DOI: https://doi.org/10.1038/s41586-025-09215-4
PMID: https://pubmed.ncbi.nlm.nih.gov/40604288
تاريخ النشر: 2025-07-02
نموذج أساسي للتنبؤ والتقاط الإدراك البشري
تم الاستلام: 26 أكتوبر 2024
تم القبول: 29 مايو 2025
تم النشر على الإنترنت: 2 يوليو 2025
الوصول المفتوح
تحقق من التحديثات
الملخص
إن إنشاء نظرية موحدة للإدراك كان هدفًا مهمًا في علم النفس
خطوة مهمة نحو نظرية موحدة للإدراك هي بناء نموذج حسابي يمكنه التنبؤ ومحاكاة سلوك الإنسان في أي مجال
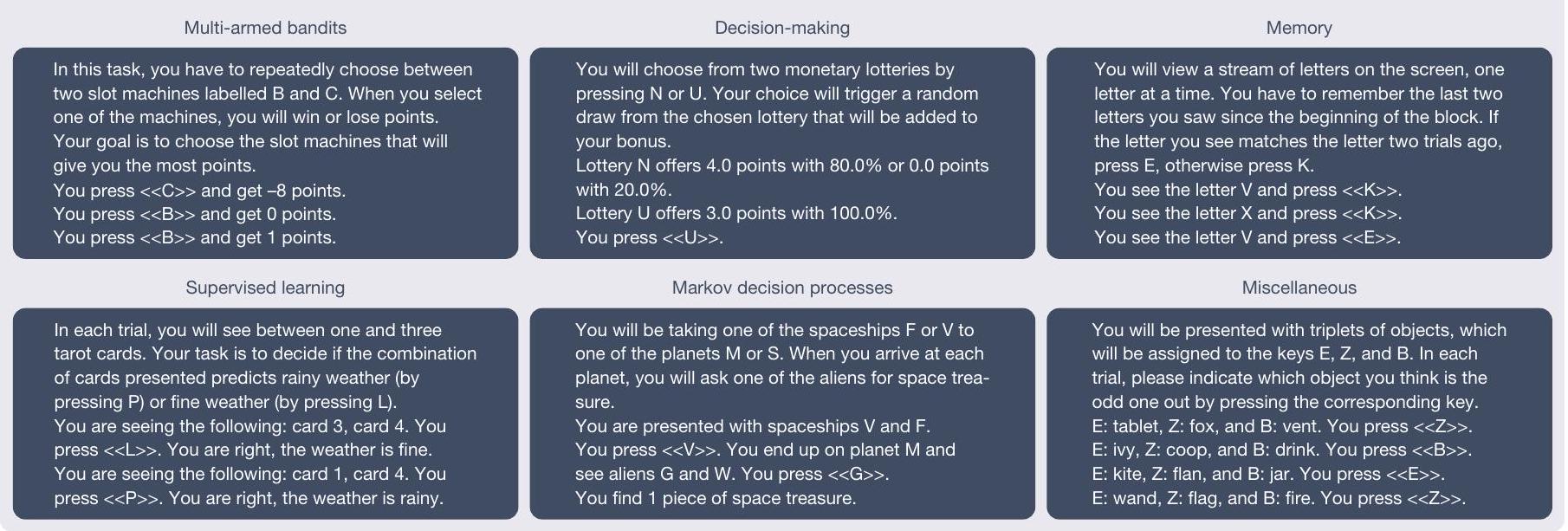
التعلم تحت الإشراف، عمليات اتخاذ القرار ماركوف وغيرها (تم تنسيق الأمثلة المعروضة واختصارها لسهولة القراءة). ب، سنتور هو نموذج أساسي للإدراك البشري يتم الحصول عليه عن طريق إضافة محولات منخفضة الرتبة إلى نموذج لغوي متطور وتحسينه على Psych-101.
تنسيق شائع للتعبير عن أنماط تجريبية مختلفة تمامًا
نظرة عامة على النموذج
العمود الفقري يسمح لنا بالاعتماد على كميات هائلة من المعرفة الموجودة في هذه النماذج. تضمنت عملية التدريب تحسينًا على Psych-101 باستخدام تقنية تحسين فعالة من حيث المعلمات تعرف باسم التكيف منخفض الرتبة الكمي (QLoRA)
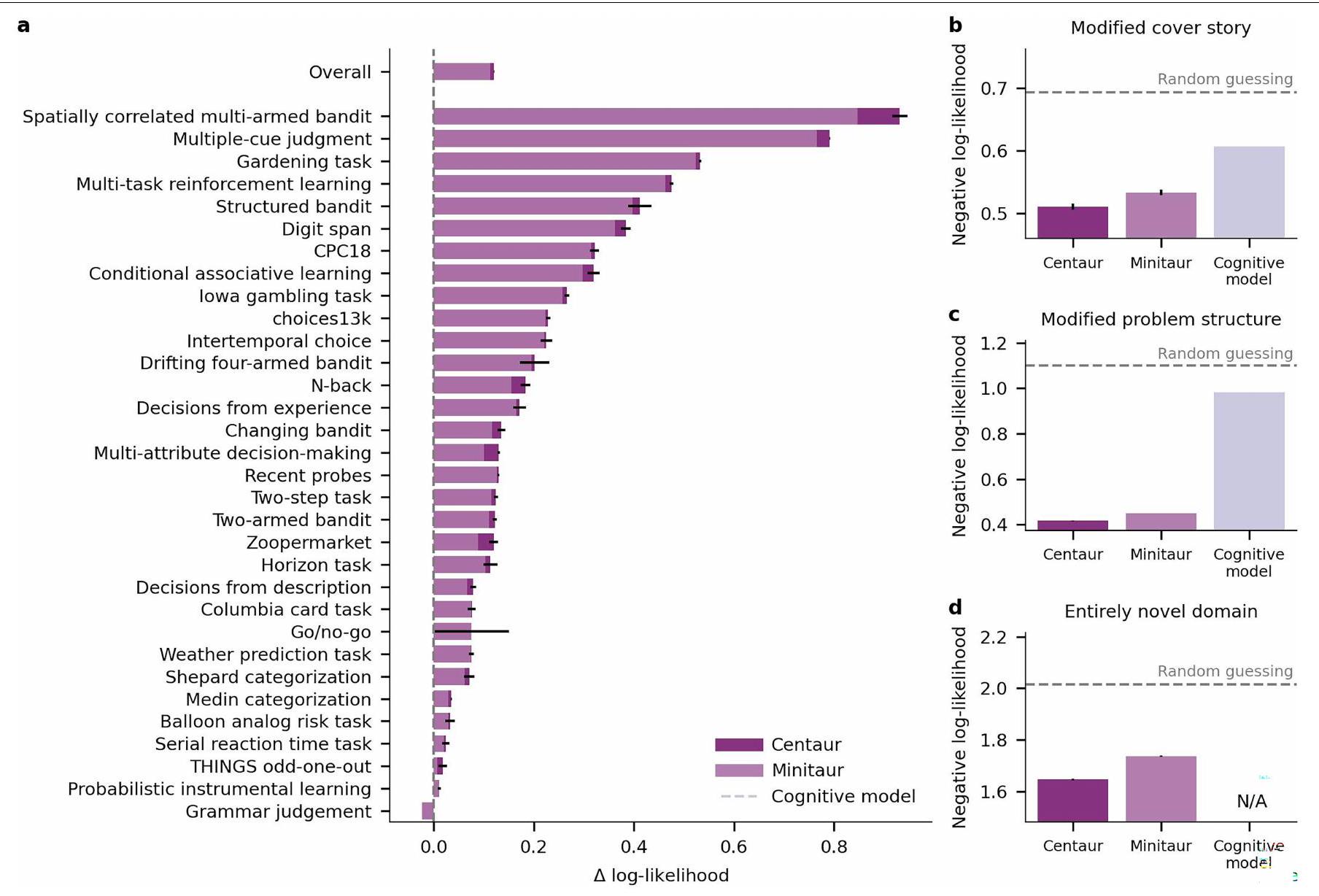
سنتور يلتقط سلوك الإنسان
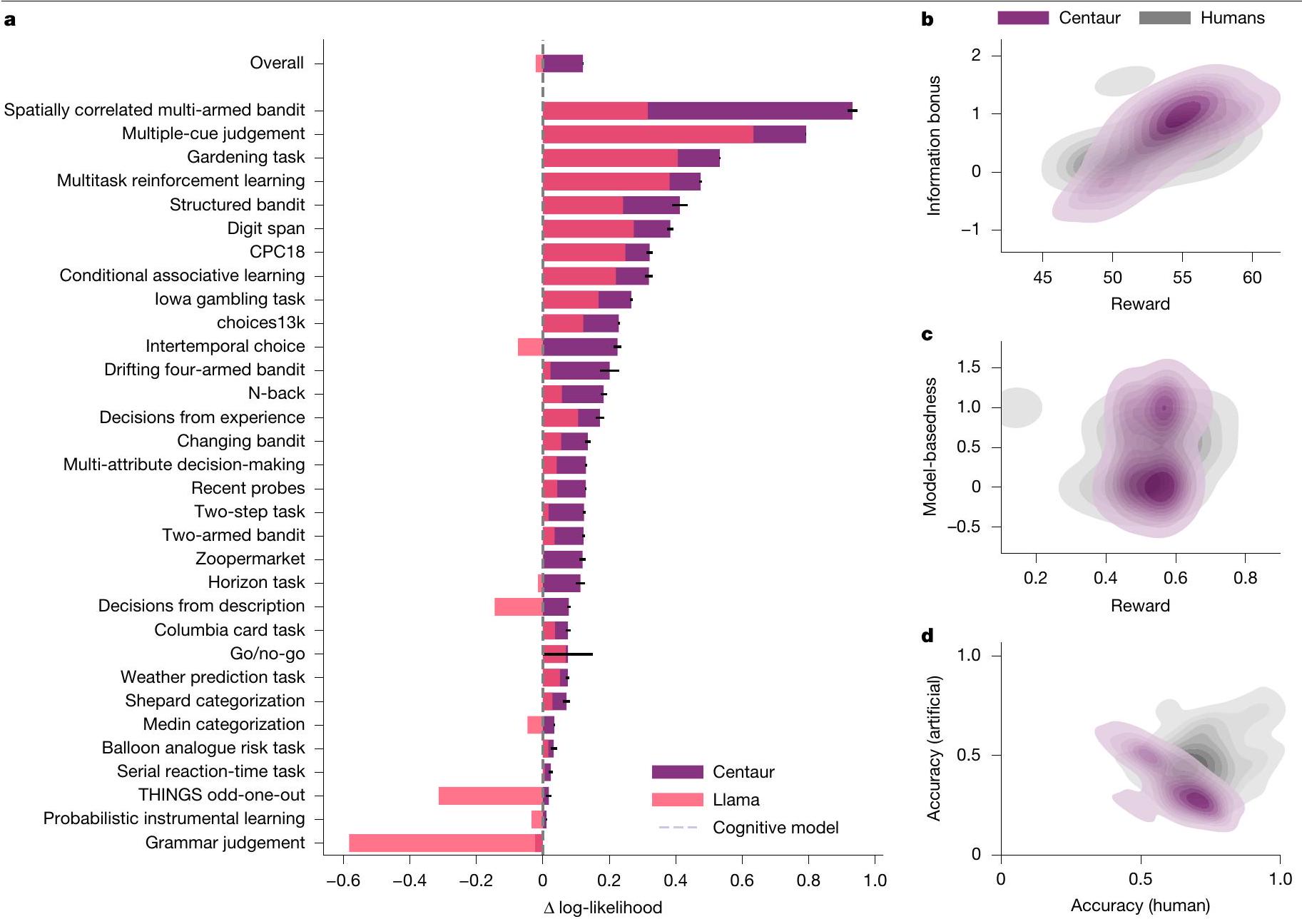
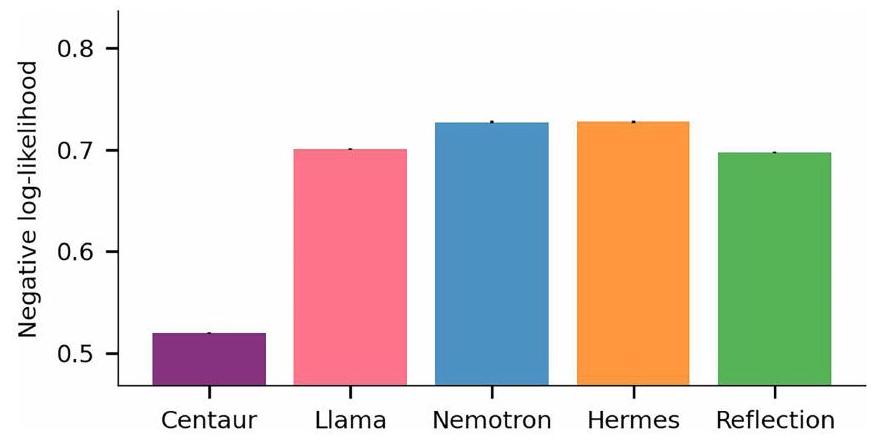
اختيارات باستخدام احتمالات السجل السلبية المتوسطة عبر الاستجابات (الطرق، ‘مقياس التقييم’). تقدم الشكل 2a نتائج هذا التحليل، مقارنةً بين Centaur والنموذج الأساسي بدون تحسين ومجموعة من النماذج الخاصة بالمجال التي تمثل أحدث ما توصلت إليه الأدبيات في علم النفس المعرفي (البيانات الموسعة الجدول 1). على الرغم من وجود تباين كبير في القابلية للتنبؤ عبر التجارب (Centaur، 0.49؛ Llama، 0.47)، إلا أن تحسين النموذج أدى دائمًا إلى تحسين جودة التوافق. كان الفرق المتوسط في احتمالات السجل عبر التجارب بعد تحسين النموذج 0.14 (احتمال السجل السلبي لـ Centaur، 0.44؛ احتمال السجل السلبي لـ Llama، 0.58؛ جانب واحد
كان النموذج المعرفي الخاص بالنطاق 0.13 (النماذج المعرفية، الاحتمالية السلبية، 0.56؛ أحادي الجانب
لقد ركزت التحليلات السابقة على توقع استجابات البشر المشروطة بالسلوكيات المنفذة سابقًا. يمكننا أن نتساءل عما إذا كان يمكن لـ Centaur أيضًا توليد سلوكيات شبيهة بالبشر عند محاكاتها بطريقة مفتوحة (أي، عند تغذية استجاباته الخاصة مرة أخرى إلى النموذج). من المحتمل أن يوفر هذا الإعداد اختبارًا أقوى بكثير لقدرات النموذج، ويشار إليه أحيانًا أيضًا باسم دحض النموذج.
