DOI: https://doi.org/10.1007/s11633-025-1562-4
تاريخ النشر: 2025-06-22
DPM-Solver++: حل سريع لأخذ عينات موجهة من نماذج الانتشار الاحتمالية
الملخص
حققت نماذج الانتشار الاحتمالية (DPMs) نجاحًا ملحوظًا في توليد الصور عالية الدقة، خاصة في التطبيقات الحديثة لتوليد النص إلى صورة على نطاق واسع. تقنية أساسية لتحسين جودة العينة من DPMs هي أخذ العينات الموجهة، والتي تحتاج عادةً إلى نطاق توجيه كبير للحصول على أفضل جودة عينة. العينة السريعة المستخدمة عادةً لأخذ العينات الموجهة هي نماذج الانتشار الضبابية غير المباشرة (DDIM)، وهي حل لمعادلة تفاضلية عادية (ODE) من الدرجة الأولى تحتاج عمومًا من 100 إلى 250 خطوة للحصول على عينات عالية الجودة. على الرغم من أن الأعمال الأخيرة تقترح حلولًا عالية الترتيب مخصصة وتحقق تسريعًا إضافيًا لأخذ العينات بدون توجيه، إلا أن فعاليتها لأخذ العينات الموجهة لم يتم اختبارها جيدًا من قبل. في هذا العمل، نوضح أن العينات السريعة السابقة من الدرجة العالية تعاني من مشاكل عدم الاستقرار، بل تصبح أبطأ من DDIM عندما يزداد نطاق التوجيه. لتسريع أخذ العينات الموجهة، نقترح DPM-Solver++، وهو حل من الدرجة العالية لأخذ العينات الموجهة من DPMs. يقوم DPM-Solver++ بحل معادلة الانتشار ODE باستخدام نموذج توقع البيانات ويتبنى طرق تحديد العتبة للحفاظ على توافق الحل مع توزيع بيانات التدريب. نقترح أيضًا متغير متعدد الخطوات من DPM-Solver++ لمعالجة مشكلة عدم الاستقرار عن طريق تقليل حجم الخطوة الفعالة. تظهر التجارب أن DPM-Solver++ يمكنه توليد عينات عالية الجودة في 15 إلى 20 خطوة فقط لأخذ العينات الموجهة من DPMs في فضاء البكسل وفضاء الكامن.
الاقتباس: C. Lu, Y. Zhou, F. Bao, J. Chen, C. Li, J. Zhu. DPM-Solver++: حل سريع لأخذ العينات الموجهة لنماذج الانتشار الاحتمالية. بحث الذكاء الآلي، المجلد 22، العدد 4، الصفحات 730-751، 2025.http://doi.org/10.1007/s11633-025-1562-4
1 المقدمة
hلول عالية الترتيب على أخذ العينات الموجهة: 1) نطاق التوجيه الكبير يضيق دائرة التقارب للحلول عالية الترتيب، مما يجعلها غير مستقرة؛ و 2
2 نماذج الانتشار الاحتمالية
2.1 أخذ العينات السريع لـ DPMs بواسطة معادلات الانتشار ODEs

مع
2.2 أخذ العينات الموجهة لـ DPMs
2.3 المحللات الأسية وحلول المعادلات التفاضلية العادية عالية الرتبة
أشكال تغيير المتغير المقابلة لـ
3 تحديات للمحللات عالية الرتبة في أخذ العينات الموجهة
4 تصميم عينات سريعة بدون تدريب لأغراض التوجيه
للتعامل مع مشكلة عدم الاستقرار.
4.1 تصميم الحلول بواسطة نموذج توقع البيانات
الخوارزمية 1. DPM-Solver++(2S).
يتطلب: القيمة الأولية
-
- لـ
إلى يفعل -
-
-
-
-
- نهاية لـ
- عودة
يتطلب: القيمة الأولية
- يدل على
لـ -
قم بتهيئة مخزن فارغ -
-
-
- لـ
إلى يفعل -
-
، ) -
- إذا
، ثم - نهاية لـ
- عودة
4.2 من خطوة واحدة إلى خطوات متعددة
طرق متعددة الخطوات حوالي
4.3 دمج العتبة مع DPMSolver++
5 حلول سريعة لمعادلات التفاضل العشوائية الانتشارية
حل-س-دي-دي-بي-إم-1.
محلّل SDE-DPM-Solver++1.
SDE-DPM-Solver-2M.
محلّل SDE-DPM-Solver++(2M).
6 العلاقة مع طرق أخذ العينات السريعة الأخرى
6.1 المقارنة مع الحلول المعتمدة على المدمجات الأسية
| دييس
|
حل DPM
|
DPM-Solver++ (خاص بنا) | SDE-DPM-Solver++ (خاصتنا) | |
| من الدرجة الأولى | دي دي آي إم (
|
دي دي آي إم (
|
دي دي آي إم (
|
|
| نوع النموذج |
|
|
|
|
| توسيع تايلور |
|
|
|
|
| نوع الحل (مرتفع الدرجة) | متعدد الخطوات | خطوة واحدة | خطوة واحدة + خطوات متعددة | متعدد الخطوات |
6.2 طرق أخذ العينات السريعة الأخرى
7 تجارب
- بالنسبة لجدول حجم الخطوة، نبحث في خطوات الزمن في الخيارات التالية: متساوي
(إعداد مستخدم على نطاق واسع في توليد الصور عالية الدقة)، موحد (المستخدمة في [32])، تقسيم موحد لدوال القدرة لـ (المستخدمة في [34]، والمفصلة في الملحق ج)، ونجد أن الخيار الأفضل هو التوزيع المتساوي . وبالتالي، نستخدم موحد لخطوات الوقت في جميع تجاربنا لجميع الحلول. - نجد أنه بالنسبة لمقياس توجيه كبير، فإن الخيار الأفضل لجميع الحلول السابقة هو من الدرجة الثانية (أي DPM-Solver-2 و DEIS-1). نقوم بتقييم جميع درجات الحلول السابقة ونختار أفضل نتيجة لكل NFE في مقارنتنا. على وجه التحديد، بالنسبة لـ DPM-Solver، نبلغ عن أفضل نتيجة بين DPM-Solver-2 و DPM-Solver-3، وبالنسبة لـ DEIS، نختار الأفضل بين DEIS-1 و DEIS-2 و DEIS-3.
7.1 نماذج DPM في فضاء البكسل مع التوجيه
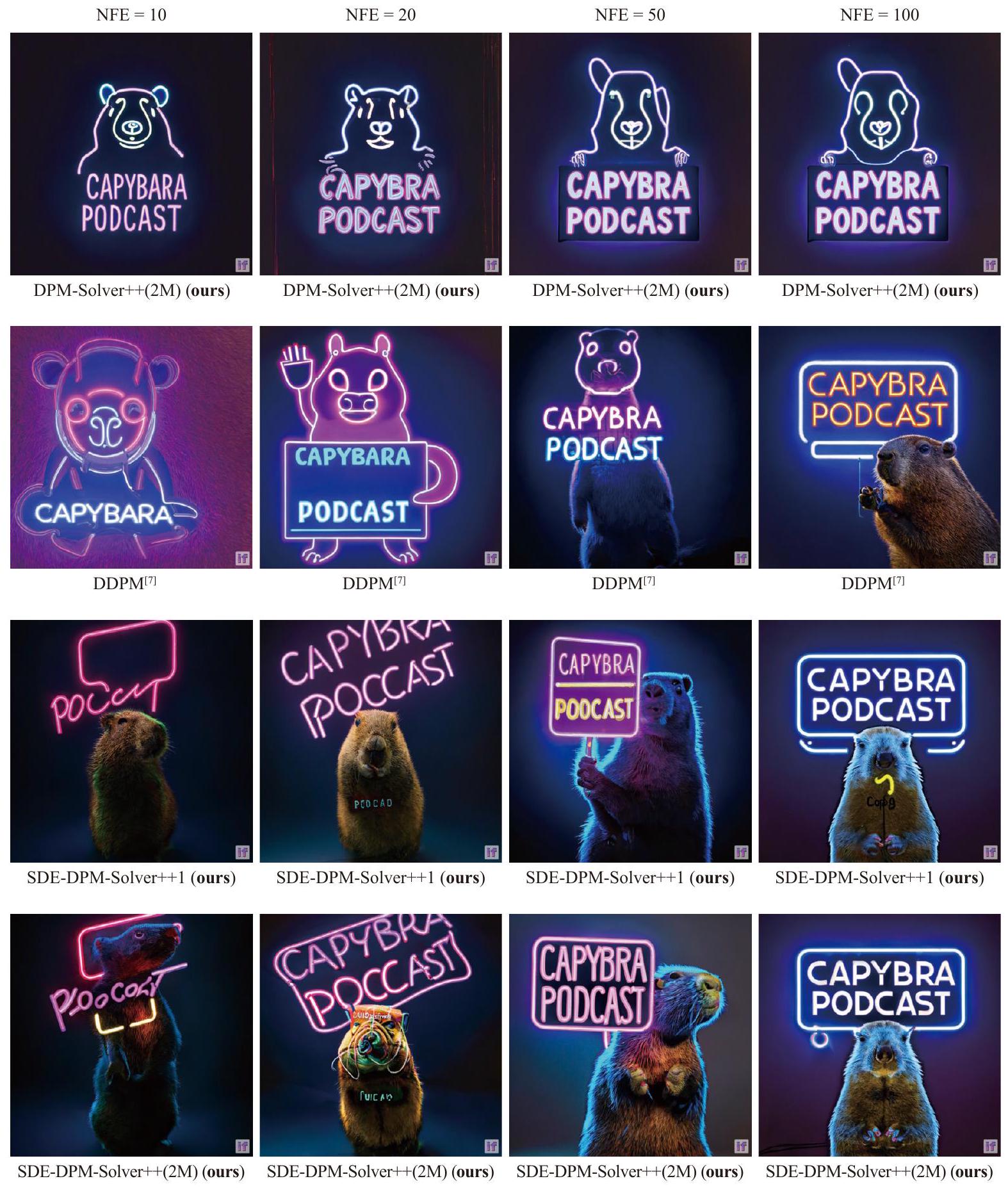
تتقارب العينات (DEIS، PNDM، DPM-Solver) بشكل أبطأ من DDIM من الدرجة الأولى، مما يظهر أن العينات عالية الدرجة السابقة غير مستقرة. بدلاً من ذلك، يحقق DPM-Solver++ أفضل أداء في تسريع الأداء لكل من مقاييس التوجيه الكبيرة والصغيرة. خاصةً بالنسبة لمقاييس التوجيه الكبيرة، يمكن لـ DPM-Solver++ أن يتقارب تقريبًا في غضون 15 NFE فقط.
