DOI: https://doi.org/10.1186/s12903-024-04120-0
PMID: https://pubmed.ncbi.nlm.nih.gov/38494481
تاريخ النشر: 2024-03-18
AI-Dentify: التعلم العميق للكشف عن تسوس الأسنان القريب في أشعة إكس للعضة – دراسة HUNT4 لصحة الفم
الملخص
الخلفية يتطلب تشخيص تسوس الأسنان الفحص اليدوي لصور الأشعة السينية التشخيصية للمرضى، يليه فحص بصري واستكشاف للأجزاء السنية المحددة التي تحتوي على آفات محتملة. ومع ذلك، فإن استخدام الذكاء الاصطناعي، وخاصة التعلم العميق، لديه القدرة على المساعدة في التشخيص من خلال تقديم تحليل سريع ومعلوماتي لصور الأشعة السينية. الطرق تم وضع مجموعة بيانات تحتوي على 13,887 صورة أشعة سينية من دراسة HUNT4 لصحة الفم، وتمت الإشارة إليها بشكل فردي من قبل ستة خبراء مختلفين، واستخدمت لتدريب ثلاث هياكل مختلفة للكشف عن الأجسام باستخدام التعلم العميق: RetinaNet (ResNet50)، YOLOv5 (حجم M)، و EfficientDet (حجم D0 و D1). تم استخدام مجموعة بيانات توافقية تحتوي على 197 صورة، تم الإشارة إليها بشكل مشترك من قبل نفس الستة من أطباء الأسنان، للتقييم. تم استخدام نظام التحقق المتقاطع بخمسة أضعاف لتقييم أداء نماذج الذكاء الاصطناعي.
النتائج تظهر النماذج المدربة زيادة في الدقة المتوسطة ودرجة F1، وانخفاض في معدل السلبية الكاذبة، بالنسبة لأطباء الأسنان. عند مقارنتها بأطباء الأسنان، يظهر نموذج YOLOv5 أكبر تحسين، حيث سجل 0.647 دقة متوسطة، 0.548 درجة F1 متوسطة، و 0.149 معدل سلبية كاذبة متوسطة. بينما أبلغ أفضل المعلقين عن كل من هذه المقاييس
*المراسلة:
خافيير بيريز دي فروس
javier.perezdefrutos@sintef.no
المقدمة
عند تحليل الصور السريرية. يتم استخدام نوعين رئيسيين من الصور لمساعدة ودعم فحص التسوس وهما الأشعة السينية (BW) والأشعة السينية البانورامية (OPG) [2، 3]. التسوس، وخاصة التسوس القريب، وهو نوع من الآفات التسوسية الموجودة على الأسطح بين الأسنان المجاورة، يصعب اكتشافه يدويًا أو بصريًا (أي باستخدام صور الأشعة السينية) بسبب العيوب. أيضًا، يمكن أن تعيق الزاوية السيئة التعرف الصحيح على الآفات أو حتى تحجب التسوسات الأقل درجة.
منذ عام 2008، زادت الأبحاث حول تطبيق الذكاء الاصطناعي (AI) و، بشكل أكثر تحديدًا، نماذج الشبكات العصبية التلافيفية (CNN) للتعلم العميق (DL) لتحليل الأسنان بشكل ملحوظ [4-13]. ومع ذلك، لا تزال الأبحاث في هذا المجال محدودة مقارنةً بالمجالات السريرية الأخرى. توفر البيانات والتعليقات الموثوقة [8، 13] هي العقبات الرئيسية في تطوير طرق التعلم الآلي (ML) في طب الأسنان. تستخدم نسبة كبيرة من الأعمال المنشورة مجموعة بيانات تحتوي على أقل من 300 صورة، فقط عدد قليل من الدراسات لديها وصول إلى مجموعات بيانات كبيرة [8] تحتوي على أكثر من 1,000 صورة مثل [11، 14، 15]. من بين هذه المنشورات، تركز الأعمال المقدمة في [4
في Devito et al. [4]، تم استخدام شبكة عصبية متعددة الطبقات تحتوي على 51 خلية عصبية اصطناعية (25 في طبقة الإدخال، 25 في الطبقة المخفية، وواحدة في طبقة الإخراج) للكشف عن التسوس القريب في صور الأشعة السينية، باستخدام مجموعة بيانات تحتوي على 160 صورة تم الإشارة إليها من قبل 25 خبيرًا. بينما في Srivastava et al. [11]، تم تدريب كاشف التسوس باستخدام شبكة عصبية متصلة بالكامل مصممة خصيصًا مع 3,000 صورة أشعة سينية تم الإشارة إليها. في Singh et al. [6]، تم بناء ميزات مصنوعة يدويًا لصور الأشعة السينية باستخدام تحويلات رادون وتحويلات كوسينوس منفصلة، وتم تصنيفها لاحقًا باستخدام مجموعة من تقنيات التعلم الآلي مثل الغابة العشوائية. اقترح Park et al. [15] مجموعة من U-Net و Fast R-CNN للكشف عن التسوس في صورة ملونة، تم تدريبها باستخدام 2,348 صورة فوتوغرافية داخل الفم RGB. على الرغم من أن العمل الذي قام به Cantu et al. [14] يركز على تقسيم الصور، إلا أنه يستحق الذكر بسبب مجموعة البيانات المستخدمة: 3,686 صورة أشعة سينية، مع تعليقات تقسيم التسوس، لتدريب نموذج U-Net للتقسيم.
أهداف الدراسة
لذا، في هذه الدراسة قمنا بتدريب الهياكل المذكورة أعلاه في الكشف وتصنيف تسوس المينا، تسوس العاج، والآفات الثانوية، في صور الأشعة السينية. ثم تمت مقارنة النماذج مع المعلقين البشريين لاختبار فرضيتنا. بالإضافة إلى ذلك، تم اقتراح خط أنابيب معالجة جديد لدمج تعليقات الكشف عن الأجسام متعددة المراقبين، استنادًا إلى نماذج المزيج الغاوسي.