تم دعمه من خلال اختبار التكافؤ باستخدام الاختبارين الجانبيين
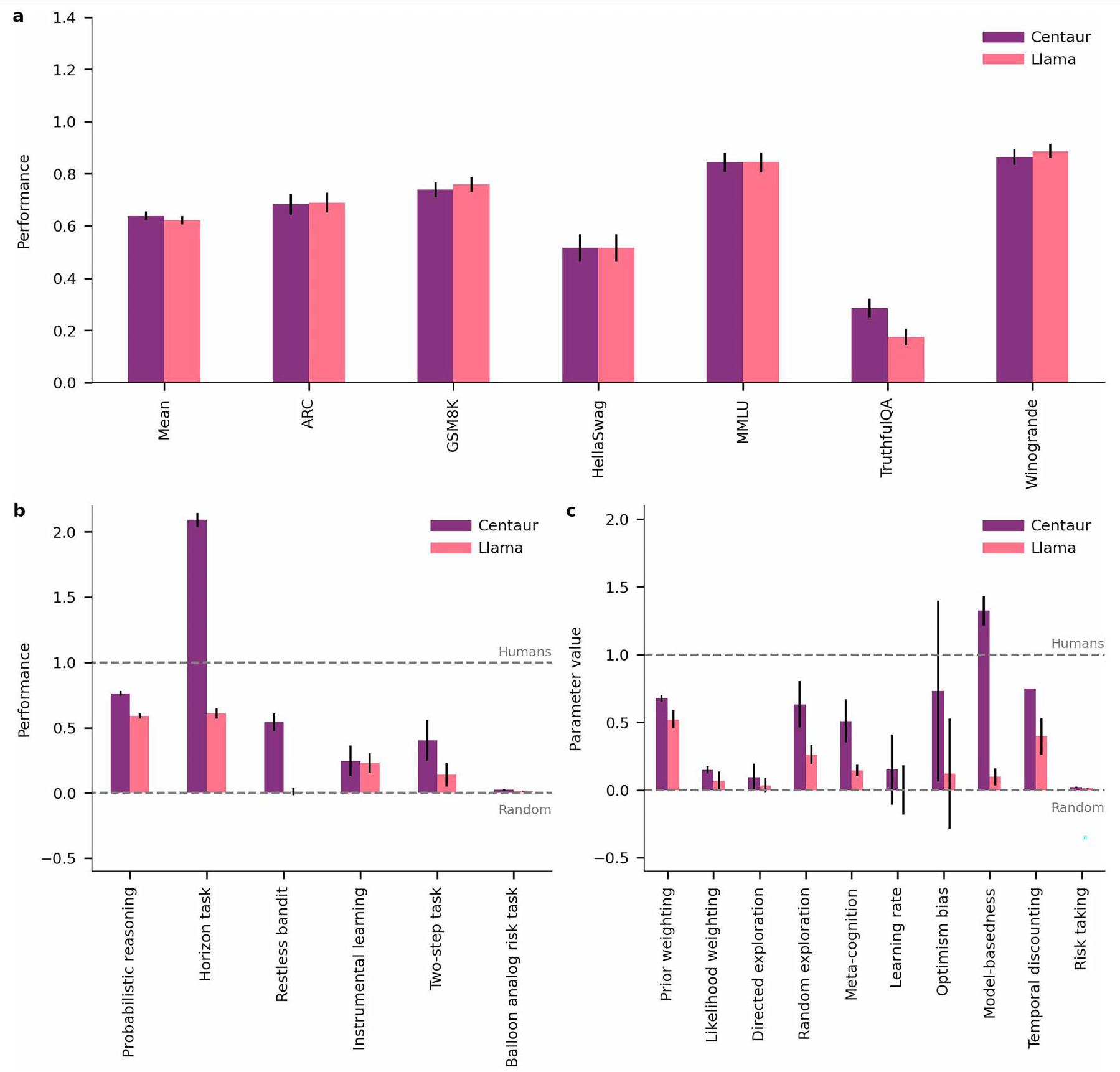
استكشاف قدرات التعميم
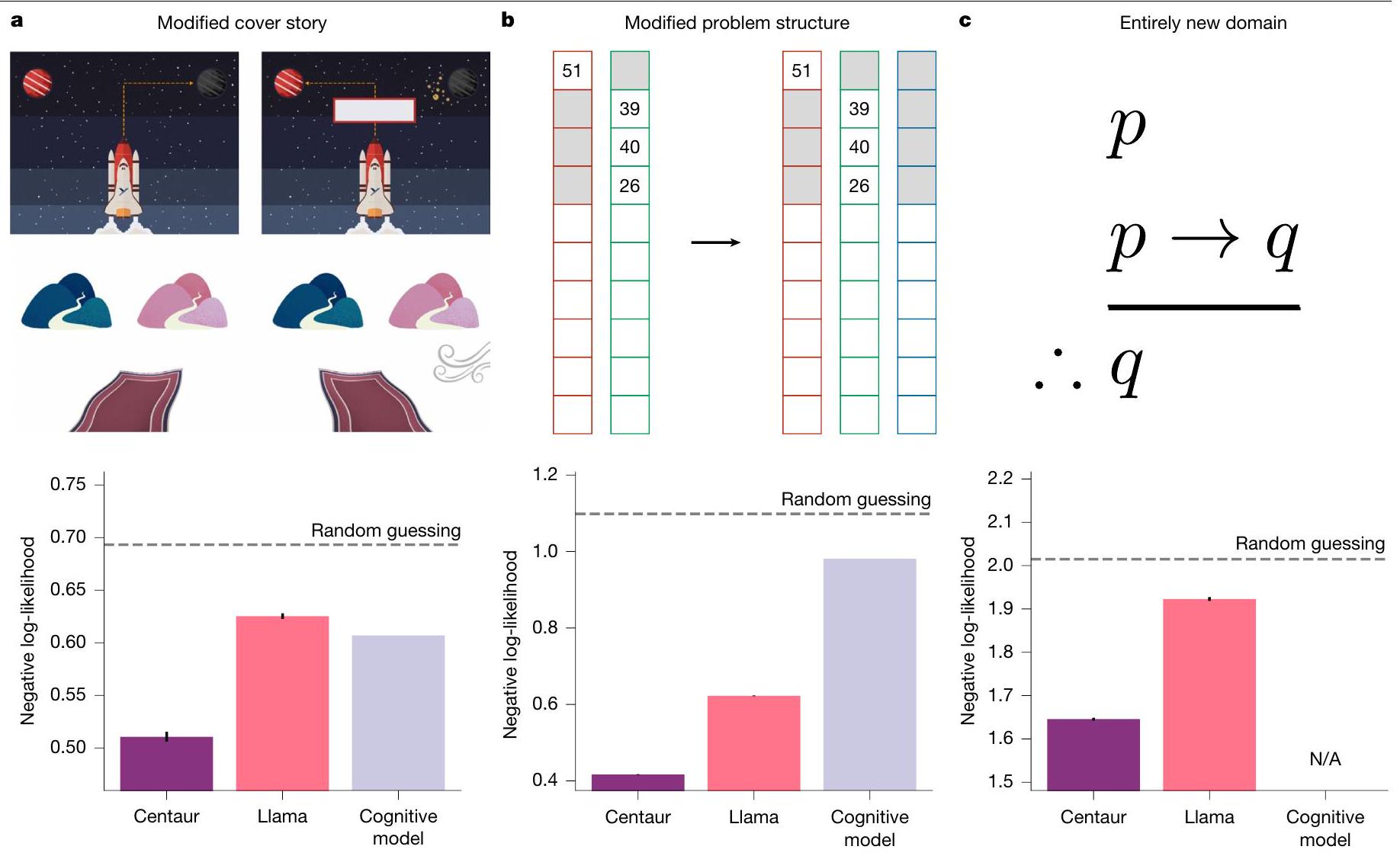
لم يكن جزءًا من بيانات التدريب. للتحقق مما إذا كان لدى سنتور هذه القدرة، عرضناه لسلسلة من التقييمات المعقدة بشكل متزايد خارج التوزيع.
