DOI: https://doi.org/10.31181/smeor11202419
تاريخ النشر: 2024-09-01
طريقة SITW: نهج جديد لإعادة تحديد أوزان المعايير المتعددة في تحليل القرارات المعقدة
معلومات المقال
تاريخ المقال:
استلمت في شكل منقح 22 أغسطس 2024
تم القبول في 30 أغسطس 2024
متاح على الإنترنت 1 سبتمبر 2024
الكلمات المفتاحية:
الملخص
تحليل القرار متعدد المعايير (MCDA) يعالج مشاكل اتخاذ القرار المعقدة عبر مجالات متنوعة مثل اللوجستيات والإدارة والطب والاستدامة. توفر أدوات MCDA نهجًا منظمًا لتقييم القرارات التي تتضمن معايير متضاربة متعددة، مما يساعد صانعي القرار في التنقل عبر السيناريوهات المعقدة. يعد إشراك الخبراء أمرًا حيويًا لتحديد نماذج متعددة المعايير نظرًا للجوانب المتنوعة لمشاكل اتخاذ القرار. تُستخدم تقنيات مثل المقارنات الثنائية وتعيين أوزان المعايير بشكل شائع لدمج معرفة الخبراء في نماذج القرار. يسمح تعيين أوزان المعايير للخبراء بالإشارة إلى أهمية كل معيار؛ ومع ذلك، يمكن أن تنشأ مشكلات إذا فقدت معلمات النموذج أو أصبح الخبراء غير متاحين. للتخفيف من هذه المشكلات، يمكن استخدام تقنيات مثل الانتروبيا أو الانحراف المعياري لتحديد الأوزان دون الحاجة إلى مدخلات مباشرة من الخبراء. في هذا السياق، تستخدم طريقة التعرف العشوائي على الأوزان (SITW) عينات التقييم الموجودة لإعادة تحديد النماذج والحصول على أوزان تعكس تصنيفات نموذج مرجعي. تقارن هذه الدراسة بين الطرق المعتمدة على المعلومات (الانتروبيا، الانحراف المعياري) مع طريقة SITW في إعادة تحديد وظيفة TRI الطبية كنموذج مرجعي. يتم تقييم فعالية هذه الطرق باستخدام معامل الارتباط الموزون لسبيرمان عبر سيناريوهات وأعداد بديلة متنوعة. تشير النتائج إلى أن طريقة SITW تقدم نتائج أكثر أهمية من الطرق الأخرى في تحديد أوزان المعايير المتعددة من خلال الاستفادة من البدائل التي تم تقييمها سابقًا. يمكن أن تستكشف الأبحاث المستقبلية نهجًا أوسع وسيناريوهات عدم اليقين لضمان دعم شامل في اتخاذ القرار في السياقات المعقدة.
1. المقدمة
2. المقدمات
2.1 تقنية تفضيل الطلب بناءً على التشابه مع الحل المثالي
كما يلي، تشمل عدة خطوات رئيسية:
الخطوة 1. قم بتطبيع مصفوفة القرار باستخدام تطبيع الحد الأدنى والحد الأقصى. يتم تطبيع قيم معايير نوع الفائدة باستخدام المعادلة (1)، بينما يتم تطبيع قيم معايير نوع التكلفة باستخدام المعادلة (2).
أين
الخطوة 4. حساب المسافات الإيجابية والسلبية باستخدام
2.2 أوزان الإنتروبيا
2.3 أوزان الانحراف المعياري
الخطوة 2. اشتق الأوزان بناءً على قيم مقياس الانحراف المعياري باستخدام المعادلة (11).