الطرق
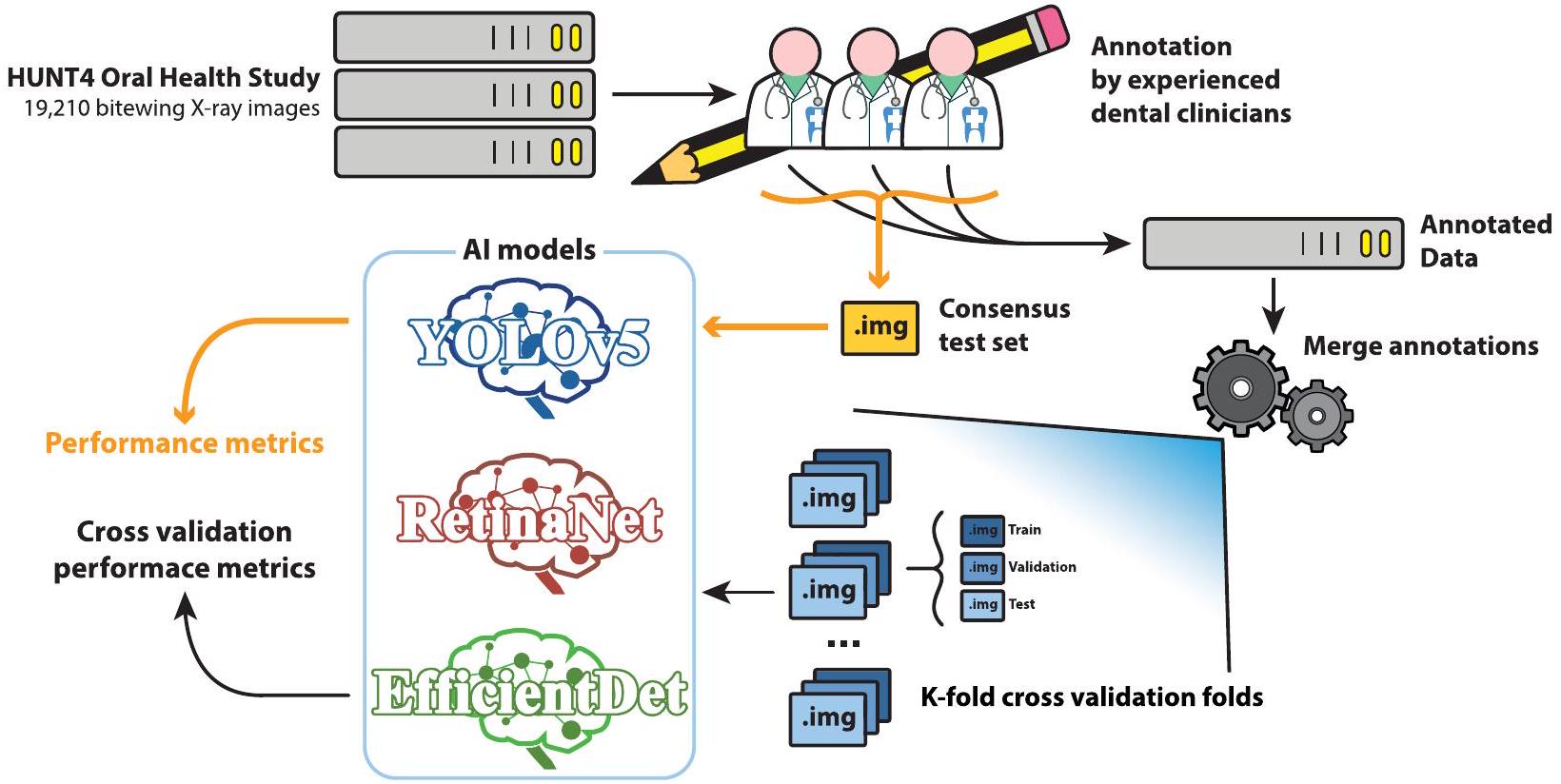
مجموعة البيانات
توضيح البيانات
| اسم الملصق | وصف |
| الصف الأول | شفاف إشعاعيًا في النصف الخارجي من المينا [21، 22] |
| الصف الثاني | شفاف شعاعياً في النصف الداخلي من المينا، ولكن ليس في العاج [21،22] |
| الصف الثالث | شفاف شعاعياً في الثلث الخارجي من العاج [21،22] |
| الصف الرابع | شفاف شعاعيًا في ثلثي العاج [21،22] |
| الصف الخامس | شفاف إشعاعيًا في الثلث الداخلي من العاج [21، 22] |
| آفة ثانوية | تسوس الأسنان المرتبط بالسدادات أو الترميمات |
| درجة غير معروفة | تسوس الأسنان الذي لا يمكن تحديد درجته بوضوح |
مرجع. أخيرًا، تم تحديد تسمية صندوق الربط المشترك بناءً على أكثر الفئات تصويتًا بين صناديق الربط في المجموعة. في حالة التعادل، تم اختيار الفئة الأكثر خطورة مثل تسوس العاج على تسوس المينا.
نماذج كشف الكائنات
| العمارة | عدد المعلمات (ملايين) |
| YOLOv5 M | 21.2 مليون |
| ريتنا نت (ResNet50) | 36.4 مليون |
| EfficientDet D0 | 3.9 مليون |
| EfficientDet D1 M | 6.6 مليون |
تم تلخيص المعلمات لكل نموذج في الجدول 3. في حالة YOLOv5 و RetinaNet، تم مراقبة معدل التعلم باستخدام جدولة معدل التعلم. بالنسبة لـ YOLOv5، تم استخدام جدولة OneCycleLR من PyTorch مع معدل تعلم أقصى قدره
بروتوكول التحقق
والمعقبين الآخرين. يتم تمييز هذا المعقب بنجمة (*) في الجدول 7.
تقييم الأداء
النتائج
| العمارة | حجم الدفعة | معدل التعلم | الحد الأقصى من العصور | محسّن | إطار عمل |
| YOLOv5 M | ٨ |
|
180 | دولار سنغافوري | بايتورتش |
| ريتنا نت | ٤ |
|
٢٠٠ | آدم | كيراس |
| EfficientDet D0 | ٨ |
|
|
آدم دبليو | بايتورتش |
| EfficientDet D1 | ٨ |
|
|
آدم دبليو | بايتورتش |
| نموذج | تسوس المينا | تسوس العاج | آفة ثانوية | معدل الدقة المتوسطة |
| YOLOv5 M |
|
|
|
|
| ريتنا نت |
|
|
|
|
| EfficientDet D0 |
|
|
|
|
| EfficientDet D1 |
|
|
|
|
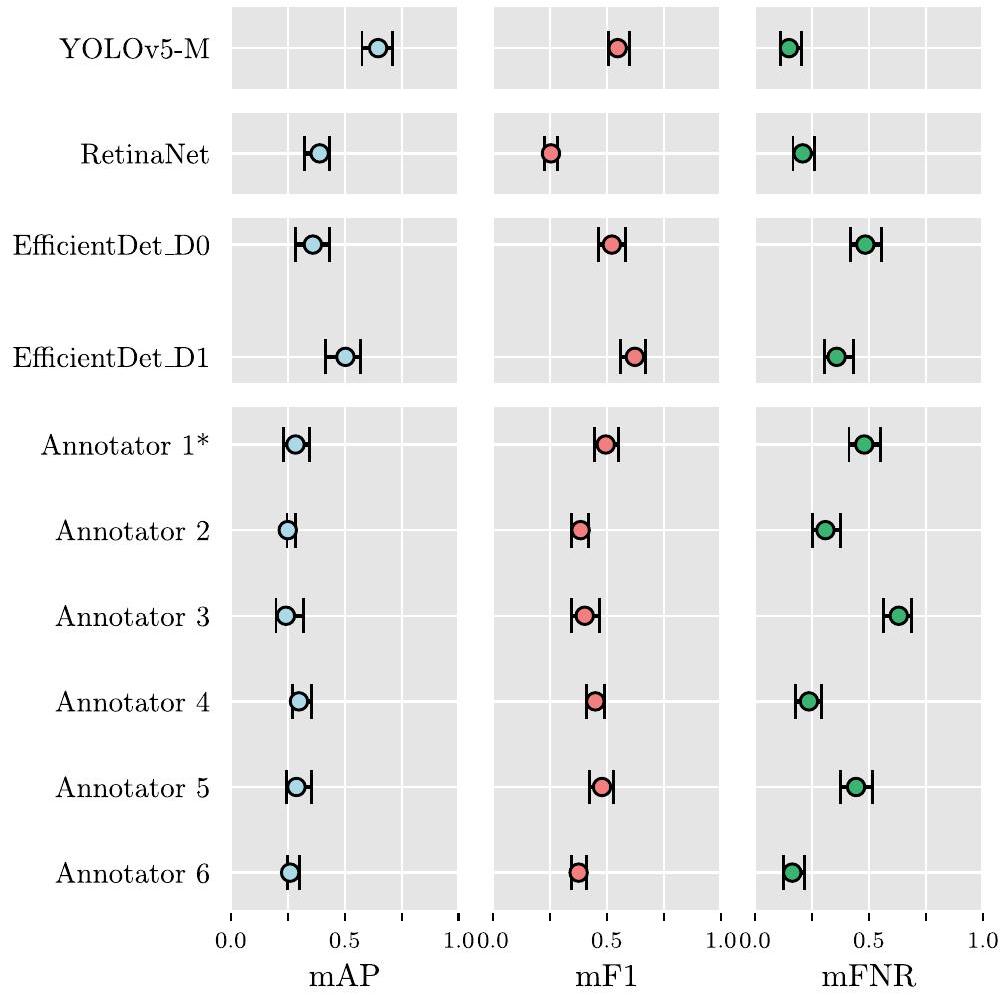
يمكن العثور على فترات الثقة لوسائل توزيعات مقاييس الأداء، المحسوبة لكل نموذج ولكل مُعَلق، في الجدول 7. كما هو موضح في قسم “تقييم الأداء”، تم استخدام هذه الفترات لتقييم الأهمية الإحصائية بين الهياكل المختلفة، وكذلك بين النماذج وأداء المُقيّم البشري. يتم عرض تمثيل بياني لهذه الفترات في الشكل 4، لتسهيل التفسير.
| نموذج | تسوس المينا | تسوس العاج | آفة ثانوية | mF1 |
