هندسة المطالبات في التوافق والموثوقية مع الإرشادات المستندة إلى الأدلة لنماذج اللغة الكبيرة Prompt engineering in consistency and reliability with the evidence-based guideline for LLMs
هندسة المطالبات في التوافق والموثوقية مع الإرشادات المستندة إلى الأدلة لنماذج اللغة الكبيرة
(D) التحقق من التحديثات
لي وانغشي تشينشيانغ وين دينغهاو وينمينغكي يووي تشي ليوتشي ليجيان لي (ب)
الملخص
استخدام نماذج اللغة الكبيرة (LLMs) في الطب السريري يزدهر حاليًا. من الضروري نقل المعرفة النظرية ذات الصلة بنماذج اللغة الكبيرة من علوم الحاسوب إلى تطبيقها في الطب السريري بشكل فعال. لقد أظهرت هندسة المطالبات إمكانات كطريقة فعالة في هذا الصدد. لاستكشاف تطبيق هندسة المطالبات في نماذج اللغة الكبيرة وفحص موثوقية هذه النماذج، تم تصميم واستخدام أنماط مختلفة من المطالبات لطرح أسئلة على نماذج لغة كبيرة مختلفة حول توافقها مع إرشادات الأكاديمية الأمريكية لجراحي العظام (AAOS) المستندة إلى الأدلة حول التهاب المفاصل (OA). تم طرح كل سؤال 5 مرات. قمنا بمقارنة اتساق النتائج مع الإرشادات عبر مستويات الأدلة المختلفة لمطالبات مختلفة وقيمنا موثوقية المطالبات المختلفة من خلال طرح نفس السؤال 5 مرات. كان لدى gpt-4-Web مع تحفيز ROT أعلى مستوى من الاتساق العام. ) وأداء ملحوظ لتوصيات قوية، مع إجمالي اتساق لم تكن موثوقية النماذج اللغوية الكبيرة المختلفة للمطالبات المختلفة مستقرة (تراوح معامل فليس من -0.002 إلى 0.984). كشفت هذه الدراسة أن المطالبات المختلفة كان لها تأثيرات متغيرة عبر النماذج المختلفة، وكان نموذج gpt-4-Web مع مطالبة ROT هو الأكثر اتساقًا. يمكن أن تحسن المطالبة المناسبة دقة الاستجابات للأسئلة الطبية المهنية.
لقد أظهرت نماذج اللغة الكبيرة (LLMs) أداءً جيدًا في مهام معالجة اللغة الطبيعية (NLP) المختلفة، مثل التلخيص، والترجمة، وتوليد الشيفرة، وحتى الاستدلال المنطقي.هناك اهتمام متزايد في استكشاف إمكانيات نماذج اللغة الكبيرة في الطب. لقد تم استخدامها في دراسات طبية ذات صلة في تشخيص الحالات، والفحوصات الطبية، وتقييم اتساق الإرشادات..
ومع ذلك، فإن الأداء الحالي لنماذج اللغة الكبيرة في المجال الطبي ليس مثالياً. في تشخيص الحالات المعقدة،كانت التشخيصات المتعلقة بـ GPT-4 متوافقة مع التشخيص النهائي، ومتوسط التوافق هوتم عرضها مع الإرشادات لأمراض الجهاز الهضميتم الحكم على ثمانية عشر في المئة من الإجابات المتعلقة بـ Med-PaLM بأنها تحتوي على محتوى غير مناسب أو غير صحيح.علاوة على ذلك، قد تولد نماذج اللغة الكبيرة إجابات مختلفة لنفس السؤال، وكانت الاتساق الذاتي دائمًا معيارًا حاسمًا لتقييم أداء نماذج اللغة الكبيرة.تحتاج الأبحاث والاستكشافات الإضافية حول كيفية تحسين أدائها في المجال الطبي..
هندسة المطالبات هي تخصص جديد يركز على تطوير وتحسين كلمات المطالبات، مما يساعد المستخدمين على تطبيق نماذج اللغة الكبيرة في سيناريوهات ومجالات بحثية متنوعة. في علوم الحاسوب، يمكن لنماذج اللغة الكبيرة الحصول على إجابات مثالية ومستقرة من خلال هندسة المطالبات، وسيؤثر اعتماد مطالبات مختلفة على أداء نماذج اللغة الكبيرة، وهو ما ينعكس إلى حد ما في المشكلات الرياضية.تشمل تصميمات المطالبات المستخدمة حديثًا حاليًا تحفيز سلسلة الأفكار (COT) وتحفيز شجرة الأفكار (TOT).مع اقتراح نظريات COT وTOT في مجال نماذج اللغة الكبيرة في علوم الكمبيوتر، تم تطوير مطالبات متCorresponding وعرضت أداءً محسنًا في المشكلات الرياضية..
في الطب السريري، أظهرت بعض الدراسات تطبيق المحفزات مثل تحفيز COT، وتحفيز القليل من الأمثلة، وتحفيز الاتساق الذاتي في دراسة كاران وآخرون.. بالإضافة إلى ذلك، دراسة بارتالان وآخرون.. يلخص الحالة الحالية للبحث في هندسة المطالبات ويقدم درسًا تعليميًا لهندسة المطالبات للمهنيين الطبيين. بشكل عام، هناك القليل من الدراسات التي ركزت على الفروق في أداء المطالبات المختلفة في الأسئلة الطبية أو فحصت ما إذا كان هناك حاجة لتطوير
توجيهات محددة للأسئلة الطبية. باختصار، فإن تطبيق نماذج اللغة الكبيرة في الطب يزدهر حاليًا. ومع ذلك، يبدو أن معظم الأبحاث الحالية تركز أكثر على نتائج استخدام نماذج اللغة الكبيرة بدلاً من كيفية استخدامها بشكل أفضل في الطب السريري. يمكن أن يؤدي اختبار موثوقية نماذج اللغة الكبيرة في الإجابة على الأسئلة الطبية، باستخدام توجيهات مختلفة، وحتى تطوير توجيهات محددة للأسئلة الطبية إلى تغيير تطبيق نماذج اللغة الكبيرة في الطب والبحث المستقبلي. من المهم التحقيق فيما إذا كان وكيف يمكن أن يحسن تصميم التوجيهات أداء نماذج اللغة الكبيرة في الإجابة على الأسئلة المتعلقة بالطب. بالإضافة إلى ذلك، يمكن أن تؤثر عوامل أخرى، مثل نوع بنية النموذج، ومعلمات النموذج، وبيانات التدريب، وتقنيات الضبط الدقيق، على أداء.
لاستكشاف تأثير أنواع مختلفة من المحفزات المدمجة مع عوامل أخرى على أداء نماذج اللغة الكبيرة، أجرينا دراسة تجريبية حول الأسئلة المتعلقة بالتهاب المفاصل العظمي (OA). حددت أداة العبء العالمي للأمراض لعام 2019 التهاب المفاصل العظمي كواحد من أكثر الأمراض انتشارًا وإعاقة.من حيث الانتشار والأثر، يُعتبر التهاب المفاصل العظمي واحدًا من أكثر الاضطرابات العضلية الهيكلية انتشارًا ويؤثر على جزء كبير من السكان العالميين، خاصةً الأفراد المسنين.هذا التأثير الواسع يجعله قضية صحة عامة ذات أهمية كبيرة، وإدارة التهاب المفاصل التنكسي معقدة ومتعددة الأبعاد، تشمل التحكم في الألم، والعلاج الطبيعي، وتعديلات نمط الحياة، وفي بعض الحالات، التدخلات الجراحية.نظرًا لأنها مرض شائع مع عدد كبير من المرضى وإدارة معقدة، قد يسعى المرضى والأطباء إلى المعرفة المهنية ذات الصلة عبر الإنترنت، والتي تشمل نماذج اللغة الكبيرة. لذلك، يمكن أن يكون التحقيق في أداء نماذج اللغة الكبيرة فيما يتعلق بالأسئلة المتعلقة بالتهاب المفاصل العظمي مثالًا مناسبًا لكيفية تحسين جودة الإجابات من خلال هندسة المطالبات. يمكن أيضًا استكشاف إمكانية هندسة المطالبات لمساعدة كل من الأطباء والمرضى في الاستفسارات الطبية حول الأمراض الشائعة باستخدام نماذج اللغة الكبيرة.
طبقت أبحاثنا نفس مجموعة من المحفزات على نماذج لغوية مختلفة، وطرحت أسئلة تتعلق بالوصول المفتوح وهدفت إلى استكشاف فعالية هندسة المحفزات. افترضنا أن المحفزات المختلفة ستؤدي إلى تباين في الاتساق والموثوقية، وأن فعالية المحفزات على النماذج اللغوية ستتأثر بعوامل متنوعة.
النتائج
الاتساق
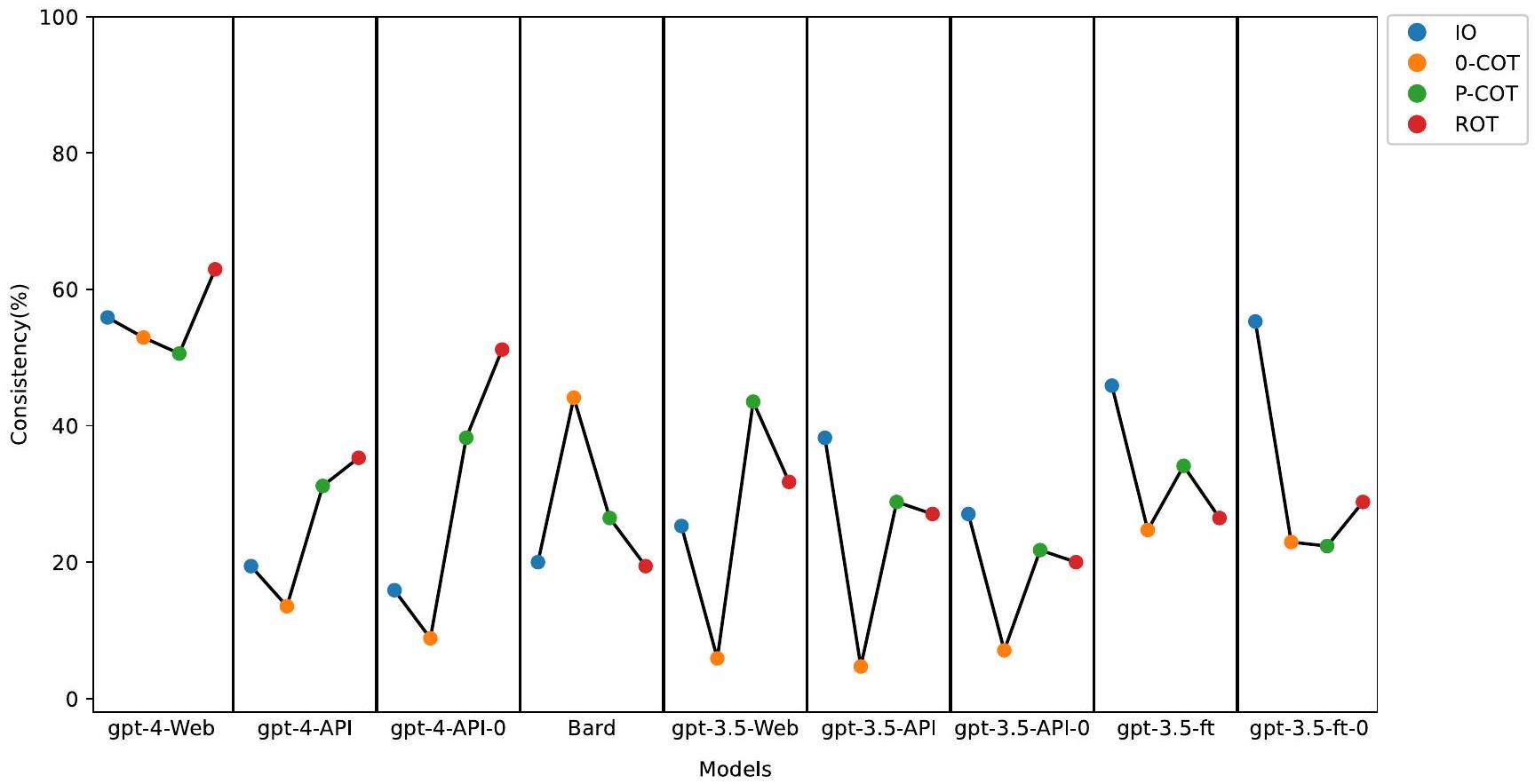
أشارت النتائج إلى أن gpt-4-Web تفوق على النماذج الأخرى، كما هو موضح في الشكل 1. كانت معدلات الاتساق للأربعة مطالب في gpt-4-Web يتراوح بين و تمت ملاحظة معدلات اتساق أخرى أيضًا مع تحفيز IO في gpt-3.5-ft-0 بنسبة 55.3% وتحفيز ROT في gpt-4-API-0 عندكانت معدلات التناسق للنماذج الأخرى جميعها أقل منإلى.
