, P., Kołodziej, M., Majkowski, A. & Rak, R. J. Emotion recognition using facial expressions. Procedia Comput. Sci. 108, 1175-1184 (2017).
- Abdat, F., Maaoui, C. & Pruski, A. Human-computer interaction using emotion recognition from facial expression. In 2011 UKSim 5th European Symposium on Computer Modeling and Simulation (ed Sterritt, R.) 196-201 (IEEE computer society, 2011).
- Akçay, M. B. & Oğuz, K. Speech emotion recognition: emotional models, databases, features, preprocessing methods, supporting modalities, and classifiers. Speech Commun. 116, 56-76 (2020).
- Issa, D., Fatih Demirci, M. & Yazici, A. Speech emotion recognition with deep convolutional neural networks. Biomed. Signal Process. Control 59, 101894 (2020).
- Lech, M., Stolar, M., Best, C. & Bolia, R. Real-time speech emotion recognition using a pre-trained image classification network: effects of bandwidth reduction and companding. Front. Comput. Sci. 2, 14 (2020).
- Nandwani, P. & Verma, R. A review on sentiment analysis and emotion detection from text. Soc. Netw. Anal. Min. 11, 81 (2021).
- Acheampong, F. A., Wenyu, C. & Nunoo-Mensah, H. Text-based emotion detection: advances, challenges, and opportunities. Eng. Rep. 2, e12189 (2020).
- Alm, C. O., Roth, D. & Sproat, R. Emotions from text: machine learning for text-based emotion prediction. In Proc. Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing 579-586 (Association for Computational Linguistics, 2005).
- Murugappan, M., Ramachandran, N. & Sazali, Y. Classification of human emotion from EEG using discrete wavelet transform. J. Biomedical Science and Engineering 3, 390-396 (2010).
- Gannouni, S., Aledaily, A., Belwafi, K. & Aboalsamh, H. Emotion detection using electroencephalography signals and a zero-time windowing-based epoch estimation and relevant electrode identification. Sci. Rep. 11, 7071 (2021).
- Jenke, R., Peer, A. & Buss, M. Feature Extraction and Selection for Emotion Recognition from EEG. IEEE Trans. Affect. Comput. 5, 327-339 (2014).
- Balconi, M., Bortolotti, A. & Gonzaga, L. Emotional face recognition, EMG response, and medial prefrontal activity in empathic behaviour. Neurosci. Res. 71, 251-259 (2011).
- Künecke, J., Hildebrandt, A., Recio, G., Sommer, W. & Wilhelm, O. Facial EMG responses to emotional expressions are related to emotion perception ability. PLoS ONE 9, e84053 (2014).
- Kulke, L., Feyerabend, D. & Schacht, A. A comparison of the affectiva imotions facial expression analysis software with EMG for identifying facial expressions of emotion. Front. Psychol. 11, 329 (2020).
- Brás, S., Ferreira, J. H. T., Soares, S. C. & Pinho, A. J. Biometric and emotion identification: an ECG compression based method. Front. Psychol. 9, 467 (2018).
- Selvaraj, J., Murugappan, M., Wan, K. & Yaacob, S. Classification of emotional states from electrocardiogram signals: a non-linear approach based on hurst. Biomed. Eng. OnLine 12, 44 (2013).
- Agrafioti, F., Hatzinakos, D. & Anderson, A. K. ECG pattern analysis for emotion detection. IEEE Trans. Affect. Comput. 3, 102-115 (2012).
- Goshvarpour, A., Abbasi, A. & Goshvarpour, A. An accurate emotion recognition system using ECG and GSR signals and matching pursuit method. Biomed. J. 40, 355-368 (2017).
- Dutta, S., Mishra, B. K., Mitra, A. & Chakraborty, A. An analysis of emotion recognition based on GSR signal. ECS Trans. 107, 12535 (2022).
- Wu, G., Liu, G. & Hao, M. The analysis of emotion recognition from GSR based on PSO. In 2010 International Symposium on Intelligence Information Processing and Trusted Computing. (ed Sterritt, R.) 360-363 (IEEE computer society, 2010).
- Wang, Y. et al. A durable nanomesh on-skin strain gauge for natural skin motion monitoring with minimum mechanical constraints. Sci. Adv. 6, eabb7043 (2020).
- Roh, E., Hwang, B.-U., Kim, D., Kim, B.-Y. & Lee, N.-E. Stretchable, transparent, ultrasensitive, and patchable strain sensor for human-machine interfaces comprising a nanohybrid of carbon nanotubes and conductive elastomers. ACS Nano 9, 6252-6261 (2015).
- Su, M. et al. Nanoparticle based curve arrays for multirecognition flexible electronics. Adv. Mater. 28, 1369-1374 (2016).
- Yoon, S., Sim, J. K. & Cho, Y.-H. A flexible and wearable human stress monitoring patch. Sci. Rep. 6, 23468 (2016).
- Jeong, Y. R. et al. A skin-attachable, stretchable integrated system based on liquid GalnSn for wireless human motion monitoring with multi-site sensing capabilities. NPG Asia Mater. 9, e443-e443 (2017).