| YOLOv5 M |
|
|
|
|
| ريتنا نت |
|
|
|
|
| EfficientDet D0 |
|
|
|
|
| EfficientDet D1 |
|
|
|
|
| نموذج | تسوس المينا | تسوس العاج | آفة ثانوية | mFNR |
| YOLOv5 M |
|
|
|
|
| ريتنا نت |
|
|
|
|
| EfficientDet D0 |
|
|
|
|
| EfficientDet D1 |
|
|
|
|
| نموذج / مُعَلِّق | معدل الدقة المتوسطة | mF1 | mFNR |
| YOLOv5،
|
0.647 [0.566, 0.707] | 0.548 [0.506، 0.598] | 0.149 [0.110، 0.203] |
| ريتنا نت
|
0.407 [0.355, 0.458] | 0.177 [0.154، 0.202] | 0.210 [0.167, 0.262] |
| EfficientDet D0،
|
0.360 [0.290, 0.431] | 0.522 [0.461، 0.588] | 0.484 [0.422، 0.552] |
| EfficientDet D1،
|
0.503 [0.421، 0.569] | 0.503 [0.421، 0.569] | 0.359 [0.306, 0.431] |
| المُعَلِّق 1* | 0.284 [0.231, 0.347] | 0.495 [0.447، 0.552] | 0.480 [0.413, 0.552] |
| المُعَلِّق 2 | 0.250 [0.247، 0.285] | 0.385 [0.346, 0.420] | 0.309 [0.251، 0.374] |
| المُعَلِّق 3 | 0.242 [0.199, 0.320] | 0.403 [0.343، 0.470] | 0.631 [0.564, 0.686] |
| المُعَلِّق 4 | 0.299 [0.270, 0.353] | 0.450 [0.411، 0.492] | 0.237 [0.180, 0.292] |
| المُعَلِّق 5 | 0.288 [0.244, 0.356] | 0.479 [0.423، 0.528] | 0.444 [0.376، 0.515] |
| المُعَلِّق 6 | 0.261 [0.248، 0.301] | 0.376 [0.346، 0.410] | 0.164 [0.124، 0.217] |
نقاش
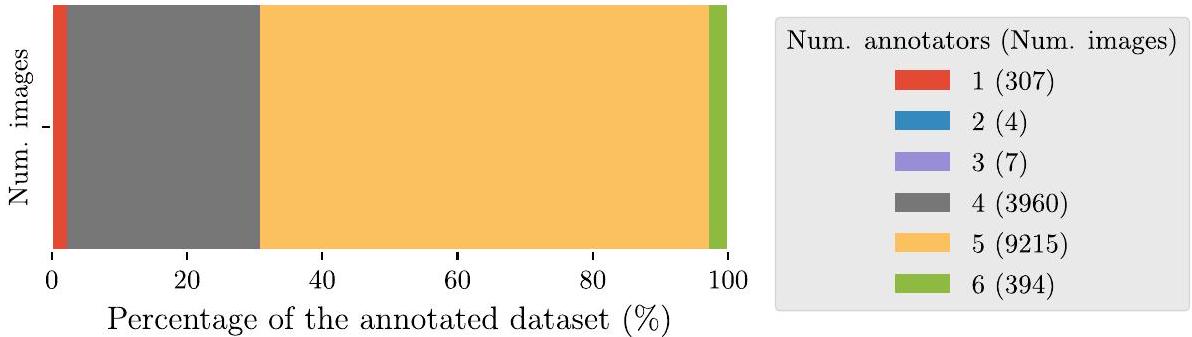
تتضمن مجموعة البيانات المقدمة في هذه الدراسة 13,882 صورة بالأشعة السينية للأسنان، مع وجود تسوسات موضحة بواسطة ستة أطباء أسنان.
لأطباء الأسنان. إلى أفضل معرفتنا، هذه هي أكبر مجموعة بيانات تم تقديمها حتى الآن لمهمة تدريب نماذج كشف الكائنات لاكتشاف التسوس، متجاوزة حجم مجموعة البيانات الموصوفة في [11] بـ 3,000 صورة، وفي [14] بـ 3,686 صورة بالأبيض والأسود. تم تقديم استراتيجية جديدة لدمج التعليقات التوضيحية من عدة معلقين على نفس الصورة، مما أدى إلى إنشاء تعليقات توضيحية قوية للحقيقة الأساسية للتدريب من خلال دمج المعرفة المتخصصة لجميع المعلقين. بالإضافة إلى ذلك، تم التعليق على مجموعة اختبار تتكون من 197 صورة بشكل مشترك من قبل جميع المعلقين من خلال اتفاق بالإجماع. تم استخدام مجموعة اختبار الإجماع لمقارنة أداء النماذج مقابل أداء المعلقين الفرديين، مما يسمح بتقييم فائدة النماذج من خلال المقارنة مع قاعدة بيانات المعرفة البشرية المتخصصة.
