DOI: https://doi.org/10.1038/s40494-025-01565-6
تاريخ النشر: 2025-03-11
خوارزمية تعتمد على ميزات دلالية خفيفة الوزن لاكتشاف عناصر الجداريات القديمة
الملخص
تعتبر الجداريات القديمة التي تم اكتشافها في الصين تراثًا ثقافيًا عالميًا ثمينًا، حيث تسجل المعلومات التاريخية لعصور مختلفة وتعمل كمواد تصويرية قيمة لدراسة المجتمع الصيني القديم. تشمل عناصر الجداريات الشخصيات والعربات والزهور والطيور والسحب الميمونة. يمكن أن تساعد الأبحاث الرقمية حول هذه العناصر في فهم التاريخ والثقافة بشكل أفضل. في هذه الورقة، أنشأنا مجموعة بيانات كبيرة لاكتشاف عناصر الجداريات المستخرجة من الصين القديمة، تتميز بتنوع غني من فئات العينات المعلّمة التي تمتد عبر فترات تاريخية ومناطق مختلفة، مما يوفر قيمة كبيرة لدراسة التاريخ الصيني القديم. في الوقت نفسه، لمعالجة العيوب الموجودة في الجداريات، قمنا بتطوير خوارزمية تعزيز عشوائية قابلة للتكيف، والتي تجبر النموذج على تعلم معلومات ميزات أكثر شمولاً، مما يمكنه من التكيف مع السيناريوهات المعيبة للجداريات. علاوة على ذلك، أنشأنا نموذج استخراج ميزات دلالية للأهداف لعناصر الجداريات الصينية القديمة، والذي يستخدم المعلومات السياقية وآلية الانتباه المتبقية لالتقاط المعلومات الدلالية، مما يعزز دقة اكتشاف عناصر الأهداف. أخيرًا، أجرينا تحليلًا مقارنًا لنتائج الاكتشاف لطريقتنا المقترحة مع عدة خوارزميات حديثة أخرى لاكتشاف الأهداف على مجموعة بيانات الجداريات التي تم إنشاؤها، وأكدت نتائج التصور تفوق طريقتنا المقترحة.
عناصر هذه الجداريات من فهم ودراسة هذه الأعمال الفنية، مما يساعد في حماية والحفاظ على هذا التراث الثقافي الثمين.
التعامل مع حالات فقدان المعلومات الجزئية في الجداريات بسبب العمر وظروف الحفظ وعوامل أخرى. بالإضافة إلى ذلك، أنشأنا شبكة هيكلية خفيفة الوزن لاستخراج الميزات متعددة المقاييس التي تقلل بشكل كبير من عدد المعلمات والعبء الحسابي مع ضمان دقة استخراج ميزات العناصر. علاوة على ذلك، لتعزيز قدرة النموذج على استخراج ميزات عناصر الجداريات، قمنا بتطوير نموذج تعزيز الميزات الدلالية لعناصر الجداريات الذي يحسن من فهم النموذج ودقة الكشف من خلال الانتباه المتبقي والمعلومات السياقية.
- مساهمة مجموعة بيانات فريدة: لقد قمنا بتجميع مجموعة بيانات كبيرة غير مسبوقة مخصصة للكشف عن الأهداف في الجداريات القديمة المستخرجة في الصين. على عكس الأعمال السابقة، تتميز هذه المجموعة بمدى زمني واسع، وتوزيع جغرافي، وتنوع أسلوبي، مما يشمل مجموعة واسعة من العينات المصنفة بدقة. تعتبر هذه المورد الشامل حجر الزاوية لتقدم البحث في الجداريات الصينية القديمة، حيث تقدم رؤى ومرجعًا لا تقدر بثمن لم تكن متاحة سابقًا.
- تقنية مبتكرة لتعزيز البيانات: لمواجهة التحديات المحددة التي تطرحها العيوب في مجموعة بيانات الجداريات القديمة المستخرجة، نقدم خوارزمية تعزيز بيانات المسح العشوائي التكيفية. تعزز هذه الطريقة الجديدة من قدرة النموذج على التعلم والتعرف على ميزات الكائنات المعيبة في الجداريات من خلال تعزيز مجموعة العينات المصنفة، مما يملأ فجوة حاسمة في المنهجيات الحالية.
- استخراج ميزات متعددة المقاييس بكفاءة: نقترح شبكة هيكلية خفيفة الوزن لاستخراج الميزات متعددة المقاييس مصممة لعناصر الجداريات. لا تلتقط هذه الشبكة ميزات الأهداف ذات الأحجام المختلفة بفعالية فحسب، بل تقلل أيضًا بشكل كبير من التعقيد الحسابي وعدد المعلمات مقارنة بالأساليب التقليدية. تجعل هذه الكفاءة مناسبة تمامًا للتطبيقات في العالم الحقيقي والبيئات ذات الموارد المحدودة.
- نموذج متقدم لاستخراج الميزات الدلالية: علاوة على ذلك، نطور نموذجًا لاستخراج الميزات الدلالية يستفيد من المعلومات السياقية والانتباه المتبقي لاشتقاق رؤى دلالية من عناصر الجداريات. يمثل هذا النموذج قفزة كبيرة إلى الأمام في دقة الكشف عن أهداف عناصر الجداريات، حيث يتضمن آليات متطورة لتحسين وتعزيز الفهم الدلالي للعناصر، مما يميز عملنا عن الجهود السابقة في هذا المجال.
الأعمال ذات الصلة
مجموعة بيانات الجداريات وخوارزمية تعزيز بيانات الصور
الكشف عن فئات مثل الأغطية، والملابس، والأدوات الدينية. ومع ذلك، فإن مجموعات بيانات الجداريات القديمة المذكورة أعلاه تُستخدم بشكل أساسي لاكتشاف عيوب الجداريات، والخياطة الافتراضية، والكشف عن أهداف فئات العناصر في سيناريوهات محددة. وهي محدودة من حيث عدد المجموعات وتوزيع الأعمار، وتفتقر أيضًا إلى الكشف والتحليل الدلالي للعناصر المهمة في الجداريات القديمة. في هذه الورقة، نقوم بإنشاء مجموعة بيانات كبيرة للكشف عن الأهداف لعناصر الجداريات الصينية القديمة، والتي تتميز بتغطية واسعة من المناطق الجغرافية والفترات التاريخية، وعدد غني من العينات المصنفة. توفر هذه المجموعة مواد بحثية مهمة للدراسات والجهود المتعلقة بالحفاظ على الجداريات الصينية القديمة.
شبكة هيكلية خفيفة لاستخراج الميزات
دمج الميزات متعددة المقاييس مع الحفاظ على تمييز الميزات مع تقليل الحمل الحسابي. في SwinWave-SR
نموذج تعزيز الميزات الدلالية
طريقة
معلمات في النموذج. علاوة على ذلك، نقوم أيضًا بتطوير نموذج لاستخراج الميزات الدلالية المستهدفة لعناصر الجداريات الصينية القديمة. يستخدم هذا النموذج الانتباه المتبقي والمعلومات السياقية لالتقاط الميزات الدلالية لعناصر الجداريات، مما يحسن بشكل فعال دقة اكتشاف أهداف عناصر الجداريات.