- Hua, Q. et al. Skin-inspired highly stretchable and conformable matrix networks for multifunctional sensing. Nat. Commun. 9, 244 (2018).
- Ramli, N. A., Nordin, A. N. & Zainul Azlan, N. Development of low cost screen-printed piezoresistive strain sensor for facial expressions recognition systems. Microelectron. Eng. 234, 111440 (2020).
- Sun, T. et al. Decoding of facial strains via conformable piezoelectric interfaces. Nat. Biomed. Eng. 4, 954-972 (2020).
- Wang, M. et al. Gesture recognition using a bioinspired learning architecture that integrates visual data with somatosensory data from stretchable sensors. Nat. Electron. 3, 563-570 (2020).
- Zhou, Z. et al. Sign-to-speech translation using machine-learningassisted stretchable sensor arrays. Nat. Electron. 3, 571-578 (2020).
- Wang, Y. et al. All-weather, natural silent speech recognition via machine-learning-assisted tattoo-like electronics. Npj Flex. Electron. 5, 20 (2021).
- Zhuang, M. et al. Highly robust and wearable facial expression recognition via deep-learning-assisted, soft epidermal electronics. Research 2021, 2021/9759601 (2021).
- Zheng, W.-L., Dong, B.-N. & Lu, B.-L. Multimodal emotion recognition using EEG and eye tracking data. In 2014 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, (ed Melley, D.) 5040-5043 (IEEE express conference publishing, Chicago, IL, USA, 2014).
- Schirmer, A. & Adolphs, R. Emotion perception from face, voice, and touch: comparisons and convergence. Trends Cogn. Sci. 21, 216-228 (2017).
- Ahmed, N., Aghbari, Z. A. & Girija, S. A systematic survey on multimodal emotion recognition using learning algorithms. Intell. Syst. Appl. 17, 200171 (2023).
- Zhang, R. & Olin, H. Material choices for triboelectric nanogenerators: a critical review. EcoMat 2, e12062 (2020).
- Kim, W.-G. et al. Triboelectric nanogenerator: structure, mechanism, and applications. ACS Nano 15, 258-287 (2021).
- Schumann, N. P., Bongers, K., Guntinas-Lichius, O. & Scholle, H. C. Facial muscle activation patterns in healthy male humans: a multichannel surface EMG study. J. Neurosci. Methods 187, 120-128 (2010).
- Lee, J.-G. et al. Quantitative anatomical analysis of facial expression using a 3D motion capture system: application to cosmetic surgery and facial recognition technology: quantitative anatomical analysis of facial expression. Clin. Anat. 28, 735-744 (2015).
- Zarins, U. Anatomy of Facial Expression (Exonicus Incorporated, 2018).
- Kim, K. N. et al. Surface dipole enhanced instantaneous charge pair generation in triboelectric nanogenerator. Nano Energy 26, 360-370 (2016).
- Lee, J. P. et al. Boosting the energy conversion efficiency of a combined triboelectric nanogenerator-capacitor. Nano Energy 56, 571-580 (2019).
- Lu, Y. et al. Decoding lip language using triboelectric sensors with deep learning. Nat. Commun. 13, 1401 (2022).
- Yang, J. et al. Triboelectrification-based organic film nanogenerator for acoustic energy harvesting and self-powered active acoustic sensing. ACS Nano 8, 2649-2657 (2014).
- Yang, J. et al. Eardrum-inspired active sensors for self-powered cardiovascular system characterization and throat-attached antiinterference voice recognition. Adv. Mater. 27, 1316-1326 (2015).
- Lee, S. et al. An ultrathin conformable vibration-responsive electronic skin for quantitative vocal recognition. Nat. Commun. 10, 2468 (2019).
- Calvert, D. R. Clinical measurement of speech and voice, by Ronald J. Baken, PhD, 528 pp, paper, College-Hill Press, Boston, MA, 1987, $35.00. Laryngoscope 98, 905-906 (1988).
- Diemer, J., Alpers, G. W., Peperkorn, H. M., Shiban, Y. & Mühlberger, A. The impact of perception and presence on emotional reactions: a review of research in virtual reality. Front. Psychol. 6, 26 (2015).
- Allcoat, D. & Mühlenen, A. von. Learning in virtual reality: Effects on performance, emotion and engagement. Res. Learn. Technol. 26, 2140 (2018).
- Colombo, D., Díaz-García, A., Fernandez-Álvarez, J. & Botella, C. Virtual reality for the enhancement of emotion regulation. Clin. Psychol. Psychother. 28, 519-537 (2021).
Acknowledgements
Author contributions
Competing interests
Additional information
http://www.nature.com/reprints
© The Author(s) 2024
School of Material Science and Engineering, Ulsan National Institute of Science and Technology, Ulsan 44919, South Korea. School of Materials Science and Engineering, Nanyang Technological University, 50 Nanyang Avenue, Singapore 639798, Singapore. Center for Multidimensional Programmable Matter, Ulsan National Institute of Science and Technology, Ulsan 44919, South Korea. e-mail: pslee@ntu.edu.sg; jiyunkim@unist.ac.kr