على مجموعة اختبار الإجماع، المقدمة في الجداول 4 و 5 و 6. تم اعتبار المقاييس المختارة، AP، وF1-score، وFNR، مناسبة لهذه التجربة، حيث تلخص جودة النماذج في التعرف بشكل صحيح على التسوس (AP)، والتوازن بين الدقة والاسترجاع (F1-score)، ومعدل تجاهل كاشفات الأجسام للتسوس الموجود في صور BW (FNR). من خلال استخدام تنفيذ PASCAL VOC للمقاييس، يتم تقليل دقة AP باستخدام عدد أكبر من النقاط، مقارنة بالتداخل ذو الـ 11 نقطة لمنحنى AP، المستخدم في تنفيذ COCO لـ AP [28]. أدى ذلك إلى تقدير أفضل لهذه المقياس، وبالتالي اعتُبر مناسبًا لهذه الدراسة. أخيرًا، لتقييم الفرق الإحصائي في أداء
تم تقدير فترات الثقة باستخدام خوارزمية BCa [27] من قبل النماذج والمعلقين الخبراء.
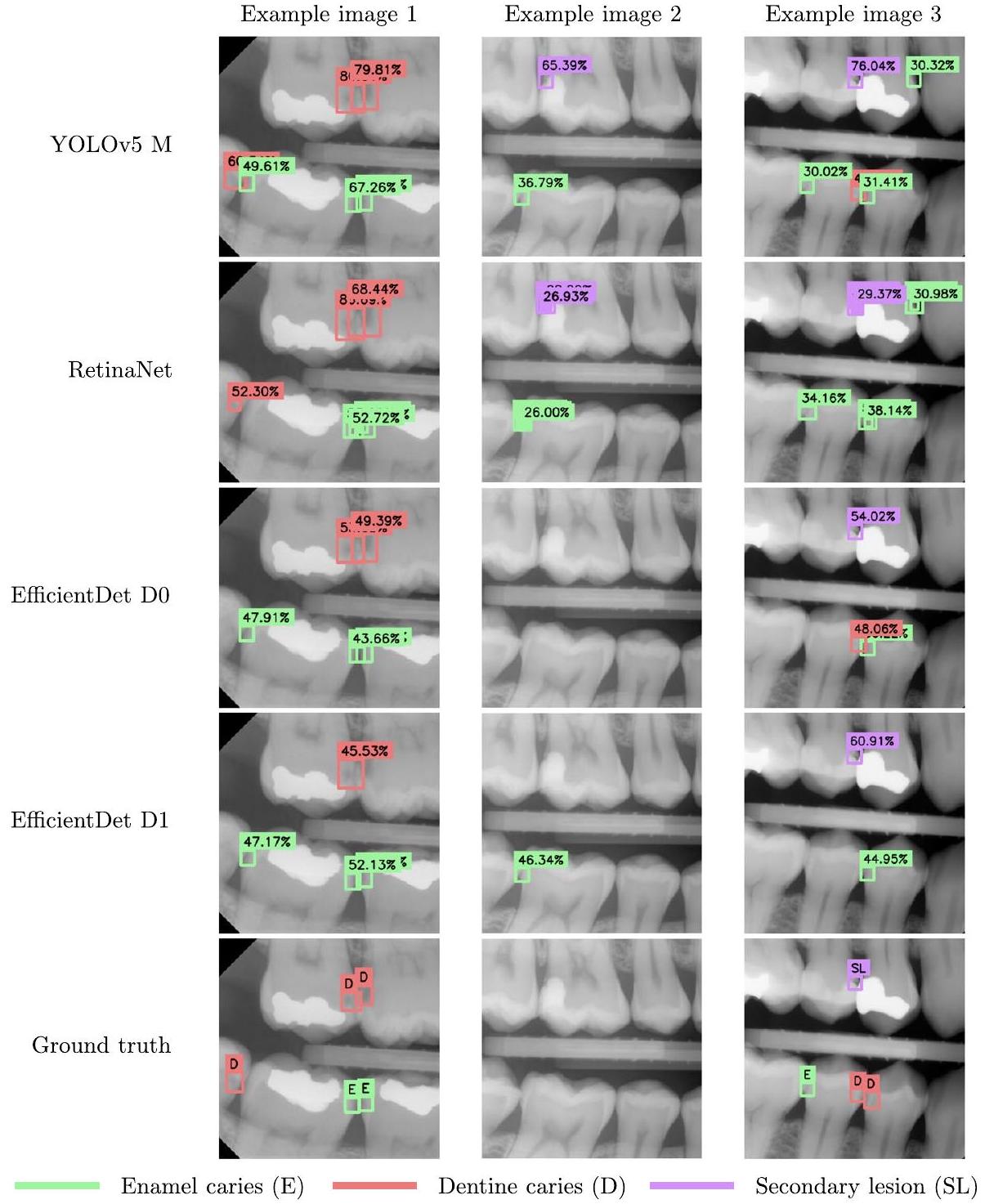
بالمقارنة مع الدراسات المنشورة سابقًا والتي تتشابه في النطاق مع العمل المقدم، فإن أداء النماذج أقل من القيم المبلغ عنها في [4، 5، 8-13، 15]، على الرغم من أن القيم ليست قابلة للمقارنة بشكل مباشر لأنها تم الإبلاغ عنها على مجموعات بيانات مختلفة. على عكس هذه الدراسات، لم يكن التركيز في هذا العمل على تحسين وبناء نموذج مخصص لاكتشاف الكائنات، بل على تقييم ما إذا كانت مجموعة البيانات كافية للحصول على أداء مكافئ أو أفضل من أطباء الأسنان، باستخدام هياكل متطورة. في الواقع، كما هو موضح في قسم “النتائج”، حققت النماذج المدربة أداءً أعلى بشكل ملحوظ في مجموع جميع المقاييس. وبالتالي، يمكن أن تكون مجموعة من نقاط القوة والضعف للنماذج أساسًا قويًا لأداة مساعدة في اكتشاف الآفات التسوسية في الممارسة السريرية.
كما تم تقديمه في قسم “المقدمة”، فإن الاستخدام الحصري لصور BW لتحديد الآفات التسوسية يعتبر غير كافٍ، حيث يتطلب فحصًا مباشرًا ومتابعة للمنطقة المصابة. ومع ذلك، فإن النماذج المقدمة في التعلم العميق لديها القدرة على تحسين كفاءة تحليل صور البايتوينغ والمساعدة في اكتشاف هذه الآفات، مما يساعد على تسريع وتحسين اكتشاف وتشخيص التسوس.