مجموعة بيانات من جدارية قديمة تم اكتشافها في الصين


نموذج زيادة الصور عن طريق مسح المناطق العشوائية التكيفية
الملخص
على الرغم من
بالإضافة إلى ذلك، يجب أن يحافظ المستطيل العشوائي المحذوف التكيفي تقريبًا على اتساق الشكل مع المنطقة المستهدفة المعلّمة. عندما يكون شكل المنطقة المحذوفة مشابهًا لشكل الهدف، يمكن للنموذج أن يدرك بسهولة المنطقة المحذوفة كحجب أو تشوه للهدف أثناء عملية الاستدلال، مما يعزز من قوته في مواجهة الحجب والتشوهات. كما هو موضح في المعادلة (3)،
عندما تكون شكل المنطقة المحذوفة مشابهًا لشكل صندوق الحدود المستهدف، يكون النموذج أكثر احتمالًا أن يدرك المنطقة المحذوفة كتغير طبيعي أو حجب للهدف أثناء معالجة هذه الصور المعززة، بدلاً من أن تكون تشتيتًا غير ذي صلة تمامًا. تساعد هذه الاتساق في الشكل النموذج على تعلم كيفية التكيف مع التغيرات في شكل الهدف، مما يعزز من قوته في مواجهة تغييرات الشكل. إذا كان شكل المنطقة المحذوفة يختلف بشكل كبير عن شكل الهدف، فقد يؤدي ذلك إلى إدخال تشوهات شكل غير ضرورية، مما قد يضلل النموذج في تعلم ميزات الهدف. من خلال الحفاظ على اتساق المنطقة المحذوفة مع شكل الهدف، يمكن تقليل هذه التشوهات غير الضرورية، مما يسمح للنموذج بالتركيز أكثر على تعلم الخصائص الأساسية للهدف. من خلال الالتزام بالمبادئ الثلاثة المذكورة أعلاه، يمكن الحفاظ على المناطق المحذوفة المولدة عشوائيًا ضمن فترة ونطاق معقولين، ويجب أن يلبي الخوارزمية جميع الشروط الثلاثة أثناء التنفيذ. إذا لم يكن الأمر كذلك، فسوف تستمر في توليد نقطة عشوائية على صندوق الحدود المسمى حتى تنتج منطقة محذوفة مقبولة.
\section*{شبكة العمود الفقري متعددة المقاييس خفيفة الوزن}
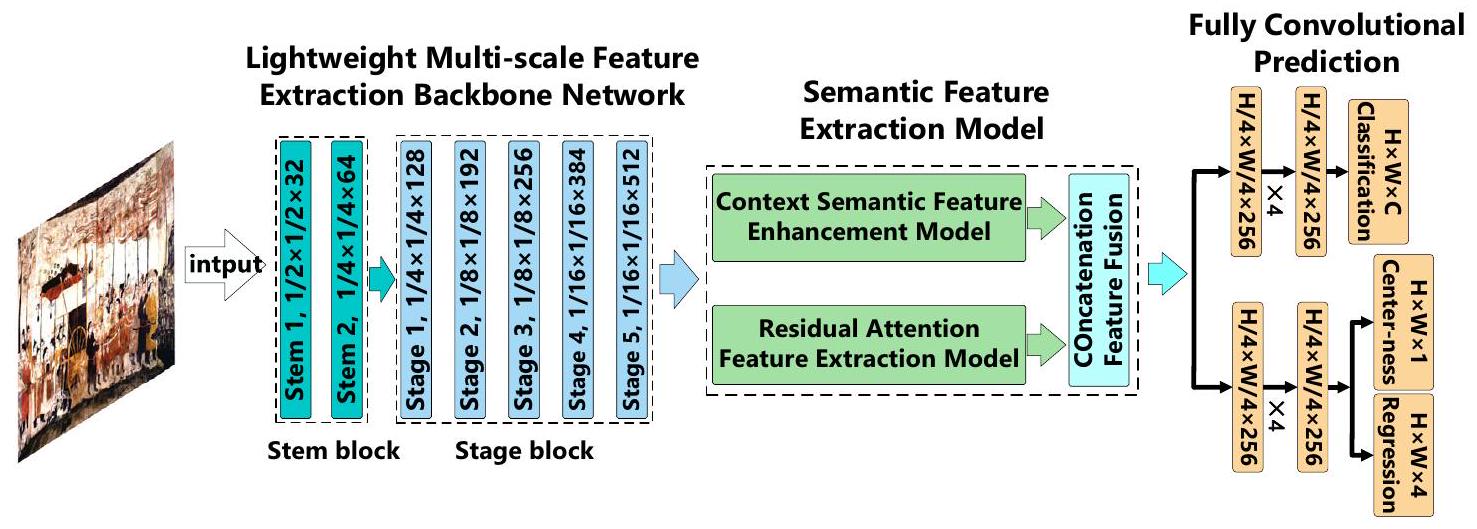
توضح الشكل 4 الإطار العام لخوارزمية الكشف عن الأجسام المقترحة لعناصر الجداريات المستخرجة من الصين القديمة. في هذه الخوارزمية، يتم أولاً تعزيز مجموعة بيانات الجداريات من خلال نموذج تعزيز الصور العشوائي التكيفي المقترح لتوسيع مجموعة بيانات التدريب. بعد ذلك، يتم إدخال مجموعة بيانات صور الجداريات المعززة في شبكة استخراج الميزات متعددة المقاييس الخفيفة المقترحة لاستخراج ميزات الهدف. ثم يتم تغذية الميزات المستخرجة في نموذج استخراج الميزات الدلالية للحصول على معلومات عالية المستوى عن أهداف عناصر الجداريات. أخيرًا، يتم التنبؤ بمواقع وفئات أهداف عناصر الجداريات بواسطة شبكة تلافيفية كاملة.
