مجموعة بيانات وصفية الحد الأدنى (MNMS) لإعادة استخدام البيانات غير السريرية في vivo لأغراض البحث biomedical A minimal metadata set (MNMS) to repurpose nonclinical in vivo data for biomedical research
على الرغم من أن البحث الطبي الحيوي يشهد انفجارًا في البيانات، فإن تراكم كميات هائلة من البيانات وحده لا يضمن تحقيق الهدف الأساسي للعلم: البناء على المعرفة الموجودة. البيانات التي تم جمعها والتي تفتقر إلى بيانات وصفية مناسبة لا يمكن استجوابها أو دمجها بالكامل في مشاريع بحثية جديدة، مما يؤدي إلى إهدار الموارد وفقدان الفرص لإعادة استخدام البيانات. هذه المشكلة تكون أكثر حدة في الأبحاث التي تستخدم الحيوانات، حيث تكون المخاوف بشأن قابلية تكرار البيانات وضمان رفاهية الحيوانات في غاية الأهمية. هنا، لمعالجة هذه المشكلة، نقترح مجموعة بيانات وصفية دنيا (MNMS) مصممة لتمكين إعادة استخدام بيانات in vivo. تتماشى MNMS مع إرشادات موثقة موجودة للإبلاغ عن بيانات in vivo (ARRIVE 2.0) وتساهم في جعل بيانات in vivo متوافقة مع مبادئ FAIR. يتم تقديم سيناريوهات حيث يجب تنفيذ MNMS في بيئات بحثية متنوعة، مع تسليط الضوء على الفرص والتحديات لإعادة استخدام البيانات على مقاييس مختلفة. نختتم بـ ‘دعوة للعمل’ إلى أصحاب المصلحة الرئيسيين في البحث الطبي الحيوي لتبني وتطبيق MNMS لتسريع كل من تقدم المعرفة وتحسين رفاهية الحيوانات.
يشهد البحث الطبي الحيوي انفجارًا في البيانات، مدفوعًا بالتطورات التكنولوجية الأخيرة التي سرعت من قدرات إنتاج البيانات. يتم استخدام أساليب متعددة الأوميات الغنية بالبيانات وقياسات وظيفية عالية الدقة، مثل التصوير متعدد الأنماط أو تسجيلات الفسيولوجيا والسلوك، بشكل روتيني عبر كامل عمر الكائنات النموذجية في حالات الصحة والمرض.
من ناحية، تقدم هذه الحقبة الجديدة فرصة كبيرة لتسريع الفهم العلمي. من ناحية أخرى، فإن مجرد جمع كميات هائلة من البيانات ليس كافياً لضمان التقدم العلمي إذا لم يكن بالإمكان استجواب هذه البيانات وإعادة دمجها في دورة البحث. إحدى عواقب محدودية مشاركة البيانات وسوء الشفافية قد تكون الحاجة إلى تكرار نتائج سابقة، وغالباً دون نجاح.. تؤدي هذه الممارسات الشائعة إلى هدر كبير في الموارد وفرص ضائعة لإعادة استخدام البيانات.
هذا الموضوع ذو صلة خاصة بالبحوث التي تت涉及 الحيوانات. إن الفشل في تكرار النتائج والفرص المفقودة لإعادة استخدام البيانات يؤدي بلا شك إلى استخدام الحيوانات الذي يوفر القليل أو لا شيء من التقدم العلمي الجديد ويشكل مصدرًا للقلق الأخلاقي. وبالتالي، هناك حاجة ملحة لتشجيع وتسهيل إعادة استخدام البيانات غير السريرية في الأبحاث الطبية الحيوية.
في أوروبا وأمريكا الشمالية، تركز التشريعات المتعلقة بتجارب الحيوانات في البحث البيولوجي الطبي بشكل كبير على تنفيذ مبادئ 3Rs (انظر التعريف في المربع 1)، والتي تشمل مفاهيم الاستبدال والتقليل والتحسين.. الهدف من 3Rs هو ضمان أن تجارب الحيوانات تحقق أعلى مستوى من الرفاهية مع تقليل العبء من خلال بروتوكولات وإجراءات بحث حيواني مصممة ومراجعة بشكل جيد. ومع ذلك، على الرغم من هذا الإطار التنظيمي القوي، فإنه يتضح بشكل متزايد أن التوجيهات التنظيمية التي تحمي
الصندوق 1 | تعريفات المصطلحات الرئيسية
واجهة برمجة التطبيقات: اختصار يعني واجهة برمجة التطبيقات. واجهة برمجة التطبيقات هي مجموعة من البروتوكولات للتواصل ونقل البيانات بشكل آلي بين تطبيقين حاسوبيين.
الوصول: تم تطوير إرشادات ARRIVE (البحث الحيواني: الإبلاغ عن التجارب الحية) في الأصل في عام 2010 لتحسين الإبلاغ عن الأبحاث الحيوانية. تتكون من قائمة مرجعية للمعلومات التي يجب تضمينها في المنشورات التي تصف التجارب الحية لتمكين الآخرين من فحص العمل بشكل كافٍ، وتقييم دقته المنهجية، وإعادة إنتاج الأساليب والنتائج..
مستودع البيانات: مستودع البيانات هو هيكل يتكون من قاعدة بيانات واحدة أو أكثر تحتوي على بيانات لغرض التحليل. تُستخدم مستودعات البيانات في الأعمال لتوفير مصدر مركزي للمعلومات. قد يُشار إلى مستودع البيانات أيضًا بمكتبة البيانات أو أرشيف البيانات.
كائن رقمي: الكائن الرقمي هو أي نوع من البيانات الموجودة في صيغة رقمية. يُعتبر التمثيل الرقمي لكائن مادي أو عملية أيضًا كائنًا رقميًا.
FAIR: اختصار يعني قابلية الاكتشاف، الوصول، التشغيل البيني، وإعادة الاستخدام.
تحليل ميتا: تحليل الميتا هو تقنية إحصائية تجمع بين النتائج من عدة دراسات علمية مستقلة. في السياق السريري/ما قبل السريري، يُستخدم تحليل الميتا غالبًا لتقييم فعالية التدخلات من خلال دمج البيانات من عدة تجارب عشوائية.
البيانات الوصفية: البيانات الوصفية هي بيانات عن البيانات (أي، معلومات عن البيانات)، وتحتوي على معلومات وصفية وإدارية حول مجموعة البيانات. تشمل الأمثلة مالك المشروع، العنوان والمعرفات الدائمة، بالإضافة إلى معلومات هيكلية حول كيفية إنشاء مجموعة البيانات. علاوة على ذلك، فإن قابلية قراءة البيانات الوصفية بواسطة الآلات هي أولوية عالية.
OBI: اختصار يعني أنطولوجيا التحقيقات الطبية الحيوية. معيار مجتمعي لدمج البيانات العلمية. يساعد OBI في التواصل بوضوح حول التحقيقات العلمية من خلال تعريف أكثر من 2500 مصطلح للاختبارات والأجهزة والأهداف والمزيد. معايير رفاهية الحيوانات وحدها ليست كافية لضمان تقليل الأبحاث التي تتضمن الحيوانات..
لزيادة الوعي بمفاهيم الصلاحية والصلابة وإمكانية التكرار (انظر التعريف في الإطار 1)، تم توسيع مبادئ 3Rs لتشمل الاستخدام المسؤول لأبحاث الحيوانات.تعتبر الممارسات البحثية المفتوحة، ومشاركة البيانات، ومبادئ FAIR (قابلة للاكتشاف، وقابلة للوصول، وقابلة للتشغيل البيني، وقابلة لإعادة الاستخدام؛ انظر أيضًا التعريف في المربع 1) حلولًا تكاملية تم اقتراحها لزيادة الشفافية وقابلية التكرار.تم إنشاء حلول محددة للمجال لمساعدة الباحثين في إنشاء مجموعات بيانات من تجاربهم على الحيوانات. تشمل الأمثلة بيانات مفتوحة لمشاكل إصابة الحبل الشوكي وإصابة الدماغ الرضحية.، وإرشادات حول ‘المعلومات الأساسية عن تجارب سمية الحيوانات’ (MIATE)في الوقت نفسه، فإن الإرشادات غير المحددة المجال وغير الإلزامية PREPAREوَتَصِل (انظر التعريف في المربع 1) تم اقتراحها أيضًا كقوائم مرجعية للعلماء عند التخطيط والإبلاغ عن التجارب الحية، على التوالي.
الأنطولوجيا: الأنطولوجيا هي نظام من المصطلحات المحددة بدقة، مرتبطة بعلاقات منطقية ومصممة للاستخدام من قبل البشر والحواسيب على حد سواء.
3Rs: اختصار يعني الاستبدال، والتقليل، والتحسين. هذه هي المبادئ التوجيهية لأبحاث الحيوانات..
البيانات الخام: المعروفة أيضًا بالبيانات الأولية أو بيانات المصدر، هي بيانات (مثل الأرقام، قراءات الأدوات، الأرقام وما إلى ذلك) تم جمعها من مصدر لم تخضع لـ (1) المعالجة، (2) ‘تنظيف’ من قبل الباحثين لإزالة، على سبيل المثال، القيم الشاذة وأخطاء قراءة الأدوات الواضحة، (3) أي تحليل (مثل تحديد جوانب النزعة المركزية مثل المتوسط أو الوسيط) أو (4) أي تلاعب آخر بواسطة برنامج برمجي أو باحث أو محلل أو فني بشري.
لاحظ أن البيانات الخام توفر قدرًا كبيرًا من المرونة من حيث إعادة استخدام البيانات، نظرًا لأنه يمكن طرح أسئلة مختلفة من مجموعة البيانات الأصلية قد لا تكون ممكنة بعد المعالجة. ومع ذلك، يمكن أن تكون البيانات الخام صعبة الإدارة، وغالبًا ما يكون من الضروري إجراء بعض المعالجة المسبقة لتمكين تفسيرها بشكل مفيد. وبالتالي، تشير ‘البيانات الأولية’ إلى البيانات المعالجة بشكل طفيف التي توفر أكبر قدر من المرونة والفائدة للتحليل الإضافي.
إمكانية التكرار: هنا نشير إلى إمكانية التكرار بشكل عام، لتشمل كل من التعريف الأكثر صرامة لإمكانية التكرار كـ ‘إمكانية تكرار التحليل’، التي تشير إلى إعادة تحليل مجموعة بيانات موجودة، وكذلك ‘إمكانية تكرار النتائج التجريبية’، التي تشير إلى جمع بيانات جديدة في تجارب متطابقة قدر الإمكان مع التجربة الأولية..
مجموعات التحكم الافتراضية: تشكل مجموعات بيانات مؤرشفة رقمياً تشمل كل من البيانات والبيانات الوصفية، مصممة لتحسين النماذج الإحصائية للتنبؤ بالنتائج بناءً على متغيرات قابلة للقياس. تعمل مجموعات التحكم الافتراضية كمرجع رقمي، تحاكي إما المعيار الحالي للرعاية (أي، التحكم المرجعي النشط) أو غياب أي تدخل (على سبيل المثال، التحكم في المركبات). عندما تخضع مجموعة من الحيوانات التجريبية لتدخل محدد، تتنبأ هذه البيانات الرقمية المتراكمة، بالتعاون مع الخوارزميات المحددة مسبقاً، بالنتيجة المحتملة لتلك المجموعة في غياب التدخل المذكور. تُسمى هذه النتائج المتوقعة ‘مجموعات التحكم الافتراضية’. بعد ذلك، يتم مقارنة النتائج الملاحظة تجريبياً بعد التدخل مع نتائج مجموعات التحكم الافتراضية هذه لتحديد أحجام التأثير (مقتبس من المرجع 44).
في بعض القطاعات، تفرض اللوائح مشاركة البيانات من الدراسات التي تشمل الحيوانات ويتم إحراز تقدم لضمان إمكانية إعادة استخدام البيانات الحية بهدف إنشاء مجموعات التحكم الافتراضية (VCGs؛ انظر التعريف في الصندوق 1). على سبيل المثال، في الاتحاد الأوروبي REACH (تسجيل، تقييم، تفويض وتقييد المواد الكيميائية)،، المواد الكيميائية الحيوية في الاتحاد الأوروبي ومنتجات حماية النباتات في الاتحاد الأوروبي، هناك متطلبات قانونية لمشاركة تقارير الاختبار والدراسة من الدراسات على الحيوانات التي تستخدم لأغراض التسجيل (انظر، على سبيل المثال، المادة 62 في اللائحة (EC) رقم 1107/2009 (المرجع 22)). يجب أن تلتزم التقديمات التنظيمية إلى إدارة الغذاء والدواء الأمريكية (FDA) بالمعيار لتبادل البيانات غير السريرية (SEND)، الذي يتطلب تقديم البيانات من دراسات السلامة السريرية وعلم السموم بشكل متسق وقابل للقراءة بواسطة الآلات. أخيراً، المبادرة الحديثة التي تم الانتهاء منها، مبادرة الأدوية المبتكرة (IMI) eTRANSAFE (تعزيز تقييم السلامة الانتقالية من خلال إدارة المعرفة التكاملية) قد عززت أيضاً الإرشادات والسياسات لمشاركة البيانات المتعلقة بسلامة الأدوية. الرؤية لهذه المبادرة هي تحسين تقييمات السلامة الانتقالية
في تطوير الأدوية، بما في ذلك إمكانية استخدام VCGs في دراسات السمية غير السريرية (انظر المرجع 23 ومؤخراً المرجع 24).
على الرغم من وجود أطر تنظيمية ومبادرات وإرشادات متنوعة، تظل مشاركة البيانات وإعادة استخدامها في مجال البحث الطبي الحيوي استثناءً بدلاً من القاعدة.. قد تشمل أسباب هذا التقدم المحدود خصوصية المجال في الأساليب، والحواجز التقنية لفهم معايير البيانات FAIR، والتردد في مشاركة البيانات، ونقص الوعي بالفوائد المحتملة وغياب الحوافز لمشاركة البيانات وإعادة استخدامها.
عنصر حاسم واحد ضروري لمشاركة البيانات وإعادة استخدامها هو توفير البيانات الوصفية (انظر التعريف في الصندوق 1) التي تصف البيانات الأولية أو الخام (انظر التعريف في الصندوق 1). البيانات الوصفية ضرورية لجعل البيانات الأولية أو الخام المخزنة في مستودعات البيانات (انظر التعريف في الصندوق 1) متوافقة مع معايير FAIR. مع البيانات الوصفية المناسبة، يمكن للباحثين استجواب البيانات الأولية أو الخام بشكل فعال وإدراك الإمكانية لإعادة استخدامها. ومع ذلك، حسب علمنا، لم يتم بعد إنشاء مجموعة بيانات وصفية دنيا (MNMS) للبحث الطبي الحيوي الحي التي يمكن استخدامها بطريقة غير مرتبطة بالمجال (أي، عبر علوم الأعصاب، وعلوم القلب والأوعية الدموية، وعلم المناعة، وما إلى ذلك). ستبني مجموعة MNMS المثالية على الإرشادات الحالية لتقارير البيانات الحية التي تم وضعها للبحث الطبي الحيوي، بينما توسع أيضاً تأثيرها وقابليتها للتطبيق من خلال فتح الباب نحو مشاركة البيانات الفعالة وإعادة استخدامها.
في هذه النظرة، مع وضع هذه الحاجة في الاعتبار، تم تشكيل مجموعة عمل من العلماء من الأكاديمية والصناعة الخاصة لاقتراح مجموعة MNMS لوصف البيانات الناتجة عن تجربة بحث طبي حيوي حية. بالإضافة إلى ذلك، نبرز الفرص والتحديات والإجراءات المستقبلية المطلوبة لدعم اعتماد MNMS في البحث الطبي الحيوي بهدف تمكين إعادة استخدام البيانات، وتقدم المعرفة العلمية وتحسين رفاهية الحيوانات.
فهم مفهومي لاختيار البيانات الوصفية الدنيا
قبل تحديد مجموعة MNMS للبيانات الحية، من الضروري أولاً فهم المزيد من التفاصيل حول كيفية مساعدة البيانات الوصفية في تشكيل مستودع البيانات وقرار إعادة استخدام البيانات، وبالتالي المساهمة في تقليل واستبدال استخدام الحيوانات. يتم مناقشة الفرص المحددة لإعادة استخدام البيانات لاحقاً في المخطوطة (انظر قسم ‘فوائد اعتماد MNMS’).
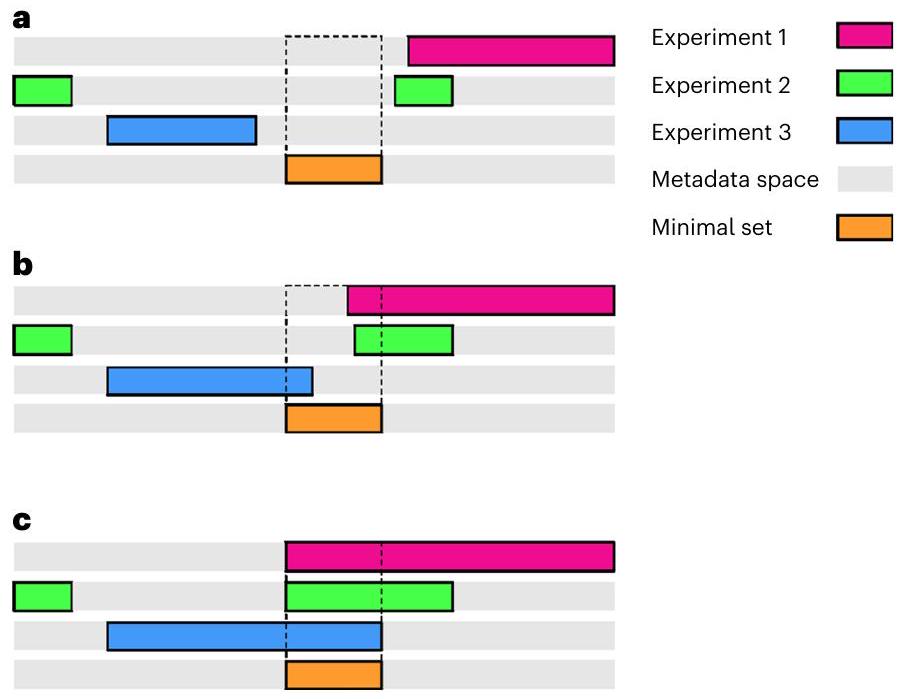
من حيث المبدأ، تغطي مدى البيانات الوصفية المطلوبة لوصف البيانات الناتجة عن جميع تجارب البحث الطبي الحيوي مساحة غير محدودة تقريباً. عملياً، يحتاج فقط جزء صغير من هذه المساحة (أي، الضروري والكافي) لوصف البيانات من تجربة واحدة بشكل فعال، ويمكن للباحثين اختيار مجموعات البيانات الوصفية التي تناسب الغرض. للتوضيح، نعرض سيناريو أسوأ حالة (الشكل 1أ) حيث تكون مجموعات البيانات الوصفية المستخدمة لوصف تجارب متميزة غير متداخلة إلى حد كبير. في هذا السيناريو الافتراضي، ستقيم البيانات التجريبية المرتبطة في مناطق متميزة من مساحة البيانات الوصفية. ستعيق هذه الفجوة التواصل والتفاعل بين مجموعات البيانات المختلفة. لذلك، فإن عدم وجود تداخل في البيانات الوصفية لن يسمح للباحث بتقييم الإمكانية لإعادة استخدام البيانات لاحتياجاته الخاصة.
في سيناريو أكثر احتمالاً (الشكل 1ب)، يمكن العثور على تداخل جزئي بين مجموعات البيانات الوصفية. ومع ذلك، قد تظل العناصر الأساسية للبيانات الوصفية المطلوبة لوصف البيانات الأساسية، والتي تكون شائعة لجميع التجارب، مفقودة. يتم مواجهة هذا السيناريو عادةً في سياق التحليل التلوي (انظر التعريف في الصندوق 1) ومراجعات النشر المنهجية. يمكن أن يحد غياب العناصر الأساسية للبيانات الوصفية من الاستنتاجات من مثل هذه الدراسات ويكون ضاراً أيضاً لإعادة استخدام البيانات. على وجه التحديد، قد يدفع التداخل الجزئي للبيانات الوصفية الباحثين إلى اللجوء إلى المعرفة الضمنية لملء المعلومات المفقودة. ستؤدي هذه الممارسة إلى تجميع البيانات التي تم جمعها إما من مصادر غير متوافقة (على سبيل المثال، محاولة تجميع البيانات من سلالات فئران متميزة)، أو بأساليب غير متوافقة (على سبيل المثال، الفئران التي تربى في ظروف سكنية مختلفة)، وهو ما سيكون غير مناسب لإعادة استخدام البيانات.
في السيناريو النهائي (الشكل 1ج)، سيوفر توافق البيانات الوصفية قابلية استخدام أكبر للبيانات الأولية المرتبطة. في هذه الحالة، ستتضمن البيانات الوصفية من جميع
الشكل 1 | ثلاثة سيناريوهات توضح العلاقات بين مجموعات البيانات الوصفية من ثلاث تجارب مختلفة. يتم تصوير مدى مساحة البيانات الوصفية كمستطيلات رمادية. يتم تصوير مجموعة MNMS وتداخلها مع التجارب الثلاثة كمستطيل برتقالي، وصندوق ممتد مع محيط منقط، على التوالي. أ، لا تتداخل البيانات الوصفية، مما يؤدي إلى أسوأ سيناريو لإعادة استخدام البيانات. لا يمكن للباحثين اتخاذ أي قرار بشأن القدرة على إعادة استخدام البيانات. ب، يوجد فقط تداخل جزئي بين جميع التجارب الثلاثة. قد يحث هذا السيناريو الباحثين على ملء المعلومات المفقودة بمعرفة ضمنية، مما يؤدي إلى عواقب ضارة على جودة إعادة استخدام البيانات. ج، ترتبط جميع التجارب الثلاثة ببيانات وصفية تشمل المنطقة التي تشغلها المجموعة الدنيا. في هذه الحالة، يمكن للباحث أن يعمل بثقة على اختيار إعادة استخدام البيانات.
ستشمل التجارب الثلاثة MNMS متداخلة بالكامل. بموجب افتراضنا الأولي، تم تسجيل التجارب في الأصل مع البيانات الوصفية الضرورية تمامًا لإعادة إنتاج مجموعة التجارب التي تنتمي إليها. لن يؤدي إضافة MNMS الإضافية تلقائيًا إلى توسيع إعادة استخدام البيانات الخام التي كانت في مناطق بعيدة من مساحة البيانات الوصفية. ومع ذلك، فإن وجود MNMS كاملة سيدعم قرار الباحث بشأن ما إذا كان يجب تضمين البيانات الخام المرتبطة في فرصة إعادة الاستخدام. بلا شك، فإن العبء الإضافي لتسجيل MNMS يتضاءل أمام المزايا التي تقدمها مثل هذه الاستراتيجية من حيث إعادة استخدام البيانات، بما في ذلك الإمكانية لاستبدال وتقليل استخدام الحيوانات، وإعادة استخدام الأصول البيانية الحيوية.