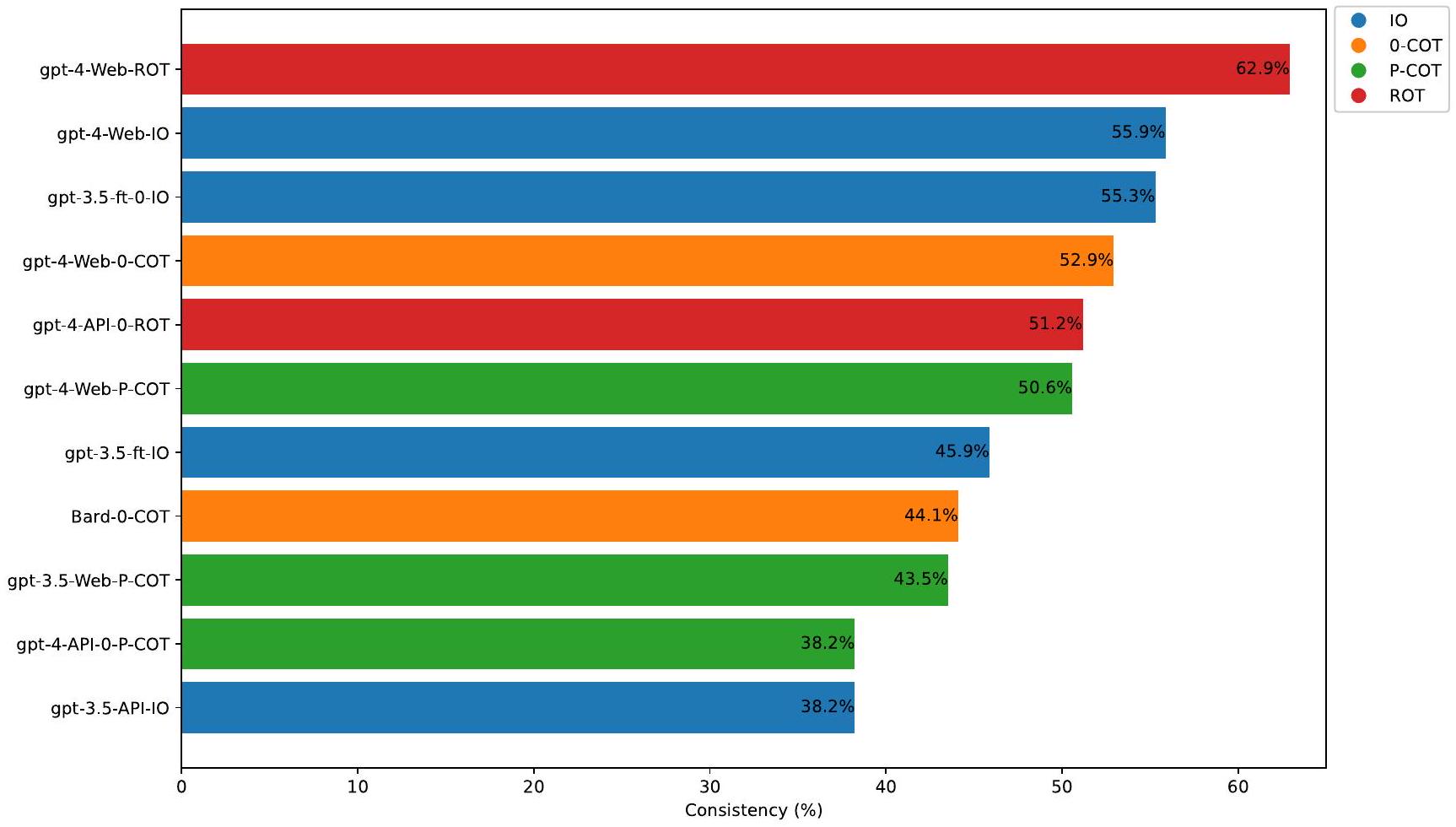
جمع بين gpt-4-Web و ROT أدى إلى توصية العلاج الأكثر توافقًا مع الإرشادات السريرية. تظهر أفضل 10 تركيبات من المطالبات والنماذج في الشكل 2. على وجه التحديد، تراوحت اتساق المطالبات المختلفة مع الإرشادات في سلسلة من نماذج GPT-4 منإلى؛ في سلسلة من نماذج GPT-3.5، بما في ذلك النسخ المعدلة، تراوحت من إلى. بالنسبة لمطالب مختلفة في بارد، تراوحت الاتساق من إلى. بالنسبة للإصدارات الثلاثة من GPT-4، كان تحفيز ROT هو الأفضل باستمرار، حيث تراوح من إلى. بالنسبة لخمس نسخ من GPT-3.5، باستثناء تحفيز P-COT، ما هو أفضل تحفيز لـ gpt-3.5-Web في كان أفضل تلميح للإصدارات الأخرى هو تلميح IO (يتراوح من إلى ). بالنسبة لـ Bard، كان أفضل تلميح هو 0-COT عند .
تحليل الفئات الفرعية
تصنف AAOS مستويات التوصيات بناءً على قوة الأدلة الداعمة، بدءًا من القوية إلى المتوسطة، المحدودة، والتوافق. افترضنا أن مستويات مختلفة من قوة الأدلة قد تؤدي إلى تباينات في الاتساق. لاستكشاف ذلك، أجرينا تحليلًا فرعيًا لفحص الفروق في الأداء بين مختلف المحفزات عبر مستويات قوة الأدلة المختلفة. ضمن نفس النموذج، أجرينا مقارنات متعددة بين المحفزات المختلفة، مع التركيز على أداء gpt-4-Web الذي تفوق عبر مختلف مستويات قوة الأدلة. يمكن العثور على نتائج التحليل الفرعي والمقارنات المتعددة ضمن كل نموذج في الجدول التكميلي 1.
مستوى قوي. يتم عرض اتساق المطالبات المختلفة في النماذج المختلفة عند المستوى القوي في الشكل 3أ. تم تصنيف ثمانية نصائح على أنها قوية وفقًا لإرشادات AAOS، مع 40 استجابة لكل مطالبة. وفقًا للمقارنات المتعددة للاتساق في gpt-4Web، كانت الفروق النسبية في درجات مطالبة ROT (77.5%) ومطالبة P-COT (75%) أكبر بكثير من تلك في مطالبة IO.وفقًا للنماذج الأخرى، كانت اتساق تحفيز IO في gpt-3.5-ft و gpt-3.5-ft-0 و على التوالي.
الشكل 1 | اتساق العبارات المختلفة في نماذج مختلفة. يمكن العثور على معلومات مفصلة عن كل نموذج في الجدول 3.
الشكل 2 | أعلى 10 من الاتساق. يمثل المحور العمودي مجموعة النموذج المختار والمطالبة، على سبيل المثال، ‘gpt-4-Web-ROT’ تشير إلى أن النموذج المختار هو gpt-، والمطالبة هي مطالبة ROT.
الشكل 3 | الاتساق في مستويات مختلفة. أ قوي؛معتدل؛محدود؛إجماع
مستوى معتدل. يتم عرض اتساق المطالبات المختلفة في النماذج المختلفة عند المستوى المعتدل في الشكل 3ب. تم تقييم ثماني نصائح على أنها معتدلة، مع 40 استجابة لكل مطالبة. وفقًا للمقارنات المتعددة للاتساق في gpt-4-Web (إلى )، لم يكن هناك فرق كبير بين المجموعات. وفقًا للنماذج الأخرى، فإن اتساق تحفيز IO في Bards هو .
مستوى محدود. يتم عرض اتساق المطالبات المختلفة في النماذج المختلفة عند المستوى المحدود في الشكل 3c. كان لدى ستة عشر نصيحة تصنيف توصية محدود، مع 80 استجابة لكل مطالبة. وفقًا للمقارنات المتعددة للاتساق في gpt-4-Web، بعد تصحيح بونفيروني، كانت نسبة المرضى الذين لديهم فرق 0 نقطة في تحفيز P-COT (كان أقل بكثير من ذلك في تحفيز ROT ) وتحفيز IO ( ). في النماذج الأخرى، تكون جميع قيم التناسق أقل من .
مستوى الإجماع. تم التوصية بالنصائحين بناءً على الإجماع. نظرًا لصغر حجم العينة، لم يتم إجراء أي اختبار إحصائي، وتظهر اتساق المحفزات المختلفة في نماذج مختلفة في الشكل 3d.
موثوقية نماذج اللغة الكبيرة
تظهر قيم كابا فليس للأربعة مطالبات في النماذج التسعة في الجدول 1. وكانت القيم تتراوح من -0.002 إلى 0.984. البيانات الإحصائية التفصيلية موضحة في الجدول التكميلي 2.
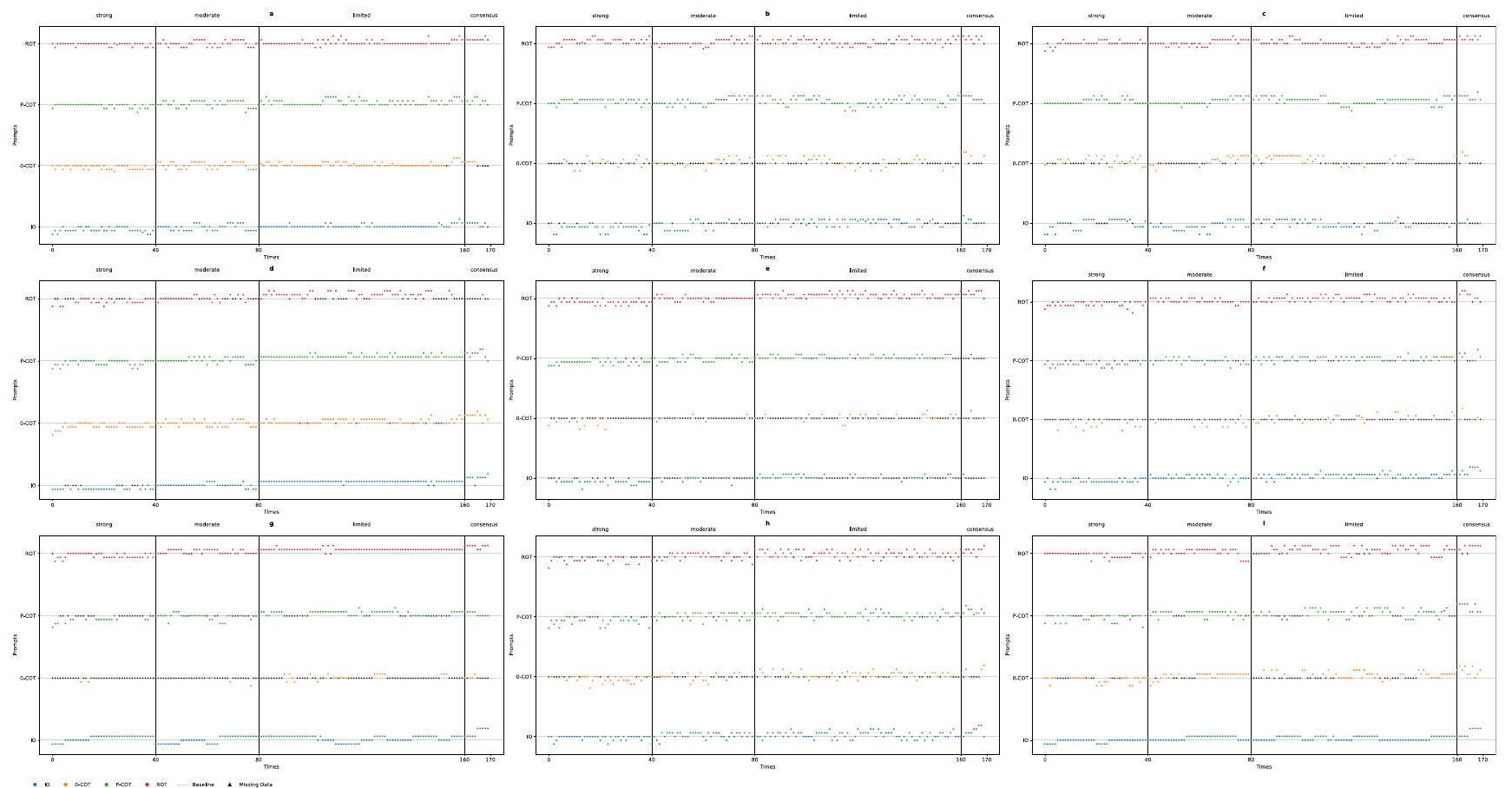
كانت قيم كابا لتحفيز IO في gpt-3.5-ft-0 و gpt-3.5-API-0 قريبة من 1 (0.982 و 0.984 على التوالي). في الرسوم البيانية المتناثرة المقابلة، كما هو موضح في الشكل 4g، i، النقاط التي تتطابق مع الإجابات مع الإرشادات تقع على الخط الأساسي (فرق المستوى ). تشير الفروق الإيجابية إلى كونها فوق الخط الأساسي، بينما تشير الفروق السلبية إلى كونها دونه. بدءًا من أول نقطة بيانات لتحفيز IO في الشكل 4g، يظهر أن كل مجموعة من خمس نقاط تقريبًا تقع على خط أفقي. تشير هذه النمطية إلى أن النماذج تولد باستمرار نفس الاستجابة خمس مرات متتالية. بالمقابل، تظهر الاستجابات في ظروف أخرى مزيدًا من التباين. كانت قيمة كابا لتحفيز P-COT استجابةً لـ gpt-4-API-0 هي 0.660. جميع قيم كابا الأخرى أقل من 0.6. بالنسبة لـ gpt-4-Web، تشير نتائج كابا فليس إلى أن موثوقية كل تحفيز تتراوح بين متوسطة إلى عادلة (0.334 إلى 0.525). بشكل عام، تحفيز IO في gpt- و جي بي تي – أظهرت تجارب API0 موثوقية مثالية. وأشارت تحفيزات P-COT في gpt-4-API-0 إلى موثوقية كبيرة، بينما كانت الأخرى متوسطة أو أقل.
بيانات غير صالحة وإجراءات المعالجة المقابلة
كانت هناك ثلاث فئات من البيانات غير الصالحة: الفئة أ: لم يتم تقديم التقييم النهائي. الفئة ب: لم يكن التقييم عددًا صحيحًا. تم معالجة جميع البيانات غير الصالحة وفقًا لإجراءات البيانات غير الصالحة.. في حساب كابا فليس، تعتبر جميع البيانات غير الصالحة في الفئة A بمثابة تصنيف مستقل، وتعتبر البيانات غير الصالحة في الفئة تُعتبر تصنيفات مختلفة بناءً على القيم (إذا كانت التقييمات ‘2 أو 3’، يتم تسجيلها كـ 2.5) التي تولدها نماذج اللغة الكبيرة. في إنشاء مخطط التشتت (الشكل 4)، تم تصنيف البيانات غير الصالحة من الفئة A على أنها بيانات مفقودة. ومن الجدير بالذكر أنه تم ملاحظة كمية كبيرة من البيانات غير الصالحة من الفئة A في مجموعات بيانات متعددة؛ على سبيل المثال،تم تسجيل 0 -COT من الاستجابات في gpt-3.5-API-0. وعلى العكس، كانت نسبة البيانات غير الصالحة في gpt-4-Web صغيرة نسبيًا (إجمالي 14 من 680 عبر جميع الأربعة مطالبات).
