https://doi.org/10.1038/s41586-025-08866-7
تاريخ الاستلام: 18 يناير 2024
تاريخ القبول: 5 مارس 2025
تاريخ النشر على الإنترنت: 9 أبريل 2025
الوصول المفتوح
تحقق من التحديثات
في قلب الطب يكمن حوار الطبيب والمريض، حيث يتيح أخذ التاريخ الطبي المهاري تشخيصًا فعالًا وإدارة موثوقة.. يمكن أن تزيد أنظمة الذكاء الاصطناعي (AI) القادرة على الحوار التشخيصي من إمكانية الوصول وجودة الرعاية. ومع ذلك، فإن تقليد خبرة الأطباء يمثل تحديًا بارزًا. هنا نقدم AMIE (مستكشف الذكاء الطبي الواضح)، وهو نظام ذكاء اصطناعي قائم على نموذج لغة كبير (LLM) مُحسّن للحوار التشخيصي. تستخدم AMIE بيئة محاكاة قائمة على اللعب الذاتي مع ملاحظات آلية لتوسيع نطاق التعلم عبر حالات المرض والتخصصات والسياقات. صممنا إطارًا لتقييم محاور الأداء ذات المعنى السريري، بما في ذلك أخذ التاريخ الطبي، دقة التشخيص، الإدارة، مهارات التواصل والتعاطف. قارننا أداء AMIE بأداء أطباء الرعاية الأولية في دراسة عشوائية مزدوجة التعمية لتشاورات نصية مع ممثلين مرضى موثوقين مشابهين للاختبار السريري المنظم الموضوعي.. شملت الدراسة 159 سيناريو حالة من مقدمي الرعاية في كندا والمملكة المتحدة والهند، 20 طبيب رعاية أولية مقارنة بـ AMIE، وتقييمات من أطباء متخصصين وممثلين مرضى. أظهرت AMIE دقة تشخيصية أكبر وأداءً متفوقًا في 30 من 32 محورًا وفقًا للأطباء المتخصصين و25 من 26 محورًا وفقًا لممثلي المرضى. تحتوي أبحاثنا على عدة قيود ويجب تفسيرها بحذر. استخدم الأطباء دردشة نصية متزامنة، مما يسمح بتفاعلات واسعة النطاق بين LLM والمرضى، لكن هذا غير مألوف في الممارسة السريرية. بينما يتطلب الأمر مزيدًا من البحث قبل أن يمكن ترجمة AMIE إلى إعدادات العالم الحقيقي، تمثل النتائج علامة فارقة نحو الذكاء الاصطناعي التشخيصي المحادثاتي.
الحوار بين الطبيب والمريض أساسي للرعاية الفعالة والرحيمة. وقد تم وصف المقابلة الطبية بأنها “أقوى وأدق وأكثر الأدوات تنوعًا المتاحة للطبيب”.. في بعض الإعدادات، يُعتقد أن من التشخيصات يتم إجراؤها من خلال أخذ التاريخ الطبي فقط.. يمتد حوار الطبيب والمريض إلى ما هو أبعد من أخذ التاريخ والتشخيص – إنه تفاعل معقد يرسخ العلاقة والثقة، ويعمل كأداة لتلبية الاحتياجات الصحية ويمكن أن يمكّن المرضى من اتخاذ قرارات مستنيرة تأخذ في الاعتبار تفضيلاتهم وتوقعاتهم واهتماماتهم.. بينما هناك تباين واسع في مهارات التواصل بين الأطباء، يمكن للمهنيين المدربين جيدًا أن يمتلكوا مهارات كبيرة في أخذ التاريخ الطبي و”الحوار التشخيصي” الأوسع. ومع ذلك، فإن الوصول إلى هذه الخبرة لا يزال متقطعًا ونادرًا عالميًا..
أظهرت التقدمات الأخيرة في نماذج اللغة الكبيرة العامة (LLMs) أن أنظمة الذكاء الاصطناعي (AI) لديها القدرة على التخطيط والتفكير ودمج السياق ذي الصلة بما يكفي لإجراء محادثات طبيعية. يوفر هذا التقدم فرصة لإعادة التفكير في
إمكانيات الذكاء الاصطناعي في الطب نحو تطوير الذكاء الاصطناعي المحادثاتي التفاعلي بالكامل. ستفهم مثل هذه الأنظمة الطبية للذكاء الاصطناعي اللغة السريرية، وتكتسب المعلومات بذكاء في ظل عدم اليقين وتشارك في محادثات طبية طبيعية ومفيدة تشخيصيًا مع المرضى ومن يهتم بهم. إن الفائدة المحتملة لأنظمة الذكاء الاصطناعي القادرة على الحوار السريري والتشخيصي واسعة، مع إمكانية تحسين الوصول إلى الخبرة التشخيصية والتنبؤية، وبالتالي تحسين الجودة والاتساق والتوافر والقدرة على تحمل التكاليف للرعاية. قد يكون النهج الذي يركز على العدالة الصحية في دمج هذه التكنولوجيا في سير العمل الحالي، والذي يتضمن العمل في مراحل التطوير والتنفيذ والسياسة، له القدرة على تحقيق نتائج صحية أفضل (خصوصًا للسكان الذين يواجهون تفاوتات في الرعاية الصحية).
ومع ذلك، بينما أظهرت LLMs أنها تشفر المعرفة السريرية وقد أثبتت قدرتها على الإجابة بدقة عالية على الأسئلة الطبية ذات الدور الواحد, فإن قدراتها المحادثاتية قد تم تخصيصها لمجالات خارج الطب السريري.. كانت الأعمال السابقة في LLMs لـ
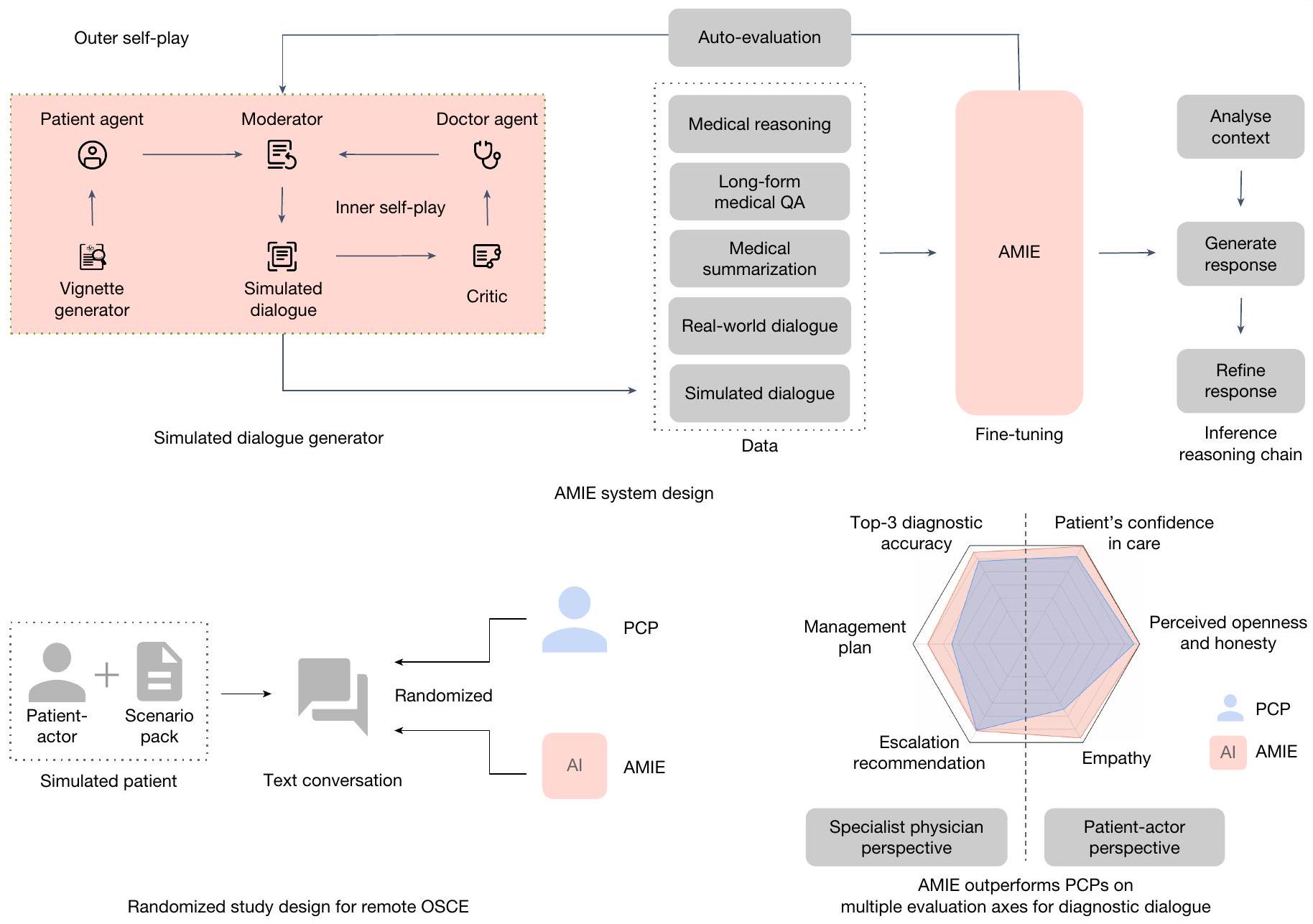
الشكل 1| نظرة عامة على المساهمات. AMIE هو ذكاء اصطناعي طبي محادثاتي مُحسّن للحوار التشخيصي. تم ضبطه بدقة مع مجموعة من الحوارات الطبية الواقعية والمحاكاة، إلى جانب مجموعة متنوعة من مجموعات بيانات التفكير الطبي، والإجابة على الأسئلة (QA) والتلخيص. من الجدير بالذكر أننا صممنا بيئة حوار محاكاة قائمة على اللعب الذاتي مع آليات ملاحظات آلية لتوسيع قدرات AMIE عبر سياقات طبية وتخصصات مختلفة. بشكل خاص، تتكون هذه العملية التكرارية للتحسين الذاتي من حلقتين من اللعب الذاتي: (1) حلقة اللعب الذاتي “الداخلية”، حيث استفادت AMIE من ملاحظات النقاد في السياق لتحسين سلوكها في المحادثات المحاكاة مع وكيل مريض ذكاء اصطناعي؛ و(2) حلقة اللعب الذاتي “الخارجية” حيث
تم دمج مجموعة الحوارات المحاكاة المكررة في دورات الضبط اللاحقة. خلال الاستدلال عبر الإنترنت، استخدمت AMIE استراتيجية سلسلة من التفكير لتحسين استجابتها تدريجيًا، مشروطة بالمحادثة الحالية، للوصول إلى رد دقيق ومؤسس للمريض في كل دورة حوار. صممنا وأجرينا اختبار OSCE عن بُعد مع ممثلين مرضى موثوقين يتفاعلون مع AMIE أو أطباء الرعاية الأولية من خلال واجهة دردشة نصية. عبر محاور متعددة، تتوافق مع كل من وجهات نظر الأطباء المتخصصين (30 من 32) وممثلي المرضى (25 من 26)، تم تقييم AMIE على أنها متفوقة على أطباء الرعاية الأولية بينما كانت غير أدنى في البقية.
الصحة لم يتم فحصها بعد بدقة من حيث قدرات أخذ التاريخ الطبي والحوار التشخيصي لأنظمة الذكاء الاصطناعي أو وضعها في سياق مقارنة مع القدرات الواسعة للأطباء العامين الممارسين.
يمثل أخذ التاريخ الطبي والحوار التشخيصي، من خلالهما يستخلص الأطباء التشخيصات وخطط الإدارة، مهارة معقدة تعتمد بشكل كبير على السياق. وبالتالي، هناك حاجة إلى محاور تقييم متعددة لتقييم جودة الحوار التشخيصي، بما في ذلك هيكل واكتمال التاريخ المستخرج، دقة التشخيص، ملاءمة خطط الإدارة وأسبابها، واعتبارات موجهة نحو المريض، مثل بناء العلاقات، واحترام الفرد، وفعالية التواصل.. إذا كان من المقرر تحقيق الإمكانات المحادثاتية لـ LLMs في الطب، فهناك حاجة ملحة لتطوير وتحسين تقييم أنظمة الذكاء الاصطناعي الطبية لخصائص مثل هذه، والتي هي فريدة من نوعها لأخذ التاريخ والحوار التشخيصي بين الأطباء والمرضى.
هنا نوضح تقدمنا نحو نظام ذكاء اصطناعي طبي محادثاتي لأخذ التاريخ الطبي، والتفكير التشخيصي وفعالية التواصل. كما نحدد بعض القيود الرئيسية والاتجاهات للبحث المستقبلي.
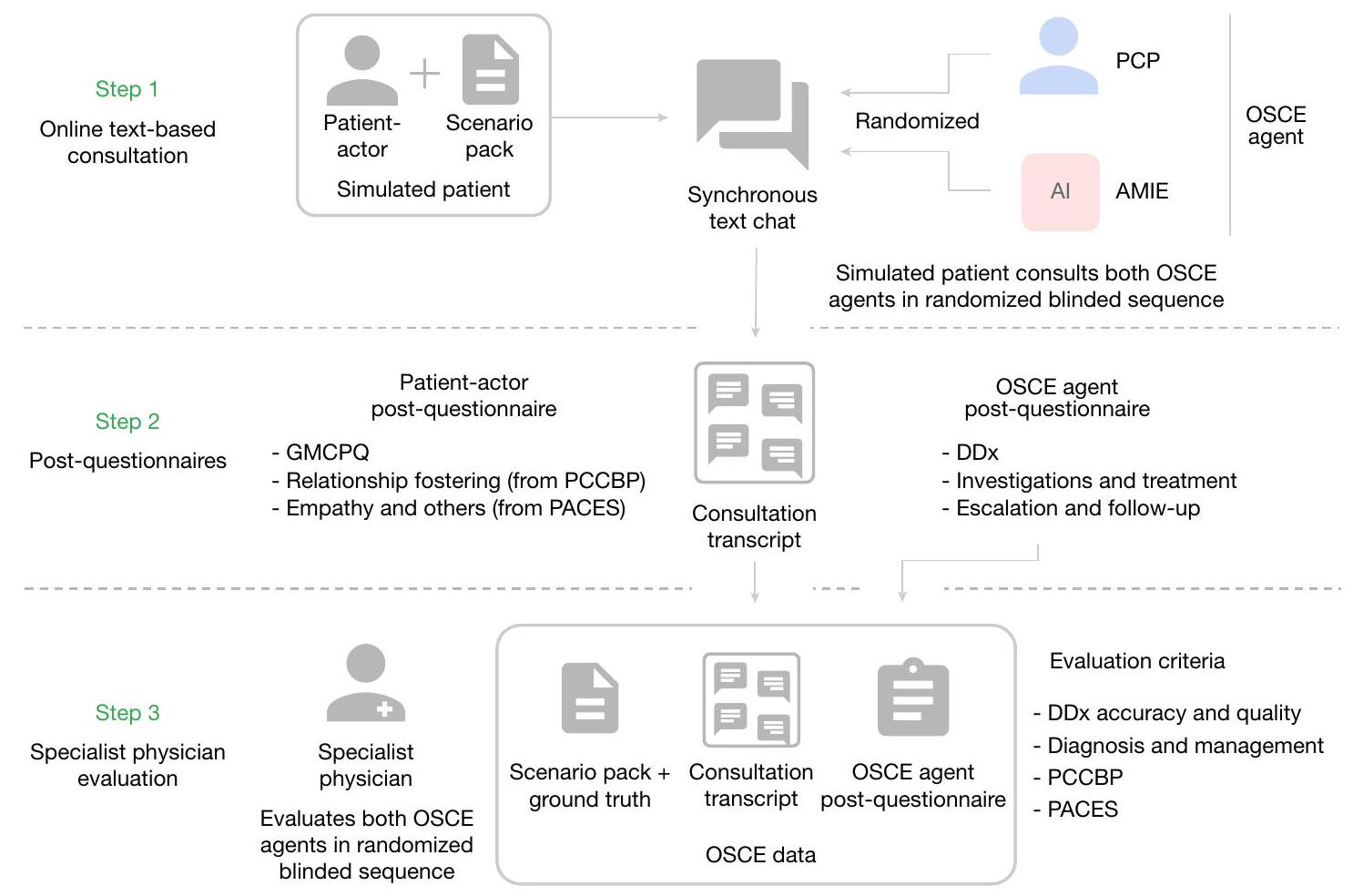
تُلخص مساهماتنا الرئيسية (الشكل 1) هنا. قدمنا أولاً AMIE (مستكشف الذكاء الطبي الواضح)، وهو نظام ذكاء اصطناعي قائم على نموذج اللغة الكبيرة مُحسّن لجمع التاريخ الطبي والحوار التشخيصي. لتوسيع نطاق AMIE عبر مجموعة متنوعة من التخصصات والسيناريوهات، قمنا بتطوير بيئة حوار تشخيصي محاكية تعتمد على اللعب الذاتي مع آليات تغذية راجعة تلقائية لتعزيز وتسريع عملية تعلمه. كما قدمنا استراتيجية سلسلة الاستدلال لتحسين دقة تشخيص AMIE وجودة المحادثة. ثم قمنا بتطوير مقياس تقييم تجريبي لتقييم جمع التاريخ الطبي، والتفكير التشخيصي، ومهارات التواصل، والتعاطف في الذكاء الاصطناعي الطبي الحواري، مع الأخذ في الاعتبار مقاييس تركز على الأطباء وأخرى تركز على المرضى. بعد ذلك، صممنا وأجرينا دراسة موضوعية منظمة سريرية (OSCE) معتمدة على التعمية عن بُعد (الشكل 2) باستخدام 159 سيناريو حالة من مقدمي الرعاية السريرية.
الشكل 2 | نظرة عامة على تصميم الدراسة العشوائية. يقوم طبيب الرعاية الأولية وAMIE (التقييم الطبي المتكامل) بإجراء (بترتيب عشوائي) اختبار OSCE الافتراضي عن بُعد مع مرضى محاكين من خلال دردشة نصية متزامنة متعددة الأدوار عبر الإنترنت ويقدمون إجابات. إلى استبيان بعد السؤال. ثم يتم تقييم كل من PCP و AMIE من قبل كل من الممثلين المرضى والأطباء المتخصصين. في كندا والمملكة المتحدة والهند، مما يتيح المقارنة العشوائية والمتوازنة بين AMIE وأطباء الرعاية الأولية (PCPs) عند إجراء الاستشارات مع ممثلي المرضى المعتمدين. أظهر AMIE دقة تشخيصية متفوقة مقارنة بأطباء الرعاية الأولية، كما تم تقييمه بواسطة مقاييس مختلفة (على سبيل المثال، دقة القائمة التفاضلية للتشخيص (DDx) في المراتب الأولى والثالثة). عبر 30 من أصل 32 محور تقييم من منظور الأطباء المتخصصين و25 من أصل 26 محور تقييم من منظور ممثلي المرضى، تم تصنيف AMIE على أنه متفوق على أطباء الرعاية الأولية بينما كان غير أدنى في المحاور المتبقية. أخيرًا، قمنا بإجراء مجموعة من التجارب لفهم وتوصيف قدرات AMIE بشكل أفضل، مع تسليط الضوء على القيود المهمة، واقترحنا خطوات رئيسية تالية للترجمة السريرية الواقعية لـ AMIE.
تحتوي أبحاثنا على قيود مهمة، وأهمها أننا استخدمنا واجهة دردشة نصية، والتي، على الرغم من أنها تتيح تفاعلًا محتملًا على نطاق واسع بين المرضى ونماذج اللغة الكبيرة المتخصصة في الحوار التشخيصي، كانت غير مألوفة للأطباء الممارسين في الاستشارات عن بُعد. لذلك، يجب ألا يُنظر إلى دراستنا على أنها تمثل الممارسة المعتادة في (الطب) عن بُعد.
دقة التشخيص التفريقي
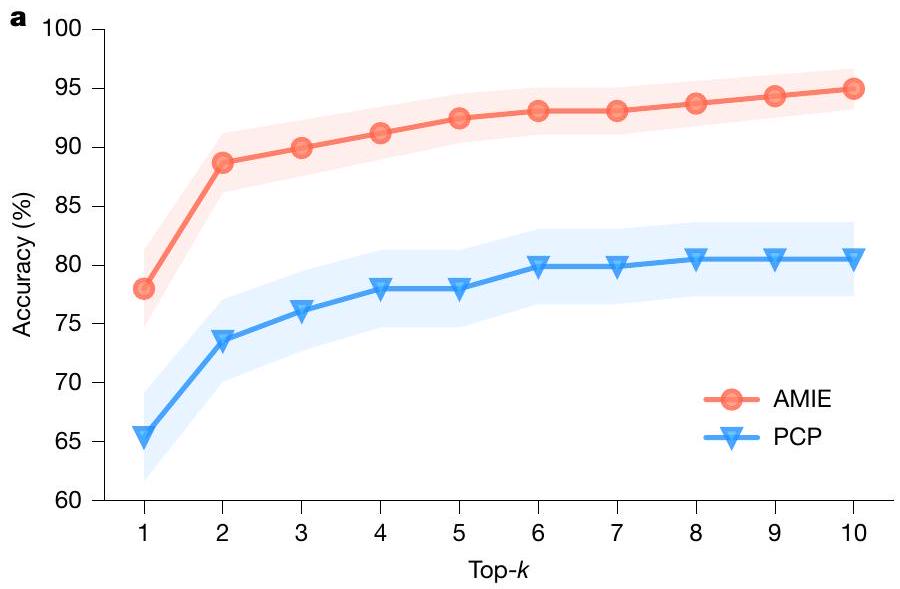
تمتلك AMIE دقة أعلى في تشخيص الفروق مقارنة بأطباء الرعاية الأولية.
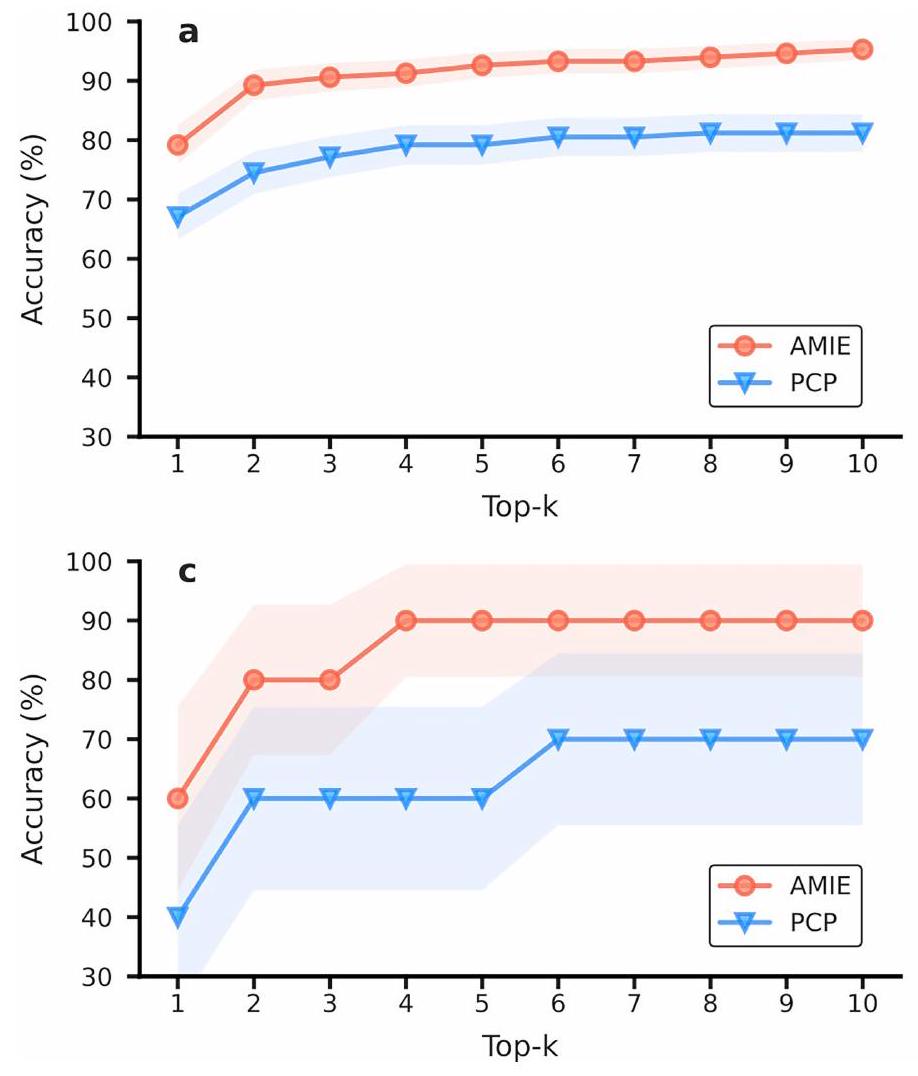
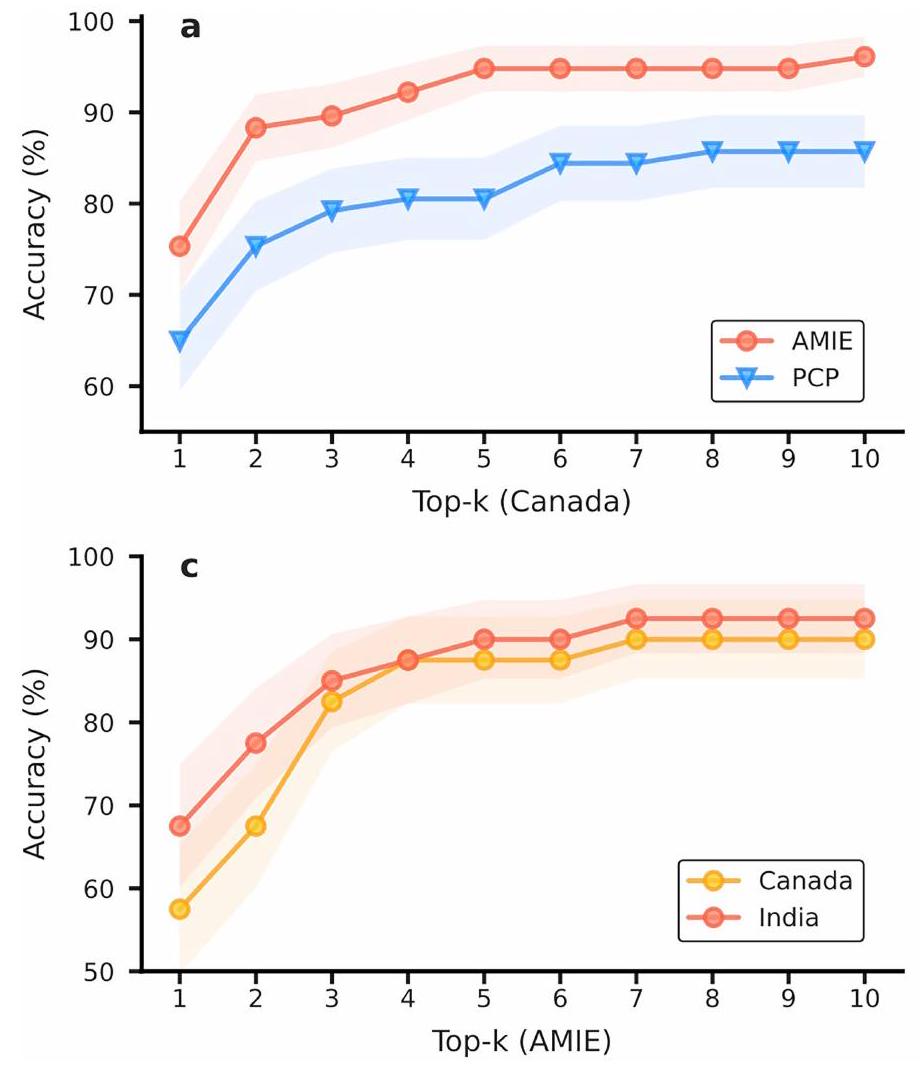
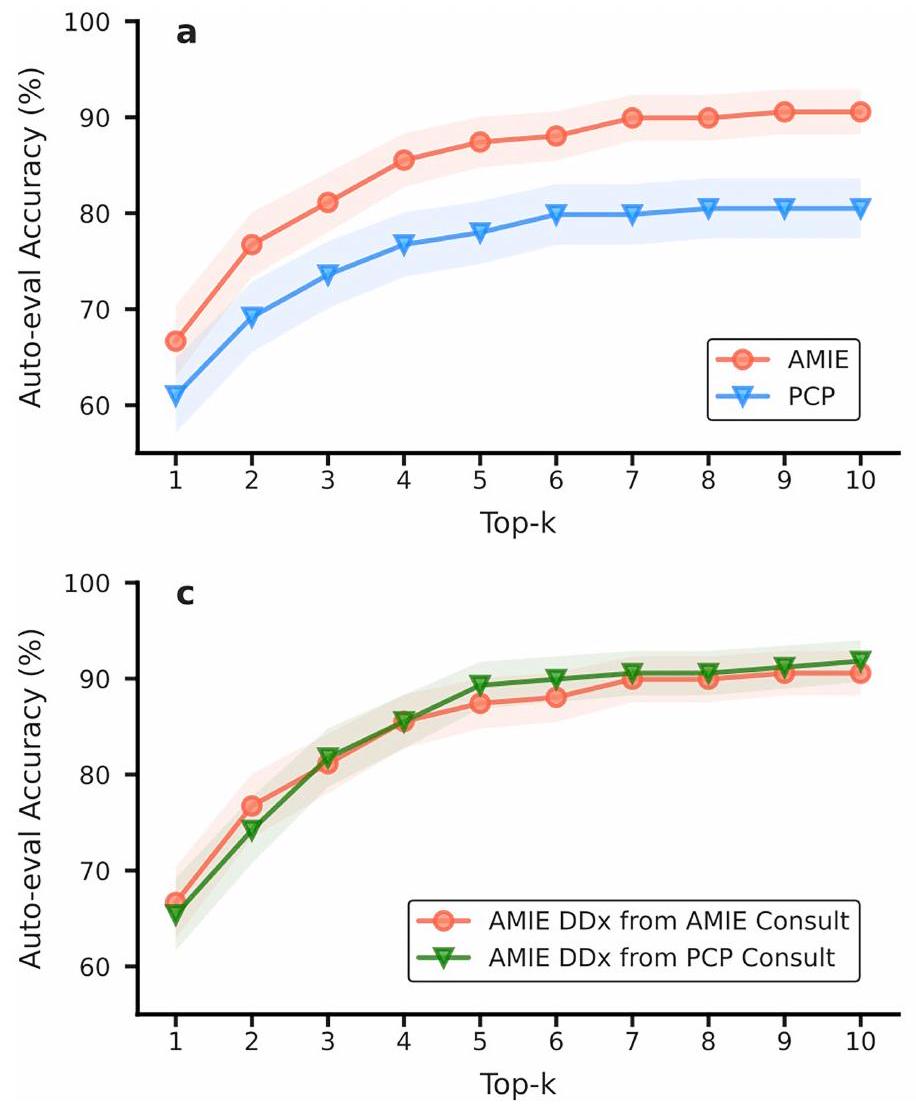
تم تقييم دقة تشخيص AMIE على أنها أعلى من دقة الأطباء العامين. الشكل 3 يوضح الأعلى-الدقة لـ AMIE و PCPs، مع الأخذ في الاعتبار المطابقات مع التشخيص الحقيقي (الشكل 3أ) والمطابقات مع أي عنصر في التفريق المقبول (الشكل 3ب). أظهرت AMIE دقة أعلى بشكل ملحوظ في القمة-دقة أكثر من تلك الخاصة بـ PCPs عبر جميع القيم لـ ( ). لاحظ أنه، على عكس AMIE، لم تقدم PCPs دائمًا عشرة تشخيصات في DDxs الخاصة بهم ( يعنيبالإضافة إلى ذلك، قمنا بإجراء مقارنة لدقة التشخيص التفريقي بين AMIE وأطباء الرعاية الأولية من خلال تغيير المعايير لتحديد التطابق (أي، يتطلب تطابقًا دقيقًا مقابل مجرد تشخيص ذي صلة عالية). النتائج الموضحة في الشكل التوضيحي الإضافي 2 تدعم بشكل أكبر أداء AMIE المتفوق في التشخيص التفريقي عبر معايير المطابقة المختلفة.
دقة الحالة غير المرضية والحالة المرضية. تم تصميم عشرة من السيناريوهات التي نفذها AMIE والأطباء الممارسون بشكل أساسي لوصف المرضى الذين لا يعانون من تشخيص مقلق جديد (على سبيل المثال، تشخيص حقيقي لحالة الإمساك التي تم حلها، أو تكرار حالة مرضية معروفة سابقًا لألم الصدر الناتج عن مرض الارتجاع المعدي المريئي). كانت هناك سيناريوهان من كل من التخصصات القلبية، وأمراض الجهاز الهضمي، والطب الباطني، والأعصاب، والتنفس. هنا قمنا برسم أعلى-دقة التشخيص التفريقي، كما تم تقييمها من خلال تصويت الأغلبية لثلاثة متخصصين في هذه الحالات غير المرضية. على الرغم من أن نتائجنا ليست ذات دلالة إحصائية، حيث تتكون فقط من عشرة سيناريوهات، يبدو أن AMIE تحافظ على نفس الاتجاه من الأداء الأفضل في هذه السيناريوهات السلبية في الغالب (الشكل البياني الممتد 2). يتمتع AMIE بدقة تشخيص تفريقي متفوقة على مجموعة من 149 سيناريو مرضي إيجابي في المقام الأول (حيث كان هناك ثلاثة سيناريوهات فقط لها حقيقة أرضية لحالة غير مرضية).
