DOI: https://doi.org/10.1016/j.jss.2024.112011
تاريخ النشر: 2024-02-22
اختبار A/B: مراجعة منهجية للأدبيات
الملخص
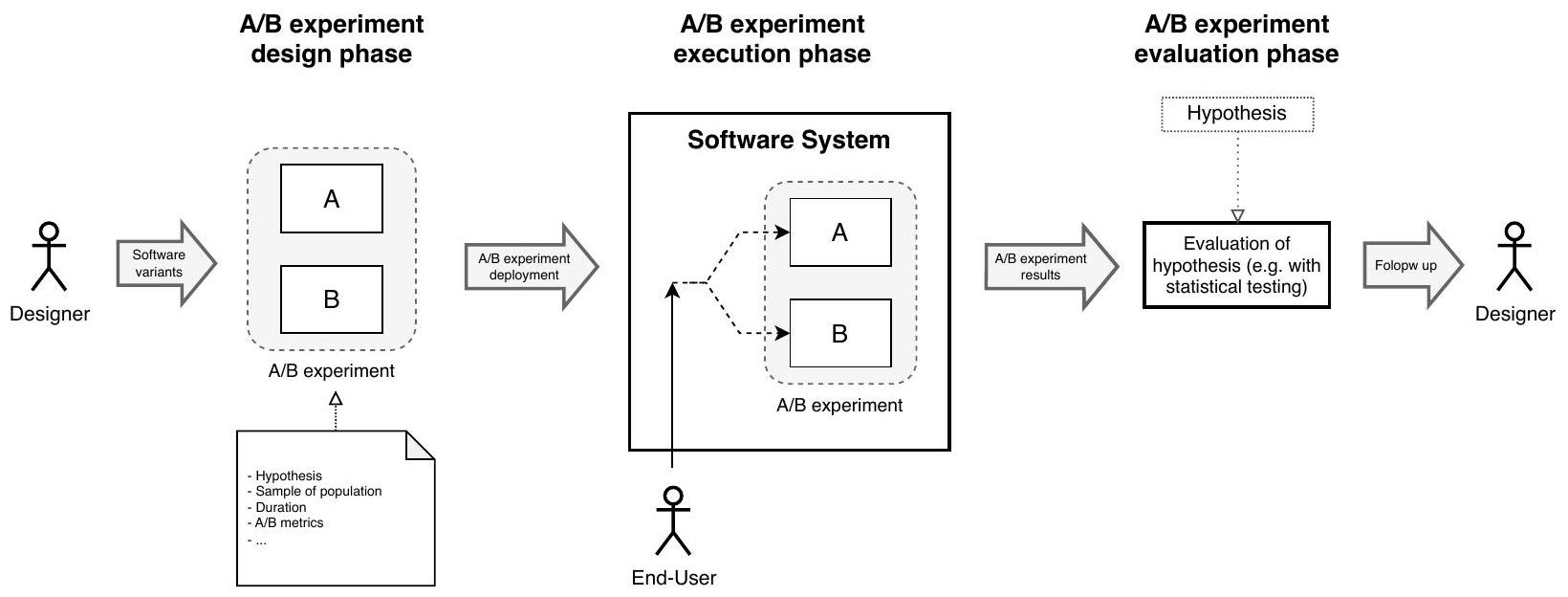
اختبار A/B، المعروف أيضًا بالتجارب المنضبطة عبر الإنترنت أو التجارب المستمرة، هو شكل من أشكال اختبار الفرضيات حيث يتم مقارنة نسختين من برنامج ما في الميدان من وجهة نظر المستخدم النهائي.
1. المقدمة
2. الخلفية والأعمال ذات الصلة
2.1. الخلفية
2.1.1. التجارب المنضبطة مقابل
2.1.2. ديف أوبس و
2.2. الدراسات الثانوية ذات الصلة
2.2.1. ملخص المراجعات ذات الصلة.
2.2.2. هدف الدراسة.
المشكلة: تصميم وتنفيذ
الموضوع: في أنظمة البرمجيات
وجهة نظر: من وجهة نظر الباحثين.
بشكل ملموس، نهدف إلى دراسة موضوع
3. المنهجية
3.1. أسئلة البحث
RQ2: كيف هي
RQ3: كيف هي
3.2. استعلام البحث
3.3. استراتيجية البحث
3.4. عملية البحث
IC1: أوراق تركز بشكل أساسي على
IC2: أوراق تتضمن تقييمًا لما تم تقديمه
لقد حددنا IC1 بحيث ندرج فقط الأعمال التي تتعلق بالأسئلة البحثية المطروحة، أي أنه من الضروري أن تركز الأعمال على
EC1: الأوراق التي تقدم مراجعات أدبية (منهجية)، استبيانات (باستخدام استبيانات)، مقابلات، وأوراق خارطة الطريق؛
EC2: أوراق قصيرة (
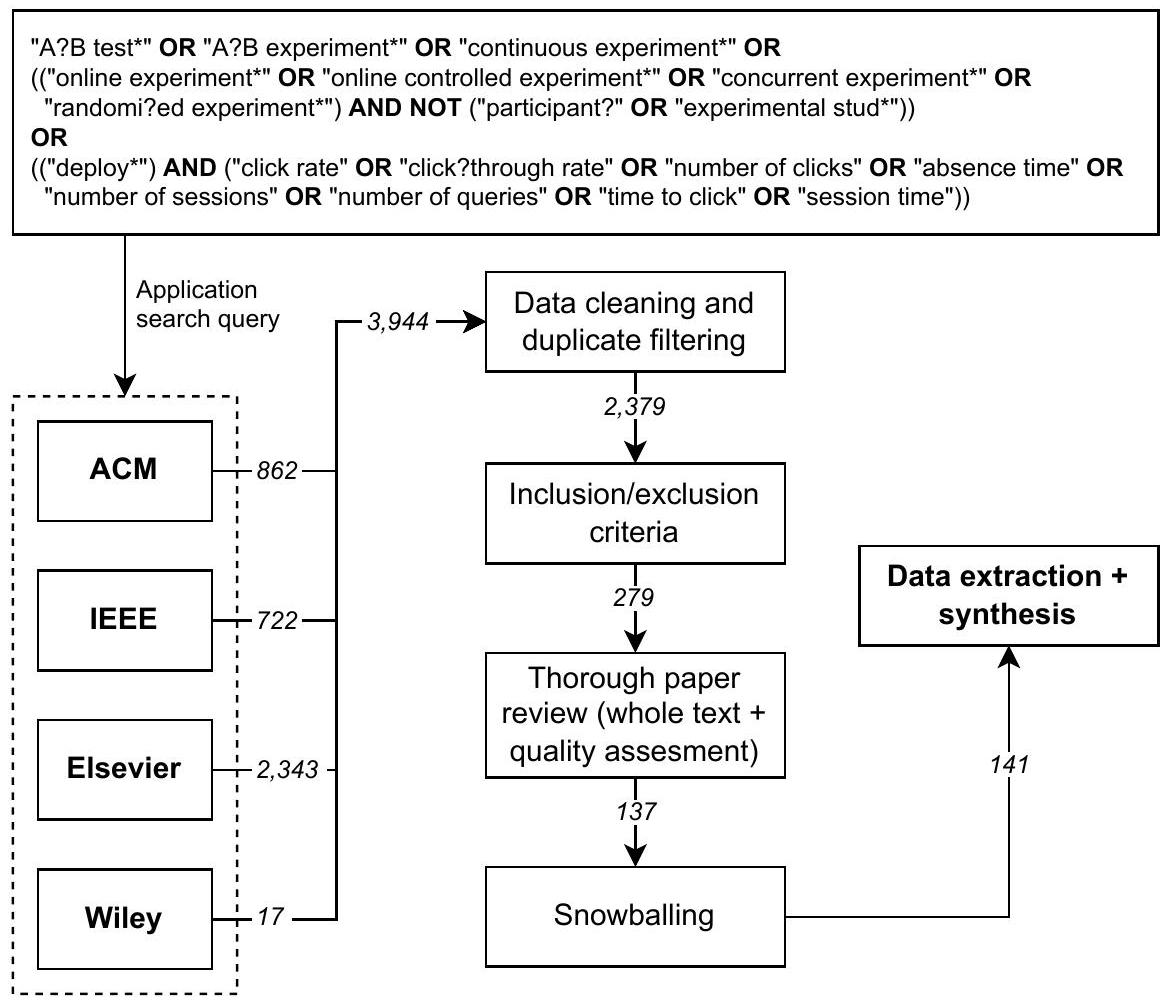
EC4: أوراق تقدم وصفًا غير كافٍ أو وصفًا موجزًا جدًا لـ
3.5. عناصر البيانات
| معرف | عنصر البيانات | غرض |
| D1 | المؤلفون | التوثيق |
| D2 | سنة | التوثيق |
| D3 | عنوان | التوثيق |
| D4 | مكان | التوثيق |
| D5 | نوع الورق | التوثيق |
| D6 | قطاع المؤلفين | التوثيق |
| D7 | درجة الجودة | التوثيق |
| D8 | مجال التطبيق | RQ1 |
| D9 | هدف A/B | RQ1 |
| D10 | نوع اختبار A/B | RQ2 |
| D11 | المقاييس المستخدمة | RQ2 |
| D12 | الطرق الإحصائية المستخدمة | RQ2 |
| D13 | دور أصحاب المصلحة في تصميم التجربة | RQ2 |
| D14 | بيانات إضافية تم جمعها | RQ3 |
| D15 | طريقة التقييم | RQ3 |
| D16 | استخدام نتائج الاختبارات | RQ3 |
| D17 | دور أصحاب المصلحة في تنفيذ التجارب | RQ3 |
| D18 | المشاكل المفتوحة | RQ4 |
| نوع |
|
||
| تركيز | 90 | ||
| مطبق | 51 |
4. النتائج
4.1. المعلومات الديموغرافية
| خلفية |
|
||
| أكاديمي | 26 | ||
| صناعة | 72 | ||
| مختلط | 43 |
|
|
||||
| شبكة | ٣٨ | ||||
| محرك بحث | ٣٥ | ||||
| التجارة الإلكترونية | 27 | ||||
| تفاعل | ٢٢ | ||||
| المالية | 16 | ||||
| النقل | ٤ | ||||
| آخر | ٨ | ||||
| غير متوفر | 9 |
4.2. RQ1: ما هو موضوع
-
يتم تطبيق اختبار الخوارزميات عبر جميع مجالات التطبيقات، وفي جميع المجالات الرئيسية، يكون الهدف الأساسي لـ اختبار. تشمل الخوارزميات التي يتم اختبارها بشكل شائع خوارزميات ترتيب المحتوى لمواقع التواصل الاجتماعي، وخوارزميات التوصية لمواقع الأخبار/الوسائط المتعددة، وخوارزميات ترتيب البحث.
| هدف A/B | وصف | عدد الحدوث |
| خوارزمية | نسخة محدثة من خوارزمية مثل خوارزمية التوصية 175، أو خوارزمية ترتيب البحث 86، أو خوارزمية عرض الإعلانات 16. | ٥٨ |
| عناصر بصرية | تغيير في المكونات المرئية مثل التحديثات على تصميم الموقع الإلكتروني [22] أو تحديث عام لواجهة المستخدم [40]. | ٣٣ |
| سير العمل / العملية | تغيير في سير العمل لتطبيق، مثل إضافة زر ملاحظات إلى لوحة التحكم [110]، أو تغيير في سير عمل المستخدم، مثل عملية أداة المساعد الافتراضي 96. | ٢٨ |
| الجزء الخلفي | تحسين مكون برمجي غير مرئي مباشرة للمستخدم، مثل تحسينات خادم الاختبار [127] أو ضبط معلمات التطبيق لأداء أفضل 60. | 10 |
| وظائف جديدة للتطبيق | وظائف جديدة تم تقديمها، مثل أداة جديدة على صفحة الويب [28] أو محتوى إضافي يتم تقديمه للمستخدم بعد إجراء استعلام بحث [112]. | ٦ |
| آخر | تتضمن هذه الفئة ثلاثة أخرى
|
٣ |
| غير محدد | هدف الـ
|
32 |
|
خوارزمية | عناصر بصرية | سير العمل / العملية | الجزء الخلفي | تطبيق جديد. وظيفة. | آخر | ||
| شبكة | 17 | ٦ | ٨ | 1 | ٣ | 0 | ||
| محرك بحث | 17 | 16 | ٣ | ٦ | 2 | 0 | ||
| التجارة الإلكترونية | 10 | 2 | ٧ | 0 | 0 | 1 | ||
| تفاعل | ٥ | ٦ | 2 | ٢ | 1 | 0 | ||
| المالية | ٧ | 2 | ٤ | 0 | 1 | 0 | ||
| النقل | 2 | 0 | 0 | 1 | 1 | 0 | ||
| آخر | 2 | 1 | ٣ | 0 | 0 | 2 |
- اختبار A/B للعناصر البصرية شائع بشكل خاص لمحركات البحث (16 دراسة) مقارنةً بمجالات التطبيقات الأخرى مثل الويب (مع 6 دراسات فقط). تشمل الأمثلة النموذجية تغييرات في لون خط نتائج محرك البحث.
وتغيير موضع الإعلانات على صفحة النتائج 121. - عناصر سير العمل والعمليات كـ
تُطبق الأهداف بشكل شائع عبر المجالات الرئيسية. هذا الهدف شائع بشكل خاص في الويب والتجارة الإلكترونية (مع 8 و7 دراسات، على التوالي). من الأمثلة النموذجية التغييرات في العملية التي يتم من خلالها تحديد الإعلانات ذات الأداء الأفضل في منصة إعلانات JD، أكبر بائع تجزئة عبر الإنترنت في الصين، والتغييرات في سياسة تخصيص الطلبات لمنصات توصيل الوجبات عند الطلب. - للمواقع ومحركات البحث، جميع أنواع
تُطبق الأهداف. التركيز الرئيسي على الويب هو على الخوارزميات وسير العمل/العمليات، بينما التركيز لمحركات البحث هو على الخوارزميات والعناصر المرئية والواجهة الخلفية. بالنسبة للويب، نلاحظ فقط دراسة رئيسية واحدة مع الواجهة الخلفية كـ الهدف. تستهدف هذه الدراسة تكوينات مختلفة للخدمات الصغيرة في اختبار من أجل ضبط الخدمات الصغيرة الفردية لتحسين الأداء. من ناحية أخرى، لاحظنا فقط ثلاث دراسات رئيسية تستهدف سير عمل أو عملية في اختبار. قامت دراسة واحدة بتقييم تغيير في صياغة الإعلانات الرقمية 18، وقامت دراسة أخرى بتقييم تغيير في استراتيجيات الإعلان 75)، بينما قامت الدراسة الأخيرة بتقييم خيار الدفع مقابل “البحث المدعوم” (لإعطاء الأولوية لنتائج البحث) 19. - بالنسبة للتجارة الإلكترونية، لاحظنا أن
يتم استخدام الاختبار بشكل أساسي لاختبار التغييرات في خوارزميات الترتيب والتوصية، وكذلك في العمليات مثل المساعدات الافتراضية. ومن الجدير بالذكر أننا حددنا دراسة رئيسية واحدة فقط قامت بتقييم التغييرات في واجهة المستخدم 103. -
تم تحديد أن الاختبار لتحسينات الواجهة الخلفية هو الأكثر شيوعًا لمحركات البحث، بينما لم نحدد ورقة في مجال التجارة الإلكترونية والمالية حيث تم استخدام الاختبار للتغييرات في الواجهة الخلفية.
4.3. السؤال البحثي 2: كيف هي
4.3.1. تصميم
| مقياس A/B |
|
||
| مقاييس التفاعل | 225 | ||
| مقاييس النقر | 82 | ||
| المؤشرات النقدية | 64 | ||
| مقاييس الأداء | 50 | ||
| المؤشرات السلبية | ٣٤ | ||
| عرض المقاييس | 21 | ||
| مقاييس التغذية الراجعة | 17 |
| الطرق الإحصائية المستخدمة | عدد الحدوث |
| فرضية – المساواة | ٥٧ |
| فرضية – المساواة (الطريقة الملموسة غير محددة) | 37 |
| التمويل الذاتي | 11 |
| فرضية – استنتاج | ٨ |
| ملاءمة النموذج | ٨ |
| طريقة التصحيح | ٧ |
| مُقدِّر | ٦ |
| فرضية – الاستقلال | ٥ |
| طريقة الانحدار | ٢ |
4.3.2. دور أصحاب المصلحة
4.3.3. التحليل المتقاطع
- المهام الأساسية للمساهمين عبر جميع الأنواع من
الاختبارات هي تصميم وضبط المتغيرات، وتحديد مدة التجارب، والسكان، والهدف أو الفرضية. تؤكد هذه الأرقام أن هذه هي مهام تصميم أساسية لأي اختبار. - تستخدم غالبية الدراسات متعددة الأذرع
اختبار وتسلسل تُبلغ الاختبارات عن تصميم وضبط المتغيرات كمهام مهمة لأصحاب المصلحة (22 و 13 حالة على التوالي).
| دور | مهمة | وصف المهمة | مناسبات |
 |
تصميم وضبط المتغيرات | تصميم وضبط المتغيرات للاختبار. من الأمثلة تعديل الـ
|
67 |
| تحديد الهدف أو الفرضية | صياغة الهدف أو الفرضية لـ
|
٤٨ | |
| قم بتنفيذ إجراءات ما قبل التصميم | الإجراءات التي يتم اتخاذها قبل التصميم
|
12 | |
| فني إعداد (31) | تحديد المدة | تحديد مدة الـ
|
60 |
| تحديد تخصيص السكان | تحديد السكان الذين يجب أن يشاركوا في
|
51 | |
| قم بتنفيذ إجراءات ما بعد التصميم | الإجراءات التي يتم اتخاذها بعد الانتهاء من تصميم الـ
|
٢٥ | |
| قم بإجراء تحليل قياسي وتهيئة | تحليل وإمكانية بدء القياسات لـ
|
٦ |
| مهمة | اختبار A/B كلاسيكي فردي (95) | اختبار A/B متعدد الأذرع (30) | سلسلة من اختبارات A/B (24) | اختبار A/B متعدد المتغيرات (6) |
| تصميم وضبط المتغيرات | ٣٣ | ٢٢ | ١٣ | 2 |
| مدة | ٤٥ | 9 | 11 | 2 |
| تعيين السكان | ٣٧ | ٧ | ٨ | 2 |
| هدف/فرضية | 27 | 17 | ٨ | 2 |
| إجراءات ما بعد التصميم | 12 | 1 | ٥ | 0 |
| إجراءات ما قبل التصميم | ٦ | ٤ | 2 | 1 |
| تحليل المقياس/التهيئة. | ٥ | 1 | 0 | 0 |
| طريقة | انخراط. | انقر | نقدي | سلبي | مثالي. | عرض | تعليق |
| H – المساواة | 31 | 14 | ٧ | 10 | ٤ | ٧ | 2 |
| H – المساواة (غير محدد) | ٢٤ | 12 | ٨ | ٨ | 11 | ٥ | ٥ |
| التمويل الذاتي | 9 | 2 | 2 | ٣ | ٣ | 1 | 1 |
| H – استنتاج | ٥ | 1 | 0 | 0 | 1 | 0 | 0 |
| ملاءمة النموذج | ٥ | 1 | 2 | 1 | 0 | 0 | 0 |
| طريقة التصحيح | ٤ | 1 | 1 | 1 | 2 | 0 | 1 |
| مُقدِّر | ٤ | 1 | 2 | 1 | 0 | 1 | 0 |
| ح – الاستقلال | 2 | 2 | ٣ | 0 | 0 | 1 | 0 |
| طريقة الانحدار | 1 | 1 | 1 | 0 | 0 | 1 | 0 |
- تحديد الهدف أو الفرضية لـ
يتم ذكر الاختبار بشكل متكرر لذوي الأذرع المتعددة اختبارات (17 حالة). بالمقارنة مع النوعين التقليديين اختبار يتضمن عادةً متغير تحكم ومتغير معدل يهدف إلى تحسين متغير التحكم، متعدد الأذرع تشمل الاختبارات أكثر من متغيرين، لذا غالبًا ما يقوم الممارسون بصياغة فرضيات حول الأداء المحتمل لكل متغير. - تُبلغ عن الإجراءات بعد التصميم بشكل أكثر شيوعًا لتسلسلات
اختبارات (5 حالات). على سبيل المثال، تذكر دراسة رئيسية نمذجة تسلسل اختبارات 139، تذكر دراسة أخرى تحديد شرط النجاح لـ اختبارات قبل تنفيذها 151، ودراسة أخرى تشير إلى تقديم نطاق النتائج لـ اختبارات 152. - فقط عدد قليل من الدراسات الأولية تقارير عن إجراءات ما قبل التصميم وتحليل المقاييس وتهيئتها، بغض النظر عن نوع
اختبار.
المقاييس مقابل الطرق الإحصائية المستخدمة. الطرق الإحصائية المستخدمة عبر أنواع مختلفة من تظهر المقاييس في الجدول 11. - تُستخدم مقاييس التفاعل ومقاييس النقر عبر جميع أنواع الطرق الإحصائية.
- الطريقة المحددة المستخدمة لاختبار الفرضيات المتعلقة بالمساواة غالبًا ما لا يتم تحديدها عبر جميع الأنواع
المقاييس. بالنسبة للمقاييس المالية وأداء المقاييس على وجه الخصوص، فإن الغالبية العظمى من الدراسات لا تذكر طريقة اختبار الفرضيات المحددة (8 و 11 حالة، على التوالي). قد يكون ذلك بسبب الحساسية في الإبلاغ عن النتائج لهذه الأنواع من المقاييس.
| البيانات المجمعة |
|
||
| بيانات المنتج/النظام | ٤٨ | ||
| بيانات مركزية حول المستخدم | 26 | ||
| البيانات المكانية الزمنية | 20 | ||
| البيانات الثانوية | ٦ |
- تُستخدم المقاييس السلبية بشكل أساسي لاختبارات مساواة الفرضيات (10 و8 حالات لمساواة الفرضيات وعدم تحديد طريقة لمساواة الفرضيات على التوالي).
- طريقة الفرضية للاستقلال تُستخدم في الغالب للمعايير النقدية، ومع ذلك، فإن استخدامها نادر (3 حالات).
- استخدام مقاييس التغذية الراجعة غير شائع أيضًا، وإذا تم استخدامها، فإن الطريقة الإحصائية المحددة المستخدمة لا يتم الإبلاغ عنها (5 حالات).
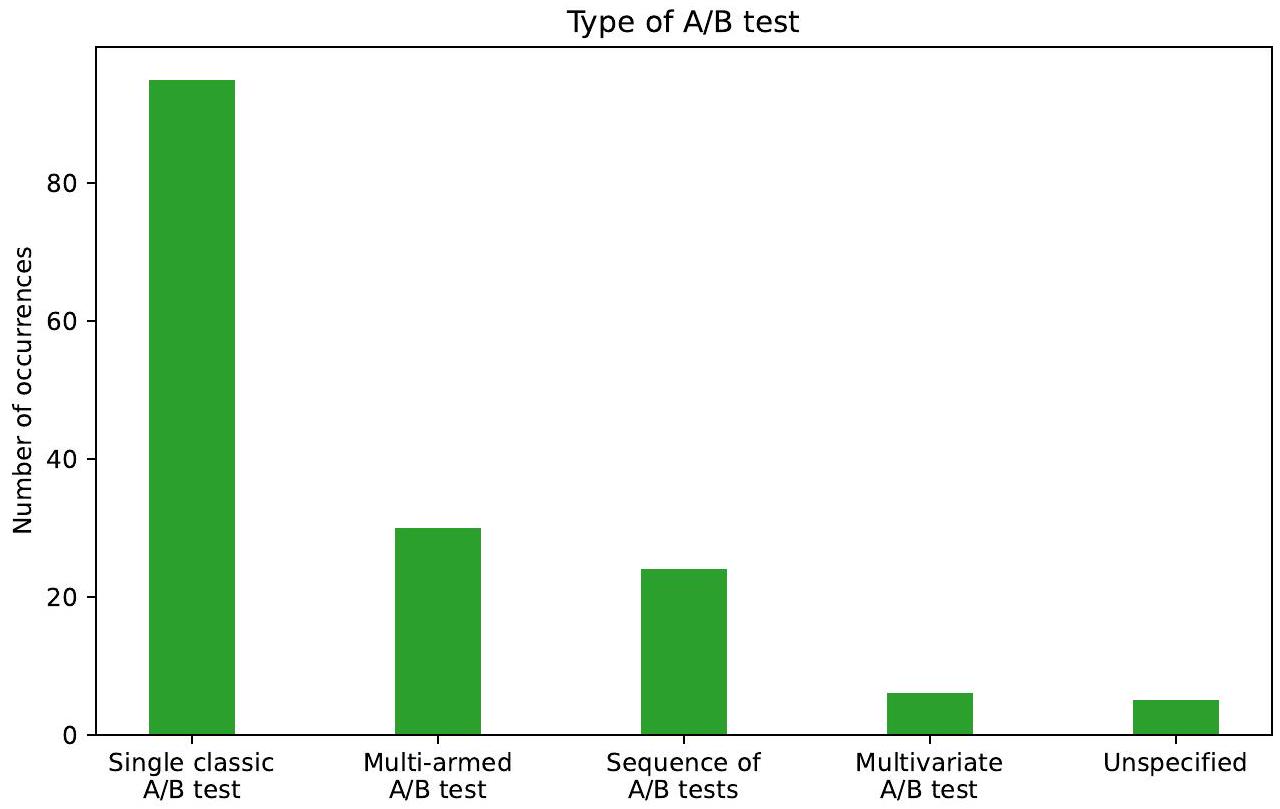
سؤال البحث 2: كيف يتمما هي الاختبارات المصممة؟ ما هو دور أصحاب المصلحة في هذه العملية؟ النوع الأساسي من الاختبار هو كلاسيكي واحد اختبار، يليه متعدد الأذرع اختبارات وتسلسل اختبار. تعتبر مقاييس التفاعل النوع السائد من المقاييس المستخدمة في اختبار. أخرى بارزة تشمل المقاييس النقر، والمقاييس المالية، ومقاييس الأداء. اختبار الفرضيات للمساواة هو إلى حد بعيد الطريقة الإحصائية الأكثر استخدامًا في اختبار. ملحوظ، حول من هذه الدراسات التي تختبر المساواة لا تحدد الطريقة المحددة التي تستخدمها لذلك. لدى أصحاب المصلحة دوران رئيسيان في تصميم اختبارات: مصمم المفاهيم وهندسة التجارب. يتم الإبلاغ عن دور ثالث وهو فني الإعداد بشكل أقل تكرارًا.