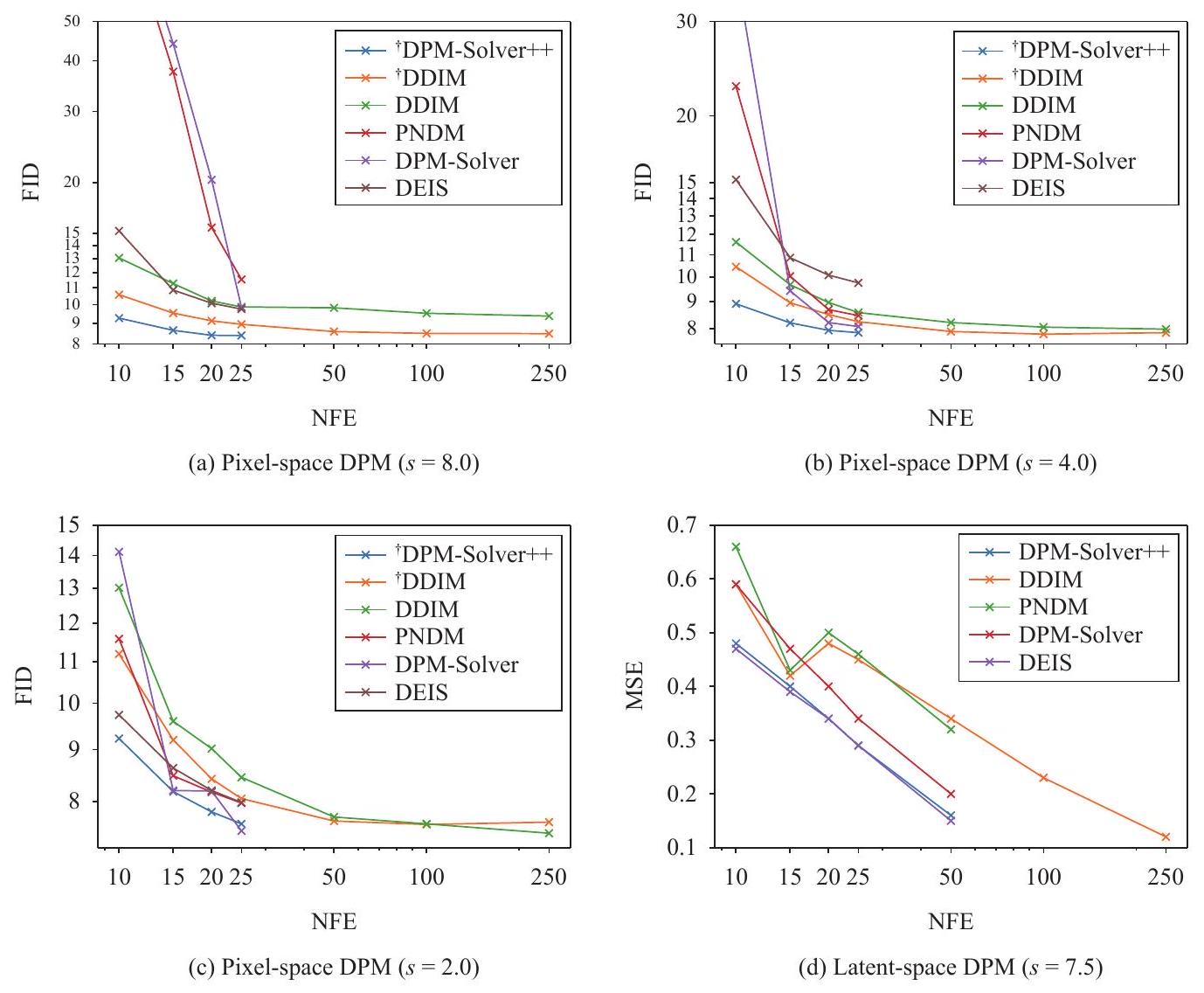
2) من خطوة واحدة إلى خطوات متعددة: كما هو موضح في الشكل 4(b)، يتقارب DPM-Solver++(2M) متعدد الخطوات بشكل أسرع قليلاً من DPM-Solver++(2S) ذو الخطوة الواحدة، الذي يتقارب تقريباً في 15 NFE. تشير هذه النتيجة إلى أنه بالنسبة لأخذ العينات الموجهة مع مقياس توجيه كبير، قد تكون الطرق متعددة الخطوات أسرع من الطرق ذات الخطوة الواحدة.
3) مع أو بدون تحديد العتبة: نقارن أداء DDIM و DPM-Solver++ مع/بدون طرق تحديد العتبة في الشكل 4(c). لاحظ أن طريقة تحديد العتبة تغير النموذج
7.2 نماذج DPM في الفضاء الكامن مع التوجيه
يمكن فهم الحلول على أنها تفكيك معادلات التفاضل الجزئي للانتشار، نقارن الرموز الكامنة المأخوذة بالحل الحقيقي
8 استنتاجات
شكر وتقدير
إعلانات تضارب المصالح
الوصول المفتوح
ترخيص المشاع الإبداعي 4.0 الدولي، الذي يسمح بالاستخدام والمشاركة والتكيف والتوزيع وإعادة الإنتاج بأي وسيلة أو صيغة، طالما أنك تعطي الائتمان المناسب للمؤلفين الأصليين والمصدر، وتوفر رابطًا لترخيص المشاع الإبداعي، وتوضح ما إذا تم إجراء تغييرات.
الملحق أ. براهين إضافية
أ. 1 إثبات الاقتراح 1
أ. 2 إثبات الاقتراح 2
أ. 3 اشتقاق حلول معادلات ستيت
- بالنسبة لـ SDE-DPM-Solver-1، لدينا
- بالنسبة لـ SDE-DPM-Solver++1، لدينا
- بالنسبة لـ SDE-DPM-Solver-2M، لدينا
- بالنسبة لـ SDE-DPM-Solver++2M، لدينا
أ. 4 تقارب الخوارزميات
-
و توجد وتكون مستمرة (ومن ثم تكون محدودة). - الخريطة
هو -ليبسشيتز. -
.
-
للجميع .