2.4 التعرف العشوائي على الأوزان
الخطوة 1. اختر مجموعة بيانات. يجب أن تحتوي مجموعة البيانات على متجهات المعايير (
الخطوة 2. اختر طريقة تحسين عشوائية. في هذه الخطوة، اختر طريقة عشوائية لحل مشكلة التحسين وحدد معلماتها. في هذه الورقة، تم اختيار تحسين سرب الجسيمات (PSO) كطريقة تحسين عشوائية، ويمكن تقديم خوارزميتها على النحو التالي:
Algorithm 1 Particle Swarm Optimization (PSO)
Input: $f, N, D,[a, b]$, max_iterations $, w, c_{1}, c_{2}$
Initialize $X, V, P, P_{text {value }}, G, G_{text {value }}$
for iteration $leftarrow 1$ to max_iterations do
for each particle $i$ do
Update velocity and position
Clip position to within bounds
Evaluate objective function
if $f_{i}>P_{text {value }}[i]$ then
Update personal best
end if
end for
Update global best
if convergence_criteria_met() then
break
end if
end for
Output: $G, G_{text {value }}$
Algorithm 2 Fitness Function
procedure Fitness(solutions):
solutions $leftarrow$ solutions/sum(solutions)
preference $leftarrow$ base $(C$, solutions,$T)$
return rw(base.rank(preference), $R$ )
end procedure
2.5 معامل ارتباط سبيرمان الموزون
3. دراسة الحالة
تم استخدام طريقة MCDA الكلاسيكية، المعروفة باسم TOPSIS، لإنشاء تصنيفات للبدائل المحددة مسبقًا وأوزان المعايير. تم الحصول على طرق MCDA المطبقة في هذه الدراسة من مكتبة pymcdm [19]. تم استخدام معامل الارتباط الموزون لسبيرمان كمقياس لتقييم دقة ملاءمة نماذج MCDA. كانت دالة المعايير المستخدمة في هذه الدراسة هي مؤشر خطر الانسداد القلبي (TRI)، المصمم لتقييم المرضى الذين يعانون من قصور التاجي الحاد. كانت دالة TRI بمثابة معيار لتقييم فعالية أساليب اختيار الأوزان المختلفة. التعبير عن دالة TRI هو كما يلي:
مثال على مصفوفة القرار لمشكلة تقييم المرضى الذين يعانون من قصور التاجي الحاد
|
|
|
|
|
|
|
|
|
|
|
|
|
|
98 | ٨٠ | ٨٠ | 72 | 84 | 77 | 71 | 76 | 79 | 94 |
|
|
٥٨ | ٥٤ | ٥٨ | 43 | ٤٤ | ٥٦ | ٥٩ | 50 | ٥٤ | 52 |
|
|
151 | 131 | 95 | 146 | 91 | 164 | 162 | 171 | 159 | ١٠٥ |
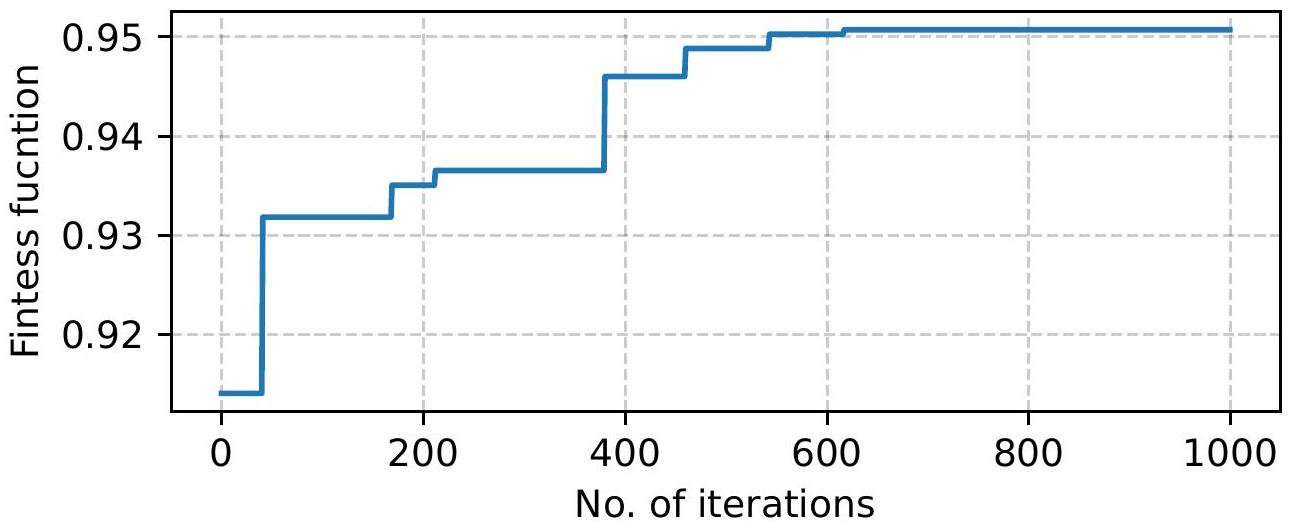
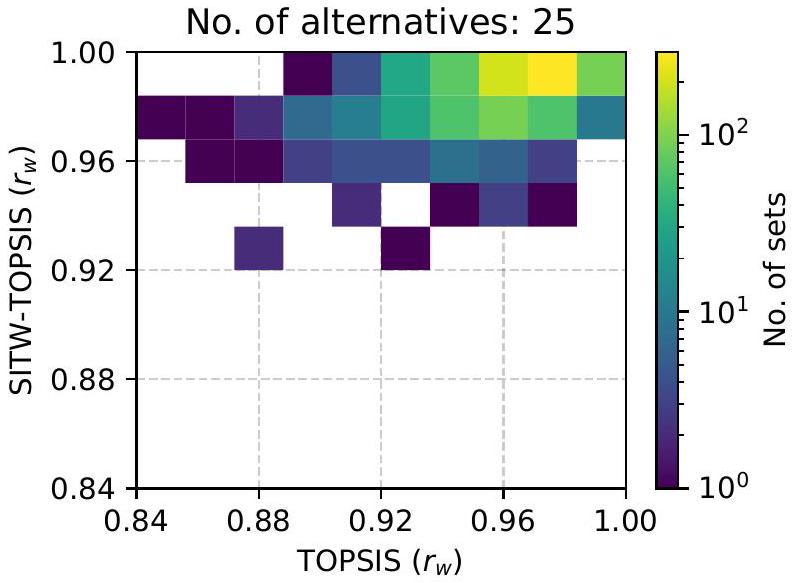
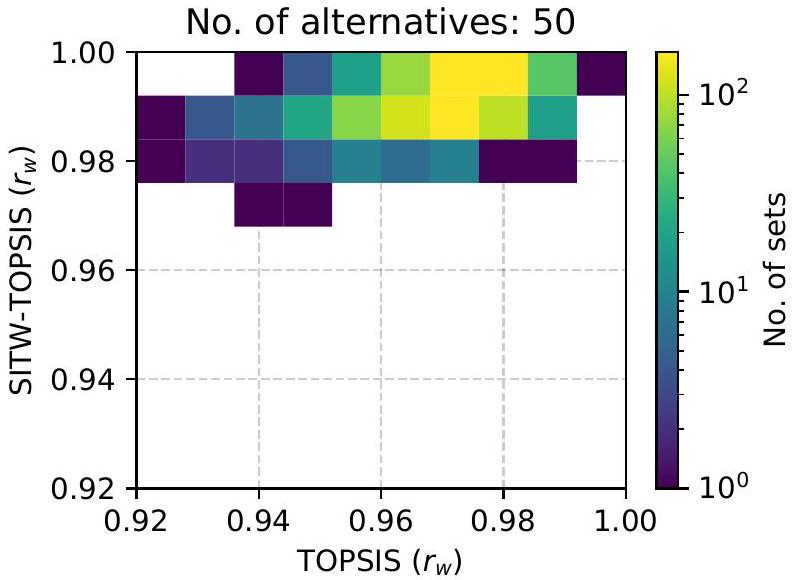
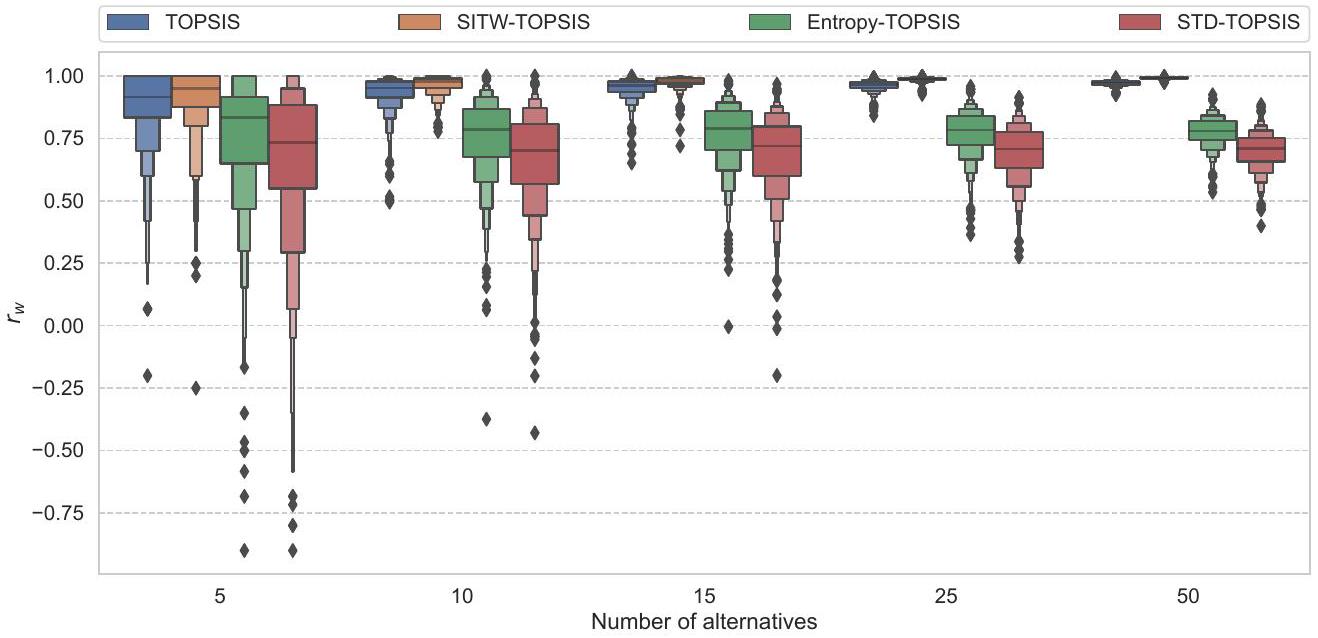
إحصائيات مقارنة التصنيفات من أساليب TOPSIS باستخدام دالة TRI