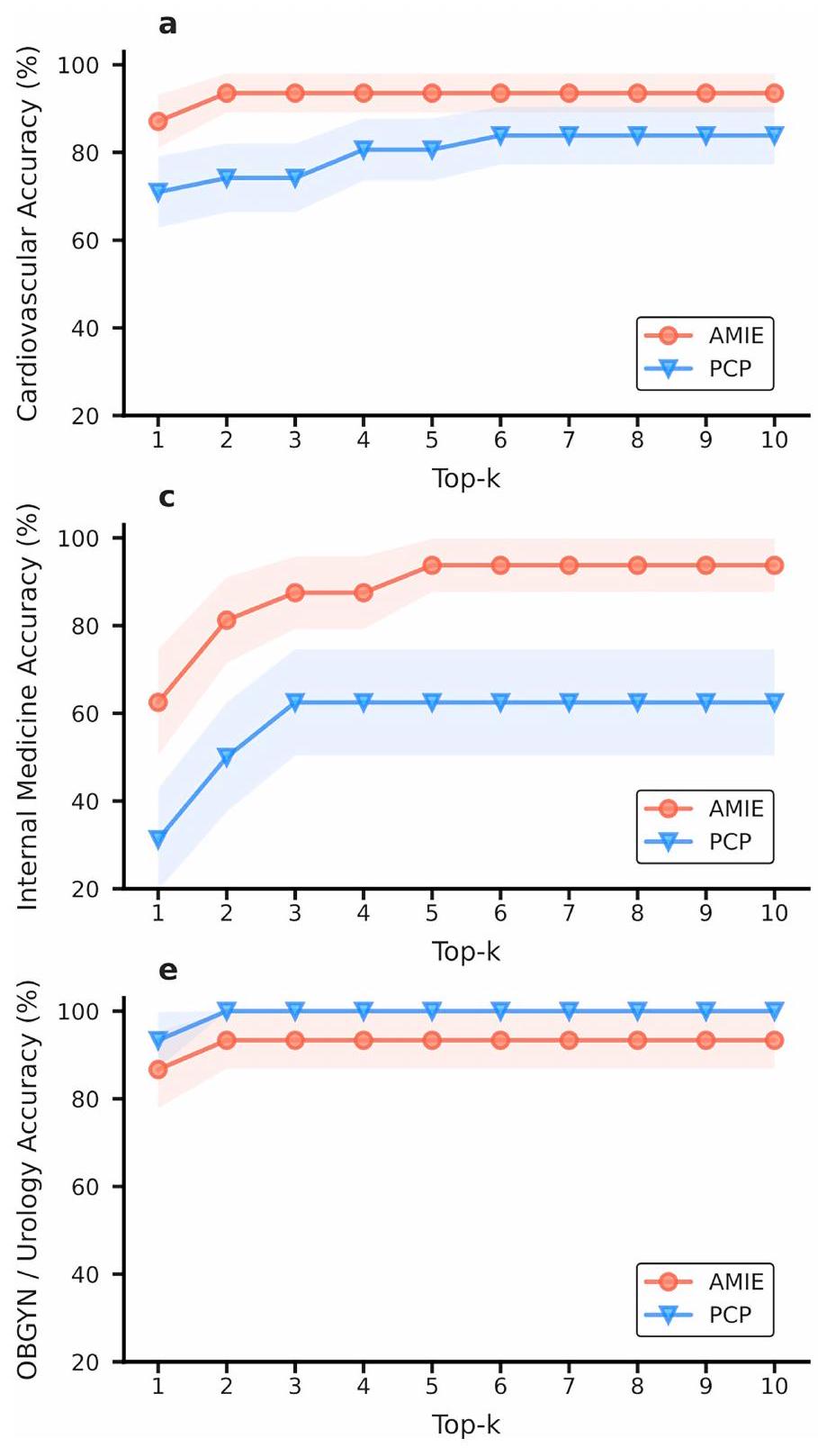
الدقة حسب التخصص. توضح الشكل الإضافي 3 دقة التشخيص التفريقي التي حققها AMIE وأطباء الرعاية الأولية عبر التخصصات الطبية الستة التي تغطيها السيناريوهات في دراستنا. لاحظنا أن أداء AMIE كان متطابقًا أو متفوقًا على أداء أطباء الرعاية الأولية في جميع التخصصات باستثناء التوليد وأمراض النساء/المسالك البولية، حيث كانت التحسينات الأكثر وضوحًا في تخصصات الجهاز التنفسي والطب الباطني.
الدقة حسب الموقع. لاحظنا أن كل من AMIE و PCPs كان لديهما دقة تشخيصية أعلى في الاستشارات التي أجريت في مختبر OSCE في كندا مقارنة بتلك التي تمت في مختبر OSCE في الهند. ومع ذلك، لم تكن الفروق ذات دلالة إحصائية، وفي مجموعة فرعية من 40 سيناريو تم تنفيذها في كل من مختبرات OSCE في كندا والهند، كانت أداءات كل من AMIE و PCPs متكافئة (الشكل 4 من البيانات الموسعة).
الكفاءة في الحصول على المعلومات
دقة التقييم الذاتي. قمنا بإعادة إنتاج تحليل دقة التشخيص التفريقي باستخدام نموذجنا القائم على التقييم الذاتي للتشخيص التفريقي باستخدام نفس الإجراء كما في الشكل 3. الاتجاهات العامة للأداء التي تم الحصول عليها من خلال
الشكل 3 | تقييم المتخصصين الأعلى-دقة التشخيص.، أعلى AMIE و PCP –تمت مقارنة دقة التشخيص التفريقي، التي تحددها أغلبية تصويت ثلاثة متخصصين، عبر 159 سيناريو بالنسبة للتشخيص الحقيقي (أ) وجميع التشخيصات في التشخيص التفريقي المقبول (ب). تتوافق الخطوط المركزية مع متوسط أعلى-الدقة، مع المناطق المظللة تشير إلىفترات الثقة المحسوبة من اختبار البوتستراب ثنائي الجانب ). جميع القمة- الفروق بين دقة AMIE و PCP DDx كبيرة، مع
بعد تصحيح FDR. تم تعديل FDRالقيم للمقارنة مع الحقيقة الأرضية هي:، و (أ). المعدل وفقًا لمعدل فائدة فدرالي القيم للمقارنة التفاضلية المقبولة هي: 0.0001, و .
جودة المحادثة
AMIE تتفوق على PCPs في جودة الحوار
تم تقييم جودة المحادثة باستخدام تقييمات المريض-الممثل، وتقييمات المتخصصين، ومخرجات التقييم الذاتي. يوضح الجدول التكميلية 5 مثالين لاستشارات مع نفس المريض المحاكي من AMIE وطبيب الرعاية الأولية.
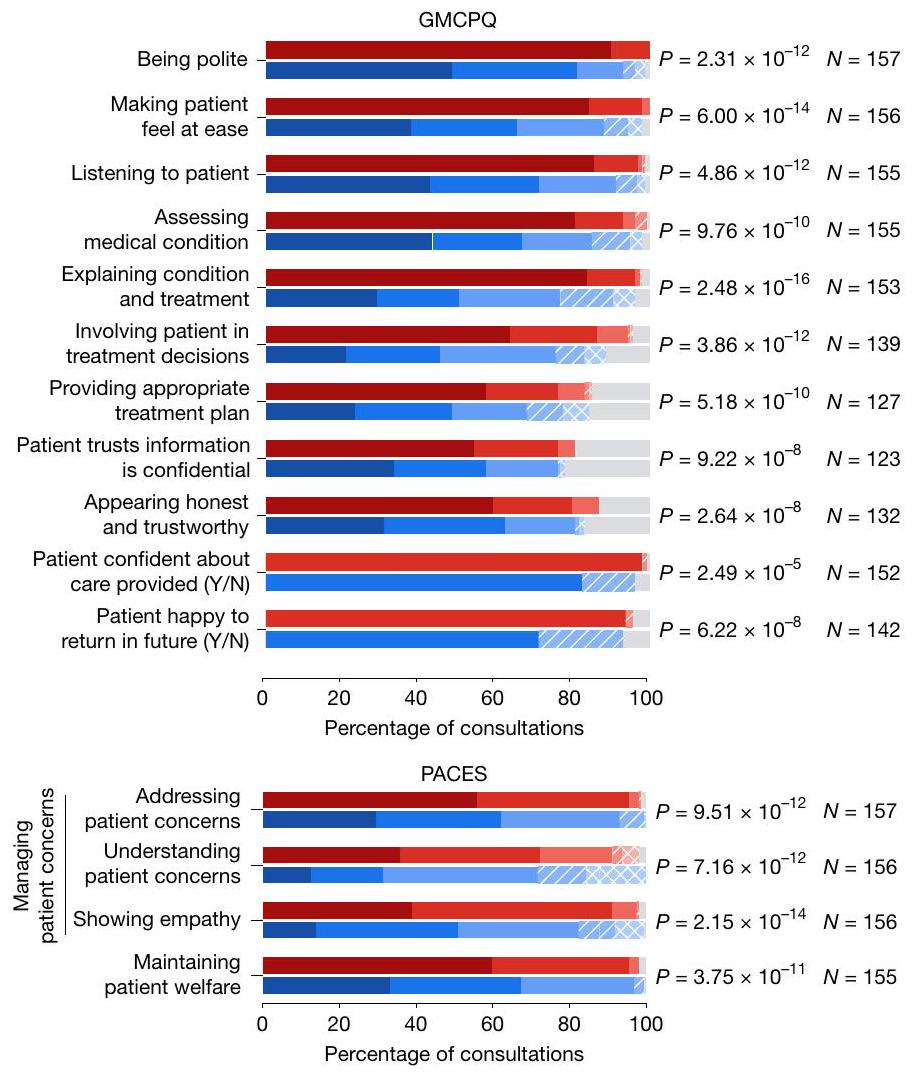
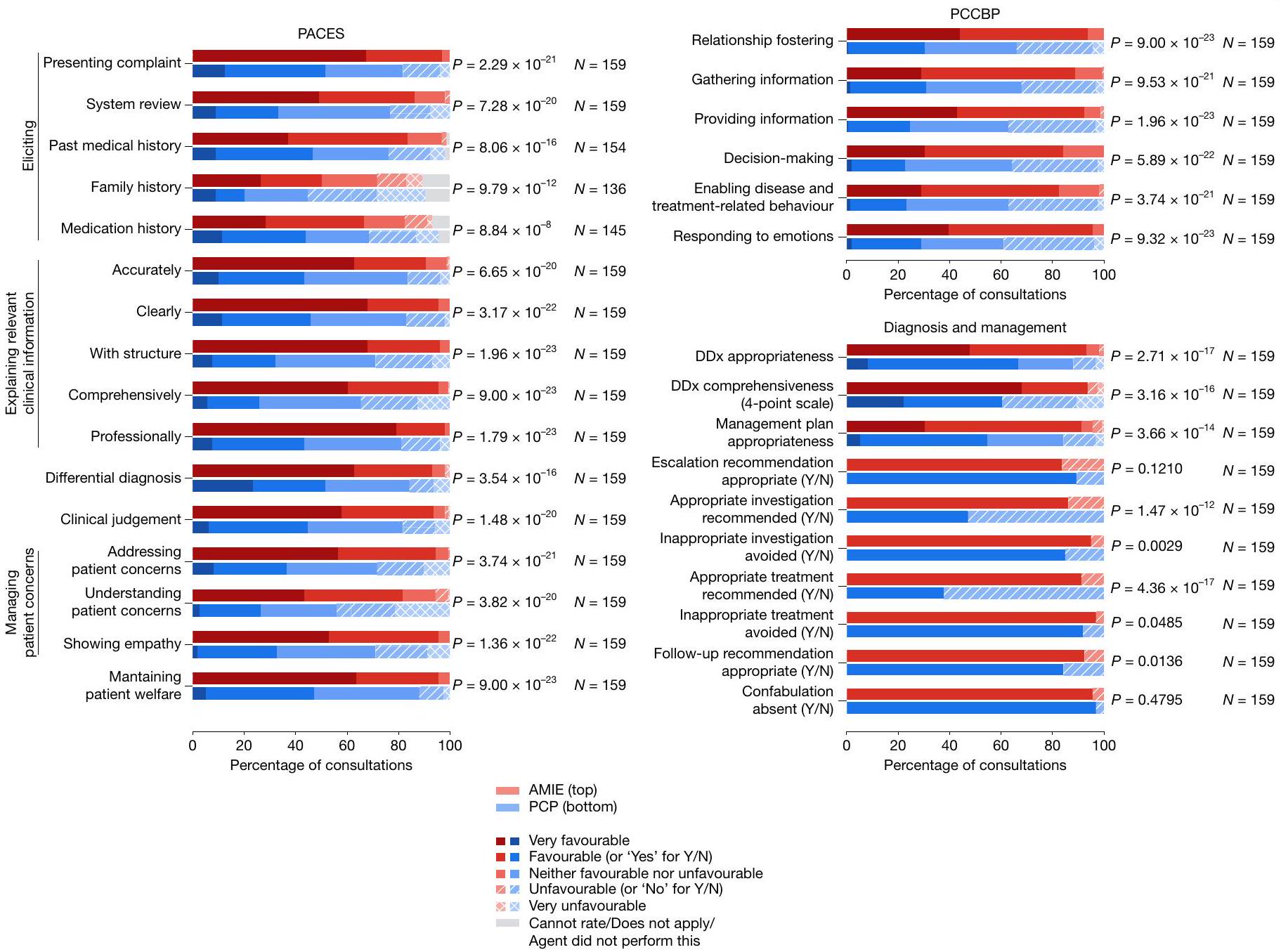
تقييمات الممثلين المرضى. الشكل 4 يعرض الصفات المختلفة للمحادثة التي قيمها الممثلون المرضى بعد استشاراتهم مع وكلاء منظمة الأمن والتعاون في أوروبا. بشكل عام، تم تقييم استشارات AMIE بشكل أفضل بشكل ملحوظ. ) من قبل الممثلين المرضى أكثر من أولئك مع مقدمي الرعاية الأولية عبر 25 من 26 محورًا. لم يتم الكشف عن اختلافات كبيرة في التقييمات لأحد محاور أفضل الممارسات في التواصل المتمركز حول المريض (PCCBP) الاعتراف بالأخطاءلذا، كان عدد الاستثناءات أعلى بكثير لأن هذا المعيار ينطبق فقط عندما تحدث أخطاء من قبل وكيل منظمة الأمن والتعاون في أوروبا وتم الإشارة إليها في المحادثة.
تقييمات الأطباء المتخصصين. قام الأطباء المتخصصون بتقييم كل من جودة المحادثة وكذلك الردود على الاستبيان بعد السؤال للسيناريوهات ضمن مجال خبرتهم (الشكل 5). مرة أخرى، تم تقييم ردود AMIE بشكل أفضل بكثير من قبل المتخصصين مقارنة بتلك التي قدمها أطباء الرعاية الأولية في 30 من أصل 32 محور تقييم، حيث فضل المتخصصون استشارات AMIE وتشخيصاتها وخطط إدارتها على تلك التي قدمها أطباء الرعاية الأولية. بالنسبة لهذه المجموعة من التقييمات، كانت الفروق في تقييمات المتخصصين بين AMIE وأطباء الرعاية الأولية ذات دلالة إحصائية. ). انظر قسم المعلومات التكميلية 7 لموثوقية التقييم بين المقيمين الثلاثة المتخصصين لكل سيناريو. لم يتم الكشف عن اختلافات كبيرة في التقييمات لاثنين من المحاور في مقياس التشخيص والإدارة – وهما ‘توصية التصعيد مناسبة’ و ‘غياب التخييل’ – على الرغم من عدم وجود استثناءات..
جودة محادثة الحوار المحاكي
لقد استخدمنا استراتيجية تقييم ذاتي قائمة على نموذج سلسلة الأفكار الذاتية (الجدول التكميلي 2) لتقييم المحادثات على أربعة محاور تقييم من مقياس تقييم مهارات الفحص السريري (PACES) ، وأكدنا أن هذه التقييمات الذاتية كانت دقيقة ومتوافقة بشكل جيد مع تقييمات المتخصصين (الملحق
الشكل 4 | تقييمات المريض-الممثل. جودة المحادثة، كما تم تقييمها من قبل الممثلين المرضى عند انتهاء الاستشارة. لأغراض التوضيح، تم رسم جميع الردود من مقاييس التقييم الخماسية إلى مقياس خماسي عام يتراوح من ‘مؤيد جداً’ إلى ‘غير مؤيد جداً’. بالنسبة لأسئلة نعم/لا (Y/N)، تم رسم رد ‘نعم’ (إيجابي) بنفس لون ‘مؤيد’ ورد ‘لا’ (سلبي) بنفس لون
الشكل 1ب). عند مقارنة الحوارات المحاكية التي تم إنشاؤها قبل وبعد إجراء اللعب الذاتي، وجدنا أن حلقة اللعب الذاتي الداخلية حسنت جودة الحوار المحاكي على هذه المحاور، كما هو موضح في الشكل التكميلي 1ج.
المناقشة
في هذه الدراسة، قدمنا AMIE، وهو نظام ذكاء اصطناعي قائم على نموذج لغوي كبير تم تحسينه للحوار السريري مع قدرات التفكير التشخيصي. قارننا استشارات AMIE بتلك التي أجراها الأطباء الممارسون باستخدام دراسة عشوائية مزدوجة التعمية مع مرضى محاكيين بأسلوب OSCE. من الجدير بالذكر أن دراستنا لم تكن مصممة لتكون ممثلة للمعايير السريرية سواء لتقييمات OSCE التقليدية، أو لممارسات الاستشارة عن بُعد أو الطب عن بُعد، أو للطرق التي يستخدمها الأطباء عادةً للتواصل مع المرضى عبر النصوص ورسائل الدردشة. بدلاً من ذلك، عكس تقييمنا الطريقة الأكثر شيوعًا التي يتفاعل بها الناس مع نماذج اللغة الكبيرة اليوم، مستفيدين من آلية محتملة قابلة للتوسع ومألوفة لأنظمة الذكاء الاصطناعي للانخراط في حوار تشخيصي عن بُعد. في هذا الإعداد، لاحظنا أن AMIE، وهو نظام ذكاء اصطناعي تم تحسينه خصيصًا لهذه المهمة، تفوق على الأطباء الممارسين في المحادثات التشخيصية المحاكية عند تقييمه على عدة محاور ذات دلالة سريرية لجودة الاستشارة.
الأداء التشخيصي
كانت التشخيصات التفريقية التي قدمها AMIE أكثر دقة واكتمالاً من تلك التي قدمها الأطباء الممارسون المعتمدون من المجلس عندما تم تقييم كلاهما من قبل أطباء متخصصين. أظهرت الأبحاث السابقة أن أنظمة الذكاء الاصطناعي قد تتطابق أو تتجاوز الأداء التشخيصي البشري في مهام محددة وضيقة في التقييم الرجعي. ومع ذلك، فإن هذه الحالات
‘غير مؤيد’. تم تعديل مقاييس التقييم من GMCPQ وPACES ومراجعة سردية حول PCCBP. تم تقديم تفاصيل حول صياغة الأسئلة وخيارات الرد في جداول البيانات الموسعة 1 و2. شمل التقييم 159 مريضًا محاكيًا. تم تحديد القيم باستخدام اختبارات ويلكوكسون ذات الرتبة الموقعة ذات الجانبين مع تصحيح FDR. تم استبعاد الحالات التي حصل فيها AMIE أو الطبيب الممارس على ‘لا يمكن التقييم/لا ينطبق’ من الاختبار.
عادة ما تتضمن كل من الذكاء الاصطناعي والأطباء تفسير نفس المدخل الثابت (على سبيل المثال، تحديد وجود نتيجة معينة في صورة طبية). كانت دراستنا أكثر تحديًا بشكل كبير لأنها تطلبت من نظام الذكاء الاصطناعي الحصول بنشاط على معلومات ذات صلة من خلال المحادثة، بدلاً من الاعتماد على المعلومات السريرية التي جمعها البشر . لذلك، كانت التشخيصات التفريقية اللاحقة للنظام تعتمد ليس فقط على قدرته على الاستنتاج التشخيصي، ولكن أيضًا على جودة المعلومات التي تم جمعها تحت عدم اليقين من خلال المحادثة الطبيعية وبناء العلاقة.
أشارت نتائجنا إلى أن AMIE كان بارعًا مثل الأطباء الممارسين في استنباط المعلومات ذات الصلة خلال الاستشارات المحاكية، وكان أكثر دقة من الأطباء الممارسين في صياغة تشخيص تفريقي كامل إذا تم إعطاؤه نفس كمية المعلومات المكتسبة. تدعم هذه النتيجة أعمالًا أخرى تشير إلى أن نماذج اللغة الكبيرة قد تكون قادرة على إنتاج تشخيصات تفريقية أكثر اكتمالاً عند إعطائها نفس المعلومات السريرية مثل الأطباء في الحالات الصعبة . على الرغم من عدم استكشاف ذلك في هذه الدراسة، فإن الأداء المساعد لـ AMIE يمثل بالتالي مسارًا مثيرًا ومهمًا للبحث المستقبلي، خاصة بالنظر إلى الأهمية الواقعية للإشراف الخبير على أنظمة الذكاء الاصطناعي في البيئات الحرجة للسلامة، مثل الطب.
استخدمت دراستنا مجموعة واسعة من المرضى المحاكيين، تتكون من ممثلين تم تدريبهم في كل من كندا والهند، وسيناريوهات عبر مجموعة من التخصصات. سمح لنا ذلك باستكشاف كيفية اختلاف الأداء على طول محاور متعددة – حسب التخصص، وحسب المواقع التي تم اشتقاق السيناريو منها وتنفيذه. بينما لاحظنا أن كل من الأطباء الممارسين وAMIE أدوا بشكل أسوأ في سيناريوهات أمراض الجهاز الهضمي والطب الباطني مقارنةً بالتخصصات الأخرى (الشكل البياني الموسع 3)، لم تكن الدراسة مصممة أو مهيأة لمقارنة الأداء بين مواضيع التخصص المختلفة والمواقع، ولا يمكننا استبعاد أن السيناريوهات في بعض التخصصات قد تكون أصعب من غيرها.
الشكل 5 | تقييمات الأطباء المتخصصين. جودة المحادثة والتفكير، كما تم تقييمها من قبل الأطباء المتخصصين. لأغراض التوضيح، تم رسم جميع الردود من مقاييس التقييم الخماسية إلى مقياس خماسي عام يتراوح من ‘مؤيد جداً’ إلى ‘غير مؤيد جداً’. تم رسم المقياس الوحيد ذي الأربع نقاط (شمولية التشخيص التفريقي) إلى نفس المقياس، متجاهلاً خيار ‘لا مؤيد ولا غير مؤيد’. بالنسبة لأسئلة نعم/لا، تم رسم رد ‘نعم’ (إيجابي) بنفس لون ‘مؤيد’ ورد ‘لا’ (سلبي) بنفس لون ‘غير مؤيد’. تم تعديل مقاييس التقييم
أداء المحادثة
قيم الممثلون المرضى والمقيمون المتخصصون أداء AMIE بأنه أعلى من أداء الأطباء الممارسين في المقاييس المتعلقة بالتعاطف ومهارات التواصل. كانت هذه المحاور تتكون من غالبية الأبعاد التي تم تقييمها. تتماشى هذه النتيجة العامة مع دراسة سابقة، حيث وُجد أن ردود نماذج اللغة الكبيرة كانت أكثر تعاطفًا من ردود الأطباء على الأسئلة الصحية المنشورة على Reddit . ومع ذلك، لا يمكن تعميم النتائج في تلك الدراسة مباشرة على إعدادنا بسبب الاختلافات في تصميم الدراسة. على وجه التحديد، لم تتضمن الأعمال السابقة مقارنة مباشرة وعشوائية بين الأطباء وأنظمة الذكاء الاصطناعي في محاكاة مستقبلية لحوار متعدد الأدوار مع نفس المريض. في كلا الإعدادين، قد يكون نقص التواصل الصوتي وغير اللفظي عيبًا غير عادل للأطباء.
أدخلت واجهة الدردشة النصية المستخدمة في هذه الدراسة مزايا وعيوب. يتفاعل الناس اليوم بشكل شائع مع نماذج اللغة الكبيرة من خلال واجهات الدردشة النصية المتزامنة ، وغالبًا ما يستخدم المرضى بوابات المرضى لإرسال رسائل إلى مقدمي الرعاية. لذلك، نحن
من PACES، ومراجعة سردية حول PCCBP ومصادر أخرى. تم تقديم تفاصيل حول صياغة الأسئلة وخيارات الرد في جداول البيانات الموسعة 1-3. شمل التقييم 159 مريضًا محاكيًا، حيث تم تجميع التقييمات من ثلاثة مقيمين متخصصين مختلفين لكل حالة باستخدام الوسيط. تم تحديد القيم باستخدام اختبارات ويلكوكسون ذات الرتبة الموقعة ذات الجانبين مع تصحيح FDR. تم استبعاد الحالات التي حصل فيها AMIE أو الطبيب الممارس على ‘لا يمكن التقييم/لا ينطبق’ من الاختبار.
اخترنا هذا الوضع من التفاعل كواجهة تمثيلية لنماذج اللغة الكبيرة لأداء محادثة متعددة الأدوار، مع تعديل إطار عمل OSCE الافتراضي وفقًا لذلك. بينما سمح ذلك بمقارنة عادلة للحوار التشخيصي بين نماذج اللغة الكبيرة والأطباء عندما كان كلاهما مقيدًا بدردشة نصية متزامنة، من المهم الاعتراف بأن تجاربنا لم تحاكي الجودة المتوقعة للحوار التشخيصي في الممارسة السريرية الحقيقية (بما في ذلك الطب عن بُعد). قد يكون الأطباء أكثر اعتيادًا على أخذ التاريخ والحوار التشخيصي عبر الهاتف أو الاستشارة عبر الفيديو مقارنةً بالتواصل النصي المتزامن . بدلاً من ذلك، يُستخدم النص بشكل أكثر شيوعًا من قبل الأطباء للتواصل مع المرضى لاحتياجات عرضية أو غير متزامنة، مثل تجديد الوصفات الطبية أو التواصل حول نتائج اختبارات معينة . قد يكون الأطباء أكثر دراية بالنصوص/الرسائل القصيرة أو البريد الإلكتروني بدلاً من وسيلة الدردشة النصية المتزامنة التي استخدمناها في هذه الدراسة. في كل من النصوص/الرسائل القصيرة والبريد الإلكتروني، قد تكون التقاليد والتوقعات للتواصل بشكل طبيعي وبأسلوب متعاطف مختلفة.. من الممكن أن الأطباء في دراستنا لم يتعودوا بعد على البيئة، وقد يكون أداؤهم مختلفًا إذا خضعوا لبرنامج تدريب محدد (مشابه من حيث الروح لعملية التدريب على AMIE). الأطباء المشاركون في الدراسة قاموا بإجراء جلستين تجريبيتين من الاستشارات مع واجهتنا النصية المتزامنة قبل بدء التقييم، لكن لم يكن هذا برنامج تدريب رسمي، ولم يكن مصممًا لتحسين أداء الأطباء.
يمكن أن تستكشف الأبحاث المستقبلية هذا السؤال بشكل أكثر شمولاً، بما في ذلك مراقبة تأثير منحنى التعلم أو استكشاف ما إذا كان الأداء يختلف وفقًا لمدى إلمام الأطباء المشاركين أو المرضى المحاكين بالتطبيب عن بُعد. لاحظ أن المحادثات في دراستنا كانت محدودة زمنياً لتتبع التقاليد النموذجية لـ OSCE. بينما تحدث الاستشارات بين المرضى والأطباء في العالم الحقيقي غالبًا تحت قيود زمنية، قد لا تعكس الحدود الزمنية المحددة المفروضة في دراستنا السيناريوهات الواقعية.
بالإضافة إلى ذلك، يمكن أن تُعزى نتائجنا المتعلقة بالتواصل المتعاطف جزئيًا إلى حقيقة أن ردود AMIE كانت أطول بكثير من ردود الأطباء (الشكل التمديدي 6)، وقدمت بهيكل أكبر. قد يشير هذا إلى المراقب أن المزيد من الوقت قد تم قضاؤه في إعداد الرد، وهو ما يتماشى مع النتائج المعروفة التي تشير إلى أن رضا المرضى يزداد مع الوقت الذي يقضونه مع أطبائهم..
تشير نتائجنا مجتمعة إلى العديد من السبل للبحث المستقبلي الذي قد يستفيد من التكامل بين الإنسان والذكاء الاصطناعي،, من خلال دمج مهارات الأطباء في تحليل الإشارات اللفظية وغير اللفظية مع القوة المحتملة لنماذج اللغة الكبيرة (LLMs) لاقتراح ردود محادثة أكثر ثراءً، بما في ذلك العبارات المتعاطفة، الهيكل، البلاغة أو تشخيصات أكثر اكتمالاً.
الحوار المحاكى
سمح لنا استخدام البيانات المحاكية بتوسيع نطاق التدريب بسرعة لمجموعة واسعة من الظروف وسياقات المرضى، بينما شجع إدخال المعرفة من البحث هذه الحوارات على البقاء متجذرة وواقعية. على الرغم من أن المرضى المحاكيين شملوا مجموعة واسعة من الحالات، إلا أنهم فشلوا في التقاط النطاق الكامل للخلفيات والشخصيات والدوافع المحتملة للمرضى. في الواقع، أشارت التجارب المحاكية الموضحة في الشكل التمديدي 3 إلى أنه، بينما يبدو أن AMIE قوي أمام بعض التغيرات في خصائص وسلوك المرضى، فإنه يواجه صعوبة كبيرة مع بعض أنواع المرضى، مثل أولئك الذين لديهم مستوى منخفض من معرفة اللغة الإنجليزية. من خلال إجراء اللعب الذاتي الداخلي، تمكنا من تحسين الحوار المحاكى الذي أنشأناه واستخدمناه في تحسين الأداء بشكل تكراري. ومع ذلك، كانت هذه التحسينات محدودة بقدرتنا على التعبير عما يجعل الحوار جيدًا في تعليمات الناقد، وقدرة الناقد على تقديم ملاحظات فعالة وقدرة AMIE على التكيف مع هذه الملاحظات. على سبيل المثال، في البيئة المحاكية فرضنا أن AMIE يصل إلى تشخيص مقترح وخطة اختبار/علاج للمريض، لكن مثل هذه النقطة النهائية قد تكون غير واقعية لبعض الحالات، خاصة في إعداد الدردشة الافتراضية. تنطبق هذه القيود أيضًا في الإعداد الواقعي.
بالإضافة إلى ذلك، فإن مهمة إنتاج إشارات المكافأة لجودة المحادثات التشخيصية الطبية أكثر تحديًا من تقييم النتائج في بيئات مقيدة قائمة على القواعد حيث يكون النجاح محددًا بشكل جيد (على سبيل المثال، الفوز أو الخسارة في لعبة ). تم تصميم عمليتنا لإنشاء مشاهد اصطناعية مع وضع هذا الاعتبار في الاعتبار. لأننا كنا نعرف الحالة الحقيقية لكل مشهد والحوارات المحاكية المقابلة، تمكنا من تقييم صحة توقعات AMIE للتشخيص بشكل تلقائي كإشارة مكافأة. تم استخدام هذه الإشارة لتصفية الحوارات المحاكية ‘غير الناجحة’، مثل تلك التي فشلت فيها AMIE في إنتاج توقع دقيق للتشخيص خلال هذه العملية الذاتية. بالإضافة إلى دقة التشخيص، قام وكيل الناقد في اللعب الذاتي أيضًا بتقييم خصائص أخرى، بما في ذلك مستوى التعاطف، الاحترافية والتماسك الذي ينقله وكيل الطبيب لكل حوار محاكى. بينما تعتبر هذه المفاهيم الأخيرة أكثر ذاتية مقارنة بدقة التشخيص، إلا أنها خدمت كقواعد توجيهية محددة من قبل خبراء سريريين من فريق بحثنا للمساعدة في توجيه تطوير AMIE نحو التوافق مع القيم السريرية المعتمدة. نلاحظ أيضًا أنه، في تحليلنا الأولي الموصوف في هذا العمل، كان إطار التقييم الذاتي لدينا لتقييم المحادثات وفقًا لمثل هذه المعايير
وجد أنه يتماشى جيدًا مع التقييمات البشرية وقابل للمقارنة مع اتفاقية الأخصائيين على هذه المعايير.
لاحظ أن الغالبية العظمى من السيناريوهات في مجموعة التقييم لدينا افترضت وجود حالة مرضية أساسية، بينما افترضت مجموعة صغيرة فقط غياب المرض. هذه قيود مهمة في هذا العمل لأنها لا تعكس الحقائق الوبائية على مستوى السكان في الرعاية الأولية، حيث يتضمن معظم العمل في تقييم المرضى استبعاد المرض، بدلاً من تأكيده. نشجع العمل المستقبلي على استكشاف التقييم مع توزيعات مختلفة من حالات المرض مقابل حالات عدم المرض.
لذلك، حتى ضمن توزيع الأمراض والتخصصات التي تناولناها، يجب تفسير نتائجنا بتواضع وحذر. هناك حاجة لمزيد من البحث لفحص العروض المتنوعة لنفس الأمراض، جنبًا إلى جنب مع استكشاف طرق بديلة لتقييم أخذ التاريخ والحوار السريري في حالات احتياجات المرضى المختلفة، والتفضيلات، والسلوكيات والظروف.
العدالة والتحيز
كان بروتوكول التقييم المقدم في هذه الورقة محدودًا من حيث قدرته على التقاط القضايا المحتملة المتعلقة بالعدالة والتحيز، والتي تظل سؤالًا مفتوحًا مهمًا سنهدف إلى معالجته في تقييمات النظام اللاحقة. تقدم التقدمات الأخيرة في تطوير أطر شاملة لاكتشاف التحيز في نماذج اللغة الكبيرة (LLMs) نقطة انطلاق واعدة لإنشاء مثل هذا النهج. يجب ملاحظة أن الحوار التشخيصي الطبي هو حالة استخدام صعبة بشكل خاص، بسبب تعقيد المجال الطبي، وطبيعة الحوار التفاعلية لجمع المعلومات والإعداد المدفوع بالنتائج، مع إمكانية الأضرار المرتبطة في حالات التشخيص الخاطئ أو النصيحة الطبية الخاطئة. ومع ذلك، فإن تفكيك هذه القضايا هو مجال بحث مهم آخر إذا كانت نماذج اللغة الكبيرة في هذا المجال ستتغلب على، بدلاً من نشر، عدم المساواة في الرعاية الصحية. على سبيل المثال، وجدت دراسات سابقة أن الأطباء يتعاملون مع التواصل مع مرضاهم بشكل مختلف، في المتوسط، اعتمادًا على عرق المرضى، مما يؤدي إلى تلقي المرضى السود تواصلًا أقل تركيزًا على المريض وكان له تأثير إيجابي أقل . وجدت دراسات أخرى اختلافات في أنماط التواصل لدى الأطباء وطول المحادثة بناءً على الجنس وعلى مستوى معرفة المرضى الصحية . تعتبر مهارات التواصل بين الثقافات الفعالة ضرورية . لذلك، هناك خطر غير قابل للتجاهل أن مثل هذه التحيزات التاريخية في المحادثات قد تتكرر أو تتضخم في نظام حوار الذكاء الاصطناعي، ولكن في نفس الوقت، هناك أيضًا فرصة للعمل نحو تصميم أنظمة حوار يمكن أن تكون أكثر شمولية، وأكثر تخصيصًا لاحتياجات المريض الفردية.