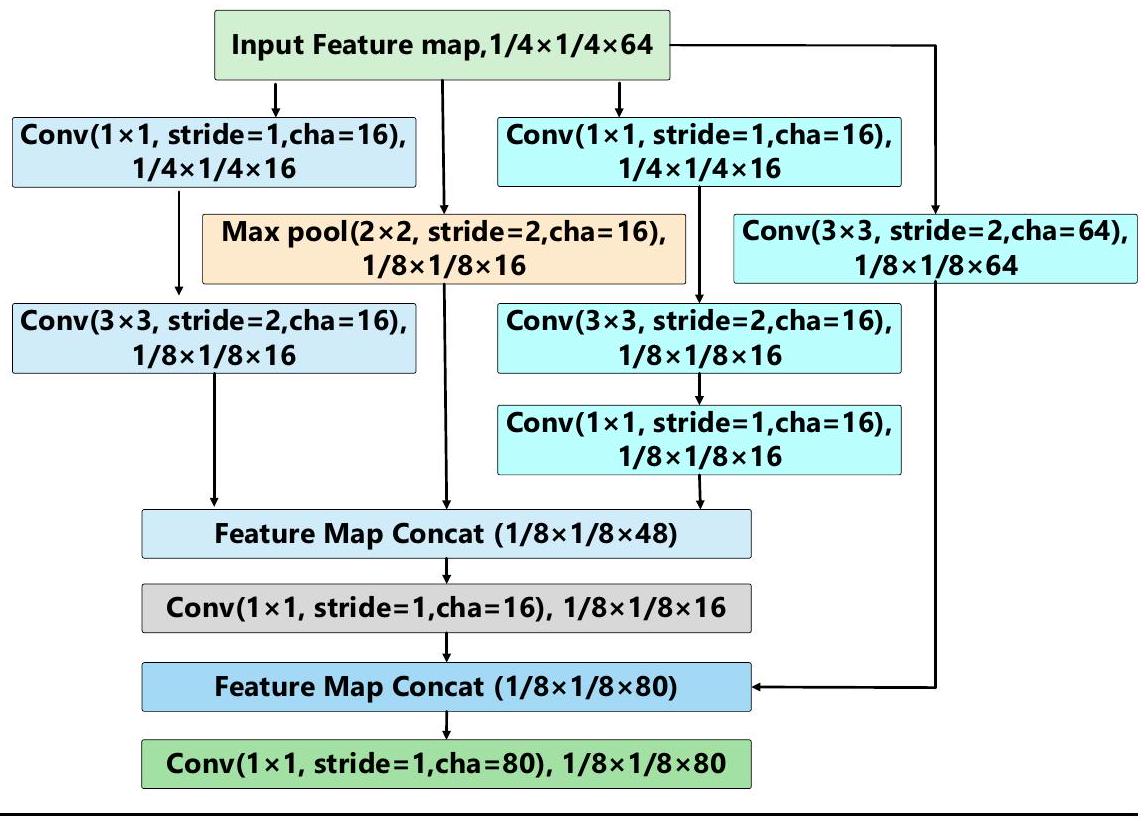
يتكون الشبكة الخفيفة متعددة المقاييس من جزئين: كتلة الساق وكتلة المرحلة. الوظيفة الأساسية لكتلة الساق هي إجراء تقليل مكاني لحجم الصور المدخلة من خلال عمليات الالتفاف والتجميع. تقلل هذه العملية من حجم الصور مع زيادة عدد قنوات الميزات لتعزيز عمق وعرض تمثيل الميزات. كما أنها تقلل من الحمل الحسابي للنموذج من خلال الحفاظ على عدد ثابت من القنوات الداخلية المتداولة. تقلل هذه الوحدة بشكل كبير من العبء الحسابي دون التأثير الملحوظ على القدرة التعبيرية للميزات. تقوم كتلة المرحلة بمزيد من تحسين الميزات المدخلة من وحدة استخراج الميزات لكتلة الساق. تزيد تدريجياً من عدد قنوات الميزات باستخدام نهج تكديس القنوات وتستخدم تقنية دمج الميزات متعددة المقاييس التي تجمع بين ميزات التفاصيل منخفضة المستوى مع المعلومات الدلالية عالية المستوى. وهذا يسمح للنموذج بالحصول على فهم أكثر شمولاً لمحتوى الصورة.
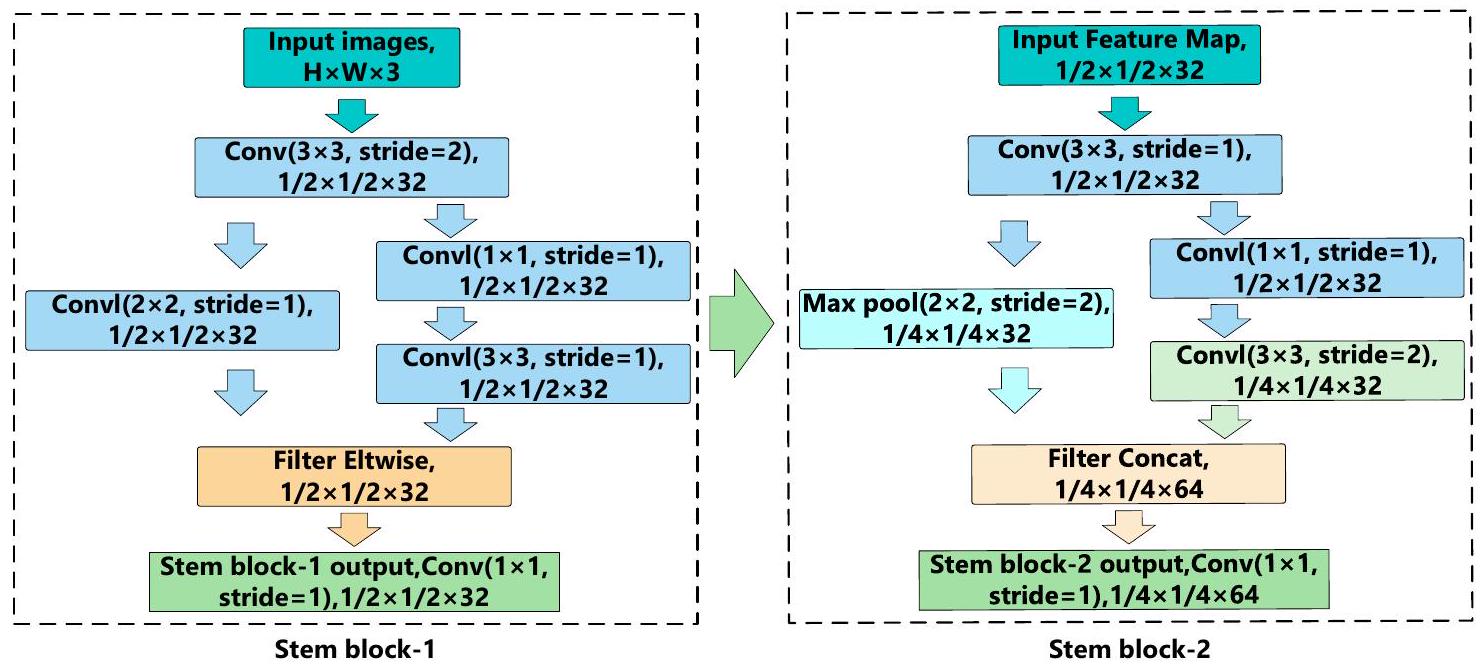
توضح الشكل 5 هيكل كتلة الساق في الشبكة المقترحة لاستخراج الميزات متعددة المقاييس الخفيفة. تنقسم كتلة الساق إلى وحدتين أصغر، وهما كتلة الساق-1 وكتلة الساق-2. في كتلة الساق-1، يكون حجم الصورة المدخلة هو
في كتلة الساق-2، تخضع خريطة الميزات المستخرجة من كتلة الساق-1 أولاً لعملية الالتفاف بحجم نواة قدره
وتداول مرة أخرى. يقوم أحد المسارات بإجراء عملية تجميع قصوى بحجم نواة قدره
نموذج تعزيز الميزات الدلالية
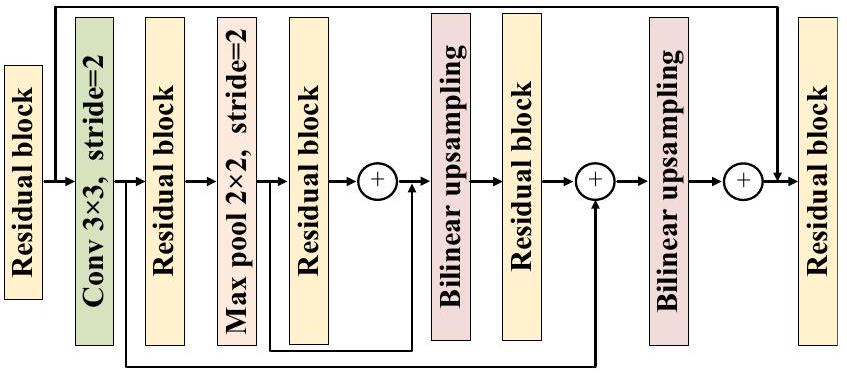
وحدة و وحدة انتباه متبقية، مما يمكّن خرائط الميزات المدخلة من الخضوع لاستخراج الميزات والدمج من خلال هذه الوحدات، وبالتالي تعزيز ميزات المعلومات الدلالية. يتضمن نموذج استخراج الميزات الدلالية المقترح في هذه الورقة وحدة دمج معلومات السياق ووحدة انتباه متبقية. تلتقط هاتان الوحدتان لاستخراج الميزات المعلومات الدلالية بين أهداف عناصر الجداريات القديمة عبر أبعاد مختلفة، وفي النهاية تحصل على معلومات ميزات دلالية عالية المستوى لأهداف العناصر من خلال دمج الميزات.