الاستنتاجات
تم العثور على آفات في الصور الطبية. في هذه الدراسة، تم إظهار كيف يمكن لمكتشفات الأجسام المدعومة بالذكاء الاصطناعي تسهيل مهمة العثور على هذه الآفات في الصور، مع أداء أفضل من أطباء الأسنان. لدعم هذا البيان، تم تدريب ثلاث هياكل متطورة لاكتشاف الأجسام على مجموعة بيانات صور دراسة صحة الفم HUNT4، وتم تقييمها مقابل أطباء الأسنان الخبراء. من بين الهياكل الثلاثة، حقق YOLOv5 (الحجم المتوسط) أفضل النتائج، حيث حصل على درجات أعلى بكثير من المعلقين الخبراء. يمكن استخدام مجموعة من النماذج المقدمة كأداة مساعدة في العيادة، لتسريع وتحسين معدل اكتشاف الآفات التسوسية. سيتم تقييم فائدة مثل هذه الأداة في دراسة تحقق سريرية مستقبلية.
الاختصارات
| الذكاء الاصطناعي | الذكاء الاصطناعي |
| تعلم الآلة | تعلم الآلة |
| دي إل | التعلم العميق |
| بي دبليو | صورة بينية |
| OPG | صورة أشعة بانورامية |
| سند دين | التقاطع على الاتحاد |
| NSM | خوارزمية قمع غير الحد الأقصى |
| MDF | دالة كثافة المزيج |
| CLAHE | تعديل تباين الهيستوغرام التكيفي المحدود |
| AP | الدقة المتوسطة |
| فورمولا 1 | درجة F1 |
| FNR | معدل السلبية الكاذبة |
| معدل الدقة المتوسطة | متوسط الدقة عبر الفئات |
| mF1 | متوسط درجة F1 عبر الفئات |
| mFNR | معدل السلبية الكاذبة المتوسطة عبر الفئات |
معلومات إضافية
المادة التكميلية 1.
شكر وتقدير
دراسة صحة تروندلاغ (HUNT) هي تعاون بين مركز أبحاث HUNT (كلية الطب وعلوم الصحة، جامعة النرويج للعلوم والتكنولوجيا NTNU)، مجلس مقاطعة تروندلاغ، هيئة الصحة الإقليمية في وسط النرويج، والمعهد النرويجي للصحة العامة.
مساهمات المؤلفين
تمويل
توفر البيانات والمواد
يمكن توفير الشيفرة والنماذج المدربة عند الطلب المعقول إلى Boneprox A.B. (الاتصال: شريا ديساي،
إعلانات
موافقة الأخلاقيات والموافقة على المشاركة
الموافقة على النشر
المصالح المتنافسة
تم النشر على الإنترنت: 18 مارس 2024
References
- Organisation WH. Global oral health status report: towards universal health coverage for oral health by 2030. Geneva: World Health Organization; 2022.
- Schwendicke F, Tzschoppe M, Paris S. Accuracy of dental radiographs for caries detection. Evid-Based Dent. 2016;17(2):43. https://doi.org/10.1038/sj.ebd. 6401166.
- Schwendicke F, Göstemeyer G. Conventional bitewing radiography. Clin Dent Rev. 2020;4(1):22. https://doi.org/10.1007/s41894-020-00086-8.
- Devito KL, de Souza Barbosa F, Filho WNF. An artificial multilayer perceptron neural network for diagnosis of proximal dental caries. Oral Surg Oral Med Oral Pathol Oral Radiol Endod. 2008;106(6):879-84. https://doi.org/10. 1016/J.TRIPLEO.2008.03.002.
- Berdouses ED, Koutsouri GD, Tripoliti EE, Matsopoulos GK, Oulis CJ, Fotiadis DI. A computer-aided automated methodology for the detection and classification of occlusal caries from photographic color images. Comput Biol Med. 2015;62:119-35. https://doi.org/10.1016/J.COMPBIOMED.2015.04.016.
- Singh P, Sehgal P. Automated caries detection based on Radon transformation and DCT. 8th International Conference on Computing, Communications and Networking Technologies, ICCCNT 2017. 2017. https://doi.org/10. 1109/ICCCNT.2017.8204030.
- Hwang JJ, Jung YH, Cho BH, Heo MS. An overview of deep learning in the field of dentistry. Imaging Sci Dent. 2019;49(1):1. https://doi.org/10.5624/isd. 2019.49.1.1.
- Prados-Privado M, García Villalón J, Martínez-Martínez CH, Ivorra C, PradosFrutos JC. Dental Caries Diagnosis and Detection Using Neural Networks: A Systematic Review. J Clin Med. 2020;9(11):3579. https://doi.org/10.3390/ jcm9113579.
- Schwendicke F, Golla T, Dreher M, Krois J. Convolutional neural networks for dental image diagnostics: A scoping review. J Dent. 2019;91:103226. https:// doi.org/10.1016/j.jdent.2019.103226.
- Choi J, Eun H, Kim C. Boosting Proximal Dental Caries Detection via Combination of Variational Methods and Convolutional Neural Network. J Signal
11. Srivastava MM, Kumar P, Pradhan L, Varadarajan S. Detection of Tooth caries in Bitewing Radiographs using Deep Learning. 2017. arXiv preprint arXiv: 1711.07312.
12. Lee JH, Kim DH, Jeong SN, Choi SH. Detection and diagnosis of dental caries using a deep learning-based convolutional neural network algorithm. J Dent. 2018;77:106-11. https://doi.org/10.1016/J.JDENT.2018.07.015.
13. Lee S, Oh Si, Jo J, Kang S, Shin Y, Park Jw. Deep learning for early dental caries detection in bitewing radiographs. Sci Rep. 2021;11(1):16807. https://doi. org/10.1038/s41598-021-96368-7.
14. Cantu AG, Gehrung S, Krois J, Chaurasia A, Rossi JG, Gaudin R, et al. Detecting caries lesions of different radiographic extension on bitewings using deep learning. J Dent. 2020;100:103425. https://doi.org/10.1016/j.jdent. 2020.103425.
15. Park EY, Cho H, Kang S, Jeong S, Kim EK. Caries detection with tooth surface segmentation on intraoral photographic images using deep learning. BMC Oral Health. 2022;22(1):573. https://doi.org/10.1186/s12903-022-02589-1.
16. Godfellow I, Bengio Y, Courville A. Deep Learning. MIT Press; 2016. http:// www.deeplearningbook.org/.
17. Krokstad S, Langhammer A, Hveem K, Holmen T, Midthjell K, Stene T, et al. Cohort Profile: The HUNT Study. Norway Int J Epidemiol. 2012;42(4):968-77. https://doi.org/10.1093/ije/dys095.
18. Stødle IH, Verket A, Høvik H, Sen A, Koldsland OC. Prevalence of periodontitis based on the 2017 classification in a Norwegian population: The HUNT study. J Clin Periodontol. 2021;48(9):1189-99. https://doi.org/10.1111/jcpe. 13507.
19. Rødseth SC, Høvik H, Schuller AA, Skudutyte-Rysstad R. Dental caries in a Norwegian adult population, the HUNT4 oral health study; prevalence, distribution and 45-year trends. Acta Odontol Scand. 2022;81(3):202-10. https://doi.org/10.1080/00016357.2022.2117735.