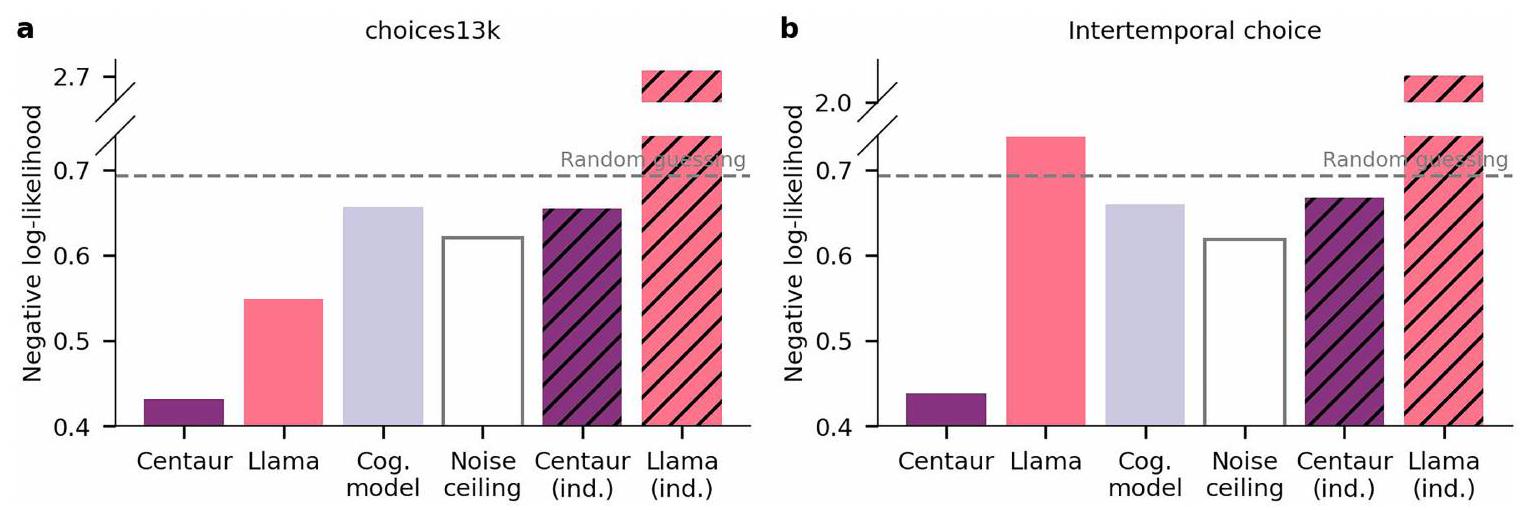
(ومع ذلك، يحتوي على تجارب متعددة الأذرع مع أكثر من ثلاثة خيارات للاختيار من بينها). وبالتالي، توفر هذه التحليل اختبارًا لصلابة Centaur تجاه التعديلات الهيكلية في المهام. وجدنا أن Centaur التقط سلوك الإنسان في مزرعة ماغي، كما هو موضح في الشكل 3ب. مرة أخرى، لاحظنا فائدة من الضبط الدقيق، بالإضافة إلى ملاءمة جيدة مقارنةً بنموذج إدراكي محدد المجال، الذي لم يتعمم بشكل جيد في هذا الإعداد (الاحتمالية السلبية لـ Centaur، 0.42؛ الاحتمالية السلبية لـ Llama، 0.62؛ الاحتمالية السلبية للنموذج الإدراكي، 0.98؛ جانب واحد
لإثبات أن النموذج لا يتدهور في المشكلات التي تم تدريبه مسبقًا عليها، قمنا أيضًا بالتحقق منه على مجموعة من المعايير من أدبيات تعلم الآلة.
محاذاة مع النشاط العصبي البشري
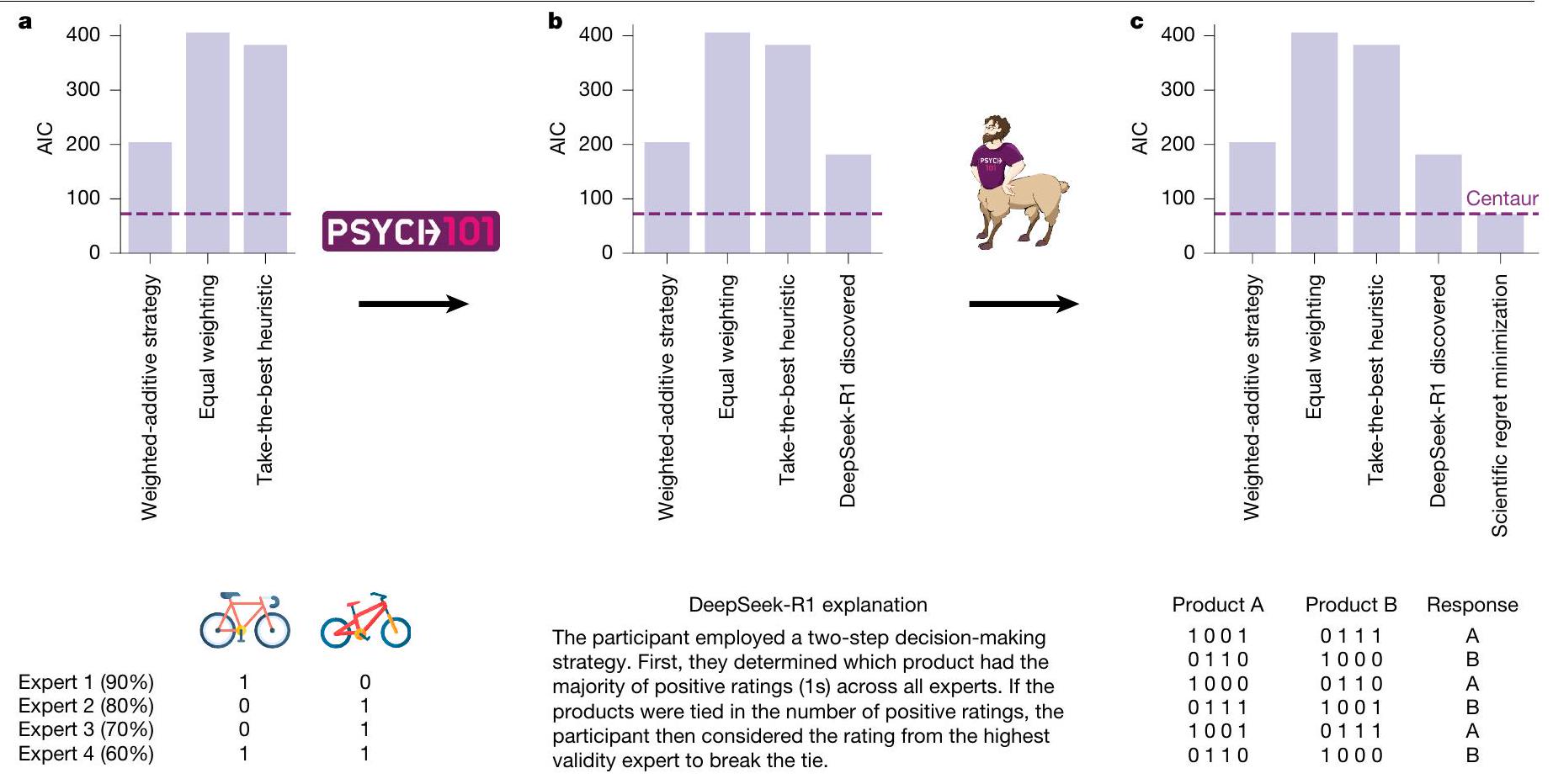
الاكتشاف العلمي الموجه بواسطة النموذج
لسلوك المشاركين في تجربة صنع القرار متعددة السمات
بمشكلات اختار فيها المشاركون الخيار الذي يحتوي على عدد أقل من التقييمات الإيجابية بشكل عام ولكن تم تقييمه بشكل إيجابي من قبل خبير ذو موثوقية أعلى (انظر الشكل 5c لتوضيح هذه المشكلات وطرق، ‘الاكتشاف العلمي الموجه بواسطة النموذج’ لمزيد من التفاصيل). تشير هذه النمطية إلى أن التحول بين الاستراتيجيتين ربما ليس صارمًا كما اقترح في البداية من قبل استراتيجية DeepSeek-R1 المكتشفة. لالتقاط ذلك، استبدلنا قاعدة إما-أو بمتوسط مرجح لكلا الاستراتيجيتين. وجدنا أن النموذج الذي نتج عن هذه العملية يتطابق مع Centaur من حيث جودته (AIC، 71.7) ولكنه لا يزال قابلًا للتفسير. أدخلنا قيم AIC الناتجة لجميع النماذج في إجراء اختيار نموذج على مستوى المجموعة
نقاش
أدبيات علم الأعصاب
حسب علمنا، فإن Psych-101 هو بالفعل أكبر وأوسع مجموعة بيانات متاحة عن سلوك الإنسان، ونعتبر تطويره عملية مستمرة ونخطط لتطويره أكثر. التركيز في حالته الحالية هو إلى حد كبير على التعلم واتخاذ القرار، لكننا نعتزم في النهاية تضمين مجالات أخرى، مثل علم النفس اللغوي وعلم النفس الاجتماعي والألعاب الاقتصادية. التجارب التي تتعلق بالمعلومات حول الفروق الفردية هي مصدر آخر للبيانات المهملة في النسخة الحالية من Psych-101. من الناحية المثالية، نريد تضمين جميع أنواع المعلومات ذات الصلة عن الموضوعات (بما في ذلك العمر، وسمات الشخصية أو الوضع الاجتماعي والاقتصادي) في الطلب، بحيث يمكن لنموذج تم تدريبه على هذه البيانات أن يلتقط الفروق الفردية. توفر التجارب من علم النفس التنموي أو الطب النفسي الحاسوبي مصدرًا مثاليًا لهذا الغرض. أخيرًا، على الرغم من أننا قد قمنا بالفعل بتضمين بعض الدراسات الثقافية المقارنة والدراسات الشاملة.
الخاتمة
المحتوى عبر الإنترنت
- أندرسون، ج. هندسة الإدراك (جامعة هارفارد للنشر، 1983).
- نيويل، أ. نظريات موحدة للإدراك (جامعة هارفارد للنشر، 1990).
- ليك، ب. م.، أولمان، ت. د.، تيننباوم، ج. ب. وجيرشمان، س. ج. بناء آلات تتعلم وتفكر مثل البشر. سلوك. علوم الدماغ 40، e253 (2017).
- ليك، ب. م.، سالاخوتدينوف، ر. وتيننباوم، ج. ب. تعلم المفاهيم على مستوى الإنسان من خلال استنتاج البرامج الاحتمالية. ساينس 350، 1332-1338 (2015).
- غودو، م. ك. وغوبنيك، أ. تطور التعلم السببي البشري والتفكير. مراجعة طبيعية. علم النفس.https://doi.org/10.1038/s44159-024-00300-5 (2024).
- تشو، ج. وشولز، ل. إ. اللعب، الفضول، والإدراك. مراجعة سنوية لعلم النفس التنموي 2، 317-343 (2020).
- سيلفر، د. وآخرون. إتقان لعبة جو دون معرفة بشرية. ناتشر 550، 354-359 (2017).
- كانيمان، د. وتفيرسكي، أ. في دليل أساسيات اتخاذ القرارات المالية (محرران: ماكلين، ل. س. وزيمبا، و. ت.) 99-127 (العالم العلمي، 2013).
- ريفيلاند، ر. وبوجيه، أ. التعليمات باللغة الطبيعية تحفز التعميم التراكبي في شبكات من الخلايا العصبية. نات. نيوروساينس. 27، 988-999 (2024).
- بومماساني، ر. وآخرون. حول الفرص والمخاطر لنماذج الأساس. مسودة مسبقة فيhttps://arxiv.org/abs/2108.07258 (2021).
- Grattafiori، أ. وآخرون. قطيع نماذج لاما 3. مسودة مسبقة فيhttps://arxiv.org/abs/2407.21783 (2024).
- بينز، م. وشولز، إ. استخدام علم النفس المعرفي لفهم GPT-3. وقائع الأكاديمية الوطنية للعلوم في الولايات المتحدة الأمريكية 120، e2218523120 (2023).
- بينز، م. وشولز، إ. تحويل نماذج اللغة الكبيرة إلى نماذج معرفية. في وقائع المؤتمر الدولي الثاني عشر حول تمثيلات التعلم (ICLR، 2024).
- هوفمان، ج. م. وآخرون. دمج الشرح والتنبؤ في العلوم الاجتماعية الحاسوبية. ناتشر 595، 181-188 (2021).
- روكا، ر. وياركوني، ت. اختبار علم النفس: إعادة التفكير في تقييم النماذج من خلال المعايير والتنبؤ. طرق متقدمة وممارسات في علوم النفس.https://doi.org/10.1177/25152459211026864 (2021).
- ديتميرز، ت.، باجنوني، أ.، هولtzمان، أ. وزيتلموير، ل. QLORA: تحسين فعال لنماذج اللغة الكمية. في إجراءات تقدم أنظمة معالجة المعلومات العصبية 36 (تحرير أوه، أ. وآخرون) (نيريبس، 2023).
- نوسوفكي، ر. م. في الأساليب الرسمية في التصنيف (تحرير باثوس، إ. م. وويلز، أ. ج.) 18-39 (مطبعة جامعة كامبريدج، 2011).