4.4. السؤال البحثي 3: كيف هي
4.4.1. تنفيذ
| طريقة التقييم |
|
||
| التقييم التجريبي | 100 | ||
| محاكاة تعتمد على بيانات تجريبية حقيقية | ٢٦ | ||
| محاكاة | 15 | ||
| مثال توضيحي | 10 | ||
| دراسة حالة | ٥ | ||
| نظري | 1 |
4.4.2. دور أصحاب المصلحة
4.4.3. التحليل المتقاطع
- يتم تطبيق إشراف التجارب بغض النظر عن استخدامات نتائج الاختبارات. بالنسبة لإطلاق الميزات كاستخدام لـ
نتائج الاختبار، غالبًا ما يتم ذكر مهمة إشراف التجارب. يتولى الإشراف مهمة رئيسية في هذا السياق لضمان أن يتم التنفيذ بطريقة خالية من المخاطر (أي، عدم التسبب في أي ضرر للمستخدمين) 165، 28.
| الجدول 14: استخدام نتائج الاختبارات المجمعة من
|
||
| استخدام نتائج الاختبارات | وصف | يحدث. |
| اختيار الميزات | نتائج الـ
|
71 |
| إطلاق الميزة | نتائج الـ
|
٢٤ |
| استمرار تطوير الميزات | نتائج الـ
|
17 |
| تصميم اختبار A/B اللاحق | نتائج الـ
|
15 |
| فعالية التحقق من
|
نتائج الـ
|
12 |
| تحقق من سؤال البحث |
|
10 |
| كشف الأخطاء / إصلاحها | نتائج الـ
|
٥ |
| لاحق
|
نتائج الـ
|
٤ |
| غير محدد | لم يتم تحديد استخدام نتائج الاختبار في الدراسة. | ٢٤ |
| دور | مهمة | وصف المهمة | مناسبات |
| إشراف على التجارب | مراقبة ومتابعة تنفيذ اختبارات A/B عن كثب [151، 43. | 19 | |
| تغيير التجربة | تغيير جوانب الـ
|
12 | |
 |
إنهاء التجربة | التوقف
|
9 |
| تحليل ما بعد التجربة | خطوات متنوعة يتم اتخاذها بعد تحليل النتائج لـ
|
17 | |
| تحفيز التجربة | بدء تنفيذ (التالي)
|
١٣ | |
|
آخر | تشمل هذه الفئة بعض المهام المتخصصة، مثل توثيق النتائج والتعلم من إجراء الـ
|
٧ |
| استخدام | الإشراف | تحليل ما بعد | تحفيز | تغيير | إنهاء |
| اختيار الميزات | ٨ | 11 | ٦ | ٨ | ٤ |
| إطلاق الميزة | 10 | ٤ | ٦ | ٦ | ٤ |
| تطوير المميزات المستمر | ٧ | ٣ | ٥ | ٢ | ٣ |
| تصميم اختبار A/B | ٦ | 0 | ٥ | ٢ | ٣ |
| تقييم فعالية اختبار A/B | 1 | 2 | 1 | 1 | 1 |
| قيمة RQ | 1 | 1 | 0 | 1 | 1 |
| كشف الأخطاء/إصلاحها | ٤ | 0 | ٣ | ٢ | 2 |
| تنفيذ اختبار A/B | 1 | 0 | 1 | 0 | 0 |
- عادةً ما يتم الإبلاغ عن مهمة تحليل ما بعد التجربة فقط للتجارب التي اكتملت بالكامل (أي، لا تمر بجولات إضافية من التكرار). في الدراسات الأساسية حيث نتائج الـ
تُستخدم الاختبارات للمتابعة في تصميم الاختبار، لم يتم تحديد أي حالات حيث يقوم أصحاب المصلحة بمهمة إجراء تحليل بعدي على نتائج التجارب. - للاحق
تصميم الاختبار، غالبًا ما يتم ذكر مهمة تحفيز التجربة. وهذا متوقع نظرًا لأن التصميم الجديد يجب أيضًا تنفيذ الاختبارات. بالإضافة إلى ذلك، يتم ذكر إنهاء الاختبار أيضًا كثيرًا (على سبيل المثال، إنهاء تجربة بسبب نتائج سيئة [76]). - في حالة إصلاح الأخطاء واكتشافها، عادةً ما يشرف المعنيون على التجارب (إما لاكتشاف الأخطاء المحتملة في الشيفرة أو لضمان فعالية إصلاح الخطأ) [57، ويقومون بتحفيز التجارب (أي إطلاق تجربة بشكل صريح لإصلاح خطأ معروف في التطبيق) 105.
- جميع المهام التي يقوم بها أصحاب المصلحة في تنفيذ
تُستخدم الاختبارات على نطاق واسع في حالة التقييم التجريبي. - بالنسبة لطريقة المحاكاة المعتمدة على البيانات التجريبية الحقيقية، يتم الإبلاغ عن مهمة التحليل اللاحق أكثر من أي مهمة أخرى. مثال على ذلك هو البحث عن القيم الشاذة في تحليل نتائج
اختبارات، واستخدام التجارب التاريخية لتأكيد فعاليتها [78]. - الدراسات الأولية التي تستخدم المحاكاة كطريقة تقييم نادراً ما تحدد المهام التي يقوم بها أصحاب المصلحة في التنفيذ.
اختبارات. نفترض أنه، نظرًا لأن المحاكاة تتيح طريقة أكثر تحكمًا لإجراء الاختبارات، المهام التي يقوم بها أصحاب المصلحة بعد تصميم الاختبارات ليست ذات صلة. - المهمة الوحيدة المعنية بالمساهمين التي تم الإبلاغ عنها للتقييم النظري هي تعديل التجربة (الدراسة الأساسية [121]).
| طريقة المهمة | الإشراف | تحليل ما بعد | تحفيز | تغيير | إنهاء | آخر |
| تجريبي | 14 | ١٣ | 10 | 10 | ٦ | ٦ |
| التوظيف البسيط | 2 | ٤ | 1 | 0 | 1 | 0 |
| محاكاة | 1 | 1 | 1 | 0 | 0 | 0 |
| مثال توضيحي | 2 | 0 | 1 | 2 | 2 | 1 |
| دراسة حالة | 0 | 0 | 0 | 0 | 0 | 0 |
| نظري | 0 | 0 | 0 | 1 | 0 | 0 |
| فئة المشكلة المفتوحة | فئة المشكلة المفتوحة | عدد الحدوث |
| متعلق بالتقييم | تمديد التقييم | 21 |
| قدم تحليلًا شاملاً للنهج | 16 | |
| متعلق بالتقييم الآخر | ٣٤ | |
| متعلق بالعملية | إضافة إرشادات العملية | 9 |
| أتمتة العملية | ٧ | |
| متعلق بالجودة | تعزيز القابلية للتوسع | ٧ |
| تعزيز القابلية للتطبيق | ٦ |
سؤال البحث 3: كيف يتمالاختبارات المنفذة في النظام؟ ما هو دور أصحاب المصلحة في هذه العملية؟ الأنواع الرئيسية من البيانات التي تم جمعها خلال تنفيذ الاختبار يتعلق بالمنتج/النظام، المستخدمين، والجوانب الزمانية والمكانية. الطريقة السائدة للتقييم المستخدمة في التجريب هو تقييم تجريبي، لكن عددًا كبيرًا من الدراسات يستخدم أيضًا المحاكاة. تُستخدم نتائج الاختبار بشكل أساسي لاختيار الميزات، تليها طرح الميزات، وتستمر في تطوير الميزات. (تلقائي) لاحقاً تنفيذ الاختبار يُستخدم بشكل هامشي فقط. الأدوار الرئيسية المبلغ عنها لأصحاب المصلحة في تنفيذ الاختبار هو مساهم في التجربة (مع مشرف التجربة كالمهمة الرئيسية) ومقيّم للتجربة (مع تحليل ما بعد التجربة كالمهمة الرئيسية).
4.5. RQ4: ما هي المشكلات البحثية المفتوحة المبلغ عنها في مجال
تقدم الجدول 18 تصنيفًا للمشكلات المفتوحة التي حددناها في الدراسات الأساسية. لكل فئة، وضعنا فئات فرعية محددة من المشكلات المفتوحة. نحن نتناول كل نوع من المشكلات المفتوحة مع أمثلة توضيحية.
4.5.1. مشكلات مفتوحة متعلقة بالتقييم
تم تقييم المقاييس المقترحة على البيانات التاريخية
4.5.2. مشكلات مفتوحة متعلقة بالعملية
لإجراء
4.5.3. مشكلات مفتوحة تتعلق بالجودة
سؤال البحث 4: ما هي المشكلات البحثية المفتوحة المبلغ عنها في مجالالاختبار؟ أكثر المشاكل المفتوحة التي تم الإبلاغ عنها بشكل شائع تتعلق بالنهج المقترح، وبشكل خاص تحسين النهج، وتوسيعه، وتقديم تحليل شامل. أما المشاكل المفتوحة الأخرى التي تم الإبلاغ عنها بشكل أقل تكرارًا فتتعلق بعملية اختبار A/B، وبشكل خاص إضافة إرشادات لـ عملية الاختبار، وأتمتة العملية. أخيرًا، تشير عدد من الدراسات إلى مشاكل مفتوحة تتعلق بخصائص الجودة، وبشكل خاص تعزيز قابلية التوسع وقابلية تطبيق النهج المقترح.
| موضوع | عدد الحدوثات | الدراسات الأولية |
| تطبيق اختبار A/B | 51 | ١٧٥، ١٢٣، ٩٥، ١٠٢، ١٦، ١٥، ١٢١، ١٧١، ٩٩، ١٤٨، ٣٣، ٧٠، ٦٦، ٥٢، ٢٠، ١٧٤، ١٠٧، ٦٣، ١٥٥، ١٥٠، ٦٥، ١٦٣، ١٧٠، ٢٧، ١٤٣، ٢، ٥، ١٣٥، ١٤٩، ٧، ٩٨، ١٤٧، ١٤١، ١٧٣، ١٩، ٢٦، ٨، ١١٤، ٦، ١٢٢، ٥٠، ٩٧، ١٣٦، ١٢٥، ٢٢، ١٢٤، ١٢٨، ١٥٩، ٦٧، ٣، ١٧٦، |
| تحسين كفاءة اختبار A/B | 20 | [1، 28، 127، 164، 23، 85، 47، 39، 44، 86، 40، 45، 46، 109، 100، 83، 18، 78، 37، 64، |
| ما وراء اختبار A/B القياسي | ١٨ |
|
| مشاكل اختبار A/B الملموسة | 17 | [١٣٨، ٧٣، ١٦٨، ١٠٥، ١٤٦، ٤٣، ١٦٢، ١٤، ١٠٣، ١١١، ٧١، ٢٤، ١٥٣، ١٣٧، ٩٦، ١٠١، ٢٥ |
| المزالق والتحديات في اختبار A/B | ١٣ | 91، 88، 54، 60، 167، 42، 169، 120، 11، 41، 110، 140، 90 |
| أطر ومنصات التجريب | ١٣ | ١٤٤، ١٥٤، ١٠٦، ١٥٦، ١٠٨، ٩، ١٣١، ٧٤، ٢١، ٣٦، ١٧٩، ١٧٧، ١٥٢ |
| اختبار A/B على نطاق واسع | ٩ | ٨٩، ١٦٠، ٥٨، ١٦٥، ٨١، ١٥٧، ٧٦، ٥٧، ٥٦ |
5. المناقشة
5.1. مواضيع البحث
5.1.1. تطبيق
5.1.2. تحسين الكفاءة لـ
| البيئة |
|
||
| نظام التجارب الداخلية | 20 | ||
| أداة بحث أو نموذج أولي | ١٣ | ||
| أداة اختبار A/B التجارية | 10 | ||
| أداة اختبار غير تجارية A/B | ٧ | ||
| استطلاع المستخدم | 1 |
5.1.3. ما وراء المعيار
5.1.4. الخرسانة
5.1.5. الفخاخ والتحديات لـ
5.1.6. أطر ومنصات التجريب
5.1.7.
5.2. البيئات والأدوات المستخدمة لـ
5.3. فرص البحث واتجاهات البحث المستقبلية
5.3.1. تحسين
5.3.2. الأتمتة
5.3.3. اعتماد وتكييف الأساليب الإحصائية
تصميم اختبار إحصائي مخصص غير ثنائي
5.4. التهديدات للصلاحية
5.4.1. الصلاحية الداخلية
5.4.2. الصلاحية الخارجية
5.4.3. صحة الاستنتاج
5.4.4. الموثوقية
6. الخاتمة
شكر وتقدير
References
[2] Deepak Agarwal, Bo Long, Jonathan Traupman, Doris Xin, and Liang Zhang. 2014. LASER: A Scalable Response Prediction Platform for Online Advertising. In Proceedings of the 7th ACM International Conference on Web Search and Data Mining (New York, New York, USA) (WSDM ’14). Association for Computing Machinery, New York, NY, USA, 173-182. https://doi.org/10.1145/2556195.2556252
[3] Michal Aharon, Yohay Kaplan, Rina Levy, Oren Somekh, Ayelet Blanc, Neetai Eshel, Avi Shahar, Assaf Singer, and Alex Zlotnik. 2019. Soft Frequency Capping for Improved Ad Click Prediction in Yahoo Gemini Native. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management (Beijing, China) (CIKM ’19). Association for Computing Machinery, New York, NY, USA, 2793-2801. https://doi.org/10.1145/3357384.3357801
[4] Michal Aharon, Oren Somekh, Avi Shahar, Assaf Singer, Baruch Trayvas, Hadas Vogel, and Dobri Dobrev. 2019. Carousel Ads Optimization in Yahoo Gemini Native. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery
[5] Luca Aiello, Ioannis Arapakis, Ricardo Baeza-Yates, Xiao Bai, Nicola Barbieri, Amin Mantrach, and Fabrizio Silvestri. 2016. The Role of Relevance in Sponsored Search. In Proceedings of the 25th ACM International on Conference on Information and Knowledge Management (Indianapolis, Indiana, USA) (CIKM ’16). Association for Computing Machinery, New York, NY, USA, 185-194. https://doi.org/10.1145/2983323.2983840
[6] Ryuya Akase, Hiroto Kawabata, Akiomi Nishida, Yuki Tanaka, and Tamaki Kaminaga. 2021. Related Entity Expansion and Ranking Using Knowledge Graph. In Complex, Intelligent and Software Intensive Systems, Leonard Barolli, Kangbin Yim, and Tomoya Enokido (Eds.). Springer International Publishing, Cham, 172-184.
[7] Rafael Alfaro-Flores, José Salas-Bonilla, Loic Juillard, and Juan Esquivel-Rodríguez. 2021. Experiment-driven improvements in Human-in-the-loop Machine Learning Annotation via significance-based A/B testing. In 2021 XLVII Latin American Computing Conference (CLEI). 1-9. https://doi.org/10.1109/CLEI53233.2021.9639977
[8] Joana Almeida and Beatriz Casais. 2022. Subject Line Personalization Techniques and Their Influence in the E-Mail Marketing Open Rate. In Information Systems and Technologies, Alvaro Rocha, Hojjat Adeli, Gintautas Dzemyda, and Fernando Moreira (Eds.). Springer International Publishing, Cham, 532-540.
[9] Xavier Amatriain. 2013. Beyond Data: From User Information to Business Value through Personalized Recommendations and Consumer Science. In Proceedings of the 22nd ACM International Conference on Information & Knowledge Management (San Francisco, California, USA) (CIKM ’13). Association for Computing Machinery, New York, NY, USA, 2201-2208. https://doi.org/10.1145/2505515.2514701
[10] Apostolos Ampatzoglou, Stamatia Bibi, Paris Avgeriou, Marijn Verbeek, and Alexander Chatzigeorgiou. 2019. Identifying, categorizing and mitigating threats to validity in software engineering secondary studies. Information and Software Technology 106 (2019), 201-230. https://doi.org/10.1016/j.infsof.2018.10.006
[11] Nirupama Appiktala, Miao Chen, Michael Natkovich, and Joshua Walters. 2017. Demystifying dark matter for online experimentation. In 2017 IEEE International Conference on Big Data (Big Data). 1620-1626. https://doi.org/10. 1109/BigData. 2017.8258096
[12] F. Auer and M. Felderer. 2018. Current State of Research on Continuous Experimentation: A Systematic Mapping Study. In 2018 44th Euromicro Conference on Software Engineering and Advanced Applications (SEAA). IEEE Computer Society, Los Alamitos, CA, USA, 335-344. https://doi.org/10.1109/SEAA.2018.00062
[13] Florian Auer, Rasmus Ros, Lukas Kaltenbrunner, Per Runeson, and Michael Felderer. 2021. Controlled experimentation in continuous experimentation: Knowledge and challenges. Information and Software Technology 134 (2021), 106551. https://doi.org/10.1016/j.infsof. 2021.106551
[14] Eytan Bakshy and Eitan Frachtenberg. 2015. Design and Analysis of Benchmarking Experiments for Distributed Internet Services. In Proceedings of the 24th International Conference on World Wide Web (Florence, Italy) (WWW ’15). International World Wide Web Conferences Steering Committee, Republic and Canton of Geneva, CHE, 108-118. https: //doi.org/10.1145/2736277.2741082
[15] Joel Barajas, Jaimie Kwon, Ram Akella, Aaron Flores, Marius Holtan, and Victor Andrei. 2012. Marketing Campaign Evaluation in Targeted Display Advertising. In Proceedings of the Sixth International Workshop on Data Mining for Online Advertising and Internet Economy (Beijing, China) (ADKDD ’12). Association for Computing Machinery, New York, NY, USA, Article 5, 7 pages. https://doi.org/10.1145/2351356.2351361
[16] Joel Barajas, Jaimie Kwon, Ram Akella, Aaron Flores, Marius Holtan, and Victor Andrei. 2012. Measuring Dynamic Effects of Display Advertising in the Absence of User Tracking Information. In Proceedings of the Sixth International Workshop on Data Mining for Online Advertising and Internet Economy (Beijing, China) (ADKDD ’12). Association for Computing Machinery, New York, NY, USA, Article 8, 9 pages. https://doi.org/10.1145/2351356.2351364
[17] Victor R. Basili, Gianluigi Caldiera, and Dieter H. Rombach. 1994. The Goal Question Metric Approach. Vol. I. John Wiley & Sons.
[18] Tobias Blask. 2013. Applying Bayesian parameter estimation to
[19] Tobias Blask, Burkhardt Funk, and Reinhard Schulte. 2011. Should companies bid on their own brand in sponsored search?. In Proceedings of the International Conference on e-Business. 1-8.
[20] Fedor Borisyuk, Siddarth Malreddy, Jun Mei, Yiqun Liu, Xiaoyi Liu, Piyush Maheshwari, Anthony Bell, and Kaushik Rangadurai. 2021. VisRel: Media Search at Scale. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery
[21] Slava Borodovsky and Saharon Rosset. 2011. A/B Testing at SweetIM: The Importance of Proper Statistical Analysis. In 2011 IEEE 11th International Conference on Data Mining Workshops. 733-740. https://doi.org/10.1109/ICDMW. 2011.19
[22] Alex Brown, Binky Lush, and Bernard J. Jansen. 2016. Pixel efficiency analysis: A quantitative web analytics approach. Proceedings of the Association for Information Science and Technology 53, 1 (2016), 1-10. https://doi.org/10.1002/ pra2.2016.14505301040 arXiv:https://asistdl.onlinelibrary.wiley.com/doi/pdf/10.1002/pra2.2016.14505301040
[23] Roman Budylin, Alexey Drutsa, Ilya Katsev, and Valeriya Tsoy. 2018. Consistent Transformation of Ratio Metrics for Efficient Online Controlled Experiments. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining (Marina Del Rey, CA, USA) (WSDM ’18). Association for Computing Machinery, New York, NY, USA, 55-63. https://doi.org/10.1145/3159652.3159699
[24] Tianchi Cai, Daxi Cheng, Chen Liang, Ziqi Liu, Lihong Gu, Huizhi Xie, Zhiqiang Zhang, Xiaodong Zeng, and Jinjie Gu. 2021. LinkLouvain: Link-Aware A/B Testing and Its Application on Online Marketing Campaign. In Database Systems for Advanced Applications, Christian S. Jensen, Ee-Peng Lim, De-Nian Yang, Wang-Chien Lee, Vincent S. Tseng, Vana Kalogeraki, Jen-Wei Huang, and Chih-Ya Shen (Eds.). Springer International Publishing, Cham, 499-510.
[25] Javier Cámara and Alfred Kobsa. 2009. Facilitating Controlled Tests of Website Design Changes: A Systematic Approach. In Web Engineering, Martin Gaedke, Michael Grossniklaus, and Oscar Díaz (Eds.). Springer Berlin Heidelberg, Berlin, Heidelberg, 370-378.
[26] Samit Chakraborty, Md. Saiful Hoque, Naimur Rahman Jeem, Manik Chandra Biswas, Deepayan Bardhan, and Edgar Lobaton. 2021. Fashion Recommendation Systems, Models and Methods: A Review. Informatics 8, 3 (2021). https: //doi.org/10.3390/informatics8030049
[27] Guangde Chen, Bee-Chung Chen, and Deepak Agarwal. 2017. Social Incentive Optimization in Online Social Networks. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining (Cambridge, United Kingdom) (WSDM ’17). Association for Computing Machinery, New York, NY, USA, 547-556. https://doi.org/10. 1145/3018661.3018700
[28] Nanyu Chen, Min Liu, and Ya Xu. 2019. How A/B Tests Could Go Wrong: Automatic Diagnosis of Invalid Online Experiments. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining (Melbourne VIC, Australia) (WSDM ’19). Association for Computing Machinery, New York, NY, USA, 501-509. https://doi. org/10.1145/3289600.3291000
[29] Russell Chen, Miao Chen, Mahendrasinh Ramsinh Jadav, Joonsuk Bae, and Don Matheson. 2017. Faster online experimentation by eliminating traditional A/A validation. In 2017 IEEE International Conference on Big Data (Big Data). 1635-1641. https://doi.org/10.1109/BigData.2017.8258098
[30] Emmanuelle Claeys, Pierre Gançarski, Myriam Maumy-Bertrand, and Hubert Wassner. 2017. Regression Tree for Bandits Models in A/B Testing. In Advances in Intelligent Data Analysis XVI, Niall Adams, Allan Tucker, and David Weston (Eds.). Springer International Publishing, Cham, 52-62.
[31] Rafael Costa, Elie Cheniaux, Pedro Rosaes, Marcele Carvalho, Rafael Freire, Márcio Versiani, Bernard Range, and Antonio Nardi. 2011. The effectiveness of cognitive behavioral group therapy in treating bipolar disorder: A randomized controlled study. Revista brasileira de psiquiatria (São Paulo, Brazil : 1999) 33 (06 2011), 144-9. https://doi.org/ 10.1590/S1516-44462011000200009
[32] John Creswell and Timothy Guetterman. 2018. Educational Research: Planning, Conducting, and Evaluating Quantitative and Qualitative Research, 6th Edition. Pearson, New York, NY, USA.
[33] Xinyi Dai, Yunjia Xi, Weinan Zhang, Qing Liu, Ruiming Tang, Xiuqiang He, Jiawei Hou, Jun Wang, and Yong Yu. 2021. Beyond Relevance Ranking: A General Graph Matching Framework for Utility-Oriented Learning to Rank. ACM Trans. Inf. Syst. 40, 2, Article 25 (nov 2021), 29 pages. https://doi.org/10.1145/3464303
[34] Maya Daneva, Daniela Damian, Alessandro Marchetto, and Oscar Pastor. 2014. Empirical research methodologies and studies in Requirements Engineering: How far did we come? Journal of Systems and Software 95 (2014), 1-9. https://doi.org/10.1016/j.jss.2014.06.035
[35] Rico de Feijter, Rob van Vliet, Erik Jagroep, Sietse Overbeek, and Sjaak Brinkkemper. 2017. Towards the adoption of DevOps in software product organizations: A maturity model approach. Technical Report. Utrecht University.
[36] Wagner S. De Souza, Fernando O. Pereira, Vanessa G. Albuquerque, Jorge Melegati, and Eduardo Guerra. 2022. A Framework Model to Support A/B Tests at the Class and Component Level. In 2022 IEEE 46th Annual Computers, Software, and Applications Conference (COMPSAC). 860-865. https://doi.org/10.1109/COMPSAC54236.2022.00136
[37] Alex Deng. 2015. Objective Bayesian Two Sample Hypothesis Testing for Online Controlled Experiments. In Proceedings of the 24th International Conference on World Wide Web (Florence, Italy) (WWW ’15 Companion). Association for Computing Machinery, New York, NY, USA, 923-928. https://doi.org/10.1145/2740908.2742563
[38] Alex Deng, Tianxi Li, and Yu Guo. 2014. Statistical Inference in Two-Stage Online Controlled Experiments with Treatment Selection and Validation. In Proceedings of the 23rd International Conference on World Wide Web (Seoul, Korea) (
[39] Alex Deng, Yicheng Li, Jiannan Lu, and Vivek Ramamurthy. 2021. On Post-Selection Inference in
[40] Drew Dimmery, Eytan Bakshy, and Jasjeet Sekhon. 2019. Shrinkage Estimators in Online Experiments. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery
[41] Pavel Dmitriev, Brian Frasca, Somit Gupta, Ron Kohavi, and Garnet Vaz. 2016. Pitfalls of long-term online controlled experiments. In 2016 IEEE International Conference on Big Data (Big Data). 1367-1376. https://doi.org/10.1109/ BigData. 2016.7840744
[42] Pavel Dmitriev, Somit Gupta, Dong Woo Kim, and Garnet Vaz. 2017. A Dirty Dozen: Twelve Common Metric Interpretation Pitfalls in Online Controlled Experiments. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (Halifax, NS, Canada) (KDD ’17). Association for Computing Machinery, New York, NY, USA, 1427-1436. https://doi.org/10.1145/3097983.3098024
[43] Jürgen Dobaj, Andreas Riel, Thomas Krug, Matthias Seidl, Georg Macher, and Markus Egretzberger. 2022. Towards Digital Twin-Enabled DevOps for CPS Providing Architecture-Based Service Adaptation & Verification at Runtime. In Proceedings of the 17th Symposium on Software Engineering for Adaptive and Self-Managing Systems (Pittsburgh, Pennsylvania) (SEAMS ’22). Association for Computing Machinery, New York, NY, USA, 132-143. https://doi.org/ 10.1145/3524844.3528057
[44] Alexey Drutsa, Gleb Gusev, and Pavel Serdyukov. 2015. Future User Engagement Prediction and Its Application to Improve the Sensitivity of Online Experiments. In Proceedings of the 24th International Conference on World Wide Web (Florence, Italy) (
[45] Alexey Drutsa, Gleb Gusev, and Pavel Serdyukov. 2017. Periodicity in User Engagement with a Search Engine and Its Application to Online Controlled Experiments. ACM Trans. Web 11, 2, Article 9 (apr 2017), 35 pages. https: //doi.org/10.1145/2856822
[46] Alexey Drutsa, Gleb Gusev, and Pavel Serdyukov. 2017. Using the Delay in a Treatment Effect to Improve Sensitivity and Preserve Directionality of Engagement Metrics in A/B Experiments. In Proceedings of the 26 th International Conference on World Wide Web (Perth, Australia) (
[47] Alexey Drutsa, Anna Ufliand, and Gleb Gusev. 2015. Practical Aspects of Sensitivity in Online Experimentation with User Engagement Metrics. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management (Melbourne, Australia) (CIKM ’15). Association for Computing Machinery, New York, NY, USA, 763-772. https://doi.org/10.1145/2806416.2806496
[48] Weitao Duan, Shan Ba, and Chunzhe Zhang. 2021. Online Experimentation with Surrogate Metrics: Guidelines and a Case Study. In Proceedings of the 14 th ACM International Conference on Web Search and Data Mining (Virtual Event, Israel) (WSDM ’21). Association for Computing Machinery, New York, NY, USA, 193-201. https://doi.org/10.1145/ 3437963.3441737
[49] Wouter Duivesteijn, Tara Farzami, Thijs Putman, Evertjan Peer, Hilde J. P. Weerts, Jasper N. Adegeest, Gerson Foks, and Mykola Pechenizkiy. 2017. Have It Both Ways-From A/B Testing to A&B Testing with Exceptional Model Mining. In Machine Learning and Knowledge Discovery in Databases, Yasemin Altun, Kamalika Das, Taneli Mielikäinen, Donato Malerba, Jerzy Stefanowski, Jesse Read, Marinka Žitnik, Michelangelo Ceci, and Sašo Džeroski (Eds.). Springer International Publishing, Cham, 114-126.