| طريقة | عدد البدائل | معنى | الأمراض المنقولة جنسياً | من | ماكس |
| إنتروبي-توبسيس | ٥ | 0.75163 | 0.26156 | -0.90000 | 1.00000 |
| 10 | 0.75526 | 0.15948 | -0.37411 | 1.00000 | |
| 15 | 0.76637 | 0.12638 | -0.00424 | 0.98170 | |
| ٢٥ | 0.77166 | 0.09119 | 0.36429 | 0.95831 | |
| 50 | 0.77589 | 0.06017 | 0.53423 | 0.92468 | |
| SITW-TOPSIS | ٥ | 0.90695 | 0.13900 | -0.25000 | 1.00000 |
| 10 | 0.96456 | 0.03794 | 0.77741 | 1.00000 | |
| 15 | 0.97658 | 0.02266 | 0.71942 | 1.00000 | |
| ٢٥ | 0.98586 | 0.00888 | 0.92583 | 0.99864 | |
| 50 | 0.99112 | 0.00336 | 0.97325 | 0.99773 | |
| STD-TOPSIS | ٥ | 0.65622 | 0.32171 | -0.90000 | 1.00000 |
| 10 | 0.66751 | 0.19499 | -0.42920 | 1.00000 | |
| 15 | 0.68753 | 0.15510 | -0.19933 | 0.96719 | |
| ٢٥ | 0.69324 | 0.11098 | 0.27544 | 0.91420 | |
| 50 | 0.70046 | 0.07538 | 0.39946 | 0.88524 | |
| توبسيس | ٥ | 0.87658 | 0.16781 | -0.20000 | 1.00000 |
| 10 | 0.93403 | 0.06500 | 0.49421 | 1.00000 | |
| 15 | 0.95054 | 0.03969 | 0.65134 | 1.00000 | |
| ٢٥ | 0.96220 | 0.02055 | 0.84139 | 0.99388 | |
| 50 | 0.97057 | 0.01021 | 0.92437 | 0.99331 |
4. الاستنتاجات
شكر وتقدير
تعارض المصالح
References
[2] Longaray, A., Ensslin, L., Ensslin, S., Alves, G., Dutra, A., & Munhoz, P. (2018). Using MCDA to evaluate the performance of the logistics process in public hospitals: the case of a Brazilian teaching hospital. International Transactions in Operational Research, 25(1), 133-156. https: //doi.org/10.1111/itor. 12387
[3] Uhde, B., Andreas Hahn, W., Griess, V. C., & Knoke, T. (2015). Hybrid MCDA methods to integrate multiple ecosystem services in forest management planning: a critical review. Environmental management, 56, 373-388. https://doi.org/10.1007/s00267-015-0503-3
[4] Wątróbski, J., & Jankowski, J. (2016). Guideline for MCDA method selection in production management area. New Frontiers in Information and Production Systems Modelling and Analysis: Incentive Mechanisms, Competence Management, Knowledge-based Production, 119-138. https://doi.org/10.1007/978-3-319-23338-3_6