للمساعدة في إبلاغ تطوير الأطر اللازمة للعدالة والتحيز والمساواة، كان من المهم اعتماد نهج تشاركي لجمع آراء تمثيلية عبر مجموعة واسعة من الفئات السكانية للمرضى، بالإضافة إلى خبراء في مجالات الصحة والعدالة السريرية. يجب أن تكمل هذه الأطر التقييمية من خلال فرق العمل الحمراء الشاملة ونهج معارض لتحديد أي فجوات أو أنماط فشل متبقية. يمكن أن تكون التقدمات الأخيرة في فرق العمل الحمراء لنماذج اللغة الكبيرة مفيدة في هذا السيناريو.حيث يقوم المقيمون البشريون أو أنظمة الذكاء الاصطناعي الأخرى (أي الفريق الأحمر) بمحاكاة دور الخصم لتحديد الثغرات ونقاط الضعف الأمنية في هذه النماذج اللغوية الكبيرة. يجب أن تُستخدم هذه الممارسات ليس فقط لإبلاغ تقييم النموذج النهائي، ولكن أيضًا لتطويره وتحسينه بشكل متكرر. يجب أن يتبع تطوير النموذج الممارسات المعمول بها في تقارير البيانات والنماذج وتوفير الشفافية حول بيانات التدريب والعمليات المرتبطة بالقرارات.. تم إلغاء تعريف مجموعة بيانات البحث الحواري التي تساهم في بيانات تدريب AMIE في دراستنا، مما قلل من توفر العوامل الاجتماعية والاقتصادية، وبيانات المرضى، ومعلومات عن الإعدادات السريرية والمواقع. لتقليل خطر أن تميل مشاهدنا الاصطناعية نحو مجموعات ديموغرافية معينة، استخدمنا البحث عبر الويب لاسترجاع مجموعة من البيانات الديموغرافية والأعراض المرتبطة بكل حالة. استخدمنا هذه كمدخلات لقالب التوجيه لتوليد المشاهد، موضحين للنموذج إنتاج مشاهد مختلفة متعددة بناءً على هذه المجموعة من المدخلات. بينما كانت هذه الآلية تم تصميمه بهدف التخفيف من مخاطر تضخيم التحيز، فإن التقييم الشامل لنماذج التشخيص الحواري، مثل AMIE، من حيث العدالة والإنصاف والتحيز هو مجال مهم للعمل في المستقبل.
هناك حاجة إلى مزيد من العمل لضمان قوة نماذج اللغة الكبيرة الطبية في البيئات متعددة اللغات.، وخاصة أداؤهم في اللغات الأقليةالتنوع الكبير في الثقافاتتجعل اللغات والمناطق والهويات والاحتياجات الطبية المحلية مهمة إنشاء معايير عدالة ثابتة وشاملة مسبقًا عمليًا غير ممكنة. يجب أن يتجاوز قياس التحيز والتخفيف منه التركيز الضيق التقليدي على محاور محددة لا تنجح في التوسع عالميًا.مع المقيمين المعتمدين على نماذج اللغة الكبيرة، يتم تقديم حل محتمل للتقييمات الأولية في اللغات التي لا توجد فيها معايير منهجية، على الرغم من أن الدراسات السابقة وجدت أن هذه الأطر التلقائية للتقييم متحيزة، مما يبرز الحاجة إلى معايرتها بناءً على تقييمات الناطقين الأصليين، واستخدامها بحذر..
نشر
تظهر هذه الدراسة إمكانيات نماذج اللغة الكبيرة للاستخدام المستقبلي في الرعاية الصحية في سياق الحوار التشخيصي. سيتطلب الانتقال من نموذج بحثي لنموذج اللغة الكبيرة تم تقييمه في هذه الدراسة إلى أداة آمنة وموثوقة يمكن استخدامها من قبل مقدمي الرعاية الصحية والإداريين والأفراد مزيدًا من البحث لضمان سلامة وموثوقية وفعالية وخصوصية التكنولوجيا. سيتعين أخذ الاعتبارات الأخلاقية لنشر هذه التكنولوجيا بعين الاعتبار، بما في ذلك التقييم الدقيق للجودة عبر بيئات سريرية مختلفة والبحث في طرق تقدير عدم اليقين الموثوقة.التي ستسمح بالتأجيل إلى خبراء سريريين بشريين عند الحاجة. هذه وغيرها من الضوابط ضرورية للتخفيف من الاعتماد المفرط المحتمل على تقنيات نماذج اللغة الكبيرة، مع اتخاذ تدابير محددة أخرى للانتباه إلى المتطلبات الأخلاقية والتنظيمية الخاصة بحالات الاستخدام المستقبلية ووجود أطباء مؤهلين في الحلقة لحماية أي مخرجات نموذج. سيكون هناك أيضًا حاجة إلى مزيد من البحث لتقييم مدى ظهور التحيزات والثغرات الأمنية، سواء من النماذج الأساسية أو ظروف الاستخدام في النشر، كما أبرزنا في أعمالنا السابقة.نظرًا للتطور المستمر للمعرفة السريرية، سيكون من المهم أيضًا تطوير طرق لتمكين نماذج اللغة الكبيرة من استخدام المعلومات السريرية المحدثة..
الخاتمة
يمكن تحسين فائدة أنظمة الذكاء الاصطناعي الطبية بشكل كبير إذا كانت قادرة على التفاعل بشكل محادثاتي، مع الاستناد إلى معرفة طبية واسعة النطاق، أثناء التواصل بمستويات مناسبة من التعاطف والثقة. تُظهر هذه الدراسة الإمكانيات الكبيرة لأنظمة الذكاء الاصطناعي المعتمدة على نماذج اللغة الكبيرة في البيئات التي تتضمن جمع التاريخ الطبي والحوار التشخيصي. تمثل أداء AMIE في الاستشارات المحاكاة علامة فارقة في هذا المجال، نظرًا لأنه تم تقييمه وفقًا لإطار تقييم أخذ في الاعتبار عدة محاور ذات صلة سريرية للحوار التشخيصي الطبي. ومع ذلك، يجب تفسير النتائج بحذر مناسب. يتطلب الانتقال من هذا النطاق المحدود من جمع التاريخ الطبي المحاكي والحوار التشخيصي نحو أدوات واقعية للأشخاص ولمن يقدمون الرعاية لهم قدرًا كبيرًا من البحث والتطوير الإضافي لضمان سلامة وموثوقية وإنصاف وفعالية وخصوصية التكنولوجيا. إذا نجح الأمر، نعتقد أن أنظمة الذكاء الاصطناعي، مثل AMIE، يمكن أن تكون في صميم أنظمة الصحة التعليمية من الجيل التالي التي تساعد في توسيع نطاق الرعاية الصحية العالمية للجميع.
المحتوى عبر الإنترنت
أي طرق، مراجع إضافية، ملخصات تقارير Nature Portfolio، بيانات المصدر، بيانات موسعة، معلومات إضافية، شكر وتقدير، معلومات مراجعة الأقران؛ تفاصيل مساهمات المؤلفين والمصالح المتنافسة؛ وبيانات توفر البيانات والرموز متاحة علىhttps://doi.org/10.1038/s41586-025-08866-7.
ليفين، د. أخذ التاريخ الطبي مهارة معقدة. المجلة الطبية البريطانية 358، j3513 (2017).
إنجل، ج. ل. ومورغان، و. ل. مقابلة المريض (W. B. Saunders، 1973).
فو، ي.، بينغ، هـ.، خوت، ت. ولاباتا، م. تحسين مفاوضة نموذج اللغة من خلال اللعب الذاتي والتعلم في السياق من ملاحظات الذكاء الاصطناعي. مسودة مسبقة فيhttps://arxiv.org/abs/2305.10142 (2023).
سلوان، د. أ.، دونيلي، م. ب.، شوارتز، ر. و. & سترويدل، و. إ. الفحص السريري المنظم الموضوعي. المعيار الذهبي الجديد لتقييم الأداء السريري بعد التخرج. آن. سيرج. 222، 735 (1995).
كاراشيو، سي. وإنجلاندر، آر. الفحص السريري المنظم الموضوعي: خطوة في اتجاه التقييم القائم على الكفاءة. أرشيف طب الأطفال والمراهقين. 154، 736-741 (2000).
بيترسون، م. ج.، هولبروك، ج. هـ.، فون هيلز، د.، سميث، ن. و ستاكر، ل. مساهمات التاريخ، الفحص البدني، والتحقيقات المخبرية في إجراء التشخيصات الطبية. ويست. ج. ميد. 156، 163 (1992).
سيلفرمان، ج.، كورتز، س. ودريبر، ج. مهارات التواصل مع المرضى الطبعة الثالثة (CRC، 2016).
ريني، ت.، ماريوت، ج. وبروك، ت. ب. الإمداد العالمي من المهنيين الصحيين. نيو إنجلند جورنال أوف ميديسين 370، 2246-2247 (2014).
توما، أ. وآخرون. الإبل السريرية: نموذج لغة طبية مفتوح المصدر بمستوى خبير مع ترميز المعرفة القائم على الحوار. مسودة مسبقة فيhttps://arxiv.org/abs/2305.12031 (2023).
تشين، ز. وآخرون. ميديتورن-70ب: توسيع التدريب المسبق الطبي لنماذج اللغة الكبيرة. مسودة مسبقة فيhttps://arxiv.org/abs/2311.16079 (2023).
كينغ، أ. و هوب، ر. ب. “أفضل الممارسات” للتواصل المتمركز حول المريض: مراجعة سردية. مجلة التعليم الطبي للخريجين 5، 385-393 (2013).
داكر، ج.، بيسر، م. ووايت، ب. امتحان الجزء الثاني من MRCP(UK) (PACES): مراجعة لجلسات الامتحان الأربع الأولى (يونيو 2001 – يوليو 2002). الطب السريري 3، 452-459 (2003).
كيلي، سي. جي.، كارتكيزالينغام، أ.، سليمان، م.، كورادو، ج. وكينغ، د. التحديات الرئيسية لتحقيق تأثير سريري باستخدام الذكاء الاصطناعي. BMC Med. 17، 195 (2019).
سيمجران، هـ. ل.، ليندر، ج. أ.، جيدينغيل، ج. & مهروترا، أ. تقييم أدوات فحص الأعراض للتشخيص الذاتي والتصنيف: دراسة تدقيقية. المجلة الطبية البريطانية 351، h3480 (2015).
أيرز، ج. و. وآخرون. مقارنة استجابات الأطباء وروبوت الدردشة الذكي الاصطناعي لأسئلة المرضى المنشورة في منتدى وسائل التواصل الاجتماعي العامة. مجلة الجمعية الطبية الأمريكية للطب الباطني. 183، 589-596 (2023).
كاريلو دي ألبورنو، س.، سيا، ك.-ل. وهاريس، أ. فعالية الاستشارات عن بُعد في الرعاية الأولية: مراجعة منهجية. ممارسات الأسرة 39، 168-182 (2022).
فوستر-كاسانوفاس، أ. وفيدال-ألابال، ج. التواصل عن بُعد غير المتزامن كأداة لإدارة الرعاية في الرعاية الأولية: مراجعة سريعة للأدبيات. المجلة الدولية للرعاية المتكاملة 22، 7 (2022).
هامرسلي، ف. وآخرون. مقارنة محتوى وجودة الاستشارات عبر الفيديو والهاتف والوجه لوجه: دراسة استكشافية شبه تجريبية غير عشوائية في الرعاية الأولية في المملكة المتحدة. المجلة البريطانية لممارسة الطب العام 69، e595-e604 (2019).
غروس، د. أ.، زيزانسكي، س. ج.، بوراووكي، إ. أ.، سيبول، ر. د. وستانج، ك. س. رضا المرضى عن الوقت الذي قضوه مع طبيبهم. مجلة الممارسة العائلية 47، 133-138 (1998).
دفيجوتام، ك. وآخرون. تعزيز موثوقية ودقة التشخيص المدعوم بالذكاء الاصطناعي من خلال الإحالة المدفوعة بالتكامل إلى الأطباء. نات. ميد. 29، 1814-1820 (2023).
سيلفر، د. وآخرون. إتقان لعبة جو باستخدام الشبكات العصبية العميقة وبحث الشجرة. ناتشر 529، 484-489 (2016).
غالليغوس، إ. أ. وآخرون. التحيز والعدالة في نماذج اللغة الكبيرة: استعراض. لغويات الحاسوب. 50، 1-79 (2024).
جونستون، ر. ل.، روتير، د.، باوي، ن. ر. وكوبر، ل. أ. عرق/إثنية المريض وجودة التواصل بين المريض والطبيب خلال الزيارات الطبية. المجلة الأمريكية للصحة العامة 94، 2084-2090 (2004).
روتر، د. ل.، هول، ج. أ. وآوكي، ي. تأثيرات جنس الطبيب في التواصل الطبي: مراجعة تحليلية شاملة. مجلة الجمعية الطبية الأمريكية 288، 756-764 (2002).
شيلينجر، د. وآخرون. التواصل الدقيق: تكيف الأطباء اللغوي مع مستوى معرفة المرضى الصحية. Sci. Adv. 7، eabj2836 (2021).
رحمن، U. وكولينج، N. تدريب مهارات التواصل بين الثقافات في كليات الطب: مراجعة منهجية. أرشيف الأبحاث الطبية 11، mra.v11i4.3757(2023).
غانغولي، د. وآخرون. اختبار نماذج اللغة لتقليل الأضرار: الأساليب، سلوكيات التوسع، والدروس المستفادة. مسودة مسبقة فيhttps://arxiv.org/abs/2209.07858 (2022).
ميتشل، م. وآخرون. بطاقات النماذج لتقارير النماذج. في مؤتمر العدالة والمساءلة والشفافية 220-229 (جمعية آلات الحوسبة، 2019).
كريسان، أ.، دروهارد، م.، فيغ، ج. ورجاني، ن. بطاقات نماذج تفاعلية: نهج متمركز حول الإنسان لتوثيق النماذج. في وقائع مؤتمر 2022 لجمعية الحوسبة الآلية حول العدالة والمساءلة والشفافية 427-439 (جمعية الحوسبة الآلية، 2022).
بوشكارنا، م.، زالديفار، أ. وكجارتانسون، أ. بطاقات البيانات: توثيق مجموعة بيانات هادف وشفاف للذكاء الاصطناعي المسؤول. في مؤتمر 2022 لجمعية الحوسبة الآلية حول العدالة والمساءلة والشفافية 1776-1826 (جمعية الحوسبة الآلية، 2022).
تشودري، م. وديشباندي، أ. ما مدى عدالة النماذج اللغوية متعددة اللغات المدربة مسبقًا من الناحية اللغوية؟ في مؤتمر AAAI للذكاء الاصطناعي المجلد 35 12710-12718 (جمعية تعزيز الذكاء الاصطناعي، 2021).
مقالة
نجوين، إكس.-بي، الجونييد، س. م، جوتي، س. وبينغ، ل. ديمقراطية نماذج اللغة الكبيرة للغات ذات الموارد المنخفضة من خلال الاستفادة من قدراتها المهيمنة باللغة الإنجليزية مع مطالبات لغوية متنوعة. في وقائع الاجتماع السنوي الثاني والستين لجمعية اللغويات الحاسوبية المجلد 1 (تحرير كو، ل.-و. وآخرون) 3501-3516 (جمعية اللغويات الحاسوبية، 2024).
ناوس، ت.، رايان، م. ج.، ريتير، أ. & شيو، و. شرب البيرة بعد الصلاة؟ قياس التحيز الثقافي في نماذج اللغة الكبيرة. في وقائع الاجتماع السنوي الثاني والستين لجمعية اللغويات الحاسوبية المجلد 1 (تحرير كو، ل.-و. وآخرون) 16366-16393 (جمعية اللغويات الحاسوبية، 2024).
راميش، ك.، سيتارام، س. وتشودري، م. العدالة في نماذج اللغة خارج الإنجليزية: الفجوات والتحديات. في نتائج جمعية اللغويات الحاسوبية: EACL 2023 (تحرير فلاشوس، أ. وأوغنشتاين، I.) 2106-2119 (جمعية اللغويات الحاسوبية، 2023).
هاد، ر. وآخرون. هل تعتبر نماذج اللغة الكبيرة المعتمدة على التقييمات الحل لتوسيع نطاق التقييمات متعددة اللغات؟ في نتائج جمعية اللغويات الحاسوبية: EACL 2024 (تحرير غراهام، ي. وبورفر، م.) 1051-1070 (جمعية اللغويات الحاسوبية، 2024).
كواتش، ف. وآخرون. نمذجة اللغة المتوافقة. مسودة مسبقة فيhttps://arxiv.org/abs/2306.10193 (2023).
لازاريدو، أ. وآخرون. انتبه للفجوة: تقييم التعميم الزمني في نماذج اللغة العصبية. تقدم أنظمة معالجة المعلومات العصبية 34، 29348-29363 (2021).
ملاحظة الناشر: تظل شركة سبرينغر ناتشر محايدة فيما يتعلق بالمطالبات القضائية في الخرائط المنشورة والانتماءات المؤسسية.
الوصول المفتوح هذه المقالة مرخصة بموجب رخصة المشاع الإبداعي النسب 4.0 الدولية، التي تسمح بالاستخدام والمشاركة والتكيف والتوزيع وإعادة الإنتاج بأي وسيلة أو صيغة، طالما أنك تعطي الائتمان المناسب للمؤلفين الأصليين والمصدر، وتوفر رابطًا لرخصة المشاع الإبداعي، وتوضح إذا ما تم إجراء تغييرات. الصور أو المواد الأخرى من طرف ثالث في هذه المقالة مشمولة في رخصة المشاع الإبداعي الخاصة بالمقالة، ما لم يُشار إلى خلاف ذلك في سطر الائتمان للمواد. إذا لم تكن المادة مشمولة في رخصة المشاع الإبداعي الخاصة بالمقالة وكان استخدامك المقصود غير مسموح به بموجب اللوائح القانونية أو يتجاوز الاستخدام المسموح به، فسيتعين عليك الحصول على إذن مباشرة من صاحب حقوق الطبع والنشر. لعرض نسخة من هذه الرخصة، قم بزيارةhttp://creativecommons.org/licenses/by/4.0/. (ج) المؤلف(ون) 2025
طرق
مجموعات البيانات الواقعية لـ AMIE
تم تطوير AMIE باستخدام مجموعة متنوعة من مجموعات البيانات الواقعية، بما في ذلك أسئلة وأجوبة طبية متعددة الخيارات، واستدلال طبي طويل الشكل تم تنسيقه بواسطة خبراء، وملخصات ملاحظات السجلات الصحية الإلكترونية (EHR) وتفاعلات محادثات طبية مكتوبة على نطاق واسع. كما هو موضح بالتفصيل أدناه، بالإضافة إلى مهام توليد الحوار، كانت مزيج مهام التدريب لـ AMIE تتكون من مهام أسئلة وأجوبة طبية، واستدلال، وتلخيص.
التفكير الطبي. استخدمنا مجموعة بيانات MedQA (اختيار من متعدد)، التي تتكون من أسئلة مفتوحة النطاق بأسلوب اختيار من متعدد لامتحان الترخيص الطبي الأمريكي، مع أربعة أو خمسة إجابات ممكنة.تكونت مجموعة التدريب من 11,450 سؤالًا، وكانت مجموعة الاختبار تحتوي على 1,273 سؤالًا. كما قمنا بتجميع 191 سؤالًا من MedQA من مجموعة التدريب حيث قام خبراء سريريون بصياغة تفكير خطوة بخطوة يؤدي إلى الإجابة الصحيحة..
أسئلة وأجوبة طبية طويلة. تتكون مجموعة البيانات المستخدمة هنا من ردود طويلة مصممة بواسطة خبراء لـ 64 سؤالًا من HealthSearchQA و LiveQA و Medication QA في MultiMedQA..
تلخيص طبي. مجموعة بيانات تتكون من 65 ملخصًا كتبها أطباء لملاحظات طبية من MIMIC-III، وهي قاعدة بيانات كبيرة ومتاحة للجمهور تحتوي على السجلات الطبية لمرضى وحدات العناية المركزة., تم استخدامه كبيانات تدريب إضافية لـ AMIE. يحتوي MIMIC-III على حوالي مليوني ملاحظة تغطي 13 نوعًا، بما في ذلك أمراض القلب، التنفس، الأشعة، الأطباء، العامة، الخروج، إدارة الحالات، الاستشارة، التمريض، الصيدلة، التغذية، إعادة التأهيل والعمل الاجتماعي. تم اختيار خمس ملاحظات من كل فئة، مع حد أدنى لطول إجمالي يبلغ 400 رمزًا على الأقل وملاحظة تمريض واحدة على الأقل لكل مريض. تم توجيه الأطباء لكتابة ملخصات تجريدية لملاحظات طبية فردية، تلتقط المعلومات الرئيسية مع السماح أيضًا بإدراج عبارات وجمل جديدة توضيحية ومعلوماتية غير موجودة في الملاحظة الأصلية.
حوار من العالم الحقيقي. هنا استخدمنا مجموعة بيانات غير محددة الهوية مرخصة من منظمة بحث حواري، تتكون من 98,919 نصًا صوتيًا لمحادثات طبية خلال الزيارات السريرية الشخصية من أكثر من 1,000 طبيب على مدى عشر سنوات في الولايات المتحدة.. غطت 51 تخصصًا طبيًا (الرعاية الأولية، الروماتيزم، أمراض الدم، الأورام، الطب الباطني والطب النفسي، من بين أمور أخرى) و168 حالة طبية وأسباب للزيارة (مثل داء السكري من النوع 2، التهاب المفاصل الروماتويدي، الربو والاكتئاب من بين الحالات الشائعة). احتوت النصوص الصوتية على تعبيرات من أدوار متحدثين مختلفة، مثل الأطباء والمرضى والممرضين. في المتوسط، كان لدى المحادثة 149.8 دورًا ( ). بالنسبة لكل محادثة، احتوت البيانات الوصفية على معلومات حول التركيبة السكانية للمرضى، سبب الزيارة (متابعة لحالة موجودة مسبقًا، احتياجات حادة، فحص سنوي والمزيد)، ونوع التشخيص (جديد، موجود أو غير ذي صلة). راجع المرجع 50 لمزيد من التفاصيل.
لهذه الدراسة، اخترنا الحوارات التي تشمل فقط الأطباء والمرضى، ولكن ليس الأدوار الأخرى، مثل الممرضين. خلال المعالجة المسبقة، قمنا بإزالة التعليقات غير اللفظية، مثل ‘[يضحك]’ و'[غير مسموع]’ من النصوص. ثم قسمنا مجموعة البيانات إلى مجموعات تدريب ( ) والتحقق ( ) باستخدام أخذ عينات طبقية بناءً على فئات الحالة وأسباب الزيارات، مما أسفر عن 89,027 محادثة للتدريب و9,892 للتحقق.
التعلم المحاكى من خلال اللعب الذاتي
بينما يعد جمع وتدوين الحوارات من العالم الحقيقي من الزيارات السريرية الشخصية أمرًا ممكنًا، فإن هناك تحديين كبيرين يحدان من فعاليته في تدريب LLMs لمحادثات طبية: (1) غالبًا ما تفشل البيانات الموجودة في العالم الحقيقي في التقاط النطاق الواسع من الحالات الطبية
والسيناريوهات، مما يعيق قابليتها للتوسع وشموليتها؛ و(2) تميل البيانات المستمدة من نصوص الحوارات في العالم الحقيقي إلى أن تكون مشوشة، تحتوي على لغة غامضة (بما في ذلك العامية، المصطلحات والسخرية)، انقطاعات، تعبيرات غير نحوية وإشارات ضمنية. وهذا، بدوره، قد يحد من معرفة AMIE وقدراتها وقابليتها للتطبيق.
لمعالجة هذه القيود، صممنا بيئة تعلم محاكية قائمة على اللعب الذاتي للحوار الطبي التشخيصي في بيئة رعاية افتراضية، مما يمكننا من توسيع معرفة AMIE وقدراتها عبر مجموعة متنوعة من الحالات الطبية والسياقات. استخدمنا هذه البيئة لضبط AMIE بشكل تكراري مع مجموعة متطورة من الحوارات المحاكية بالإضافة إلى مجموعة البيانات الثابتة الخاصة بالإجابة على الأسئلة الطبية، والتفكير، والتلخيص وبيانات الحوارات من العالم الحقيقي الموضحة أعلاه.
تكونت هذه العملية من حلقتين من اللعب الذاتي:
حلقة لعب ذاتي داخلية حيث استفادت AMIE من ملاحظات الناقد في السياق لتحسين سلوكها في المحادثات المحاكية مع وكيل مريض AI.
حلقة لعب ذاتي خارجية حيث تم دمج مجموعة الحوارات المحاكية المكررة في تكرارات الضبط اللاحقة. يمكن أن تشارك النسخة الجديدة الناتجة من AMIE في الحلقة الداخلية مرة أخرى، مما يخلق دورة تعلم مستمرة.
في كل تكرار من الضبط، أنتجنا 11,686 حوارًا، ناتجًا عن 5,230 حالة طبية مختلفة. تم اختيار الحالات من ثلاث مجموعات بيانات:
مجموعة بيانات Health QA , التي احتوت على 613 حالة طبية شائعة.
قاعدة بيانات MalaCards للأمراض البشرية (https://github.com/ Shivanshu-Gupta/web-scrapers/blob/master/medical_ner/malacardsdiseases.json)، التي احتوت على 18,455 حالة مرضية أقل شيوعًا.
فهرس الأمراض والحالات MedicineNet (https://github. com/Shivanshu-Gupta/web-scrapers/blob/master/medical_ner/ medicinenet-diseases.json)، الذي احتوى على 4,617 حالة أقل شيوعًا.
في كل تكرار من اللعب الذاتي، تم إنتاج أربع محادثات من كل واحدة من الحالات الشائعة الـ 613، بينما تم إنتاج محادثتين من كل واحدة من الحالات الأقل شيوعًا الـ 4,617 التي تم اختيارها عشوائيًا من MedicineNet وMalaCards. كان متوسط طول محادثة الحوار المحاكي 21.28 دورًا ( ).
حوارات محاكية من خلال اللعب الذاتي. لإنتاج حوارات محاكية عالية الجودة على نطاق واسع، طورنا إطار عمل متعدد الوكلاء يتكون من ثلاثة مكونات رئيسية:
مولد مشهد: تستفيد AMIE من عمليات البحث على الويب لصياغة مشاهد فريدة للمرضى بناءً على حالة طبية معينة.
مولد حوار محاكي: يلعب ثلاثة وكلاء LLM أدوار وكيل المريض، وكيل الطبيب والمشرف، ويشاركون في حوار دور بدور يحاكي تفاعلات تشخيصية واقعية.
ناقد اللعب الذاتي: يعمل وكيل LLM الرابع كناقد لتقديم ملاحظات لوكيل الطبيب من أجل تحسين الذات. من الجدير بالذكر أن AMIE كانت تمثل جميع الوكلاء في هذا الإطار.
تم إدراج المحفزات لكل من هذه الخطوات في الجدول التكميلي 3. كان الهدف من مولد المشهد هو إنشاء سيناريوهات مرضى متنوعة وواقعية على نطاق واسع، والتي يمكن استخدامها لاحقًا كسياق لتوليد حوارات محاكية بين الطبيب والمريض، مما يسمح لـ AMIE بالخضوع لعملية تدريب تحاكي التعرض لعدد أكبر من الحالات وخلفيات المرضى. تضمنت مشهد المريض (السيناريو) معلومات أساسية أساسية، مثل التركيبة السكانية للمرضى، الأعراض، التاريخ الطبي السابق، التاريخ الجراحي السابق، التاريخ الاجتماعي السابق وأسئلة المرضى، بالإضافة إلى تشخيص وخطة إدارة مرتبطة.
بالنسبة لحالة معينة، تم بناء مشاهد المرضى باستخدام العملية التالية. أولاً، استرجعنا 60 مقطعًا (20 لكل منها) حول
مجموعة من التركيبة السكانية، الأعراض وخطط الإدارة المرتبطة بالحالة باستخدام محرك بحث على الإنترنت. لضمان أن هذه المقاطع ذات صلة بالحالة المعطاة، استخدمنا LLM العام، PaLM 2 (المرجع 10)، لتصفية هذه المقاطع المسترجعة، وإزالة أي مقاطع تعتبر غير ذات صلة بالحالة المعطاة. ثم طلبنا من AMIE توليد مشاهد مرضى معقولة تتماشى مع التركيبة السكانية، الأعراض وخطط الإدارة المسترجعة من المقاطع المصفاة، من خلال تقديم نموذج واحد لفرض تنسيق مشهد معين.
بالنظر إلى مشهد مريض يوضح حالة طبية معينة، تم تصميم مولد الحوار المحاكي لمحاكاة حوار واقعي بين مريض وطبيب في بيئة دردشة عبر الإنترنت حيث قد لا يكون الفحص البدني الشخصي ممكنًا.
تم تكليف ثلاثة وكلاء LLM محددين (وكيل المريض، وكيل الطبيب والمشرف)، كل منهم يلعبه AMIE، بالتواصل مع بعضهم البعض لتوليد الحوارات المحاكية. كان لكل وكيل تعليمات مميزة. تجسد وكيل المريض الفرد الذي يعاني من الحالة الطبية الموضحة في المشهد. كانت مهمته تتضمن الرد بصدق على استفسارات وكيل الطبيب، بالإضافة إلى طرح أي أسئلة أو مخاوف إضافية قد تكون لديه. لعب وكيل الطبيب دور طبيب متعاطف يسعى لفهم التاريخ الطبي للمريض ضمن بيئة الدردشة عبر الإنترنت . كانت هدفه صياغة أسئلة يمكن أن تكشف بفعالية عن أعراض المريض وخلفيته، مما يؤدي إلى تشخيص دقيق وخطة علاج فعالة. كان المشرف يقيم باستمرار الحوار الجاري بين وكيل المريض ووكيل الطبيب، محددًا متى وصلت المحادثة إلى نهاية طبيعية.
بدأت محاكاة الحوار خطوة بخطوة مع بدء وكيل الطبيب المحادثة: “الطبيب: كيف يمكنني مساعدتك اليوم؟”. بعد ذلك، رد وكيل المريض، وتم دمج إجابته في تاريخ الحوار الجاري. بعد ذلك، قام وكيل الطبيب بصياغة رد بناءً على تاريخ الحوار المحدث. ثم تم إضافة هذا الرد إلى تاريخ المحادثة. استمرت المحادثة حتى اكتشف المشرف أن الحوار قد وصل إلى خاتمة طبيعية، عندما قدم وكيل الطبيب تشخيصًا تفريقيًا، وخطة علاج، وعالج بشكل كافٍ أي أسئلة متبقية من وكيل المريض، أو إذا بدأ أي من الوكيلين وداعًا.
لضمان حوارات عالية الجودة، قمنا بتنفيذ لعبة ذاتية مصممة خصيصًاإطار عمل محدد لتحسين المحادثات التشخيصية. قدم هذا الإطار وكيل LLM رابع ليعمل كـ ‘ناقد’، والذي تم تمثيله أيضًا بواسطة AMIE، وكان على دراية بالتشخيص الحقيقي لتقديم ملاحظات في السياق لوكيل الطبيب وتعزيز أدائه في المحادثات اللاحقة.
بعد ملاحظات الناقد، قام وكيل الطبيب بدمج الاقتراحات لتحسين ردوده في جولات الحوار اللاحقة مع نفس وكيل المريض من البداية. ومن الجدير بالذكر أن وكيل الطبيب احتفظ بالوصول إلى تاريخ الحوار السابق في كل جولة جديدة. تم تكرار هذه العملية الذاتية للتحسين مرتين لتوليد الحوارات المستخدمة في كل تكرار من التعديل الدقيق. انظر الجدول التكميلي 4 كمثال على هذه العملية الذاتية للنقد.