النتائج
| المكونات | نتائج الكشف | ||||
| النموذج الأصلي | ✓ | ✓ | ✓ | ✓ |
|
| نموذج المسح العشوائي التكيفي |
|
✓ | ✓ | ✓ | |
| شبكة العمود الفقري الخفيفة | ✓ | ✓ | ✓ | ||
| ميزة السياق الدلالية |
|
|
|||
| ميزة دلالية متبقية | ✓ | ||||
| mAP (متوسط الدقة) | 76.7% | 82.6% | 84.9% | 86.2% | 87.5% |
| FLOPs (تكلفة حسابية) | 478 م | 478 م |
|
265 م | 268 م |
| الإطارات في الثانية (FPS) | 21 | 21 | 45 | 39 | 35 |
| طريقة | معدل الاسترجاع | معدل الدقة | درجة F1 | معدل الدقة المتوسطة | وقت الكشف (ثواني) |
| سام نت
|
86.7% | 87.9٪ | 0.873 | 85.6٪ | 0.109 |
| SEConv-MSFE
|
83.5% | 84.1٪ | 0.838 | ٨٣.٢٪ | 0.097 |
| ADMNet
|
85.7٪ | 87.6% | 0.866 | 86.4% | 0.083 |
| SFSANet
|
85.8% | ٨٨.٣٪ | 0.870 | 86.7% | 0.186 |
| شبكة SCF
|
٨٣.٦٪ | 85.2% | 0.857 | 84.6٪ | 0.235 |
| SLMS-SSD
|
٨٣.٢٪ | ٨٤.٧٪ | 0.839 | ٨٤.٢٪ | 0.267 |
| طريقتنا | 87.6% | 89.3٪ | 0.884 | 87.5% | 0.022 |
| فئة | عدد العينات | معدل الاسترجاع | معدل الدقة | معدل الدقة المتوسطة | وقت الكشف (مللي ثانية) |
| ذكر | 8109 | 91.3% | 93.6% | 91.8٪ | 1.98 |
| أنثى | 5008 | 90.2% | 91.5% | 89.7% | 2.13 |
| وحش | ٣٣٣٩ | 86.2% | 85.7٪ | 85.3% | ٢.٤٧ |
| زهرة | 2862 | 76.8٪ | 79.3% | 78.9% | ٢.٢٦ |
| طائر | 2623 | 73.8٪ | 76.9% | 75.2% | 2.35 |
| سحابة | 1901 | 71.4٪ | 74.9% | 73.6% | 2.42 |
| فئة | المسح العشوائي التكيفي | شبكة العمود الفقري خفيفة الوزن | نموذج الميزات الدلالية | معدل الدقة المتوسطة | وقت الكشف |
| ذكر | ✓ | × | × | ٨٨.٦٪ | 2.67 مللي ثانية |
| ✓ |
|
× | 89.4% | 1.72 مللي ثانية | |
| × |
|
|
٨٨.٧٪ | 2.28 مللي ثانية | |
| أنثى |
|
× | × | 85.2% | 3.52 مللي ثانية |
| ✓ |
|
× | 87.2% | 1.86 مللي ثانية | |
| × |
|
✓ | 86.2% | 2.78 مللي ثانية | |
| وحش |
|
× | × | 82.6% | 3.96 مللي ثانية |
| ✓ |
|
× | ٨٣.٨٪ | 2.08 مللي ثانية | |
| × |
|
|
81.9% | 1.89 مللي ثانية | |
| زهرة | ✓ | × | × | 73.2% | 4.13 مللي ثانية |
|
|
|
× | 72.8% | 1.64 مللي ثانية | |
| × |
|
|
75.2% | 2.13 مللي ثانية | |
| طائر |
|
× | × | 69.5% | 5.36 مللي ثانية |
| ✓ |
|
× | 70.3% | 2.06 مللي ثانية | |
| × |
|
|
73.2% | 2.28 مللي ثانية | |
| سحابة |
|
× | × | 65.3% | 4.98 مللي ثانية |
| ✓ |
|
× | 66.7% | 2.14 مللي ثانية | |
| × |
|
✓ | 70.6% | 2.36 مللي ثانية |

الخاتمة والمناقشة
عدد هائل من العينات، وتنوع غني من الفئات المعلّمة. لتعزيز عدد عينات الصور الجدارية، قمنا بإنشاء نموذج تكبير عشوائي للتآكل للصور الجدارية، قادر على توليد مناطق تآكل عشوائية لمحاكاة الأضرار التي قد توجد في الجداريات، مما يجبر النموذج على تعلم القدرة على التعرف على الأهداف العنصرية وفهمها من خلال معلومات الصورة غير المكتملة. بالإضافة إلى ذلك، قمنا بتطوير شبكة هيكلية خفيفة متعددة المقاييس لاستخراج ميزات العناصر الجدارية. يقلل هذا النموذج بشكل كبير من الحمل الحاسوبي مع الحفاظ على دقة الكشف من خلال شبكة عصبية تلافيفية خفيفة ودمج ميزات متعددة المقاييس.
طرق. علاوة على ذلك، لتعزيز الفهم الدلالي لعناصر الجداريات، قدمنا نموذج تحسين الميزات الدلالية لعناصر الجداريات، الذي يحسن الفهم الدلالي ويزيد من دقة الكشف من خلال المعلومات السياقية وآلية الانتباه المتبقية. يحقق خوارزمية كشف عناصر الجداريات القديمة المقترحة في هذه الورقة معدل استرجاع قدره
توفر البيانات
تاريخ الاستلام: 5 نوفمبر 2024؛ تاريخ القبول: 4 يناير 2025؛
نُشر على الإنترنت: 11 مارس 2025
References
- Jia, Y. et al. Multi-analytical investigations on a tomb mural painting of the Yuan dynasty in Chongqing, China. Vib. Spectrosc. 124, 103457 (2023).
- Dong, S. et al. Multi-Method Analysis of Painting Materials in Murals of the North Mosque (Linqing, China). Coatings 13, 1298 (2023).
- Guo, R. et al. Rare colour in medieval China: Case study of yellow pigments on tomb mural paintings at Xi’an, the capital of the Chinese Tang dynasty. Archaeometry 64, 759-778 (2022).
- Cao, J., Cui, H., Zhang, Z. & Zhao, A. Mural classification model based on high- and low-level vision fusion. Herit. Sci. 8, 121 (2020).
- Cao, J., Cui, H., Zhang, Q. & Zhang, Z. Ancient Mural Classification Method Based on Improved AlexNet Network. Stud. Conserv 65, 411-423 (2020).
- Chen Z., Rajamanickam L., Tian X. & Cao J. Application of Optimized Convolution Neural Network Model in Mural Segmentation. Appl Comput Intell Soft Comput. 2022, 5485117 (2022).