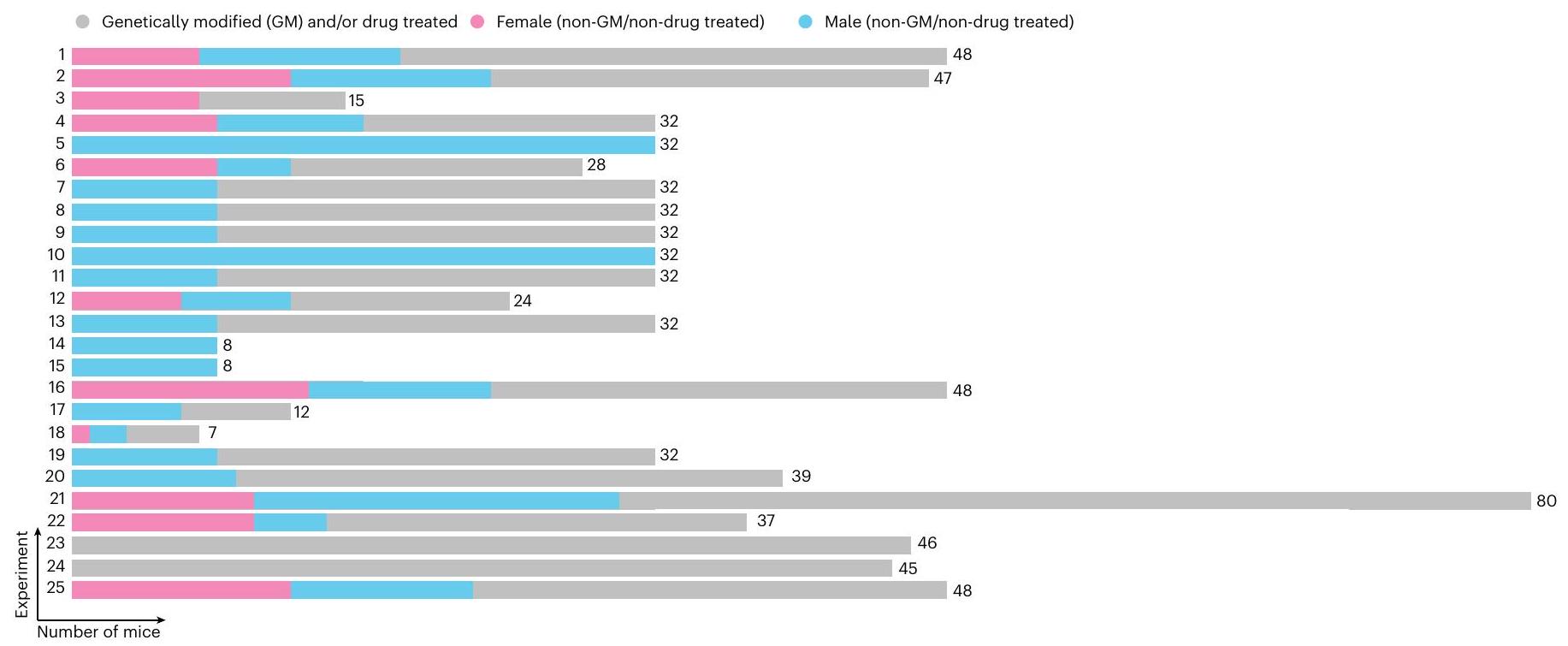
كمثال عملي أكثر حول كيفية دعم البيانات الوصفية وتشكيل قاعدة البيانات لإعادة استخدام البيانات، يتم عرض مخطط لمستودع بيانات تم تنفيذه في مركز الابتكار Roche في بازل (سويسرا) في عام 2022. يخزن هذا المستودع بيانات من تسجيلات النشاط الحركي في الفئران التي تم الحصول عليها باستخدام بروتوكول موحد (الشكل 2). نظرًا لأن البيانات من كل فأر تم توضيحها بالبيانات الوصفية، فمن الممكن تحديد ‘الحيوانات الضابطة’ التي لم تتعرض لأي تحدٍ دوائي و/أو التي لم يتم تعديلها وراثيًا بسرعة. يمكن رسم بيانات هذه الحيوانات بسرعة واستجوابها من قبل أي عالم من Roche لديه وصول إلى قاعدة البيانات، مما يدعم إعادة استخدام الأصول الرقمية الموجودة. مع هذا المثال البسيط، يبدأ المرء في تقدير كيف يمكن طرح أسئلة جديدة على مستودعات البيانات، بينما كانت هذه الأسئلة خارج نطاق التجارب الأصلية المخزنة داخل تلك المستودعات (على سبيل المثال، كيف يختلف النشاط الحركي بين سلالات الفئران المختلفة وبين الجنسين؟). تأخذ هذه الطريقة أهمية أكبر مع استمرار نمو مستودع البيانات، مما يدعم تحليلات ميتا أكثر تعقيدًا. يمكن أن يسهل تخزين البيانات بهذه الطريقة فهم التباين بين التجارب ويدعم تحسين تصميم التجارب المستقبلية. علاوة على ذلك، فإن إنشاء مثل هذا المستودع للبيانات الموصوفة بالبيانات الوصفية يفتح الباب نحو تنفيذ VCGs (تم مناقشة هذه النقطة بشكل أكبر في قسم ‘فوائد اعتماد MNMS’).
الشكل 2 | مثال عملي لاستخدام البيانات الوصفية لدعم تشكيل مستودع بيانات. يمثل المخطط مثالًا واقعيًا لمستودع بيانات من تسجيلات النشاط الحركي في الفئران، حيث يتم توضيح جميع البيانات بالبيانات الوصفية. يتم توضيح ما مجموعه 25 تجربة كصفوف منفصلة، تحتوي على تسجيلات من 828 فأرًا فرديًا. يمكن أن تحدد قاعدة البيانات بسرعة باستخدام مصطلحات البيانات الوصفية
يمكن أن تحدد بسرعة الفئران الضابطة، غير المعدلة وراثيًا و/أو غير المعالجة دوائيًا من الذكور (الأزرق، ) والإناث (الوردي، ) في كل تجربة. يمكن تقسيم البيانات بشكل أكبر (على سبيل المثال، حسب السلالة، العمر وما إلى ذلك)، مما يمكّن المجرب من فهم الإمكانية لإعادة استخدام هذه البيانات لأسئلتهم واحتياجاتهم المحددة.
المبادئ الأساسية لنشر MNMS
مع الفهم المفاهيمي لـ MNMS في مكانه، نبرز بعد ذلك المبادئ الأساسية المطلوبة لنشر MNMS لأبحاث in vivo.
FAIR
لقد زادت قابلية تطبيق مبادئ FAIR لمجموعات البيانات المتنوعة في العقد الماضي. مع ظهور التعلم الآلي الآلي وأنظمة الذكاء الاصطناعي، يتم إعطاء أهمية متزايدة لنشر مبادئ FAIR لجعل البيانات قابلة للتنفيذ بواسطة الآلات (أي، يمكن للأنظمة الحاسوبية العثور على البيانات والوصول إليها والتفاعل معها وإعادة استخدامها دون تدخل بشري أو بتدخل ضئيل). وفقًا لذلك، يجب أن توفر البيانات الوصفية أولاً معلومات سياقية كافية حول البيانات. فيما يتعلق بالدراسات الحية، يتم توفير الدقة بشكل مثالي على مستوى الحيوان الفردي ويجب أن يكون لكل كائن رقمي (انظر التعريف في الصندوق 1) ‘قابل للاكتشاف’. وهذا يعني أنه يجب تعيين معرف فريد لكل حيوان (أي، معرف مورد موحد (URI)) داخل مستودع البيانات المحتمل.
على مستوى ثانٍ، يجب أن تلتزم البيانات الوصفية نفسها أيضًا بمبادئ FAIR. لتمكين الجانب القابل للتشغيل البيني، يجب فرض هيكل على البيانات الوصفية باستخدام نموذج مفاهيمي محدد جيدًا لوصف العلاقات والقيود بين الكيانات المختلفة (على سبيل المثال، حيوان أو دراسة). يمكّن هذا النموذج المفاهيمي من فهم مشترك لعناصر البيانات الوصفية ويمكن وصفه باستخدام معايير معتمدة لتمثيل المعلومات داخل أنظمة الكمبيوتر (على سبيل المثال، إطار وصف الموارد، لغة الويب للأونتولوجيا وبيانات JSON المرتبطة). لتجنب التباين والغموض، يجب أن تتكون البيانات الوصفية من عناصر موحدة مثل المصطلحات الخاضعة للرقابة لضمان إمكانية إعادة استخدامها. لهذا الغرض، يُوصى بشدة بالالتزام بالأونتولوجيات الموجودة لكل مجال، إذا كانت متاحة (على سبيل المثال، SEND/CDISC أو الأونتولوجيا للتحقيقات الطبية الحيوية (OBI)؛ انظر التعريفات في الصندوق 1). بالإضافة إلى وجود بيانات وصفية متجانسة وموحدة، وفقًا لمبادئ FAIR، يجب أيضًا تعريف كل مصطلح من مصطلحات البيانات الوصفية بشكل كافٍ، مع وصف لاستخدامه، ومنحه معرفًا فريدًا. يجب أيضًا التقاط مرادفات مختلفة للمصطلح. بشكل جماعي، ستؤدي هذه الطريقة إلى جودة عالية وثقة في مجموعة البيانات الوصفية المقدمة.
مقياس النزاهة
بمجرد الاتفاق على MNMS، فإن التحقق من التغطية وجودة العناصر المبلغ عنها في هذه المجموعة الدنيا سيؤدي إلى ‘درجة اكتمال’
مرتبطة بكل مجموعة بيانات، والتي ستعمل كمقياس للنزاهة. تعتبر درجة الاكتمال المرتبطة بمجموعة البيانات الوصفية أمرًا حيويًا لتمكين قرار قائم على العتبة بشأن رفض أو تضمين البيانات الخام المرتبطة داخل مستودع البيانات. بالإضافة إلى ذلك، فإن معرفة اكتمال مجموعة البيانات الوصفية ستدعم الباحثين في تقييم عمومية الاستنتاجات التي يمكن استخلاصها من أي بيانات معاد استخدامها.
التحديد المسبق
تماشيًا مع أفضل الممارسات الأخرى للبحث القابل للتكرار، يجب أن يتم تحديد تصميم هياكل البيانات الوصفية عالية الجودة مسبقًا. يتجنب التحديد المسبق ‘الحلول بعد الوفاة’ التي تؤدي إلى كل من تقارير البيانات منخفضة الجودة وثقة غير مبررة في صرامة الأساليب المعتمدة. في الواقع، فإن التطبيق الرجعي لهياكل البيانات الوصفية لا يضمن النجاح. على سبيل المثال، تعتبر بيئات البحث إعدادات ديناميكية للغاية مع معدلات عالية من دوران الموظفين. في هذه الحالات، تصبح مهمة استعادة مجموعة شاملة من البيانات الوصفية بناءً على كمية محدودة من البيانات الوصفية المتاحة غير قابلة للتجاوز وعرضة للأخطاء. لهذا السبب، سعينا لتصميم MNMS يركز على تحديد مسبق لعدد محدود من العناصر القابلة للتنفيذ. يعد تحديد عدد حقول البيانات الوصفية المحددة مسبقًا أمرًا حيويًا لتجنب وضع عبء إداري إضافي على الباحثين.
الأصل
يعتبر الأصل وملكية البيانات جوانب مهمة لـ MNMS وهي ضرورية للتنظيم في سياق الاستخدام الواسع النطاق لمجموعات البيانات والبيانات الوصفية. لتمكين تحديد الأصل والملكية، يجب أن تحتوي كل إدخال بيانات في مستودع محتمل على البيانات الوصفية التشغيلية التالية المرتبطة به: منشئ السجل (الذي يُعتبر أيضًا كائن FAIR مع معرف فريد معين)، تاريخ الإنشاء وتاريخ التعديل. أخيرًا، يجب إعطاء تعريف لكل من هذه المصطلحات لتجنب الغموض المحتمل.
MNMS
تستند MNMS المقترحة هنا (الجدول 1 و 2) إلى إرشادات ARRIVE 2.0 . على وجه التحديد، كانت ‘Essential 10′ من ARRIVE (الجدول 1) و’المجموعة الموصى بها’ (الجدول 2) هي الأساس لبناء MNMS لأبحاث الطب الحيوي. تم اختيار هذه الإرشادات الموجودة لأنها معروفة جيدًا داخل مجتمع البحث الطبي الحيوي
الجدول 1 | MNMS (ARRIVE 2.0 Essential 10)
موضوع ARRIVE – الأساسيات 10
MNMS
تفاصيل MNMS
نوع البيانات
الأونتولوجيا الموجودة
تصميم الدراسة
نعم، ولكن فقط تاريخ البدء والانتهاء من المرحلة الحية
تاريخ البدء والانتهاء من المرحلة الحية
تاريخ
ISO8601
حجم العينة
NA
NA
NA
NA
معايير الإدراج/الاستبعاد
NA
NA
NA
NA
العشوائية
NA
NA
غير متوفر
غير متوفر
مُعَمي
غير متوفر
غير متوفر
غير متوفر
غير متوفر
مقاييس النتائج
نعم، موسع، محدد للاختبار
مقياس النتيجة (بما في ذلك أي إحصائيات وصفية إذا كانت قابلة للتطبيق، على سبيل المثال، السرعة المتوسطة)
المفردات المتحكم بها
متعددة، محددة حسب الفحص لكل مجال
وحدة قياس لكل مقياس
المفردات المتحكم بها
يو، أوبى
طرق إحصائية
غير متوفر
غير متوفر
غير متوفر
غير متوفر
الحيوانات التجريبية
نعم، موسع، جميع الفحوصات
معرف حيواني فريد
معرف الموارد الموحد
غير متوفر
معرفات محلية/معرفات أخرى
سلسلة
غير متوفر
نوع
المفردات المتحكم بها
أوبي، NCIt
سلالة (ILAR والاسم المختصر)
المفردات المتحكم بها
إيلارMGI
جنس
المفردات المتحكم بها
NCIt، CDISC/SEND
ترانسجيني
بوليني
غير متوفر
معلومات النمط الجيني
المفردات المتحكم بها
MGI
معلومات الأليل
المفردات المنضبطة
MGI
معلومات بائع الحيوانات (الموقع والمكان)
المفردات المتحكم بها
تاريخ الميلاد
تاريخ
ISO8601
المرحلة التنموية
المفردات المتحكم بها
أوبو فاوندي
وزن الحيوان في بداية التجربة والوحدة
رقم + مفردات مسيطر عليها
يو
درجة شدة التلاعب
رقم
إجراءات تجريبية
نعم، ولكن مع التركيز على العلاج المركب؛ الشروط للإجراءات التي تتجاوز ذلك تتطلب توافقًا محددًا في المجال.
مادة الاختبار (الاسم الشائع)
المفردات المتحكم بها
شيبى، ديرون
مادة الاختبار (رقم CAS)
رقم
غير متوفر
الجرعة العددية
رقم
غير متوفر
وحدة الجرعة (يفضل أن تكون ملغ/كغ أو مليمول)
المفردات المنضبطة
يو، أوبى
تركيب المركبة
المفردات المتحكم بها
شيبى
طريق الإعطاء
المفردات المتحكم بها
أوبي
طريقة الإدارة
المفردات المتحكم بها
أوبي
النتائج
غير متوفر
غير متوفر
غير متوفر
غير متوفر
ChEBI، الكيانات الكيميائية ذات الاهتمام البيولوجي؛ CDISC، اتحاد معايير تبادل البيانات السريرية؛ DrON، أنطولوجيا الأدوية؛ NA، غير قابل للتطبيق؛ NCIt، معجم المعهد الوطني للسرطان؛ OBO، الأنطولوجيات البيولوجية والطبية المفتوحة؛ UO، أنطولوجيا وحدات القياس.تحتاج إلى مزيد من التطوير لتوفير أنطولوجيا رسمية.
الجدول 2 | مجموعة MNMS (المجموعة الموصى بها من ARRIVE)
مجموعة ARRIVE الموصى بها
MNMS
تفاصيل MNMS
نوع البيانات
الأنطولوجيا الحالية
ملخص
غير متوفر
غير متوفر
غير متوفر
غير متوفر
خلفية
غير متوفر
غير متوفر
غير متوفر
غير متوفر
الأهداف
غير متوفر
غير متوفر
غير متوفر
غير متوفر
بيان أخلاقي
غير متوفر
غير متوفر
غير متوفر
غير متوفر
الإسكان وتربية الحيوانات
نعم
دورة الضوء
رقم
غير متوفر
موقع الاختبار / موقع البحث
المفردات المتحكم بها
إثراء
نعم/لا
غير متوفر
غير متوفر، غير قابل للتطبيق (انظر النص الرئيسي).تحتاج إلى مزيد من التطوير لتوفير أنطولوجيا رسمية. وتمت الموافقة عليها من قبل مجلات محكمة، مما قد يسهل اعتماد MNMS في المستقبل. وقد قامت الأبحاث السابقة حول إرشادات ARRIVE 1.0 بتحويلها إلى قائمة تضم أكثر من 100 عنصر.، مما قد يكون من الصعب على المؤلفين الامتثال له بالكامل؛ هذه القائمة الشاملة تعقد أيضًا تتمثل مهمة فريق التحرير في التحقق من الامتثال. مع مراجعة الإرشادات في عام 2020، تم تقديم ARRIVE 2.0 ‘الأساسيات العشر’ كحد أدنى من المعلومات المطلوبة للإبلاغ عن تجارب الحيوانات.. وبالتالي، قمنا بإعطاء الأولوية لتوافق MNMS مع ‘العشرة الأساسية’، مما سيساعد أيضًا في تقليل عبء العمل على MNMS وبالتالي دعم اعتماده بشكل أكبر. ستساهم MNMS المقترحة هنا بشكل كبير في جعل البيانات الحية من الأبحاث الطبية الحيوية متوافقة مع FAIR، بما يتماشى مع الأهداف الأصلية لإرشادات ARRIVE. في الواقع، فإن ضمان أن تكون البيانات من تجارب الحيوانات قابلة للتنفيذ من خلال اعتماد MNMS يزيد من تأثير إرشادات ARRIVE. أدناه، نوضح المزيد عن مصطلحات البيانات الوصفية المدرجة في MNMS. يتم تقديم تعريفات للمصطلحات المحددة المستخدمة في القسم التالي في المربع 2.
مواضيع ARRIVE المضمنة مع تركيز موسع في MNMS
تشمل هذه المواضيع الحيوانات التجريبية، مقاييس النتائج والأساليب التجريبية. تشكل تفاصيل الحيوانات التجريبية الجانب الرئيسي من MNMS، لأن الإبلاغ غير الكافي أو غير الدقيق عن هذه الخصائص يعتبر أحد التحديات الرئيسية لإعادة إنتاج البيانات. لذلك، نقترح أن يقوم أي مستودع بيانات مستقبلي بتعيين معرف فريد لكل حيوان. سيمكن ذلك ليس فقط من مجموعات بيانات FAIR ولكن، جنبًا إلى جنب مع معرفات فريدة أخرى محتملة تم إدخالها (على سبيل المثال،
الصندوق 2 | المصطلحات الرئيسية المتعلقة بحقول البيانات الوصفية المهيكلة المقترحة في MNMS
طريقة الإدارة: تشير إلى الطريقة المستخدمة للتعرض وتستثني مسار الإدارة.
طريق الإدارة: يشير إلى جزء من الجسم يتم من خلاله أو إلى داخله إدخال كيان مادي.
الأليل: شكل متغير من نفس الجين في نفس الموقع، أو الموقع الجيني، على الكروموسوم.
مزود الحيوانات: موقع منظمة يزود الحيوانات النموذجية (يحتاج إلى اسم المنظمة والموقع).
التركيب الجيني: يشير إلى التركيب الجيني لكائن حي. على أوسع نطاق، يشمل التركيب الجيني التركيبة الوراثية الكاملة لفرد ما. وغالبًا ما يُطبق بشكل أضيق على مجموعة الأليلات الموجودة في موقع واحد أو أكثر محددة.
النوع: مجموعة من الكائنات الحية التي تختلف عن جميع المجموعات الأخرى من الكائنات الحية والتي تكون قادرة على التزاوج وإنتاج نسل خصب.
سلالة: مجموعة أو نوع من الكائنات الحية تختلف جينياً عن غيرها من نفس النوع وتشارك مجموعة من الخصائص المحددة.
حيوان معدّل وراثيًا: حيوان نموذجي تم إدخال DNA أجنبي فيه باستخدام التكنولوجيا الحيوية. يُعرّف DNA الأجنبي (الجين المنقول) هنا بأنه DNA من نوع آخر، أو DNA مؤتلف من نفس النوع تم التلاعب به في المختبر قبل إعادة إدخاله. تقدم علامات تحديد الهوية باستخدام ترددات الراديو (RFID) أيضًا تحديدًا غير ملتبس لسجل الحيوان في مستودع البيانات والمجموعات البيانية المرتبطة. هذا الأمر مهم بشكل خاص إذا كان الحيوان مشمولًا في أكثر من دراسة واحدة، لتجنب التكرارات الخاطئة وإدخال عوامل تداخل صناعية في أي مجموعات بيانات معاد استخدامها.
بالنسبة للسمات الأساسية للحيوانات التجريبية، يجب أن يكون وجود اسم المعهد القياسي لأبحاث الحيوانات المخبرية (ILAR) بالإضافة إلى أي أسماء سلالات قصيرة أو مرادفات أمرًا إلزاميًا. كما ذُكر في قسم ‘FAIR’، يجب أن يكون لكل مصطلح مُراقب لكل مصطلح (مثل السلالة) معرف فريد ووصف مختصر يربط أي مرادفات موجودة. معلومات السلالة وحدها غير كافية لأن التزاوج الداخلي على مدى فترة طويلة قد يتسبب في انحرافات جينية قد تؤثر على نتائج التجارب. لذلك، فإن معلومات المصدر الدقيقة أمر حاسم. بالنسبة للحيوانات المعدلة وراثيًا على وجه الخصوص، يتطلب الأمر معلومات عن النمط الجيني والأليل بدقة، مرة أخرى باستخدام مصطلحات مُراقبة ومعرفات فريدة. بالنسبة لمعلومات الأليل، يجب على الباحثين استخدام معرفات من معلومات جينوم الفئران (MGI) إذا كانت متاحة. MGI هو المصدر المعتمد في مجال جينوم الفئران نظرًا لأن تسميته تتبع القواعد والإرشادات التي وضعتها اللجنة الدولية للتسمية الجينية القياسية للفئران. وبالمثل، بالنسبة للسلالات ومعرف السلالة، يمكن استخدام معرف مرجع خارجي (على سبيل المثال، إدخال موقع المزود أو إدخال المستودع).