- بيترسون، ج. س.، بورجين، د. د.، أغراوال، م.، رايشمان، د. و غريفيثس، ت. ل. استخدام التجارب واسعة النطاق وتعلم الآلة لاكتشاف نظريات اتخاذ القرار البشري. ساينس 372، 1209-1214 (2021).
- داو، ن. د.، جيرشمان، س. ج.، سيمور، ب.، دايان، ب. ودولان، ر. ج. التأثيرات المستندة إلى النموذج على اختيارات البشر وأخطاء التوقع في العقدة. نيورون 69، 1204-1215 (2011).
- ويلسون، ر. س.، جيانا، أ.، وايت، ج. م.، لودفيغ، إ. أ. وكوهين، ج. د. يستخدم البشر الاستكشاف الموجه والعشوائي لحل معضلة الاستكشاف والاستغلال. مجلة علم النفس التجريبي: علم النفس العام 143، 2074-2081 (2014).
- بالمنتييري، س.، ويارت، ف. وكويتشلين، إ. أهمية التزوير في النمذجة المعرفية الحاسوبية. اتجاهات العلوم المعرفية 21، 425-433 (2017).
- فان بار، ج. م.، نصار، م. ر.، دينغ، و. وفيلدمان هول، أ. الدوافع الكامنة توجه تعلم الهيكل خلال الاختيار الاجتماعي التكيفي. نات. هوم. بيه. 6، 404-414 (2022).
- فيهر دا سيلفا، سي. وهير، تي. أ. يستخدم البشر بشكل أساسي الاستدلال القائم على النموذج في مهمة المرحلتين. نات. هوم. بيه. 4، 1053-1066 (2020).
- كول، و.، كوشمان، ف. أ. وجيرشمان، س. ج. متى يكون التحكم القائم على النموذج مجديًا؟ PLoS Comput. Biol. 12، e1005090 (2016).
- دو بوا، م. وهاوزر، ت. ي. الاستكشاف العشوائي الخالي من القيمة مرتبط بالاندفاع. نات. كوميونيك. 13، 4542 (2022).
- جانسن، ر. أ.، رافرتي، أ. ن. وغريفيثس، ت. ل. نموذج عقلاني لتأثير دانيغ-كروجر يدعم عدم الحساسية للأدلة لدى ذوي الأداء المنخفض. نات. هوم. بيه. 5، 756-763 (2021).
- عوض، إ. وآخرون. تجربة الآلة الأخلاقية. نيتشر 563، 59-64 (2018).
- أكاتا، إ. وآخرون. لعب الألعاب المتكررة مع نماذج اللغة الكبيرة. نات. سلوك الإنسان.https://doi.org/10.1038/s41562-025-02172-y (2025).
- دميرجان، سي. وآخرون. تقييم التوافق بين البشر وتمثيلات الشبكات العصبية في مهام التعلم المعتمدة على الصور. في وقائع تقدم أنظمة معالجة المعلومات العصبية 37 (تحرير غلوبيرسون، أ. وآخرون) (نيريبس، 2024).
- سينغ، م.، ريتشي، ر. وباتيا، س. تمثيل وتوقع السلوك اليومي. الحوسبة، الدماغ، السلوك. 5، 1-21 (2022).
- شو، هـ. أ.، موديرشانيشي، أ.، ليهمان، م. ب.، جيرستنر، و. & هيرزوغ، م. هـ. الجدة ليست مفاجأة: السلوك الاستكشافي والتكيفي البشري في اتخاذ القرارات المتسلسلة. PLoS Comput. Biol. 17، e1009070 (2021).
- هيك، و. إ. حول معدل اكتساب المعلومات. مجلة علم النفس التجريبي ربع السنوية 4، 11-26 (1952).
- كودا-فورنو، ج.، بينز، م.، وانغ، ج. إكس. وشولز، إ. كوغ بنش: نموذج لغوي كبير يدخل مختبر علم النفس. إجراءات. أبحاث تعلم الآلة. 235، 9076-9108 (2024).
- كيبنيس، أ.، فودوريس، ك.، شولتز بوشوف، ل. م. وشولتز، إ. ميتابنش – معيار نادر للتفكير والمعرفة في نماذج اللغة الكبيرة. في مؤتمر 13 الدولي لتمثيل التعلم (ICLR، 2025).
- يامينز، د. ل. ك. وآخرون. النماذج الهرمية المحسّنة للأداء تتنبأ بالاستجابات العصبية في القشرة البصرية العليا. وقائع الأكاديمية الوطنية للعلوم في الولايات المتحدة الأمريكية 111، 8619-8624 (2014).
- شريمبف، م. وآخرون. البنية العصبية للغة: النمذجة التكاملية تتقارب نحو المعالجة التنبؤية. وقائع الأكاديمية الوطنية للعلوم في الولايات المتحدة الأمريكية 118، e2105646118 (2021).
- فيهر دا سيلفا، سي.، لومباردي، ج.، إيدلسون، م. وهير، ت. إعادة التفكير في التأثيرات القائمة على النموذج وغير القائمة على النموذج على الجهد العقلي وأخطاء التوقع في النواة المتكئة. نات. هوم. بيه. 7، 956-969 (2023).
- توكوت، ج. وآخرون. قيادة وكبح شبكة اللغة البشرية باستخدام نماذج اللغة الكبيرة. نات. إنساني. سلوك. 8، 544-561 (2024).
- كوخران، و. ج. دمج التقديرات من تجارب مختلفة. البيومترية 10، 101-129 (1954).
- DeepSeek-AI وآخرون. DeepSeek-R1: تحفيز القدرة على التفكير في نماذج اللغة الكبيرة من خلال التعلم المعزز. مسودة مسبقة فيhttps://arxiv.org/abs/2501.12948 (2025).
- هيلبيغ، ب. إ. وموشاغن، م. تصنيف الاستراتيجيات المعتمدة على النتائج العامة: مقارنة النماذج الحتمية والنماذج الاحتمالية للاختيار. مراجعة علم النفس. 21، 1431-1443 (2014).
- أغراوال، م.، بيترسون، ج. س. و غريفيثس، ت. ل. توسيع علم النفس من خلال تقليل الندم العلمي. وقائع الأكاديمية الوطنية للعلوم في الولايات المتحدة الأمريكية 117، 8825-8835 (2020).
- ريغو، ل.، ستيفان، ك. إ.، فريستون، ك. ج. وداونيزو، ج. اختيار النموذج البايزي للدراسات الجماعية – إعادة النظر. صورة عصبيةhttps://doi.org/10.1016/j.neuroimage.2013.08.065 (2014).
- بينز، م.، جيرشمان، س. ج.، شولتز، إ. & إندريس، د. استدلالات من استنتاجات ميتا-متقيدة. مراجعة علم النفس 129، 1042-1077 (2022).
- موسليك، س. وآخرون. أتمتة ممارسة العلوم: الفرص والتحديات والآثار. وقائع الأكاديمية الوطنية للعلوم في الولايات المتحدة الأمريكية 122، e2401238121 (2025).
- رمس، م.، جاجاديش، أ. ك.، ماثوني، م.، لودفيغ، ت. وشولز، إ. توليد نماذج معرفية حسابية باستخدام نماذج اللغة الكبيرة. مسودة مسبقة فيhttps://arxiv.org/abs/2502.00879 (2025).
- ديليون، د.، تاندون، ن.، غو، ي. وغراي، ك. هل يمكن لنماذج اللغة المدعومة بالذكاء الاصطناعي استبدال المشاركين البشريين؟ اتجاهات العلوم المعرفية 27، 597-600 (2023).
- هوبي، ر.، كانينغهام، هـ.، سميث، ل. ر.، إيوارت، أ. وشيركي، ل. تكتشف المشفرات التلقائية النادرة ميزات قابلة للتفسير بشكل كبير في نماذج اللغة. في مؤتمر تمثيلات التعلم الدولي الثاني عشر (ICLR، 2024).
- تشيفر، هـ.، غور، س. و وولف، ل. قابلية تفسير المحولات تتجاوز تصور الانتباه. في مؤتمر IEEE/CVF لعام 2021 حول رؤية الكمبيوتر والتعرف على الأنماط (CVPR) 782-791 (IEEE، 2021).
- فاسواني، أ. وآخرون. الانتباه هو كل ما تحتاجه. في وقائع تقدم أنظمة معالجة المعلومات العصبية 30 (تحرير غويون، إ. وآخرون) (نيريبس، 2017).
- زادور، أ. وآخرون. تحفيز الذكاء الاصطناعي من الجيل التالي من خلال NeuroAI. نات. كوميونيك. 14، 1597 (2023).
- روجرى، ك. وآخرون. قابلية العولمة لتخفيض القيمة الزمنية. نات. سلوك إنساني. 6، 1386-1397 (2022).
- Wulff، د. أ.، Mergenthaler-Canseco، م. و Hertwig، ر. مراجعة تحليلية شاملة لطريقتين من التعلم والفجوة بين الوصف والتجربة. مجلة علم النفس. 144، 140-176 (2018).
- فراي، ر.، بيدروني، أ.، ماتا، ر.، ريسكامب، ج. وهيرتويغ، ر. تفضيل المخاطر يشترك في الهيكل السيكومتري للسمات النفسية الرئيسية. ساي. أدف. 3، e1701381 (2017).
- إنكافي، أ. ز. وآخرون. تحليل واسع النطاق لموثوقية الاختبارات المتكررة لقياسات التنظيم الذاتي. وقائع الأكاديمية الوطنية للعلوم في الولايات المتحدة الأمريكية 116، 5472-5477 (2019).
- هنريش، ج.، هاين، س. ج. ونورينزايان، أ. معظم الناس ليسوا غريبين. الطبيعة 466، 29 (2010).
- شريمبف، م. وآخرون. تقييم تكاملي لتقدم النماذج الآلية العصبية للذكاء البشري. نيورون 108، 413-423 (2020).
- بولدراك، ر. أ. وآخرون. الماضي والحاضر والمستقبل لبنية بيانات تصوير الدماغ (BIDS). تصوير الأعصاب. 2، 1-19 (2024).
- شولتز بوشوف، ل. م.، أكاتا، إ.، بيثغ، م. وشولتز، إ. الإدراك البصري في نماذج اللغة الكبيرة متعددة الوسائط. نات. ماك. إنتل.https://doi.org/10.1038/s42256-024-00963-y (2025).
- فير، س. أ. قشرة عملية معرفية. سلوك. علوم الدماغ 15، 460-461 (1992).
(ج) المؤلف(ون) 2025
طرق
جمع البيانات
إجراء الضبط الدقيق
مقياس التقييم
نماذج معرفية محددة المجال
محاذاة عصبية
تم إجراء تحليل المحاذاة العصبية على مهمة قراءة الجمل باستخدام كود متاح للجمهور من الدراسة الأصلية
الاكتشاف العلمي الموجه بالنموذج
مشارك باستخدام تقدير الاحتمالية القصوى. تمت مقارنة النماذج مع بعضها باستخدام AIC. تم تنفيذ النماذج الثلاثة من الدراسة الأصلية بواسطة المعادلات التالية:
بالنسبة لخط أنابيب تقليل الندم العلمي، قمنا بحساب الفرق في الاحتمالات بين Centaur ونموذج DeepSeek-R1 المكتشف. قمنا بتصور وفحص النقاط العشر التي تحتوي على أكبر فرق. أدت هذه العملية إلى النموذج الحسابي التالي:
ملخص التقرير
توفر البيانات
توفر الكود
لإعادة إنتاج نتائجنا متاح على https://github.com/marcelbinz/ Llama-3.1-Centaur-70B.
61. لوششيلوف، I. & هوتير، F. تنظيم انحدار الوزن المفصول. في مؤتمر ICLR الدولي السابع حول تمثيلات التعلم (ICLR، 2019).
62. شيفر، A. وآخرون. تقسيم محلي-عالمي لقشرة الدماغ البشرية من خلال التصوير بالرنين المغناطيسي الوظيفي. Cereb. Cortex 28، 3095-3114 (2018).
63. استيبان، O. وآخرون. fMRIPrep: خط أنابيب معالجة قوي للتصوير بالرنين المغناطيسي الوظيفي. Nat. Methods 16، 111-116 (2019).
