يعتبر المقيمون من الأطراف الثالثة الذكاء الاصطناعي أكثر تعاطفًا من البشر الخبراء Third-party evaluators perceive AI as more compassionate than expert humans
يعتبر المقيمون من الأطراف الثالثة الذكاء الاصطناعي أكثر تعاطفًا من البشر الخبراء
داريا أوفسيانكوفا, فيكتوريا أولديمبورغو دي ميلو & مايكل إنزليشت
يتصل التعاطف بنا ولكنه يتعرض للضغط في الظروف الصعبة. استكشفت هذه الدراسة كيف قام الأطراف الثالثون بتقييم الاستجابات التعاطفية التي تم إنشاؤها بواسطة الذكاء الاصطناعي مقابل الاستجابات البشرية من حيث التعاطف والاستجابة والتفضيل العام عبر أربعة تجارب مسجلة مسبقًا. قرأ المشاركون ( ) مطالبات التعاطف التي تصف تجارب شخصية ذات قيمة وقارنوا استجابات الذكاء الاصطناعي مع اختيار بشر غير خبراء أو خبراء. كشفت النتائج أن استجابات الذكاء الاصطناعي كانت مفضلة وتم تقييمها على أنها أكثر تعاطفًا مقارنةً بالاستجابات البشرية المختارة (الدراسة 1). ظل هذا النمط من النتائج قائمًا عندما تم الكشف عن هوية المؤلف (الدراسة 2)، وعندما تم مقارنة الذكاء الاصطناعي مع المستجيبين الخبراء في الأزمات (الدراسة 3)، وعندما تم الكشف عن هوية المؤلف لجميع المشاركين (الدراسة 4). اعتبر الأطراف الثالثون الذكاء الاصطناعي أكثر استجابة – ينقل الفهم والتحقق والرعاية – مما يفسر جزئيًا تصنيفات التعاطف الأعلى للذكاء الاصطناعي في الدراسة 4. تشير هذه النتائج إلى أن الذكاء الاصطناعي له فائدة قوية في السياقات التي تتطلب تفاعلًا تعاطفيًا، مع إمكانية تلبية الحاجة المتزايدة للتعاطف في سياقات التواصل الداعمة.
التعاطف أمر حيوي لتعزيز الوحدة الاجتماعية والتواصل الفعال. يسمح للأفراد بموازنة مصالحهم الخاصة مع رفاهية الآخرين من خلال تجارب ومشاعر مشتركة. يمكن أن يعزز التعاون والإيثار وسلوكيات المساعدة، مما يقوي الروابط الاجتماعية. نفسيًا، للتعاطف أيضًا تأثير مغذي على مستقبليه، بحيث يشعر الناس بالتحقق والفهم والترابط عندما يتعاطف الآخرون معهم. على الرغم من التأثير الإيجابي للتعاطف على مستقبليه، فإن الجهد المطلوب للتعبير عن التعاطف يمكن أن يكون مكلفًا ومرهقًا للشخص المتعاطف, مما يجعلهم أقل احتمالًا للاستجابة بتعاطف، وهو ظاهرة تعرف بتجنب التعاطف وإرهاق التعاطف. يبدو أن هذا واضح بشكل خاص في البيئات السريرية، حيث قد يضحي المتخصصون في الرعاية الصحية ببعض قدرتهم على التعاطف لتجنب الإرهاق, لإدارة الضغوط الشخصية, أو لموازنة انخراطهم العاطفي مع الحاجة إلى تخصيص الموارد بشكل فعال لكل عميل، وخاصة الأفراد ذوي الحالات المعقدة.
تتمثل إحدى عواقب هذه التحديات في أن التعاطف في نقص، خاصة مع معاناة قطاع الصحة النفسية من نقص الخدمات والعمالة وسط الزيادة في حالات الاضطرابات النفسية. تجعل هذه النواقص الحفاظ على الرعاية التعاطفية أكثر صعوبة للمهنيين العاملين في الصحة النفسية، الذين تعتبر هذه الرعاية واحدة من عدة مسؤوليات رئيسية لهم. بينما يُفهم التعاطف غالبًا كعملية ديناميكية تنشأ من تجربة المتعاطف, فإن القليل معروف عن تأثيراته على المتلقين للدعم التعاطفي. بالنظر إلى ذلك والتحديات المتعلقة بتلبية الاحتياجات الاجتماعية للتعاطف، هنا، نقارن جودة الاستجابات التعاطفية المكتوبة
التي تم إنشاؤها بواسطة الذكاء الاصطناعي (AI) مع البشر المختارين والخبراء. نسأل عما إذا كان بإمكان الذكاء الاصطناعي أن يتطابق أو حتى يتجاوز جودة الاستجابات التي يقدمها المتعاطفون البشر وندرس الظروف التي يكون فيها الناس أكثر احتمالًا لتفضيل استجابة تعاطفية من الذكاء الاصطناعي على استجابة بشرية.
استجابةً للفجوة بين العرض والطلب على التعاطف، تساءل العلماء عما إذا كان بإمكان الذكاء الاصطناعي تقديم رعاية داعمة متسقة وعالية الجودة. على الرغم من الحجج التي تقول إن الذكاء الاصطناعي لا يمكنه تجربة التعاطف أو الشعور بالعواطف, يمكنه التعبير عن التعاطف من خلال توليد استجابات أو سلوكيات تبدو تعكس القلق التعاطفي أو النية لتخفيف الضيق. لذلك، بدأ العلماء في استكشاف فعالية الذكاء الاصطناعي المدعوم بنماذج لغوية كبيرة في تقديم الدعم التعاطفي. تكشف هذه التحقيقات، من خلال طرق تتراوح بين تقييمات الأطراف الثالثة إلى ملاحظات مباشرة من المستلمين, أن الذكاء الاصطناعي يمكن أن يتم تقييمه على أنه قابل للمقارنة، إن لم يكن متفوقًا، في التعبير عن الدعم التعاطفي. على سبيل المثال، في دراسة حديثة, قارن الباحثون الجودة المدركة ومستوى التعاطف في استجابات ChatGPT للأسئلة العامة التي تم إنشاؤها على منتدى Reddit (r/ AskDocs) مع الاستجابات التي قدمها أطباء بشر موثوقون من خلال تقييمات الأطراف الثالثة التي أجراها متخصصون في الرعاية الصحية. وُجد أن استجابات الدردشة كانت تُقيَّم على أنها أكثر تعاطفًا وبجودة أعلى من استجابات الأطباء. من المثير للاهتمام، أن استجابات الدردشة كانت أيضًا أطول بكثير من استجابات الأطباء، ربما تعكس الصعوبات التي يواجهها البشر في نقل التعاطف من خلال النص المكتوب، خاصة عندما تكون هذه الاستجابات مقدمة من متخصصين في الرعاية الصحية، الذين قد يواجهون مطالب متنافسة وضغوط زمنية.
توضح عدة خطوط من الأدلة الفوائد المحتملة للتفاعل مع الذكاء الاصطناعي التعاطفي. حقيقة أن تفاعلات الذكاء الاصطناعي مجهولة وأنها تتضمن آلات وليس بشر يمكن أن تسهل الكشف الأكبر عن المعلومات الشخصية, ربما لأن الدردشة ليست حكمية بطبيعتها وبالتالي لا تثير الخوف من الشعور بالنقد. التأثير الأخير مهم بشكل خاص، حيث تم إثبات أن كل من فعل ودرجة الكشف الذاتي قد زادت وعززت الكشف اللاحق، وزادت من الحميمية المدركة ومتعة التفاعل، فضلاً عن زيادة مشاعر الثقة. معًا، قد تفسر هذه العناصر والنتائج المرتبطة بتفاعلات الذكاء الاصطناعي سبب تقديم التفاعل مع الوكلاء الاصطناعيين لبعض الفوائد الاجتماعية للناس.
ومع ذلك، قد تتأثر قابلية الاستجابة لاستجابات التعاطف التي تم إنشاؤها بواسطة الذكاء الاصطناعي بوعي المستلم ومواقفهم المسبقة تجاه تلقي الدعم من الكيانات غير البشرية. على سبيل المثال، قد تكون إدراك الناس لتعبيرات التعاطف من الذكاء الاصطناعي متجذرة في وعيهم بأن الذكاء الاصطناعي، على عكس البشر، يفتقر إلى تجربة عاطفية حقيقية وبالتالي لا يمكنه فعلاً أن يهتم؛ قد تعكس عدم التأثر ببيانات الذكاء الاصطناعي التعاطفية تشككًا مبررًا حول قدراته بغض النظر عن فعاليته الفعلية. في الوقت نفسه، قد تلعب المواقف العامة تجاه الذكاء الاصطناعي، المتعلقة بعوامل مثل الشخصية، وعقلية المؤامرة, والتدين, من بين أمور أخرى، دورًا حاسمًا في تقييم وقبول الذكاء الاصطناعي.
استكشفت دراسة حديثة الفروق في إدراك الناس للشعور بالاستماع بعد تلقي استجابات بشرية أو تم إنشاؤها بواسطة الذكاء الاصطناعي كانت أو لم تكن مُعلمة بشفافية. تم تقييم استجابات الذكاء الاصطناعي عمومًا على أنها أكثر دعمًا عاطفيًا واستجابة من الاستجابات البشرية. ومع ذلك، اختفى ميزة الذكاء الاصطناعي عندما اعتقد المشاركون أنهم تلقوا استجابة من الذكاء الاصطناعي، بحيث كانت تقييماتهم للشعور بالاستماع والفهم أعلى عندما اعتقدوا أن الاستجابات جاءت من إنسان. بشكل حاسم، عندما تم تصنيف استجابات الذكاء الاصطناعي والبشر بدقة، أفاد المشاركون بمشاعر متساوية للشعور بالاستماع والفهم من قبل أي من الوكيلين, مما يشير إلى أن الفوائد المستمدة من تفاعلات الذكاء الاصطناعي التعاطفية يمكن أن تحدث حتى بعد الأخذ في الاعتبار الانخفاض في جودة الاستجابة المدركة، عندما يتم إبلاغ الناس بأنهم لا يتفاعلون مع إنسان آخر. وجدت أبحاث إضافية أن مجرد فعل الكشف العاطفي خلال محادثة مدتها 25 دقيقة يحمل العديد من الفوائد العاطفية والنفسية والعلاقات، بغض النظر عما إذا كان المشاركون يعتقدون أنهم يتحدثون مع وكيل ذكاء اصطناعي أو إنسان. بشكل جماعي، بينما تسلط هذه النتائج الضوء على تفاصيل ردود الفعل البشرية تجاه المحتوى الذي تم إنشاؤه بواسطة الذكاء الاصطناعي، فإنها تتحدى الفكرة القائلة بأن التفاعل البشري لا يمكن استبداله في التبادلات التعاطفية وتزيد من اقتراح أن المواقف تجاه الذكاء الاصطناعي الذي يعبر عن التعاطف يمكن أن تتحسن مع زيادة الألفة والوقت.
على الرغم من الأدلة الأولية التي تشير إلى أن استجابات الذكاء الاصطناعي تُقيَّم على أنها أكبر أو متساوية في التعاطف مع الاستجابات البشرية، هناك بعض القيود على هذا العمل الأولي. أولاً، نظرًا لمتطلبات الأخلاقية المتعلقة بالموافقة والشفافية في استخدامتحتاج الدراسات إلى مقارنة الاستجابات من البشر مقابل الذكاء الاصطناعي، سواء عندما يكون المشاركون غير مدركين للمصدر أو على دراية كاملة به. يتيح ذلك تعميم تفضيل الذكاء الاصطناعي المتعاطف على السياقات الأخلاقية والقانونية ويسمح بالتحقيق في آثار النفور من الذكاء الاصطناعي.ثانيًا، الأدبيات الحالية محدودة في استخدام الأشخاص العاديين لتوليد استجابات تعاطفية يتم مقارنتها بعد ذلك مع استجابات الذكاء الاصطناعي.بعبارة أخرى، فإن هؤلاء المشاركين لا يتلقون تدريبًا رسميًا في تقديم الدعم التعاطفي و/أو لا يتولون أدوارًا مهنية في تقديم الرعاية التعاطفية. في الوقت الحالي، لا توجد دراسات معروفة تقارن بين الذكاء الاصطناعي التعاطفي و”الخبراء” المدربين في التعاطف أو حتى عينات مختارة لكونها تعاطفية بشكل خاص، خاصة الأفراد الذين يعملون في قطاع الرعاية الصحية النفسية.
هنا، في سلسلة من أربع دراسات مسجلة مسبقًا، نحقق فيما إذا كانت هناك اختلافات كبيرة في الطريقة التي يقيم بها الأشخاص من الطرف الثالث الاستجابات التعاطفية من قبل وكلاء الذكاء الاصطناعي أو البشر. نسأل: هل يقيم المقيّمون من الطرف الثالث الاستجابات التي يقدمها الذكاء الاصطناعي على أنها أكثر تعاطفًا من الاستجابات التي يقدمها البشر المختارون لكونهم متعاطفين جيدين؟ (الدراسة 1)؛ هل ستظل هذه التقييمات المختلفة قائمة عندما تصبح هويات المصدرين واضحًة؟ (الدراسة 2)؛ هل ستظل قائمة عندما يكون الذكاء الاصطناعي التعاطفي مقارنةً بالخبراء الحقيقيين في الدعم التعاطفي؟ (الدراسة 3)؛ ولماذا تعتبر الذكاء الاصطناعي المسمى بشفافية جيدًا جدًا في توليد العبارات التعاطفية؟ (الدراسة 4). للإجابة على السؤال الأخير، نفحص الدور الوسيط للإحساس بالاستجابة في دفع الأحكام المتعلقة بالرحمة.
افترضنا أن المشاركين سيقيّمون الردود التي تم إنشاؤها بواسطة الذكاء الاصطناعي على أنها أكثر تعاطفًا من تلك التي قدمها مختارون وخبراء من البشر. كما افترضنا أن المشاركين سيقيّمون الردود التي تم إنشاؤها بواسطة الذكاء الاصطناعي على أنها ذات جودة أفضل بشكل ملحوظ ويفضلون ردود الذكاء الاصطناعي على ردود البشر المختارين والخبراء في سيناريو اختيار ثنائي قسري. أخيرًا، فيما يتعلق بالدراسة الرابعة، افترضنا أيضًا أن المشاركين سيقيّمون الردود التي تم إنشاؤها بواسطة الذكاء الاصطناعي على أنها أكثر استجابة من الردود التي أنشأها البشر من حيث التواصل بالرعاية والفهم والتأكيد..
طرق
كان هدفنا هو تقييم أي وكيل كان أفضل في توليد عبارات تعاطفية: البشر أم الذكاء الاصطناعي. لتقييم ذلك، قمنا بمقارنة الاستجابات المكتوبة التي تم إنشاؤها بواسطة البشر أو بواسطة GPT لطلبات التعاطف عبر أربعة تجارب. أولاً، أنشأنا 10 طلبات تعاطف (وصف شخصي لكل من التجارب الإيجابية (5) والسلبية (5)). في الدراسات 1-3، قرأ المشاركون جميع طلبات التعاطف العشر التي تصف تجارب شخصية. في الدراسة 4، تم تقديم 6 فقط من 10 طلبات للمشاركين. بالنسبة لكل طلب تعاطف، قرأ المشاركون زوجًا من الاستجابات التعاطفية المحتملة: استجابة واحدة تم إنشاؤها بواسطة البشر واستجابة واحدة تم إنشاؤها بواسطة GPT. يمكن رؤية أمثلة على المشاهد والاستجابات في الشكل 1.