لإظهار النمط الجيني وزيجوت الأليل، باستخدام الاتفاقيات المتفق عليها التي تحد من المصطلحات المتاحة، تقلل من خطر الغموض. يوفر مختبر جاكسون مثلًا على ذلك.. علاوة على ذلك، يجب اتخاذ مزيد من الحذر بالنسبة للأليلات المتعددة المتحولة/المتغيرة لتحديد الجينوتيب الصحيح بشكل لا لبس فيه لكل أليل في التسلسل الذي سيشكل الجينوتيب الكامل (على سبيل المثال، الأليل 1: ; الأليل 2: ).
المعلومة الأساسية الأخيرة الثابتة هي تاريخ ميلاد الحيوان. نظرًا للممارسات الحالية أو الصعوبات في الحصول على معلومات دقيقة، يجب أن يتم تمييز هذه المعلومة إضافيًا على أنها ‘دقيقة’ أو ‘تقريبية’ للإشارة إلى موثوقيتها. يُوصى باستخدام تنسيق تاريخ موحد، يكون واضحًا للمستخدم أثناء إدخال البيانات.
من مجموعة بيانات الحيوانات غير القابلة للتغيير، يعتبر وزن الحيوان في بداية التجربة (مع استخدام مفردات محددة لوحدة القياس) إلزاميًا في نظام إدارة بيانات الحيوانات. يمكن أن يكون الوزن، جنبًا إلى جنب مع عمر الحيوان، مؤشرًا مفيدًا على الرفاهية عندما يمكن إجراء مقارنات مع منحنيات النمو القياسية إذا كانت معروفة لنوع أو سلالة معينة. يعد الإبلاغ عن درجة الشدة القصوى القياسية للتلاعب، لكل حيوان فردي، إضافة مهمة. قد تكون هذه المعلومات بمثابة مؤشر لمستويات التوتر والمعاناة، وقد تفسر الانحرافات في البيانات التجريبية، مما يسمح باستبعاد الحيوان (أو الحيوانات) من التحليل الإضافي إذا لزم الأمر.
فيما يتعلق بمصطلحات تصميم الدراسة، تطلب MNMS تواريخ بدء وانتهاء التجربة (المعرفة بأنها بداية ونهاية مرحلة الحياة). يمكن أن تشير هذه البيانات الوصفية إلى (1) الحيوانات التي تنتمي إلى نفس الدراسة؛ (2) تسهيل إعادة استخدام مجموعات البيانات الطولية، حيث يمكن أن تتغير الإدخالات المرتبطة بوزن الجسم والعمر على مدار التجربة؛ و(3) ضمان الوعي بموعد إنتاج البيانات، وهو ما قد يكون اعتبارًا مهمًا في حالة عوامل مثل الانجراف الجيني.
نظرًا لأن التلاعبات الدوائية شائعة في البحث الطبي الحيوي، فإن أشكال التعرض المختلفة لمادة نشطة ولأغراض مختلفة (على سبيل المثال، كعلاج، أو لتحفيز حالة معينة مثل المرض أو تحفيز الجين المنقول) ممثلة بشكل واسع في MNMS. لضمان الإبلاغ الدقيق عن أي مادة اختبار، من الضروري استخدام معرف فريد لمادة الاختبار، مثل رقم خدمة الملخصات الكيميائية (CAS). يمكن أن تكمل المرادفات مثل اسم الدواء الشائع، الذي يشير إلى نفس الكيان، سجلًا رقميًا لمعرف المادة ووجوده في الأنطولوجيات الحالية. الجرعة العددية ووحدة الجرعة (على سبيل المثال، أو التركيز المولي) تمثل جرعة المادة. تشمل العوامل المهمة الأخرى في إدارة المركب طريقة الإدارة وطريق الإدارة (على سبيل المثال، داخل الصفاق، عن طريق الفم، وهكذا) وتركيب المركب الحامل. يجب تعريف هذه البيانات الوصفية، بما في ذلك وحدات الجرعة، من خلال مصطلحات محكومة أو من الناحية المثالية من خلال أنطولوجيات موجودة مثل وفقًا لمبادئ FAIR الموصوفة سابقًا.
المواضيع الموصى بها لمجموعة ARRIVE المدرجة في MNMS
تشمل هذه الإسكان وتربية الحيوانات، تسجيل البروتوكولات والوصول إلى البيانات. من مجموعة ARRIVE 2.0 الموصى بها، اعتبرنا بعض السمات أساسية لإعادة إنتاج مجموعات البيانات التجريبية، ولذلك قمنا بتضمينها في MNMS. هذه السمات هي دورة الضوء، المشار إليها كعدد ساعات الضوء:الظلام في اليوم، حالة النظام الغذائي، الإثراء وموقع الاختبار أو موقع البحث. لتجنب توسيع المصطلحات لتشمل أنظمة غذائية مختلفة أو جداول تغذية وأنواع إثراء، والتي قد تعكس بشكل أكبر إجراءات تجريبية محددة وبالتالي تتجاوز نطاق MNMS، يتم تمثيل كل من حالة النظام الغذائي والإثراء بإحدى حالتين فقط (أي، صائم أو مُغذى/غير صائم، ووجود الإثراء أو عدمه). يُعتبر الإبلاغ عن إذن ترخيص تجارب الحيوانات التي تم استخدام الحيوانات فيها كحاجز إضافي يضمن أن مجموعة البيانات المبلغ عنها تم إنشاؤها باستخدام الإجراءات المذكورة. كما يضمن إذن ترخيص تجارب الحيوانات أن معايير رفاهية الحيوانات معتمدة من قبل السلطة المعنية برفاهية الحيوانات. وأخيرًا، ولكن ليس آخرًا، يمتد الوصول إلى البيانات في MNMS إلى ما هو أبعد من نطاق إرشادات ARRIVE ويشكل جانبًا حاسمًا لتحديد ملكية مجموعة البيانات. يتم منح كل مستخدم، من الناحية المثالية، معرفًا فريدًا، مثل معرف ORCID (معرف الباحث والمساهم المفتوح). يتيح هذا المعرف تسجيل أي تعديلات على مجموعة البيانات والبيانات الوصفية عبر طوابع زمنية تظهر تاريخ الإنشاء وتاريخ التعديل. يضمن مسار الوصول إلى البيانات والتدقيق سلامة البيانات وجودتها. لهذا الغرض، لا يمكن أن يكون أي نظام يواجه المستخدمين بشكل كامل عامًا، بل يجب أن يكون قائمًا على خدمة التسجيل والمصادقة.
مواضيع ARRIVE غير المدرجة في MNMS
تشمل هذه تصميم الدراسة، حجم عينة الدراسة، الوحدة التجريبية، معايير الإدراج والاستبعاد، العشوائية والتعمية. أظهرت المحاولات السابقة تحديات كبيرة عند محاولة تنفيذ مواضيع تتعلق بتصميم الدراسة في مستودع بيانات واسع النطاق.تتضاعف هذه التحديات عند توسيع نطاق مجموعة البيانات لإنشاء مستودع أكثر عمومية يمكن أن يمكّن من مشاركة البيانات بين عدة أصحاب مصلحة. لهذه الأسباب، تم استبعاد العديد من مواضيع ARRIVE بشكل صريح من MNMS، لأنها لا تدعم الهدف الأساسي لإعادة استخدام البيانات. بشكل أكثر تحديدًا، استخدام مستوى الحيوان الفردي للبيانات الوصفية (وتقارير البيانات) يلغي الحاجة للإبلاغ عن حجم العينة والوحدة التجريبية. جوانب تصميم الدراسة قبل التلاعبات التجريبية، مثل تعريف المجموعات التي يتم مقارنتها، العشوائية، التعتيم ومعايير الإدراج والاستبعاد، هي بالتأكيد مهمة لتكرار الدراسة نفسها. ومع ذلك، تضيف هذه المواضيع قيمة قليلة لإعادة الاستخدام لأن البيانات ستُستخدم في دراسات مختلفة مع خوارزميات عشوائية جديدة ومعايير اختيار. أخيرًا، ولكن بشكل مهم، فإن التسمية بين مجموعات التحكم المختلفة غير موحدة إلى حد كبير، مما يشكل تحديًا آخر.; لذلك توفر MNMS مجموعة من المعايير والإرشادات الموضوعية لتضمين سجل حيواني من مجموعة التحكم.
فوائد اعتماد MNMS
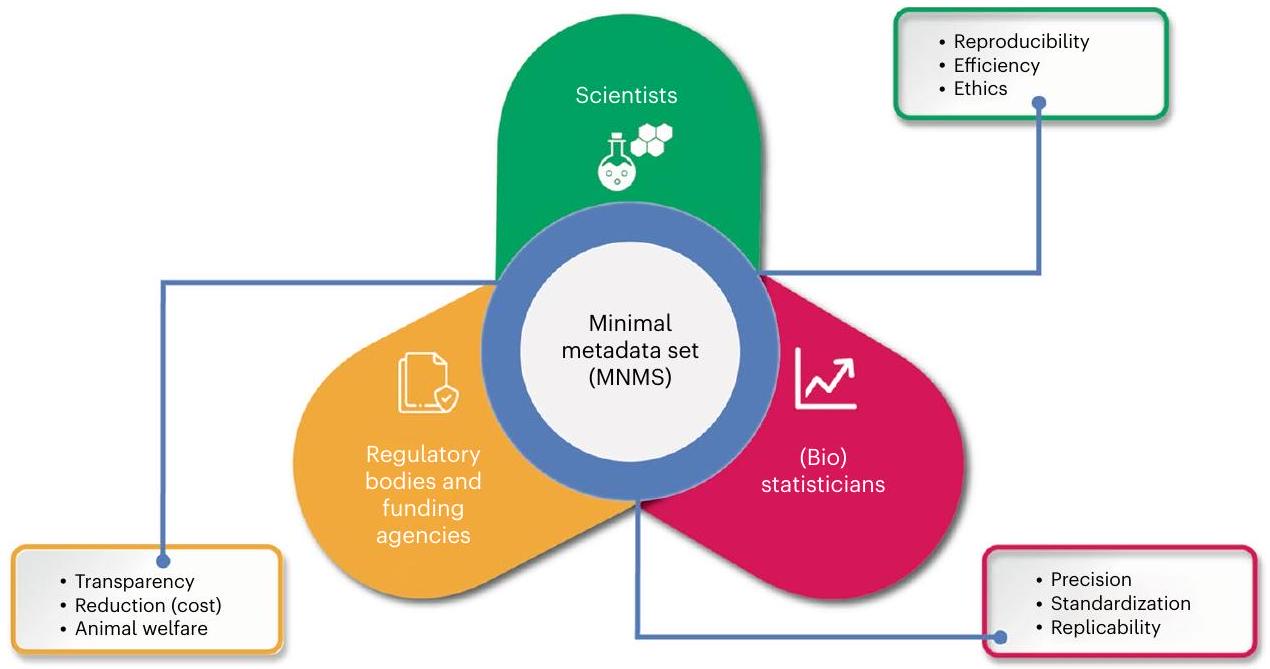
مع توضيح MNMS، في القسم التالي نبرز الفوائد التي قد تنجم عن اعتماد MNMS ضمن مجتمع البحث البيولوجي. تشمل هذه الفوائد إعادة استخدام البيانات، وتوليد VCGs، وتسهيل البحث الشامل من الدراسات الحية. يتم تسليط الضوء على الفوائد لمختلف أصحاب المصلحة في تنفيذ MNMS في الشكل 3.
إعادة استخدام
إعادة استخدام البيانات المستمدة من تجارب الحيوانات تخدم وظيفة ‘إعادة التوجيه’، وتندرج بوضوح ضمن مجالات 3R الخاصة بالاستبدال والتقليل. إن الوصف الفعال واسترجاع البيانات الخام يمكّن من تطبيقها لأغراض تتجاوز تلك التي كانت مقصودة خلال الجمع الأصلي، وبالتالي تقليل عدد الحيوانات أو، في بعض الحالات، استبدال الحيوانات اللازمة للتجارب الجديدة. تم توضيح مثال على هذا النهج مؤخرًا من قبل فوشي وآخرين، الذين أعادوا استجواب البيانات التي تم الحصول عليها من مراقبة القفص المنزلي للحصول على رؤى جديدة حول سلوك الفئران..
VCGs
نحن نتخيل أن استخدام VCGs، الذي أصبح ممكنًا من خلال مشاركة البيانات ومستودعات البيانات التي تتبع MNMS، سيفيد بشكل خاص عدة أصحاب مصلحة (الشكل 3). كانت الفرص والتحديات لتنفيذ VCGs محور مشروع IMI eTRANSAFE، الذي جمع وحلل بيانات سلامة الأدوية وعلم السموم من أكثر من 60,000 فأر، و1,300 كلب و500 قرد (انظر المرجع 23 ومؤخراً المرجع 24). مع ظهور المزيد من المنشورات حول VCGs من هذا المشروع، ستدعم الدروس والرؤى الإضافية بلا شك التنفيذ العملي لـ VCGs في مجال البحث الطبي الحيوي.
توقعاتنا هي أن تتيح VCGs للباحثين إنشاء ظروف تجريبية منظمة للغاية ومتجانسة، مما يمكن أن يحسن من قابلية تكرار التجارب وإعادة إنتاجها. قد تحسن الضوابط الحيوانية الافتراضية أيضًا من كفاءة البحث من خلال توفير الوقت والتكاليف والموارد اللازمة للتجارب على الحيوانات. علاوة على ذلك، يمكن أن تعالج تنفيذ VCGs بعض الاحتياجات الأخلاقية للبحث المسؤول على الحيوانات من خلال تقليل عدد الحيوانات المطلوبة للدراسات الطبية الحيوية.
بالنسبة للمنظمات التنظيمية ووكالات التمويل، يمكن أن يدعم نشر مجموعات التحكم الافتراضية الأهداف المتعلقة بزيادة الشفافية والمساءلة ورفاهية الحيوانات. يمكن أن يساعد استخدام مجموعات التحكم الافتراضية في توحيد التجارب الحيوانية الوكالات التنظيمية في مراقبة وإنفاذ اللوائح، وتحسين شفافية البيانات وسهولة الوصول إليها، وتقليل عدد الحيوانات المستخدمة في البحث. علاوة على ذلك، يمكن أن يقلل اعتماد مجموعات التحكم الافتراضية من تكاليف البحث بينما يشجع أيضًا على إجراء أبحاث حيوانية أكثر أخلاقية ومسؤولة. إن التنفيذ الناجح لـ ستعزز هذه الاستراتيجية بلا شك ثقة الجمهور في التنظيمات المتعلقة بتجارب الحيوانات.
من منظور (علماء) الإحصاء الحيوي، يمكن أن تزيد VCGs من دقة وقابلية تكرار التحليلات الإحصائية. ومن الجدير بالذكر أن VCGs يمكن أن تقضي على المتغيرات المربكة، وتزيد من جودة البيانات ودقتها، وتوحد جمع البيانات والتقارير، وتخلق بيئة أكثر تنظيمًا وانتظامًا لأبحاث الحيوانات. بشكل جماعي، يمكن أن تسهم هذه المزايا في تحسين نتائج الدراسات، وقيمة البيانات، وموثوقية النتائج.
بينما قد توفر مجموعات التحكم الافتراضية فوائد لمختلف أصحاب المصلحة، ندرك أن تنفيذ هذه المجموعات لن يكون خالياً من التحديات في البحث البيولوجي. يجب أن يتم النظر بعناية في بناء مجموعات التحكم الافتراضية. هل يجب أن تكون مجموعة التحكم افتراضية بالكامل، أم مزيج من البيانات الافتراضية والحقيقية؟ إذا كان الأمر كذلك، ما هو التوازن الأمثل بين البيانات الافتراضية والحقيقية؟ يجب أخذ عوامل إحصائية في الاعتبار، مثل معايير الاختيار لمجموعات التحكم الافتراضية، واعتبارات توزيع البيانات، والتباين وعدد نقاط البيانات. من الناحية المثالية، يجب أن يتم التحقق من تصميم واستخدام مجموعات التحكم الافتراضية تجريبياً، لضمان أن الاستنتاجات التجريبية متسقة إذا تم استخدام مجموعات التحكم الافتراضية بدلاً من البيانات الحقيقية. يجب أيضاً أخذ عوامل بيولوجية في الاعتبار، مثل التباين الموسمي، وتأثير الباحثين الأفراد أو إمكانية الانجراف الجيني، والتي قد لا يمكن تمثيلها بسهولة بواسطة مجموعات التحكم الافتراضية. وبالتالي، لن تتمكن جميع التجارب من الاستفادة من مجموعات التحكم الافتراضية، وستظل هناك توقعات مستمرة لتشغيل حيوانات تحكم “حقيقية” عندما لا يكون استخدام مجموعات التحكم الافتراضية قابلاً للتطبيق أو موثوقاً به بشكل كافٍ. مجتمعة، يجب أن يتم النظر بعناية والتحقق من تنفيذ مجموعات التحكم الافتراضية، ولكن قد يوفر اعتمادها الناجح مزايا كبيرة لمجتمع البحث البيولوجي.
البحث الميتا في أبحاث الحيوانات
تقدم التحليلات التلوية للبيانات من الدراسات الحية الموجودة (داخل وخارج نطاق المراجعات المنهجية) أداة قوية لاستكشاف تأثير التغيرات في تصميم التجارب ويمكن أن تقلل من الحاجة إلى استخدام الحيوانات بشكل إضافي. يمكن أن يؤدي تجميع البيانات من دراسات متعددة حول نفس الموضوع إلى زيادة دقة تقديرات التأثير المجمعة. تُستخدم التحليلات التلوية للبيانات الحيوانية أيضًا لإبلاغ التصميم الأمثل للتجارب بعدة طرق، بما في ذلك مقارنة الأداء وتقييم ضرورة اختبارات النتائج.إبلاغ حسابات حجم العينةتحديد مدة التجارب ونقاط النهاية الإنسانيةوتحسين اختيار تقنية استنتاج النموذج.
على الرغم من أن التحليلات الميتا هي نهج مهم لاستكشاف التباين بين الدراساتإنها تتطلب موارد كثيفة بسبب الطريقة التي يتم بها الإبلاغ عن البيانات في المقالات البحثية المنشورة، عادةً كرسوم بيانية أو كملخصات جماعية (أي، متوسط المجموعة والتباين). تنطوي الصيغة الرسومية على تحديات، حيث تحتاج أدوات متخصصة لاستخراج المعلومات الملخصة العددية المقدرة قبل أن يمكن إجراء تحليلات إضافية. وبالتالي، فإن الاستنتاجات ودقة التحليلات التلوية محدودة بجودة البيانات الأولية المتاحة. إن اعتماد MNMS كمعيار للإبلاغ، لكل من البيانات الضابطة والتجريبية، سيوفر خطوة كبيرة إلى الأمام لتحسين الإبلاغ عن الدراسات الحية وتسهيل إجراء التحليل التلوي بشكل عام. كما أن استخدام MNMS مع مستودعات موحدة لجمع البيانات سيسمح أيضًا بإجراء تحليلات تلوية معقدة تكون حاليًا غير ممكنة بسبب غياب البيانات الأولية أو الخام. يمكن أن تولد مثل هذه الأعمال رؤى علمية جديدة دون استخدام إضافي للحيوانات المختبرية.
فائدة إضافية لاعتماد MNMS هي أنها يمكن أن تبسط العملية لإنشاء مجموعة أغنى من البيانات الوصفية والرؤى مع الحد الأدنى من الجهد الإضافي، مما يمكن أن يدعم التحليل التلوي بشكل أكبر. مثال لتوضيح هذه الفكرة هو كيفية استرجاع العمر عند الاختبار، وهو مصطلح بيانات وصفية قد يكون حرجًا للتحليل التلوي، ولكنه غير مدرج في MNMS. يمكن الحصول على العمر عند الاختبار من خلال تقاطع تاريخ الميلاد وتاريخ بدء الدراسة (كلا العنصرين مدرجين في MNMS) أو تاريخ الاختبار الذي قد يكون مضمنًا في ملف البيانات الخام (على سبيل المثال، الطابع الزمني للبيانات الخام). لذلك، تعمل MNMS كطبقة إضافية من البيانات الوصفية التي تبني على كل من مجموعة البيانات الأساسية وأي بيانات وصفية سلبية تم إنشاؤها من خلال عملية جمع البيانات. تقاطع و/أو دمج MNMS مع الحد الأدنى من المعلومات المستمدة من البيانات الخام.
الشكل 3 | مزايا تنفيذ MNMS للمساهمين الرئيسيين. يوضح هذا الشكل الفوائد المتعددة الجوانب لـ MNMS عبر مختلف المساهمين. بالنسبة للباحثين، يسهل MNMS إنشاء ظروف تجريبية منظمة للغاية ومتجانسة، مما يعزز قابلية تكرار التجارب، ويقلل من استخدام الموارد، ويعالج الاعتبارات الأخلاقية. تستفيد المنظمات التنظيمية ووكالات التمويل من دعم الشفافية الأكبر، والمساءلة و
رفاهية الحيوان، مع تمكين MNMS من إجراء تجارب موحدة وتقليل تكاليف البحث. من منظور (علم) الإحصاء، يزيد MNMS من دقة وقابلية تكرار التحليلات الإحصائية من خلال القضاء على المتغيرات المربكة، وتوحيد جمع البيانات وضمان بيئة بحث أكثر تنظيمًا. هذه التمثيل الشامل يبرز دور MNMS في تعزيز ممارسات البحث المسؤولة والفعالة وعالية الجودة. يعزز من قيمتها وفائدتها. تحتوي هذه المقاربة أيضًا على حجم MNMS إلى الحد الأدنى مع تعظيم تأثيرها على إعادة استخدام البيانات وإجراء التحليل الشامل.
التحديات في اعتماد MNMS
إن مفهوم نشر نظام إدارة البيانات متعددة الأبعاد (MNMS) لتمكين إنشاء مستودعات بيانات منظمة وفرصة إعادة استخدام البيانات جذاب للغاية من وجهة نظر علمية (على سبيل المثال، المعرفة المتزايدة والرؤى الجديدة) وأخلاقية (أي، استبدال و/أو تقليل استخدام الحيوانات). ومع ذلك، فإن الفكرة الجوهرية لإعادة الاستخدام تتضمن أن قاعدة مستخدمين كبيرة ضرورية لتحقيق الفرص الكاملة لإعادة استخدام البيانات. هنا نعترف بأن تطبيق مفهوم إعادة الاستخدام على نطاق واسع ليس خاليًا من التحديات.