نقاش
أشارت نتائج هذه الدراسة إلى أن هندسة المطالبات قد تغير دقة نماذج اللغة الكبيرة في الإجابة على الأسئلة الطبية. بالإضافة إلى ذلك، لا تقدم نماذج اللغة الكبيرة دائمًا نفس الإجابة على نفس الأسئلة الطبية. وقد تفوقت مجموعة المطالبات ROT وgpt-4-Web على المجموعات الأخرى في تقديم معرفة احترافية متوافقة مع الإرشادات السريرية.
لقد قمنا بتلخيص الأداء الحالي لنماذج اللغة الكبيرة في تشخيص المرضى، واستجواب المرضى، وفحص المرضى ضمن الطب السريري في الجدول التكميلي 3. في الواقع، أظهرت GPT-4 نتائج متفوقة و
الجدول 1 | كابا فليس لمختلف المحفزات في نماذج مختلفة
نموذج
مُحفِّز
كابا فليس
فترة الثقة 95%
جي بي تي-4 ويب
IO
0.525
0.523
0.527
0-قطن
0.450
0.448
0.452
P-COT
0.334
0.332
0.٣٣٧
تعفن
0.467
0.465
0.470
واجهة برمجة التطبيقات GPT-4
IO
0.288
0.286
0.290
0-COT
0.067
0.065
0.069
بي-كوت
0.331
0.330
0.333
تعفن
0.205
0.203
0.206
جي بي تي-4-API-0
IO
0.525
0.523
0.526
0-COT
0.285
0.283
0.287
P-COT
0.660
0.658
0.661
تعفن
0.٤٥١
0.449
0.453
بارد
IO
0.374
0.372
0.376
0-قطن
0.355
0.353
0.357
P-COT
0.٣٢٣
0.321
0.326
تعفن
0.180
0.178
0.182
جي بي تي-3.5-ويب
IO
0.٤٠٩
0.407
0.411
0-قطن
-0.002
-0.004
0.000
P-COT
0.276
0.274
0.278
تعفن
0.016
0.014
0.018
واجهة برمجة التطبيقات gpt-3.5
IO
0.188
0.186
0.190
0-قطن
0.004
0.002
0.006
P-COT
0.031
0.029
0.033
تعفن
0.014
0.012
0.016
جي بي تي-3.5-API-0
IO
0.984
0.983
0.986
0-قطن
0.461
0.459
0.464
P-COT
0.533
0.531
0.535
تعفن
0.581
0.578
0.583
جي بي تي-3.5-إف تي
IO
0.162
0.160
0.164
0-قطن
0.021
0.020
0.023
P-COT
0.065
0.063
0.067
تعفن
0.033
0.032
0.035
جي بي تي-3.5-إف تي-0
IO
0.982
0.980
0.984
0-COT
0.412
0.410
0.414
P-COT
0.355
0.353
0.356
تعفن
0.398
0.396
0.400
أظهر أداءً متفوقًا مقارنةً بكل من GPT-3.5 وBard في مجال الطب السريريفي دراستنا، من خلال دمج أداء الأنواع الأربعة من المحفزات عبر نماذج مختلفة، كما هو موضح في الشكل 1، أظهر gpt-4-Web، المعروف أيضًا باسم ChatGPT-4، أداءً أكثر توازنًا وبارزًا.
لقد قامت الأبحاث السابقة بتقييم GPT-4 بشكل أساسي من خلال واجهات الويب في الطب السريري. دراسة فares وآخرون.تم الوصول إلى GPT-4 عبر واجهة برمجة التطبيقات وضبط درجات حرارة مختلفة (درجة الحرارة ) ووجدنا أن النموذج الذي تم ضبطه على درجة حرارة 0.3 كان أداؤه أفضل في الإجابة على الأسئلة المتعلقة بعلم العيون. كشفت دراستنا عن اختلافات في الاتساق والموثوقية بين درجات GPT-4 التي تم الوصول إليها عبر الويب ودرجات GPT-4 التي تم الوصول إليها من خلال واجهة برمجة التطبيقات (API). في دراستنا، وجدنا أنه من بين منتجات gpt-4-Web ذات إعدادات المعلمات المحددة، كان gpt-4-API بدرجة حرارة 0 (gpt-4-API-0) وgpt-4-API بدرجة حرارة 1، حيث أظهر gpt4-Web الأداء الأكثر بروزًا. وهذا يشير إلى أن ضبط المعلمات الداخلية لنماذج اللغة الكبيرة (LLMs) خلال المهام المختلفة يمكن أن يغير أداء هذه النماذج.
الشكل 4 | مخططات التشتت لكل إجابة. أ gpt-4-Web؛ ب gpt-4-API؛ ج gpt-4-API-0؛ د Bard؛ هـ gpt-3.5-Web؛ و gpt-3.5-API؛ ز gpt-3.5-API-0؛ ح gpt-3.5-ft؛ ط gpt-3.5-ft-0.
حسب علمنا، لم يتم بعد إجراء أبحاث تستكشف تأثير تحسين ChatGPT على الطب السريري. بالنسبة لنماذج اللغة الكبيرة الأخرى، في الدراسة التي أجراها كاران وآخرون, ميد-بالْم، وهو إصدار من فلان-بالْم تم ضبطه على التعليمات وليس متاحًا حاليًا للجمهور، تم تقييمه من قبل لجنة من الأطباء. وجدوا أن من الإجابات التي تم توليدها بواسطة ميد-بالْم كانت متوافقة مع الإجماع العلمي. في دراستنا، في إصدارات الضبط الدقيق من GPT-3.5، حيث يتم استخدام إدخال IO كجزء من مجموعة البيانات أثناء الضبط الدقيق، تحقق النموذجان من الضبط الدقيق اتساقًا قدره و عند استخدام إدخال IO. ومع ذلك، عندما يتم استخدام أنواع أخرى من التعليمات كمدخلات في نماذج الضبط الدقيق، تتدهور الأداء ( إلى ). علاوة على ذلك، لم يتمكن الضبط الدقيق من ضمان أن GPT-3.5 فهم تمامًا المنطق وراء كل نصيحة في مجموعة البيانات. ونتيجة لذلك، يمكن توليد إجابات مع منطق غير صحيح. قد تكون نتائج الضبط الدقيق غير المثالية في دراستنا بسبب إعداد مجموعة بيانات الضبط الدقيق، أو قدرة النموذج الأساسي، أو طرق الضبط الدقيق التي استخدمتها OpenAI.
بشكل عام، تشير مقارنة تسعة نماذج لغوية كبيرة إلى أن إعدادات المعلمات والضبط الدقيق، جنبًا إلى جنب مع هندسة التعليمات، يمكن أن تؤثر على أداء النماذج اللغوية الكبيرة. يتطلب تحسين النماذج اللغوية الكبيرة في الطب السريري مجموعة من الأساليب المتعددة، مع الأخذ في الاعتبار عوامل متنوعة، بما في ذلك بنية النموذج، وإعدادات المعلمات، وتقنيات الضبط الدقيق.
تلخص الجدول التكميلي 4 باختصار التطبيق الحالي لأنواع مختلفة من التعليمات في الطب السريري. الدراسات حول موضوع هندسة التعليمات في الطب السريري محدودة، ومعظم الدراسات تطبق تقنيات هندسة التعليمات مباشرة أو تقدم نظرة عامة على هندسة التعليمات في الطب السريري. لم تختلف دراسة كاران وآخرون بشكل كبير بين استراتيجيات التعليمات COT واستراتيجيات التعليمات القليلة. ومع ذلك، أظهرت التعليمات الذاتية، لا سيما في سياق مجموعة بيانات MedQA، تحسنًا بأكثر من . على العكس، أدت التعليمات الذاتية إلى انخفاض في الأداء لمجموعة بيانات PubMedQA. أظهر وان وآخرون أن التعليمات القليلة والتعليمات بدون أمثلة تظهر مستويات مختلفة من الحساسية والنوعية في تحويل روايات الأعراض باستخدام ChatGPT-4.
تشير هذه الدراسة، التي بُنيت على أبحاث سابقة، إلى أن هندسة التعليمات يمكن أن تؤثر على أداء النماذج اللغوية الكبيرة في الطب السريري. بناءً على النظريات الحالية لهندسة التعليمات، طورنا إطار عمل جديد
إطار التعليمات ROT، الذي أظهر أداءً جيدًا على gpt-4-Web. كما هو موضح في الشكل 2، حقق إطار التعليمات ROT أعلى معدل اتساق. وفقًا لتحليلنا الفرعي، مقارنةً بأنواع التعليمات الثلاثة الأخرى ضمن gpt-4-Web، كان أداء إطار التعليمات ROT أكثر توازنًا ووضوحًا. من حيث الشدة ‘القوية’، يتفوق إطار التعليمات ROT على إدخال IO، وليس أدنى بشكل كبير من التعليمات الأخرى على مستويات أخرى. بالمقابل، على الرغم من أن إجابات التعليمات P-COT عند الشدة ‘القوية’ أفضل من تلك الخاصة بإدخال IO، فإن أدائها عند مستوى الشدة ‘المحدود’ أسوأ بشكل ملحوظ من تلك الخاصة بالتعليمات الأخرى.
ومع ذلك، فإن تعزيز ROT ليس بالضرورة أفضل تعليمات للنماذج اللغوية الكبيرة الأخرى. على سبيل المثال، بالنسبة لخمس إصدارات من GPT-3.5، باستثناء كون التعليمات P-COT هي أفضل تعليمات لـ GPT-3.5-Web، كانت أفضل تعليمات للإصدارات الأخرى هي إدخال IO. بالنسبة لبارد، كانت أفضل تعليمات هي 0-COT. وهذا يشير إلى أنه يمكننا تجربة استراتيجيات تعليمات مختلفة للحصول على أفضل الاستجابات.
طلبت التعليمات ROT من النموذج اللغوي الكبير العودة إلى الأفكار السابقة وفحص ما إذا كانت مناسبة، مما قد يحسن من قوة الإجابة. علاوة على ذلك، يمكن أن يقلل التصميم القائم على ROT من حدوث إجابات خاطئة بشكل صارخ من gpt-4-Web. على سبيل المثال، فيما يتعلق باقتراح على مستوى ‘قوي’، “لا يُوصى باستخدام نعال مائلة جانبية للمرضى الذين يعانون من التهاب المفاصل العظمي في الركبة.” قدمت التعليمات ROT أربع إجابات ‘قوية’ وإجابة ‘متوسطة’ في خمس استجابات. في البداية، في هذه الاستجابة ‘المتوسطة’ (الملاحظة التكميلية 1)، قدم اثنان من “الخبراء” إجابات “محدودة”، وأجاب “خبير” واحد بـ”متوسطة”. بعد “النقاش”، اتفق جميع “الخبراء” على توصية ‘متوسطة’. كانت السبب النهائي هو أنه على الرغم من وجود أدلة عالية الجودة لدعم النصيحة، قد تكون هناك فوائد طفيفة محتملة لبعض الأفراد. ومن الجدير بالذكر أن الأسباب التي قدمها الخبيران لـ”التحديد” تبدو أكثر توافقًا مع البيان “يُوصى باستخدام نعال مائلة جانبية للمرضى الذين يعانون من التهاب المفاصل العظمي في الركبة.” وهذا يعني أن هذين “الخبيرين” لم يفهما النصيحة الطبية بشكل صحيح، كما ذكر “الخبير C” في الخطوة الخامسة: “يلاحظ أن النتائج مختلطة إلى حد ما، ولكن هناك اتفاق عام على أن الفوائد، إن وجدت، من النعال المائلة الجانبية محدودة.” ومع ذلك، بعد “النقاش”، تم اعتبار التوصية النهائية المعدلة والسبب مقبولين. بالإشارة إلى تطبيق TOT في لعبة النقاط 24 ، فإن التعليمات المصممة على طراز TOT وكذلك
يمكن أن تقدم التعليمات ROT في هذه الدراسة المزيد من الاحتمالات في كل خطوة من المهمة، ويمكن أن يُطلب من النموذج اللغوي الكبير العودة إلى الأفكار السابقة، بهدف تحفيز النموذج اللغوي الكبير على توليد إجابات أكثر دقة.
في الدراسات المستقبلية، مع الأخذ في الاعتبار الفعالية المتفاوتة للتعليمات ROT عبر نماذج مختلفة، قد تتضمن الاتجاهات المحتملة تحسينها بناءً على اختلافات النموذج. في المستقبل، يحتاج تصميم التعليمات ROT إلى أن يكون أكثر توافقًا مع السيناريوهات السريرية المختلفة. على سبيل المثال، يمكن أن يوفر إعداد أدوار بخلفيات مهنية متنوعة في تشخيص الأمراض وعلاجها نصائح أكثر تخصصًا. بالإضافة إلى ذلك، سيكون من الضروري دمج سيناريوهات تطبيق سريرية مختلفة، مثل اختبار وتحسين فعالية التعليمات ROT في تشخيص الأمراض وصياغة خطط علاج المرضى.
وصف ثلاث دراسات سابقة باختصار الموثوقية. أعاد يوشياسو وآخرون إنتاج استجابات غير دقيقة فقط. أفاد ووكر وآخرون أن التوافق الداخلي للمعلومات المقدمة كان كاملاً ( ) وفقًا للتقييم البشري. في دراسة فاريز وآخرون ، كرر المؤلفون التجارب 3 مرات واستخرجوا الاستجابات من ChatGPT-3.5؛ كانت قيم 0.769 لمجموعة BCSC و0.798 لمجموعة OphthoQuestions.
في هذه الدراسة، تم التحقيق في الموثوقية من خلال طرح نفس السؤال على النماذج اللغوية الكبيرة خمس مرات، ووفقًا لنتائج دراستنا، يُقترح أن النماذج اللغوية الكبيرة لا يمكنها دائمًا تقديم إجابات متسقة لنفس السؤال الطبي (الجدول 1 والشكل 4). استخدمت الدراسة قوة التوصية من AAOS كمعيار تقييم ووجدت أن النماذج اللغوية الكبيرة دائمًا ما تقدم قوى مختلفة لنفس النصيحة في إجابات متعددة. فقط إدخال IO في gpt-3.5-API-0 وgpt-3.5-ft-0، وكلاهما تم ضبطه عند درجة حرارة 0، أظهر موثوقية مثالية.