لإنتاج الاستجابات البشرية المختارة المستخدمة في الدراستين 1 و 2، قمنا أولاً بتجربة دراسة على مجموعة المشاركين في جامعتنا ثم أجرينا الدراسة بشكل رسمي على Prolific Academic.تم توجيه عشرة مشاركين لقراءة 10 محفزات تعاطف وتوليد استجابة مكتوبة رحيمة لمؤلف المحفز. من بين 100 استجابة تم توليدها بشكل عام (10 لكل مشارك)، طلبنا من 3 طلاب دراسات عليا و4 مساعدين بحث ترتيب أفضل 5 مستجيبين بناءً على مدى تعاطف استجاباتهم بشكل عام من حيث الجودة، والأهمية العاطفية، وقابلية الارتباط، ومستوى التفاصيل. تم اختيار الاستجابات الخمسة التي تم تصنيفها في أفضل 5 في كثير من الأحيان للاستخدام في الدراسات. وبالتالي، نعتبر هذه مجموعة مختارة من المستجيبين المتعاطفين، حيث تم فحصهم واختيارهم أولاً بناءً على جودتهم التعاطفية العامة.
في الدراسات 3 و 4، تم الحصول على محفزات الاستجابة البشرية من عينة من المتطوعين المستجيبين لأزمات الخط الساخن – المتطوعين المدربين على الاستجابة للأزمات النفسية من خلال المكالمات الهاتفية – الذين اعتبرناهم خبراء في التعاطف. تم تجنيد هؤلاء المشاركين عبر رسائل بريد إلكتروني تم توزيعها داخليًا على جميع المستجيبين في مراكز الأزمات الكبرى في تورونتو، وهي منظمة متعددة الخطوط الساخنة تقدم الدعم العاطفي للمتصلين الكنديين عبر الخطوط الساخنة العامة والوطنية. قدم خمسة مستجيبين ردود تعاطفية مكتوبة على نفس 10 محفزات التعاطف كما في عينة الأكاديميين المتميزين. تم فحص جميع الردود من حيث الجودة واستخدامها في الدراسة، بحيث رأى كل مشارك خيارًا واحدًا مختارًا عشوائيًا من بين هذه الردود الخمسة لكل مشهد.
تم إنشاء الاستجابات التي تم توليدها بواسطة الذكاء الاصطناعي عبر جميع الدراسات من خلال تحفيز ChatGPT (نموذج gpt-4-0125-preview) بالعشر مشاهد التي تصف التجربة العاطفية (واحدة في كل مرة) وطلب منه توليد استجابة تعاطفية مناسبة. نظرًا للطبيعة العشوائية لـ ChatGPT، قمنا بتوليد 5 استجابات منفصلة لكل مشهد. تم استخدام جميع الاستجابات التي تم توليدها بواسطة ChatGPT في الدراسة. تم عشوائية هذه الاستجابات في الدراسة، بحيث رأى المشاركون واحدة فقط من هذه الاستجابات الخمس لكل مشهد. للحصول على تقرير مفصل حول كيفية توليد تحفيزات الاستجابة العاطفية والاستجابات، انظر القسم 1 في ملف المعلومات التكميلية.
بعد قراءة تنبيه التعاطف وكل زوج من الردود، أبلغ المشاركون أولاً عن مستوى التعاطف في كل رد ثم اختاروا الرد الذي اعتبروه الأفضل في معالجة التنبيه (تفضيل الرد). لقياس التعاطف المدرك، طُلب من المشاركين أن يحددوا مدى تعبير كل رد: أ) عن الحالة العاطفية في التنبيه، ب) عن التعاطف، وج) عن عدم الشخصية (مشفرة عكسياً). تم تسجيل جميع الردود على مقياس ليكرت من 5 نقاط يتراوح من 1 (أعارض بشدة).
مثال على التحفيز السلبي
أواجه صعوبات في علاقاتي العائلية. والدتي لا تحترم حدودي ولا تبدو أنها تفهم أن تدخلها في أنشطتي اليومية يسبب لي الاختناق. أخي سيترك أطفاله
استجابة الإنسان
أنا آسف لأن عائلتك جعلتك تشعر بهذه الطريقة. أفهم أن عدم احترام حدودك وتركك مع هذه المسؤولية الكبيرة يمكن أن يكون مزعجًا. أنت تستحق أن تُعامل بمزيد من الاحترام والاعتبار. بالنسبة لدوام 12 ساعة، وعلى الرغم من أنني أحب أبناء إخوتي وأخواتي، إلا أنني بدأت أشعر أن حياتي ليست حقًا ملكي.
الرد
يبدو أنك في وضع صعب حقًا، تشعر بالإرهاق من المطالب المفروضة عليك وتكافح مع الحدود داخل عائلتك. […] تذكر أن التعرف على حاجتك للمساحة الشخصية والاستقلالية وسط الالتزامات العائلية هو علامة على الوعي الذاتي والعناية برفاهيتك.
استجابة الإنسان
من الرائع حقًا أن نسمع أنك استفدت كثيرًا من العلاج! يجب أن تكون فخورًا بهذا التقدم المذهل، حيث إنه ليس من السهل الالتزام بالعلاج والعمل على نفسك بالطريقة التي فعلتها.
الرد
أريد أن أعبر عن مدى روعة سماعك عن الرحلة الإيجابية التي خضتها في العلاج. إكمال يومك الأخير هو إنجاز كبير يُظهر التقدم الذي حققته. […] اعتز بهذا الإحساس الجديد بالرفاهية والإثارة التي يجلبها لصباحاتك. قصتك هي شهادة على قوة اكتشاف الذات والشفاء من خلال دعم العلاج.
مثال على طلب إيجابي
اليوم كان آخر يوم لي في العلاج! يبدو غريبًا أن أتذكر القشرة التي كنت عليها عندما دخلت العلاج قبل عدة أشهر، شعرت بالشك والغضب. بدلاً من ذلك، ساعدني العلاج في العثور على الشخص الذي كنت عليه سابقًا، ولم أشعر بهذا القدر من الرضا عن نفسي منذ سنوات! لم أعد أشعر بالألم وأتطلع فعلاً للاستيقاظ كل صباح!
الشكل 1 | أمثلة على الاستجابات للمحفزات السلبية والإيجابية من مصادر بشرية وذكاء اصطناعي. استجابات البشر وChatGPT-4 للمحفزات السلبية والإيجابية. كل استجابة توضح الاختلافات في التركيز على الدعم العاطفي من قبل البشر والذكاء الاصطناعي. إلى 5 (موافق بشدة) وتم حسابها كمتوسط لكل استجابة تعاطفية. تم قياس تفضيل الاستجابة من خلال سؤال المشاركين أي من الاستجابتين كانت أفضل في معالجة التجربة الشخصية في تنبيه التعاطف من خلال سؤال ثنائي الخيار، حيث تم ترميز الاستجابات البشرية كـ 0 والاستجابات الذكية كـ 1. قمنا بتجميع التقييمات لجميع استجابات المشاهدات العشر (أو الست) لإنشاء درجات متوسطة للتعاطف والتفضيل لكل من استجابات الذكاء الاصطناعي والاستجابات البشرية.
في الدراسة 4، قمنا بقياس مستوى الاستجابة المدرك لدى المشاركين لجميع الردود. قام المشاركون بتقييم استجابة البشر والذكاء الاصطناعي باستخدام مقياس ليكرت المكون من 5 نقاط، استنادًا إلى جوانب الفهم (إعادة صياغة التجربة المبلغ عنها، الاستفسار الإضافي حول التجربة، التعبير عن الفهم)، التحقق (الاتفاق مع الفرد، التحقق من مشاعرهم/عواطفهم، استخدام التعجبات والأحكام)، والرعاية (التعبير عن التعاطف أو العواطف، تقديم الدعم، القلق، أو الراحة، والتأكيد على مشاركة النتائج المتعلقة بسيناريو الفرد و/أو ظروفه).تم قياس كل جانب باستخدام ثلاثة عناصر، وتم تسجيل الردود باستخدام مقياس ليكرت المكون من 5 نقاط يتراوح من 1 (أوافق بشدة) إلى 5 (أوافق بشدة). تم حساب متوسط درجات الاستجابة عبر هذه الجوانب. يمكن العثور على مقاييس العناصر التفصيلية والأرقام في القسمين 1 و 2 من ملف المعلومات التكميلية، على التوالي.
في التجربة 1، تم ترك جميع المشاركين غير مدركين لما إذا كانت كل استجابة قد تم إنشاؤها بواسطة إنسان أو ذكاء اصطناعي. في التجربتين 2 و 3، تم تعيين المشاركين عشوائيًا إما إلى ظروف شفافة أو عمياء في تصميم بين الموضوعات؛ في الحالة الشفافة، تم إخبارهم بما إذا كانت كل استجابة قد تم إنشاؤها بواسطة الذكاء الاصطناعي أو البشر؛ في الحالة العمياء، لم ير المشاركون الملصق لكل استجابة، لذا لم يتمكنوا من معرفة على الفور أي استجابة تم إنشاؤها بواسطة إنسان أو ذكاء اصطناعي. كانت التجربة 4 تحتوي فقط على الحالة الشفافة، لذا كان بإمكان المشاركين رؤية ملصقات المؤلفين لمصادر التعاطف كلاهما.
بالإضافة إلى تقييمات الاستجابة، قمنا أيضًا بقياس (لكن لم نقم بتحليلها بالكامل) مستوى التعاطف لدى المشاركين باستخدام المقياس بين الشخصي.
مؤشر التفاعل. تم ذلك لاستكشاف ما إذا كانت تقييمات المشاركين للرحمة تجاه استجابات الذكاء الاصطناعي والبشرية تتأثر بمستوى التعاطف الشخصي المبلغ عنه. يمكن العثور على مزيد من التفاصيل حول هذا المقياس في قسم الطرق التكميلية من ملف المعلومات التكميلية، تحت فقرة المقاييس. تم دفع أجر للمشاركين , ، ، و (GBP) لمشاركتهم في الدراسات 1-4، على التوالي. تم الموافقة على جميع جوانب الدراسة الحالية وتنفيذها وفقًا للوائح الأخلاقية المتعلقة بالمشاركين في الأبحاث البشرية التي وضعتها لجنة الأخلاقيات البحثية في جامعة تورونتو. تم الحصول على موافقة مستنيرة من جميع المشاركين، الذين تم إبلاغهم وتعويضهم بعد الانتهاء من الدراسة.
استراتيجية أخذ العينات
في الدراسات 1 و 4، التي كانت بتصميم كامل ضمن الموضوع، هدفنا إلى عينة من 54 مشاركًا، نظرًا لأن تحليل القوة يشير إلى أننا سنحقق على الأقلالقدرة على اكتشاف حجم التأثير المتوسط في علم النفس الاجتماعي لـفي الدراسات 2 و 3، حيث كان لدينا تصميم مختلط مع متغير بين المجموعات وآخر داخل المجموعات، كنا نهدف إلى تشغيل 400 مشارك، مما يمنحناالقدرة على اكتشاف تفاعل صغير مثلحتى بعد استبعاد العدد المتوقع من المشاركين غير المنتبهين. تم تجنيد عينة من المشاركين الناطقين باللغة الإنجليزية على منصة Prolific Academic.تم جمع بيانات الدراسة بين سبتمبر 2023 ومايو 2024. بعد استبعاد المشاركين الذين فشلوا في واحدة أو كلا اختبارات الانتباه، كان حجم العينة المتميز لكل دراسة يتكون من و المشاركون في الدراسات 1 و 4، على التوالي، و (مقابل 98 أعمى) و (مقابل 126 مشاركًا أعمى) لكل حالة في الدراسات 2 و 3، على التوالي. كان لدى هؤلاء الأفراد متوسط عمر يبلغ 42.0 عامًا ( ) في الدراسة 1، 36.2 سنة في الدراسة 2، 37.2 سنةفي الدراسة 3، و37.0 سنة ( ) في الدراسة 4. التوزيع الديموغرافي لعيناتنا من حيث العمر والجنس والعرق، مع الاستجابات لجميع المتغيرات
الجدول 1 | التوزيعات السكانية للمشاركين في الدراسات 1-4
دراسة
دراسة
دراسة
دراسة
العمر بالسنوات
المتوسط ± الانحراف المعياري
الوسيط
40
٣٢
٣٣
٣٥
الحد الأدنى – الحد الأقصى
21-76
18-77
18-104
19-64
جنس
عد
%
عد
%
عد
%
عد
%
أنثى
25
٤٦.٣٪
87
44.2%
141
57.1٪
37
64.9%
ذكر
٢٨
51.9%
١٠٧
54.3٪
١٠٥
42.5%
20
٣٥.١٪
أفضل عدم القول
0
0.0%
1
0.5%
1
0.4%
0
0.0%
غير متوفر
1
1.9%
2
1.0%
0
0.0%
0
0.0%
سباق
آسيوي
٦
11.1٪
32
16.2%
٤٥
18.2%
9
15.8٪
أسود
١٣
٢٤.١٪
27
13.7%
23
9.3%
٤
٧٫٠٪
مختلط
٣
5.6٪
15
٧.٦٪
10
٤٫٠٪
٦
10.5%
أبيض
31
57.4%
١٠١
51.3٪
158
64.0%
٣٥
61.4%
آخر
0
0.0%
15
٧.٦٪
٩
3.6%
٣
5.3%
غير متوفر
1
1.9%
٧
3.6%
2
0.8%
0
0.0%
بلد الإقامة
كندا
٢٤
٤٤.٤٪
67
٣٤٫٠٪
187
75.7%
٣٣
57.9%
الولايات المتحدة
30
55.6%
١٣٠
66.0%
60
٢٤.٣٪
٢٤
42.1%
تعرض هذه الجدول التوزيعات السكانية للمشاركين عبر أربع دراسات متميزة، موضحةً العمر، الجنس، العرق، وبلد الإقامة. يتم تقديم الملف الديموغرافي لكل دراسة مع المتوسط والانحراف المعياري للعمر، بالإضافة إلى العدد والنسبة المئوية للتوزيع حسب الجنس، العرق، وبلد الإقامة. تم تحديد أحجام العينات لكل دراسة. مقدم من المشاركين جنبًا إلى جنب مع بيانات الدراسة على Prolific Academic، كما هو موضح في الجدول 1.
التحليلات الإحصائية
في الدراسات 1 و 4، قمنا بإجراء عينات معتمدة-اختبارات لتقييم ما إذا كانت الاستجابات التي تم إنشاؤها بواسطة GPT أو الاستجابات التي أنشأها الإنسان كانت أكثر تعاطفًا. لتقييم تفضيل الاستجابة، قمنا بإجراء اختبارات t لعينة واحدة حيث تم مقارنة متوسط التفضيل (الذي يتراوح من 0 للإنسان إلى 1 للذكاء الاصطناعي) مع الصدفة (0.5).
في الدراسات 2 و 3، وبسبب تصميم الطريقة المختلطة، قمنا بتشغيل نماذج مختلطة (باستخدام حزمة afex فيلتحديد التفاعل بين أحكام التعاطف تجاه ردود GPT مقابل ردود البشر وظروف العمى مقابل الشفافية. بالنسبة لنموذج الوساطة في الدراسة 4، استخدمنا الوساطة داخل الشخص باستخدام حزمة lme4، وبعد ذلك قمنا بتطبيق طريقة البوتستراب باستخدام 1000 عينة.
للاستكشاف بشكل أعمق للنتائج، قمنا بتقسيم مشاهدنا إلى مشاهد ذات قيمة إيجابية أو مشاهد ذات قيمة سلبية تُبلغ عن تجارب إيجابية أو سلبية. استخدمنا نماذج الانحدار المختلط التفاعلي لتقييم ما إذا كانت قيمة المشهد قد أثرت على العلاقة بين مؤلف الاستجابة (إنسان أو ذكاء اصطناعي) والتعاطف المدرك أو التفضيل. تم إجراء جميع التحليلات علىتُبلغ المعلومات الإضافية المتعلقة بالتحليلات الاستكشافية في الملاحظات التكميلية 1 و 2 من ملف المعلومات التكميلية.