[50] Joshua Eckroth and Eric Schoen. 2019. A genetic algorithm for finding a small and diverse set of recent news stories on a given subject: How we generate aaai’s ai-alert. 33rd AAAI Conference on Artificial Intelligence, AAAI 2019, 31st Innovative Applications of Artificial Intelligence Conference, IAAI 2019 and the 9th AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2019 (2019), 9357-9364. https://www.scopus.com/inward/record.uri? eid=2-s2.0-85090801224&partnerID=40&md5=f3391d595e00df8a0cba7802c9043ebd Cited by: 2.
[51] B. Efron and R.J. Tibshirani. 1994. An Introduction to the Bootstrap. CRC Press. https://books.google.be/books? id=MWC1DwAAQBAJ
[52] Beyza Ermis, Patrick Ernst, Yannik Stein, and Giovanni Zappella. 2020. Learning to Rank in the Position Based Model with Bandit Feedback. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management (Virtual Event, Ireland) (CIKM ’20). Association for Computing Machinery, New York, NY, USA, 2405-2412. https://doi.org/10.1145/3340531.3412723
[53] Vladimir M. Erthal, Bruno P. de Souza, Paulo Sérgio M. dos Santos, and Guilherme H. Travassos. 2022. A Literature Study to Characterize Continuous Experimentation in Software Engineering. CIbSE 2022-XXV Ibero-American Conference on Software Engineering (2022). https://www.scopus.com/inward/record.uri?eid=2-s2.0-85137064966& partnerID=40&md5=04240b73ab90eb841083173be558b33f Cited by: 0.
[54] Maria Esteller-Cucala, Vicenc Fernandez, and Diego Villuendas. 2019. Experimentation Pitfalls to Avoid in A/B Testing for Online Personalization. In Adjunct Publication of the 27th Conference on User Modeling, Adaptation and Personalization (Larnaca, Cyprus) (UMAP’19 Adjunct). Association for Computing Machinery, New York, NY, USA, 153-159. https://doi.org/10.1145/3314183.3323853
[55] Aleksander Fabijan, Benjamin Arai, Pavel Dmitriev, and Lukas Vermeer. 2021. It takes a Flywheel to Fly: Kickstarting and Growing the
[56] Aleksander Fabijan, Pavel Dmitriev, Colin McFarland, Lukas Vermeer, Helena Holmström Olsson, and Jan Bosch. 2018. Experimentation growth: Evolving trustworthy
[57] Aleksander Fabijan, Pavel Dmitriev, Helena Holmström Olsson, and Jan Bosch. 2017. The Benefits of Controlled Experimentation at Scale. In 2017 43rd Euromicro Conference on Software Engineering and Advanced Applications (SEAA). 18-26. https://doi.org/10.1109/SEAA. 2017.47
[58] Aleksander Fabijan, Pavel Dmitriev, Helena Holmström Olsson, and Jan Bosch. 2017. The Evolution of Continuous Experimentation in Software Product Development: From Data to a Data-Driven Organization at Scale. In Proceedings of the 39th International Conference on Software Engineering (Buenos Aires, Argentina) (ICSE ’17). IEEE Press, Los Alamitos, CA, USA, 770-780. https://doi.org/10.1109/ICSE.2017.76
[59] A. Fabijan, P. Dmitriev, H. Holmstrom Olsson, and J. Bosch. 2020. The Online Controlled Experiment Lifecycle. IEEE Software 37, 02 (mar 2020), 60-67. https://doi.org/10.1109/MS.2018.2875842
[60] Aleksander Fabijan, Jayant Gupchup, Somit Gupta, Jeff Omhover, Wen Qin, Lukas Vermeer, and Pavel Dmitriev. 2019. Diagnosing Sample Ratio Mismatch in Online Controlled Experiments: A Taxonomy and Rules of Thumb for Practitioners. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery 88 Data Mining (Anchorage, AK, USA) (KDD ’19). Association for Computing Machinery, New York, NY, USA, 2156-2164. https://doi.org/10.1145/3292500.3330722
[61] Aleksander Fabijan, Helena Holmström Olsson, and Jan Bosch. 2015. Customer Feedback and Data Collection Techniques in Software R&D: A Literature Review. In Software Business, João M. Fernandes, Ricardo J. Machado, and Krzysztof Wnuk (Eds.). Springer International Publishing, Cham, 139-153. https://doi.org/10.1007/978-3-319-19593-3_12
[62] Aleksander Fabijan, Helena Holmström Olsson, and Jan Bosch. 2016. The Lack of Sharing of Customer Data in Large Software Organizations: Challenges and Implications. In Agile Processes, in Software Engineering, and Ex-
treme Programming, Helen Sharp and Tracy Hall (Eds.). Springer International Publishing, Cham, 39-52. https: //doi.org/10.1007/978-3-319-33515-5_4
[63] Yaron Fairstein, Elad Haramaty, Arnon Lazerson, and Liane Lewin-Eytan. 2022. External Evaluation of Ranking Models under Extreme Position-Bias. In Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining (Virtual Event, AZ, USA) (WSDM ’22). Association for Computing Machinery, New York, NY, USA, 252-261. https://doi.org/10.1145/3488560.3498420
[64] Elea McDonnell Feit and Ron Berman. 2019. Test & Roll: Profit-Maximizing A/B Tests. Marketing Science 38, 6 (2019), 1038-1058. https://doi.org/10.1287/mksc.2019.1194
[65] Antonino Freno. 2017. Practical Lessons from Developing a Large-Scale Recommender System at Zalando. In Proceedings of the Eleventh ACM Conference on Recommender Systems (Como, Italy) (RecSys ’17). Association for Computing Machinery, New York, NY, USA, 251-259. https://doi.org/10.1145/3109859.3109897
[66] Kun Fu, Fanlin Meng, Jieping Ye, and Zheng Wang. 2020. CompactETA: A Fast Inference System for Travel Time Prediction. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery
[67] Burkhardt Funk. 2009. Optimizing price levels in e-commerce applications: An empirical study. ICETE 2009 – International Joint Conference on e-Business and Telecommunications (2009), 37-43. https://www.scopus.com/inward/ record.uri?eid=2-s2.0-74549181430&partnerID=40&md5=6dfdde67b807b3964c62fc8c1929dcf0 Cited by: 1.
[68] Matthias Galster and Danny Weyns. 2016. Empirical Research in Software Architecture: How Far have We Come?. In 2016 13th Working IEEE/IFIP Conference on Software Architecture (WICSA). IEEE Press, Los Alamitos, CA, USA, 11-20. https://doi.org/10.1109/WICSA.2016.10
[69] Federico Giaimo, Hugo Andrade, and Christian Berger. 2020. Continuous experimentation and the cyber-physical systems challenge: An overview of the literature and the industrial perspective. Journal of Systems and Software 170 (2020), 110781. https://doi.org/10.1016/j.jss.2020.110781
[70] Carlos A. Gomez-Uribe and Neil Hunt. 2016. The Netflix Recommender System: Algorithms, Business Value, and Innovation. ACM Trans. Manage. Inf. Syst. 6, 4, Article 13 (dec 2016), 19 pages. https://doi.org/10.1145/2843948
[71] Anjan Goswami, Wei Han, Zhenrui Wang, and Angela Jiang. 2015. Controlled experiments for decision-making in eCommerce search. In 2015 IEEE International Conference on Big Data (Big Data). IEEE Press, Los Alamitos, CA, USA, 1094-1102. https://doi.org/10.1109/BigData.2015.7363863
[72] Alois Gruson, Praveen Chandar, Christophe Charbuillet, James McInerney, Samantha Hansen, Damien Tardieu, and Ben Carterette. 2019. Offline Evaluation to Make Decisions About PlaylistRecommendation Algorithms. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining (Melbourne VIC, Australia) (WSDM ’19). Association for Computing Machinery, New York, NY, USA, 420-428. https://doi.org/10.1145/3289600.3291027
[73] Huan Gui, Ya Xu, Anmol Bhasin, and Jiawei Han. 2015. Network A/B Testing: From Sampling to Estimation. In Proceedings of the 24th International Conference on World Wide Web (Florence, Italy) (
[74] Jayant Gupchup, Yasaman Hosseinkashi, Pavel Dmitriev, Daniel Schneider, Ross Cutler, Andrei Jefremov, and Martin Ellis. 2018. Trustworthy Experimentation Under Telemetry Loss. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management (Torino, Italy) (CIKM ’18). Association for Computing Machinery, New York, NY, USA, 387-396. https://doi.org/10.1145/3269206.3271747
[75] Shubham Gupta and Sneha Chokshi. 2020. Digital Marketing Effectiveness Using Incrementality. In Advances in Computing and Data Sciences, Mayank Singh, P. K. Gupta, Vipin Tyagi, Jan Flusser, Tuncer Oren, and Gianluca Valentino (Eds.). Springer Singapore, Singapore, 66-75.
[76] Somit Gupta, Lucy Ulanova, Sumit Bhardwaj, Pavel Dmitriev, Paul Raff, and Aleksander Fabijan. 2018. The Anatomy of a Large-Scale Experimentation Platform. In 2018 IEEE International Conference on Software Architecture (ICSA). 1-109. https://doi.org/10.1109/ICSA. 2018.00009
[77] Viet Ha-Thuc, Avishek Dutta, Ren Mao, Matthew Wood, and Yunli Liu. 2020. A Counterfactual Framework for SellerSide A/B Testing on Marketplaces. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval (Virtual Event, China) (SIGIR ’20). Association for Computing Machinery, New York, NY, USA, 2288-2296. https://doi.org/10.1145/3397271.3401434
[78] Yan He and Miao Chen. 2017. A Probabilistic, Mechanism-Indepedent Outlier Detection Method for Online Experimentation. In 2017 IEEE International Conference on Data Science and Advanced Analytics (DSAA). 640-647. https://doi.org/10.1109/DSAA. 2017.64
[79] Yan He, Lin Yu, Miao Chen, William Choi, and Don Matheson. 2022. A Cluster-Based Nearest Neighbor Matching Algorithm for Enhanced A/A Validation in Online Experimentation. In Companion Proceedings of the Web Conference 2022 (Virtual Event, Lyon, France) (
[80] Jez Humble and David Farley. 2010. Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation (1st ed.). Addison-Wesley Professional, Illinois, IL, USA.
[81] Hao Jiang, Fan Yang, and Wutao Wei. 2020. Statistical Reasoning of Zero-Inflated Right-Skewed User-Generated Big Data A/B Testing. In 2020 IEEE International Conference on Big Data (Big Data). 1533-1544. https://doi.org/10. 1109/BigData50022.2020.9377996
[82] Ramesh Johari, Pete Koomen, Leonid Pekelis, and David Walsh. 2017. Peeking at A/B Tests: Why It Matters, and What to Do about It. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and
[83] Nianqiao Ju, Diane Hu, Adam Henderson, and Liangjie Hong. 2019. A Sequential Test for Selecting the Better Variant: Online A/B Testing, Adaptive Allocation, and Continuous Monitoring. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining (Melbourne VIC, Australia) (WSDM ’19). Association for Computing Machinery, New York, NY, USA, 492-500. https://doi.org/10.1145/3289600.3291025
[84] Staffs Keele et al. 2007. Guidelines for performing systematic literature reviews in software engineering. Technical Report. Technical report, Ver. 2.3 EBSE Technical Report. EBSE.
[85] Eugene Kharitonov, Alexey Drutsa, and Pavel Serdyukov. 2017. Learning Sensitive Combinations of A/B Test Metrics. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining (Cambridge, United Kingdom) (WSDM ’17). Association for Computing Machinery, New York, NY, USA, 651-659. https://doi.org/10. 1145/3018661.3018708
[86] Eugene Kharitonov, Aleksandr Vorobev, Craig Macdonald, Pavel Serdyukov, and Iadh Ounis. 2015. Sequential Testing for Early Stopping of Online Experiments. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval (Santiago, Chile) (SIGIR ’15). Association for Computing Machinery, New York, NY, USA, 473-482. https://doi.org/10.1145/2766462.2767729
[87] Rochelle King, Elizabeth F. Churchill, and Caitlin Tan. 2017. Designing with Data: Improving the User Experience with
[88] Ron Kohavi, Alex Deng, Brian Frasca, Roger Longbotham, Toby Walker, and Ya Xu. 2012. Trustworthy Online Controlled Experiments: Five Puzzling Outcomes Explained. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (Beijing, China) (KDD ’12). Association for Computing Machinery, New York, NY, USA, 786-794. https://doi.org/10.1145/2339530.2339653
[89] Ron Kohavi, Alex Deng, Brian Frasca, Toby Walker, Ya Xu, and Nils Pohlmann. 2013. Online Controlled Experiments at Large Scale. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (Chicago, Illinois, USA) (KDD ’13). Association for Computing Machinery, New York, NY, USA, 1168-1176. https://doi.org/10.1145/2487575.2488217
[90] Ron Kohavi, Alex Deng, Roger Longbotham, and Ya Xu. 2014. Seven Rules of Thumb for Web Site Experimenters. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (New York, New York, USA) (KDD ’14). Association for Computing Machinery, New York, NY, USA, 1857-1866. https: //doi.org/10.1145/2623330.2623341
[91] Ron Kohavi and Roger Longbotham. 2011. Unexpected Results in Online Controlled Experiments. SIGKDD Explor. Newsl. 12, 2 (mar 2011), 31-35. https://doi.org/10.1145/1964897.1964905
[92] Ron Kohavi and Roger Longbotham. 2017. Online Controlled Experiments and A/B Testing. Encyclopedia of machine learning and data mining 7,8 (2017), 922-929.
[93] Ron Kohavi, Roger Longbotham, Dan Sommerfield, and Randal Henne. 2009. Controlled experiments on the web: Survey and practical guide. Data Mining and Knowledge Discovery 18 (02 2009), 140-181. https://doi.org/10.1007/ s10618-008-0114-1
[94] Ron Kohavi, Diane Tang, and Ya Xu. 2020. Trustworthy Online Controlled Experiments: A Practical Guide to
[95] Anastasiia Kornilova and Lucas Bernardi. 2021. Mining the Stars: Learning Quality Ratings with User-Facing Explanations for Vacation Rentals. In Proceedings of the 14th ACM International Conference on Web Search and Data Mining (Virtual Event, Israel) (WSDM ’21). Association for Computing Machinery, New York, NY, USA, 976-983. https://doi.org/10.1145/3437963.3441812
[96] Kostantinos Koukouvis, Roberto Alcañiz Cubero, and Patrizio Pelliccione. 2016. A/B Testing in E-commerce Sales Processes. In Software Engineering for Resilient Systems, Ivica Crnkovic and Elena Troubitsyna (Eds.). Springer International Publishing, Cham, 133-148.
[97] Anuj Kumar and Kartik Hosanagar. 2017. Measuring the Value of Recommendation Links on Product Demand. SSRN Electronic Journal (01 2017). https://doi.org/10.2139/ssrn. 2909971
[98] Ratnakar Kumar and Nitasha Hasteer. 2017. Evaluating usability of a web application: A comparative analysis of opensource tools. In 2017 2nd International Conference on Communication and Electronics Systems (ICCES). 350-354. https://doi.org/10.1109/CESYS. 2017.8321296
[99] Mounia Lalmas, Janette Lehmann, Guy Shaked, Fabrizio Silvestri, and Gabriele Tolomei. 2015. Promoting Positive PostClick Experience for In-Stream Yahoo Gemini Users. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (Sydney, NSW, Australia) (KDD ’15). Association for Computing Machinery, New York, NY, USA, 1929-1938. https://doi.org/10.1145/2783258.2788581
[100] Minyong R. Lee and Milan Shen. 2018. Winner’s Curse: Bias Estimation for Total Effects of Features in Online Controlled Experiments. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery
[101] Florian Lettner, Clemens Holzmann, and Patrick Hutflesz. 2013. Enabling A/B Testing of Native Mobile Applications by Remote User Interface Exchange. In Computer Aided Systems Theory – EUROCAST 2013, Roberto Moreno-Díaz, Franz Pichler, and Alexis Quesada-Arencibia (Eds.). Springer Berlin Heidelberg, Berlin, Heidelberg, 458-466.
[102] Chengbo Li, Lin Zhu, Guangyuan Fu, Longzhi Du, Canhua Zhao, Tianlun Ma, Chang Ye, and Pei Lee. 2021. Learning to Bundle Proactively for On-Demand Meal Delivery. In Proceedings of the 30th ACM International Conference on Information
[103] Hannah Li, Geng Zhao, Ramesh Johari, and Gabriel Y. Weintraub. 2022. Interference, Bias, and Variance in TwoSided Marketplace Experimentation: Guidance for Platforms. In Proceedings of the ACM Web Conference 2022 (Virtual Event, Lyon, France) (
[104] Lihong Li, Jin Young Kim, and Imed Zitouni. 2015. Toward Predicting the Outcome of an A/B Experiment for Search Relevance. In Proceedings of the Eighth ACM International Conference on Web Search and Data Mining (WSDM ’15). Association for Computing Machinery, New York, NY, USA, 37-46. https://doi.org/10.1145/2684822.2685311
[105] Paul Luo Li, Xiaoyu Chai, Frederick Campbell, Jilong Liao, Neeraja Abburu, Minsuk Kang, Irina Niculescu, Greg Brake, Siddharth Patil, James Dooley, and Brandon Paddock. 2021. Evolving Software to be ML-Driven Utilizing RealWorld A/B Testing: Experiences, Insights, Challenges. In 2021 IEEE/ACM 43rd International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP). 170-179. https://doi.org/10.1109/ICSE-SEIP52600. 2021.00026
[106] Paul Luo Li, Pavel Dmitriev, Huibin Mary Hu, Xiaoyu Chai, Zoran Dimov, Brandon Paddock, Ying Li, Alex Kirshenbaum, Irina Niculescu, and Taj Thoresen. 2019. Experimentation in the Operating System: The Windows Experimentation Platform. In 2019 IEEE/ACM 41st International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP). 21-30. https://doi.org/10.1109/ICSE-SEIP.2019.00011
[107] Yiyang Li, Guanyu Tao, Weinan Zhang, Yong Yu, and Jun Wang. 2017. Content Recommendation by Noise Contrastive Transfer Learning of Feature Representation. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management (Singapore, Singapore) (CIKM ’17). Association for Computing Machinery, New York, NY, USA, 1657-1665. https://doi.org/10.1145/3132847.3132855
[108] Ye Li, Hong Xie, Yishi Lin, and John C.S. Lui. 2021. Unifying Offline Causal Inference and Online Bandit Learning for Data Driven Decision. In Proceedings of the Web Conference 2021 (Ljubljana, Slovenia) (WWW ’21). Association for Computing Machinery, New York, NY, USA, 2291-2303. https://doi.org/10.1145/3442381.3449982
[109] Kevin Liou and Sean J. Taylor. 2020. Variance-Weighted Estimators to Improve Sensitivity in Online Experiments. In Proceedings of the 21st ACM Conference on Economics and Computation (Virtual Event, Hungary) (EC ’20). Association for Computing Machinery, New York, NY, USA, 837-850. https://doi.org/10.1145/3391403.3399542
[110] Sophia Liu, Aleksander Fabijan, Michael Furchtgott, Somit Gupta, Pawel Janowski, Wen Qin, and Pavel Dmitriev. 2019. Enterprise-Level Controlled Experiments at Scale: Challenges and Solutions. In 2019 45th Euromicro Conference on Software Engineering and Advanced Applications (SEAA). 29-37. https://doi.org/10.1109/SEAA.2019.00013
[111] Yuchu Liu, David Issa Mattos, Jan Bosch, Helena Holmström Olsson, and Jonn Lantz. 2021. Size matters? Or not: A/B testing with limited sample in automotive embedded software. In 2021 47th Euromicro Conference on Software Engineering and Advanced Applications (SEAA). 300-307. https://doi.org/10.1109/SEAA53835.2021.00046
[112] Widad Machmouchi, Ahmed Hassan Awadallah, Imed Zitouni, and Georg Buscher. 2017. Beyond Success Rate: Utility as a Search Quality Metric for Online Experiments. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management (Singapore, Singapore) (CIKM ’17). Association for Computing Machinery, New York, NY, USA, 757-765. https://doi.org/10.1145/3132847.3132850
[113] Lech Madeyski, Wojciech Orzeszyna, Richard Torkar, and Mariusz Józala. 2014. Overcoming the Equivalent Mutant Problem: A Systematic Literature Review and a Comparative Experiment of Second Order Mutation. IEEE Transactions on Software Engineering 40, 1 (2014), 23-42. https://doi.org/10.1109/TSE. 2013.44
[114] Maria Madlberger and Jiri Jizdny. 2021. Impact of promotional social media content on click-through rate – Evidence from a FMCG company. 20th International Conferences on WWW/Internet 2021 and Applied Computing 2021 (2021), 3-10. https://www.scopus.com/inward/record.uri?eid=2-s2.0-85124068035&partnerID=40&md5= c0b8f49a3b48b3d561fd0ed305eb1895 Cited by: 0.
[115] Sara Mahdavi-Hezavehi, Vinicius H.S. Durelli, Danny Weyns, and Paris Avgeriou. 2017. A systematic literature review on methods that handle multiple quality attributes in architecture-based self-adaptive systems. Information and Software Technology 90 (2017), 1-26. https://doi.org/10.1016/j.infsof.2017.03.013
[116] Taisei Masuda, Kyoko Murakami, Kenkichi Sugiura, Sho Sakui, Ron Philip Schuring, and Mitsuhiro Mori. 2022. A phase
[117] David Issa Mattos, Jan Bosch, and Helena Holmström Olsson. 2017. More for Less: Automated Experimentation in Software-Intensive Systems. In Product-Focused Software Process Improvement, Michael Felderer, Daniel Méndez Fernández, Burak Turhan, Marcos Kalinowski, Federica Sarro, and Dietmar Winkler (Eds.). Springer International Publishing, Cham, 146-161.
[118] David Issa Mattos, Jan Bosch, and Helena Holmström Olsson. 2017. Your System Gets Better Every Day You Use It: Towards Automated Continuous Experimentation. In 2017 43rd Euromicro Conference on Software Engineering and Advanced Applications (SEAA). 256-265. https://doi.org/10.1109/SEAA.2017.15
[119] David Issa Mattos, Jan Bosch, and Helena Holmström Olsson. 2018. Challenges and Strategies for Undertaking Continuous Experimentation to Embedded Systems: Industry and Research Perspectives. In Agile Processes in Software Engineering and Extreme Programming, Juan Garbajosa, Xiaofeng Wang, and Ademar Aguiar (Eds.). Springer International Publishing, Cham, 277-292. https://doi.org/10.1007/978-3-319-91602-6_20
[120] David Issa Mattos, Jan Bosch, Helena Holmstrom Olsson, Aita Maryam Korshani, and Jonn Lantz. 2020. Automotive A/B testing: Challenges and Lessons Learned from Practice. In 2020 46th Euromicro Conference on Software Engineering and Advanced Applications (SEAA). 101-109. https://doi.org/10.1109/SEAA51224.2020.00026
[121] Pavel Metrikov, Fernando Diaz, Sebastien Lahaie, and Justin Rao. 2014. Whole Page Optimization: How Page Elements
[122] Risto Miikulainen, Myles Brundage, Jonathan Epstein, Tyler Foster, Babak Hodjat, Neil Iscoe, Jingbo Jiang, Diego Legrand, Sam Nazari, Xin Qiu, Michael Scharff, Cory Schoolland, Robert Severn, and Aaron Shagrin. 2020. Ascend by Evolv: AI-Based Massively Multivariate Conversion Rate Optimization. AI Magazine 41, 1 (Apr. 2020), 44-60. https://doi.org/10.1609/aimag.v41i1.5256
[123] Tadashi Okoshi, Kota Tsubouchi, and Hideyuki Tokuda. 2019. Real-World Product Deployment of Adaptive Push Notification Scheduling on Smartphones. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery
[124] Takumi Ozawa, Akiyuki Sekiguchi, and Kazuhiko Tsuda. 2016. A Method for the Construction of User Targeting Knowledge for B2B Industry Website. Procedia Computer Science 96 (2016), 1147-1155. https://doi.org/10.1016/ j.procs.2016.08.157 Knowledge-Based and Intelligent Information & Engineering Systems: Proceedings of the 20th International Conference KES-2016.