استنادًا إلى الوصف الموجود على الموقع الرسمي لـ OpenAI بشأن نقطة النهاية للصوت (https://platform.openai.com/docs/api-reference/audio/createTranscription)، “تؤثر درجة حرارة العينة، بين 0 و1، على العشوائية. القيم الأعلى، مثل 0.8، تزيد من العشوائية، بينما القيم الأقل، مثل 0.2، تجعل المخرجات أكثر تركيزًا وتحديدًا. يسمح إعداد 0 للنموذج بضبط درجة الحرارة تلقائيًا بناءً على احتمالية السجل حتى يتم الوصول إلى عتبات معينة.” نفترض أن هذه الآلية تنطبق أيضًا على نقطة النهاية للدردشة (https://platform.openai. com/docs/api-reference/chat/object)، على الرغم من أنه لم يتم ذكر ذلك صراحة في القسم المقابل. قد تختلف العتبات المحددة لـ GPT-3.5 وGPT-4، ويمكن أن تؤثر التعليمات على هذه العتبات، حيث لوحظت استجابات متسقة فقط في المجموعتين المقابلتين لإدخال IO في gpt-3.5-API-0 وgpt-3.5-ft-0. لذلك، يُوصى بأن تُطرح على النماذج اللغوية الكبيرة نفس الأسئلة عدة مرات للحصول على إجابات أكثر شمولاً وأن تستمر في طرح نفس السؤال على ChatGPT-4 حتى لا تقدم أي معلومات إضافية.
في الأبحاث المستقبلية، ضمن التطبيق السريري لنماذج اللغة الكبيرة، وخاصة من منظور المريض، يُعتبر التهاب المفاصل العظمي حالة شائعة ومتكررة ترتبط بطرق علاج متنوعة. ومن ثم، يمكن أن تلعب هندسة الطلبات دورًا حاسمًا في توجيه المرضى لطرح الأسئلة الطبية بشكل صحيح، مما قد يعزز من تعليم المرضى والإجابة على استفساراتهم بشكل أكثر فعالية. من جانب الأطباء، أظهرت دراستنا أن نموذج ROT الذي تم تطويره للإصدار الويب من GPT-4 حقق نتائج أفضل. ومع ذلك، يمكن أن تعقد متغيرات متعددة، مثل هياكل النماذج المختلفة والمعلمات، النتائج. لذلك، نعتقد أنه يجب دمج هندسة الطلبات مع تطوير النماذج، وضبط المعلمات، وتقنيات الضبط الدقيق لتطوير نماذج لغة كبيرة متخصصة ذات خبرة طبية، والتي يمكن أن تساعد الأطباء في اتخاذ القرارات السريرية.
تواجه تطبيقات هندسة الموجهات عدة تحديات في المستقبل. أولاً، هناك مسألة قوة الموجهات. قد تؤدي الموجهات المستندة إلى نفس الإطار إلى إجابات مختلفة بسبب تغييرات طفيفة في بعض الكلمات.. قد يتلقى المرضى أو الأطباء إجابات مختلفة حتى عند استخدامهم لمطالبات من نفس الإطار. ثانياً، تعتمد فعالية هندسة المطالبات على القدرات الجوهرية لنموذج اللغة الكبير نفسه. قد لا تكون المطالبات الفعالة لنموذج واحد مناسبة لنموذج آخر. يجب تطوير إرشادات لهندسة المطالبات مصممة للمرضى والأطباء وفقًا للمتطلبات المقابلة. بشكل عام، الدراسات المستقبلية ذات الصلة يجب فحص قابلية تطبيق وموثوقية العبارات وصياغة إرشادات ذات صلة.
من المهم أن بحثنا لا يتضمن تفاعلات أو تحقق في الوقت الحقيقي مع المتخصصين في الرعاية الصحية أو المرضى. ومع ذلك، فإن نهجنا في جمع البيانات يعتمد على تقييمات غير بشرية ذات طابع ذاتي، مما يقيم موضوعياً اتساق وموثوقية استجابات نماذج اللغة الكبيرة. علاوة على ذلك، تم تصميم الدراسة بناءً على الإجابات المتوقعة المستمدة من الإرشادات وافتقرت إلى التحقق الاستباقي. ومع ذلك، نعترف أن هذا المجال لا يزال غير مستكشف بشكل كاف وأن هناك العديد من التقنيات التي تستحق المزيد من التحقيق. تمثل دراستنا مجرد محاولة أولية في هذا المجال الواسع.
نظرًا لهذه القيود، يجب أن تهدف الأبحاث المستقبلية إلى تطوير كل من إطار تقييم مرجعي موضوعي لاستجابات نماذج اللغة الكبيرة وإطار تقييم بشري.يشمل المهنيين الصحيين والمرضى.
يمثل عملنا خطوة أولى في هذا المجال الواسع، مما يبرز أهمية مواصلة البحث لتطوير وتعزيز تطبيق نماذج اللغة الكبيرة في الرعاية الصحية. يجب أن تستكشف الدراسات المستقبلية المزيد من المنهجيات لتحسين فعالية وموثوقية نماذج اللغة الكبيرة في البيئات الطبية.
كشفت هذه الدراسة أن العبارات المختلفة كان لها تأثيرات متغيرة عبر نماذج مختلفة، وأن نموذج GPT-4-Web مع تحفيز ROT كان لديه أعلى مستوى من الاتساق. قد يحسن التحفيز المناسب دقة الردود على الأسئلة الطبية المهنية. علاوة على ذلك، يُنصح بطرح الأسئلة المدخلة عدة مرات لجمع رؤى أكثر شمولاً، حيث قد تختلف الردود مع كل استفسار. في مستقبل الرعاية الصحية بالذكاء الاصطناعي الذي يتضمن نماذج اللغة الكبيرة، سيكون تصميم العبارات جسرًا حيويًا في التواصل بين نماذج اللغة الكبيرة والمرضى، وكذلك بين نماذج اللغة الكبيرة والأطباء.
طريقة
اختيار المرض واختيار إرشادات الممارسة السريرية المستندة إلى الأدلة
تم استخدام إرشادات الممارسة السريرية المستندة إلى الأدلة (CPGs) من الأكاديمية الأمريكية لجراحي العظام (AAOS) لاختبار اتساق الإجابات المقدمة من نماذج اللغة الكبيرة (LLMs). مع أكثر من 39,000 عضو، تُعتبر AAOS أكبر جمعية طبية في العالم مختصة بأمراض الجهاز العضلي الهيكلي.، وتدعم إرشادات OA المقدمة من AAOS أدلة مفصلة وتقارير مراجعةتشمل إرشادات التهاب المفاصل العظمي نظام تقييم أدلة مفصل يعتمد على الأدلة البحثية وتغطي توصيات إدارة متنوعة، بما في ذلك العلاج الدوائي لالتهاب المفاصل العظمي، والعلاج الطبيعي، وتثقيف المرضى. إنها دليل موثوق وشامل بمحتوى مفصل. يمكن العثور على معلومات أكثر تفصيلاً في النسخة الكاملة من إرشادات التهاب المفاصل العظمي..
تصميم المطالبات
استنادًا إلى التطبيق الحالي لهندسة التحفيز في علوم الحاسوب ومهمة هذه الدراسة، تم تطبيق أربعة أنواع من التحفيز لهذه الدراسة: تحفيز IO، تحفيز 0-COT، تحفيز P-COT وتحفيز ROT. تم تطوير هذه الأنواع من التحفيز لاختبار توافق إجابات نماذج اللغة الكبيرة مع إرشادات AAOS ولتقييم موثوقية الإجابات في الطلبات المتكررة. تم تكليف نماذج اللغة الكبيرة بتوليد إجابة تتضمن درجة التقييم كالناتج النهائي.
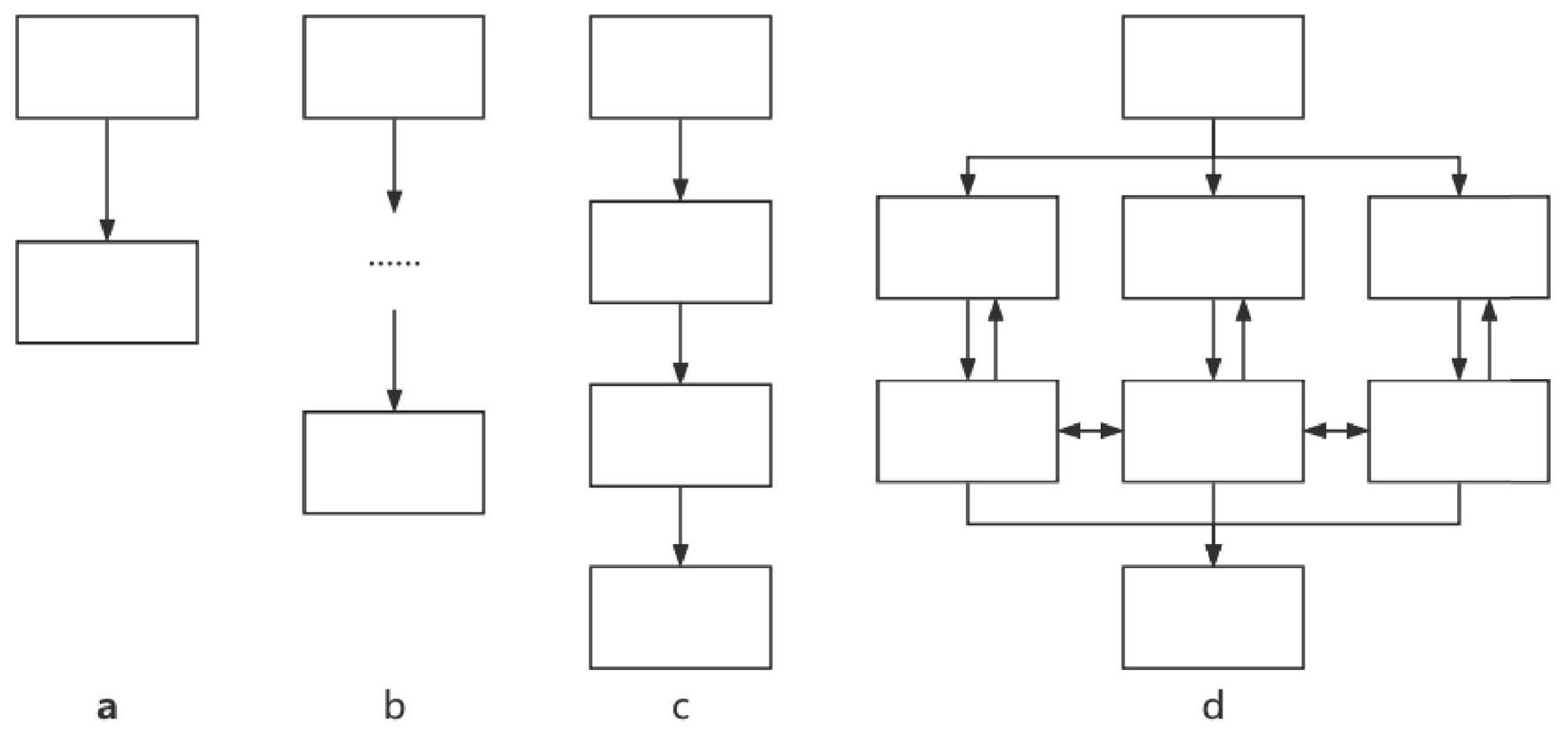
يوضح الشكل 5 والجدول 2 توضيحًا موجزًا وأمثلة لكل نوع من أنواع المطالبات. لمحتوى مفصل حول المطالبات الأربعة، يرجى الرجوع إلى الجدول التكميلي 5.
إعداد النموذج
استخدمنا ما مجموعه 9 نماذج لغوية كبيرة، وتفاصيلها موضحة في الجدول 3. تم الوصول إلى النسخ الافتراضية على الويب من GPT-4 وGPT-3.5 وBard عبر واجهات الويب، بينما تم الوصول إلى النماذج اللغوية الأخرى من خلال واجهة برمجة التطبيقات (API). تم إجراء التخصيص واستدعاء واجهة برمجة التطبيقات كما هو موضح في منصة OpenAI. بالنسبة لبيانات التخصيص، تم استخدام تحفيز IO وسبب كل نصيحة في AAOS لتشكيل بيانات التخصيص، ويمكن العثور على جميع بيانات التخصيص في الجدول التكميلية 6.
الشكل 5 | الرسم التخطيطي لأربعة كلمات تحفيزية توجه نماذج اللغة الكبيرة لإنتاج الإجابات. أ تحفيز IO؛ ب تحفيز 0 -COT؛ ج تحفيز P -COT؛ د تحفيز ROT. تم استلهام تصميم هذا الشكل من دراسة ياو وآخرون.، وحقوق الطبع والنشر مرخصة بموجب CC BY 4.0 DEED (https://creativecommons.org/licenses/by/4.0/).
الجدول 2 | تعريف وشرح كل موجه
مُحفِّز
تعريف
شرح موجز
تحفيز الإدخال والإخراج (IO)
أدخل التعليمات مباشرة
اعتبر النصيحة الطبية التالية: <أدخل النصيحة>
قيم النصيحة الطبية باستخدام المعايير التالية، واختر من الأعداد الصحيحة 1، 2، 3، 4
<أدخل المعايير>
تحفيز سلسلة الأفكار بدون عينة (0COT)
استخدم “فكر فيها خطوة بخطوة” على أساس IO لتوجيه LLM لإكمال التفكير.
<وصف مهمتك>
أكمل المهمة أعلاه خطوة بخطوة.
تحفيز سلسلة الأفكار المنفذة (P-COT)
قم بتقسيم المهمة إلى خطوات مختلفة لأداء العمليات المنطقية التي يجب أن يقوم بها نموذج اللغة.
<وصف مهمتك>
أكمل المهمة أعلاه خطوة بخطوة:
الخطوة 1…..