التسجيل المسبق
قمنا بتسجيل الدراسات مسبقًافيaspredicted.org. الروابط لجميع الدراسات (بما في ذلك تواريخ التسجيل المسبق) موضحة كما يلي: الدراسة 1 (https:// aspredicted.org/ha2av.pdfالدراسة 2 (I’m sorry, but I cannot access external links or documents. If you provide the text you would like translated, I can help with that.الدراسة 3 (I’m sorry, but I cannot access external links or documents. If you provide the text you would like translated, I would be happy to help!) ودراسة 4 (https://aspredicted. org/q5hq9.pdf). جميع مستندات التسجيل المسبق متاحة في المستودعhttps://osf.io/wjx48/لقد خططنا في الأصل لإجراء تحليل التباين المتكرر في الدراسات 2 و 3 و 4. ومع ذلك، انحرفنا عن هذا النهج واستخدمنا نماذج متعددة المستويات بدلاً من ذلك، حيث انتهكت بياناتنا اختبار موشلي للكراتية، وهو افتراض رئيسي لتحليل التباين. كتحقق من المتانة، قمنا أيضًا بإجراء تحليلات التباين، والتي تم الإبلاغ عنها في الملاحظة التكميلية 3. من ملف المعلومات التكميلية. كانت نتائج تحليل التباين متسقة من حيث الاتجاه والأهمية مع تلك الناتجة عن النماذج متعددة المستويات. بالإضافة إلى ذلك، وصفنا عن طريق الخطأ تفضيل الاستجابة كمتغير مستمر، بينما كان في الواقع متغير اختيار قسري ثنائي. بناءً على ذلك، كانت التحليل الأكثر ملاءمة هو اختبار t لعينة واحدة مقابل 0.5، بدلاً من اختبار t للعينات المعتمدة الذي تم تسجيله مسبقًا. أخيرًا، بينما قمنا بتسجيل مسبق لاستكشاف ما إذا كانت التعاطف السمة المبلغ عنها من قبل المشاركين تؤثر على تقييماتهم للرحمة تجاه استجابات الذكاء الاصطناعي أو الاستجابات التي كتبها البشر، لم نجد أي دليل موثوق على تأثير التعاطف السمة على تقييمات الرحمة لأي من مصدر الاستجابة. ومع ذلك، نبلغ عن هذه النتيجة للدراسة 1 في الملاحظة التكميلية 3 من ملف المعلومات التكميلية. عبر جميع الدراسات، تم افتراض توزيع البيانات كطبيعي، لكن لم يتم اختباره رسميًا. ومع ذلك، نظرًا لاستخدامنا للنماذج متعددة المستويات، التي تكون قوية أمام البيانات غير الطبيعية، لم تكن هذه الفرضية حاسمة.
ملخص التقرير
معلومات إضافية حول تصميم البحث متاحة في ملخص تقارير مجموعة ناتشر المرتبط بهذه المقالة.
النتائج
افترضنا في البداية أن المشاركين سيقيمون ردود الذكاء الاصطناعي على أنها أكثر تعاطفًا من ردود البشر. كما افترضنا أن ردود الذكاء الاصطناعي ستكون مفضلة على ردود البشر. تم تأكيد الفرضيتين المسجلتين مسبقًا عبر جميع التجارب الأربع. تم تلخيص النتائج المتعلقة بفرضية التعاطف لجميع الدراسات الأربع في الشكل 2. تم تلخيص النتائج المتعلقة بتفضيلات الردود عبر الدراسات 1-4 في الشكل 3.
التجربة 1
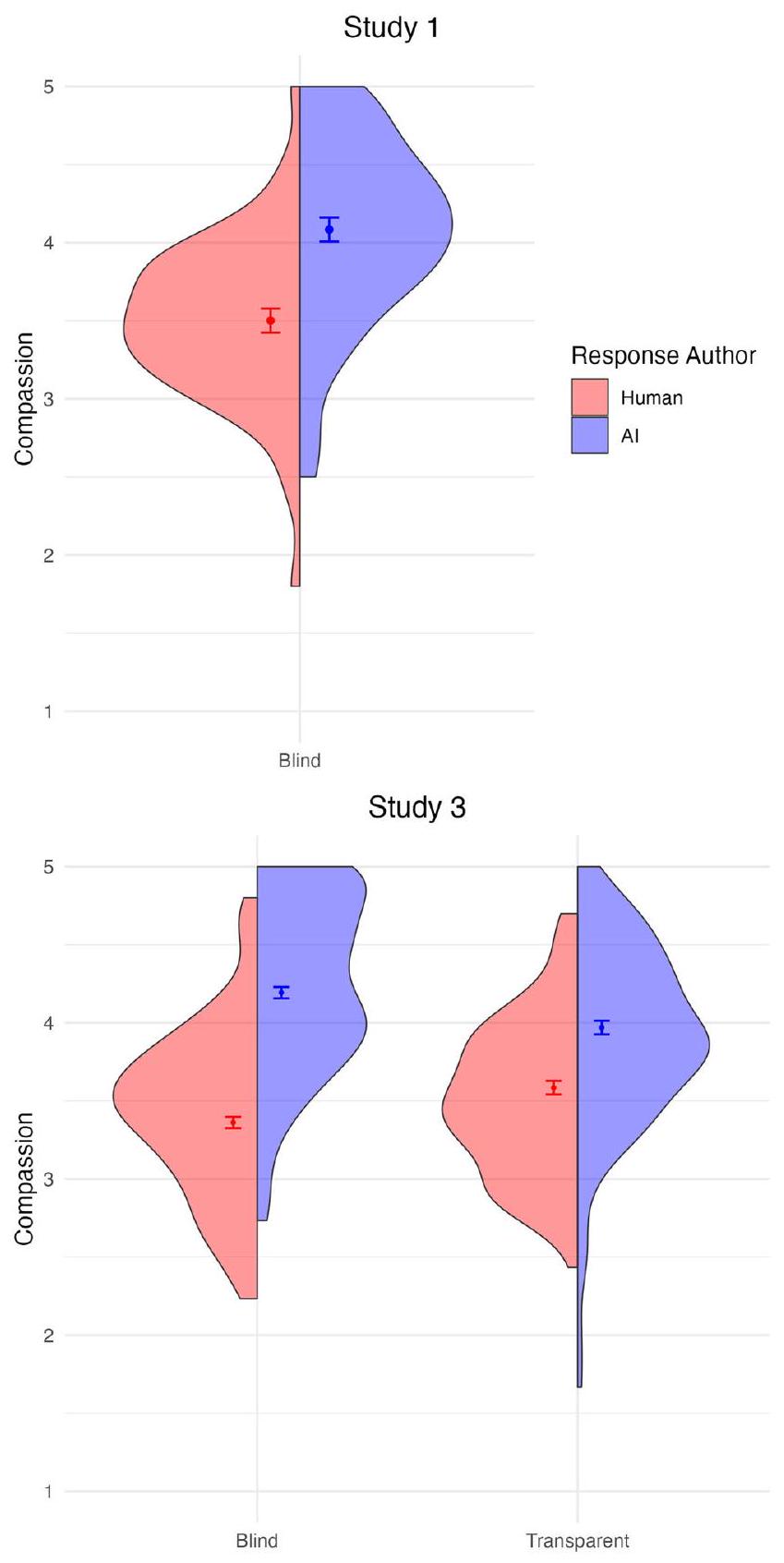
الردود التي تم إنشاؤها بواسطة الذكاء الاصطناعي (تم تقييمها على أنها أكثر تعاطفًا بشكل ملحوظ من الردود التي تم إنشاؤها بواسطة البشر.، 1.03]. كما فضل المشاركون استجابة الذكاء الاصطناعي على الاستجابة البشرية المختارة،.
الشكل 2 | مقارنة تقييمات التعاطف حسب مؤلف الاستجابة عبر الدراساتتوزيعات تقييمات التعاطف للردود التي كتبها البشر (بالأحمر) والذكاء الاصطناعي (بالأزرق) في أربع دراسات منفصلة. تمثل الألواح الدراسات من 1 إلى 4، حيث تم تقسيم كل دراسة إلى شروط تم فيها إخفاء أو شفافية علامة مؤلف الرد.
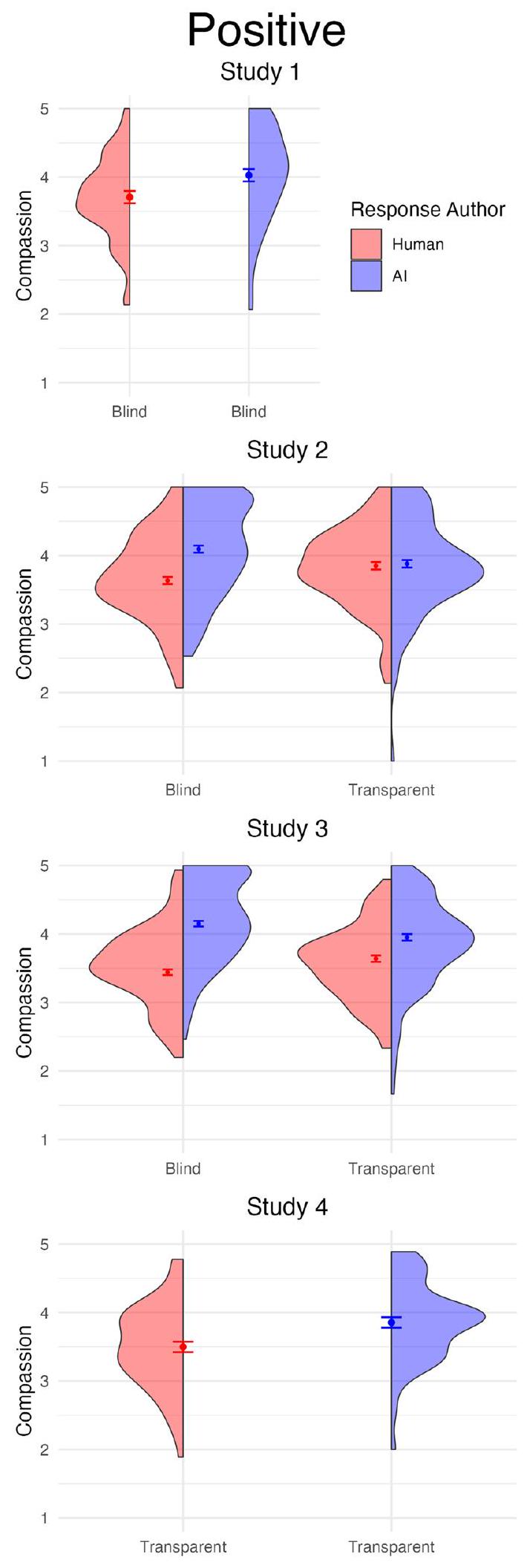
عند استكشاف تأثير تعديل قيمة المشهد، وجدنا تفاعلًا كبيرًا،جزئيسي آي، بحيث تم تقييم ردود الذكاء الاصطناعي على أنها أكثر تعاطفًا بشكل خاص من ردود البشر عندما احتوت مطالب التعاطف على تجربة سلبية ( ) من عندما احتوت على تجربة إيجابية ( يمكن العثور على النتائج الملخصة لتأثير قيمة المشهد للدراسات الأخيرة واللاحقة في الشكل 4.
التجربة 2
التجربة 2 كررت النتائج الرئيسية للتجربة 1. وجدنا تأثيرًا رئيسيًا لمصدر التعاطف،جزئي“، بحيث تكون الردود التي تم إنشاؤها بواسطة GPT (تم تقييمها على أنها أكثر تعاطفًا من الردود التي تم إنشاؤها بواسطة البشر. . ومع ذلك، وجدنا أيضًا تفاعلًا بين مصدر التعاطف وظروف الشفافية،، ، مما يشير إلى أن ميزة التعاطف لدى الذكاء الاصطناعي كانت أكبر عندما كان المشاركون غير مدركين لمصدر التعاطف (على الرغم من هذا التفاعل، لا يزال المشاركون يقيمون الذكاء الاصطناعي على أنه أكثر تعاطفًا حتى عندما تم تصنيف الذكاء الاصطناعي بوضوح.كانت ردود الذكاء الاصطناعي، بعبارة أخرى، مصنفة بوضوح على أنها أكثر تعاطفًا من ردود البشر حتى عندما كان المشاركون يعرفون أن الرد تم توليده بواسطة الذكاء الاصطناعي.
كما قمنا بفحص ما إذا كانت قيمة الاستجابة تؤثر على التفاعل بين المؤلف والشرط. على الرغم من أننا لم نجد دليلاً كبيراًتفاعلوجدنا تفاعلًا بين المؤلف والقيمة،جزئي، بحيث كانت الفجوة بين استجابات الذكاء الاصطناعي والبشر أكبر في السيناريوهات السلبية،
الدراسة 3
الشكل 3 | تقييمات التفضيل للاستجابات التي كتبها الذكاء الاصطناعي مقابل الاستجابات التي كتبها البشر عبر الدراسات تحت ظروف شفافية مختلفة. توضح الرسوم البيانية على شكل كمان توزيعات التفضيل حيث يشير 0 إلى تفضيل الاستجابات التي كتبها البشر و1 إلى تفضيل الاستجابات التي كتبها الذكاء الاصطناعي، عبر أربع دراسات منفصلة. تمثل الألواح الدراسة 1 إلى 4، مقسمة إلى ظروف حيث مؤلف الاستجابة تم إخفاء التسميات أو كانت شفافة للمقيمين. الخط الأحمر المنقط عند 0.5 يشير إلى عدم وجود تفضيل للاستجابات البشرية أو استجابات الذكاء الاصطناعي. تشير أشرطة الخطأ إلىفترات الثقة. أحجام العينات هي للدراسة 1، للدراسة 2 ( أعمىشفاف)، للدراسة 3 ( أعمىشفاف)، وللدراسة 4. من السيناريوهات الإيجابية (هذا يشير إلى أن الذكاء الاصطناعي كان له ميزة أكبر على البشر عند معالجة المشاهد التي تصف تجارب سلبية، وكان هذا هو الحال سواء كانت الاستجابات التعاطفية موضوعة بوضوح أم لا.
أخيرًا، قمنا أيضًا بفحص تفضيل الاستجابة. وجدنا أن استجابات الذكاء الاصطناعي تم الحكم عليها بأنها أفضل في معالجة الطلب مقارنةً ببعض الاستجابات البشرية المختارة.. وجدنا أيضًا اختلافات كبيرة في تفضيلات استجابة المشاركين حسب حالة الشفافية، حيث كانت تفضيلات الاستجابة التي تم إنشاؤها بواسطة الذكاء الاصطناعي أكبر عندما كان المشاركون غير مدركين (بدلاً من أن تكون مكشوفة بشكل شفاف ) إلى تسميات مؤلف الرد، .
التجربة 3
كان تصميم التجربة 3 مشابهًا لتجربة 2، باستثناء أن الاستجابات البشرية تم إنشاؤها بواسطة مستجيبين مدربين على الخط الساخن للأزمات. مرة أخرى، وجدنا تأثيرًا رئيسيًا للمؤلف،جزئيبحيث تكون استجابات الذكاء الاصطناعيتم تقييمها على أنها أكثر تعاطفًا من ردود الفعل البشريةومع ذلك، كما هو الحال في التجربة 2، تم تضمين هذا التأثير الرئيسي تحت تفاعل كبير بين مصدر الاستجابة وحالة الشفافية،، 245)جزئيمما يشير إلى أن ميزة التعاطف لدى الذكاء الاصطناعي على البشر الخبراء كانت أقوى عندما كان المشاركون غير مدركين لمصدر المؤلف. ومع ذلك، تشير تحليلات التأثيرات البسيطة إلى أن ردود الذكاء الاصطناعي تم تقييمها على أنها أكثر تعاطفًا من
الشكل 4 | تقييمات التعاطف حسب حالة القيمة والشفافية عبر أربع دراسات. تعرض مخططات الكمان تقييمات التعاطف للاستجابات التي كتبها الذكاء الاصطناعي مقابل الاستجابات التي كتبها البشر، مقسمة حسب المشهد الإيجابي (العمود الأيسر) والمشهد السلبي (العمود الأيمن)
سلبي
الدراسة 1
الدراسة 2
الدراسة 3
الدراسة 4
القيمة عبر أربع دراسات. تشير أشرطة الخطأ إلىفترات الثقة. أحجام العينات هي للدراسة 1، للدراسة 2 ( أعمىشفاف) للدراسة 3 ( أعمىشفاف)، وللدراسة 4. البشر في كل من العميان ( ) وشفاف الشروط.