[125] Dan Pelleg, Oleg Rokhlenko, Idan Szpektor, Eugene Agichtein, and Ido Guy. 2016. When the Crowd is Not Enough: Improving User Experience with Social Media through Automatic Quality Analysis. In Proceedings of the 19th ACM Conference on Computer-Supported Cooperative Work & Social Computing (San Francisco, California, USA) (CSCW ’16). Association for Computing Machinery, New York, NY, USA, 1080-1090. https://doi.org/10.1145/2818048. 2820022
[126] Ladislav Peska and Peter Vojtas. 2020. Off-Line vs. On-Line Evaluation of Recommender Systems in Small E-Commerce. In Proceedings of the 31st ACM Conference on Hypertext and Social Media (Virtual Event, USA) (HT ’20). Association for Computing Machinery, New York, NY, USA, 291-300. https://doi.org/10.1145/3372923.3404781
[127] Alexey Poyarkov, Alexey Drutsa, Andrey Khalyavin, Gleb Gusev, and Pavel Serdyukov. 2016. Boosted Decision Tree Regression Adjustment for Variance Reduction in Online Controlled Experiments. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (San Francisco, California, USA) (KDD ’16). Association for Computing Machinery, New York, NY, USA, 235-244. https://doi.org/10.1145/2939672.2939688
[128] Jia Qu and Jing Zhang. 2016. Validating Mobile Designs with Agile Testing in China: Based on Baidu Map for Mobile. In Design, User Experience, and Usability: Design Thinking and Methods, Aaron Marcus (Ed.). Springer International Publishing, Cham, 491-498.
[129] Federico Quin, Danny Weyns, and Matthias Galster. 2023. Study Systematic Literature Review on A/B Testing. https: //people.cs.kuleuven.be/danny.weyns/material/SLR_AB/
[130] Jan Renz, Daniel Hoffmann, Thomas Staubitz, and Christoph Meinel. 2016. Using A/B testing in MOOC environments. In Proceedings of the Sixth International Conference on Learning Analytics 6 Knowledge (LAK ’16). Association for Computing Machinery, New York, NY, USA, 304-313. https://doi.org/10.1145/2883851.2883876
[131] Mohi Reza, Juho Kim, Ananya Bhattacharjee, Anna N. Rafferty, and Joseph Jay Williams. 2021. The MOOClet Framework: Unifying Experimentation, Dynamic Improvement, and Personalization in Online Courses. In Proceedings of the Eighth ACM Conference on Learning @ Scale (Virtual Event, Germany) (L@S ’21). Association for Computing Machinery, New York, NY, USA, 15-26. https://doi.org/10.1145/3430895.3460128
[132] Pilar Rodríguez, Alireza Haghighatkhah, Lucy Ellen Lwakatare, Susanna Teppola, Tanja Suomalainen, Juho Eskeli, Teemu Karvonen, Pasi Kuvaja, June M. Verner, and Markku Oivo. 2017. Continuous deployment of software intensive products and services: A systematic mapping study. Journal of Systems and Software 123 (2017), 263-291. https: //doi.org/10.1016/j.jss.2015.12.015
[133] Rasmus Ros and Per Runeson. 2018. Continuous Experimentation and A/B Testing: A Mapping Study. In Proceedings of the 4 th International Workshop on Rapid Continuous Software Engineering (Gothenburg, Sweden) (RCoSE ’18). Association for Computing Machinery, New York, NY, USA, 35-41. https://doi.org/10.1145/3194760.3194766
[134] Nir Rosenfeld, Yishay Mansour, and Elad Yom-Tov. 2017. Predicting Counterfactuals from Large Historical Data and Small Randomized Trials. In Proceedings of the 26th International Conference on World Wide Web Companion (Perth, Australia) (
[135] Sandra Sajeev, Jade Huang, Nikos Karampatziakis, Matthew Hall, Sebastian Kochman, and Weizhu Chen. 2021. Contextual Bandit Applications in a Customer Support Bot. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining (Virtual Event, Singapore) (KDD ’21). Association for Computing Machinery, New York, NY, USA, 3522-3530. https://doi.org/10.1145/3447548.3467165
[136] Suhrid Satyal, Ingo Weber, Hye-young Paik, Claudio Di Ciccio, and Jan Mendling. 2017. AB-BPM: Performance-Driven Instance Routing for Business Process Improvement. In Business Process Management, Josep Carmona, Gregor Engels, and Akhil Kumar (Eds.). Springer International Publishing, Cham, 113-129.
[137] Suhrid Satyal, Ingo Weber, Hye young Paik, Claudio Di Ciccio, and Jan Mendling. 2019. Business process improvement with the AB-BPM methodology. Information Systems 84 (2019), 283-298. https://doi.org/10.1016/j.is.2018.06. 007
[138] Martin Saveski, Jean Pouget-Abadie, Guillaume Saint-Jacques, Weitao Duan, Souvik Ghosh, Ya Xu, and Edoardo M. Airoldi. 2017. Detecting Network Effects: Randomizing Over Randomized Experiments. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (Halifax, NS, Canada) (KDD ’17). Association for Computing Machinery, New York, NY, USA, 1027-1035. https://doi.org/10.1145/3097983.3098192
[139] Gerald Schermann, Dominik Schöni, Philipp Leitner, and Harald C. Gall. 2016. Bifrost: Supporting Continuous De-
ployment with Automated Enactment of Multi-Phase Live Testing Strategies. In Proceedings of the 17 th International Middleware Conference (Trento, Italy) (Middleware ’16). Association for Computing Machinery, New York, NY, USA, Article 12, 14 pages. https://doi.org/10.1145/2988336.2988348
[140] Shahriar Shariat, Burkay Orten, and Ali Dasdan. 2017. Online Evaluation of Bid Prediction Models in a Large-Scale Computational Advertising Platform: Decision Making and Insights. Knowl. Inf. Syst. 51, 1 (apr 2017), 37-60. https: //doi.org/10.1007/s10115-016-0972-6
[141] Fanjuan Shi, Chirine Ghedira, and Jean-Luc Marini. 2015. Context Adaptation for Smart Recommender Systems. IT Professional 17, 6 (2015), 18-26. https://doi.org/10.1109/MITP. 2015.96
[142] Janet Siegmund, Norbert Siegmund, and Sven Apel. 2015. Views on Internal and External Validity in Empirical Software Engineering. In 2015 IEEE/ACM 37th IEEE International Conference on Software Engineering, Vol. 1. IEEE Press, Los Alamitos, CA, USA, 9-19. https://doi.org/10.1109/ICSE.2015.24
[143] Natalia Silberstein, Oren Somekh, Yair Koren, Michal Aharon, Dror Porat, Avi Shahar, and Tingyi Wu. 2020. Ad Close Mitigation for Improved User Experience in Native Advertisements. In Proceedings of the 13th International Conference on Web Search and Data Mining (Houston, TX, USA) (WSDM ’20). Association for Computing Machinery, New York, NY, USA, 546-554. https://doi.org/10.1145/3336191.3371798
[144] Jorge Gabriel Siqueira and Melise M. V. de Paula. 2018. IPEAD A/B Test Execution Framework. In Proceedings of the XIV Brazilian Symposium on Information Systems (Caxias do Sul, Brazil) (SBSI’18). Association for Computing Machinery, New York, NY, USA, Article 14, 8 pages. https://doi.org/10.1145/3229345.3229360
[145] Dan Siroker and Pete Koomen. 2013. A/B Testing: The Most Powerful Way to Turn Clicks Into Customers (1st ed.). Wiley Publishing, Hoboken, NJ, USA.
[146] Bruce Spang, Veronica Hannan, Shravya Kunamalla, Te-Yuan Huang, Nick McKeown, and Ramesh Johari. 2021. Unbiased Experiments in Congested Networks. In Proceedings of the 21st ACM Internet Measurement Conference (Virtual Event) (IMC ’21). Association for Computing Machinery, New York, NY, USA, 80-95. https://doi.org/10.1145/ 3487552.3487851
[147] Akshitha Sriraman, Abhishek Dhanotia, and Thomas F. Wenisch. 2019. SoftSKU: Optimizing Server Architectures for Microservice Diversity @Scale. In 2019 ACM/IEEE 46th Annual International Symposium on Computer Architecture (ISCA). 513-526.
[148] Fei Sun, Peng Jiang, Hanxiao Sun, Changhua Pei, Wenwu Ou, and Xiaobo Wang. 2018. Multi-Source Pointer Network for Product Title Summarization. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management (Torino, Italy) (CIKM ’18). Association for Computing Machinery, New York, NY, USA, 7-16. https: //doi.org/10.1145/3269206.3271722
[149] Idan Szpektor, Yoelle Maarek, and Dan Pelleg. 2013. When Relevance is Not Enough: Promoting Diversity and Freshness in Personalized Question Recommendation. In Proceedings of the 22nd International Conference on World Wide Web (Rio de Janeiro, Brazil) (
[150] Yukihiro Tagami, Toru Hotta, Yusuke Tanaka, Shingo Ono, Koji Tsukamoto, and Akira Tajima. 2014. Filling Context-Ad Vocabulary Gaps with Click Logs. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (New York, New York, USA) (KDD ’14). Association for Computing Machinery, New York, NY, USA, 1955-1964. https://doi.org/10.1145/2623330. 2623334
[151] Giordano Tamburrelli and Alessandro Margara. 2014. Towards Automated A/B Testing. In Search-Based Software Engineering, Claire Le Goues and Shin Yoo (Eds.). Springer International Publishing, Cham, 184-198.
[152] Diane Tang, Ashish Agarwal, Deirdre O’Brien, and Mike Meyer. 2010. Overlapping Experiment Infrastructure: More, Better, Faster Experimentation. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (Washington, DC, USA) (KDD ’10). Association for Computing Machinery, New York, NY, USA, 17-26. https://doi.org/10.1145/1835804.1835810
[153] Mert Toslali, Srinivasan Parthasarathy, Fabio Oliveira, and Ayse K. Coskun. 2020. JACKPOT: Online experimentation of cloud microservices. HotCloud 2020-12th USENIX Workshop on Hot Topics in Cloud Computing, co-located with USENIX ATC 2020 (2020). https://www.scopus.com/inward/record.uri?eid=2-s2.0-85091892156&partnerID=40& md5=cae12fe24f34f2bb0818e448f8c07fbf Cited by: 1.
[154] Ye Tu, Kinjal Basu, Cyrus DiCiccio, Romil Bansal, Preetam Nandy, Padmini Jaikumar, and Shaunak Chatterjee. 2021. Personalized Treatment Selection Using Causal Heterogeneity. In Proceedings of the Web Conference 2021 (Ljubljana, Slovenia) (WWW ’21). Association for Computing Machinery, New York, NY, USA, 1574-1585. https://doi.org/10. 1145/3442381.3450075
[155] Yutaro Ueoka, Kota Tsubouchi, and Nobuyuki Shimizu. 2020. Tackling Cannibalization Problems for Online Advertisement. In Proceedings of the 28th ACM Conference on User Modeling, Adaptation and Personalization (Genoa, Italy) (UMAP ’20). Association for Computing Machinery, New York, NY, USA, 358-362. https://doi.org/10.1145/ 3340631.3394875
[156] Jean Vanderdonckt, Mathieu Zen, and Radu-Daniel Vatavu. 2019. AB4Web: An On-Line A/B Tester for Comparing User Interface Design Alternatives. Proc. ACM Hum.-Comput. Interact. 3, EICS, Article 18 (jun 2019), 28 pages. https://doi.org/10.1145/3331160
[157] Deepak Kumar Vasthimal, Pavan Kumar Srirama, and Arun Kumar Akkinapalli. 2019. Scalable Data Reporting Platform for A/B Tests. In 2019 IEEE 5th Intl Conference on Big Data Security on Cloud (BigDataSecurity), IEEE Intl Conference on High Performance and Smart Computing, (HPSC) and IEEE Intl Conference on Intelligent Data and Security (IDS). 230-238. https://doi.org/10.1109/BigDataSecurity-HPSC-IDS. 2019.00052
[158] Daniel Walper, Julia Kassau, Philipp Methfessel, Timo Pronold, and Wolfgang Einhauser. 2020. Optimizing user inter-
faces in food production: gaze tracking is more sensitive for A-B-testing than behavioral data alone. In ACM Symposium on Eye Tracking Research and Applications (ETRA ’20 Short Papers). Association for Computing Machinery, New York, NY, USA, 1-4. https://doi.org/10.1145/3379156.3391351
[159] Jian Wang and David Hardtke. 2015. User Latent Preference Model for Better Downside Management in Recommender Systems. In Proceedings of the 24th International Conference on World Wide Web (Florence, Italy) (
[160] Weinan Wang and Xi Zhang. 2021. CONQ: CONtinuous Quantile Treatment Effects for Large-Scale Online Controlled Experiments. In Proceedings of the 14th ACM International Conference on Web Search and Data Mining (Virtual Event, Israel) (WSDM ’21). Association for Computing Machinery, New York, NY, USA, 202-210. https://doi.org/10.1145/ 3437963.3441779
[161] Yu Wang, Somit Gupta, Jiannan Lu, Ali Mahmoudzadeh, and Sophia Liu. 2019. On Heavy-user Bias in A/B Testing. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management (CIKM ’19). Association for Computing Machinery, New York, NY, USA, 2425-2428. https://doi.org/10.1145/3357384.3358143
[162] Zenan Wang, Carlos Carrion, Xiliang Lin, Fuhua Ji, Yongjun Bao, and Weipeng Yan. 2022. Adaptive Experimentation with Delayed Binary Feedback. In Proceedings of the ACM Web Conference 2022 (Virtual Event, Lyon, France) (WWW ’22). Association for Computing Machinery, New York, NY, USA, 2247-2255. https://doi.org/10.1145/3485447. 3512097
[163] Liang Wu and Mihajlo Grbovic. 2020. How Airbnb Tells You Will Enjoy Sunset Sailing in Barcelona? Recommendation in a Two-Sided Travel Marketplace. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval (Virtual Event, China) (SIGIR ’20). Association for Computing Machinery, New York, NY, USA, 2387-2396. https://doi.org/10.1145/3397271.3401444
[164] Yuhang Wu, Zeyu Zheng, Guangyu Zhang, Zuohua Zhang, and Chu Wang. 2022. Non-Stationary A/B Tests. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (Washington DC, USA) (KDD ’22). Association for Computing Machinery, New York, NY, USA, 2079-2089. https://doi.org/10.1145/3534678. 3539325
[165] Tong Xia, Sumit Bhardwaj, Pavel Dmitriev, and Aleksander Fabijan. 2019. Safe Velocity: A Practical Guide to Software Deployment at Scale using Controlled Rollout. In 2019 IEEE/ACM 41st International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP). 11-20. https://doi.org/10.1109/ICSE-SEIP.2019.00010
[166] Yuxiang Xie, Nanyu Chen, and Xiaolin Shi. 2018. False Discovery Rate Controlled Heterogeneous Treatment Effect Detection for Online Controlled Experiments. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery
[167] Yuxiang Xie, Meng Xu, Evan Chow, and Xiaolin Shi. 2021. How to Measure Your App: A Couple of Pitfalls and Remedies in Measuring App Performance in Online Controlled Experiments. In Proceedings of the 14 th ACM International Conference on Web Search and Data Mining (Virtual Event, Israel) (WSDM ’21). Association for Computing Machinery, New York, NY, USA, 949-957. https://doi.org/10.1145/3437963.3441742
[168] Ya Xu and Nanyu Chen. 2016. Evaluating Mobile Apps with A/B and Quasi A/B Tests. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (San Francisco, California, USA) (KDD ’16). Association for Computing Machinery, New York, NY, USA, 313-322. https://doi.org/10.1145/2939672.2939703
[169] Ya Xu, Nanyu Chen, Addrian Fernandez, Omar Sinno, and Anmol Bhasin. 2015. From Infrastructure to Culture: A/B Testing Challenges in Large Scale Social Networks. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (Sydney, NSW, Australia) (KDD ’15). Association for Computing Machinery, New York, NY, USA, 2227-2236. https://doi.org/10.1145/2783258.2788602
[170] Ye Xu, Zang Li, Abhishek Gupta, Ahmet Bugdayci, and Anmol Bhasin. 2014. Modeling Professional Similarity by Mining Professional Career Trajectories. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (New York, New York, USA) (KDD ’14). Association for Computing Machinery, New York, NY, USA, 1945-1954. https://doi.org/10.1145/2623330.2623368
[171] Yanbo Xu, Divyat Mahajan, Liz Manrao, Amit Sharma, and Emre Kıcıman. 2021. Split-Treatment Analysis to Rank Heterogeneous Causal Effects for Prospective Interventions. In Proceedings of the 14 th ACM International Conference on Web Search and Data Mining (Virtual Event, Israel) (WSDM ’21). Association for Computing Machinery, New York, NY, USA, 409-417. https://doi.org/10.1145/3437963.3441821
[172] Sezin Gizem Yaman, Myriam Munezero, Jürgen Münch, Fabian Fagerholm, Ossi Syd, Mika Aaltola, Christina Palmu, and Tomi Männistö. 2017. Introducing continuous experimentation in large software-intensive product and service organisations. Journal of Systems and Software 133 (2017), 195-211. https://doi.org/10.1016/j.jss.2017.07.009
[173] Wanshan Yang, Gemeng Yang, Ting Huang, Lijun Chen, and Youjian Eugene Liu. 2018. Whales, Dolphins, or Minnows? Towards the Player Clustering in Free Online Games Based on Purchasing Behavior via Data Mining Technique. In 2018 IEEE International Conference on Big Data (Big Data). 4101-4108. https://doi.org/10.1109/BigData.2018.8622067
[174] Runlong Ye, Pan Chen, Yini Mao, Angela Wang-Lin, Hammad Shaikh, Angela Zavaleta Bernuy, and Joseph Jay Williams. 2022. Behavioral Consequences of Reminder Emails on Students’ Academic Performance: A Real-World Deployment. In Proceedings of the 23rd Annual Conference on Information Technology Education (Chicago, IL, USA) (SIGITE ’22). Association for Computing Machinery, New York, NY, USA, 16-22. https://doi.org/10.1145/3537674.3554740
[175] Takeshi Yoneda, Shunsuke Kozawa, Keisuke Osone, Yukinori Koide, Yosuke Abe, and Yoshifumi Seki. 2019. Algorithms and System Architecture for Immediate Personalized News Recommendations. In IEEE/WIC/ACM International Conference on Web Intelligence (Thessaloniki, Greece) (WI ’19). Association for Computing Machinery, New York, NY,
[176] Scott W. H. Young. 2014. Improving Library User Experience with A/B Testing: Principles and Process. Weave: Journal of Library User Experience 1 (08 2014). https://doi.org/10.3998/weave.12535642.0001.101
[177] Miao Yu, Wenbin Lu, and Rui Song. 2020. A new framework for online testing of heterogeneous treatment effect.
[178] He Zhang and Muhammad Ali Babar. 2010. On Searching Relevant Studies in Software Engineering. In Proceedings of the 14 th International Conference on Evaluation and Assessment in Software Engineering (UK) (EASE’10). BCS Learning & Development Ltd., Swindon, GBR, 111-120.
[179] Zhenyu Zhao, Yan He, and Miao Chen. 2017. Inform Product Change through Experimentation with Data-Driven Behavioral Segmentation. In 2017 IEEE International Conference on Data Science and Advanced Analytics (DSAA). 69-78. https://doi.org/10.1109/DSAA. 2017.65
الملحق أ. قائمة الدراسات الأساسية
| معرف الورقة | مرجع | عنوان |
| 1 | [1] | اختبار غير معلمي تسلسلي للتجارب العشوائية عبر الإنترنت |
| 2 | [138] | كشف تأثيرات الشبكة: التوزيع العشوائي على التجارب العشوائية |
| ٣ | 91 | نتائج غير متوقعة في التجارب المنضبطة عبر الإنترنت |
| ٤ | [28] | كيف يمكن أن تسوء اختبارات A/B: التشخيص التلقائي للتجارب عبر الإنترنت غير الصالحة |
| ٥ | [127] | تعديل انحدار شجرة القرار المعزز لتقليل التباين في التجارب المسيطر عليها عبر الإنترنت |
| ٦ | ٨٨ | تجارب عبر الإنترنت تحت السيطرة موثوقة: خمسة نتائج محيرة مشروحة |
| ٧ | 89 | التجارب المنضبطة عبر الإنترنت على نطاق واسع |
| ٨ | [164] | اختبارات A/B غير الثابتة |
| 9 | 73 | اختبار الشبكة A/B: من أخذ العينات إلى التقدير |
| 10 | [166] | الكشف عن تأثير العلاج المتنوع مع التحكم في معدل الاكتشاف الخاطئ للتجارب المنضبطة عبر الإنترنت |
| 11 | ٥٤ | فخاخ التجريب التي يجب تجنبها في اختبار A/B للتخصيص عبر الإنترنت |
| 12 | [٣٨] | الاستدلال الإحصائي في التجارب المتحكم بها عبر الإنترنت ذات المرحلتين مع اختيار العلاج والتحقق |
| 13 | 23 | تحويل متسق لمقاييس النسبة لتجارب التحكم عبر الإنترنت بكفاءة |
| 14 | ١٦٠ | CONQ: تأثيرات العلاج الكمي المستمر للتجارب المنضبطة عبر الإنترنت على نطاق واسع |
| 15 | 60 | تشخيص عدم تطابق نسبة العينة في التجارب المنضبطة عبر الإنترنت: تصنيف وقواعد إرشادية للممارسين |
| 16 | [144] | إطار تنفيذ اختبار A/B لـ IPEAD |
| 17 | 82 | التجسس على اختبارات A/B: لماذا هو مهم، وماذا تفعل حيال ذلك |
| ١٨ | 85 | تعلم التركيبات الحساسة لمقاييس اختبار A/B |
| 19 | [47] | الجوانب العملية للحساسية في التجارب عبر الإنترنت مع مقاييس تفاعل المستخدم |
| 20 | [168] | تقييم التطبيقات المحمولة باستخدام اختبارات A/B واختبارات شبه A/B |
| 21 | ٣٩] | حول الاستدلال بعد الاختيار في اختبار A/B |
| ٢٢ | ٤٨ | التجريب عبر الإنترنت باستخدام مقاييس بديلة: إرشادات ودراسة حالة |
| 23 | ٤٤ | توقع تفاعل المستخدمين في المستقبل وتطبيقه لتحسين حساسية التجارب عبر الإنترنت |
| ٢٤ | ٥٨ | تطور التجريب المستمر في تطوير منتجات البرمجيات: من البيانات إلى منظمة مدفوعة بالبيانات على نطاق واسع |
| ٢٥ | 167 | كيفية قياس تطبيقك: بعض الفخاخ والعلاجات في قياس أداء التطبيق في التجارب المنضبطة عبر الإنترنت |
| 26 | 86 | الاختبار المتسلسل للتوقف المبكر للتجارب عبر الإنترنت |
| 27 | 40 | مقدرات الانكماش في التجارب عبر الإنترنت |
| ٢٨ | 77 | إطار مضاد للحقائق لاختبار A/B من جانب البائع في الأسواق |
| ٢٩ | ٤٥ | الدورية في تفاعل المستخدم مع محرك البحث وتطبيقها على التجارب المنضبطة عبر الإنترنت |
| 30 | ١٠٥ | تطوير البرمجيات لتكون مدفوعة بالتعلم الآلي باستخدام اختبارات A/B في العالم الحقيقي: التجارب، الرؤى، التحديات |
| 31 | ٤٦ | استخدام التأخير في تأثير العلاج لتحسين الحساسية والحفاظ على اتجاهية مقاييس التفاعل في تجارب A/B |
| ٣٢ | 79 | خوارزمية مطابقة الجوار الأقرب المعتمدة على التجمع لتحسين التحقق من A/A في التجارب عبر الإنترنت |
| ٣٣ | ١٠٩ | مقدرات موزونة بالتباين لتحسين الحساسية في التجارب عبر الإنترنت |
| ٣٤ |
|
اثنا عشر قذراً: اثنا عشر فخاً شائعاً في تفسير القياسات في التجارب المسيطر عليها عبر الإنترنت |
| ٣٥ | 100 | لعنة الفائز: تقدير التحيز للتأثيرات الكلية للميزات في التجارب المنضبطة عبر الإنترنت |
| ٣٦ | [169] | من البنية التحتية إلى الثقافة: تحديات اختبار A/B في الشبكات الاجتماعية الكبيرة |
| 37 | 83 | اختبار تسلسلي لاختيار النسخة الأفضل: اختبار A/B عبر الإنترنت، التخصيص التكيفي، والمراقبة المستمرة |
| ٣٨ | 146 | تجارب غير متحيزة في الشبكات المزدحمة |
| ٣٩ | 154 | اختيار العلاج المخصص باستخدام التباين السببي |
| 40 | ١١٢ | ما وراء معدل النجاح: الفائدة كمقياس لجودة البحث للتجارب عبر الإنترنت |
| 41 | [175] | الخوارزميات وهندسة النظام لتوصيات الأخبار الشخصية الفورية |
| 42 | [106] | التجريب في نظام التشغيل: منصة تجريب ويندوز |
| 43 |
|
AB4Web: أداة اختبار A/B على الإنترنت لمقارنة بدائل تصميم واجهة المستخدم |
| ٤٤ | 123 | نشر المنتج في العالم الحقيقي لجدولة الإشعارات التكيفية على الهواتف الذكية |
| ٤٥ | 95 | تعدين النجوم: تعلم تقييمات الجودة مع تفسيرات موجهة للمستخدمين لإيجارات العطلات |
| ٤٦ | 43 | نحو عمليات تطوير مدعومة بالتوأم الرقمي للأنظمة السيبرانية الفيزيائية تقدم تكيف الخدمة القائم على الهندسة المعمارية والتحقق في وقت التشغيل |
| ٤٧ |
|
التجريب التكيفي مع ردود الفعل الثنائية المتأخرة |
| ٤٨ | [108] | توحيد الاستدلال السببي غير المتصل وتعلم الباندت عبر الإنترنت من أجل اتخاذ قرارات مدفوعة بالبيانات |
| ٤٩ | [9] | ما وراء البيانات: من معلومات المستخدم إلى قيمة الأعمال من خلال التوصيات الشخصية وعلوم المستهلك |
| 50 | ١٠٢ | تعلم تجميع الطلبات بشكل استباقي لتوصيل الوجبات عند الطلب |
| 51 |
|
قياس التأثيرات الديناميكية للإعلانات المعروضة في غياب معلومات تتبع المستخدم |
| 52 | 15 | تقييم حملة التسويق في الإعلانات المعروضة المستهدفة |
| 53 | 121 | تحسين الصفحة بالكامل: كيف تتفاعل عناصر الصفحة مع مزاد الموضع |
| ٥٤ | 131 | إطار MOOClet: توحيد التجريب، التحسين الديناميكي، والتخصيص في الدورات التدريبية عبر الإنترنت |
| ٥٥ | [171] | تحليل العلاج المقسم لتصنيف التأثيرات السببية المتنوعة للتدخلات المستقبلية |
| ٥٦ | 99 | تعزيز تجربة إيجابية بعد النقر لمستخدمي ياهو جيميني في البث |
| ٥٧ | ١٣٤ | توقع العواقب المضادة من بيانات تاريخية كبيرة وتجارب عشوائية صغيرة |
| ٥٨ | 148 | شبكة المؤشر متعددة المصادر لتلخيص عناوين المنتجات |
| ٥٩ | ٣٣ | ما وراء تصنيف الأهمية: إطار عمل عام لمطابقة الرسوم البيانية للتعلم القائم على الفائدة |
| 60 | 72 | التقييم غير المتصل لاتخاذ قرارات حول خوارزميات توصية قوائم التشغيل |
| 61 | 74 | تجارب موثوقة تحت فقدان التليمتر |
| 62 | [70] | نظام توصيات نتفليكس: الخوارزميات، القيمة التجارية، والابتكار |