[5] Angelis, A., & Kanavos, P. (2017). Multiple criteria decision analysis (MCDA) for evaluating new medicines in health technology assessment and beyond: the advance value framework. Social Science & Medicine, 188, 137-156. https://doi.org/10.1016/j.socscimed.2017.06.024
[6] Badia, X., Chugani, D., Abad, M. R., Arias, P., Guillén-Navarro, E., Jarque, I., Posada, M., Vitoria, I., & Poveda, J. L. (2019). Development and validation of an MCDA framework for evaluation and decision-making of orphan drugs in Spain. Expert Opinion on Orphan Drugs, 7(7-8), 363372. https://doi.org/10.1080/21678707.2019.1652163
[7] Deshpande, P. C., Skaar, C., Brattebø, H., & Fet, A. M. (2020). Multi-criteria decision analysis (MCDA) method for assessing the sustainability of end-of-life alternatives for waste plastics: A case study of Norway. Science of the total environment, 719, 137353. https://doi.org/10.1016/ j.scitotenv.2020.137353
[8] Puška, A., Stević, Ž., & Pamučar, D. (2022). Evaluation and selection of healthcare waste incinerators using extended sustainability criteria and multi-criteria analysis methods. Environment, Development and Sustainability, 1-31. https://doi.org/10.1007/s10668-021-01902-2
[9] Colapinto, C., Jayaraman, R., Ben Abdelaziz, F., & La Torre, D. (2020). Environmental sustainability and multifaceted development: multi-criteria decision models with applications. Annals of Operations Research, 293(2), 405-432. https://doi.org/10.1007/s10479-019-03403-y
[10] Lahdelma, R., Miettinen, K., & Salminen, P. (2005). Reference point approach for multiple decision makers. European Journal of Operational Research, 164(3), 785-791. https://doi.org/10. 1016/j.ejor.2004.01.030
[11] Hatefi, S., & Torabi, S. A. (2010). A common weight MCDA-DEA approach to construct composite indicators. Ecological Economics, 70(1), 114-120. https://doi.org/10.1016/j.ecolecon.2010. 08.014
[12] Zborowski, M., & Chmielarz, W. (2023). Sensitivity analysis of the criteria weights used in selected MCDA methods in the multi-criteria assessment of banking services in Poland in 2022. 2023 18th Conference on Computer Science and Intelligence Systems (FedCSIS), 1217-1222. https: //doi.org/10.15439/2023F3745