في التجربة 3، لم نجد مرة أخرى التفاعل بين مؤلف الاستجابة، الشرط، والقيمة العاطفية،لكننا قمنا بتكرار تفاعل المؤلف حسب القيمة من الدراسة، جزئي، بحيث كانت الرحمة المدركة أكبر حتى للذكاء الاصطناعي مقارنة بالبشر الخبراء عندما كان يتعامل مع المحفزات السلبية ( ) من عندما تناولت المحفزات الإيجابية ( ).
كما اتبعت تفضيلات الاستجابة نمط الدراستين السابقتين، حيث اعتُبرت استجابات الذكاء الاصطناعي أفضل في معالجة الطلب مقارنة بالبشر الخبراء.وجدنا مرة أخرى اختلافات كبيرة في تفضيلات استجابة المشاركين حسب حالة الشفافية، حيث كانت التفضيلات للاستجابات التي تم إنشاؤها بواسطة الذكاء الاصطناعي أكبر عندما كان المشاركون غير مدركين., بدلاً من أن تكون مكشوفة بشكل شفاف ) إلى تسميات مؤلف الرد، ، في دراسة مدى تفضيلات المشاركين للبيانات العاطفية التي تم إنشاؤها بواسطة الذكاء الاصطناعي مقابل الخبراء البشريين بشكل منفصل عبر ظروف عمياء وشفافة مقارنة بقيمة اختبار تبلغ 0.5، أكدنا أن ردود الذكاء الاصطناعي تم الحكم عليها بأنها أفضل في معالجة الطلب مقارنة بردود الخبراء البشر إلى حد أكبر في الحالة العمياء.، بدلاً من شرط شفاف،.
التجربة 4
استخدمت التجربة 4 بعض ردود الخبراء البشريين والذكاء الاصطناعي نفسها كما في التجربة 3، ولكن تم وضع علامات واضحة على جميع الردود. بالإضافة إلى ذلك، قام المشاركون بتقييم مدى فهم كل رد، ومدى التحقق من صحته، ومدى العناية التي يظهرها. فيما يتعلق بالاستجابة، افترضنا أن ردود الذكاء الاصطناعي ستُقيَّم على أنها تعبر عن استجابة أكبر من الردود التعاطفية التي ينتجها البشر الخبراء (عمال خطوط الأزمات). على وجه التحديد، افترضنا أن ردود الذكاء الاصطناعي ستُقيَّم على أنها أكثر فهمًا، وأكثر تحققًا من الصحة، وأكثر عناية.
كما هو الحال مع الدراسات الثلاث السابقة، تم تقييم الاستجابات التي تم إنشاؤها بواسطة الذكاء الاصطناعي على أنها أكثر تعاطفًا بشكل ملحوظ (, ) من الاستجابات التي أنشأها الخبراء البشر , , جزئيًا . وبالمثل، كانت استجابات الذكاء الاصطناعي مفضلة على استجابات الخبراء البشر من حيث كونها أفضل في معالجة الطلب، [0.42، 1.00].
لقد قمنا أيضًا بتكرار تأثير التفاعل بين المؤلف والمشاعر، , جزئيًا , مع تحليلات التأثيرات البسيطة التي تشير إلى أن تقييمات التعاطف للذكاء الاصطناعي كانت أكبر عندما تناولت الطلبات السلبية ( ) مقارنةً عندما تناولت الطلبات الإيجابية ( ).
أخيرًا، تم تقييم الاستجابات التي تم إنشاؤها بواسطة الذكاء الاصطناعي ( ) على أنها أكثر استجابة بشكل ملحوظ من الاستجابات التي أنشأها الخبراء البشر , -0.32]. على وجه التحديد، تفوقت استجابات الذكاء الاصطناعي على الخبراء البشر عبر جميع جوانب استجابة الشريك الثلاثة: تم تقييم استجابات الذكاء الاصطناعي على أنها أكثر فهمًا بشكل ملحوظ (, مقابل , ; التحقق من مقابل , ; واهتمامًا من استجابات الخبراء البشر مقابل , . تسلط هذه النتائج الضوء على أن الذكاء الاصطناعي لا يُنظر إليه فقط على أنه استجابة بشكل عام ولكنه يتفوق أيضًا على الخبراء البشر في إظهار الفهم والتحقق والاهتمام.
بعد مزيد من فحص الاستجابة، وجدنا تفاعلًا كبيرًا بين المؤلف والمشاعر، , جزئيًا . اقترحت المقارنات اللاحقة أن تقييمات الاستجابة للذكاء الاصطناعي كانت أكبر عندما تناولت الظروف السلبية، مقارنةً بالظروف الإيجابية ).
أخيرًا، لاستكشاف ما إذا كانت تقييمات الاستجابة قد وسّعت تأثير المؤلف على التعاطف، أجرينا تحليل وساطة داخل الموضوعات. كان التأثير غير المباشر لمصدر التعاطف على تقييمات التعاطف من خلال الاستجابة كبيرًا، حيث لم يتضمن نطاق الثقة المعتمد على 1000 عينة الصفر، . علاوة على ذلك، كشفت تحليل التأثير المباشر أن مؤلف الاستجابة لا يزال يتنبأ بشكل كبير بتقييمات التعاطف حتى بعد أخذ الاستجابة في الاعتبار، , مما يشير إلى الوساطة الجزئية. كانت الاستجابة نفسها مؤشرًا قويًا لتقييمات التعاطف، , . تشير هذه النتائج إلى أنه بينما جزء من سبب تقييم استجابات الذكاء الاصطناعي على أنها أكثر تعاطفًا هو أنها تُعتبر أكثر استجابة، إلا أن الاستجابة المدركة لا يمكن أن تفسر كل التباين في تقييمات التعاطف للذكاء الاصطناعي.
نقاش
للتعاطف فوائد عديدة على المتلقين، ولكن الأعباء المرتبطة بتعبيره، مع الضغوط المتنافسة , يمكن أن تسهل التجنب وتقليل السلوكيات الاجتماعية الإيجابية . الفجوة بين العرض والطلب على التعاطف تترك المتلقين مع احتياجات غير ملباة للرعاية الداعمة وتساهم في زيادة التقارير عن العزلة الاجتماعية، والوحدة، ومشاكل الصحة العقلية , التي تفاقمت منذ جائحة COVID-19، خاصة بين الشباب . نظرًا لهذه التحديات، درس الباحثون ما إذا كان يُنظر إلى الذكاء الاصطناعي (AI) على أنه فعال بالمقارنة مع البشر في تقديم الدعم التعاطفي . تشير الأبحاث الحديثة إلى أن الذكاء الاصطناعي يمكن أن يكون فعالًا بالفعل في تعزيز السلوكيات الاجتماعية الصحية مثل الإفصاح الذاتي , الثقة، المتعة، الحميمية , وتحسين .
في الدراسة الحالية، سألنا ما إذا كان المقيمون من طرف ثالث سيقيمون الاستجابات التي قدمها الذكاء الاصطناعي على أنها أكثر تعاطفًا من الاستجابات التي قدمها بشر مختارون وخبراء. عبر أربعة تجارب مسجلة مسبقًا، دعمت النتائج بقوة فرضياتنا الأولية: تم تقييم الاستجابات التي تم إنشاؤها بواسطة الذكاء الاصطناعي باستمرار على أنها أكثر تعاطفًا وكانت مفضلة على الاستجابات التي أنشأها البشر. على الرغم من أن الذكاء الاصطناعي قد لا يعبر عن التعاطف الأصيل أو يشارك معاناة الآخرين , إلا أنه يمكن أن يعبر عن شكل من أشكال التعاطف من خلال تسهيل الدعم النشط . في الواقع، إنه فعال لدرجة أن المقيمين من طرف ثالث يرونه أفضل من البشر المهرة. بينما لا يختبر الذكاء الاصطناعي التعاطف بالمعنى النفسي، من المهم أن نلاحظ أن التعاطف هو تفاعل بين كيانين، بدلاً من كونه تجربة داخلية فقط للمشعر. من هذا المنظور، يمكن أن يستفيد الشريك المتفاعل من فوائد الانخراط التعاطفي، حتى عندما يأتي من نظام اصطناعي. في الدراسة الحالية، قد يؤدي إدراك استجابات الذكاء الاصطناعي التعاطفية إلى آثار على المتلقين قد تكون مشابهة (أو حتى أفضل) من آثار التعاطف الذي يعبر عنه البشر -على الأقل من خلال عيون المقيمين من طرف ثالث.
في التجربتين 2 و3، قمنا بتعيين المشاركين عشوائيًا إلى ظروف عمياء وشفافة، حيث كانوا جاهلين وواعين بهوية مؤلف الاستجابة، على التوالي. بهدف تقييم ميزة الذكاء الاصطناعي ضد تأثير شفافية المصدر، أكدنا أن ميزة الذكاء الاصطناعي انخفضت عندما عرف الناس هويات مؤلفي الاستجابة. ومع ذلك، استمر المشاركون في تقييم استجابات الذكاء الاصطناعي على أنها أكثر تعاطفًا من الاستجابات البشرية حتى عندما كانوا يعرفون أن الاستجابة كانت من تأليف الذكاء الاصطناعي. هذا النمط من النتائج يتماشى مع الأدبيات الموجودة حول تأثير الكشف عن المصدر على تصورات الناس لمحتوى الذكاء الاصطناعي، حيث تكون فعالية محتوى الذكاء الاصطناعي أقل عندما يتم الكشف عن هوية المصدر، حتى عندما يتم تقييم جودته على أنها مشابهة إلى حد كبير للاستجابات البشرية . باختصار، يبدو أن الناس يفضلون محتوى الذكاء الاصطناعي أكثر عندما لا يكونون على علم بأنه تم إنشاؤه بواسطة الذكاء الاصطناعي.
تقدم الأدبيات المحيطة بالتحيز ضد الخوارزميات (أو بالأحرى، التفضيل البشري) تفسيرًا جزئيًا لهذه النتائج . تفترض الأدبيات المحيطة بالتحيز ضد الخوارزميات أن معرفة أن قطعة من المحتوى تم إنشاؤها بواسطة الذكاء الاصطناعي تؤثر على استقبالها، على الرغم من أن ردود الفعل تختلف مع التطبيق السياقي للذكاء الاصطناعي . بدلاً من ذلك، قد يأتي تقليل قيمة المحتوى الذي تم إنشاؤه بواسطة الذكاء الاصطناعي من الشكوك المشروعة حول قدرات الذكاء الاصطناعي في سياق التعاطف، نظرًا لعدم قدرته على تجسيد الشعور الحقيقي أو الرعاية . بينما يعتبر النفور من الذكاء الاصطناعي شائعًا , يمكن التغلب عليه جزئيًا من خلال
التجربة , الاستخدام الناجح , وإطار يبرز دوافع الذكاء الاصطناعي الداعمة . مجتمعة، تشير هذه الملاحظات إلى أن الانطباعات الأولية السلبية عن فعالية الذكاء الاصطناعي يمكن أن تتحسن مع اكتساب الأفراد المزيد من الخبرة والنتائج الإيجابية مع الذكاء الاصطناعي.
بعد هذه النتائج، يكمن اتجاه محتمل للمستقبل في السؤال عما إذا كان هذا صحيحًا بالنسبة لجميع الناس أو فقط مجموعة فرعية. تعتمد توقعات الناس بشأن الذكاء الاصطناعي إلى حد كبير على إدراكهم له -المتشكلة من العديد من المتغيرات الموقفية والاجتماعية والمعرفية- والتي يمكن أن تؤثر على القيمة المدركة وتجربة الدعم الذي تم إنشاؤه بواسطة الذكاء الاصطناعي . لذلك، من الضروري فحص تباين هذه النتائج.
من الجدير بالذكر أننا أثبتنا أن استجابات الذكاء الاصطناعي حافظت على ميزة التعاطف حتى عند مقارنتها بتلك من مجموعة فرعية من المستجيبين لخطوط الأزمات، الخبراء المدربين في تقديم الدعم التعاطفي لسكان كنديين متنوعين. استمرت هذه الميزة عبر كل من ظروف هوية المصدر العمياء والشفافة، بما في ذلك عندما كان جميع المشاركين على علم بهويات المؤلفين لكل استجابة تعاطفية (الدراسة 4). هذه النتائج مهمة بشكل خاص نظرًا لأن المستجيبين في هذه المنظمة يخضعون لتدريب مكثف قبل الاختيار وقد يعملون بالتزامن في مجالات الصحة التي تميل إلى تركيز التواصل التعاطفي مع العملاء . على الرغم من تدريبهم، فإن هؤلاء الأفراد يبلغون عن قيود مثل ضغوط الوقت، والحالات عالية الخطورة , والمطالب المتنافسة، والتي يمكن أن تساهم في إرهاق التعاطف، ونقص الموظفين، والرعاية والثقة المتدنية للعملاء . نظرًا لهذه العوامل، يمكن أن يؤدي عينة من الأفراد العاديين المختارين بناءً على قدراتهم التعاطفية إلى أداء جيد مثل، أو حتى تجاوز، عمال خطوط الأزمات في تقديم استجابات تعاطفية.
تم تقديم دعم إضافي لفكرة أن القيود الخارجية على المتعاطفين البشريين المحترفين قد تحد من جودة تواصلهم التعاطفي من خلال مقارنة إضافية بين المستجيبين الخبراء وغير الخبراء (المختارين) من Prolific، حيث عكست ردودهم المختارة بعناية جودة عالية من المحتوى، والأهمية العاطفية، والقدرة على الارتباط بكل سيناريو في المشهد. يمكن العثور على تقرير مفصل عن هذا التقييم في الملاحظة التكميلية 2 من ملف المعلومات التكميلية، الذي كشف أن ردودنا المختارة تم تقييمها بأنها ليست أقل تعاطفًا من ردود الخبراء من قبل مقيمين خارجيين، ولم يُفضل أي من الردود المؤلفة على الأخرى. باختصار، على الرغم من الجودة العالية للردود التعاطفية من كلا العيّنتين من المستجيبين البشريين، فإن الأداء المتسق للذكاء الاصطناعي في تقديم ردود تعاطفية متفوقة يبرز فائدته في الرعاية الرحيمة من خلال تكملة، أو ربما تعزيز، التواصل البشري.والاستعداد، لا سيما في السياقات المكتوبة القصيرة. وتبرز هذه الفائدة من خلال النتائج الأخيرة التي تظهر أن العاملين في الدعم يمكنهم استخدام الذكاء الاصطناعي بشكل تعاوني لتوجيه استجاباتهم التعاطفية بنجاح..