20. Smistad E, Østvik A, Lovstakken L. Annotation Web – An open-source webbased annotation tool for ultrasound images. 2021. p. 1-4. https://doi.org/ 10.1109/IUS52206.2021.9593336.
21. Westberg TE, Døving LM, Bjørg A. Kliniske rutiner- Kariologi. 2010. https:// www.odont.uio.no/iko/om/organisasjon/fagavd/kariologi-gerodontologi/ rutiner-metoder/. Accessed 12/07/2021.
22. Hansson HH, Espelid I. Kan vi stole på kariesregistreringen? Validering av to visuelle indekser for registrering av okklusalkaries basert på ekstraherte tenner. Nor Tannlegeforen Tid. 2012;(122):676-682. https://doi.org/10.56373/ 2012-9-11.
23. Lin TY, Goyal P, Girshick R, He K, Dollár P. Focal Loss for Dense Object Detection. 2017. arXiv preprint arXiv:1708.02002.
24. Jocher G, Chaurasia A, Stoken A, Borovec J, NanoCode012, Kwon Y, et al. ultralytics/yolov5: v7.0- YOLOv5 SOTA Realtime Instance Segmentation. 2022. https://doi.org/10.5281/ZENODO.7347926.
25. Tan M, Pang R, Le QV. EfficientDet: Scalable and efficient object detection. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. 2020. p. 10778-10787. https://doi.org/10.1109/ CVPR42600.2020.01079.
26. Georgieva VM, Mihaylova AD, Petrov PP. An application of dental X-ray image enhancement. 2017 13th International Conference on Advanced Technologies, Systems and Services in Telecommunications, TELSIKS. 2017. p. 447-450. https://doi.org/10.1109/TELSKS.2017.8246321.
27. Davison AC, Hinkley DV. Boostrap methods and their applications. New York: Cambridge University Press; 1997.
28. Padilla R, Passos WL, Dias TLB, Netto SL, Da Silva EAB. A comparative analysis of object detection metrics with a companion open-source toolkit. Electronics. 2021;10(3):279. https://doi.org/10.3390/ELECTRONICS10030279.
ملاحظة الناشر
DOI: https://doi.org/10.1186/s12903-024-04120-0
PMID: https://pubmed.ncbi.nlm.nih.gov/38494481
Publication Date: 2024-03-18
AI-Dentify: deep learning for proximal caries detection on bitewing x-ray – HUNT4 Oral Health Study
Abstract
Background Dental caries diagnosis requires the manual inspection of diagnostic bitewing images of the patient, followed by a visual inspection and probing of the identified dental pieces with potential lesions. Yet the use of artificial intelligence, and in particular deep-learning, has the potential to aid in the diagnosis by providing a quick and informative analysis of the bitewing images. Methods A dataset of 13,887 bitewings from the HUNT4 Oral Health Study were annotated individually by six different experts, and used to train three different object detection deep-learning architectures: RetinaNet (ResNet50), YOLOv5 (M size), and EfficientDet (D0 and D1 sizes). A consensus dataset of 197 images, annotated jointly by the same six dental clinicians, was used for evaluation. A five-fold cross validation scheme was used to evaluate the performance of the AI models.
Results The trained models show an increase in average precision and F1-score, and decrease of false negative rate, with respect to the dental clinicians. When compared against the dental clinicians, the YOLOv5 model shows the largest improvement, reporting 0.647 mean average precision, 0.548 mean F1-score, and 0.149 mean false negative rate. Whereas the best annotators on each of these metrics reported
*Correspondence:
Javier Pérez de Frutos
javier.perezdefrutos@sintef.no
Introduction
when analysing the clinical images. The two main image modalities used to assist and support the examination of caries are bitewing (BW) and panoramic radiography (OPG) [2, 3]. Caries, particularly proximal caries, a type of carious lesion located on the surfaces between adjacent teeth, are difficult to detect manually or visually (i.e. using radiographic X-ray images) due to artifacts. Also, poor angulation can hinder the correct identification of the lesions or even occlude lesser grade caries.
Since 2008, the research on the application of artificial intelligence (AI) and, more specifically, deep learning (DL) convolutional neural networks (CNN) models for the analysis of dental has noticeably increased [4-13]. However, research on this field is still limited compared to other clinical areas. Data availability and reliable annotations [ 8,13 ] are the main bottlenecks in the development of machine learning (ML) methods in dentistry. A large portion of the published work uses a dataset of fewer than 300 images, only few studies have access to large datasets [8] with more than 1,000 images like [11, 14, 15]. Of these publications, the work presented in [4
In Devito et al. [4], a multi-layer perceptron with 51 artificial neurons ( 25 in the input layer, 25 in the hidden layer, and one in the output layer) is used to detect proximal caries on BW images, using a dataset of 160 images annotated by 25 experts. Whereas in Srivastava et al. [11], a caries detector built using a tailor designed fully connected neural network was trained with 3,000 annotated BW images. In Singh et al. [6], hand-crafted features for X-ray images are built using Radon and discrete cosine transformations, and further classified using an ensemble of ML techniques such as random forest. Park et al. [15] proposed an ensemble of U-Net and Fast R-CNN for caries detection in colour image, trained with 2,348 RGB intraoral photographic images. Even though, the work done by Cantu et al. [14] focuses on image segmentation, it is worth mentioning because of the dataset used: 3,686 BW images, with caries segmentation annotations, to train a U-Net model for segmentation.
Study goals
clinicians. Hence, in this study we trained the aforementioned architectures in detection and classification of enamel caries, dentine caries, and secondary lesions, in BW images. Then, the models were compared to human annotators in order to test our hypothesis. In addition, a novel processing pipeline for merging multi-observer object detection annotations, based on Gaussian Mixture Models, is proposed.
Methods
Dataset
Data annotation
| Label name | Description |
| Grade 1 | Radiolucent in outer half of the enamel [21, 22] |
| Grade 2 | Radiolucent in the inner half of the enamel, but not in the dentine [21,22] |
| Grade 3 | Radiolucent in the outer third of the dentine [21,22] |
| Grade 4 | Radiolucent in 2/3 of the dentine [21,22] |
| Grade 5 | Radiolucent in the inner third of the dentine [21, 22] |
| Secondary lesion | Caries related to sealants or restorations |
| Unknown grade | Caries whose grade cannot be clearly identified |
a reference. Lastly, the label of the common bonding box was determined based on the most voted class among the bounding boxes in the group. In case of tie, the most severe class was chosen e.g., dentine caries over enamel caries.
Object detection models
| Architecture | Number of parameters (millions) |
| YOLOv5 M | 21.2 M |
| RetinaNet (ResNet50) | 36.4 M |
| EfficientDet D0 | 3.9 M |
| EfficientDet D1 M | 6.6M |
parameters for each model are summarised in Table 3. In the case of YOLOv5 and RetinaNet, the learning rate was monitored using a learning rate scheduler. For YOLOv5, the OneCycleLR scheduler from PyTorch was used with a maximum learning rate of
Validation protocol
and other annotators. This annotator is marked with an asterisk (*) in Table 7.