| 63 | [139] | بيفروست: دعم النشر المستمر من خلال تنفيذ آلي لاستراتيجيات الاختبار الحي متعددة المراحل |
| 64 | 66 | CompactETA: نظام استدلال سريع لتوقع وقت السفر |
| 65 | 14 | تصميم وتحليل تجارب القياس المرجعي للخدمات الإنترنت الموزعة |
| 66 | 52 | تعلم الترتيب في النموذج القائم على الموضع مع ملاحظات البانديت |
| 67 | 20] | VisRel: البحث الإعلامي على نطاق واسع |
| 68 | 174 | العواقب السلوكية لرسائل التذكير على الأداء الأكاديمي للطلاب: نشر في العالم الحقيقي |
| 69 | [107] | توصية المحتوى من خلال تعلم نقل التباين الضوضائي لتمثيل الميزات |
| 70 | 63 | التقييم الخارجي لنماذج الترتيب تحت انحياز الموقف الشديد |
| 71 | 155 | معالجة مشاكل التهام الإعلانات عبر الإنترنت |
| 72 | [150] | ملء فجوات مفردات السياق الإعلاني بسجلات النقر |
| 73 | 65 | دروس عملية من تطوير نظام توصية على نطاق واسع في زالاندو |
| 74 | [163] | كيف تخبرك Airbnb أنك ستستمتع بالإبحار عند غروب الشمس في برشلونة؟ توصية في سوق السفر ذي الجانبين |
| 75 | [170] | نمذجة التشابه المهني من خلال استخراج مسارات الحياة المهنية |
| 76 | [27] | تحسين الحوافز الاجتماعية في الشبكات الاجتماعية عبر الإنترنت |
| 77 | [143] | تخفيف إغلاق الإعلانات لتحسين تجربة المستخدم في الإعلانات الأصلية |
| 78 | [126] | التقييم غير المتصل مقابل التقييم المتصل لأنظمة التوصية في التجارة الإلكترونية الصغيرة |
| 79 | [2] | ليزر: منصة قابلة للتوسع لتوقع الاستجابة للإعلانات عبر الإنترنت |
| ٨٠ | [5] | دور الصلة في البحث المدعوم |
| 81 | [135] | تطبيقات اللصوص السياقية في روبوت دعم العملاء |
| 82 | [165] | السرعة الآمنة: دليل عملي لنشر البرمجيات على نطاق واسع باستخدام التوزيع المنضبط |
| 83 | [149] | عندما لا تكون الصلة كافية: تعزيز التنوع والحداثة في توصية الأسئلة المخصصة |
| 84 | [103] | التداخل، والتحيز، والتباين في تجارب الأسواق ذات الجانبين: إرشادات للمنصات |
| 85 | [120] | اختبار A/B في صناعة السيارات: التحديات والدروس المستفادة من الممارسة |
| 86 | [21] | اختبار A/B في SweetIM: أهمية التحليل الإحصائي الصحيح |
| 87 | ٣٦] | نموذج إطار لدعم اختبارات A/B على مستوى الصف والمكون |
| ٨٨ | [81] | التحليل الإحصائي للبيانات الكبيرة الناتجة عن المستخدمين مع زيادة صفرية وانحراف يميني في اختبار A/B |
| 89 | [111] | الحجم مهم؟ أم لا؟
|
| 90 | [157] | منصة تقارير بيانات قابلة للتوسع لاختبارات A/B |
| 91 | 18 | تطبيق تقدير المعلمات بايزي
|
| 92 | [7] | تحسينات مدفوعة بالتجارب في تعليم الآلة بمشاركة الإنسان عبر الأساس القائم على الأهمية
|
| 93 | 76 | تشريح منصة تجارب واسعة النطاق |
| 94 | 11 | فك غموض المادة المظلمة للتجارب عبر الإنترنت |
| 95 | 71 | تجارب محكومة لاتخاذ القرار في بحث التجارة الإلكترونية |
| 96 | 98 | تقييم قابلية استخدام تطبيق ويب: تحليل مقارن للأدوات مفتوحة المصدر |
| 97 | ٢٩ | تجارب عبر الإنترنت أسرع من خلال القضاء على التحقق التقليدي A/A |
| 98 | 41 | مخاطر التجارب الطويلة الأمد التي تجرى عبر الإنترنت |
| 99 | [147] | SoftSKU: تحسين هياكل الخادم لتنوع الخدمات الصغيرة على نطاق واسع |
| 100 | [57] | فوائد التجارب المنضبطة على نطاق واسع |
| ١٠١ | [141] | تكييف السياق لأنظمة التوصية الذكية |
| ١٠٢ | [173] | الحيتان، الدلافين، أم الأسماك الصغيرة؟ نحو تجميع اللاعبين في الألعاب المجانية عبر الإنترنت بناءً على سلوك الشراء من خلال تقنية تنقيب البيانات |
| ١٠٣ | [110] | التجارب المنضبطة على مستوى المؤسسات على نطاق واسع: التحديات والحلول |
| ١٠٤ | 19 | هل يجب على الشركات تقديم عروض على علامتها التجارية في البحث المدعوم؟ |
| ١٠٥ | 78] | طريقة كشف الشواذ الاحتمالية المستقلة عن الآلية للتجارب عبر الإنترنت |
| ١٠٦ | [179] | إبلاغ تغيير المنتج من خلال التجريب مع تقسيم سلوكي قائم على البيانات |
| ١٠٧ | [118] | نظامك يتحسن كل يوم تستخدمه: نحو التجريب المستمر الآلي |
| ١٠٨ | [26] | أنظمة توصية الموضة، النماذج والأساليب: مراجعة |
| ١٠٩ | [8] | تقنيات تخصيص سطر الموضوع وتأثيرها على معدل فتح البريد الإلكتروني |
| ١١٠ | [114] | أثر المحتوى الترويجي على وسائل التواصل الاجتماعي على معدل النقر – دليل من شركة السلع الاستهلاكية سريعة الحركة |
| 111 | [6] | توسيع الكيانات ذات الصلة وترتيبها باستخدام الرسم البياني المعرفي |
| ١١٢ | [24] | LinkLouvain: اختبار A/B مع الوعي بالروابط وتطبيقه على حملات التسويق عبر الإنترنت |
| 113 | [122] | Ascend بواسطة Evolv: تحسين معدل التحويل القائم على الذكاء الاصطناعي متعدد المتغيرات بشكل كبير |
| 114 | ١٧٧ | إطار جديد للاختبار عبر الإنترنت لتأثير العلاج المتنوع |
| ١١٥ | [153] | الجائزة الكبرى: التجريب عبر الإنترنت لخدمات الميكروسيرفيس السحابية |
| ١١٦ | 75] | فعالية التسويق الرقمي باستخدام الزيادة |
| ١١٧ | [137] | تحسين عمليات الأعمال باستخدام منهجية AB-BPM |
| ١١٨ | [50] | خوارزمية جينية للعثور على مجموعة صغيرة ومتنوعة من الأخبار الحديثة حول موضوع معين: كيف نولد تنبيه الذكاء الاصطناعي لـ aaai |
| ١١٩ | 97 | قياس قيمة روابط التوصية على طلب المنتج |
| ١٢٠ | ٥٦ | نمو التجريب: تطور موثوق
|
| 121 | ١٤٠ | التقييم عبر الإنترنت لنماذج توقع العطاءات في منصة إعلانات حاسوبية واسعة النطاق: اتخاذ القرار والرؤى |
| ١٢٢ | [136] | AB-BPM: توجيه الحالات المدفوع بالأداء لتحسين العمليات التجارية |
| 123 | ٤٩ | احصل على كلا الجانبين – من اختبار A/B إلى اختبار A&B مع تعدين النماذج الاستثنائية |
| ١٢٤ | [117] | المزيد مقابل القليل: التجارب الآلية في الأنظمة المعتمدة على البرمجيات |
| ١٢٥ | 30 | شجرة الانحدار لنماذج اللصوص في اختبار A/B |
| ١٢٦ | [125] | عندما لا تكون الحشود كافية: تحسين تجربة المستخدم مع وسائل التواصل الاجتماعي من خلال التحليل التلقائي للجودة |
| 127 | [22] | تحليل كفاءة البكسل: نهج تحليلات الويب الكمية |
| 128 | 96 | اختبار A/B في عمليات مبيعات التجارة الإلكترونية |
| ١٢٩ | [124] | طريقة لبناء معرفة استهداف المستخدم لمواقع صناعة B2B |
| ١٣٠ | [128] | تحقق من تصاميم الهواتف المحمولة من خلال الاختبار السريع في الصين: استنادًا إلى خريطة بايدو للهواتف المحمولة |
| 131 | [159] | نموذج تفضيل المستخدم الكامن لإدارة أفضل للجانب السلبي في أنظمة التوصية |
| 132 | [151] | نحو اختبار A/B آلي |
| ١٣٣ | 90] | سبع قواعد عامة لمجربي مواقع الويب |
| ١٣٤ | [101] | تمكين اختبار A/B لتطبيقات الهواتف المحمولة الأصلية من خلال تبادل واجهة المستخدم عن بُعد |
| 135 | [152] | البنية التحتية للتجارب المتداخلة: المزيد، الأفضل، أسرع في التجارب |
| ١٣٦ | 67 | تحسين مستويات الأسعار في تطبيقات التجارة الإلكترونية: دراسة تجريبية |
| 137 | [25] | تسهيل الاختبارات المنضبطة لتغييرات تصميم الموقع: نهج منهجي |
| 138 | [3] | تحديد تردد ناعم لتحسين توقعات نقرات الإعلانات في ياهو جمني نيتيف |
| ١٣٩ | 37] | اختبار الفرضيات الثنائية البايزية الموضوعية للعينات في التجارب المنضبطة عبر الإنترنت |
| ١٤٠ | 64 | اختبار وتدوير: اختبارات A/B لتعظيم الأرباح |
| 141 | [176] | تحسين تجربة مستخدمي المكتبة من خلال اختبار A/B: المبادئ والعملية |
- *المؤلف المراسل
عناوين البريد الإلكتروني: فيدرico.quin@kuleuven.be (فيديريكو كوين)، داني.وينز@كوليفن.be (داني وينز)، ماثياس.غالستر@كانterbury.ac.nz (ماتياس غالستر)، camila.costasilva@pg.canterbury.ac.nz (كاميلا كوستا سيلفا) نستخدم مصطلح “ورقة بحثية” للإشارة إلى الأوراق التي اعتبرناها لتطبيق معايير الشمول والاستبعاد في المراجعة النظامية، ومصطلح “دراسة أولية” للأوراق البحثية التي اخترناها لاستخراج البيانات. الأوراق المنشورة في تنسيق ملاحظات المحاضرات في علوم الحاسوب مع تعتبر الصفحات أيضًا قصيرة. الأكاديمي يشير إلى الانتماءات التي تكون مؤهلة لتخريج طلاب الماجستير و/أو الدكتوراه. نميز بين البيانات المستخرجة من التقييم التجريبي في نظام حي والبيانات المستخرجة من المحاكاة أو مثال توضيحي لتقديم رؤى مستهدفة حول التنفيذ. اختبارات أثناء تحليل البيانات لـ SLR. استبعدنا التجارب والمقاييس المقابلة للدراسات الأساسية التي حللت عددًا كبيرًا من الدراسات السابقة التي أجريت. اختبارات.
التحويل هو إجراء مرغوب يتم في اختبار.
يرجى ملاحظة أن بعض الدراسات الأساسية لا تحدد بشكل صريح المقاييس بسبب حساسية الأعمال. استنادًا إلى المعلومات المتاحة في الدراسة، قمنا بتضمينها في مقاييس المشاركة العامة.
تُوصف النقرات الجيدة بأنها نقرات ذات معنى خلال جلسة استعلام البحث 20.
ومع ذلك، فقد أبلغت هذه الدراسات عن قيم p جنبًا إلى جنب مع النتائج، أو أشارت بشكل صريح إلى فترات الثقة والنتائج ذات الدلالة الإحصائية. اختبارات. انظر عنصر البيانات الهدف في القسم 4.2 للمراجع المحددة.
غير صالح يشير إلى التجارب المصممة بشكل سيء أو سوء تفسير النتائج المستخلصة من التجربة. يوفر التحليل المضاد للواقع إجابات حول السبب والنتيجة لمجموعة العلاج والنتائج المقابلة لها، مقارنة بما كان سيحدث لو لم يتم تطبيق العلاج. أو بدلاً من ذلك، ذكر صريح لعدم استخدام الطرق الإحصائية.
DOI: https://doi.org/10.1016/j.jss.2024.112011
Publication Date: 2024-02-22
A/B Testing: A Systematic Literature Review
Abstract
A/B testing, also referred to as online controlled experimentation or continuous experimentation, is a form of hypothesis testing where two variants of a piece of software are compared in the field from an end user’s point of view.
1. Introduction
2. Background and related work
2.1. Background
2.1.1. Controlled experiments vs
2.1.2. DevOps and
2.2. Related secondary studies
2.2.1. Summary of related reviews.
2.2.2. Aim of the study.
Issue: The design and execution of
Object: In software systems
Viewpoint: From the view point of researchers.
Concretely, we aim to investigate the subject of
3. Methodology
3.1. Research questions
RQ2: How are
RQ3: How are
3.2. Search query
3.3. Search strategy
3.4. Search process
IC1: Papers that either (1) have a primary focus on
IC2: Papers that include an assessment of the presented
We defined IC1 such that we only include works that are relevant to the posed research questions, i.e., it is essential that the work focuses on
EC1: Papers that report (systematic) literature reviews, surveys (using questionnaires), interviews, and roadmap papers;
EC2: Short papers (
EC4: Papers that provide no or only a very brief description of the
3.5. Data items
| Identifier | Data item | Purpose |
| D1 | Authors | Documentation |
| D2 | Year | Documentation |
| D3 | Title | Documentation |
| D4 | Venue | Documentation |
| D5 | Paper type | Documentation |
| D6 | Authors sector | Documentation |
| D7 | Quality score | Documentation |
| D8 | Application domain | RQ1 |
| D9 | A/B target | RQ1 |
| D10 | A/B test type | RQ2 |
| D11 | Used metrics | RQ2 |
| D12 | Statistical methods employed | RQ2 |
| D13 | Role of stakeholders in the experiment design | RQ2 |
| D14 | Additional data collected | RQ3 |
| D15 | Evaluation method | RQ3 |
| D16 | Use of test results | RQ3 |
| D17 | Role of stakeholder in experiment execution | RQ3 |
| D18 | Open problems | RQ4 |
| Type |
|
||
| Focus | 90 | ||
| Applied | 51 |
4. Results
4.1. Demographic information
| Background |
|
||
| Academic | 26 | ||
| Industry | 72 | ||
| Mixed | 43 |
|
|
||||
| Web | 38 | ||||
| Search engine | 35 | ||||
| E-commerce | 27 | ||||
| Interaction | 22 | ||||
| Finances | 16 | ||||
| Transportation | 4 | ||||
| Other | 8 | ||||
| N/A | 9 |
4.2. RQ1: What is the subject of
-
testing of algorithms is applied across all application domains and for all major domains it is the primary target of testing. Commonly tested algorithms include feed ranking algorithms for social media websites, recommendation algorithms for news/multimedia websites, search ranking algorithms
| A/B target | Description | Number of occurrences |
| Algorithm | Updated version of an algorithm such as a recommendation algorithm 175, a search ranking algorithm 86, or an ad serving algorithm 16. | 58 |
| Visual elements | Change to visual components such as updates to a website layout [22] or a general user interface update [40]. | 33 |
| Workflow / process | Alteration to the workflow of an application, e.g. the addition of a feedback button to a dashboard [110], or a change in a user workflow, e.g. the process of a virtual assistant tool 96 . | 28 |
| Back-end | Optimization of a software component that is not directly visible to the user, such as testing server optimizations [127] or adjusting application parameters for better performance 60 . | 10 |
| New application functionality | Newly introduced functionality, such as a new widget on a web-page [28] or additional content that is presented to the user after performing a search query [112]. | 6 |
| Other | This category comprises three other
|
3 |
| Unspecified | The target of the
|
32 |
|
Algorithm | Visual elements | Workflow / process | Back-end | New app. func. | Other | ||
| Web | 17 | 6 | 8 | 1 | 3 | 0 | ||
| Search engine | 17 | 16 | 3 | 6 | 2 | 0 | ||
| E-commerce | 10 | 2 | 7 | 0 | 0 | 1 | ||
| Interaction | 5 | 6 | 2 | 2 | 1 | 0 | ||
| Finances | 7 | 2 | 4 | 0 | 1 | 0 | ||
| Transportation | 2 | 0 | 0 | 1 | 1 | 0 | ||
| Other | 2 | 1 | 3 | 0 | 0 | 2 |
- A/B testing of visual elements is particularly popular for search engines ( 16 studies) compared to other application domains such as Web (with only 6 studies). Typical examples include changes to font color of search engine results
and changing the position of advertisements on the result page 121 . - Workflow and process elements as
target are commonly applied across the major domains. This target is particularly popular for the Web and E-commerce (with 8 and 7 studies, respectively). Typical examples are changes to the process in which best-performing advertisements are determined in JD’s advertisement platform, China’s largest online retailer 162, and changes to the order assignment policy for on-demand meal delivery platforms 102 . - For the Web and search engines, all types of
targets are applied. The main focus for the Web is on algorithms and workflow/processes, while the focus for search engines is on algorithms, visual elements, and back-end. For the Web, we notice only a single primary study with back-end as target. This study targets different microservice configurations in testing in order tune individual microservices for performance improvements [147. On the other hand, for search engines, we only noted three primary studies that target a workflow or process in testing. One study evaluated a change of wording in digital advertisements 18, one study evaluated a change in advertisement strategies 75), the last study evaluated the option to pay for “sponsored search” (to prioritize search results) 19. - For e-commerce, we noticed that
testing is mainly used to test changes to ranking and recommendation algorithms, and to processes such as virtual assistants. Notably, we only identified a single primary study that evaluated changes to the user interface 103. -
testing for back-end optimizations was identified to be most common for search engines, while we did not identify a paper in e-commerce and finances domain where testing was used for back-end changes.
4.3. RQ2: How are
4.3.1. Design of
| A/B metric |
|
||
| Engagement metrics | 225 | ||
| Click metrics | 82 | ||
| Monetary metrics | 64 | ||
| Performance metrics | 50 | ||
| Negative metrics | 34 | ||
| View metrics | 21 | ||
| Feedback metrics | 17 |
| Statistical methods employed | Number of occurrences |
| Hypothesis – equality | 57 |
| Hypothesis – equality (concrete method unspecified) | 37 |
| Bootstrapping | 11 |
| Hypothesis – inference | 8 |
| Goodness of fit | 8 |
| Correction method | 7 |
| Estimator | 6 |
| Hypothesis – independence | 5 |
| Regression method | 2 |
4.3.2. Role of stakeholders
4.3.3. Cross analysis
- The primary tasks of stakeholders across all types of
tests are the design and tune of variants, determining the duration of experiments, the population, and the goal or hypothesis. These numbers confirm that these are essential design tasks for any test. - A majority of the studies that use multi-armed
testing and sequence of tests report the design and tuning of variants as important stakeholder task ( 22 and 13 occurrences respectively).
| Role | Task | Task description | Occ. |
|
Design and tune variants | Designing and tuning the variants to test. Examples are tweaking the
|
67 |
| Determine goal or hypothesis | Formulating the goal or hypothesis of the
|
48 | |
| Perform pre-design actions | Actions that are taken before designing the
|
12 | |
| Setup technician (31) | Determine duration | Determining the duration of the
|
60 |
| Determine population assignment | Determining the population that should take part in the
|
51 | |
| Perform post-design actions | Actions that are taken after completing the design of the
|
25 | |
| Perform metric analysis and initialization | Analyzing and potentially initializing metrics for the
|
6 |
| Task | Single classic A/B test (95) | Multi-armed A/B test (30) | Sequence of A/B tests (24) | Multivariate A/B test (6) |
| Design and tune variants | 33 | 22 | 13 | 2 |
| Duration | 45 | 9 | 11 | 2 |
| Population assignment | 37 | 7 | 8 | 2 |
| Goal/hypothesis | 27 | 17 | 8 | 2 |
| Post-design actions | 12 | 1 | 5 | 0 |
| Pre-design actions | 6 | 4 | 2 | 1 |
| Metric analysis/init. | 5 | 1 | 0 | 0 |
| Method | Engag. | Click | Monetary | Negative | Perf. | View | Feedback |
| H – equality | 31 | 14 | 7 | 10 | 4 | 7 | 2 |
| H – equality (unsp.) | 24 | 12 | 8 | 8 | 11 | 5 | 5 |
| Bootstrapping | 9 | 2 | 2 | 3 | 3 | 1 | 1 |
| H – inference | 5 | 1 | 0 | 0 | 1 | 0 | 0 |
| Goodness of fit | 5 | 1 | 2 | 1 | 0 | 0 | 0 |
| Correction method | 4 | 1 | 1 | 1 | 2 | 0 | 1 |
| Estimator | 4 | 1 | 2 | 1 | 0 | 1 | 0 |
| H – independence | 2 | 2 | 3 | 0 | 0 | 1 | 0 |
| Regression method | 1 | 1 | 1 | 0 | 0 | 1 | 0 |
- Determining the goal or hypothesis for
testing is frequently mentioned for multi-armed tests ( 17 occurrences). In contrast to conventional two-variant testing that typically involves a control variant and an altered variant aimed at improving the control variant, multi-armed tests involve more than two variants, so practitioners often formulate hypotheses regarding the potential performance of each variant. - Post-design actions are more often reported for sequences of
tests ( 5 instances). For instance, one primary study mentions modeling the sequence of tests 139, another study mentions determining the success condition of the tests before executing them 151, and another study refers to providing an outcome range of the tests 152 . - Only a few primary studies report pre-design actions and metrics analysis and initialization, independently of the type of
test.
metrics vs statistical methods used. The statistical methods used across different types of metrics are shown in Table 11. - Engagement metrics and click metrics are used across all types of statistical methods.
- The concrete method used for hypothesis testing of equality is often not specified across all types of
metrics. For monetary and performance metrics in particular, a majority of studies do not mention the concrete hypothesis testing method ( 8 and 11 occurrences, respectively). This might be due to the sensitivity in reporting results for these types of metrics.
| Data collected |
|
||
| Product/system data | 48 | ||
| User-centric data | 26 | ||
| Spatial-temporal data | 20 | ||
| Secondary data | 6 |
- Negative metrics are primarily used for hypothesis equality tests ( 10 and 8 occurrences for hypothesis equality and hypothesis equality no method specified respectively).
- Hypothesis method for independence is most frequently used for the monetary metrics, yet, the use is uncommon (3 instances).
- The use of feedback metrics is also uncommon and if used, the specific statistical method used is not reported (5 occurrences).
Research question 2: How aretests designed? What is the role of stakeholders in this process? The primary type of test is a single classic test, followed by multi-armed tests and sequence of test. Engagement metrics are the dominating type of metrics used in testing. Other prominent metrics include click, monetary, and performance metrics. Hypothesis testing for equality is by far the most commonly used statistical method used in testing. Remarkable, about of these studies that test on equality do not specify the concrete method they use for that. Stakeholders have two main roles in the design of tests: concept designer and experiment architecture. Less frequently reported is a third role of setup technician.
4.4. RQ3: How are
4.4.1. Execution of
| Evaluation method |
|
||
| Empirical evaluation | 100 | ||
| Simulation based on real empirical data | 26 | ||
| Simulation | 15 | ||
| Illustrative example | 10 | ||
| Case study | 5 | ||
| Theoretical | 1 |
4.4.2. Role of stakeholders
4.4.3. Cross analysis
- Experiment supervision is applied regardless of the usages of test results. For feature rollout as a use of
test results, the task of experiment supervision is often mentioned. Supervision takes on a key task in this context to ensure that the rollout happens in a hazard-free manner (i.e., no harm is caused to users) 165, 28.
| Table 14: Use of test results gathered from
|
||
| Use of test results | Description | Occur. |
| Feature selection | The results of the
|
71 |
| Feature rollout | The results of the
|
24 |
| Continue feature development | The results of the
|
17 |
| Subsequent A/B test design | The results of the
|
15 |
| Validation effectiveness of
|
The results of the
|
12 |
| Validation of a research question |
|
10 |
| Bug detection / fixing | The results of the
|
5 |
| Subsequent
|
The results of the
|
4 |
| Unspecified | The use of the test results was not specified in the study. | 24 |
| Role | Task | Task description | Occ. |
| Experiment supervision | Monitoring and closely following up on the execution of A/B tests [151, 43. | 19 | |
| Experiment alteration | Altering aspects of the
|
12 | |
|
Experiment termination | Stopping
|
9 |
| Experiment post-analysis | Various steps that are taken after analyzing the results of the
|
17 | |
| Experiment triggering | Starting the execution of (subsequent)
|
13 | |
|
Other | This category encompasses a few niche tasks, such as documenting the findings and learning from conducting the
|
7 |
| Use | Supervision | Postanalysis | Triggering | Alteration | Termination |
| Feature selection | 8 | 11 | 6 | 8 | 4 |
| Feature rollout | 10 | 4 | 6 | 6 | 4 |
| Cont. feature dev. | 7 | 3 | 5 | 2 | 3 |
| A/B test design | 6 | 0 | 5 | 2 | 3 |
| Val. eff. A/B testing | 1 | 2 | 1 | 1 | 1 |
| Val. of a RQ | 1 | 1 | 0 | 1 | 1 |
| Bug detection/fixing | 4 | 0 | 3 | 2 | 2 |
| A/B test execution | 1 | 0 | 1 | 0 | 0 |
- The task of experiment post-analysis is typically only reported for experiments that are fully complete (i.e., do not go through additional rounds of iteration). In the primary studies where the results of the
tests are used for subsequent test design, no instances were identified where stakeholders take the task of performing post-analysis on the results of the experiments. - For subsequent
test design, the task of experiment triggering is often mentioned. This is to be expected since the newly designed tests also need to be executed. Additionally, test termination is also mentioned often (e.g., terminating an experiment due to bad results [76]). - In the case of bug fixing and detection, stakeholders typically supervise experiments (either to detect possible bugs in the code or ensure the bugfix is effective) [57, and trigger the experiments (i.e. launch an experiment explicitly to fix a known bug in the application) 105 .