الاقتراح 3. بموجب الافتراضات المذكورة أعلاه، عندما
أ.4.1 تقارب الخوارزمية 1
أ.4.2 تقارب الخوارزمية 2
ب. المقارنة بين DPM-Solver و DPM-Solver++
ب. 1 اشتقاق مفصل
ج. تفاصيل التنفيذ
ج. 1 تحويل نماذج إدارة العمليات الزمنية المنفصلة إلى نماذج إدارة العمليات الزمنية المستمرة
ج. 2 خطوات الوقت للإزالة
ج. 3 إعدادات التجربة
د. تفاصيل التجربة
| طريقة | مقياس التوجيه | ||||||||
| 8.0 | ٧.٠ | 6.0 | 5.0 | ٤.٠ | 3.0 | 2.0 | 1.0 | 0.0 | |
| دي دي آي إم | 13.04 | 12.38 | 11.81 | 11.55 | 11.62 | 11.95 | 13.01 | ١٦.٣٥ | ٢٩.٣٣ |
| DEIS-2،
|
19.12 | 14.83 | 12.39 | 10.94 | 10.13 | 9.76 | 9.74 | 11.01 | ٢٠.٣٤ |
| DEIS-2،
|
٣٣.٣٧ | ٢٤.٦٦ | 18.03 | ١٣.٥٧ | 11.16 | 10.54 | 10.88 | ١٣.٦٧ | ٢٦.٢٦ |
| DEIS-2،
|
٥٥.٦٩ | 44.01 | ٣٣.٠٤ | ٢٤.٥٠ | 18.66 | ١٦.٣٥ | 16.87 | ٢١.٩١ | ٣٨.٤١ |
| DEIS-3،
|
66.81 | ٤٨.٧١ | ٣٣.٨٩ | ٢٢.٥٦ | 15.84 | 11.96 | 10.18 | 10.19 | 18.70 |
| DEIS-3،
|
٣٤.٥١ | ٢٥.٤٢ | 18.52 | 13.68 | 11.20 | 10.46 | 10.75 | ١٣.٣٦ | ٢٥.٥٩ |
| DEIS-3،
|
٥٦.٤٩ | 44.51 | ٣٣.٣٤ | ٢٤.٦٨ | 18.72 | ١٦.٣٨ | 16.79 | 21.76 | ٣٨.٠٢ |



| مقياس التوجيه | العتبة | طريقة أخذ العينات | NFE | ||||||
| 10 | 15 | 20 | ٢٥ | 50 | 100 | ٢٥٠ | |||
| دي دي آي إم
|
13.04 | 11.27 | 10.21 | 9.87 | 9.82 | 9.52 | 9.37 | ||
| PNDM
|
99.80 | ٣٧.٥٩ | 15.50 | 11.54 | – | – | – | ||
| DPM-Solver-2
|
١١٤.٦٢ | 44.05 | ٢٠.٣٣ | 9.84 | – | – | – | ||
| DPM-Solver-3
|
164.74 | 91.59 | 64.11 | ٢٩.٤٠ | – | – | – | ||
| لا | DEIS-1
|
15.20 | 10.86 | 10.26 | 10.01 | – | – | – | |
| 8.0 | DEIS-2
|
19.12 | 11.37 | 10.08 | 9.75 | – | – | – | |
| DEIS-3
|
66.86 | ٢٤.٤٨ | 12.98 | 10.87 | – | – | – | ||
| DPM-Solver++(S) (خاص بنا) | ١٢.٢٠ | 9.85 | 9.19 | 9.32 | – | – | – | ||
| DPM-Solver++(M) (خاص بنا) | ١٤.٤٤ | 9.46 | 9.10 | 9.11 | – | – | – | ||
| نعم | دي دي آي إم
|
10.58 | 9.53 | 9.12 | 8.94 | 8.58 | ٨.٤٩ | 8.48 | |
| DPM-Solver++(S) (خاص بنا) | 9.26 | 8.93 | 8.40 | 8.63 | – | – | – | ||
| دي بي إم-سولفر++(م) (خاص بنا) | 9.56 | 8.64 | ٨.٥٠ | 8.39 | – | – | – | ||
| مقياس التوجيه | العتبة | طريقة أخذ العينات | NFE | ||||||
| 10 | 15 | 20 | ٢٥ | 50 | 100 | ٢٥٠ | |||
| ٤.٠ | دي دي آي إم
|
11.62 | 9.67 | 8.96 | ٨.٥٨ | 8.22 | 8.06 | 7.99 | |
| PNDM
|
٢٢.٧١ | 10.03 | 8.69 | 8.47 | - | - | - | ||
| دي بي إم – سولفر – 2
|
٣٧.٦٨ | 9.42 | 8.22 | 8.08 | - | - | - | ||
| دي بي إم – سولفر – 3
|
٧٤.٩٧ | 15.65 | 9.99 | 8.15 | - | - | - | ||
| لا | DEIS-1
|
10.55 | 9.47 | 8.88 | 8.65 | - | - | - | |
| DEIS-2
|
10.13 | 9.09 | 8.68 | 8.45 | - | - | - | ||
| DEIS-3
|
15.84 | 9.25 | 8.63 | 8.43 | - | - | - | ||
| DPM-Solver++(S)(خاصتنا) | 9.08 | 8.51 | ٨.٠٠ | 8.07 | - | - | - | ||
| دي بي إم – سولفر ++ (م) (خاص بنا) | 8.98 | 8.26 | 8.06 | 8.06 | - | - | - | ||
| نعم | دي دي آي إم
|
10.45 | ٨.٩٥ | 8.51 | 8.25 | 7.91 | 7.82 | 7.87 | |
| دي بي إم – سولفر بلس بلس (S) (خاصتنا) | 8.94 | 8.26 | ٧.٩٥ | 7.87 | - | - | - | ||
| DPM-Solver++(M)(خاص بنا) | 8.91 | 8.21 | 7.99 | 7.96 | - | - | - | ||
| 2.0 | دي دي آي إم
|
13.01 | 9.60 | 9.02 | 8.45 | 7.72 | ٧.٦٠ | 7.44 | |
| PNDM
|
11.58 | 8.48 | 8.17 | 7.97 | - | - | - | ||
| دي بي إم – سولفر – 2
|
14.12 | 8.20 | ٨.٥٩ | 7.48 | - | - | - | ||
| دي بي إم – سولفر – 3
|
21.06 | ٨.٥٧ | 8.19 | 7.85 | - | - | - | ||
| لا | DEIS-1
|
10.40 | 9.11 | 8.52 | 8.21 | - | - | - | |
| DEIS-2
|
9.74 | ٨.٨٠ | 8.28 | 8.06 | - | - | - | ||
| DEIS-3
|
10.18 | 8.63 | 8.20 | 7.98 | - | - | - | ||
| دي بي إم – سولفر بلس بلس (S) (خاصتنا) | 9.18 | 8.17 | ٧.٧٧ | ٧.٥٦ | - | - | - | ||
| DPM-Solver++(M)(خاص بنا) | 9.19 | 8.47 | 8.17 | 8.07 | - | - | - | ||
| نعم | دي دي آي إم
|
11.19 | 9.20 | 8.42 | 8.05 | 7.65 | ٧.٥٩ | 7.63 | |
| DPM-Solver++(S)(خاصتنا) | 9.23 | 8.18 | 7.81 | ٧.٦٠ | - | - | - | ||
| دي بي إم – سولفر بلس بلس (م) (خاص بنا) | 9.28 | 8.56 | 8.28 | 8.18 | - | - | - | ||
| مقياس التوجيه | العتبة | طريقة أخذ العينات | NFE | ||||||
| 10 | 15 | 20 | ٢٥ | 50 | 100 | ٢٥٠ | |||
| دي دي آي إم
|
0.59 | 0.42 | 0.48 | 0.45 | 0.34 | 0.23 | 0.12 | ||
| PNDM
|
0.66 | 0.43 | 0.50 | 0.46 | 0.32 | - | - | ||
| دي بي إم – سولفر – 2
|
0.66 | 0.47 | 0.40 | 0.34 | 0.20 | واحد | - | ||
| دي بي إم – سولفر – 3 [32] | 0.59 | 0.48 | 0.43 | 0.37 | 0.23 | - | - | ||
| ٧.٥ | لا | DEIS-1
|
0.47 | 0.39 | 0.34 | 0.29 | 0.16 | واحد | - |
| DEIS-2
|
0.48 | 0.40 | 0.34 | 0.29 | 0.15 | - | - | ||
| DEIS-3
|
0.57 | 0.45 | 0.38 | 0.34 | 0.19 | واحد | واحد | ||
| دي بي إم – سولفر بلس بلس (S) (خاصتنا) | 0.48 | 0.41 | 0.36 | 0.32 | 0.19 | - | - | ||
| دي بي إم – سولفر ++ (م) (خاص بنا) | 0.49 | 0.40 | 0.34 | 0.29 | 0.16 | - | - | ||
| مقياس التوجيه | العتبة | طريقة أخذ العينات | NFE | ||||||
| 10 | 15 | 20 | ٢٥ | 50 | 100 | ٢٥٠ | |||
| 15.0 | دي دي آي إم
|
0.83 | 0.78 | 0.71 | 0.67 | – | – | – | |
| PNDM
|
0.99 | 0.87 | 0.79 | 0.75 | – | – | – | ||
| DPM-Solver-2
|
1.13 | 1.08 | 0.96 | 0.86 | – | – | – | ||
| DEIS-1
|
0.84 | 0.72 | 0.64 | 0.58 | – | – | – | ||
| DEIS-2
|
0.87 | 0.76 | 0.68 | 0.63 | – | – | – | ||
| دييس-3
|
1.06 | 0.88 | 0.78 | 0.73 | – | – | – | ||
| DPM-Solver++(S) (خاص بنا) | 0.88 | 0.75 | 0.68 | 0.61 | – | – | – | ||
| DPM-Solver++(M) (خاص بنا) | 0.84 | 0.72 | 0.64 | 0.58 | – | – | – | ||
References
[2] J. Sohl-Dickstein, E. A. Weiss, N. Maheswaranathan, S. Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, vol.37, pp.2256-2265, 2015.