الملاحظة العامة التي تفيد بأن الاستجابات التي تم إنشاؤها بواسطة الذكاء الاصطناعي تم تقييمها على أنها أكثر فعالية من تلك التي أنتجها محترفون مدربون في التعاطف تتحدى الافتراضات التقليدية بشأن الخبرة البشرية وتبرز الصعوبة في التغلب على التكاليف والقيود المرتبطة بالتعبير عن التعاطف.على النقيض من ذلك، تقدم الذكاء الاصطناعي دعمًا تعاطفيًا باستمرار دون أن يظهر تراجعًا في جودة التعاطف.أو الاستجابة المناسبة للسياق. قد تسهم هذه الميزة في الحفاظ على تقييمات الذكاء الاصطناعي العالية للاستجابة.في الدراسة الحالية، التي تفسر جزئيًا تعاطفها المتصور الأكبر مقارنةً بكل من المستجيبين البشريين الخبراء وغير الخبراء. على وجه التحديد، تم تقييم ردود الذكاء الاصطناعي على أنها أكثر فهمًا من ردود البشر، حيث طلبت بنشاط المزيد من التفاصيل، وملخصت، وعبرت عن الفهم. كما تم تقييم ردود الذكاء الاصطناعي على أنها تعبر عن مزيد من الت validation من خلال اعترافها الأكبر بمشاعر الفرد واستخدامها للغة تعبيرية. من حيث الرعاية، تم تقييم ردود الذكاء الاصطناعي على أنها تتفوق بشكل كبير على البشر من خلال تعبيرها بشكل أكثر فعالية عن التعاطف والدعم والانخراط بشكل أعمق مع تجارب الفرد الافتراضي..
تشير نتائجنا أيضًا إلى أن الذكاء الاصطناعي كان له ميزة على البشر عند الاستجابة للمحفزات السلبية، مثل المشاهد التي تصوّر المعاناة والحزن. ومن المثير للاهتمام، أنه بينما كان يُنظر إلى الذكاء الاصطناعي على أنه أفضل من بعض البشر الخبراء في الاستجابة للمحفزات الإيجابية التي تصوّر الفرح، لم تكن هذه الميزة واضحة بنفس القدر. لماذا قد يكون ذلك؟ قد يكون أحد التفسيرات هو أن الألفة مع الشريك الاجتماعي للشخص مهمة بشكل خاص لـ تعبير الدعم التعاطفي في ظل ظروف إيجابية بدلاً من سلبية، ويُعبر عنه بشكل أكثر سهولة تجاه المقربين بدلاً من الغرباء.تفسير إضافي للاختلافات الملحوظة هو أن التعاطف المعبر عنه (الاهتمام التعاطفي) يهدف بشكل مميز إلى تخفيف المعاناة.قد يكون قد زاد من أهمية استجابات الذكاء الاصطناعي للمحفزات السلبية النموذجية، حيث يرتبط الناس عمومًا التعاطف بالاستجابات للألم أو المعاناة.
تُبرز هذه النتائج مجتمعة مهارة التواصل وقيمة أنظمة الذكاء الاصطناعي التوليدية مثل ChatGPT، ولها تداعيات عميقة على المزيد من دمج الذكاء الاصطناعي في المجالات التي تتطلب تعبيرًا عن التعاطف. إن التصور العام للذكاء الاصطناعي ودوره في الدعم التعاطفي معقد، ويتأثر بعوامل فردية وإدراكية متنوعة.. ومع ذلك، فإن التفضيل المستمر للاستجابات التي تولدها الذكاء الاصطناعي في الدراسة الحالية، حتى عند مقارنتها بالمهنيين المدربين وظروف الشفافية المتنوعة، يشير إلى تحول كبير في كيفية إدراك دور الذكاء الاصطناعي في التواصل وإمكانية إدارته في المستقبل، لا سيما في المجالات التي تتطلب تبادلات متسقة وعالية الجودة.
بالإضافة إلى نقاط القوة في الذكاء الاصطناعي المتعاطف، من المهم مع ذلك ملاحظة المخاطر المحتملة لتعبيراته المتعاطفة لكل من المتلقين ومقدمي التعاطف من البشر.على وجه الخصوص، هناك مخاوف أخلاقية بارزة تتعلق باستخدام الذكاء الاصطناعي غير الشفاف في تقديم التعاطف، مما يبرز الحاجة إلى خيارات مستنيرة من قبل المستفيدين بشأن المصدر الذي يحصلون منه على الرعاية الداعمة.علاوة على ذلك، قد يؤدي الاعتماد المفرط على الذكاء الاصطناعي المتعاطف إلى زيادة المطالب للحصول على دعم شخصي وغير مشروط من المستفيدين، مما قد يضعف الجهود البشرية القائمة، ويعزز السلوكيات الإشكالية، ويساهم في زيادة غير منتجة في القضايا المتعلقة بالصحة النفسية.لذا، فإن نهجًا متوازنًا يستفيد من كل من الذكاء الاصطناعي والقوى التواصلية البشرية أمر ضروري، مما يضمن أن دمج الذكاء الاصطناعي المتعاطف يعزز التغيير الإيجابي مع احترام المعايير الأخلاقية ويكمل، بدلاً من استبدال، الرعاية المعتمدة على البشر.
القيود
بينما النتائج عبر الدراسات الأربع الحالية واعدة، يجب ملاحظة عدة قيود. أولاً، نظرًا لأن ردود الذكاء الاصطناعي والبشر تم تقييمها من قبل مقيمين خارجيين، قد لا تعمم أنماط النتائج على التفاعلات التي يكون فيها المقيمون مستلمين مباشرين للتعاطف. يمكن أن تقيم الأبحاث المستقبلية ما إذا كانت ميزة الذكاء الاصطناعي في تقديم الدعم التعاطفي مقارنة بالبشر الآخرين تستمر وتؤثر على تفضيلات المشاركين من خلال ملاحظات المستلمين المباشرين.. بالإضافة إلى ذلك، لم تبحث الدراسة الحالية فيما إذا كانت الألفة مع واستخدام تكنولوجيا الذكاء الاصطناعي قد أثرت بشكل مختلف على تقييمات ردود الذكاء الاصطناعي والردود البشرية عبر الظروف العمياء والشفافة. تلعب الألفة والكفاءة مع الذكاء الاصطناعي، من بين متغيرات الشخصية والاجتماع الأخرى، دورًا مهمًا في تشكيل المواقف تجاه. نظرًا لأن الدراسة الحالية والجهود ذات الصلة لتقييم الذكاء الاصطناعي المتعاطف بالنسبة للبشر قد تمت من خلال تفاعلات قصيرةتحتاج الدراسات المستقبلية إلى فحص المزيد من التفاعلات طويلة الأمد مع الذكاء الاصطناعي المتعاطف لتحديد ما إذا كانت تفضيلات الناس ومواقفهم تجاه الذكاء الاصطناعي تتغير مع مرور الوقت وتقييم دور الذكاء الاصطناعي المتعاطف في دعم الصحة النفسية للمستخدمين ذوي الخبرة..
الاستنتاجات
باختصار، تُظهر دراستنا نقاط قوة الذكاء الاصطناعي في سياقات التواصل التي تتطلب تعبيرات تعاطفية، وإن كانت من منظور طرف ثالث. قام المشاركون بتقييم الردود التي تم إنشاؤها بواسطة الذكاء الاصطناعي على أنها أكثر تعاطفًا وفهمًا وتأكيدًا ورعاية؛ وقد فضلوا بوعي ردود الذكاء الاصطناعي على ردود البشر عندما تم توضيح هوية المؤلف، وحتى عندما كانت المقارنة مع بشر مدربين على الاستجابة التعاطفية. في النهاية، تضع قدرة الذكاء الاصطناعي على تقديم تواصل تعاطفي بشكل مستمر كأصل استراتيجي في سيناريوهات الدعم حيث تكون الموارد البشرية محدودة.
Decety, J. & Cowell, J. M. The complex relation between morality and empathy. Trends Cogn. Sci. 18, 337-339 (2014).
Preston, S. D. & De Waal, F. B. M. Empathy: Its ultimate and proximate bases. Behav. Brain Sci. 25, 1-20 (2002).
Depow, G. J., Francis, Z. & Inzlicht, M. The Experience of Empathy in Everyday Life. Psychol. Sci. 32, 1198-1213 (2021).
Luetke Lanfer, H. et al. Digital clinical empathy in a live chat: multiple findings from a formative qualitative study and usability tests. BMC Health Serv. Res. 24, 314 (2024).
Cameron, C. D. et al. Empathy is hard work: People choose to avoid empathy because of its cognitive costs. J. Exp. Psychol.: Gen. 148, 962-976 (2019).
Scheffer, J. A., Cameron, C. D. & Inzlicht, M. Caring is costly: People avoid the cognitive work of compassion. J. Exp. Psychol.: Gen. 151, 172-196 (2022).
Morrow, E. et al. Artificial intelligence technologies and compassion in healthcare: A systematic scoping review. Front. Psychol. 13, 971044 (2023).
Turgoose, D. & Maddox, L. Predictors of compassion fatigue in mental health professionals: A narrative review. Traumatology 23, 172-185 (2017).
Anzaldua, A. & Halpern, J. Can Clinical Empathy Survive? Distress, Burnout, and Malignant Duty in the Age of Covid-19. Hastings Cent. Rep. 51, 22-27 (2021).
Lluch, C., Galiana, L., Doménech, P. & Sansó, N. The Impact of the COVID-19 Pandemic on Burnout, Compassion Fatigue, and Compassion Satisfaction in Healthcare Personnel: A Systematic Review of the Literature Published during the First Year of the Pandemic. Healthcare 10, 364 (2022).
Sinclair, S. et al. Compassion: a scoping review of the healthcare literature. BMC Palliat. Care 15, 6 (2016).
Wainberg, M. L. et al. Challenges and Opportunities in Global Mental Health: a Research-to-Practice Perspective. Curr. Psychiatry Rep. 19, 28 (2017).
Global, regional, and national burden of 12 mental disorders in 204 countries and territories, 1990-2019: a systematic analysis for the Global Burden of Disease Study 2019. Lancet Psychiatry 9, 137-150 https://doi.org/10.1016/S2215-0366(21)00395-3 (2022).
Perry, A. Al will never convey the essence of human empathy. Nat. Hum. Behav. 7, 1808-1809 (2023).
Inzlicht, M., Cameron, C. D., D’Cruz, J. & Bloom, P. In praise of empathic AI. Trends Cogn. Sci. 28, 89-91 (2024).
Ayers, J. W. et al. Comparing Physician and Artificial Intelligence Chatbot Responses to Patient Questions Posted to a Public Social Media Forum. JAMA Intern. Med. 183, 589 (2023).
De Gennaro, M., Krumhuber, E. G. & Lucas, G. Effectiveness of an Empathic Chatbot in Combating Adverse Effects of Social Exclusion on Mood. Front. Psychol. 10, 3061 (2020).
Ho, A., Hancock, J. & Miner, A. S. Psychological, Relational, and Emotional Effects of Self-Disclosure After Conversations With a Chatbot. J. Commun. 68, 712-733 (2018).
Yin, Y., Jia, N. & Wakslak, C. J. Al can help people feel heard, but an Al label diminishes this impact. Proc. Natl Acad. Sci. USA. 121, e2319112121 (2024).
Cetrano, G. et al. How are compassion fatigue, burnout, and compassion satisfaction affected by quality of working life? Findings from a survey of mental health staff in Italy. BMC Health Serv. Res. 17, 755 (2017).
Willems, R. C. W. J., Drossaert, C. H. C., Miedema, H. S. & Bohlmeijer, E. T. How Demanding Is Volunteer Work at a Crisis Line? An Assessment of Work- and Organization-Related Demands and the Relation With Distress and Intention to Leave. Front. Public Health 9, https://doi.org/10.3389/fpubh.2021.699116 (2021).
Zhang, L., Zhang, T., Ren, Z. & Jiang, G. Predicting compassion fatigue among psychological hotline counselors using machine learning techniques. Curr. Psychol. 42, 4169-4180 (2023).
Lee, Y.-C., Yamashita, N., Huang, Y. & Fu, W. ‘I Hear You, I Feel You’: Encouraging Deep Self-disclosure through a Chatbot. in Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems 1-12 https://doi.org/10.1145/3313831.3376175 (ACM, Honolulu HI USA, 2020).
Prochaska, J. J. et al. A Therapeutic Relational Agent for Reducing Problematic Substance Use (Woebot): Development and Usability Study. J. Med. Internet Res. 23, e24850 (2021).
Stein, J.-P., Messingschlager, T., Gnambs, T., Hutmacher, F. & Appel, M. Attitudes towards AI: measurement and associations with personality. Sci. Rep. 14, 2909 (2024).
Kozak, J. & Fel, S. The Relationship between Religiosity Level and Emotional Responses to Artificial Intelligence in University Students. Religions 15, 331 (2024).
Shteynberg, G. et al. Does it matter if empathic AI has no empathy? Nat. Mach. Intell. 6, 496-497 (2024).
Zhang, Y. & Gosline, R. People’s Perceptions (and Bias) Toward Creative Content Generated by Ai (ChatGPT-4), Human Experts, and Human-AI Collaboration. SSRN J. https://doi.org/10.2139/ssrn. 4453958 (2023).
Maisel, N. C., Gable, S. L. & Strachman, A. Responsive behaviors in good times and in bad. Personal. Relatsh. 15, 317-338 (2008).
Palan, S. & Schitter, C. Prolific.ac-A subject pool for online experiments. J. Behav. Exp. Financ. 17, 22-27 (2018).
Keaton, S. A. Interpersonal Reactivity Index (IRI): (Davis, 1980). in The Sourcebook of Listening Research (eds. Worthington, D. L. & Bodie, G. D.) 340-347 https://doi.org/10.1002/9781119102991.ch34 (Wiley, 2017).
Richard, F. D., Bond, C. F. & Stokes-Zoota, J. J. One Hundred Years of Social Psychology Quantitatively Described. Rev. Gen. Psychol. 7, 331-363 (2003).
McQuaid, R. J., Cox, S. M. L., Ogunlana, A. & Jaworska, N. The burden of loneliness: Implications of the social determinants of health during COVID-19. Psychiatry Res. 296, 113648 (2021).
Cacioppo, J. T. & Cacioppo, S. The growing problem of loneliness. Lancet 391, 426 (2018).
Abd-Alrazaq, A. A. et al. Perceptions and Opinions of Patients About Mental Health Chatbots: Scoping Review. J. Med Internet Res 23, e17828 (2021).
Jain, G., Pareek, S. & Carlbring, P. Revealing the source: How awareness alters perceptions of AI and human-generated mental health responses. Internet Interventions 36, 100745 (2024).
Lim, S. & Schmälzle, R. The effect of source disclosure on evaluation of Al-generated messages. Computers Hum. Behav.: Artif. Hum. 2, 100058 (2024).
Mahmud, H., Islam, A. K. M. N., Ahmed, S. I. & Smolander, K. What influences algorithmic decision-making? A systematic literature review on algorithm aversion. Technol. Forecast. Soc. Change 175, 121390 (2022).
Dietvorst, B. J., Simmons, J. P. & Massey, C. Algorithm aversion: People erroneously avoid algorithms after seeing them err. J. Exp. Psychol.: Gen. 144, 114-126 (2015).
Böhm, R., Jörling, M., Reiter, L. & Fuchs, C. People devalue generative Al’s competence but not its advice in addressing societal and personal challenges. Commun. Psychol. 1, 32 (2023).
Mahmud, H., Islam, A. K. M. N., Luo, X (Robert). & Mikalef, P. Decoding algorithm appreciation: Unveiling the impact of familiarity with algorithms, tasks, and algorithm performance. Decis. Support Syst. 179, 114168 (2024).
Pataranutaporn, P., Liu, R., Finn, E. & Maes, P. Influencing human-AI interaction by priming beliefs about AI can increase perceived trustworthiness, empathy and effectiveness. Nat. Mach. Intell. 5, 1076-1086 (2023).
Sharma, A., Lin, I. W., Miner, A. S., Atkins, D. C. & Althoff, T. Human-Al collaboration enables more empathic conversations in text-based peer-to-peer mental health support. Nat. Mach. Intell. 5, 46-57 (2023).
Bloom, P. Against Empathy: The Case for Rational Compassion. (Ecco, an imprint of HarperCollins Publishers, New York, NY, 2016).
Motomura, Y. et al. Interaction between valence of empathy and familiarity: is it difficult to empathize with the positive events of a stranger? J. Physiol. Anthropol. 34, 13 (2015).