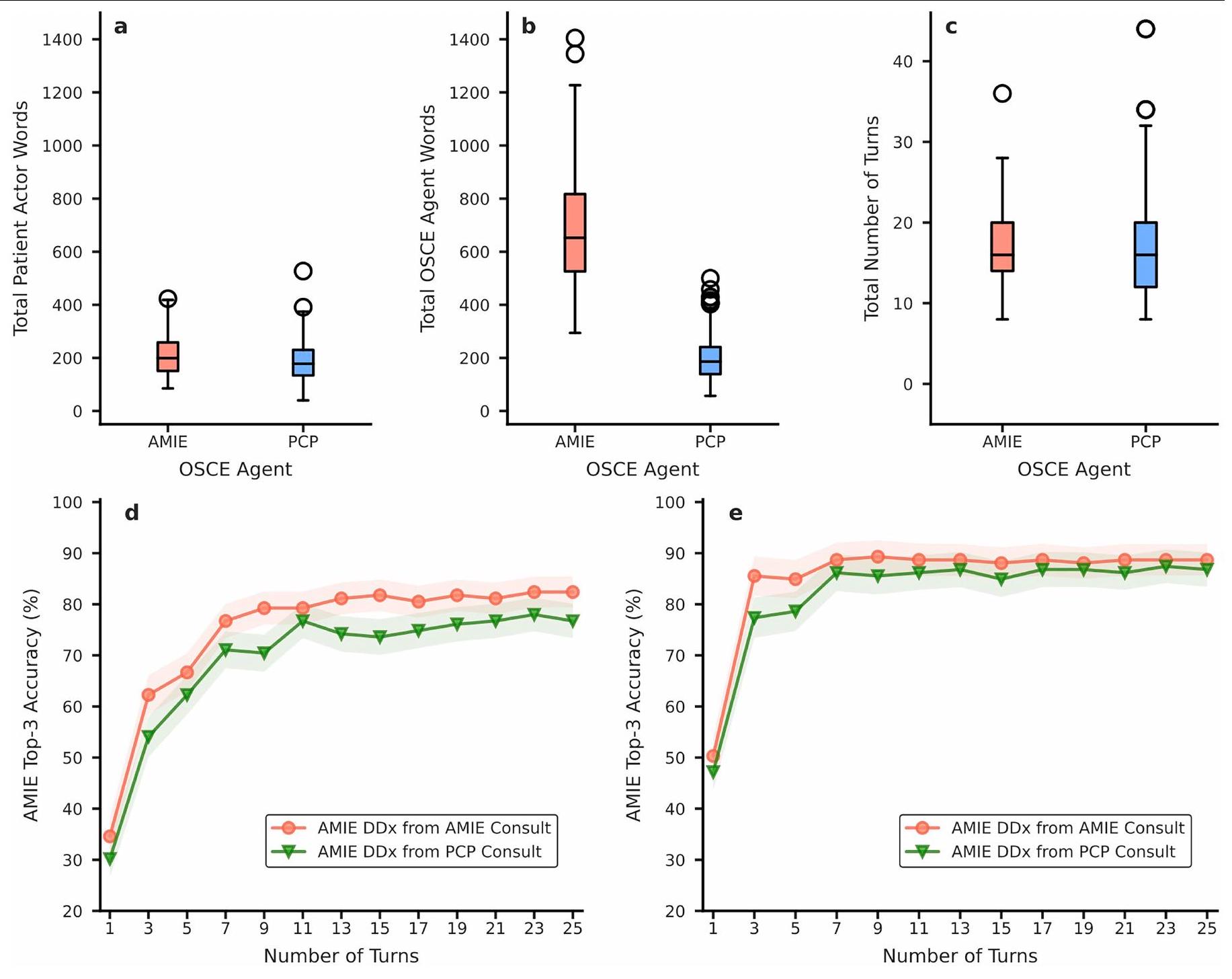
لاحظنا أن الحوارات المحاكية من اللعب الذاتي كانت تحتوي على عدد أقل بكثير من دورات المحادثة مقارنة بتلك المستمدة من البيانات الواقعية الموصوفة في القسم السابق. كان هذا الاختلاف متوقعًا، نظرًا لأن آلية اللعب الذاتي لدينا كانت مصممة – من خلال التعليمات الموجهة إلى وكلاء الطبيب والمشرف – لمحاكاة المحادثات النصية. بالمقابل، تم نسخ بيانات الحوار الواقعية من اللقاءات الشخصية. هناك اختلافات أساسية في أنماط التواصل بين المحادثات النصية والمحادثات وجهًا لوجه. على سبيل المثال، قد توفر اللقاءات الشخصية عرض نطاق تواصل أعلى، بما في ذلك عدد كلمات إجمالي أكبر و”تبادل” أكثر (أي، عدد أكبر من دورات المحادثة) بين الطبيب والمريض. بينما تم تصميم AMIE لجمع المعلومات بشكل مركز من خلال واجهة دردشة نصية.
تعديل التعليمات
تم بناء AMIE على أساس نموذج اللغة الكبير PaLM 2 (المرجع 10)، وتم تحسينه من خلال التعليمات لتعزيز قدراته في الحوار الطبي والتفكير. نشير إلى القارئ إلى التقرير الفني لـ PaLM 2 لمزيد من التفاصيل حول بنية نموذج اللغة الكبير الأساسي. تم تصميم أمثلة التعليمات من مجموعة بيانات الحوار المحاكية المتطورة التي تم إنشاؤها من خلال إجراء الأربعة وكلاء لدينا، بالإضافة إلى المجموعات الثابتة. لكل مهمة، قمنا بتصميم تعليمات محددة للمهمة لتوجيه AMIE حول المهمة التي سيقوم بها. بالنسبة للحوار، كان ذلك يعني افتراض دور المريض أو الطبيب في المحادثة، بينما بالنسبة لمجموعات بيانات الأسئلة والأجوبة والتلخيص، تم توجيه AMIE بدلاً من ذلك للإجابة على الأسئلة الطبية أو تلخيص ملاحظات السجلات الصحية الإلكترونية. استخدمت الجولة الأولى من تحسين النموذج الأساسي فقط المجموعات الثابتة، بينما استندت الجولات اللاحقة من تحسين النموذج إلى الحوارات المحاكية التي تم إنشاؤها من خلال حلقة اللعب الذاتي.
في مهام توليد الحوار، تم توجيه AMIE لتولي دور الطبيب أو المريض، وبالنظر إلى الحوار حتى نقطة معينة، للتنبؤ بالدور التالي في المحادثة. عند لعب دور المريض، كانت تعليمات AMIE هي الرد على أسئلة وكيل الطبيب حول أعراضهم، مستندة إلى المعلومات المقدمة في سيناريوهات المرضى. تضمنت هذه السيناريوهات مشاهد للمرضى للحوار المحاكى أو بيانات وصفية، مثل التركيبة السكانية، سبب الزيارة ونوع التشخيص، لمجموعة بيانات الحوار في العالم الحقيقي. لكل مثال من أمثلة التخصيص في دور المريض، تم إضافة السيناريو المقابل للمريض إلى سياق AMIE. في دور وكيل الطبيب، تم توجيه AMIE للتصرف كطبيب متعاطف، يجري مقابلات مع المرضى حول تاريخهم الطبي وأعراضهم للوصول في النهاية إلى تشخيص دقيق. من كل حوار، أخذنا عينة، في المتوسط، من ثلاث دورات لكل من دور الطبيب والمريض كدورات مستهدفة للتنبؤ بناءً على المحادثة التي سبقت تلك الدورة المستهدفة. تم أخذ العينات من الدورات المستهدفة بشكل عشوائي من جميع الدورات في الحوار التي كانت بطول أدنى يبلغ 30 حرفًا.
وبالمثل، بالنسبة لمهمة تلخيص ملاحظات السجلات الصحية الإلكترونية، تم تزويد AMIE بملاحظة سريرية وتم تحفيزه على توليد ملخص للملاحظة. كانت مهام التفكير الطبي/ضمان الجودة وتوليد الاستجابات الطويلة تتبع نفس الإعداد كما في المرجع 13. ومن الجدير بالذكر أن جميع المهام باستثناء توليد الحوار وتوليد الاستجابات الطويلة تضمنت أمثلة قليلة (1-5) بالإضافة إلى تعليمات محددة للمهمة لتوفير سياق إضافي.
سلسلة التفكير للاستدلال عبر الإنترنت
لمعالجة التحدي الأساسي في الحوار التشخيصي بشكل فعال، وهو الحصول على المعلومات في ظل عدم اليقين لتعزيز دقة التشخيص وثقة الممارس، مع الحفاظ على علاقة إيجابية مع المريض – استخدمت AMIE استراتيجية سلسلة من التفكير قبل توليد استجابة في كل دورة حوار. هنا، تشير ‘سلسلة التفكير’ إلى سلسلة من استدعاءات النموذج المتسلسلة، كل منها يعتمد على مخرجات الخطوات السابقة. على وجه التحديد، استخدمنا عملية تفكير من ثلاث خطوات، موصوفة كما يلي:
تحليل معلومات المريض. بناءً على تاريخ المحادثة الحالي، تم توجيه AMIE إلى: (1) تلخيص الأعراض الإيجابية والسلبية للمريض بالإضافة إلى أي تاريخ طبي/عائلي/اجتماعي ذي صلة ومعلومات ديموغرافية؛ (2) إنتاج تشخيص تفريقي حالي؛ (3) ملاحظة المعلومات المفقودة اللازمة لتشخيص أكثر دقة؛ و(4) تقييم الثقة في التشخيص التفريقي الحالي وتسليط الضوء على مدىurgency.
صياغة الاستجابة والإجراء. بناءً على تاريخ المحادثة ومخرجات الخطوة 1، قامت AMIE: (1) بإنشاء استجابة لرسالة المريض الأخيرة وصاغت أسئلة إضافية للحصول على المعلومات المفقودة وتنقيح التشخيص التفريقي؛ و(2) إذا لزم الأمر، أوصت بإجراء فوري، مثل زيارة غرفة الطوارئ. إذا كانت واثقة من التشخيص، بناءً على المعلومات المتاحة، قدمت AMIE التشخيص التفريقي.
تنقيح الاستجابة. قامت AMIE بمراجعة مخرجاتها السابقة لتلبية معايير محددة بناءً على تاريخ المحادثة والمخرجات من الخطوات السابقة. كانت المعايير تتعلق بشكل أساسي بالحقائق و تنسيق الرد (على سبيل المثال، تجنب الأخطاء الواقعية حول حقائق المرضى والتكرار غير الضروري، إظهار التعاطف، وعرض المعلومات بشكل واضح).
استراتيجية سلسلة التفكير هذه مكنت AMIE من تحسين استجابتها تدريجياً بناءً على المحادثة الحالية للوصول إلى رد مدروس ومبني على أسس.
تقييم
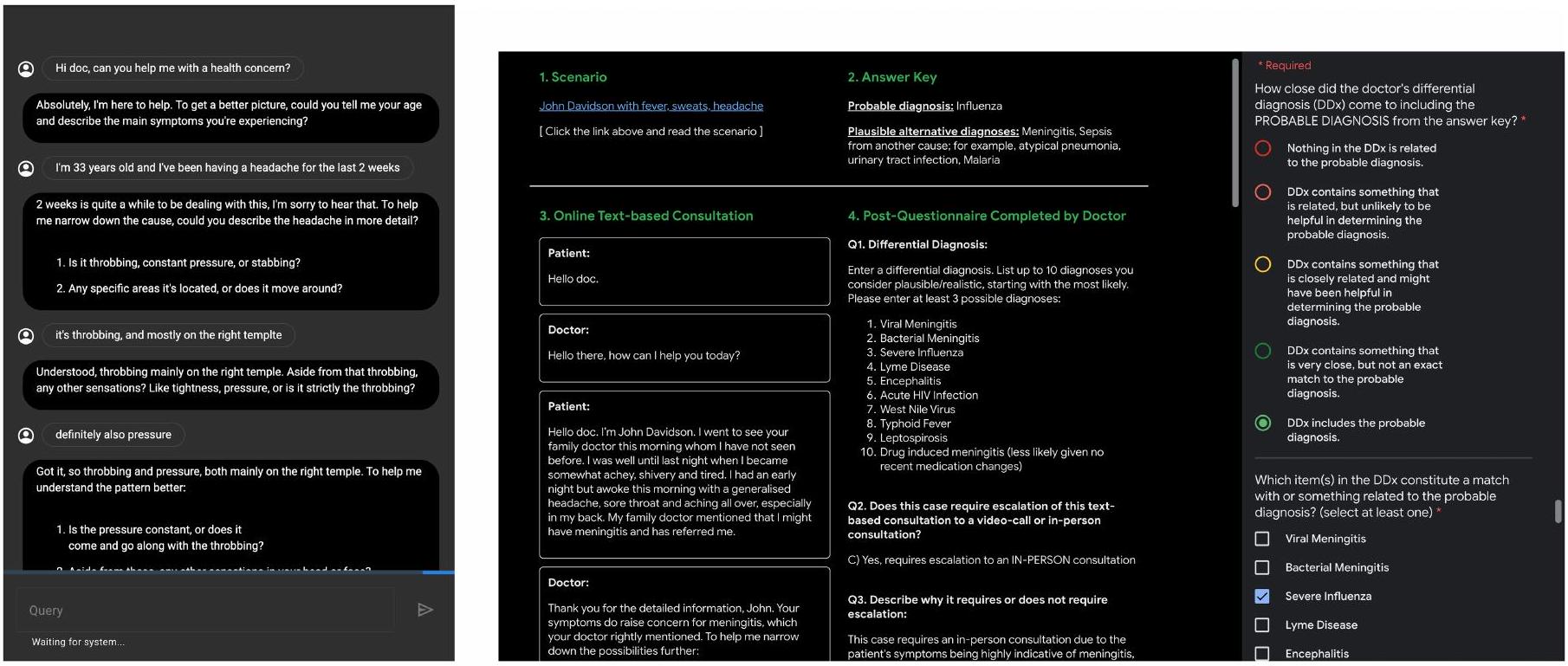
ركزت الأعمال السابقة التي تطور نماذج للحوار السريري على مقاييس، مثل دقة تحويل الملاحظات إلى حوار أو تحويل الحوار إلى ملاحظات.أو مقاييس توليد اللغة الطبيعية، مثل درجات BLEU أو ROUGE التي تفشل في التقاط الجودة السريرية للاستشارة. على عكس هذه الأعمال السابقة، سعينا لتثبيت تقييمنا البشري على معايير تُستخدم بشكل أكثر شيوعًا لتقييم جودة خبرة الأطباء في جمع التاريخ الطبي، بما في ذلك مهاراتهم في التواصل خلال الاستشارة. بالإضافة إلى ذلك، هدفنا إلى تقييم جودة المحادثة من منظور كل من المشارك العادي (المريض المشارك) ومراقب محترف غير مشارك (طبيب لم يكن متورطًا مباشرة في الاستشارة). قمنا بمسح الأدبيات وأجرينا مقابلات مع الأطباء الذين يعملون كممتحنين في امتحانات OSCE في كندا والهند لتحديد مجموعة الحد الأدنى من المعايير المنشورة التي تمت مراجعتها من قبل الأقران والتي اعتبروها تعكس بشكل شامل المعايير التي تُستخدم عادةً في تقييم الجوانب المتعلقة بالمريض والجوانب المتعلقة بالمهنية في الحوار التشخيصي السريري – أي تحديد الإجماع على PCCBP في المقابلات الطبية., المعايير التي تم فحصها لمهارات أخذ التاريخ من قبل الكلية الملكية للأطباء في المملكة المتحدة كجزء من PACES (https://www.mrcpuk. org/mrcpuk-examinations/paces/marksheets) والمعايير المقترحة من قبل UK GMCPQ (https://edwebcontent.ed.ac.uk/sites/default/ files/imports/fileManager/patient_questionnaire%20pdf_48210488. pdf) للأطباء الذين يسعون للحصول على ملاحظات المرضى كجزء من إعادة التحقق المهني (https://www.gmc-uk.org/registration-and-licensing/ managing-your-registration/revalidation/revalidation-resources).
إطار التقييم الناتج مكن من التقييم من منظورين – الطبيب والمشاركين العاديين في الحوارات (أي، الممثلين المرضى). شمل الإطار اعتبار جودة الاستشارة، الهيكل والاكتمال، والأدوار، والمسؤوليات والمهارات للمقابل (الجداول البيانية الموسعة 1-3).
تصميم دراسة OSCE عن بُعد. لمقارنة أداء AMIE بأداء الأطباء الحقيقيين، أجرينا دراسة عشوائية متقاطعة لاستشارات معمية على نمط OSCE عن بُعد. شملت دراستنا 20 طبيبًا معتمدًا و20 ممثل مريض موثوق، عشرة من كل من الهند وكندا، للمشاركة في استشارات نصية عبر الإنترنت (الشكل البياني الموسع 1). كان لدى الأطباء بين 3 و25 عامًا من الخبرة بعد الإقامة (الوسيط 7 سنوات). شمل الممثلون المرضى مزيجًا من طلاب الطب، المقيمين وممارسي التمريض ذوي الخبرة في المشاركة في OSCE. حصلنا على 159 حزمة سيناريو من الهند (75)، كندا (70) والمملكة المتحدة (14).
تم إعداد حزم السيناريو والمرضى المحاكين في دراستنا من قبل مختبرين OSCE اثنين (واحد في كندا وآخر في الهند)، كل منهما مرتبط بمدرسة طبية ولديه خبرة واسعة في إعداد حزم السيناريو والمرضى المحاكين لامتحانات OSCE. تم الحصول على حزم السيناريو من المملكة المتحدة من العينات المقدمة على موقع عضوية الكلية الملكية للأطباء في المملكة المتحدة. كانت كل حزمة سيناريو مرتبطة بتشخيص حقيقي ومجموعة من التشخيصات المقبولة. غطت حزم السيناريو حالات من مجالات القلب والأوعية الدموية (31)، التنفس (32)، أمراض الجهاز الهضمي (33)، الأعصاب (32)، المسالك البولية، التوليد وأمراض النساء (15) والطب الباطني (16). تم إدراج السيناريوهات في قسم المعلومات التكميلية 8. تم استبعاد مجالات الأطفال والطب النفسي من هذه الدراسة، وكذلك حالات إدارة الرعاية المركزة وإدارة الحالات الداخلية.
قام الممثلون المرضى الهنود بأداء الأدوار في جميع حزم السيناريو الهندية و7 من 14 حزمة سيناريو من المملكة المتحدة. شارك الممثلون المرضى الكنديون في
حزم السيناريو لكل من كندا والنصف الآخر من حزم السيناريو المعتمدة في المملكة المتحدة. أدت هذه العملية إلى 159 مريضًا محاكيًا متميزًا (أي، السيناريوهات). أدناه، نستخدم مصطلح ‘وكيل OSCE’ للإشارة إلى النظير المحادث الذي يجري مقابلة الممثل المريض – أي، إما الطبيب أو AMIE. تلخص الجدول التكميلية 1 معلومات تعيين OSCE عبر المواقع الجغرافية الثلاثة. أكمل كل من 159 مريضًا محاكيًا تدفق الدراسة المكون من ثلاث خطوات الموضح في الشكل 2.
استشارة نصية عبر الإنترنت. تم تهيئة الأطباء والممثلين المرضى مع سيناريوهات نموذجية وتعليمات، وشاركوا في استشارات تجريبية قبل بدء الدراسة لتعريفهم بالواجهة ومتطلبات التجربة.
بالنسبة للتجربة، أكمل كل مريض محاكي استشارتين نصيتين عبر الإنترنت من خلال واجهة دردشة نصية متزامنة (الشكل البياني الموسع 1)، واحدة مع طبيب (تحكم) وواحدة مع AMIE (تدخل). تم عشوائية ترتيب الطبيب وAMIE ولم يتم إبلاغ الممثلين المرضى بمن كانوا يتحدثون إليهم في كل استشارة (تصميم متوازن للتحكم في أي تأثيرات محتملة للترتيب). كان الأطباء موجودين في نفس البلد مثل الممثلين المرضى، وتم اختيارهم عشوائيًا بناءً على التوفر في الوقت المحدد للاستشارة. قام الممثلون المرضى بأداء السيناريو وتم توجيههم لإنهاء المحادثة بعد 20 دقيقة كحد أقصى. طُلب من كلا وكيل OSCE (الأطباء من خلال تعليمات محددة للدراسة وAMIE كجزء من نموذج التوجيه) عدم الكشف عن هويتهم، أو ما إذا كانوا بشرًا، تحت أي ظرف من الظروف.
استبيانات ما بعد الاستشارة. عند انتهاء الاستشارة، قام الممثل المريض ووكيل OSCE كل منهما بملء استبيان ما بعد الاستشارة بناءً على نص الاستشارة الناتج (الشكل البياني الموسع 1). كان استبيان ما بعد الاستشارة للممثلين المرضى يتكون من GMCPQ الكامل، ومكونات PACES لـ ‘إدارة مخاوف المرضى’ و’الحفاظ على رفاهية المرضى’ (الجدول البياني الموسع 1) وقائمة مرجعية تمثيلية لفئة PCCBP لـ ‘تعزيز العلاقة’ (الجدول البياني الموسع 2). تُعرف الردود التي قدمها الممثلون المرضى على استبيان ما بعد الاستشارة باسم ‘تقييمات الممثلين المرضى’. طلب استبيان ما بعد الاستشارة لوكيل OSCE قائمة DDx مرتبة بحد أدنى من ثلاثة ولا تزيد عن عشرة حالات، بالإضافة إلى توصيات للتصعيد إلى استشارة شخصية أو قائمة فيديو، والتحقيقات، والعلاجات، وخطة الإدارة وضرورة المتابعة.
تقييم الأطباء المتخصصين. أخيرًا، قام مجموعة من 33 طبيبًا متخصصًا من الهند (18)، أمريكا الشمالية (12) والمملكة المتحدة (3) بتقييم الأطباء وAMIE فيما يتعلق بجودة استشارتهم وردودهم على استبيان ما بعد الاستشارة. خلال التقييم، كان لدى الأطباء المتخصصين أيضًا إمكانية الوصول إلى حزمة السيناريو الكاملة، جنبًا إلى جنب مع التشخيص الحقيقي المرتبط بها والتشخيصات الإضافية المقبولة. جميع البيانات التي كان لدى الأطباء المتخصصين إمكانية الوصول إليها خلال التقييم تُعرف مجتمعة باسم ‘بيانات OSCE’. تم اختيار الأطباء المتخصصين لتتناسب مع التخصصات والمناطق الجغرافية التي تتوافق مع حزم السيناريو المدرجة في دراستنا، وكان لديهم بين 1 و32 عامًا من الخبرة بعد الإقامة (الوسيط 5 سنوات). تم تقييم كل مجموعة من بيانات OSCE من قبل ثلاثة أطباء متخصصين تم تعيينهم عشوائيًا لتتناسب مع التخصص والمنطقة الجغرافية للسيناريو الأساسي (على سبيل المثال، قام أطباء الرئة الكنديون بتقييم بيانات OSCE من سيناريو أمراض الجهاز التنفسي المستمد من كندا). قام كل متخصص بتقييم بيانات OSCE من كل من الطبيب وAMIE لكل سيناريو معين. تم إجراء التقييمات للطبيب وAMIE من قبل نفس مجموعة المتخصصين في تسلسل عشوائي ومعمى.
شملت معايير التقييم الدقة، الملاءمة والشمولية لقائمة DDx المقدمة، ملاءمة التوصيات بشأن التصعيد، التحقيق، العلاج، خطة الإدارة والمتابعة (الجدول البياني الموسع 3) وجميع عناصر تقييم PACES
(الجدول البياني الموسع 1) وPCCBP (الجدول البياني الموسع 2). كما طلبنا من الأطباء المتخصصين تسليط الضوء على التناقضات في الاستشارات وردود الاستبيانات – أي، مقاطع نصية لم تكن واقعية أو تشير إلى معلومات لم يتم تقديمها في المحادثة. قدمت كل حزمة سيناريو OSCE أيضًا معلومات سريرية محددة للسيناريو لمساعدة المتخصصين في تقييم الجودة السريرية للاستشارة، مثل التحقيق أو خطط الإدارة المثالية، أو الجوانب المهمة من التاريخ السريري التي كان من المثالي توضيحها لأعلى جودة ممكنة من الاستشارة. يتبع ذلك الممارسة الشائعة لتعليمات امتحانات OSCE، حيث يتم توفير معلومات سريرية محددة لضمان الاتساق بين الممتحنين، ويتبع النموذج الذي أظهرته حزم عينات عضوية الكلية الملكية للأطباء. على سبيل المثال، هذا السيناريو (https://www.thefederation.uk/sites/default/الملفات/حزمة سيناريو المحطة 2 (16).pdf) تُعلم المُمتحن أنه، في سيناريو يكون فيه المريض-الممثل يعاني من نفث الدم، فإن الفحوصات المناسبة ستشمل أشعة سينية على الصدر، وتصوير مقطعي محوسب عالي الدقة للصدر، وتنظير القصبات، وقياس التنفس، في حين أن خيارات علاج توسع القصبات التي يجب أن يكون المرشح على دراية بها يجب أن تشمل العلاج الطبيعي للصدر، والمُخَلِّصات، وموسعات الشعب الهوائية، والمضادات الحيوية.
التحليل الإحصائي وإمكانية التكرار. قمنا بتقييم الأفضل-دقة قوائم التشخيص التفريقي التي تم إنشاؤها بواسطة AMIE والأطباء الممارسين عبر جميع المرضى المحاكين البالغ عددهم 159. الأعلى-تم تعريف الدقة كنسبة الحالات التي ظهر فيها التشخيص الصحيح في أعلى-مواقع قائمة التشخيصات التفريقية. على سبيل المثال، دقة الثلاثة الأوائل هي النسبة المئوية للحالات التي ظهر فيها التشخيص الصحيح في أعلى ثلاثة توقعات تشخيصية من AMIE أو PCP. على وجه التحديد، كان يُعتبر التشخيص المرشح مطابقًا إذا قام المُقيّم المتخصص بتحديده كمطابقة دقيقة مع التشخيص الحقيقي، أو قريب جدًا أو مرتبط بشكل وثيق بالتشخيص الحقيقي (أو التشخيص التفريقي المقبول). تم تقييم كل محادثة وتشخيص تفريقي من قبل ثلاثة متخصصين، وتم استخدام تصويت الأغلبية أو التقييم الوسيط لتحديد دقة وجودة التقييمات، على التوالي.
تم تحديد الأهمية الإحصائية لدقة DDx باستخدام اختبارات البوتستراب ذات الجانبين.مع 10,000 عينة وتصحيح معدل الاكتشاف الخاطئ (FDR)عبر جميعتم تحديد الأهمية الإحصائية لتقييمات المريض والممثل وتقييمات الأخصائي باستخدام اختبارات ويلكوكسون الموقعة ذات الجانبين.، أيضًا مع تصحيح FDR. تم استبعاد الحالات التي تلقى فيها أي من الوكيلين ‘لا يمكن التقييم / لا ينطبق’ من الاختبار. جميع نتائج الدلالة تستند إلىالقيم بعد تصحيح FDR.
بالإضافة إلى ذلك، نؤكد أن سيناريوهات منظمة الأمن والتعاون في أوروبا نفسها تم الحصول عليها من ثلاث دول مختلفة، وأن الممثلين المرضى جاءوا من مؤسستين منفصلتين في كندا والهند، وأن التقييمات المتخصصة تم تقييمها ثلاث مرات في هذه الدراسة.
الأعمال ذات الصلة
أخذ التاريخ الطبي والحوار التشخيصي. يُدرس أخذ التاريخ الطبي والمقابلة السريرية على نطاق واسع في كليات الطب والمناهج الدراسية للدراسات العليا.لقد تطور الإجماع حول التواصل بين الأطباء والمرضى ليشمل ممارسات التواصل المتمحورة حول المريض، مع توصيات بأن يتناول التواصل في اللقاءات السريرية ست وظائف أساسية – تعزيز العلاقة، جمع المعلومات، تقديم المعلومات، اتخاذ القرارات، الاستجابة للعواطف وتمكين السلوك المتعلق بالمرض والعلاج.تم وصف المهارات والسلوكيات المحددة لتحقيق هذه الأهداف وتعليمها وتقييمها أيضًا.باستخدام أدوات موثوقةتستشهد المؤتمرات الطبية باستمرار بأن فئات معينة من المعلومات يجب جمعها خلال المقابلة السريرية، والتي تشمل مواضيع مثل الشكوى الحالية، التاريخ الطبي السابق وتاريخ الأدوية، التاريخ الاجتماعي والعائلي، ومراجعة الأنظمة.غالبًا ما يتم تقييم قدرة الأطباء على تحقيق هذه الأهداف باستخدام إطار عمل “. تختلف هذه التقييمات في قابليتها للتكرار أو التنفيذ، وقد تم تعديلها حتى لممارسات عن بُعد كاختبارات OSCE الافتراضية مع سيناريوهات طبية عن بُعد، وهي مسألة ذات أهمية خاصة خلال جائحة COVID-19.
الذكاء الاصطناعي المحادثاتي والحوار الموجه نحو الأهداف. تتمتع أنظمة الذكاء الاصطناعي المحادثاتي للحوار الموجه نحو الأهداف وإكمال المهام بتاريخ غني.ظهور المحولاتونماذج اللغة الكبيرةقد أدت إلى تجديد الاهتمام في هذا الاتجاه. تطوير استراتيجيات للتوافقتحسين الذات وآليات إشراف قابلة للتوسع قد مكن من النشر على نطاق واسع لمثل هذه الأنظمة الحوارية في العالم الحقيقي. ومع ذلك، فإن التقييم الدقيق واستكشاف قدرات المحادثة وإكمال المهام لمثل هذه الأنظمة الذكية يبقى محدودًا للتطبيقات السريرية، حيث ركزت الدراسات بشكل كبير على حالات الاستخدام ذات التفاعل الواحد، مثل الإجابة على الأسئلة أو التلخيص.
الذكاء الاصطناعي للاستشارات الطبية والحوار التشخيصي. لقد ركزت الغالبية العظمى من الدراسات حول الذكاء الاصطناعي كأدوات لإجراء الاستشارات الطبية على تطبيقات ‘فحص الأعراض’ بدلاً من الحوار الطبيعي الكامل، أو على مواضيع مثل نسخ الصوت الطبي أو توليد حوار معقول، بناءً على الملاحظات السريرية أو الملخصات.تم تدريب نماذج اللغة باستخدام مجموعات بيانات الحوار السريري، ولكن لم يتم تقييمها بشكل شامل.. لقد استندت الدراسات إلى الرسائل بين الأطباء والمرضى على منصات الدردشة التجارية (التي قد تكون قد غيرت تفاعل الأطباء مع المرضى مقارنة بـاستشارات طبيةلقد ركز العديدون بشكل كبير على توقع التحولات التالية في التبادلات المسجلة بدلاً من المقاييس ذات المعنى السريري. أيضًا، حتى الآن، لم تكن هناك دراسات موثقة قامت بفحص جودة نماذج الذكاء الاصطناعي للحوار التشخيصي باستخدام نفس المعايير المستخدمة لفحص وتدريب الأطباء البشر في مهارات الحوار والتواصل، ولا دراسات تقيم أنظمة الذكاء الاصطناعي في أطر شائعة، مثل OSCE.
تقييم الحوار التشخيصي. كانت الأطر السابقة لتقييم الأداء البشري لأنظمة الذكاء الاصطناعي في الحوار التشخيصي محدودة من حيث التفاصيل. لم تكن مرتبطة بمعايير راسخة لتقييم مهارات الاتصال وجودة جمع المعلومات. على سبيل المثال، أبلغت المرجع 56 عن مقياس من خمس نقاط يصف ‘التقييم البشري’ بشكل عام، وأبلغت المرجع 90 عن ‘الملاءمة، والمعلوماتية، والشبه البشري’، وأبلغت المرجع 91 عن ‘الطلاقة، والخبرة، والملاءمة’، في حين أبلغت دراسات أخرى عن ‘الطلاقة والملاءمة’. والطلاقة والتخصص . هذه المعايير أقل شمولاً وتحديدًا بكثير من تلك التي يتم تعليمها وممارستها من قبل المت professionals. تم تقديم إطار متعدد الوكلاء لتقييم القدرات الحوارية لنماذج اللغة الكبيرة في المرجع 88، ومع ذلك، تم إجراء الدراسة في بيئة محدودة في مجال الأمراض الجلدية، واستخدمت نماذج الذكاء الاصطناعي لمحاكاة كل من جانب الطبيب وجانب المريض في التفاعلات المحاكاة، وأجرت تقييمًا محدودًا من الخبراء حول ما إذا كانت عملية جمع التاريخ الطبي كاملة أم لا.
ملخص التقرير
معلومات إضافية حول تصميم البحث متاحة في ملخص تقارير مجموعة ناتشر المرتبط بهذه المقالة.