[3] Y. Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, B. Poole. Score-based generative modeling through stochastic differential equations. In Proceedings of the 9th International Conference on Learning Representations, 2021.
[4] P. Dhariwal, A. Nichol. Diffusion models beat GANs on image synthesis. In Proceedings of the 35th International Conference on Neural Information Processing Systems, Article number 672, 2021.
[5] J. Ho, C. Saharia, W. Chan, D. J. Fleet, M. Norouzi, T. Salimans. Cascaded diffusion models for high fidelity image generation. Journal of Machine Learning Research, vol. 23, no. 1, Article number 47, 2022.
[6] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, B. Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, pp. 10674-10685, 2022. DOI: 10.1109/CVPR52688.2022. 01042.
[7] C. Meng, Y. Song, J. Song, J. Wu, J. Y. Zhu, S. Ermon. SDEdit: Guided image synthesis and editing with stochastic differential equations. In Proceedings of the 10th International Conference on Learning Representations, 2022.
[8] C. Saharia, W. Chan, H. Chang, C. Lee, J. Ho, T. Salimans, D. Fleet, M. Norouzi. Palette: Image-to-image diffusion models. In Proceedings of ACM SIGGRAPH Conference Proceedings, Vancouver, Canada, Article number 15, 2022. DOI: 10.1145/3528233.3530757.
[9] M. Zhao, F. Bao, C. Li, J. Zhu. EGSDE: Unpaired image-to-image translation via energy-guided stochastic differential equations. In Proceedings of the 36th International Conference on Neural Information Processing Systems, New Orleans, USA, Article number 261, 2022.
[10] C. Saharia, W. Chan, S. Saxena, L. Li, J. Whang, E. Denton, S. K. S. Ghasemipour, B. K. Ayan, S. S. Mahdavi, R. G. Lopes, T. Salimans, J. Ho, D. J. Fleet, M. Norouzi. Photorealistic text-to-image diffusion models with deep language understanding. In Proceedings of the 36th International Conference on Neural Information Processing Systems, New Orleans, USA, Article number 2643, 2022.
[11] A. Q. Nichol, P. Dhariwal, A. Ramesh, P. Shyam, P. Mishkin, B. McGrew, I. Sutskever, M. Chen. GLIDE: Towards photorealistic image generation and editing with text-guided diffusion models. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, USA, pp. 16784-16804, 2022.
[12] A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, M. Chen. Hierarchical text-conditional image generation with CLIP latents, [Online], Available: https://arxiv.org/abs/2204. 06125, 2022.
[13] S. Gu, D. Chen, J. Bao, F. Wen, B. Zhang, D. Chen, L. Yuan, B. Guo. Vector quantized diffusion model for text-to-image synthesis. In Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, pp. 10686-10696, 2022. DOI: 10.1109/CVPR52688.2022.01043.
[14] J. Liu, C. Li, Y. Ren, F. Chen, Z. Zhao. DiffSinger: Singing voice synthesis via shallow diffusion mechanism. In Proceedings of the 36th AAAI Conference on Artificial Intelligence, vol.36, pp.11020-11028, 2022. DOI: 10.1609/aaai. v36i10.21350.
[15] N. Chen, Y. Zhang, H. Zen, R. J. Weiss, M. Norouzi, W. Chan. WaveGrad: Estimating gradients for waveform generation. In Proceedings of the 9th International Conference on Learning Representations, 2021.
[16] N. Chen, Y. Zhang, H. Zen, R. J. Weiss, M. Norouzi, N. Dehak, W. Chan. WaveGrad 2: Iterative refinement for text-to-speech synthesis. In Proceedings of the 22nd International Speech Communication Association, Brno, Czech Republic, pp. 3765-3769, 2021.
[17] B. Poole, A. Jain, J. T. Barron, B. Mildenhall. DreamFusion: Text-to-3D using 2D diffusion. In Proceedings of the 11th International Conference on Learning Representations, Kigali, Rwanda, 2023.
[18] Z. Wang, C. Lu, Y. Wang, F. Bao, C. Li, H. Su, J. Zhu. ProlificDreamer: High-fidelity and diverse text-to-3D generation with variational score distillation. In Proceedings of the 37th International Conference on Neural Informa-
tion Processing Systems, New Orleans, USA, Article number 368, 2023.
[20] M. Xu, L. Yu, Y. Song, C. Shi, S. Ermon, J. Tang. GeoDiff: A geometric diffusion model for molecular conformation generation. In Proceedings of the 10th International Conference on Learning Representations, 2022.
[21] E. Hoogeboom, V. G. Satorras, C. Vignac, M. Welling. Equivariant diffusion for molecule generation in 3D. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, USA, pp. 8867-8887, 2022.
[23] A. Blattmann, T. Dockhorn, S. Kulal, D. Mendelevitch, M. Kilian, D. Lorenz, Y. Levi, Z. English, V. Voleti, A. Letts, V. Jampani, R. Rombach. Stable video diffusion: Scaling latent video diffusion models to large datasets, [Online], Available: https://arxiv.org/abs/2311.15127, 2023.
[25] F. Bao, C. Xiang, G. Yue, G. He, H. Zhu, K. Zheng, M. Zhao, S. Liu, Y. Wang, J. Zhu. Vidu: A highly consistent, dynamic and skilled text-to-video generator with diffusion models, [Online], Available: https://arxiv.org/abs/2405. 04233, 2024.
[28] I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, Y. Bengio. Generative adversarial nets. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, Canada, vol.2, pp.2672-2680, 2014.
[30] J. Ho, T. Salimans. Classifier-free diffusion guidance. In Proceedings of the 34th International Conference on Neural Information Processing Systems, 2021.
[31] J. Song, C. Meng, S. Ermon. Denoising diffusion implicit models. In Proceedings of the 9th International Conference on Learning Representations, 2021.
[32] C. Lu, Y. Zhou, F. Bao, J. Chen, C. Li, J. Zhu. DPM-solver: A fast ODE solver for diffusion probabilistic model sampling in around 10 steps. In Proceedings of the 36th International Conference on Neural Information Processing
[33] T. Salimans, J. Ho. Progressive distillation for fast sampling of diffusion models. In Proceedings of the 10th International Conference on Learning Representations, 2022.
[34] Q. Zhang, Y. Chen. Fast sampling of diffusion models with exponential integrator. In Proceedings of the 11th International Conference on Learning Representations, Kigali, Rwanda, 2023.
[35] DeepFloyd: IF. GitHub, [Online], Available, https://git-hub.com/deep-floyd/IF, 2023.
[36] L. Liu, Y. Ren, Z. Lin, Z. Zhao. Pseudo numerical methods for diffusion models on manifolds. In Proceedings of the 10th International Conference on Learning Representations, 2022.
[37] M. Hochbruck, A. Ostermann. Exponential integrators. Acta Numerica, vol.19, pp.209-286, 2010. DOI: 10.1017/ S0962492910000048.
[38] K. E. Atkinson, W. Han, D. Stewart. Numerical Solution of Ordinary Differential Equations, Hoboken, USA: John Wiley & Sons, 2009.
[39] A. Jolicoeur-Martineau, K. Li, R. Piché-Taillefer, T. Kachman, I. Mitliagkas. Gotta go fast when generating data with score-based models, [Online], Available: https:// arxiv.org/abs/2105.14080, 2021.
[40] H. Tachibana, M. Go, M. Inahara, Y. Katayama, Y. Watanabe. Itô-Taylor sampling scheme for denoising diffusion probabilistic models using ideal derivatives, [Online], Available: https://arxiv.org/abs/2112.13339v1, 2021.
[41] Z. Kong, W. Ping. On fast sampling of diffusion probabilistic models, [Online], Available: https://arxiv.org/abs/ 2106.00132, 2021.
[42] F. Bao, C. Li, J. Zhu, B. Zhang. Analytic-DPM: An analytic estimate of the optimal reverse variance in diffusion probabilistic models. In Proceedings of the 10th International Conference on Learning Representations, 2022.
[43] Q. Zhang, M. Tao, Y. Chen. gDDIM: Generalized denoising diffusion implicit models. In Proceedings of the 11th International Conference on Learning Representations, Kigali, Rwanda, 2023.
[44] E. Luhman, T. Luhman. Knowledge distillation in iterative generative models for improved sampling speed, [Online], Available: https://arxiv.org/abs/2101.02388, 2021.