- Liu, W., Li, X. & Wu, F. Research on Restoration Algorithm of Tomb Murals Based on Sequential Similarity Detection. Sci Program. 2021, 6842353, (2021).
- Cheng, G. et al. Towards Large-Scale Small Object Detection: Survey and Benchmarks. IEEE Trans. Pattern Anal. Mach. Intell. 45, 13467-13488 (2023).
- Wu, L., Zhang, L., Shi, J., Zhang, Y. & Wan, J. Damage detection of grotto murals based on lightweight neural network. Comput Electr. Eng. 102, 108237 (2022).
- Sun, D., Zhang, J., Pan, G. & Zhan, R. Mural2Sketch: A Combined Line Drawing Generation Method for Ancient Mural Painting. 2018 IEEE International Conference on Multimedia and Expo (2018).
- Ni, X., Yu, Y., Zhao, H. & Li, Y. Mural Disease Detection Based on ConvUNeXt with Improved Up-Sampling and Feature Fusion. 2024 5th International Seminar on Artificial Intelligence, Networking and Information Technology (2024).
-
. et al. A comprehensive dataset for digital restoration of Dunhuang murals. Sci. Data 11, 955 (2024). - Cao, J., Yan, M., Jia, Y., Tian, X. & Zhang, Z. Application of a modified Inception-v3 model in the dynasty-based classification of ancient murals. EURASIP J. Adv. Signal Process 2021, 1-25 (2021).
- Cao, J., Jia, Y., Chen, H., Yan, M. & Chen, Z. Ancient mural classification methods based on a multichannel separable network. Herit. Sci. 9, 88 (2021).
- Huang, R., Feng, W., Fan, M., Guo, Q. & Sun, J. Learning multi-path CNN for mural deterioration detection. J. Ambient Intell. Hum. Comput 11, 3101-3108 (2017).
- Pan G., Sun D., Zhan R. & Zhang J. Mural Sketch Generation via Styleaware Convolutional Neural Network. CGI 2018: Proceedings of Computer Graphics International (2018).
- Yu, Z. et al. AGD-GAN: Adaptive Gradient-Guided and Depthsupervised generative adversarial networks for ancient mural sketch extraction. Expert Syst. Appl. 255, 124639 (2024).
- Wu, Z. et al. Enhanced Spatial Feature Learning for Weakly Supervised Object Detection. IEEE Trans. Neural Netw. Learn Syst. 35, 961-972 (2022).
- Wang, X., Song, N., Zhang, L. & Jiang, Y. Understanding subjects contained in Dunhuang mural images for deep semantic annotation. J. Doc. 74, 333-353 (2018).
- Zeng, Z., Sun, S., Sun, J., Yin, J. & Shen, Y. Constructing a mobile visual search framework for Dunhuang murals based on fine-tuned CNN and ontology semantic distance. Electron Libr. 40, 121-139 (2022).
- Wang, N., Wang, W., Hu, W., Fenster, A. & Li, S. Damage Sensitive and Original Restoration Driven Thanka Mural Inpainting. Pattern Recognition and Computer Vision. 142-154 (2020).
- Xu, Z. et al. MuralDiff: Diffusion for Ancient Murals Restoration on Large-Scale Pre-Training. IEEE Trans. Emerg. Top. Comput Intell. 8, 2169-2181 (2024).
- Wang, N., Wang, W., Hu, W., Fenster, A. & Li, S. Thanka Mural Inpainting Based on Multi-Scale Adaptive Partial Convolution and Stroke-Like Mask. IEEE Trans. Image Process 30, 3720-3733 (2021).
- Mei Y., Yang L., Wang M., Yu T. & Wu K. DunHuangStitch: Unsupervised Deep Image Stitching of Dunhuang Murals. IEEE Trans. Vis. Comput. Graph. Early Access (2024).
- Chen, Y., Fan, Z. & Liu, X. RPTK1: A New Thangka Data Set for Object Detection of Thangka Images. IEEE Access 9, 131696-131707 (2021).
- Dai, Y., Ma, F., Hu, W. & Zhang, F. SPGC: Shape-Prior-Based Generated Content Data Augmentation for Remote Sensing Object Detection. IEEE Trans. Geosci. Remote Sens. 62, 4504111 (2024).
- Dvornik, N., Mairal, J. & Schmid, C. On the Importance of Visual Context for Data Augmentation in Scene Understanding. IEEE Trans. Pattern Anal. Mach. Intell. 43, 2014-2028 (2021).
- Tang, Y. et al. AutoPedestrian: An Automatic Data Augmentation and Loss Function Search Scheme for Pedestrian Detection. IEEE Trans. Image Process. 30, 8483-8496 (2021).
- Chen, P. Y., Hsieh, J. W., Gochoo, M. & Chen, Y. S. Mixed Stage Partial Network and Background Data Augmentation for Surveillance Object Detection. IEEE Trans. Image Process 23, 23533-23547 (2022).
- Liu, Y., Zhang, X. Y., Bian, J. W., Zhang, L. & Cheng, M. M. SAMNet: Stereoscopically Attentive Multi-Scale Network for Lightweight Salient Object Detection. IEEE Trans. Image Process 30, 3804-3814 (2021).
- Zhou, Q. et al. Boundary-Guided Lightweight Semantic Segmentation With Multi-Scale Semantic Context. IEEE Trans. Multimed. 26, 7887-7900 (2024).
- Zhou, Q., Qu, Z. & Ju, F. A Lightweight Network for Crack Detection With Split Exchange Convolution and Multi-Scale Features Fusion. IEEE Trans. Intell. Veh. 8, 2296-2306 (2023).
- Yuan, Z. et al. A Lightweight Multi-Scale Crossmodal Text-Image Retrieval Method in Remote Sensing. IEEE Trans. Geosci. Remote Sens 60, 5612819 (2022).
- Li, Q., Sun, B. & Bhanu, B. Lite-FENet: Lightweight multi-scale feature enrichment network for few-shot segmentation. Knowl. Based Syst. 278, 110887 (2023).
- Dharejo, F. A. et al. SwinWave-SR: Multi-scale lightweight underwater image super-resolution. Inf. Fusion 103, 102127 (2024).
- Zhou, X., Shen, K. & Liu, Z. ADMNet: Attention-guided Densely Multiscale Network for Lightweight Salient Object Detection. IEEE Trans. Multimed. 26, 10828-10841 (2024).
- Wu, H. et al. PolypSeg+: A Lightweight Context-Aware Network for Real-Time Polyp Segmentation. IEEE Trans. Cybern. 53, 2610-2621 (2023).
- Gou, S. et al. Weakly-Supervised Semantic Feature Refinement Network for MMW Concealed Object Detection. IEEE Trans. Circuits Syst. Video Technol. 33, 1363-1373 (2023).
- Zhang, Y., Liu, T., Yu, P., Wang, S. & Tao, R. SFSANet: Multiscale Object Detection in Remote Sensing Image Based on Semantic Fusion and Scale Adaptability. IEEE Trans. Geosci. Remote Sens. 62, 4406410 (2024).
- Yan, C. et al. Semantics-Guided Contrastive Network for Zero-Shot Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 46, 1530-1544 (2024).
- Song, K., Sun, X., Ma, S. & Yan, Y. Surface Defect Detection of Aeroengine Blades Based on Cross-Layer Semantic Guidance. IEEE Trans. Instrum. Meas. 72, 2514411 (2023).