التبني داخل المجتمع العلمي
ظهرت عدة مبادرات لزيادة إمكانية التكرار وإعادة الإنتاج، ولدعم إعادة استخدام البيانات المستمدة من الدراسات الحية.لسوء الحظ، لم يتم اعتماد هذه المبادرات والإرشادات المرتبطة بها بشكل روتيني عبر مجتمع البحث البيولوجي. أحد التفسيرات هو أن الجهود المطلوبة لاتباع مثل هذه الإرشادات، والمكافآت الناتجة عن القيام بذلك، قد لا تكون ذات اهتمام فوري للمنتج البيانات في المختبر. خاصة في مجال البحث البيولوجي الاكتشافي، قد تكون الفائدة المدركة محدودة لتضمين بيانات وصفية تم الإبلاغ عنها بدقة وتخزين البيانات الناتجة عن دراسات مخصصة للغاية ‘فريدة من نوعها’ ضمن مستودع مركزي. قد تعكس الممارسات التاريخية داخل المختبرات، جنبًا إلى جنب مع الموارد المحدودة، الحاجة إلى مزيد من التغيير داخل المجتمع العلمي للاعتراف بأهمية مشاركة البيانات ومسؤوليات العلماء في الإبلاغ عن بياناتهم.
لتقليل الجهد المطلوب لتوفير MNMS وزيادة تأثيرها، اقترحنا MNMS يتماشى مع ARRIVE 2.0، كإرشادات تحظى بقبول متزايد داخل مجتمع البحث البيولوجي وتقبلها المجلات التي تخضع لمراجعة الأقران. من خلال توفير مجموعة إلزامية وأدنى من المصطلحات المنضبطة لوصف البيانات، ستتغلب MNMS على تحديات إدخالات ‘النص الحر’ المطلوبة من ARRIVE، والتي يمكن أن تؤدي إلى إدخالات ذات جودة متغيرة لا يمكن مقارنتها بسهولة بين المنشورات، أو عدم وجود إدخالات على الإطلاق.
ومع ذلك، نعترف بأن ضمان سهولة الاستخدام وحده ربما لا يكون كافياً لضمان اعتماد وتنفيذ نظام إدارة الشبكات المتنقلة.
عبر مجتمع البحث البيولوجي. لدعم الاستخدام بشكل أكبر، ستكون هناك حاجة إلى أدوات إضافية، وتدريب، وفي النهاية تنظيم. قد تشمل هذه الأدوات استخدام الذكاء الاصطناعي لدعم تحديد وتقرير البيانات الوصفية من المنشورات بتنسيقات موحدة، ولتسليط الضوء على الأماكن التي لا توجد فيها بيانات وصفية معينة ويجب تقديمها قبل النشر. بالإضافة إلى ذلك، قد يكون نظام ‘تحفيزي’ فعالًا للغاية لدعم اعتماد MNMS وإعادة استخدام البيانات. على سبيل المثال، يمكن ربط مجموعات البيانات والبيانات الوصفية بمقاييس الجودة ويمكن تنفيذ نظام مرجعي. وبالتالي، ستتلقى مجموعات البيانات والبيانات الوصفية التي دعمت إعادة الاستخدام معدل مرجعي أعلى وتوفر اعترافًا للعلماء المساهمين، ومجموعات البحث ومؤسساتهم.
خطوة رئيسية لزيادة مشاركة البيانات وإعادة استخدامها في البحث البيولوجي ستكون تنفيذ مصطلحات محكومة حيث أن مثل هذه المعايير ليست شائعة في هذا المجال. ستوفر MNMS إطارًا ابتدائيًا لتنفيذ هذه المصطلحات. مساحة البحث البيولوجي كبيرة ومتنوعة، مما يجعل تنفيذ أي معيار تحديًا. ومع ذلك، فإن هذا الحجم والتنوع في مساحة البحث يمثل أيضًا فرصة هائلة للاستفادة بشكل أفضل من المعرفة التي يتم توليدها ودعم 3Rs بشكل أكبر. في هذا الصدد، من المهم تسليط الضوء على أن تقدمًا في هذا الاتجاه قد تم إحرازه في مجالات أخرى. على سبيل المثال، في صناعة الكيمياء، يوجد متطلب قانوني لمشاركة البيانات من الدراسات الحية في التقارير التي تستخدم لأغراض التسجيل (انظر، على سبيل المثال، المادة 62 (مرجع 22)). وبالمثل، قامت إدارة الغذاء والدواء بتنفيذ SEND للإبلاغ الموحد عن الدراسات غير السريرية للسلامة، بينما تقدم مشروع IMI eTRANSAFE الذي تم الانتهاء منه مؤخرًا في مشاركة البيانات لتحسين تقييمات السلامة الانتقالية في تطوير الأدوية..
تقييد الفضاء التجريبي
نعتقد أنه من الممكن تحديد مجموعة الحد الأدنى من البيانات الوصفية للتجارب الحيوانية بحيث يمكن إعادة استخدام البيانات الخام عبر عائلات مختلفة من التجارب. ومع ذلك، فإن هذه النظرة المتفائلة مقيدة بمدى الفضاء التجريبي ومساحته النسبية من البيانات الوصفية (أي جميع التجارب الممكنة عبر تخصصات مختلفة).
لا يسمح هذا الفضاء الواسع بتحديد مجموعة الحد الأدنى من البيانات الوصفية التي تضمن اتخاذ قرار دائمًا بشأن إعادة استخدام البيانات من تخصصات متنوعة (على سبيل المثال، أمراض القلب، علم الأعصاب، علم الأورام، وما إلى ذلك). في مثل هذه المهمة الضخمة، سيكون من الضروري توسيع MNMS إلى حجم غير قابل للإدارة، وبالتالي فقدان الجودة الجذابة المتمثلة في كونها ‘حد أدنى’. على سبيل المثال، بينما قد تتعلق الخصائص المتعلقة بالحيوانات
وسكنها بمجموعة محدودة من الأبعاد (على سبيل المثال، النمط الجيني، العمر، الوزن، دورة الضوء، وما إلى ذلك)، تغطي البيانات الوصفية من مجال التلاعبات التجريبية مساحة أوسع بكثير. ظهرت هذه القضية بسرعة في سياق مجموعة العمل الحالية أثناء البحث عن توافق حول العناصر التي يجب تضمينها في MNMS. تم التوصل إلى توافق حول عدة عناصر تنتمي إلى مجال ‘الحيوانات’ (على سبيل المثال، العمر، النمط الجيني والوزن)، بينما انهار الاتفاق بسرعة عند محاولة تحديد البيانات الوصفية المتعلقة بالتلاعبات التجريبية. تعكس هذه التجزئة خلفيات البحث المختلفة للمؤلفين، ومن المؤكد أن المجالات المختلفة من المحتمل أن تشغل مناطق مختلفة من مساحة البيانات الوصفية.
لمعالجة التحدي الذي يقدمه الفضاء التجريبي الواسع في البحث البيولوجي، نقترح أنه يجب اتخاذ قرار مسبق بشأن نطاق الأسئلة التجريبية (والمقاييس الناتجة المرتبطة بها) التي ستكون ذات أهمية لمعالجتها في مبادرة إعادة الاستخدام، مثل في توليد VCGs. سيساعد تحديد الأسئلة البحثية (والمقاييس الناتجة) بشكل مسبق وجعلها واضحة في منح هيكل (الشكل 1c) للبيانات الوصفية. سيسمح هذا بدوره للباحثين بتقدير إمكانيات إعادة الاستخدام للبيانات الخام المجمعة في تخصصات مختلفة وعبر المؤسسات. من الضروري بالفعل أن تشارك عدة أطراف (على سبيل المثال، خبراء المجال، مهندسو البيانات، وكالات التمويل، وما إلى ذلك) في عمل منسق لتحديد الحدود والجسور لهذه المجموعات الحد الأدنى من البيانات الوصفية ولجعل إعادة استخدام البيانات عبر التخصصات واقعًا ناجحًا.
الاعتبارات القانونية لمشاركة البيانات
يطرح هدف نشر MNMS لتسهيل مشاركة البيانات وإعادة استخدامها بعض الأسئلة المهمة من منظور قانوني. نعتقد أن المبادرات المستقبلية لدعم مشاركة البيانات ستحتاج إلى أخذ عشرة مواضيع على الأقل في الاعتبار.
ضمان خصوصية الأفراد. كما تم مناقشته، فإن جانبًا مهمًا من البيانات الوصفية هو ضمان الأصل والملكية. ستتطلب فكرة تحفيز والاعتراف بالمساهمين والمستخدمين للبيانات لإعادة الاستخدام أيضًا أن يرتبط الأفراد بمعرف FAIR مثل معرف ORCID. ومع ذلك، فإن معرف ORCID هو رمز يمكن ربطه بشخص يمكن التعرف عليه، مما قد يجعل الرمز ‘بيانات شخصية’ في بعض أجزاء العالم. لذلك، قد يحتاج المساهمون إلى إبلاغهم بكيفية استخدام بياناتهم الشخصية ومشاركتها مع الآخرين. قد تكون هناك تدابير أخرى مطلوبة أيضًا لضمان الامتثال لمتطلبات الخصوصية.
التحكم في من يمكنه الوصول إلى البيانات ولأي أغراض. لحماية قيمة البيانات، يجب أن تكون البيانات متاحة فقط لأولئك الذين لديهم نية حقيقية لإجراء مزيد من البحث.
تقليل الكشف عن المعلومات الحساسة تجاريًا. حيث يتم تقديم طلبات الوصول من قبل منافس للمساهم، من المحتمل أن تكون هناك حاجة إلى تدابير وقائية لحماية مثل هذه المعلومات الحساسة تجاريًا وضمان الامتثال لقانون المنافسة.. قد تشمل الخيارات المحتملة استخدام طرف ثالث للإشراف والموافقة على طلبات الوصول دون تدخل المساهم.
ضمان حماية البيانات الملكية. لزيادة قاعدة مستخدمي الحشد، نقترح الحفاظ على نطاق مركز على الحيوانات المستخدمة فقط في مجموعات التحكم، حيث لم يتم تطبيق أي منتج ملكي.
الوصول العادل. على الرغم من أن الشركات ليست ملزمة بمشاركة البيانات، سيكون من الحكمة ضمان أن جميع شروط الوصول عادلة ومعقولة وغير تمييزية (أي، يجب أن يكون أولئك في وضع مماثل قادرين على الوصول إلى البيانات بنفس الشروط).
توقيت الوصول. هل يجب أن تكون البيانات متاحة للآخرين للوصول إليها على الفور، أم أنه من المعقول فرض تأخير زمني لحماية المصالح التجارية للمساهم؟ بعض الأدوات الحالية تأخذ بالفعل توقيت الوصول
للمعلومات كميزة ذات صلة (على سبيل المثال، انظر animalstudyregistry.org، الذي يسمح بفترات حظر زمنية).
الملكية وحقوق الاستخدام. من المحتمل أن يرغب المساهمون في الاحتفاظ بملكية بياناتهم ومنح المستلمين فقط حق استخدام البيانات لأغراض معينة (مع حقوق محدودة لمشاركتها مع الآخرين). حيث يتم مشاركة بيانات ذراع التحكم فقط، من المحتمل أن يتوقع الطالب أن يمتلك النتائج التي ينتجها باستخدام تلك البيانات.
المسؤولية. قد يتوقع الطالب بشكل معقول أن يؤكد المساهم أن لديه الحق في المساهمة بالبيانات. ومع ذلك، من المحتمل أن يرغب المساهمون في أن يقبل الطالب المسؤولية الكاملة عن تأكيد أن البيانات مناسبة للأغراض التي يرغبون في استخدامها من أجلها وأن يقبلوا جميع المسؤوليات المرتبطة بإعادة استخدام البيانات. قد يحتاج الطلاب لذلك إلى فحص البيانات بدقة للتأكد من أنها مناسبة بالفعل للغرض، ويجب إدارة ذلك بشكل مناسب.
السعر الواجب دفعه. هل يجب أن يُطلب من الطالب تقديم مساهمة مالية نحو تكاليف توليد البيانات؟ إذا كان القرار هو نعم، فإن الإرشادات التي نشرتها الوكالة الأوروبية للمواد الكيميائية بشأن مشاركة البيانات قد تكون نقطة مرجعية مفيدة لكيفية حساب المبالغ المعقولة.
ضمان الحق في المشاركة. سيتعين على المساهمين التأكد من أن اتفاقياتهم مع منظمات البحث التعاقدي من الطرف الثالث (CROs) أو المتعاونين في البحث تسمح بمشاركة البيانات ذات الصلة في أي نظام لمشاركة البيانات وإعادة استخدامها من قبل أطراف ثالثة. هذه المسألة مهمة بشكل خاص حيث لا يكون مشاركة البيانات متطلبًا قانونيًا واضحًا وحيث توجد نية لفرض رسوم على الأطراف الثالثة للوصول إلى البيانات (والتي قد تُعتبر استخدامًا تجاريًا للنتائج).
سيناريوهات لتنفيذ MNMS
على الرغم من التحديات المعترف بها التي تم مناقشتها أعلاه، فإن القسم التالي يسلط الضوء على الفرص للاستفادة من MNMS لدعم إنشاء مستودعات بيانات in vivo وإعادة استخدام البيانات عبر سياقات البحث المختلفة في in vivo، بما في ذلك المرافق الأساسية السلوكية في الأوساط الأكاديمية، ومنظمات البحث التعاقدية، والشركات الصيدلانية، ومزودي معدات البحث في in vivo.
المرافق الأساسية السلوكية في الأوساط الأكاديمية
تزداد شيوع مرافق السلوك الأساسية داخل المؤسسات البحثية الأكاديمية، وهي في وضع جيد لتحسين جودة الأبحاث الطبية الحيوية ما قبل السريرية من خلال ضمان تدابير مراقبة الجودة.توفر المرافق الأساسية للمستخدمين المحليين (عادةً المحققين الرئيسيين والمختبرات من الجامعة التي تستضيفها) الوصول إلى مجموعة من الاختبارات والمعدات التي تسهل البحث الوظيفي في الجسم الحي (انظر المرجع 43 لمزيد من المعلومات). تُعتبر هذه الاختبارات والمعدات عادةً من الأساليب المعتمدة كمعيار ذهبي في هذا المجال. البروتوكولات التجريبية المطبقة تكون متشابهة إلى حد كبير وتُكرر بانتظام من قبل مستخدمين مختلفين يحتفظون بالحيوانات المختبرية في نفس المنشأة وظروف التربية.
فرصة. قد تسمح الوضعية الفريدة والموارد لمرفق أساسي ضمن البحث الأكاديمي بمشاركة البيانات وإعادة استخدامها بطريقة مباشرة وقابلة للتطبيق. لدعم تنفيذ نظام إدارة البيانات متعددة الأبعاد (MNMS)، يمكن سحب عدة حقول بيانات وصفية (على سبيل المثال، السلالة، الجنس، العمر، وما إلى ذلك) تلقائيًا من سجلات مرفق الحيوانات بدعم من موظفي الرعاية لتوفير معلومات حول ظروف التربية (على سبيل المثال، دورة الضوء اليومية). يمكن لموظفي الوحدة الأساسية (إذا كانوا موجودين) تقديم معلومات حول البروتوكول التجريبي (على سبيل المثال، إعدادات الأجهزة إذا كانت مدرجة في مجموعة البيانات الوصفية الموسعة) ويمكن للباحث تقديم حقول إضافية (على سبيل المثال، العلاج، الجرعة، والطريقة). قد يتم تسريع تنفيذ نظام إدارة البيانات متعددة الأبعاد والأنظمة الداعمة بشكل أكبر بدعم من خدمات المعلومات المحلية والبنية التحتية. باختصار، قد تكون المرافق السلوكية الأساسية في الأوساط الأكاديمية نقطة انطلاق ممتازة للدعوة وتنفيذ نظام إدارة البيانات متعددة الأبعاد.
CROs
توفر منظمات الأبحاث التعاقدية (CROs) الوصول إلى تجارب حية على أساس الدفع مقابل الخدمة لعميل راعي. عادةً ما تكون العملاء مؤسسات خاصة، مثل شركات الأدوية أو التكنولوجيا الحيوية، التي قد لا تمتلك خبرة داخلية في التجارب الحية أو قد ترغب في توسيع قدرتها الداخلية. تقدم منظمات الأبحاث التعاقدية عادةً كتالوجًا من الاختبارات الحية القياسية التي تُقبل ضمن مجال البحث الطبي الحيوي المعني وتتبع المعايير المحلية والدولية للتنظيم المتعلقة بتجارب الحيوانات. تقدم العديد من منظمات الأبحاث التعاقدية أيضًا دراسات علم الأدوية السليمة وعلم السموم في الحيوانات التي يمكن استخدامها لدعم التقديمات التنظيمية. في كل من بيئة الاكتشاف والسلامة، يمكن تطوير وتكييف اختبارات حية مخصصة لتلبية احتياجات العميل. ومن الجدير بالذكر أن منظمات الأبحاث التعاقدية تستخدم لتخزين البيانات بطريقة منظمة في قواعد بيانات مخصصة. خاصة بالنسبة لمنظمات الأبحاث التعاقدية التي نفذت SEND، كما هو مطلوب من قبل إدارة الغذاء والدواء الأمريكية لدراسات السلامة، فإن إطار العمل للتمثيل الإلكتروني القياسي لبيانات دراسات الحيوانات الفردية موجود بالفعل.
فرصة. مع الخبرة المكتسبة من توحيد تخزين البيانات ضمن دراسات سلامة الأدوية لـ SEND، فإن الانتقال إلى الدراسات الحية للبحث البيولوجي الاكتشافي هو خطوة سهلة للعديد من شركات الأبحاث التعاقدية (CROs). سيكون هناك العديد من الفوائد لاعتماد MNMS وإعادة استخدام البيانات في مجال CRO للبحث الاكتشافي. أولاً، من خلال جعل بيانات التحكم أو بيانات تجريبية أخرى (على سبيل المثال، من علاجات مرجعية قياسية) متاحة لإعادة الاستخدام، يمكن للعملاء الممولين تجنب تكرار بعض التجارب واختيار استخدام مجموعات التحكم الافتراضية بدلاً من بيانات التحكم التي تم إنشاؤها حديثًا. ستؤدي هذه العملية بلا شك إلى تقليل كبير في استخدام الحيوانات المختبرية. ثانياً، يجب أن يعزز تبادل البيانات من العميل إلى CRO، والعكس بالعكس، القوة الجوهرية لاختبار معين، مما سيعود بالفائدة على كل من CRO من خلال التأكيد على جودة الاختبار وعلى العميل من خلال اتخاذ قرارات قوية بناءً على نتيجة الاختبار. على سبيل المثال، قد يتم الإبلاغ عن نتائج تشير إلى تأثير مركب عندما يكون مدفوعًا في الواقع باستجابة تحكم شاذة. إن القدرة على استخدام مجموعات تحكم افتراضية أكبر ستقلل من هذا الخطر. أخيرًا، سيدعم اعتماد MNMS مجموعات البيانات الموحدة، والتي بدورها يمكن أن تنسق البيانات لمزيد من التوافق وتحسين تصميمات الدراسات. في تطوير أدوية جديدة، الوقت هو جوهر الأمر. لن تؤدي مجموعات التحكم الافتراضية وتصميمات الدراسات المحسّنة فقط إلى تقليل عدد الحيوانات وضمان أبحاث أكثر أخلاقية، ولكنها ستسرع أيضًا من مسار تطوير الأدوية وتقلل التكاليف، وهو ما يعد غالبًا عاملاً حاسمًا لشركات التكنولوجيا الحيوية الأصغر حجمًا.
بينما يتم تصور العديد من الفوائد في مجال CRO لاعتماد MNMS وإعادة استخدام البيانات، تظل مشاركة البيانات نقطة اهتمام. قد تحتوي القيود على استخدام البيانات في الاتفاق بين CRO والعميل الراعي، وقد تتطلب مشاركة البيانات شروطًا إضافية يجب الاتفاق عليها (كما تم مناقشته أعلاه في الاعتبارات القانونية لمشاركة البيانات).
البحث والتطوير في صناعة الأدوية
بينما يتم إجراء الغالبية العظمى من التجارب في أبحاث وتطوير الأدوية (Pharma R&D) في دراسات غير حيوانية، تظل الأبحاث الحيوانية مكونًا مهمًا لاكتشاف بيولوجيا جديدة وفرص علاجية، ولتوقع فعالية وأمان الأدوية الجديدة قبل دخولها التجارب البشرية. داخل شركة أدوية واحدة، قد تكون هناك برامج متعددة لاكتشاف الأدوية تعمل في وقت واحد، وغالبًا عبر مواقع جغرافية متنوعة ومن خلال جهود داخلية و/أو مع شركاء خارجيين بما في ذلك التعاون الأكاديمي، والاتحادات أو منظمات الأبحاث التعاقدية (CROs). يمكن أن تستمر برامج البحث لسنوات، أو حتى عقود، كما هو الحال مع الجدول الزمني المطول الذي يعد نموذجيًا لتطوير الأدوية الجديدة. في هذا السياق، يعد تخزين البيانات وفقًا لمبادئ FAIR والحاجة إلى تجنب تكرار البيانات التاريخية بشكل مستمر أمرًا في غاية الأهمية لضمان تقدم البحث وتحسين اكتشاف الرؤى.
فرصة. لمعالجة التحديات الخاصة بأبحاث وتطوير الأدوية، فإن اتباع نهج موحد في هندسة تكنولوجيا المعلومات وإدارة البيانات أمر حاسم. سيسهل اعتماد MNMS في الجسم الحي. إعادة استخدام البيانات، بينما ستساعد المعايير المفتوحة وواجهات برمجة التطبيقات (APIs؛ انظر التعريف في المربع 1) في تسهيل التوافق بين الأنظمة المختلفة، مما يمكّن الباحثين من العمل بشكل أكثر كفاءة وتعاونًا. من خلال إنشاء منصة غير مرتبطة بمجال معين مدمجة مع برامج إدارة الحيوانات، يمكن للباحثين جعل بياناتهم أكثر وصولاً للآخرين، مما يؤدي إلى زيادة التعاون والابتكار. ستسمح هذه الوصولية للبيانات للباحثين بالبناء على أعمال بعضهم البعض ودمج البيانات من دراسات مختلفة لمعالجة أسئلة بحث جديدة.