[13] Martin, T. G., Burgman, M. A., Fidler, F., Kuhnert, P. M., Low-Choy, S., McBride, M., & Mengersen, K. (2012). Eliciting expert knowledge in conservation science. Conservation Biology, 26(1), 2938. https://doi.org/10.1111/j.1523-1739.2011.01806.x
[14] Paradowski, B., Shekhovtsov, A., Bączkiewicz, A., Kizielewicz, B., & Sałabun, W. (2021). Similarity Analysis of Methods for Objective Determination of Weights in Multi-Criteria Decision Support Systems. Symmetry, 13(10), 1874. https://doi.org/10.3390/sym13101874
[15] Kizielewicz, B., Paradowski, B., Więckowski, J., & Sałabun, W. (2022). Identification of weights in multi-cteria decision problems based on stochastic optimization. AMCIS 2022 Proceedings, (17). https://aisel.aisnet.org/amcis2O22/sig_odis/sig_odis/17
[16] Yoon, K. P., & Kim, W. K. (2017). The behavioral TOPSIS. Expert Systems with Applications, 89, 266-272. https://doi.org/10.1016/j.eswa.2017.07.045
[17] Kizielewicz, B., Więckowski, J., & Wątrobski, J. (2021). A study of different distance metrics in the TOPSIS method. Intelligent Decision Technologies: Proceedings of the 13th KES-IDT 2021 Conference, 275-284. https://doi.org/10.1007/978-981-16-2765-1_23
[18] Dancelli, L., Manisera, M., & Vezzoli, M. (2013). On two classes of Weighted Rank Correlation measures deriving from the Spearman’s
[19] Kizielewicz, B., Shekhovtsov, A., & Sałabun, W. (2023). pymcdm-The universal library for solving multi-criteria decision-making problems. SoftwareX, 22, 101368. https://doi.org/10.1016/j. softx.2023.101368
[20] Sałabun, W., & Piegat, A. (2017). Comparative analysis of MCDM methods for the assessment of mortality in patients with acute coronary syndrome. Artificial Intelligence Review, 48, 557571. https://doi.org/10.1007/s10462-016-9511-9
[21] Van Thieu, N., & Mirjalili, S. (2023). MEALPY: An open-source library for latest meta-heuristic algorithms in Python. Journal of Systems Architecture, 139, 102871. https://doi.org/10.1016/j. sysarc.2023.102871
- *Wojciech Sałabun.