- All tasks that stakeholders undertake in the execution of
tests are widely encountered in the case of empirical evaluation. - For the method of simulation based on real empirical data, the task of post-analysis is reported more often than any other task. An example is looking for outliers in the analysis of the results of
tests, and using historical experiments to confirm its effectiveness [78]. - Primary studies that use simulation as an evaluation method rarely specify the tasks stakeholders undertake in the execution of
tests. We hypothesize that, since simulations allow for a more controlled way of conducting tests, the tasks stakeholders undertake after the design of tests are not pertinent. - The only stakeholder task reported for theoretical evaluation is experiment alteration (primary study [121]).
| Task Method | Supervision | Postanalysis | Triggering | Alteration | Termination | Other |
| Empirical | 14 | 13 | 10 | 10 | 6 | 6 |
| Emp. sim. | 2 | 4 | 1 | 0 | 1 | 0 |
| Simulation | 1 | 1 | 1 | 0 | 0 | 0 |
| Ill. example | 2 | 0 | 1 | 2 | 2 | 1 |
| Case study | 0 | 0 | 0 | 0 | 0 | 0 |
| Theoretical | 0 | 0 | 0 | 1 | 0 | 0 |
| Open problem category | Open problem sub-category | Number of occurrences |
| Evaluation-related | Extend the evaluation | 21 |
| Provide thorough analysis of approach | 16 | |
| Other evaluation-related | 34 | |
| Process-related | Add process guidelines | 9 |
| Automate process | 7 | |
| Quality-related | Enhance scalability | 7 |
| Enhance applicability | 6 |
Research Question 3: How aretests executed in the system? What is the role of stakeholders in this process? The main types of data collected during the test execution relate to the product/system, users, and spatial-temporal aspects. The dominating evaluation method used in testing is empirical evaluation, but a relevant number of studies also use simulation. test results are primarily used for feature selection, followed by feature rollout, and continue feature development. (Automatic) subsequent test execution is only used marginally. The main reported roles of stakeholders in test execution is experiment contributor (with experiment supervisor as main task) and experiment assessor (with experiment post-analysis as main task).
4.5. RQ4: What are the reported open research problems in the field of
Table 18 present a categorization of open problems we have identified in the primary studies. For each category we devised concrete sub-categories of open problems. We elaborate on each type of open problem with illustrative examples.
4.5.1. Evaluation-related open problems
evaluated the proposed metrics on historical
4.5.2. Process-related open problems
to conduct
4.5.3. Quality-related open problems
Research Question 4: What are the reported open research problems in the field oftesting? The most commonly reported open problems directly related to the proposed approach, in particular improving the approach, extending the approach and providing a thorough analysis. Other less frequently reported open problems relate to the A/B testing process, in particular adding guidelines for the testing process, and automating the process. Finally, a number of studies report open problems regarding quality properties, specifically enhancing scalability and applicability of the proposed approach.
| Topic | Number of occurrences | Primary studies |
| Application of A/B testing | 51 | 175, 123, 95, 102, 16, 15, 121, 171, 99, 148, 33, 70, 66, 52, 20, 174, 107, 63, 155, 150, 65, 163, 170, 27, 143, 2, 5, 135, 149, 7, 98, 147, 141, 173, 19, 26, 8, 114, 6, 122, 50, 97, 136, 125, 22, 124, 128, 159, 67, 3, 176 , |
| Improving efficiency of A/B testing | 20 | [1, 28, 127, 164, 23, 85, 47, 39, 44, 86, 40, 45, 46, 109, 100, 83, 18, 78, 37, 64, |
| Beyond standard A/B testing | 18 |
|
| Concrete A/B testing problems | 17 | [138, 73, 168, 105, 146, 43, 162, 14, 103, 111, 71, 24, 153, 137, 96, 101, 25 |
| Pitfalls and challenges of A/B testing | 13 | 91, 88, 54, 60, 167, 42, 169, 120, 11, 41, 110, 140, 90 |
| Experimentation frameworks and platforms | 13 | 144, 154, 106, 156, 108, 9, 131, 74, 21, 36, 179, 177, 152 |
| A/B testing at scale | 9 | 89, 160, 58, 165, 81, 157, 76, 57, 56] |
5. Discussion
5.1. Research topics
5.1.1. Application of
5.1.2. Improving the efficiency of
| Environment |
|
||
| In-house experimentation system | 20 | ||
| Research tool or prototype | 13 | ||
| Commercial A/B testing tool | 10 | ||
| Commercial non A/B testing tool | 7 | ||
| User survey | 1 |
5.1.3. Beyond standard
5.1.4. Concrete
5.1.5. Pitfalls and challenges of
5.1.6. Experimentation frameworks and platforms
5.1.7.
5.2. Environments and tools used for
5.3. Research opportunities and future research directions
5.3.1. Improving the
5.3.2. Automation
5.3.3. Adoption and tailoring statistical methods
forward designing a custom statistical test for non-binomial
5.4. Threats to validity
5.4.1. Internal validity
5.4.2. External validity
5.4.3. Conclusion validity
5.4.4. Reliability
6. Conclusion
Acknowledgement
References
[2] Deepak Agarwal, Bo Long, Jonathan Traupman, Doris Xin, and Liang Zhang. 2014. LASER: A Scalable Response Prediction Platform for Online Advertising. In Proceedings of the 7th ACM International Conference on Web Search and Data Mining (New York, New York, USA) (WSDM ’14). Association for Computing Machinery, New York, NY, USA, 173-182. https://doi.org/10.1145/2556195.2556252
[3] Michal Aharon, Yohay Kaplan, Rina Levy, Oren Somekh, Ayelet Blanc, Neetai Eshel, Avi Shahar, Assaf Singer, and Alex Zlotnik. 2019. Soft Frequency Capping for Improved Ad Click Prediction in Yahoo Gemini Native. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management (Beijing, China) (CIKM ’19). Association for Computing Machinery, New York, NY, USA, 2793-2801. https://doi.org/10.1145/3357384.3357801
[4] Michal Aharon, Oren Somekh, Avi Shahar, Assaf Singer, Baruch Trayvas, Hadas Vogel, and Dobri Dobrev. 2019. Carousel Ads Optimization in Yahoo Gemini Native. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery
[5] Luca Aiello, Ioannis Arapakis, Ricardo Baeza-Yates, Xiao Bai, Nicola Barbieri, Amin Mantrach, and Fabrizio Silvestri. 2016. The Role of Relevance in Sponsored Search. In Proceedings of the 25th ACM International on Conference on Information and Knowledge Management (Indianapolis, Indiana, USA) (CIKM ’16). Association for Computing Machinery, New York, NY, USA, 185-194. https://doi.org/10.1145/2983323.2983840
[6] Ryuya Akase, Hiroto Kawabata, Akiomi Nishida, Yuki Tanaka, and Tamaki Kaminaga. 2021. Related Entity Expansion and Ranking Using Knowledge Graph. In Complex, Intelligent and Software Intensive Systems, Leonard Barolli, Kangbin Yim, and Tomoya Enokido (Eds.). Springer International Publishing, Cham, 172-184.
[7] Rafael Alfaro-Flores, José Salas-Bonilla, Loic Juillard, and Juan Esquivel-Rodríguez. 2021. Experiment-driven improvements in Human-in-the-loop Machine Learning Annotation via significance-based A/B testing. In 2021 XLVII Latin American Computing Conference (CLEI). 1-9. https://doi.org/10.1109/CLEI53233.2021.9639977
[8] Joana Almeida and Beatriz Casais. 2022. Subject Line Personalization Techniques and Their Influence in the E-Mail Marketing Open Rate. In Information Systems and Technologies, Alvaro Rocha, Hojjat Adeli, Gintautas Dzemyda, and Fernando Moreira (Eds.). Springer International Publishing, Cham, 532-540.
[9] Xavier Amatriain. 2013. Beyond Data: From User Information to Business Value through Personalized Recommendations and Consumer Science. In Proceedings of the 22nd ACM International Conference on Information & Knowledge Management (San Francisco, California, USA) (CIKM ’13). Association for Computing Machinery, New York, NY, USA, 2201-2208. https://doi.org/10.1145/2505515.2514701
[10] Apostolos Ampatzoglou, Stamatia Bibi, Paris Avgeriou, Marijn Verbeek, and Alexander Chatzigeorgiou. 2019. Identifying, categorizing and mitigating threats to validity in software engineering secondary studies. Information and Software Technology 106 (2019), 201-230. https://doi.org/10.1016/j.infsof.2018.10.006
[11] Nirupama Appiktala, Miao Chen, Michael Natkovich, and Joshua Walters. 2017. Demystifying dark matter for online experimentation. In 2017 IEEE International Conference on Big Data (Big Data). 1620-1626. https://doi.org/10. 1109/BigData. 2017.8258096
[12] F. Auer and M. Felderer. 2018. Current State of Research on Continuous Experimentation: A Systematic Mapping Study. In 2018 44th Euromicro Conference on Software Engineering and Advanced Applications (SEAA). IEEE Computer Society, Los Alamitos, CA, USA, 335-344. https://doi.org/10.1109/SEAA.2018.00062
[13] Florian Auer, Rasmus Ros, Lukas Kaltenbrunner, Per Runeson, and Michael Felderer. 2021. Controlled experimentation in continuous experimentation: Knowledge and challenges. Information and Software Technology 134 (2021), 106551. https://doi.org/10.1016/j.infsof. 2021.106551
[14] Eytan Bakshy and Eitan Frachtenberg. 2015. Design and Analysis of Benchmarking Experiments for Distributed Internet Services. In Proceedings of the 24th International Conference on World Wide Web (Florence, Italy) (WWW ’15). International World Wide Web Conferences Steering Committee, Republic and Canton of Geneva, CHE, 108-118. https: //doi.org/10.1145/2736277.2741082
[15] Joel Barajas, Jaimie Kwon, Ram Akella, Aaron Flores, Marius Holtan, and Victor Andrei. 2012. Marketing Campaign Evaluation in Targeted Display Advertising. In Proceedings of the Sixth International Workshop on Data Mining for Online Advertising and Internet Economy (Beijing, China) (ADKDD ’12). Association for Computing Machinery, New York, NY, USA, Article 5, 7 pages. https://doi.org/10.1145/2351356.2351361
[16] Joel Barajas, Jaimie Kwon, Ram Akella, Aaron Flores, Marius Holtan, and Victor Andrei. 2012. Measuring Dynamic Effects of Display Advertising in the Absence of User Tracking Information. In Proceedings of the Sixth International Workshop on Data Mining for Online Advertising and Internet Economy (Beijing, China) (ADKDD ’12). Association for Computing Machinery, New York, NY, USA, Article 8, 9 pages. https://doi.org/10.1145/2351356.2351364
[17] Victor R. Basili, Gianluigi Caldiera, and Dieter H. Rombach. 1994. The Goal Question Metric Approach. Vol. I. John Wiley & Sons.
[18] Tobias Blask. 2013. Applying Bayesian parameter estimation to
[19] Tobias Blask, Burkhardt Funk, and Reinhard Schulte. 2011. Should companies bid on their own brand in sponsored search?. In Proceedings of the International Conference on e-Business. 1-8.
[20] Fedor Borisyuk, Siddarth Malreddy, Jun Mei, Yiqun Liu, Xiaoyi Liu, Piyush Maheshwari, Anthony Bell, and Kaushik Rangadurai. 2021. VisRel: Media Search at Scale. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery
[21] Slava Borodovsky and Saharon Rosset. 2011. A/B Testing at SweetIM: The Importance of Proper Statistical Analysis. In 2011 IEEE 11th International Conference on Data Mining Workshops. 733-740. https://doi.org/10.1109/ICDMW. 2011.19
[22] Alex Brown, Binky Lush, and Bernard J. Jansen. 2016. Pixel efficiency analysis: A quantitative web analytics approach. Proceedings of the Association for Information Science and Technology 53, 1 (2016), 1-10. https://doi.org/10.1002/ pra2.2016.14505301040 arXiv:https://asistdl.onlinelibrary.wiley.com/doi/pdf/10.1002/pra2.2016.14505301040
[23] Roman Budylin, Alexey Drutsa, Ilya Katsev, and Valeriya Tsoy. 2018. Consistent Transformation of Ratio Metrics for Efficient Online Controlled Experiments. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining (Marina Del Rey, CA, USA) (WSDM ’18). Association for Computing Machinery, New York, NY, USA, 55-63. https://doi.org/10.1145/3159652.3159699
[24] Tianchi Cai, Daxi Cheng, Chen Liang, Ziqi Liu, Lihong Gu, Huizhi Xie, Zhiqiang Zhang, Xiaodong Zeng, and Jinjie Gu. 2021. LinkLouvain: Link-Aware A/B Testing and Its Application on Online Marketing Campaign. In Database Systems for Advanced Applications, Christian S. Jensen, Ee-Peng Lim, De-Nian Yang, Wang-Chien Lee, Vincent S. Tseng, Vana Kalogeraki, Jen-Wei Huang, and Chih-Ya Shen (Eds.). Springer International Publishing, Cham, 499-510.
[25] Javier Cámara and Alfred Kobsa. 2009. Facilitating Controlled Tests of Website Design Changes: A Systematic Approach. In Web Engineering, Martin Gaedke, Michael Grossniklaus, and Oscar Díaz (Eds.). Springer Berlin Heidelberg, Berlin, Heidelberg, 370-378.
[26] Samit Chakraborty, Md. Saiful Hoque, Naimur Rahman Jeem, Manik Chandra Biswas, Deepayan Bardhan, and Edgar Lobaton. 2021. Fashion Recommendation Systems, Models and Methods: A Review. Informatics 8, 3 (2021). https: //doi.org/10.3390/informatics8030049
[27] Guangde Chen, Bee-Chung Chen, and Deepak Agarwal. 2017. Social Incentive Optimization in Online Social Networks. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining (Cambridge, United Kingdom) (WSDM ’17). Association for Computing Machinery, New York, NY, USA, 547-556. https://doi.org/10. 1145/3018661.3018700
[28] Nanyu Chen, Min Liu, and Ya Xu. 2019. How A/B Tests Could Go Wrong: Automatic Diagnosis of Invalid Online Experiments. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining (Melbourne VIC, Australia) (WSDM ’19). Association for Computing Machinery, New York, NY, USA, 501-509. https://doi. org/10.1145/3289600.3291000
[29] Russell Chen, Miao Chen, Mahendrasinh Ramsinh Jadav, Joonsuk Bae, and Don Matheson. 2017. Faster online experimentation by eliminating traditional A/A validation. In 2017 IEEE International Conference on Big Data (Big Data). 1635-1641. https://doi.org/10.1109/BigData.2017.8258098
[30] Emmanuelle Claeys, Pierre Gançarski, Myriam Maumy-Bertrand, and Hubert Wassner. 2017. Regression Tree for Bandits Models in A/B Testing. In Advances in Intelligent Data Analysis XVI, Niall Adams, Allan Tucker, and David Weston (Eds.). Springer International Publishing, Cham, 52-62.
[31] Rafael Costa, Elie Cheniaux, Pedro Rosaes, Marcele Carvalho, Rafael Freire, Márcio Versiani, Bernard Range, and Antonio Nardi. 2011. The effectiveness of cognitive behavioral group therapy in treating bipolar disorder: A randomized controlled study. Revista brasileira de psiquiatria (São Paulo, Brazil : 1999) 33 (06 2011), 144-9. https://doi.org/ 10.1590/S1516-44462011000200009
[32] John Creswell and Timothy Guetterman. 2018. Educational Research: Planning, Conducting, and Evaluating Quantitative and Qualitative Research, 6th Edition. Pearson, New York, NY, USA.
[33] Xinyi Dai, Yunjia Xi, Weinan Zhang, Qing Liu, Ruiming Tang, Xiuqiang He, Jiawei Hou, Jun Wang, and Yong Yu. 2021. Beyond Relevance Ranking: A General Graph Matching Framework for Utility-Oriented Learning to Rank. ACM Trans. Inf. Syst. 40, 2, Article 25 (nov 2021), 29 pages. https://doi.org/10.1145/3464303
[34] Maya Daneva, Daniela Damian, Alessandro Marchetto, and Oscar Pastor. 2014. Empirical research methodologies and studies in Requirements Engineering: How far did we come? Journal of Systems and Software 95 (2014), 1-9. https://doi.org/10.1016/j.jss.2014.06.035
[35] Rico de Feijter, Rob van Vliet, Erik Jagroep, Sietse Overbeek, and Sjaak Brinkkemper. 2017. Towards the adoption of DevOps in software product organizations: A maturity model approach. Technical Report. Utrecht University.
[36] Wagner S. De Souza, Fernando O. Pereira, Vanessa G. Albuquerque, Jorge Melegati, and Eduardo Guerra. 2022. A Framework Model to Support A/B Tests at the Class and Component Level. In 2022 IEEE 46th Annual Computers, Software, and Applications Conference (COMPSAC). 860-865. https://doi.org/10.1109/COMPSAC54236.2022.00136
[37] Alex Deng. 2015. Objective Bayesian Two Sample Hypothesis Testing for Online Controlled Experiments. In Proceedings of the 24th International Conference on World Wide Web (Florence, Italy) (WWW ’15 Companion). Association for Computing Machinery, New York, NY, USA, 923-928. https://doi.org/10.1145/2740908.2742563
[38] Alex Deng, Tianxi Li, and Yu Guo. 2014. Statistical Inference in Two-Stage Online Controlled Experiments with Treatment Selection and Validation. In Proceedings of the 23rd International Conference on World Wide Web (Seoul, Korea) (
[39] Alex Deng, Yicheng Li, Jiannan Lu, and Vivek Ramamurthy. 2021. On Post-Selection Inference in
[40] Drew Dimmery, Eytan Bakshy, and Jasjeet Sekhon. 2019. Shrinkage Estimators in Online Experiments. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery
[41] Pavel Dmitriev, Brian Frasca, Somit Gupta, Ron Kohavi, and Garnet Vaz. 2016. Pitfalls of long-term online controlled experiments. In 2016 IEEE International Conference on Big Data (Big Data). 1367-1376. https://doi.org/10.1109/ BigData. 2016.7840744
[42] Pavel Dmitriev, Somit Gupta, Dong Woo Kim, and Garnet Vaz. 2017. A Dirty Dozen: Twelve Common Metric Interpretation Pitfalls in Online Controlled Experiments. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (Halifax, NS, Canada) (KDD ’17). Association for Computing Machinery, New York, NY, USA, 1427-1436. https://doi.org/10.1145/3097983.3098024
[43] Jürgen Dobaj, Andreas Riel, Thomas Krug, Matthias Seidl, Georg Macher, and Markus Egretzberger. 2022. Towards Digital Twin-Enabled DevOps for CPS Providing Architecture-Based Service Adaptation & Verification at Runtime. In Proceedings of the 17th Symposium on Software Engineering for Adaptive and Self-Managing Systems (Pittsburgh, Pennsylvania) (SEAMS ’22). Association for Computing Machinery, New York, NY, USA, 132-143. https://doi.org/ 10.1145/3524844.3528057
[44] Alexey Drutsa, Gleb Gusev, and Pavel Serdyukov. 2015. Future User Engagement Prediction and Its Application to Improve the Sensitivity of Online Experiments. In Proceedings of the 24th International Conference on World Wide Web (Florence, Italy) (
[45] Alexey Drutsa, Gleb Gusev, and Pavel Serdyukov. 2017. Periodicity in User Engagement with a Search Engine and Its Application to Online Controlled Experiments. ACM Trans. Web 11, 2, Article 9 (apr 2017), 35 pages. https: //doi.org/10.1145/2856822
[46] Alexey Drutsa, Gleb Gusev, and Pavel Serdyukov. 2017. Using the Delay in a Treatment Effect to Improve Sensitivity and Preserve Directionality of Engagement Metrics in A/B Experiments. In Proceedings of the 26 th International Conference on World Wide Web (Perth, Australia) (
[47] Alexey Drutsa, Anna Ufliand, and Gleb Gusev. 2015. Practical Aspects of Sensitivity in Online Experimentation with User Engagement Metrics. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management (Melbourne, Australia) (CIKM ’15). Association for Computing Machinery, New York, NY, USA, 763-772. https://doi.org/10.1145/2806416.2806496
[48] Weitao Duan, Shan Ba, and Chunzhe Zhang. 2021. Online Experimentation with Surrogate Metrics: Guidelines and a Case Study. In Proceedings of the 14 th ACM International Conference on Web Search and Data Mining (Virtual Event, Israel) (WSDM ’21). Association for Computing Machinery, New York, NY, USA, 193-201. https://doi.org/10.1145/ 3437963.3441737
[49] Wouter Duivesteijn, Tara Farzami, Thijs Putman, Evertjan Peer, Hilde J. P. Weerts, Jasper N. Adegeest, Gerson Foks, and Mykola Pechenizkiy. 2017. Have It Both Ways-From A/B Testing to A&B Testing with Exceptional Model Mining. In Machine Learning and Knowledge Discovery in Databases, Yasemin Altun, Kamalika Das, Taneli Mielikäinen, Donato Malerba, Jerzy Stefanowski, Jesse Read, Marinka Žitnik, Michelangelo Ceci, and Sašo Džeroski (Eds.). Springer International Publishing, Cham, 114-126.
[50] Joshua Eckroth and Eric Schoen. 2019. A genetic algorithm for finding a small and diverse set of recent news stories on a given subject: How we generate aaai’s ai-alert. 33rd AAAI Conference on Artificial Intelligence, AAAI 2019, 31st Innovative Applications of Artificial Intelligence Conference, IAAI 2019 and the 9th AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2019 (2019), 9357-9364. https://www.scopus.com/inward/record.uri? eid=2-s2.0-85090801224&partnerID=40&md5=f3391d595e00df8a0cba7802c9043ebd Cited by: 2.
[51] B. Efron and R.J. Tibshirani. 1994. An Introduction to the Bootstrap. CRC Press. https://books.google.be/books? id=MWC1DwAAQBAJ
[52] Beyza Ermis, Patrick Ernst, Yannik Stein, and Giovanni Zappella. 2020. Learning to Rank in the Position Based Model with Bandit Feedback. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management (Virtual Event, Ireland) (CIKM ’20). Association for Computing Machinery, New York, NY, USA, 2405-2412. https://doi.org/10.1145/3340531.3412723
[53] Vladimir M. Erthal, Bruno P. de Souza, Paulo Sérgio M. dos Santos, and Guilherme H. Travassos. 2022. A Literature Study to Characterize Continuous Experimentation in Software Engineering. CIbSE 2022-XXV Ibero-American Conference on Software Engineering (2022). https://www.scopus.com/inward/record.uri?eid=2-s2.0-85137064966& partnerID=40&md5=04240b73ab90eb841083173be558b33f Cited by: 0.
[54] Maria Esteller-Cucala, Vicenc Fernandez, and Diego Villuendas. 2019. Experimentation Pitfalls to Avoid in A/B Testing for Online Personalization. In Adjunct Publication of the 27th Conference on User Modeling, Adaptation and Personalization (Larnaca, Cyprus) (UMAP’19 Adjunct). Association for Computing Machinery, New York, NY, USA, 153-159. https://doi.org/10.1145/3314183.3323853
[55] Aleksander Fabijan, Benjamin Arai, Pavel Dmitriev, and Lukas Vermeer. 2021. It takes a Flywheel to Fly: Kickstarting and Growing the
[56] Aleksander Fabijan, Pavel Dmitriev, Colin McFarland, Lukas Vermeer, Helena Holmström Olsson, and Jan Bosch. 2018. Experimentation growth: Evolving trustworthy
[57] Aleksander Fabijan, Pavel Dmitriev, Helena Holmström Olsson, and Jan Bosch. 2017. The Benefits of Controlled Experimentation at Scale. In 2017 43rd Euromicro Conference on Software Engineering and Advanced Applications (SEAA). 18-26. https://doi.org/10.1109/SEAA. 2017.47
[58] Aleksander Fabijan, Pavel Dmitriev, Helena Holmström Olsson, and Jan Bosch. 2017. The Evolution of Continuous Experimentation in Software Product Development: From Data to a Data-Driven Organization at Scale. In Proceedings of the 39th International Conference on Software Engineering (Buenos Aires, Argentina) (ICSE ’17). IEEE Press, Los Alamitos, CA, USA, 770-780. https://doi.org/10.1109/ICSE.2017.76
[59] A. Fabijan, P. Dmitriev, H. Holmstrom Olsson, and J. Bosch. 2020. The Online Controlled Experiment Lifecycle. IEEE Software 37, 02 (mar 2020), 60-67. https://doi.org/10.1109/MS.2018.2875842
[60] Aleksander Fabijan, Jayant Gupchup, Somit Gupta, Jeff Omhover, Wen Qin, Lukas Vermeer, and Pavel Dmitriev. 2019. Diagnosing Sample Ratio Mismatch in Online Controlled Experiments: A Taxonomy and Rules of Thumb for Practitioners. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery 88 Data Mining (Anchorage, AK, USA) (KDD ’19). Association for Computing Machinery, New York, NY, USA, 2156-2164. https://doi.org/10.1145/3292500.3330722
[61] Aleksander Fabijan, Helena Holmström Olsson, and Jan Bosch. 2015. Customer Feedback and Data Collection Techniques in Software R&D: A Literature Review. In Software Business, João M. Fernandes, Ricardo J. Machado, and Krzysztof Wnuk (Eds.). Springer International Publishing, Cham, 139-153. https://doi.org/10.1007/978-3-319-19593-3_12
[62] Aleksander Fabijan, Helena Holmström Olsson, and Jan Bosch. 2016. The Lack of Sharing of Customer Data in Large Software Organizations: Challenges and Implications. In Agile Processes, in Software Engineering, and Ex-
treme Programming, Helen Sharp and Tracy Hall (Eds.). Springer International Publishing, Cham, 39-52. https: //doi.org/10.1007/978-3-319-33515-5_4
[63] Yaron Fairstein, Elad Haramaty, Arnon Lazerson, and Liane Lewin-Eytan. 2022. External Evaluation of Ranking Models under Extreme Position-Bias. In Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining (Virtual Event, AZ, USA) (WSDM ’22). Association for Computing Machinery, New York, NY, USA, 252-261. https://doi.org/10.1145/3488560.3498420
[64] Elea McDonnell Feit and Ron Berman. 2019. Test & Roll: Profit-Maximizing A/B Tests. Marketing Science 38, 6 (2019), 1038-1058. https://doi.org/10.1287/mksc.2019.1194
[65] Antonino Freno. 2017. Practical Lessons from Developing a Large-Scale Recommender System at Zalando. In Proceedings of the Eleventh ACM Conference on Recommender Systems (Como, Italy) (RecSys ’17). Association for Computing Machinery, New York, NY, USA, 251-259. https://doi.org/10.1145/3109859.3109897
[66] Kun Fu, Fanlin Meng, Jieping Ye, and Zheng Wang. 2020. CompactETA: A Fast Inference System for Travel Time Prediction. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery
[67] Burkhardt Funk. 2009. Optimizing price levels in e-commerce applications: An empirical study. ICETE 2009 – International Joint Conference on e-Business and Telecommunications (2009), 37-43. https://www.scopus.com/inward/ record.uri?eid=2-s2.0-74549181430&partnerID=40&md5=6dfdde67b807b3964c62fc8c1929dcf0 Cited by: 1.