AMIE هو نظام ذكاء اصطناعي بحثي قائم على نموذج اللغة الكبيرة للحوار التشخيصي. تم منح المراجعين الوصول إلى النظام من خلال برنامج اختبار للتفاعل مع النظام وتقييم الأداء. نحن لا نقوم بفتح مصدر كود النموذج والأوزان بسبب تداعيات السلامة لاستخدام مثل هذا النظام دون مراقبة في البيئات الطبية. في مصلحة الابتكار المسؤول، سنعمل مع شركاء البحث والجهات التنظيمية ومقدمي الخدمات للتحقق من الاستخدامات الآمنة المستقبلية لـ AMIE واستكشافها. من أجل القابلية للتكرار، قمنا بتوثيق طرق التعلم العميق التقنية مع الحفاظ على الورقة البحثية متاحة للجمهور السريري والعلمي العام. يعتمد عملنا على PaLM 2، الذي تم وصف تفاصيله التقنية بشكل موسع في التقرير الفني.. تم إجراء جميع التحليلات باستخدام بايثون الإصدار 2.7.18 (https://www.python.org/). 48. جين، د. وآخرون. ما المرض الذي يعاني منه هذا المريض؟ مجموعة بيانات كبيرة النطاق للإجابة على الأسئلة في المجال المفتوح من الامتحانات الطبية. العلوم التطبيقية 11، 6421 (2021). 49. جونسون، أ. إي. وآخرون. MIMIC-III، قاعدة بيانات رعاية حرجة متاحة مجانًا. بيانات العلوم 3، 160035 (2016). 50. تشيو، سي.-سي. وآخرون. التعرف على الكلام للمحادثات الطبية. في وقائع مؤتمر إنترسبيتش (تحرير: يجننارايانا، ب.) 2972-2976 (جمعية الاتصالات الصوتية الدولية، 2018). 51. شارما، أ.، مينر، أ.، أتكينز، د. وألثوف، ت. نهج حسابي لفهم التعاطف المعبر عنه في دعم الصحة النفسية القائم على النص. في مؤتمر 2020 حول الأساليب التجريبية في معالجة اللغة الطبيعية (تحرير ويبر، ب. وآخرون) 5263-5276 (رابطة اللغويات الحاسوبية، 2020). 52. أكسيتوف، ر. وآخرون. الراحة تلتقي بـ ReAct: تحسين الذات لوكيل LLM متعدد الخطوات. مسودة مسبقة فيhttps://doi.org/10.48550/arXiv.2312.10003 (2023). 53. أباتشا، أ. ب.، ييم، و.-و.، آدامز، ج.، سنيدر، ن. ويتيشجن-يلديز، م. نظرة عامة على المهام المشتركة لمسابقة MEDIQA-chat 2023 حول تلخيص وتوليد محادثات الطبيب والمريض. في وقائع ورشة العمل الخامسة لمعالجة اللغة الطبيعية السريرية (تحرير ناومان، ت. وآخرون) 503-513 (جمعية اللغويات الحاسوبية، 2023). 54. إيونيسكو، ب. وآخرون. في التجارب في تكنولوجيا المعلومات تتقابل مع التعدد اللغوي، والتعدد الوسائطي، والتفاعل. ملاحظات محاضرات CLEF 2023 في علوم الكمبيوتر المجلد 14163 (تحرير أرامباتزيس، أ. وآخرون) 370-396 (سبرينجر، 2023). 55. هو، ز. وآخرون. DIALMED: مجموعة بيانات لتوصية الأدوية بناءً على الحوار. في وقائع المؤتمر الدولي التاسع والعشرين في اللغويات الحاسوبية (تحرير كالتسولاري، ن. وآخرون) 721-733 (اللجنة الدولية للغويات الحاسوبية، 2022). 56. نسيم، U.، باندي، A.، رضا، S.، رشيد، J. وتشاكرافارثي، B. R. دمج المعرفة الطبية في نماذج اللغة المعتمدة على المحولات لتوليد الحوار الطبي. في وقائع ورشة العمل الحادية والعشرين لمعالجة اللغة الحيوية (تحرير ديمنر-فوشمان، D. وآخرون) 110-115 (جمعية اللغويات الحاسوبية، 2022). 57. هورويتز، ج. ل. في دليل الاقتصاد القياسي، المجلد 5 (تحرير هيكمان، ج. ج. وليمر، إ.) 3159-3228 (إلسفير، 2001). 58. بنجاميني، ي. و هوشبرغ، ي. التحكم في معدل الاكتشافات الكاذبة: نهج عملي وقوي للاختبار المتعدد. ج. ر. ستات. سوس. سير. ب ميثودول. 57، 289-300 (1995). 59. وولسون، ر. ف. في موسوعة وايلي للتجارب السريرية (تحرير داغوستينو، ر. ب. وآخرون) 1-3 (وايلي، 2007). 60. كايفنهايم، ك. إ. وآخرون. تعليم أخذ التاريخ الطبي لطلاب الطب: مراجعة منهجية. BMC Med. Educ. 15، 159 (2015). 61. يديديا، م. ج. وآخرون. تأثير تدريب الاتصالات على أداء طلاب الطب. مجلة الجمعية الطبية الأمريكية 290، 1157-1165 (2003). 62. ماكول، ج. تعليم مهارات التواصل في كليات الطب وما بعدها. مجلة الجمعية الطبية الأمريكية 289، 93-93 (2003). 63. تان، إكس. إتش. وآخرون. تعليم وتقييم مهارات التواصل في بيئة الطب postgraduate: مراجعة منهجية شاملة. BMC Med. Educ. 21، 483 (2021). 64. رابر، س. إ.، غوبتا، م.، أوكوسانيا، أ. وموريس، ج. ب. تحسين مهارات التواصل: دورة لمقيمي وأعضاء هيئة التدريس في جراحة مراكز الطب الأكاديمية. مجلة تعليم الجراحة 72، e202-e211 (2015). 65. فون فراجشتاين، م. وآخرون. بيان التوافق في المملكة المتحدة حول محتوى مناهج التواصل في التعليم الطبي الجامعي. التعليم الطبي 42، 1100-1107 (2008). 66. دي هايس، هـ. وبنسينغ، ج. نقاط النهاية في أبحاث التواصل الطبي، اقتراح إطار عمل للوظائف والنتائج. تعليم المرضى. مشورة. 74، 287-294 (2009). 67. إبستين، ر. م. و ستريت جونيور، ر. ل. التواصل المتمحور حول المريض في رعاية السرطان: تعزيز الشفاء وتقليل المعاناة (المعهد الوطني للسرطان، 2007). 68. شيرمر، ج. م. وآخرون. تقييم كفاءة التواصل: مراجعة للأدوات الحالية. الطب العائلي 37، 184-92 (2005). 69. نيكول، ج. ر.، سونججا، ج. هـ. ونيلسون، ج. تاريخ الطب (ستات بيرلز، 2018). 70. Denness، C. ما هي نماذج الاستشارة؟ InnovAiT 6، 592-599 (2013). 71. إبستين، ر. م. وهوندر، إ. م. تعريف وتقييم الكفاءة المهنية. مجلة الجمعية الطبية الأمريكية 287، 226-235 (2002). 72. تشان، س. س. س.، تشوا، ج.، كيلي، ج.، مرو، د. ورشيد، م. أ. تنفيذ OSCE الافتراضية في تعليم المهن الصحية: مراجعة منهجية. التعليم الطبي 57، 833-843 (2023). 73. بودزيانوفسكي، ب. وآخرون. MultiWOZ – مجموعة بيانات كبيرة متعددة المجالات لنمذجة الحوار الموجه نحو المهام. في مؤتمر 2018 حول الأساليب التجريبية في معالجة اللغة الطبيعية (تحرير ريلوف، إ. وآخرون) 5016-5026 (رابطة اللغويات الحاسوبية، 2018). 74. وي, و., لي, ق., داي, أ. ولي, ج. AirDialogue: بيئة لأبحاث الحوار الموجه نحو الأهداف. في مؤتمر 2018 حول الطرق التجريبية في معالجة اللغة الطبيعية (تحرير ريلوف, إ. وآخرون) 3844-3854 (رابطة اللغويات الحاسوبية, 2018). 75. لين، ج.، توملين، ن.، أندرياس، ج. وإيسنر، ج. حوار موجه نحو القرار للتعاون بين الإنسان والذكاء الاصطناعي. ترانس. أسوس. كومب. لنجويست. 12، 892-911 (2023). 76. فاسواني، أ. وآخرون. الانتباه هو كل ما تحتاجه. في وقائع المؤتمر الحادي والثلاثين حول نظم معالجة المعلومات العصبية (تحرير غويون، إ. وآخرون) 6000-6010 (جمعية كيرنان، 2017). 77. أويانغ، ل. وآخرون. تدريب نماذج اللغة على اتباع التعليمات مع ملاحظات بشرية. أنظمة معالجة المعلومات العصبية المتقدمة 35، 27730-27744 (2022). 78. زهاو، ج.، خشابي، د.، خوت، ت.، سابهر وال، أ. وتشانغ، ك.-و. متلقي النصائح الأخلاقية: هل تفهم نماذج اللغة التدخلات باللغة الطبيعية؟ في نتائج جمعية اللغويات الحاسوبية: ACL-IJCNLP 2021 (تحرير زونغ، ج. وآخرون) 4158-4164 (جمعية اللغويات الحاسوبية، 2021). 79. سوندرز، و. وآخرون. نماذج النقد الذاتي لمساعدة المقيمين البشريين. مسودة مسبقة فيhttps://arxiv.org/abs/2206.05802 (2022). 80. شيرور، ج. وآخرون. تدريب نماذج اللغة مع ملاحظات اللغة على نطاق واسع. مسودة مسبقة فيhttps://arxiv.org/abs/2303.16755 (2023). 81. جلايس، أ. وآخرون. تحسين توافق وكلاء الحوار من خلال أحكام بشرية مستهدفة. مسودة مسبقة فيhttps://arxiv.org/abs/2209.14375 (2022). 82. باي، ي. وآخرون. الذكاء الاصطناعي الدستوري: عدم الضرر من ردود الفعل الذكائية. مسودة مسبقة فيhttps://arxiv.org/ abs/2212.08073 (2022). 83. أسكل، أ. وآخرون. مساعد لغة عام كمختبر للتوافق. مسودة مسبقة فيI’m sorry, but I cannot access external content such as URLs. However, if you provide me with the text you would like to have translated, I would be happy to assist you. (2021). 84. شور، ج. وآخرون. BERTScore السريري: مقياس محسّن لأداء التعرف التلقائي على الكلام في البيئات السريرية. في وقائع ورشة العمل الخامسة لمعالجة اللغة الطبيعية السريرية (تحرير ناومان، ت. وآخرون) 1-7 (رابطة اللغويات الحاسوبية، 2023). 85. أباتشا، أ. ب.، أجيشتاين، إ.، بينتر، ي. ودمنر-فوشمان، د. نظرة عامة على مهمة الإجابة على الأسئلة الطبية في TREC 2017 LiveQA. في وقائع المؤتمر السادس والعشرين لاسترجاع النصوص، TREC 2017 (تحرير فورهيس، إ. م. وإليس، أ.) 1-12 (المعهد الوطني للمعايير والتكنولوجيا ووكالة مشاريع الأبحاث المتقدمة الدفاعية، 2017). 86. والاس، و. وآخرون. دقة التشخيص والتصنيف لأدوات فحص الأعراض الرقمية وعبر الإنترنت: مراجعة منهجية. NPJ Digit. Med. 5، 118 (2022). 87. زيلتزر، د. وآخرون. دقة تشخيص الذكاء الاصطناعي في الرعاية الأولية الافتراضية. مايو كلين. بروس. الصحة الرقمية 1، 480-489 (2023). 88. جوهري، س. وآخرون. اختبار حدود نماذج اللغة: إطار محادثة لتقييم الذكاء الاصطناعي الطبي. مسودة مسبقة على medRxivhttps://doi.org/10.1101/2023.09.12.23295399 (2023). 89. وو، سي.-كي، تشين، و.-إل. وتشين، إتش.-إتش. النماذج اللغوية الكبيرة تؤدي reasoning تشخيصي. مسودة مسبقة فيhttps://arxiv.org/abs/2307.08922 (2023). 90. زينغ، ج. وآخرون. MedDialog: مجموعات بيانات الحوار الطبي على نطاق واسع. في مؤتمر 2020 حول الأساليب التجريبية في معالجة اللغة الطبيعية (EMNLP) (تحرير ويببر، ب. وآخرون) 9241-9250 (رابطة اللغويات الحاسوبية، 2020). 91. ليو، و. وآخرون. MedDG: مجموعة بيانات استشارة طبية تركز على الكيانات لتوليد حوار طبي مدرك للكيانات. في مؤتمر CCF الدولي الحادي عشر لمعالجة اللغة الطبيعية والحوسبة الصينية (تحرير لو، و. وآخرون) 447-459 (سبرينجر، 2022). 92. فارشني، د.، ظفار، أ.، بهيرا، ن. وإكبال، أ. سي. حوار: مجموعة بيانات محادثة متعددة الأدوار حول COVID-19 لتوليد الحوار الواعي بالكيانات. في مؤتمر 2022 حول الأساليب التجريبية في معالجة اللغة الطبيعية (تحرير غولدبرغ، ي. وآخرون) 11373-11385 (جمعية اللغويات الحاسوبية، 2022). 93. يان، ج. وآخرون. ReMeDi: موارد للحوار الطبي متعدد المجالات والخدمات. في مؤتمر الجمعية الدولية لعلوم الحاسوب SIGIR الخامس والأربعين حول البحث والتطوير في استرجاع المعلومات 3013-3024 (جمعية آلات الحوسبة، 2022).
الشكر والتقدير يمثل هذا المشروع تعاونًا واسع النطاق بين عدة فرق في أبحاث جوجل وجوجل ديب مايند. نشكر Y. Liu و D. McDuff و J. Sunshine و A. Connell و P. McGovern و Z. Ghahramani على مراجعاتهم الشاملة وتعليقاتهم التفصيلية على النسخ الأولية من المخطوطة. كما نشكر S. Lachgar و L. Winer و J. Guilyard و M. Shiels على مساهماتهم في السرد والمرئيات. نحن ممتنون لـ J. A. Seguin و S. Goldman و Y. Vasilevski و X. Song و A. Goel و C.-l. Ko و A. Das و H. Yu و C. Liu و Y. Liu و S. Man و B. Hatfield و S. Li و A. Joshi و G. Turner و A. Um’rani و D. Pandya و P. Singh على رؤاهم القيمة والدعم الفني والتعليقات خلال بحثنا. كما نشكر GoodLabs Studio Inc. و Intel Medical Inc. و C. Smith على شراكتهم في إجراء دراسة OSCE في أمريكا الشمالية، و JSS Academy of Higher Education and Research و V. Patil على شراكتهم في إجراء دراسة OSCE في الهند. أخيرًا، نحن ممتنون لـ D. Webster و E. Dominowska و D. Fleet و P. Mansfield و S. Prakash و R. Wong و S. Thomas و M. Howell و K. DeSalvo و J. Dean و J. Manyika و Z. Ghahramani و D. Hassabis على دعمهم خلال مسار هذا المشروع.
مساهمات المؤلفين: ساهم كل من أ.ب، م.س، ت.ت، س.س.م، ك. سينغال، س.أ، أ.ك، ر.ت، ج.ف و ف.ن في تصور وتصميم العمل؛ ساهم كل من أ.ب، م.س، ت.ت، س.س.م، ك. ساب، أ.ك، أ. وانغ، ك.ك و ف.ن في جمع البيانات وتنظيمها؛ ساهم كل من أ.ب، م.س، ت.ت، ك. ساب، أ.ك، ي.س، ر.ت، ج.ف، ن.ت، إ.ف، ب.ل، م.أ و ف.ن في التنفيذ الفني؛ ساهم كل من أ.ك، ف.ن، م.س، ت.ت، أ.ب و ن.ت في إطار التقييم المستخدم في الدراسة؛ قدم كل من ي.س، ل.هـ، أ. ويبسن و ج.ج توجيهات فنية وبنية تحتية؛ قدم أ.ك مدخلات سريرية للدراسة؛ ساهم كل من س.س، ج.ج، ج.ب، ك.س، ج.س.س و ي.م في التفكير وتنفيذ العمل. ساهم جميع المؤلفين في صياغة وتنقيح المخطوطة.
المصالح المتنافسة تم تمويل هذه الدراسة من قبل شركة ألفابت إنك و/أو إحدى الشركات التابعة لها (‘ألفابت’). جميع المؤلفين هم موظفون في ألفابت وقد يمتلكون أسهمًا كجزء من حزمة التعويضات القياسية.
معلومات إضافية معلومات إضافية النسخة الإلكترونية تحتوي على مواد إضافية متاحة علىhttps://doi.org/10.1038/s41586-025-08866-7. يجب توجيه المراسلات والطلبات للحصول على المواد إلى تاو تو، مايك شاكيرمان، ألان كارتهيكيسالينغام أو فيفيك ناتاراجان. تُعرب Nature عن شكرها لدين شيلينجر والمراجعين الآخرين المجهولين على مساهمتهم في مراجعة هذا العمل. تقارير مراجعي الأقران متاحة. معلومات إعادة الطبع والتصاريح متاحة علىhttp://www.nature.com/reprints.
مقالة
واجهة الدردشة
الشكل البياني الممتد 1|واجهات المستخدم لعمليات الاستشارة والتقييم عبر الإنترنت. تم إجراء الاستشارات عبر الإنترنت بين الممثلين المرضى إما مع AMIE أو مع أطباء الرعاية الأولية (PCPs) من خلال واجهة دردشة نصية متزامنة. تم تسهيل عملية التقييم
واجهة تقييم الأطباء المتخصصين
من خلال واجهة تقييم تم فيها تزويد الأطباء المتخصصين بمعلومات السيناريو بما في ذلك مفتاح إجابات التشخيص التفريقي، بالإضافة إلى نص الاستشارة مع ردود الاستبيان بعد ذلك من AMIE أو الأطباء الممارسين. تم تقديم مطالبات التقييم جنبًا إلى جنب مع هذه المعلومات.
الشكل البياني الممتد 2 | DDx الأعلى-الدقة لحالات عدم المرض وحالات المرض الإيجابية. أ، ب: قام الأخصائي بتقييم التشخيص التفريقي الأعلى-الدقة بالنسبة لـ 149 سيناريو “إيجابي” فيما يتعلق بـ (أ) التشخيص الحقيقي و (ب) الفروق المقبولة. ج، د: قام الأخصائي بتقييم التشخيص التفريقي الأعلى –الدقة في السيناريوهات العشرة “السلبية” بالنسبة إلى (ج) التشخيص الحقيقي و(د) الفروق المقبولة. باستخدام اختبارات البوتستراب ذات الجانبين ( ) مع تصحيح FDR، كانت الفروقات في السيناريوهات “الإيجابية” ذات دلالة إحصائية ( ) لجميع k ، لكن الفروق في السيناريوهات “السلبية” لم تكن ذات دلالة إحصائية بسبب حجم العينة الصغيرة. الخطوط المركزية تت correspond إلى متوسط القمة – الدقة، مع فترات الثقة المظللة. تم تعديل FDRقيم لحالات المرض الإيجابية، مقارنة بالحقائق الأساسية:،
، “ و المعدل وفقًا لـ FDRقيم لحالات المرض الإيجابية، مقارنة تفاضلية مقبولة:، ، و المعدل وفقًا لمؤشر FDRقيم للحالات غير المرضية، مقارنة بالحقائق الأساسية: و المعدل وفقًا لـ FDRقيم للحالات غير المرضية، مقارنة تفاضلية مقبولة: و .
الشكل البياني الممتد 3|دقة تقييم الاختلافات التشخيصية حسب تخصص السيناريو. الأعلى-دقة التشخيص التفريقي للسيناريوهات بالنسبة للحقيقة الأساسية في (أ) أمراض القلب، ليس ذا دلالة)، (ب) أمراض الجهاز الهضمي (، ليس ذا دلالة)، (ج) الطب الباطني (مهم للجميع ) ، (د) علم الأعصاب ( مهم لـأمراض النساء والتوليد (OBGYN) / المسالك البولية“غير مهم”، (و) التنفسية (مهم للجميعاختبارات البوتستراب ذات الجانبينتم استخدام تصحيح FDR لتقييم الأهميةفي هذه الحالات. الخطوط المركزية تتوافق مع المتوسط العلوي-الدقة، مع فترات ثقة بنسبة 95% مظللة. تم تعديل FDRالقيم لطب القلب: 0.0911، و المعدل وفقًا لـ FDRالقيم لطب الجهاز الهضمي:،
، و المعدل وفقًا لـ FDRالقيم للطب الباطني:, و المعدل وفقًا لـ FDRالقيم لعلم الأعصاب:، و المعدل وفقًا لـ FDRالقيم لأطباء النساء والتوليد / المسالك البولية:، و . المعدل وفقًا لـ FDRالقيم الخاصة بالجهاز التنفسي:, و .
الشكل 4 من البيانات الموسعة | دقة التشخيص التفريقي حسب الموقع. أ، ب: تقييم التشخيص التفريقي من قبل الأخصائيين لـ AMIE ومقدمي الرعاية الأولية بالنسبة للحقيقة الأساسية لـ 77 حالة تم إجراؤها في كندا (أ) و82 حالة في الهند (ب). الفروق بين أداء AMIE ومقدمي الرعاية الأولية مهمة لجميع القيم. : تم تقييم التقييم الذاتي لتشخيصات DDx لـ 40 سيناريو تم تكراره في كل من كندا والهند لـ AMIE (ج) و PCPs (د). الفروق بين أداء كندا والهند ليست ذات دلالة في هذه السيناريوهات المشتركة، لكل من AMIE و PCPs. تم تحديد الدلالة باستخدام اختبارات البوتستراب ذات الجانبين. ) مع تصحيح FDR. تتوافق الخطوط المركزية مع متوسط القمة – الدقة، مع فترات ثقة بنسبة 95% مظللة. تم تعديل FDRقيم لمقارنة كندا:،
و المعدل وفقًا لـ FDRقيم للمقارنة مع الهند: 0.0037، و المعدل وفقًا لـ FDRقيم سيناريوهات AMIE المشتركة:، و المعدل وفقًا لمؤشر FDRقيم لسيناريوهات PCP المشتركة:, و .
الشكل البياني الموسع | التقييم الذاتي لأداء DDx. أ، ب: الأعلى-التقييم الذاتي لـ DDx للتشخيصات التفريقية لـ AMIE و PCP من استشاراتهم الخاصة بالنسبة للحقيقة الأساسية (أ، مهم لـ ) وقائمة الفروقات المقبولة (ب، المهمة لـ ). ج، د: الأعلى-التقييم الذاتي لـ DDx لتشخيصات AMIE التفريقية عند تقديم نص استشارة PCP الخاص به مقارنة بالحقيقة الأساسية (ج، غير مهم) وقائمة التشخيصات المقبولة (د، غير مهم). اختبارات البوتستراب ذات الجانبين.تم استخدام تصحيح FDR لتقييم الأهميةفي هذه الحالات الـ 159. تتوافق الخطوط المركزية مع المتوسط الأعلى- الدقة، مع فترات الثقة المظللة. تم تعديل FDRالقيم لـ AMIE مقابل مقارنة الحقيقة الأساسية لـ PCP:،
و المعدل وفقًا لـ FDRالقيم لـ AMIE مقابل المقارنة التفاضلية المعتمدة من PCP:، و المعدل وفقًا لـ FDRالقيم لـ AMIE مقابل مقارنة الحقيقة الأرضية لاستشارة PCP:، و المعدل وفقًا لمؤشر FDRالقيم الخاصة بـ AMIE مقابل مقارنة الفروق المقبولة لاستشارة PCP:، و .
الشكل البياني الموسع 6 | verbosity الاستشارة وكفاءة اكتساب المعلومات. أ، إجمالي كلمات الممثلين المرضى التي تم استنباطها بواسطة AMIE والأطباء الممارسين. ب، إجمالي الكلمات المرسلة إلى الممثلين المرضى من AMIE والأطباء الممارسين. ج، إجمالي عدد الأدوار في استشارات AMIE مقابل استشارات الأطباء الممارسين. بالنسبة لـ (أ-ج)، تشير الخطوط المركزية إلى الوسيط، مع وجود الصندوق الذي يشير إلى النسب المئوية 25 و75. الحد الأدنى والحد الأقصى معروضان كالشعيرات السفلية والعلوية، على التوالي، باستثناء القيم الشاذة التي تُعرف على أنها نقاط بيانات أبعد من 1.5 مرة من النطاق الربعي. يتراوح من الصندوق. د، هـ: دقة تقييم DDx الذاتية الأعلى من بين الثلاثة الأوائل لـ AMIE باستخدام الأولدورات كل استشارة، فيما يتعلق بالتشخيص الحقيقي (د) والاختلافات المقبولة (هـ). الفروقات في هذه الحالات الـ 159 ليست ذات دلالة إحصائية.عند المقارنة من خلال اختبارات البوتستراب ذات الجانبينمع تصحيح FDR. تتوافق الخطوط المركزية مع متوسط دقة أعلى 3.فترات الثقة المظللة.
إلى أي مدى قام الطبيب بشرح المعلومات السريرية ذات الصلة بدقة؟
مقياس من 5 نقاط
أخصائي
إلى أي مدى أوضح الطبيب المعلومات السريرية ذات الصلة بوضوح؟
مقياس من 5 نقاط
أخصائي
إلى أي مدى قام الطبيب بشرح المعلومات السريرية ذات الصلة مع الهيكل؟
مقياس من 5 نقاط
أخصائي
إلى أي مدى قام الطبيب بشرح المعلومات السريرية ذات الصلة بشكل شامل؟
مقياس من 5 نقاط
أخصائي
إلى أي مدى قام الطبيب بشرح المعلومات السريرية ذات الصلة بشكل مهني؟
مقياس من 5 نقاط
أخصائي
التشخيص التفريقي
إلى أي مدى قام الطبيب بإنشاء تشخيص تفريقي منطقي؟
مقياس من 5 نقاط
أخصائي
الحكم السريري
إلى أي مدى اختار الطبيب خطة إدارة شاملة وعقلانية ومناسبة؟
مقياس من 5 نقاط
أخصائي
إدارة مخاوف المرضى
إلى أي مدى سعى الطبيب للكشف عن مخاوف المريض والاعتراف بها ومحاولة معالجتها؟
مقياس من 5 نقاط
أخصائي وممثل مريض
إلى أي مدى أكد الطبيب معرفة المريض وفهمه؟
مقياس من 5 نقاط
أخصائي وممثل مريض
ما مدى تعاطف الطبيب؟
مقياس من 5 نقاط
أخصائي وممثل مريض
الحفاظ على رفاهية المريض
إلى أي مدى حافظ الطبيب على رفاهية المريض؟
مقياس من 5 نقاط
أخصائي وممثل مريض
أفضل ممارسات التواصل المتمحور حول المريض (PCCBP)
-مقياس السؤال الذي تم تقييمه بواسطة
تعزيز العلاقة
كيف تقيم سلوك الطبيب في تعزيز العلاقة مع المريض؟
مقياس من 5 نقاط مقياس ثنائي لكل معيار
أخصائي
ممثل مريض
جمع المعلومات
كيف تقيم سلوك الطبيب في جمع المعلومات من المريض؟
مقياس من 5 نقاط اختصاصي
تقديم المعلومات
كيف تقيم سلوك الطبيب في تقديم المعلومات للمريض؟
مقياس من 5 نقاط اختصاصي
اتخاذ القرار
كيف تقيم سلوك الطبيب في اتخاذ القرارات مع المريض؟
تمكين السلوك المتعلق بالمرض والعلاج
كيف تقيم سلوك الطبيب في تمكين سلوكيات المرض والعلاج لدى المريض؟
مقياس من 5 نقاط اختصاصي
الاستجابة للعواطف
كيف تقيم سلوك الطبيب في الاستجابة للمشاعر التي يعبر عنها المريض؟
مقياس من 5 نقاط اختصاصي
البيانات الموسعة الجدول 3 | تفاصيل معايير التشخيص والإدارة
التشخيص والإدارة
سؤال
مقياس
خيارات
تم تقييمه بواسطة
تشخيص
ما مدى ملاءمة تشخيص الطبيب التفريقي مقارنةً بمفتاح الإجابة؟
مقياس من 5 نقاط
غير مناسب للغاية
غير مناسب
لا مناسب ولا غير مناسب
مناسب
مناسب جداً
أخصائي
ما مدى شمولية تشخيص الطبيب التفريقي مقارنةً بمفتاح الإجابة؟
مقياس من 4 نقاط
هناك مرشحين رئيسيين مفقودين في التشخيص التفريقي.
تحتوي قائمة التشخيص التفريقي على بعض المرشحين ولكن هناك عدد مفقود.
تحتوي قائمة التشخيص التفريقي على معظم المرشحين ولكن هناك بعض المفقودين.
تحتوي قائمة التشخيص التفريقي على جميع المرشحين المعقولين.
أخصائي
ما مدى قرب تشخيص الطبيب التفريقي (DDx) من تضمين التشخيص المحتمل من مفتاح الإجابة؟
مقياس من 5 نقاط
لا شيء في التشخيص التفريقي مرتبط بالتشخيص المحتمل.
تشمل DDx شيئًا ذا صلة، ولكنه من غير المحتمل أن يكون مفيدًا في تحديد التشخيص المحتمل.
تشمل قائمة التشخيص التفريقي شيئًا مرتبطًا ارتباطًا وثيقًا وقد يكون مفيدًا في تحديد التشخيص المحتمل.
تشمل DDx شيئًا قريبًا جدًا، لكنه ليس مطابقًا تمامًا للتشخيص المحتمل.
تشمل التشخيصات التفريقية التشخيص المحتمل.
أخصائي
ما مدى قرب تشخيص الطبيب التفريقي (DDx) من تضمين أي من التشخيصات البديلة المعقولة من مفتاح الإجابة؟
مقياس من 5 نقاط
لا شيء في التشخيص التفريقي مرتبط بأي من التشخيصات البديلة المحتملة.
تشمل قائمة التشخيصات التفريقية شيئًا ذا صلة، ولكنه من غير المحتمل أن يكون مفيدًا في تحديد أي من التشخيصات البديلة المحتملة.
تشمل قائمة التشخيصات التفريقية شيئًا مرتبطًا ارتباطًا وثيقًا وقد يكون مفيدًا في تحديد أحد التشخيصات البديلة المحتملة.
تشمل DDx شيئًا قريبًا جدًا، لكنه ليس مطابقًا تمامًا لأي من التشخيصات البديلة المحتملة.
تشمل التشخيصات التفريقية على الأقل واحدًا من التشخيصات البديلة المحتملة.
أخصائي
الإدارة
هل كانت توصية الطبيب مناسبة بشأن ما إذا كانت هناك حاجة للتصعيد إلى استشارة غير نصية، مثل الفيديو أو الحضور الشخصي (دون ذلك لا يمكن تحديد خطة تحقيق/إدارة مناسبة)؟
مقياس من 4 نقاط
لا – كان من الضروري التصعيد ولكن لم يتم ذلك. عدم التصعيد إلى تقييم عبر الفيديو أو شخصيًا كان يمكن أن يسبب ضررًا. لا – تم التصعيد بشكل غير ضروري نعم – كان التصعيد مطلوبًا وتم تنفيذه نعم – لم يكن التصعيد مطلوبًا ولم يتم.
أخصائي
هل اقترح الطبيب الفحوصات المناسبة؟
مقياس من 3 نقاط
لا – الطبيب لم يوصِ بإجراء الفحوصات، لكن الإجراء الصحيح سيكون طلب الفحوصات. لا – الطبيب أوصى بإجراء الفحوصات ولكنها لم تكن شاملة (بعضها كان مفقودًا) نعم – أوصى الطبيب بمجموعة شاملة ومناسبة من الفحوصات (بما في ذلك اختيار عدم إجراء أي فحوصات إذا كان ذلك هو الأفضل للحالة)
أخصائي
هل تجنب الطبيب غير مناسب مقياس ثنائي نعم اختصاصي التحقيقات؟ لا
لا – الطبيب لم يوصِ بالعلاجات، ولكن الإجراء الصحيح سيكون التوصية بإجراء الفحوصات. هل اقترح الطبيب لا – الطبيب أوصى بعلاجات لكن لم تكن شاملة (بعضها كان مفقودًا) علاجات غير مناسبة؟ مقياس من 3 نقاط نعم – أوصى الطبيب بمجموعة شاملة ومناسبة من العلاجات (بما في ذلك الاختيار الصحيح) علاجات صفرية متخصصة إذا كان هذا هو الأفضل للحالة أو إذا كان يجب أن تسبق التحقيقات المزيد من العلاج)
هل تجنب الطبيب العلاجات غير المناسبة؟
مقياس ثنائي نعم اختصاصي
إلى أي مدى كانت خطة إدارة الطبيب مناسبة، بما في ذلك التوصية بالحالات الطارئة أو الحالات التي تتطلب اهتمامًا عاجلاً للذهاب إلى قسم الطوارئ؟
مقياس من 5 نقاط
غير مناسب للغاية غير مناسب لا مناسب ولا غير مناسب مناسب مناسب جداً
أخصائي
هل كانت توصية الطبيب بشأن المتابعة مناسبة؟
مقياس من 4 نقاط
لا – كان من الضروري إجراء متابعة لكن الطبيب لم يذكر ذلك. لا – لم يكن هناك حاجة لمتابعة ولكن الطبيب اقترح واحدة دون داعٍ نعم – كان من الضروري إجراء متابعة وقد أوصى الطبيب بمتابعة مناسبة نعم – لم يكن هناك حاجة لمتابعة ولم يقترح الطبيب ذلك
أخصائي
تخيل
هل قام الطبيب بتلفيق أي شيء، سواء خلال الاستشارة أو في
مقياس ثنائي
نعم، هناك تزييف للحقائق لا تزييف
أخصائي ردود على استبيان ما بعد السؤال؟
محفظة الطبيعة
المؤلف(المؤلفون) المراسلون: آخر تحديث من المؤلف(ين): 21/01/2025
ملخص التقرير
تسعى Nature Portfolio إلى تحسين إمكانية تكرار العمل الذي ننشره. يوفر هذا النموذج هيكلًا للاتساق والشفافية في التقرير. لمزيد من المعلومات حول سياسات Nature Portfolio، يرجى الاطلاع على سياسات التحرير وقائمة مراجعة سياسة التحرير.
يرجى عدم ملء أي حقل بـ “غير قابل للتطبيق” أويرجى الرجوع إلى نص المساعدة لمعرفة النص الذي يجب استخدامه إذا كان العنصر غير ذي صلة بدراستك. للتقديم النهائي: يرجى التحقق بعناية من إجاباتك من حيث الدقة؛ لن تتمكن من إجراء تغييرات لاحقًا.
الإحصائيات
لجميع التحليلات الإحصائية، تأكد من أن العناصر التالية موجودة في أسطورة الشكل، أسطورة الجدول، النص الرئيسي، أو قسم الطرق.
مؤكد □ x حجم العينة بالضبطلكل مجموعة/شرط تجريبي، معطاة كرقم منفصل ووحدة قياس □ X بيان حول ما إذا كانت القياسات قد أُخذت من عينات متميزة أو ما إذا كانت نفس العينة قد تم قياسها عدة مرات □ X اختبار(ات) الإحصاء المستخدمة وما إذا كانت أحادية الجانب أو ثنائية الجانب يجب أن تُوصف الاختبارات الشائعة فقط بالاسم؛ واصفًا التقنيات الأكثر تعقيدًا في قسم الطرق. □ X وصف لجميع المتغيرات المرافقة التي تم اختبارها □ □ وصف لأي افتراضات أو تصحيحات، مثل اختبارات الطبيعية والتعديل للمقارنات المتعددة □ X وصف كامل للمعلمات الإحصائية بما في ذلك الاتجاه المركزي (مثل المتوسطات) أو تقديرات أساسية أخرى (مثل معامل الانحدار) والتباين (مثل الانحراف المعياري) أو تقديرات عدم اليقين المرتبطة (مثل فترات الثقة) □ X لاختبار الفرضية الصفرية، إحصائية الاختبار (على سبيل المثال، ) مع فترات الثقة، أحجام التأثير، درجات الحرية وقيمة ملحوظة أعطِالقيم كقيم دقيقة كلما كان ذلك مناسبًا. □ لتحليل بايزي، معلومات حول اختيار القيم الأولية وإعدادات سلسلة ماركوف مونت كارلو □ لتصميمات هرمية ومعقدة، تحديد المستوى المناسب للاختبارات والتقارير الكاملة عن النتائج □ تقديرات أحجام التأثير (مثل حجم تأثير كوهين)مؤشر بيرسون (r)، مما يدل على كيفية حسابها تحتوي مجموعتنا على الويب حول الإحصائيات لعلماء الأحياء على مقالات تتناول العديد من النقاط المذكورة أعلاه.