E-mail address: w.salabun@il-pib.pl
DOI: https://doi.org/10.31181/smeor11202419
Publication Date: 2024-09-01
SITW method: a new approach to re-identifying multi-criteria weights in complex decision analysis
ARTICLE INFO
Article history:
Received in revised form22 August 2024
Accepted 30 August 2024
Available online 1 September 2024
Keywords:
Abstract
Multi-Criteria Decision Analysis (MCDA) addresses complex decision-making problems across various fields such as logistics, management, medicine, and sustainability. MCDA tools provide a structured approach to evaluating decisions with multiple conflicting criteria, assisting decision-makers in navigating intricate scenarios. Engaging experts is crucial for identifying multi-criteria models due to the diverse aspects of decision-making problems. Techniques such as pairwise comparisons and criterion weight assignment are commonly used to incorporate expert knowledge into decision models. Criterion weight assignment allows experts to indicate the importance of each criterion; however, issues can arise if model parameters are lost or experts become unavailable. To mitigate these issues, techniques like entropy or standard deviation can determine weights without direct expert input. In this context, the Stochastic Identification of Weights (SITW) method utilizes existing assessment samples to re-identify models and obtain weights that replicate the rankings of a reference model. This study compares information-based methods (Entropy, STD) with the SITW method in re-identifying the TRI medical function as a benchmark. The effectiveness of these methods is evaluated using Spearman’s weighted correlation coefficient across various scenarios and alternative numbers. Results indicate that the SITW method provides more significant results than other methods in identifying multicriteria weights by leveraging previously evaluated alternatives. Future research could explore broader approaches and uncertainty scenarios to ensure comprehensive decision support in complex contexts.
1. Introduction
2. Preliminaries
2.1 Technique for Order Preference by Similarity to an Ideal Solution
as follows, encompassing several key steps:
Step 1. Normalize the decision matrix by using min-max normalization. The values of benefit type criteria are normalized using the Eq. (1), while the values of cost type criteria are normalized using the Eq. (2).
where
Step 4. Calculation of the Positive and Negative Distances using the
2.2 Entropy weights
2.3 Standard deviation weights
Step 2. Derive the weights based on the values of the standard deviation measure with Eq. (11).
2.4 Stochastic IdenTification of Weights
Step 1. Select a dataset. The dataset should contain criteria vectors (
Step 2. Select a stochastic optimization method. In this step, choose a stochastic method for solving the optimization problem and select its parameters. In this paper, Particle swarm optimization (PSO) was selected as the stochastic optimization method, whose algorithm can be presented as follows:
Algorithm 1 Particle Swarm Optimization (PSO)
Input: $f, N, D,[a, b]$, max_iterations $, w, c_{1}, c_{2}$
Initialize $X, V, P, P_{text {value }}, G, G_{text {value }}$
for iteration $leftarrow 1$ to max_iterations do
for each particle $i$ do
Update velocity and position
Clip position to within bounds
Evaluate objective function
if $f_{i}>P_{text {value }}[i]$ then
Update personal best
end if
end for
Update global best
if convergence_criteria_met() then
break
end if
end for
Output: $G, G_{text {value }}$
Algorithm 2 Fitness Function
procedure Fitness(solutions):
solutions $leftarrow$ solutions/sum(solutions)
preference $leftarrow$ base $(C$, solutions,$T)$