لدعم تنفيذ MNMS في البحث والتطوير في مجال الأدوية، من الضروري وجود فريق متعدد التخصصات يتكون من علماء البيانات، باحثين علميين ومتخصصين في الحيوانات المختبرية لتنفيذ نهج موحد عالميًا بشكل فعال. يمكن أن تساعد التعاون بين هذه المجالات في ضمان أن استراتيجية إدارة البيانات شاملة ومتوافقة مع أهداف ومتطلبات البحث في الشركة. يمكن لعلماء البيانات أن يساهموا بخبراتهم في نمذجة البيانات، التحليلات والتصور لتطوير نموذج بيانات مشترك يمكن استخدامه عبر أنظمة مختلفة. يمكن للباحثين العلميين تقديم مدخلات حول الاحتياجات والأهداف البيوميدانية المحددة، بالإضافة إلى تحديد الأسئلة البحثية المحتملة التي يمكن معالجتها من خلال إعادة استخدام البيانات. يمكن لمتخصصي الحيوانات المختبرية تقديم رؤى حول التحديات التشغيلية للعمل مع أنظمة مختلفة والمساعدة في ضمان توافق الاستراتيجية مع اللوائح المحلية والعالمية لرفاهية الحيوانات. من المهم أن يتعرف المديرون الكبار في البحث والتطوير في مجال الأدوية على أهمية مثل هذه المبادرات ويدعموا مواردها لضمان تنفيذ ناجح وفي الوقت المناسب.
يمكن أن يؤدي هذا النموذج التعاوني إلى نتائج بحثية أكثر كفاءة ودقة، مما يعود بالنفع في النهاية على التقدم العلمي، وتطوير أدوية جديدة ورفاهية الحيوانات. يمكن أن يؤدي التوحيد في إدارة البيانات أيضًا إلى تحسين جودة البيانات وتناسقها، وهو أمر ضروري للامتثال التنظيمي ومبادرات مشاركة البيانات. من خلال تنفيذ نهج شامل يعالج تحديات العمل مع أنظمة حية متعددة، يمكن للباحثين في البحث والتطوير في مجال الأدوية إعادة استخدام ودمج البيانات من دراسات مختلفة، مما يؤدي إلى رؤى واكتشافات أكبر.
مطورون ومزودو برامج و/أو أجهزة أبحاث الحيوانات
تُعزز أبحاث الحيوانات من خلال نظام بيئي غني من الأجهزة والبرامج، بما في ذلك برامج إدارة الحيوانات المستعمرة وأنظمة إدارة المعلومات المختبرية، والأدوات المستخدمة في المختبر لمختلف القياسات (على سبيل المثال، أجهزة مراقبة معدل ضربات القلب أو أجهزة التصوير) والبرامج التي تمكن من تحليل العينات البيولوجية وتصور البيانات (على سبيل المثال، أدوات تحليل الصور أو الأدوات الإحصائية).
فرصة. من خلال دمج MNMS وخاصة مصطلحات المفردات المتناغمة في منصاتهم، يمكن للشركات التي تشارك في توفير المعدات التجريبية والبرامج لأبحاث الحية أن تساهم بشكل كبير في تحسين مشاركة البيانات وإعادة استخدامها. الشركات التي تقدم برامج إدارة الحيوانات، والتي يمكن أن توفر للمستخدمين الوصول إلى MNMS وإنشاء ودعم واجهات برمجية لدفع MNMS إلى أنظمة أخرى معنية بجمع البيانات وتحليلها، هي ذات أهمية خاصة في هذا السياق. وبالمثل، يمكن للشركات التي تدعم جمع البيانات التجريبية أن تضمن تضمين MNMS في البيانات الخام لضمان تحليل سلس وسهولة التكامل عند الاستفادة من أنظمة تجارية متاحة. من الجدير بالذكر أنه لتضمين MNMS في منتجاتها، يجب على الشركات التجارية التأكد من استخدام نفس المفردات المتحكم فيها طوال عملية جمع البيانات وإدارتها وتحليلها. سيسهل النهج الموحد وصول الباحثين إلى البيانات ومقارنتها وإعادة استخدامها التي تم إنشاؤها عبر العديد من المنصات والدراسات.
من خلال اعتماد MNMS، يمكن لمزودي الأنظمة التجارية أن يساهموا بشكل كبير في المجتمع العلمي من خلال جعل المعلومات المهمة متاحة بسهولة لأغراض متنوعة، بما في ذلك طلبات المنح، المنشورات الأكاديمية، طلبات تراخيص الحيوانات وتقديم براءات الاختراع المتعلقة بأبحاث الحيوانات. بالإضافة إلى تعزيز جودة البحث ودعم قابليته للتكرار، ستعزز هذه الخطوة أيضًا
تشجيع الاعتبارات الأخلاقية وفي النهاية تسهيل عملية إدارة بيانات الحيوانات وإعادة استخدامها.
ملاحظات ختامية واتجاهات مستقبلية
لقد اقترحنا MNMS متوافق مع FAIR للدراسات الحية في البحث البيوميداني. إن MNMS الذي نقترحه، إذا تم اعتماده على نطاق أوسع، سيوفر فوائد متعددة. أولاً، يبني MNMS على المبادرات الحالية (على سبيل المثال، الإرشادات مثل PREPARE وARRIVE) لزيادة الشفافية في توليد البيانات. إن الإبلاغ الشفاف عن المنهجية والبيانات المطلوبة لتكرار التحليلات هو خطوة أساسية لتمكين وضمان القابلية للتكرار. MNMS هو أداة تدعم الإبلاغ الشفاف.
ثانيًا، سيسهل تنفيذ MNMS مشاركة البيانات، ويفضل أن يكون ذلك من خلال مستودعات بيانات عامة كبيرة. بدوره، سيمكن ذلك من إعادة استخدام البيانات، مع كون أحد الأمثلة العديدة المميزة هو توليد VCGs. إن استخدام VCGs هو فرصة غير مستغلة حاليًا يمكن أن تقلل بشكل كبير من عدد الحيوانات المستخدمة في البحث البيوميداني عند تطبيقها على نطاق واسع.
معًا، نعتقد أن نشر MNMS جنبًا إلى جنب مع المبادرات الحالية (ARRIVE) يمثل الحدود التالية لتعزيز الاستخدام الأخلاقي للحيوانات في البحث. لذلك، ندعو إلى استخدامه ونقترح استراتيجيات لمزيد من تطوير MNMS وتبنيه بين أصحاب المصلحة في البحث. على الرغم من وجود تحديات لتنفيذ MNMS، يمكن تعلم الدروس من مجالات أخرى بما في ذلك صناعة الكيمياء واختبار سلامة الأدوية.
لتعزيز تنفيذ MNMS، نقترح نهج تدريجي وتعاوني للتنقيح، الاختبار، التحقق والتنفيذ. ستكون الخطوة الأولى المنطقية هي تجربة استخدامها مع أصحاب المصلحة الرئيسيين (الشكل 3). يمكن أن تتضمن هذه الخطوة تنقيح MNMS من خلال عمليات التواصل المشتركة والتوافق المجتمعي بين المشاركين من كل من المجموعات الرئيسية (العلماء، الهيئات التنظيمية و(البيو)إحصائيين) عبر القطاعات الأكاديمية، الصيدلانية وقطاع البحث التعاقدي، لتحديد المزيد من الحواجز الممكنة والعوامل المساعدة للتنفيذ. تسمح تقنية مثل دلفي المعدلة بإدخال المجتمع والتوافق عند اتخاذ القرار بشأن إضافة وتنقيح مصطلحات أخرى حاسمة في مجالات محددة، مثل أهمية حالة الصحة أو الميكروبيوم الحيواني. في الوقت نفسه، هناك حاجة إلى جهود متعددة التخصصات إضافية لإنشاء وتنقيح أطر قانونية شاملة وسياسات لمشاركة البيانات عبر أصحاب المصلحة من صناعات متعددة. يمكن أن تركز هذه الجهود على مواضيع مثل: التطوير المشترك للأدوات لدعم التكامل مع البنية التحتية الحالية للبيانات؛ تطوير وثائق جديدة وتعليم لدعم التبني؛ والتكامل مع المبادرات الحالية في 3Rs. نقترح أن تُدار هذه الأنشطة في جولات تكرارية لتسريع توافق وجهات النظر داخل هذه المجموعة المتنوعة من أصحاب المصلحة.
سيكون السلوك المفتوح للعديد من الأنشطة التعاونية بين أصحاب المصلحة أمرًا حاسمًا لتطوير مشاريع نموذجية لإثبات المفهوم، أوراق بيضاء أو توصيات يمكن أن تدعم دمج MNMS في مبادرات 3Rs عبر الصناعات الحالية. تشمل أمثلة هذه المبادرات تسجيل البروتوكولات (على سبيل المثال، animalstudyregistry.org وpreclinicaltrials.eu) ومبادرات لتحسين جودة تصميم التجارب ومعايير الإبلاغ عن تجارب الحيوانات (على سبيل المثال، إرشادات PREPARE وARRIVE). في هذا السياق، سيكون لصانعي السياسات، والهيئات التنظيمية، والجهات الممولة دور أساسي في دعم اعتماد MNMS ضمن الإعداد البحثي الأوسع.
نبرز الحاجة إلى استراتيجيات إضافية يمكن أن تدعم اعتماد وتنفيذ MNMS لمشاركة البيانات. سيمكن الحصول على رؤى حول الأدوات التي يستخدمها المجتمع البحثي حاليًا (على سبيل المثال، مبادرات تحالف بيانات البحث أو الأنطولوجيات والمفردات الخاصة بالمجال)، وكيف يمكن أن يتماشى MNMS بشكل أفضل ويتكامل مع هذه الأدوات، من تطوير استراتيجيات جديدة لمعالجة الحواجز أمام اعتماد MNMS وتسهيل مشاركة البيانات. على سبيل المثال، قد تكون هناك حاجة إلى وثائق إضافية للمستخدمين غير التقنيين حول كيفية استخدام MNMS ضمن سير العمل الحالي لديهم. قد يتم أيضًا تنقيح MNMS بشكل أكبر لتقليل التداخل أو التكرار غير الضروري في عبء العمل المطلوب من قبل
المعنيون الرئيسيون. من المحتمل أن تكون الحاجة الملحة هي توحيد المصطلحات والمفردات الخاضعة للرقابة، مما قد يدعم اعتماد MNMS من قبل المعنيين الرئيسيين، بما في ذلك الشركات التي تقدم معدات البحث العلمي والبرمجيات للباحثين في vivo عبر القطاعات. نحن نعتبر هذه الشركات كعامل تمكين رئيسي لتسهيل استخدام MNMS ومشاركة البيانات. في الواقع، لقد حقق قطاع الصناعة الخاصة بالفعل تقدمًا كبيرًا في تطوير وتنفيذ المفردات الخاضعة للرقابة، ومن المحتمل أن تسارع التعاون الوثيق بين المؤسسات الخاصة والعامة التقدم في هذا المجال.
مع ملاحظات من المعنيين الرئيسيين، يمكن وضع خارطة طريق لنشر MNMS، ربما تنتقل من الاستخدام المحلي إلى العالمي بطريقة تدريجية ومتزايدة، وضمان التوافق بين هذه الجهود في كل مرحلة. يمكن أن تشمل أنشطة النشر استضافة ورش عمل لعرض وظائف MNMS مع مشاريع نموذجية؛ وتوضيح تأثير MNMS على نتائج البحث لكل مجموعة من المعنيين؛ وتطوير مواد تسويقية مستهدفة، مثل الرسوم البيانية لتسليط الضوء على فوائد MNMS؛ وإنتاج مواد تعليمية ووثائق لدعم جهود التدريب حول كيفية استخدام MNMS بشكل فعال؛ وإجراء تجارب تجريبية لإظهار فائدة MNMS في البيئات الشائعة. يمكن أن تسرع هذه الاستراتيجيات من استخدام هذه الأداة في سير العمل الحالي وزيادة الوعي بفوائد MNMS لجمهور واسع.
تقف الأبحاث الطبية الحيوية عند مفترق طرق حرج، حيث هناك إمكانات كبيرة لتوليد رؤى جديدة، بفضل التقنيات الغنية بالبيانات التي يمكن الآن نشرها بسرعة وبتكلفة نسبية منخفضة. ومع ذلك، في غياب الأدوات لإعادة دمج الكميات الهائلة من البيانات الناتجة بشكل فعال في دورة البحث، يواجه الباحثون وضعًا من عدم كفاءة الموارد الضخمة مع مكاسب علمية ضئيلة. هذه القضية تثير القلق بشكل خاص في سياق الأبحاث مع الحيوانات حيث يلتزم الباحثون باتباع 3Rs التي تعترف أيضًا بالحاجة إلى الاستخدام المسؤول للحيوانات. الخطوة الأولى والضرورية نحو إعادة استخدام البيانات من الدراسات في vivo في الأبحاث الطبية الحيوية هي ضمان وصف البيانات الخام بشكل فعال مع البيانات الوصفية. يتماشى MNMS الذي نقترحه هنا مع الإرشادات الحالية للإبلاغ عن الدراسات في vivo، وإذا تم اعتماده، فسيوفر خطوة مهمة نحو تعزيز المعرفة العلمية وضمان الاستخدام الأخلاقي المستمر للحيوانات في الأبحاث الطبية الحيوية.
تاريخ الاستلام: 21 يونيو 2023؛ تاريخ القبول: 31 يناير 2024
تم النشر عبر الإنترنت: 4 مارس 2024
References
Bespalov, A. & Steckler, T. Lacking quality in research: Is behavioral neuroscience affected more than other areas of biomedical science? J. Neurosci. Methods 300, 4-9 (2018).
Frye, S. V. et al. Tackling reproducibility in academic preclinical drug discovery. Nat. Rev. Drug Discov. 14, 733-734 (2015).
Prinz, F., Schlange, T. & Asadullah, K. Believe it or not: how much can we rely on published data on potential drug targets? Nat. Rev. Drug Discov. 10, 712-712 (2011).
Russell, W. M. S. & Burch, R. L. The Principles of Humane Experimental Technique (Methuen, 1959).
Begley, C. G. & loannidis, J. P. A. Reproducibility in science: improving the standard for basic and preclinical research. Circ. Res. 116, 116-126 (2015).
Macleod, M. et al. Biomedical research: increasing value, reducing waste. Lancet 383, 101-104 (2014).
Eggel, M. & Würbel, H. Internal consistency and compatibility of the 3Rs and 3Vs principles for project evaluation of animal research. Lab Anim. 55, 233-243 (2021).
Strech, D. & Dirnagl, U. 3Rs missing: animal research without scientific value is unethical. BMJ Open Sci. 3, e000035 (2019).
Würbel, H. More than 3 Rs : the importance of scientific validity for harm-benefit analysis of animal research. Lab Anim. 46, 164-166 (2017).
Diederich, K., Schmitt, K., Schwedhelm, P., Bert, B. & Heinl, C. A guide to open science practices for animal research. PLoS Biol. 20, e3001810 (2022).
Chou, A. et al. Empowering data sharing and analytics through the open data commons for traumatic brain injury research. Neurotrauma Rep. 3, 139-157 (2022).
Fouad, K. et al. FAIR SCI Ahead: the evolution of the open data commons for pre-clinical spinal cord injury research. J. Neurotrauma 37, 831-838 (2019).
Torres-Espín, A. et al. Promoting FAIR data through community-driven agile design: the open data commons for spinal cord injury (odc-sci.org). Neuroinformatics 20, 203-219 (2022).
FAIRsharing Team. FAIRsharing record for: Minimum Information about Animal Toxicology Experiments (in vivo). FAIRsharing https://doi.org/10.25504/FAIRSHARING.WYSCSE (2018).
Koopmans, B., Smit, A. B., Verhage, M. & Loos, M. AHCODA-DB: a data repository with web-based mining tools for the analysis of automated high-content mouse phenomics data. BMC Bioinform. 18, 200 (2017).
Nault, R. et al. A case for accelerating standards to achieve the FAIR principles of environmental health research experimental data. Environ. Health Perspect. 131, 065001 (2023).
Smith, A. J., Clutton, R. E., Lilley, E., Hansen, K. E. A. & Brattelid, T. PREPARE: guidelines for planning animal research and testing. Lab Anim. 52, 135-141 (2018).
Kilkenny, C., Browne, W. J., Cuthill, I. C., Emerson, M. & Altman, D. G. Improving bioscience research reporting: the ARRIVE guidelines for reporting animal research. PLoS Biol. 8, e1000412 (2010).
Percie du Sert, N. et al. The ARRIVE guidelines 2.0: updated guidelines for reporting animal research. PLoS Biol. 18, e3000410 (2020).
Regulation (EC) No 1907/2006 of the European Parliament and of the Council of 18 December 2006 Concerning the Registration, Evaluation, Authorisation and Restriction of Chemicals (REACH), Establishing a European Chemicals Agency, Amending Directive 1999/45/EC and Repealing Council Regulation (EEC) No 793/93 and Commission Regulation (EC) No 1488/94 as Well as Council Directive 76/769/EEC and Commission Directives 91/155/EEC, 93/67/EEC, 93/105/EC and 2000/21/EC (Text with EEA Relevance) (Publications Office of the European Union, 2006).
Regulation (EU) No 528/2012 of the European Parliament and of the Council of 22 May 2012 Concerning the Making Available on the Market and Use of Biocidal productsText with EEA Relevance. No 528/2012 (Publications Office of the European Union, 2012).
Regulation (EC) No 1107/2009 of the European Parliament and of the Council of 21 October 2009 Concerning the Placing of Plant Protection Products on the Market and Repealing Council Directives 79/117/EEC and 91/414/EEC. No 1107/2009 (Publications Office of the European Union, 2009).
Steger-Hartmann, T. et al. Introducing the concept of virtual control groups into preclinical toxicology testing. ALTEX 37, 343-349 (2020).
Steger-Hartmann, T. et al. Perspectives of data science in preclinical safety assessment. Drug Discovery Today 28, 103642 (2023).
Almeida, C. A. et al. Excavating FAIR data: the case of the Multicenter Animal Spinal Cord Injury Study (MASCIS), blood pressure, and neuro-recovery. Neuroinformatics 20, 39-52 (2022).
Bonapersona, V., Hoijtink, H., Sarabdjitsingh, R. A. & Joëls, M. Increasing the statistical power of animal experiments with historical control data. Nat. Neurosci. 24, 470-477 (2021).
Nolte, T. et al. RITA-registry of industrial toxicology animal data: the application of historical control data for Leydig cell tumors in rats. Exp. Toxicol. Pathol. 63, 645-656 (2011).
Wilkinson, M. D. et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci Data 3, 160018 (2016).
Hair, K., Macleod, M. R. & Sena, E. S., on behalf of the IICARus Collaboration. A randomised controlled trial of an Intervention to Improve Compliance with the ARRIVE guidelines (IICARus). Res. Integr. Peer Rev. 4, 12 (2019).
Yeadon, J. Designating genotypes: what does ‘+’ really mean? The Jackson Laboratory https://www.jax.org/news-and-insights/ jax-blog/2011/May/designating-genotypes-what-does-plus-reallymean20150422t150455 (2011).
Hastings, J. et al. ChEBI in 2016: improved services and an expanding collection of metabolites. Nucleic Acids Res. 44, D1214-D1219 (2016).
Karp, N. A. et al. Applying the ARRIVE guidelines to an in vivo database. PLoS Biol. 13, e1002151 (2015).
Fuochi, S. et al. Data repurposing from digital home cage monitoring enlightens new perspectives on mouse motor behaviour and reduction principle. Sci. Rep. 13, 10851 (2023).
Groenink, L., Verdouw, P. M., Bakker, B. & Wever, K. E. Pharmacological and methodological aspects of the separation-induced vocalization test in guinea pig pups; a systematic review and meta-analysis. Eur. J. Pharmacol. 753, 191-208 (2015).
Currie, G. L. et al. Animal models of chemotherapy-induced peripheral neuropathy: a machine-assisted systematic review and meta-analysis. PLoS Biol. 17, e3000243 (2019).
Mei, J. et al. Refining humane endpoints in mouse models of disease by systematic review and machine learning-based endpoint definition. ALTEX 36, 555-571 (2019).
van Drongelen, J., Hooijmans, C. R., Lotgering, F. K., Smits, P. & Spaanderman, M. E. A. Adaptive changes of mesenteric arteries in pregnancy: a meta-analysis. Am. J. Physiol. Heart Circ. Physiol. 303, H639-H657 (2012).
Macleod, M. R., Tanriver-Ayder, E., Hair, K. & Sena, E. in Good Research Practice in Non-clinical Pharmacology and Biomedicine (eds Bespalov, A., Michel, M. C. & Steckler, T.) 299-317 (Springer, 2020).
robonaultran. Minimum Information about Animal Toxicology Experiments In Vivo (MIATE/invivo). FAIRsharing https://fairsharing. org/FAIRsharing.wYScsE (2020).
Communication from the Commission-Guidelines on the Applicability of Article 101 of the Treaty on the Functioning of the European Union to Horizontal Co-Operation Agreements Text with EEA Relevance (Publications Office of the European Union, 2011).
Restivo, L. et al. Towards best practices in research: role of academic core facilities. EMBO Rep. 22, e53824 (2021).
Bikovski, L. et al. Lessons, insights and newly developed tools emerging from behavioral phenotyping core facilities. J. Neurosci. Methods 334, 108597 (2020).
Strayhorn, J. M. Virtual controls as an alternative to randomized controlled trials for assessing efficacy of interventions. BMC Med. Res. Methodol. 21, 3 (2021).
الشكر والتقدير
نشكر M. Markert (Boehringer Ingelheim) وY.-P. Zhang (F. Hoffmann-La Roche) على المناقشات الأولية حول مفهوم المخطوطة، وD. Roqueiro وM. Ghraichy وY.-P. Zhang وزملائهم في قسم البيانات والتحليلات، Roche Pharma Research and Early Development، F. Hoffmann-La Roche على الدعم في تطوير قاعدة البيانات الموضحة في الشكل 2. L.R. وG.R. وF.S. وM.T. وE.C.O. وS.G. هم أعضاء في عمل COST CA20135 (TEATIME). نشكر S. Dalla Costa
(Tecniplast S.p.A.) على الرسوم البيانية في الشكل 3. A.B.-B. مدعوم من منحة ‘Impulse für das Wissenschaftssystem’ من مؤسسة فولكس فاجن، ألمانيا. M.T. هو حامل كرسي زمالة Carolito Stiftung في الأبحاث المتعلقة بالأمراض التنكسية العصبية.