[45] R. San-Roman, E. Nachmani, L. Wolf. Noise estimation for generative diffusion models, [Online], Available: https://arxiv.org/abs/2104.02600, 2021.
[46] A. Q. Nichol, P. Dhariwal. Improved denoising diffusion probabilistic models. In Proceedings of the 38th International Conference on Machine Learning, pp. 8162-8171, 2021.
[47] F. Bao, C. Li, J. Sun, J. Zhu, B. Zhang. Estimating the optimal covariance with imperfect mean in diffusion probabilistic models. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, USA, pp. 1555-1584, 2022.
[48] M. W. Y. Lam, J. Wang, R. Huang, D. Su, D. Yu. Bilateral denoising diffusion models, [Online], Available: https:// arxiv.org/abs/2108.11514, 2021.
[49] D. Watson, W. Chan, J. Ho, M. Norouzi. Learning fast samplers for diffusion models by differentiating through sample quality. In Proceedings of the 10th International Conference on Learning Representations, 2022.
[50] A. Vahdat, K. Kreis, J. Kautz. Score-based generative modeling in latent space. In Proceedings of the 35th International Conference on Neural Information Processing Systems, Article number 863, 2021.
[51] T. Dockhorn, A. Vahdat, K. Kreis. Score-based generative modeling with critically-damped Langevin diffusion. In Proceedings of the 10th International Conference on Learning Representations, 2022.
[52] Z. Xiao, K. Kreis, A. Vahdat. Tackling the generative learning trilemma with denoising diffusion GANs. In Proceedings of the 10th International Conference on Learning Representations, 2022.
[53] Z. Wang, H. Zheng, P. He, W. Chen, M. Zhou. DiffusionGAN: Training GANs with diffusion. In Proceedings of the 11th International Conference on Learning Representations, Kigali, Rwanda, 2023.
[54] W. Zhao, L. Bai, Y. Rao, J. Zhou, J. Lu. UniPC: A unified predictor-corrector framework for fast sampling of diffusion models. In Proceedings of the 37th International Conference on Neural Information Processing Systems, New Orleans, USA, Article number 2170, 2023.
[55] E. Liu, X. Ning, H. Yang, Y. Wang. A unified sampling framework for solver searching of diffusion probabilistic models. In Proceedings of the 12th International Conference on Learning Representations, Vienna, Austria, 2024.
[56] W. Zhao, H. Wang, J. Zhou, J. Lu. DC-Solver: Improving predictor-corrector diffusion sampler via dynamic compensation. In Proceedings of the 18th European Conference on Computer Vision, Milan, Italy, pp. 450-466, 2024. DOI: 10.1007/978-3-031-73247-8_26.
[57] K. Zheng, C. Lu, J. Chen, J. Zhu. DPM-Solver-v3: Improved diffusion ODE solver with empirical model statistics. In Proceedings of the 37th International Conference on Neural Information Processing Systems, New Orleans, USA, Article number 2423, 2023.
[58] S. Li, L. Liu, Z. Chai, R. Li, X. Tan. ERA-Solver: Error-robust Adams solver for fast sampling of diffusion probabilistic models, [Online], Available: https://arxiv.org/abs/ 2301.12935, 2023.
[59] T. Karras, M. Aittala, T. Aila, S. Laine. Elucidating the design space of diffusion-based generative models. In Proceedings of the 36th International Conference on Neural Information Processing Systems, New Orleans, USA, Article number 1926, 2022.
[60] S. Wizadwongsa, S. Suwajanakorn. Accelerating guided diffusion sampling with splitting numerical methods. In Proceedings of the 11th International Conference on Learning Representations, Kigali, Rwanda, 2023.
[61] C. Meng, R. Gao, D. Kingma, S. Ermon, J. Ho, T. Salimans. On distillation of guided diffusion models. In Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, pp. 1429714306, 2023. DOI: 10.1109/CVPR52729.2023.01374.
[62] Z. Zhou, D. Chen, C. Wang, C. Chen. Fast ODE-based sampling for diffusion models in around 5 steps. In Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, pp.7777-7786,
2024. DOI: 10.1109/CVPR52733.2024.00743.
[65] J. Heek, E. Hoogeboom, T. Salimans. Multistep consistency models, [Online], Available: https://arxiv.org/abs/ 2403.06807, 2024.
[66] J. T. J. Tee, K. Zhang, H. S. Yoon, D. N. Gowda, C. Kim, C. D. Yoo. Physics informed distillation for diffusion models. Transactions on Machine Learning Research, vol. 2024, 2024.
[67] H. Zheng, W. Nie, A. Vahdat, K. Azizzadenesheli, A. Anandkumar. Fast sampling of diffusion models via operator learning. In Proceedings of the 40th International Conference on Machine Learning, Honolulu, USA, pp. 42390-42402, 2023.
[68] Y. Song, P. Dhariwal, M. Chen, I. Sutskever. Consistency models. In Proceedings of the 40th International Conference on Machine Learning, Honolulu, USA, Article number 1335, 2023.
[69] C. Lu, Y. Song. Simplifying, stabilizing and scaling con-tinuous-time consistency models. In Proceedings of the 13th International Conference on Learning Representations, Singapore, 2025.
[70] W. Luo, Z. Huang, Z. Geng, J. Z. Kolter, G. J. Qi. Onestep diffusion distillation through score implicit matching. In Proceedings of the 38th International Conference on Neural Information Processing Systems, Vancouver, Canada, pp. 115377-115408, 2024.
[71] T. Yin, M. Gharbi, R. Zhang, E. Shechtman, F. Durand, W. T. Freeman, T. Park. One-step diffusion with distribution matching distillation. In Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, pp.6613-6623, 2024. DOI: 10.1109/ CVPR52733.2024.00632.
[72] L. Zhou, S. Ermon, J. Song. Inductive moment matching, [Online], Available: https://arxiv.org/abs/2503.07565, 2025.
[73] M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, S. Hochreiter. GANs trained by a two time-scale update rule converge to a local Nash equilibrium. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, USA, pp. 6629-6640, 2017.

E-mail: lucheng.lc15@gmail.com
ORCID iD: 0009-0003-5616-0556

ORCID iD: 0000-0002-6254-2388
- Research Article
Manuscript received on March 15, 2025; accepted on May 8, 2025; published online on June 23, 2025Recommended by Associate Editor Cheng-Lin Liu
Colored figures are available in the online version at https://link. springer.com/journal/11633
© The Author(s) 2025
DOI: https://doi.org/10.1007/s11633-025-1562-4
Publication Date: 2025-06-22
DPM-Solver++: Fast Solver for Guided Sampling of Diffusion Probabilistic Models
Abstract
Diffusion probabilistic models (DPMs) have achieved impressive success in high-resolution image synthesis, especially in recent large-scale text-to-image generation applications. An essential technique for improving the sample quality of DPMs is guided sampling, which usually needs a large guidance scale to obtain the best sample quality. The commonly-used fast sampler for guided sampling is denoising diffusion implicit models (DDIM), a first-order diffusion ordinary differential equation (ODE) solver that generally needs 100 to 250 steps for high-quality samples. Although recent works propose dedicated high-order solvers and achieve a further speedup for sampling without guidance, their effectiveness for guided sampling has not been well-tested before. In this work, we demonstrate that previous high-order fast samplers suffer from instability issues, and they even become slower than DDIM when the guidance scale grows larger. To further speed up guided sampling, we propose DPM-Solver++, a high-order solver for the guided sampling of DPMs. DPM-Solver++ solves the diffusion ODE with the data prediction model and adopts thresholding methods to keep the solution matches training data distribution. We further propose a multistep variant of DPM-Solver++ to address the instability issue by reducing the effective step size. Experiments show that DPM-Solver++ can generate high-quality samples within only 15 to 20 steps for guided sampling by pixel-space and latent-space DPMs.
Citation: C. Lu, Y. Zhou, F. Bao, J. Chen, C. Li, J. Zhu. DPM-Solver++: Fast solver for guided sampling of diffusion probabilistic models. Machine Intelligence Research, vol.22, no.4, pp.730-751, 2025. http://doi.org/10.1007/s11633-025-1562-4
1 Introduction
high-order solvers to guided sampling: 1) The large guidance scale narrows the convergence radius of high-order solvers, making them unstable; and 2
2 Diffusion probabilistic models
2.1 Fast sampling for DPMs by diffusion ODEs
following ODE
2.2 Guided sampling for DPMs
2.3 Exponential integrators and high-order ODE solvers
corresponding change-of-variable forms for
3 Challenges of high-order solvers for guided sampling
4 Designing training-free fast samplers for guided sampling
er to address the instability issue.
4.1 Designing solvers by data prediction model
Algorithm 1. DPM-Solver++(2S).