الخطوة 2…..
أظهر عملك في كل خطوة.
تحفيز تأمل الأفكار (ROT)
قم بتقسيم المهمة إلى خطوات مختلفة ووجه النموذج اللغوي الكبير للعودة إلى الخطوات السابقة من خلال السماح للنموذج بمحاكاة نمط المناقشة.
<وصف مهمتك>
تخيل أن 3 خبراء طبيين يكملون المهمة أعلاه خطوة بخطوة: من الخطوة 1 إلى الخطوة X: كل خبير يكمل التفكير بشكل مستقل.
بعد الخطوة X: يناقش الخبراء معًا ويعودون إلى الخطوات السابقة ويصلون في النهاية إلى اتفاق.
الجدول 3 | تفاصيل النماذج المضمنة
اسم الطراز
اسم الإصدار
تفاصيل
جي بي تي-4
جي بي تي-4 ويب
كانت النسخة الافتراضية من الويب لـ GPT-4 وملاحظات الإصدار في 20 يوليو 2023.
واجهة برمجة التطبيقات GPT-4
gpt-4-0613 مع المعلمات عند تقييم واجهة برمجة التطبيقات (درجة الحرارة = 1).
جي بي تي-4-API-0
gpt-4-0613 مع ضبط درجة الحرارة على 0 عند تقييم واجهة برمجة التطبيقات.
بارد
بارد
تقييم من خلال الويب وملاحظات الإصدار كانت في 30 أكتوبر 2023.
جي بي تي-3.5
جي بي تي-3.5-ويب
تقييم من خلال الويب وملاحظات الإصدار كانت في 17 أكتوبر 2023.
واجهة برمجة التطبيقات gpt-3.5
gpt-3.5-turbo-0613 مع المعلمات الافتراضية عند تقييم واجهة برمجة التطبيقات.
جي بي تي-3.5-API-0
gpt-3.5-turbo-0613 مع ضبط درجة الحرارة على 0 عند تقييم واجهة برمجة التطبيقات.
جي بي تي-3.5-إف تي
gpt-3.5-turbo-0613 مع تقنيات التخصيص والمعلمات الافتراضية (درجة الحرارة=1) عند تقييم واجهة برمجة التطبيقات.
جي بي تي-3.5-إف تي-0
gpt-3.5-ft مع ضبط درجة الحرارة على 0 عند تقييم واجهة برمجة التطبيقات.
الجدول 4 | مثال على حساب فرق المستوى
مدخل
مخرجات
اعتبر النصيحة الطبية التالية:
يمكن استخدام الإبر الجافة لتحسين الألم والوظيفة لدى المرضى الذين يعانون من التهاب المفاصل العظمي في الركبة.
قيم النصيحة الطبية باستخدام المعايير التالية، واختر من الأعداد الصحيحة 1، 2، 3، 4:
الدرجة 1 (الإجماع): لا توجد أدلة داعمة، وقد تكون النصيحة الطبية مبنية على الممارسة الشائعة أو رأي الخبراء.
الدرجة 2 (محدودة): مدعومة بأدلة من دراسة واحدة أو أكثر ذات جودة منخفضة مع نتائج متسقة، أو أدلة من دراسة واحدة ذات جودة متوسطة.
الدرجة 3 (متوسطة): مدعومة بأدلة من دراستين أو أكثر ذات جودة متوسطة مع نتائج متسقة، أو أدلة من دراسة واحدة عالية الجودة.
الدرجة 4 (قوي): مدعوم بأدلة من دراستين أو أكثر عالية الجودة مع نتائج متسقة.
اعتبارًا من تاريخ معرفتي في سبتمبر 2021، يمكن تصنيف استخدام الإبر الجافة لتحسين الألم والوظيفة لدى المرضى الذين يعانون من التهاب المفاصل العظمي في الركبة على أنه 2 (محدود). تأتي الأدلة على هذه الممارسة من عدد قليل من الدراسات ذات الجودة المنخفضة إلى المتوسطة التي تظهر بعض الفوائد المحتملة. ومع ذلك، هناك حاجة إلى دراسات أكثر صرامة وعالية الجودة لتأكيد هذه النتائج وإقامة توافق قوي في المجتمع الطبي.
يرجى استشارة متخصص في الرعاية الصحية للحصول على معلومات أو نصائح محدثة حيث إن حالة المعرفة الطبية والبحث تتطور باستمرار.
جمع البيانات ومعالجة البيانات
تم إعادة صياغة كل عنصر من إرشادات AAOS كتعليمات لتقييم قوة التوصية لمختلف نماذج اللغة الكبيرة، وأظهرت النتائج مستوى التوصية. كان مستوى التوصية من AAOS يعتمد على مستوى الأدلة، وأي ترقية أو تخفيض في قوة التوصية بناءً على الأدلة يتطلب موافقة أغلبية كبيرة من مجموعة العمل التابعة لـ AAOS.تمت مقارنة الإجابات المقدمة من نماذج اللغة الكبيرة مع تلك الخاصة بإرشادات AAOS، وتم تعويض كل مستوى مقدم من نماذج اللغة الكبيرة عن المستوى المقابل له في إرشادات AAOS، كما هو موضح في الجدول 4.
قمنا باستخراج 34 عنصرًا (الجدول التكميلية 7) من إرشادات الممارسة السريرية المستندة إلى الأدلة لالتهاب المفاصل العظمي المقدمة من AAOS. تم طرح كل نصيحة 5 مرات. عند التقييم عبر واجهات الويب، تم طرح كل سؤال في مربع حوار منفصل لتجنب تأثير السياق على الإجابات. عند تقييم واجهة برمجة التطبيقات، تم إكمال العملية بواسطة أكواد بلغة بايثون (الإصدار 3.9.7). أخيرًا، تم طرح كل طلب إجمالي 170 مرة، وتم طرح الطلبات الأربعة إجمالي 680 مرة لكل نموذج لغوي كبير. تم تسجيل إجابة كل سؤال. كانت الإجابات التي لم تتبع تعليمات الطلب تعتبر بيانات غير صالحة.
مقاييس النتائج والتحليل الإحصائي
تم إجراء التحليل الإحصائي باستخدام SPSS 23.0 (IBM، نيويورك، نيويورك، الولايات المتحدة الأمريكية) وPython (الإصدار 3.9.7). تم استخدام الاتساق والموثوقية لتقييم أداء نماذج اللغة الكبيرة. يُعرف الاتساق بأنه النسبة المئوية للحالات التي يكون فيها الفارق في المستوى يساوي صفر. لمقارنة الاتساق، قمنا بتجميع البيانات الفئوية المجمعة في فئة ذات فرق رتبة يساوي 0 وأخرى ذات فرق رتبة لا يساوي 0 ثم أجرينا اختبار كاي-تربيع، اختبار فيشر الدقيق، أو تصحيح الاستمرارية لياتس.تم استخدام تصحيح بونفيروني للمقارنات المتعددةتشير الموثوقية إلى قابلية تكرار الاستجابات لنفس الأسئلة وتم تقييمها باستخدام اختبار فليز كابا. تم تفسير قيم فليز كابا استنادًا إلى الدراسات السابقة.تعتبر دليلاً على عدم الموثوقية )، موثوقية طفيفة ( موثوقية عادلةموثوقية معتدلةموثوقية كبيرة )، أو موثوقية شبه مثالية ( تم التعامل مع البيانات غير الصالحة وفقًا لإجراءات البيانات غير الصالحة في التحليل الإحصائي..
ملخص التقرير
معلومات إضافية حول تصميم البحث متاحة في ملخص تقارير أبحاث Nature المرتبط بهذه المقالة.
توفر البيانات
الإجابات الأصلية لـ gpt-يمكن العثور عليه في الملفات التكميلية للنسخة الأولية من هذه المقالة علىhttps://www.researchsquare. com/article/rs-3336823/v1، وغيرها متاحة على https://doi.org/10. 6084/m9.figshare. 25232381 على figShare.
توفر الشيفرة
رموز تحليل البيانات واستدعاءات واجهة برمجة التطبيقات متاحة فيhttps://doi.org/10. 6084/m9.figshare. 25232381 على figShare.
تاريخ الاستلام: 8 سبتمبر 2023؛ تاريخ القبول: 5 فبراير 2024؛ نُشر على الإنترنت: 20 فبراير 2024
References
Lee, P., Bubeck, S. & Petro, J. Benefits, Limits, and Risks of GPT-4 as an AI Chatbot for Medicine. N. Engl. J. Med. 388, 1233-1239 (2023).
Waisberg, E. et al. GPT-4: a new era of artificial intelligence in medicine. Ir. J. Med. Sci. 192, 3197-3200 (2023).
Scanlon, M., Breitinger, F., Hargreaves, C., Hilgert, J.-N. & Sheppard, J. ChatGPT for digital forensic investigation: The good, the bad, and the unknown. Forensic Science International: Digital Investigation (2023).
Kanjee, Z., Crowe, B. & Rodman, A. Accuracy of a Generative Artificial Intelligence Model in a Complex Diagnostic Challenge. JAMA 330, 78-80 (2023).
Cai, L. Z. et al. Performance of Generative Large Language Models on Ophthalmology Board Style Questions. Am. J. Ophthalmol. 254, 141-149 (2023).
Walker, H. L. et al. Reliability of Medical Information Provided by ChatGPT: Assessment Against Clinical Guidelines and Patient Information Quality Instrument. J. Med. Internet Res. 25, e47479 (2023).
Yoshiyasu, Y. et al. GPT-4 accuracy and completeness against International Consensus Statement on Allergy and Rhinology: Rhinosinusitis. Int Forum Allergy Rhinol. 13, 2231-2234 (2023).
Singhal, K. et al. Large language models encode clinical knowledge. Nature 620, 172-180 (2023).
Omiye, J. A., Lester, J. C., Spichak, S., Rotemberg, V. & Daneshjou, R. Large language models propagate race-based medicine. NPJ digital Med. 6, 1-4 (2023).
Strobelt, H. et al. Interactive and Visual Prompt Engineering for Adhoc Task Adaptation with Large Language Models. IEEE Trans. Vis. Comput. Graph. 29, 1146-1156 (2023).
Wei, J. et al. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. Preprint at: https://arxiv.org/abs/2201.11903 (2023).
Yao, S. et al. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. Preprint at: https://arxiv.org/abs/2305.10601 (2023).
Meskó, B. Prompt Engineering as an Important Emerging Skill for Medical Professionals: Tutorial. J. Med. Internet Res. 25, e50638 (2023).
Fischer, M., Bartler, A. & Yang, B. Prompt tuning for parameter-efficient medical image segmentation. Med. image Anal. 91, 103024 (2023).
Toyama, Y. et al. Performance evaluation of ChatGPT, GPT-4, and Bard on the official board examination of the Japan Radiology Society. Jpn. J. Radiol. 42, 201-207 (2023).
Kozachek, D. Investigating the Perception of the Future in GPT-3, -3.5 and GPT-4. C&C ’23: Creativity and Cognition, 282-287 (2023).
Safiri, S. et al. Global, regional and national burden of osteoarthritis 1990-2017: a systematic analysis of the Global Burden of Disease Study 2017. Ann. Rheum. Dis. 79, 819-828 (2020).
Perruccio, A. V. et al. Osteoarthritis Year in Review 2023: Epidemiology & therapy. Osteoarthr. Cartil. S1063-4584, 00990-00991 (2023).
Pigott, T. D. A Review of Methods for Missing Data. Educ. Res. Eval. 7, 353-383 (2001).
Koga, S., Martin, N. B. & Dickson, D. W. Evaluating the performance of large language models: ChatGPT and Google Bard in generating differential diagnoses in clinicopathological conferences of neurodegenerative disorders. Brain Pathol., e13207, https://doi.org/ 10.1111/bpa. 13207 (2023).
Lim, Z. W. et al. Benchmarking large language models’ performances for myopia care: a comparative analysis of ChatGPT-3.5, ChatGPT4.0, and Google Bard. EBioMedicine 95, 104770 (2023).
Fraser, H. et al. Comparison of Diagnostic and Triage Accuracy of Ada Health and WebMD Symptom Checkers, ChatGPT, and Physicians for Patients in an Emergency Department: Clinical Data Analysis Study. JMIR mHealth uHealth 11, e49995 (2023).
Ali, R. et al. Performance of ChatGPT and GPT-4 on Neurosurgery Written Board Examinations. Neurosurgery 93, 1353-1365 (2023).
Fowler, T., Pullen, S. & Birkett, L. Performance of ChatGPT and Bard on the official part 1 FRCOphth practice questions. Br. J. Ophthalmol., bjo-2023-324091, https://doi.org/10.1136/bjo-2023-324091 (2023).
Passby, L., Jenko, N. & Wernham, A. Performance of ChatGPT on dermatology Specialty Certificate Examination multiple choice questions. Clin. Exp. Dermatol., llad197, https://doi.org/10.1093/ced/llad197 (2023).
Smith, J., Choi, P. M. & Buntine, P. Will code one day run a code? Performance of language models on ACEM primary examinations and implications. Emerg. Med. Australas. 35, 876-878 (2023).
Pushpanathan, K. et al. Popular large language model chatbots’ accuracy, comprehensiveness, and self-awareness in answering ocular symptom queries. iScience 26, 108163 (2023).
Antaki, F. et al. Capabilities of GPT-4 in ophthalmology: an analysis of model entropy and progress towards human-level medical question answering. Br J Ophthalmol, bjo-2023-324438, https://doi.org/10. 1136/bjo-2023-324438 (2023).
Wei, W. I. et al. Extracting symptoms from free-text responses using ChatGPT among COVID-19 cases in Hong Kong. Clin. Microbiol Infect. https://doi.org/10.1016/j.cmi.2023.11.002 (2023).
Kleinig, O. et al. How to use large language models in ophthalmology: from prompt engineering to protecting confidentiality. Eye https://doi. org/10.1038/s41433-023-02772-w (2023).
Akinci D’Antonoli, T. et al. Large language models in radiology: fundamentals, applications, ethical considerations, risks, and future directions. Diagnostic Interventional Radiol. https://doi.org/10.4274/ dir.2023.232417 (2023).