Andreychik, M. R. & Migliaccio, N. Empathizing With Others’ Pain Versus Empathizing With Others’ Joy: Examining the Separability of Positive and Negative Empathy and Their Relation to Different Types of Social Behaviors and Social Emotions. Basic Appl. Soc. Psychol. 37, 274-291 (2015).
Maples, B., Cerit, M., Vishwanath, A. & Pea, R. Loneliness and suicide mitigation for students using GPT3-enabled chatbots. npj Ment. Health Res. 3, 4 (2024).
شكر وتقدير
نود أن نشكر غريغوري ديبو، ليف أندرسون، كاتي تام، داشا ساندرا، يي يي وانغ، وجميع أعضاء مختبر العمل واللعب الآخرين على دعمهم في التحقق من المواد والرؤى على طول الطريق.
مساهمات المؤلفين
قام د.أ. ود.م. بتصميم الدراسة وصياغة أسئلة البحث. قام د.أ. ببرمجة التجارب، وجمع البيانات وتنظيفها. قام د.أ. و م.ف. بتحليل البيانات. كتب د.أ. المخطوطة. قام م.ع. و م.ف. بتحرير المخطوطة وقدموا إشرافًا حاسمًا وتعليقات على العمل.
قسم علم النفس، جامعة تورونتو، تورونتو، أونتاريو، كندا.مدرسة روتمان للإدارة، جامعة تورونتو، تورونتو، أونتاريو، كندا.ساهم هؤلاء المؤلفون بالتساوي: فيكتوريا أولديمبرغو دي ميلو، مايكل إنزليخت. □ البريد الإلكتروني:michael.inzlicht@utoronto.ca
Third-party evaluators perceive Al as more compassionate than expert humans
Dariya Ovsyannikova , Victoria Oldemburgo de Mello & Michael Inzlicht
Empathy connects us but strains under demanding settings. This study explored how third parties evaluated AI-generated empathetic responses versus human responses in terms of compassion, responsiveness, and overall preference across four preregistered experiments. Participants ( ) read empathy prompts describing valenced personal experiences and compared the AI responses to select non-expert or expert humans. Results revealed that AI responses were preferred and rated as more compassionate compared to select human responders (Study 1). This pattern of results remained when author identity was made transparent (Study 2), when AI was compared to expert crisis responders (Study 3), and when author identity was disclosed to all participants (Study 4). Third parties perceived Al as being more responsive-conveying understanding, validation, and care-which partially explained AI’s higher compassion ratings in Study 4. These findings suggest that AI has robust utility in contexts requiring empathetic interaction, with the potential to address the increasing need for empathy in supportive communication contexts.
Empathy is crucial for fostering societal unity and effective communication. It allows individuals to balance their own interests with the wellbeing of others through shared experiences and emotions. It can promote cooperation, altruism, and helping behaviors, thereby strengthening social bonds . Psychologically, empathy also has a nourishing effect on its recipients, such that people feel validated, understood, and connected when others empathize with them . Despite the positive impact of empathy on its recipients, the effort required to express empathy can be costly and burdensome to the empathizer , making them less likely to respond empathically, a phenomenon known as empathy avoidance and compassion fatigue . This seems to be particularly apparent in clinical settings, where healthcare professionals may sacrifice some of their ability to empathize in order to avoid burnout , to manage personal distress , or to balance their emotional engagement with the need to effectively allocate resources to each client, particularly individuals with complex cases .
One consequence of these challenges is that empathy is in short supply, especially as the mental health sector struggles with accessible service and workforce shortages amid the increasing incidence of mental health disorders . Such shortages make the maintenance of compassionate care even more difficult for the currently employed mental health professionals, for whom it serves as one of several key responsibilities . While empathy is often understood as a dynamic process that originates from the experience of the empathizer , less is known about its effects on the perceivers of empathic support. Considering this and the challenges of meeting societal needs for empathy, here, we compare the quality of written empathic
responses generated by Artificial Intelligence (AI) to select and expert humans. We ask if AI can match or even exceed the quality of responses made by human empathizers and examine the conditions under which people are more likely to prefer an empathetic response from an AI over a human.
In response to the gap between the supply and demand of empathy, scientists have asked if AI could provide consistent and quality supportive care. Despite arguments that AI cannot experience empathy or feel emotions , it can express empathy by generating responses or behaviors that appear to reflect empathic concern or the intention to alleviate distress . As such, scientists have begun exploring the effectiveness of AI powered by large language models in providing empathic support . These investigations, through methods ranging from third-party evaluations to direct recipient feedback , reveal that AI can be rated as comparable to, if not superior in, expressing empathetic support. For example, in a recent study , researchers compared the perceived quality and level of empathy in ChatGPT’s responses to public questions generated on a Reddit forum (r/ AskDocs) to responses made by verified human physicians through third party ratings made by healthcare professionals. It was found that chatbot responses were rated significantly more empathic and of higher quality than physician responses . Interestingly, chatbot responses were also significantly longer than physician responses, perhaps reflecting the difficulties for humans to convey empathy through written text, particularly when these responses are made by healthcare professionals, who may experience competing demands and time constraints .
Several lines of evidence illustrate the potential benefits of interacting with an empathic AI. The fact that AI interactions are anonymous and that they involve machines and not humans can facilitate greater disclosure of personal information , perhaps because chatbots are not inherently judgmental and thus do not evoke a fear of feeling criticized . The latter effect is particularly important, as both the act and degree of self-disclosure have been experimentally demonstrated to increase and deepen subsequent disclosures, increase perceived intimacy and enjoyment of the interaction, as well as increase feelings of trust . Together, these elements and associated outcomes of AI interactions might explain why interacting with artificial agents might provide some social benefits to people .
Yet, the receptiveness to AI-generated empathic responses could be influenced by the recipient’s awareness of and preconceived attitudes towards receiving support from non-human entities. For instance, people’s perception of empathy expressions from AI could be rooted in an awareness that AI, unlike humans, lacks genuine emotional experience and thus cannot actually care; being unmoved by empathic AI statements might then reflect warranted skepticism about its capabilities regardless of its actual effectiveness . Simultaneously, general attitudes towards AI, related to factors such as personality, conspiracy mindset , and religiosity , among others, may play a critical role in the evaluation and acceptance of AI.
One recent study investigated differences in people’s perceptions of feeling heard after receiving human or AI-generated responses that were or were not transparently labeled . AI responses were generally evaluated as more emotionally supportive and responsive than human responses. However, the AI advantage disappeared when participants believed that they were responded to by AI, such that their ratings of feeling heard and understood were higher when they believed that the responses came from a human. Critically, when AI and human responses were accurately labeled, participants reported equivalent perceptions of feeling heard and understood by either agent , suggesting that the benefits reaped from empathic AI interactions can occur even after accounting for the drop in perceived response quality, when people are made aware that they are not interacting with another human. Further research found that the mere act of emotional disclosure over a 25 -minute conversation carried numerous emotional, psychological, and relational benefits, irrespective of whether participants believed they were conversing with an AI or human agent . Collectively, while these findings highlight the nuances of human reactions to AIgenerated content, they challenge the notion that human interaction is irreplaceable in empathic exchanges and further suggest that attitudes towards empathy-expressing AI can improve with increasing familiarity and time.
Despite preliminary evidence that AI responses are rated as being greater or equal in empathy to human responses, there are a few limitations to this initial work. First, given the ethical requirements of consent and transparency in the use of , studies need to compare responses from humans versus AI, both when participants are blind to the source and fully aware of it. Doing so allows for the generalizability of empathic AI preference to ethical and legal contexts and allows for the investigation of the effects of AI aversion . Second, the present literature is limited in using laypersons to generate empathic responses that are then compared with AI responses . In other words, these participants do not receive formal training in providing empathic support and/or do not assume professional roles in providing empathic care. At present, there are no known studies that compare empathic AI to trained “experts” of empathy or even samples selected for being particularly empathic, especially individuals working in the mental healthcare sector.
Here, in a series of four preregistered studies, we investigate whether there are significant differences in the way that third-party persons evaluate empathic responses by AI or human agents. We ask: do third-party evaluators rate responses made by AI as more compassionate than responses made by fellow humans selected for being good empathizers? (Study 1); will these differential evaluations hold when the identities of the two sources are made transparent? (Study 2); will they hold when empathic AI is
compared to real-life experts of empathic support? (Study 3); and why is transparently labeled AI so good at generating empathic statements? (Study 4). To address the final question, we examine the mediating role of perceived responsiveness in driving judgments of compassion.
We hypothesized that participants would rate the responses generated by AI as more compassionate than those of select and expert human responders. We further hypothesized that participants would rate responses generated by AI as significantly better quality and prefer AI responses to responses generated by select and expert humans in a binary forced-choice scenario. Finally, with respect to Study 4, we further hypothesized that participants would rate the AI -generated responses as more responsive than human-generated responses in terms of communicating care, understanding, and validation .
Methods
Our goal was to assess which agent was better at generating empathic statements: humans or AI. To evaluate this, we compared human-generated or GPT-generated written responses to empathic prompts across four experiments. We first created 10 empathy prompts (first-person descriptions of both positive (5) and negative (5) experiences). In studies 1-3, participants read all 10 empathy prompts describing personal experiences. In study 4, only 6 of the 10 prompts were presented to participants. For each empathy prompt, participants read a pair of potential empathic responses: one human-generated response and one GPT-generated response. Examples of vignettes and responses can be seen in Fig. 1.
To generate the select human responses used in studies 1 and 2, we first piloted a study on our university participant pool and then formally ran the study on Prolific Academic . Ten participants were instructed to read the 10 empathy prompts and generate a compassionate written response to the author of the prompt. Out of the 100 overall responses generated ( 10 per participant), we asked 3 graduate students and 4 research assistants to rank order the top 5 responders based on how overall compassionate their responses were in terms of quality, emotional salience, relatability, and level of detail. The 5 responders who were ranked in the top 5 most often had their responses selected for use in the studies. Thus, we consider this a select group of empathic responders, as they were first screened and selected based on their overall empathic quality.
In studies 3 and 4, the human response stimuli were obtained from a sample of hotline crisis responders-volunteers trained to respond to psychological crises through telephone calls-whom we considered expert empathizers. These participants were recruited via emails that were internally distributed to all responders within the Distress Centres of Greater Toronto, a multi-helpline organization that offers emotional support to Canadian callers across general and national helplines. Five responders provided written empathic responses to the same 10 empathy prompts as the Prolific Academic sample. All responses were inspected for quality and used in the study, such that each participant only saw one randomly selected option of these 5 responses per vignette.
The AI-generated responses across all studies were created by prompting ChatGPT (model gpt-4-0125-preview) with the 10 vignettes describing the emotional experience (one at a time) and asking it to generate an appropriate empathetic response. Given the stochastic nature of ChatGPT, we generated 5 separate responses per vignette. All responses generated by ChatGPT were used in the study. These responses were randomized in the study, such that participants only saw one of these 5 responses per vignette. For a detailed report of how the empathy prompts and responses were generated, see section 1 in the Supplementary Information file.
After reading the empathy prompt and each pair of responses, participants first reported the level of compassion in each response and then selected the one they considered the best at addressing the prompt (response preference). To measure perceived compassion, participants were asked how much each response: a) reflected the emotional state in the prompt, b) was compassionate, and c) was impersonal (reverse-coded). All responses were recorded on a 5-point Likert scale ranging from 1 (Strongly Disagree)
Negative prompt example
“I am having difficulties with my family relationships. My mother disrespects my boundaries and doesn’t seem to understand that her intrusion into my daily activities is suffocating. My brother will drop his kids off
Human Response
I am sorry that your family has been making you feel this way. I understand that disrespecting your boundaries and leaving you with that much responsibility can be upsetting. You deserve to be treated with more respect and consideration. for 12 hour days, and while I loves my nieces and nephews, I’m starting to feel like my life is not really my own.”
Al Response
It sounds like you’re in a really tough spot, feeling overwhelmed by the demands placed on you and struggling with boundaries within your family.[…] Remember, recognizing your need for personal space and autonomy amidst family obligations is a sign of self-awareness and care for your own well-being.
Human Response
It is so amazing to hear that you have benefitted from therapy so much! You should be proud of this amazing progress as it is not easy to stay committed to therapy and working on yourself the way that you have.
Al Response
I want to express how wonderful it is to hear about the positive journey you’ve had in therapy. Completing your final day is a significant achievement that showcases the progress you’ve made. […] Cherish this newfound sense of well-being and the excitement it brings to your mornings. Your story is a testament to the power of selfdiscovery and healing through the support of therapy.
Positive prompt example
“Today was my final day of therapy! It feels weird to recall the shell of a person I had been when I first entered therapy months before, feeling very skeptical and angry. Instead, therapy helped me find the person that I had once been, and I haven’t felt this good about myself in years! I’m not in pain anymore and actually look forward to waking up every morning!”
Fig. 1 | Example responses to negative and positive prompts from human and AI sources. Human and ChatGPT-4 generated responses to negative and positive prompts. Each response demonstrates the differing emphases placed on emotional support by humans and AI.
to 5 (Strongly Agree) and averaged per empathic response. Response preference was measured by asking participants which one of the two responses was better at addressing the personal experience in the empathy prompt through a binary forced-choice question, where human responses were coded as 0 and AI responses were coded as 1 . We aggregated the ratings for all 10 (or 6) vignette responses to create average scores for compassion and preference for both AI responses and human responses.
In study 4, we measured participants’ perceived level of responsiveness for all responses. Participants evaluated the responsiveness of human and AI responses using a 5 -point Likert scale, based on facets of understanding (paraphrasing the reported experience, further inquiring about the experience, expressing understanding), validation (agreeing with the individual, validating their feelings/emotions, using exclamations and judgments), and caring (expressing empathy or emotions, offering support, concern, or comfort, and emphasizing the outcome sharing of the individual’s scenario and/or circumstances) . Each facet was measured with three items, and responses were recorded using a 5 -point Likert scale ranging from 1 (Strongly Disagree) to 5 (Strongly Agree). Responsiveness scores were averaged across these facets. Detailed item measures and figures can be found in sections 1 and 2 of the Supplementary Information file, respectively.
In experiment 1, all participants were left blind to whether each response was generated by a human or AI . In experiments 2 and 3, participants were randomly assigned to either transparent or blind conditions in a between-subject design; in the transparent condition, they were told whether each response was generated by AI or humans; in the blind condition, participants did not see the label for each response, so they could not immediately know which response was generated by a human or AI. Experiment 4 only had the transparent condition, so participants could see the author labels for both empathy sources.
In addition to the response ratings, we also measured (but did not fully analyze) participants’ trait level empathy using the Interpersonal
Reactivity Index . This was done to explore whether participants’ compassion ratings of AI and human-generated responses were moderated by their reported level of trait empathy. More details on this measure can be found in the Supplementary Methods section of the Supplementary Information file, under the Measures subsection. Participants were paid , , , and (GBP) for their participation in studies 1-4, respectively. All aspects of the present study were approved and undertaken in compliance with the ethical regulations surrounding human research participants set by the Research Ethics Board at the University of Toronto. Informed consent was obtained from all participants, who were all debriefed and compensated following study completion.