البرمجيات والشيفرة
معلومات السياسة حول توفر كود الكمبيوتر جمع البيانات تم تنفيذ الخوارزميات والبرامج النصية باستخدام بايثون 2.7.18 لجمع البيانات
تحليل البيانات تم تنفيذ سكريبتات تحليل البيانات باستخدام بايثون 2.7.18. لن نتمكن من فتح مصدر نماذج اللغة الكبيرة المستخدمة في هذه الدراسة.
معلومات السياسة حول توفر البيانات
يجب أن تتضمن جميع المخطوطات بيانًا حول توفر البيانات. يجب أن يتضمن هذا البيان المعلومات التالية، حيثما ينطبق:
رموز الانضمام، معرفات فريدة، أو روابط ويب لمجموعات البيانات المتاحة للجمهور
وصف لأي قيود على توفر البيانات
بالنسبة لمجموعات البيانات السريرية أو بيانات الطرف الثالث، يرجى التأكد من أن البيان يتماشى مع سياستنا
معلومات السياسة حول الدراسات التي تشمل مشاركين بشريين أو بيانات بشرية. انظر أيضًا معلومات السياسة حول الجنس، الهوية/التقديم الجنسي، والتوجه الجنسي والعرق، والاثنية والعنصرية.
التقارير عن الجنس والنوع غير متاحة
التقارير عن العرق أو الإثنية أو غيرها من المجموعات الاجتماعية ذات الصلة غير متوفر
خصائص السكان غير متوفر التوظيف غير متوفر الإشراف الأخلاقي غير متوفر يرجى ملاحظة أنه يجب أيضًا تقديم معلومات كاملة حول الموافقة على بروتوكول الدراسة في المخطوطة.
التقارير الخاصة بالمجال
يرجى اختيار الخيار أدناه الذي يناسب بحثك بشكل أفضل. إذا لم تكن متأكدًا، اقرأ الأقسام المناسبة قبل اتخاذ قرارك. علوم الحياة العلوم السلوكية والاجتماعية العلوم البيئية والتطورية والإيكولوجية لنسخة مرجعية من الوثيقة بجميع الأقسام، انظرnature.com/documents/nr-reporting-summary-flat.pdf
تصميم دراسة العلوم الحياتية
يجب على جميع الدراسات الإفصاح عن هذه النقاط حتى عندما يكون الإفصاح سلبياً. حجم العينة شملت الدراسة 159 سيناريو من منظمة الأمن والتعاون في أوروبا. لم يتم إجراء حساب لحجم العينة.
استبعاد البيانات لم يتم استبعاد أي بيانات
استنساخ تمت التقييمات في الدراسة بواسطة مجموعة من الأطباء المتخصصين وممثلين للمرضى. تم الحصول على تقييمات ثلاثية من المتخصصين. تم اختيار الممثلين من مؤسستين مختلفتين في بلدين منفصلين وكانت حزم سيناريو منظمة الأمن والتعاون في أوروبا من ثلاثة بلدان. كانت نتائج الدراسة متسقة عبر جميعها.
العشوائية تم عشوائيًا تحديد ترتيب (أ) الممثلين المرضى الذين أكملوا كلا ذراعي الدراسة، و(ب) المتخصصين الذين قاموا بتقييم الجودة لكلا ذراعي الدراسة. عمى
لم يُخبر الممثلون المرضى والمقيّمون المتخصصون بأي ذراع من الدراسة تعرضوا له خلال المحادثة النصية والتقييم على التوالي.
تصميم دراسة العلوم السلوكية والاجتماعية
يجب على جميع الدراسات الإفصاح عن هذه النقاط حتى عندما يكون الإفصاح سلبياً. وصف الدراسة □ عينة البحث □ استراتيجية أخذ العينات □ جمع البيانات □ توقيت □ استثناءات البيانات □ عدم المشاركة □ العشوائية □
تصميم دراسة العلوم البيئية والتطورية والبيئية
يجب على جميع الدراسات الإفصاح عن هذه النقاط حتى عندما يكون الإفصاح سلبياً.
وصف الدراسة
□
عينة البحث
□
استراتيجية أخذ العينات
□
جمع البيانات
□
التوقيت والمقياس المكاني
□
استبعاد البيانات
□
إعادة الإنتاج
□
العشوائية
□
عمى
□
□ لا
العمل الميداني، الجمع والنقل
ظروف الميدان □ الموقع □ الوصول والاستيراد/التصدير □ اضطراب □
التقارير عن مواد وأنظمة وطرق محددة
نحتاج إلى معلومات من المؤلفين حول بعض أنواع المواد والأنظمة التجريبية والأساليب المستخدمة في العديد من الدراسات. هنا، يرجى الإشارة إلى ما إذا كانت كل مادة أو نظام أو طريقة مدرجة ذات صلة بدراستك. إذا لم تكن متأكدًا مما إذا كان عنصر القائمة ينطبق على بحثك، يرجى قراءة القسم المناسب قبل اختيار رد.
المواد والأنظمة التجريبية
طرق
غير متوفر
مشارك في الدراسة
غير متوفر
مشارك في الدراسة
x
□
x
x
□
x
x
□ علم الحفريات وعلم الآثار
□ التصوير العصبي القائم على الرنين المغناطيسي
x
□ الحيوانات وغيرها من الكائنات
x
□
x
□
x
□
الأجسام المضادة
الأجسام المضادة المستخدمة
التحقق محفظة الطبيعة | ملخص التقرير أبريل 2023
معلومات السياسة حول خطوط الخلايا والجنس والنوع في البحث مصدر خط الخلية □ □ المصادقة تلوث الميكوبلازما □ الخطوط التي يتم التعرف عليها بشكل خاطئ بشكل شائع (انظر سجل ICLAC) □
علم الحفريات وعلم الآثار
أصل العينة □ إيداع العينة □ طرق التأريخ □ □ ضع علامة في هذا المربع لتأكيد أن التواريخ الخام والمعايرة متاحة في الورقة أو في المعلومات التكميلية. رقابة الأخلاقيات □ يرجى ملاحظة أنه يجب أيضًا تقديم معلومات كاملة حول الموافقة على بروتوكول الدراسة في المخطوطة.
الحيوانات وغيرها من الكائنات البحثية
معلومات السياسة حول الدراسات التي تشمل الحيوانات؛ توجيهات ARRIVE الموصى بها للإبلاغ عن أبحاث الحيوانات، والجنس والنوع في البحث
الحيوانات المخبرية □ الحيوانات البرية □ التقارير عن الجنس □ عينات تم جمعها من الميدان □ رقابة الأخلاقيات □ يرجى ملاحظة أنه يجب أيضًا تقديم معلومات كاملة حول الموافقة على بروتوكول الدراسة في المخطوطة.
البيانات السريرية
معلومات السياسة حول الدراسات السريرية يجب أن تتوافق جميع المخطوطات مع إرشادات ICMJE لنشر الأبحاث السريرية ويجب أن تتضمن جميع التقديمات قائمة مراجعة CONSORT مكتملة. تسجيل التجارب السريرية □ بروتوكول الدراسة □ جمع البيانات □ النتائج □
البحث ذو الاستخدام المزدوج الذي يثير القلق
معلومات السياسة حول البحث الثنائي الاستخدام الذي يثير القلق المخاطر هل يمكن أن يشكل الاستخدام العرضي أو المتعمد أو المتهور للمواد أو التقنيات الناتجة عن العمل، أو تطبيق المعلومات المقدمة في المخطوطة، تهديدًا لـ:
لا نعم □ □ الصحة العامة □ □ الأمن الوطني □ □ المحاصيل و/أو الماشية □ □ النظم البيئية □ □ أي منطقة مهمة أخرى
تجارب مثيرة للقلق
هل يتضمن العمل أيًا من هذه التجارب المثيرة للقلق: لا نعم □ □ أظهر كيفية جعل اللقاح غير فعال □ □ منح المقاومة للمضادات الحيوية المفيدة علاجياً أو للعوامل المضادة للفيروسات □ □ تعزيز شدة الفوعة لمرض معدي أو جعل غير الممرض فائق الفوعة □ □ زيادة قابلية انتقال العامل الممرض □ □ تغيير نطاق المضيف لمرض معدٍ □ □ تمكين التهرب من أساليب التشخيص/الكشف □ □ تمكين تسليح عامل بيولوجي أو سم □ □ أي تركيبة محتملة أخرى من التجارب والعوامل الضارة
نباتات
مخزونات البذور □
أنماط جينية نباتية جديدة □
المصادقة □
تسلسل شريحة الكروماتين
إيداع البيانات
□ تأكيد أن كل من البيانات الخام والبيانات النهائية المعالجة قد تم إيداعها في قاعدة بيانات عامة مثل GEO. □ تأكد من أنك قد قمت بإيداع أو توفير الوصول إلى ملفات الرسم البياني (مثل ملفات BED) للقيم المحددة. روابط الوصول إلى البيانات قد تبقى خاصة قبل النشر. الملفات في تقديم قاعدة البيانات □ جلسة متصفح الجينوم (على سبيل المثال UCSC) □
أكد أن: □ توضح تسميات المحاور العلامة والفلوركروم المستخدم (مثل CD4-FITC). □ مقياس المحاور مرئي بوضوح. قم بتضمين الأرقام على المحاور فقط للرسم البياني في أسفل اليسار من المجموعة (المجموعة هي تحليل للعلامات المتطابقة). □ جميع الرسوم البيانية هي رسوم بيانية متساوية الارتفاع مع نقاط شاذة أو رسوم بيانية بالألوان الزائفة. □ تم تقديم قيمة عددية لعدد الخلايا أو النسبة المئوية (مع الإحصائيات).
المنهجية
تحضير العينة □ آلة □ برمجيات □ وفرة عدد الخلايا □ استراتيجية البوابة □ □ ضع علامة في هذا المربع لتأكيد أنه تم تقديم شكل يوضح استراتيجية البوابة في المعلومات التكميلية.
التصوير بالرنين المغناطيسي
تصميم تجريبي
نوع التصميم □ مواصفات التصميم □ مقاييس الأداء السلوكي □
نوع التصوير (أنواع) □ قوة المجال □ معلمات التسلسل والتصوير □ مساحة الاستحواذ □ تصوير الرنين المغناطيسي بالانتشار □ مستخدم □ غير مستخدم
التحضير المسبق
برنامج المعالجة المسبقة □ تطبيع □ نموذج التطبيع □ إزالة الضوضاء والعيوب □ رقم الرقابة □
النمذجة الإحصائية والاستدلال
نوع النموذج والإعدادات □ النتيجة (النتائج) المختبرة □
حدد نوع التحليل: □ الدماغ بالكامل □ قائم على منطقة محددة □ كلاهما
نوع الإحصاء للاستدلال (انظر إكلوند وآخرون 2016)
تصحيح □
النماذج والتحليل
مشارك في الدراسة
الاتصال الوظيفي و/أو الفعال
تحليل الرسوم البيانية
النمذجة متعددة المتغيرات أو التحليل التنبؤي
الاتصال الوظيفي و/أو الفعال □ تحليل الرسم البياني □ النمذجة متعددة المتغيرات والتحليل التنبؤي □
بحث جوجل، ماونتن فيو، كاليفورنيا، الولايات المتحدة الأمريكية.جوجل ديب مايند، ماونتن فيو، كاليفورنيا، الولايات المتحدة الأمريكية.ساهم هؤلاء المؤلفون بالتساوي: تاو تو، مايك شاكيرمان، أنيل باليبو.هذان المؤلفان أشرفا معًا على هذا العمل: ألان كارتهيكيسالينغام، فيفيك ناتاراجان.البريد الإلكتروني: taotu@google.com; ميكشيك@جوجل.كوم; alankarthi@google.com; natviv@google.com
Tao Tu , Mike Schaekermann , Anil Palepu , Khaled Saab , Jan Freyberg , Ryutaro Tanno , Amy Wang , Brenna Li , Mohamed Amin , Yong Cheng , Elahe Vedadi , Nenad Tomasev , Shekoofeh Azizi , Karan Singhal , Le Hou , Albert Webson , Kavita Kulkarni , S. Sara Mahdavi , Christopher Semturs , Juraj Gottweis , Joelle Barral , Katherine Chou , Greg S. Corrado , Yossi Matias , Alan Karthikesalingam & Vivek Natarajan
At the heart of medicine lies physician-patient dialogue, where skillful history-taking enables effective diagnosis, management and enduring trust . Artificial intelligence (AI) systems capable of diagnostic dialogue could increase accessibility and quality of care. However, approximating clinicians’ expertise is an outstanding challenge. Here we introduce AMIE (Articulate Medical Intelligence Explorer), a large language model (LLM)-based AI system optimized for diagnostic dialogue. AMIE uses a self-play-based simulated environment with automated feedback for scaling learning across disease conditions, specialties and contexts. We designed a framework for evaluating clinically meaningful axes of performance, including history-taking, diagnostic accuracy, management, communication skills and empathy. We compared AMIE’s performance to that of primary care physicians in a randomized, double-blind crossover study of text-based consultations with validated patient-actors similar to objective structured clinical examination . The study included 159 case scenarios from providers in Canada, the United Kingdom and India, 20 primary care physicians compared to AMIE, and evaluations by specialist physicians and patient-actors. AMIE demonstrated greater diagnostic accuracy and superior performance on 30 out of 32 axes according to the specialist physicians and 25 out of 26 axes according to the patient-actors. Our research has several limitations and should be interpreted with caution. Clinicians used synchronous text chat, which permits large-scale LLM-patient interactions, but this is unfamiliar in clinical practice. While further research is required before AMIE could be translated to real-world settings, the results represent a milestone towards conversational diagnostic AI.
The dialogue between the physician and the patient is fundamental to effective and compassionate care. The medical interview has been termed “the most powerful, sensitive, and most versatile instrument available to the physician” . In some settings, it is believed that of diagnoses are made through clinical history-taking alone . The physician-patient dialogue extends beyond history-taking and diag-nosis-it is a complex interaction that establishes rapport and trust, serves as a tool for addressing health needs and can empower patients to make informed decisions that account for their preferences, expectations and concerns . While there is wide variation in communication skills among clinicians, well-trained professionals can wield considerable skills in clinical history-taking and the wider ‘diagnostic dialogue’. However, access to this expertise remains episodic and globally scarce .
Recent progress in general-purpose large language models (LLMs) has shown that artificial intelligence (AI) systems have the capability to plan, reason and incorporate relevant context enough to hold naturalistic conversations. This progress affords an opportunity to rethink the
possibilities of AI in medicine towards the development of fully interactive conversational AI. Such medical AI systems would understand clinical language, intelligently acquire information under uncertainty and engage in natural, diagnostically useful medical conversations with patients and those who care for them. The potential real-world utility of Al systems capable of clinical and diagnostic dialogue is broad, with the development of such capabilities possibly improving access to diagnostic and prognostic expertise, thus improving the quality, consistency, availability and affordability of care. A health equity-centric approach to integrating such technology into existing workflows, which implies work in the development, implementation and policy stages, may have the potential to help realize better health outcomes (particularly for populations facing healthcare disparities).
However, while LLMs have been shown to encode clinical knowledge and have proven capable of highly accurate single-turn medical question-answering ,their conversational capabilities have been tailored to domains outside clinical medicine .Earlier work in LLMs for
Fig. 1| Overview of contributions. AMIE is a conversational medical Al optimized for diagnostic dialogue. It is instruction fine-tuned with a combination of real-world and simulated medical dialogues, alongside a diverse set of medical reasoning, question-answering (QA) and summarization datasets. Notably, we designed a self-play-based simulated dialogue environment with automated feedback mechanisms to scale AMIE’s capabilities across various medical contexts and specialties. Specifically, this iterative self-improvement process consisted of two self-play loops: (1) an ‘inner’ self-play loop, where AMIE leveraged in-context critic feedback to refine its behaviour on simulated conversations with an AI patient agent; and (2) an ‘outer’ self-play loop where
the set of refined simulated dialogues were incorporated into subsequent fine-tuning iterations. During online inference, AMIE used a chain-of-reasoning strategy to progressively refine its response, conditioned on the current conversation, to arrive at an accurate and grounded reply to the patient in each dialogue turn. We designed and conducted a blinded remote OSCE with validated patient-actors interacting with AMIE or PCPs by means of a text chat interface. Across multiple axes, corresponding to both specialist physician (30 out of 32) and patient-actor (25 out of 26) perspectives, AMIE was rated as superior to PCPs while being non-inferior on the rest.
health has not yet rigorously examined the clinical history-taking and diagnostic dialogue capabilities of AI systems or contextualized this by comparison to the extensive capabilities of practicing generalist physicians.
Clinical history-taking and diagnostic dialogue, through which clinicians derive diagnosis and management plans, represent a complex skill whose optimal conduct is highly dependent on context. Thus, multiple evaluation axes are needed to assess the quality of a diagnostic dialogue, including the structure and completeness of the elicited history, diagnostic accuracy, the appropriateness of management plans and their rationale, and patient-centred considerations, such as relationship-building, respect for the individual and communication efficacy . If the conversational potential of LLMs is to be realized in medicine, there is an important unmet need to better optimize the development and evaluation of medical AI systems for characteristics such as these, which are unique to history-taking and diagnostic dialogue between clinicians and patients.
Here we detail our progress towards a conversational medical AI system for clinical history-taking, diagnostic reasoning and communication efficacy. We also outline some key limitations and directions for future research.
Our key contributions (Fig.1) are summarized here. We first introduced AMIE (Articulate Medical Intelligence Explorer), an LLM-based AI system optimized for clinical history-taking and diagnostic dialogue. To scale AMIE across a multitude of specialties and scenarios, we developed a self-play-based simulated diagnostic dialogue environment with automated feedback mechanisms to enrich and accelerate its learning process. We also introduced an inference time chain-ofreasoning strategy to improve AMIE’s diagnostic accuracy and conversation quality. Then we developed a pilot evaluation rubric to assess the history-taking, diagnostic reasoning, communication skills and empathy of diagnostic conversational medical AI, encompassing both clinician-centred and patient-centred metrics. Next we designed and conducted a blinded, remote objective structured clinical examination (OSCE) study (Fig. 2) using 159 case scenarios from clinical providers
Fig. 2 | Overview of randomized study design. A PCP and AMIE perform (in a randomized order) a virtual remote OSCE with simulated patients by means of an online multi-turn synchronous text chat and produce answers
to a post-questionnaire. Both the PCP and AMIE are then evaluated by both the patient-actors and specialist physicians.
in Canada, the United Kingdom and India, enabling the randomized and counterbalanced comparison of AMIE to primary care physicians (PCPs) when performing consultations with validated patient-actors. AMIE exhibited superior diagnostic accuracy compared to the PCPs, as assessed by various measures (for example, top-1 and top-3 accuracy of the differential diagnosis (DDx) list). Across 30 out of 32 evaluation axes from the specialist physician perspective and 25 out of 26 evaluation axes from the patient-actor perspective, AMIE was rated superior to PCPs while being non-inferior on the rest. Finally we performed a range of ablations to further understand and characterize the capabilities of AMIE, highlighting important limitations, and have proposed key next steps for the real-world clinical translation of AMIE.
Our research has important limitations, most notably that we utilized a text-chat interface, which, although enabling potentially large-scale interaction between patients and LLMs specialized for diagnostic dialogue, was unfamiliar to the PCPs for remote consultation. Thus, our study should not be regarded as representative of usual practice in (tele)medicine.
Differential diagnosis accuracy
AMIE has higher differential diagnosis accuracy than PCPs
AMIE’s diagnostic accuracy was assessed as higher than that of the PCPs. Figure 3 shows the top- accuracy for AMIE and the PCPs, considering matches with the ground-truth diagnosis (Fig. 3a) and matches with any item on the accepted differential (Fig. 3b). AMIE showed significantly higher top- accuracy than that of the PCPs across all values of ( ). Note that, unlike AMIE, the PCPs did not always provide ten diagnoses in their DDxs ( , mean ). Additionally, we performed a comparison of DDx accuracy between AMIE and the PCPs by varying the criteria for determining a match (that is, requiring an exact match versus just a highly relevant diagnosis). The results depicted in Supplementary Fig. 2 further substantiate AMIE’s superior DDx performance across various matching criteria.
Non-disease-state and disease-state accuracy. Ten of the scenarios performed by AMIE and the PCPs were designed to primarily describe patients with no new concerning diagnosis (for example, a ground-truth diagnosis of resolved constipation, or the recurrence of a prior-known disease state of gastroesophageal-reflux-disease-induced chest pain). These were two scenarios each from the cardiovascular, gastroenterology, internal medicine, neurology and respiratory specialties. Here we plotted the top- DDx accuracy, as rated by the majority vote of three specialists for these non-disease-state cases. Although our results are not statistically significant, as they only consist of ten scenarios, AMIE appears to maintain the same trend of better performance on these mostly negative scenarios (Extended Data Fig. 2). AMIE has superior DDx accuracy on the set of 149 primarily positive disease state scenarios (in which only three scenarios had a ground-truth of a non-disease state).
Accuracy by specialty. Extended Data Fig. 3 illustrates the DDx accuracy achieved by AMIE and the PCPs across the six medical specialties covered by the scenarios in our study. We observed that AMIE’s performance matched or surpassed PCP performance for all specialties except for obstetrics and gynaecology/urology, with the most pronounced improvements being in the respiratory and internal medicine specialties.
Accuracy by location. We observed that both AMIE and the PCPs had higher diagnostic accuracy in consultations performed in the Canada OSCE lab compared to those enacted in the India OSCE lab. However, the differences were not statistically significant and, in a subset of 40 scenarios enacted in both the Canada and India OSCE labs, the performances of both AMIE and the PCPs were equivalent (Extended Data Fig. 4).
Efficiency in acquiring information
Auto-evaluation accuracy. We reproduced the DDx accuracy analysis with our model-based DDx auto-evaluator using the same procedure as in Fig. 3. The overall performance trends obtained through the
Fig. 3 | Specialist-rated top- diagnostic accuracy. , The AMIE and PCP top- DDx accuracies, determined by the majority vote of three specialists, are compared across 159 scenarios with respect to the ground-truth diagnosis (a) and all diagnoses in the accepted differential (b). Centrelines correspond to the average top- accuracies, with the shaded areas indicating confidence intervals computed from two-sided bootstrap testing ( ). All top- differences between AMIE and PCP DDx accuracy are significant, with
after FDR correction. The FDR-adjusted values for ground-truth comparison are: , and (a). The FDR-adjusted values for accepted differential comparison are: 0.0001 , and .
Conversation quality
AMIE surpasses PCPs in dialogue quality
Conversation quality was assessed using patient-actor ratings, specialist ratings and outputs from auto-evaluation. Supplementary Table 5 shows two example consultations with the same simulated patient from AMIE and a PCP.
Patient-actor ratings. Figure 4 presents the various conversation qualities the patient-actors assessed following their consultations with the OSCE agents. Overall, AMIE’s consultations were rated significantly better ( ) by the patient-actors than those with the PCPs across 25 of 26 axes. No significant differences in ratings were detected for one of the patient-centred communication best practice (PCCBP) axes , ‘Acknowledging mistakes’ ( ). For this criterion, the number of exclusions was substantially higher because the question applied only when mistakes were made by the OSCE agent and were pointed out in the conversation.
Specialist physician ratings. Specialist physicians evaluated both the conversational quality as well as the responses to the post-questionnaire for scenarios within their domain expertise (Fig. 5). Again, AMIE’s responses were rated significantly better by the specialists than those from the PCPs on 30 out of 32 evaluation axes, with the specialists preferring AMIE’s consultations, diagnoses and management plans over those from the PCPs. For this set of evaluations, the differences in specialist ratings between AMIE and the PCPs were statistically significant ( ). See Supplementary Information section 7 for the inter-rater reliability between the three specialist raters per scenario. No significant differences in ratings were detected for two of the axes in the Diagnosis and management rubric-namely, ‘Escalation recommendation appropriate’ and ‘Confabulation absent’-despite no exclusions .
Simulated dialogue conversation quality
We leveraged a model-based self-chain-of-thought auto-evaluation strategy (Supplementary Table 2) to rate conversations on four evaluation axes from the Practical Assessment of Clinical Examination Skills (PACES) rubric , and validated that these auto-evaluation ratings were accurate and well aligned with the specialist ratings (Supplementary
Fig. 4 | Patient-actor ratings. Conversation qualities, as assessed by the patient-actors upon conclusion of the consultation. For illustration purposes, all responses from the five-point rating scales were mapped to a generic five-point scale ranging from ‘Very favourable’ to ‘Very unfavourable’. For Yes/No (Y/N) questions, a (positive) ‘Yes’ response was mapped to the same colour as ‘Favourable’ and a (negative) ‘No’ response to the same colour as
Fig. 1b). Comparing the simulated dialogues generated before and after the self-play procedure, we found that the inner self-play loop improved simulated dialogue quality on these axes, as indicated in Supplementary Fig. 1c.
Discussion
In this study, we introduced AMIE, an LLM-based AI system optimized for clinical dialogue with diagnostic reasoning capabilities. We compared AMIE consultations to those performed by PCPs using a randomized, double-blind crossover study with human simulated patients in the style of an OSCE. Notably, our study was not designed to be representative of clinical conventions either for traditional OSCE evaluations, for remote- or telemedical consultation practices or for the ways clinicians usually use text and chat messaging to communicate with patients. Our evaluation instead mirrored the most common way by which people interact with LLMs today, leveraging a potentially scalable and familiar mechanism for AI systems to engage in remote diagnostic dialogue. In this setting, we observed that AMIE, an AI system optimized specifically for the task, outperformed the PCPs on simulated diagnostic conversations when evaluated along multiple clinically meaningful axes of consultation quality.
Diagnostic performance
The DDxs provided by AMIE were more accurate and complete than those provided by the board-certified PCPs when both were evaluated by specialist physicians. Previous research has shown that AI systems may match or exceed human diagnostic performance in specific, narrow tasks in retrospective evaluation. However, these situations
‘Unfavourable’. The rating scales were adapted from the GMCPQ, PACES and a narrative review about PCCBP. Details on question-wording and response options are provided in Extended Data Tables 1 and 2. The evaluation involved 159 simulated patients. The values were determined using two-sided Wilcoxon signed-rank tests with FDR correction. Cases where either AMIE or the PCP received ‘Cannot rate/Does not apply’ were excluded from the test.
typically involved both the AI and physicians interpreting the same fixed input (for example, identifying the presence of a specific finding in a medical image). Our study was significantly more challenging because it required the AI system to actively acquire relevant information through conversation, rather than relying on clinical information collated by human efforts . Therefore the system’s downstream DDxs depended on not only its diagnostic inference capability, but also the quality of information gathered under uncertainty through natural conversation and building rapport.
Our results suggested that AMIE was as adept as the PCPs in eliciting pertinent information during the simulated consultations, and was more accurate than the PCPs in formulating a complete DDx if given the same amount of acquired information. This finding corroborates other work that LLMs may be able to produce more complete DDxs given the same clinical information as physicians in challenging cases . Although not explored in this study, the assistive performance of AMIE therefore represents an interesting and important avenue for future research, particularly given the real-world importance of expert oversight for AI systems in safety-critical settings, such as medicine.
Our study utilized a wide variety of simulated patients, comprising actors trained in both Canada and India, and scenarios across a range of specialties. This allowed us to explore how performance varied along multiple axes-by specialty, and by the locations in which the scenario was derived and enacted. While we observed that both the PCPs and AMIE performed worse in gastroenterology and internal medicine scenarios than with other specialties (Extended Data Fig. 3), the study was not powered or designed to compare performance between different specialty topics and locations, and we cannot exclude that the scenarios in some specialties might have been harder than others.
Fig.5|Specialist physician ratings. Conversation and reasoning qualities, as assessed by specialist physicians. For illustration purposes, all responses from the five-point rating scales were mapped to a generic five-point scale ranging from ‘Very favourable’ to ‘Very unfavourable’. The only four-point scale (DDx comprehensiveness) was mapped to the same scale, ignoring the ‘Neither favourable nor unfavourable’ option. For Yes/No questions, a (positive) ‘Yes’ response was mapped to the same colour as ‘Favourable’ and a (negative) ‘No’ response to the same colour as ‘Unfavourable’. The rating scales were adapted
Conversational performance
The patient-actors and specialist raters both evaluated AMIE’s performance to be higher than that of the PCPs on metrics related to empathy and communication skills. These axes comprised a majority of the dimensions that were evaluated. This general finding is consistent with a prior study, where LLM responses were found to be more empathetic than the responses from clinicians to health questions posted on Reddit . However, the findings in that study cannot be generalized directly to our setting due to the differences in study design. Specifically, prior work has not involved a direct, randomized comparison of physicians and AI systems in a prospective simulation of multi-turn dialogue with the same patient. In both settings, the lack of voice-based and non-verbal visual communication may have been an unfair disadvantage to the clinicians.
The text-based chat interface used in this study introduced both advantages and disadvantages. People today most commonly engage with LLMs through synchronous text-chat interfaces , and patients often use patient portals to send messages to their providers. We therefore
from PACES, a narrative review about PCCBP and other sources. Details on question-wording and response options are provided in Extended Data Tables 1-3. The evaluation involved 159 simulated patients, with the ratings from three distinct specialist physician raters for each case being aggregated using the median. The values were determined using two-sided Wilcoxon signed-rank tests with FDR correction. Cases where either AMIE or the PCP received ‘Cannot rate/Does not apply’ were excluded from the test.
chose this mode of interaction as a representative interface for LLMs to perform multi-turn conversation, adapting the virtual OSCE framework accordingly. While this allowed a fair comparison of diagnostic dialogue between the LLMs and the clinicians when both were restricted to a synchronous text chat, it is important to acknowledge that our experiments did not emulate the expected quality of diagnostic dialogue in real clinical practice (including telemedicine). Physicians may be more used to history-taking and diagnostic dialogue by telephone or video consultation than synchronous text-chat communication .Instead, text is more commonly used by clinicians to communicate with patients for episodic or asynchronous needs, such as prescription refills or communication about specific test results . Physicians may thus be more familiar with text/SMS or email rather than the synchronous text-chat medium we employed in this study. In both text/SMS and email, the conventions and expectations for communicating naturally and with empathic style might be different . It is possible that the PCPs in our study had not yet become accustomed to the setting, and may have performed differently if subjected to a specific training programme (similar in spirit to the training process for AMIE). Clinicians participating in the study undertook two
preparatory pilot sessions of consultations with our synchronous text interface before the evaluation began, but this was not a formal training programme, nor was it designed to optimize the clinicians’ performance. Future research could explore this question more thoroughly, including monitoring for the impact of a learning curve or exploring whether performance varies according to the extent to which participating clinicians or simulated patients are familiar with telemedicine. Note that the conversations in our study were time-limited to follow typical OSCE conventions. While real-world patient-physician consultations often also take place under time constraints, the specific time limit imposed in our study may not be reflective of real-world scenarios.
Additionally, our findings regarding empathic communication could also be partially attributed to the fact that the AMIE responses were significantly longer than the clinician responses (Extended Data Fig. 6), and presented with greater structure. This could potentially suggest to an observer that more time was spent preparing the response, analogous to known findings that patient satisfaction increases with time spent with their physicians .
Collectively, our findings suggest many avenues for further research that might leverage human-AI complementarity , combining clinicians’ skills in the analysis of verbal and non-verbal cues with the potential strengths of LLMs to suggest more enriched conversational responses, including empathic statements, structure, eloquence or more complete DDxs.
Simulated dialogue
The use of simulated data allowed us to quickly scale the training to a broad set of conditions and patient contexts, while the injection of knowledge from search encouraged these dialogues to remain grounded and realistic. Although the simulated patients encompassed a wide range of conditions, they failed to capture the full range of potential patient backgrounds, personalities and motivations. Indeed, the simulated experiments shown in Supplementary Fig. 3 suggested that, while AMIE appears robust to certain variations in patient characteristics and behaviour, it has significant difficulty with some types of patients, such as those with low English literacy. Through the inner self-play procedure, we were able to iteratively improve the simulated dialogue we generated and used in fine-tuning. However, these improvements were limited by our ability to articulate what made good dialogue in the critic instructions, the critic’s ability to produce effective feedback and AMIE’s ability to adapt to such feedback. For example, in the simulated environment we imposed that AMIE reaches a proposed differential and testing/treatment plan for the patient, but such an endpoint may be unrealistic for some conditions, especially in the virtual chat-based setting. This limitation also applies in the real-world setting.
Additionally, the task of producing reward signals for the quality of medical diagnostic conversations is more challenging than evaluating outcomes in rule-based constrained environments where success is well-defined (for example, winning or losing a game of ). Our process for generating synthetic vignettes was designed with this consideration in mind. Because we knew the ground-truth condition for each vignette and the corresponding simulated dialogue(s) rollout, we were able to automatically assess the correctness of AMIE’s DDx predictions as a proxy reward signal. This reward signal was used to filter out ‘unsuccessful’ simulated dialogues, such as those for which AMIE failed to produce an accurate DDx prediction during this self-play process. Beyond DDx accuracy, the self-play critic agent also assessed other qualities, including the level of empathy, professionalism and coherence conveyed by the doctor agent for each simulated dialogue. While these latter constructs are more subjective compared to diagnostic accuracy, they served as domain-specific heuristics imposed by clinical experts from our research team to help steer AMIE’s development towards alignment with established clinical values. We also note that, in our preliminary analysis described in this work, our auto-evaluation framework for assessing the conversations along such rubrics was
found to be in good alignment with human ratings and comparable to the inter-specialist agreement on these criteria.
Note that the majority of scenarios in our evaluation set assumed an underlying disease state, while only a small subset assumed the absence of disease. This is an important limitation of this work because it does not reflect the population-level epidemiological realities of primary care, where the majority of work in assessing patients involves ruling out disease, rather than ruling it in. We encourage future work to explore evaluation with various distributions of disease versus non-disease states.