return rw(base.rank(preference), $R$ )
end procedure
2.5 Weighted Spearman’s correlation coefficient
3. Study case
classic MCDA method, known as TOPSIS, was employed to generate rankings for predefined alternatives and criterion weights. The MCDA methods implemented in this investigation were sourced from the pymcdm library [19]. Spearman’s weighted correlation coefficient served as a metric to assess the fitting accuracy of the MCDA models. The benchmark function utilized in this study was the Thrombolysis In Myocardial Infarction Risk Index (TRI), designed to evaluate patients with acute coronary insufficiency. The TRI function served as a benchmark to evaluate the effectiveness of various weight selection approaches. The expression for the TRI function is as follows:
Example decision matrix for the problem of evaluating patients suffering from acute coronary insufficiency
|
|
|
|
|
|
|
|
|
|
|
|
|
|
98 | 80 | 80 | 72 | 84 | 77 | 71 | 76 | 79 | 94 |
|
|
58 | 54 | 58 | 43 | 44 | 56 | 59 | 50 | 54 | 52 |
|
|
151 | 131 | 95 | 146 | 91 | 164 | 162 | 171 | 159 | 105 |
Statistics of comparison of rankings from TOPSIS approaches with TRI function using
| Method | No. of. alts. | Mean | STD | Min | Max |
| Entropy-TOPSIS | 5 | 0.75163 | 0.26156 | -0.90000 | 1.00000 |
| 10 | 0.75526 | 0.15948 | -0.37411 | 1.00000 | |
| 15 | 0.76637 | 0.12638 | -0.00424 | 0.98170 | |
| 25 | 0.77166 | 0.09119 | 0.36429 | 0.95831 | |
| 50 | 0.77589 | 0.06017 | 0.53423 | 0.92468 | |
| SITW-TOPSIS | 5 | 0.90695 | 0.13900 | -0.25000 | 1.00000 |
| 10 | 0.96456 | 0.03794 | 0.77741 | 1.00000 | |
| 15 | 0.97658 | 0.02266 | 0.71942 | 1.00000 | |
| 25 | 0.98586 | 0.00888 | 0.92583 | 0.99864 | |
| 50 | 0.99112 | 0.00336 | 0.97325 | 0.99773 | |
| STD-TOPSIS | 5 | 0.65622 | 0.32171 | -0.90000 | 1.00000 |
| 10 | 0.66751 | 0.19499 | -0.42920 | 1.00000 | |
| 15 | 0.68753 | 0.15510 | -0.19933 | 0.96719 | |
| 25 | 0.69324 | 0.11098 | 0.27544 | 0.91420 | |
| 50 | 0.70046 | 0.07538 | 0.39946 | 0.88524 | |
| TOPSIS | 5 | 0.87658 | 0.16781 | -0.20000 | 1.00000 |
| 10 | 0.93403 | 0.06500 | 0.49421 | 1.00000 | |
| 15 | 0.95054 | 0.03969 | 0.65134 | 1.00000 | |
| 25 | 0.96220 | 0.02055 | 0.84139 | 0.99388 | |
| 50 | 0.97057 | 0.01021 | 0.92437 | 0.99331 |
4. Conclusions
Acknowledgement
Conflicts of Interest
References
[2] Longaray, A., Ensslin, L., Ensslin, S., Alves, G., Dutra, A., & Munhoz, P. (2018). Using MCDA to evaluate the performance of the logistics process in public hospitals: the case of a Brazilian teaching hospital. International Transactions in Operational Research, 25(1), 133-156. https: //doi.org/10.1111/itor. 12387
[3] Uhde, B., Andreas Hahn, W., Griess, V. C., & Knoke, T. (2015). Hybrid MCDA methods to integrate multiple ecosystem services in forest management planning: a critical review. Environmental management, 56, 373-388. https://doi.org/10.1007/s00267-015-0503-3
[4] Wątróbski, J., & Jankowski, J. (2016). Guideline for MCDA method selection in production management area. New Frontiers in Information and Production Systems Modelling and Analysis: Incentive Mechanisms, Competence Management, Knowledge-based Production, 119-138. https://doi.org/10.1007/978-3-319-23338-3_6
[5] Angelis, A., & Kanavos, P. (2017). Multiple criteria decision analysis (MCDA) for evaluating new medicines in health technology assessment and beyond: the advance value framework. Social Science & Medicine, 188, 137-156. https://doi.org/10.1016/j.socscimed.2017.06.024
[6] Badia, X., Chugani, D., Abad, M. R., Arias, P., Guillén-Navarro, E., Jarque, I., Posada, M., Vitoria, I., & Poveda, J. L. (2019). Development and validation of an MCDA framework for evaluation and decision-making of orphan drugs in Spain. Expert Opinion on Orphan Drugs, 7(7-8), 363372. https://doi.org/10.1080/21678707.2019.1652163