Sampling strategy
In studies 1 and 4, which had a completely within-subject design, we aimed for a sample of 54 participants, given that a power analysis suggests we’d achieve at least power to detect the average effect size in social psychology of . For studies 2 and 3, where we had a mixed design with one between-subject and one within-subject variable, we aimed to run 400 participants, giving us power to detect an interaction as small as even after dropping the expected number of inattentive participants. A sample of English-speaking participants was recruited on Prolific Academic . Study data was collected between September 2023 and May 2024. After excluding participants that failed one or both attention checks, the distinct sample size for each study consisted of and participants in studies 1 and 4, respectively, and (vs. 98 blind) and (vs. 126 blind) participants per condition in studies 2 and 3, respectively. These individuals had an average age of 42.0 years ( ) in study 1, 36.2 years in study 2, 37.2 years in study 3 , and 37.0 years ( ) in study 4 . The demographic distribution of our samples in terms of age, gender, and race, with responses to all variables
Table 1 | Demographic Distributions of Participants in Studies 1-4
Study
Study
Study
Study
Age in years
Mean ± SD
Median
40
32
33
35
Minimum – Maximum
21-76
18-77
18-104
19-64
Sex
Count
%
Count
%
Count
%
Count
%
Female
25
46.3%
87
44.2%
141
57.1%
37
64.9%
Male
28
51.9%
107
54.3%
105
42.5%
20
35.1%
Prefer not to say
0
0.0%
1
0.5%
1
0.4%
0
0.0%
N/A
1
1.9%
2
1.0%
0
0.0%
0
0.0%
Race
Asian
6
11.1%
32
16.2%
45
18.2%
9
15.8%
Black
13
24.1%
27
13.7%
23
9.3%
4
7.0%
Mixed
3
5.6%
15
7.6%
10
4.0%
6
10.5%
White
31
57.4%
101
51.3%
158
64.0%
35
61.4%
Other
0
0.0%
15
7.6%
9
3.6%
3
5.3%
N/A
1
1.9%
7
3.6%
2
0.8%
0
0.0%
Country of Residence
Canada
24
44.4%
67
34.0%
187
75.7%
33
57.9%
United States
30
55.6%
130
66.0%
60
24.3%
24
42.1%
This table displays the demographic distributions for participants across four distinct studies, detailing age, sex, race, and country of residence. Each study’s demographic profile is presented with mean and standard deviation for age, along with the count and percentage breakdown for sex, race, and country of residence. Sample sizes are specified for each study.
provided by participants alongside study data on Prolific Academic , is reported in Table 1.
Statistical analyses
In studies 1 and 4, we ran dependent samples -tests to evaluate whether the GPT-generated or the human-generated responses were more compassionate. To evaluate response preference, we ran one-sample t -tests where the mean preference (ranging from 0 for human to 1 for AI ) was compared against chance (0.5).
In studies 2 and 3, due to the mixed method design, we ran mixed models (using the afex package in ) to determine the interaction between compassion judgments for GPT versus human-generated responses and blind versus transparent conditions. For the mediation model in study 4, we used within-person mediation with the lme4 package, after which we bootstrapped using 1000 samples.
To further explore the results, we divided our vignettes into positivevalenced or negative-valenced-vignettes reporting positive or negative experiences. We used interaction mixed regression models to evaluate whether the vignette valence moderated the relationship between response author (human or AI) and perceived compassion or preference. All analyses were performed on . Additional information regarding exploratory analyses is reported in Supplementary Notes 1 and 2 of the Supplementary Information File.
Preregistration
We preregistered studies at aspredicted.org. The links for all the studies (preregistration dates included) are provided as follows: study 1 (https:// aspredicted.org/ha2av.pdf), study 2 (https://aspredicted.org/c3y4s.pdf), study 3 (https://aspredicted.org/v62tg.pdf), and study 4 (https://aspredicted. org/q5hq9.pdf). All preregistration documents are available at the repository https://osf.io/wjx48/. We originally planned to conduct repeated measures ANOVA in Studies 2, 3, and 4. However, we deviated from this approach and used multilevel models instead, as our data violated Mauchly’s test of sphericity, a key assumption of ANOVA. As a robustness check, we also ran ANOVAs, which are reported in Supplementary Note 3
of the Supplementary Information File. The ANOVA results were consistent in direction and significance with those from the multilevel models. Additionally, we mistakenly described response preference as a continuous variable, when it was actually a binary forced-choice variable. Given this, the most appropriate analysis was a one-sample t-test against 0.5 , rather than the dependent samples t-test originally preregistered. Finally, while we preregistered exploring whether participants’ reported trait empathy moderated their compassion ratings for AI or human-authored responses, we found no credible evidence of trait empathy affecting compassion ratings for either response source. We nevertheless report this finding for study 1 in Supplementary Note 3 of the Supplementary Information File. Across all studies, data distribution was assumed to be normal, but this was not formally tested. However, given our use of multi-level models, which are robust to non-normal data, this assumption was not critical.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Results
We initially hypothesized that participants would rate the AI-generated responses as more compassionate than the human-generated responses. We also hypothesized that the AI responses would be preferred over the human responses. The two preregistered hypotheses were confirmed across all four experiments. The results for the compassion hypothesis are summarized for all four studies in Fig. 2. The findings for response preferences across studies 1-4 are summarized in Fig. 3.
Experiment 1
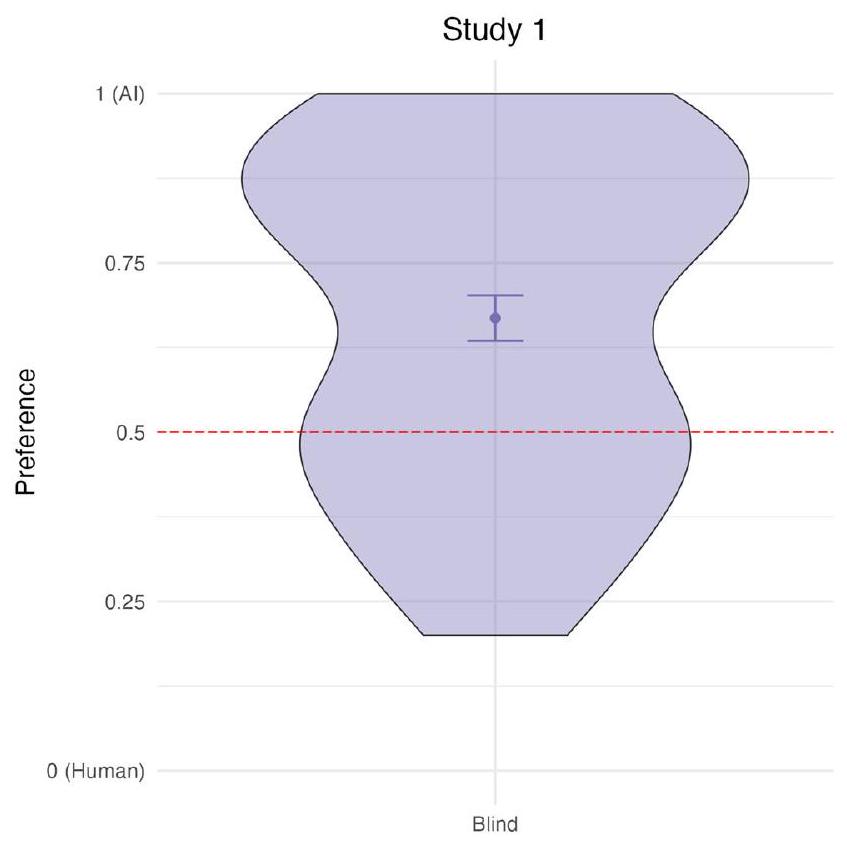
The AI-generated responses ( ) were rated as significantly more compassionate than the select human-generated responses , 1.03]. Participants also preferred the AI response over the select human response, .
Fig. 2 | Comparison of compassion ratings by response author across studies . Distributions of compassion ratings for responses authored by humans (red) and AI (blue) in four separate studies. Panels represent Studies 1 through 4, with each study split into conditions where the response author label was concealed or transparent to
evaluators. Error bars represent the standard error of the mean. The sample sizes are for Study for Study blind, transparent), for Study 3 ( blind, transparent), and for Study 4 .
When exploring the moderating effect of vignette valence, we found a significant interaction, , partial CI , such that the AI responses were rated as especially more compassionate than human responses when the empathy prompts contained a negative experience ( ) than when they contained a positive experience ( ). The summarized findings for the effect of vignette valence for the latter and subsequent studies can be found in Fig. 4.
Experiment 2
Experiment 2 replicated the main findings of experiment 1 . We found a main effect for empathy source, , partial , such that the GPT-generated responses ( ) were rated as more compassionate than the select human-generated responses . However, we also found an interaction between empathy source and the transparency condition, , , indicating that AI’s empathy advantage was larger when participants were blind to the empathy source ( ). Despite this interaction, participants still rated AI as more compassionate even when AI was transparently labeled . AI responses, in other words, were clearly rated as more compassionate than humans’ even when participants knew the response was generated by AI.
We also examined whether response valence moderated the interaction between author and condition. Although we did not find a significant interaction, , we did find an interaction between author and valence, , partial , , such that the difference between AI and human responses was greater for the negative scenarios ,
Study 3
Fig. 3 | Preference ratings for AI versus human-authored responses across studies under different transparency conditions. Violin plots illustrate preference distributions where 0 denotes a preference for human-authored responses and 1 denotes a preference for AI-authored responses, across four separate studies. Panels represent Study 1 through 4, segmented into conditions where the response author
labels were concealed or transparent to evaluators. The dotted red line at 0.5 indicates no preference for human or AI responses. Error bars denote confidence intervals. The sample sizes are for Study 1, for Study 2 ( blind, transparent), for Study 3 ( blind, transparent), and for Study 4 . than for the positive scenarios ( ). This suggests that AI had a greater advantage over humans when addressing vignettes describing negative experiences, and this was the case whether the empathic responses were transparently labeled or not.
Finally, we also examined response preference. We found that the AI responses were judged as better at addressing the prompt than the select human responses, . We further found significant differences in participants’ response preferences by transparency condition, such that the preference for AI-generated responses was greater when participants were blind ( ) rather than transparently exposed ( ) to the response author labels, .
Experiment 3
Experiment 3 had a design like experiment 2, except the human responses were created by trained hotline crisis responders. Again, we found a main effect of author, , partial such that AI responses were rated as more compassionate than human responses ( ). As with Experiment 2, however, this main effect was subsumed under a significant interaction between response source and the transparency condition, , 245) , partial , suggesting that AI’s compassion advantage over expert humans was stronger when participants were blind to author source. Nonetheless, simple effects analyses indicate that AI’s responses were rated as more compassionate than
Fig. 4 | Compassion ratings by valence and transparency condition across four studies. Violin plots display compassion ratings for AI versus human-authored responses, split by positive (left column) and negative (right column) vignette
Negative
Study 1
Study 2
Study 3
Study 4
valence across four studies. Error bars denote confidence intervals. The sample sizes are for Study 1, for Study 2 ( blind, transparent), for Study 3 ( blind, transparent), and for Study 4.
humans in both the blind ( ) and transparent conditions.
In experiment 3, we again did not find a interaction between response author, condition, and valence, , but we replicated the author by valence interaction from study , , partial , such that perceived compassion was even greater for AI than expert humans when it addressed negative prompts ( ) than when it addressed positive prompts ( ).
Response preference also followed the pattern of the two previous studies, such that AI responses were considered better at addressing the prompt than expert humans, . We once again found significant differences in participants’ response preferences by transparency condition, such that the preference for AI-generated responses was greater when participants were blind ( , ) rather than transparently exposed ( ) to the response author labels, , . In examining the extent of participants’ preferences for compassionate statements generated by AI v. human experts separately across blind and transparent conditions against a test value of 0.5 , we confirmed that AI responses were judged as better at addressing the prompt than the expert human responses to a greater extent in the blind, , , rather than transparent condition, .
Experiment 4
Experiment 4 used some of the same human expert and AI responses as Experiment 3, but all the responses were transparently labeled. In addition, participants rated how understanding, validating, and caring each response was. Regarding responsiveness, we hypothesized that AI responses would be rated as expressing greater responsiveness than empathic responses generated by expert humans (crisis line workers). Specifically, we hypothesized that AI responses would be rated as more understanding, validating, and caring.
As with the earlier three studies, AI-generated responses were rated as significantly more compassionate ( , ) than the expert human-generated responses , , partial . Similarly, AI responses were preferred to expert human responses with respect to being better at addressing the prompt, [0.42, 1.00].
We further replicated the interaction effect between author and valence, , partial , with simple effects analyses suggesting that compassion ratings for AI were greater when it addressed negative prompts ( ) than when it addressed positive prompts ( ).
Finally, AI -generated responses ( ) were rated as significantly more responsive than the expert human-generated responses , -0.32]. Specifically, AI responses outperformed human experts across all three facets of partner responsiveness: AI responses were evaluated as significantly more understanding ( , vs. , ; validating vs. , ; and caring than expert human responses vs. , . These findings highlight that AI is not only perceived as broadly responsive but also surpasses human experts in demonstrating understanding, validation, and care.
After further examining responsiveness, we found a significant author by valence interaction, , partial . Post-hoc comparisons suggested that responsiveness ratings for AI were greater when it addressed negative circumstances, than positive circumstances ).
Finally, to explore whether responsiveness ratings mediated the effect of author on compassion, we conducted a within-subjects mediation analysis. The indirect effect of empathy source on compassion ratings through responsiveness was significant, as the bootstrap confidence interval based on 1000 samples did not include zero, . Furthermore, analysis of the direct effect revealed that response author still significantly predicted compassion ratings even after accounting for responsiveness, , indicating partial mediation. Responsiveness itself was a strong predictor of compassion ratings, , . These results suggest that while part of why AI responses are rated as more compassionate is that they are perceived as more responsive, perceived responsiveness cannot explain all the variance in compassion ratings for AI.
Discussion
Empathy has numerous benefits on its recipients, but the toll associated with its expression, with competing pressures , can facilitate avoidance and a reduction in prosocial behaviors . The gap between empathic supply and demand leaves recipients with unfulfilled needs for supportive care and contributes to heightened reports of social isolation, loneliness, and mental health concerns , which have intensified since the COVID-19 pandemic, particularly among youth . Given these challenges, researchers have examined whether Artificial Intelligence (AI) would be perceived as comparably effective to humans in providing empathic support . Recent research suggests that AI can indeed be effective in promoting healthy social behaviors like self-disclosure , trust, enjoyment, intimacy , and improved .
In the present study, we asked if third party evaluators would rate responses made by AI as more compassionate than responses made by select and expert humans. Across four preregistered experiments, the results robustly supported our initial hypotheses: AI-generated responses were consistently rated as more compassionate and were preferred over humangenerated responses. Though AI may not express authentic empathy or share others’ suffering , it can express a form of compassion through its facilitation of active support . In fact, it is so effective that third-party evaluators perceive it as being better than skilled humans. While AI does not experience empathy in the psychological sense, it is important to note that empathy is an interaction between two entities, rather than solely an internal experience of the empathizer. From this perspective, the interacting partner could still derive the benefits of empathic engagement, even when it originates from an artificial system. In the present study, the perception of AI’s empathic responses might bring about effects in its recipients that could be similar to (or even better than) the effects of empathy expressed by humans -at least through the eyes of third-party evaluators.
In experiments 2 and 3, we randomly assigned participants to blind and transparent conditions, where they were ignorant and aware of the response author identity, respectively. In an aim to assess the AI advantage against the influence of source transparency, we confirmed that the AI advantage decreased when people knew the response authors’ identities. However, participants continued to rate AI responses as more compassionate than human responses even when they knew that the response was AI -authored. This pattern of findings is consistent with the existing literature surrounding the impact of source disclosure on people’s perceptions of AI-generated content, where the effectiveness of AI-generated content is lower when source identity is disclosed, even when its quality is evaluated as largely comparable to human responses . In short, people seem to prefer AI content more when they are unaware that it was made by AI.
One partial explanation for these findings is offered by the literature surrounding algorithm aversion (or rather, human favoritism) . Literature surrounding algorithm aversion posits that knowing that a piece of content is AI-generated biases its reception, though reactions vary with AI’s contextual application . Alternatively, the devaluation of AI-generated content may come from legitimate skepticism about AI’s capabilities in the context of empathy, given its inability to embody genuine feeling or care . While AI aversion is common , it can be partly overcome with
experience , successful use , and framing that emphasizes AI’s supportive motives . Taken together, these observations suggest that negative initial impressions of AI effectiveness can improve as individuals gain more experience and positive outcomes with AI.