64. فونوف، V. S.، إيفانز، A. C.، مكينستري، R. C.، ألملي، C. R. & كولينز، D. L. قوالب دماغية غير متحيزة وغير خطية مناسبة للعمر من الولادة إلى البلوغ. Neuroimage 47، S102 (2009).
65. فريستون، K. J.، آشبورنر، J. T.، كيبيل، S. J.، نيكولز، T. E. & بيني، W. D. (محررون) تخطيط المعلمات الإحصائية: تحليل صور الدماغ الوظيفية (إلسيفير، 2011).
66. غاو، R. nilearn. GitHub https://github.com/nilearn/nilearn (2024).
67. يكس، N.، أودير، P.-Y. & بالمنتييري، S. تقييم التلوث في نماذج اللغة الكبيرة: تقديم طريقة LogProber. Preprint at https://arxiv.org/abs/2408.14352 (2024).
68. وارنر، B. وآخرون. أذكى، أفضل، أسرع، أطول: مشفر ثنائي الاتجاه حديث للتدريب الدقيق والاستدلال السريع والفعال من حيث الذاكرة والسياق الطويل. Preprint at https://arxiv.org/ abs/2412.13663 (2024).
69. وانغ، ز. وآخرون. HelpSteer2-Preference: تكملة التقييمات بالتفضيلات. في مؤتمر 13 الدولي لتمثيلات التعلم (ICLR، 2025).
70. تيكنيوم، ر.، كيوزينيل، ج. وغوانغ، ج. تقرير فني هيرميس 3. مسودة مسبقة فيhttps://arxiv. org/abs/2408.11857 (2024).
71. لين، س.، هيلتون، ج. وإيفانز، أ. TruthfulQA: قياس كيفية تقليد النماذج للأكاذيب البشرية. في وقائع الاجتماع السنوي الستين لجمعية اللغويات الحاسوبية (تحرير موريشان، س. وآخرون) 3214-3252 (جمعية اللغويات الحاسوبية، 2022).
معلومات إضافية
يجب توجيه المراسلات والطلبات للحصول على المواد إلى مارسيل بينز. تشكر مجلة نيتشر راسل بولدراك، وجيوسوي باجيو، والمراجعين الآخرين المجهولين على مساهمتهم في مراجعة الأقران لهذا العمل.
معلومات إعادة الطبع والتصاريح متاحة علىhttp://www.nature.com/reprints.
الشكل 2 من البيانات الموسعة | اللوغاريتم السالب للاحتمالات لسينتاور والبدائل
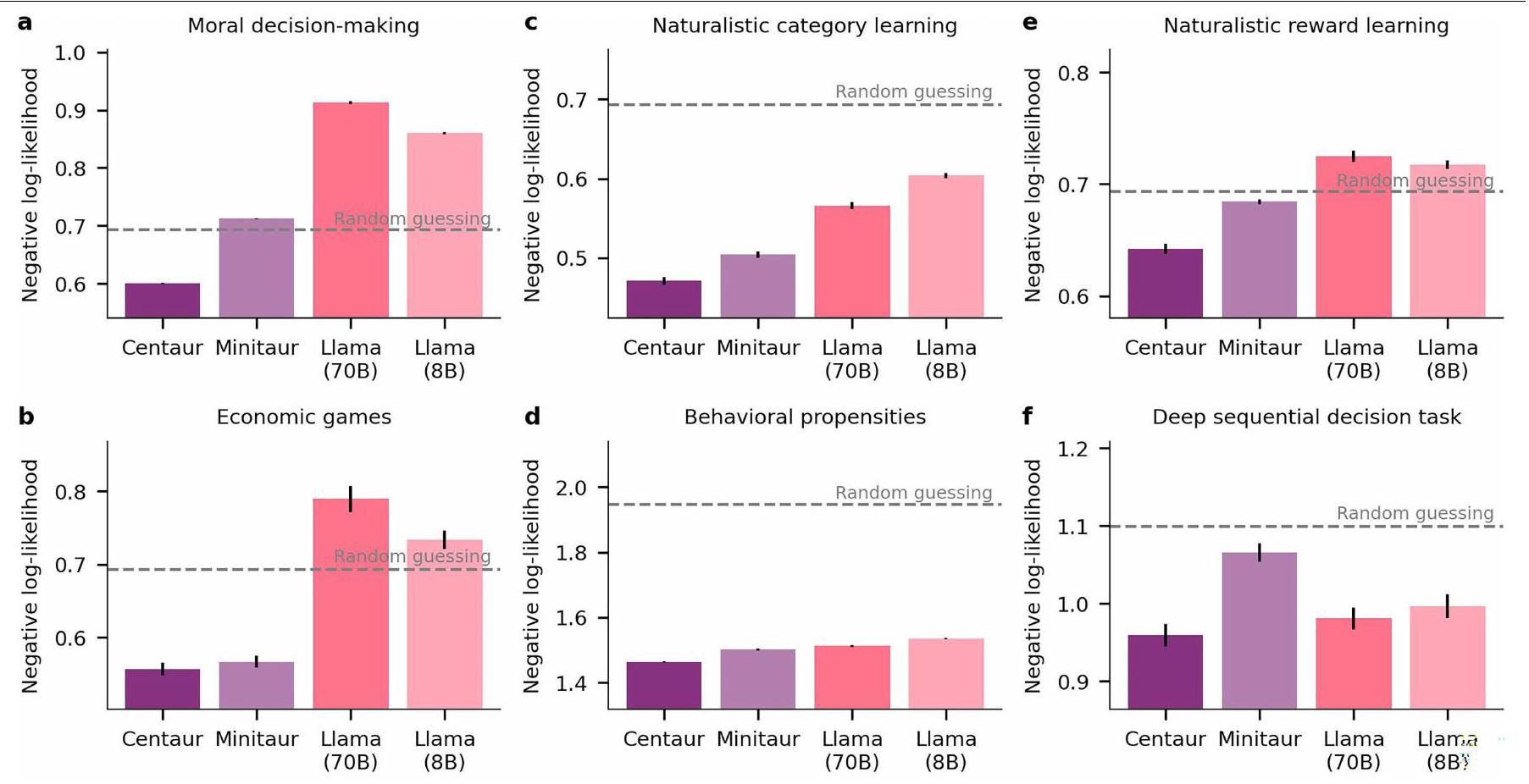
أ، لوغاريتمات الاحتمالية السلبية في اتخاذ القرارات الأخلاقية
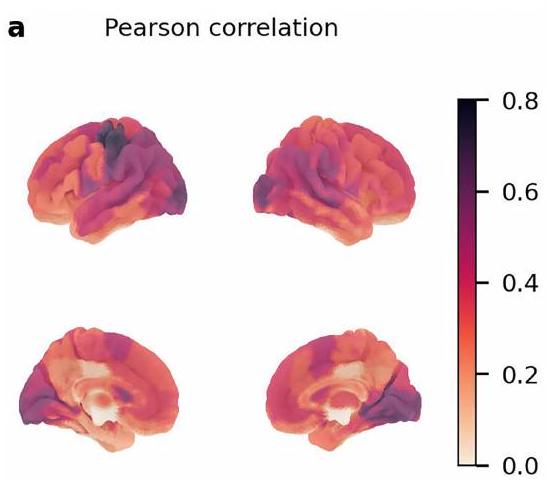
الطرود الثنائية المقابلة في أطلس شيفر. يتم تعريف المنطقة القشرية الجانبية (الأكومبنس) بناءً على أطلس هارفارد-أكسفورد. يتم عرض معاملات الارتباط لبيرسون للطبقة 20 ولكنها تظهر نمطًا مشابهًا عبر جميع الطبقات. تفوقت سنتور على لاما والنموذج المعرفي في التنبؤ بالنشاط في الأكومبنس، وهي منطقة الاهتمام من الدراسة الأصلية التي أظهرت تأثير خطأ توقع المكافأة.
| تجربة | سنتور | لاما | نموذج معرفي |
| تصنيف شيفارد | 0.5394 | 0.5818 | 0.6108 |
| لص ذو أربعة أذرع يتجول | 0.7029 | 0.8810 | 0.9043 |
| ن-باك | 0.3954 | 0.5209 | 0.5787 |
| مدى الأرقام | 0.5520 | 0.6618 | 0.9359 |
| اذهب/لا تذهب | 0.0000 | 0.0062 | 0.0757 |
| تحقيقات حديثة | 0.2572 | 0.3433 | 0.3868 |
| مهمة الأفق | 0.4032 | 0.5237 | 0.3595 |
| مهمة البستنة | 0.3783 | 0.5040 | 0.9105 |
| مهمة بطاقة كولومبيا | 0.1867 | 0.2261 | 0.2629 |
| مهمة مخاطر البالون التناظرية | 0.0593 | 0.0753 | 0.0922 |
| لص ذو ذراعين | 0.2963 | 0.3829 | 0.4187 |
| التعلم الشرطي الترابطي | 0.5380 | 0.6373 | 0.8575 |
| أشياء مختلفة | 0.8068 | 1.1386 | 0.8253 |
| اتخاذ القرار متعدد الخصائص | 0.0619 | 0.1502 | 0.1922 |
| مهمة من خطوتين | 0.4998 | 0.6075 | 0.6043 |
| التعلم الآلي الاحتمالي | 0.4937 | 0.5382 | 0.5047 |
| تصنيف المدينة | 0.4967 | 0.5772 | 0.5313 |
| زوبرماركت | 0.4850 | 0.6026 | 0.6047 |
| خيارات13k | 0.4274 | 0.5342 | 0.6563 |
| CPC18 | 0.٣٣٩٠ | 0.4118 | 0.6607 |
| اختيار بين الأوقات | 0.4340 | 0.7336 | 0.6591 |
| لص منظم | 0.6410 | 0.8114 | 1.0530 |
| مهمة توقع الطقس | 0.5514 | 0.5749 | 0.6267 |
| مهمة القمار لوا | 0.8890 | 0.9880 | 1.1555 |
| شبكة المترو الافتراضية | 1.1271 | ١.٥٣٤٧ | نان |
| تعلم التعزيز متعدد المهام | 0.5672 | 0.6604 | 1.0424 |
| مهمة زمن رد الفعل التسلسلي | 0.1718 | 0.1900 | 0.1962 |
| قرارات من الوصف | 0.5336 | 0.7569 | 0.6120 |
| قرارات من الخبرة | 0.3686 | 0.4339 | 0.5404 |
| لص متغير | 0.3025 | 0.3824 | 0.4378 |
| حكم متعدد الإشارات | 1.1236 | 1.2818 | 1.9157 |
| استرجاع والتعرف | 1.0591 | 1.3759 | نان |
| مهمة تجريبية رمزية | 0.4536 | 0.6983 | نان |
| حكم القواعد | 1.4355 | 1.9949 | 1.4127 |
| خيار محفوف بالمخاطر | 0.4281 | 0.6475 | نان |
| مهمة كشف البلاط | 1.8713 | 2.7380 | نان |
| الذاكرة طويلة الأمد العرضية | 0.8684 | 1.1344 | نان |
| التعلم المنفر | ٤.٠٧٣٣ | 5.1066 | نان |
| لعبة اللصوص متعددة الأذرع المرتبطة مكانيًا | 1.8319 | ٢.٤٤٧٩ | ٢.٧٦٣٥ |
| الاستدلال الاحتمالي | 2.3731 | ٢.٦٤٠٦ | نان |
محفظة الطبيعة
مارسيل بينز
آخر تحديث من المؤلف(ين): 27 أبريل 2025
ملخص التقرير
الإحصائيات
غير متوفر
تم التأكيد
□
□ حجم العينة بالضبط

□ بيان حول ما إذا كانت القياسات قد أُخذت من عينات متميزة أو ما إذا كانت نفس العينة قد تم قياسها عدة مرات
يجب أن تُوصف الاختبارات الشائعة فقط بالاسم؛ واصفًا التقنيات الأكثر تعقيدًا في قسم الطرق.