- Yue, C. et al. SCFNet: Semantic correction and focus network for remote sensing image object detection. Expert Syst. Appl. 224, 119980 (2023).
- Zhang X. & Chou C. H. Source-free Domain Adaptation for Video Object Detection Under Adverse Image Conditions. IEEE/CVF Conference on ComputerVision and Pattern Recognition Workshops. 5010-5019 (2024).
- Guo, Y. et al. DSCA: A Dual Semantic Correlation Alignment Method for domain adaptation object detection. Pattern Recognit. 150, 110329 (2024).
شكر وتقدير
مساهمات المؤلفين
المصالح المتنافسة
معلومات إضافية
http://www.nature.com/reprints
© المؤلف(ون) 2025
كلية تكنولوجيا المعلومات، جامعة لويوانغ العادية، لويوانغ، الصين. كلية علوم الحاسوب والتكنولوجيا، جامعة نانجينغ للطيران والفضاء، نانجينغ، الصين. □ البريد الإلكتروني: shenjiaquan_cv@163.com
DOI: https://doi.org/10.1038/s40494-025-01565-6
Publication Date: 2025-03-11
An algorithm based on lightweight semantic features for ancient mural element object detection
Abstract
The ancient mural paintings unearthed in China are precious world cultural heritages, which record the historical information of various eras and serve as valuable image materials for studying ancient Chinese society. The elements of the murals include figures, carriages, flowers, birds, and auspicious clouds. The digital research on these elements can better help us understand history and culture. In this paper, we have established a large-scale target detection dataset for mural elements excavated from ancient China, featuring a rich variety of labeled sample categories that span across different historical periods and regions, which provides significant value for the study of ancient Chinese history. Meanwhile, to address the defects present in the mural paintings, we have developed an adaptive random erasing augmentation algorithm, which forces the model to learn more comprehensive feature information, enabling it to adapt to the defective scenarios of the mural paintings. Moreover, we have created a target semantic feature extraction model for elements of ancient Chinese murals, which utilizes contextual information and residual attention mechanism to capture the semantic information, thereby enhancing the accuracy of element target detection. Finally, we have conducted a comparative analysis of the detection results of our proposed method with several other state-of-the-art target detection algorithms on the created mural dataset, and the visualization results validated the superiority of our proposed method.
detection of these elements on murals can enhance the understanding and study of these artworks, thereby aiding in the protection and preservation of this precious cultural heritage
handling cases of partial information loss in murals due to age, preservation conditions, and other factors. Additionally, we have established a lightweight multi-scale feature extraction backbone network that significantly reduces the number of parameters and computational load while ensuring the accuracy of feature element extraction. Moreover, to enhance the model’s ability to extract mural element features, we have developed a semantic feature enhancement model for mural elements that improves the model’s understanding and detection accuracy through residual attention and contextual information.
- Unique Dataset Contribution: We have curated an unprecedented large-scale dataset dedicated to object detection in ancient murals excavated in China. Unlike previous works, this dataset boasts a broad temporal span, geographical distribution, and stylistic diversity, encompassing a vast array of meticulously labeled samples. This comprehensive resource serves as a cornerstone for advancing research on ancient Chinese murals, offering invaluable insights and references that were previously unavailable.
- Innovative Data Augmentation Technique: Addressing the specific challenges posed by defects in the dataset of ancient excavated murals, we introduce an adaptive random erasing data augmentation algorithm. This novel approach enhances the model’s ability to learn and recognize defective mural object features by augmenting the labeled sample pool, thereby filling a critical gap in existing methodologies.
- Efficient Multi-Scale Feature Extraction: We propose a lightweight multi-scale feature extraction backbone network tailored for mural elements. This network not only effectively captures features of targets of varying sizes but also significantly reduces computational complexity and parameter count compared to traditional approaches. This efficiency makes it well-suited for real-world applications and resource-constrained environments.
- Advanced Semantic Feature Extraction Model: Furthermore, we develop a semantic feature extraction model that leverages contextual information and residual attention to derive semantic insights from mural elements. This model represents a significant leap forward in detection accuracy for mural element targets, as it incorporates sophisticated mechanisms to refine and enrich the semantic understanding of the elements, distinguishing our work from previous efforts in this domain.
Related work
Mural Dataset and Image Data Augmentation Algorithm
detecting categories such as headwear, clothing, and religious tools. However, the aforementioned ancient mural datasets are primarily used for mural defect detection, virtual stitching, and target detection of element categories in specific scenarios. They are limited in terms of the number of datasets and the distribution of ages, and they also lack detection and semantic analysis of important elements in ancient murals. In this paper, we establish a large-scale target detection dataset for elements in ancient Chinese murals, which boasts a wide coverage of geographical regions and historical periods, and a rich number of labeled samples. This dataset provides important research materials for subsequent studies and conservation efforts related to ancient Chinese murals.
Lightweight feature extraction backbone network
fusion of multi-scale features while maintaining feature discriminability with a lower computational load. In SwinWave-SR
Semantic feature enhancement model
Method
parameters in the model. Moreover, we also develop a target semantic feature extraction model for ancient Chinese mural elements. This model utilizes residual attention and contextual information to capture the semantic features of mural elements, thereby effectively improving the detection accuracy of mural element targets.
Dataset of ancient mural unearthed in China
Adaptive random region erasing augmentation model
Abstract
Although
Additionally, the adaptive random erased rectangle should roughly maintain consistency in shape with the target labeled area. When the shape of the erased region is similar to that of the target, the model can more easily perceive the erased area as an occlusion or deformation of the target during the inference process, thereby enhancing its robustness to occlusions and deformations. As shown in Eq. (3),
When the shape of the erased region is similar to the shape of the target bounding box, the model is more likely to perceive the erased area as a natural variation or occlusion of the target while processing these augmented images, rather than as an entirely unrelated distraction. This consistency in shape helps the model learn how to adapt to variations in the target’s shape, thereby enhancing its robustness to shape changes. If the shape of the erased region differs significantly from the target shape, it could introduce unnecessary shape distortions, which may mislead the model in learning the target features. By maintaining the consistency of the erased region with the target’s shape, such unnecessary distortions can be reduced, allowing the model to focus more on learning the essential characteristics of the target. By adhering to the three principles mentioned above, the randomly generated erased regions can be kept within a reasonable interval and range, and the algorithm must satisfy all three conditions during execution. If not, it will continue to randomly generate a point on the labeled bounding box until it produces an acceptable erased region.
section*{Lightweight multi-scale backbone network}
Figure 4 illustrates the overall framework of the proposed object detection algorithm for mural elements excavated from ancient China. In this algorithm, the mural dataset is first augmented through the proposed adaptive random erasing image augmentation model to expand the training dataset. Subsequently, the augmented mural image dataset is input into the proposed lightweight multi-scale feature extraction backbone network for target feature extraction. The extracted features are then fed into the semantic feature extraction model to obtain highlevel information of the mural element targets. Finally, the positions and categories of the mural element targets are predicted by a fully convolutional network.