[68] Matthias Galster and Danny Weyns. 2016. Empirical Research in Software Architecture: How Far have We Come?. In 2016 13th Working IEEE/IFIP Conference on Software Architecture (WICSA). IEEE Press, Los Alamitos, CA, USA, 11-20. https://doi.org/10.1109/WICSA.2016.10
[69] Federico Giaimo, Hugo Andrade, and Christian Berger. 2020. Continuous experimentation and the cyber-physical systems challenge: An overview of the literature and the industrial perspective. Journal of Systems and Software 170 (2020), 110781. https://doi.org/10.1016/j.jss.2020.110781
[70] Carlos A. Gomez-Uribe and Neil Hunt. 2016. The Netflix Recommender System: Algorithms, Business Value, and Innovation. ACM Trans. Manage. Inf. Syst. 6, 4, Article 13 (dec 2016), 19 pages. https://doi.org/10.1145/2843948
[71] Anjan Goswami, Wei Han, Zhenrui Wang, and Angela Jiang. 2015. Controlled experiments for decision-making in eCommerce search. In 2015 IEEE International Conference on Big Data (Big Data). IEEE Press, Los Alamitos, CA, USA, 1094-1102. https://doi.org/10.1109/BigData.2015.7363863
[72] Alois Gruson, Praveen Chandar, Christophe Charbuillet, James McInerney, Samantha Hansen, Damien Tardieu, and Ben Carterette. 2019. Offline Evaluation to Make Decisions About PlaylistRecommendation Algorithms. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining (Melbourne VIC, Australia) (WSDM ’19). Association for Computing Machinery, New York, NY, USA, 420-428. https://doi.org/10.1145/3289600.3291027
[73] Huan Gui, Ya Xu, Anmol Bhasin, and Jiawei Han. 2015. Network A/B Testing: From Sampling to Estimation. In Proceedings of the 24th International Conference on World Wide Web (Florence, Italy) (
[74] Jayant Gupchup, Yasaman Hosseinkashi, Pavel Dmitriev, Daniel Schneider, Ross Cutler, Andrei Jefremov, and Martin Ellis. 2018. Trustworthy Experimentation Under Telemetry Loss. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management (Torino, Italy) (CIKM ’18). Association for Computing Machinery, New York, NY, USA, 387-396. https://doi.org/10.1145/3269206.3271747
[75] Shubham Gupta and Sneha Chokshi. 2020. Digital Marketing Effectiveness Using Incrementality. In Advances in Computing and Data Sciences, Mayank Singh, P. K. Gupta, Vipin Tyagi, Jan Flusser, Tuncer Oren, and Gianluca Valentino (Eds.). Springer Singapore, Singapore, 66-75.
[76] Somit Gupta, Lucy Ulanova, Sumit Bhardwaj, Pavel Dmitriev, Paul Raff, and Aleksander Fabijan. 2018. The Anatomy of a Large-Scale Experimentation Platform. In 2018 IEEE International Conference on Software Architecture (ICSA). 1-109. https://doi.org/10.1109/ICSA. 2018.00009
[77] Viet Ha-Thuc, Avishek Dutta, Ren Mao, Matthew Wood, and Yunli Liu. 2020. A Counterfactual Framework for SellerSide A/B Testing on Marketplaces. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval (Virtual Event, China) (SIGIR ’20). Association for Computing Machinery, New York, NY, USA, 2288-2296. https://doi.org/10.1145/3397271.3401434
[78] Yan He and Miao Chen. 2017. A Probabilistic, Mechanism-Indepedent Outlier Detection Method for Online Experimentation. In 2017 IEEE International Conference on Data Science and Advanced Analytics (DSAA). 640-647. https://doi.org/10.1109/DSAA. 2017.64
[79] Yan He, Lin Yu, Miao Chen, William Choi, and Don Matheson. 2022. A Cluster-Based Nearest Neighbor Matching Algorithm for Enhanced A/A Validation in Online Experimentation. In Companion Proceedings of the Web Conference 2022 (Virtual Event, Lyon, France) (
[80] Jez Humble and David Farley. 2010. Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation (1st ed.). Addison-Wesley Professional, Illinois, IL, USA.
[81] Hao Jiang, Fan Yang, and Wutao Wei. 2020. Statistical Reasoning of Zero-Inflated Right-Skewed User-Generated Big Data A/B Testing. In 2020 IEEE International Conference on Big Data (Big Data). 1533-1544. https://doi.org/10. 1109/BigData50022.2020.9377996
[82] Ramesh Johari, Pete Koomen, Leonid Pekelis, and David Walsh. 2017. Peeking at A/B Tests: Why It Matters, and What to Do about It. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and
[83] Nianqiao Ju, Diane Hu, Adam Henderson, and Liangjie Hong. 2019. A Sequential Test for Selecting the Better Variant: Online A/B Testing, Adaptive Allocation, and Continuous Monitoring. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining (Melbourne VIC, Australia) (WSDM ’19). Association for Computing Machinery, New York, NY, USA, 492-500. https://doi.org/10.1145/3289600.3291025
[84] Staffs Keele et al. 2007. Guidelines for performing systematic literature reviews in software engineering. Technical Report. Technical report, Ver. 2.3 EBSE Technical Report. EBSE.
[85] Eugene Kharitonov, Alexey Drutsa, and Pavel Serdyukov. 2017. Learning Sensitive Combinations of A/B Test Metrics. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining (Cambridge, United Kingdom) (WSDM ’17). Association for Computing Machinery, New York, NY, USA, 651-659. https://doi.org/10. 1145/3018661.3018708
[86] Eugene Kharitonov, Aleksandr Vorobev, Craig Macdonald, Pavel Serdyukov, and Iadh Ounis. 2015. Sequential Testing for Early Stopping of Online Experiments. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval (Santiago, Chile) (SIGIR ’15). Association for Computing Machinery, New York, NY, USA, 473-482. https://doi.org/10.1145/2766462.2767729
[87] Rochelle King, Elizabeth F. Churchill, and Caitlin Tan. 2017. Designing with Data: Improving the User Experience with
[88] Ron Kohavi, Alex Deng, Brian Frasca, Roger Longbotham, Toby Walker, and Ya Xu. 2012. Trustworthy Online Controlled Experiments: Five Puzzling Outcomes Explained. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (Beijing, China) (KDD ’12). Association for Computing Machinery, New York, NY, USA, 786-794. https://doi.org/10.1145/2339530.2339653
[89] Ron Kohavi, Alex Deng, Brian Frasca, Toby Walker, Ya Xu, and Nils Pohlmann. 2013. Online Controlled Experiments at Large Scale. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (Chicago, Illinois, USA) (KDD ’13). Association for Computing Machinery, New York, NY, USA, 1168-1176. https://doi.org/10.1145/2487575.2488217
[90] Ron Kohavi, Alex Deng, Roger Longbotham, and Ya Xu. 2014. Seven Rules of Thumb for Web Site Experimenters. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (New York, New York, USA) (KDD ’14). Association for Computing Machinery, New York, NY, USA, 1857-1866. https: //doi.org/10.1145/2623330.2623341
[91] Ron Kohavi and Roger Longbotham. 2011. Unexpected Results in Online Controlled Experiments. SIGKDD Explor. Newsl. 12, 2 (mar 2011), 31-35. https://doi.org/10.1145/1964897.1964905
[92] Ron Kohavi and Roger Longbotham. 2017. Online Controlled Experiments and A/B Testing. Encyclopedia of machine learning and data mining 7,8 (2017), 922-929.
[93] Ron Kohavi, Roger Longbotham, Dan Sommerfield, and Randal Henne. 2009. Controlled experiments on the web: Survey and practical guide. Data Mining and Knowledge Discovery 18 (02 2009), 140-181. https://doi.org/10.1007/ s10618-008-0114-1
[94] Ron Kohavi, Diane Tang, and Ya Xu. 2020. Trustworthy Online Controlled Experiments: A Practical Guide to
[95] Anastasiia Kornilova and Lucas Bernardi. 2021. Mining the Stars: Learning Quality Ratings with User-Facing Explanations for Vacation Rentals. In Proceedings of the 14th ACM International Conference on Web Search and Data Mining (Virtual Event, Israel) (WSDM ’21). Association for Computing Machinery, New York, NY, USA, 976-983. https://doi.org/10.1145/3437963.3441812
[96] Kostantinos Koukouvis, Roberto Alcañiz Cubero, and Patrizio Pelliccione. 2016. A/B Testing in E-commerce Sales Processes. In Software Engineering for Resilient Systems, Ivica Crnkovic and Elena Troubitsyna (Eds.). Springer International Publishing, Cham, 133-148.
[97] Anuj Kumar and Kartik Hosanagar. 2017. Measuring the Value of Recommendation Links on Product Demand. SSRN Electronic Journal (01 2017). https://doi.org/10.2139/ssrn. 2909971
[98] Ratnakar Kumar and Nitasha Hasteer. 2017. Evaluating usability of a web application: A comparative analysis of opensource tools. In 2017 2nd International Conference on Communication and Electronics Systems (ICCES). 350-354. https://doi.org/10.1109/CESYS. 2017.8321296
[99] Mounia Lalmas, Janette Lehmann, Guy Shaked, Fabrizio Silvestri, and Gabriele Tolomei. 2015. Promoting Positive PostClick Experience for In-Stream Yahoo Gemini Users. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (Sydney, NSW, Australia) (KDD ’15). Association for Computing Machinery, New York, NY, USA, 1929-1938. https://doi.org/10.1145/2783258.2788581
[100] Minyong R. Lee and Milan Shen. 2018. Winner’s Curse: Bias Estimation for Total Effects of Features in Online Controlled Experiments. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery
[101] Florian Lettner, Clemens Holzmann, and Patrick Hutflesz. 2013. Enabling A/B Testing of Native Mobile Applications by Remote User Interface Exchange. In Computer Aided Systems Theory – EUROCAST 2013, Roberto Moreno-Díaz, Franz Pichler, and Alexis Quesada-Arencibia (Eds.). Springer Berlin Heidelberg, Berlin, Heidelberg, 458-466.
[102] Chengbo Li, Lin Zhu, Guangyuan Fu, Longzhi Du, Canhua Zhao, Tianlun Ma, Chang Ye, and Pei Lee. 2021. Learning to Bundle Proactively for On-Demand Meal Delivery. In Proceedings of the 30th ACM International Conference on Information
[103] Hannah Li, Geng Zhao, Ramesh Johari, and Gabriel Y. Weintraub. 2022. Interference, Bias, and Variance in TwoSided Marketplace Experimentation: Guidance for Platforms. In Proceedings of the ACM Web Conference 2022 (Virtual Event, Lyon, France) (
[104] Lihong Li, Jin Young Kim, and Imed Zitouni. 2015. Toward Predicting the Outcome of an A/B Experiment for Search Relevance. In Proceedings of the Eighth ACM International Conference on Web Search and Data Mining (WSDM ’15). Association for Computing Machinery, New York, NY, USA, 37-46. https://doi.org/10.1145/2684822.2685311
[105] Paul Luo Li, Xiaoyu Chai, Frederick Campbell, Jilong Liao, Neeraja Abburu, Minsuk Kang, Irina Niculescu, Greg Brake, Siddharth Patil, James Dooley, and Brandon Paddock. 2021. Evolving Software to be ML-Driven Utilizing RealWorld A/B Testing: Experiences, Insights, Challenges. In 2021 IEEE/ACM 43rd International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP). 170-179. https://doi.org/10.1109/ICSE-SEIP52600. 2021.00026
[106] Paul Luo Li, Pavel Dmitriev, Huibin Mary Hu, Xiaoyu Chai, Zoran Dimov, Brandon Paddock, Ying Li, Alex Kirshenbaum, Irina Niculescu, and Taj Thoresen. 2019. Experimentation in the Operating System: The Windows Experimentation Platform. In 2019 IEEE/ACM 41st International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP). 21-30. https://doi.org/10.1109/ICSE-SEIP.2019.00011
[107] Yiyang Li, Guanyu Tao, Weinan Zhang, Yong Yu, and Jun Wang. 2017. Content Recommendation by Noise Contrastive Transfer Learning of Feature Representation. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management (Singapore, Singapore) (CIKM ’17). Association for Computing Machinery, New York, NY, USA, 1657-1665. https://doi.org/10.1145/3132847.3132855
[108] Ye Li, Hong Xie, Yishi Lin, and John C.S. Lui. 2021. Unifying Offline Causal Inference and Online Bandit Learning for Data Driven Decision. In Proceedings of the Web Conference 2021 (Ljubljana, Slovenia) (WWW ’21). Association for Computing Machinery, New York, NY, USA, 2291-2303. https://doi.org/10.1145/3442381.3449982
[109] Kevin Liou and Sean J. Taylor. 2020. Variance-Weighted Estimators to Improve Sensitivity in Online Experiments. In Proceedings of the 21st ACM Conference on Economics and Computation (Virtual Event, Hungary) (EC ’20). Association for Computing Machinery, New York, NY, USA, 837-850. https://doi.org/10.1145/3391403.3399542
[110] Sophia Liu, Aleksander Fabijan, Michael Furchtgott, Somit Gupta, Pawel Janowski, Wen Qin, and Pavel Dmitriev. 2019. Enterprise-Level Controlled Experiments at Scale: Challenges and Solutions. In 2019 45th Euromicro Conference on Software Engineering and Advanced Applications (SEAA). 29-37. https://doi.org/10.1109/SEAA.2019.00013
[111] Yuchu Liu, David Issa Mattos, Jan Bosch, Helena Holmström Olsson, and Jonn Lantz. 2021. Size matters? Or not: A/B testing with limited sample in automotive embedded software. In 2021 47th Euromicro Conference on Software Engineering and Advanced Applications (SEAA). 300-307. https://doi.org/10.1109/SEAA53835.2021.00046
[112] Widad Machmouchi, Ahmed Hassan Awadallah, Imed Zitouni, and Georg Buscher. 2017. Beyond Success Rate: Utility as a Search Quality Metric for Online Experiments. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management (Singapore, Singapore) (CIKM ’17). Association for Computing Machinery, New York, NY, USA, 757-765. https://doi.org/10.1145/3132847.3132850
[113] Lech Madeyski, Wojciech Orzeszyna, Richard Torkar, and Mariusz Józala. 2014. Overcoming the Equivalent Mutant Problem: A Systematic Literature Review and a Comparative Experiment of Second Order Mutation. IEEE Transactions on Software Engineering 40, 1 (2014), 23-42. https://doi.org/10.1109/TSE. 2013.44
[114] Maria Madlberger and Jiri Jizdny. 2021. Impact of promotional social media content on click-through rate – Evidence from a FMCG company. 20th International Conferences on WWW/Internet 2021 and Applied Computing 2021 (2021), 3-10. https://www.scopus.com/inward/record.uri?eid=2-s2.0-85124068035&partnerID=40&md5= c0b8f49a3b48b3d561fd0ed305eb1895 Cited by: 0.
[115] Sara Mahdavi-Hezavehi, Vinicius H.S. Durelli, Danny Weyns, and Paris Avgeriou. 2017. A systematic literature review on methods that handle multiple quality attributes in architecture-based self-adaptive systems. Information and Software Technology 90 (2017), 1-26. https://doi.org/10.1016/j.infsof.2017.03.013
[116] Taisei Masuda, Kyoko Murakami, Kenkichi Sugiura, Sho Sakui, Ron Philip Schuring, and Mitsuhiro Mori. 2022. A phase
[117] David Issa Mattos, Jan Bosch, and Helena Holmström Olsson. 2017. More for Less: Automated Experimentation in Software-Intensive Systems. In Product-Focused Software Process Improvement, Michael Felderer, Daniel Méndez Fernández, Burak Turhan, Marcos Kalinowski, Federica Sarro, and Dietmar Winkler (Eds.). Springer International Publishing, Cham, 146-161.
[118] David Issa Mattos, Jan Bosch, and Helena Holmström Olsson. 2017. Your System Gets Better Every Day You Use It: Towards Automated Continuous Experimentation. In 2017 43rd Euromicro Conference on Software Engineering and Advanced Applications (SEAA). 256-265. https://doi.org/10.1109/SEAA.2017.15
[119] David Issa Mattos, Jan Bosch, and Helena Holmström Olsson. 2018. Challenges and Strategies for Undertaking Continuous Experimentation to Embedded Systems: Industry and Research Perspectives. In Agile Processes in Software Engineering and Extreme Programming, Juan Garbajosa, Xiaofeng Wang, and Ademar Aguiar (Eds.). Springer International Publishing, Cham, 277-292. https://doi.org/10.1007/978-3-319-91602-6_20
[120] David Issa Mattos, Jan Bosch, Helena Holmstrom Olsson, Aita Maryam Korshani, and Jonn Lantz. 2020. Automotive A/B testing: Challenges and Lessons Learned from Practice. In 2020 46th Euromicro Conference on Software Engineering and Advanced Applications (SEAA). 101-109. https://doi.org/10.1109/SEAA51224.2020.00026
[121] Pavel Metrikov, Fernando Diaz, Sebastien Lahaie, and Justin Rao. 2014. Whole Page Optimization: How Page Elements
[122] Risto Miikulainen, Myles Brundage, Jonathan Epstein, Tyler Foster, Babak Hodjat, Neil Iscoe, Jingbo Jiang, Diego Legrand, Sam Nazari, Xin Qiu, Michael Scharff, Cory Schoolland, Robert Severn, and Aaron Shagrin. 2020. Ascend by Evolv: AI-Based Massively Multivariate Conversion Rate Optimization. AI Magazine 41, 1 (Apr. 2020), 44-60. https://doi.org/10.1609/aimag.v41i1.5256
[123] Tadashi Okoshi, Kota Tsubouchi, and Hideyuki Tokuda. 2019. Real-World Product Deployment of Adaptive Push Notification Scheduling on Smartphones. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery
[124] Takumi Ozawa, Akiyuki Sekiguchi, and Kazuhiko Tsuda. 2016. A Method for the Construction of User Targeting Knowledge for B2B Industry Website. Procedia Computer Science 96 (2016), 1147-1155. https://doi.org/10.1016/ j.procs.2016.08.157 Knowledge-Based and Intelligent Information & Engineering Systems: Proceedings of the 20th International Conference KES-2016.
[125] Dan Pelleg, Oleg Rokhlenko, Idan Szpektor, Eugene Agichtein, and Ido Guy. 2016. When the Crowd is Not Enough: Improving User Experience with Social Media through Automatic Quality Analysis. In Proceedings of the 19th ACM Conference on Computer-Supported Cooperative Work & Social Computing (San Francisco, California, USA) (CSCW ’16). Association for Computing Machinery, New York, NY, USA, 1080-1090. https://doi.org/10.1145/2818048. 2820022
[126] Ladislav Peska and Peter Vojtas. 2020. Off-Line vs. On-Line Evaluation of Recommender Systems in Small E-Commerce. In Proceedings of the 31st ACM Conference on Hypertext and Social Media (Virtual Event, USA) (HT ’20). Association for Computing Machinery, New York, NY, USA, 291-300. https://doi.org/10.1145/3372923.3404781
[127] Alexey Poyarkov, Alexey Drutsa, Andrey Khalyavin, Gleb Gusev, and Pavel Serdyukov. 2016. Boosted Decision Tree Regression Adjustment for Variance Reduction in Online Controlled Experiments. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (San Francisco, California, USA) (KDD ’16). Association for Computing Machinery, New York, NY, USA, 235-244. https://doi.org/10.1145/2939672.2939688
[128] Jia Qu and Jing Zhang. 2016. Validating Mobile Designs with Agile Testing in China: Based on Baidu Map for Mobile. In Design, User Experience, and Usability: Design Thinking and Methods, Aaron Marcus (Ed.). Springer International Publishing, Cham, 491-498.
[129] Federico Quin, Danny Weyns, and Matthias Galster. 2023. Study Systematic Literature Review on A/B Testing. https: //people.cs.kuleuven.be/danny.weyns/material/SLR_AB/
[130] Jan Renz, Daniel Hoffmann, Thomas Staubitz, and Christoph Meinel. 2016. Using A/B testing in MOOC environments. In Proceedings of the Sixth International Conference on Learning Analytics 6 Knowledge (LAK ’16). Association for Computing Machinery, New York, NY, USA, 304-313. https://doi.org/10.1145/2883851.2883876
[131] Mohi Reza, Juho Kim, Ananya Bhattacharjee, Anna N. Rafferty, and Joseph Jay Williams. 2021. The MOOClet Framework: Unifying Experimentation, Dynamic Improvement, and Personalization in Online Courses. In Proceedings of the Eighth ACM Conference on Learning @ Scale (Virtual Event, Germany) (L@S ’21). Association for Computing Machinery, New York, NY, USA, 15-26. https://doi.org/10.1145/3430895.3460128
[132] Pilar Rodríguez, Alireza Haghighatkhah, Lucy Ellen Lwakatare, Susanna Teppola, Tanja Suomalainen, Juho Eskeli, Teemu Karvonen, Pasi Kuvaja, June M. Verner, and Markku Oivo. 2017. Continuous deployment of software intensive products and services: A systematic mapping study. Journal of Systems and Software 123 (2017), 263-291. https: //doi.org/10.1016/j.jss.2015.12.015
[133] Rasmus Ros and Per Runeson. 2018. Continuous Experimentation and A/B Testing: A Mapping Study. In Proceedings of the 4 th International Workshop on Rapid Continuous Software Engineering (Gothenburg, Sweden) (RCoSE ’18). Association for Computing Machinery, New York, NY, USA, 35-41. https://doi.org/10.1145/3194760.3194766
[134] Nir Rosenfeld, Yishay Mansour, and Elad Yom-Tov. 2017. Predicting Counterfactuals from Large Historical Data and Small Randomized Trials. In Proceedings of the 26th International Conference on World Wide Web Companion (Perth, Australia) (
[135] Sandra Sajeev, Jade Huang, Nikos Karampatziakis, Matthew Hall, Sebastian Kochman, and Weizhu Chen. 2021. Contextual Bandit Applications in a Customer Support Bot. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining (Virtual Event, Singapore) (KDD ’21). Association for Computing Machinery, New York, NY, USA, 3522-3530. https://doi.org/10.1145/3447548.3467165
[136] Suhrid Satyal, Ingo Weber, Hye-young Paik, Claudio Di Ciccio, and Jan Mendling. 2017. AB-BPM: Performance-Driven Instance Routing for Business Process Improvement. In Business Process Management, Josep Carmona, Gregor Engels, and Akhil Kumar (Eds.). Springer International Publishing, Cham, 113-129.
[137] Suhrid Satyal, Ingo Weber, Hye young Paik, Claudio Di Ciccio, and Jan Mendling. 2019. Business process improvement with the AB-BPM methodology. Information Systems 84 (2019), 283-298. https://doi.org/10.1016/j.is.2018.06. 007
[138] Martin Saveski, Jean Pouget-Abadie, Guillaume Saint-Jacques, Weitao Duan, Souvik Ghosh, Ya Xu, and Edoardo M. Airoldi. 2017. Detecting Network Effects: Randomizing Over Randomized Experiments. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (Halifax, NS, Canada) (KDD ’17). Association for Computing Machinery, New York, NY, USA, 1027-1035. https://doi.org/10.1145/3097983.3098192
[139] Gerald Schermann, Dominik Schöni, Philipp Leitner, and Harald C. Gall. 2016. Bifrost: Supporting Continuous De-
ployment with Automated Enactment of Multi-Phase Live Testing Strategies. In Proceedings of the 17 th International Middleware Conference (Trento, Italy) (Middleware ’16). Association for Computing Machinery, New York, NY, USA, Article 12, 14 pages. https://doi.org/10.1145/2988336.2988348
[140] Shahriar Shariat, Burkay Orten, and Ali Dasdan. 2017. Online Evaluation of Bid Prediction Models in a Large-Scale Computational Advertising Platform: Decision Making and Insights. Knowl. Inf. Syst. 51, 1 (apr 2017), 37-60. https: //doi.org/10.1007/s10115-016-0972-6
[141] Fanjuan Shi, Chirine Ghedira, and Jean-Luc Marini. 2015. Context Adaptation for Smart Recommender Systems. IT Professional 17, 6 (2015), 18-26. https://doi.org/10.1109/MITP. 2015.96
[142] Janet Siegmund, Norbert Siegmund, and Sven Apel. 2015. Views on Internal and External Validity in Empirical Software Engineering. In 2015 IEEE/ACM 37th IEEE International Conference on Software Engineering, Vol. 1. IEEE Press, Los Alamitos, CA, USA, 9-19. https://doi.org/10.1109/ICSE.2015.24
[143] Natalia Silberstein, Oren Somekh, Yair Koren, Michal Aharon, Dror Porat, Avi Shahar, and Tingyi Wu. 2020. Ad Close Mitigation for Improved User Experience in Native Advertisements. In Proceedings of the 13th International Conference on Web Search and Data Mining (Houston, TX, USA) (WSDM ’20). Association for Computing Machinery, New York, NY, USA, 546-554. https://doi.org/10.1145/3336191.3371798
[144] Jorge Gabriel Siqueira and Melise M. V. de Paula. 2018. IPEAD A/B Test Execution Framework. In Proceedings of the XIV Brazilian Symposium on Information Systems (Caxias do Sul, Brazil) (SBSI’18). Association for Computing Machinery, New York, NY, USA, Article 14, 8 pages. https://doi.org/10.1145/3229345.3229360
[145] Dan Siroker and Pete Koomen. 2013. A/B Testing: The Most Powerful Way to Turn Clicks Into Customers (1st ed.). Wiley Publishing, Hoboken, NJ, USA.