Therefore, even within the distribution of diseases and specialties we addressed, our findings should be interpreted with humility and caution. There is a need for further research to examine varied presentations of the same diseases, alongside an exploration of alternative approaches to evaluating history-taking and clinical dialogue in situations of different patient needs, preferences, behaviours and circumstances.
Fairness and bias
The evaluation protocol presented in this paper was limited in terms of its ability to capture potential issues related to fairness and bias, which remains an important open question that we will aim to address in subsequent system evaluations. Recent advances in the development of comprehensive frameworks for bias detection in LLMs present a promising starting point for establishing such an approach. It should be noted that medical diagnostic dialogue is a particularly challenging use case, due to the complexity of the medical domain, the interactive information-gathering nature of the dialogue and the outcome-driven setting, with the potential of associated harms in cases of incorrect diagnosis or incorrect medical advice. Nevertheless, disentangling these issues is an important further research area if LLMs in the domain are to overcome, rather than propagate, inequities in healthcare. For example, previous studies have found that physicians approach communication with their patients differently, on average, depending on the patients’ race, resulting in Black patients receiving communication that was less patient-centred and had a lower positive affect . Other studies have found differences in physicians’ communication styles and conversation length based on gender and on patients’ level of health literacy .Effective intercultural communication skills are essential . There is therefore a non-negligible risk that such historical conversational biases may be replicated or amplified in an AI dialogue system, but at the same time, there is also an opportunity to work towards designing conversational systems that can be more inclusive, and more personalized to the individual patient’s needs.
To help inform the development of the necessary fairness, bias and equity frameworks, it was important to employ a participatory approach to solicit representative views across a wide range of patient demographics, as well as clinical and health equity domain experts. Such evaluation frameworks should be complemented by extensive model red-teaming and an adversarial approach to identifying any remaining gaps and failure modes. Recent advances in red-teaming LLMs could be useful in this scenario , where human raters or other AI systems (that is, the red team) simulate the role of an adversary to identify vulnerabilities and security gaps in these LLMs. These practices should not only inform the evaluation of the final model, but also its development and iterative refinement. Model development should follow the established data and model reporting practices and provide transparency into the training data and the associated decision processes . The dialogue research dataset contributing to the AMIE training data in our study was de-identified, reducing the availability of socioeconomic factors, patient demographics and information about clinical settings and locations. To mitigate the risk that our synthetic vignettes would skew towards certain demographic groups, we leveraged web search to retrieve a range of demographics and associated symptoms relevant to each condition. We used these as input to the prompt template for vignette generation, instructing the model to produce multiple different vignettes given this range of inputs. While this mechanism was
designed with the intent of mitigating risks of bias amplification, a comprehensive evaluation of conversational diagnostic models, such as AMIE, for equity, fairness and bias is an important scope for future work.
Further work is also needed to ensure the robustness of medical LLMs in multilingual settings , and particularly their performance in minority languages . The great variety of cultures , languages, localities, identities and localized medical needs makes the task of generating a priori static yet comprehensive fairness benchmarks practically infeasible. The measurement and mitigation of bias must move beyond the traditional narrow focus on specific axes that fails to scale globally . With LLM-based evaluators, a potential solution is presented for preliminary assessments in languages where there are no systematic benchmarks, although prior studies have found these auto-evaluation frameworks to be biased, underscoring the need for calibrating them on native speaker evaluations, and using them with caution .
Deployment
This study demonstrates the potential of LLMs for future use in healthcare in the context of diagnostic dialogue. Transitioning from an LLM research prototype that has been evaluated in this study to a safe and robust tool that can be used by healthcare providers, administrators and people will require significant additional research to ensure the safety, reliability, efficacy and privacy of the technology. Careful consideration will need to be given to the ethical deployment of this technology, including rigorous quality assessment across different clinical settings and research into reliable uncertainty estimation methods that would allow for deferral to human clinical experts when needed. These and other guardrails are needed to mitigate the potential overreliance on LLM technologies, with other specific measures for attention to ethical and regulatory requirements particular to future use cases and the presence of qualified physicians in the loop to safeguard any model outputs. Additional research will also be needed to assess the extent to which biases and security vulnerabilities might arise, either from base models or the circumstances of use in deployment, as we have highlighted in our prior work . Given the continuous evolution of clinical knowledge, it will also be important to develop ways for LLMs to utilize up-to-date clinical information .
Conclusion
The utility of medical AI systems could be greatly improved if they are better able to interact conversationally, anchoring on large-scale medical knowledge, while communicating with appropriate levels of empathy and trust. This work demonstrates the great potential capabilities of LLM-based AI systems for settings involving clinical history-taking and diagnostic dialogue. The performance of AMIE in simulated consultations represents a milestone for the field, given it was assessed along an evaluation framework that considered multiple clinically relevant axes for conversational diagnostic medical AI. However, the results should be interpreted with appropriate caution. Translating from this limited scope of experimental simulated history-taking and diagnostic dialogue towards real-world tools for people and those who provide care for them requires a substantial amount of additional research and development to ensure the safety, reliability, fairness, efficacy and privacy of the technology. If successful, we believe AI systems, such as AMIE, can be at the core of next-generation-learning health systems that help scale world-class healthcare to everyone.
Online content
Any methods, additional references, Nature Portfolio reporting summaries, source data, extended data, supplementary information, acknowledgements, peer review information; details of author contributions and competing interests; and statements of data and code availability are available at https://doi.org/10.1038/s41586-025-08866-7.
Levine, D. History taking is a complex skill. Br. Med. J. 358, j3513 (2017).
Engel, G. L. & Morgan, W. L. Interviewing the Patient (W. B. Saunders, 1973).
Fu, Y., Peng, H., Khot, T. & Lapata, M. Improving language model negotiation with self-play and in-context learning from AI feedback. Preprint at https://arxiv.org/abs/2305.10142 (2023).
Sloan, D. A., Donnelly, M. B., Schwartz, R. W. & Strodel, W. E. The objective structured clinical examination. The new gold standard for evaluating postgraduate clinical performance. Ann. Surg. 222, 735 (1995).
Carraccio, C. & Englander, R. The objective structured clinical examination: a step in the direction of competency-based evaluation. Arch. Pediatr. Adolesc. Med. 154, 736-741 (2000).
Peterson, M. C., Holbrook, J. H., Von Hales, D., Smith, N. & Staker, L. Contributions of the history, physical examination, and laboratory investigation in making medical diagnoses. West. J. Med. 156, 163 (1992).
Silverman, J., Kurtz, S. & Draper, J. Skills for Communicating with Patients 3rd edn (CRC, 2016).
Rennie, T., Marriott, J. & Brock, T. P. Global supply of health professionals. N. Engl. J. Med. 370, 2246-2247 (2014).
Gemini Team Google et al. Gemini: a family of highly capable multimodal models. Preprint at https://arxiv.org/abs/2312.11805 (2023).
Singhal, K. et al. Large language models encode clinical knowledge. Nature 620, 172-180 (2023).
Singhal, K. et al. Toward expert-level medical question answering with large language models. Nat. Med. 31, 943-950 (2025).
Nori, H. et al. Can generalist foundation models outcompete special-purpose tuning? Case study in medicine. Preprint at https://arxiv.org/abs/2311.16452 (2023).
Thoppilan, R. et al. LaMDA: language models for dialog applications. Preprint at https:// arxiv.org/abs/2201.08239 (2022).
Toma, A. et al. Clinical Camel: an open-source expert-level medical language model with dialogue-based knowledge encoding. Preprint at https://arxiv.org/abs/2305.12031 (2023).
Chen, Z. et al. MEDITRON-70B: scaling medical pretraining for large language models. Preprint at https://arxiv.org/abs/2311.16079 (2023).
King, A. & Hoppe, R. B. “Best practice” for patient-centered communication: a narrative review. J. Grad. Med. Educ. 5, 385-393 (2013).
Dacre, J., Besser, M. & White, P. MRCP(UK) part 2 clinical examination (PACES): a review of the first four examination sessions (June 2001 – July 2002). Clin. Med. 3, 452-459 (2003).
Kelly, C. J., Karthikesalingam, A., Suleyman, M., Corrado, G. & King, D. Key challenges for delivering clinical impact with artificial intelligence. BMC Med. 17, 195 (2019).
Semigran, H. L., Linder, J. A., Gidengil, C. & Mehrotra, A. Evaluation of symptom checkers for self diagnosis and triage: audit study. Br. Med. J. 351, h3480 (2015).
Ayers, J. W. et al. Comparing physician and artificial intelligence chatbot responses to patient questions posted to a public social media forum. JAMA Intern. Med. 183, 589-596 (2023).
Carrillo de Albornoz, S., Sia, K.-L. & Harris, A. The effectiveness of teleconsultations in primary care: systematic review. Fam. Pract. 39, 168-182 (2022).
Fuster-Casanovas, A. & Vidal-Alaball, J. Asynchronous remote communication as a tool for care management in primary care: a rapid review of the literature. Int. J. Integr. Care 22, 7 (2022).
Hammersley, V. et al. Comparing the content and quality of video, telephone, and face-to-face consultations: a non-randomised, quasi-experimental, exploratory study in UK primary care. Br. J. Gen. Pract. 69, e595-e604 (2019).
Gross, D. A., Zyzanski, S. J., Borawski, E. A., Cebul, R. D. & Stange, K. C. Patient satisfaction with time spent with their physician. J. Fam. Pract. 47, 133-138 (1998).
Dvijotham, K. et al. Enhancing the reliability and accuracy of AI-enabled diagnosis via complementarity-driven deferral to clinicians. Nat. Med. 29, 1814-1820 (2023).
Silver, D. et al. Mastering the game of Go with deep neural networks and tree search. Nature 529, 484-489 (2016).
Gallegos, I. O. et al. Bias and fairness in large language models: a survey. Comput. Linguist. 50, 1-79 (2024).
Johnson, R. L., Roter, D., Powe, N. R. & Cooper, L. A. Patient race/ethnicity and quality of patient-physician communication during medical visits. Am. J. Public Health 94, 2084-2090 (2004).
Roter, D. L., Hall, J. A. & Aoki, Y. Physician gender effects in medical communication: a meta-analytic review. JAMA 288, 756-764 (2002).
Schillinger, D. et al. Precision communication: physicians’ linguistic adaptation to patients’ health literacy. Sci. Adv. 7, eabj2836 (2021).
Rahman, U. & Cooling, N. Inter-cultural communication skills training in medical schools: a systematic review. Med. Res. Arch. 11, mra.v11i4.3757(2023).
Ganguli, D. et al. Red teaming language models to reduce harms: methods, scaling behaviors, and lessons learned. Preprint at https://arxiv.org/abs/2209.07858 (2022).
Mitchell, M. et al. Model cards for model reporting. In Proc. Conference on Fairness, Accountability, and Transparency 220-229 (Association for Computing Machinery, 2019).
Crisan, A., Drouhard, M., Vig, J. & Rajani, N. Interactive model cards: a human-centered approach to model documentation. In Proc. 2022 ACM Conference on Fairness, Accountability, and Transparency 427-439 (Association for Computing Machinery, 2022).
Pushkarna, M., Zaldivar, A. & Kjartansson, O. Data cards: purposeful and transparent dataset documentation for responsible AI. In Proc. 2022 ACM Conference on Fairness, Accountability, and Transparency 1776-1826 (Association for Computing Machinery, 2022).
Choudhury, M. & Deshpande, A. How linguistically fair are multilingual pre-trained language models? In Proc. AAAI Conference on Artificial Intelligence Vol. 35 12710-12718 (Association for the Advancement of Artificial Intelligence, 2021).
Article
Nguyen, X.-P., Aljunied, S. M., Joty, S. & Bing, L. Democratizing LLMs for low-resource languages by leveraging their English dominant abilities with linguistically-diverse prompts. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics Vol. 1 (eds Ku, L.-W. et al.) 3501-3516 (Association for Computational Linguistics, 2024).
Naous, T., Ryan, M. J., Ritter, A. & Xu, W. Having beer after prayer? Measuring cultural bias in large language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics Vol. 1 (eds Ku, L.-W. et al.) 16366-16393 (Association for Computational Linguistics, 2024).
Ramesh, K., Sitaram, S. & Choudhury, M. Fairness in language models beyond English: gaps and challenges. In Findings of the Association for Computational Linguistics: EACL 2023 (eds Vlachos, A. & Augenstein, I.) 2106-2119 (Association for Computational Linguistics, 2023).
Hada, R. et al. Are large language model-based evaluators the solution to scaling up multilingual evaluation? In Findings of the Association for Computational Linguistics: EACL 2024 (eds Graham, Y. & Purver, M.) 1051-1070 (Association for Computational Linguistics, 2024).
Quach, V. et al. Conformal language modeling. Preprint at https://arxiv.org/abs/ 2306.10193 (2023).
Lazaridou, A. et al. Mind the gap: assessing temporal generalization in neural language models. Adv. Neural Inf. Process. Syst. 34, 29348-29363 (2021).
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
(c) The Author(s) 2025
Methods
Real-world datasets for AMIE
AMIE was developed using a diverse suite of real-world datasets, including multiple-choice medical question-answering, expert-curated long-form medical reasoning, electronic health record (EHR) note summaries and large-scale transcribed medical conversation interactions. As described in detail below, in addition to dialogue generation tasks, the training task mixture for AMIE consisted of medical question-answering, reasoning and summarization tasks.
Medical reasoning. We used the MedQA (multiple-choice) dataset, consisting of US Medical Licensing Examination multiple-choice-style open-domain questions with four or five possible answers . The training set consisted of 11,450 questions and the test set had 1,273 questions. We also curated 191 MedQA questions from the training set where clinical experts had crafted step-by-step reasoning leading to the correct answer .
Long-form medical question-answering. The dataset used here consisted of expert-crafted long-form responses to 64 questions from HealthSearchQA, LiveQA and Medication QA in MultiMedQA .
Medical summarization. A dataset consisting of 65 clinician-written summaries of medical notes from MIMIC-III, a large, publicly available database containing the medical records of intensive care unit patients , was used as additional training data for AMIE. MIMIC-III contains approximately two million notes spanning 13 types, including cardiology, respiratory, radiology, physician, general, discharge, case management, consult, nursing, pharmacy, nutrition, rehabilitation and social work. Five notes from each category were selected, with a minimum total length of 400 tokens and at least one nursing note per patient. Clinicians were instructed to write abstractive summaries of individual medical notes, capturing key information while also permitting the inclusion of new informative and clarifying phrases and sentences not present in the original note.
Real-world dialogue. Here we used a de-identified dataset licensed from a dialogue research organization, comprising 98,919 audio transcripts of medical conversations during in-person clinical visits from over 1,000 clinicians over a ten-year period in the United States . It covered 51 medical specialties (primary care, rheumatology, haematology, oncology, internal medicine and psychiatry, among others) and 168 medical conditions and visit reasons (type 2 diabetes, rheumatoid arthritis, asthma and depression being among the common conditions). Audio transcripts contained utterances from different speaker roles, such as doctors, patients and nurses. On average, a conversation had 149.8 turns ( ). For each conversation, the metadata contained information about patient demographics, reason for the visit (follow-up for pre-existing condition, acute needs, annual exam and more), and diagnosis type (new, existing or other unrelated). Refer to ref. 50 for more details.
For this study, we selected dialogues involving only doctors and patients, but not other roles, such as nurses. During preprocessing, we removed paraverbal annotations, such as ‘[LAUGHING]’ and ‘[INAUDIBLE]’, from the transcripts. We then divided the dataset into training ( ) and validation ( ) sets using stratified sampling based on condition categories and reasons for visits, resulting in 89,027 conversations for training and 9,892 for validation.
Simulated learning through self-play
While passively collecting and transcribing real-world dialogues from in-person clinical visits is feasible, two substantial challenges limit its effectiveness in training LLMs for medical conversations: (1) existing real-world data often fail to capture the vast range of medical conditions
and scenarios, hindering its scalability and comprehensiveness; and (2) the data derived from real-world dialogue transcripts tend to be noisy, containing ambiguous language (including slang, jargon and sarcasm), interruptions, ungrammatical utterances and implicit references. This, in turn, may have limited AMIE’s knowledge, capabilities and applicability.
To address these limitations, we designed a self-play-based simulated learning environment for diagnostic medical dialogues in a virtual care setting, enabling us to scale AMIE’s knowledge and capabilities across a multitude of medical conditions and contexts. We used this environment to iteratively fine-tune AMIE with an evolving set of simulated dialogues in addition to the static corpus of medical question-answering, reasoning, summarization and real-world dialogue data described above.
This process consisted of two self-play loops:
An inner self-play loop where AMIE leveraged in-context critic feedback to refine its behaviour on simulated conversations with an AI patient agent.
An outer self-play loop where the set of refined simulated dialogues were incorporated into subsequent fine-tuning iterations. The resulting new version of AMIE could then participate in the inner loop again, creating a continuous learning cycle.
At each iteration of fine-tuning, we produced 11,686 dialogues, stemming from 5,230 different medical conditions. The conditions were selected from three datasets:
The Health QA dataset , which contained 613 common medical conditions.
The MalaCards Human Disease Database (https://github.com/ Shivanshu-Gupta/web-scrapers/blob/master/medical_ner/malacardsdiseases.json), which contained 18,455 less-common disease conditions.
The MedicineNet Diseases & Conditions Index (https://github. com/Shivanshu-Gupta/web-scrapers/blob/master/medical_ner/ medicinenet-diseases.json), which contained 4,617 less-common conditions.
At each self-play iteration, four conversations were generated from each of the 613 common conditions, while two conversations were generated from each of the 4,617 less-common conditions randomly chosen from MedicineNet and MalaCards. The average simulated dialogue conversation length was 21.28 turns ( ).
Simulated dialogues through self-play. To produce high-quality simulated dialogues at scale, we developed a new multi-agent framework that comprised three key components:
A vignette generator: AMIE leverages web searches to craft unique patient vignettes given a specific medical condition.
A simulated dialogue generator: three LLM agents play the roles of patient agent, doctor agent and moderator, engaging in a turn-by-turn dialogue simulating realistic diagnostic interactions.
A self-play critic: a fourth LLM agent acts as a critic to give feedback to the doctor agent for self-improvement. Notably, AMIE acted as all agents in this framework.
The prompts for each of these steps are listed in Supplementary Table 3. The vignette generator aimed to create varied and realistic patient scenarios at scale, which could be subsequently used as context for generating simulated doctor-patient dialogues, thereby allowing AMIE to undergo a training process emulating exposure to a greater number of conditions and patient backgrounds. The patient vignette (scenario) included essential background information, such as patient demographics, symptoms, past medical history, past surgical history, past social history and patient questions, as well as an associated diagnosis and management plan.
For a given condition, patient vignettes were constructed using the following process. First, we retrieved 60 passages ( 20 each) on
the range of demographics, symptoms and management plans associated with the condition from using an internet search engine. To ensure these passages were relevant to the given condition, we used the general-purpose LLM, PaLM 2 (ref.10), to filter these retrieved passages, removing any passages deemed unrelated to the given condition. We then prompted AMIE to generate plausible patient vignettes aligned with the demographics, symptoms and management plans retrieved from the filtered passages, by providing a one-shot exemplar to enforce a particular vignette format.
Given a patient vignette detailing a specific medical condition, the simulated dialogue generator was designed to simulate a realistic dialogue between a patient and a doctor in an online chat setting where in-person physical examination may not be feasible.
Three specific LLM agents (patient agent, doctor agent and moderator), each played by AMIE, were tasked with communicating among each other to generate the simulated dialogues. Each agent had distinct instructions. The patient agent embodied the individual experiencing the medical condition outlined in the vignette. Their role involved truthfully responding to the doctor agent’s inquiries, as well as raising any additional questions or concerns they may have had. The doctor agent played the role of an empathetic clinician seeking to comprehend the patient’s medical history within the online chat environment . Their objective was to formulate questions that could effectively reveal the patient’s symptoms and background, leading to an accurate diagnosis and an effective treatment plan. The moderator continually assessed the ongoing dialogue between the patient agent and doctor agent, determining when the conversation had reached a natural conclusion.
The turn-by-turn dialogue simulation started with the doctor agent initiating the conversation: “Doctor: So, how can I help you today?”. Following this, the patient agent responded, and their answer was incorporated into the ongoing dialogue history. Subsequently, the doctor agent formulated a response based on the updated dialogue history. This response was then appended to the conversation history. The conversation progressed until the moderator detected the dialogue had reached a natural conclusion, when the doctor agent had provided a DDx, treatment plan, and adequately addressed any remaining patient agent questions, or if either agent initiated a farewell.
To ensure high-quality dialogues, we implemented a tailored selfplay framework specifically for the self-improvement of diagnostic conversations. This framework introduced a fourth LLM agent to act as a ‘critic’, which was also played by AMIE, and that was aware of the ground-truth diagnosis to provide in-context feedback to the doctor agent and enhance its performance in subsequent conversations.
Following the critic’s feedback, the doctor agent incorporated the suggestions to improve its responses in subsequent rounds of dialogue with the same patient agent from scratch. Notably, the doctor agent retained access to its previous dialogue history in each new round. This self-improvement process was repeated twice to generate the dialogues used for each iteration of fine-tuning. See Supplementary Table 4 as an example of this self-critique process.
We noted that the simulated dialogues from self-play had significantly fewer conversational turns than those from the real-world data described in the previous section. This difference was expected, given that our self-play mechanism was designed-through instructions to the doctor and moderator agents-to simulate text-based conversations. By contrast, real-world dialogue data was transcribed from in-person encounters. There are fundamental differences in communication styles between text-based and face-to-face conversations. For example, in-person encounters may afford a higher communication bandwidth, including a higher total word count and more ‘back and forth’ (that is, a greater number of conversational turns) between the physician and the patient. AMIE, by contrast, was designed for focused information gathering by means of a text-chat interface.
Instruction fine-tuning
AMIE, built upon the base LLM PaLM 2 (ref. 10), was instruction finetuned to enhance its capabilities for medical dialogue and reasoning. We refer the reader to the PaLM 2 technical report for more details on the base LLM architecture. Fine-tuning examples were crafted from the evolving simulated dialogue dataset generated by our four-agent procedure, as well as the static datasets. For each task, we designed task-specific instructions to instruct AMIE on what task it would be performing. For dialogue, this was assuming either the patient or doctor role in the conversation, while for the question-answering and summarization datasets, AMIE was instead instructed to answer medical questions or summarize EHR notes. The first round of fine-tuning from the base LLM only used the static datasets, while subsequent rounds of fine-tuning leveraged the simulated dialogues generated through the self-play inner loop.
For dialogue generation tasks, AMIE was instructed to assume either the doctor or patient role and, given the dialogue up to a certain turn, to predict the next conversational turn. When playing the patient agent, AMIE’s instruction was to reply to the doctor agent’s questions about their symptoms, drawing upon information provided in patient scenarios. These scenarios included patient vignettes for simulated dialogues or metadata, such as demographics, visit reason and diagnosis type, for the real-world dialogue dataset. For each fine-tuning example in the patient role, the corresponding patient scenario was added to AMIE’s context. In the doctor agent role, AMIE was instructed to act as an empathetic clinician, interviewing patients about their medical history and symptoms to ultimately arrive at an accurate diagnosis. From each dialogue, we sampled, on average, three turns for each doctor and patient role as the target turns to predict based on the conversation leading up to that target turn. Target turns were randomly sampled from all turns in the dialogue that had a minimum length of 30 characters.
Similarly, for the EHR note summarization task, AMIE was provided with a clinical note and prompted to generate a summary of the note. Medical reasoning/QA and long-form response generation tasks followed the same set-up as in ref. 13. Notably, all tasks except dialogue generation and long-form response generation incorporated few-shot (1-5) exemplars in addition to task-specific instructions for additional context.
Chain-of-reasoning for online inference
To address the core challenge in diagnostic dialogue-effectively, acquiring information under uncertainty to enhance diagnostic accuracy and confidence, while maintaining positive rapport with the patient-AMIE employed a chain-of-reasoning strategy before generating a response in each dialogue turn. Here ‘chain-of-reasoning’ refers to a series of sequential model calls, each dependent on the outputs of prior steps. Specifically, we used a three-step reasoning process, described as follows:
Analysing patient information. Given the current conversation history, AMIE was instructed to: (1) summarize the positive and negative symptoms of the patient as well as any relevant medical/family/social history and demographic information; (2) produce a current DDx; (3) note missing information needed for a more accurate diagnosis; and (4) assess confidence in the current differential and highlight its urgency.
Formulating response and action. Building upon the conversation history and the output of step1, AMIE: (1) generated a response to the patient’s last message and formulated further questions to acquire missing information and refine the DDx; and (2) if necessary, recommended immediate action, such as an emergency room visit. If confident in the diagnosis, based on the available information, AMIE presented the differential.
Refining the response. AMIE revised its previous output to meet specific criteria based on the conversation history and outputs from earlier steps. The criteria were primarily related to factuality and
formatting of the response (for example, avoid factual inaccuracies on patient facts and unnecessary repetition, show empathy, and display in a clear format).
This chain-of-reasoning strategy enabled AMIE to progressively refine its response conditioned on the current conversation to arrive at an informed and grounded reply.
Evaluation
Prior works developing models for clinical dialogue have focused on metrics, such as the accuracy of note-to-dialogue or dialogue-to-note generations , or natural language generation metrics, such as BLEU or ROUGE scores that fail to capture the clinical quality of a consultation .
In contrast to these prior works, we sought to anchor our human evaluation in criteria more commonly used for evaluating the quality of physicians’ expertise in history-taking, including their communication skills in consultation. Additionally, we aimed to evaluate conversation quality from the perspective of both the lay participant (the participating patient-actor) and a non-participating professional observer (a physician who was not directly involved in the consultation). We surveyed the literature and interviewed clinicians working as OSCE examiners in Canada and India to identify a minimum set of peer-reviewed published criteria that they considered comprehensively reflected the criteria that are commonly used in evaluating both patient-centred and professional-centred aspects of clinical diagnostic dialogue-that is, identifying the consensus for PCCBP in medical interviews , the criteria examined for history-taking skills by the Royal College of Physicians in the United Kingdom as part of their PACES (https://www.mrcpuk. org/mrcpuk-examinations/paces/marksheets) and the criteria proposed by the UK GMCPQ (https://edwebcontent.ed.ac.uk/sites/default/ files/imports/fileManager/patient_questionnaire%20pdf_48210488. pdf) for doctors seeking patient feedback as part of professional revalidation (https://www.gmc-uk.org/registration-and-licensing/ managing-your-registration/revalidation/revalidation-resources).
The resulting evaluation framework enabled assessment from two perspectives-the clinician, and lay participants in the dialogues (that is, the patient-actors). The framework included the consideration of consultation quality, structure and completeness, and the roles, responsibilities and skills of the interviewer (Extended Data Tables 1-3).
Remote OSCE study design. To compare AMIE’s performance to that of real clinicians, we conducted a randomized crossover study of blinded consultations in the style of a remote OSCE. Our OSCE study involved 20 board-certified PCPs and 20 validated patient-actors, ten each from India and Canada, respectively, to partake in online text-based consultations (Extended Data Fig. 1). The PCPs had between 3 and 25 years of post-residency experience (median 7 years). The patient-actors comprised of a mix of medical students, residents and nurse practitioners with experience in OSCE participation. We sourced 159 scenario packs from India (75), Canada (70) and the United Kingdom (14).
The scenario packs and simulated patients in our study were prepared by two OSCE laboratories (one each in Canada and India), each affiliated with a medical school and with extensive experience in preparing scenario packs and simulated patients for OSCE examinations. The UK scenario packs were sourced from the samples provided on the Membership of the Royal Colleges of Physicians UK website. Each scenario pack was associated with a ground-truth diagnosis and a set of acceptable diagnoses. The scenario packs covered conditions from the cardiovascular (31), respiratory (32), gastroenterology (33), neurology (32), urology, obstetric and gynaecology (15) domains and internal medicine (16). The scenarios are listed in Supplementary Information section 8 . The paediatric and psychiatry domains were excluded from this study, as were intensive care and inpatient case management scenarios.
Indian patient-actors played the roles in all India scenario packs and 7 of the 14 UK scenario packs. Canadian patient-actors participated in
scenario packs for both Canada and the other half of the UK-based scenario packs. This assignment process resulted in 159 distinct simulated patients (that is, scenarios). Below, we use the term ‘OSCE agent’ to refer to the conversational counterpart interviewing the patient-actorthat is, either the PCP or AMIE. Supplementary Table 1 summarizes the OSCE assignment information across the three geographical locations. Each of the 159 simulated patients completed the three-step study flow depicted in Fig. 2.
Online text-based consultation. The PCPs and patient-actors were primed with sample scenarios and instructions, and participated in pilot consultations before the study began to familiarize them with the interface and experiment requirements.
For the experiment, each simulated patient completed two online text-based consultations by means of a synchronous text-chat interface (Extended Data Fig. 1), one with a PCP (control) and one with AMIE (intervention). The ordering of the PCP and AMIE was randomized and the patient-actors were not informed as to which they were talking to in each consultation (counterbalanced design to control for any potential order effects). The PCPs were located in the same country as the patient-actors, and were randomly drawn based on availability at the time slot specified for the consultation. The patient-actors role-played the scenario and were instructed to conclude the conversation after no more than 20 minutes. Both OSCE agents were asked (the PCPs through study-specific instructions and AMIE as part of the prompt template) to not reveal their identity, or whether they were human, under any circumstances.
Post-questionnaires. Upon conclusion of the consultation, the patient-actor and OSCE agent each filled in a post-questionnaire in light of the resulting consultation transcript (Extended Data Fig. 1). The post-questionnaire for patient-actors consisted of the complete GMCPQ, the PACES components for ‘Managing patient concerns’ and ‘Maintaining patient welfare’ (Extended Data Table 1) and a checklist representation of the PCCBP category for ‘Fostering the relationship’ (Extended Data Table 2). The responses the patient-actors provided to the post-questionnaire are referred to as ‘patient-actor ratings’. The post-questionnaire for the OSCE agent asked for a ranked DDx list with a minimum of three and no more than ten conditions, as well as recommendations for escalation to in-person or video-based consultation, investigations, treatments, a management plan and the need for a follow-up.
Specialist physician evaluation. Finally, a pool of 33 specialist physicians from India (18), North America (12) and the United Kingdom (3) evaluated the PCPs and AMIE with respect to the quality of their consultation and their responses to the post-questionnaire. During evaluation, the specialist physicians also had access to the full scenario pack, along with its associated ground-truth differential and additional accepted differentials. All of the data the specialist physicians had access to during evaluation are collectively referred to as ‘OSCE data’. Specialist physicians were sourced to match the specialties and geographical regions corresponding to the scenario packs included in our study, and had between 1 and 32 years of post-residency experience (median 5 years). Each set of OSCE data was evaluated by three specialist physicians randomly assigned to match the specialty and geographical region of the underlying scenario (for example, Canadian pulmonologists evaluated OSCE data from the Canada-sourced respiratory medicine scenario). Each specialist evaluated the OSCE data from both the PCP and AMIE for each given scenario. Evaluations for the PCP and AMIE were conducted by the same set of specialists in a randomized and blinded sequence.
Evaluation criteria included the accuracy, appropriateness and comprehensiveness of the provided DDx list, the appropriateness of recommendations regarding escalation, investigation, treatment, management plan and follow-up (Extended Data Table 3) and all PACES
(Extended Data Table 1) and PCCBP (Extended Data Table 2) rating items. We also asked specialist physicians to highlight confabulations in the consultations and questionnaire responses-that is, text passages that were non-factual or that referred to information not provided in the conversation. Each OSCE scenario pack additionally supplied the specialists with scenario-specific clinical information to assist with rating the clinical quality of the consultation, such as the ideal investigation or management plans, or important aspects of the clinical history that would ideally have been elucidated for the highest quality of consultation possible. This follows the common practice for instructions for OSCE examinations, in which specific clinical scenario-specific information is provided to ensure consistency among examiners, and follows the paradigm demonstrated by Membership of the Royal Colleges of Physicians sample packs. For example, this scenario (https://www.thefederation.uk/sites/default/ files/Station%202%20Scenario%20Pack%20%2816%29.pdf) informs an examiner that, for a scenario in which the patient-actor has haemoptysis, the appropriate investigations would include a chest X-ray, a high-resolution computed tomography scan of the chest, a bronchoscopy and spirometry, whereas bronchiectasis treatment options a candidate should be aware of should include chest physiotherapy, mucolytics, bronchodilators and antibiotics.
Statistical analysis and reproducibility. We evaluated the top- accuracy of the DDx lists generated by AMIE and the PCPs across all 159 simulated patients. Top- accuracy was defined as the percentage of cases where the correct ground-truth diagnosis appeared within the top- positions of the DDx list. For example, top-3 accuracy is the percentage of cases for which the correct ground-truth diagnosis appeared in the top three diagnosis predictions from AMIE or the PCP. Specifically, a candidate diagnosis was considered a match if the specialist rater marked it as either an exact match with the ground-truth diagnosis, or very close to or closely related to the ground-truth diagnosis (or accepted differential). Each conversation and DDx was evaluated by three specialists, and their majority vote or median rating was used to determine the accuracy and quality ratings, respectively.
The statistical significance of the DDx accuracy was determined using two-sided bootstrap tests with 10,000 samples and false discovery rate (FDR) correction across all . The statistical significance of the patient-actor and specialist ratings was determined using two-sided Wilcoxon signed-rank tests , also with FDR correction. Cases where either agent received ‘Cannot rate/Does not apply’ were excluded from the test. All significance results are based on values after FDR correction.
Additionally, we reiterate that the OSCE scenarios themselves were sourced from three different countries, the patient-actors came from two separate institutions in Canada and India, and the specialist evaluations were triplicate rated in this study.