Require: Initial value
-
- for
to do -
-
-
-
-
- end for
- return
Require: Initial value
- Denote
for -
. Initialize an empty buffer -
-
-
- for
to do -
-
, ) -
- If
, then - end for
- return
4.2 From singlestep to multistep
of multistep methods is around
4.3 Combining thresholding with DPMSolver++
5 Fast solvers for diffusion SDEs
SDE-DPM-Solver-1.
SDE-DPM-Solver++1.
SDE-DPM-Solver-2M.
SDE-DPM-Solver++(2M).
6 Relationship with other fast sampling methods
6.1 Comparison with solvers based on exponential integrators
| DEIS
|
DPM-Solver
|
DPM-Solver++ (ours) | SDE-DPM-Solver++ (ours) | |
| First-order | DDIM (
|
DDIM (
|
DDIM (
|
|
| Model type |
|
|
|
|
| Taylor expansion |
|
|
|
|
| Solver type (high-order) | Multistep | Singlestep | Singlestep + multistep | Multistep |
6.2 Other fast sampling methods
7 Experiments
- For the step size schedule, we search the time steps in the following choices: uniform
(a widely-used setting in high-resolution image synthesis), uniform (used in [32]), uniform split of the power functions of (used in [34], detailed in Appendix C), and we find that the best choice is uniform . Thus, we use uniform for the time steps in all of our experiments for all of the solvers. - We find that for a large guidance scale, the best choice for all the previous solvers is the second-order (i.e., DPM-Solver-2 and DEIS-1). We evaluate all orders of the previous solvers and select the best result for each NFE in our comparison. Specifically, for DPM-Solver, we report the best result among DPM-Solver-2 and DPM-Solv-er-3, and for DEIS, we select the best among DEIS-1, DEIS-2, and DEIS-3.
7.1 Pixel-space DPMs with guidance
samplers (DEIS, PNDM, DPM-Solver) converge slower than the first-order DDIM, which shows that previous high-order samplers are unstable. Instead, DPM-Solver++ achieves the best speedup performance for both large guidance scales and small guidance scales. Especially for large guidance scales, DPM-Solver++ can almost converge within only 15 NFE .
2) From singlestep to multistep: As show in Fig. 4(b), the multistep DPM-Solver++(2M) converges slightly faster than the singlestep DPM-Solver++(2S), which almost converges in 15 NFE. Such result indicates that for guided sampling with a large guidance scale, multistep methods may be faster than singlestep methods.
3) With or without thresholding: We compare the performance of DDIM and DPM-Solver++ with/without thresholding methods in Fig.4(c). Note that the thresholding method changes the model
7.2 Latent-space DPMs with guidance
solvers can be understood as discretizing diffusion ODEs, we compare the sampled latent codes by the true solution
8 Conclusions
Acknowledgements
Declarations of conflict of interest
Open Access
tribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
Appendix A. Additional proofs
A. 1 Proof of proposition 1
A. 2 Proof of proposition 2
A. 3 Derivation of SDE solvers
- For SDE-DPM-Solver-1, we have
- For SDE-DPM-Solver++1, we have
- For SDE-DPM-Solver-2M, we have
- For SDE-DPM-Solver++2M, we have
A. 4 Convergence of algorithms
-
and exist and are continuous (and hence are bounded). - The map
is -Lipschitz. -
.
-
for all .
Proposition 3. Under the above assumptions, when
A.4.1 Convergence of Algorithm 1
A.4.2 Convergence of Algorithm 2
B. Comparison between DPM-Solver and DPM-Solver++
B. 1 Detailed derivation
C. Implementation details
C. 1 Converting discrete-time DPMs to continuous-time DPMs
C. 2 Ablating time steps
C. 3 Experiment settings
D. Experiment details
| Method | Guidance scale | ||||||||
| 8.0 | 7.0 | 6.0 | 5.0 | 4.0 | 3.0 | 2.0 | 1.0 | 0.0 | |
| DDIM | 13.04 | 12.38 | 11.81 | 11.55 | 11.62 | 11.95 | 13.01 | 16.35 | 29.33 |
| DEIS-2,
|
19.12 | 14.83 | 12.39 | 10.94 | 10.13 | 9.76 | 9.74 | 11.01 | 20.34 |
| DEIS-2,
|
33.37 | 24.66 | 18.03 | 13.57 | 11.16 | 10.54 | 10.88 | 13.67 | 26.26 |
| DEIS-2,
|
55.69 | 44.01 | 33.04 | 24.50 | 18.66 | 16.35 | 16.87 | 21.91 | 38.41 |
| DEIS-3,
|
66.81 | 48.71 | 33.89 | 22.56 | 15.84 | 11.96 | 10.18 | 10.19 | 18.70 |
| DEIS-3,
|
34.51 | 25.42 | 18.52 | 13.68 | 11.20 | 10.46 | 10.75 | 13.36 | 25.59 |
| DEIS-3,
|
56.49 | 44.51 | 33.34 | 24.68 | 18.72 | 16.38 | 16.79 | 21.76 | 38.02 |
| Guidance scale | Thresholding | Sampling method | NFE | ||||||
| 10 | 15 | 20 | 25 | 50 | 100 | 250 | |||
| DDIM
|
13.04 | 11.27 | 10.21 | 9.87 | 9.82 | 9.52 | 9.37 | ||
| PNDM
|
99.80 | 37.59 | 15.50 | 11.54 | – | – | – | ||
| DPM-Solver-2
|
114.62 | 44.05 | 20.33 | 9.84 | – | – | – | ||
| DPM-Solver-3
|
164.74 | 91.59 | 64.11 | 29.40 | – | – | – | ||
| No | DEIS-1
|
15.20 | 10.86 | 10.26 | 10.01 | – | – | – | |
| 8.0 | DEIS-2
|
19.12 | 11.37 | 10.08 | 9.75 | – | – | – | |
| DEIS-3
|
66.86 | 24.48 | 12.98 | 10.87 | – | – | – | ||
| DPM-Solver++(S) (ours) | 12.20 | 9.85 | 9.19 | 9.32 | – | – | – | ||
| DPM-Solver++(M) (ours) | 14.44 | 9.46 | 9.10 | 9.11 | – | – | – | ||
| Yes | DDIM
|
10.58 | 9.53 | 9.12 | 8.94 | 8.58 | 8.49 | 8.48 | |
| DPM-Solver++(S) (ours) | 9.26 | 8.93 | 8.40 | 8.63 | – | – | – | ||
| DPM-Solver++(M) (ours) | 9.56 | 8.64 | 8.50 | 8.39 | – | – | – | ||
| Guidance scale | Thresholding | Sampling method | NFE | ||||||
| 10 | 15 | 20 | 25 | 50 | 100 | 250 | |||
| 4.0 | DDIM
|
11.62 | 9.67 | 8.96 | 8.58 | 8.22 | 8.06 | 7.99 | |
| PNDM
|
22.71 | 10.03 | 8.69 | 8.47 | - | - | - | ||
| DPM-Solver-2
|
37.68 | 9.42 | 8.22 | 8.08 | - | - | - | ||
| DPM-Solver-3
|
74.97 | 15.65 | 9.99 | 8.15 | - | - | - | ||
| No | DEIS-1
|
10.55 | 9.47 | 8.88 | 8.65 | - | - | - | |
| DEIS-2
|
10.13 | 9.09 | 8.68 | 8.45 | - | - | - | ||
| DEIS-3
|
15.84 | 9.25 | 8.63 | 8.43 | - | - | - | ||
| DPM-Solver++(S)(ours) | 9.08 | 8.51 | 8.00 | 8.07 | - | - | - | ||
| DPM-Solver++(M)(ours) | 8.98 | 8.26 | 8.06 | 8.06 | - | - | - | ||
| Yes | DDIM
|
10.45 | 8.95 | 8.51 | 8.25 | 7.91 | 7.82 | 7.87 | |
| DPM-Solver++(S)(ours) | 8.94 | 8.26 | 7.95 | 7.87 | - | - | - | ||
| DPM-Solver++(M)(ours) | 8.91 | 8.21 | 7.99 | 7.96 | - | - | - | ||
| 2.0 | DDIM
|
13.01 | 9.60 | 9.02 | 8.45 | 7.72 | 7.60 | 7.44 | |
| PNDM
|
11.58 | 8.48 | 8.17 | 7.97 | - | - | - | ||
| DPM-Solver-2
|
14.12 | 8.20 | 8.59 | 7.48 | - | - | - | ||
| DPM-Solver-3
|
21.06 | 8.57 | 8.19 | 7.85 | - | - | - | ||
| No | DEIS-1
|
10.40 | 9.11 | 8.52 | 8.21 | - | - | - | |
| DEIS-2
|
9.74 | 8.80 | 8.28 | 8.06 | - | - | - | ||
| DEIS-3
|
10.18 | 8.63 | 8.20 | 7.98 | - | - | - | ||
| DPM-Solver++(S)(ours) | 9.18 | 8.17 | 7.77 | 7.56 | - | - | - | ||
| DPM-Solver++(M)(ours) | 9.19 | 8.47 | 8.17 | 8.07 | - | - | - | ||
| Yes | DDIM
|
11.19 | 9.20 | 8.42 | 8.05 | 7.65 | 7.59 | 7.63 | |
| DPM-Solver++(S)(ours) | 9.23 | 8.18 | 7.81 | 7.60 | - | - | - | ||
| DPM-Solver++(M)(ours) | 9.28 | 8.56 | 8.28 | 8.18 | - | - | - | ||