[146] Bruce Spang, Veronica Hannan, Shravya Kunamalla, Te-Yuan Huang, Nick McKeown, and Ramesh Johari. 2021. Unbiased Experiments in Congested Networks. In Proceedings of the 21st ACM Internet Measurement Conference (Virtual Event) (IMC ’21). Association for Computing Machinery, New York, NY, USA, 80-95. https://doi.org/10.1145/ 3487552.3487851
[147] Akshitha Sriraman, Abhishek Dhanotia, and Thomas F. Wenisch. 2019. SoftSKU: Optimizing Server Architectures for Microservice Diversity @Scale. In 2019 ACM/IEEE 46th Annual International Symposium on Computer Architecture (ISCA). 513-526.
[148] Fei Sun, Peng Jiang, Hanxiao Sun, Changhua Pei, Wenwu Ou, and Xiaobo Wang. 2018. Multi-Source Pointer Network for Product Title Summarization. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management (Torino, Italy) (CIKM ’18). Association for Computing Machinery, New York, NY, USA, 7-16. https: //doi.org/10.1145/3269206.3271722
[149] Idan Szpektor, Yoelle Maarek, and Dan Pelleg. 2013. When Relevance is Not Enough: Promoting Diversity and Freshness in Personalized Question Recommendation. In Proceedings of the 22nd International Conference on World Wide Web (Rio de Janeiro, Brazil) (
[150] Yukihiro Tagami, Toru Hotta, Yusuke Tanaka, Shingo Ono, Koji Tsukamoto, and Akira Tajima. 2014. Filling Context-Ad Vocabulary Gaps with Click Logs. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (New York, New York, USA) (KDD ’14). Association for Computing Machinery, New York, NY, USA, 1955-1964. https://doi.org/10.1145/2623330. 2623334
[151] Giordano Tamburrelli and Alessandro Margara. 2014. Towards Automated A/B Testing. In Search-Based Software Engineering, Claire Le Goues and Shin Yoo (Eds.). Springer International Publishing, Cham, 184-198.
[152] Diane Tang, Ashish Agarwal, Deirdre O’Brien, and Mike Meyer. 2010. Overlapping Experiment Infrastructure: More, Better, Faster Experimentation. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (Washington, DC, USA) (KDD ’10). Association for Computing Machinery, New York, NY, USA, 17-26. https://doi.org/10.1145/1835804.1835810
[153] Mert Toslali, Srinivasan Parthasarathy, Fabio Oliveira, and Ayse K. Coskun. 2020. JACKPOT: Online experimentation of cloud microservices. HotCloud 2020-12th USENIX Workshop on Hot Topics in Cloud Computing, co-located with USENIX ATC 2020 (2020). https://www.scopus.com/inward/record.uri?eid=2-s2.0-85091892156&partnerID=40& md5=cae12fe24f34f2bb0818e448f8c07fbf Cited by: 1.
[154] Ye Tu, Kinjal Basu, Cyrus DiCiccio, Romil Bansal, Preetam Nandy, Padmini Jaikumar, and Shaunak Chatterjee. 2021. Personalized Treatment Selection Using Causal Heterogeneity. In Proceedings of the Web Conference 2021 (Ljubljana, Slovenia) (WWW ’21). Association for Computing Machinery, New York, NY, USA, 1574-1585. https://doi.org/10. 1145/3442381.3450075
[155] Yutaro Ueoka, Kota Tsubouchi, and Nobuyuki Shimizu. 2020. Tackling Cannibalization Problems for Online Advertisement. In Proceedings of the 28th ACM Conference on User Modeling, Adaptation and Personalization (Genoa, Italy) (UMAP ’20). Association for Computing Machinery, New York, NY, USA, 358-362. https://doi.org/10.1145/ 3340631.3394875
[156] Jean Vanderdonckt, Mathieu Zen, and Radu-Daniel Vatavu. 2019. AB4Web: An On-Line A/B Tester for Comparing User Interface Design Alternatives. Proc. ACM Hum.-Comput. Interact. 3, EICS, Article 18 (jun 2019), 28 pages. https://doi.org/10.1145/3331160
[157] Deepak Kumar Vasthimal, Pavan Kumar Srirama, and Arun Kumar Akkinapalli. 2019. Scalable Data Reporting Platform for A/B Tests. In 2019 IEEE 5th Intl Conference on Big Data Security on Cloud (BigDataSecurity), IEEE Intl Conference on High Performance and Smart Computing, (HPSC) and IEEE Intl Conference on Intelligent Data and Security (IDS). 230-238. https://doi.org/10.1109/BigDataSecurity-HPSC-IDS. 2019.00052
[158] Daniel Walper, Julia Kassau, Philipp Methfessel, Timo Pronold, and Wolfgang Einhauser. 2020. Optimizing user inter-
faces in food production: gaze tracking is more sensitive for A-B-testing than behavioral data alone. In ACM Symposium on Eye Tracking Research and Applications (ETRA ’20 Short Papers). Association for Computing Machinery, New York, NY, USA, 1-4. https://doi.org/10.1145/3379156.3391351
[159] Jian Wang and David Hardtke. 2015. User Latent Preference Model for Better Downside Management in Recommender Systems. In Proceedings of the 24th International Conference on World Wide Web (Florence, Italy) (
[160] Weinan Wang and Xi Zhang. 2021. CONQ: CONtinuous Quantile Treatment Effects for Large-Scale Online Controlled Experiments. In Proceedings of the 14th ACM International Conference on Web Search and Data Mining (Virtual Event, Israel) (WSDM ’21). Association for Computing Machinery, New York, NY, USA, 202-210. https://doi.org/10.1145/ 3437963.3441779
[161] Yu Wang, Somit Gupta, Jiannan Lu, Ali Mahmoudzadeh, and Sophia Liu. 2019. On Heavy-user Bias in A/B Testing. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management (CIKM ’19). Association for Computing Machinery, New York, NY, USA, 2425-2428. https://doi.org/10.1145/3357384.3358143
[162] Zenan Wang, Carlos Carrion, Xiliang Lin, Fuhua Ji, Yongjun Bao, and Weipeng Yan. 2022. Adaptive Experimentation with Delayed Binary Feedback. In Proceedings of the ACM Web Conference 2022 (Virtual Event, Lyon, France) (WWW ’22). Association for Computing Machinery, New York, NY, USA, 2247-2255. https://doi.org/10.1145/3485447. 3512097
[163] Liang Wu and Mihajlo Grbovic. 2020. How Airbnb Tells You Will Enjoy Sunset Sailing in Barcelona? Recommendation in a Two-Sided Travel Marketplace. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval (Virtual Event, China) (SIGIR ’20). Association for Computing Machinery, New York, NY, USA, 2387-2396. https://doi.org/10.1145/3397271.3401444
[164] Yuhang Wu, Zeyu Zheng, Guangyu Zhang, Zuohua Zhang, and Chu Wang. 2022. Non-Stationary A/B Tests. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (Washington DC, USA) (KDD ’22). Association for Computing Machinery, New York, NY, USA, 2079-2089. https://doi.org/10.1145/3534678. 3539325
[165] Tong Xia, Sumit Bhardwaj, Pavel Dmitriev, and Aleksander Fabijan. 2019. Safe Velocity: A Practical Guide to Software Deployment at Scale using Controlled Rollout. In 2019 IEEE/ACM 41st International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP). 11-20. https://doi.org/10.1109/ICSE-SEIP.2019.00010
[166] Yuxiang Xie, Nanyu Chen, and Xiaolin Shi. 2018. False Discovery Rate Controlled Heterogeneous Treatment Effect Detection for Online Controlled Experiments. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery
[167] Yuxiang Xie, Meng Xu, Evan Chow, and Xiaolin Shi. 2021. How to Measure Your App: A Couple of Pitfalls and Remedies in Measuring App Performance in Online Controlled Experiments. In Proceedings of the 14 th ACM International Conference on Web Search and Data Mining (Virtual Event, Israel) (WSDM ’21). Association for Computing Machinery, New York, NY, USA, 949-957. https://doi.org/10.1145/3437963.3441742
[168] Ya Xu and Nanyu Chen. 2016. Evaluating Mobile Apps with A/B and Quasi A/B Tests. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (San Francisco, California, USA) (KDD ’16). Association for Computing Machinery, New York, NY, USA, 313-322. https://doi.org/10.1145/2939672.2939703
[169] Ya Xu, Nanyu Chen, Addrian Fernandez, Omar Sinno, and Anmol Bhasin. 2015. From Infrastructure to Culture: A/B Testing Challenges in Large Scale Social Networks. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (Sydney, NSW, Australia) (KDD ’15). Association for Computing Machinery, New York, NY, USA, 2227-2236. https://doi.org/10.1145/2783258.2788602
[170] Ye Xu, Zang Li, Abhishek Gupta, Ahmet Bugdayci, and Anmol Bhasin. 2014. Modeling Professional Similarity by Mining Professional Career Trajectories. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (New York, New York, USA) (KDD ’14). Association for Computing Machinery, New York, NY, USA, 1945-1954. https://doi.org/10.1145/2623330.2623368
[171] Yanbo Xu, Divyat Mahajan, Liz Manrao, Amit Sharma, and Emre Kıcıman. 2021. Split-Treatment Analysis to Rank Heterogeneous Causal Effects for Prospective Interventions. In Proceedings of the 14 th ACM International Conference on Web Search and Data Mining (Virtual Event, Israel) (WSDM ’21). Association for Computing Machinery, New York, NY, USA, 409-417. https://doi.org/10.1145/3437963.3441821
[172] Sezin Gizem Yaman, Myriam Munezero, Jürgen Münch, Fabian Fagerholm, Ossi Syd, Mika Aaltola, Christina Palmu, and Tomi Männistö. 2017. Introducing continuous experimentation in large software-intensive product and service organisations. Journal of Systems and Software 133 (2017), 195-211. https://doi.org/10.1016/j.jss.2017.07.009
[173] Wanshan Yang, Gemeng Yang, Ting Huang, Lijun Chen, and Youjian Eugene Liu. 2018. Whales, Dolphins, or Minnows? Towards the Player Clustering in Free Online Games Based on Purchasing Behavior via Data Mining Technique. In 2018 IEEE International Conference on Big Data (Big Data). 4101-4108. https://doi.org/10.1109/BigData.2018.8622067
[174] Runlong Ye, Pan Chen, Yini Mao, Angela Wang-Lin, Hammad Shaikh, Angela Zavaleta Bernuy, and Joseph Jay Williams. 2022. Behavioral Consequences of Reminder Emails on Students’ Academic Performance: A Real-World Deployment. In Proceedings of the 23rd Annual Conference on Information Technology Education (Chicago, IL, USA) (SIGITE ’22). Association for Computing Machinery, New York, NY, USA, 16-22. https://doi.org/10.1145/3537674.3554740
[175] Takeshi Yoneda, Shunsuke Kozawa, Keisuke Osone, Yukinori Koide, Yosuke Abe, and Yoshifumi Seki. 2019. Algorithms and System Architecture for Immediate Personalized News Recommendations. In IEEE/WIC/ACM International Conference on Web Intelligence (Thessaloniki, Greece) (WI ’19). Association for Computing Machinery, New York, NY,
[176] Scott W. H. Young. 2014. Improving Library User Experience with A/B Testing: Principles and Process. Weave: Journal of Library User Experience 1 (08 2014). https://doi.org/10.3998/weave.12535642.0001.101
[177] Miao Yu, Wenbin Lu, and Rui Song. 2020. A new framework for online testing of heterogeneous treatment effect.
[178] He Zhang and Muhammad Ali Babar. 2010. On Searching Relevant Studies in Software Engineering. In Proceedings of the 14 th International Conference on Evaluation and Assessment in Software Engineering (UK) (EASE’10). BCS Learning & Development Ltd., Swindon, GBR, 111-120.
[179] Zhenyu Zhao, Yan He, and Miao Chen. 2017. Inform Product Change through Experimentation with Data-Driven Behavioral Segmentation. In 2017 IEEE International Conference on Data Science and Advanced Analytics (DSAA). 69-78. https://doi.org/10.1109/DSAA. 2017.65
Appendix A. List of primary studies
| Paper ID | Reference | Title |
| 1 | [1] | A Nonparametric Sequential Test for Online Randomized Experiments |
| 2 | [138] | Detecting Network Effects: Randomizing Over Randomized Experiments |
| 3 | 91 | Unexpected Results in Online Controlled Experiments |
| 4 | [28] | How A/B Tests Could Go Wrong: Automatic Diagnosis of Invalid Online Experiments |
| 5 | [127] | Boosted Decision Tree Regression Adjustment for Variance Reduction in Online Controlled Experiments |
| 6 | 88 | Trustworthy Online Controlled Experiments: Five Puzzling Outcomes Explained |
| 7 | 89 | Online Controlled Experiments at Large Scale |
| 8 | [164] | Non-Stationary A/B Tests |
| 9 | 73 | Network A/B Testing: From Sampling to Estimation |
| 10 | [166] | False Discovery Rate Controlled Heterogeneous Treatment Effect Detection for Online Controlled Experiments |
| 11 | 54 | Experimentation Pitfalls to Avoid in A/B Testing for Online Personalization |
| 12 | [38] | Statistical Inference in Two-Stage Online Controlled Experiments with Treatment Selection and Validation |
| 13 | 23 | Consistent Transformation of Ratio Metrics for Efficient Online Controlled Experiments |
| 14 | 160 | CONQ: CONtinuous Quantile Treatment Effects for Large-Scale Online Controlled Experiments |
| 15 | 60 | Diagnosing Sample Ratio Mismatch in Online Controlled Experiments: A Taxonomy and Rules of Thumb for Practitioners |
| 16 | [144] | IPEAD A/B Test Execution Framework |
| 17 | 82 | Peeking at A/B Tests: Why It Matters, and What to Do about It |
| 18 | 85 | Learning Sensitive Combinations of A/B Test Metrics |
| 19 | [47] | Practical Aspects of Sensitivity in Online Experimentation with User Engagement Metrics |
| 20 | [168] | Evaluating Mobile Apps with A/B and Quasi A/B Tests |
| 21 | 39] | On Post-Selection Inference in A/B Testing |
| 22 | 48 | Online Experimentation with Surrogate Metrics: Guidelines and a Case Study |
| 23 | 44 | Future User Engagement Prediction and Its Application to Improve the Sensitivity of Online Experiments |
| 24 | 58 | The Evolution of Continuous Experimentation in Software Product Development: From Data to a Data-Driven Organization at Scale |
| 25 | 167 | How to Measure Your App: A Couple of Pitfalls and Remedies in Measuring App Performance in Online Controlled Experiments |
| 26 | 86 | Sequential Testing for Early Stopping of Online Experiments |
| 27 | 40 | Shrinkage Estimators in Online Experiments |
| 28 | 77 | A Counterfactual Framework for Seller-Side A/B Testing on Marketplaces |
| 29 | 45 | Periodicity in User Engagement with a Search Engine and Its Application to Online Controlled Experiments |
| 30 | 105 | Evolving Software to be ML-Driven Utilizing Real-World A/B Testing: Experiences, Insights, Challenges |
| 31 | 46 | Using the Delay in a Treatment Effect to Improve Sensitivity and Preserve Directionality of Engagement Metrics in A/B Experiments |
| 32 | 79 | A Cluster-Based Nearest Neighbor Matching Algorithm for Enhanced A/A Validation in Online Experimentation |
| 33 | 109 | Variance-Weighted Estimators to Improve Sensitivity in Online Experiments |
| 34 |
|
A Dirty Dozen: Twelve Common Metric Interpretation Pitfalls in Online Controlled Experiments |
| 35 | 100 | Winner’s Curse: Bias Estimation for Total Effects of Features in Online Controlled Experiments |
| 36 | [169] | From Infrastructure to Culture: A/B Testing Challenges in Large Scale Social Networks |
| 37 | 83 | A Sequential Test for Selecting the Better Variant: Online A/B Testing, Adaptive Allocation, and Continuous Monitoring |
| 38 | 146 | Unbiased Experiments in Congested Networks |
| 39 | 154 | Personalized Treatment Selection Using Causal Heterogeneity |
| 40 | 112 | Beyond Success Rate: Utility as a Search Quality Metric for Online Experiments |
| 41 | [175] | Algorithms and System Architecture for Immediate Personalized News Recommendations |
| 42 | [106] | Experimentation in the Operating System: The Windows Experimentation Platform |
| 43 |
|
AB4Web: An On-Line A/B Tester for Comparing User Interface Design Alternatives |
| 44 | 123 | Real-World Product Deployment of Adaptive Push Notification Scheduling on Smartphones |
| 45 | 95 | Mining the Stars: Learning Quality Ratings with User-Facing Explanations for Vacation Rentals |
| 46 | 43 | Towards Digital Twin-Enabled DevOps for CPS Providing Architecture-Based Service Adaptation & Verification at Runtime |
| 47 |
|
Adaptive Experimentation with Delayed Binary Feedback |
| 48 | [108] | Unifying Offline Causal Inference and Online Bandit Learning for Data Driven Decision |
| 49 | [9] | Beyond Data: From User Information to Business Value through Personalized Recommendations and Consumer Science |
| 50 | 102 | Learning to Bundle Proactively for On-Demand Meal Delivery |
| 51 |
|
Measuring Dynamic Effects of Display Advertising in the Absence of User Tracking Information |
| 52 | 15 | Marketing Campaign Evaluation in Targeted Display Advertising |
| 53 | 121 | Whole Page Optimization: How Page Elements Interact with the Position Auction |
| 54 | 131 | The MOOClet Framework: Unifying Experimentation, Dynamic Improvement, and Personalization in Online Courses |
| 55 | [171] | Split-Treatment Analysis to Rank Heterogeneous Causal Effects for Prospective Interventions |
| 56 | 99 | Promoting Positive Post-Click Experience for In-Stream Yahoo Gemini Users |
| 57 | 134 | Predicting Counterfactuals from Large Historical Data and Small Randomized Trials |
| 58 | 148 | Multi-Source Pointer Network for Product Title Summarization |
| 59 | 33 | Beyond Relevance Ranking: A General Graph Matching Framework for UtilityOriented Learning to Rank |
| 60 | 72 | Offline Evaluation to Make Decisions About PlaylistRecommendation Algorithms |
| 61 | 74 | Trustworthy Experimentation Under Telemetry Loss |
| 62 | [70] | The Netflix Recommender System: Algorithms, Business Value, and Innovation |
| 63 | [139] | Bifrost: Supporting Continuous Deployment with Automated Enactment of Multi-Phase Live Testing Strategies |
| 64 | 66 | CompactETA: A Fast Inference System for Travel Time Prediction |
| 65 | 14 | Design and Analysis of Benchmarking Experiments for Distributed Internet Services |
| 66 | 52 | Learning to Rank in the Position Based Model with Bandit Feedback |
| 67 | 20] | VisRel: Media Search at Scale |
| 68 | 174 | Behavioral Consequences of Reminder Emails on Students’ Academic Performance: A Real-World Deployment |
| 69 | [107] | Content Recommendation by Noise Contrastive Transfer Learning of Feature Representation |
| 70 | 63 | External Evaluation of Ranking Models under Extreme Position-Bias |
| 71 | 155 | Tackling Cannibalization Problems for Online Advertisement |
| 72 | [150] | Filling Context-Ad Vocabulary Gaps with Click Logs |
| 73 | 65 | Practical Lessons from Developing a Large-Scale Recommender System at Zalando |
| 74 | [163] | How Airbnb Tells You Will Enjoy Sunset Sailing in Barcelona? Recommendation in a Two-Sided Travel Marketplace |
| 75 | [170] | Modeling Professional Similarity by Mining Professional Career Trajectories |
| 76 | [27] | Social Incentive Optimization in Online Social Networks |
| 77 | [143] | Ad Close Mitigation for Improved User Experience in Native Advertisements |
| 78 | [126] | Off-Line vs. On-Line Evaluation of Recommender Systems in Small ECommerce |
| 79 | [2] | LASER: A Scalable Response Prediction Platform for Online Advertising |
| 80 | [5] | The Role of Relevance in Sponsored Search |
| 81 | [135] | Contextual Bandit Applications in a Customer Support Bot |
| 82 | [165] | Safe Velocity: A Practical Guide to Software Deployment at Scale using Controlled Rollout |
| 83 | [149] | When Relevance is Not Enough: Promoting Diversity and Freshness in Personalized Question Recommendation |
| 84 | [103] | Interference, Bias, and Variance in Two-Sided Marketplace Experimentation: Guidance for Platforms |
| 85 | [120] | Automotive A/B testing: Challenges and Lessons Learned from Practice |
| 86 | [21] | A/B Testing at SweetIM: The Importance of Proper Statistical Analysis |
| 87 | 36] | A Framework Model to Support A/B Tests at the Class and Component Level |
| 88 | [81] | Statistical Reasoning of Zero-Inflated Right-Skewed User-Generated Big Data A/B Testing |
| 89 | [111] | Size matters? Or not:
|
| 90 | [157] | Scalable Data Reporting Platform for A/B Tests |
| 91 | 18 | Applying Bayesian parameter estimation to
|
| 92 | [7] | Experiment-driven improvements in Human-in-the-loop Machine Learning Annotation via significance-based
|
| 93 | 76 | The Anatomy of a Large-Scale Experimentation Platform |
| 94 | 11 | Demystifying dark matter for online experimentation |
| 95 | 71 | Controlled experiments for decision-making in e-Commerce search |
| 96 | 98 | Evaluating usability of a web application: A comparative analysis of opensource tools |
| 97 | 29 | Faster online experimentation by eliminating traditional A/A validation |
| 98 | 41 | Pitfalls of long-term online controlled experiments |
| 99 | [147] | SoftSKU: Optimizing Server Architectures for Microservice Diversity @Scale |
| 100 | [57] | The Benefits of Controlled Experimentation at Scale |
| 101 | [141] | Context Adaptation for Smart Recommender Systems |
| 102 | [173] | Whales, Dolphins, or Minnows? Towards the Player Clustering in Free Online Games Based on Purchasing Behavior via Data Mining Technique |
| 103 | [110] | Enterprise-Level Controlled Experiments at Scale: Challenges and Solutions |
| 104 | 19 | Should companies bid on their own brand in sponsored search? |
| 105 | 78] | A Probabilistic, Mechanism-Indepedent Outlier Detection Method for Online Experimentation |
| 106 | [179] | Inform Product Change through Experimentation with Data-Driven Behavioral Segmentation |
| 107 | [118] | Your System Gets Better Every Day You Use It: Towards Automated Continuous Experimentation |
| 108 | [26] | Fashion Recommendation Systems, Models and Methods: A Review |
| 109 | [8] | Subject Line Personalization Techniques and Their Influence in the E-Mail Marketing Open Rate |
| 110 | [114] | Impact of promotional social media content on click-through rate – Evidence from a FMCG company |
| 111 | [6] | Related Entity Expansion and Ranking Using Knowledge Graph |
| 112 | [24] | LinkLouvain: Link-Aware A/B Testing and Its Application on Online Marketing Campaign |
| 113 | [122] | Ascend by Evolv: Artificial intelligence-based massively multivariate conversion rate optimization |
| 114 | 177 | A new framework for online testing of heterogeneous treatment effect |
| 115 | [153] | JACKPOT: Online experimentation of cloud microservices |
| 116 | 75] | Digital Marketing Effectiveness Using Incrementality |
| 117 | [137] | Business process improvement with the AB-BPM methodology |
| 118 | [50] | A genetic algorithm for finding a small and diverse set of recent news stories on a given subject: How we generate aaai’s ai-alert |
| 119 | 97 | Measuring the value of recommendation links on product demand |
| 120 | 56 | Experimentation growth: Evolving trustworthy
|
| 121 | 140 | Online Evaluation of Bid Prediction Models in a Large-Scale Computational Advertising Platform: Decision Making and Insights |
| 122 | [136] | AB-BPM: Performance-driven instance routing for business process improvement |
| 123 | 49 | Have It Both Ways-From A/B Testing to A&B Testing with Exceptional Model Mining |
| 124 | [117] | More for Less: Automated Experimentation in Software-Intensive Systems |
| 125 | 30 | Regression Tree for Bandits Models in A/B Testing |
| 126 | [125] | When the Crowd is Not Enough: Improving User Experience with Social Media through Automatic Quality Analysis |
| 127 | [22] | Pixel efficiency analysis: A quantitative web analytics approach |
| 128 | 96 | A/B Testing in E-commerce Sales Processes |
| 129 | [124] | A Method for the Construction of User Targeting Knowledge for B2B Industry Website |
| 130 | [128] | Validating Mobile Designs with Agile Testing in China: Based on Baidu Map for Mobile |
| 131 | [159] | User Latent Preference Model for Better Downside Management in Recommender Systems |
| 132 | [151] | Towards Automated A/B Testing |
| 133 | 90] | Seven rules of thumb for web site experimenters |
| 134 | [101] | Enabling A/B Testing of Native Mobile Applications by Remote User Interface Exchange |
| 135 | [152] | Overlapping Experiment Infrastructure: More, Better, Faster Experimentation |
| 136 | 67 | Optimizing price levels in e-commerce applications: An empirical study |
| 137 | [25] | Facilitating Controlled Tests of Website Design Changes: A Systematic Approach |
| 138 | [3] | Soft Frequency Capping for Improved Ad Click Prediction in Yahoo Gemini Native |
| 139 | 37] | Objective Bayesian Two Sample Hypothesis Testing for Online Controlled Experiments |
| 140 | 64 | Test & Roll: Profit-Maximizing A/B Tests |
| 141 | [176] | Improving Library User Experience with A/B Testing: Principles and Process |
- *Corresponding author
Email addresses: federico.quin@kuleuven.be (Federico Quin), danny.weyns@kuleuven.be (Danny Weyns), matthias.galster@canterbury.ac.nz (Matthias Galster), camila.costasilva@pg.canterbury.ac.nz (Camila Costa Silva) We use the term “research paper” to refer to papers that we considered for the application of inclusion and exclusion criteria in the SLR, and the term “primary study” for the research papers that we selected for data extraction. Papers published in the Lecture Notes in Computer Science format with pages are also considered short. Academic refers to affiliations that are eligible to graduate master and/or PhD students. We distinguish data retrieved from empirical evaluation in a live system from data retrieved from simulation or an illustrative example to provide targeted insights into the execution of tests during data analysis of the SLR. We excluded experiments and corresponding metrics of primary studies that analyzed a large number of previously conducted tests.
conversion is a desired action taken in the test.
Note that some of the primary studies do not specify explicitly the metrics due to business sensitivity. Based on the available information in the study, we have included these in general engagement metrics.
Good clicks are described as clicks that are meaningful during the search query session 20.
However, these studies did report p-values alongside the results, or explicitly refer to confidence intervals and statistically significant results of the tests. See data item target in Section 4.2 for specific references.
Invalid refers to badly designed experiments or misinterpretation of the results retrieved from the experiment. Counterfactual analysis provides answers to the cause and effect of the treatment group and their corresponding outcomes, compared to what would have happened if the treatment would not have been applied. Or alternatively an explicit mention of lack of statistical methods used.