Performance evaluation
Results
| Architecture | Batch size | Learning rate | Max. epochs | Optimiser | Framework |
| YOLOv5 M | 8 |
|
180 | SGD | PyTorch |
| RetinaNet | 4 |
|
200 | Adam | Keras |
| EfficientDet D0 | 8 |
|
|
AdamW | PyTorch |
| EfficientDet D1 | 8 |
|
|
AdamW | PyTorch |
| Model | Enamel caries | Dentine caries | Secondary lesion | mAP |
| YOLOv5 M |
|
|
|
|
| RetinaNet |
|
|
|
|
| EfficientDet D0 |
|
|
|
|
| EfficientDet D1 |
|
|
|
|
The confidence intervals for the means of the distributions of the performance metrics, calculated for each model and each annotator, can be found in Table 7. As described in “Performance evaluation” section, these intervals were used to assess statistical significance between the different architectures, as well as between the models and the human expert rater performance. A graphical representation of these is show in Fig. 4, for ease of interpretation.
| Model | Enamel caries | Dentine caries | Secondary lesion | mF1 |
| YOLOv5 M |
|
|
|
|
| RetinaNet |
|
|
|
|
| EfficientDet D0 |
|
|
|
|
| EfficientDet D1 |
|
|
|
|
| Model | Enamel caries | Dentine caries | Secondary lesion | mFNR |
| YOLOv5 M |
|
|
|
|
| RetinaNet |
|
|
|
|
| EfficientDet D0 |
|
|
|
|
| EfficientDet D1 |
|
|
|
|
| Model / Annotator | mAP | mF1 | mFNR |
| YOLOv5,
|
0.647 [0.566, 0.707] | 0.548 [0.506, 0.598] | 0.149 [0.110, 0.203] |
| RetinaNet,
|
0.407 [0.355, 0.458] | 0.177 [0.154, 0.202] | 0.210 [0.167, 0.262] |
| EfficientDet D0,
|
0.360 [0.290, 0.431] | 0.522 [0.461, 0.588] | 0.484 [0.422, 0.552] |
| EfficientDet D1,
|
0.503 [0.421, 0.569] | 0.503 [0.421, 0.569] | 0.359 [0.306, 0.431] |
| Annotator 1* | 0.284 [0.231, 0.347] | 0.495 [0.447, 0.552] | 0.480 [0.413, 0.552] |
| Annotator 2 | 0.250 [0.247, 0.285] | 0.385 [0.346, 0.420] | 0.309 [0.251, 0.374] |
| Annotator 3 | 0.242 [0.199, 0.320] | 0.403 [0.343, 0.470] | 0.631 [0.564, 0.686] |
| Annotator 4 | 0.299 [0.270, 0.353] | 0.450 [0.411, 0.492] | 0.237 [0.180, 0.292] |
| Annotator 5 | 0.288 [0.244, 0.356] | 0.479 [0.423, 0.528] | 0.444 [0.376, 0.515] |
| Annotator 6 | 0.261 [0.248, 0.301] | 0.376 [0.346, 0.410] | 0.164 [0.124, 0.217] |
Discussion
The dataset presented in this study features 13,882 BW images, with carious lesions annotated by six dental
clinicians. To the best of our knowledge, this is the largest dataset presented so far for the task of training object detection models for caries detection, exceeding the size of the dataset described in [11] with 3,000 images, and in [14] with 3,686 BW images. A novel strategy for combining the annotations from multiple annotators on the same image was presented, creating robust ground truth annotations for training by combining the expert knowledge of all the annotators. In addition, a test set consisting of 197 images was jointly annotated by all the annotators by consensus agreement. The consensus test set was used to compare the model performances against the performance of the individual annotators, allowing for an assessment of the models usefulness by comparison against a baseline of human expert knowledge.
on the consensus test set, presented in Tables 4, 5 and 6. The selected metrics, AP, F1-score, and FNR, were deemed appropriate for this experiment, as they summarise the goodness of the models to correctly identify the caries (AP), the trade off between precision and recall (F1-score), and the rate at which the object detectors disregard the caries which are in the BW images (FNR). By using the PASCAL VOC implementation of the metrics, the AP precision is regressed using a larger amount of points, compared to the 11-point interpolation of the AP curve, used in the COCO implementation of AP [28]. This resulted in a better estimate of this metric, and was therefore considered adequate for this study. Lastly, to assess the statistical difference in performance of the
models and the expert annotators, confidence intervals were estimated using the BCa algorithm [27].
Compared to equivalent previously published studies, comparable in scope with the presented work, the performances of the models are lower than the values reported in [4, 5, 8-13, 15], although the values are not directly comparable as they are reported on different datasets. Unlike in these studies, the focus of this work was not to optimise and build a tailored object detection model, but to assess if the dataset was sufficient to obtain equivalent or better performance than dental clinicians, using state-of-the-art architectures. Indeed, as shown in “Results” section, the trained models achieved significantly higher performances in sum on all of the metrics. A combination of the models strengths and weaknesses could thus be a solid foundation for an assistive tool for carious lesion detection in clinical practice.
As introduced in “Introduction” section, the exclusive use of BW images to identify carious lesions is under-par, as it requires a follow-up direct inspection and probing of the infected area. However, the presented deep learning models have the potential to improve the efficiency of the analysis of the bitewing images and aid in the detection of these lesions, helping to speed up and improve the detection and diagnosis of caries.
Conclusions
lesions found in the medical images. In this study, it has been shown how AI-powered object detectors can ease the task of finding these lesions in the images, with better performance than dental clinicians. To support this statement, three state-of-the-art object detection architectures were trained on the HUNT4 Oral Health Study BW image dataset, and evaluated against expert dental clinicians. Out of the three architectures, YOLOv5 (medium size) yielded the best results, achieving significantly higher scores than the expert annotators. A combination of the presented models can be used as an assistive tool in the clinic, to speed up and improve the detection rate of carious lesions. The usefulness of such a tool will be assessed in a future clinical validation study.
Abbreviations
| AI | Artificial intelligence |
| ML | Machine learning |
| DL | Deep learning |
| BW | Bitewing image |
| OPG | Panoramic X-ray image |
| IoU | Intersection over union |
| NSM | Non-maximum suppression algorithm |
| MDF | Mixture density function |
| CLAHE | Contrast limited adaptive histogram equalization |
| AP | Average precision |
| F1 | F1-score |
| FNR | False negative rate |
| mAP | Mean average precision across classes |
| mF1 | Mean F1-score across classes |
| mFNR | Mean false negative rate across classes |
Supplementary Information
Supplementary Material 1.
Acknowledgements
The Trøndelag Health Study (HUNT) is a collaboration between HUNT Research Centre (Faculty of Medicine and Health Sciences, Norwegian University of Science and Technology NTNU), Trøndelag County Council, Central Norway Regional Health Authority, and the Norwegian Institute of Public Health.