| Guidance scale | Thresholding | Sampling method | NFE | ||||||
| 10 | 15 | 20 | 25 | 50 | 100 | 250 | |||
| DDIM
|
0.59 | 0.42 | 0.48 | 0.45 | 0.34 | 0.23 | 0.12 | ||
| PNDM
|
0.66 | 0.43 | 0.50 | 0.46 | 0.32 | - | - | ||
| DPM-Solver-2
|
0.66 | 0.47 | 0.40 | 0.34 | 0.20 | 一 | - | ||
| DPM-Solver-3[32] | 0.59 | 0.48 | 0.43 | 0.37 | 0.23 | - | - | ||
| 7.5 | No | DEIS-1
|
0.47 | 0.39 | 0.34 | 0.29 | 0.16 | 一 | - |
| DEIS-2
|
0.48 | 0.40 | 0.34 | 0.29 | 0.15 | - | - | ||
| DEIS-3
|
0.57 | 0.45 | 0.38 | 0.34 | 0.19 | 一 | 一 | ||
| DPM-Solver++(S)(ours) | 0.48 | 0.41 | 0.36 | 0.32 | 0.19 | - | - | ||
| DPM-Solver++(M)(ours) | 0.49 | 0.40 | 0.34 | 0.29 | 0.16 | - | - | ||
| Guidance scale | Thresholding | Sampling method | NFE | ||||||
| 10 | 15 | 20 | 25 | 50 | 100 | 250 | |||
| 15.0 | DDIM
|
0.83 | 0.78 | 0.71 | 0.67 | – | – | – | |
| PNDM
|
0.99 | 0.87 | 0.79 | 0.75 | – | – | – | ||
| DPM-Solver-2
|
1.13 | 1.08 | 0.96 | 0.86 | – | – | – | ||
| DEIS-1
|
0.84 | 0.72 | 0.64 | 0.58 | – | – | – | ||
| DEIS-2
|
0.87 | 0.76 | 0.68 | 0.63 | – | – | – | ||
| DEIS-3
|
1.06 | 0.88 | 0.78 | 0.73 | – | – | – | ||
| DPM-Solver++(S) (ours) | 0.88 | 0.75 | 0.68 | 0.61 | – | – | – | ||
| DPM-Solver++(M) (ours) | 0.84 | 0.72 | 0.64 | 0.58 | – | – | – | ||
References
[2] J. Sohl-Dickstein, E. A. Weiss, N. Maheswaranathan, S. Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, vol.37, pp.2256-2265, 2015.
[3] Y. Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, B. Poole. Score-based generative modeling through stochastic differential equations. In Proceedings of the 9th International Conference on Learning Representations, 2021.
[4] P. Dhariwal, A. Nichol. Diffusion models beat GANs on image synthesis. In Proceedings of the 35th International Conference on Neural Information Processing Systems, Article number 672, 2021.
[5] J. Ho, C. Saharia, W. Chan, D. J. Fleet, M. Norouzi, T. Salimans. Cascaded diffusion models for high fidelity image generation. Journal of Machine Learning Research, vol. 23, no. 1, Article number 47, 2022.
[6] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, B. Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, pp. 10674-10685, 2022. DOI: 10.1109/CVPR52688.2022. 01042.
[7] C. Meng, Y. Song, J. Song, J. Wu, J. Y. Zhu, S. Ermon. SDEdit: Guided image synthesis and editing with stochastic differential equations. In Proceedings of the 10th International Conference on Learning Representations, 2022.
[8] C. Saharia, W. Chan, H. Chang, C. Lee, J. Ho, T. Salimans, D. Fleet, M. Norouzi. Palette: Image-to-image diffusion models. In Proceedings of ACM SIGGRAPH Conference Proceedings, Vancouver, Canada, Article number 15, 2022. DOI: 10.1145/3528233.3530757.
[9] M. Zhao, F. Bao, C. Li, J. Zhu. EGSDE: Unpaired image-to-image translation via energy-guided stochastic differential equations. In Proceedings of the 36th International Conference on Neural Information Processing Systems, New Orleans, USA, Article number 261, 2022.
[10] C. Saharia, W. Chan, S. Saxena, L. Li, J. Whang, E. Denton, S. K. S. Ghasemipour, B. K. Ayan, S. S. Mahdavi, R. G. Lopes, T. Salimans, J. Ho, D. J. Fleet, M. Norouzi. Photorealistic text-to-image diffusion models with deep language understanding. In Proceedings of the 36th International Conference on Neural Information Processing Systems, New Orleans, USA, Article number 2643, 2022.
[11] A. Q. Nichol, P. Dhariwal, A. Ramesh, P. Shyam, P. Mishkin, B. McGrew, I. Sutskever, M. Chen. GLIDE: Towards photorealistic image generation and editing with text-guided diffusion models. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, USA, pp. 16784-16804, 2022.
[12] A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, M. Chen. Hierarchical text-conditional image generation with CLIP latents, [Online], Available: https://arxiv.org/abs/2204. 06125, 2022.
[13] S. Gu, D. Chen, J. Bao, F. Wen, B. Zhang, D. Chen, L. Yuan, B. Guo. Vector quantized diffusion model for text-to-image synthesis. In Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, pp. 10686-10696, 2022. DOI: 10.1109/CVPR52688.2022.01043.
[14] J. Liu, C. Li, Y. Ren, F. Chen, Z. Zhao. DiffSinger: Singing voice synthesis via shallow diffusion mechanism. In Proceedings of the 36th AAAI Conference on Artificial Intelligence, vol.36, pp.11020-11028, 2022. DOI: 10.1609/aaai. v36i10.21350.
[15] N. Chen, Y. Zhang, H. Zen, R. J. Weiss, M. Norouzi, W. Chan. WaveGrad: Estimating gradients for waveform generation. In Proceedings of the 9th International Conference on Learning Representations, 2021.
[16] N. Chen, Y. Zhang, H. Zen, R. J. Weiss, M. Norouzi, N. Dehak, W. Chan. WaveGrad 2: Iterative refinement for text-to-speech synthesis. In Proceedings of the 22nd International Speech Communication Association, Brno, Czech Republic, pp. 3765-3769, 2021.
[17] B. Poole, A. Jain, J. T. Barron, B. Mildenhall. DreamFusion: Text-to-3D using 2D diffusion. In Proceedings of the 11th International Conference on Learning Representations, Kigali, Rwanda, 2023.
[18] Z. Wang, C. Lu, Y. Wang, F. Bao, C. Li, H. Su, J. Zhu. ProlificDreamer: High-fidelity and diverse text-to-3D generation with variational score distillation. In Proceedings of the 37th International Conference on Neural Informa-
tion Processing Systems, New Orleans, USA, Article number 368, 2023.
[20] M. Xu, L. Yu, Y. Song, C. Shi, S. Ermon, J. Tang. GeoDiff: A geometric diffusion model for molecular conformation generation. In Proceedings of the 10th International Conference on Learning Representations, 2022.
[21] E. Hoogeboom, V. G. Satorras, C. Vignac, M. Welling. Equivariant diffusion for molecule generation in 3D. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, USA, pp. 8867-8887, 2022.
[23] A. Blattmann, T. Dockhorn, S. Kulal, D. Mendelevitch, M. Kilian, D. Lorenz, Y. Levi, Z. English, V. Voleti, A. Letts, V. Jampani, R. Rombach. Stable video diffusion: Scaling latent video diffusion models to large datasets, [Online], Available: https://arxiv.org/abs/2311.15127, 2023.
[25] F. Bao, C. Xiang, G. Yue, G. He, H. Zhu, K. Zheng, M. Zhao, S. Liu, Y. Wang, J. Zhu. Vidu: A highly consistent, dynamic and skilled text-to-video generator with diffusion models, [Online], Available: https://arxiv.org/abs/2405. 04233, 2024.
[28] I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, Y. Bengio. Generative adversarial nets. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, Canada, vol.2, pp.2672-2680, 2014.
[30] J. Ho, T. Salimans. Classifier-free diffusion guidance. In Proceedings of the 34th International Conference on Neural Information Processing Systems, 2021.
[31] J. Song, C. Meng, S. Ermon. Denoising diffusion implicit models. In Proceedings of the 9th International Conference on Learning Representations, 2021.