Related work
Clinical history-taking and the diagnostic dialogue. History-taking and the clinical interview are widely taught in both medical schools and postgraduate curricula .Consensus on physician-patient communication has evolved to embrace patient-centred communication practices, with recommendations that communication in clinical encounters should address six core functions-fostering the relationship, gathering information, providing information, making decisions, responding to emotions and enabling disease- and treatment-related behaviour . The specific skills and behaviours for meeting these goals have also been described, taught and assessed using validated tools . Medical conventions consistently cite that certain categories of information should be gathered during a clinical interview, comprising topics such as the presenting complaint, past medical history and medication history, social and family history, and systems review . Clinicians’ ability to meet these goals is commonly assessed using the
framework of an . Such assessments vary in their reproducibility or implementation, and have even been adapted for remote practice as virtual OSCEs with telemedical scenarios, an issue of particular relevance during the COVID-19 pandemic .
Conversational AI and goal-oriented dialogue. Conversational AI systems for goal-oriented dialogue and task completion have a rich history . The emergence of transformers and large language models have led to renewed interest in this direction. The development of strategies for alignment , self-improvement and scalable oversight mechanisms has enabled the large-scale deployment of such conversational systems in the real world . However, the rigorous evaluation and exploration of conversational and task-completion capabilities of such AI systems remains limited for clinical applications, where studies have largely focused on single-turn interaction use cases, such as question-answering or summarization.
Al for medical consultations and diagnostic dialogue. The majority of explorations of AI as tools for conducting medical consultations have focused on ‘symptom-checker’ applications rather than a full natural dialogue, or on topics such as the transcription of medical audio or the generation of plausible dialogue, given clinical notes or summaries . Language models have been trained using clinical dialogue datasets, but these have not been comprehensively evaluated . Studies have been grounded in messages between doctors and patients in commercial chat platforms (which may have altered doctor-patient engagement compared to medical consultations) . Many have focused largely on predicting next turns in the recorded exchanges rather than clinically meaningful metrics. Also, to date, there have been no reported studies that have examined the quality of AI models for diagnostic dialogue using the same criteria used to examine and train human physicians in dialogue and communication skills, nor studies evaluating AI systems in common frameworks, such as the OSCE.
Evaluation of diagnostic dialogue. Prior frameworks for the human evaluation of AI systems’ performance in diagnostic dialogue have been limited in detail. They have not been anchored in established criteria for assessing communication skills and the quality of history-taking. For example, ref. 56 reported a five-point scale describing overall ‘human evaluation’, ref. 90 reported ‘relevance, informativeness and human likeness’, and ref. 91 reported ‘fluency, expertise and relevance’, whereas other studies have reported ‘fluency and adequacy’ and ‘fluency and specialty . These criteria are far less comprehensive and specific than those taught and practiced by medical professionals. A multi-agent framework for assessing the conversational capabilities of LLMs was introduced in ref. 88, the study, however, was performed in the restricted setting of dermatology, used AI models to emulate both the doctor and patient sides of simulated interactions, and it performed limited expert evaluation of the history-taking as being complete or not.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
AMIE is an LLM-based research AI system for diagnostic dialogue. Reviewers were provided access to the system through a testing program to interact with the system and evaluate the performance. We are not open-sourcing model code and weights due to the safety implications of the unmonitored use of such a system in medical settings. In the interest of responsible innovation, we will be working with research partners, regulators and providers to validate and explore safe onward uses of AMIE. For reproducibility, we have documented technical deep-learning methods while keeping the paper accessible to a clinical and general scientific audience. Our work builds upon PaLM 2, for which technical details have been described extensively in the technical report . All analyses were conducted using Python v.2.7.18 (https://www.python.org/).
48. Jin, D. et al. What disease does this patient have? A large-scale open domain question answering dataset from medical exams. Appl. Sci. 11, 6421 (2021).
49. Johnson, A. E. et al. MIMIC-III, a freely accessible critical care database. Sci. Data 3, 160035 (2016).
50. Chiu, C.-C. et al. Speech recognition for medical conversations. In Proc. Interspeech (ed. Yegnanarayana, B.) 2972-2976 (International Speech Communication Association, 2018).
51. Sharma, A., Miner, A., Atkins, D. & Althoff, T. A computational approach to understanding empathy expressed in text-based mental health support. In Proc. 2020 Conference on Empirical Methods in Natural Language Processing (eds Webber, B. et al.) 5263-5276 (Association for Computational Linguistics, 2020).
52. Aksitov, R. et al. Rest meets ReAct: self-improvement for multi-step reasoning LLM agent. Preprint at https://doi.org/10.48550/arXiv.2312.10003 (2023).
53. Abacha, A. B., Yim, W.-W., Adams, G., Snider, N. & Yetisgen-Yildiz, M. Overview of the MEDIQA-chat 2023 shared tasks on the summarization & generation of doctor-patient conversations. In Proc. 5th Clinical Natural Language Processing Workshop (eds Naumann, T. et al.) 503-513 (Association for Computational Linguistics, 2023).
54. Ionescu, B. et al. in Experimental IR Meets Multilinguality, Multimodality, and Interaction. CLEF 2023 Lecture Notes in Computer Science Vol. 14163 (eds Arampatzis, A. et al.) 370-396 (Springer, 2023).
55. He, Z. et al. DIALMED: a dataset for dialogue-based medication recommendation. In Proc. 29th International Conference on Computational Linguistics (eds Calzolari, N. et al.) 721-733 (International Committee on Computational Linguistics, 2022).
56. Naseem, U., Bandi, A., Raza, S., Rashid, J. & Chakravarthi, B. R. Incorporating medical knowledge to transformer-based language models for medical dialogue generation. In Proc. 21st Workshop on Biomedical Language Processing (eds Demner-Fushman, D. et al.) 110-115 (Association for Computational Linguistics, 2022).
57. Horowitz, J. L. in Handbook of Econometrics, Vol. 5 (eds Heckman, J. J. & Leamer, E.) 3159-3228 (Elsevier, 2001).
58. Benjamini, Y. & Hochberg, Y. Controlling the false discovery rate: a practical and powerful approach to multiple testing. J. R. Stat. Soc. Ser. B Methodol. 57, 289-300 (1995).
59. Woolson, R. F. in Wiley Encyclopedia of Clinical Trials (eds D’Agostino, R. B. et al.) 1-3 (Wiley, 2007).
60. Keifenheim, K. E. et al. Teaching history taking to medical students: a systematic review. BMC Med. Educ. 15, 159 (2015).
61. Yedidia, M. J. et al. Effect of communications training on medical student performance. JAMA 290, 1157-1165 (2003).
62. Makoul, G. Communication skills education in medical school and beyond. JAMA 289, 93-93 (2003).
63. Tan, X. H. et al. Teaching and assessing communication skills in the postgraduate medical setting: a systematic scoping review. BMC Med. Educ. 21, 483 (2021).
64. Raper, S. E., Gupta, M., Okusanya, O. & Morris, J. B. Improving communication skills: a course for academic medical center surgery residents and faculty. J. Surg. Educ. 72, e202-e211 (2015).
65. Von Fragstein, M. et al. UK consensus statement on the content of communication curricula in undergraduate medical education. Med. Educ. 42, 1100-1107 (2008).
66. De Haes, H. & Bensing, J. Endpoints in medical communication research, proposing a framework of functions and outcomes. Patient Educ. Couns. 74, 287-294 (2009).
67. Epstein, R. M. & Street Jr, R. L. Patient-Centered Communication in Cancer Care: Promoting Healing and Reducing Suffering (National Cancer Institute, 2007).
68. Schirmer, J. M. et al. Assessing communication competence: a review of current tools. Fam. Med. 37, 184-92 (2005).
69. Nichol, J. R., Sundjaja, J. H. & Nelson, G. Medical History (StatPearls, 2018).
70. Denness, C. What are consultation models for? InnovAiT 6, 592-599 (2013).
71. Epstein, R. M. & Hundert, E. M. Defining and assessing professional competence. JAMA 287, 226-235 (2002).
72. Chan, S. C. C., Choa, G., Kelly, J., Maru, D. & Rashid, M. A. Implementation of virtual OSCE in health professions education: a systematic review. Med. Educ. 57, 833-843 (2023).
73. Budzianowski, P. et al. MultiWOZ-a large-scale multi-domain Wizard-of-Oz dataset for task-oriented dialogue modelling. In Proc. 2018 Conference on Empirical Methods in Natural Language Processing (eds Riloff, E. et al.) 5016-5026 (Association for Computational Linguistics, 2018).
74. Wei, W., Le, Q., Dai, A. & Li, J. AirDialogue: an environment for goal-oriented dialogue research. In Proc. 2018 Conference on Empirical Methods in Natural Language Processing (eds Riloff, E. et al.) 3844-3854 (Association for Computational Linguistics, 2018).
75. Lin, J., Tomlin, N., Andreas, J. & Eisner, J. Decision-oriented dialogue for human-AI collaboration. Trans. Assoc. Comput. Linguist. 12, 892-911 (2023).
76. Vaswani, A. et al. Attention is all you need. In Proc. 31st Conference on Neural Information Processing Systems (eds Guyon, I. et al.) 6000-6010 (Curran Associates, 2017).
77. Ouyang, L. et al. Training language models to follow instructions with human feedback. Adv. Neural Inf. Process. Syst. 35, 27730-27744 (2022).
78. Zhao, J., Khashabi, D., Khot, T., Sabharwal, A. & Chang, K.-W. Ethical-advice taker: do language models understand natural language interventions? In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021 (eds Zong, C. et al.) 4158-4164 (Association for Computational Linguistics, 2021).
79. Saunders, W. et al. Self-critiquing models for assisting human evaluators. Preprint at https://arxiv.org/abs/2206.05802 (2022).
80. Scheurer, J. et al. Training language models with language feedback at scale. Preprint at https://arxiv.org/abs/2303.16755 (2023).
81. Glaese, A. et al. Improving alignment of dialogue agents via targeted human judgements. Preprint at https://arxiv.org/abs/2209.14375 (2022).
82. Bai, Y. et al. Constitutional AI: harmlessness from AI feedback. Preprint at https://arxiv.org/ abs/2212.08073 (2022).
83. Askell, A. et al. A general language assistant as a laboratory for alignment. Preprint at https://arxiv.org/abs/2112.00861 (2021).
84. Shor, J. et al. Clinical BERTScore: an improved measure of automatic speech recognition performance in clinical settings. In Proc. 5th Clinical Natural Language Processing Workshop (eds Naumann, T. et al.) 1-7 (Association for Computational Linguistics, 2023).
85. Abacha, A. B., Agichtein, E., Pinter, Y. & Demner-Fushman, D. Overview of the medical question answering task at TREC 2017 LiveQA. In Proc. 26th Text Retrieval Conference, TREC 2017 (eds Voorhees, E. M. & Ellis, A.) 1-12 (National Institute of Standards and Technology and the Defense Advanced Research Projects Agency, 2017).
86. Wallace, W. et al. The diagnostic and triage accuracy of digital and online symptom checker tools: a systematic review. NPJ Digit. Med. 5, 118 (2022).
87. Zeltzer, D. et al. Diagnostic accuracy of artificial intelligence in virtual primary care. Mayo Clin. Proc. Digital Health 1, 480-489 (2023).
88. Johri, S. et al. Testing the limits of language models: a conversational framework for medical AI assessment. Preprint at medRxiv https://doi.org/10.1101/2023.09.12.23295399 (2023).
89. Wu, C.-K., Chen, W.-L. & Chen, H.-H. Large language models perform diagnostic reasoning. Preprint at https://arxiv.org/abs/2307.08922 (2023).
90. Zeng, G. et al. MedDialog: large-scale medical dialogue datasets. In Proc. 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) (eds Webber, B. et al.) 9241-9250 (Association for Computational Linguistics, 2020).
91. Liu, W. et al. MedDG: an entity-centric medical consultation dataset for entity-aware medical dialogue generation. In Proc. 11th CCF International Conference on Natural Language Processing and Chinese Computing (eds Lu, W. et al.) 447-459 (Springer, 2022).
92. Varshney, D., Zafar, A., Behera, N. & Ekbal, A. CDialog: a multi-turn COVID-19 conversation dataset for entity-aware dialog generation. In Proc. 2022 Conference on Empirical Methods in Natural Language Processing (eds Goldberg, Y. et al.) 11373-11385 (Association for Computational Linguistics, 2022).
93. Yan, G. et al. ReMeDi: resources for multi-domain, multi-service, medical dialogues. In Proc. 45th International ACM SIGIR Conference on Research and Development in Information Retrieval 3013-3024 (Association for Computing Machinery, 2022).
Acknowledgements This project represents an extensive collaboration between several teams at Google Research and Google DeepMind. We thank Y. Liu, D. McDuff, J. Sunshine, A. Connell, P. McGovern and Z. Ghahramani for their comprehensive reviews and detailed feedback on early versions of the manuscript. We also thank S. Lachgar, L. Winer, J. Guilyard and M. Shiels for contributions to the narratives and visuals. We are grateful to J. A. Seguin, S. Goldman, Y. Vasilevski, X. Song, A. Goel, C.-l. Ko, A. Das, H. Yu, C. Liu, Y. Liu, S. Man, B. Hatfield, S. Li, A. Joshi, G. Turner, A. Um’rani, D. Pandya and P. Singh for their valuable insights, technical support and feedback during our research. We also thank GoodLabs Studio Inc., Intel Medical Inc. and C. Smith for their partnership in conducting the OSCE study in North America, and the JSS Academy of Higher Education and Research and V. Patil for their partnership in conducting the OSCE study in India. Finally, we are grateful to D. Webster, E. Dominowska, D. Fleet, P. Mansfield, S. Prakash, R. Wong, S. Thomas, M. Howell, K. DeSalvo, J. Dean, J. Manyika, Z. Ghahramani and D. Hassabis for their support during the course of this project.
Author contributions A.P., M.S., T.T., S.S.M., K. Singhal, S.A., A.K., R.T., J.F. and V.N. contributed to the conception and design of the work; A.P., M.S., T.T., S.S.M., K. Saab, A.K., A. Wang, K.K. and V.N. contributed to the data acquisition and curation; A.P., M.S., T.T., K. Saab, A.K., Y.C., R.T., J.F., N.T., E.V., B.L., M.A. and V.N. contributed to the technical implementation; A.K., V.N., M.S., T.T., A.P. and N.T. contributed to the evaluation framework used in the study; Y.C., L.H., A. Webson and J.G. provided technical and infrastructure guidance; A.K. provided clinical inputs to the study; C.S., J.G., J.B., K.C., G.S.C. and Y.M. contributed to the ideation and execution of the work. All authors contributed to the drafting and revising of the manuscript.
Competing interests This study was funded by Alphabet Inc. and/or a subsidiary thereof (‘Alphabet’). All authors are employees of Alphabet and may own stock as part of the standard compensation package.
Additional information
Supplementary information The online version contains supplementary material available at https://doi.org/10.1038/s41586-025-08866-7.
Correspondence and requests for materials should be addressed to Tao Tu, Mike Schaekermann, Alan Karthikesalingam or Vivek Natarajan.
Peer review information Nature thanks Dean Schillinger and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Peer reviewer reports are available.
Reprints and permissions information is available at http://www.nature.com/reprints.
Article
Chat Interface
Extended Data Fig. 1|User interfaces for the online consultation and evaluation processes. Online consultations between patient actors and either AMIE or the primary care physicians (PCPs) were conducted by means of a synchronous text-based chat interface. The evaluation process was facilitated
Specialist Physician Evaluation Interface
through a rating interface in which specialist physicians were provided the scenario information including differential diagnosis answer key, as well as a consultation transcript along with post-questionnaire responses from AMIE or the PCPs. Rating prompts were provided alongside these pieces of information.
Extended Data Fig. 2 | DDx top- accuracy for non-disease-states and positive disease-states. a,b: Specialist rated DDx top- accuracy for the 149 “positive” scenarios with respect to (a) the ground-truth diagnosis and (b) the accepted differentials.c,d: Specialist rated DDx top- accuracy for the 10 “negative” scenarios with respect to (c) the ground-truth diagnosis and (d) the accepted differentials. Using two-sided bootstrap tests ( ) with FDR correction, differences in the “positive” scenarios were significant ( ) for all k , but differences in “negative” scenarios were not significant due to the small sample size. Centrelines correspond to the average top- accuracy, with confidence intervals shaded. The FDR-adjusted values for positive disease states, ground-truth comparison: ,
, and . The FDR-adjusted values for positive disease states, accepted differential comparison: , , and . The FDR-adjusted values for non-disease states, ground-truth comparison: and . The FDR-adjusted values for non-disease states, accepted differential comparison: and .
Extended Data Fig. 3|Specialist rated DDx accuracy by scenario specialty.
Top- DDx accuracy for scenarios with respect to the ground-truth in (a) Cardiology ( , not significant), (b) Gastroenterology ( , not significant), (c) Internal Medicine ( , significant for all ), (d) Neurology ( , significant for ), (e) Obstetrics and Gynaecology (OBGYN)/Urology ( , not significant), (f) Respiratory ( , significant for all ). Two-sided bootstrap tests with FDR correction were used to assess significance on these cases. Centrelines correspond to the average top- accuracy, with 95% confidence intervals shaded. The FDR-adjusted values for Cardiology: 0.0911 , and . The FDR-adjusted values for Gastroenterology: ,
, and . The FDR-adjusted values for Internal Medicine: , and . The FDR-adjusted values for Neurology: , and . The FDR-adjusted values for OBGYN/ Urology: , and .
The FDR-adjusted values for Respiratory: , and .
Extended Data Fig. 4 | DDx accuracy by location. a, b: Specialist DDx rating of AMIE and the PCPs with respect to the ground-truth for the 77 cases conducted in Canada (a) and 82 cases in India (b). The differences between AMIE and the PCPs performance are significant for all values of : Auto-evaluation rated DDx for 40 scenarios which were duplicated in both Canada and India for AMIE (c) and the PCPs (d). The differences between Canada and India performance are not significant on these shared scenarios, for both AMIE and the PCPs. Significance was determined using two-sided bootstrap tests ( ) with FDR correction. Centrelines correspond to the average top- accuracy, with 95% confidence intervals shaded. The FDR-adjusted values for Canada comparison: ,
and . The FDR-adjusted values for India comparison: 0.0037 , and . The FDR-adjusted values for shared AMIE scenarios: , and . The FDR-adjusted values for shared PCP scenarios: , and .
Extended Data Fig. | Auto-evaluation of DDx performance. a, b: Top- DDx auto-evaluation of AMIE’s and the PCP’s differential diagnoses from their own consultations with respect to the ground-truth (a, significant for ) and the list of accepted differentials (b, significant for ). c, d: Top- DDx autoevaluation of AMIE’s differential diagnoses when provided its own vs. the PCP’s consultation transcript with respect to the ground-truth (c, not significant) and the list of accepted differentials (d, not significant). Two-sided bootstrap tests with FDR correction were used to assess significance on these 159 cases. Centrelines correspond to the average top- accuracy, with confidence intervals shaded. The FDR-adjusted values for AMIE vs. the PCP ground-truth comparison: ,
and . The FDR-adjusted values for AMIE vs. the PCP accepted differential comparison: , and . The FDR-adjusted values for AMIE vs. the PCP consultation ground-truth comparison: , and . The FDR-adjusted values for AMIE vs. the PCP consultation accepted differential comparison: , and .
Extended Data Fig. 6 | Consultation verbosity and efficiency of information acquisition. a, Total patient actor words elicited by AMIE and the PCPs.b, Total words sent to patient actor from AMIE and the PCPs. c, Total number of turns in AMIE vs. the PCP consultations. For (a-c), Centrelines correspond to the median, with the box indicating 25th and 75th percentiles. The minimum and maximum are presented as the bottom and top whiskers, respectively, excluding the outliers which are defined as data points further than 1.5 times the inter-quartile
range from the box.d, e: The top-3 auto-evaluation rated DDx accuracy of AMIE using the first turns of each consultation, with respect to the ground-truth diagnosis (d) and the accepted differentials (e). Differences on these 159 cases are not significant when compared through two-sided bootstrap tests with FDR correction. Centrelines correspond to the average top-3 accuracy, with confidence intervals shaded.
Article
Extended Data Table 1 | Practical Assessment of Clinical Examination Skills (PACES) rubric details
Practical Assessment of Clinical Examination Skills (PACES)
Question
Scale
Assessed by
Clinical Communication Skills
To what extent did the doctor elicit the PRESENTING COMPLAINT?
5-point scale
Specialist
To what extent did the doctor elicit the SYSTEMS REVIEW?
5-point scale
Specialist
To what extent did the doctor elicit the PAST MEDICAL HISTORY?
5-point scale
Specialist
To what extent did the doctor elicit the FAMILY HISTORY?
5-point scale
Specialist
To what extent did the doctor elicit the MEDICATION HISTORY?
5-point scale
Specialist
To what extent did the doctor explain relevant clinical information ACCURATELY?
5-point scale
Specialist
To what extent did the doctor explain relevant clinical information CLEARLY?
5-point scale
Specialist
To what extent did the doctor explain relevant clinical information WITH STRUCTURE?
5-point scale
Specialist
To what extent did the doctor explain relevant clinical information COMPREHENSIVELY?
5-point scale
Specialist
To what extent did the doctor explain relevant clinical information PROFESSIONALLY?
5-point scale
Specialist
Differential Diagnosis
To what extent did the doctor construct a sensible DIFFERENTIAL DIAGNOSIS?
5-point scale
Specialist
Clinical Judgement
To what extent did the doctor select a comprehensive, sensible and appropriate MANAGEMENT PLAN?
5-point scale
Specialist
Managing Patient Concerns
To what extent did the doctor seek, detect, acknowledge and attempt to address the patient’s concerns?
5-point scale
Specialist & Patient Actor
To what extent did the doctor confirm the patient’s knowledge and understanding?
5-point scale
Specialist & Patient Actor
How empathic was the doctor?
5-point scale
Specialist & Patient Actor
Maintaining Patient Welfare
To what extent did the doctor maintain the patient’s welfare?
5-point scale
Specialist & Patient Actor
Patient-Centered Communication Best Practice (PCCBP)
-Question Scale Assessed by
Fostering the Relationship
How would you rate the doctor’s behavior of FOSTERING A RELATIONSHIP with the patient?
5-point scale
Binary scale per criterion
Specialist
Patient Actor
Gathering Information
How would you rate the doctor’s behavior of GATHERING INFORMATION from the patient?
5-point scale
Specialist
Providing Information
How would you rate the doctor’s behavior of PROVIDING INFORMATION to the patient?
5-point scale
Specialist
Decision Making
How would you rate the doctor’s behavior of MAKING DECISIONS with the patient?
Enabling Disease and Treatment-Related Behavior
How would you rate the doctor’s behavior of ENABLING DISEASE AND TREATMENT-RELATED BEHAVIOR in the patient?
5-point scale
Specialist
Responding to Emotions
How would you rate the doctor’s behavior of RESPONDING TO EMOTIONS expressed by the patient?
5-point scale
Specialist
Extended Data Table 3 | Diagnosis and Management rubric details
Diagnosis & Management
Question
Scale
Options
Assessed by
Diagnosis
How APPROPRIATE was the doctor’s differential diagnosis (DDx) compared to the answer key?
5-point scale
Very Inappropriate
Inappropriate
Neither Appropriate Nor Inappropriate
Appropriate
Very Appropriate
Specialist
How COMPREHENSIVE was the doctor’s differential diagnosis (DDx) compared to the answer key?
4-point scale
The DDx has major candidates missing.
The DDx contains some of the candidates but a number are missing.
The DDx contains most of the candidates but some are missing.
The DDx contains all candidates that are reasonable.
Specialist
How close did the doctor’s differential diagnosis (DDx) come to including the PROBABLE DIAGNOSIS from the answer key?
5-point scale
Nothing in the DDx is related to the probable diagnosis.
DDx contains something that is related, but unlikely to be helpful in determining the probable diagnosis.
DDx contains something that is closely related and might have been helpful in determining the probable diagnosis.
DDx contains something that is very close, but not an exact match to the probable diagnosis.
DDx includes the probable diagnosis.
Specialist
How close did the doctor’s differential diagnosis (DDx) come to including any of the PLAUSIBLE ALTERNATIVE DIAGNOSES from the answer key?
5-point scale
Nothing in the DDx is related to any of the plausible alternative diagnoses.
DDx contains something that is related, but unlikely to be helpful in determining any of the plausible alternative diagnoses.
DDx contains something that is closely related and might have been helpful in determining one of the plausible alternative diagnoses.
DDx contains something that is very close, but not an exact match to any of the plausible alternative diagnoses.
DDx includes at least one of the plausible alternative diagnoses.
Specialist
Management
Was the doctor’s recommendation appropriate as to whether an escalation to a non-text consultation is needed, e.g. video or in-person (without which an appropriate investigation/management plan cannot be decided)?
4-point scale
No – Escalation was required but not performed. Failure to escalate to video or in-person assessment could have caused harm
No – Escalation was performed unnecessarily
Yes – Escalation was required and performed
Yes – Escalation was not required and not performed
Specialist
Did the doctor SUGGEST appropriate INVESTIGATIONS?
3-point scale
No – The doctor did not recommend investigations, but the correct action would be to order investigations
No – The doctor recommended investigations but these were not comprehensive (some were missing)
Yes – The doctor recommended a comprehensive and appropriate set of investigations (including correctly selecting zero investigations if this was best for the case)
Specialist
Did the doctor AVOID
INappropriate
Binary scale
Yes
Specialist
INVESTIGATIONS?
No
No – The doctor did not recommend treatments, but the correct action would be to recommend investigations
Did the doctor SUGGEST
No – The doctor recommended treatments but these were not comprehensive (some were missing)
appropriate TREATMENTS?
3-point scale
Yes – The doctor recommended a comprehensive and appropriate set of treatments (including correctly selecting
Specialist zero treatments if this was best for the case or if further investigation should precede treatment)
Did the doctor AVOID INappropriate TREATMENTS?
Binary scale
Yes
Specialist
To what extent was the doctor’s MANAGEMENT PLAN appropriate, including recommending emergency or red-flag presentations to go to ED ?
5-point scale
Very Inappropriate
Inappropriate
Neither Appropriate Nor Inappropriate
Appropriate
Very Appropriate
Specialist
Was the doctor’s recommendation about a FOLLOW-UP appropriate?
4-point scale
No – A follow-up was needed but the doctor failed to mention this
No – A follow-up was not needed but the doctor unnecessarily suggested one
Yes – A follow-up was needed and the doctor recommended an appropriate follow-up
Yes – A follow-up was not needed and the doctor did not suggest it
Specialist
Confabulation
Did the doctor CONFABULATE anything, either within the consultation or in their
Binary scale
Yes, there are confabulations
No confabulations
Specialist
responses to the postquestionnaire?
natureportfolio
Corresponding author(s):
Last updated by author(s): 01/ 21/ 2025
Reporting Summary
Nature Portfolio wishes to improve the reproducibility of the work that we publish. This form provides structure for consistency and transparency in reporting. For further information on Nature Portfolio policies, see our Editorial Policies and the Editorial Policy Checklist.
Please do not complete any field with “not applicable” or . Refer to the help text for what text to use if an item is not relevant to your study. For final submission: please carefully check your responses for accuracy; you will not be able to make changes later.
Statistics
For all statistical analyses, confirm that the following items are present in the figure legend, table legend, main text, or Methods section.
Confirmed
□ x The exact sample size for each experimental group/condition, given as a discrete number and unit of measurement
□ X
A statement on whether measurements were taken from distinct samples or whether the same sample was measured repeatedly
□ X
The statistical test(s) used AND whether they are one- or two-sided
Only common tests should be described solely by name; describe more complex techniques in the Methods section.
□ X A description of all covariates tested
□
□ A description of any assumptions or corrections, such as tests of normality and adjustment for multiple comparisons
□ X
A full description of the statistical parameters including central tendency (e.g. means) or other basic estimates (e.g. regression coefficient) AND variation (e.g. standard deviation) or associated estimates of uncertainty (e.g. confidence intervals)
□ X
For null hypothesis testing, the test statistic (e.g. ) with confidence intervals, effect sizes, degrees of freedom and value noted Give values as exact values whenever suitable.
□ For Bayesian analysis, information on the choice of priors and Markov chain Monte Carlo settings
□ For hierarchical and complex designs, identification of the appropriate level for tests and full reporting of outcomes
x □ Estimates of effect sizes (e.g. Cohen’s , Pearson’s r), indicating how they were calculated
Our web collection on statistics for biologists contains articles on many of the points above.
Software and code
Policy information about availability of computer code
Data collection The algorithms and scripts were implemented using Python 2.7.18 for data collection
Data analysis The data analysis scripts were implemented in Python 2.7.18. We will not be able to open source the LLMs used in this study.
Policy information about availability of data
All manuscripts must include a data availability statement. This statement should provide the following information, where applicable:
Accession codes, unique identifiers, or web links for publicly available datasets
A description of any restrictions on data availability
For clinical datasets or third party data, please ensure that the statement adheres to our policy
Policy information about studies with human participants or human data. See also policy information about sex, gender (identity/presentation), and sexual orientation and race, ethnicity and racism.
Reporting on sex and gender n/a
Reporting on race, ethnicity, or other socially relevant groupings
n/a
Population characteristics
n/a
Recruitment
n/a
Ethics oversight
n/a
Note that full information on the approval of the study protocol must also be provided in the manuscript.
Field-specific reporting
Please select the one below that is the best fit for your research. If you are not sure, read the appropriate sections before making your selection.
Life sciences
Behavioural & social sciences
Ecological, evolutionary & environmental sciences
For a reference copy of the document with all sections, see nature.com/documents/nr-reporting-summary-flat.pdf
Life sciences study design
All studies must disclose on these points even when the disclosure is negative.
Sample size The study involved 159 OSCE scenarios. No sample size calculation was performed.
Data exclusions No data was excluded
Replication
The evaluations in the study were performed by multiple specialist physicans and patient actors. Triplicate ratings were obtained from specialists. The actors were sourced from two different institutions in two separate countries and the OSCE scenario packs were from three countries. The results of the study were consistent across all of them.
Randomization
The order in which (a) patient actors completed both study arms, and (b) specialists assessed quality for both study arms, was randomized.
Blinding
Patient actors and specialist evaluators were not told which study arm they were exposed to during text-based conversation and evaluation respectively.
Behavioural & social sciences study design
All studies must disclose on these points even when the disclosure is negative.
Study description □
Research sample □
Sampling strategy □
Data collection □
Timing □
Data exclusions □
Non-participation □
Randomization □
Ecological, evolutionary & environmental sciences study design
All studies must disclose on these points even when the disclosure is negative.
Reporting for specific materials, systems and methods
We require information from authors about some types of materials, experimental systems and methods used in many studies. Here, indicate whether each material, system or method listed is relevant to your study. If you are not sure if a list item applies to your research, read the appropriate section before selecting a response.
Materials & experimental systems
Methods
n/a
Involved in the study
n/a
Involved in the study
x
□
x
x
□
x
x
□ Palaeontology and archaeology
□ MRI-based neuroimaging
x
□ Animals and other organisms
x
□
x
□
x
□
Antibodies
Antibodies used
Validation
nature portfolio | reporting summary
April 2023
Policy information about cell lines and Sex and Gender in Research
Cell line source(s) □
Authentication □
Mycoplasma contamination □
Commonly misidentified lines
(See ICLAC register) □
Palaeontology and Archaeology
Specimen provenance □
Specimen deposition □
Dating methods □
□ Tick this box to confirm that the raw and calibrated dates are available in the paper or in Supplementary Information.
Ethics oversight □
Note that full information on the approval of the study protocol must also be provided in the manuscript.
Animals and other research organisms
Policy information about studies involving animals; ARRIVE guidelines recommended for reporting animal research, and Sex and Gender in Research
Laboratory animals □
Wild animals □
Reporting on sex □
Field-collected samples □
Ethics oversight □
Note that full information on the approval of the study protocol must also be provided in the manuscript.
Clinical data
Policy information about clinical studies
All manuscripts should comply with the ICMJE guidelines for publication of clinical research and a completed CONSORT checklist must be included with all submissions.
Clinical trial registration □
Study protocol □
Data collection □
Outcomes □
Dual use research of concern
Policy information about dual use research of concern
Hazards
Could the accidental, deliberate or reckless misuse of agents or technologies generated in the work, or the application of information presented in the manuscript, pose a threat to:
No
Yes
□
□ Public health
□
□ National security
□
□ Crops and/or livestock
□
□ Ecosystems
□
□ Any other significant area
Experiments of concern
Does the work involve any of these experiments of concern:
No
Yes
□
□ Demonstrate how to render a vaccine ineffective
□
□ Confer resistance to therapeutically useful antibiotics or antiviral agents
□
□ Enhance the virulence of a pathogen or render a nonpathogen virulent
□
□ Increase transmissibility of a pathogen
□
□ Alter the host range of a pathogen
□
□ Enable evasion of diagnostic/detection modalities
□
□ Enable the weaponization of a biological agent or toxin
□
□ Any other potentially harmful combination of experiments and agents
Plants
Seed stocks □
Novel plant genotypes □
Authentication □
ChIP-seq
Data deposition
□ Confirm that both raw and final processed data have been deposited in a public database such as GEO.
□ Confirm that you have deposited or provided access to graph files (e.g. BED files) for the called peaks.
Data access links
May remain private before publication.
Files in database submission □
Genome browser session
(e.g. UCSC) □
Confirm that:
□ The axis labels state the marker and fluorochrome used (e.g. CD4-FITC).
□ The axis scales are clearly visible. Include numbers along axes only for bottom left plot of group (a ‘group’ is an analysis of identical markers).
□ All plots are contour plots with outliers or pseudocolor plots.
□ A numerical value for number of cells or percentage (with statistics) is provided.
Methodology
Sample preparation □
Instrument □
Software □
Cell population abundance □
Gating strategy □
□ Tick this box to confirm that a figure exemplifying the gating strategy is provided in the Supplementary Information.
Magnetic resonance imaging
Experimental design
Design type □
Design specifications □
Behavioral performance measures □
Imaging type(s) □
Field strength □
Sequence & imaging parameters □
Area of acquisition □
Diffusion MRI □ Used □ Not used
Google Research, Mountain View, CA, USA. Google DeepMind, Mountain View, CA, USA. These authors contributed equally: Tao Tu, Mike Schaekermann, Anil Palepu. These authors jointly supervised this work: Alan Karthikesalingam, Vivek Natarajan. e-mail: taotu@google.com; mikeshake@google.com; alankarthi@google.com; natviv@google.com