The lightweight multi-scale backbone network consists of two parts: the Stem block and the Stage block. The primary function of the Stem block is to perform spatial downsampling on the input images through convolution and pooling operations. This downsampling operation reduces the size of the images while increasing the number of feature channels to enhance the depth and breadth of feature representation. It also reduces the computational load of the model by maintaining a consistent number of internal propagating channels. This module significantly decreases the computational burden without noticeably compromising the expressive capability of the features. The Stage block further refines the features input from the Stem block feature extraction module. It progressively increases the number of feature channels using a channel-stacking approach and employs a multi-scale feature fusion technique that combines low-level detail features with high-level semantic information. This allows the model to gain a more comprehensive understanding of the image content.
Figure 5 illustrates the structure of the Stem block in the proposed lightweight multi-scale feature extraction backbone network. The Stem block is divided into two smaller modules, namely Stem block-1 and Stem block-2. In Stem block-1, the input image size is
In Stem block-2, the feature map extracted from Stem block-1 is first subjected to a convolution operation with a kernel size of
and propagation again. One path performs a Max Pooling operation with a kernel size of
Semantic Feature Enhancement Model
module and a residual attention module, enabling the input feature maps to undergo feature extraction and fusion through these modules, thereby enhancing the semantic information features. The semantic feature extraction model proposed in this paper includes a context information fusion module and a residual attention module. These two feature extraction modules capture semantic information between ancient mural element targets across different dimensions, and ultimately obtain high-level semantic feature information of the element targets through Concat feature fusion.
Results
| Components | Detection Results | ||||
| Original Model | ✓ | ✓ | ✓ | ✓ |
|
| Adaptive Random Erasing Model |
|
✓ | ✓ | ✓ | |
| Lightweight Backbone Network | ✓ | ✓ | ✓ | ||
| Context Semantic Feature |
|
|
|||
| Residual Semantic Feature | ✓ | ||||
| mAP (Mean Average Precision) | 76.7% | 82.6% | 84.9% | 86.2% | 87.5% |
| FLOPs (Computational Cost) | 478 M | 478 M |
|
265 M | 268 M |
| Frames Per Second (FPS) | 21 | 21 | 45 | 39 | 35 |
| Method | Recall Rate | Precision Rate | F1-Score | mAP | Detection Time(s) |
| SAMNet
|
86.7% | 87.9% | 0.873 | 85.6% | 0.109 |
| SEConv-MSFE
|
83.5% | 84.1% | 0.838 | 83.2% | 0.097 |
| ADMNet
|
85.7% | 87.6% | 0.866 | 86.4% | 0.083 |
| SFSANet
|
85.8% | 88.3% | 0.870 | 86.7% | 0.186 |
| SCFNet
|
83.6% | 85.2% | 0.857 | 84.6% | 0.235 |
| SLMS-SSD
|
83.2% | 84.7% | 0.839 | 84.2% | 0.267 |
| Our method | 87.6% | 89.3% | 0.884 | 87.5% | 0.022 |
| Category | Number of samples | Recall Rate | Precision Rate | mAP | Detection Time (ms) |
| Male | 8109 | 91.3% | 93.6% | 91.8% | 1.98 |
| Female | 5008 | 90.2% | 91.5% | 89.7% | 2.13 |
| Beast | 3339 | 86.2% | 85.7% | 85.3% | 2.47 |
| Flower | 2862 | 76.8% | 79.3% | 78.9% | 2.26 |
| Bird | 2623 | 73.8% | 76.9% | 75.2% | 2.35 |
| Cloud | 1901 | 71.4% | 74.9% | 73.6% | 2.42 |
| Category | Adaptive Random Erasing | Lightweight Backbone Network | Semantic Feature Model | mAP | Detection Time |
| Male | ✓ | × | × | 88.6% | 2.67 ms |
| ✓ |
|
× | 89.4% | 1.72 ms | |
| × |
|
|
88.7% | 2.28 ms | |
| Female |
|
× | × | 85.2% | 3.52 ms |
| ✓ |
|
× | 87.2% | 1.86 ms | |
| × |
|
✓ | 86.2% | 2.78 ms | |
| Beast |
|
× | × | 82.6% | 3.96 ms |
| ✓ |
|
× | 83.8% | 2.08 ms | |
| × |
|
|
81.9% | 1.89 ms | |
| Flower | ✓ | × | × | 73.2% | 4.13 ms |
|
|
|
× | 72.8% | 1.64 ms | |
| × |
|
|
75.2% | 2.13 ms | |
| Bird |
|
× | × | 69.5% | 5.36 ms |
| ✓ |
|
× | 70.3% | 2.06 ms | |
| × |
|
|
73.2% | 2.28 ms | |
| Cloud |
|
× | × | 65.3% | 4.98 ms |
| ✓ |
|
× | 66.7% | 2.14 ms | |
| × |
|
✓ | 70.6% | 2.36 ms |
Conclusion and discussion
a vast number of samples, and a rich variety of labeled categories. To further enrich the number of mural image samples, we have established an adaptive random erasure augmentation model for mural images, capable of randomly generating erasure regions to simulate the damage that may exist in murals, thereby forcing the model to learn the ability to recognize and understand element targets through incomplete image information. Additionally, we have developed a lightweight multi-scale backbone network for feature extraction of mural elements. This model significantly reduces computational load while maintaining detection accuracy through a lightweight convolutional neural network and multi-scale feature fusion
methods. Furthermore, to enhance the semantic understanding of mural elements, we have introduced a semantic feature enhancement model for mural elements, which improves semantic understanding and increases detection accuracy through contextual information and residual attention mechanism. The ancient mural element object detection algorithm proposed in this paper achieves a recall rate of
Data availability
Received: 5 November 2024; Accepted: 4 January 2025;
Published online: 11 March 2025
References
- Jia, Y. et al. Multi-analytical investigations on a tomb mural painting of the Yuan dynasty in Chongqing, China. Vib. Spectrosc. 124, 103457 (2023).
- Dong, S. et al. Multi-Method Analysis of Painting Materials in Murals of the North Mosque (Linqing, China). Coatings 13, 1298 (2023).
- Guo, R. et al. Rare colour in medieval China: Case study of yellow pigments on tomb mural paintings at Xi’an, the capital of the Chinese Tang dynasty. Archaeometry 64, 759-778 (2022).
- Cao, J., Cui, H., Zhang, Z. & Zhao, A. Mural classification model based on high- and low-level vision fusion. Herit. Sci. 8, 121 (2020).
- Cao, J., Cui, H., Zhang, Q. & Zhang, Z. Ancient Mural Classification Method Based on Improved AlexNet Network. Stud. Conserv 65, 411-423 (2020).
- Chen Z., Rajamanickam L., Tian X. & Cao J. Application of Optimized Convolution Neural Network Model in Mural Segmentation. Appl Comput Intell Soft Comput. 2022, 5485117 (2022).
- Liu, W., Li, X. & Wu, F. Research on Restoration Algorithm of Tomb Murals Based on Sequential Similarity Detection. Sci Program. 2021, 6842353, (2021).
- Cheng, G. et al. Towards Large-Scale Small Object Detection: Survey and Benchmarks. IEEE Trans. Pattern Anal. Mach. Intell. 45, 13467-13488 (2023).
- Wu, L., Zhang, L., Shi, J., Zhang, Y. & Wan, J. Damage detection of grotto murals based on lightweight neural network. Comput Electr. Eng. 102, 108237 (2022).
- Sun, D., Zhang, J., Pan, G. & Zhan, R. Mural2Sketch: A Combined Line Drawing Generation Method for Ancient Mural Painting. 2018 IEEE International Conference on Multimedia and Expo (2018).