مساهمات المؤلفين
A.B.-B. وA.M. وE.C.O. وL.R. وS.G. قاموا بتصميم المقالة. S.G. وL.R. وE.C.O. قاموا بتصميم وتوفير الأشكال. ساهم جميع المؤلفين في كتابة المسودة الأصلية للمخطوطة. A.B.-B. وA.M. وE.C.O. وL.R. وS.G. قاموا بمراجعة المخطوطة بشكل نقدي. ساهم جميع المؤلفين في الموافقة على النسخة النهائية من المخطوطة.
التمويل
تم تمكين وتنظيم تمويل الوصول المفتوح بواسطة مشروع DEAL.
المصالح المتنافسة
S.G. وG.R. يعملان لدى Tecniplast S.p.A. E.C.O. وA.M. وS.B. يعملون لدى F. Hoffmann-La Roche Ltd. G.F. يعمل لدى Charles River. F.S. يعمل لدى Novartis AG. جميع المؤلفين الآخرين يعلنون عدم وجود مصالح متنافسة.
معلومات إضافية
يجب توجيه المراسلات وطلبات المواد إلى Eoin C. O’Connor أو Stefano Gaburro أو Alexandra Bannach-Brown.
تقدم Lab Animal شكرها لـ Sabine Hölter وPaul A. Garner والمراجعين الآخرين المجهولين على مساهمتهم في مراجعة الأقران لهذا العمل.
ملاحظة الناشر تظل Springer Nature محايدة فيما يتعلق بالمطالبات القضائية في الخرائط المنشورة والانتماءات المؤسسية.
الوصول المفتوح هذه المقالة مرخصة بموجب ترخيص المشاع الإبداعي 4.0 الدولي، الذي يسمح بالاستخدام والمشاركة والتكيف والتوزيع وإعادة الإنتاج في أي وسيلة أو تنسيق، طالما أنك تعطي الائتمان المناسب للمؤلفين الأصليين والمصدر، وتوفر رابطًا إلى ترخيص المشاع الإبداعي، وتوضح ما إذا كانت هناك تغييرات قد تم إجراؤها. الصور أو المواد الأخرى من طرف ثالث في هذه المقالة مشمولة في ترخيص المشاع الإبداعي للمقالة، ما لم يُشار إلى خلاف ذلك في سطر ائتمان المادة. إذا لم تكن المادة مشمولة في ترخيص المشاع الإبداعي للمقالة واستخدامك المقصود غير مسموح به بموجب اللوائح القانونية أو يتجاوز الاستخدام المسموح به، ستحتاج إلى الحصول على إذن مباشرة من صاحب حقوق الطبع والنشر. لعرض نسخة من هذا الترخيص، قم بزيارة http://creativecommons.org/licenses/by/4.0/.
(ج) المؤلفون 2024
Roche Pharma Research and Early Development، قسم البيانات والتحليلات، مركز الابتكار Roche Basel، F. Hoffmann-La Roche Ltd، بازل، سويسرا. وحدة التحليل العصبي السلوكي، كلية البيولوجيا والطب، جامعة لوزان، لوزان، سويسرا. القسم القانوني، F. Hoffmann-La Roche Ltd، بازل، سويسرا. الاكتشاف، مختبرات Charles River، غرونينجن، هولندا. Tecniplast S.p.A.، Buguggiate، إيطاليا. التقنيات الناشئة، الطب المقارن، Novartis International AG، بازل، سويسرا. وحدة تحليل السلوك والظواهر الفسيولوجية، قسم الموارد البيطرية، معهد وايزمان للعلوم، رحوفوت، إسرائيل. Roche Pharma Research and Early Development، علوم الأعصاب والأمراض النادرة، مركز الابتكار Roche Basel، F. Hoffmann-La Roche Ltd، بازل، سويسرا. مركز QUEST للبحث المسؤول، معهد الصحة في برلين في Charité-Universitätsmedizin برلين، برلين، ألمانيا. ساهم هؤلاء المؤلفون بالتساوي: أنستاسيوس موريزيس، ليوناردو رستيفو.
Although biomedical research is experiencing a data explosion, the accumulation of vast quantities of data alone does not guarantee a primary objective for science: building upon existing knowledge. Data collected that lack appropriate metadata cannot be fully interrogated or integrated into new research projects, leading to wasted resources and missed opportunities for data repurposing. This issue is particularly acute for research using animals, where concerns regarding data reproducibility and ensuring animal welfare are paramount. Here, to address this problem, we propose a minimal metadata set (MNMS) designed to enable the repurposing of in vivo data. MNMS aligns with an existing validated guideline for reporting in vivo data (ARRIVE 2.0) and contributes to making in vivo data FAIR-compliant. Scenarios where MNMS should be implemented in diverse research environments are presented, highlighting opportunities and challenges for data repurposing at different scales. We conclude with a ‘call for action’ to key stakeholders in biomedical research to adopt and apply MNMS to accelerate both the advancement of knowledge and the betterment of animal welfare.
Biomedical research is experiencing a data explosion, fueled by recent technological advancements that have accelerated data production capabilities. Data-rich multiomics approaches and high-resolution functional measures, such as multimodal imaging or recordings of physiology and behavior, are routinely being employed across the entire lifespan of model organisms in both health and disease states.
On the one hand, this new era presents a great opportunity to accelerate scientific understanding. On the other hand, the mere collection of vast amounts of data is not sufficient to ensure scientific progress if these data cannot be interrogated and reintegrated into the research cycle. One consequence of limited data sharing and poor transparency might be the need for repeated replication of prior findings, frequently without success . These common practices result in a substantial waste of resources and missed opportunities for data repurposing.
This topic is especially pertinent to research involving animals. Failures to replicate findings and missed opportunities for data repurposing undoubtedly lead to animal use that provides little or no new scientific progress and is cause for ethical concern. Thus, there is an urgent need to encourage and facilitate repurposing of nonclinical in vivo data in biomedical research.
In Europe and North America, legislation for animal experimentation in biomedical research focuses heavily on implementation of the 3Rs (see definition in Box 1), which encompasses the concepts of replacement, reduction and refinement . The objective of the 3Rs is to ensure that animal experimentation achieves the highest level of welfare while minimizing burden through well-designed and reviewed animal research protocols and procedures. Yet, despite this robust regulatory framework, it is becoming increasingly clear that regulatory guidance protecting
Box 1 | Definitions of key terms
API: an acronym that stands for application programming interface. An API is a set of protocols for communication and automated data transfer between two computer applications.
ARRIVE: the ARRIVE guidelines (Animal Research: Reporting of In Vivo Experiments) were originally developed in 2010 to improve the reporting of animal research. They consist of a checklist of information to include in publications describing in vivo experiments to enable others to scrutinize the work adequately, evaluate its methodological rigor and reproduce the methods and results .
Data repository: a data repository is a structure consisting of one or more databases containing data for the purpose of analysis. Data repositories are used in business to provide a centralized source of information. A data repository may also be referred to as a data library or a data archive.
Digital object: a digital object is any kind of data that exists in a digital modality. A digital representation of a physical object or a process is also a considered a digital object.
FAIR: an acronym that stands for Findable Accessible Interoperable Reusable.
Meta-analysis: a meta-analysis is a statistical technique that combines findings from multiple independent scientific studies. In the clinical/preclinical context, meta-analysis is most often used to assess the effectiveness of interventions by combining data from several randomized trials.
Metadata: metadata are data on data (that is, information about the data), and contain descriptive and administrative information about the dataset. Examples include the project owner, title and persistent identifiers, as well as structural information about how the dataset was created. Further, machine readability of metadata is a high priority.
OBI: an acronym that stands for ontology of biomedical investigations. Community standard for scientific data integration. The OBI helps communicate clearly about scientific investigations by defining more than 2,500 terms for assays, devices, objectives and more.
animal welfare standards alone is not sufficient to guarantee that research involving animals is minimized .
To draw more awareness to concepts of validity, robustness and reproducibility (see definition in Box 1), the 3Rs principles have since been expanded to include the responsible use of animal research . Open research practices, data sharing and FAIR (Findable Accessible Interoperable and Reusable; see also definition in Box 1) principles are complementary solutions that have been proposed to increase transparency and reproducibility . Domain-specific solutions to assist researchers in creating datasets from their animal experiments have also been established. Examples include the Open Data Commons for Spinal Cord Injury and Traumatic Brain Injury , and guidelines on the ‘Minimum Information about Animal Toxicology Experiments’ (MIATE) . Meanwhile, the domain-agnostic and nonmandatory guidelines PREPARE and ARRIVE (see definition in Box 1) were also proposed as checklists for scientists when planning and reporting in vivo experiments, respectively.
Ontology: an ontology is a system of carefully defined terminology, connected by logical relationships and designed for both humans and computers to use.
3Rs: an acronym that stands for replacement, reduction and refinement. These are the guiding principles of animal research .
Raw data: also known as primary or source data, raw data are data (for example, numbers, instrument readings, figures and so on) collected from a source that was not subjected to (1) processing, (2) ‘cleaning’ by researchers to remove, for example outliers and obvious instrument-reading errors, ( 3 ) any analysis (for example, determining central tendency aspects such as the average or median result) or (4) any other manipulation by a software program or a human researcher, analyst or technician.
Note that raw data provide a great deal of flexibility in terms of data repurposing, given that different questions can be asked from the original dataset that may not be possible after processing. However, raw data can be cumbersome to manage, and some preprocessing is often necessary to enable its useful interpretation. As such, ‘primary data’ refers to minimally processed data that provide the most flexibility and utility for additional analysis.
Reproducibility: here we refer to reproducibility broadly, to include both the stricter definition of reproducibility as ‘reproducibility of analysis’, referring to the re-analysis of an existing dataset, as well as ‘reproducibility of experimental findings’, which refers to the collection of new data in experiments as identical as possible to the initial experiment .
VCGs: constitute digitally archived datasets encompassing both data and metadata, designed to optimize statistical models for predicting outcomes on the basis of quantifiable variables. Virtual controls act as a digital reference, simulating either the existing standard of care (that is, active reference control) or an absence of any intervention (for example, vehicle control). When an experimental animal cohort undergoes a specific intervention, these amassed digital data, in conjunction with predefined algorithms, forecast the potential outcome for that cohort in the absence of the said intervention. These predicted outcomes are termed ‘virtual controls’. Subsequently, the empirically observed outcomes postintervention are juxtaposed with these virtual control outcomes to ascertain effect magnitudes (adapted from ref. 44).
In certain sectors, regulation mandates data sharing from studies involving animals and progress is being made to ensure that in vivo data can be repurposed with a view to generating virtual control groups (VCGs; see definition in Box 1). For example, in the EU REACH (Registration, Evaluation, Authorisation and Restriction of Chemicals) , European Union (EU) biocides and EU plant protection products , there is a legal requirement to share test and study reports from studies in animals that are used for registration purposes (see, for example, Article 62 in Regulation (EC) No. 1107/2009 (ref. 22)). Regulatory submissions to the US Food and Drug Administration (FDA) must adhere to the Standard for Exchange of Nonclinical Data (SEND), which requires presentation of data from nonclinical safety and toxicology studies in a consistent and machine-readable format. Finally, the recently concluded Innovative Medicines Initiative (IMI) eTRANSAFE (Enhancing Translational safety assessment through Integrative Knowledge Management) has further promoted guidelines and policies for the sharing of drug-safety-related data. The vision for this initiative is to improve translational safety assessments
in drug development, including the potential for use of VCGs in nonclinical toxicity studies (see ref. 23 and more recently ref. 24).
Despite various regulatory frameworks, initiatives and guidelines, data sharing and repurposing within the field of biomedical research remains an exception rather than the rule . Reasons for this limited progress may include domain-specificity of approaches, technical barriers to understanding FAIR data standards, a reluctance to share data, a lack of awareness of potential benefits and an absence of incentives for data sharing and repurposing.
One critical element necessary for data sharing and repurposing is to provide metadata (see definition in Box 1) that describe the raw or primary data (see definition in Box 1). Metadata are essential to make raw or primary data that are stored in data repositories (see definition in Box 1) FAIR. With appropriate metadata, researchers can effectively interrogate the underlying raw or primary data and realize the potential for repurposing. However, to our knowledge, a minimal metadata set (MNMS) for in vivo biomedical research that could be used in a domain-agnostic way (that is, across neuroscience, cardiovascular science, immunology and so on) has not yet been established. An ideal MNMS would build on existing guidelines for in vivo data reporting that are established for biomedical research, while also expanding their impact and applicability by opening the door toward effective data sharing and repurposing.
In this Perspective, with this need in mind, a working group of scientists from academia and private industry was formed to propose a MNMS to describe data generated from an in vivo biomedical research experiment. Additionally, we highlight opportunities, challenges and future actions required to support the adoption of MNMS in biomedical research with a view to ultimately enable data repurposing, the advancement of scientific knowledge and the betterment of animal welfare.
Conceptual understanding of minimal metadata selection
Before outlining a MNMS for in vivo data, it is first essential to understand in more detail how metadata can aid the formation of a data repository and the decision to repurpose data, thus contributing to a reduction and replacement of animal use. Specific opportunities for data repurposing are discussed later in the manuscript (see ‘Benefits of adopting MNMS’ section).
In principle, the extent of metadata required to describe data generated from all biomedical research experiments covers an almost unlimited space. Practically, only a small portion of this space is needed (that is, necessary and sufficient) to effectively describe data from one experiment, and researchers can freely choose metadata sets that are fit for purpose. For illustration, we show a worst-case scenario (Fig. 1a) where metadata sets used to describe distinct experiments are disjointed and largely nonoverlapping. In this hypothetical scenario, the associated experimental data would reside in distinct regions of the metadata space. This segregation would hinder communication and interaction between different data sets. Therefore, the lack of metadata overlap would not allow the researcher to evaluate the potential to repurpose the data for their own needs.
In a more plausible scenario (Fig. 1b), a partial overlap between metadata sets can be found. However, critical metadata items required to describe the underlying data, and that are common to all the experiments, may still be missing. This scenario is typically encountered in the context of meta-analysis (see definition in Box 1) and systematic publication reviews. The absence of key metadata items can limit inference from such studies and is also detrimental for data repurposing. Specifically, a partial overlap of metadata may prompt researchers to resort to tacit knowledge for filling in missing information. This practice would lead to the aggregation of data collected either on incompatible sources (for example, the attempt to aggregate data from distinct mouse strains), or with discordant methodologies (for example, mice reared under different housing conditions), which would be inappropriate for data repurposing.
In the final scenario (Fig. 1c), aligning the metadata would yield a greater usability of the associated raw data. In this case, metadata from all
Fig. 1 | Three scenarios illustrating the relations between metadata sets from three different experiments. The extent of the metadata space is depicted as gray rectangles. The MNMS and its overlap with the three experiments is depicted as an orange rectangle, and an extending box with a dotted contour, respectively. a, Metadata do not overlap, leading to a worst-case scenario for data repurposing. The researchers cannot make any decision on the ability to repurpose data. b, Only a partial overlap is present between all three experiments. This scenario may incite researchers to fill in missing information with implicit knowledge, leading to detrimental consequences for the quality of data repurposing. c, All three experiments are associated with metadata that include the region occupied by the minimal set. In this case, the researcher can confidently operate a choice for repurposing the data.
three experiments would include a complete overlapping MNMS. Under our initial assumption, the experiments were originally logged with the metadata strictly necessary to reproduce the family of experiments they belong to. Adding the extra MNMS would not automatically extend the repurposing of the raw data that lay in distant regions of the metadata space. However, the presence of a complete MNMS would support the decision of the researcher as to whether include the associated raw data in a repurposing opportunity. Undoubtedly, the additional burden of logging the MNMS is eclipsed by the advantages that such a strategy offers in terms of data repurposing, including the potential for replacement and reduction of animal use, and reusage of critical data assets.
As a more practical example for how metadata and database formation can support data repurposing, a schematic is shown of a data repository that was implemented at the Roche Innovation Center Basel (Switzerland) in 2022. This repository stores data from recordings of locomotor activity in mice obtained using a standardized protocol (Fig. 2). Given that data from each mouse are annotated with metadata, it is possible to quickly identify ‘control’ animals that were not subject to any pharmacological challenge and/or which were not genetically modified. Data from these animals can be quickly plotted and further interrogated by any Roche scientist with access to the database, thus supporting reuse of existing digital assets. With this simple example, one begins to appreciate how new questions can be asked of data repositories, while these questions were outside the scope of the original experiments stored within those repositories (for example, how does locomotor activity differ between different mouse strains and between sexes?). This approach takes on even more importance as the data repository continues to grow, supporting more complex meta-analyses. Having data stored in this way can facilitate the understanding of between-experiment variability and supports optimization of future experimental design. Moreover, establishing such a data repository annotated with metadata opens the door toward implementation of VCGs (this point is discussed further in ‘Benefits of adopting MNMS’ section).
Fig. 2 | A practical example of using metadata to support the formation of a data repository. The schematic represents a real-world example of a repository of data from recordings of locomotor activity in mice, where all data are annotated with metadata. A total of 25 experiments are illustrated as separate rows, containing recordings from 828 individual mice. Filtering the database using metadata terms
can quickly identify control, non-genetically modified and/or non-drug-treated male (blue, ) and female (pink, ) mice in each experiment. Data can be further segregated (for example, by strain, age and so on), enabling the experimenter to understand the potential for repurposing these data for their specific questions and needs.
Key principles for the deployment of a MNMS
With the conceptual understanding of a MNMS in place, we next highlight key principles required for deploying a MNMS for in vivo research.
FAIR
The applicability of the FAIR principles for diverse datasets has increased in the past decade. With the emergence of automated machine learning and artificial intelligence pipelines, emphasis is increasingly given to deploying FAIR principles to render data machine-actionable (that is, computational systems can find, access, interoperate and reuse data with no or minimal human intervention). Accordingly, metadata must foremost provide sufficient contextual information on the data. With regard to in vivo studies, granularity is optimally provided at the individual animal level and each digital object (see definition in Box 1) should be ‘findable’. This means that each animal should be assigned a unique identifier (that is, a uniform resource identifier (URI)) within the prospective data repository.
On a second level, metadata itself must also adhere to FAIR principles. To enable the interoperable aspect, a structure must be imposed on the metadata using a well-defined conceptual model to describe relationships and constraints between the different entities (for example, an animal or a study). This conceptual model enables a common understanding of metadata items and can be described using established standards to represent information within computer systems (for example, Resource Description Framework, Web-Ontology Language and JSON-Linked Data). To avoid variability and ambiguity, the metadata should consist of standardized elements such as controlled terminologies to ensure that these can be reused. For this purpose, adhering to existing ontologies per domain, if available, is strongly recommended (for example, SEND/CDISC or Ontology for Biomedical Investigations (OBI); see definitions in Box 1). In addition to having harmonized and standardized metadata, according to the FAIR principles, each metadata term should also be adequately defined, with a description of its use, and be given a unique identifier. Different synonyms of the term should also be captured. Collectively, this approach will lead to high quality and confidence in the metadata set provided.
Integrity metric
Once a MNMS is agreed upon, checking the coverage and quality of the items reported in this minimal set would yield a ‘completeness score’
attached to each dataset, which would serve as an integrity metric. A completeness score associated to the metadata set is critical to enable a threshold-based decision concerning the rejection or inclusion of the associated raw data within a data repository. In addition, knowing the completeness of the metadata set would support researchers in assessing the generalizability of inferences that can be drawn from any repurposed data.
Prespecification
In line with other best practices for reproducible research, the design of high-quality metadata structures should be prespecified. Prespecification avoids ‘post-mortem solutions’ that lead to both low-quality data reporting and an unwarranted confidence in the rigor of the methods adopted. Indeed, retrograde application of metadata structure is not guaranteed to succeed. For example, research environments are highly dynamic settings with often high rates of personnel turnover. In these situations, the task of recovering a comprehensive set of metadata based on a limited amount of metadata available becomes unsurmountable and error prone. For this reason, we strived to design a MNMS that emphasizes the prespecification of a limited number of actionable items. Limiting the number of prespecified metadata fields is critical to avoid placing an extra administrative burden on researchers.
Provenance
Provenance and ownership of data are important aspects for a MNMS and are essential for curation in the context of large-scale usage of data and metadata sets. To enable identification of provenance and ownership, each data entry in a prospective repository must have the following operational metadata associated to it: creator of the record (which is also treated as a FAIR object with an assigned unique identifier), date of creation and date of modification. Finally, each of these terms should be given a definition to avoid potential ambiguity.
The MNMS
The MNMS proposed here (Tables 1 and 2) builds on the ARRIVE 2.0 guidelines . Specifically, the ARRIVE ‘Essential 10’ (Table 1) and the ‘Recommended Set’ (Table 2) served as the foundation for building the MNMS for biomedical research. These existing guidelines were selected because they are well known within the biomedical research community
Table 1 | The MNMS (ARRIVE 2.0 Essential 10)
ARRIVE topic-essential 10
MNMS
MNMS detailed
Data type
Existing ontology
Study design
Yes, but only start and end date of the in-life phase
Start and end date of the in-life phase
Date
ISO8601
Sample size
NA
NA
NA
NA
Inclusion/exclusion criteria
NA
NA
NA
NA
Randomization
NA
NA
NA
NA
Blinding
NA
NA
NA
NA
Outcome measures
Yes, extended, assay specific
Outcome measure (including any descriptive statistics if applicable, for example, average speed)
Controlled vocabulary
Multiple, assay specific per domain
Unit of measurement per measure
Controlled vocabulary
UO, OBI
Statistical methods
NA
NA
NA
NA
Experimental animals
Yes, extended, all assays
Unique animal identifier
URI
NA
Local identifiers/other IDs
String
NA
Species
Controlled vocabulary
OBI, NCIt
Strain (ILAR and short name)
Controlled vocabulary
ILAR , MGI
Sex
Controlled vocabulary
NCIt, CDISC/SEND
Transgenic
Boolean
NA
Genotype information
Controlled vocabulary
MGI
Allele information
Controlled vocabulary
MGI
Animal vendor (site and location) information
Controlled vocabulary
Date of birth
Date
ISO8601
Developmental stage
Controlled vocabulary
OBO Foundry
Animal weight at start of experiment and unit
Number + controlled vocabulary
UO
Severity grade of manipulation
Number
Experimental procedures
Yes, but focused on compound treatment; terms for procedures beyond require domain-specific alignment
Test substance (common name)
Controlled vocabulary
ChEBI, DrON
Test substance (CAS number)
Number
NA
Numerical dose
Number
NA
Dose unit (ideally mg/kg or mM)
Controlled vocabulary
UO, OBI
Vehicle composition
Controlled vocabulary
ChEBI
Route of administration
Controlled vocabulary
OBI
Administration method
Controlled vocabulary
OBI
Results
NA
NA
NA
NA
ChEBI, Chemical Entities of Biological Interest; CDISC, Clinical Data Interchange Standards Consortium; DrON, drug ontology; NA, not applicable; NCIt, National Cancer Institute thesaurus; OBO, Open Biological and Biomedical Ontologies; UO, units of measurement ontology. Further development needed to provide a formal ontology.