Antaki, F., Touma, S., Milad, D., El-Khoury, J. & Duval, R. Evaluating the Performance of ChatGPT in Ophthalmology: An Analysis of Its Successes and Shortcomings. Ophthalmol. Sci. 3, 100324 (2023).
Zhu, K. et al. PromptBench: Towards Evaluating the Robustness of Large Language Models on Adversarial Prompts. Preprint at https:// arxiv.org/abs/2306.04528v4 (2023).
Newsroom. AAOS Updates Clinical Practice Guideline for Osteoarthritis of the Knee, https://www.aaos.org/aaos-home/ newsroom/press-releases/aaos-updates-clinical-practice-guideline-for-osteoarthritis-of-the-knee/ (2021).
The American Academy of Orthopaedic Surgeons Board of Directors. Management of Osteoarthritis of the Knee (Non-Arthroplasty) https:// www.aaos.org/globalassets/quality-and-practice-resources/ osteoarthritis-of-the-knee/oak3cpg.pdf (2019).
Goldstein, M., Wolf, E. & Dillon, W. On a test of independence for contingency tables. Commun. Stat. Theory Methods 5, 159-169 (1976).
Gurcan, A. T. & Seymen, F. Clinical and radiographic evaluation of indirect pulp capping with three different materials: a 2-year follow-up study. Eur. J. Paediatr. Dent. 20, 105-110 (2019).
Armstrong, R. A. When to use the Bonferroni correction. Ophthalmic Physiol. Opt. 34, 502-508 (2014).
Pokutnaya, D. et al. Inter-rater reliability of the infectious disease modeling reproducibility checklist (IDMRC) as applied to COVID-19 computational modeling research. BMC Infect. Dis. 23, 733 (2023).
Zapf, A., Castell, S., Morawietz, L. & Karch, A. Measuring inter-rater reliability for nominal data – which coefficients and confidence intervals are appropriate? BMC Med. Res. Methodol. 16, 93 (2016).
شكر وتقدير
تم تمويل هذا العمل من قبل صندوق البحث والتطوير الرئيسي لوزارة التخطيط العلمي والتكنولوجي في سيتشوان. رقم المنحة 2022YFS0372 (استلمها J.L.) وصندوق البحث للشباب لوزارة التخطيط العلمي والتكنولوجي في سيتشوان. رقم المنحة 23NSFSC4894 (استلمها X.C.).
مساهمات المؤلفين
لي وانغ وشي تشين هما المصممان الرئيسيان والمنفذان للدراسة والمخطوطة. لقد قاما بالوصول إلى البيانات والتحقق منها ويتشاركان في التأليف الأول. جيان لي مسؤول عن اقتراح التعديلات على المخطوطة وقرار تقديم المخطوطة. تشي لي ساهم في الدراسة من خلال إدارة والإشراف على أعمال التعديل وتقديم ملاحظات نقدية خلال عملية التعديل الرئيسية. شيانغ وين دينغ وهاو وين هما مستشاران في المعرفة المتعلقة بعلوم الكمبيوتر. مينغ كي يو ووي تشي ليو يشاركان في صياغة المخطوطة.
مركز الطب الرياضي، مستشفى غرب الصين، جامعة سيتشوان، تشنغدو، الصين.قسم جراحة العظام ومعهد أبحاث جراحة العظام، مستشفى غرب الصين، جامعة سيتشوان، تشنغدو، الصين.مدرسة شنتشن الدولية للدراسات العليا، جامعة تسينغhua، بكين، الصين.ساهم هؤلاء المؤلفون بالتساوي: لي وانغ، شي تشين.البريد الإلكتروني: liqi_sports@scu.edu.cn; lijian_sportsmed@163.com
Prompt engineering in consistency and reliability with the evidence-based guideline for LLMs
(D) Check for updates
Li Wang , Xi Chen , XiangWen Deng , Hao Wen , MingKe You , WeiZhi Liu , Qi Li Jian Li (B)
Abstract
The use of large language models (LLMs) in clinical medicine is currently thriving. Effectively transferring LLMs’ pertinent theoretical knowledge from computer science to their application in clinical medicine is crucial. Prompt engineering has shown potential as an effective method in this regard. To explore the application of prompt engineering in LLMs and to examine the reliability of LLMs, different styles of prompts were designed and used to ask different LLMs about their agreement with the American Academy of Orthopedic Surgeons (AAOS) osteoarthritis (OA) evidence-based guidelines. Each question was asked 5 times. We compared the consistency of the findings with guidelines across different evidence levels for different prompts and assessed the reliability of different prompts by asking the same question 5 times. gpt- 4 -Web with ROT prompting had the highest overall consistency ( ) and a significant performance for strong recommendations, with a total consistency of . The reliability of the different LLMs for different prompts was not stable (Fleiss kappa ranged from -0.002 to 0.984 ). This study revealed that different prompts had variable effects across various models, and the gpt- 4 -Web with ROT prompt was the most consistent. An appropriate prompt could improve the accuracy of responses to professional medical questions.
Large language models (LLMs) have shown good performance in various natural language processing (NLP) tasks, such as summarizing, translating, code synthesis, and even logical reasoning . There is growing interest in exploring the potential of LLMs in medicine. They have been used in related medical studies in case diagnoses, medical examinations, and guideline consistency assessments .
However, the current performance of LLMs in the medical field is not perfect. In the diagnosis of complex cases, of the GPT-4related diagnoses were consistent with the final diagnosis, and an average consistency of was shown with the guidelines for digestive system diseases . Eighteen percent of the Med-PaLMrelated answers were judged to contain inappropriate or incorrect content . Moreover, LLMs may generate different answers to the same question, and self-consistency has always been a crucial parameter for assessing the performance of LLMs . Further research and exploration on how to optimize its performance in the medical field are necessary .
Prompt engineering is a new discipline that focuses on the development and optimization of prompt words, thereby helping users apply LLMs to various scenarios and research fields. In computer science, LLMs can obtain ideal and stable answers through prompt engineering, and adopting different prompts will affect the performance of LLMs, which is somewhat reflected in mathematical problems . The newly used prompt designs currently include chain of thoughts (COT) prompting and tree of thoughts (TOT) prompting . With the proposal of the COT and TOT theories in the computer science LLM field, corresponding prompts have been developed and exhibited improved performance in mathematical problems .
In clinical medicine, a few studies have shown the application of prompts such as COT prompting, few-shot prompting and self-consistency prompting in the study of Karan et al. . In addition, the study of Bertalan et al. . Summarizes the current state of research on prompt engineering and provides a tutorial for prompt engineering for medical professionals. Overall, few studies have focused on the differences in the performance of different prompts in medical questions or examined whether there is a need to develop
prompts specifically for medical questions. In summary, the application of LLMs in medicine is currently thriving. However, most of the current research seems to focus more on the results of using LLMs rather than how to better use LLMs in clinical medicine. Testing the reliability of LLMs in answering medical questions, using different prompts, and even developing prompts specifically for medical questions could change the application of LLMs in medicine and future research. It is important to investigate whether and how prompt engineering may improve the performance of LLMs in answering medical-related questions. Additionally, other factors, such as the type of model architecture, model parameters, training data, and fine-tuning techniques, can influence the performance of .
To explore the influence of different types of prompts combined with other factors on the performance of LLMs, we conducted a pilot study on osteoarthritis (OA)-related questions. The 2019 Global Burden of Disease tool identified OA as one of the most prevalent and debilitating diseases . In terms of prevalence and impact, OA is one of the most prevalent musculoskeletal disorders and affects a substantial portion of the global population, especially elderly individuals . This widespread impact makes it a public health concern of significant importance, and the management of OA is complex and multifaceted, encompassing pain control, physical therapy, lifestyle modifications, and, in some cases, surgical interventions . Given that it is a common disease with a large patient population and complex management, patients and doctors may seek relevant professional knowledge online, which includes LLMs. Therefore, investigating the performance of LLMs with respect to OA-related questions could serve as an appropriate example of how to improve answer quality through prompt engineering. The potential of prompt engineering to assist both doctors and patients in medical queries of common diseases could also be explored by using LLMs.
Our research applied the same set of prompts to different LLMs, asking OA-related questions and aiming to explore the effectiveness of prompt engineering. We hypothesized that different prompts would result in different consistency and reliability and that the effectiveness of prompts on LLMs would be influenced by various factors.
Results
Consistency
The results indicated that gpt-4-Web outperformed the other models, as shown in Fig. 1. The consistency rates for the four prompts in gpt-4-Web
ranged between and . Other consistency rates were also observed with IO prompting in the gpt-3.5-ft-0 at 55.3% and ROT prompting in gpt-4-API-0 at . The consistency rates for the other models were all less than to .
The combination of gpt-4-Web and ROT generated the treatment recommendation most adherent to the clinical guidelines. The top 10 combinations of prompts and models are shown in Fig. 2. Specifically, the consistency of different prompts with the guidelines in a series of GPT-4 models ranged from to ; in a series of GPT-3.5 models, including fine-tuned versions, it ranged from to . For different prompts in Bard, the consistency ranged from to . For the three versions of the GPT-4, the ROT prompting was consistently the best prompt, ranging from to . For five versions of the GPT-3.5, except for P-COT prompting, which was the best prompt for gpt-3.5-Web at , the best prompt for the other versions was IO prompting (ranging from to ). For Bard, the best prompt was 0-COT prompting at .
Subgroup analysis
The AAOS categorizes recommendation levels based on the strength of supporting evidence, ranging from strong to moderate, limited, and consensus. We hypothesized that different levels of evidence strength might lead to variations in consistency. To explore this, we conducted a subgroup analysis to examine the performance differences of various prompts across different evidence strength levels. Within the same model, we conducted multiple comparisons between different prompts, with a focus on the performance of the outperformed gpt- 4 -Web across various evidence strengths. The results of the subgroup analysis and the multiple comparisons within each model can be found in Supplementary Table 1.
Strong level. The consistency of the different prompts in the different models at the strong level is shown in Fig. 3a. Eight pieces of advice are rated as strong by the AAOS guidelines, with 40 responses for each prompt. According to the multiple comparisons of consistency in gpt-4Web, the percentage differences in the ROT prompting (77.5%) and P-COT prompting (75%) scores were significantly greater than that in the IO prompting ( ). According to the other models, the consistency of the IO prompting at gpt-3.5-ft and gpt-3.5-ft-0 was and , respectively.
Fig. 1 | Consistency of different prompts in different models. Detailed information of each model could be found in Table 3.
Fig. 2 | Top 10 consistency. The vertical axis represents the combination of the chosen model and prompt, for example, ‘gpt-4-Web-ROT’ indicates that the selected model is gpt- , and the prompt is ROT prompting.
Fig. 3 | Consistency in different levels. a Strong; moderate; limited; consensus.
Moderate level. The consistency of the different prompts in the different models at the moderate level is shown in Fig. 3b. Eight pieces of advice were rated as moderate, with 40 responses for each prompt. According to the multiple comparisons of consistency in gpt-4-Web ( to ), there was no significant difference between the groups. According to the other models, the consistency of the IO prompting in Bards is .
Limited level. The consistency of the different prompts in the different models at the limited level is shown in Fig. 3c. Sixteen pieces of advice had a limited recommendation rating, with 80 responses for each prompt. According to the multiple comparisons of consistency in gpt-4-Web, after Bonferroni correction, the percentage of patients with a 0 -point difference in P-COT prompting ( ) was significantly lower than that in ROT prompting ( ) and IO prompting ( ). In the other models, all the consistency is lower than .
Consensus level. The two pieces of advice were recommended upon consensus. Considering the small sample size, no statistical test was conducted, and the consistency of different prompts in different models is shown in Fig. 3d.
Reliability of LLMs
The Fleiss kappa values of the 4 prompts in the 9 models are shown in Table 1. and the values ranged from -0.002 to 0.984 . Detailed statistical data are shown in Supplementary Table 2.
The kappa values for IO prompting in gpt-3.5-ft-0 and gpt-3.5-API-0 were nearly 1 ( 0.982 and 0.984 , respectively). In the corresponding scatter plots, as shown in Fig. 4g, i, points that match the answers with the guidelines fall on the baseline (level difference ). A positive difference indicates being above the baseline, while a negative difference indicates being below it. Starting from the first data point of IO prompting in Fig. 4g, i shows that almost every set of five points lies on a horizontal line. This pattern indicates that the models consistently generate the same response five times in a row. In contrast, the responses in other circumstances exhibit more variability. The kappa of P-COT prompting in response to the gpt-4-API-0 was 0.660 . The other kappa values are all lower than 0.6 . For the gpt-4-Web, the Fleiss kappa results indicate that the reliability of each prompt is fair to moderate ( 0.334 to 0.525 ). Overall, IO prompting in the gpt- and gpt- API0 trials demonstrated perfect reliability. P-COT prompting in the gpt-4-API-0 indicated substantial reliability, and others were moderate or lower.
Invalid data and corresponding processing measures
There were three categories of invalid data: Category A: the final rating was not provided. Category B: the rating was not an integer. All the invalid data were processed according to the invalid data procedure . In the calculation of Fleiss kappa, all invalid data in category A are considered to constitute an independent classification, and the invalid data in category are treated as different classifications based on the values (if the rating is ‘ 2 or 3 ‘, it is recorded as 2.5 ) generated by the LLMs. In the creation of the scatter plot (Fig. 4), invalid data from category A were labeled missing data. Notably, a significant amount of invalid data from category A was observed in multiple datasets; for instance, of the responses to 0 -COT prompting were recorded in gpt-3.5-API-0. Conversely, the proportion of invalid data in gpt-4-Web was relatively small (a total of 14 out of 680 across all four prompts).
Discussion
The results of this study suggested that prompt engineering may change the accuracy of LLMs in answering medical questions. Additionally, LLMs do not always provide the same answer to the same medical questions. The combination of ROT prompting and gpt-4-Web outperformed the other combinations in providing professional OA knowledge consistent with clinical guidelines.