□ وصف لجميع المتغيرات المرافقة التي تم اختبارها
□ وصف لأي افتراضات أو تصحيحات، مثل اختبارات الطبيعية والتعديل للمقارنات المتعددة
□ X
لاختبار الفرضية الصفرية، يتم استخدام إحصائية الاختبار (مثل F، t، r) مع فترات الثقة، وأحجام التأثير، ودرجات الحرية و
□ لتحليل بايزي، معلومات حول اختيار القيم الأولية وإعدادات سلسلة ماركوف مونت كارلو
□ لتصميمات هرمية ومعقدة، تحديد المستوى المناسب للاختبارات والتقارير الكاملة عن النتائج
□ تقديرات أحجام التأثير (مثل حجم تأثير كوهين)
تحتوي مجموعتنا على الإنترنت حول الإحصائيات لعلماء الأحياء على مقالات تتناول العديد من النقاط المذكورة أعلاه.
البرمجيات والشيفرة
جمع البيانات
لم يتم جمع بيانات جديدة في هذه الدراسة.
رمز مخصص علىhttps://github.com/marcelbinz/Llama-3.1-Centaur-70B
بالنسبة للمخطوطات التي تستخدم خوارزميات أو برامج مخصصة تكون مركزية في البحث ولكن لم يتم وصفها بعد في الأدبيات المنشورة، يجب أن تكون البرمجيات متاحة للمحررين والمراجعين. نحن نشجع بشدة على إيداع الشيفرة في مستودع مجتمعي (مثل GitHub). راجع إرشادات مجموعة Nature لتقديم الشيفرة والبرمجيات لمزيد من المعلومات.
بيانات
معلومات السياسة حول توفر البيانات
- رموز الانضمام، معرفات فريدة، أو روابط ويب لمجموعات البيانات المتاحة للجمهور
- وصف لأي قيود على توفر البيانات
- بالنسبة لمجموعات البيانات السريرية أو بيانات الطرف الثالث، يرجى التأكد من أن البيان يتماشى مع سياستنا
أبريل 2023
البحث الذي يتضمن مشاركين بشريين، بياناتهم، أو مواد بيولوجية
| التقارير عن الجنس والنوع الاجتماعي | غير متوفر |
| التقارير عن العرق أو الإثنية أو غيرها من المجموعات الاجتماعية ذات الصلة | غير متوفر |
| خصائص السكان | غير متوفر |
| التوظيف | غير متوفر |
| رقابة الأخلاقيات | غير متوفر |
التقارير الخاصة بالمجال
□ علوم الحياة
العلوم السلوكية والاجتماعية □ العلوم البيئية والتطورية والبيئية
لنسخة مرجعية من الوثيقة مع جميع الأقسام، انظرnature.com/documents/nr-reporting-summary-flat.pdf
تصميم دراسة العلوم السلوكية والاجتماعية
| وصف الدراسة | تحليل ميتا |
| عينة البحث | تحليل ميتا |
| استراتيجية أخذ العينات | تحليل ميتا |
| جمع البيانات | المعلومات المتاحة كجزء من الدراسات الأصلية |
| توقيت | المعلومات المتاحة كجزء من الدراسات الأصلية |
| استثناءات البيانات | المعلومات المتاحة كجزء من الدراسات الأصلية |
| عدم المشاركة | المعلومات المتاحة كجزء من الدراسات الأصلية |
| التوزيع العشوائي | المعلومات المتاحة كجزء من الدراسات الأصلية |
التقارير عن مواد وأنظمة وطرق محددة
| المواد والأنظمة التجريبية | طرق | ||
| غير متوفر | مشارك في الدراسة | غير متوفر | مشارك في الدراسة |
| إكس | □ |  |
□ |
| إكس | □ | |
□ |
| إكس | □ | □ | تصوير الأعصاب القائم على الرنين المغناطيسي |
| إكس | □ | ||
| إكس | □ | ||
| إكس | □ | ||
| إكس | □ | ||
| مخزونات البذور | غير متوفر | ||||
| أنماط جينية نباتية جديدة | غير متوفر | ||||
| المصادقة | غير متوفر | ||||
| التصوير بالرنين المغناطيسي | |||||
| تصميم تجريبي | |||||
| نوع التصميم | مهمة من خطوتين ومهمة قراءة جمل | ||||
| مواصفات التصميم |
|
||||
| مقاييس الأداء السلوكي |
|
||||
|
|||||
| شدة المجال | 3T | ||||
| معلمات التسلسل والتصوير |
|
||||
| مجال الاستحواذ | الدماغ الكامل | ||||
| الرنين المغناطيسي الانتشاري | □ | غير مستخدم | |||
| التحضير المسبق | |||||
| برمجيات المعالجة المسبقة | fMRIprep 24.0.0، SPM12 ونصوص MATLAB مخصصة | ||||
| التطبيع | مطابق للدراسة الأصلية | ||||
| قالب التطبيع | مطابق للدراسة الأصلية | ||||
| إزالة الضوضاء والعيوب | مطابق للدراسة الأصلية | ||||
| تصفية الحجم |
|
||||
| النمذجة الإحصائية والاستدلال | |||||
| نوع النموذج والإعدادات | النمذجة التنبؤية | ||||
| التأثيرات المختبرة | ما إذا كان يمكن التنبؤ بسلوك الإنسان من خلال نشاط نموذج اللغة | ||||
| حدد نوع التحليل: | □ الدماغ بالكامل □ | ||||
| الموقع(ات) التشريحية | |||||
| نوع الإحصاء للاستدلال | غير متوفر | ||||
النماذج والتحليل

المتغيرات المستقلة: نشاط نموذج اللغة استخراج الميزات: تم استخراج التمثيلات الداخلية من تدفق بقايا النماذج وتحويلها باستخدام تحليل المكونات الرئيسية. لقد حددنا عدد المكونات المحتفظ بها بحيث تفسر
معهد الذكاء الاصطناعي الموجه نحو الإنسان، مركز هيلمهولتز، ميونيخ، ألمانيا. جامعة توبنغن، توبنغن، ألمانيا. جامعة أكسفورد، أكسفورد، المملكة المتحدة. معهد ماكس بلانك للسيبرنتيك البيولوجية، توبنغن، ألمانيا. جامعة نيويورك، نيويورك، نيويورك، الولايات المتحدة الأمريكية. جوجل ديب مايند، لندن، المملكة المتحدة. جامعة برينستون، برينستون، نيو جيرسي، الولايات المتحدة الأمريكية. مدرسة ماكس بلانك للإدراك، لايبزيغ، ألمانيا. جامعة كاليفورنيا، سان دييغو، سان دييغو، كاليفورنيا، الولايات المتحدة الأمريكية. جامعة بوسطن، بوسطن، ماساتشوستس، الولايات المتحدة الأمريكية. جامعة تي يو دارمشتات، دارمشتات، ألمانيا. معهد البيولوجيا الحاسوبية، مركز هيلمهولتز، ميونيخ، ألمانيا. مدرسة تي يو إم للحوسبة والمعلومات والتكنولوجيا، الجامعة التقنية في ميونيخ، ميونيخ، ألمانيا. مدرسة تي يو إم لعلوم الحياة، الجامعة التقنية في ميونيخ، ميونيخ، ألمانيا. جامعة كامبريدج، كامبريدج، المملكة المتحدة. معهد جورجيا للتكنولوجيا، أتلانتا، جورجيا، الولايات المتحدة الأمريكية. جامعة بازل، بازل، سويسرا. معهد ماكس بلانك للتنمية البشرية، برلين، ألمانيا. البريد الإلكتروني: marcel.binz@helmholtz-munich.de - الاحتمالات السلبية الكاملة على المشاركين المحجوزين.
- Psych-101 متاحة للجمهور على منصة Huggingface: https://huggingface. co/datasets/marcelbinz/Psych-101. مجموعة الاختبار متاحة بموجب ترخيص CC-BY-ND-4.0 عبر مستودع محمي: https://huggingface.co/datasets/marcelbinz/ Psych-101-test.
DOI: https://doi.org/10.1038/s41586-025-09215-4
PMID: https://pubmed.ncbi.nlm.nih.gov/40604288
Publication Date: 2025-07-02
A foundation model to predict and capture human cognition
Received: 26 October 2024
Accepted: 29 May 2025
Published online: 2 July 2025
Open access
Check for updates
Abstract
Establishing a unified theory of cognition has been an important goal in psychology
An important step towards a unified theory of cognition is to build a computational model that can predict and simulate human behaviour in any domain
supervised learning, Markov decision processes and others (the examples shown have been stylized and abbreviated for readability).b, Centaur is a foundation of model human cognition that is obtained by adding low-rank adapters to a state-of-the-art language model and fine-tuning it on Psych-101.
common format for expressing vastly different experimental paradigms
Model overview
the backbone allowed us to rely on the vast amounts of knowledge that is present in these models. The training process involved fine-tuning on Psych-101 using a parameter-efficient fine-tuning technique known as quantized low-rank adaptation (QLoRA)
Centaur captures human behaviour
choices using negative log-likelihoods averaged across responses (Methods, ‘Evaluation metric’). Figure 2a presents the results of this analysis, comparing Centaur with the base model without fine-tuning and a collection of domain-specific models that represent the state-of-the-art in the cognitive-science literature (Extended Data Table 1). Although there was substantial variance in predictability across experiments (Centaur, 0.49; Llama, 0.47), fine-tuning always improved goodness-of-fit. The average difference in log-likelihoods across experiments after fine-tuning was 0.14 (Centaur negative log-likelihood, 0.44; Llama negative log-likelihood, 0.58; one-sided
to the domain-specific cognitive models was 0.13 (cognitive models, negative log-likelihood, 0.56 ; one-sided
The previous analyses have focused on predicting human responses conditioned on previously executed behaviour. We may ask whether Centaur can also generate human-like behaviour when simulated in an open-loop fashion (that is, when feeding its own responses back into the model). This setting arguably provides a much stronger test of the model’s capabilities and is sometimes also referred to as model falsification
was supported by an equivalence test using the two one-sided
Probing generalization abilities
was not part of the training data. To probe whether Centaur has this ability, we exposed it to a series of increasingly complex out-of-distribution evaluations.