Table 2 | The MNMS (ARRIVE Recommended Set)
ARRIVE recommended set
MNMS
MNMS detailed
Data type
Existing ontology
Abstract
NA
NA
NA
NA
Background
NA
NA
NA
NA
Objectives
NA
NA
NA
NA
Ethical statement
NA
NA
NA
NA
Housing and husbandry
Yes
Light cycle
Number
NA
Testing location/ research site
Controlled vocabulary
Enrichment
Yes/no
NA
NA, not applicable (see main text). Further development needed to provide a formal ontology.
and are endorsed by peer-reviewed journals, which may facilitate future adoption of MNMS. Previous research on the ARRIVE 1.0 guidelines operationalized them into a list of over 100 items , which can be difficult for authors to fully comply with; this extensive list also complicates the
editorial staff’s task to check for compliance. With the revision of the guidelines in 2020, the ARRIVE 2.0 ‘Essential 10’ was put forward as the minimum information required for reporting of animal experiments . Thus, we prioritized alignment of MNMS with the ‘Essential 10’, which would also help to minimize the workload for MNMS and thus further support its uptake. The MNMS proposed here would substantially contribute to making in vivo data from biomedical research FAIR compliant, in line with the original goals of the ARRIVE guidelines. Indeed, ensuring data from animal experiments is actionable through the adoption of MNMS further increases the impact of the ARRIVE guidelines. Below we further elaborate on the metadata terms included in MNMS. Definitions for specific terms used in the following section are provided in Box 2.
ARRIVE topics included with extended focus in MNMS
These topics include experimental animals, outcome measures and experimental methods. Details on experimental animals constitute the main aspect of MNMS, because insufficient or inaccurate reporting of these attributes is considered one of the main challenges for data reproducibility. Therefore, we propose that any prospective data repository assigns a unique identifier to each animal. This will enable not only FAIR datasets but, along with other potentially unique identifiers entered (for example,
Box 2 | Key terms related to structured metadata fields proposed in the MNMS
Administration method: indicates the method that is used for exposure and excludes the route of administration.
Administration route: indicates a part of the body through which or into which a material entity has/is/will be introduced.
Allele: a variant form of the same gene at the same position, or genetic locus, on a chromosome.
Animal supplier: an organization site that supplies model animals (needs organization name and site).
Genotype: indicates the genotype of an organism. At its broadest level, genotype includes the entire genetic constitution of an individual. It is often applied more narrowly to the set of alleles present at one or more specific loci.
Species: a group of organisms that differ from all other groups of organisms and that are capable of breeding and producing fertile offspring.
Strain: a population or type of organism that is genetically different from others of the same species and shares a set of defined characteristics.
Transgenic animal: a model animal in which foreign DNA has been introduced using biotechnology. Foreign DNA (the transgene) is defined here as DNA from another species, or recombinant DNA from the same species that has been manipulated in the laboratory before being reintroduced.
radio frequency identification (RFID) tags), also provide unambiguous identification of the animal record in the data repository and the associated datasets. The latter is especially important if an animal is included in more than one study, to avoid false duplicates and the introduction of artificial confounders of variability in any repurposed datasets.
With respect to the basic attributes for experimental animals, having the standardized Institute for Laboratory Animal Research (ILAR) name in addition to any short strain names or synonyms should be mandatory. As mentioned in ‘FAIR’ section, each controlled term for each terminology (such as strain) should have a unique identifier and a concise description that maps any existing synonyms. Strain information alone is insufficient because inbreeding over a long period of time may cause genetic drifts that might influence experimental outcomes. Therefore, precise source information is critical. For transgenic animals in particular, genotype and precise allele information is required, again using controlled terminologies and unique identifiers. For allele information, researchers must use IDs from Mouse Genome Informatics (MGI) if available. MGI is the authoritative source in the field of mouse genomics given that its nomenclature follows the rules and guidelines established by the International Committee on Standardized Genetic Nomenclature for Mice. Similarly, for strains and the strain identifier, an external reference ID (for example, the provider website entry or repository entry) can be used.
To indicate genotype and allele zygosity, using agreed conventions that restrict the available terms reduce the risk of ambiguities. The Jackson Laboratory provides such an example . Furthermore, for multiple transgenic/mutant alleles additional care should be taken to unambiguously map the correct genotype to each allele in the sequence that would constitute the full genotype (for example, allele 1: ; allele 2: ).
The last essential immutable information is the date of birth of the animal. Due to current practices or difficulties in obtaining precise information, this information should be additionally marked as ‘precise’ or ‘approximate’ to indicate its reliability. A unified date format, explicit to the user during data entry, is recommended.
From the set of nonimmutable animal metadata, animal weight at the start of the experiment (with controlled vocabulary for the unit) is mandatory in the MNMS. Weight, together with animal age, may serve as a useful indicator of well-being when comparisons can be made with standard growth curves if they are known for a particular species or strain. Reporting on the standardized maximum severity grade of manipulation, per individual animal, is an important addition. This information may serve as a proxy for stress levels and suffering, and may explain deviations in the experimental data, allowing exclusion of the animal(s) from further analysis if necessary.
With regard to study-design terms, MNMS requests the experiment start and end dates (defined as the start and end of the in-life phase). These metadata can (1) signify which animals belonged to the same study; (2) facilitate the reuse of longitudinal data sets, where entries linked to body weight and age can change over the course of the experiment; and (3) ensure awareness of when the data were produced, which may be an important consideration in the case of factors such as genetic drift.
Since pharmacological manipulations are common in biomedical research, different forms of exposure to an active substance and for different purposes (for example, as a therapeutic, or to induce a specific condition like disease or transgene induction) are represented extensively in MNMS. To ensure accurate reporting of any test substance, the use of a unique test substance identifier, such as a Chemical Abstracts Service (CAS) number is necessary. Synonyms such as the common drug name, pointing to the same entity, can complement a digital record of the substance identifier and its existing ontologies. The numerical dose and the dose unit (for example, or molar concentration) represent the substance dosing. Other important factors in the administration of a compound are the method of administration and the administration route (for example, intraperitoneally, per os and so on) and the vehicle composition. These metadata, including the dose units, must be defined through controlled terminologies or ideally through existing ontologies such as according to the FAIR principles described previously.
Recommended ARRIVE set topics included in MNMS
These include housing and husbandry, protocol registration and data access. From the ARRIVE 2.0 recommended set, we considered some attributes to be essential for reproducibility of experimental datasets and have therefore included them in MNMS. These attributes are the light cycle, denoted as number of light:dark hours in a day, dietary status, enrichment and testing location or research site. To avoid extending terminology to different diets or feeding schedules and enrichment types, which may be more reflective of specific experimental procedures and thus beyond the scope of MNMS, both dietary status and enrichment are represented with one of only two states (that is, fasted or fed/not fasted, and the presence of enrichment or not). Reporting the animal experimentation license permission in which animals were used is as an additional guardrail that ensures the reported dataset was generated using the stated procedures. The animal experimentation license permission additionally ensures that animal welfare standards are certified by the respective animal welfare authority. Last, but not least, data access in MNMS extends beyond the scope of the ARRIVE guidelines and constitutes a critical aspect for identifying dataset ownership. Each user is given ideally a unique identifier, such as the ORCID ID (Open Researcher and Contributor IDentifier). This identifier allows for logging any modifications to the data and metadata set via timestamps showing creation date and modification date. A data access and audit trail ensure data integrity and quality. To this end, any prospective user-facing system cannot be completely public but rather based on a registration and authentication service.
ARRIVE topics not included in MNMS
These include study design, study sample size, experimental unit, inclusion and exclusion criteria, randomization and blinding. Previous attempts have shown considerable challenges when trying to implement topics pertinent to study design in a large-scale data repository . These challenges multiply further when broadening the scope of the dataset for a more general-purpose repository that can enable data sharing between multiple stakeholders. For these reasons, several ARRIVE topics are explicitly not included within MNMS, because they do not support the core objective of data repurposing. More specifically, using the single-animal level for metadata (and data reporting) negates the need for reporting the sample size and experimental unit. Aspects of study design before experimental manipulations, such as the definition of groups being compared, randomization, blinding and inclusion and exclusion criteria are clearly important for reproducing the study itself. However, these topics add little value for repurposing because data will be reused in different studies with new randomization algorithms and selection criteria. Finally, yet importantly, nomenclature among different control groups is largely nonstandardized, posing another challenge ; therefore MNMS provides a set of objective criteria and guidelines for including an animal record from a control group.
Benefits of adopting MNMS
With the MNMS outlined, in the following section we highlight the benefits that may come from adopting MNMS within the biomedical research community. These benefits include data repurposing, the generation of VCGs and facilitation of meta-research from in vivo studies. The benefits for various stakeholders in implementing MNMS are highlighted in Fig. 3.
Repurposing
Reusing data obtained from animal experimentation serves a ‘repurpose’ function, and clearly falls within the 3R domains of replacement and reduction. The efficient description and retrieval of raw data enables their application for scopes beyond those intended during the original collection, therefore reducing the number of animals or, in some cases, replacing animals needed for novel experiments. An example of this approach was recently demonstrated by Fuochi et al., who reinterrogated data obtained by home-cage monitoring to gain new insights into mouse behavior .
VCGs
We envision that the use of VCGs, made possible from data sharing and data repositories that follow MNMS, would particularly benefit several stakeholders (Fig. 3). The opportunities and challenges for implementing VCGs were the focus of the IMI eTRANSAFE project, which has collected and analyzed drug safety and toxicology data from more than 60,000 rats, 1,300 dogs and 500 monkeys (see ref. 23 and more recently ref. 24). As further publications on VCGs emerge from this project, additional lessons and insights will undoubtedly further support the practical implementation of VCGs in the biomedical research field.
Our expectations are that VCGs would enable researchers to construct highly regulated and homogeneous experimental circumstances, which can improve experiment repeatability and reproducibility. Virtual animal controls may also improve research efficiency by saving time, costs and resources needed for animal experimentation. Furthermore, implementation of VCGs can address some of the ethical needs for responsible animal research by minimizing the number of animals required for biomedical studies.
For regulatory organizations and funding agencies, the deployment of VCGs can support objectives for greater transparency, accountability and animal welfare. Using VCGs to standardize animal experiments can assist regulatory agencies in monitoring and enforcing regulations, improving data transparency and accessibility, and reducing the number of animals utilized in research. Furthermore, adopting virtual animal controls can reduce research costs while also encouraging more ethical and responsible animal research. Successful implementation of
this strategy would undoubtedly enhance public faith in regulation surrounding animal experimentation.
From the perspective of (bio)statisticians, VCGs can increase the precision and replicability of statistical analyses. Notably, VCGs can eliminate confounding variables, increase data quality and precision, harmonize data collection and reporting and create a more regulated and uniform environment for animal research. Collectively, these advantages can contribute to improve study results, data value and reliability of findings.
While VCGs may provide benefits for various stakeholders, we recognize that VCG implementation will not be without challenges in biomedical research. Careful consideration must be given to the construction of the VCGs. Should the control group be entirely virtual, or a mix of virtual and real data? If the latter, what is the optimal balance between virtual and real data? Statistical factors, such as selection criteria for virtual controls, data distribution considerations, variability and number of data points need to be considered. Ideally, the design and use of VCGs should be empirically validated, ensuring that experimental conclusions are consistent if VCGs are deployed in place of real data. Biological factors must also be considered, such as seasonal variability, the influence of individual experimenters or the potential for genetic drift, which may not be easily represented by VCGs. Thus, not all experiments will be able to benefit from VCGs and there will be continued expectation to run ‘real’ control animals when the use of VCGs is not feasible or sufficiently validated. Taken together, the implementation of VCGs must be carefully considered and validated, but their successful adoption may still provide major advantages to the biomedical research community.
Meta-research in animal research
Meta-analysis of data from existing in vivo studies (within and beyond the scope of systematic reviews) provides a powerful tool to explore the impact of variations in experimental design and can reduce the need for further animal use. Pooling data from multiple studies on the same topic can increase the precision of pooled effect estimates. Meta-analyses of animal data are also used to inform the optimal design of experiments in a number of ways, including comparing performance and evaluating the necessity of outcome tests , informing sample-size calculations , refining the duration of experiments and humane endpoints and optimizing the choice of model induction technique .
Although meta-analyses are an important approach to explore between-study heterogeneity , they are resource intensive because of how data are currently reported in published research articles, typically as graphs or as group summaries (that is, group mean and variation). The graphical format poses challenges, as specialized tools are needed to first extract the estimated numerical summary information before further analyses can be conducted. The conclusions and accuracy of meta-analyses are therefore limited by the quality of primary data available. Adoption of MNMS as a reporting standard, for both control and experimental data, would provide a large step forward to improve the reporting of in vivo studies and facilitate the overall conduct of meta-analysis. The use of MNMS together with standardized repositories for data collection would also allow for complex meta-analyses that are currently prohibitive due to the absence of raw or primary data. Such work could generate novel scientific insights without additional use of laboratory animals.
A further benefit for adopting MNMS is that they can streamline the process for generating a richer set of metadata and insights with minimal additional effort, which can further support meta-analysis. One example to illustrate this logic is how to retrieve age-at-test, a metadata term that may be critical for meta-analysis, but which is not included in MNMS. The age-at-test can be obtained by intersecting the date-of-birth and the date of study start (both items included in MNMS) or the date of testing that may be embedded in the raw data file (for example, raw data timestamp). Therefore, MNMS serves as an additional layer of metadata that builds upon both the underlying dataset and any passive metadata generated through the data collection process. Intersecting and/or merging MNMS with the bare minimum of information derived from raw data
Fig. 3 | Advantages of implementing MNMS for key stakeholders. This figure illustrates the multifaceted benefits of MNMS across different stakeholders. For researchers, MNMS facilitates the creation of highly regulated and homogeneous experimental conditions, enhancing experiment repeatability, reducing resource use and addressing ethical considerations. Regulatory organizations and funding agencies benefit through the support of greater transparency, accountability and
animal welfare, with MNMS enabling standardized experiments and reduced research costs. From the perspective of (bio)statisticians, MNMS increases the precision and replicability of statistical analyses by eliminating confounding variables, harmonizing data collection and ensuring a more regulated research environment. This comprehensive representation underscores MNMS’s role in advancing responsible, efficient and high-quality research practices.
enhances their value and utility. This approach also contains MNMS size to a minimum while maximizing its impact on data repurposing and the conduct of meta-analysis.
Challenges for adopting MNMS
The concept of deploying a MNMS to enable the creation of structured data repositories and the opportunity to repurpose data is highly appealing from both a scientific (for example, incremental knowledge and new insights) and an ethical point of view (that is, replacing and/or reducing animal use). However, intrinsic to the concept of repurposing is the idea that a large user base is necessary to fully realize the opportunities for data reuse. Here we acknowledge that applying the repurposing concept on a large scale is not void of challenges.
Adoption within the scientific community
Several initiatives have emerged to increase replicability and reproducibility, and to support reuse of data derived from in vivo studies . Unfortunately, these initiatives and associated guidelines have not been routinely adopted across the biomedical research community. One explanation is that the efforts required to follow such guidelines, and the rewards gained from doing so, may not be of immediate interest to the data producer in the laboratory. Particularly within the field of discovery biomedical research, there may be limited perceived benefit to include accurately reported metadata and store data generated from highly customized ‘one-of-a-kind’ studies within a central repository. Historical practices within laboratories, combined with finite resources, may reflect the need for further change within the scientific community to recognize the importance of data sharing and the responsibilities of scientists to report their data.
To minimize the effort needed for providing MNMS and maximize their impact, we have proposed a MNMS that aligns with ARRIVE 2.0, as set of guidelines that are gaining increasing acceptance within the biomedical research community and are accepted by peer-reviewed journals. By providing a mandatory and minimal set of controlled terminologies to describe the data, the MNMS would overcome challenges of ‘free text’ entries required by ARRIVE, which can result in entries of variable quality that are not easily comparable between publications, or no entries at all.
Nevertheless, we acknowledge that ensuring ease of use alone is probably not sufficient to ensure uptake and implementation of MNMS
across the biomedical research community. To further support uptake, additional tools, training and ultimately regulation will be required. Such tools may include the use of artificial intelligence to support identification and reporting of metadata from publications in standardized formats, and to highlight where certain metadata are not found and must be provided before publication. In addition, an ‘incentivizing’ system may be highly effective to support adoption of MNMS and data reuse. For example, data and metadata sets could be associated with quality metrics and a referencing system could be implemented. Thus, data and metadata sets that have supported reuse will receive a higher reference rate and provide recognition to the contributing scientists, research groups and their institutions.
A key step to increase data sharing and repurposing in biomedical research will be to implement controlled terminologies since such standards are not common in this field. The MNMS would provide a starting framework in which to implement these terminologies. The biomedical research space is large and diverse, which makes implementation of any standard challenging. However, this size and diversity of the research space also presents a tremendous opportunity to better leverage the knowledge being generated and further support the 3Rs. In that regard, it is valuable to highlight that progress in this direction has been made in other fields. For example, in the chemical industry, a legal requirement exists to share data from in vivo studies in reports that are used for registration purposes (see, for example, Article 62 (ref. 22)). Likewise, the FDA has implemented SEND for standardized reporting of nonclinical safety studies, while the recently concluded IMI eTRANSAFE project has advanced data sharing to improve translational safety assessments in drug development .
Constraining the experimental space
We believe that it is possible to identify a minimal set of metadata for animal experiments such that raw data can be repurposed across distinct families of experiments. However, this optimistic view is restrained by the extent of the experimental space and its relative metadata space (that is, all possible experiments across distinct disciplines).
This vast space does not allow the identification of a minimal set of metadata that guarantees a decision is always taken on the reuse of data from across diverse disciplines (for example, cardiology, neuroscience, oncology and so on). In such a massive task, MNMS would need to be expanded to an unmanageable size, therefore losing the appealing quality of being ‘minimal’. For example, while properties related to the animals
and their housing may range over a limited number of dimensions (for example, genotype, age, weight, light cycle and so on), metadata from the domain of experimental manipulations cover a far more extensive space. This issue quickly emerged in the context of the present workgroup while searching for a consensus on the items to include in MNMS. Consensus was reached on several items belonging to the ‘Animal’ domain (for example, age, genotype and weight), while agreement quickly broke down when attempting to identify metadata pertaining to experimental manipulations. This fragmentation reflects the authors’ different research backgrounds, and, indeed, distinct domains are likely to occupy different regions of the metadata space.
To address the challenge given by the vast experimental space in biomedical research, we suggest that an a priori decision must be made concerning the range of experimental questions (and their associated outcome measures) that would be of interest to address in a repurposing initiative, such as in the generation of VCGs. Prespecifying and making explicit research questions (and outcome measures) will help impart a structure (Fig. 1c) to the metadata. This, in turn, will allow researchers to gauge the repurposing potential of the collected raw data in different disciplines and across institutions. Indeed, it is critical that multiple parties (for example, domain experts, data architects, funding agencies and so on) join in a concerted action to define the boundaries and bridges of these minimal sets of metadata and to make repurposing of data across disciplines a successful reality.
Legal considerations for data sharing
The objective of deploying MNMS to facilitate data sharing and repurposing raises some important questions from a legal perspective. We believe that future initiatives to support data sharing would need to take at least the following ten topics into account.
Ensuring privacy of individuals. As discussed, an important aspect of metadata is to ensure provenance and ownership. The idea of incentivizing and recognizing contributors and users of data for repurposing would also require that individuals are associated with a FAIR identifier such as an ORCID ID. However, the ORCID ID is a code that can be linked back to an identifiable person, which is likely to make the code ‘personal data’ in some parts of the world. Contributors may therefore need to be given notice of how their personal data will be used and shared with others. Other measures may also be needed to ensure compliance with privacy requirements.
Control over who can access the data and for what purposes. To protect the value of the data, the data should be accessible only by those with genuine intent to conduct further research.
Minimizing disclosure of commercially sensitive information. Where requests for access are made by a competitor of the contributor, protective measures are likely to be necessary to protect such commercially sensitive information and to ensure compliance with competition law . Potential options might include use of a third party to oversee and approve requests for access without involvement of the contributor.
Ensuring protection of proprietary data. For increasing the crowdsourcing user base, we propose keeping a focused scope on animals used only in control groups, where no proprietary product has been applied.
Fair access. Although companies are not forced to share data, it would be prudent to ensure that all the terms of access are fair, reasonable and nondiscriminatory (that is, those in a similar position should be able to access the data on equivalent terms).
Timing of access. Should data be available for others to access immediately, or is it reasonable to impose a time delay to protect the commercial interests of the contributor? Some existing tools already consider timing
of access to information as a relevant feature (for example, see animalstudyregistry.org, which allows embargo time periods).
Ownership and rights of use. Contributors are likely to want to keep ownership of their data and only give recipients a right to use the data for certain uses (with limited rights to share with others). Where only control arm data are shared, the requestor will probably expect to own the results they generate using that data.
Liability. Requestors might reasonably expect that the contributor confirms that they have the right to contribute the data. However, contributors are likely to want the requestor to accept full responsibility for confirming that the data are suitable for the purposes for which they want to use it and to accept all liability associated with reuse of the data. Requestors might therefore need to thoroughly check the data to confirm that it is indeed fit for purpose, and this would need to be appropriately managed.
Price payable. Should the requestor be required to make a financial contribution toward the costs of generating data? If the decision is yes, then the guidance published by the European Chemicals Agency on data sharing may be a helpful reference point for how to calculate reasonable sums.
Ensuring the right to share. Contributors will need to ensure that their agreements with third-party contract research organizations (CROs) or research collaborators permit the sharing of the relevant data into any data-sharing scheme and the further reuse by third parties. This issue is particularly important where the sharing of the data is not a clear legal requirement and where there is an intent to charge third parties for access to the data (which may be viewed as commercial use of the results).
Scenarios for MNMS implementation
Despite the recognized challenges discussed above, the following section highlights opportunities to leverage MNMS to support in vivo data repository creation and data repurposing across different in vivo research contexts, including behavioral core facilities in academia, CROs, pharmaceutical companies and in vivo research equipment providers.
Behavioral core facilities in academia
Behavioral core facilities are increasingly common within academic research institutions, and they are well positioned to improve the quality of preclinical biomedical research by ensuring quality control measures . Core facilities provide local users (typically principal investigators and laboratories from the university in which they are hosted) with access to a range of assays and equipment that facilitate functional in vivo research (see ref. 43 for more information). These assays and equipment are typically accepted as gold-standard approaches within the field. Experimental protocols applied are quite invariant and routinely repeated by different users who maintain the laboratory animals in the same facility and rearing conditions.