We have summarized the current performance of LLMs in diagnosing patients, querying patients, and examining patients within clinical medicine in Supplementary Table 3. Indeed, GPT-4 has shown superior results and
Table 1 | Fleiss Kappa of different prompts in different models
Model
Prompt
Fleiss Kappa
95% CI
gpt-4-Web
IO
0.525
0.523
0.527
0-COT
0.450
0.448
0.452
P-COT
0.334
0.332
0.337
ROT
0.467
0.465
0.470
gpt-4-API
IO
0.288
0.286
0.290
0-COT
0.067
0.065
0.069
P-COT
0.331
0.330
0.333
ROT
0.205
0.203
0.206
gpt-4-API-0
IO
0.525
0.523
0.526
0-COT
0.285
0.283
0.287
P-COT
0.660
0.658
0.661
ROT
0.451
0.449
0.453
Bard
IO
0.374
0.372
0.376
0-COT
0.355
0.353
0.357
P-COT
0.323
0.321
0.326
ROT
0.180
0.178
0.182
gpt-3.5-Web
IO
0.409
0.407
0.411
0-COT
-0.002
-0.004
0.000
P-COT
0.276
0.274
0.278
ROT
0.016
0.014
0.018
gpt-3.5-API
IO
0.188
0.186
0.190
0-COT
0.004
0.002
0.006
P-COT
0.031
0.029
0.033
ROT
0.014
0.012
0.016
gpt-3.5-API-0
IO
0.984
0.983
0.986
0-COT
0.461
0.459
0.464
P-COT
0.533
0.531
0.535
ROT
0.581
0.578
0.583
gpt-3.5-ft
IO
0.162
0.160
0.164
0-COT
0.021
0.020
0.023
P-COT
0.065
0.063
0.067
ROT
0.033
0.032
0.035
gpt-3.5-ft-0
IO
0.982
0.980
0.984
0-COT
0.412
0.410
0.414
P-COT
0.355
0.353
0.356
ROT
0.398
0.396
0.400
exhibited superior performance compared to both GPT-3.5 and Bard in the field of clinical medicine . In our study, by combining the performance of the four types of prompts across different models, as shown in Fig. 1, gpt-4-Web, also known as ChatGPT-4, demonstrated a more balanced and prominent performance.
Previous research has primarily assessed GPT-4 through web interfaces in clinical medicine. The study of Fares et al. accessed GPT-4 via the API and set different temperatures (temperature ) and found that the model set at a temperature of 0.3 performed better in answering ophthalmology-related questions. Our study revealed differences in consistency and reliability between GPT-4 scores accessed via the web and GPT-4 scores accessed through the API. In our study, we found that among the gpt-4-Web products with specific parameter settings, gpt-4-API with a temperature of 0 (gpt-4-API-0) and gpt-4-API with a temperature of 1 , gpt4 -Web exhibited the most prominent performance. This indicated that adjusting the internal parameters of LLMs during different tasks can alter the performance of LLMs.
Fig. 4 | Scatter plots of each answer. a gpt-4-Web; b gpt-4-API; c gpt-4-API-0; d Bard; e gpt-3.5-Web; f gpt-3.5-API; g gpt-3.5-API-0; h gpt-3.5-ft; i gpt-3.5-ft-0.
To our knowledge, there has not yet been research exploring the impact of fine-tuning ChatGPT on clinical medicine. For other LLMs, in the study by Karan et al. , Med-PaLM, which is a version of Flan-PaLM that has been instruction prompt-tuned and is not currently publicly available, was evaluated by a panel of clinicians. They found that of the answers generated by Med-PaLM were consistent with the scientific consensus. For our study, in the fine-tuning versions of GPT-3.5, where IO prompting is used as the input part of the dataset during fine-tuning, the 2 fine-tuning models achieve consistencies of and when IO prompting is used for inputs. However, when other types of prompts are used as inputs in the fine-tuning models, the performance deteriorates ( to ). Furthermore, fine-tuning could not ensure that GPT-3.5 fully understood the rationale behind each piece of advice in the dataset. As a result, answers can be generated with incorrect rationales. The less-than-ideal fine-tuning results in our study might be due to the setup of the fine-tuning dataset, the capability of the base model or the fine-tuning methods employed by OpenAI.
Overall, the comparison of nine LLMs indicates that parameter settings and fine-tuning, along with prompt engineering, could influence the performance of LLMs. Improving LLMs in clinical medicine requires a combination of multiple approaches, accounting for various factors, including model architecture, parameter settings, and fine-tuning techniques.
Supplementary Table 4 briefly summarizes the current application of different types of prompts in clinical medicine. Studies on the topic of prompt engineering in clinical medicine are limited, and most studies primarily apply prompt engineering techniques directly or provide an overview of prompt engineering in clinical medicine. The study of Karan et al. did not significantly differ between the COT and few-shot prompting strategies. However, self-consistency prompting, particularly in the context of the MedQA dataset, showed an improvement of more than . Conversely, self-consistency led to a decrease in performance for the PubMedQA dataset. Wan et al. demonstrated that few-shot prompting and zero-shot prompting exhibit different levels of sensitivity and specificity in converting symptom narratives using the ChatGPT-4.
This study, built upon previous research, further indicated that prompt engineering could influence the performance of LLMs in clinical medicine. Based on current theories of prompt engineering, we developed a new
prompting framework, ROT prompting, which demonstrated good performance on the gpt-4-Web. As shown in Fig. 2, ROT prompting achieved the highest consistency rate. According to our subgroup analysis, compared to those of the other three types of prompts within gpt-4-Web, the ROT prompting performed more evenly and prominently. In terms of ‘strong’ intensity, ROT prompting is superior to IO prompting, and it is not significantly inferior to other prompts at other levels. In contrast, although answers of P-COT prompting at ‘strong’ intensity are better than those of IO prompting, its performance at the ‘limited’ intensity level is significantly worse than that of other prompts.
However, ROT promoting is not necessarily the best prompt for other LLMs. For instance, for five versions of GPT-3.5, except for P-COT prompting being the best prompt for GPT-3.5-Web, the best prompt for other versions was IO prompting. For Bard, the best prompt was 0-COT. This indicated that we could try different prompting strategies to obtain the best responses.
The ROT prompting asked LLM to return to previous thoughts and examine if they were appropriate, which may improve the robustness of the answer. Furthermore, the ROT-based design can minimize the occurrence of egregiously incorrect answers from the gpt-4-Web. For instance, regarding a ‘strong’ level suggestion, “Lateral wedge insoles are not recommended for patients with knee osteoarthritis.” ROT prompting provided four ‘strong’ answers and one ‘moderate’ answer in five responses. Initially, in this ‘moderate’ response (Supplementary Note 1), two “experts” provided “limited” answers, and one “expert” answered “moderate”. After “discussion”, all “experts” agreed on a ‘moderate’ recommendation. The final reason was that even though there was high-quality evidence to support the advice, there might still be slight potential benefits for some individuals. Notably, the reasons given by the two experts for “limiting” seem to be more in line with the statement “Lateral wedge insoles are recommended for patients with knee osteoarthritis.” This implies that these two “experts” did not fully understand the medical advice correctly, as “Expert C” mentioned in step five: “Observes that the results are somewhat mixed, but there’s a general agreement that the benefits, if any, from lateral wedge insoles are limited.” However, after the “discussion”, the final revised recommendation and reason were deemed acceptable. Referring to the application of TOT in the 24-point game , the prompt designed in the style of TOT as well as the
ROT prompting in this study could offer more possibilities at every step of the task, and LLM could be asked to return to previous thoughts, aiming to induce LLM to generate more accurate answers.
In future studies, considering the varying effectiveness of the ROT prompting across different models, a potential direction might involve optimizing it based on model differences. In the future, the design of the ROT prompting needs to be more closely aligned with different clinical scenarios. For instance, setting up roles with various professional backgrounds in disease diagnosis and treatment could provide more specialized advice. Additionally, incorporating different clinical application scenarios, such as testing and improving the effectiveness of ROT prompting in disease diagnosis and patient treatment plan formulation, will be crucial.
Three previous studies briefly described reliability. Yoshiyasu et al. reproduced inaccurate responses only. Walker et al. reported that the internal concordance of the provided information was complete ( ) according to human evaluation. In the study of Fares et al. , the authors repeated the experiments 3 times and extracted the responses from ChatGPT-3.5; the values were 0.769 for the BCSC set and 0.798 for the OphthoQuestions set.
In this study, reliability was investigated by asking LLMs the same question five times, and according to the results of our study, it is suggested that LLMs cannot always provide consistent answers to the same medical question (Table 1 and Fig. 4). The study used the strength of recommendation of the AAOS as an evaluation standard and found that LLMs always provide different strengths for the same advice in multiple answers. Only IO prompting in gpt-3.5-API-0 and gpt-3.5-ft-0, both of which were set at a temperature of 0 , demonstrated perfect reliability.
Based on the description on the official OpenAI website regarding the endpoint of Audio (https://platform.openai.com/docs/api-reference/audio/ createTranscription), “The sampling temperature, between 0 and 1 , affects randomness. Higher values, such as 0.8 , increase randomness, while lower values, such as 0.2 , make outputs more focused and deterministic. A setting of 0 allows the model to automatically adjust the temperature based on log probability until certain thresholds are met.” We hypothesize that this mechanism also applies to the endpoint of Chat (https://platform.openai. com/docs/api-reference/chat/object), although this is not explicitly stated in the corresponding section. The specific thresholds for GPT-3.5 and GPT-4 might differ, and the prompts could influence these thresholds, as consistent responses were observed only in the two groups corresponding to the IO prompting in gpt-3.5-API-0 and gpt-3.5-ft-0. Therefore, it is recommended that LLMs be asked the same questions several times to obtain more comprehensive answers and that they keep asking the ChatGPT-4 the same question until it does not provide any additional information.
In future research, within the clinical application of LLMs, particularly from the patient’s perspective, OA is a common and frequently occurring condition associated with various treatment methods. Hence, prompt engineering could play a crucial role in guiding patients to ask medical questions correctly, potentially enhancing patient education and answering their queries more effectively. On the side of doctors, our study demonstrated that the ROT developed for the web version of the gpt- 4 generated better results. However, multiple variables, such as different model architectures and parameters, can complicate outcomes. Therefore, we believe that prompt engineering should be combined with model development, parameter adjustment, and fine-tuning techniques to develop specialized LLMs with medical expertise, which could assist physicians in making clinical decisions.
The application of prompt engineering faces several challenges in the future. First, there is the issue of the robustness of prompts. Prompts based on the same framework may yield different answers due to minor changes in a few words . Patients or doctors might receive different answers even when using prompts from the same framework. Second, prompt engineering performance depends on the inherent capabilities of the LLM itself. Prompts effective for one model may not be suitable for another. Guidelines for prompt engineering tailored for patients and doctors need to be developed according to the corresponding requirements. Overall, future related studies
should examine the applicability and robustness of prompts and formulate relevant guidelines.
Importantly, our research does not include real-time interactions or validations with healthcare professionals or patients. However, our approach to data collection relies on nonhuman subjective scoring, objectively assessing the consistency and reliability of LLM responses. Furthermore, the study was designed based on expected answers derived from guidelines and lacked prospective validation. Nevertheless, we acknowledge that this field remains underexplored and that a multitude of techniques warrant further investigation. Our study represents only a preliminary foray into this vast domain.
Given these limitations, future research should aim to develop both an objective benchmark evaluation framework for LLM responses and a human evaluation framework involving healthcare professionals and patients.
Our work represents an initial step into this expansive domain, highlighting the importance of continuing research to refine and enhance the application of large language models in healthcare. Future studies should further explore various methodologies to improve the effectiveness and reliability of LLMs in medical settings.
This study revealed that different prompts had variable effects across various models, and gpt- 4 -Web with ROT prompting had the highest consistency. An appropriate prompt may improve the accuracy of responses to professional medical questions. Moreover, it is advisable to pose the input questions multiple times to gather more comprehensive insights, as responses may vary with each inquiry. In the future of AI healthcare involving LLMs, prompt engineering will serve as a crucial bridge in communication between LLMs and patients, as well as between LLMs and doctors.
Method
Disease selection and evidence-based CPG selection
The American Academy of Orthopedic Surgeons (AAOS) evidence-based clinical practice guidelines (CPGs) for OA were used to test the consistency of the answers given by the LLMs. With more than 39,000 members, the AAOS is the world’s largest medical association of musculoskeletal specialists , and the OA guidelines provided by the AAOS are supported by detailed evidence and review reports . The OA guidelines include a detailed evidence assessment system based on research evidence and cover various management recommendations, including drug treatment for OA, physical therapy, and patient education. It is an authoritative and comprehensive guide with detailed content. More detailed information can be found in the complete version of the OA guidelines .
Prompt design
Based on the current application of prompting engineering in computer science and the task of this study, four types of prompts were applied for this study: IO prompting, 0-COT prompting, P-COT prompting and ROT prompting. These types of prompts were developed to test the compliance of LLMs’ answers regarding the AAOS guidelines and to assess the reliability of the answers in repeated requests. LLMs were tasked with generating an answer that included the rating score as the final output.
A brief illustration and examples of each prompt type are shown in Fig. 5 and Table 2. For the detailed content of the four prompts, please refer to Supplementary Table 5.
Model setting
We utilized a total of 9 LLMs, the details of which are shown in Table 3. The default web versions of GPT-4, GPT-3.5 and Bard were accessed via web interfaces, while other LLMs were accessed through the Application Programming Interface (API). The fine-tuning and calling of an API were conducted as described in the OpenAI platform. For the fine-tuning data, the IO prompting and the rationale of each advice in AAOS were used to form the fine-tuning data, and all the fine-tuning data can be found in Supplementary Table 6.
Fig. 5 | The schematic diagram of four prompt words guiding LLMs to output answers. a IO prompting; b 0 -COT prompting; c P -COT prompting; d ROT prompting. The design of this figure was inspired by the study of Yao et al. , and the copyright is authorized under the CC BY 4.0 DEED (https://creativecommons.org/licenses/by/4.0/).
Table 2 | Definition and explanation of each prompt
Prompt
Definition
Brief explanation
Input-output (IO) prompting
Input the instruction directly
Consider the following medical advice: <insert the advice>
Rate the medical advice using the following criteria, and make a selection from integer 1,2,3,4
<insert the criteria>
0-shot-Chain of thought (0COT) prompting
Use “Think it step by step” on the base of IO to steer the LLM complete reasoning.