[32] C. Lu, Y. Zhou, F. Bao, J. Chen, C. Li, J. Zhu. DPM-solver: A fast ODE solver for diffusion probabilistic model sampling in around 10 steps. In Proceedings of the 36th International Conference on Neural Information Processing
[33] T. Salimans, J. Ho. Progressive distillation for fast sampling of diffusion models. In Proceedings of the 10th International Conference on Learning Representations, 2022.
[34] Q. Zhang, Y. Chen. Fast sampling of diffusion models with exponential integrator. In Proceedings of the 11th International Conference on Learning Representations, Kigali, Rwanda, 2023.
[35] DeepFloyd: IF. GitHub, [Online], Available, https://git-hub.com/deep-floyd/IF, 2023.
[36] L. Liu, Y. Ren, Z. Lin, Z. Zhao. Pseudo numerical methods for diffusion models on manifolds. In Proceedings of the 10th International Conference on Learning Representations, 2022.
[37] M. Hochbruck, A. Ostermann. Exponential integrators. Acta Numerica, vol.19, pp.209-286, 2010. DOI: 10.1017/ S0962492910000048.
[38] K. E. Atkinson, W. Han, D. Stewart. Numerical Solution of Ordinary Differential Equations, Hoboken, USA: John Wiley & Sons, 2009.
[39] A. Jolicoeur-Martineau, K. Li, R. Piché-Taillefer, T. Kachman, I. Mitliagkas. Gotta go fast when generating data with score-based models, [Online], Available: https:// arxiv.org/abs/2105.14080, 2021.
[40] H. Tachibana, M. Go, M. Inahara, Y. Katayama, Y. Watanabe. Itô-Taylor sampling scheme for denoising diffusion probabilistic models using ideal derivatives, [Online], Available: https://arxiv.org/abs/2112.13339v1, 2021.
[41] Z. Kong, W. Ping. On fast sampling of diffusion probabilistic models, [Online], Available: https://arxiv.org/abs/ 2106.00132, 2021.
[42] F. Bao, C. Li, J. Zhu, B. Zhang. Analytic-DPM: An analytic estimate of the optimal reverse variance in diffusion probabilistic models. In Proceedings of the 10th International Conference on Learning Representations, 2022.
[43] Q. Zhang, M. Tao, Y. Chen. gDDIM: Generalized denoising diffusion implicit models. In Proceedings of the 11th International Conference on Learning Representations, Kigali, Rwanda, 2023.
[44] E. Luhman, T. Luhman. Knowledge distillation in iterative generative models for improved sampling speed, [Online], Available: https://arxiv.org/abs/2101.02388, 2021.
[45] R. San-Roman, E. Nachmani, L. Wolf. Noise estimation for generative diffusion models, [Online], Available: https://arxiv.org/abs/2104.02600, 2021.
[46] A. Q. Nichol, P. Dhariwal. Improved denoising diffusion probabilistic models. In Proceedings of the 38th International Conference on Machine Learning, pp. 8162-8171, 2021.
[47] F. Bao, C. Li, J. Sun, J. Zhu, B. Zhang. Estimating the optimal covariance with imperfect mean in diffusion probabilistic models. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, USA, pp. 1555-1584, 2022.
[48] M. W. Y. Lam, J. Wang, R. Huang, D. Su, D. Yu. Bilateral denoising diffusion models, [Online], Available: https:// arxiv.org/abs/2108.11514, 2021.
[49] D. Watson, W. Chan, J. Ho, M. Norouzi. Learning fast samplers for diffusion models by differentiating through sample quality. In Proceedings of the 10th International Conference on Learning Representations, 2022.
[50] A. Vahdat, K. Kreis, J. Kautz. Score-based generative modeling in latent space. In Proceedings of the 35th International Conference on Neural Information Processing Systems, Article number 863, 2021.
[51] T. Dockhorn, A. Vahdat, K. Kreis. Score-based generative modeling with critically-damped Langevin diffusion. In Proceedings of the 10th International Conference on Learning Representations, 2022.
[52] Z. Xiao, K. Kreis, A. Vahdat. Tackling the generative learning trilemma with denoising diffusion GANs. In Proceedings of the 10th International Conference on Learning Representations, 2022.
[53] Z. Wang, H. Zheng, P. He, W. Chen, M. Zhou. DiffusionGAN: Training GANs with diffusion. In Proceedings of the 11th International Conference on Learning Representations, Kigali, Rwanda, 2023.
[54] W. Zhao, L. Bai, Y. Rao, J. Zhou, J. Lu. UniPC: A unified predictor-corrector framework for fast sampling of diffusion models. In Proceedings of the 37th International Conference on Neural Information Processing Systems, New Orleans, USA, Article number 2170, 2023.
[55] E. Liu, X. Ning, H. Yang, Y. Wang. A unified sampling framework for solver searching of diffusion probabilistic models. In Proceedings of the 12th International Conference on Learning Representations, Vienna, Austria, 2024.
[56] W. Zhao, H. Wang, J. Zhou, J. Lu. DC-Solver: Improving predictor-corrector diffusion sampler via dynamic compensation. In Proceedings of the 18th European Conference on Computer Vision, Milan, Italy, pp. 450-466, 2024. DOI: 10.1007/978-3-031-73247-8_26.
[57] K. Zheng, C. Lu, J. Chen, J. Zhu. DPM-Solver-v3: Improved diffusion ODE solver with empirical model statistics. In Proceedings of the 37th International Conference on Neural Information Processing Systems, New Orleans, USA, Article number 2423, 2023.
[58] S. Li, L. Liu, Z. Chai, R. Li, X. Tan. ERA-Solver: Error-robust Adams solver for fast sampling of diffusion probabilistic models, [Online], Available: https://arxiv.org/abs/ 2301.12935, 2023.
[59] T. Karras, M. Aittala, T. Aila, S. Laine. Elucidating the design space of diffusion-based generative models. In Proceedings of the 36th International Conference on Neural Information Processing Systems, New Orleans, USA, Article number 1926, 2022.
[60] S. Wizadwongsa, S. Suwajanakorn. Accelerating guided diffusion sampling with splitting numerical methods. In Proceedings of the 11th International Conference on Learning Representations, Kigali, Rwanda, 2023.
[61] C. Meng, R. Gao, D. Kingma, S. Ermon, J. Ho, T. Salimans. On distillation of guided diffusion models. In Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, pp. 1429714306, 2023. DOI: 10.1109/CVPR52729.2023.01374.
[62] Z. Zhou, D. Chen, C. Wang, C. Chen. Fast ODE-based sampling for diffusion models in around 5 steps. In Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, pp.7777-7786,
2024. DOI: 10.1109/CVPR52733.2024.00743.
[65] J. Heek, E. Hoogeboom, T. Salimans. Multistep consistency models, [Online], Available: https://arxiv.org/abs/ 2403.06807, 2024.
[66] J. T. J. Tee, K. Zhang, H. S. Yoon, D. N. Gowda, C. Kim, C. D. Yoo. Physics informed distillation for diffusion models. Transactions on Machine Learning Research, vol. 2024, 2024.
[67] H. Zheng, W. Nie, A. Vahdat, K. Azizzadenesheli, A. Anandkumar. Fast sampling of diffusion models via operator learning. In Proceedings of the 40th International Conference on Machine Learning, Honolulu, USA, pp. 42390-42402, 2023.
[68] Y. Song, P. Dhariwal, M. Chen, I. Sutskever. Consistency models. In Proceedings of the 40th International Conference on Machine Learning, Honolulu, USA, Article number 1335, 2023.
[69] C. Lu, Y. Song. Simplifying, stabilizing and scaling con-tinuous-time consistency models. In Proceedings of the 13th International Conference on Learning Representations, Singapore, 2025.
[70] W. Luo, Z. Huang, Z. Geng, J. Z. Kolter, G. J. Qi. Onestep diffusion distillation through score implicit matching. In Proceedings of the 38th International Conference on Neural Information Processing Systems, Vancouver, Canada, pp. 115377-115408, 2024.
[71] T. Yin, M. Gharbi, R. Zhang, E. Shechtman, F. Durand, W. T. Freeman, T. Park. One-step diffusion with distribution matching distillation. In Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, pp.6613-6623, 2024. DOI: 10.1109/ CVPR52733.2024.00632.
[72] L. Zhou, S. Ermon, J. Song. Inductive moment matching, [Online], Available: https://arxiv.org/abs/2503.07565, 2025.
[73] M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, S. Hochreiter. GANs trained by a two time-scale update rule converge to a local Nash equilibrium. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, USA, pp. 6629-6640, 2017.
E-mail: lucheng.lc15@gmail.com
ORCID iD: 0009-0003-5616-0556
ORCID iD: 0000-0002-6254-2388
- Research Article
Manuscript received on March 15, 2025; accepted on May 8, 2025; published online on June 23, 2025Recommended by Associate Editor Cheng-Lin Liu
Colored figures are available in the online version at https://link. springer.com/journal/11633
© The Author(s) 2025