(it does, however, contain multi-armed bandit experiments with more than three options to choose between). Thus, this analysis provides a test of Centaur’s robustness to structural task modifications. We found that Centaur captured human behaviour on Maggie’s farm, as shown in Fig. 3b. We again observed a benefit of fine-tuning, as well as a favourable goodness-of-fit compared with a domain-specific cognitive model, which did not generalize well to this setting (Centaur negative log-likelihood, 0.42; Llama negative log-likelihood, 0.62; cognitive model negative log-likelihood, 0.98; one-sided
To demonstrate that the model does not degrade on problems it was pretrained for, we furthermore verified it on a collection of benchmarks from the machine-learning literature
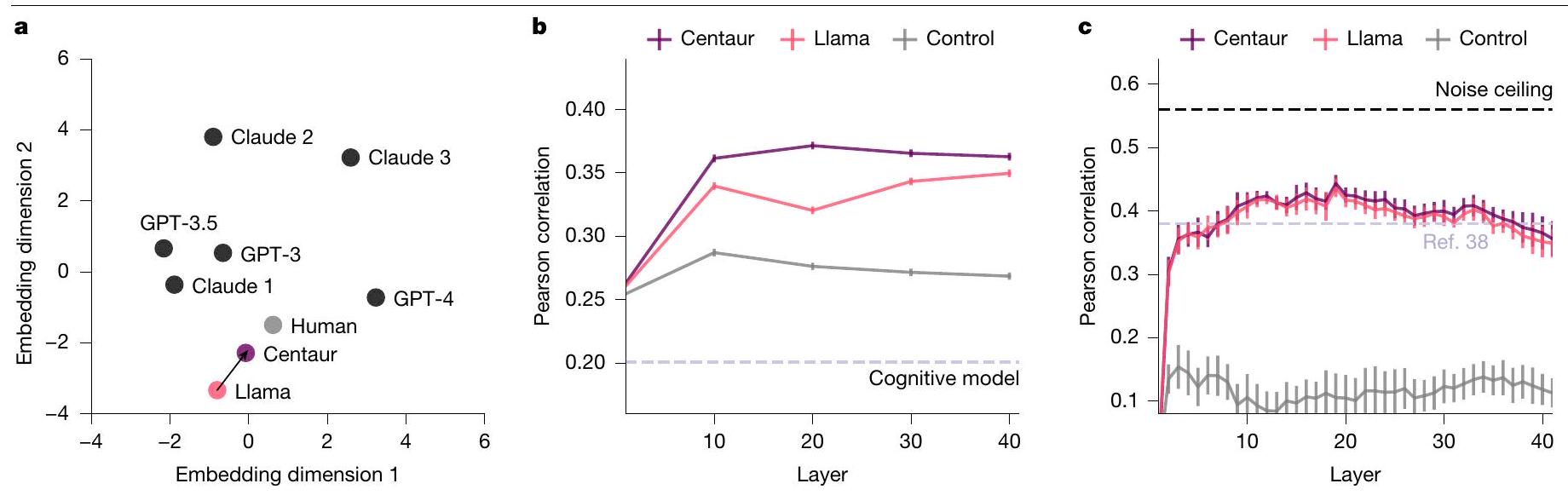
Alignment to human neural activity
Model-guided scientific discovery
of participants’ behaviour in a multi-attribute decision-making experiment
problems in which participants chose the option with fewer positive ratings overall but which was rated positively by a higher-validity expert (see Fig. 5c for an illustration of these problems and Methods, ‘Model-guided scientific discovery’ for further details). This pattern indicates that the switch between the two heuristics is probably not as strict as initially suggested by the DeepSeek-R1-discovered strategy. To capture this, we replaced the either-or rule with a weighted average of both heuristics. We found that the model that resulted from this process matched Centaur in terms of its goodness-of-fit (AIC, 71.7) but was still interpretable. We entered the resulting AIC values of all the models in a group-level model-selection procedure
Discussion
the neuroscience literature
As far as we know, Psych-101 is already the broadest and largest dataset of human behaviour available, and we view its development as an ongoing process and plan to develop it further. The focus in its current state is largely on learning and decision-making, but we intend to eventually include more domains, such as psycholinguistics, social psychology and economic games. Experiments with information about individual differences are another source of neglected data in the current iteration of Psych-101. Ideally, we want to include all types of relevant information about subjects (including age, personality traits or socioeconomic status) in the prompt, such that a model trained on these data can capture individual differences. Experiments from developmental psychology or computational psychiatry provide an ideal source for this purpose. Finally, although we have already included some cross-cultural and meta-studies
Conclusion
Online content
- Anderson, J. The Architecture of Cognition (Harvard Univ. Press, 1983).
- Newell, A. Unified Theories of Cognition (Harvard Univ. Press, 1990).
- Lake, B. M., Ullman, T. D., Tenenbaum, J. B. & Gershman, S. J. Building machines that learn and think like people. Behav. Brain Sci. 40, e253 (2017).
- Lake, B. M., Salakhutdinov, R. & Tenenbaum, J. B. Human-level concept learning through probabilistic program induction. Science 350, 1332-1338 (2015).
- Goddu, M. K. & Gopnik, A. The development of human causal learning and reasoning. Nat. Rev. Psychol. https://doi.org/10.1038/s44159-024-00300-5 (2024).
- Chu, J. & Schulz, L. E. Play, curiosity, and cognition. Annu. Rev. Dev. Psychol. 2, 317-343 (2020).
- Silver, D. et al. Mastering the game of Go without human knowledge. Nature 550, 354-359 (2017).
- Kahneman, D. & Tversky, A. in Handbook of the Fundamentals of Financial Decision Making (eds MacLean, L. C. & Ziemba, W. T.) 99-127 (World Scientific, 2013).
- Riveland, R. & Pouget, A. Natural language instructions induce compositional generalization in networks of neurons. Nat. Neurosci. 27, 988-999 (2024).
- Bommasani, R. et al. On the opportunities and risks of foundation models. Preprint at https://arxiv.org/abs/2108.07258 (2021).
- Grattafiori, A. et al. The Llama 3 herd of models. Preprint at https://arxiv.org/abs/2407.21783 (2024).
- Binz, M. & Schulz, E. Using cognitive psychology to understand GPT-3. Proc. Natl Acad. Sci. USA 120, e2218523120 (2023).
- Binz, M. & Schulz, E. Turning large language models into cognitive models. In Proc. 12th International Conference on Learning Representations (ICLR, 2024).
- Hofman, J. M. et al. Integrating explanation and prediction in computational social science. Nature 595, 181-188 (2021).
- Rocca, R. & Yarkoni, T. Putting psychology to the test: rethinking model evaluation through benchmarking and prediction. Adv. Methods Pract. Psychol. Sci. https://doi.org/ 10.1177/25152459211026864 (2021).
- Dettmers, T., Pagnoni, A., Holtzman, A. & Zettlemoyer, L. QLORA: efficient finetuning of quantized LLMs. In Proc. Advances in Neural Information Processing Systems 36 (eds Oh, A. et al.) (NeurIPS, 2023).
- Nosofsky, R. M. in Formal Approaches in Categorization (eds Pothos, E. M. & Wills, A. J.) 18-39 (Cambridge Univ. Press, 2011).
- Peterson, J. C., Bourgin, D. D., Agrawal, M., Reichman, D. & Griffiths, T. L. Using large-scale experiments and machine learning to discover theories of human decision-making. Science 372, 1209-1214 (2021).
- Daw, N. D., Gershman, S. J., Seymour, B., Dayan, P. & Dolan, R. J. Model-based influences on humans’ choices and striatal prediction errors. Neuron 69, 1204-1215 (2011).
- Wilson, R. C., Geana, A., White, J. M., Ludvig, E. A. & Cohen, J. D. Humans use directed and random exploration to solve the explore-exploit dilemma. J. Exp. Psychol. Gen. 143, 2074-2081 (2014).
- Palminteri, S., Wyart, V. & Koechlin, E. The importance of falsification in computational cognitive modeling. Trends Cogn. Sci. 21, 425-433 (2017).
- van Baar, J. M., Nassar, M. R., Deng, W. & FeldmanHall, O. Latent motives guide structure learning during adaptive social choice. Nat. Hum. Behav. 6, 404-414 (2022).
- Feher da Silva, C. & Hare, T. A. Humans primarily use model-based inference in the two-stage task. Nat. Hum. Behav. 4, 1053-1066 (2020).
- Kool, W., Cushman, F. A. & Gershman, S. J. When does model-based control pay off? PLoS Comput. Biol. 12, e1005090 (2016).
- Dubois, M. & Hauser, T. U. Value-free random exploration is linked to impulsivity. Nat. Commun. 13, 4542 (2022).
- Jansen, R. A., Rafferty, A. N. & Griffiths, T. L. A rational model of the Dunning-Kruger effect supports insensitivity to evidence in low performers. Nat. Hum. Behav. 5, 756-763 (2021).
- Awad, E. et al. The Moral Machine experiment. Nature 563, 59-64 (2018).
- Akata, E. et al. Playing repeated games with large language models. Nat. Hum. Behav. https://doi.org/10.1038/s41562-025-02172-y (2025).
- Demircan, C. et al. Evaluating alignment between humans and neural network representations in image-based learning tasks. In Proc. Advances in Neural Information Processing Systems 37 (eds Globerson, A. et al.) (NeurIPS, 2024).
- Singh, M., Richie, R. & Bhatia, S. Representing and predicting everyday behavior. Comput. Brain Behav. 5, 1-21 (2022).
- Xu, H. A., Modirshanechi, A., Lehmann, M. P., Gerstner, W. & Herzog, M. H. Novelty is not surprise: human exploratory and adaptive behavior in sequential decision-making. PLoS Comput. Biol. 17, e1009070 (2021).
- Hick, W. E. On the rate of gain of information. Q. J. Exp. Psychol. 4, 11-26 (1952).
- Coda-Forno, J., Binz, M., Wang, J. X. & Schulz, E. CogBench: a large language model walks into a psychology lab. Proc. Mach. Learn. Res. 235, 9076-9108 (2024).
- Kipnis, A., Voudouris, K., Schulze Buschoff, L. M. & Schulz, E. metabench – a sparse benchmark of reasoning and knowledge in large language models. In Proc. 13th International Conference on Learning Representations (ICLR, 2025).
- Yamins, D. L. K. et al. Performance-optimized hierarchical models predict neural responses in higher visual cortex. Proc. Natl Acad. Sci. USA 111, 8619-8624 (2014).
- Schrimpf, M. et al. The neural architecture of language: integrative modeling converges on predictive processing. Proc. Natl Acad. Sci. USA 118, e2105646118 (2021).
- Feher da Silva, C., Lombardi, G., Edelson, M. & Hare, T. A. Rethinking model-based and model-free influences on mental effort and striatal prediction errors. Nat. Hum. Behav. 7, 956-969 (2023).
- Tuckute, G. et al. Driving and suppressing the human language network using large language models. Nat. Hum. Behav. 8, 544-561 (2024).
- Cochran, W. G. The combination of estimates from different experiments. Biometrics 10, 101-129 (1954).
- DeepSeek-AI et al. DeepSeek-R1: incentivizing reasoning capability in LLMs via reinforcement learning. Preprint at https://arxiv.org/abs/2501.12948 (2025).
- Hilbig, B. E. & Moshagen, M. Generalized outcome-based strategy classification: comparing deterministic and probabilistic choice models. Psychon. Bull. Rev. 21, 1431-1443 (2014).
- Agrawal, M., Peterson, J. C. & Griffiths, T. L. Scaling up psychology via scientific regret minimization. Proc. Natl Acad. Sci. USA 117, 8825-8835 (2020).
- Rigoux, L., Stephan, K. E., Friston, K. J. & Daunizeau, J. Bayesian model selection for group studies – revisited. Neuroimage https://doi.org/10.1016/j.neuroimage.2013.08.065 (2014).
- Binz, M., Gershman, S. J., Schulz, E. & Endres, D. Heuristics from bounded meta-learned inference. Psychol. Rev. 129, 1042-1077 (2022).
- Musslick, S. et al. Automating the practice of science: opportunities, challenges, and implications. Proc. Natl. Acad. Sci. USA 122, e2401238121 (2025).
- Rmus, M., Jagadish, A. K., Mathony, M., Ludwig, T. & Schulz, E. Generating computational cognitive models using large language models. Preprint at https://arxiv.org/abs/2502.00879 (2025).
- Dillion, D., Tandon, N., Gu, Y. & Gray, K. Can AI language models replace human participants? Trends Cogn. Sci. 27, 597-600 (2023).
- Huben, R., Cunningham, H., Smith, L. R., Ewart, A. & Sharkey, L. Sparse autoencoders find highly interpretable features in language models. In Proc. 12th International Conference on Learning Representations (ICLR, 2024).
- Chefer, H., Gur, S. & Wolf, L. Transformer interpretability beyond attention visualization. In Proc. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 782-791 (IEEE, 2021).
- Vaswani, A. et al. Attention is all you need. In Proc. Advances in Neural Information Processing Systems 30 (eds Guyon, I. et al.) (NeurIPS, 2017).
- Zador, A. et al. Catalyzing next-generation artificial intelligence through NeuroAI. Nat. Commun. 14, 1597 (2023).
- Ruggeri, K. et al. The globalizability of temporal discounting. Nat. Hum. Behav. 6, 1386-1397 (2022).
- Wulff, D. U., Mergenthaler-Canseco, M. & Hertwig, R. A meta-analytic review of two modes of learning and the description-experience gap. Psychol. Bull. 144, 140-176 (2018).
- Frey, R., Pedroni, A., Mata, R., Rieskamp, J. & Hertwig, R. Risk preference shares the psychometric structure of major psychological traits. Sci. Adv. 3, e1701381 (2017).
- Enkavi, A. Z. et al. Large-scale analysis of test-retest reliabilities of self-regulation measures. Proc. Natl Acad. Sci. USA 116, 5472-5477 (2019).
- Henrich, J., Heine, S. J. & Norenzayan, A. Most people are not WEIRD. Nature 466, 29 (2010).
- Schrimpf, M. et al. Integrative benchmarking to advance neurally mechanistic models of human intelligence. Neuron 108, 413-423 (2020).