<Describe your task>
Complete the task above step by step.
Performed-Chain of thought (P-COT) prompting
Break down the task into different steps to perform what reasoning processes need to be conducted by the LLM.
<Describe your task>
Complete the task above step by step:
Step 1…..
Step 2…..
Show your work of each step.
Reflection of thoughts (ROT) prompting
Break down the task into different steps and steer the LLM to backtrack previous steps by let the LLM simulates the mode of discussion.
<Describe your task>
Imagine 3 medical experts are completing the task above step by step: Step 1 to Step X: Each expert independently completes reasoning.
After step X: Experts discuss together and backtrack previous steps and finally reach agreement.
Table 3 | Details of included models
Model name
Version name
Details
GPT-4
gpt-4-Web
The default web version of GPT-4 and the release notes were on July 20, 2023.
gpt-4-API
gpt-4-0613 with parameters when assessing API (temperature = 1).
gpt-4-API-0
gpt-4-0613 with setting temperature as 0 when assessing API.
Bard
Bard
Assess through web and the release notes were on October 30, 2023.
GPT-3.5
gpt-3.5-Web
Assess through web and the release notes were on October 17, 2023.
gpt-3.5-API
gpt-3.5-turbo-0613 with default parameters when assessing API.
gpt-3.5-API-0
gpt-3.5-turbo-0613 with setting temperature as 0 when assessing API.
gpt-3.5-ft
gpt-3.5-turbo-0613 with fine-tuning techniques and default parameters (temperature=1) when assessing API.
gpt-3.5-ft-0
gpt-3.5-ft with setting temperature as 0 when assessing API.
Table 4 | An example of calculating level difference
Input
Output
Consider the following medical advice:
Dry needling may be used to improve pain and function in patients with knee osteoarthritis.
Rate the medical advice using the following criteria, and make a selection from integer 1,2,3,4:
Score 1 (Consensus): There is no supporting evidence, and the medical advice is possibly based on common practice or expert opinion.
Score 2 (Limited): Supported by evidence from one or more low-quality studies with consistent findings, or evidence from a single moderate-quality study.
Score 3 (Moderate): Supported by evidence from two or more moderate-quality studies with consistent findings, or evidence from a single high-quality study.
Score 4 (Strong): Supported by evidence from two or more high-quality studies with consistent findings.
As of my knowledge cut-off in September 2021, the use of dry needling for the improvement of pain and function in patients with knee osteoarthritis may be rated as 2 (Limited). The evidence for this practice comes from a few low to moderate-quality studies showing some potential benefits. However, more rigorous, high-quality studies are needed to confirm these findings and establish a solid consensus in the medical community.
Please consult with a healthcare professional for updated information or advice as the state of medical knowledge and research is constantly evolving.
Data collection and data processing
Each item from the AAOS guidelines was reformatted as an instruction for assessing the strength of the recommendation to different LLMs, and the results showed the level of recommendation. The AAOS’s level of recommendation was based on the level of evidence, and any upgrade or downgrade of the recommendation strength based on evidence to the decision framework requires supermajority approval by the AAOS working group . The answers provided by the LLMs were compared to those of the AAOS guidelines, and each level provided by the LLMs was offset from the corresponding AAOS level, as shown in Table 4.
We extracted 34 items (Supplementary Table 7) from the evidencedbased OA CPG provided by the AAOS. Each piece of advice was asked 5 times. When assessing via web interfaces, each question was asked in a separate dialog box to avoid the influence of context on the answers. When assessing the API, the process was completed by means of codes in Python (version 3.9.7). Finally, each prompt was asked a total of 170 times, and the four prompts were asked a total of 680 times for each LLM. The answer to each question was recorded. Answers that did not follow the instructions of the prompt were considered invalid data.
Outcome measures and statistical analysis
Statistical analysis was conducted using SPSS 23.0 (IBM, New York, NY, USA) and Python (version 3.9.7). Consistency and reliability were used to evaluate the performance of the LLMs. Consistency is defined as the proportion of instances where the level gap equals zero. To compare consistency, we grouped the categorical data collected into a category with a rank difference of 0 and another with a rank difference not equal to 0 and then conducted the chi-square test, Fisher’s exact test, or Yates’s continuity correction . Bonferroni correction was used for multiple comparisons . Reliability refers to the repeatability of responses to the same questions and was assessed using the Fleiss kappa test. The values of Fleiss kappa, as interpreted based on previous studies , are considered to indicate no reliability ( ), slight reliability ( ), fair reliability ( ), moderate reliability ( ), substantial reliability ( ), or almost perfect reliability ( ). Invalid data were treated according to invalid data procedures in the statistical analysis .
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Data availability
The original answers for the gpt- can be found in the supplementary files of the preprint version of this article at https://www.researchsquare. com/article/rs-3336823/v1, and others are available at https://doi.org/10. 6084/m9.figshare. 25232381 on figShare.
Code availability
The codes for data analysis and API calls are available at https://doi.org/10. 6084/m9.figshare. 25232381 on figShare.
Received: 8 September 2023; Accepted: 5 February 2024;
Published online: 20 February 2024
References
Lee, P., Bubeck, S. & Petro, J. Benefits, Limits, and Risks of GPT-4 as an AI Chatbot for Medicine. N. Engl. J. Med. 388, 1233-1239 (2023).
Waisberg, E. et al. GPT-4: a new era of artificial intelligence in medicine. Ir. J. Med. Sci. 192, 3197-3200 (2023).
Scanlon, M., Breitinger, F., Hargreaves, C., Hilgert, J.-N. & Sheppard, J. ChatGPT for digital forensic investigation: The good, the bad, and the unknown. Forensic Science International: Digital Investigation (2023).
Kanjee, Z., Crowe, B. & Rodman, A. Accuracy of a Generative Artificial Intelligence Model in a Complex Diagnostic Challenge. JAMA 330, 78-80 (2023).
Cai, L. Z. et al. Performance of Generative Large Language Models on Ophthalmology Board Style Questions. Am. J. Ophthalmol. 254, 141-149 (2023).
Walker, H. L. et al. Reliability of Medical Information Provided by ChatGPT: Assessment Against Clinical Guidelines and Patient Information Quality Instrument. J. Med. Internet Res. 25, e47479 (2023).
Yoshiyasu, Y. et al. GPT-4 accuracy and completeness against International Consensus Statement on Allergy and Rhinology: Rhinosinusitis. Int Forum Allergy Rhinol. 13, 2231-2234 (2023).
Singhal, K. et al. Large language models encode clinical knowledge. Nature 620, 172-180 (2023).
Omiye, J. A., Lester, J. C., Spichak, S., Rotemberg, V. & Daneshjou, R. Large language models propagate race-based medicine. NPJ digital Med. 6, 1-4 (2023).
Strobelt, H. et al. Interactive and Visual Prompt Engineering for Adhoc Task Adaptation with Large Language Models. IEEE Trans. Vis. Comput. Graph. 29, 1146-1156 (2023).
Wei, J. et al. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. Preprint at: https://arxiv.org/abs/2201.11903 (2023).
Yao, S. et al. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. Preprint at: https://arxiv.org/abs/2305.10601 (2023).
Meskó, B. Prompt Engineering as an Important Emerging Skill for Medical Professionals: Tutorial. J. Med. Internet Res. 25, e50638 (2023).
Fischer, M., Bartler, A. & Yang, B. Prompt tuning for parameter-efficient medical image segmentation. Med. image Anal. 91, 103024 (2023).
Toyama, Y. et al. Performance evaluation of ChatGPT, GPT-4, and Bard on the official board examination of the Japan Radiology Society. Jpn. J. Radiol. 42, 201-207 (2023).
Kozachek, D. Investigating the Perception of the Future in GPT-3, -3.5 and GPT-4. C&C ’23: Creativity and Cognition, 282-287 (2023).
Safiri, S. et al. Global, regional and national burden of osteoarthritis 1990-2017: a systematic analysis of the Global Burden of Disease Study 2017. Ann. Rheum. Dis. 79, 819-828 (2020).
Perruccio, A. V. et al. Osteoarthritis Year in Review 2023: Epidemiology & therapy. Osteoarthr. Cartil. S1063-4584, 00990-00991 (2023).
Pigott, T. D. A Review of Methods for Missing Data. Educ. Res. Eval. 7, 353-383 (2001).
Koga, S., Martin, N. B. & Dickson, D. W. Evaluating the performance of large language models: ChatGPT and Google Bard in generating differential diagnoses in clinicopathological conferences of neurodegenerative disorders. Brain Pathol., e13207, https://doi.org/ 10.1111/bpa. 13207 (2023).
Lim, Z. W. et al. Benchmarking large language models’ performances for myopia care: a comparative analysis of ChatGPT-3.5, ChatGPT4.0, and Google Bard. EBioMedicine 95, 104770 (2023).
Fraser, H. et al. Comparison of Diagnostic and Triage Accuracy of Ada Health and WebMD Symptom Checkers, ChatGPT, and Physicians for Patients in an Emergency Department: Clinical Data Analysis Study. JMIR mHealth uHealth 11, e49995 (2023).
Ali, R. et al. Performance of ChatGPT and GPT-4 on Neurosurgery Written Board Examinations. Neurosurgery 93, 1353-1365 (2023).
Fowler, T., Pullen, S. & Birkett, L. Performance of ChatGPT and Bard on the official part 1 FRCOphth practice questions. Br. J. Ophthalmol., bjo-2023-324091, https://doi.org/10.1136/bjo-2023-324091 (2023).
Passby, L., Jenko, N. & Wernham, A. Performance of ChatGPT on dermatology Specialty Certificate Examination multiple choice questions. Clin. Exp. Dermatol., llad197, https://doi.org/10.1093/ced/llad197 (2023).
Smith, J., Choi, P. M. & Buntine, P. Will code one day run a code? Performance of language models on ACEM primary examinations and implications. Emerg. Med. Australas. 35, 876-878 (2023).
Pushpanathan, K. et al. Popular large language model chatbots’ accuracy, comprehensiveness, and self-awareness in answering ocular symptom queries. iScience 26, 108163 (2023).
Antaki, F. et al. Capabilities of GPT-4 in ophthalmology: an analysis of model entropy and progress towards human-level medical question answering. Br J Ophthalmol, bjo-2023-324438, https://doi.org/10. 1136/bjo-2023-324438 (2023).
Wei, W. I. et al. Extracting symptoms from free-text responses using ChatGPT among COVID-19 cases in Hong Kong. Clin. Microbiol Infect. https://doi.org/10.1016/j.cmi.2023.11.002 (2023).
Kleinig, O. et al. How to use large language models in ophthalmology: from prompt engineering to protecting confidentiality. Eye https://doi. org/10.1038/s41433-023-02772-w (2023).
Akinci D’Antonoli, T. et al. Large language models in radiology: fundamentals, applications, ethical considerations, risks, and future directions. Diagnostic Interventional Radiol. https://doi.org/10.4274/ dir.2023.232417 (2023).
Antaki, F., Touma, S., Milad, D., El-Khoury, J. & Duval, R. Evaluating the Performance of ChatGPT in Ophthalmology: An Analysis of Its Successes and Shortcomings. Ophthalmol. Sci. 3, 100324 (2023).
Zhu, K. et al. PromptBench: Towards Evaluating the Robustness of Large Language Models on Adversarial Prompts. Preprint at https:// arxiv.org/abs/2306.04528v4 (2023).
Newsroom. AAOS Updates Clinical Practice Guideline for Osteoarthritis of the Knee, https://www.aaos.org/aaos-home/ newsroom/press-releases/aaos-updates-clinical-practice-guideline-for-osteoarthritis-of-the-knee/ (2021).
The American Academy of Orthopaedic Surgeons Board of Directors. Management of Osteoarthritis of the Knee (Non-Arthroplasty) https:// www.aaos.org/globalassets/quality-and-practice-resources/ osteoarthritis-of-the-knee/oak3cpg.pdf (2019).
Goldstein, M., Wolf, E. & Dillon, W. On a test of independence for contingency tables. Commun. Stat. Theory Methods 5, 159-169 (1976).
Gurcan, A. T. & Seymen, F. Clinical and radiographic evaluation of indirect pulp capping with three different materials: a 2-year follow-up study. Eur. J. Paediatr. Dent. 20, 105-110 (2019).
Armstrong, R. A. When to use the Bonferroni correction. Ophthalmic Physiol. Opt. 34, 502-508 (2014).
Pokutnaya, D. et al. Inter-rater reliability of the infectious disease modeling reproducibility checklist (IDMRC) as applied to COVID-19 computational modeling research. BMC Infect. Dis. 23, 733 (2023).
Zapf, A., Castell, S., Morawietz, L. & Karch, A. Measuring inter-rater reliability for nominal data – which coefficients and confidence intervals are appropriate? BMC Med. Res. Methodol. 16, 93 (2016).
Acknowledgements
This work was funded by the Key Research and Development Fund of Sichuan Science and Technology Planning Department. Grant number 2022YFS0372 (received by J.L.) and the Youth Research Fund of Sichuan Science and Technology Planning Department. Grant number 23NSFSC4894 (received by X.C.).
Author contributions
Li Wang and Xi Chen are the main designers and executors of the study and manuscript. They have accessed and verified the data and share the first authorship. Jian Li is responsible for proposing revisions of the manuscript and the decision to submit the manuscript. Qi Li contributed to the study in managing and supervising the revision work and providing critical feedback during the major revision process. XiangWen Deng and HaoWen are consultants of knowledge related about computer science. MingKe You and WeiZhi Liu participate in the drafting of the manuscript.
Sports Medicine Center, West China Hospital, Sichuan University, Chengdu, China. Department of Orthopedics and Orthopedic Research Institute, West China Hospital, Sichuan University, Chengdu, China. Shenzhen International Graduate School, Tsinghua University, Beijing, China. These authors contributed equally: Li Wang, Xi Chen. e-mail: liqi_sports@scu.edu.cn; lijian_sportsmed@163.com