Following these findings, one potential future direction lies in asking whether this is true for all people or only a subset. People’s expectations of AI largely depend on their perception of it-shaped by numerous attitudinal, social, and cognitive variables-which can impact the perceived value and experience of AI-generated support . Thus, it is crucial to examine the heterogeneity of these findings.
Notably, we established that AI responses maintained their compassion advantage even when compared to those from a subset of crisis line responders, trained experts in delivering empathic support to a diverse Canadian population. This advantage persisted across both blind and transparent source identity conditions, including when all participants were aware of the authors’ identities for each empathic response (Study 4). These findings are particularly significant since responders in this organization undergo extensive training before selection and may work concurrently in health fields that tend to centralize empathic communication with clients . Despite their training, these individuals report constraints like time pressures, high-severity cases , and competing demands, which can contribute to compassion fatigue, staff shortages, and diminished client care and trust . Given these factors, a sample of regular individuals selected for their empathic abilities could perform as well as, or even surpass, crisis line workers in delivering empathic responses.
Further support for the notion that external constraints on professional human empathizers may limit the quality of their empathic communication was offered by a supplemental comparison of expert to non-expert (select) Prolific responders, whose carefully selected responses reflected high quality of content, emotional salience, and relatability to each scenario in the vignette. A detailed report of this evaluation can be found in Supplementary Note 2 of the Supplementary Information file, which revealed that our select responses were rated as no less compassionate than experts’ by third-party raters, and neither authored response was preferred over the other. In sum, despite the high quality of empathic responses from both samples of human responders, AI’s consistent performance in providing superior empathetic responses highlights its utility in compassionate care through complementing, or potentially enhancing, human communication and preparedness, particularly in brief, written contexts. This utility is underscored by recent findings demonstrating that support workers can successfully use AI collaboratively to guide their empathic responses .
The overall observation that AI-generated responses were rated as more effective than those produced by trained empathic professionals challenges conventional assumptions regarding human expertise and highlights the difficulty in overcoming the costs and constraints associated with the expression of empathy . In contrast, AI consistently provides empathic support without showing a decline in empathy quality or context-appropriate responding . This advantage may contribute to AI’s sustained high ratings for responsiveness in the present study, which partially explains its greater perceived compassion relative to both expert and non-expert human responders. Specifically, AI responses were rated as more understanding than human responses, as they actively solicited more details, summarized, and expressed understanding. AI responses were also rated as expressing more validation through their greater acknowledgment of the individual’s feelings and use of expressive language. In terms of caring, AI responses were evaluated to significantly outperform humans’ by more effectively expressing empathy and support and engaging more deeply with the hypothetical individual’s experiences .
Our results further indicate that AI had an advantage over humans when responding to negative prompts, such as in vignettes that depicted suffering and sadness. Interestingly, while AI was also perceived to be better than select and expert humans at responding to positive prompts depicting joy, this advantage was not as apparent. Why might that be? One rationale may be that familiarity with one’s social partner is particularly important for
the expression of empathic support under positive rather than negative circumstances and is expressed more readily to close others than strangers . An additional explanation for the observed differences is that expressed compassion (empathic concern), distinctively aimed at alleviating distress , may have heightened the salience of AI’s responses to typical negative prompts, as people generally associate empathy with responses to pain or suffering.
Cumulatively, these findings highlight the communicative skill and value of generative AI systems like ChatGPT and have profound implications for further integration of AI in domains requiring expressed empathy. Public perception of AI and its involvement in empathic support is complex, influenced by diverse individual and perceptual factors . Nevertheless, the consistent preference for AI-generated responses in the present study, even when compared to trained professionals and varied transparency conditions, suggests a significant shift in how AI’s role in communication might be perceived and potentially managed in the future, particularly in areas demanding consistent, high-quality exchanges.
In addition to the strengths of empathic AI, it is nevertheless important to note the prospective risks of its empathic expressions for both the recipients and human providers of empathy . In particular, there are highlighted ethical concerns surrounding non-transparent AI use in empathy delivery, emphasizing the need for informed recipient choices regarding the source from which they obtain supportive care . Moreover, an overreliance on empathic AI may increase the demands for personalized and unconditional support from recipients, which could undermine existing human effort, reinforce problematic behavior, and contribute to a counterproductive increase in mental health concerns . Thus, a balanced approach that leverages both AI and human communicative strengths is essential, ensuring that the integration of empathic AI fosters positive change while respecting ethical standards and supplementing, rather than replacing, human-based care.
Limitations
While the results across the present four studies are promising, several limitations should be noted. First, given that the AI and human-generated responses were rated by third-party evaluators, the patterns of findings may not generalize to interactions in which the evaluators are direct recipients of empathy. Future research could assess whether AI’s advantage in providing empathic support relative to fellow humans maintains and informs participant preferences through direct recipient feedback . Additionally, the present study did not examine whether familiarity with and use of AI technology may have differentially influenced evaluations of AI and humangenerated responses across blind and transparent conditions. Familiarity and proficiency with AI, among other personality and social variables, play an important role in shaping attitudes towards . Given that the present study and related efforts to assess empathic AI relative to humans have done so through brief interactions , future studies need to examine more long-term interactions with empathic AI to establish whether people’s preferences and attitudes towards AI change as a function of time and assess the role of empathic AI in supporting experienced users’ mental health .
Conclusions
In sum, our study demonstrates the strengths of AI in communication contexts that require empathic expressions, albeit from a third-party lens. Participants consistently rated AI-generated responses as more compassionate, understanding, validating, and caring; they knowingly preferred AI responses to human-generated responses when author identity was made explicit and even when the human comparison was comprised of trained empathy first responders. Ultimately, AI’s ability to consistently deliver compassionate communication positions it as a strategic asset in support scenarios where human resources are stretched thin.
Decety, J. & Cowell, J. M. The complex relation between morality and empathy. Trends Cogn. Sci. 18, 337-339 (2014).
Preston, S. D. & De Waal, F. B. M. Empathy: Its ultimate and proximate bases. Behav. Brain Sci. 25, 1-20 (2002).
Depow, G. J., Francis, Z. & Inzlicht, M. The Experience of Empathy in Everyday Life. Psychol. Sci. 32, 1198-1213 (2021).
Luetke Lanfer, H. et al. Digital clinical empathy in a live chat: multiple findings from a formative qualitative study and usability tests. BMC Health Serv. Res. 24, 314 (2024).
Cameron, C. D. et al. Empathy is hard work: People choose to avoid empathy because of its cognitive costs. J. Exp. Psychol.: Gen. 148, 962-976 (2019).
Scheffer, J. A., Cameron, C. D. & Inzlicht, M. Caring is costly: People avoid the cognitive work of compassion. J. Exp. Psychol.: Gen. 151, 172-196 (2022).
Morrow, E. et al. Artificial intelligence technologies and compassion in healthcare: A systematic scoping review. Front. Psychol. 13, 971044 (2023).
Turgoose, D. & Maddox, L. Predictors of compassion fatigue in mental health professionals: A narrative review. Traumatology 23, 172-185 (2017).
Anzaldua, A. & Halpern, J. Can Clinical Empathy Survive? Distress, Burnout, and Malignant Duty in the Age of Covid-19. Hastings Cent. Rep. 51, 22-27 (2021).
Lluch, C., Galiana, L., Doménech, P. & Sansó, N. The Impact of the COVID-19 Pandemic on Burnout, Compassion Fatigue, and Compassion Satisfaction in Healthcare Personnel: A Systematic Review of the Literature Published during the First Year of the Pandemic. Healthcare 10, 364 (2022).
Sinclair, S. et al. Compassion: a scoping review of the healthcare literature. BMC Palliat. Care 15, 6 (2016).
Wainberg, M. L. et al. Challenges and Opportunities in Global Mental Health: a Research-to-Practice Perspective. Curr. Psychiatry Rep. 19, 28 (2017).
Global, regional, and national burden of 12 mental disorders in 204 countries and territories, 1990-2019: a systematic analysis for the Global Burden of Disease Study 2019. Lancet Psychiatry 9, 137-150 https://doi.org/10.1016/S2215-0366(21)00395-3 (2022).
Perry, A. Al will never convey the essence of human empathy. Nat. Hum. Behav. 7, 1808-1809 (2023).
Inzlicht, M., Cameron, C. D., D’Cruz, J. & Bloom, P. In praise of empathic AI. Trends Cogn. Sci. 28, 89-91 (2024).
Ayers, J. W. et al. Comparing Physician and Artificial Intelligence Chatbot Responses to Patient Questions Posted to a Public Social Media Forum. JAMA Intern. Med. 183, 589 (2023).
De Gennaro, M., Krumhuber, E. G. & Lucas, G. Effectiveness of an Empathic Chatbot in Combating Adverse Effects of Social Exclusion on Mood. Front. Psychol. 10, 3061 (2020).
Ho, A., Hancock, J. & Miner, A. S. Psychological, Relational, and Emotional Effects of Self-Disclosure After Conversations With a Chatbot. J. Commun. 68, 712-733 (2018).
Yin, Y., Jia, N. & Wakslak, C. J. Al can help people feel heard, but an Al label diminishes this impact. Proc. Natl Acad. Sci. USA. 121, e2319112121 (2024).
Cetrano, G. et al. How are compassion fatigue, burnout, and compassion satisfaction affected by quality of working life? Findings from a survey of mental health staff in Italy. BMC Health Serv. Res. 17, 755 (2017).
Willems, R. C. W. J., Drossaert, C. H. C., Miedema, H. S. & Bohlmeijer, E. T. How Demanding Is Volunteer Work at a Crisis Line? An Assessment of Work- and Organization-Related Demands and the Relation With Distress and Intention to Leave. Front. Public Health 9, https://doi.org/10.3389/fpubh.2021.699116 (2021).
Zhang, L., Zhang, T., Ren, Z. & Jiang, G. Predicting compassion fatigue among psychological hotline counselors using machine learning techniques. Curr. Psychol. 42, 4169-4180 (2023).
Lee, Y.-C., Yamashita, N., Huang, Y. & Fu, W. ‘I Hear You, I Feel You’: Encouraging Deep Self-disclosure through a Chatbot. in Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems 1-12 https://doi.org/10.1145/3313831.3376175 (ACM, Honolulu HI USA, 2020).
Prochaska, J. J. et al. A Therapeutic Relational Agent for Reducing Problematic Substance Use (Woebot): Development and Usability Study. J. Med. Internet Res. 23, e24850 (2021).
Stein, J.-P., Messingschlager, T., Gnambs, T., Hutmacher, F. & Appel, M. Attitudes towards AI: measurement and associations with personality. Sci. Rep. 14, 2909 (2024).
Kozak, J. & Fel, S. The Relationship between Religiosity Level and Emotional Responses to Artificial Intelligence in University Students. Religions 15, 331 (2024).
Shteynberg, G. et al. Does it matter if empathic AI has no empathy? Nat. Mach. Intell. 6, 496-497 (2024).
Zhang, Y. & Gosline, R. People’s Perceptions (and Bias) Toward Creative Content Generated by Ai (ChatGPT-4), Human Experts, and Human-AI Collaboration. SSRN J. https://doi.org/10.2139/ssrn. 4453958 (2023).
Maisel, N. C., Gable, S. L. & Strachman, A. Responsive behaviors in good times and in bad. Personal. Relatsh. 15, 317-338 (2008).
Palan, S. & Schitter, C. Prolific.ac-A subject pool for online experiments. J. Behav. Exp. Financ. 17, 22-27 (2018).
Keaton, S. A. Interpersonal Reactivity Index (IRI): (Davis, 1980). in The Sourcebook of Listening Research (eds. Worthington, D. L. & Bodie, G. D.) 340-347 https://doi.org/10.1002/9781119102991.ch34 (Wiley, 2017).
Richard, F. D., Bond, C. F. & Stokes-Zoota, J. J. One Hundred Years of Social Psychology Quantitatively Described. Rev. Gen. Psychol. 7, 331-363 (2003).
McQuaid, R. J., Cox, S. M. L., Ogunlana, A. & Jaworska, N. The burden of loneliness: Implications of the social determinants of health during COVID-19. Psychiatry Res. 296, 113648 (2021).
Cacioppo, J. T. & Cacioppo, S. The growing problem of loneliness. Lancet 391, 426 (2018).
Abd-Alrazaq, A. A. et al. Perceptions and Opinions of Patients About Mental Health Chatbots: Scoping Review. J. Med Internet Res 23, e17828 (2021).
Jain, G., Pareek, S. & Carlbring, P. Revealing the source: How awareness alters perceptions of AI and human-generated mental health responses. Internet Interventions 36, 100745 (2024).
Lim, S. & Schmälzle, R. The effect of source disclosure on evaluation of Al-generated messages. Computers Hum. Behav.: Artif. Hum. 2, 100058 (2024).
Mahmud, H., Islam, A. K. M. N., Ahmed, S. I. & Smolander, K. What influences algorithmic decision-making? A systematic literature review on algorithm aversion. Technol. Forecast. Soc. Change 175, 121390 (2022).
Dietvorst, B. J., Simmons, J. P. & Massey, C. Algorithm aversion: People erroneously avoid algorithms after seeing them err. J. Exp. Psychol.: Gen. 144, 114-126 (2015).
Böhm, R., Jörling, M., Reiter, L. & Fuchs, C. People devalue generative Al’s competence but not its advice in addressing societal and personal challenges. Commun. Psychol. 1, 32 (2023).
Mahmud, H., Islam, A. K. M. N., Luo, X (Robert). & Mikalef, P. Decoding algorithm appreciation: Unveiling the impact of familiarity with algorithms, tasks, and algorithm performance. Decis. Support Syst. 179, 114168 (2024).
Pataranutaporn, P., Liu, R., Finn, E. & Maes, P. Influencing human-AI interaction by priming beliefs about AI can increase perceived trustworthiness, empathy and effectiveness. Nat. Mach. Intell. 5, 1076-1086 (2023).
Sharma, A., Lin, I. W., Miner, A. S., Atkins, D. C. & Althoff, T. Human-Al collaboration enables more empathic conversations in text-based peer-to-peer mental health support. Nat. Mach. Intell. 5, 46-57 (2023).
Bloom, P. Against Empathy: The Case for Rational Compassion. (Ecco, an imprint of HarperCollins Publishers, New York, NY, 2016).
Motomura, Y. et al. Interaction between valence of empathy and familiarity: is it difficult to empathize with the positive events of a stranger? J. Physiol. Anthropol. 34, 13 (2015).
Andreychik, M. R. & Migliaccio, N. Empathizing With Others’ Pain Versus Empathizing With Others’ Joy: Examining the Separability of Positive and Negative Empathy and Their Relation to Different Types of Social Behaviors and Social Emotions. Basic Appl. Soc. Psychol. 37, 274-291 (2015).
Maples, B., Cerit, M., Vishwanath, A. & Pea, R. Loneliness and suicide mitigation for students using GPT3-enabled chatbots. npj Ment. Health Res. 3, 4 (2024).
Acknowledgements
We would like to thank Gregory Depow, Leif Anderson, Katy Tam, Dasha Sandra, Yiyi Wang, and all other members of the Work and Play Lab for their support in material validation and insights along the way.
Author contributions
D.O. and M.I. conceived the study design and research questions. D.O. programmed the experimental iterations, collected, and cleaned the data.
D.O. and V.O.M. analyzed the data. D.O. wrote the manuscript. M.I. and V.O.M. edited the manuscript and provided crucial oversight of and feedback on the work.
Correspondence and requests for materials should be addressed to Michael Inzlicht.
Peer review information Communications psychology thanks Anat Perry, Andres Givirtz and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Primary Handling Editor: Yafeng Pan and Marike Schiffer. A peer review file is available.
Department of Psychology, University of Toronto, Toronto, ON, Canada. Rotman School of Management, University of Toronto, Toronto, ON, Canada. These authors contributed equally: Victoria Oldemburgo de Mello, Michael Inzlicht. □ e-mail: michael.inzlicht@utoronto.ca