- Poldrack, R. A. et al. The past, present, and future of the brain imaging data structure (BIDS). Imaging Neurosci. 2, 1-19 (2024).
- Schulze Buschoff, L. M., Akata, E., Bethge, M. & Schulz, E. Visual cognition in multimodal large language models. Nat. Mach. Intell. https://doi.org/10.1038/s42256-024-00963-y (2025).
- Vere, S. A. A cognitive process shell. Behav. Brain Sci. 15, 460-461 (1992).
(c) The Author(s) 2025
Methods
Data collection
Fine-tuning procedure
Evaluation metric
Domain-specific cognitive models
Neural alignment
The neural alignment analysis on the sentence-reading task was conducted using publicly available code from the original study
Model-guided scientific discovery
participant using a maximum-likelihood estimation. Models were compared with each other using the AIC. The three models from the original study were implemented by the following equations:
For the scientific regret minimization pipeline, we computed the difference in log-likelihoods between Centaur and the DeepSeek-R1-discovered model. We visualized and inspected the ten data points with the greatest difference. This process resulted in the following computational model:
Reporting summary
Data availability
Code availability
to reproduce our results is available at https://github.com/marcelbinz/ Llama-3.1-Centaur-70B.
61. Loshchilov, I. & Hutter, F. Decoupled weight decay regularization. In Proc. 7th International Conference on Learning Representations (ICLR, 2019).
62. Schaefer, A. et al. Local-global parcellation of the human cerebral cortex from intrinsic functional connectivity MRI. Cereb. Cortex 28, 3095-3114 (2018).
63. Esteban, O. et al. fMRIPrep: a robust preprocessing pipeline for functional MRI. Nat. Methods 16, 111-116 (2019).
64. Fonov, V. S., Evans, A. C., McKinstry, R. C., Almli, C. R. & Collins, D. L. Unbiased nonlinear average age-appropriate brain templates from birth to adulthood. Neuroimage 47, S102 (2009).
65. Friston, K. J., Ashburner, J. T., Kiebel, S. J., Nichols, T. E. & Penny, W. D. (eds) Statistical Parametric Mapping: The Analysis of Functional Brain Images (Elsevier, 2011).
66. Gau, R. nilearn. GitHub https://github.com/nilearn/nilearn (2024).
67. Yax, N., Oudeyer, P.-Y. & Palminteri, S. Assessing contamination in large language models: introducing the LogProber method. Preprint at https://arxiv.org/abs/2408.14352 (2024).
68. Warner, B. et al. Smarter, better, faster, longer: a modern bidirectional encoder for fast, memory efficient, and long context finetuning and inference. Preprint at https://arxiv.org/ abs/2412.13663 (2024).
69. Wang, Z. et al. HelpSteer2-Preference: complementing ratings with preferences. In Proc. 13th International Conference on Learning Representations (ICLR, 2025).
70. Teknium, R., Quesnelle, J. & Guang, C. Hermes 3 technical report. Preprint at https://arxiv. org/abs/2408.11857 (2024).
71. Lin, S., Hilton, J. & Evans, O. TruthfulQA: measuring how models mimic human falsehoods. In Proc. 60th Annual Meeting of the Association for Computational Linguistics (eds Muresan, S. et al.) 3214-3252 (Association for Computational Linguistics, 2022).
Additional information
Correspondence and requests for materials should be addressed to Marcel Binz. Peer review information Nature thanks Russell Poldrack, Giosue Baggio and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Reprints and permissions information is available at http://www.nature.com/reprints.
Extended Data Fig. 2 | Negative log-likelihoods of Centaur and alternative
a, Negative log-likelihoods on moral decision-making
corresponding bilateral parcels in the Schaefer atlas. The accumbens is defined based on the Harvard-Oxford atlas. Pearson correlation coefficients are shown for layer 20 but exhibit a similar pattern across all layers. Centaur outperformed Llama and the cognitive model in predicting activity in accumbens, the ROI from the original study that showed a reward prediction error effect
| Experiment | Centaur | Llama | Cognitive model |
| Shepard categorization | 0.5394 | 0.5818 | 0.6108 |
| Drifting four-armed bandit | 0.7029 | 0.8810 | 0.9043 |
| N-back | 0.3954 | 0.5209 | 0.5787 |
| Digit span | 0.5520 | 0.6618 | 0.9359 |
| Go/no-go | 0.0000 | 0.0062 | 0.0757 |
| Recent probes | 0.2572 | 0.3433 | 0.3868 |
| Horizon task | 0.4032 | 0.5237 | 0.3595 |
| Gardening task | 0.3783 | 0.5040 | 0.9105 |
| Columbia card task | 0.1867 | 0.2261 | 0.2629 |
| Balloon analog risk task | 0.0593 | 0.0753 | 0.0922 |
| Two-armed bandit | 0.2963 | 0.3829 | 0.4187 |
| Conditional associative learning | 0.5380 | 0.6373 | 0.8575 |
| THINGS odd-one-out | 0.8068 | 1.1386 | 0.8253 |
| Multi-attribute decision-making | 0.0619 | 0.1502 | 0.1922 |
| Two-step task | 0.4998 | 0.6075 | 0.6043 |
| Probabilistic instrumental learning | 0.4937 | 0.5382 | 0.5047 |
| Medin categorization | 0.4967 | 0.5772 | 0.5313 |
| Zoopermarket | 0.4850 | 0.6026 | 0.6047 |
| choices13k | 0.4274 | 0.5342 | 0.6563 |
| CPC18 | 0.3390 | 0.4118 | 0.6607 |
| Intertemporal choice | 0.4340 | 0.7336 | 0.6591 |
| Structured bandit | 0.6410 | 0.8114 | 1.0530 |
| Weather prediction task | 0.5514 | 0.5749 | 0.6267 |
| lowa gambling task | 0.8890 | 0.9880 | 1.1555 |
| Virtual subway network | 1.1271 | 1.5347 | nan |
| Multi-task reinforcement learning | 0.5672 | 0.6604 | 1.0424 |
| Serial reaction time task | 0.1718 | 0.1900 | 0.1962 |
| Decisions from description | 0.5336 | 0.7569 | 0.6120 |
| Decisions from experience | 0.3686 | 0.4339 | 0.5404 |
| Changing bandit | 0.3025 | 0.3824 | 0.4378 |
| Multiple-cue judgment | 1.1236 | 1.2818 | 1.9157 |
| Recall and recognition | 1.0591 | 1.3759 | nan |
| Experiential-symbolic task | 0.4536 | 0.6983 | nan |
| Grammar judgement | 1.4355 | 1.9949 | 1.4127 |
| Risky choice | 0.4281 | 0.6475 | nan |
| Tile-revealing task | 1.8713 | 2.7380 | nan |
| Episodic long-term memory | 0.8684 | 1.1344 | nan |
| Aversive learning | 4.0733 | 5.1066 | nan |
| Spatially correlated multi-armed bandit | 1.8319 | 2.4479 | 2.7635 |
| Probabilistic reasoning | 2.3731 | 2.6406 | nan |
natureportfolio
Marcel Binz
Last updated by author(s): Apr 27, 2025
Reporting Summary
Statistics
n/a
Confirmed
□
□ The exact sample size
□ A statement on whether measurements were taken from distinct samples or whether the same sample was measured repeatedly
Only common tests should be described solely by name; describe more complex techniques in the Methods section.
□ A description of all covariates tested
□ A description of any assumptions or corrections, such as tests of normality and adjustment for multiple comparisons
□ X
For null hypothesis testing, the test statistic (e.g. F, t, r) with confidence intervals, effect sizes, degrees of freedom and
□ For Bayesian analysis, information on the choice of priors and Markov chain Monte Carlo settings
□ For hierarchical and complex designs, identification of the appropriate level for tests and full reporting of outcomes
□ Estimates of effect sizes (e.g. Cohen’s
Our web collection on statistics for biologists contains articles on many of the points above.
Software and code
Data collection
No new data was collected in this study.
custom code on https://github.com/marcelbinz/Llama-3.1-Centaur-70B
For manuscripts utilizing custom algorithms or software that are central to the research but not yet described in published literature, software must be made available to editors and reviewers. We strongly encourage code deposition in a community repository (e.g. GitHub). See the Nature Portfolio guidelines for submitting code & software for further information.
Data
Policy information about availability of data
- Accession codes, unique identifiers, or web links for publicly available datasets
- A description of any restrictions on data availability
- For clinical datasets or third party data, please ensure that the statement adheres to our policy
April 2023
Research involving human participants, their data, or biological material
| Reporting on sex and gender | N/A |
| Reporting on race, ethnicity, or other socially relevant groupings | N/A |
| Population characteristics | N/A |
| Recruitment | N/A |
| Ethics oversight | N/A |
Field-specific reporting
□ Life sciences
Behavioural & social sciences □ Ecological, evolutionary & environmental sciences
For a reference copy of the document with all sections, see nature.com/documents/nr-reporting-summary-flat.pdf
Behavioural & social sciences study design
| Study description | Meta-analysis |
| Research sample | Meta-analysis |
| Sampling strategy | Meta-analysis |
| Data collection | information available as part of the original studies |
| Timing | information available as part of the original studies |
| Data exclusions | information available as part of the original studies |
| Non-participation | information available as part of the original studies |
| Randomization | information available as part of the original studies |
Reporting for specific materials, systems and methods
| Materials & experimental systems | Methods | ||
| n/a | Involved in the study | n/a | Involved in the study |
| X | □ | |
□ |
| X | □ | |
□ |
| X | □ | □ | 【 MRI-based neuroimaging |
| X | □ | ||
| X | □ | ||
| X | □ | ||
| X | □ | ||
| Seed stocks | N/A | ||||
| Novel plant genotypes | N/A | ||||
| Authentication | N/A | ||||
| Magnetic resonance imaging | |||||
| Experimental design | |||||
| Design type | two-step task and sentence-reading task | ||||
| Design specifications |
|
||||
| Behavioral performance measures |
|
||||
|
|||||
| Field strength | 3T | ||||
| Sequence & imaging parameters |
|
||||
| Area of acquisition | Whole brain | ||||
| Diffusion MRI | □ | Not used | |||
| Preprocessing | |||||
| Preprocessing software | fMRIprep 24.0.0, SPM12 and custom MATLAB scripts | ||||
| Normalization | identical to original study | ||||
| Normalization template | identical to original study | ||||
| Noise and artifact removal | identical to original study | ||||
| Volume censoring |
|
||||
| Statistical modeling & inference | |||||
| Model type and settings | predictive modeling | ||||
| Effect(s) tested | whether human behavior can be predicted by language model activity | ||||
| Specify type of analysis: | □ Whole brain □ | ||||
| Anatomical location(s) | |||||
| Statistic type for inference | N/A | ||||
Models & analysis
independent variables: language model activity feature extraction: internal representations were extracted from the models’ residual stream and transformed using a principal component analysis. We set the number of retained components such that they explain
Institute for Human-Centered AI, Helmholtz Center, Munich, Germany. University of Tübingen, Tübingen, Germany. University of Oxford, Oxford, UK. Max Planck Institute for Biological Cybernetics, Tübingen, Germany. New York University, New York, NY, USA. Google DeepMind, London, UK. Princeton University, Princeton, NJ, USA. Max Planck School of Cognition, Leipzig, Germany. University of California, San Diego, San Diego, CA, USA. Boston University, Boston, MA, USA. TU Darmstadt, Darmstadt, Germany. Institute of Computational Biology, Helmholtz Center, Munich, Germany. TUM School of Computation, Information and Technology, Technical University of Munich, Munich, Germany. TUM School of Life Sciences, Technical University of Munich, Munich, Germany. University of Cambridge, Cambridge, UK. Georgia Institute of Technology, Atlanta, GA, USA. University of Basel, Basel, Switzerland. Max Planck Institute for Human Development, Berlin, Germany. e-mail: marcel.binz@helmholtz-munich.de - Full negative log-likelihoods on held-out participants.
- Psych-101 is publicly available on the Huggingface platform: https://huggingface. co/datasets/marcelbinz/Psych-101. The test set is accessible under a CC-BY-ND-4.0 license via a gated repository: https://huggingface.co/datasets/marcelbinz/ Psych-101-test.