Opportunity. The unique position and resources of a core facility within academic research may allow data sharing and repurposing in a very straightforward and applicable manner. To support implementation of MNMS, several metadata fields (for example, strain, sex, age and so on) may be automatically drawn from the animal facility records with support from husbandry staff to provide information regarding rearing conditions (for example, diurnal light cycle). Core unit staff (if in place) can provide information regarding the experimental protocol (for example, apparatus setups if included in an extended metadata set) and the researcher can provide additional fields (for example, treatment, dose and route). The implementation of MNMS and supporting systems may be further expedited with support from local informatics services and infrastructure. In summary, behavioral core facilities in academia may be an excellent starting point for advocating and implementing MNMS.
CROs
CROs provide access to in vivo experiments on a fee-for-service basis to a sponsoring client. Clients are typically private institutions, such as pharmaceutical or biotechnology companies, which may not have internal in vivo expertise or may wish to extend their in-house capacity. CROs typically offer a catalog of standardized in vivo assays that are accepted within the respective biomedical research field and follow local and international standards of regulation concerning animal experimentation. Many CROs also offer safety pharmacology and toxicology studies in animals that may be used to support regulatory submissions. In both the discovery and safety setting, customized in vivo assays can be developed and adapted to a client’s need. Notably, CROs are used to store data in a structured way in dedicated databases. Particularly for CROs that have implemented SEND, as required by the FDA for safety studies, a framework for the standardized, electronic representation of individual animal study data is already in place.
Opportunity. With the experience gained from data storage standardization within drug safety studies for SEND, a pull-through to in vivo studies for discovery biomedical research is an easy step for many CROs. There would be numerous benefits for adoption of MNMS and data repurposing in the CRO space for discovery research. First, by making control data or other experimental data (for example, from standard reference treatments) available for repurposing, sponsoring clients could avoid repetition of some experiments and choose to use VCGs instead of newly generated control data. This process would undoubtedly lead to a substantial reduction in the use of laboratory animals. Second, the exchange of data from client to CRO, and vice versa, should enhance the inherent robustness of a given assay, which would benefit both the CRO by emphasizing assay quality and the client by making robust decisions based on the assay result. For example, results may be reported that suggest a compound effect when it is rather driven by an aberrant control response. Having the ability to use larger VCGs would reduce this risk. Finally, the adoption of MNMS would support standardized datasets, which in turn can harmonize data to further align and optimize study designs. In the development of new medicines, time is of the essence. VCGs and optimized study designs will not only result in a reduction in the number of animals and ensure more ethical research, but it will also speed up the drug development trajectory and reduce costs, which is often a critical factor for smaller-sized biotechnology companies.
While numerous benefits are envisioned in the CRO space for adoption of MNMS and data repurposing, sharing data remains a point of attention. Restrictions on data use may be contained in the agreement between the CRO and the sponsoring client, and sharing data may require additional terms to be agreed (as discussed above in legal considerations for data sharing).
Pharmaceutical research and development
While the vast majority of experimentation in pharmaceutical research and development (Pharma R&D) is undertaken in non-animal studies, animal research remains an important component to discover new biology and treatment opportunities, and to predict the efficacy and safety of new medicines before entering human trials. Within a single pharmaceutical company, multiple drug discovery programs may be running simultaneously, often over diverse geographical locations and via internal efforts and/or with external partners including academic collaborations, consortia or CROs. Research programs can last for years, or even decades, as is the protracted timeline typical for developing new medicines. In this context, FAIR data storage and the need to avoid continuous data replication of historical data is of paramount importance to ensure research progress and optimize insights discovery.
Opportunity. To address the challenges that are particular to Pharma R&D, a standardized approach to information technology architecture and data management is critical. Adopting MNMS would facilitate in vivo
data repurposing, while open standards and application programming interfaces (APIs; see definition in Box 1) would facilitate interoperability between different systems, enabling researchers to work more efficiently and collaboratively. By creating a domain-agnostic platform integrated with animal management software, researchers can make their data more accessible to others, leading to greater collaboration and innovation. This data accessibility would allow researchers to build upon each other’s work and combine data from different studies to address new research questions.
To support implementation of MNMS into Pharma R&D, a multidisciplinary team consisting of data scientists, scientific researchers and laboratory animal specialists is essential for effectively implementing a global standardized approach. Collaboration between these fields can help ensure that the data management strategy is comprehensive and aligned with company research goals and requirements. Data scientists can contribute their expertise in data modeling, analytics and visualization to develop a common data model that can be used across different systems. Scientific researchers can provide input on the specific biomedical needs and objectives, as well as identify potential research questions that can be addressed through data repurposing. Laboratory animal specialists can provide insights into the operational challenges of working with different systems and help ensure that the strategy is compatible with local and global animal welfare regulations. Importantly, senior managers within Pharma R&D can recognize the importance of such initiatives and support their resourcing to ensure successful and timely implementation.
This collaboration model can lead to more efficient and accurate research outcomes, ultimately benefiting scientific progress, the development of new medicines and animal welfare. Standardization in data management can also improve data quality and consistency, which is essential for regulatory compliance and data sharing initiatives. By implementing a comprehensive approach that addresses the challenges of working with multiple in vivo systems, researchers in Pharma R&D can repurpose and combine data from different studies, leading to greater insights and discoveries.
Animal research software and/or hardware developers and providers
Animal research is enabled by a rich ecosystem of hardware and software, including colony animal management software and laboratory information management systems, tools used in the laboratory for various measurements (for example, heart rate monitors or imaging devices) and software that enables biospecimen analysis and data visualization (for example, image analysis or statistical tools).
Opportunity. By incorporating MNMS and especially harmonized vocabulary terms into their platforms, businesses engaged in providing experimental equipment and software for in vivo research can greatly contribute to improving data sharing and repurposing. Particularly important in this context are companies that offer animal management software, which can provide users with access to MNMS and create and support software interfaces to push MNMS to other systems involved in data collection and analysis. Likewise, companies that support experimental data collection can ensure that MNMS are embedded into raw data to ensure seamless analysis and ease of integration when leveraging different commercially available systems. Notably, to incorporate MNMS in their products, commercial businesses must ensure that the same controlled vocabulary is used throughout data collection, management and analysis. A standardized approach would facilitate researchers’ access to, comparison of and reuse of data created across many platforms and studies.
By adopting MNMS, commercial system providers can contribute substantially to the scientific community by making important information readily accessible for a variety of purposes, including grant applications, academic publications, animal license applications and patent filings related to animal research. In addition to enhancing the quality and supporting reproducibility of research, this advance would further
encourage ethical considerations and ultimately facilitate the process of animal-data management and repurposing.
Concluding remarks and future directions
We have proposed a FAIR-compliant MNMS for in vivo studies in biomedical research. The MNMS that we propose, if adopted more widely, would provide multiple benefits. First, MNMS builds upon existing initiatives (for example, guidelines such as PREPARE and ARRIVE) to increase transparency in data generation. Transparent reporting of methodology and data required to replicate analyses is a fundamental step for enabling and ensuring reproducibility. MNMS is a tool that supports transparent reporting.
Second, implementing MNMS would facilitate data sharing, ideally through large publicly accessible data repositories. In turn, this would enable data repurposing, with just one of many examples highlighted being the generation of VCGs. The use of VCGs is a currently underexploited opportunity that could substantially reduce the number of animals used in biomedical research when applied at scale.
Taken together, we believe that the deployment of MNMS alongside existing initiatives (ARRIVE) represents the next frontier for advancing the ethical use of animals in research. Therefore, we advocate for its use and propose strategies for further development of MNMS and uptake among research stakeholders. While there will be challenges for MNMS implementation, lessons for successful in vivo data sharing can be learned from other fields including the chemical industry and drug safety testing.
To advance MNMS implementation, we propose an incremental and collaborative approach to refinement, testing, validation and implementation. A logical first step would be to pilot their use with the primary stakeholders (Fig. 3). This step could involve refining MNMS with co-creation and community-consensus communication processes between participants from each of the key groups (scientists, regulatory bodies and (bio)statisticians) across academic, pharmaceutical and contract research sectors, to identify further potential barriers and enablers to implementation. A technique such as a modified Delphi allows for community input and consensus when deciding on adding and refining other terms that are critical in specific fields, such as the importance of health status or animal microbiomes. Concurrently, additional cross-disciplinary efforts are required to create and refine comprehensive legal frameworks and policies for data sharing across stakeholders from multiple industries. These efforts could focus on topics such as the following: joint development of tools to support integration with existing data infrastructure; development of new documentation and education to support uptake; and integration with existing initiatives in 3Rs. We propose these activities are run in iterative rounds to align viewpoints within this diverse stakeholder group more rapidly.
The open conduct of multiple collaborative stakeholder activities will be critical for developing proof-of-concept exemplar projects, white papers or recommendations that can support integration of MNMS into existing cross-industry 3Rs initiatives. Examples of these initiatives include protocol registration (for example, animalstudyregistry.org and preclinicaltrials.eu) and initiatives to improve experimental design quality and reporting standards for animal experiments (for example, PREPARE and ARRIVE guidelines). In this context, policy makers, regulatory agencies and funding bodies will have a fundamental role in supporting adoption of MNMS within the wider research setting.
We highlight the need for further strategies that can support adoption and implementation of MNMS for data sharing. Obtaining insights on what tools the research community currently uses (for example, Research Data Alliance initiatives or domain ontologies and vocabularies), and how MNMS can best align and integrate with these tools, will enable the development of new strategies to tackle barriers to adoption of MNMS and facilitate data sharing. For example, additional documentation may be required for nontechnical users on how to use MNMS within their existing workflows. MNMS may also be further refined to reduce unnecessary overlap or redundancy in the workload required by
primary stakeholders. A critical need is likely to be the harmonization of terminologies and controlled vocabularies, which could support MNMS adoption by key stakeholders, including companies providing scientific research equipment and software to in vivo researchers across sectors. We recognize these companies as a key enabler to facilitate uptake of MNMS and data sharing. Indeed, the private industry sector has already made considerable progress in the advancement and implementation of controlled vocabularies, and close collaboration between private and public institutions is likely to accelerate progress in this field.
With feedback from the primary stakeholders, a roadmap to MNMS dissemination can be put in place, probably moving from local to global use in a stepwise, incremental manner and ensuring alignment between these efforts at each stage. Dissemination activities could include hosting workshops to showcase MNMS functionality with exemplar projects; outlining the impact MNMS on research outcomes for each stakeholder group; developing targeted marketing materials, such as infographics to highlight the benefits of MNMS; producing educational materials and documentation to support training efforts on how to effectively use MNMS; and performing pilot experiments to demonstrate the utility of MNMS in common settings. These strategies can accelerate the uptake and use of this tool into existing workflows and increase awareness of the benefits of MNMS for a broad audience.
Biomedical research stands at a critical juncture, where there is great potential to generate new insights, owing to data-rich technologies that can now be rapidly deployed and at relatively little cost. However, in the absence of tools to effectively reintegrate the vast quantities of data generated into the research cycle, researchers face a situation of massive resource inefficiency with minimal scientific gain. This issue is particularly concerning in the context of research with animals where researchers are committed to follow the 3Rs that also recognize the need for responsible use of animals. A first and necessary step toward effective repurposing of data from in vivo studies in biomedical research is to ensure that raw data are effectively described with metadata. The MNMS that we propose here aligns with existing guidelines for reporting in vivo studies and, if adopted, would provide an important step toward advancing scientific knowledge and ensuring the continued ethical use of animals in biomedical research.
Received: 21 June 2023; Accepted: 31 January 2024
Published online: 4 March 2024
References
Bespalov, A. & Steckler, T. Lacking quality in research: Is behavioral neuroscience affected more than other areas of biomedical science? J. Neurosci. Methods 300, 4-9 (2018).
Frye, S. V. et al. Tackling reproducibility in academic preclinical drug discovery. Nat. Rev. Drug Discov. 14, 733-734 (2015).
Prinz, F., Schlange, T. & Asadullah, K. Believe it or not: how much can we rely on published data on potential drug targets? Nat. Rev. Drug Discov. 10, 712-712 (2011).
Russell, W. M. S. & Burch, R. L. The Principles of Humane Experimental Technique (Methuen, 1959).
Begley, C. G. & loannidis, J. P. A. Reproducibility in science: improving the standard for basic and preclinical research. Circ. Res. 116, 116-126 (2015).
Macleod, M. et al. Biomedical research: increasing value, reducing waste. Lancet 383, 101-104 (2014).
Eggel, M. & Würbel, H. Internal consistency and compatibility of the 3Rs and 3Vs principles for project evaluation of animal research. Lab Anim. 55, 233-243 (2021).
Strech, D. & Dirnagl, U. 3Rs missing: animal research without scientific value is unethical. BMJ Open Sci. 3, e000035 (2019).
Würbel, H. More than 3 Rs : the importance of scientific validity for harm-benefit analysis of animal research. Lab Anim. 46, 164-166 (2017).
Diederich, K., Schmitt, K., Schwedhelm, P., Bert, B. & Heinl, C. A guide to open science practices for animal research. PLoS Biol. 20, e3001810 (2022).
Chou, A. et al. Empowering data sharing and analytics through the open data commons for traumatic brain injury research. Neurotrauma Rep. 3, 139-157 (2022).
Fouad, K. et al. FAIR SCI Ahead: the evolution of the open data commons for pre-clinical spinal cord injury research. J. Neurotrauma 37, 831-838 (2019).
Torres-Espín, A. et al. Promoting FAIR data through community-driven agile design: the open data commons for spinal cord injury (odc-sci.org). Neuroinformatics 20, 203-219 (2022).
FAIRsharing Team. FAIRsharing record for: Minimum Information about Animal Toxicology Experiments (in vivo). FAIRsharing https://doi.org/10.25504/FAIRSHARING.WYSCSE (2018).
Koopmans, B., Smit, A. B., Verhage, M. & Loos, M. AHCODA-DB: a data repository with web-based mining tools for the analysis of automated high-content mouse phenomics data. BMC Bioinform. 18, 200 (2017).
Nault, R. et al. A case for accelerating standards to achieve the FAIR principles of environmental health research experimental data. Environ. Health Perspect. 131, 065001 (2023).
Smith, A. J., Clutton, R. E., Lilley, E., Hansen, K. E. A. & Brattelid, T. PREPARE: guidelines for planning animal research and testing. Lab Anim. 52, 135-141 (2018).
Kilkenny, C., Browne, W. J., Cuthill, I. C., Emerson, M. & Altman, D. G. Improving bioscience research reporting: the ARRIVE guidelines for reporting animal research. PLoS Biol. 8, e1000412 (2010).
Percie du Sert, N. et al. The ARRIVE guidelines 2.0: updated guidelines for reporting animal research. PLoS Biol. 18, e3000410 (2020).
Regulation (EC) No 1907/2006 of the European Parliament and of the Council of 18 December 2006 Concerning the Registration, Evaluation, Authorisation and Restriction of Chemicals (REACH), Establishing a European Chemicals Agency, Amending Directive 1999/45/EC and Repealing Council Regulation (EEC) No 793/93 and Commission Regulation (EC) No 1488/94 as Well as Council Directive 76/769/EEC and Commission Directives 91/155/EEC, 93/67/EEC, 93/105/EC and 2000/21/EC (Text with EEA Relevance) (Publications Office of the European Union, 2006).
Regulation (EU) No 528/2012 of the European Parliament and of the Council of 22 May 2012 Concerning the Making Available on the Market and Use of Biocidal productsText with EEA Relevance. No 528/2012 (Publications Office of the European Union, 2012).
Regulation (EC) No 1107/2009 of the European Parliament and of the Council of 21 October 2009 Concerning the Placing of Plant Protection Products on the Market and Repealing Council Directives 79/117/EEC and 91/414/EEC. No 1107/2009 (Publications Office of the European Union, 2009).
Steger-Hartmann, T. et al. Introducing the concept of virtual control groups into preclinical toxicology testing. ALTEX 37, 343-349 (2020).
Steger-Hartmann, T. et al. Perspectives of data science in preclinical safety assessment. Drug Discovery Today 28, 103642 (2023).
Almeida, C. A. et al. Excavating FAIR data: the case of the Multicenter Animal Spinal Cord Injury Study (MASCIS), blood pressure, and neuro-recovery. Neuroinformatics 20, 39-52 (2022).
Bonapersona, V., Hoijtink, H., Sarabdjitsingh, R. A. & Joëls, M. Increasing the statistical power of animal experiments with historical control data. Nat. Neurosci. 24, 470-477 (2021).
Nolte, T. et al. RITA-registry of industrial toxicology animal data: the application of historical control data for Leydig cell tumors in rats. Exp. Toxicol. Pathol. 63, 645-656 (2011).
Wilkinson, M. D. et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci Data 3, 160018 (2016).
Hair, K., Macleod, M. R. & Sena, E. S., on behalf of the IICARus Collaboration. A randomised controlled trial of an Intervention to Improve Compliance with the ARRIVE guidelines (IICARus). Res. Integr. Peer Rev. 4, 12 (2019).
Yeadon, J. Designating genotypes: what does ‘+’ really mean? The Jackson Laboratory https://www.jax.org/news-and-insights/ jax-blog/2011/May/designating-genotypes-what-does-plus-reallymean20150422t150455 (2011).
Hastings, J. et al. ChEBI in 2016: improved services and an expanding collection of metabolites. Nucleic Acids Res. 44, D1214-D1219 (2016).
Karp, N. A. et al. Applying the ARRIVE guidelines to an in vivo database. PLoS Biol. 13, e1002151 (2015).
Fuochi, S. et al. Data repurposing from digital home cage monitoring enlightens new perspectives on mouse motor behaviour and reduction principle. Sci. Rep. 13, 10851 (2023).
Groenink, L., Verdouw, P. M., Bakker, B. & Wever, K. E. Pharmacological and methodological aspects of the separation-induced vocalization test in guinea pig pups; a systematic review and meta-analysis. Eur. J. Pharmacol. 753, 191-208 (2015).
Currie, G. L. et al. Animal models of chemotherapy-induced peripheral neuropathy: a machine-assisted systematic review and meta-analysis. PLoS Biol. 17, e3000243 (2019).
Mei, J. et al. Refining humane endpoints in mouse models of disease by systematic review and machine learning-based endpoint definition. ALTEX 36, 555-571 (2019).
van Drongelen, J., Hooijmans, C. R., Lotgering, F. K., Smits, P. & Spaanderman, M. E. A. Adaptive changes of mesenteric arteries in pregnancy: a meta-analysis. Am. J. Physiol. Heart Circ. Physiol. 303, H639-H657 (2012).
Macleod, M. R., Tanriver-Ayder, E., Hair, K. & Sena, E. in Good Research Practice in Non-clinical Pharmacology and Biomedicine (eds Bespalov, A., Michel, M. C. & Steckler, T.) 299-317 (Springer, 2020).
robonaultran. Minimum Information about Animal Toxicology Experiments In Vivo (MIATE/invivo). FAIRsharing https://fairsharing. org/FAIRsharing.wYScsE (2020).
Communication from the Commission-Guidelines on the Applicability of Article 101 of the Treaty on the Functioning of the European Union to Horizontal Co-Operation Agreements Text with EEA Relevance (Publications Office of the European Union, 2011).
Restivo, L. et al. Towards best practices in research: role of academic core facilities. EMBO Rep. 22, e53824 (2021).
Bikovski, L. et al. Lessons, insights and newly developed tools emerging from behavioral phenotyping core facilities. J. Neurosci. Methods 334, 108597 (2020).
Strayhorn, J. M. Virtual controls as an alternative to randomized controlled trials for assessing efficacy of interventions. BMC Med. Res. Methodol. 21, 3 (2021).
Acknowledgements
We thank M. Markert (Boehringer Ingelheim) and Y.-P. Zhang (F. Hoffmann-La Roche) for initial discussions on the manuscript concept, and D. Roqueiro, M. Ghraichy, Y.-P. Zhang and colleagues in Data & Analytics, Roche Pharma Research and Early Development, F. Hoffmann-La Roche for support in developing the database illustrated in Fig. 2. L.R., G.R., F.S., M.T., E.C.O. and S.G. are members of the COST Action CA20135 (TEATIME). We thank S. Dalla Costa
(Tecniplast S.p.A.) for the graphics of Fig. 3. A.B.-B. is funded by an ‘Impulse für das Wissenschaftssystem’ grant from Volkswagen Foundation, Germany. M.T. is the incumbent of the Carolito Stiftung Research Fellow Chair in Neurodegenerative Diseases.
Author contributions
A.B.-B., A.M., E.C.O., L.R. and S.G. conceptualized the article. S.G., L.R. and E.C.O. conceptualized and provided the figures. All authors contributed to writing the original draft manuscript. A.B.-B., A.M., E.C.O., L.R. and S.G. critically reviewed the manuscript. All authors contributed to and approved the final version of the manuscript.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Competing interests
S.G. and G.R. are employed by Tecniplast S.p.A. E.C.O., A.M. and S.B. are employed by F. Hoffmann-La Roche Ltd. G.F. is employed by Charles River. F.S. is employed by Novartis AG. All other authors declare no competing interests.
Additional information
Correspondence and requests for materials should be addressed to Eoin C. O’Connor, Stefano Gaburro or Alexandra Bannach-Brown.
Peer review information Lab Animal thanks Sabine Hölter, Paul A. Garner and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/ licenses/by/4.0/.
(C) The Author(s) 2024
Roche Pharma Research and Early Development, Data & Analytics, Roche Innovation Center Basel, F. Hoffmann-La Roche Ltd, Basel, Switzerland. Neuro-Behavioral Analysis Unit, Faculty of Biology & Medicine, University of Lausanne, Lausanne, Switzerland. Group Legal Department, F. Hoffmann-La Roche Ltd, Basel, Switzerland. Discovery, Charles River Laboratories, Groningen, the Netherlands. Tecniplast S.p.A., Buguggiate, Italy. Emerging Technologies, Comparative Medicine, Novartis International AG, Basel, Switzerland. Behavioral and Physiological Phenotyping Unit, Department of Veterinary Resources, Weizmann Institute of Science, Rehovot, Israel. Roche Pharma Research and Early Development, Neuroscience & Rare Diseases, Roche Innovation Center Basel, F. Hoffmann-La Roche Ltd, Basel, Switzerland. QUEST Center for Responsible Research, Berlin Institute of Health at Charité-Universitätsmedizin Berlin, Berlin, Germany. These authors contributed equally: Anastasios Moresis, Leonardo Restivo.