- Ni, X., Yu, Y., Zhao, H. & Li, Y. Mural Disease Detection Based on ConvUNeXt with Improved Up-Sampling and Feature Fusion. 2024 5th International Seminar on Artificial Intelligence, Networking and Information Technology (2024).
-
. et al. A comprehensive dataset for digital restoration of Dunhuang murals. Sci. Data 11, 955 (2024). - Cao, J., Yan, M., Jia, Y., Tian, X. & Zhang, Z. Application of a modified Inception-v3 model in the dynasty-based classification of ancient murals. EURASIP J. Adv. Signal Process 2021, 1-25 (2021).
- Cao, J., Jia, Y., Chen, H., Yan, M. & Chen, Z. Ancient mural classification methods based on a multichannel separable network. Herit. Sci. 9, 88 (2021).
- Huang, R., Feng, W., Fan, M., Guo, Q. & Sun, J. Learning multi-path CNN for mural deterioration detection. J. Ambient Intell. Hum. Comput 11, 3101-3108 (2017).
- Pan G., Sun D., Zhan R. & Zhang J. Mural Sketch Generation via Styleaware Convolutional Neural Network. CGI 2018: Proceedings of Computer Graphics International (2018).
- Yu, Z. et al. AGD-GAN: Adaptive Gradient-Guided and Depthsupervised generative adversarial networks for ancient mural sketch extraction. Expert Syst. Appl. 255, 124639 (2024).
- Wu, Z. et al. Enhanced Spatial Feature Learning for Weakly Supervised Object Detection. IEEE Trans. Neural Netw. Learn Syst. 35, 961-972 (2022).
- Wang, X., Song, N., Zhang, L. & Jiang, Y. Understanding subjects contained in Dunhuang mural images for deep semantic annotation. J. Doc. 74, 333-353 (2018).
- Zeng, Z., Sun, S., Sun, J., Yin, J. & Shen, Y. Constructing a mobile visual search framework for Dunhuang murals based on fine-tuned CNN and ontology semantic distance. Electron Libr. 40, 121-139 (2022).
- Wang, N., Wang, W., Hu, W., Fenster, A. & Li, S. Damage Sensitive and Original Restoration Driven Thanka Mural Inpainting. Pattern Recognition and Computer Vision. 142-154 (2020).
- Xu, Z. et al. MuralDiff: Diffusion for Ancient Murals Restoration on Large-Scale Pre-Training. IEEE Trans. Emerg. Top. Comput Intell. 8, 2169-2181 (2024).
- Wang, N., Wang, W., Hu, W., Fenster, A. & Li, S. Thanka Mural Inpainting Based on Multi-Scale Adaptive Partial Convolution and Stroke-Like Mask. IEEE Trans. Image Process 30, 3720-3733 (2021).
- Mei Y., Yang L., Wang M., Yu T. & Wu K. DunHuangStitch: Unsupervised Deep Image Stitching of Dunhuang Murals. IEEE Trans. Vis. Comput. Graph. Early Access (2024).
- Chen, Y., Fan, Z. & Liu, X. RPTK1: A New Thangka Data Set for Object Detection of Thangka Images. IEEE Access 9, 131696-131707 (2021).
- Dai, Y., Ma, F., Hu, W. & Zhang, F. SPGC: Shape-Prior-Based Generated Content Data Augmentation for Remote Sensing Object Detection. IEEE Trans. Geosci. Remote Sens. 62, 4504111 (2024).
- Dvornik, N., Mairal, J. & Schmid, C. On the Importance of Visual Context for Data Augmentation in Scene Understanding. IEEE Trans. Pattern Anal. Mach. Intell. 43, 2014-2028 (2021).
- Tang, Y. et al. AutoPedestrian: An Automatic Data Augmentation and Loss Function Search Scheme for Pedestrian Detection. IEEE Trans. Image Process. 30, 8483-8496 (2021).
- Chen, P. Y., Hsieh, J. W., Gochoo, M. & Chen, Y. S. Mixed Stage Partial Network and Background Data Augmentation for Surveillance Object Detection. IEEE Trans. Image Process 23, 23533-23547 (2022).
- Liu, Y., Zhang, X. Y., Bian, J. W., Zhang, L. & Cheng, M. M. SAMNet: Stereoscopically Attentive Multi-Scale Network for Lightweight Salient Object Detection. IEEE Trans. Image Process 30, 3804-3814 (2021).
- Zhou, Q. et al. Boundary-Guided Lightweight Semantic Segmentation With Multi-Scale Semantic Context. IEEE Trans. Multimed. 26, 7887-7900 (2024).
- Zhou, Q., Qu, Z. & Ju, F. A Lightweight Network for Crack Detection With Split Exchange Convolution and Multi-Scale Features Fusion. IEEE Trans. Intell. Veh. 8, 2296-2306 (2023).
- Yuan, Z. et al. A Lightweight Multi-Scale Crossmodal Text-Image Retrieval Method in Remote Sensing. IEEE Trans. Geosci. Remote Sens 60, 5612819 (2022).
- Li, Q., Sun, B. & Bhanu, B. Lite-FENet: Lightweight multi-scale feature enrichment network for few-shot segmentation. Knowl. Based Syst. 278, 110887 (2023).
- Dharejo, F. A. et al. SwinWave-SR: Multi-scale lightweight underwater image super-resolution. Inf. Fusion 103, 102127 (2024).
- Zhou, X., Shen, K. & Liu, Z. ADMNet: Attention-guided Densely Multiscale Network for Lightweight Salient Object Detection. IEEE Trans. Multimed. 26, 10828-10841 (2024).
- Wu, H. et al. PolypSeg+: A Lightweight Context-Aware Network for Real-Time Polyp Segmentation. IEEE Trans. Cybern. 53, 2610-2621 (2023).
- Gou, S. et al. Weakly-Supervised Semantic Feature Refinement Network for MMW Concealed Object Detection. IEEE Trans. Circuits Syst. Video Technol. 33, 1363-1373 (2023).
- Zhang, Y., Liu, T., Yu, P., Wang, S. & Tao, R. SFSANet: Multiscale Object Detection in Remote Sensing Image Based on Semantic Fusion and Scale Adaptability. IEEE Trans. Geosci. Remote Sens. 62, 4406410 (2024).
- Yan, C. et al. Semantics-Guided Contrastive Network for Zero-Shot Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 46, 1530-1544 (2024).
- Song, K., Sun, X., Ma, S. & Yan, Y. Surface Defect Detection of Aeroengine Blades Based on Cross-Layer Semantic Guidance. IEEE Trans. Instrum. Meas. 72, 2514411 (2023).
- Yue, C. et al. SCFNet: Semantic correction and focus network for remote sensing image object detection. Expert Syst. Appl. 224, 119980 (2023).
- Zhang X. & Chou C. H. Source-free Domain Adaptation for Video Object Detection Under Adverse Image Conditions. IEEE/CVF Conference on ComputerVision and Pattern Recognition Workshops. 5010-5019 (2024).
- Guo, Y. et al. DSCA: A Dual Semantic Correlation Alignment Method for domain adaptation object detection. Pattern Recognit. 150, 110329 (2024).
Acknowledgements
Author contributions
Competing interests
Additional information
http://www.nature.com/reprints
© The Author(s) 2025
School of Information Technology, Luoyang Normal University, Luoyang, China. College of Computer Science and Technology, Nanjing University of Aeronautics and Astronautics, Nanjing, China. □ e-mail: shenjiaquan_cv@163.com