[7] Deshpande, P. C., Skaar, C., Brattebø, H., & Fet, A. M. (2020). Multi-criteria decision analysis (MCDA) method for assessing the sustainability of end-of-life alternatives for waste plastics: A case study of Norway. Science of the total environment, 719, 137353. https://doi.org/10.1016/ j.scitotenv.2020.137353
[8] Puška, A., Stević, Ž., & Pamučar, D. (2022). Evaluation and selection of healthcare waste incinerators using extended sustainability criteria and multi-criteria analysis methods. Environment, Development and Sustainability, 1-31. https://doi.org/10.1007/s10668-021-01902-2
[9] Colapinto, C., Jayaraman, R., Ben Abdelaziz, F., & La Torre, D. (2020). Environmental sustainability and multifaceted development: multi-criteria decision models with applications. Annals of Operations Research, 293(2), 405-432. https://doi.org/10.1007/s10479-019-03403-y
[10] Lahdelma, R., Miettinen, K., & Salminen, P. (2005). Reference point approach for multiple decision makers. European Journal of Operational Research, 164(3), 785-791. https://doi.org/10. 1016/j.ejor.2004.01.030
[11] Hatefi, S., & Torabi, S. A. (2010). A common weight MCDA-DEA approach to construct composite indicators. Ecological Economics, 70(1), 114-120. https://doi.org/10.1016/j.ecolecon.2010. 08.014
[12] Zborowski, M., & Chmielarz, W. (2023). Sensitivity analysis of the criteria weights used in selected MCDA methods in the multi-criteria assessment of banking services in Poland in 2022. 2023 18th Conference on Computer Science and Intelligence Systems (FedCSIS), 1217-1222. https: //doi.org/10.15439/2023F3745
[13] Martin, T. G., Burgman, M. A., Fidler, F., Kuhnert, P. M., Low-Choy, S., McBride, M., & Mengersen, K. (2012). Eliciting expert knowledge in conservation science. Conservation Biology, 26(1), 2938. https://doi.org/10.1111/j.1523-1739.2011.01806.x
[14] Paradowski, B., Shekhovtsov, A., Bączkiewicz, A., Kizielewicz, B., & Sałabun, W. (2021). Similarity Analysis of Methods for Objective Determination of Weights in Multi-Criteria Decision Support Systems. Symmetry, 13(10), 1874. https://doi.org/10.3390/sym13101874
[15] Kizielewicz, B., Paradowski, B., Więckowski, J., & Sałabun, W. (2022). Identification of weights in multi-cteria decision problems based on stochastic optimization. AMCIS 2022 Proceedings, (17). https://aisel.aisnet.org/amcis2O22/sig_odis/sig_odis/17
[16] Yoon, K. P., & Kim, W. K. (2017). The behavioral TOPSIS. Expert Systems with Applications, 89, 266-272. https://doi.org/10.1016/j.eswa.2017.07.045
[17] Kizielewicz, B., Więckowski, J., & Wątrobski, J. (2021). A study of different distance metrics in the TOPSIS method. Intelligent Decision Technologies: Proceedings of the 13th KES-IDT 2021 Conference, 275-284. https://doi.org/10.1007/978-981-16-2765-1_23
[18] Dancelli, L., Manisera, M., & Vezzoli, M. (2013). On two classes of Weighted Rank Correlation measures deriving from the Spearman’s
[19] Kizielewicz, B., Shekhovtsov, A., & Sałabun, W. (2023). pymcdm-The universal library for solving multi-criteria decision-making problems. SoftwareX, 22, 101368. https://doi.org/10.1016/j. softx.2023.101368
[20] Sałabun, W., & Piegat, A. (2017). Comparative analysis of MCDM methods for the assessment of mortality in patients with acute coronary syndrome. Artificial Intelligence Review, 48, 557571. https://doi.org/10.1007/s10462-016-9511-9
[21] Van Thieu, N., & Mirjalili, S. (2023). MEALPY: An open-source library for latest meta-heuristic algorithms in Python. Journal of Systems Architecture, 139, 102871. https://doi.org/10.1016/j. sysarc.2023.102871
- *Wojciech Sałabun.
E-mail address: w.salabun@il-pib.pl