Authors’ contributions
Funding
Availability of data and materials
The code and trained models can be provided upon reasonable request to Boneprox A.B. (contact: Shreya Desai,
Declarations
Ethics approval and consent to participate
Consent for publication
Competing interests
Published online: 18 March 2024
References
- Organisation WH. Global oral health status report: towards universal health coverage for oral health by 2030. Geneva: World Health Organization; 2022.
- Schwendicke F, Tzschoppe M, Paris S. Accuracy of dental radiographs for caries detection. Evid-Based Dent. 2016;17(2):43. https://doi.org/10.1038/sj.ebd. 6401166.
- Schwendicke F, Göstemeyer G. Conventional bitewing radiography. Clin Dent Rev. 2020;4(1):22. https://doi.org/10.1007/s41894-020-00086-8.
- Devito KL, de Souza Barbosa F, Filho WNF. An artificial multilayer perceptron neural network for diagnosis of proximal dental caries. Oral Surg Oral Med Oral Pathol Oral Radiol Endod. 2008;106(6):879-84. https://doi.org/10. 1016/J.TRIPLEO.2008.03.002.
- Berdouses ED, Koutsouri GD, Tripoliti EE, Matsopoulos GK, Oulis CJ, Fotiadis DI. A computer-aided automated methodology for the detection and classification of occlusal caries from photographic color images. Comput Biol Med. 2015;62:119-35. https://doi.org/10.1016/J.COMPBIOMED.2015.04.016.
- Singh P, Sehgal P. Automated caries detection based on Radon transformation and DCT. 8th International Conference on Computing, Communications and Networking Technologies, ICCCNT 2017. 2017. https://doi.org/10. 1109/ICCCNT.2017.8204030.
- Hwang JJ, Jung YH, Cho BH, Heo MS. An overview of deep learning in the field of dentistry. Imaging Sci Dent. 2019;49(1):1. https://doi.org/10.5624/isd. 2019.49.1.1.
- Prados-Privado M, García Villalón J, Martínez-Martínez CH, Ivorra C, PradosFrutos JC. Dental Caries Diagnosis and Detection Using Neural Networks: A Systematic Review. J Clin Med. 2020;9(11):3579. https://doi.org/10.3390/ jcm9113579.
- Schwendicke F, Golla T, Dreher M, Krois J. Convolutional neural networks for dental image diagnostics: A scoping review. J Dent. 2019;91:103226. https:// doi.org/10.1016/j.jdent.2019.103226.
- Choi J, Eun H, Kim C. Boosting Proximal Dental Caries Detection via Combination of Variational Methods and Convolutional Neural Network. J Signal
11. Srivastava MM, Kumar P, Pradhan L, Varadarajan S. Detection of Tooth caries in Bitewing Radiographs using Deep Learning. 2017. arXiv preprint arXiv: 1711.07312.
12. Lee JH, Kim DH, Jeong SN, Choi SH. Detection and diagnosis of dental caries using a deep learning-based convolutional neural network algorithm. J Dent. 2018;77:106-11. https://doi.org/10.1016/J.JDENT.2018.07.015.
13. Lee S, Oh Si, Jo J, Kang S, Shin Y, Park Jw. Deep learning for early dental caries detection in bitewing radiographs. Sci Rep. 2021;11(1):16807. https://doi. org/10.1038/s41598-021-96368-7.
14. Cantu AG, Gehrung S, Krois J, Chaurasia A, Rossi JG, Gaudin R, et al. Detecting caries lesions of different radiographic extension on bitewings using deep learning. J Dent. 2020;100:103425. https://doi.org/10.1016/j.jdent. 2020.103425.
15. Park EY, Cho H, Kang S, Jeong S, Kim EK. Caries detection with tooth surface segmentation on intraoral photographic images using deep learning. BMC Oral Health. 2022;22(1):573. https://doi.org/10.1186/s12903-022-02589-1.
16. Godfellow I, Bengio Y, Courville A. Deep Learning. MIT Press; 2016. http:// www.deeplearningbook.org/.
17. Krokstad S, Langhammer A, Hveem K, Holmen T, Midthjell K, Stene T, et al. Cohort Profile: The HUNT Study. Norway Int J Epidemiol. 2012;42(4):968-77. https://doi.org/10.1093/ije/dys095.
18. Stødle IH, Verket A, Høvik H, Sen A, Koldsland OC. Prevalence of periodontitis based on the 2017 classification in a Norwegian population: The HUNT study. J Clin Periodontol. 2021;48(9):1189-99. https://doi.org/10.1111/jcpe. 13507.
19. Rødseth SC, Høvik H, Schuller AA, Skudutyte-Rysstad R. Dental caries in a Norwegian adult population, the HUNT4 oral health study; prevalence, distribution and 45-year trends. Acta Odontol Scand. 2022;81(3):202-10. https://doi.org/10.1080/00016357.2022.2117735.
20. Smistad E, Østvik A, Lovstakken L. Annotation Web – An open-source webbased annotation tool for ultrasound images. 2021. p. 1-4. https://doi.org/ 10.1109/IUS52206.2021.9593336.
21. Westberg TE, Døving LM, Bjørg A. Kliniske rutiner- Kariologi. 2010. https:// www.odont.uio.no/iko/om/organisasjon/fagavd/kariologi-gerodontologi/ rutiner-metoder/. Accessed 12/07/2021.
22. Hansson HH, Espelid I. Kan vi stole på kariesregistreringen? Validering av to visuelle indekser for registrering av okklusalkaries basert på ekstraherte tenner. Nor Tannlegeforen Tid. 2012;(122):676-682. https://doi.org/10.56373/ 2012-9-11.
23. Lin TY, Goyal P, Girshick R, He K, Dollár P. Focal Loss for Dense Object Detection. 2017. arXiv preprint arXiv:1708.02002.
24. Jocher G, Chaurasia A, Stoken A, Borovec J, NanoCode012, Kwon Y, et al. ultralytics/yolov5: v7.0- YOLOv5 SOTA Realtime Instance Segmentation. 2022. https://doi.org/10.5281/ZENODO.7347926.
25. Tan M, Pang R, Le QV. EfficientDet: Scalable and efficient object detection. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. 2020. p. 10778-10787. https://doi.org/10.1109/ CVPR42600.2020.01079.
26. Georgieva VM, Mihaylova AD, Petrov PP. An application of dental X-ray image enhancement. 2017 13th International Conference on Advanced Technologies, Systems and Services in Telecommunications, TELSIKS. 2017. p. 447-450. https://doi.org/10.1109/TELSKS.2017.8246321.
27. Davison AC, Hinkley DV. Boostrap methods and their applications. New York: Cambridge University Press; 1997.
28. Padilla R, Passos WL, Dias TLB, Netto SL, Da Silva EAB. A comparative analysis of object detection metrics with a companion open-source toolkit. Electronics. 2021;10(3):279. https://doi.org/10.3390/ELECTRONICS10030279.